
20 Tips, Tricks and Techniques That You Can Use To
Fight Overfitting and Get Better Generalization
How can you get better performance from your deep learning model?
It is one of the most common questions I get asked.
It might be asked as:
How can I improve accuracy?
…or it may be reversed as:
What can I do if my neural network performs poorly?
I often reply with “I don’t know exactly, but I have lots of ideas.”
Then I proceed to list out all of the ideas I can think of that might give a lift in performance.
Rather than write out that list again, I’ve decided to put all of my ideas into this post.
The ideas won’t just help you with deep learning, but really any machine learning algorithm.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
It’s a big post, you might want to bookmark it.

How To Improve Deep Learning Performance
Photo by Pedro Ribeiro Simões, some rights reserved.
Ideas to Improve Algorithm Performance
This list of ideas is not complete but it is a great start.
My goal is to give you lots ideas of things to try, hopefully, one or two ideas that you have not thought of.
You often only need one good idea to get a lift.
If you get results from one of the ideas, let me know in the comments.
I’d love to hear about it!
If you have one more idea or an extension of one of the ideas listed, let me know, I and all readers would benefit! It might just be the one idea that helps someone else get their breakthrough.
I have divided the list into 4 sub-topics:
- Improve Performance With Data.
- Improve Performance With Algorithms.
- Improve Performance With Algorithm Tuning.
- Improve Performance With Ensembles.
The gains often get smaller the further down the list. For example, a new framing of your problem or more data is often going to give you more payoff than tuning the parameters of your best performing algorithm. Not always, but in general.
I have included lots of links to tutorials from the blog, questions from related sites as well as questions on the classic Neural Net FAQ.
Some of the ideas are specific to artificial neural networks, but many are quite general. General enough that you could use them to spark ideas on improving your performance with other techniques.
Let’s dive in.
1. Improve Performance With Data
You can get big wins with changes to your training data and problem definition. Perhaps even the biggest wins.
Here’s a short list of what we’ll cover:
- Get More Data.
- Invent More Data.
- Rescale Your Data.
- Transform Your Data.
- Feature Selection.
1) Get More Data
Can you get more training data?
The quality of your models is generally constrained by the quality of your training data. You want the best data you can get for your problem.
You also want lots of it.
Deep learning and other modern nonlinear machine learning techniques get better with more data. Deep learning especially. It is one of the main points that make deep learning so exciting.
Take a look at the following cartoon:
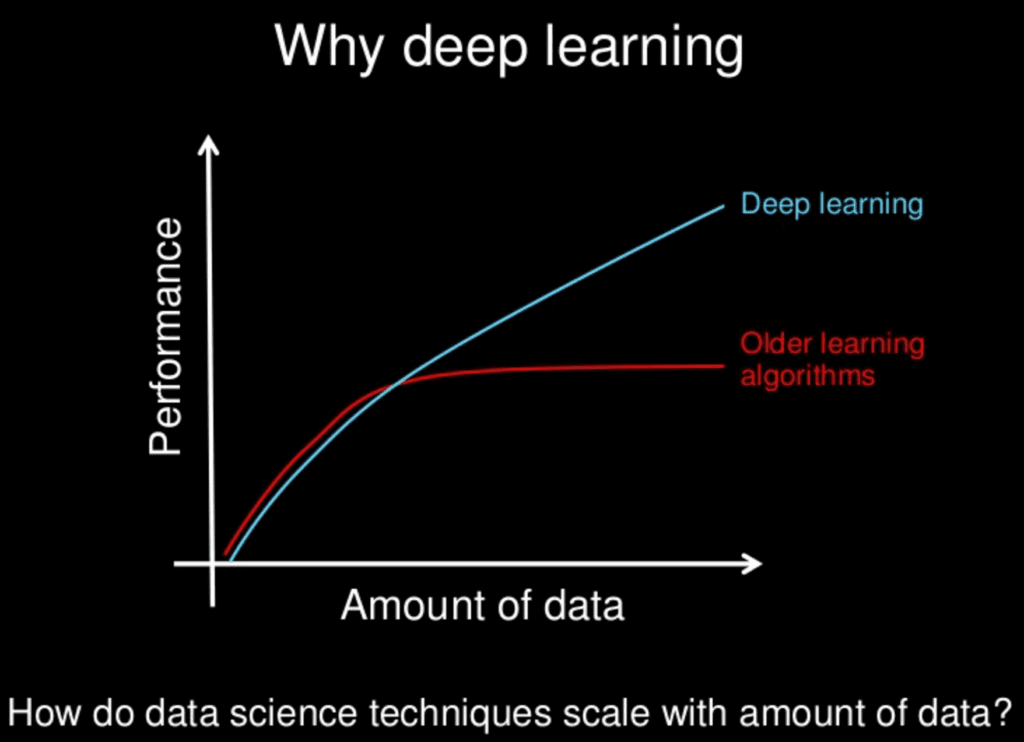
Why Deep Learning?
Slide by Andrew Ng, all rights reserved.
More data does not always help, but it can. If I am given the choice, I will get more data for the optionality it provides.
Related:
2) Invent More Data
Deep learning algorithms often perform better with more data.
We mentioned this in the last section.
If you can’t reasonably get more data, you can invent more data.
- If your data are vectors of numbers, create randomly modified versions of existing vectors.
- If your data are images, create randomly modified versions of existing images.
- If your data are text, you get the idea…
Often this is called data augmentation or data generation.
You can use a generative model. You can also use simple tricks.
For example, with photograph image data, you can get big gains by randomly shifting and rotating existing images. It improves the generalization of the model to such transforms in the data if they are to be expected in new data.
This is also related to adding noise, what we used to call adding jitter. It can act like a regularization method to curb overfitting the training dataset.
Related:
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
3) Rescale Your Data
This is a quick win.
A traditional rule of thumb when working with neural networks is:
Rescale your data to the bounds of your activation functions.
If you are using sigmoid activation functions, rescale your data to values between 0-and-1. If you’re using the Hyperbolic Tangent (tanh), rescale to values between -1 and 1.
This applies to inputs (x) and outputs (y). For example, if you have a sigmoid on the output layer to predict binary values, normalize your y values to be binary. If you are using softmax, you can still get benefit from normalizing your y values.
This is still a good rule of thumb, but I would go further.
I would suggest that you create a few different versions of your training dataset as follows:
- Normalized to 0 to 1.
- Rescaled to -1 to 1.
- Standardized.
Then evaluate the performance of your model on each. Pick one, then double down.
If you change your activation functions, repeat this little experiment.
Big values accumulating in your network are not good. In addition, there are other methods for keeping numbers small in your network such as normalizing activation and weights, but we’ll look at these techniques later.
Related:
- Should I standardize the input variables (column vectors)?
- How To Prepare Your Data For Machine Learning in Python with Scikit-Learn
4) Transform Your Data
Related to rescaling suggested above, but more work.
You must really get to know your data. Visualize it. Look for outliers.
Guesstimate the univariate distribution of each column.
- Does a column look like a skewed Gaussian, consider adjusting the skew with a Box-Cox transform.
- Does a column look like an exponential distribution, consider a log transform.
- Does a column look like it has some features, but they are being clobbered by something obvious, try squaring, or square-rooting.
- Can you make a feature discrete or binned in some way to better emphasize some feature.
Lean on your intuition. Try things.
- Can you pre-process data with a projection method like PCA?
- Can you aggregate multiple attributes into a single value?
- Can you expose some interesting aspect of the problem with a new boolean flag?
- Can you explore temporal or other structure in some other way?
Neural nets perform feature learning. They can do this stuff.
But they will also learn a problem much faster if you can better expose the structure of the problem to the network for learning.
Spot-check lots of different transforms of your data or of specific attributes and see what works and what doesn’t.
Related:
- How to Define Your Machine Learning Problem
- Discover Feature Engineering, How to Engineer Features and How to Get Good at It
- How To Prepare Your Data For Machine Learning in Python with Scikit-Learn
5) Feature Selection
Neural nets are generally robust to unrelated data.
They’ll use a near-zero weight and sideline the contribution of non-predictive attributes.
Still, that’s data, weights, training cycles used on data not needed to make good predictions.
Can you remove some attributes from your data?
There are lots of feature selection methods and feature importance methods that can give you ideas of features to keep and features to boot.
Try some. Try them all. The idea is to get ideas.
Again, if you have time, I would suggest evaluating a few different selected “Views” of your problem with the same network and see how they perform.
- Maybe you can do as well or better with fewer features. Yay, faster!
- Maybe all the feature selection methods boot the same specific subset of features. Yay, consensus on useless features.
- Maybe a selected subset gives you some ideas on further feature engineering you can perform. Yay, more ideas.
Related:
6) Reframe Your Problem
Step back from your problem.
Are the observations that you’ve collected the only way to frame your problem?
Maybe there are other ways. Maybe other framings of the problem are able to better expose the structure of your problem to learning.
I really like this exercise because it forces you to open your mind. It’s hard. Especially if you’re invested (ego!!!, time, money) in the current approach.
Even if you just list off 3-to-5 alternate framings and discount them, at least you are building your confidence in the chosen approach.
- Maybe you can incorporate temporal elements in a window or in a method that permits timesteps.
- Maybe your classification problem can become a regression problem, or the reverse.
- Maybe your binary output can become a softmax output?
- Maybe you can model a sub-problem instead.
It is a good idea to think through the problem and it’s possible framings before you pick up the tool, because you’re less invested in solutions.
Nevertheless, if you’re stuck, this one simple exercise can deliver a spring of ideas.
Also, you don’t have to throw away any of your prior work. See the ensembles section later on.
Related:
2. Improve Performance With Algorithms
Machine learning is about algorithms.
All the theory and math describes different approaches to learn a decision process from data (if we constrain ourselves to predictive modeling).
You’ve chosen deep learning for your problem. Is it really the best technique you could have chosen?
In this section, we’ll touch on just a few ideas around algorithm selection before next diving into the specifics of getting the most from your chosen deep learning method.
Here’s the short list
- Spot-Check Algorithms.
- Steal From Literature.
- Resampling Methods.
Let’s get into it.
1) Spot-Check Algorithms
Brace yourself.
You cannot know which algorithm will perform best on your problem beforehand.
If you knew, you probably would not need machine learning.
What evidence have you collected that your chosen method was a good choice?
Let’s flip this conundrum.
No single algorithm can perform better than any other, when performance is averaged across all possible problems. All algorithms are equal. This is a summary of the finding from the no free lunch theorem.
Maybe your chosen algorithms is not the best for your problem.
Now, we are not trying to solve all possible problems, but the new hotness in algorithm land may not be the best choice on your specific dataset.
My advice is to collect evidence. Entertain the idea that there are other good algorithms and given them a fair shot on your problem.
Spot-check a suite of top methods and see which fair well and which do not.
- Evaluate some linear methods like logistic regression and linear discriminate analysis.
- Evaluate some tree methods like CART, Random Forest and Gradient Boosting.
- Evaluate some instance methods like SVM and kNN.
- Evaluate some other neural network methods like LVQ, MLP, CNN, LSTM, hybrids, etc.
Double down on the top performers and improve their chance with some further tuning or data preparation.
Rank the results against your chosen deep learning method, how do they compare?
Maybe you can drop the deep learning model and use something a lot simpler, a lot faster to train, even something that is easy to understand.
Related:
- A Data-Driven Approach to Machine Learning
- Why you should be Spot-Checking Algorithms on your Machine Learning Problems
- Spot-Check Classification Machine Learning Algorithms in Python with scikit-learn
2) Steal From Literature
A great shortcut to picking a good method, is to steal ideas from literature.
Who else has worked on a problem like yours and what methods did they use.
Check papers, books, blog posts, Q&A sites, tutorials, everything Google throws at you.
Write down all the ideas and work your way through them.
This is not about replicating research, it is about new ideas that you have not thought of that may give you a lift in performance.
Published research is highly optimized.
There are a lot of smart people writing lots of interesting things. Mine this great library for the nuggets you need.
Related:
3) Resampling Methods
You must know how good your models are.
Is your estimate of the performance of your models reliable?
Deep learning methods are slow to train.
This often means we cannot use gold standard methods to estimate the performance of the model such as k-fold cross validation.
- Maybe you are using a simple train/test split, this is very common. If so, you need to ensure that the split is representative of the problem. Univariate stats and visualization are a good start.
- Maybe you can exploit hardware to improve the estimates. For example, if you have a cluster or an Amazon Web Services account, we can train n-models in parallel then take the mean and standard deviation of the results to get a more robust estimate.
- Maybe you can use a validation hold out set to get an idea of the performance of the model as it trains (useful for early stopping, see later).
- Maybe you can hold back a completely blind validation set that you use only after you have performed model selection.
Going the other way, maybe you can make the dataset smaller and use stronger resampling methods.
- Maybe you see a strong correlation with the performance of the model trained on a sample of the training dataset as to one trained on the whole dataset. Perhaps you can perform model selection and tuning using the smaller dataset, then scale the final technique up to the full dataset at the end.
- Maybe you can constrain the dataset anyway, take a sample and use that for all model development.
You must have complete confidence in the performance estimates of your models.
Related:
- Evaluate the Performance Of Deep Learning Models in Keras
- Evaluate the Performance of Machine Learning Algorithms in Python using Resampling
3. Improve Performance With Algorithm Tuning
This is where the meat is.
You can often unearth one or two well-performing algorithms quickly from spot-checking. Getting the most from those algorithms can take, days, weeks or months.
Here are some ideas on tuning your neural network algorithms in order to get more out of them.
- Diagnostics.
- Weight Initialization.
- Learning Rate.
- Activation Functions.
- Network Topology.
- Batches and Epochs.
- Regularization.
- Optimization and Loss.
- Early Stopping.
You may need to train a given “configuration” of your network many times (3-10 or more) to get a good estimate of the performance of the configuration. This probably applies to all the aspects that you can tune in this section.
For a good post on hyperparameter optimization see:
1) Diagnostics
You will get better performance if you know why performance is no longer improving.
Is your model overfitting or underfitting?
Always keep this question in mind. Always.
It will be doing one or the other, just by varying degrees.
A quick way to get insight into the learning behavior of your model is to evaluate it on the training and a validation dataset each epoch, and plot the results.
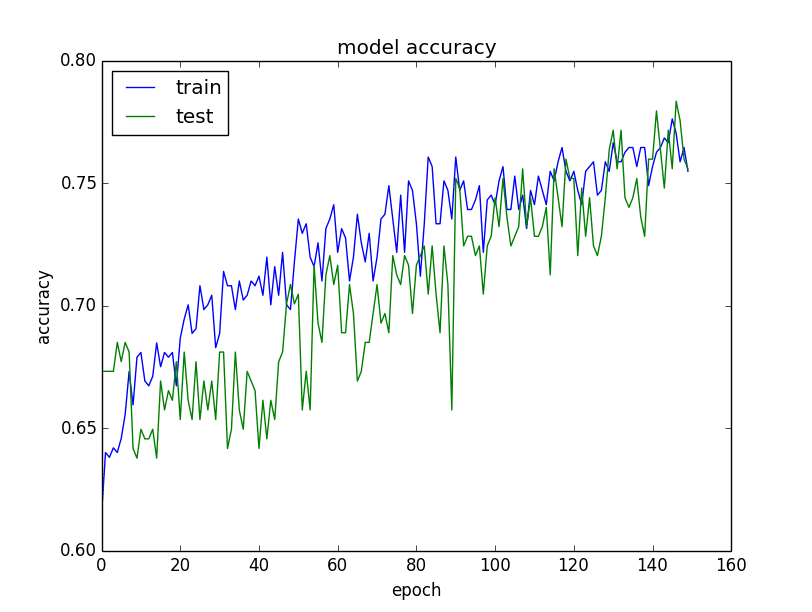
Plot of Model Accuracy on Train and Validation Datasets
- If training is much better than the validation set, you are probably overfitting and you can use techniques like regularization.
- If training and validation are both low, you are probably underfitting and you can probably increase the capacity of your network and train more or longer.
- If there is an inflection point when training goes above the validation, you might be able to use early stopping.
Create these plots often and study them for insight into the different techniques you can use to improve performance.
These plots might be the most valuable diagnostics you can create.
Another useful diagnostic is to study the observations that the network gets right and wrong.
On some problems, this can give you ideas of things to try.
- Perhaps you need more or augmented examples of the difficult-to-train on examples.
- Perhaps you can remove large samples of the training dataset that are easy to model.
- Perhaps you can use specialized models that focus on different clear regions of the input space.
Related
- Display Deep Learning Model Training History in Keras
- Overfitting and Underfitting With Machine Learning Algorithms
2) Weight Initialization
The rule of thumb used to be:
Initialize using small random numbers.
In practice, that is still probably good enough. But is it the best for your network?
There are also heuristics for different activation functions, but I don’t remember seeing much difference in practice.
Keep your network fixed and try each initialization scheme.
Remember, the weights are the actual parameters of your model that you are trying to find. There are many sets of weights that give good performance, but you want better performance.
- Try all the different initialization methods offered and see if one is better with all else held constant.
- Try pre-learning with an unsupervised method like an autoencoder.
- Try taking an existing model and retraining a new input and output layer for your problem (transfer learning).
Remember, changing the weight initialization method is closely tied with the activation function and even the optimization function.
Related
3) Learning Rate
There is often payoff in tuning the learning rate.
Here are some ideas of things to explore:
- Experiment with very large and very small learning rates.
- Grid search common learning rate values from the literature and see how far you can push the network.
- Try a learning rate that decreases over epochs.
- Try a learning rate that drops every fixed number of epochs by a percentage.
- Try adding a momentum term then grid search learning rate and momentum together.
Larger networks need more training, and the reverse. If you add more neurons or more layers, increase your learning rate.
Learning rate is coupled with the number of training epochs, batch size and optimization method.
Related:
- Using Learning Rate Schedules for Deep Learning Models in Python with Keras
- What learning rate should be used for backprop?
4) Activation Functions
You probably should be using rectifier activation functions.
They just work better.
Before that it was sigmoid and tanh, then a softmax, linear or sigmoid on the output layer. I don’t recommend trying more than that unless you know what you’re doing.
Try all three though and rescale your data to meet the bounds of the functions.
Obviously, you want to choose the right transfer function for the form of your output, but consider exploring different representations.
For example, switch your sigmoid for binary classification to linear for a regression problem, then post-process your outputs. This may also require changing the loss function to something more appropriate. See the section on Data Transforms for more ideas along these lines.
Related:
5) Network Topology
Changes to your network structure will pay off.
How many layers and how many neurons do you need?
No one knows. No one. Don’t ask.
You must discover a good configuration for your problem. Experiment.
- Try one hidden layer with a lot of neurons (wide).
- Try a deep network with few neurons per layer (deep).
- Try combinations of the above.
- Try architectures from recent papers on problems similar to yours.
- Try topology patterns (fan out then in) and rules of thumb from books and papers (see links below).
It’s hard. Larger networks have a greater representational capability, and maybe you need it.
More layers offer more opportunity for hierarchical re-composition of abstract features learned from the data. Maybe you need that.
Later networks need more training, both in epochs and in learning rate. Adjust accordingly.
Related:
These links will give you lots of ideas of things to try, well they do for me.
6) Batches and Epochs
The batch size defines the gradient and how often to update weights. An epoch is the entire training data exposed to the network, batch-by-batch.
Have you experimented with different batch sizes and number of epochs?
Above, we have commented on the relationship between learning rate, network size and epochs.
Small batch sizes with large epoch size and a large number of training epochs are common in modern deep learning implementations.
This may or may not hold with your problem. Gather evidence and see.
- Try batch size equal to training data size, memory depending (batch learning).
- Try a batch size of one (online learning).
- Try a grid search of different mini-batch sizes (8, 16, 32, …).
- Try training for a few epochs and for a heck of a lot of epochs.
Consider a near infinite number of epochs and setup check-pointing to capture the best performing model seen so far, see more on this further down.
Some network architectures are more sensitive than others to batch size. I see Multilayer Perceptrons as often robust to batch size, whereas LSTM and CNNs quite sensitive, but that is just anecdotal.
Related
- What are batch, incremental, on-line … learning?
- Intuitively, how does mini-batch size affect the performance of (stochastic) gradient descent?
7) Regularization
Regularization is a great approach to curb overfitting the training data.
The hot new regularization technique is dropout, have you tried it?
Dropout randomly skips neurons during training, forcing others in the layer to pick up the slack. Simple and effective. Start with dropout.
- Grid search different dropout percentages.
- Experiment with dropout in the input, hidden and output layers.
There are extensions on the dropout idea that you can also play with like drop connect.
Also consider other more traditional neural network regularization techniques , such as:
- Weight decay to penalize large weights.
- Activation constraint, to penalize large activations.
Experiment with the different aspects that can be penalized and with the different types of penalties that can be applied (L1, L2, both).
Related:
8) Optimization and Loss
It used to be stochastic gradient descent, but now there are a ton of optimizers.
Have you experimented with different optimization procedures?
Stochastic Gradient Descent is the default. Get the most out of it first, with different learning rates, momentum and learning rate schedules.
Many of the more advanced optimization methods offer more parameters, more complexity and faster convergence. This is good and bad, depending on your problem.
To get the most out of a given method, you really need to dive into the meaning of each parameter, then grid search different values for your problem. Hard. Time Consuming. It might payoff.
I have found that newer/popular methods can converge a lot faster and give a quick idea of the capability of a given network topology, for example:
- ADAM
- RMSprop
You can also explore other optimization algorithms such as the more traditional (Levenberg-Marquardt) and the less so (genetic algorithms). Other methods can offer good starting places for SGD and friends to refine.
The loss function to be optimized might be tightly related to the problem you are trying to solve.
Nevertheless, you often have some leeway (MSE and MAE for regression, etc.) and you might get a small bump by swapping out the loss function on your problem. This too may be related to the scale of your input data and activation functions that are being used.
Related:
- An overview of gradient descent optimization algorithms
- What are conjugate gradients, Levenberg-Marquardt, etc.?
- On Optimization Methods for Deep Learning, 2011 [PDF]
9) Early Stopping
You can stop learning once performance starts to degrade.
This can save a lot of time, and may even allow you to use more elaborate resampling methods to evaluate the performance of your model.
Early stopping is a type of regularization to curb overfitting of the training data and requires that you monitor the performance of the model on training and a held validation datasets, each epoch.
Once performance on the validation dataset starts to degrade, training can stop.
You can also setup checkpoints to save the model if this condition is met (measuring loss of accuracy), and allow the model to keep learning.
Checkpointing allows you to do early stopping without the stopping, giving you a few models to choose from at the end of a run.
Related:
4. Improve Performance With Ensembles
You can combine the predictions from multiple models.
After algorithm tuning, this is the next big area for improvement.
In fact, you can often get good performance from combining the predictions from multiple “good enough” models rather than from multiple highly tuned (and fragile) models.
We’ll take a look at three general areas of ensembles you may want to consider:
- Combine Models.
- Combine Views.
- Stacking.
1) Combine Models
Don’t select a model, combine them.
If you have multiple different deep learning models, each that performs well on the problem, combine their predictions by taking the mean.
The more different the models, the better. For example, you could use very different network topologies or different techniques.
The ensemble prediction will be more robust if each model is skillful but in different ways.
Alternately, you can experiment with the converse position.
Each time you train the network, you initialize it with different weights and it converges to a different set of final weights. Repeat this process many times to create many networks, then combine the predictions of these networks.
Their predictions will be highly correlated, but it might give you a small bump on those patterns that are harder to predict.
Related:
- Ensemble Machine Learning Algorithms in Python with scikit-learn
- How to Improve Machine Learning Results
2) Combine Views
As above, but train each network on a different view or framing of your problem.
Again, the objective is to have models that are skillful, but in different ways (e.g. uncorrelated predictions).
You can lean on the very different scaling and transform techniques listed above in the Data section for ideas.
The more different the transforms and framing of the problem used to train the different models, the more likely your results will improve.
Using a simple mean of predictions would be a good start.
3) Stacking
You can also learn how to best combine the predictions from multiple models.
This is called stacked generalization or stacking for short.
Often you can get better results over that of a mean of the predictions using simple linear methods like regularized regression that learns how to weight the predictions from different models.
Baseline reuslts using the mean of the predictions from the submodels, but lift performance with learned weightings of the models.
Conclusions
You made it.
Additional Resources
There’s a lot of good resources, but few tie all the ideas together.
I’ll list some resources and related posts that you may find interesting if you want to dive deeper.
- Neural Network FAQ
- How to Grid Search Hyperparameters for Deep Learning Models in Python With Keras
- Must Know Tips/Tricks in Deep Neural Networks
- How to increase validation accuracy with deep neural net?
Know a good resource? Let me know, leave a comment.
Handle The Overwhelm
This is a big post and we’ve covered a lot of ground.
You do not need to do everything. You just need one good idea to get a lift in performance.
Here’s how to handle the overwhelm:
- Pick one group
- Data.
- Algorithms.
- Tuning.
- Ensembles.
- Pick one method from the group.
- Pick one thing to try of the chosen method.
- Compare the results, keep if there was an improvement.
- Repeat.
Share Your Results
Did you find this post useful?
Did you get that one idea or method that made a difference?
Let me know, leave a comment!
I would love to hear about it.
Develop Better Deep Learning Models Today!

Train Faster, Reduce Overftting, and Ensembles
...with just a few lines of python code
Discover how in my new Ebook:
Better Deep Learning
It provides self-study tutorials on topics like:
weight decay, batch normalization, dropout, model stacking and much more...
Bring better deep learning to your projects!
Skip the Academics. Just Results.






Thank you for your advice!
I’m glad you found it useful Xu Lu.
It is really a comprehensive explanation, going to try it.
Thanks Nitin, let me know how you go.
How I can Train Land Use Images for classification
Perhaps start with a pre-trained CNN model?
VGG or ResNet would be a great starting point, then train the weights in just the output layer.
I have examples of this in my book:
https://machinelearningmastery.com/deep-learning-for-computer-vision/
Thank you for sharing – this is very useful information.
I’m glad to hear it!
What are mathematical challenges for Deep learning in Big data?
Great question.
Generally, deep learning is empirical. We don’t have good theory for why large networks work or even what the heck is going on inside.
How many layers? What learning rate? These are problems that can only be solved empirically, not analytically. For now.
A strong math theory could push back the empirical side/voodoo and improve understanding.
Thank you for sharing great post, I really appreciate.
I think it is very helpful, so I’d like to share the idea with my Japanese followers.
So I’m making translated summary of this post.
Could I ask for permission to post my summary in http://qiita.com/daisukelab ?
(Japanese tech blog media)
And could I ask the detail for 2-3),
“Maybe you can constrain the dataset anyway, take a sample and use that for all model development.”
Do you mean:
“If we use smaller subset of dataset, we could use the subset for completing model development to the end”?
Thank you!
Please do not repost the material Daisuke.
My that comment I meant that working with a sample of your data, rather than all of the data has benefits – like increasing the speed of turning around models.
Hi Jason,
OK I will not repost, though it is for spreading your idea with translation and lead people visit here.
And thank you for clarification!
Amazing post.. Thanx for sharing information about deep learning and enhancing current models
Thanks Chintan, I’m glad you found it useful.
This is my current favorite website!
I’m currently working on implementing some nlp for regressions and was wondering if I could improve my results. I’ll try ensembles, as I have many models already trained.
Thanks!
Best of luck Fernando, I’d love to hear how you go.
This is really good information what I found. Actually, I am working in Semantic Segmentation using Deep learning. It can view as an extension task of recognition task. As I read, I felt that all segmentation techniques have come from recognition (We can think that the recognition as encoding phase provides probability map, the segmentation task maps the probability maps to the image by using decode phase). Hence my opinion, I think that if any state-of-the-art recognition network architecture applies for segmentation task which can achieve more accuracy than segmentation using older recognition network architecture. Do you think so? What is good direction to improve segmentation accuracy? Thank you in advance
I am a newbie in deep learning and experimenting with existing examples, using the digits interface. Thank you for all the effort to simplify the topic, a technical documentation still well understandable for newcomers.
My interest is on detecting (and counting) particles via deep learning. After many many experiments with various samples, I realised particles too close to each (almost touching) other are counted as one, while there is a clear seperation, to my eye.
I am looking for an approach in how to handle this.
I tried some thresholding techniques on individual images in an image processing software and best results obtained with color thresholding. Although I have no idea whether thresholding is a part of particle detection in object detection processes by deep learning, but wondering if is it possible to integrate an equivalent process into object detection models ?(currently using the detectnet model)
Regards,
thank you. I’ll try some techniques of this post.
You’re welcome Naoki, I’d love to hear about your results.
very comprehensive blog! Great work!
Thanks emma, I hope it helps with your project.
Hello,
I would like to know if there is an implementation in Keras of “drop connect”.
Thanks you for your time
I have not seen one Max, but I expect there will be something out there!
Hi Jason,
Thank you for sharing great post, I really appreciate.
you mentioned in section 2: Invent More Data
-If you can’t reasonably get more data, you can invent more data.
-If your data are vectors of numbers, create randomly modified versions of existing vectors.
—-> Have you an example how to create randomly modified versions of existing vectors.?
Thank you!
I don’t but you could experiment with different perturbation methods to see what works best.
Some good ideas to try include:
– randomly replace a subset of values with randomly selected values in the data population
– add a small random value (select distribution to meet the data distribution for a column)
It is tricky, because you need the new data to be “reasonable” for the assigned class.
Consider a skim of the literature for more sophisticated methods.
First of all thank you for the thorough explanation and rich material, it’s been helping me quite a lot.
One thing that still troubles me is applying Levenberg-Marquardt in Python, more specifically in Keras. I’m dealing with non-ideal input variables to infer target and would like to go through a range of optimizers to test the network performance.
Since one of the best available in Matlab is Levenberg-Marquardt, it would very good (and provide comparison value between languages) if I could accurately apply it in keras to train my network.
I am currently using Keras with Theano backend. Any help at all would be appreciated.
Best,
Lucas
Here is an example of grid searching optimization algorithms:
https://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/
Sorry, I do not have an example of the Levenberg-Marquardt algorithm in Python for Keras.
Hi Jason,
Thank you for the great work and posts.
I have got a question- after improving deep learning performance in my project i achieve accuracy of 75% in a binary classification problem. Using other methods gives me in the best shot 77%. My question is when do i know that my model is the best possbile? Is there any measure that can explain to which extend my data has explanatory power?
Well done!
Great question. We can never know for sure, but only when we run out of time or ideas.
Generally, no, I’m not aware of methods to estimate explanatory power, I’m not even clear what that might mean.
What I meant by ‘explanatory power’, was the ability of data to distinguish that one record belongs to class 1, second to class 2, third again to class 1 and so on.
It is some kind of limitation of the dataset, that it can achieve max. accuracy for example at 80% and my question was is it a way to measure, that level.
Thank you for your answer, now i am ready to accept my model 🙂
You can configure the model to output probabilities instead of classes, this may give the result you require.
Finally! Come across all the techniques to improve your deep learning model in a nutshell!
Thanks a lot Jason!
I hope that you find them useful Cyrus.
Hi, I’m working on my final year project which is detecting nsfw content in images and further for videos (if possible). My problem is that i cannot find any dataset for working so if you could please help me out with this problem by giving me some suggestions will really help me in this project.I need data of about (150-200 gb) to make my algorithm more precise. I have reached out to yahoo open nsfw team but there is no response from them.
Sorry, I don’t know where to get such a dataset.
Hey Jason, Do you know of any empirical evidence for the “Why Deep Learning?” slide by Andrew Ng. Specifically I am working on a text classification problem, I am finding BoW + (Linear SVM’s or Logistic Regression) giving me the best performance (which is what I find in the literature at least pre 2015). I’m fairly new to Deep learning, I have been testing it out on my problem having seen stuff like https://arxiv.org/abs/1408.5882 perform well in the Rotten Tomatoes Kaggle text classification problem. Although there was some other fancy tricks that I think gave the CNN extra juice. Do you have any recommendations or any benchmarking studies in this area that demonstrate what Andrew Ng is claiming?
Not specifically, sorry.
Dear Jason,
Thanks for this article 🙂 I have a question : how to calculate the total error of a network ?!
thanks in advance.
Nunu
Evaluate it on test data and calculate an error score, such as RMSE for regression or Accuracy on classification.
ok I will try it. Thanks a lot
Let me know what works for you.
(“Hyperbolic Tangent (tanh), rescale to values between -1 and 1” )
WHOOOOPS!!, that might be important,now i know, lol!
Finalllllllllly! someone who has explain this wonderfully with structure, and not just said its a black box!
great info Doc
I have a question! do you have any pointers for unbalanced data?
is it better to sacrifice other data to balance every class out?
Thanks Danny.
Yes, see this post on imbalanced data:
https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
Examples of what I mean by unbalance data
=== self drive car ===
left = [0,1,0] =5k samples
right = [0,0,1]= 5k samples
forward = [1,0,0]=100k samples
===stocks====
Buy = [0,1,0] =5k samples
Sell = [0,0,1]= 5k samples
Hold = [1,0,0]=100k samples
etc……..
Undersampling, Oversampling, or Smote
thanks for allll your articles in this website ,it is favorite for me <3 <3
You’re welcome.
great article
Thanks!
Hi Jason,
A long try-and-test process led me to the same conclusions. So thank you very much! This post will serve for a lot of new comers to the keras/ deep learning area.
Question:
In a classic case, you normalize your data, you train the model and then you “de-normalize” (inverse using the scaler). Now, imagine that the model you are training is fed with its own output and the predicted outpùt is out of the scaler range, what would you do to improve the model’s performance.
Thank you in advance for your feedback!
Kind Regards.
Thanks, I’m glad it helped.
If you have data outside of the scalers range, you can force it in bounds or update the scaling.
I hope that helps.
Hi Jason,
Thanks for sharing this valuable post
One thing I am still wondering about, I am interested to apply deep learning in data stream classification (real time prediction), but my concern is the execution time that the deep learning needs. Any idea how to speed it up or how to handle it for real time prediction.
Regards
For modestly sized data, the feed-forward part of the neural network (to make predictions) is very fast.
As for training the network in real-time, I would suggest that it is perhaps a bad fit for the problem.
Many thanks Jason
Been learning a lot from your posts. Thanks for posting. Just curious, what’s up with the random pictures?:)
Thanks!
I figure the pictures would lighten the mood, be something interesting to look at as we get deep into technical topics. I often choose pictures based on where I am going or want to go for a holiday, e.g. the beach, the forest, etc. Sometimes they are a pun (e.g. a pic of a gas pipeline for a pipeline method). Sometimes they are just random.
You’re the first person in 4 years to ask about them 🙂
Under “Rescale Your Data”, you have pointed about scaling and activation function. So if we scale the data between [-1,1], then we have to implicitly mention about activation function (i.e tanh function) in LSTM using Keras. Am i correct in assumption, or Keras will pass tanh activation function default in LSTM.
For LSTMs at the first hidden layer, you will want to scale your data to the range 0-1.
Hi Jason,
In https://machinelearningmastery.com/time-series-forecasting-long-short-term-memory-network-python/ artcle , you have mentioned to scale data between -1 to1. In the same article you have not used any activation function.
In keras documentation, https://keras.io/layers/recurrent/#lstm, default activation is actually linear or no activation (i.e a(x) =x).
So my question is whether i need to add implicit activation function as “tanh” in LSTM layer.
The default for the LSTM is sigmoid outputs with tanh used for internal gates. I would recommend scaling input data for LSTMs to between [0,1].
Some testing shows this results in better model skill, generally.
Thanks for this amazing writing. It is very useful.
Thanks, I’m glad it is helping.
A bit outdated but still very useful. Thanks for this great article!
Thanks. What do you think it is missing Robin?
Would you publish technique for “DNN/CNN incremental learning” please.
Thank you.
Thanks for the suggestion.
Thanks Jason, I really love this blog. Pls I have a little questions. In what ways can you improve existing machine learning with deep learning?.
Thanks
Do the ideas in this post help?
Hi, Jason,
I got a question about the training epoch. During the training process, does the weights we get from previous epoch have any impact on later epoch? Or in every epoch, the weights will be initialized?
Thanks
Alan
The weights are initialized once at the beginning of the process and updated at the end of each batch. One epoch may be comprised of one or more batches (weight updates).
A quick question, (I will simplify my explanation), I have a total of 11 classes. where 10 classes have a 50 data points and one class has only 1 datapoint. I train a model. Can i retrain a same model with former 10 classes with no datapoints and later one class with 50 datapoints. Does that work.
Reason i am trying to do this is because, i will have datapoints for later class after some time later.
Does my proposed plan work ?
You might want to use data augmentation to create a larger training dataset, it does not sound like enough data.
Actually, I have enough data, the above example is just for the illustration only.
Let me put it this way (this might be more specific [Incremental Learning]): Initially, I trained a model with 10 classes/labels. Later, How do I re-trained the same model, with new classes, keeping old class intact. So that, I can use the re-trained model to predict former and later classes.
Perhaps create a new dataset with examples of old and new classes and update the model weights on the new dataset?
Thanks, @Jason Brownlee, Indeed that way I could retain all of my previous classes along with new classes.
Let me know how you go.
Great post with broader details. Thanks.
I’m glad it helped.
Perfect 🙂
Thanks.
//Fredrik
I’m glad it helped.
Dear sir
I am creating an NN for predicting as the House pricing by Keras example of yours: https://machinelearningmastery.com/regression-tutorial-keras-deep-learning-library-python/.
Number of experiment data (training data + testing data) is X1, small group in the boundaries. In your example, X1 = 506 data
Number of data for predicting data is X2, covering almost the boundaries.
It means that X1 are much smaller than X2.
And to achieve a high accuracy of prediction, we should enlarge the X1 as much as we can.
So, I would like to ask that how many percentage of X1 we should collect compared with X2?
X1 = 10%(X2), 20%…
Thank you very much
I don’t follow. Do you mean X2 are observations on which you need to make predictions?
yes, it is.
Because I have 5k data to make prediction. So, I need to know how much data should I collect for NN (Training + testing+ validation).
Use all of your data to help find the best model, train a final model then use the final model to start making predictions.
Learn more here:
https://machinelearningmastery.com/train-final-machine-learning-model/
Dear Jason,
I am trying to predict about 40 related time series with Seq2seq networks. I have read about autoencoders to automatically engineer features witthout having to do it manually. Could you please explain how you use the autoencoder outputs in iorder to make prédictions? Do you concatenate them with the original time series before feeding the prediction network.
Thank you very much
Regards
I hope to cover the topic in the future.
Can you suggest some data augmentation methods for time-series data (or 1D data) that do not employ windowing techniques. It seems that for time-series data the most popular data augmentation technique are the window based techniques, which does not sit well with the problem I have at hand. I have some audio sensor data and I want to predict the exact location of the sound source. Windowing may have some negative impact on the problem as the time difference of arrival (TDOA) is one the most important feature for such type of tasks and it might get corrupted by windowing.
What are other method I can use to increase my data.
Information about data:
5 sensors are placed on 4 wall and ceiling in a room. We are trying to find the exact location of a sound source from the sensor data.
At any given point of time two different sound are active at different locations within the room.
This post might give you some ideas:
https://machinelearningmastery.com/basic-feature-engineering-time-series-data-python/
Dear Jason
I really appreciate your post and that is helpful for us. Actually, I am working in Deep learning last 6 months and most of the idea that you mention here comes to my mind during learning Deep learning and I applied all these ideas that come to my mind on my problem most of the tricks work perfectly. And Today I saw your post and I was surprised all these tricks that I was applied to my problem included in this post. Before viewing this post I was always thinking maybe I am in wrong way. But now I am happy to get a reference. Thank you very much for sharing this valuable post.
I’m glad to confirm your intuitions.
Hi Jason, I am just a beginner to using neural networks. I wanted to know that if my input to neural networks is 5 but i have almost a number of 185 distinct outputs in my dataset , But my output can be a different value than those 185 values , so what method could I use?? rather than using one hot encoding and how can I increase performance of my model??
Neural networks require a fixed number of inputs.
If the number of inputs vary, you can use padding to ensure the input vector is always the same size.
Hi Dr. Jason,
Thanks for the comprehensive posts. As you may have known, I have become an addicted reader of your blog resources.
I don’t think you have been able to address the following questions vividly:
How do I save a combined predictions(models) from ensample for use in productions?
What’s the difference between Walk-forward Validation method and combined predictions from ensambles technique? Little bit confused here.
Looking forward to your answers soon.
Putting an ensemble into production is no different to putting a model into production.
Walk forward validation and ensembles are orthogonal ideas, they are not directly related.
Thanks Jason.
In this post: https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
You talked about a model may be updated each time step a new data is received -> Walk forward Validation. This being the k-fold cross validation for time series.
Don’t I have to combine all the models created by the Walk-forward Validation to one single model using either Bagging or Stalking approach? Otherwise, how do I create a final model from Walk-forward Validation?
Walk-forward validation is ONLY used to evaluate the performance of an approach.
Once you have evaluated it, you can train a final model on all available data and use it to make predictions.
I got it, Jason.
I used ModelCheckpoint to select the best model among models evaluated with Walk-forward Validation. Hence, I will build the final model by fitting the entire dataset.
Thanks for your patience and response.
I don’t recommend that approach. If it works for you, glad to hear it.
Hello,
In my case I have a very good accuracy percentage (91.6%) but my score is really low (30%). Actually, I don’t really understand the difference. Can yoy please help?
I use these lines to print them:
score, acc = model.evaluate(new_X, y = dummy_y_new, batch_size=1000, verbose=1)
print(‘Test score:’, score)
print(‘Test accuracy:’, acc)
Sounds like overfitting.
What’s rhe optimal range for score?
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/how-to-know-if-a-model-has-good-performance
Thank you very much for your time
Hi Jason,
Thanks for sharing such a useful article. I have a naive question, tough.
I’m trying to solve a classification problem using LSTM network and I’m experiencing about 99.90% accuracy (the other metrics shows more or less same percentage) on the test set.
Nevertheless, the training and validation accuracies are also similar. I understand that this is suspiciously higher.
I observed the learning graph and found that both training and validation errors were homogeneous.
I’m really confused since both the accuracies for the training, validation, and test are higher. Am I under/overfitting? Or doing something wrong?
One more thing is that the label is not included in the training set.
Any clue would be very helpful and appreciated.
Thanks.
You are training on unlabelled data? I don’t understand?
Hi Jason,
Please ignore the following sentence: “One more thing is that the label is not included in the training set”. I couldn’t edit in the comment.
Actually, my dataset is labeled.
With such high accuracies, it sounds like your problem is easily solved. Perhaps try a simpler method.
Did you mean using linear or tree-based method would be a better idea? Well, I’ll try.
But I have a few other concerns too. Although I’m experiencing about 98~99% accuracies on both training, validation and test sets, the ‘score’ (i.e. score, acc = model.evaluate(….)) value is very low about 40%.
This signifies that perhaps my LSTM model is overfitting (according to your comment on Chrisa’s question). But in that case, I was supposed to experience lower accuracy for the test set too, but I didn’t.
I’m really confused on whether my model is underfitting or overfitting!
I’m using a very high-dimensional gene expression data having 20,309 features and 14 classes.
Do you think achieving 99% accuracy is possible for such a high-dimensional dataset?
Yes sounds like overfitting, but what are you evaluating on exactly? A new test set?
Yes, on a new test set (totally unseen) and again have about 99% accuracy.
Dear Jason,
I have a question that my single deep neural network model gives above 90% accuracy for one data set and the same model gives an accuracy between 70-80% for the other data set. I want to know why this variation in accuracy happens in spite of the fact that i am using the same deep neural network model for both datasets(contain textual content).
You may be over fit. Perhaps try some regularization methods to reduce error on the other dataset.
What an article! i am still new in the neural network thingy and this help me a lot. We still need “trial and error” element. But this article at least give me an idea where to start on improving my model. Thank you Jason!
Thanks, I’m happy that it helped!
This is the most helpful Machine Learning article I’ve seen. Thanks very much.
Thanks.
Thanks Jason! I learned quite a lot from your blogs!
Thanks.
Hi Jason, thank you for these wonderful ideas. But, don’t you think AI is reduced to;
1) Find some data
2) Apply built-in algoirthms
3) Tune (mostly this!)
I see the people often have no idea about what’s going on (including me sometimes). So, what do you think?
Not AI, instead a small subfield that is the most useful part of AI right now called “predictive modeling”.
Results over understanding is accepted almost everywhere else, why not here?
Thank you very much for this grate post, it is really useful.
I’m glad it helped.
Hi Jason, thanks a lot for sharing the other best post,
I have a question please answer the question that I lined the StackOverflow,
If possible, reply to this question here, thanks,
https://stackoverflow.com/questions/55075256/how-to-deal-with-noisy-images-in-deep-learning-based-object-detection-task
Perhaps you can summarize the question for me?
Thank you
You’re welcome, I’m glad it helped.
siva has no teeth
What is siva?
Hi Jason,
Thank you for sharing great post, I really appreciate.
you mentioned in section 2: Invent More Data
-If you can’t reasonably get more data, you can invent more data.
-If your data are vectors of numbers, create randomly modified versions of existing vectors.
—-> Have you an example how to create randomly modified versions of existing vectors.?
Thank you!
Not directly.
A simple approach would be to add gaussian noise.
HIIII JASON
Hi!
I am a newbie in deep learning and experimenting with existing examples, using the digits interface. Thank you for all the effort to simplify the topic, a technical documentation still well understandable for newcomers.
My interest is on detecting (and counting) particles via deep learning. After many many experiments with various samples, I realised particles too close to each (almost touching) other are counted as one, while there is a clear seperation, to my eye.
I am looking for an approach in how to handle this.
I tried some thresholding techniques on individual images in an image processing software and best results obtained with color thresholding. Although I have no idea whether thresholding is a part of particle detection in object detection processes by deep learning, but wondering if is it possible to integrate an equivalent process into object detection models ?(currently using the detectnet model)
Regards,
Perhaps you can try a suite of different preparations for each input image and either model them with parallel models in an ensemble or a multi-input model?
Also, as images, consider a multi-head cnn with different kernel size on each head.
Perhaps also try leveraging pre-trained models.
I like your smile Jason
Thanks!
Hi Jason,
Thank you very much for sharing your knowledge and experience with all of us.
It made my life as a ML newcomer much easier and answered a lot of open questions. Furthermore, your style of writing is nice to read, it makes curious to know more 🙂
Thanks. I’mm happy the posts help.
Thank you very much!
You’re welcome.
Dear Sir,
Thank u for ur post. Its really helpful for me for my phd research which few months back i have started. Can u suggest me which algorithm of Machine learning/ Deep learning will be best for text classification?
Thank u.
Yes, a CNN.
You can learn more here:
https://machinelearningmastery.com/best-practices-document-classification-deep-learning/
incredibly, overwhelming good article! 🙂
Thanks!
Nice, big thanks 🙂
You’re welcome.
Hi Jason, thank you so much for this post. I’ve been overwhelmed by tuning parameters for weeks and your post gives me a clear direction on how to do that. I just found the two links under 3.5 network topology: how many hidden layers and units should I used don’t work. Could you update those links? Thanks!
Thanks.
See this post on the number of nodes and layers:
https://machinelearningmastery.com/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
Thank you so much Jason, By using weight initialization accuracy increased from 0.05 to o.9497, your tutorial is the best in machine learning, I’m going to publish paper with this excellent results, thank you so much
Thanks, well done on the improvement!
you are great. All my questions answered by you
keep on Jason and thanks a lot 🙂
Thanks!
I have a question.
let suppose I have a data set of thousands of the images. It took several hours to train the DL model. After training I realize that I should go with some other configuration of hyper parameters (selection by errors and trails). In that way I will again have to wait for several hour to train the model on new hyper parameters and parameters and same situation is going on.
Can you suggest me tutorial or relevant topics, so that after performing my training once, I get the best model, instead of trying the training on various configurations. . . ?
Thanks for you cooperation.
No such method is known.
You can short-cut the process with transfer learning – adapting a pre-trained model from another domain, or one of your own pre-trained models.
sir how can i do clear segmentation in cnn
what parameters i have to change to give clear segmentation sir
filter size or, padding size in maxpool ,
sir i am getting wrong segmentation with 3 class (using softmax as af)
What do you mean by clear segmentation exactly?
Hi sir. Again great article. I have a question regarding all this.
It is difficult to implement all these for a beginner and self implemented network might not be accurate. So can you please suggest me a good open source implementation of all this in R language or python in which we can change our own new activation function or just change the aforementioned (in your post) parameters and check the results. Does such implementation exists covering all these things where we are supposed to change just parameters.
Thanks four your kind response sir.
Thanks.
Yes, I implement them all and more here:
https://machinelearningmastery.com/start-here/#better
Hi Jason.
Sometimes some part of too old data , if we include in training data become “toxic” to our model.
But the problem is we don’t know which part of old data that cause this, it can be from
oldest data, can be in the middle, and it can be only 10% percent bad data, 15 % percent bad data.
By looking maybe we can find it manually, but how to create automatic to detect this “toxic” data and remove it.
any suggestion
Thanks
Mike
Perhaps fit the model with each subset of data removed and compare the performance from each experiment.
Hi Jason, thanks a lot for this post! I am using it for my computer science school project and it really helps. I have one question though in section 2. A don’t quite understand why resampling methods are in the algorithm section and not in section 1. Is this just because resampling methods are section 1 material applied?
They are tied to model evaluation in my mind.
Thank you!
You’re welcome.
Thank you so much for this article! It really helped and it wasn’t the only one that did. I have been using your website for a while now to help with my school project.
Forgot I already commented here 🙂
No problem. We’re one big community of practitioners.
You’re very welcome!
Hi Jason,
thanks for these great supports.
I am trying binary classification using VGG transfer learning. I would like to share few observations for your comments:
1. My training accuracy is not increasing beyond 87%. How can I increase training accuracy to beyond 99%.
2. For large number of epochs, validation accuracy remains higher than training accuracy. When both converge and validation accuracy goes down to training accuracy, training loop exits based on Early Stopping criterion.
3. Test accuracy comes higher than training and validation accuracy.
4. Do we need to use SGD or Adam, using very low learning rate, while re-training VGG?
Any suggestions for improvement will make me grateful.
Great questions!
Here are some ideas for diagnosing issues and techniques for lifting the performance of deep learning models:
https://machinelearningmastery.com/start-here/#better
SGD gives a more fine grained control over the learning rate.
Thank you so much for your valuable support.
You’re welcome.
sir kindly provide the information about ensembling of cnn with fine tunning and freezing
You can find examples of all of this on the blog, use the search box at the top of the page.
Jason, I am not able to open any of the related links provided in this blog. Can you please check and confirm once.
Sorry to hear that, perhaps you can try a different browser or different internet connection.
Still a great article all these years later! Thanks! Bookmarking this for forever.
There’s a tiny typo, by the way… “Spot-check a suite of top methods and see which fair well and which do not” should actually be “…which fare well…”.
Thank you for the feedback Kevin!
Thanks for your efforts and apprectiating your work, have helped in understanding the basix of deep learning.
You are very welcome Zahoor! We appreciate your support!