Text classification describes a general class of problems such as predicting the sentiment of tweets and movie reviews, as well as classifying email as spam or not.
Deep learning methods are proving very good at text classification, achieving state-of-the-art results on a suite of standard academic benchmark problems.
In this post, you will discover some best practices to consider when developing deep learning models for text classification.
After reading this post, you will know:
- The general combination of deep learning methods to consider when starting your text classification problems.
- The first architecture to try with specific advice on how to configure hyperparameters.
- That deeper networks may be the future of the field in terms of flexibility and capability.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Best Practices for Document Classification with Deep Learning
Photo by storebukkebruse, some rights reserved.
Overview
This tutorial is divided into 5 parts; they are:
- Word Embeddings + CNN = Text Classification
- Use a Single Layer CNN Architecture
- Dial in CNN Hyperparameters
- Consider Character-Level CNNs
- Consider Deeper CNNs for Classification
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
1. Word Embeddings + CNN = Text Classification
The modus operandi for text classification involves the use of a word embedding for representing words and a Convolutional Neural Network (CNN) for learning how to discriminate documents on classification problems.
Yoav Goldberg, in his primer on deep learning for natural language processing, comments that neural networks in general offer better performance than classical linear classifiers, especially when used with pre-trained word embeddings.
The non-linearity of the network, as well as the ability to easily integrate pre-trained word embeddings, often lead to superior classification accuracy.
— A Primer on Neural Network Models for Natural Language Processing, 2015.
He also comments that convolutional neural networks are effective at document classification, namely because they are able to pick out salient features (e.g. tokens or sequences of tokens) in a way that is invariant to their position within the input sequences.
Networks with convolutional and pooling layers are useful for classification tasks in which we expect to find strong local clues regarding class membership, but these clues can appear in different places in the input. […] We would like to learn that certain sequences of words are good indicators of the topic, and do not necessarily care where they appear in the document. Convolutional and pooling layers allow the model to learn to find such local indicators, regardless of their position.
— A Primer on Neural Network Models for Natural Language Processing, 2015.
The architecture is therefore comprised of three key pieces:
- Word Embedding: A distributed representation of words where different words that have a similar meaning (based on their usage) also have a similar representation.
- Convolutional Model: A feature extraction model that learns to extract salient features from documents represented using a word embedding.
- Fully Connected Model: The interpretation of extracted features in terms of a predictive output.
Yoav Goldberg highlights the CNNs role as a feature extractor model in his book:
… the CNN is in essence a feature-extracting architecture. It does not constitute a standalone, useful network on its own, but rather is meant to be integrated into a larger network, and to be trained to work in tandem with it in order to produce an end result. The CNNs layer’s responsibility is to extract meaningful sub-structures that are useful for the overall prediction task at hand.
— Page 152, Neural Network Methods for Natural Language Processing, 2017.
The tying together of these three elements is demonstrated in perhaps one of the most widely cited examples of the combination, described in the next section.
2. Use a Single Layer CNN Architecture
You can get good results for document classification with a single layer CNN, perhaps with differently sized kernels across the filters to allow grouping of word representations at different scales.
Yoon Kim in his study of the use of pre-trained word vectors for classification tasks with Convolutional Neural Networks found that using pre-trained static word vectors does very well. He suggests that pre-trained word embeddings that were trained on very large text corpora, such as the freely available word2vec vectors trained on 100 billion tokens from Google news may offer good universal features for use in natural language processing.
Despite little tuning of hyperparameters, a simple CNN with one layer of convolution performs remarkably well. Our results add to the well-established evidence that unsupervised pre-training of word vectors is an important ingredient in deep learning for NLP
— Convolutional Neural Networks for Sentence Classification, 2014.
He also discovered that further task-specific tuning of the word vectors offer a small additional improvement in performance.
Kim describes the general approach of using CNN for natural language processing. Sentences are mapped to embedding vectors and are available as a matrix input to the model. Convolutions are performed across the input word-wise using differently sized kernels, such as 2 or 3 words at a time. The resulting feature maps are then processed using a max pooling layer to condense or summarize the extracted features.
The architecture is based on the approach used by Ronan Collobert, et al. in their paper “Natural Language Processing (almost) from Scratch“, 2011. In it, they develop a single end-to-end neural network model with convolutional and pooling layers for use across a range of fundamental natural language processing problems.
Kim provides a diagram that helps to see the sampling of the filters using differently sized kernels as different colors (red and yellow).
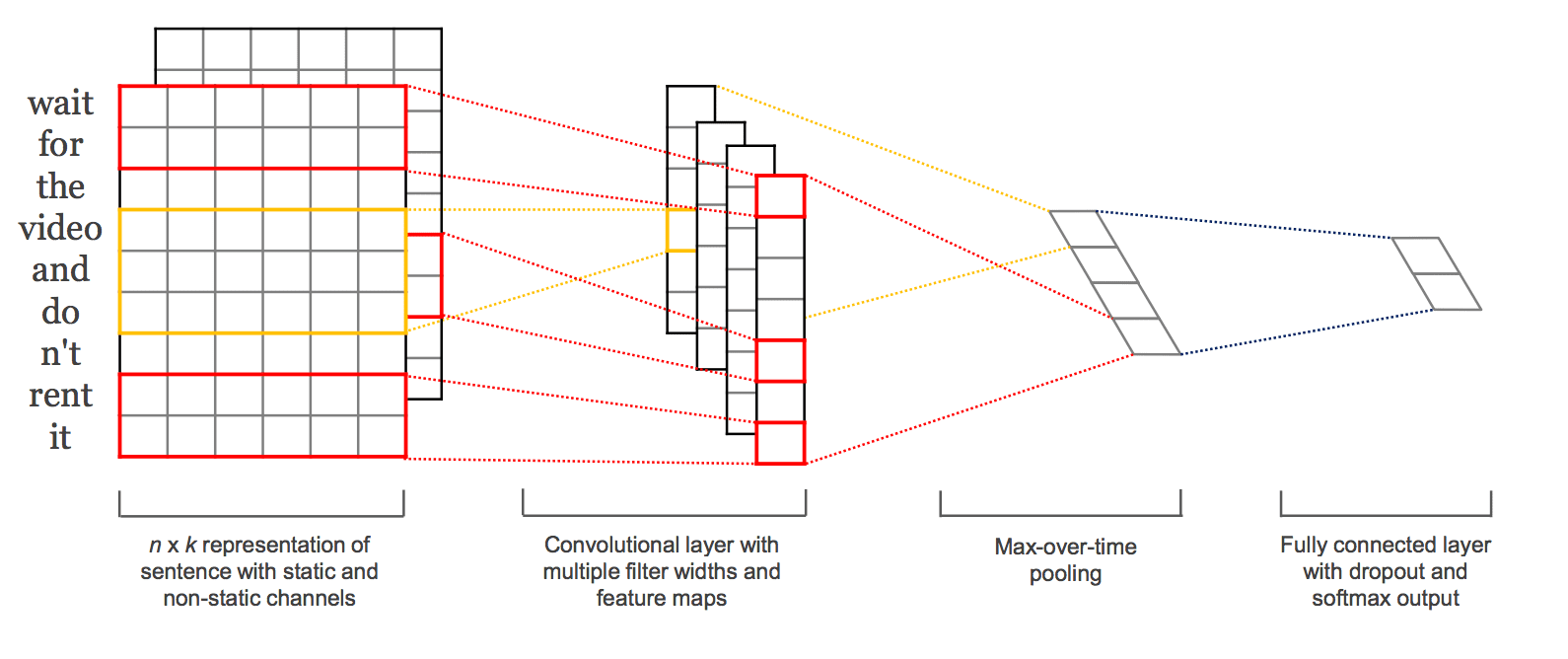
An example of a CNN Filter and Polling Architecture for Natural Language Processing.
Taken from “Convolutional Neural Networks for Sentence Classification”, 2014.
Usefully, he reports his chosen model configuration, discovered via grid search and used across a suite of 7 text classification tasks, summarized as follows:
- Transfer function: rectified linear.
- Kernel sizes: 3, 4, 5.
- Number of filters: 100
- Dropout rate: 0.5
- Weight regularization (L2): 3
- Batch Size: 50
- Update Rule: Adadelta
These configurations could be used to inspire a starting point for your own experiments.
3. Dial in CNN Hyperparameters
Some hyperparameters matter more than others when tuning a convolutional neural network on your document classification problem.
Ye Zhang and Byron Wallace performed a sensitivity analysis into the hyperparameters needed to configure a single layer convolutional neural network for document classification. The study is motivated by their claim that the models are sensitive to their configuration.
Unfortunately, a downside to CNN-based models – even simple ones – is that they require practitioners to specify the exact model architecture to be used and to set the accompanying hyperparameters. To the uninitiated, making such decisions can seem like something of a black art because there are many free parameters in the model.
Their aim was to provide general configurations that can be used for configuring CNNs on new text classification tasks.
They provide a nice depiction of the model architecture and the decision points for configuring the model, reproduced below.
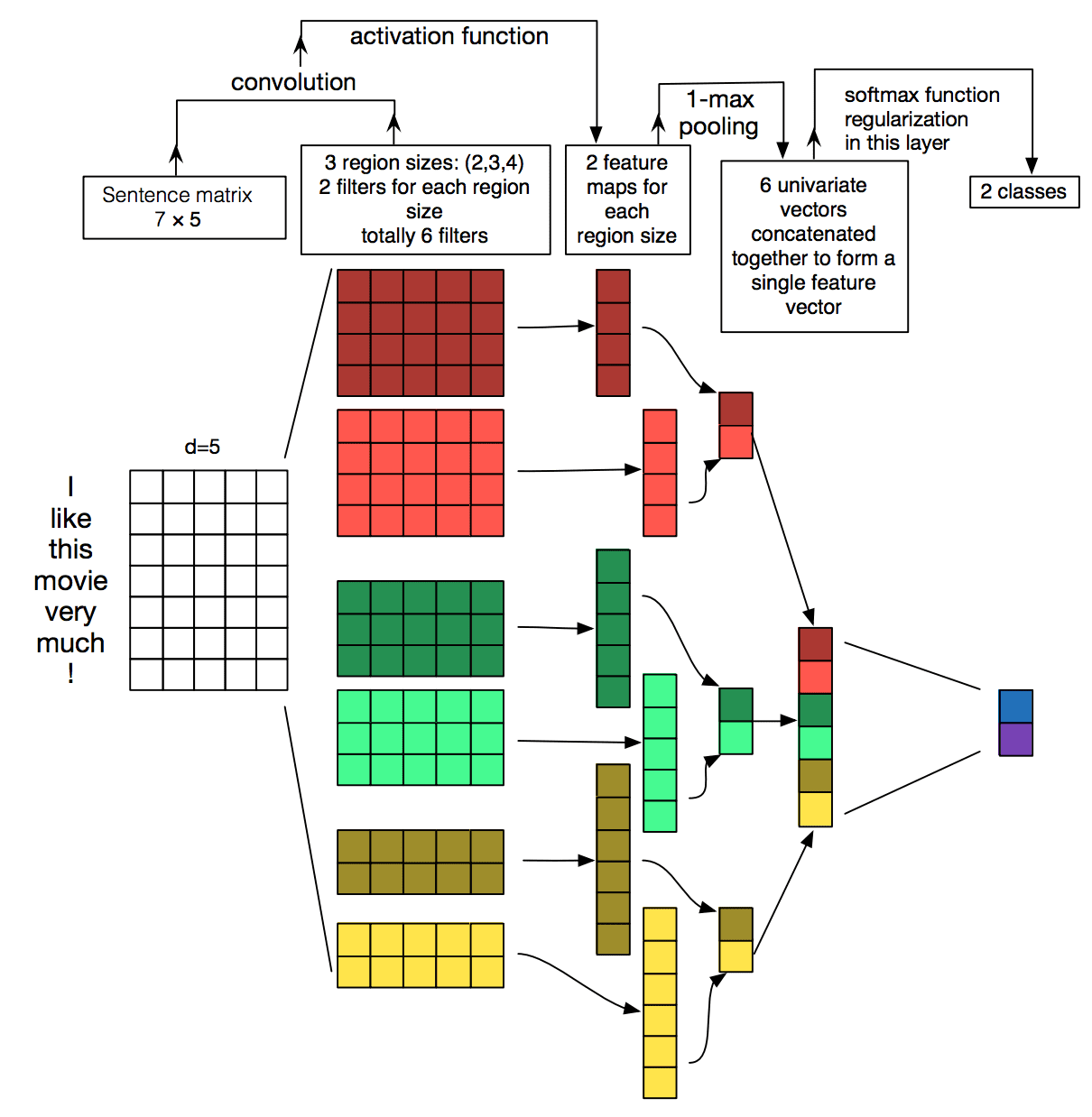
Convolutional Neural Network Architecture for Sentence Classification
Taken from “A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification“, 2015.
The study makes a number of useful findings that could be used as a starting point for configuring shallow CNN models for text classification.
The general findings were as follows:
- The choice of pre-trained word2vec and GloVe embeddings differ from problem to problem, and both performed better than using one-hot encoded word vectors.
- The size of the kernel is important and should be tuned for each problem.
- The number of feature maps is also important and should be tuned.
- The 1-max pooling generally outperformed other types of pooling.
- Dropout has little effect on the model performance.
They go on to provide more specific heuristics, as follows:
- Use word2vec or GloVe word embeddings as a starting point and tune them while fitting the model.
- Grid search across different kernel sizes to find the optimal configuration for your problem, in the range 1-10.
- Search the number of filters from 100-600 and explore a dropout of 0.0-0.5 as part of the same search.
- Explore using tanh, relu, and linear activation functions.
The key caveat is that the findings are based on empirical results on binary text classification problems using single sentences as input.
I recommend reading the full paper to get more details:
4. Consider Character-Level CNNs
Text documents can be modeled at the character level using convolutional neural networks that are capable of learning the relevant hierarchical structure of words, sentences, paragraphs, and more.
Xiang Zhang, et al. use a character-based representation of text as input for a convolutional neural network. The promise of the approach is that all of the labor-intensive effort required to clean and prepare text could be overcome if a CNN can learn to abstract the salient details.
… deep ConvNets do not require the knowledge of words, in addition to the conclusion from previous research that ConvNets do not require the knowledge about the syntactic or semantic structure of a language. This simplification of engineering could be crucial for a single system that can work for different languages, since characters always constitute a necessary construct regardless of whether segmentation into words is possible. Working on only characters also has the advantage that abnormal character combinations such as misspellings and emoticons may be naturally learnt.
— Character-level Convolutional Networks for Text Classification, 2015.
The model reads in one-hot encoded characters in a fixed-sized alphabet. Encoded characters are read in blocks or sequences of 1,024 characters. A stack of 6 convolutional layers with pooling follows, with 3 fully connected layers at the output end of the network in order to make a prediction.
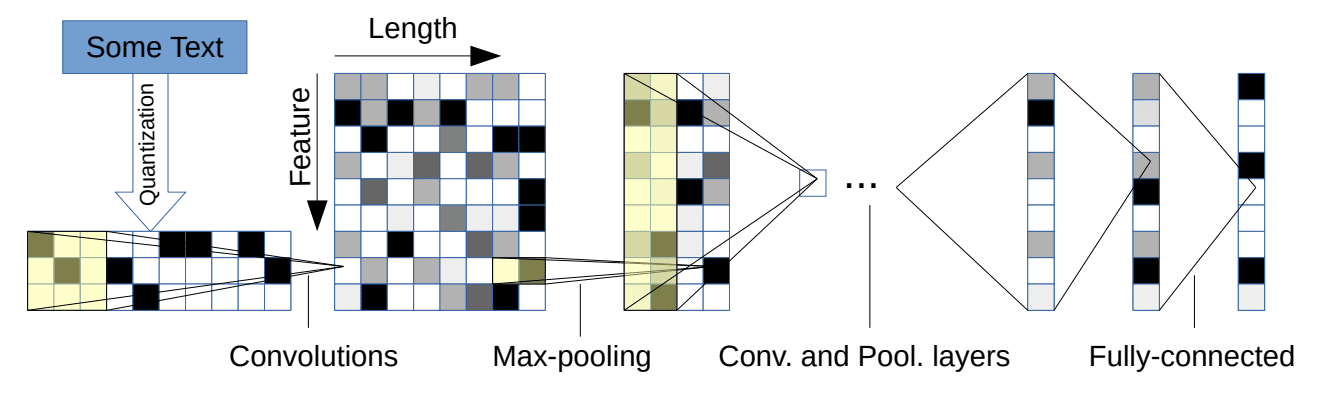
Character-based Convolutional Neural Network for Text Classification
Taken from “Character-level Convolutional Networks for Text Classification“, 2015.
The model achieves some success, performing better on problems that offer a larger corpus of text.
… analysis shows that character-level ConvNet is an effective method. […] how well our model performs in comparisons depends on many factors, such as dataset size, whether the texts are curated and choice of alphabet.
— Character-level Convolutional Networks for Text Classification, 2015.
Results using an extended version of this approach were pushed to the state-of-the-art in a follow-up paper covered in the next section.
5. Consider Deeper CNNs for Classification
Better performance can be achieved with very deep convolutional neural networks, although standard and reusable architectures have not been adopted for classification tasks, yet.
Alexis Conneau, et al. comment on the relatively shallow networks used for natural language processing and the success of much deeper networks used for computer vision applications. For example, Kim (above) restricted the model to a single convolutional layer.
Other architectures used for natural language reviewed in the paper are limited to 5 and 6 layers. These are contrasted with successful architectures used in computer vision with 19 or even up to 152 layers.
They suggest and demonstrate that there are benefits for hierarchical feature learning with very deep convolutional neural network model, called VDCNN.
… we propose to use deep architectures of many convolutional layers to approach this goal, using up to 29 layers. The design of our architecture is inspired by recent progress in computer vision […] The proposed deep convolutional network shows significantly better results than previous ConvNets approach.
Key to their approach is an embedding of individual characters, rather than a word embedding.
We present a new architecture (VDCNN) for text processing which operates directly at the character level and uses only small convolutions and pooling operations.
— Very Deep Convolutional Networks for Text Classification, 2016.
Results on a suite of 8 large text classification tasks show better performance than more shallow networks. Specifically, state-of-the-art results on all but two of the datasets tested, at the time of writing.
Generally, they make some key findings from exploring the deeper architectural approach:
- The very deep architecture worked well on small and large datasets.
- Deeper networks decrease classification error.
- Max-pooling achieves better results than other, more sophisticated types of pooling.
- Generally going deeper degrades accuracy; the shortcut connections used in the architecture are important.
… this is the first time that the “benefit of depths” was shown for convolutional neural networks in NLP.
— Very Deep Convolutional Networks for Text Classification, 2016.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
- A Primer on Neural Network Models for Natural Language Processing, 2015.
- Convolutional Neural Networks for Sentence Classification, 2014.
- Natural Language Processing (almost) from Scratch, 2011.
- Very Deep Convolutional Networks for Text Classification, 2016.
- Character-level Convolutional Networks for Text Classification, 2015.
- A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification, 2015.
Have you come across some good resources on deep learning for document classification?
Let me know in the comments below.
Summary
In this post, you discovered some best practices for developing deep learning models for document classification.
Specifically, you learned:
- That a key approach is to use word embeddings and convolutional neural networks for text classification.
- That a single layer model can do well on moderate-sized problems, and ideas on how to configure it.
- That deeper models that operate directly on text may be the future of natural language processing.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning models for Text Data Today!

Develop Your Own Text models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Natural Language Processing
It provides self-study tutorials on topics like:
Bag-of-Words, Word Embedding, Language Models, Caption Generation, Text Translation and much more...
Finally Bring Deep Learning to your Natural Language Processing Projects
Skip the Academics. Just Results.




")
")
Thank you Jason for this article. However, it’s unclear how the entire document gets classified.
You write “Sentences are mapped to embedding vectors and are available as a matrix input to the model.”.
So if my document has 100 sentences, I have to make 100 predictions, one per sentence? An then pick the most frequently predicted class?
No, you can map the whole document to embedding vectors.
Yeah, but most libraries, like Keras, take matrices of fixed size as input. So I have to fix in advance the size of the input. Fixing it to the maximum size of the document would create huge input matrices. Am I right or I miss something?
This is true for many formulations, but not a rule.
You can define models that do not specify the i/o length and truly process variable lengthed inputs and outputs. I have a post this week on exactly this topic.
I understand that in this formulation https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2017/08/Convolutional-Neural-Network-Architecture-for-Sentence-Classification.png the input can be of a variable length. I was wondering how can get this work in libraries like Keras. I’ll wait for your post then 🙂
I have a post on this scheduled. It will also appear in my new book on the topic.
Jason – What is new book 🙂 What is the topic?
My new book is on deep learning for NLP. It is being edited now and should be released soon.
Can you explain how to map the whole document to embedding vectors in detail?
Sure, see this step-by-step tutorial:
https://machinelearningmastery.com/develop-word-embeddings-python-gensim/
This article is a very good starting point imho. However, what I do not quite understand is how one would approach large documents which contain hundreds (or thousands) of sentences. How would we represent such a large document? Of course, theoretically we could just build a very large CNN but in practice there will be memory issues.
So, is there a smarter way to do this? I was thinking of e.g. compressing each sentence into features through a convolutional layer and then use this feature as sentence representation for a whole document. However, a document with thousands of sentences might still be too much to process. What would be the way to do this – or can somebody recommend me some literature?
You would use a word embedding on the front end of the network which means that the document need only be stored as a long list of integers (e.g. small). Further, the model could process subsequences of the document at a time, e.g. LSTMs top-out at about 200-400 time steps.
But wouldn’t this generate another sequence? If the task would be to assign a number of labels to an entire document, this LSTM approach might be useful to compress documents into another lower dimensional feature space (sequence) but in order to generate a final prediction one might still have to apply another layer of “compression”.
This looks interesting: http://www.aclweb.org/anthology/N16-1174
The LSTM encoder-decoder architecture can be used to create a compressed interpretation of the input and then output a sequence with a different length. I have many posts on the topic.
Attention is a nice optimization on top of the encoder-decoder. I also have many posts on the topic. Try the blog search.
Hi,
I found RJ also did good research on Text Classififcation. Their paper
“Convolutional Neural Networks for Text Categorization: Shallow Word-level vs. Deep Character-level” (https://arxiv.org/abs/1609.00718) shows good result on the same dataset.
And they had good progress on text classification thereafter and published paper “Deep Pyramid Convolutional Neural Networks for Text Categorization” (http://aclanthology.coli.uni-saarland.de/pdf/P/P17/P17-1052.pdf) in 2017 ACL.
Great, thanks for sharing!
Thank you Jason for this useful article. I have question about combination of CNN with LSTM for sentiment classification. is it possible to combine them to improve the performance? and how can I do the training procedure?
I will have some tutorials on the topic soon, they are scheduled.
Thanks for this article Jason. Could you also give some pointers on how to go about web content extraction (mostly news articles) using CNNs or RNNs. I think they also fall in doc classification (content or not-content classifier), but not sure which type of features and deep architecture work best. Plus I’m also searching for a good training corpus for this type of problem. Can you point me in the right direction, or a dedicated tutorial would be nice. Thanks.
Content extraction is the summarizing of nouns in the data.
I hope to cover this topic in the future.
Are CNN > LSTM for document classification?
Yes, I believe so in practice. I would recommend pushing embeddings + CNNs as far as you can and only move to LSTM if they can do better on your specific data.
Jason, help me please.
I tried many times to start my net from Convolutional layer instead of Embedding. But every time I received error message (shape of input).
This is my pad_sequences:
[7 5 4 3 0 0 0 0]
..
[1 5 8 9 11 5 3 6]
Tell me please how can I configure my Conv1D?
What is the error exactly?
Thanks for feedback. Yesterday I tried again and we could develop Convoltional layer as first layer instead of Embedding layer.
The key was in shape of input. I used numpy.reshape function to prepare data.
Nice Alex!
For more help regarding reshaping in the future, see this post:
https://machinelearningmastery.com/index-slice-reshape-numpy-arrays-machine-learning-python/
Hi Jason, thank you for sharing. Many times I searched the Internet for my problems and ended up here. Your articles are always helpful and very well written. And… a kind of trivial thing, about the font. I know it’s subjective and I find them too thin and light to be very readable. I decided to tell you because chances are I’m going to read more of your helpful articles in the future. 😉
Thanks for the suggestion.
my cnn model predicting the same class for each and every input. can you help me ?
Here are some ideas:
https://machinelearningmastery.com/improve-deep-learning-performance/
Hi Jason, This is a nice article. Well, what if if the document is an image(tiff) and it contains text. Can CNN’s be used for classification ? And also suppose the document is an invoice, how can I extract information using CNN’s?
Sure, I don’t see why you couldn’t train models in these situations.
Thanks, but this post does not talk at all about document classification as the title suggest.
I believe it does. What do you mean exactly?
What do you need help with?
Do you have any ideas as to how one could incorporate document level metadata to help improve classification? For example, information like the type of document, where the document was retrieved, the date it was retrieved, or additional text data describing the document. Thanks in advance!
Yes, have a vector along side the document with this data and condition the model on the document and the vector. Perhaps a multi-headed model.
Here are some examples:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Hi Jason, thank you for the reply!
What do you mean by “conditioning the model on the document and the vector”? Would the multiple input model featured in the link you referenced encapsulate that process? How well would you guess attention mechanisms used in many Question-Answering Models work to achieve the “conditioning”? Thank you again for the insight!
Yes, a multi-headed input model.
Try attention and see if it can lift skill over a model without attention.
Hi Jason,
How would I got about performing supervised multiclass classification of text data (sentences) with deep learning methods?
Here’s an example:
https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/
Hi Jason,
Currently i am using dataset which is having input sentences and corresponding labels( This is JSON file). This is basically text classification problem. First i am preprocessing the data set and converting it to bag of words to train the DNN. Now, i want to use Doc2Vec instead of bag of words approach. Could you share some link. How vectors generated for each sentences will be used as training examples.
Yes, see this post:
https://machinelearningmastery.com/use-word-embedding-layers-deep-learning-keras/
Hi Jason Can we build a model which classifies the document based on language
I don’t see why not. Sounds like a fun project!
Google translate does this – detects the language.
Hi Jason, I am new to deep learning what i want to ask is why we use CNN’s after the embeding layer rather than RNN?
Either can be used. On some problems CNNs can perform better than an LSTM. We must discover what works best for our specific dataset.
Hello, for day 6 I’ve found the following articles which may provide some hints on hyperparameters on CNN models +Embeddings
with reference to various CNN-based approach to text classification and other NLP tasks.
1) ” Comparative Study of CNN and RNN for Natural Language Processing ” (https://arxiv.org/pdf/1702.01923.pdf) compares CNN and RNN (GRU, LSTM) appilcation to a suite of NLP tasks and the results obtained. It also provides a description of models and the hyperparameters used.
2) “Hyperparameter Tuning for Deep Learning in Natural Language Processing” (http://ceur-ws.org/Vol-2458/paper5.pdf) provides methodology and values for the tuning of hyperperameter, in CNN and Bidirectional LMST models.
3) “Convolutional Neural Network with Word Embeddings for Chinese Word Segmentation” (https://www.aclweb.org/anthology/I17-1017.pdf) describes the model for the task and provides the table of adopted hyperparameters.
Other CNN-based model are discussed and described (and detail as for hyperparameters) in the following papers:
4) In “Very Deep Convolutional Networks for Natural Language Processing” (https://arxiv.org/pdf/1606.01781.pdf), where they state that stacked LSTMs networks cannot go deeper, while CNN (which however is not a real sequence-to-sequence network), can get semantics at hyerarchical levels. Going deeper, however requires specific network solutions both for hyperparameter setting and for structural arrangements (e.g. inception layers). Arrangements for allowing deep CNN are proposed in “Squeezed Very Deep Convolutional Neural
Networks for Text Classification” (https://arxiv.org/pdf/1901.09821.pdf), “Text Classification based on Multiple Block Convolutional Highways” (https://arxiv.org/ftp/arxiv/papers/1807/1807.09602.pdf).
5) Attention-based CNN for text classification is proposed in “An attention-gated convolutional neural network for sentence classification” (https://arxiv.org/ftp/arxiv/papers/1808/1808.07325.pdf) in order to assign context-based weighs to feature maps before pooling, so to maintan local semantic also at higher abstraction levels. This is useful for finer-grain task as multilabel classification, and a different approach for the same goal has been used in “Ensemble Application of Convolutional and Recurrent Neural Networks for Multi-label Text Categorization” (https://sentic.net/convolutional-and-recurrent-neural-networks-for-text-categorization.pdf).
Best Regards
Paolo Bussotti
Well done!
very helpful article as usual
i have one question
can we use word2vec with n grams i mean instead of building and transfer every word to embedding vector can we make this but for two grams i mean the embedding vector will represent two grams (bi gram) instead of only one word?(unigram)
Perhaps, I don’t have tutorials on this sorry.
thank you for reply
You’re welcome.
This is really an amazing tutorial about the text classification. I really appreciate to author for providing such an informative and useful tutorial. Thanks You Sir..
You’re very welcome!
Hi jason!
Nice tutorial about NLP text classification concepts!.
two theoretical questions about this ML/DL CNN Text Classification model architecture tutorial:
1º) in order to apply Conv1D Convolutional layer, on ML/DL for text classification, do we have to have a previous Embedded layer? I guess so because they need a 3D input tensor, right?
2º) is there any approach for Text Classification, similar e..g. to VGG16 in computer vision, where several blocks of several Convolution layers plus Pooling Layer could be applied sequentially ?
kind regards,
JG
An embedding is typically a good idea, but is not required. You can run the integer encoded words straight into a CNN or LSTM if you want.
There didn’t used to be, but there may be now. e.g. transformers/BERT dominants for language models.
Love this summary. You made a small typo:
“Kernel sizes: 2, 4, 5.” in Chapter 2 should be “Kernel sizes: 3, 4, 5.” according to page 1748, chapter 3.1 of the original paper: https://www.aclweb.org/anthology/D14-1181.pdf.
Thanks! fixed.
Hi Jason, may I ask you what you think about this
https://datascience.stackexchange.com/questions/87222/problem-of-multi-class-classification-sklearn-tfidfvectorizer-and-sgdclassifier
Thank you
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-you-comment-on-my-stackoverflow-question
Hi,thanks for this post! In a sentiment problem, is it possible to find out which words contribute to the given label? Or is the process too black box?
Mostly black box. It is unfortunate but deep learning make it quite difficult to understand why the network gives out a particular answer.
Hi Jason,
what are the best ways to handle text of size more than 512 characters? Does BERT support that long text? Or any other libraries what would best fit to handle this situation.
512 characters is not long. BERT can do that.
Dear Sir,
Which deep learning method is better for text classification CNN or RNN? Do have any link regarding this?
Hi Sheetal…They both are good considerations for this purpose. The following resource may be of interest:
https://towardsdatascience.com/model-selection-in-text-classification-ac13eedf6146