Develop a Deep Learning Model to Automatically
Translate from German to English in Python with Keras, Step-by-Step.
Machine translation is a challenging task that traditionally involves large statistical models developed using highly sophisticated linguistic knowledge.
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
German to English Translation Dataset
In this tutorial, we will use a dataset of German to English terms used as the basis for flashcards for language learning.
The dataset is available from the ManyThings.org website, with examples drawn from the Tatoeba Project. The dataset is comprised of German phrases and their English counterparts and is intended to be used with the Anki flashcard software.
The page provides a list of many language pairs, and I encourage you to explore other languages:
Take a look at the raw data and note what you see that we might need to handle in a data cleaning operation.
For example, here are some observations I note from reviewing the raw data:
There is punctuation.
The text contains uppercase and lowercase.
There are special characters in the German.
There are duplicate phrases in English with different translations in German.
The file is ordered by sentence length with very long sentences toward the end of the file.
Did you note anything else that could be important?
Let me know in the comments below.
A good text cleaning procedure may handle some or all of these observations.
Data preparation is divided into two subsections:
Clean Text
Split Text
1. Clean Text
First, we must load the data in a way that preserves the Unicode German characters. The function below called load_doc() will load the file as a blob of text.
1
2
3
4
5
6
7
8
9
# load doc into memory
def load_doc(filename):
# open the file as read only
file=open(filename,mode='rt',encoding='utf-8')
# read all text
text=file.read()
# close the file
file.close()
returntext
Each line contains a single pair of phrases, first English and then German, separated by a tab character.
We must split the loaded text by line and then by phrase. The function to_pairs() below will split the loaded text.
1
2
3
4
5
# split a loaded document into sentences
def to_pairs(doc):
lines=doc.strip().split('\n')
pairs=[line.split('\t')forline inlines]
returnpairs
We are now ready to clean each sentence. The specific cleaning operations we will perform are as follows:
Remove all non-printable characters.
Remove all punctuation characters.
Normalize all Unicode characters to ASCII (e.g. Latin characters).
Normalize the case to lowercase.
Remove any remaining tokens that are not alphabetic.
We will perform these operations on each phrase for each pair in the loaded dataset.
The clean_pairs() function below implements these operations.
Running the example creates a new file in the current working directory with the cleaned text called english-german.pkl.
Some examples of the clean text are printed for us to evaluate at the end of the run to confirm that the clean operations were performed as expected.
1
2
3
4
5
6
7
8
9
10
11
[hi] => [hallo]
[hi] => [gru gott]
[run] => [lauf]
[wow] => [potzdonner]
[wow] => [donnerwetter]
[fire] => [feuer]
[help] => [hilfe]
[help] => [zu hulf]
[stop] => [stopp]
[wait] => [warte]
...
2. Split Text
The clean data contains a little over 150,000 phrase pairs and some of the pairs toward the end of the file are very long.
This is a good number of examples for developing a small translation model. The complexity of the model increases with the number of examples, length of phrases, and size of the vocabulary.
Although we have a good dataset for modeling translation, we will simplify the problem slightly to dramatically reduce the size of the model required, and in turn the training time required to fit the model.
You can explore developing a model on the fuller dataset as an extension; I would love to hear how you do.
We will simplify the problem by reducing the dataset to the first 10,000 examples in the file; these will be the shortest phrases in the dataset.
Further, we will then stake the first 9,000 of those as examples for training and the remaining 1,000 examples to test the fit model.
Below is the complete example of loading the clean data, splitting it, and saving the split portions of data to new files.
Running the example creates three new files: the english-german-both.pkl that contains all of the train and test examples that we can use to define the parameters of the problem, such as max phrase lengths and the vocabulary, and the english-german-train.pkl and english-german-test.pkl files for the train and test dataset.
We are now ready to start developing our translation model.
Train Neural Translation Model
In this section, we will develop the neural translation model.
If you are new to neural translation models, see the post:
This involves both loading and preparing the clean text data ready for modeling and defining and training the model on the prepared data.
Let’s start off by loading the datasets so that we can prepare the data. The function below named load_clean_sentences() can be used to load the train, test, and both datasets in turn.
We will use the “both” or combination of the train and test datasets to define the maximum length and vocabulary of the problem.
This is for simplicity. Alternately, we could define these properties from the training dataset alone and truncate examples in the test set that are too long or have words that are out of the vocabulary.
We can use the Keras Tokenize class to map words to integers, as needed for modeling. We will use separate tokenizer for the English sequences and the German sequences. The function below-named create_tokenizer() will train a tokenizer on a list of phrases.
1
2
3
4
5
# fit a tokenizer
def create_tokenizer(lines):
tokenizer=Tokenizer()
tokenizer.fit_on_texts(lines)
returntokenizer
Similarly, the function named max_length() below will find the length of the longest sequence in a list of phrases.
1
2
3
# max sentence length
def max_length(lines):
returnmax(len(line.split())forline inlines)
We can call these functions with the combined dataset to prepare tokenizers, vocabulary sizes, and maximum lengths for both the English and German phrases.
Each input and output sequence must be encoded to integers and padded to the maximum phrase length. This is because we will use a word embedding for the input sequences and one hot encode the output sequences The function below named encode_sequences() will perform these operations and return the result.
1
2
3
4
5
6
7
# encode and pad sequences
def encode_sequences(tokenizer,length,lines):
# integer encode sequences
X=tokenizer.texts_to_sequences(lines)
# pad sequences with 0 values
X=pad_sequences(X,maxlen=length,padding='post')
returnX
The output sequence needs to be one-hot encoded. This is because the model will predict the probability of each word in the vocabulary as output.
The function encode_output() below will one-hot encode English output sequences.
We will use an encoder-decoder LSTM model on this problem. In this architecture, the input sequence is encoded by a front-end model called the encoder then decoded word by word by a backend model called the decoder.
The function define_model() below defines the model and takes a number of arguments used to configure the model, such as the size of the input and output vocabularies, the maximum length of input and output phrases, and the number of memory units used to configure the model.
The model is trained using the efficient Adam approach to stochastic gradient descent and minimizes the categorical loss function because we have framed the prediction problem as multi-class classification.
The model configuration was not optimized for this problem, meaning that there is plenty of opportunity for you to tune it and lift the skill of the translations. I would love to see what you can come up with.
For more advice on configuring neural machine translation models, see the post:
A plot of the model is also created providing another perspective on the model configuration.
Plot of Model Graph for NMT
Next, the model is trained.
Each epoch takes about 30 seconds on modern CPU hardware; no GPU is required.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
During the run, the model will be saved to the file model.h5, ready for inference in the next step.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
...
Epoch 26/30
Epoch 00025: val_loss improved from 2.20048 to 2.19976, saving model to model.h5
17s - loss: 0.7114 - val_loss: 2.1998
Epoch 27/30
Epoch 00026: val_loss improved from 2.19976 to 2.18255, saving model to model.h5
17s - loss: 0.6532 - val_loss: 2.1826
Epoch 28/30
Epoch 00027: val_loss did not improve
17s - loss: 0.5970 - val_loss: 2.1970
Epoch 29/30
Epoch 00028: val_loss improved from 2.18255 to 2.17872, saving model to model.h5
17s - loss: 0.5474 - val_loss: 2.1787
Epoch 30/30
Epoch 00029: val_loss did not improve
17s - loss: 0.5023 - val_loss: 2.1823
Evaluate Neural Translation Model
We will evaluate the model on the train and the test dataset.
The model should perform very well on the train dataset and ideally have been generalized to perform well on the test dataset.
Ideally, we would use a separate validation dataset to help with model selection during training instead of the test set. You can try this as an extension.
The clean datasets must be loaded and prepared as before.
Evaluation involves two steps: first generating a translated output sequence, and then repeating this process for many input examples and summarizing the skill of the model across multiple cases.
Starting with inference, the model can predict the entire output sequence in a one-shot manner.
1
translation=model.predict(source,verbose=0)
This will be a sequence of integers that we can enumerate and lookup in the tokenizer to map back to words.
The function below, named word_for_id(), will perform this reverse mapping.
1
2
3
4
5
6
# map an integer to a word
def word_for_id(integer,tokenizer):
forword,index intokenizer.word_index.items():
ifindex==integer:
returnword
returnNone
We can perform this mapping for each integer in the translation and return the result as a string of words.
The function predict_sequence() below performs this operation for a single encoded source phrase.
1
2
3
4
5
6
7
8
9
10
11
# generate target given source sequence
def predict_sequence(model,tokenizer,source):
prediction=model.predict(source,verbose=0)[0]
integers=[argmax(vector)forvector inprediction]
target=list()
foriinintegers:
word=word_for_id(i,tokenizer)
ifwordisNone:
break
target.append(word)
return' '.join(target)
Next, we can repeat this for each source phrase in a dataset and compare the predicted result to the expected target phrase in English.
We can print some of these comparisons to screen to get an idea of how the model performs in practice.
We will also calculate the BLEU scores to get a quantitative idea of how well the model has performed.
Running the example first prints examples of source text, expected and predicted translations, as well as scores for the training dataset, followed by the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Looking at the results for the test dataset first, we can see that the translations are readable and mostly correct.
For example: “ich bin brillentrager” was correctly translated to “i wear glasses“.
We can also see that the translations were not perfect, with “hab ich nicht recht” translated to “am i fat” instead of the expected “am i wrong“.
We can also see the BLEU-4 score of about 0.45, which provides an upper bound on what we might expect from this model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
src=[er ist ein blodmann], target=[hes a jerk], predicted=[hes a jerk]
src=[ich bin brillentrager], target=[i wear glasses], predicted=[i wear glasses]
src=[tom hat mich aufgezogen], target=[tom raised me], predicted=[tom tricked me]
src=[ich zahle auf tom], target=[i count on tom], predicted=[ill call tom tom]
src=[ich kann rauch sehen], target=[i can see smoke], predicted=[i can help you]
src=[tom fuhlte sich einsam], target=[tom felt lonely], predicted=[tom felt uneasy]
src=[hab ich nicht recht], target=[am i wrong], predicted=[am i fat]
src=[gestatten sie mir zu gehen], target=[allow me to go], predicted=[do me to go]
src=[du hast mir gefehlt], target=[i missed you], predicted=[i missed you]
src=[es ist zu spat], target=[it is too late], predicted=[its too late]
BLEU-1: 0.844852
BLEU-2: 0.779819
BLEU-3: 0.699516
BLEU-4: 0.452614
Looking at the results on the test set, do see readable translations, which is not an easy task.
For example, we see “tom erblasste” correctly translated to “tom turned pale“.
We also see some poor translations and a good case that the model could suffer from further tuning, such as “ich brauche erste hilfe” translated as “i need them you” instead of the expected “i need first aid“.
A BLEU-4 score of about 0.153 was achieved, providing a baseline skill to improve upon with further improvements to the model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
src=[mein hund hat es gefressen], target=[my dog ate it], predicted=[my dog is tom]
src=[ich hore das telefon], target=[i hear the phone], predicted=[i want this this]
src=[reden sie weiter], target=[keep talking], predicted=[keep them]
src=[was fur ein spa], target=[what fun], predicted=[what an fun]
src=[ich bin auch siebzehn], target=[im too], predicted=[im so expert]
src=[ich bin dein vater], target=[im your father], predicted=[im your your]
src=[ich brauche erste hilfe], target=[i need first aid], predicted=[i need them you]
BLEU-1: 0.499623
BLEU-2: 0.365875
BLEU-3: 0.295824
BLEU-4: 0.153535
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Data Cleaning. Different data cleaning operations could be performed on the data, such as not removing punctuation or normalizing case, or perhaps removing duplicate English phrases.
Vocabulary. The vocabulary could be refined, perhaps removing words used less than 5 or 10 times in the dataset and replaced with “unk“.
More Data. The dataset used to fit the model could be expanded to 50,000, 100,000 phrases, or more.
Input Order. The order of input phrases could be reversed, which has been reported to lift skill, or a Bidirectional input layer could be used.
Layers. The encoder and/or the decoder models could be expanded with additional layers and trained for more epochs, providing more representational capacity for the model.
Units. The number of memory units in the encoder and decoder could be increased, providing more representational capacity for the model.
Regularization. The model could use regularization, such as weight or activation regularization, or the use of dropout on the LSTM layers.
Pre-Trained Word Vectors. Pre-trained word vectors could be used in the model.
Recursive Model. A recursive formulation of the model could be used where the next word in the output sequence could be conditional on the input sequence and the output sequence generated so far.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
In this tutorial, you discovered how to develop a neural machine translation system for translating German phrases to English.
Specifically, you learned:
How to clean and prepare data ready to train a neural machine translation system.
How to develop an encoder-decoder model for machine translation.
How to use a trained model for inference on new input phrases and evaluate the model skill.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Note: This post is an excerpt chapter from: “Deep Learning for Natural Language Processing“. Take a look, if you want more step-by-step tutorials on getting the most out of deep learning methods when working with text data.
Perhaps progressively load the dataset and convert it?
Perhaps use a smaller data sample?
Perhaps use a machine with more ram?
Perhaps use a big data pipeline like hadoop?
Hello Jason Iam getting three different elements after cleaning the data i can’t understand what the third element in this list means could you explain ?
array([[‘theres nothing left to eat at home’,
‘es ist nichts zu essen mehr im haus’,
‘ccby france attribution tatoebaorg shekitten pfirsichbaeumchen’]
Your tutorials are amazing indeed. Thank you!
Hope you will have the time to work on the Extensions lists above. This will complete this amazing tutorial.
hey i want to know one thing that if we are giving english to german translations to the model for training 9000 and for testing 1000.. then what is the encoder decoder model is actually doing ..as we are giving everything to the model at the time of testing.
Hi , Jason your wok is amazing and while i was doing this code i found this and i want to know i it’s required ti reshape the sequence ? and what sequence.shape[0],sequence.shape[1] is doing.
and why we need the vocab size ?
y = y.reshape(sequences.shape[0], sequences.shape[1], vocab_size)
i have used bidirectional lstm,got a better result…i want to improve more …but i dont know how to implement attention layer in keras…could you please help me out…
Just a quick question, when you configure the encoder-decoder model, there seems no inference model as you mentioned in your previous articles? If this model has achieved what inference model did, in which layer? If not, how does it compare to the suite of train model, inference-encoder model and inference-decoder model? Thank you so much!
Could you verify This documentation. It is mentionned that text_to_sequences return STR.
I am confusing right now. https://keras.io/preprocessing/text/
By following your tutorial, I was able to find BLEU scores on test dataset as follow :
BLEU-1: 0.069345
BLEU-2: 0.255634
BLEU-3: 0.430785
BLEU-4: 0.490818
So we can notice that they are very close to the scores on train dataset.
Is it about overfitting or it is a normal behavior ?
Hello sir, you are using test data as validation data. This means model has seen test data during training phase only. I think test data is kept separated. Am I right?? If yes please explain logic behind it.
Hello sir, great explanation. everything works well with the given corpus.when i am using the own corpus it says .pkl file is not encoded in utf-8.
can you please share the the encoding of the text files used for the above project?
It is giving following error
—————————————————————————
IndexError Traceback (most recent call last)
in ()
65 # spot check
66 for i in range(100):
—> 67 print(‘[%s] => [%s]’ % (clean_pairs[i,0], clean_pairs[i,1]))
yes jason i have updated all the libraries. it is working completely fine for the deu,txt file .
when ever i use my own text file it is giving the following error.
can you kindly tell what formatting is used in text file.
hi Jason i am a fan of yours and i have implemented this machine translation and it was awesome i got all the results perfectly .. now i wanted to generate code using natural language by using RNN.. and when i am reading my file which is of declartaion and docstrings it is not showing as it is the ouput .. like it should show the declarations but it is showing something like x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/
but it should show
if cint(frappe.db.get_single_value(u’System DCSP Settings’, u’setup_complete’)):
Hi,
I am trying to use pre trained word embeddings to make translation.
But, after making some researrch I found that pre-trained word embeddings are just only user for initialize encoder and decoder and also we nedd only the src embeddings.
So, for the moment I am confused.
Normally, must we provide source and target embeddings to the algorithme ?
Please if they are some documentation or links about this topic.
Regarding recursive model in extensions, isn’t it already implemented in the current code? Because the decoder part is lstm and is lstm output of one unit is fed to the next unit.
Hi Jason,
I have just tested the clean_pairs method against ENG-PL set provided on the same website.One of the characters does not print on the screen( ‘all the other non ASCII chars are converted correctly), it is ignored as per this line I guess:
I did an experiment with replacing the above with line = normalize(‘NFD’, line).encode(‘utf-8’, ‘ignore’), but there is no difference between these two in results.I am not sure why this is happening as it is only one letter.Also,( I assume your chose was ascii as you built a German to English translator am I correct?).Could you plase share your thoughts, if possible?
Does removing punctuation not preventing the model to be used to predict a paragraph? How can you evaluate it with one sentence or paragraph not in the test set?
From Keras. Proprocessing. Text import Tokenizer
..
Does not woking after installing keras..
..
It’s says that no module named tensorflow
..
I have windows 32 it machine.
..
Your article very good…!
.
But I can’t process ahead due to this problem!
I have one question about the difference between your implementation and the Keras Tutorial “https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html”. It seems to me that, there is a ‘teaching forcing’ element in the “Keras Tutorial” using “target” (offset by one step) as “decoder input data”. This element is not presented in your model. My question is: is it necessary? or you just use “RepeatedVector” and “TimeDistributed” to implement the similar function?
Thank you very much. Could you please help where can I get good dataset for Thai to English. The dataset for Thai language is available from the ManyThings.org website is with lesser data.I am trying to use this approach to build similar for Thai.
Hi Jason, thank you for the amazing tutorial. It really helped me. I implemented the above code and understood each function. Further, I want to implement Neural conversation model as given in https://arxiv.org/pdf/1506.05869.pdf on dialogue data. So, I have 2 questions, first is how to make pairing in dialogue data and second is how to feed previous conversations as input to the decoder model.
Hi Jason,
Great and helpful work, I am trying the code to translate Arabic to English but in first step (Clean Text) and it give me an empty [ ]?! how can I solve this one.
[hi] => []
[run] => []
[help] => []
Thanks for sharing a easy and simple approach for translations.
I tried your code to work with Indian languages and found Hindi data set in the same location from where you shared the German dataset.
The following normalize code for Hindi removes the character from line. I have tried with NFC, still facing the same problem. If I skip this line then, the non-printable character line is skipping the hindi text.
I am working on building a translator which translates from English to Hindi (or any other Indian language). But I am facing a problem while cleaning the data.
The normalize code does not work for Indian languages, and if I skip that line of code then I am not getting any output after training my data.
Is there a way to use the same code on your post and some other way to clean the data for Indian languages to get the desired output..? Like are there any python modules/Libraries that i should install so as to use them for Indian Languages.?
Aren’t we supposed to pass the English data along with the encoded data to decoder.As per my understanding only the encoded German data has been passed to the decoder right??
I have now progressed upto Training the model. Cleaning & tokenizing the data set took time as i used a different language, but was a good learning.
Wanted to know whats the significance of “30 epochs and a batch size of 64 examples” in your example. Are these anyways related to Total vocabulary (or) total trainable parameters ?
Also, could you please guide me to any article of yours where i can learn more around what is epochs, what is BLEU score , what is loss etc.
I have a silly question, but wanted to seek clarification.
In step “Train Neural Translation Model” :- have used 10,000 rows from the dataset, and established the model in file model.h5 for xxx number of vocabularies.
If I extract next 10,000 rows from data and continue to train the model using the same lines of code above, would it use the previously established model from model.h5 or would it be overwritten and start as fresh data being used to train ?
Hi Jason,
Can Word2Vec be used as the input embedding to boost the LSTM model ? Or say that pre-trained word vector by Word2Vec as input of the model can get better?
Hello Jason,
Excellently written article with intricate concepts explained in such a simple manner.However it would be great if you can add a attention layer for handling larger sentences.
How about including the attention snippet as you did in the later case.this code is working fine for me except that attention can handle longer sentences and this is where I am facing issues.I was actually asking for adding attention to the above code as you did in the later case.
Hi, I want to convert from english to german, Please help me what kind of changes required? I did few changes but it didn’t work. Please help me how can I reverse it?
i mean is to use pretrained models for next running (example : chatbot), so when i running chatbot for question and answer, must not training a model. thq
Hi Jason! Thanks for your amazing tutorial! Very clear and easy to understand. One question comes up during my reproducing of your code: the console warns that “The hypothesis contains 0 counts of 2-gram, 3-gram and 4-gram overlaps”, which leads to BLEU-2 to 4 are 0. I can’t find the reason, coz I just completely copied your code and it still doesn’t work. Can you help me with that? Thank you!
Hi,
amazing article! Here we encode the sequences(into one hot vector) and then give them input to encoder lstm and this is passed onto the decoder lstm. Is my understanding correct? how can I give an input to hidden states of an lstm?
Really amazing post! Was surprised by the accuracy and limited training time. I have tried the model with a different dataset (two columns of sentences), but get a problem in the code for loading the clean data, splitting it, and saving the split portions of data to new files. line 20:
dataset = raw_dataset[:n_sentences, :]
IndexError: too many indices for array
For print(raw_dataset) with your deu.txt, I get:
[[‘Sentence A’ ‘Sentence a’] [‘Sentence B’ ‘Sentence b’] etc. ]
But for print(raw_dataset) with my file, I get:
[ list([‘sentence A’, ‘sentence a’]) list([‘sentence B’, ‘sentence b’]) etc.]
Hey Jason, amazing article, this helped immensely improve my understanding of how NMT works in the background!
I experienced the same issue as Alex J where the evaluation portion of the code where BLEU-2, 3 and 4 scores are all 0 and throw warnings like:
“The hypothesis contains 0 counts of 2-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()”
I’m not sure if something within nltk.bleu_score.corpus_bleu changed since you created this script but it looks like you need an additional list around each entry in actual. This is fixed by changing line 60 in that script from:
actual.append(raw_target.split())
to:
actual.append([raw_target.split()])
Dear Jason, would it also be possible to use this model to do ‘translations’ within one language? For example, to use duplicate sentences as pairs such as:
[‘The distance from the earth to the moon is 384.400 km’ ‘The moon is located 384.400 km away from the earth’]
Given enough good examples, do you think this would work? I have tried it but get lousy results. Perhaps doing something wrong.
Dear Jason, I have just replaced the deu.txt dataset with a dataset containing two columns of English sentences and get the following (strange) predictions. Any suggestions what might cause this?
src=[the best apps for increasing vocabulary are], target=[what are the best apps for increasing vocabulary], predicted=[and and and and and and and and and and and does does el el el el el]
BLEU-1: 0.027778
BLEU-2: 0.166667
BLEU-3: 0.341279
BLEU-4: 0.408248
Hi,
I’m currently doing something similar as I am trying to translate grammatically wrong french to correct french. Thing is, I also get some strange results like yours
I’m not sure you will see this message but have you solved your problem? 🙂
“There are duplicate phrases in English with different translations in German”. What problems does having duplicate phrases cause? What if I want a model to learn sentences similar in meaning to the input sentence( i.e. multiple possible outputs for the same input)? Which model would you recommend for such a situation?
how much time does it take to print the Bleu score?
Actually that part of the code is not working for me and its not printing the Bleu score and again again when i try to plot the model, it shows install Graphviz but i already have that.
Would it be possible to include a diagram or visualization to show how the dimensions match up in layers used? I am having a hard time figuring out how does the network exactly look like. Thanks in advance. For example, why repeat vector is necessary.
Prepare the new data in the same way as training (cleaning and tokenization) then provide it to the model the same as we do in the last section fo the above tutorial.
H Jason,
Thanks for this tutorial.
I was trying to translate from Chinese to English and looking at clean_pairs function, I think for Chinese characters, this can’t be applied.
Can you give me some pointers on how to generate the clean text for translation model.
I am using the dataset from many.org.
Hello Jason, It was a great article. I tried to implement it for ger – eng and it worked fine. But when I am implementing it for Korean to English junk output is coming
src=[경고 고마워], target=[thanks for the warning], predicted=[i i the]
src=[입조심해라], target=[watch your language], predicted=[i i you]
src=[없다], target=[there arent any], predicted=[i i you]
src=[톰은 외롭고 불행해], target=[tom is lonely and unhappy], predicted=[i i the]
src=[그녀의 신앙심은 굳건하다], target=[her faith in god is unshaken], predicted=[i i the to]
src=[세계는 너를 중심으로 돌아가지 않는다], target=[the world doesnt revolve around you], predicted=[i i i to to]
src=[못 믿겠는데], target=[i can hardly believe it], predicted=[i i the]
src=[그 약은 효과가 있었다], target=[that medicine worked], predicted=[i i]
src=[모두 그녀를 사랑한다], target=[everybody loves her], predicted=[i i]
I have used training data from manythings.org having 773 lines(600 lines for training ,173 lines for testing).
Hey Jason,thanks for such an awesome content.I have a doubt regarding why it is necessary to convert unicode to ascii for preparing the dataset.And why NFD format is exclusively used?
HI, Very Nice works in this blog. This LSTM also i applied for native Indian languages and got good results and scores. Great tutorial.!!!
My question is, i want to make kind of federated learning here. The model created by this dataset will be kept as general model. Suppose I have a another dataset (similar, but small), and I train a model using same code and a new model is generated. Now i want to merge the weights of this new model with the one previously generated.
How can I work around to achieve this. ? Any suggestions would be greatly appreciated.
Hi Jason
great tutorial – works fine with german -> english, but when I am using my own dictoniary then the predicted output is empty (“[]”).
My dictionary is quite specific, it is sentence to sentence, like:
“when raining then use umbrella6” -> “trigger raining check umbrella6”
I have like 1000 lines (maybe too little) of simillar sentences and they contain this strange “umbrella6” strings (so string+ID).
I was expecting that the results may not make any sense, but empty predict is something strange – there should be something?
Great tutorial, love your blog! I was just wondering how I can pass in my own input to be translated. How do I just pass in one sentence. Everything I have tried is not working!
If you have text to be translated, you can use google translate.
If you want to use the model to make a prediction, you must encode new text using the same scheme used to prepare the training data then call model.predict().
When I run the evaluation I get the following result:
UserWarning:
The hypothesis contains 0 counts of 4-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
BLEU-1: 0.077830
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
How do we fix the issue? I tried re-running the model from the start again. It is showing the same result.
/usr/local/lib/python3.5/dist-packages/nltk/translate/bleu_score.py:503: UserWarning:
The hypothesis contains 0 counts of 4-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
BLEU-1: 0.077346
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
Thank you for sharing this great article. Because of my null progress in learning German, after four years living in a German speaking country, I decided to create an application that I think could help me with it, and maybe to others too.
As a first step I think your approach may fit well with my requirements. My question is, are all the codes shown here free to reproduce or is there and copyright?
hello
could you please help me
i m doing same work neural translation from English to arabic !!
how I follow the steps which is provided but I got an error
hello sir
I got this result while running but does not apear probably
train
src=[], target=[continue digging], predicted=[i is to]
src=[], target=[tom laid the gun down on the floor], predicted=[i is to]
src=[], target=[i have to find it], predicted=[i is to]
src=[], target=[i believe in god], predicted=[i is to]
src=[], target=[im a free man], predicted=[i is to]
src=[], target=[can i use my credit card], predicted=[i is to]
src=[], target=[she is about to leave], predicted=[i is to]
src=[], target=[she raised her hands], predicted=[i is to]
src=[], target=[my uncle died a year ago], predicted=[i is to]
src=[], target=[im sitting alone in my house], predicted=[i is to]
/anaconda3/lib/python3.6/site-packages/nltk/translate/bleu_score.py:490: UserWarning:
Corpus/Sentence contains 0 counts of 2-gram overlaps.
BLEU scores might be undesirable; use SmoothingFunction().
warnings.warn(_msg)
BLEU-1: 0.266528
BLEU-2: 0.516264
BLEU-3: 0.672548
BLEU-4: 0.718515
test
src=[], target=[im working in a town near rome], predicted=[i is to]
src=[], target=[she despised him], predicted=[i is to]
src=[], target=[the clock is ticking], predicted=[i is to]
src=[], target=[this river is one mile across], predicted=[i is to]
src=[], target=[birds of a feather flock together], predicted=[i is to]
src=[], target=[why did you turn down his offer], predicted=[i is to]
src=[], target=[shes as clever as they make em], predicted=[i is to]
src=[], target=[how can i help], predicted=[i is to]
src=[], target=[our living room is sunny], predicted=[i is to]
src=[], target=[can you speak french], predicted=[i is to]
BLEU-1: 0.260667
BLEU-2: 0.510555
BLEU-3: 0.668076
BLEU-4: 0.714531
Can i use this model to train chinese to english translation, as chinese is something different then other language what precaution i need to take care.
Hello Sir, Thank you very much for this wonderful guide!!!
I just have one doubt….Can we build a model which could translate both-ways…i.e. Language1 to Language2 and also Language2 to Language1?
Thanks for a wonderful post. I am trying to run the code on a different translation (English to Hindi), the training runs fine but while evaluating I am getting the following error:
Using TensorFlow backend.
train
Traceback (most recent call last):
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\ptvsd_launcher.py”, line 119, in
vspd.debug(filename, port_num, debug_id, debug_options, run_as)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\debugger.py”, line 37, in deb
ug
run(address, filename, *args, **kwargs)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_local.py”, line 64, in run_f
ile
run(argv, addr, **kwargs)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_local.py”, line 125, in _run
_pydevd.main()
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_vendored\pydevd\pydevd.py”,
line 1752, in main
globals = debugger.run(setup[‘file’], None, None, is_module)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_vendored\pydevd\pydevd.py”,
line 1099, in run
return self._exec(is_module, entry_point_fn, module_name, file, globals, loc
als)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_vendored\pydevd\pydevd.py”,
line 1106, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_vendored\pydevd\_pydev_imps\
_pydev_execfile.py”, line 25, in execfile
exec(compile(contents+”\n”, file, ‘exec’), glob, loc)
File “D:\kudave\EEM\Code\EEMDNN\EEMDNN\infer.py”, line 88, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “D:\kudave\EEM\Code\EEMDNN\EEMDNN\infer.py”, line 56, in evaluate_model
translation = predict_sequence(model, eng_tokenizer, source)
File “D:\kudave\EEM\Code\EEMDNN\EEMDNN\infer.py”, line 40, in predict_sequence
prediction = model.predict(source, verbose=0)[0]
File “C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64\lib\si
te-packages\keras\engine\training.py”, line 1149, in predict
x, _, _ = self._standardize_user_data(x)
File “C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64\lib\si
te-packages\keras\engine\training.py”, line 751, in _standardize_user_data
exception_prefix=’input’)
File “C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64\lib\si
te-packages\keras\engine\training_utils.py”, line 138, in standardize_input_data
str(data_shape))
ValueError: Error when checking input: expected embedding_1_input to have shape
(8,) but got array with shape (11,)
————————————————————–
I get the same error when I evaluate on test data. Do you know what is wrong. To start with I have not changed much except the data in the code.
train
src=[i have no idea what i need to do now], target=[i had no idea what i need to do then], predicted=[i had not to had had had had had]
src=[i will get by if i have a place to sleep], target=[i will get by if i had a place to sleep], predicted=[i had not had had had had had had had]
src=[this is the worst book i have ever read], target=[this was the worst book i had ever read], predicted=[i had not had had had had had had]
src=[does anybody have any good news], target=[does anybody had any good news], predicted=[i had a a a]
src=[i have everything here that i need], target=[i had everything here that i need], predicted=[i had had to to had]
src=[can i have my gun back], target=[could i have my gun back], predicted=[i had have a a]
src=[i want to go and have a drink], target=[i want to go and had a drink], predicted=[i had to to to to the me]
src=[i have an orange and an apple], target=[i had an orange and an apple], predicted=[i had had to to my]
src=[i have a dog that can run fast], target=[i had a dog that could run fast], predicted=[i had had to had had had]
src=[i have a sweet tooth], target=[i had a sweet tooth], predicted=[i had a a]
src=[i have already told tom i will not help him], target=[i had already told tom i will not help him], predicted=[i had not had had had had had had]
and on test data
src=[i have no regrets for what i have done], target=[i had no regrets for what i had done], predicted=[i had had to to had had the]
src=[tom must have heard about what happened], target=[tom must had heard about what happened], predicted=[i had had had had to you]
src=[i have left my umbrella in a bus], target=[i had left my umbrella in a bus], predicted=[i had had to to for for]
src=[could i have money for my piano lesson], target=[could i had money for my piano lesson], predicted=[i had had to to to for me]
src=[i have said i am sorry], target=[i had said i was sorry], predicted=[i had had to to you]
src=[i have been to the u], target=[i had been to the u], predicted=[i had had to to you]
src=[may i have a glass of milk please], target=[may i had a glass of milk please], predicted=[i had had had to to to me]
src=[recently i have had no appetite], target=[recently i had had no appetite], predicted=[i had had had been]
src=[my friend has been here this week], target=[my friend had been here this week], predicted=[i had to to to the]
src=[i have waited two whole hours], target=[i had waited two whole hours], predicted=[i had had a my]
can you tell what i am doing wrong. The source an target both languages are english.
I have a trained model and it will successfully evaluate in the model.h5 and i want a code for translate single line sentence . like i passed hallo! the it will say hello
great work Jason , i tried to built the same model but for English to Arabic langauge , but a got an error when trying to load and validate the model
Using TensorFlow backend.
2019-01-22 10:00:35.388677: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
train
Traceback (most recent call last):
File “validation.py”, line 88, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “validation.py”, line 56, in evaluate_model
translation = predict_sequence(model, eng_tokenizer, source)
File “validation.py”, line 40, in predict_sequence
prediction = model.predict(source, verbose=0)[0]
ValueError: Error when checking input: expected embedding_1_input to have shape (36,) but got array with shape (14,)
i tried this code and it works very well , but when am trying much bigger data set i have an error
English Vocabulary Size: 20428
English Max Length: 48
arabic Vocabulary Size: 33623
arabic Max Length: 59
Traceback (most recent call last):
File “tokniezer.py”, line 79, in
trainY = encode_output(trainY, eng_vocab_size)
File “tokniezer.py”, line 43, in encode_output
y = array(ylist)
MemoryError
Can i solve this error without increasing my RAM memory , i am using now 16GB memory and a data set about 100000 Line
I’m sorry if this is the wrong place to ask, but I’m having trouble with cleaning and saving the Data, it keeps saying IndexError: index 1 is out of bounds for axis 1 with size 1, does this mean i’m creating clean_pairs wrong?
Hey jason,
I saw your post nice work. Well i am also working on a SMT project using python. I would like to know if can you provide a running project code about it or help me in some how to get it.
Thanks.
I am trying to convert this to run on TPUs. Following other notebooks for TPUs, I use the Keras layer in Tensorflow rather than the other way around. Before getting to the TPU part, I am doing this conversion to see if it still runs on GPU. This means mainly changing this function:
# define NMT model
def define_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Embedding(src_vocab, n_units, input_length=src_timesteps, mask_zero=True))
model.add(tf.keras.layers.LSTM(n_units))
model.add(tf.keras.layers.RepeatVector(tar_timesteps))
model.add(tf.keras.layers.LSTM(n_units, return_sequences=True))
model.add(tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tar_vocab, activation=’softmax’)))
return model
However this results in a complaint followed by a runtime error when I run fit:
lib\site-packages\tensorflow\python\ops\gradients_impl.py:112: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
“Converting sparse IndexedSlices to a dense Tensor of unknown shape. ”
Then during the fit inside the GPU it fails on a BLAS load as follows:
/usr/local/lib/python3.6/dist-packages/nltk/translate/bleu_score.py in corpus_bleu(list_of_references, hypotheses, weights, smoothing_function, auto_reweigh, emulate_multibleu)
181 # Collects the various precision values for the different ngram orders.
182 p_n = [Fraction(p_numerators[i], p_denominators[i], _normalize=False)
–> 183 for i, _ in enumerate(weights, start=1)]
184
185 # Returns 0 if there’s no matching n-grams
/usr/local/lib/python3.6/dist-packages/nltk/translate/bleu_score.py in (.0)
181 # Collects the various precision values for the different ngram orders.
182 p_n = [Fraction(p_numerators[i], p_denominators[i], _normalize=False)
–> 183 for i, _ in enumerate(weights, start=1)]
184
185 # Returns 0 if there’s no matching n-grams
/usr/lib/python3.6/fractions.py in __new__(cls, numerator, denominator, _normalize)
176
177 if denominator == 0:
–> 178 raise ZeroDivisionError(‘Fraction(%s, 0)’ % numerator)
179 if _normalize:
180 if type(numerator) is int is type(denominator):
I am facing a problem while running the code using English and another Indian language.
while printing the sentence pair it shows blank in the right hand side. please suggest something to fix it.
[jaipur popularly known as the pink city is the capital of rajasthan state india] => []
[the city is famous for its majestic forts palaces and beautiful lakes which attract tourists from all over the world] => []
[the city palace was built by maharaja jai singh ii and is a synthesis of mughal and rajasthani architecture] => []
[the hawa mahal was built by the maharaja sawai pratap singh in ad and lal chand usta was the architect] => []
[the amber fort complex has several apartments with palaces halls stairways pillared pavilions gardens and temples] => []
[the amber palace is a classic example of mughal and hindu architecture] => []
[the government central museum was constructed in when the prince of wales had visited india and was opened to public in] => []
[the government central museum has a rich collection of ivory work textiles jewellery carved wooden objects miniature paintings marble statues arms and weapons] => []
[sisodiya ranikabagh was built by sawai jai singh ii for his sisodiya queen] => []
[the jal mahal is a picturesque palace which was built for royal duck shooting parties] => []
[kanak vrindavan is a popular picnic spot in jaipur] => []
[jaipur bazaars are vibrant and the shops are full with colorful items which include handicraft items precious stones textiles minakari items jewellery rajasthani paintings etc] => []
[jaipur is also famous for marble statues blue pottery and the rajasthani shoes] => []
Hi I am having issue with my code and unable to find error. For every prediction it gives almost same result. I tried the your tutorial with English-Hindi example. Please find code and tell me where I am making mistake.
print(english_test_preproc.shape)
hindi_index_to_words = {id:word for word, id in hindi_tokenize.word_index.items()}
hindi_index_to_words[0] = ”
english_index_to_words = {id:word for word, id in english_tokenize.word_index.items()}
english_index_to_words[0] = ”
english_test_preproc_temp = english_train_preproc[600:620,:]
for i, source in enumerate(english_test_preproc_temp):
print(‘ ‘.join([english_index_to_words[p] for p in source.tolist()]))
source = source.reshape((1, source.shape[0]))
prediction = model.predict(source, verbose=0)
print(ids_to_text(prediction[0], hindi_tokenize))
All the variables have values as their names meaning.
Thank You very much once again Sir.
After following the above steps, all the errors were solved.
Our code is now running for small dataset, but for the dataset which this tutorial contains it is gives error as Memory Load and not giving us the Final output.
Also is there some way where instead of our output occuring as src[], target[] and prdicted[], can we ask the user to enter the input in german whether it may be a word or paragraph and on running the code gives us the output in English Language. In short giving the Test Data as input from user.
When you talk about “A BLEU-4 score of 0.076238 was achieved, providing a baseline skill to improve upon with further improvements to the model.” Is it necessary to train the model whenever new lines are added to improve the translation?
Hello,
When I run the code along with the whole dataset I get an error saying IndexError: too many indices for array
And it says that error is at eng_tokenizer = create_tokenizer(dataset[:,0]).
Can you please help.
Hello,
I went through the instructions given in the link and everything seems in accordance with the points.
I am still getting this error when I run the code
File “”, line 1, in
runfile(‘/home/ccoewitlab1-99/.config/spyder-py3/temp.py’, wdir=’/home/ccoewitlab1-99/.config/spyder-py3′)
File “/home/ccoewitlab1-99/anaconda3/lib/python3.6/site-packages/spyder/utils/site/sitecustomize.py”, line 866, in runfile
execfile(filename, namespace)
File “/home/ccoewitlab1-99/anaconda3/lib/python3.6/site-packages/spyder/utils/site/sitecustomize.py”, line 102, in execfile
exec(compile(f.read(), filename, ‘exec’), namespace)
File “/home/ccoewitlab1-99/.config/spyder-py3/temp.py”, line 203, in
eng_tokenizer = create_tokenizer(dataset[:, 0])
IndexError: too many indices for array
Please help I am stuck over this error since two weeks. Your help will be of great value sir.
Hello,
keras fit_on_texts assign a unique integer to each word. So can you please tell if this considers
similar words and if yes, how? Thanks in advance
Hello, Does this NMT support training long sentences? I am trying to train 3000 sentences of my own and and test data of 900 sentences but after evaluating, all the predicted results are the same characters for all test data.
Sir, I just started the training using 23000 sentence pair and I am getting this memory error:
trainY = encode_output(trainY, eng_vocab_size)
File “nmt.py”, line 43, in encode_output
y = array(ylist)
MemoryError
Sir,
I am a student and i am trying to translate from Hindi to English using your code.The code works fine for training but when it predicts sequences it is giving null.The predicted output is coming as empty.I changed only one thing in the code which is that i transliterated the Hindi devanagiri script to Latin script so that normalization of source language data can be done.Can you give your views on the issue?
Hi Sir. I tried doing Hindi to English translator making few changes to your code. I get a bleu of 0.74 for 4 gram but the prediction is very bad. It almost gives the same prediction for all the sentences. Any suggestions on that?
Hi
I tried doing English to Indonesian but i have problem with prediction. It predicts only the english words I had, I do, I you repeatedly. But the BLEU value is ok at 0.5 – 9.0.
I’ve tried fixing the weights on the BLEU code but it remains the same.
And I you know you’ve said the model needs fine tuning, but can you perhaps suggest what is problem? Is it the tokenizer or not too much training, or verbose?
I’ve changed every parameter in the Model following your book, but I still get the same result on prediction
Hi , I had a problem that I got the different result when I used the model after it was trained instantly and when I saved and then loaded to use it with other dataset. Maybe it is because the change of tokenizer that is the new data have different tokenizer to encode which is different from tokenizer we create before training . How can I fix this problem , or I have to train the new model every time before use it.
There is some errors in the code. To be specific, you have to use to actual.append([raw_target.split()]) according to the definition of the references in corpus-level BLEU score.
list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
hypotheses = [hyp1, hyp2]
corpus_bleu(list_of_references, hypotheses)
the code above is from [bleu_score.html](https://www.nltk.org/_modules/nltk/translate/bleu_score.html). As you can see, each item in list_of_references is **a list of list**.
Hi Jason ,
You post one of the best deep learning content on internet. A must appreciated effort.
Can you please post a project on building an automatic speech recognition in tensorflow using LSTMs and teach how to process the audio data and label sentences. usually ASR with preprocess data is given which is not my requirement. Not only me many people will benefit from it.
Thank you very much
i guess that that previous poster has a very large dataset, running out of memory and would like to know how to use to use model.fit_generator instead of model.fit to solve the NMT example above
Hi
The tutorial is really helpful, i would just like to know if you can provide the translation for the whole data set. here I can see only few translations.
Hi Jason!
im working on NMT for English to Vietnamese, i went throught all step in the article but my BLEU score is really bad, my custom data set contain 50000 sentences:
Perhaps try running fitting the model a few times?
Perhaps the model requires tuning to your dataset?
Perhaps the dataset requires diffrent preparation?
Good question, so that we leave room for 0==no word or “unknown”, therefore the first word in the vocab will be mapped to 1 and we can use 0 for all words we don’t have in our vocab.
Data Cleaning. Different data cleaning operations could be performed on the data, such as not removing punctuation or normalizing case, or perhaps removing duplicate English phrases
Jason, why do you think removing punctuations or not normalizing cases would help? becasue converting all into one lower case seems to be better idea than leaving as-is. Please share your thoughts
Jason, I was running the model with larger corpus data i.e. about 160000 records, model stopped after 5th epoch as there isnt any improvement in loss…
So I though to consider the points listed in your extension and start training, I have modified the model as below i.e. adding Bidirectional (to input/encoder), including more units (256 to 512)and adding dropout aftre encoder and decorder LSTM layers.
I an not sure how to add more additional layers and where to add them for more represntational capacity…appreciate if you can help me in that.
# define the model
model = Sequential()
model.add(Embedding(ger_vocab_size, 512, input_length=ger_length, mask_zero=True))
model.add(Bidirectional(LSTM(512), merge_mode=’concat’))
model.add(Dropout(0.2))
model.add(RepeatVector(eng_length))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.2))
model.add(TimeDistributed(Dense(eng_vocab_size, activation=’softmax’)))
I have gone through one of your post where a baseline model configuration was described.
Embedding: 512-dimensions
RNN Cell: Gated Recurrent Unit or GRU
Encoder: Bidirectional
Encoder Depth: 2-layers (1 layer in each direction)
Decoder Depth: 2-layers
Attention: Bahdanau-style
Optimizer: Adam
Dropout: 20% on input
I am confused on below thing…
Encoder: Bidirectional
Encoder Depth: 2-layers (1 layer in each direction)
Is it how we frame the above Encoder Bidirectional with 2 layers depth (1-layer in each direction)
Sure, I’ll try with it and update you.
Meanwhile, I have tried with below model architecture passing
1. Huge data around 160000 (progressive loading through generator),
2. Limited vocabulary converting words which are occuring less than 5 times to ‘unk’
2. Increased units i.e. 256 -> 512
3. Bidirections Input/Encoder Layer
4. Dropout/regularization for Encoder and Decoder (20%)
and surprisingly found that loss isn’t decreasing further after 1 or 2 epochs. any ideas? Please help
Jason, I would try to build a deeper encoder/decoder. meanwhile could you please confirm if we can implement Attention and Beam Search things in Keras, like is Keras supporting ? else how can I try to implement using the base model I pasted above.
Hey Json, I am not asking to confirm my model/code.
I just want to know, if we have support from Keras in implementing Attention Layers and Beam Search? if so do we have any reference material for that?
Using TensorFlow backend.
Traceback (most recent call last):
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow.py”, line 58, in
from tensorflow.python.pywrap_tensorflow_internal import *
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py”, line 28, in
_pywrap_tensorflow_internal = swig_import_helper()
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py”, line 24, in swig_import_helper
_mod = imp.load_module(‘_pywrap_tensorflow_internal’, fp, pathname, description)
File “D:\anaconda\envs\myenv\lib\imp.py”, line 243, in load_module
return load_dynamic(name, filename, file)
File “D:\anaconda\envs\myenv\lib\imp.py”, line 343, in load_dynamic
return _load(spec)
ImportError: DLL load failed: %1 is not a valid Win32 application.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “train.py”, line 3, in
from keras.preprocessing.text import Tokenizer
File “D:\anaconda\envs\myenv\lib\site-packages\keras\__init__.py”, line 3, in
from . import utils
File “D:\anaconda\envs\myenv\lib\site-packages\keras\utils\__init__.py”, line 6, in
from . import conv_utils
File “D:\anaconda\envs\myenv\lib\site-packages\keras\utils\conv_utils.py”, line 9, in
from .. import backend as K
File “D:\anaconda\envs\myenv\lib\site-packages\keras\backend\__init__.py”, line 89, in
from .tensorflow_backend import *
File “D:\anaconda\envs\myenv\lib\site-packages\keras\backend\tensorflow_backend.py”, line 5, in
import tensorflow as tf
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\__init__.py”, line 22, in
from tensorflow.python import pywrap_tensorflow # pylint: disable=unused-import
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\__init__.py”, line 49, in
from tensorflow.python import pywrap_tensorflow
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow.py”, line 74, in
raise ImportError(msg)
ImportError: Traceback (most recent call last):
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow.py”, line 58, in
from tensorflow.python.pywrap_tensorflow_internal import *
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py”, line 28, in
_pywrap_tensorflow_internal = swig_import_helper()
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py”, line 24, in swig_import_helper
_mod = imp.load_module(‘_pywrap_tensorflow_internal’, fp, pathname, description)
File “D:\anaconda\envs\myenv\lib\imp.py”, line 243, in load_module
return load_dynamic(name, filename, file)
File “D:\anaconda\envs\myenv\lib\imp.py”, line 343, in load_dynamic
return _load(spec)
ImportError: DLL load failed: %1 is not a valid Win32 application.
Hello Sir Nice Tutorial .Please Help me how can i translate other sentence like i just want to translate “I Love You” just this sentence using the saved model please help me please?
Nice tutorial, Jason. When I was reading the section where you clean the text, I was wondering how the commercial translators deal with numbers and other special symbols (e.g., currency). On Google Translator, for instance, If we input a text that contains numbers, uppercase words, and so on; they output the final text with the same symbols. Do you have any idea on how they implement that? I’d like to have an idea on how they recover the information that is “missed” on the preprocessing steps.
I translate from French into English and have used the French – English corpus. I added some steps to understand better what is happening. I want to get a performance at least as good as Moses and tried to train a model using much more data using your code. I made the dataset 100000 instead of 10000 but got the following error categorical = np.zeros((n, num_classes))
MemoryError. It seems that my RAM (8GB) is not big enough. I do not use BLUE but evaluate the output manually by post editing. With Moses I used the whole Europarl Corpus and expect to do so with NMT. I need to find a way to train a lot of data on a machine with 8GB memory for it to be any good for use by individuals.
Perhaps try using less data?
Perhaps try running on a larger machine, e.g. AWS EC2?
Perhaps try using a data generator to prepare one batch of data at a time?
Anymore than 10000 sentences and the one hot coding takes up all my memory. I can train moses with 8G of ram but NMT training using your code seems useless to build a serious system. Don’t want to use AWS and how does a data generator work?
I have managed to train a model using 100000 sentences on Floydhub using a machine with 59 GB cpu and 11GB GPU memory. The trouble for me is that this is really a tiny amount of data in MT terms. I used 1million segments to train Moses and Koehn et al show that in tests with Nematus and Moses, Nematus did not equal Moses until this amount of data was used. The problem is that using your method is likely to use resources that are mind blowing, mainly because of all the one hot vectors that have to be stored, wheras I can train my Moses engines on my laptop.
Going from French to English with 10000 sentences the only thing that can be said is that the output is in English. It has to be, because the words are represented by tokens that are translated into English.
My next step is to try 150000 sentences because this is all the data.
In your tutorial you fix the number of epochs to 30. How can I arrange to keep going until the cost is not changing?
And I have also discovered that this code can able to predict only first two lines of my given input. How can we code to predict and translate the sentences of two or more lines????
if i give an example as “Als Jugendlicher war Tom sehr beliebt.” that means “As a teenager, Tom was very popular.” in English but i get output as “you you you to to to you”. Its somewhat translating the sentence partially but how to get the exact output?????
This model is only a toy and will not in reality translate anything. This only uses 10K sentences (or segments) and I think you will need to train with getting on for 1 million sentences to get a reasonable performance. Remember that Google have put huge resources into developing neural translation. I found this tutorial very good for learning using python, keras and tensorflow etc but its a bit like learning to weld. In my case the instructor demonstrated how to do it in five minutes, but I never managed to master it.
The trouble is it does not look like kick-starting my own project. Yesterday I tried to train a model with 149,000 sentences. It had an English vocabulary of 12004 words and max length of 12 but 59 GB memory was not enough. This turns out to be a known problem (Khan 201, p61 https://arxiv.org/abs/1709.07809) and vocabularies are restricted to between 20000 and 80000 words.
The main lesson here, for me, is that NMT is not all that it is cracked up to be.
Hi Browniee,
Thank you very much for nice representation of simple neural machine translation system,
Could you please provide the link for trained model. I could’nt find over there and i am not been able to train even with the use of gtx-1070 8gb graphics , 12 core processor 😐
Nice presentation Jason! May I ask do we need to mask all the padding tokens in the targeted set so that it will not be included in the loss function? If we want to try that, then what changes do we need to make?
Or you think the following embedding layer already did it? But I thought this is just for embedding layer right? It will not affect how the loss function is calculated.
Thanks, sir for the nice post and your quick reply
After the model is saved in model.h5 then i executed
model = load_model(‘model.h5’)
and the next statement is
translation = model.predict(source, verbose=0)
what here the source is can we give the source as text file containing sentences?
The “source” is the data prepared in the same way as training data (same transforms) and represents one or more samples that you wish to have translated.
Hi Jason,
Thanks for your fast reply. I have checked the error in Internet.
“ValueError: too many values to unpack (expected 2)” is due to the dimension difference.
I opened raw_dataset and relized that this data set has 3 columns, therefore I changed your code a little bit, just adding “,test”. And your code works fine, again.
_________________________________________________________________________
raw_target, raw_src = raw_dataset[i] #original code with error
raw_target, raw_src, test = raw_dataset[i] #it runs! test is for the 3. column of raw_dataset
_________________________________________________________________________
B.t.w. the 3. column of raw_dataset has strange content such as:
“ccby france attribution …”
I think maybe this is due to different versions of python packages. The raw_dataset has the 1. and 2. clean columns but somehow the unuseful 3. column, which leads the error. Anyway, after adding “, test” as mentioned above. The 2. part of your code works well.
Finally I fixed the error :
raw_target, raw_src= raw_dataset[i] changed to => raw_target, raw_src,test = raw_dataset[i]
and got the below results:
train
src=[er respektiert mich], target=[he respects me], predicted=[he respects me]
src=[sei tapfer], target=[be brave], predicted=[be brave]
src=[uns wird es gut gehen], target=[well be fine], predicted=[well be fine]
src=[tom drehte durch], target=[tom went nuts], predicted=[tom went pale]
src=[wer fastet], target=[whos fasting], predicted=[whos fasting]
src=[wahlen sie mich], target=[vote for me], predicted=[vote for me]
src=[sind sie im ruhestand], target=[are you retired], predicted=[are you retired]
src=[darf ich gehen], target=[may i go], predicted=[can i go]
src=[wir brauchen das], target=[we need this], predicted=[we need this]
src=[tom wird tanzen], target=[tom will dance], predicted=[tom will dance]
BLEU-1: 0.874297
BLEU-2: 0.822932
BLEU-3: 0.727685
BLEU-4: 0.407115
test
src=[tom gesellte sich zu uns], target=[tom joined us], predicted=[tom grabbed us]
src=[ich bin besser], target=[im better], predicted=[im am better]
src=[ich muss mich sputen], target=[i must hurry], predicted=[i must to you]
src=[seid diskret], target=[be discreet], predicted=[be discreet]
src=[er ist sauber], target=[its clean], predicted=[its is]
src=[es war meine absicht], target=[it was my plan], predicted=[it was be]
src=[konnt ihr mich auslassen], target=[can you skip me], predicted=[can you read]
src=[schau genau zu], target=[watch closely], predicted=[look closely]
src=[boston ist der hammer], target=[boston is great], predicted=[my my fun]
src=[ich benotige sie], target=[i need them], predicted=[i need you]
BLEU-1: 0.551442
BLEU-2: 0.427450
BLEU-3: 0.347021
BLEU-4: 0.171442
I just recently stumbled upon your website. Your work is absolutely awesome!
Thanks for sharing your knowledge!
This tutorial is also really great. But I’m wondering, is there a way to save the whole machine translation output to a txt file?
Because, I only get 10 translations. Is there a way to see the remaining 990 sentences from the test set?
hii sir.. i am getting
value error: too many values to unpack (expected 2) at model_evalute() function this error at the end of code.
i just changed training & test data sets size to 1500 and 500.
how can i solve this issue.
can you help me plz..
yes..i also tried with the same values for training and testing.but again same problem is coming.
clearly the error was this.
ValueError Traceback (most recent call last)
in
86 # test on some training sequences
87 print(‘train’)
—> 88 evaluate_model(model, eng_tokenizer, trainX, train)
89 # test on some test sequences
90 print(‘test’)
Hi, I am facing the same issue even though I’ve copied the code as it is. Please Help.
ValueError Traceback (most recent call last)
in
86 # test on some training sequences
87 print(‘train’)
—> 88 evaluate_model(model, eng_tokenizer, trainX, train)
89 # test on some test sequences
90 print(‘test’)
hi Jason . . .i have faced problem on Preparation parts (last two rows)..working on ethiopian language pairs
Saved: AAO.pkl
Traceback (most recent call last):
File “D:\Python Projects\Amh-AO\1_Prepare-AAO.py”, line 58, in
print(‘[%s] => [%s]’ % (clean_pairs[i,0], clean_pairs[i,1]))
IndexError: too many indices for array
the problem is happened due to the unwanted spaces between words and sentences in the corpus document. i have got an error:
1. [today] => []
[me] => []
[like] => []
[hard] => []
[interesting] => []
[answer] => []
the empty box([]) should show non-english language.
temporary solution . .#line = [re_print.sub(”, w) for w in line] . . .worked
Hi Mr. Daniel am also trying neural machine translation for Ethiopian language. I have got the same problem would you write me the solution in detail please.
Thank you Jason your tutorial always helped me a lot.
I have the following error what will be the possible reason
NameError Traceback (most recent call last)
in
9 file = open(filename, mode=’rt’, encoding=’utf-8′)
10 # read all text
—> 11 text = file.read()
12 # close the file
13 file.close()
I need help
—————————————————————————
NameError Traceback (most recent call last)
in
8 return max(len(line.split()) for line in lines)
9 # prepare english tokenizer
—> 10 eng_tokenizer = create_tokenizer(dataset[:, 0])
11 eng_vocab_size = len(eng_tokenizer.word_index) + 1
12 eng_length = max_length(dataset[:, 0])
in create_tokenizer(lines)
1 # fit a tokenizer
2 def create_tokenizer(lines):
—-> 3 tokenizer = Tokenizer()
4 tokenizer.fit_on_texts(lines)
5 return tokenizer
Hi Jason,
In training I have the following error.
please I need usual help.
thank you!!
C:\Users\Habib\Anaconda3\lib\site-packages\theano\scan_module\scan_perform_ext.py:76: UserWarning: The file scan_perform.c is not available. This donot happen normally. You are probably in a strangesetup. This mean Theano can not use the cython code for scan. If youwant to remove this warning, use the Theano flag’cxx=’ (set to an empty string) to disable all ccode generation.
“The file scan_perform.c is not available. This do”
Hi Jason
This the result I have got is I think the worst
i dont know why
pls help
train
src=[japan und nordkorea unterhalten noch immer keine diplomatischen beziehungen], target=[diplomatic relations have not yet been established between japan and north korea], predicted=[the the the the the the the the the the]
src=[lasst uns losgehen], target=[lets go], predicted=[tom]
src=[tom hat gezahlt], target=[tom paid], predicted=[tom]
src=[ich bin sicher], target=[im sure], predicted=[tom]
src=[mir geht es gut], target=[im fine], predicted=[tom]
src=[er kleidet sich wie ein gentleman aber er spricht und benimmt sich wie ein clown], target=[his dress is that of gentleman but his speech and behavior are those of a clown], predicted=[the the the the the the the the the the the the the]
src=[ist dir schon mal der gedanke gekommen dass ich vielleicht noch ein paar tage in boston konnte bleiben wollen], target=[did it ever occur to you that i might want to stay in boston for a few more days], predicted=[the the the the the the the the the the the the the the the the the]
src=[je mehr zeit tom und maria zusammen verbrachten desto besser lernten sie sich kennen], target=[as tom and mary spent time together they began to get to know each other better], predicted=[the the the the the the the the the the the the the]
src=[tom ist total geistesabwesend und vergisst manchmal die kinder von der schule abzuholen], target=[tom is quite absentminded and sometimes forgets to pick the kids up from school], predicted=[the the the the the the the the the the the the]
src=[tom fand dass der lehrer ihm viel mehr hausaufgaben aufgegeben hatte als er an einem tage schaffen konnte], target=[tom thought the teacher had given him way too much homework to finish in one day], predicted=[the the the the the the the the the the the the the the]
BLEU-1: 0.062208
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
test
src=[einige begebenheiten aus meiner kindheit sind kristallklar andere hingegen sind nur eine dunkle erinnerung], target=[some incidents from my childhood are crystal clear others are just a dim memory], predicted=[the the the the the the the the the the the the]
src=[als ich seine mutter gestern traf sagte diese er ware vor einer woche aus dem krankenhaus entlassen worden], target=[when i saw his mother yesterday she said he had left the hospital a week before], predicted=[the the the the the the the the the the the the the]
src=[es klappt], target=[it works], predicted=[]
src=[letztendlich wird jemand tom sagen mussen dass er sich zu benehmen hat], target=[eventually someone is going to have to tell tom that he needs to behave himself], predicted=[the the the the the the the the the the the the]
src=[tom sagt er habe dem polizisten mitgeteilt er sei nur zum fotografieren dort gewesen], target=[tom says he told the police officer that he was just there to take some pictures], predicted=[the the the the the the the the the the the the]
src=[vertraue mir], target=[trust me], predicted=[]
src=[schauen sie uns zu], target=[watch us], predicted=[tom]
src=[dieses worterbuch dessen dritter band fehlt hat mich hundert dollar gekostet], target=[this dictionary of which the third volume is missing cost me a hundred dollars], predicted=[the the the the the the the the the the]
src=[nimm das hier], target=[use this], predicted=[tom]
src=[wegen seines groen beruflichen geschicks hat der anwalt eine groe klientel], target=[because of his great professional skill the lawyer has a large number of clients], predicted=[the the the the the the the the the the the]
BLEU-1: 0.052077
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
C:\Users\Habib\Anaconda3\lib\site-packages\nltk\translate\bleu_score.py:523: UserWarning:
The hypothesis contains 0 counts of 2-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
C:\Users\Habib\Anaconda3\lib\site-packages\nltk\translate\bleu_score.py:523: UserWarning:
The hypothesis contains 0 counts of 3-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
C:\Users\Habib\Anaconda3\lib\site-packages\nltk\translate\bleu_score.py:523: UserWarning:
The hypothesis contains 0 counts of 4-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
Sorry I post the question in the wrong article earlier (but thanks for the quick response), as I’m reading and comparing information across multiple posts. They are all very informative and helpful, thanks!!
So I understand your Franch-to-English example is a seq2seq model, but how about this one – the English-to-German model (this is the one I meant to ask about originally)? It is because the structure of this one seems to be simpler that doesn’t specify the states.
I think my confusion is that what is the difference between a many-to-many RNN Sequence Prediction model and a Seq2seq, or are they just the same? Hope you can help me to clarify that.
Traceback (most recent call last):
File “D:\ANANTH\onlinetry\translatess\punjabi\german\preparedataset1.py”, line 286, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “D:\ANANTH\onlinetry\translatess\punjabi\german\preparedataset1.py”, line 255, in evaluate_model
raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
As to the value error: There may be a bug in the evaluation part: Since raw_dataset has 3 items per inner list, the unpacking in line 57 with only two variables can’t work. I completed it with ‘source’ to ‘raw_target, raw_src, source = raw_dataset[i]’ and it worked. Could you check out if that’s the correct code?
I have one question here:
When I am trying English to Hindi, I am getting only English tokens:
[wow] => []
[help] => []
[jump] => []
[jump] => []
…..
….
But code is working for English to German.
[hi] => [hallo]
[hi] => [gru gott]
[run] => [lauf]
[wow] => [potzdonner]
…..
….
Hi, Jason
Thanks for an amazing tutorial. Is this code still going to work in case we do not reduce the dataset to the first 10 000 examples and use the complete dataset instead?
I did the following thing:
Made a script that regenerates training and testing files, and another script that loads the module and trains it. after 10 epochs it generates new training and testing files.
but I’m not sure if the model is getting better. every new training starts with ~2.1 val_loss and the file size does not change.
is it normal?
also, how can I change the learning rate?
Thanks in advance.
Hi Jason. First and foremost, thank you deeply for everything.
I need help with something. I’ve tried going through the example more times than I can count. I’ve re-installed everything many times and when I get to the Tokenizer part, I keep getting this error:
>>> eng_tokenizer = create_tokenizer(dataset[:, 0])
Traceback (most recent call last):
File “”, line 1, in
File “”, line 2, in create_tokenizer
NameError: name ‘Tokenizer’ is not defined
I am at a loss as to what might be wrong. I’ve searched everywhere, even here. You’ve told others to check if they’ve missed code lines. I’ve repeated the code several times to make sure I did not miss a thing, and I keep getting this error.
Hi again, Jason. I achieved it! I couldn’t be happier. 🙂
In case it helps anyone: the best way to clean the data (since it has three columns like another person said) is to import to Excel, delete the third column and then save as tab-delimited text file (.txt).
Just one last query: would it be possible to add more training data after training to improve results? Do you have any post explaining this, perhaps? I will be reading more of your posts to try and understand the science behind this.
What I mean is, if I do the process all over again with other data (other translations in the desired language combination [for example, EN-DE]) but load the previous model (model.h5), will it learn more from the new data while still making use of the previous datasets loaded?
I hope I was more clear now. Bascially, I mean that if I can add more data for it to learn.
I am going to develop bidirectional English-Ethiopian language machine translation by NMT approach…using data that are in different formats in pdf,word ,excel,etc not organized like English-Germen data set in one.What would you recommend me sir?thank you
While running the example, I see the following warning:
/Users/XXXX/opt/anaconda2/envs/XXXX/lib/python3.6/site-packages/tensorflow_core/python/framework/indexed_slices.py:433: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
Is this because the way we set up the NMT model?
Also the following which is probably harmless:
2020-03-18 12:31:12.023801: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:561] remapper failed: Invalid argument: MutableGraphView::MutableGraphView error: node ‘loss/time_distributed_1_loss/categorical_crossentropy/weighted_loss/concat’ has self cycle fanin ‘loss/time_distributed_1_loss/categorical_crossentropy/weighted_loss/concat’.
2020-03-18 12:31:12.046204: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:717] Iteration = 0, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-18 12:31:12.060268: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:717] Iteration = 1, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-18 12:31:12.174409: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:561] arithmetic_optimizer failed: Invalid argument: The graph couldn’t be sorted in topological order.
Code copied as is fails in the evaluate_model. evaluate_model crashes with ValueError:
Traceback (most recent call last):
File “/Users/XXXXX/evaluate.py”, line 96, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “/Users/XXXXX/evaluate.py”, line 64, in evaluate_model
raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
Am I correct to say the model here is a Generative Auto-encoder? Then why in reddit I see this post “Why are autoencoders not considered as generative?”
Here the first encoder is implemented with a LSTM and the decoder is implemented with the later LSTM.
The output of the first LSTM (encoder) is directly fed into the Decoder.
And here we have implemented this for unsupervised learning.
For the output sequence you mentioned it needs to be one hot encoded. Why the Keras same tokenizer that we we used for the input sequences will not work?
ValueError: too many values to unpack (expected 2)
Hi Jason,
I am getting this error, can you please helo me into this?
As per I already gone through FAQ and all comments, I tried all the required things and steps as mentioned in (turorial not work for me) article.
Hey there,
Let’s say I’m training the model with 10k samples.
After done training, If I generate a new dataset with 10k samples, Will the model forget the previous dataset it trained? If so. How can you provide the model with a bigger dataset?
Right now my only option is to train only on 30k samples because I ran out of RAM.
Thanks!
How much phrases do you recommend training the network on? I want eventually to train it on all the dataset.
So I train it at the moment on 28000 training data and 2000 testing. Do you
Think that’s ok?
I tried my own dataset in a tab-delimieted .txt file (encoding UTF-8), but it keeps giving me these three errors:
File “”, line 1, in
File “C:\Users\John\Desktop\Attempts\Attempt #4 – Ubuntu\env\lib\site packages\keras\engine\training.py”, line 1239, in fit
validation_freq=validation_freq)
File “C:\Users\John\Desktop\Attempts\Attempt #4 – Ubuntu\env\lib\site-packages\keras\engine\training_arrays.py”, line 210, in fit_loop
verbose=0)
File “C:\Users\John\Desktop\Attempts\Attempt #4 – Ubuntu\env\lib\site-packages\keras\engine\training_arrays.py”, line 469, in test_loop
outs[0] /= num_samples # Index 0 == Loss
IndexError: list index out of range
I copied the whole code correctly and I tried several times… with the dataset from the website you mentioned, it works fine, but with mine it doesn’t. I tried looking everywhere and found no fix…
Keras version is 2.3.0 (I tried with 2.3.1 and the same happens), tensorflow 2.1.0 if it helps.
ValueError Traceback (most recent call last)
in
86 # test on some training sequences
87 print(‘train’)
—> 88 evaluate_model(model, eng_tokenizer, trainX, train)
89 # test on some test sequences
90 print(‘test’)
sajjad dehghani mahmoud abadMay 7, 2020 at 10:28 pm#
Because of OOM by to_categorical, I used sparse_categorical_crossentropy and removed encode_output and the result was that I could train lots of more data with my system. Is it right?
Hi Jason , Thanks for your awesome explanation of NMT step by step.
I have tried similar code logics to convert Tamil to English translation .My input file had 130 pair of sentences, my model trained with less deviation with validation & training set.
I have tried both optimizer: RMSPROP as well as ADAM. in both case i have obtained similar result.
When i tried to predict_class of my test data, the output variable had only zeros. Due to this prediction out class in empty data. Please advice which parameter to tune to get desired result. I think many people face similar issue , kindly debug my colab clode & advice me to get result.
actual predicted
0 she danced with him
1 she hit him
2 she has 2000 books
3 its the third biggest city of serbia
4 leave it to me
5 he has three sons
6 thats our house
7 thats the way
8 who is she
9 see you again
10 is he a friend of yours
11 i am afraid of bears
12 be kind to old people
13 i thought youd be angry
14 raise your hand
in load_doc(filename)
8 def load_doc(filename):
9 # open the file as read only
—> 10 file = open(filename, mode=’rt’, encoding=’utf-8′)
11 # read all text
12 text = file.read()
TypeError: expected str, bytes or os.PathLike object, not dict
good work Jason
please I have a problem in the last function evaluate_model() exactly in
raw_target, raw_src = raw_dataset[i] !
when I apply to evaluate_model(model, eng_tokenizer, trainX, train)
I have this error :
in evaluate_model(model, tokenizer, sources, raw_dataset)
55 source = source.reshape((1, source.shape[0]))
56 translation = predict_sequence(model, eng_tokenizer, source)
—> 57 raw_target, raw_src = raw_dataset[i]
58 if i < 10:
59 print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
ValueError: too many values to unpack (expected 2)
Hi! Great tutorial as usual, but I have a question: If I understand the model correctly you predefine the maximum possible output length via RepeatVector(tar_timesteps), so no output sentence can be longer than tar_timesteps? So also during inference it will not be possible to get a longer output than tar_timesteps? Is there a reason you chose this approach over the idea of having a “stop” token, as they use e.g. here https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html, which would provide a more variable output length?
is it necessary to convert non-latin characters into latin? I just wonder what can I do, to be sure that my model will translate i.e. english word “angle” into polish word “kąt” instead of “kat” (what means executioner :)). Can I just omit this part of code?
The linked article uses an dynamic RNN encoder-decoder model, here we use an encoder-decoder based on an LSTM autoencoder (simpler) with fixed length inout.
Hi Jason thanks for this great tutorial.
I have a question, what if I want the model to be trained on a sequence(input) to sequence(output) data and make the prediction output fixed (say 10 words), I know it doesn’t make scene in the context of translation, but I’m using this architecture for another application, so is that possible?
Thanks for the post. Quick question: can I use similar model for string character to character prediction instead of word to word prediction? If yes, what parameters should I change like tokens will be characters instead of words and unique character size instead of vocabulary size, etc. Do you know any examples?
Thanks!
Dear thank you very much for your commitment.
i need support from you.
while I’m running the code bellow on Pycharm IDE
import string
import re
from pickle import dump
from unicodedata import normalize
from numpy import array
# load doc into memory
def load_doc(filename):
# open the file as read only
file = open(filename, mode=’rt’, encoding=’utf-8′)
# read all text
text = file.read()
# close the file
file.close()
return text
# split a loaded document into sentences
def to_pairs(doc):
lines = doc.strip().split(‘\n’)
pairs = [line.split(‘\t’) for line in lines]
return pairs
# clean a list of lines
def clean_pairs(lines):
cleaned = list()
# prepare regex for char filtering
re_print = re.compile(‘[^%s]’ % re.escape(string.printable))
# prepare translation table for removing punctuation
table = str.maketrans(”, ”, string.punctuation)
for pair in lines:
clean_pair = list()
for line in pair:
# normalize unicode characters
line = normalize(‘NFD’, line).encode(‘ascii’, ‘ignore’)
line = line.decode(‘UTF-8’)
# tokenize on white space
line = line.split()
# convert to lowercase
line = [word.lower() for word in line]
# remove punctuation from each token
line = [word.translate(table) for word in line]
# remove non-printable chars form each token
line = [re_print.sub(”, w) for w in line]
# remove tokens with numbers in them
line = [word for word in line if word.isalpha()]
# store as string
clean_pair.append(‘ ‘.join(line))
cleaned.append(clean_pair)
return array(cleaned)
# save a list of clean sentences to file
def save_clean_data(sentences, filename):
dump(sentences, open(filename, ‘wb’))
print(‘Saved: %s’ % filename)
# load dataset
filename = ‘deu.txt’
doc = load_doc(filename)
# split into english-german pairs
pairs = to_pairs(doc)
# clean sentences
clean_pairs = clean_pairs(pairs)
# save clean pairs to file
save_clean_data(clean_pairs, ‘english-german.pkl’)
# spot check
for i in range(100):
print(“[%s] => [%s]” % (clean_pairs[i, 0], clean_pairs[i, 1]))
I found the error bellow how can I fix this error?
IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed
Thanks jason, I’m trying to implement your code on my machine all steps are executed fine but, at the last step while I’m running a code that evaluate the model, it display the error bellow:
in evaluate_model raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
how can I fix this error? Thanks a lot.
my intension is after successfully implement your experiment, I will prepare my own corpus and I will try to develop model for our local language.
Hi, I’m trying to use your code to implement an English-Sanskrit translator. I tried your code using the english-german data set and it worked.
The problems in my case are two:
1. I need to use UTF-8 throughout the process. I modified the cleanup code in order to retain the UTF-8 character encoding and it produces an UTF-8 english-sanskrit.pkl file.
When I try the code which should create the model, though, it spits an error:
W tensorflow/core/framework/op_kernel.cc:1753] OP_REQUIRES failed at cudnn_rnn_ops.cc:1517 : Unknown: CUDNN_STATUS_BAD_PARAM
in tensorflow/stream_executor/cuda/cuda_dnn.cc(1496): ‘cudnnSetRNNDataDescriptor( data_desc.get(), data_type, layout, max_seq_length, batch_size, data_size, seq_lengths_array, (void*)&padding_fill)’
2. If I normalize the UTF-8 data source to ASCII, I can complete the creation of the model and also the evaluation of its effectiveness.
The problem is that i get weird results, like:
src=[aham grhe eva tyaktva agatavan], target=[i have left it at home], predicted=[i is you the the]
src=[kintu asyah bhayam asti], target=[but she is afraid], predicted=[i is the the]
src=[idanim samayah atitah], target=[it is getting late], predicted=[i is you]
src=[adya api sarah eva], target=[just soup today also], predicted=[i is the]
Is the dataset (2300 phrases) too small? Or is there another problem?
Hi, I think it is a problem of corpus size.
I demonstrated that by limiting the size of the german corpus to 2300 and by performing all the steps again.
The results are similar to the ones obtained in Sanskrit:
src=[ich bin spion], target=[im a spy], predicted=[im a]
src=[es ist sieben uhr funfundvierzig], target=[its], predicted=[its]
src=[ich vermisse sie], target=[i miss you], predicted=[i can you]
src=[such dir eine aus], target=[choose one], predicted=[we you]
I think 10000 may be the very minimum size for getting some valid results.
Unfortunately it is extremely difficult to get such amount of modern-day common-usage phrases in Sanskrit.
Anyway, compliments for your site and for your code.
And, for the UTF-8 encoding, as a last resource if I don’t find a solution for using UTF-8 in the process, Sanskrit can be written in many ways, some of which are plain ASCII, like the Harvard-Kyoto transiteration, so I may convert the text at the beginning of the process and convert it back at the end of it.
It’s all numbers. Define a set of integers for your chars, and define a process to map from chars to integers and back. It can handle any character set that way.
jason thanks for your post, finally I debug the error and I got the required output.
I have one suggestion on your code, the code that evaluate the precision of the model at line 57 please add variable “test” and re-post it,=============raw_target, raw_src , test= raw_dataset[i] unless it create the error below while runing the code.
in evaluate_model raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
Hello, jason, it is awesome tutorial. i want to develop the language model for our Ethiopian local languages, and I prepared sample corpus from different source and I tried to develop the model and im in trouble, i guess the trouble is while I prepare the sample corpus, while preparing the corpus what are the tips that I have to consider? or the above algorithm works only for those tab-delimited corpus only?
Perhaps use the above code as a starting point and be sure to inspect your raw training data prior to training to see if it contains anything unexpected.
Hello Dear, Do you have any idea how tatoeba dataset including english-germany datasets are prepared? i want to prepare my own dataset based on their standards and requirements.
Just to make sure my understanding of the translation model here is good… I have 3 questions:
1- How many hidden layers are there in this LSTM encoder-decoder model?
2- What is the purpose of model.add(RepeatVector(tar_timesteps))? I think that this line is separating the encoder and the decoder. Am I right? What lines correspond to the encoder and what lines correspond to the decoder?
3- Where would you add other hidden layers if you wanted to?
Hello, I’m a professional translator (mostly English-to-French) with 20 years of experience. In the last couple of years I’ve stared using DeepL on a fairly regular basis. I would like to be able to use NMT based on more selective data, e.g. exclusively high quality translations. Assuming I use my own production of the past few years, say, about 7 million words, plus some other selected documents I know to be of good quality, would that quantity be enough to train a strong translation system ? Or do systems typically, even with NMT, still require a much larger body of data to get trained properly?
Where do I come from ? I want to start my own translation business after many years in a large organization. I see MT pragmatically as a productivity tool for translation foremost, especially now that it’s giving better results. The technical, scientific and philisophical dimensions are of course very interesting but I have little time for them realistically.
As a translation product I’m looking for high output, yet with no compromise on quality. I rate DeepL highly for what it is, and compared to what was previously available. In the right hands it is very useful (but actually a disservice to non-proficient translators). I asked DeepL if their system could be tailored as I described, using my own corpus, but they don’t allow that option. A slightly better DeepL, say 15-25 % better quality, would be all I need, in order to be able to more “comfortably” deliver high output to my own standards of quality.
It’s tempting to give it a shot
On the plus side, I know what I want.
On the down side, I have almost zero experience in programming,. DeepL and others have teams of qualified people and I’m all by myself with baby skills… have no clear idea of what I would be embarking into, and for how long.
NDAYO FONTENG ROLLIN RAMUSFebruary 22, 2021 at 10:46 am#
Hi, thanks so much for the tutorials it help me a lot. I don’t know how to deploy the model so that it can be used either in a standalone app or a website. Please help me out
i am trying to go from german to english and was wondering, if i had made changes to the evaluate to perform this, would this be a valid way of reversing the phrase order?
Note, i was suspecting something within the train script would affect the accuracy of the project, specifically the “trainY = encode_output(trainY, eng_vocab_size)” is what I am believing to have some affect on the data that is going to ultimately be the predicted data in german
the changes i made within the evaluate includes
changing translation = predict_sequence(model, eng_tokenizer, source) to translation = predict_sequence(model, ger_tokenizer, source)
as well as re arranging of these variables raw_target, raw_src = raw_dataset[i] to raw_src, raw_target = raw_dataset[i]
Off the cuff, I think reversing the dataset is the only change required. You can then see if changes to the model, vocab size, etc. impact performance.
I am also starting to believe that the define NMT model it self is what i may need to make a change to inorder to accomplish what i want instead of what i original suggested for modifying with the Train script.
First of all, I want to thank you for your amazing work, which I appreciated!!!.
I try the algo using the data set from english to italian and I got some problem during the evaluation. I get the following error: ValueError: too many values to unpack (expected 2). This refers to this line of code: for i, source in enumerate(sources):
# translate encoded source text
source = source.reshape((1, source.shape[0]))
translation = predict_sequence(model, eng_tokenizer, source)
raw_target, raw_src = raw_dataset[i].
I think maybe it is due to the fact that we have too many values with respect to the number of target variables. Could you help me to avoid this error?
I wish you a good day and I thank you in advance for your help.
Hi Jason! thankyou for this wonderful tutorial, will this model work for a large number of phrase for ex. if the length of the German and English phrase here is for ex 300 or 400.Also it will be great if you provide some reference of other neural machine translation models which could do this. Thanks!
Hello,
your tutorial is superb!
I would like to do the same thing but also add a translation from English to German.
Is it possible to translate both ways in one notebook?
Hi there,
I have run the same code (the one published on this page) on my laptop and on a p3.2xlarge AWS instance.
Is it normal to have a very little difference in performance between an NVIDIA GeForce GTX 850M (9 seconds per iteration) and the Tesla V100-SXM2-16GB (3 seconds)?
Here the result of a code reporting the boards used by Tensorflow:
Hi Jason,
Thank you for the amazing instructions, can you please add a part to this to do Progressive Loading instead of loading all the data at once, I really want to see how you do it.
I got an error : NotImplementedError: Cannot convert a symbolic Tensor (lstm/strided_slice:0) to a numpy array. This error may indicate that you’re trying to pass a Tensor to a NumPy call, which is not supported
You exhausted your memory. Can’t really help unless you replace numpy. Or you can see if you can load data in half-precision (float16). That might help too.
I tried with the English and Hindi Data file and execute the same as the above code. I removed encoding so that I can read Hindi text as well but at the output in the predicted section I get nothing there is no output how should I do this when I wanted to translate my Hindi text into English text
The code here guarantee you must get some output; whether it is sensible in a language or just gibberish is another issue (in that case, maybe the language is too complicated and need a more complex model). If you see nothing there, probably you should check your code.
Input data is in the same format as your first column of input data is in the English Language (that is target language ) and then space and then source language that is Hindi in my case for example
Komal had married only two months ago. कोमल की दो महीने पहले ही शादी हुई थी।
hello Nikhil Garg ,
what is your progress using the English Hindi dataset? I am also interested in the same . So please let me know if u have any progress .
If You can help I would really appreciate although all the other output like plot model and model summary works fine except it differs from your model output and that is understandable but I am not getting any output if you could please help me out in this
ValueError: too many values to unpack (expected 2)
i am getting this error at 3rd last line of code
# test on some training sequences
print(‘train’)
evaluate_model(model, eng_tokenizer, trainX, train)
# test on some test sequences
print(‘test’)
evaluate_model(model, eng_tokenizer, testX, test)
error:
—————————————————————————
ValueError Traceback (most recent call last)
in ()
1 # test on some training sequences
2 print(‘train’)
—-> 3 evaluate_model(model, eng_tokenizer, trainX, train)
4 # test on some test sequences
5 print(‘test’)
Hi Akansha…While I am not able to speak to your specific code listing and debugging, I would recommend that you review the following for additional insight.
Hi author i am facing these while running the code
# prepare german tokenizer
ger_tokenizer = create_tokenizer(dataset[:, 1])
ger_vocab_size = len(ger_tokenizer.word_index) + 1
ger_length = max_length(dataset[:, 1])
# prepare data
trainX = encode_sequences(ger_tokenizer, ger_length, train[:, 1])
testX = encode_sequences(ger_tokenizer, ger_length, test[:, 1])
# load model
model = load_model(‘model.h5’)
translation = model.predict(source, verbose=0)
the error is
NameError Traceback (most recent call last)
in ()
42 # load model
43 model = load_model(‘model.h5’)
—> 44 translation = model.predict(source, verbose=0)
NameError: name ‘source’ is not defined
kindly help me to find out this error where is source file is exist. i want to train the model on roman English
Thank you for this awesome tutorial. I want to know how I can adapt this same code for protein desordered region prediction.
Input is a sequence of protein and output is a binary sequence (1 if the corresponding residus is desordered and 0 otherwise.)
Example:
input: AAAALLLLAKKK
output: 111111100001
Hi, i have been able to run your code on a windows machine with Python 3.12.2 and Tensorflow 2.16.1 by tweaking the code a little bit but, as you may know, this version of Tensorflow does not support CUDA GPUs, so it works but it uses the CPU and it is therefore very slow.
What would be the code for this encoding-decoding model in C#? I have been able to work with Microsoft’s ML.NET using my Nvidia GPU. ML.NET is a C# port of Tensorflow using Torchsharp-cuda-windows for GPU.
THe code of a simple model for Language Classification is this:
var pipeline = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName:@”col0″,inputColumnName:@”col0″,addKeyValueAnnotationsAsText:false)
.Append(mlContext.MulticlassClassification.Trainers.TextClassification(labelColumnName: @”col0″, sentence1ColumnName: @”col1″))
.Append(mlContext.Transforms.Conversion.MapKeyToValue(outputColumnName:@”PredictedLabel”,inputColumnName:@”PredictedLabel”));
I have not been able to find LSTMs in this library.

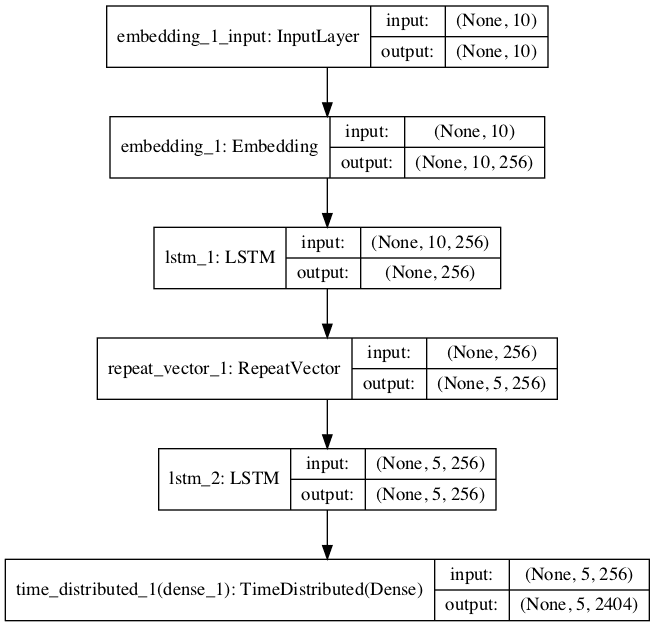







amazing work again. One Question. Do you have a seperate tutorial where you explain the LSTM layers (Timedistributed, Repeatvector,…)?
Yes, you might want to start here:
https://machinelearningmastery.com/timedistributed-layer-for-long-short-term-memory-networks-in-python/
Hi, Jason your work is amazing. I am having one issue . How to convert large dataset in one-hot vectors as it will take more memory??
Perhaps progressively load the dataset and convert it?
Perhaps use a smaller data sample?
Perhaps use a machine with more ram?
Perhaps use a big data pipeline like hadoop?
translation = model.predict(source, verbose=0) i cant working this. I get error. Source is not defined. how can i solve?
You may have skipped some of the code in the example.
This might help:
https://machinelearningmastery.com/faq/single-faq/how-do-i-copy-code-from-a-tutorial
Hello,
Have you resolved this issue? because I’m also facing the same issue, please if you resolved this issue means let me know how to resolve this.
suppose, i have two files- 1st one has eng- germany text and the 2nd one has eng-spanish text. now i can i translate from germany to spain?
Why? The question seems flawed/incomplete.
Extract the German text and the corresponding Spanish text to form a new file, then use it to train the model. I guess 🙂
Hello Jason, in python there is nothing like re_print , can you please guide me here.
“re_print” is a variable name.
Hello Jason Iam getting three different elements after cleaning the data i can’t understand what the third element in this list means could you explain ?
array([[‘theres nothing left to eat at home’,
‘es ist nichts zu essen mehr im haus’,
‘ccby france attribution tatoebaorg shekitten pfirsichbaeumchen’]
Perhaps you can try re-training the model?
how to translate new english text to german using predicted results?
Your tutorials are amazing indeed. Thank you!
Hope you will have the time to work on the Extensions lists above. This will complete this amazing tutorial.
Thanks again!
Thanks!
Brilliant, thanks Jason. I’m looking forward to giving this a try.
You’re welcome.
hey i want to know one thing that if we are giving english to german translations to the model for training 9000 and for testing 1000.. then what is the encoder decoder model is actually doing ..as we are giving everything to the model at the time of testing.
The model is not given the answer, it must translate new examples.
Perhaps I don’t follow your question?
Then how do i enter the example? on which line are you picking it
Hi Jason,
I am regular reader of your articles and purchased books.i want to work on translation of a local language to english.kindly advice on the steps.
thanks you
Just start!
# prepare regex for char filtering
re_print = re.compile(‘[^%s]’ % re.escape(string.printable))
can u please explain me the meaning of this code for ex what is string.printable actually doing and what is the meaning of (‘[^%s]’
I am selecting “not the printable characters”.
You can learn more about regex from a good book on Python.
Excellent explanation i would say!!!! damn good !!!looking to develop text-phonemes with your model !!!
Thanks!
Hi , Jason your wok is amazing and while i was doing this code i found this and i want to know i it’s required ti reshape the sequence ? and what sequence.shape[0],sequence.shape[1] is doing.
and why we need the vocab size ?
y = y.reshape(sequences.shape[0], sequences.shape[1], vocab_size)
You can learn more about numpy arrays and their shape in this post:
https://machinelearningmastery.com/index-slice-reshape-numpy-arrays-machine-learning-python/
*want to know why it’s required to reshape the sequence ? and what
We must ensure that the data is the correct shape that is expected by the model, e.g. 2d for MLPs, 3D for LSTMs, etc.
hi ,
i wanted to ask tyou why we have not done one-hot encoding for text in german.?
The input data is integer encoded and passed through a word embedding. No need to one hot encode in this case.
hello sir,
over here the load_model is not defined .
thank you .
from keras.models import load_model
can please tell me where the
translation = model.predict(source, verbose=0)
error: source is not deifined
Sorry, I have not seen that error. Perhaps try copying the entire example at the end of the post?
while running above code i am facing memory error in to_categorical function. I am doing translation for english to hindi. Pls give any suggestion.
Perhaps try updating Keras?
Perhaps try modifying the code to use progressive loading?
Perhaps try running on AWS with an instance that has more RAM?
please do a model on attention with gru and beam search
Thanks for the suggestion.
i have used bidirectional lstm,got a better result…i want to improve more …but i dont know how to implement attention layer in keras…could you please help me out…
I have some posts here that may help:
https://machinelearningmastery.com/?s=attention&submit=Search
Hi, I want know why you use model.add(RepeatVector(tar_timesteps))?
To repeat the encoded input vector n times.
Learn more about this approach here:
https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/
is it possible to calculate the NMT model score with this method
model.compile(optimizer=’adam’, loss=’categorical_crossentropy’, metrics=[‘accuracy’])
scores = model.evaluate(testX,testY)
It will estimate accuracy and loss, but not bot give you any insight into the skill of the NMT on text data.
Hi Jason, brilliant article!
Just a quick question, when you configure the encoder-decoder model, there seems no inference model as you mentioned in your previous articles? If this model has achieved what inference model did, in which layer? If not, how does it compare to the suite of train model, inference-encoder model and inference-decoder model? Thank you so much!
Here, the same model is used for inference.
Does text_to_sequences encode data ?
according to the documentation it just transform texts to a list of sequences
Yes, it encodes words in text to integers.
Could you verify This documentation. It is mentionned that text_to_sequences return STR.
I am confusing right now.
https://keras.io/preprocessing/text/
For “texts_to_sequences” on Tokenizer it says:
“Return: list of sequences (one per text input).”
ImportError: cannot import name ‘corpus_bleu’
Did anyone have an idea about this error.
You must install a modern version of NLTK.
For example, I am using: nltk: 3.2.5
save in your package the code on this link as bleu_score: https://www.nltk.org/_modules/nltk/translate/bleu_score.html
then from bleu_score import corpus_bleu
By following your tutorial, I was able to find BLEU scores on test dataset as follow :
BLEU-1: 0.069345
BLEU-2: 0.255634
BLEU-3: 0.430785
BLEU-4: 0.490818
So we can notice that they are very close to the scores on train dataset.
Is it about overfitting or it is a normal behavior ?
Nice work!
Similar scores on train and test is a sign of a stable model. If the skill is poor, it might be a stable but underfit model.
Hello sir, you are using test data as validation data. This means model has seen test data during training phase only. I think test data is kept separated. Am I right?? If yes please explain logic behind it.
No, data was split into train and test and used for those purposes.
Learn more about datasets here:
https://machinelearningmastery.com/difference-test-validation-datasets/
Hello sir, great explanation. everything works well with the given corpus.when i am using the own corpus it says .pkl file is not encoded in utf-8.
can you please share the the encoding of the text files used for the above project?
It is giving following error
—————————————————————————
IndexError Traceback (most recent call last)
in ()
65 # spot check
66 for i in range(100):
—> 67 print(‘[%s] => [%s]’ % (clean_pairs[i,0], clean_pairs[i,1]))
IndexError: too many indices for array
Kindly help
Perhaps double check you are using Python 3?
yes i am using python 3.5
Are you able to confirm that all other libs are up to date and that you copied all of the code from the example?
yes jason i have updated all the libraries. it is working completely fine for the deu,txt file .
when ever i use my own text file it is giving the following error.
can you kindly tell what formatting is used in text file.
Thanks
As stated in the post, the format is “Tab-delimited Bilingual Sentence Pairs”.
hi Jason i am a fan of yours and i have implemented this machine translation and it was awesome i got all the results perfectly .. now i wanted to generate code using natural language by using RNN.. and when i am reading my file which is of declartaion and docstrings it is not showing as it is the ouput .. like it should show the declarations but it is showing something like x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/x00/
but it should show
if cint(frappe.db.get_single_value(u’System DCSP Settings’, u’setup_complete’)):
Interesting project.
Perhaps the model requires more training/tuning or the problem requires reframing?
Here’s a great list of ideas:
https://machinelearningmastery.com/improve-deep-learning-performance/
In your data x is English and y is german… but in the code x is German, and y is english… why that difference????????????
We are translating from German (X) to English (Y).
You can learn the reverse if you prefer. I chose not to because my english is better than my german.
Hi,
I am trying to use pre trained word embeddings to make translation.
But, after making some researrch I found that pre-trained word embeddings are just only user for initialize encoder and decoder and also we nedd only the src embeddings.
So, for the moment I am confused.
Normally, must we provide source and target embeddings to the algorithme ?
Please if they are some documentation or links about this topic.
Not sure I follow, what do you mean exactly?
You can use a pre-trained embedding. This is separate from needing to have input and output data pairs to train the model.
Regarding recursive model in extensions, isn’t it already implemented in the current code? Because the decoder part is lstm and is lstm output of one unit is fed to the next unit.
*in the section ‘extensions’
*and in lstm the output of one time unit is fed to the next time unit.
No, see this post for more interesting architectures:
https://machinelearningmastery.com/caption-generation-inject-merge-architectures-encoder-decoder-model/
“be stolen returned” is my systems translation of “vielen dank jason”, which ist supposed to mean: Thank you so much Jason!
This post helped me a lot and I’ll now continue to tune it. Keep up the awesome work!
Well done!
Thanks Max, I’m glad to hear it.
In machine translation why we need vocabulary with the english text and german text …?
We need to limit the number of words that we model, it cannot be unbounded, at least in the way I’m choosing to model the problem.
That suggests that it can be unbounded if you model it in a different way.
Sure, it’s all just code.
Hi Jason,
I have just tested the clean_pairs method against ENG-PL set provided on the same website.One of the characters does not print on the screen( ‘all the other non ASCII chars are converted correctly), it is ignored as per this line I guess:
I did an experiment with replacing the above with line = normalize(‘NFD’, line).encode(‘utf-8’, ‘ignore’), but there is no difference between these two in results.I am not sure why this is happening as it is only one letter.Also,( I assume your chose was ascii as you built a German to English translator am I correct?).Could you plase share your thoughts, if possible?
Perhaps you’re able to inspect the text or search the text for non-ascii chars to see what the offending characters are?
This might give you insight into what is going on.
I am working on it -it looks like it may be the issue with re.escape method rather than with encoding itself.
Does removing punctuation not preventing the model to be used to predict a paragraph? How can you evaluate it with one sentence or paragraph not in the test set?
You can provide data to the model and make a prediction.
call the predict_sequence() function we wrote above.
From Keras. Proprocessing. Text import Tokenizer
..
Does not woking after installing keras..
..
It’s says that no module named tensorflow
..
I have windows 32 it machine.
..
Your article very good…!
.
But I can’t process ahead due to this problem!
It sounds like your environment is not installed correctly.
See thus tutorial:
https://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
Thank you for your article, Jason!
I have one question about the difference between your implementation and the Keras Tutorial “https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html”. It seems to me that, there is a ‘teaching forcing’ element in the “Keras Tutorial” using “target” (offset by one step) as “decoder input data”. This element is not presented in your model. My question is: is it necessary? or you just use “RepeatedVector” and “TimeDistributed” to implement the similar function?
Thank you!
Correct, we are using a simplified version of the architecture.
I give an example of teacher forcing here:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Great help Jason, thank you one more time, i want to ask you:
How can i implement bidirectional lstm code for further improvements? at below what i did on codes please fix it with your knowledge.
def define_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
model = Sequential()
model.add(Embedding(src_vocab, n_units, input_length=src_timesteps, mask_zero=True))
model.add(Bidirectional(LSTM(n_units)))
model.add(RepeatVector(tar_timesteps))
model.add(Bidirectional(LSTM(n_units, return_sequences=True)))
model.add(TimeDistributed(Dense(tar_vocab, activation=’softmax’)))
return model
I believe bidirectional would only make sense on the input/encoder.
See this post for configuration suggestions:
https://machinelearningmastery.com/configure-encoder-decoder-model-neural-machine-translation/
In this below code
# remove non-printable chars form each token
line = [re_print.sub(”, w) for w in line]
in Turkish words i got this sample errors for example
“kaç” -> “kac” , “koş”->”kos”
how can i fix it ?
thank you
I don’t follow sorry. What is the problem exactly?
i have used these codes on a Turkish-English corpus file and some Turkish characters are
missing (ç,ğ,ü,ğ,Ö,Ğ,Ü,İ,ı)
thank you.
Missing after the conversion?
Perhaps normalizing to Latin characters is not the best approach for your specific problem?
Thank you very much. Could you please help where can I get good dataset for Thai to English. The dataset for Thai language is available from the ManyThings.org website is with lesser data.I am trying to use this approach to build similar for Thai.
Sorry, I don’t know off hand.
Please ignore my query, i have searched and got the dataset. Thank you for these articles
No problem.
Sai can you please send me the dataset (eng thai)
fexex44@gmail.com
Once the model is trained, could be used the model to predict in both directions, I mean: english-german, german-english.
No, only in the direction it was trained.
Hi Jason, thank you for the amazing tutorial. It really helped me. I implemented the above code and understood each function. Further, I want to implement Neural conversation model as given in https://arxiv.org/pdf/1506.05869.pdf on dialogue data. So, I have 2 questions, first is how to make pairing in dialogue data and second is how to feed previous conversations as input to the decoder model.
Sorry, I don’t have an example of a dialog system. I hope to cover it in the future.
G.M Mr Jason …
In my model , I find BLEU scores on train dataset as follow :
BLEU-1: 0.736022
BLEU-2: 0.717377
BLEU-3: 0.710192
BLEU-4: 0.692681
So we can notice that they are higher from the scores on train dataset.
Is it normal behavior or is it bad ?
Better scores on the test set than train set does happen, I explain some ideas about this here:
https://machinelearningmastery.com/faq/single-faq/what-if-model-skill-on-the-test-dataset-is-better-than-the-training-dataset
Hi Jason,
Great and helpful work, I am trying the code to translate Arabic to English but in first step (Clean Text) and it give me an empty [ ]?! how can I solve this one.
[hi] => []
[run] => []
[help] => []
Hi Jason,
Thanks for sharing a easy and simple approach for translations.
I tried your code to work with Indian languages and found Hindi data set in the same location from where you shared the German dataset.
The following normalize code for Hindi removes the character from line. I have tried with NFC, still facing the same problem. If I skip this line then, the non-printable character line is skipping the hindi text.
print(‘Before: ‘, line)
# normalize unicode characters
line = normalize(‘NFD’, line).encode(‘ascii’, ‘ignore’)
print(‘After: ‘,line)
Before: Go.
After: b’Go.’
Before: जा.
After: b’.’
Does skipping these two lines of code affect the training in any way?
Thanks,
Sastry
Yes, the code example expects to work with Latin characters.
Hi Sastry sir
Does your problem with hindi data resolve?
Hello sir
what is minimum Hardware requirement to train nmt using keras?
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/do-i-need-special-hardware-for-deep-learning
Hi Jason,
This post is really helpful. Thanks for this.
I am working on building a translator which translates from English to Hindi (or any other Indian language). But I am facing a problem while cleaning the data.
The normalize code does not work for Indian languages, and if I skip that line of code then I am not getting any output after training my data.
Is there a way to use the same code on your post and some other way to clean the data for Indian languages to get the desired output..? Like are there any python modules/Libraries that i should install so as to use them for Indian Languages.?
Thanks!
You may have to research how to prepare hindi data for NLP.
Perhaps converting to latin chars in not the best approach.
Hello,
Aren’t we supposed to pass the English data along with the encoded data to decoder.As per my understanding only the encoded German data has been passed to the decoder right??
Not in this example.
Hi Jason,
I have now progressed upto Training the model. Cleaning & tokenizing the data set took time as i used a different language, but was a good learning.
Wanted to know whats the significance of “30 epochs and a batch size of 64 examples” in your example. Are these anyways related to Total vocabulary (or) total trainable parameters ?
Also, could you please guide me to any article of yours where i can learn more around what is epochs, what is BLEU score , what is loss etc.
Thank you
Unrelated. I used trial and error (systematic experiments) to configure the model.
More on epochs here:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-a-batch-and-an-epoch
More on BLEU here:
https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
Loss is an error score that is being optimized.
Hi Jason,
I have a silly question, but wanted to seek clarification.
In step “Train Neural Translation Model” :- have used 10,000 rows from the dataset, and established the model in file model.h5 for xxx number of vocabularies.
If I extract next 10,000 rows from data and continue to train the model using the same lines of code above, would it use the previously established model from model.h5 or would it be overwritten and start as fresh data being used to train ?
Thank you,
Yes, the model will be trained using the existing model as a starting point.
Hi Jason,
ok, understood.
Referred to your article https://machinelearningmastery.com/check-point-deep-learning-models-keras/ and understood that, before compiling the model using model.compile(), i have to load the model from file, to use existing model as starting point in training.
Thank you very much.
Glad it helped.
DId you try using model.fit_generator?
Hi Jason,
Can Word2Vec be used as the input embedding to boost the LSTM model ? Or say that pre-trained word vector by Word2Vec as input of the model can get better?
Thanks!
Yes. I have examples, search word embedding.
Hello Jason,
Excellently written article with intricate concepts explained in such a simple manner.However it would be great if you can add a attention layer for handling larger sentences.
I tried to add a attention layer to the code above by referring the below one.
https://github.com/keras-team/keras/issues/4962
I am unable to add the attention layer..I have read your previous blog on adding attention
https://machinelearningmastery.com/encoder-decoder-attention-sequence-to-sequence-prediction-keras/
But the vocabulary at the output end is too large to be processed and this is not solving the problem
It would be great if you add attention ( bahdanu’s or luong’s ) to your above code and solve the problem of larger sentences
Thanking you !
Thanks, I hope to develop some attention tutorials once it is officially supported by Keras.
How about including the attention snippet as you did in the later case.this code is working fine for me except that attention can handle longer sentences and this is where I am facing issues.I was actually asking for adding attention to the above code as you did in the later case.
Sorry, I cannot create a custom example for you.
I hope to give more examples of attention when Keras officially supports attention.
Hi, I want to convert from english to german, Please help me what kind of changes required? I did few changes but it didn’t work. Please help me how can I reverse it?
It should be straight forward. Sorry, I don’t have the capacity to prepare an example for you.
halo sir, how to modification this project to use existing model (.h5) for next project running without training again, so i just use the model ?
You can save the model, then later load it and make predictions.
More on how to make predictions here:
https://machinelearningmastery.com/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
i mean is to use pretrained models for next running (example : chatbot), so when i running chatbot for question and answer, must not training a model. thq
Sorry, I don’t know about chatbots.
Jason – What’s your next tutorial, would be waiting for the next one eagerly, how would i get notified about your next one?
I send out an email about new tutorials, you can sign up for it here:
https://www.getdrip.com/forms/387997427/submissions/new
Hi Jason! Thanks for your amazing tutorial! Very clear and easy to understand. One question comes up during my reproducing of your code: the console warns that “The hypothesis contains 0 counts of 2-gram, 3-gram and 4-gram overlaps”, which leads to BLEU-2 to 4 are 0. I can’t find the reason, coz I just completely copied your code and it still doesn’t work. Can you help me with that? Thank you!
You can ignore that warning, it has to do with the calculation of the performance metric:
https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
Hi,
Could you please help me to convert a German word to a sequence of numbers?
See this post:
https://machinelearningmastery.com/prepare-text-data-deep-learning-keras/
Hi,
amazing article! Here we encode the sequences(into one hot vector) and then give them input to encoder lstm and this is passed onto the decoder lstm. Is my understanding correct? how can I give an input to hidden states of an lstm?
No, we do not one hot encode the input, we provide sequences of integers to the word embedding.
Hi,
thank you for answering. I have another question. How can I use one hot encoding for the sequences in which it returns a 2D array not a 3D?
Perhaps this will help:
https://machinelearningmastery.com/why-one-hot-encode-data-in-machine-learning/
Really amazing post! Was surprised by the accuracy and limited training time. I have tried the model with a different dataset (two columns of sentences), but get a problem in the code for loading the clean data, splitting it, and saving the split portions of data to new files. line 20:
dataset = raw_dataset[:n_sentences, :]
IndexError: too many indices for array
For print(raw_dataset) with your deu.txt, I get:
[[‘Sentence A’ ‘Sentence a’] [‘Sentence B’ ‘Sentence b’] etc. ]
But for print(raw_dataset) with my file, I get:
[ list([‘sentence A’, ‘sentence a’]) list([‘sentence B’, ‘sentence b’]) etc.]
Any tips what I could do about this?
I have some suggestions here to try:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
I have got the same error.Any solutions?
Hey Jason, amazing article, this helped immensely improve my understanding of how NMT works in the background!
I experienced the same issue as Alex J where the evaluation portion of the code where BLEU-2, 3 and 4 scores are all 0 and throw warnings like:
“The hypothesis contains 0 counts of 2-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()”
I’m not sure if something within nltk.bleu_score.corpus_bleu changed since you created this script but it looks like you need an additional list around each entry in actual. This is fixed by changing line 60 in that script from:
actual.append(raw_target.split())
to:
actual.append([raw_target.split()])
Thanks Josh.
Yes, indeed it works with:
actual.append([raw_target.split()])
The reference for each sentence should be a list of different correct sentences.
Dear Jason, would it also be possible to use this model to do ‘translations’ within one language? For example, to use duplicate sentences as pairs such as:
[‘The distance from the earth to the moon is 384.400 km’ ‘The moon is located 384.400 km away from the earth’]
Given enough good examples, do you think this would work? I have tried it but get lousy results. Perhaps doing something wrong.
With enough training data, yes, you could do this.
Dear Jason, I have just replaced the deu.txt dataset with a dataset containing two columns of English sentences and get the following (strange) predictions. Any suggestions what might cause this?
src=[the best apps for increasing vocabulary are], target=[what are the best apps for increasing vocabulary], predicted=[and and and and and and and and and and and does does el el el el el]
BLEU-1: 0.027778
BLEU-2: 0.166667
BLEU-3: 0.341279
BLEU-4: 0.408248
Perhaps confirm that you are loading the dataset as you expect.
You may then have to tune the model to this new dataset.
Hi,
I’m currently doing something similar as I am trying to translate grammatically wrong french to correct french. Thing is, I also get some strange results like yours
I’m not sure you will see this message but have you solved your problem? 🙂
Perhaps try tuning the model?
Perhaps try more data?
Perhaps try a different model architecture?
“There are duplicate phrases in English with different translations in German”. What problems does having duplicate phrases cause? What if I want a model to learn sentences similar in meaning to the input sentence( i.e. multiple possible outputs for the same input)? Which model would you recommend for such a situation?
It can be confusing to the model and result in lower skill.
Simplify the problem for the model whenever possible.
how much time does it take to print the Bleu score?
Actually that part of the code is not working for me and its not printing the Bleu score and again again when i try to plot the model, it shows install Graphviz but i already have that.
It depends on your hardware, but it should not take excessively long.
If you are getting strange results, ensure you have the latest versions of all of the libraries and that you have copied all of the code required.
First of all thanks for the tutorial, it helps me a lot.
If i like to incorporate attention mechanism and beam search in the decoder, which part of the code need to be changed?
From my basic understanding i received from the your following tutorial:
https://machinelearningmastery.com/encoder-decoder-attention-sequence-to-sequence-prediction-keras/
I need to replace the following code:
def define_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
model = Sequential()
model.add(Embedding(src_vocab, n_units, input_length=src_timesteps, mask_zero=True))
model.add(LSTM(n_units))
model.add(RepeatVector(tar_timesteps))
model.add(LSTM(n_units, return_sequences=True))
model.add(TimeDistributed(Dense(tar_vocab, activation=’softmax’)))
return model
into
def define_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
model = Sequential()
model.add(Embedding(src_vocab, n_units, input_length=src_timesteps, mask_zero=True))
model.add(LSTM(n_units))
model.add(AttentionDecoder(n_units, n_features))
return model
After writing the custom attention layer code given in that post.
I am not sure about the parameter n_features for this problem. Can you clarify it? Beside, can you help me to find the implementation of beam search?
Thanks for your time.
Sorry, I cannot help with these extensions.
Sir, i’m using english-hindi translation dataset. while printing the saved file code is showing the output like…
[has tom left] => []
[he is french] => []
[i am at home] => []
[i cant move] => []
[i dont know] => []
Why i’m not able to see Hindi text. Is there any requirement of encoding decoding again?
Sorry, I don’t know. I don’t have any examples working with Hindi text.
Use these Steps and you will get hindi text.
def clean_pairs(lines):
cleaned = list()
table = str.maketrans(”, ”, string.punctuation)
for pair in lines:
clean_pair = list()
for line in pair:
line = line.split()
line = [word.lower() for word in line]
line = [word.translate(table) for word in line]
clean_pair.append(‘ ‘.join(line))
cleaned.append(clean_pair)
return np.array(cleaned)
Hello Jason,
Would it be possible to include a diagram or visualization to show how the dimensions match up in layers used? I am having a hard time figuring out how does the network exactly look like. Thanks in advance. For example, why repeat vector is necessary.
Yes, you can summarize what the model expects:
And you can review your data:
After save the model and load the model then i want to translate only one line randomly then how can i do that?
model.predict(…)
how to check with my custom input??Instead of test data set
Prepare the new data in the same way as training (cleaning and tokenization) then provide it to the model the same as we do in the last section fo the above tutorial.
H Jason,
Thanks for this tutorial.
I was trying to translate from Chinese to English and looking at clean_pairs function, I think for Chinese characters, this can’t be applied.
Can you give me some pointers on how to generate the clean text for translation model.
I am using the dataset from many.org.
You may have to update the example to work with unicode instead of chars.
Hello Jason, It was a great article. I tried to implement it for ger – eng and it worked fine. But when I am implementing it for Korean to English junk output is coming
src=[경고 고마워], target=[thanks for the warning], predicted=[i i the]
src=[입조심해라], target=[watch your language], predicted=[i i you]
src=[없다], target=[there arent any], predicted=[i i you]
src=[톰은 외롭고 불행해], target=[tom is lonely and unhappy], predicted=[i i the]
src=[그녀의 신앙심은 굳건하다], target=[her faith in god is unshaken], predicted=[i i the to]
src=[세계는 너를 중심으로 돌아가지 않는다], target=[the world doesnt revolve around you], predicted=[i i i to to]
src=[못 믿겠는데], target=[i can hardly believe it], predicted=[i i the]
src=[그 약은 효과가 있었다], target=[that medicine worked], predicted=[i i]
src=[모두 그녀를 사랑한다], target=[everybody loves her], predicted=[i i]
I have used training data from manythings.org having 773 lines(600 lines for training ,173 lines for testing).
Can you please guide me what can be the issue.
Perhaps the Korean characters need special handling?
Perhaps the model needs further tuning?
Hey Jason,thanks for such an awesome content.I have a doubt regarding why it is necessary to convert unicode to ascii for preparing the dataset.And why NFD format is exclusively used?
It is not required, it just made my example simpler.
HI, Very Nice works in this blog. This LSTM also i applied for native Indian languages and got good results and scores. Great tutorial.!!!
My question is, i want to make kind of federated learning here. The model created by this dataset will be kept as general model. Suppose I have a another dataset (similar, but small), and I train a model using same code and a new model is generated. Now i want to merge the weights of this new model with the one previously generated.
How can I work around to achieve this. ? Any suggestions would be greatly appreciated.
Nice work!
You could keep both models and use them in an ensemble.
Hi Bhimasen
i am also doing work on Indian languages.
getting stuck in preprocessing of Punjabi
Hi Jason
great tutorial – works fine with german -> english, but when I am using my own dictoniary then the predicted output is empty (“[]”).
My dictionary is quite specific, it is sentence to sentence, like:
“when raining then use umbrella6” -> “trigger raining check umbrella6”
I have like 1000 lines (maybe too little) of simillar sentences and they contain this strange “umbrella6” strings (so string+ID).
I was expecting that the results may not make any sense, but empty predict is something strange – there should be something?
You may need to change and tune the model to the new dataset.
The smaller number of samples may mean the model may overfit quickly, you can try to limit this with regularization.
For future ref, comments are moderated and I process them once per day. No need to re-post if they don’t appear immediately. More here:
https://machinelearningmastery.com/faq/single-faq/where-is-my-blog-comment
May be I missed that but what happens if there is a new/unseen word in the input text? Rather what is expected in the output?
Unseen words are marked as 0 by the Tokenizer.
Hi Jason,
Great tutorial, love your blog! I was just wondering how I can pass in my own input to be translated. How do I just pass in one sentence. Everything I have tried is not working!
If you have text to be translated, you can use google translate.
If you want to use the model to make a prediction, you must encode new text using the same scheme used to prepare the training data then call model.predict().
Hi Jason,
Thanks for your detailed step by step process in walking everyone through. I have one help needed.
What needs to be changed above for Chinese Portuguese machine translator?
I target to do a (bi-directional) LSTM but cannot find existing word data file as the source.
Hope you can point me the direction and thanks.
B.Rgds,
Tom
The model may need to be tuned for your new dataset.
When I run the evaluation I get the following result:
UserWarning:
The hypothesis contains 0 counts of 4-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
BLEU-1: 0.077830
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
How can I fix this?
Perhaps check the types of text generated by your model, your model may not have converged to a useful solution.
How do we fix the issue? I tried re-running the model from the start again. It is showing the same result.
/usr/local/lib/python3.5/dist-packages/nltk/translate/bleu_score.py:503: UserWarning:
The hypothesis contains 0 counts of 4-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
BLEU-1: 0.077346
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
The same warning is there for 2-gram and 3-gram.
Perhaps try changing the configuration of the model?
Hi, thanks for your contribution.
Could you please clarify some of the doubts:
1. In the CLEAN TEXT step, inside clean_pairs() function, line number 7 talks about making a translation table for removing punctuation.
In the code, str.maketrans(”, ”, string.punctuation)
gives error with str as an undefined attribute.
And also what is “maketrans” function?
2. Regarding the function “to_pairs”, this function converts the dataset in the following format:
Original:
Hi. Hallo!
Hi. Grüß Gott!
Run! Lauf!
After:
Hi.
Hallo!
Hi.
Grüß Gott!
Run!
Lauf!
i.e. put the corresponding translation in the next line by splitting the phrase pairs.
Thanks.
You may be trying to use Python 2.7, I recommend using Python 3.5 or higher.
how this implementation differs from keras implemenation ?
https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
which one to prefer ?
Here we use an auto-encoder approach, in the keras blog post an encoder-decoder using only internal state is used instead.
Use an approach that results in the best performance for your problem.
Hiii Jason,
Thanks for this wonderful article. I have been trying to implement this and I got a doubt in
prediction = model.predict(testX, verbose=1)[0]
Why we only take single encoded source?
There is only one prediction/row, so we take it from the 2D array.
Sorry I don’t understand, the shape of prediction would be (1000, 5, 2309) but we only take the zeroth element from it. Why?
No, we are only translating one sentence of words at a time.
To confirm, print the shape of the input and output of the predict function prior to only selecting the zero’th element.
Hi Jason,
Thank you for sharing this great article. Because of my null progress in learning German, after four years living in a German speaking country, I decided to create an application that I think could help me with it, and maybe to others too.
As a first step I think your approach may fit well with my requirements. My question is, are all the codes shown here free to reproduce or is there and copyright?
Thanks again,
Dani.
They are copyright, but you can use them as long as you clearly credit their origin.
More details here:
https://machinelearningmastery.com/faq/single-faq/can-i-use-your-code-in-my-own-project
hello
could you please help me
i m doing same work neural translation from English to arabic !!
how I follow the steps which is provided but I got an error
Perhaps post your error to stackoverflow?
hello sir
I got this result while running but does not apear probably
train
src=[], target=[continue digging], predicted=[i is to]
src=[], target=[tom laid the gun down on the floor], predicted=[i is to]
src=[], target=[i have to find it], predicted=[i is to]
src=[], target=[i believe in god], predicted=[i is to]
src=[], target=[im a free man], predicted=[i is to]
src=[], target=[can i use my credit card], predicted=[i is to]
src=[], target=[she is about to leave], predicted=[i is to]
src=[], target=[she raised her hands], predicted=[i is to]
src=[], target=[my uncle died a year ago], predicted=[i is to]
src=[], target=[im sitting alone in my house], predicted=[i is to]
/anaconda3/lib/python3.6/site-packages/nltk/translate/bleu_score.py:490: UserWarning:
Corpus/Sentence contains 0 counts of 2-gram overlaps.
BLEU scores might be undesirable; use SmoothingFunction().
warnings.warn(_msg)
BLEU-1: 0.266528
BLEU-2: 0.516264
BLEU-3: 0.672548
BLEU-4: 0.718515
test
src=[], target=[im working in a town near rome], predicted=[i is to]
src=[], target=[she despised him], predicted=[i is to]
src=[], target=[the clock is ticking], predicted=[i is to]
src=[], target=[this river is one mile across], predicted=[i is to]
src=[], target=[birds of a feather flock together], predicted=[i is to]
src=[], target=[why did you turn down his offer], predicted=[i is to]
src=[], target=[shes as clever as they make em], predicted=[i is to]
src=[], target=[how can i help], predicted=[i is to]
src=[], target=[our living room is sunny], predicted=[i is to]
src=[], target=[can you speak french], predicted=[i is to]
BLEU-1: 0.260667
BLEU-2: 0.510555
BLEU-3: 0.668076
BLEU-4: 0.714531
Perhaps try fitting the model again?
my dataset English-arabic
when load it and clean the data I got this
[hi] => []
[run] => []
[help] => []
[jump] => []
[stop] => []
[go on] => []
[go on] => []
[hello] => []
[hurry] => []
[hurry] => []
[i see] => []
[i won] => []
[relax] => []
[smile] => []
[cheers] => []
[got it] => []
[he ran] => []
[i know] => []
[i know] => []
[i know] => []
[im] => []
[im ok] => []
[listen] => []
[no way] => []
[really] => []
[thanks] => []
[why me] => []
[awesome] => []
[call me] => []
[call me] => []
[come in] => []
[come in] => []
[come on] => []
[come on] => []
[come on] => []
[get out] => []
[get out] => []
[get out] => []
[go away] => []
[go away] => []
[go away] => []
[goodbye] => []
[he came] => []
[he runs] => []
[help me] => []
[help me] => []
[im sad] => []
[me too] => []
[shut up] => []
[shut up] => []
[shut up] => []
[shut up] => []
[stop it] => []
[take it] => []
[tom won] => []
[tom won] => []
[wake up] => []
[welcome] => []
[welcome] => []
[welcome] => []
[welcome] => []
[who won] => []
[who won] => []
[why not] => []
[why not] => []
[have fun] => []
[hurry up] => []
[i forgot] => []
[i got it] => []
[i got it] => []
[i got it] => []
[i use it] => []
[ill pay] => []
[im busy] => []
[im busy] => []
[im cold] => []
[im free] => []
[im here] => []
[im home] => []
[im poor] => []
[im rich] => []
[it hurts] => []
[its hot] => []
[its new] => []
[lets go] => []
[lets go] => []
[lets go] => []
[lets go] => []
[lets go] => []
[look out] => []
[look out] => []
[look out] => []
[speak up] => []
[stand up] => []
[terrific] => []
[terrific] => []
[tom died] => []
[tom died] => []
[tom left] => []
[tom lied] => []
Perhaps your model requires further tuning?
l need Universal networking language based algorithms how it works and l want to integrate other algorithms with UNL framwork enco and deco functions
I don’t have material in that topic, sorry.
Excellent work! Thank you, Jason!
Thanks!
Can i use this model to train chinese to english translation, as chinese is something different then other language what precaution i need to take care.
Perhaps.
Hello Sir, Thank you very much for this wonderful guide!!!
I just have one doubt….Can we build a model which could translate both-ways…i.e. Language1 to Language2 and also Language2 to Language1?
Maybe, I don’t see how off the cuff.
Hi Jason, can you please clarify: in this model, are we giving the word embeddings as hidden state input to the encoder- lstm?
Thanks in advance!
The embedding is provided as input to the LSTM, not hidden state.
Thankyou for your reply 🙂 Is any direct input given to the second LSTM? or it receives only hidden input from the first one?
You can use the output and hidden state or just the output. I prefer the latter – like an autoencoder. It is simpler and performs very well.
what you have implemented here is an Autoencoder?
No, it is an encoder-decoder:
https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/
Can I develop a multilingual machine translation using any pretrained model? How to do that?
Perhaps.
I don’t have a tutorial on this topic, sorry.
Hi Jason,
Thanks for a wonderful post. I am trying to run the code on a different translation (English to Hindi), the training runs fine but while evaluating I am getting the following error:
Using TensorFlow backend.
train
Traceback (most recent call last):
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\ptvsd_launcher.py”, line 119, in
vspd.debug(filename, port_num, debug_id, debug_options, run_as)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\debugger.py”, line 37, in deb
ug
run(address, filename, *args, **kwargs)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_local.py”, line 64, in run_f
ile
run(argv, addr, **kwargs)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_local.py”, line 125, in _run
_pydevd.main()
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_vendored\pydevd\pydevd.py”,
line 1752, in main
globals = debugger.run(setup[‘file’], None, None, is_module)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_vendored\pydevd\pydevd.py”,
line 1099, in run
return self._exec(is_module, entry_point_fn, module_name, file, globals, loc
als)
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_vendored\pydevd\pydevd.py”,
line 1106, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File “c:\program files (x86)\microsoft visual studio\2017\enterprise\common7\i
de\extensions\microsoft\python\core\Packages\ptvsd\_vendored\pydevd\_pydev_imps\
_pydev_execfile.py”, line 25, in execfile
exec(compile(contents+”\n”, file, ‘exec’), glob, loc)
File “D:\kudave\EEM\Code\EEMDNN\EEMDNN\infer.py”, line 88, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “D:\kudave\EEM\Code\EEMDNN\EEMDNN\infer.py”, line 56, in evaluate_model
translation = predict_sequence(model, eng_tokenizer, source)
File “D:\kudave\EEM\Code\EEMDNN\EEMDNN\infer.py”, line 40, in predict_sequence
prediction = model.predict(source, verbose=0)[0]
File “C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64\lib\si
te-packages\keras\engine\training.py”, line 1149, in predict
x, _, _ = self._standardize_user_data(x)
File “C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64\lib\si
te-packages\keras\engine\training.py”, line 751, in _standardize_user_data
exception_prefix=’input’)
File “C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64\lib\si
te-packages\keras\engine\training_utils.py”, line 138, in standardize_input_data
str(data_shape))
ValueError: Error when checking input: expected embedding_1_input to have shape
(8,) but got array with shape (11,)
————————————————————–
I get the same error when I evaluate on test data. Do you know what is wrong. To start with I have not changed much except the data in the code.
Sorry, I don’t have the capacity to debug your changes, perhaps post your code and error to stackoverflow?
Hi Jason!
I am using your NMT code for converting sentences from present perfect to past perfect tense. I trained it for 50 epochs
Epoch 50/50
2500/2500 [==============================] – 37s 15ms/step – loss: 1.0273 – acc: 0.8178 – val_loss: 1.1926 – val_acc: 0.8187
But its giving me out put like this
train
src=[i have no idea what i need to do now], target=[i had no idea what i need to do then], predicted=[i had not to had had had had had]
src=[i will get by if i have a place to sleep], target=[i will get by if i had a place to sleep], predicted=[i had not had had had had had had had]
src=[this is the worst book i have ever read], target=[this was the worst book i had ever read], predicted=[i had not had had had had had had]
src=[does anybody have any good news], target=[does anybody had any good news], predicted=[i had a a a]
src=[i have everything here that i need], target=[i had everything here that i need], predicted=[i had had to to had]
src=[can i have my gun back], target=[could i have my gun back], predicted=[i had have a a]
src=[i want to go and have a drink], target=[i want to go and had a drink], predicted=[i had to to to to the me]
src=[i have an orange and an apple], target=[i had an orange and an apple], predicted=[i had had to to my]
src=[i have a dog that can run fast], target=[i had a dog that could run fast], predicted=[i had had to had had had]
src=[i have a sweet tooth], target=[i had a sweet tooth], predicted=[i had a a]
src=[i have already told tom i will not help him], target=[i had already told tom i will not help him], predicted=[i had not had had had had had had]
and on test data
src=[i have no regrets for what i have done], target=[i had no regrets for what i had done], predicted=[i had had to to had had the]
src=[tom must have heard about what happened], target=[tom must had heard about what happened], predicted=[i had had had had to you]
src=[i have left my umbrella in a bus], target=[i had left my umbrella in a bus], predicted=[i had had to to for for]
src=[could i have money for my piano lesson], target=[could i had money for my piano lesson], predicted=[i had had to to to for me]
src=[i have said i am sorry], target=[i had said i was sorry], predicted=[i had had to to you]
src=[i have been to the u], target=[i had been to the u], predicted=[i had had to to you]
src=[may i have a glass of milk please], target=[may i had a glass of milk please], predicted=[i had had had to to to me]
src=[recently i have had no appetite], target=[recently i had had no appetite], predicted=[i had had had been]
src=[my friend has been here this week], target=[my friend had been here this week], predicted=[i had to to to the]
src=[i have waited two whole hours], target=[i had waited two whole hours], predicted=[i had had a my]
can you tell what i am doing wrong. The source an target both languages are english.
Perhaps try re-fitting the model a few times and compare results?
TypeError : int() argument must be a string, a bytes-like object or a number, not ‘TensorShapeProto’
i got this error
I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
I have a trained model and it will successfully evaluate in the model.h5 and i want a code for translate single line sentence . like i passed hallo! the it will say hello
I show how to use the model in inference mode in the above tutorial.
from tensorflow.python import pywrap_tensorflow
ImportError: cannot import name ‘pywrap_tensorflow’ from ‘tensorflow.python’ (unknown location)
how can I solve this bug
Seems unrelated to this post, try posting to stackoverflow.
Hi Jason,
can u please let me know how to give only one input sentence in german language and find its translation using the model constructed??
Use the final code example and call:
Where “source” is your integer encoded sentence of text with the shape [1, n]
Is this meaning that we have to convert our text using a tokenizer before?
Yes.
Hey did you translate it……if you please help me
great work Jason , i tried to built the same model but for English to Arabic langauge , but a got an error when trying to load and validate the model
Using TensorFlow backend.
2019-01-22 10:00:35.388677: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
train
Traceback (most recent call last):
File “validation.py”, line 88, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “validation.py”, line 56, in evaluate_model
translation = predict_sequence(model, eng_tokenizer, source)
File “validation.py”, line 40, in predict_sequence
prediction = model.predict(source, verbose=0)[0]
ValueError: Error when checking input: expected embedding_1_input to have shape (36,) but got array with shape (14,)
Looks like there is a mismatch between the data provided and the model’s expectations.
Change the data or the model.
hi , Jason
thank you for this great article,
i tried this code and it works very well , but when am trying much bigger data set i have an error
English Vocabulary Size: 20428
English Max Length: 48
arabic Vocabulary Size: 33623
arabic Max Length: 59
Traceback (most recent call last):
File “tokniezer.py”, line 79, in
trainY = encode_output(trainY, eng_vocab_size)
File “tokniezer.py”, line 43, in encode_output
y = array(ylist)
MemoryError
Can i solve this error without increasing my RAM memory , i am using now 16GB memory and a data set about 100000 Line
Perhaps try on a machine with more RAM?
Perhaps try working on a subset of the dataset?
I tried to use this for English Urdu but after cleaning i am getting blank from urdu side
[we won] => []
[beat it] => []
[beat it] => []
[we lost] => []
[good job] => []
[lets go] => []
[toms up] => []
[i am sick] => []
[let me in] => []
[lets try] => []
[stay thin] => []
[stay thin] => []
[stay thin] => []
[stay thin] => []
[toms fat] => []
[toms mad] => []
[toms sad] => []
[toms shy] => []
[we talked] => []
[well try] => []
[well win] => []
[whats up] => []
[are you ok] => []
[i like tea] => []
[i love her] => []
[i love you] => []
[i love you] => []
[i need you] => []
[i need you] => []
[im sleepy] => []
[im sleepy] => []
[toms dead] => []
[toms deaf] => []
[toms died] => []
[toms fast] => []
[toms free] => []
[toms gone] => []
[toms here] => []
[toms home] => []
[toms hurt] => []
[toms safe] => []
[toms sick] => []
[toms weak] => []
[toms well] => []
[well help] => []
[well wait] => []
[how are you] => []
[how are you] => []
[i live here] => []
[i live here] => []
[i love rock] => []
[i need help] => []
[i trust you] => []
[im at home] => []
[is it white] => []
[it may rain] => []
[it may snow] => []
[lets do it] => []
[toms bored] => []
[toms drunk] => []
[toms right] => []
Perhaps your model requires tuning?
Dear Ashraf,
I got the same problem.
ValueError: Error when checking input: expected embedding_1_input to have shape (26,) but got array with shape (19,)
Any advice on how you tackled this problem. Your support will be greatly appreciated.
Zahra
This might help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
I’m sorry if this is the wrong place to ask, but I’m having trouble with cleaning and saving the Data, it keeps saying IndexError: index 1 is out of bounds for axis 1 with size 1, does this mean i’m creating clean_pairs wrong?
Perhaps try posting your code and your error to stackoverflow?
If i worked with languages such as hindi how would I go about the cleaning of data since the scripts and symbols are entirely different
You may have to update the examples to support unicode characters.
Hey jason,
I saw your post nice work. Well i am also working on a SMT project using python. I would like to know if can you provide a running project code about it or help me in some how to get it.
Thanks.
Sorry, I don’t understand, can you please restate or elaborate your question?
I am trying to convert this to run on TPUs. Following other notebooks for TPUs, I use the Keras layer in Tensorflow rather than the other way around. Before getting to the TPU part, I am doing this conversion to see if it still runs on GPU. This means mainly changing this function:
# define NMT model
def define_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Embedding(src_vocab, n_units, input_length=src_timesteps, mask_zero=True))
model.add(tf.keras.layers.LSTM(n_units))
model.add(tf.keras.layers.RepeatVector(tar_timesteps))
model.add(tf.keras.layers.LSTM(n_units, return_sequences=True))
model.add(tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tar_vocab, activation=’softmax’)))
return model
However this results in a complaint followed by a runtime error when I run fit:
lib\site-packages\tensorflow\python\ops\gradients_impl.py:112: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
“Converting sparse IndexedSlices to a dense Tensor of unknown shape. ”
Then during the fit inside the GPU it fails on a BLAS load as follows:
InternalError: Blas GEMM launch failed : a.shape=(64, 256), b.shape=(256, 256), m=64, n=256, k=256
[[{{node lstm/while/MatMul}} = MatMul[T=DT_FLOAT, _class=[“loc:@training/Adam/gradients/lstm/while/strided_slice_grad/StridedSliceGrad”], transpose_a=false, transpose_b=false, _device=”/job:localhost/replica:0/task:0/device:GPU:0″](lstm/while/TensorArrayReadV3, lstm/while/strided_slice)]]
[[{{node loss/time_distributed_loss/broadcast_weights/assert_broadcastable/AssertGuard/Assert/Switch/_175}} = _Recv[client_terminated=false, recv_device=”/job:localhost/replica:0/task:0/device:CPU:0″, send_device=”/job:localhost/replica:0/task:0/device:GPU:0″, send_device_incarnation=1, tensor_name=”edge_2728_…ert/Switch”, tensor_type=DT_BOOL, _device=”/job:localhost/replica:0/task:0/device:CPU:0″]()]]
Any thoughts?
Sorry, I have not used kf.keras and I don’t use notebooks or TPUs, I don’t have any good advice for you.
Perhaps try posting on a tensorflow user group or stackoverflow?
Hi Jason,
Great job.. Thank you for the tutorial.
I gave it a try. I used your dataset only but facing some issue. Here it is like—
train
src=[er lief], target=[he ran], predicted=[he he]
src=[er rannte], target=[he ran], predicted=[ran he]
src=[donnerwetter], target=[wow], predicted=[]
src=[keine bewegung], target=[freeze], predicted=[]
src=[ich verstehe], target=[i see], predicted=[i fell]
src=[feuer], target=[fire], predicted=[]
src=[im ernst], target=[really], predicted=[]
src=[mach mit], target=[hop in], predicted=[he he]
src=[ich bin jahre alt], target=[im], predicted=[i fell]
src=[ausgeschlossen], target=[no way], predicted=[]
BLEU-1: 0.066384
BLEU-2: 0.128366
BLEU-3: 0.167111
BLEU-4: 0.178502
test
/usr/local/lib/python3.6/dist-packages/nltk/translate/bleu_score.py:490: UserWarning:
Corpus/Sentence contains 0 counts of 2-gram overlaps.
BLEU scores might be undesirable; use SmoothingFunction().
warnings.warn(_msg)
—————————————————————————
ZeroDivisionError Traceback (most recent call last)
in ()
89 # test on some test sequences
90 print(‘test’)
—> 91 evaluate_model(model, eng_tokenizer, testX, test)
in evaluate_model(model, tokenizer, sources, raw_dataset)
61 predicted.append(translation.split())
62 # calculate BLEU score
—> 63 print(‘BLEU-1: %f’ % corpus_bleu(actual, predicted, weights=(1.0, 0, 0, 0)))
64 print(‘BLEU-2: %f’ % corpus_bleu(actual, predicted, weights=(0.5, 0.5, 0, 0)))
65 print(‘BLEU-3: %f’ % corpus_bleu(actual, predicted, weights=(0.3, 0.3, 0.3, 0)))
/usr/local/lib/python3.6/dist-packages/nltk/translate/bleu_score.py in corpus_bleu(list_of_references, hypotheses, weights, smoothing_function, auto_reweigh, emulate_multibleu)
181 # Collects the various precision values for the different ngram orders.
182 p_n = [Fraction(p_numerators[i], p_denominators[i], _normalize=False)
–> 183 for i, _ in enumerate(weights, start=1)]
184
185 # Returns 0 if there’s no matching n-grams
/usr/local/lib/python3.6/dist-packages/nltk/translate/bleu_score.py in (.0)
181 # Collects the various precision values for the different ngram orders.
182 p_n = [Fraction(p_numerators[i], p_denominators[i], _normalize=False)
–> 183 for i, _ in enumerate(weights, start=1)]
184
185 # Returns 0 if there’s no matching n-grams
/usr/lib/python3.6/fractions.py in __new__(cls, numerator, denominator, _normalize)
176
177 if denominator == 0:
–> 178 raise ZeroDivisionError(‘Fraction(%s, 0)’ % numerator)
179 if _normalize:
180 if type(numerator) is int is type(denominator):
ZeroDivisionError: Fraction(0, 0)
Not sure why you got an error.
Perhaps try fitting the model again and see if it gives different results.
Hello Sir.
I am facing a problem while running the code using English and another Indian language.
while printing the sentence pair it shows blank in the right hand side. please suggest something to fix it.
[jaipur popularly known as the pink city is the capital of rajasthan state india] => []
[the city is famous for its majestic forts palaces and beautiful lakes which attract tourists from all over the world] => []
[the city palace was built by maharaja jai singh ii and is a synthesis of mughal and rajasthani architecture] => []
[the hawa mahal was built by the maharaja sawai pratap singh in ad and lal chand usta was the architect] => []
[the amber fort complex has several apartments with palaces halls stairways pillared pavilions gardens and temples] => []
[the amber palace is a classic example of mughal and hindu architecture] => []
[the government central museum was constructed in when the prince of wales had visited india and was opened to public in] => []
[the government central museum has a rich collection of ivory work textiles jewellery carved wooden objects miniature paintings marble statues arms and weapons] => []
[sisodiya ranikabagh was built by sawai jai singh ii for his sisodiya queen] => []
[the jal mahal is a picturesque palace which was built for royal duck shooting parties] => []
[kanak vrindavan is a popular picnic spot in jaipur] => []
[jaipur bazaars are vibrant and the shops are full with colorful items which include handicraft items precious stones textiles minakari items jewellery rajasthani paintings etc] => []
[jaipur is also famous for marble statues blue pottery and the rajasthani shoes] => []
I have a few ideas:
Perhaps there’s a bug in your code?
Perhaps the model has not fit the problem?
Perhaps a different model configuration is required?
Hi I am having issue with my code and unable to find error. For every prediction it gives almost same result. I tried the your tutorial with English-Hindi example. Please find code and tell me where I am making mistake.
def define_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
model = Sequential()
model.add(Embedding(src_vocab, n_units, input_length=src_timesteps, mask_zero=True))
model.add(LSTM(n_units))
model.add(RepeatVector(tar_timesteps))
model.add(LSTM(n_units, return_sequences=True))
model.add(TimeDistributed(Dense(tar_vocab, activation=’softmax’)))
return model
# define model
model = define_model(english_vocab_size, hindi_vocab_size, english_max_sentence_size, hindi_max_sentence_size, 32)
print(english_vocab_size, hindi_vocab_size, english_max_sentence_size, hindi_max_sentence_size)
model.compile(optimizer=’adam’, loss=’categorical_crossentropy’)
# summarize defined model
print(model.summary())
# plot_model(model, to_file=’model.png’, show_shapes=True)
checkpoint = ModelCheckpoint(“model.h6″, monitor=’val_loss’, verbose=1, save_best_only=True, mode=’min’)
# print(hindi_preproc.shape, english_preproc.shape)
model.fit(english_train_preproc, hindi_train_preproc, epochs=30, validation_data=(english_test_preproc, hindi_test_preproc), batch_size=16, callbacks=[checkpoint], verbose=2)
model = load_model(‘model.h6’)
print(english_test_preproc.shape)
hindi_index_to_words = {id:word for word, id in hindi_tokenize.word_index.items()}
hindi_index_to_words[0] = ”
english_index_to_words = {id:word for word, id in english_tokenize.word_index.items()}
english_index_to_words[0] = ”
english_test_preproc_temp = english_train_preproc[600:620,:]
for i, source in enumerate(english_test_preproc_temp):
print(‘ ‘.join([english_index_to_words[p] for p in source.tolist()]))
source = source.reshape((1, source.shape[0]))
prediction = model.predict(source, verbose=0)
print(ids_to_text(prediction[0], hindi_tokenize))
All the variables have values as their names meaning.
Perhaps the model does not have a good fit, I have some suggestions to try here:
https://machinelearningmastery.com/framework-for-better-deep-learning/
In the code, str.maketrans(””, ””, string.punctuation)
gives error as str as an undefined attribute maketrans.
We even tried it as using string.maketrans then it gives error as –
maketrans() takes excatly 2 arguments
And if we pass only 2 arguments then it gives error as – arguments must have same length.
We are using Python 3.5 and Platform as Eclipse still its giving us an error.
What could be the possible solution ?
Thank You.
I believe maketrans() is a Python 2 function, try Python 2.7.
Alternately, try this in Python 3:
Thank you Sir. This helped.
Sir but we are now facing an issue with keras.
Please help us in moving forward as we have tried all ways of installing keras.
This is the copy pasted error shown on Spyder even after we have installed keras with conda
runfile(‘/home/ccoewitlab1-99/.spyder2-py3/temp.py’, wdir=’/home/ccoewitlab1-99/.spyder2-py3′)
Traceback (most recent call last):
File “”, line 1, in
runfile(‘/home/ccoewitlab1-99/.spyder2-py3/temp.py’, wdir=’/home/ccoewitlab1-99/.spyder2-py3′)
File “/usr/lib/python3/dist-packages/spyderlib/widgets/externalshell/sitecustomize.py”, line 699, in runfile
execfile(filename, namespace)
File “/usr/lib/python3/dist-packages/spyderlib/widgets/externalshell/sitecustomize.py”, line 88, in execfile
exec(compile(open(filename, ‘rb’).read(), filename, ‘exec’), namespace)
File “/home/ccoewitlab1-99/.spyder2-py3/temp.py”, line 10, in
from keras.preprocessing.sequence import pad_sequences
ImportError: No module named ‘keras’
It looks like Keras is not installed, perhaps try this tutorial to setup your environment:
https://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
Thank You very much once again Sir.
After following the above steps, all the errors were solved.
Our code is now running for small dataset, but for the dataset which this tutorial contains it is gives error as Memory Load and not giving us the Final output.
Also is there some way where instead of our output occuring as src[], target[] and prdicted[], can we ask the user to enter the input in german whether it may be a word or paragraph and on running the code gives us the output in English Language. In short giving the Test Data as input from user.
Thanks and Regards.
Perhaps try running the code on a machine with more memory, e.g. on an EC2 instance:
https://machinelearningmastery.com/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
You can use the model within normal software, but that is a software engineering question, not a machine learning question.
Dear Jason
please add attention layer in this example. it will help us a lot.
thanks a lot.
Thanks for the suggestion.
Great article, thank you very much.
When you talk about “A BLEU-4 score of 0.076238 was achieved, providing a baseline skill to improve upon with further improvements to the model.” Is it necessary to train the model whenever new lines are added to improve the translation?
Regards!
Perhaps. This is something that can be tested and considered.
Hello,
When I run the code along with the whole dataset I get an error saying IndexError: too many indices for array
And it says that error is at eng_tokenizer = create_tokenizer(dataset[:,0]).
Can you please help.
I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hello,
I went through the instructions given in the link and everything seems in accordance with the points.
I am still getting this error when I run the code
runfile(‘/home/ccoewitlab1-99/.config/spyder-py3/temp.py’, wdir=’/home/ccoewitlab1-99/.config/spyder-py3′)
Saved: english-german.pkl
[hi] => [hallo]
[hi] => [gru gott]
[run] => [lauf]
[wow] => [potzdonner]
[wow] => [donnerwetter]
[fire] => [feuer]
[help] => [hilfe]
[help] => [zu hulf]
[stop] => [stopp]
[wait] => [warte]
[go on] => [mach weiter]
[hello] => [hallo]
[i ran] => [ich rannte]
[i see] => [ich verstehe]
[i see] => [aha]
[i try] => [ich probiere es]
[i won] => [ich hab gewonnen]
[i won] => [ich habe gewonnen]
[smile] => [lacheln]
[cheers] => [zum wohl]
[freeze] => [keine bewegung]
[freeze] => [stehenbleiben]
[got it] => [kapiert]
[got it] => [verstanden]
[got it] => [einverstanden]
[he ran] => [er rannte]
[he ran] => [er lief]
[hop in] => [mach mit]
[hug me] => [druck mich]
[hug me] => [nimm mich in den arm]
Saved: english-german-both.pkl
Saved: english-german-train.pkl
Saved: english-german-test.pkl
Traceback (most recent call last):
File “”, line 1, in
runfile(‘/home/ccoewitlab1-99/.config/spyder-py3/temp.py’, wdir=’/home/ccoewitlab1-99/.config/spyder-py3′)
File “/home/ccoewitlab1-99/anaconda3/lib/python3.6/site-packages/spyder/utils/site/sitecustomize.py”, line 866, in runfile
execfile(filename, namespace)
File “/home/ccoewitlab1-99/anaconda3/lib/python3.6/site-packages/spyder/utils/site/sitecustomize.py”, line 102, in execfile
exec(compile(f.read(), filename, ‘exec’), namespace)
File “/home/ccoewitlab1-99/.config/spyder-py3/temp.py”, line 203, in
eng_tokenizer = create_tokenizer(dataset[:, 0])
IndexError: too many indices for array
Please help I am stuck over this error since two weeks. Your help will be of great value sir.
Sorry to hear that, what version of Keras are you using?
TypeError: data type not understood
This the error i am getting at model.fit()
Help me solve this pls
Sorry to hear that, this might help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hello,
keras fit_on_texts assign a unique integer to each word. So can you please tell if this considers
similar words and if yes, how? Thanks in advance
No, similar words are not considered.
Hello, Does this NMT support training long sentences? I am trying to train 3000 sentences of my own and and test data of 900 sentences but after evaluating, all the predicted results are the same characters for all test data.
Yes, some models can do quite well on long sentences. It really depends on the model and choice of training data.
What should be the input shape if I am using Bidirectional layer?
The input shape is unaffected.
Hello Sir. I am a novice in Deep Learning. Can you suggest me how to use Bidirectional as input layer?
Yes, see this post:
https://machinelearningmastery.com/develop-bidirectional-lstm-sequence-classification-python-keras/
Sir, I just started the training using 23000 sentence pair and I am getting this memory error:
trainY = encode_output(trainY, eng_vocab_size)
File “nmt.py”, line 43, in encode_output
y = array(ylist)
MemoryError
I have 16gb of ram BTW.
Perhaps try progressive loading (e.g. a data generator)?
Perhaps try AWS EC2?
Perhaps try less data?
Sir,
I am a student and i am trying to translate from Hindi to English using your code.The code works fine for training but when it predicts sequences it is giving null.The predicted output is coming as empty.I changed only one thing in the code which is that i transliterated the Hindi devanagiri script to Latin script so that normalization of source language data can be done.Can you give your views on the issue?
Perhaps the model requires tuning for your specific dataset, I have some suggestions here:
https://machinelearningmastery.com/start-here/#better
Are we supposed to transliterate if the source language is Hindi?
Hi Sir. I tried doing Hindi to English translator making few changes to your code. I get a bleu of 0.74 for 4 gram but the prediction is very bad. It almost gives the same prediction for all the sentences. Any suggestions on that?
Perhaps the model requires some tuning:
https://machinelearningmastery.com/start-here/#better
I got Error in creating Tokenizer
# fit a tokenizer
2 def create_tokenizer(lines):
—-> 3 tokenizer = Tokenizer()
4 tokenizer.fit_on_texts(lines)
5 return tokenizer
NameError: name ‘Tokenizer’ is not defined
Sorry to hear that, perhaps ensure that you have copied all of the lines of code for the full code example.
hi, how did you resolve this error @Syed Abdul Basit
ur problem solved?
Glad to hear it.
Hi
I tried doing English to Indonesian but i have problem with prediction. It predicts only the english words I had, I do, I you repeatedly. But the BLEU value is ok at 0.5 – 9.0.
I’ve tried fixing the weights on the BLEU code but it remains the same.
And I you know you’ve said the model needs fine tuning, but can you perhaps suggest what is problem? Is it the tokenizer or not too much training, or verbose?
I’ve changed every parameter in the Model following your book, but I still get the same result on prediction
Perhaps confirm that the inputs and outputs in the data are as you expect?
Hi , I had a problem that I got the different result when I used the model after it was trained instantly and when I saved and then loaded to use it with other dataset. Maybe it is because the change of tokenizer that is the new data have different tokenizer to encode which is different from tokenizer we create before training . How can I fix this problem , or I have to train the new model every time before use it.
You must use the same tokenizer. Perhaps save it along with the model or develop a consistent way of creating it?
How can I do that ? .Do you have any suggestion ? , Thank you in advance.
You can use pickle, I have many examples on the blog, including an example of using pickle in the above tutorial.
There is some errors in the code. To be specific, you have to use to
actual.append([raw_target.split()])according to the definition of the references in corpus-level BLEU score.Are you sure? Does it impact your results? Are your libraries up to date?
list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
hypotheses = [hyp1, hyp2]
corpus_bleu(list_of_references, hypotheses)
the code above is from [bleu_score.html](https://www.nltk.org/_modules/nltk/translate/bleu_score.html). As you can see, each item in
list_of_referencesis **a list of list**.Yes, also demonstrated here:
https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
Thanks, fixed!
Hi Jason ,
You post one of the best deep learning content on internet. A must appreciated effort.
Can you please post a project on building an automatic speech recognition in tensorflow using LSTMs and teach how to process the audio data and label sentences. usually ASR with preprocess data is given which is not my requirement. Not only me many people will benefit from it.
Thank you very much
Thanks for the suggestion.
Can you suggest me how to use model.fit_generator here? Thanks in advance
What problem are you having exactly?
i guess that that previous poster has a very large dataset, running out of memory and would like to know how to use to use model.fit_generator instead of model.fit to solve the NMT example above
Good question, you can develop a function to progressively data, I give an example in this tutorial that you can use as a starting point:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Hi
The tutorial is really helpful, i would just like to know if you can provide the translation for the whole data set. here I can see only few translations.
The dataset used in the post contains all english phrases and their translations.
This started ok but pydot.py was called but not there.
(base) C:\Users\Roger\Documents\Python Scripts>python model.py
Using Theano backend.
English Vocabulary Size: 2233
English Max Length: 5
German Vocabulary Size: 3566
German Max Length: 10
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 10, 256) 912896
_________________________________________________________________
lstm_1 (LSTM) (None, 256) 525312
_________________________________________________________________
repeat_vector_1 (RepeatVecto (None, 5, 256) 0
_________________________________________________________________
lstm_2 (LSTM) (None, 5, 256) 525312
_________________________________________________________________
time_distributed_1 (TimeDist (None, 5, 2233) 573881
=================================================================
Total params: 2,537,401
Trainable params: 2,537,401
Non-trainable params: 0
_________________________________________________________________
None
Traceback (most recent call last):
File “model.py”, line 79, in
plot_model(model, to_file=’model.png’, show_shapes=True)
File “C:\Users\Roger\Anaconda3\lib\site-packages\keras\utils\vis_utils.py”, line 132, in plot_model
dot = model_to_dot(model, show_shapes, show_layer_names, rankdir)
File “C:\Users\Roger\Anaconda3\lib\site-packages\keras\utils\vis_utils.py”, line 55, in model_to_dot
_check_pydot()
File “C:\Users\Roger\Anaconda3\lib\site-packages\keras\utils\vis_utils.py”, line 20, in _check_pydot
‘Failed to import
pydot. ‘ImportError: Failed to import
pydot. Please installpydot. For example withpip install pydot.You can comment out the plot_model line if you like.
Hi Jason!
im working on NMT for English to Vietnamese, i went throught all step in the article but my BLEU score is really bad, my custom data set contain 50000 sentences:
train
BLEU-1: 0.015223
BLEU-2: 0.004198
BLEU-3: 0.003481
BLEU-4: 0.001052
test
BLEU-1: 0.013051
BLEU-2: 0.001648
BLEU-3: 0.001538
BLEU-4: 0.000486
How can i improve the result? Thank you!
I have suggestions here:
https://machinelearningmastery.com/start-here/#better
Perhaps try running fitting the model a few times?
Perhaps the model requires tuning to your dataset?
Perhaps the dataset requires diffrent preparation?
Hi Jason,
may be a very basic thing,but I am not getting the reason behind adding + 1 to voab size
eng_vocab_size = len(eng_tokenizer.word_index) + 1
Good question, so that we leave room for 0==no word or “unknown”, therefore the first word in the vocab will be mapped to 1 and we can use 0 for all words we don’t have in our vocab.
Okay, so when we have that code to replace OOV with UNK in place, we should make sure to have that use ‘0’…am i right
Correct.
I get empty string ‘ ‘ as output for predict_sequence() function. Why is it so?
Perhaps the model did not converge for you, try fitting the model again?
Data Cleaning. Different data cleaning operations could be performed on the data, such as not removing punctuation or normalizing case, or perhaps removing duplicate English phrases
Jason, why do you think removing punctuations or not normalizing cases would help? becasue converting all into one lower case seems to be better idea than leaving as-is. Please share your thoughts
It would give a larger vocab and more nuance to the words. It would also require more training data, larger models and long training times.
Jason, I was running the model with larger corpus data i.e. about 160000 records, model stopped after 5th epoch as there isnt any improvement in loss…
So I though to consider the points listed in your extension and start training, I have modified the model as below i.e. adding Bidirectional (to input/encoder), including more units (256 to 512)and adding dropout aftre encoder and decorder LSTM layers.
I an not sure how to add more additional layers and where to add them for more represntational capacity…appreciate if you can help me in that.
# define the model
model = Sequential()
model.add(Embedding(ger_vocab_size, 512, input_length=ger_length, mask_zero=True))
model.add(Bidirectional(LSTM(512), merge_mode=’concat’))
model.add(Dropout(0.2))
model.add(RepeatVector(eng_length))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.2))
model.add(TimeDistributed(Dense(eng_vocab_size, activation=’softmax’)))
I have some suggestions here that might help:
https://machinelearningmastery.com/start-here/#better
Jason, Need your help…
I have gone through one of your post where a baseline model configuration was described.
Embedding: 512-dimensions
RNN Cell: Gated Recurrent Unit or GRU
Encoder: Bidirectional
Encoder Depth: 2-layers (1 layer in each direction)
Decoder Depth: 2-layers
Attention: Bahdanau-style
Optimizer: Adam
Dropout: 20% on input
I am confused on below thing…
Encoder: Bidirectional
Encoder Depth: 2-layers (1 layer in each direction)
Is it how we frame the above Encoder Bidirectional with 2 layers depth (1-layer in each direction)
model = Sequential()
model.add(Embedding(ger_vocab_size, 256, input_length=ger_length, mask_zero=True))
model.add(Bidirectional(LSTM(256, return_sequences=True), merge_mode=’concat’))
model.add(Bidirectional(LSTM(256, go_backwards=True),merge_mode=’concat’))
model.add(Dropout(0.2))
That looks reasonable, perhaps test it to confirm.
Sure, I’ll try with it and update you.
Meanwhile, I have tried with below model architecture passing
1. Huge data around 160000 (progressive loading through generator),
2. Limited vocabulary converting words which are occuring less than 5 times to ‘unk’
2. Increased units i.e. 256 -> 512
3. Bidirections Input/Encoder Layer
4. Dropout/regularization for Encoder and Decoder (20%)
and surprisingly found that loss isn’t decreasing further after 1 or 2 epochs. any ideas? Please help
model = Sequential()
model.add(Embedding(ger_vocab_size, 512, input_length=ger_length, mask_zero=True))
model.add(Bidirectional(LSTM(512), merge_mode=’concat’))
model.add(Dropout(0.2))
model.add(RepeatVector(eng_length))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.2))
model.add(TimeDistributed(Dense(eng_vocab_size, activation=’softmax’)))
Perhaps you need a deeper encoder, decoder or both?
Perhaps try relu?
I have a ton of suggestions here:
https://machinelearningmastery.com/start-here/#better
Jason, I would try to build a deeper encoder/decoder. meanwhile could you please confirm if we can implement Attention and Beam Search things in Keras, like is Keras supporting ? else how can I try to implement using the base model I pasted above.
Sorry, I cannot confirm your code/models.
I recommend testing a suite of approaches in order to discover what works best for your specific dataset.
Hey Json, I am not asking to confirm my model/code.
I just want to know, if we have support from Keras in implementing Attention Layers and Beam Search? if so do we have any reference material for that?
Keras does not support attention or beam search, you must implement them yourself.
This may help for attention:
https://machinelearningmastery.com/?s=attention&post_type=post&submit=Search
This may help for beam search:
https://machinelearningmastery.com/?s=beam+search&post_type=post&submit=Search
i am getting memoryError as:
Traceback (most recent call last):
File “cleantext.py”, line 70, in
save_clean_data(clean_pairs, ‘english-german.pkl’)
File “cleantext.py”, line 56, in save_clean_data
dump(sentences, open(filename, ‘wb’))
MemoryError
please tell me how to resolve it.
Sorry to hear that.
Perhaps try working with less data?
Perhaps try running on a machine with more memory?
Error in training neural model:
Using TensorFlow backend.
Traceback (most recent call last):
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow.py”, line 58, in
from tensorflow.python.pywrap_tensorflow_internal import *
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py”, line 28, in
_pywrap_tensorflow_internal = swig_import_helper()
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py”, line 24, in swig_import_helper
_mod = imp.load_module(‘_pywrap_tensorflow_internal’, fp, pathname, description)
File “D:\anaconda\envs\myenv\lib\imp.py”, line 243, in load_module
return load_dynamic(name, filename, file)
File “D:\anaconda\envs\myenv\lib\imp.py”, line 343, in load_dynamic
return _load(spec)
ImportError: DLL load failed: %1 is not a valid Win32 application.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “train.py”, line 3, in
from keras.preprocessing.text import Tokenizer
File “D:\anaconda\envs\myenv\lib\site-packages\keras\__init__.py”, line 3, in
from . import utils
File “D:\anaconda\envs\myenv\lib\site-packages\keras\utils\__init__.py”, line 6, in
from . import conv_utils
File “D:\anaconda\envs\myenv\lib\site-packages\keras\utils\conv_utils.py”, line 9, in
from .. import backend as K
File “D:\anaconda\envs\myenv\lib\site-packages\keras\backend\__init__.py”, line 89, in
from .tensorflow_backend import *
File “D:\anaconda\envs\myenv\lib\site-packages\keras\backend\tensorflow_backend.py”, line 5, in
import tensorflow as tf
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\__init__.py”, line 22, in
from tensorflow.python import pywrap_tensorflow # pylint: disable=unused-import
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\__init__.py”, line 49, in
from tensorflow.python import pywrap_tensorflow
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow.py”, line 74, in
raise ImportError(msg)
ImportError: Traceback (most recent call last):
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow.py”, line 58, in
from tensorflow.python.pywrap_tensorflow_internal import *
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py”, line 28, in
_pywrap_tensorflow_internal = swig_import_helper()
File “D:\anaconda\envs\myenv\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py”, line 24, in swig_import_helper
_mod = imp.load_module(‘_pywrap_tensorflow_internal’, fp, pathname, description)
File “D:\anaconda\envs\myenv\lib\imp.py”, line 243, in load_module
return load_dynamic(name, filename, file)
File “D:\anaconda\envs\myenv\lib\imp.py”, line 343, in load_dynamic
return _load(spec)
ImportError: DLL load failed: %1 is not a valid Win32 application.
PLease someone help me…
Thankyou…
Looks like a problem with tensorflow.
Perhaps try this tutorial to setup and test your environment:
https://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
how how to find number of sentences in the complete dataset?
The number of lines in the original files is the number of sentences.
GETTING ERROR
NameError: name ‘Tokenizer’ is not defined
Perhaps you missed an import statement.
Hello Sir Nice Tutorial .Please Help me how can i translate other sentence like i just want to translate “I Love You” just this sentence using the saved model please help me please?
You can load the model and make translations directly. What problem are you having exactly?
Nice tutorial, Jason. When I was reading the section where you clean the text, I was wondering how the commercial translators deal with numbers and other special symbols (e.g., currency). On Google Translator, for instance, If we input a text that contains numbers, uppercase words, and so on; they output the final text with the same symbols. Do you have any idea on how they implement that? I’d like to have an idea on how they recover the information that is “missed” on the preprocessing steps.
Great question.
I would expect that system that have access to so much text can actually handle almost all symbols directly. E.g. they’re all used so many times.
A stupid question. How do you determin a good value for output size of LSTM?
model.add(LSTM(n_units))must I usen_units?determin -> determine
Good question, I answer it here:
https://machinelearningmastery.com/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
Hello
I translate from French into English and have used the French – English corpus. I added some steps to understand better what is happening. I want to get a performance at least as good as Moses and tried to train a model using much more data using your code. I made the dataset 100000 instead of 10000 but got the following error categorical = np.zeros((n, num_classes))
MemoryError. It seems that my RAM (8GB) is not big enough. I do not use BLUE but evaluate the output manually by post editing. With Moses I used the whole Europarl Corpus and expect to do so with NMT. I need to find a way to train a lot of data on a machine with 8GB memory for it to be any good for use by individuals.
Perhaps try using less data?
Perhaps try running on a larger machine, e.g. AWS EC2?
Perhaps try using a data generator to prepare one batch of data at a time?
Hello Jason!
Where can I learn how to prepare data generator for model.fit_generator()?
You can see many examples on the blog for image and text data.
Maybe this example of a generator will help:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Anymore than 10000 sentences and the one hot coding takes up all my memory. I can train moses with 8G of ram but NMT training using your code seems useless to build a serious system. Don’t want to use AWS and how does a data generator work?
You can adapt the example here:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
I have managed to train a model using 100000 sentences on Floydhub using a machine with 59 GB cpu and 11GB GPU memory. The trouble for me is that this is really a tiny amount of data in MT terms. I used 1million segments to train Moses and Koehn et al show that in tests with Nematus and Moses, Nematus did not equal Moses until this amount of data was used. The problem is that using your method is likely to use resources that are mind blowing, mainly because of all the one hot vectors that have to be stored, wheras I can train my Moses engines on my laptop.
Going from French to English with 10000 sentences the only thing that can be said is that the output is in English. It has to be, because the words are represented by tokens that are translated into English.
My next step is to try 150000 sentences because this is all the data.
In your tutorial you fix the number of epochs to 30. How can I arrange to keep going until the cost is not changing?
Note that the model in this tutorial is for educational purposes, it might not be the most efficient model for broader use.
Perhaps you could use early stopping:
https://machinelearningmastery.com/how-to-stop-training-deep-neural-networks-at-the-right-time-using-early-stopping/
I love your blog really It is very amazing.
But I am not getting how to make a prediction with the model. Could you please remove my doubt
Yes, see this post:
https://machinelearningmastery.com/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
Hello Jason.
Very nice work here.
In your code for
predict_sequenceI think you could use the predict_classes method .Agreed. Thanks.
How can I give my own input into the model??????
And I have also discovered that this code can able to predict only first two lines of my given input. How can we code to predict and translate the sentences of two or more lines????
See the evaluate_model() function, for example this line:
How can i create my own datasets????
You can translate yourself?
It may be too time consuming, perhaps start with public datasets?
I can translate only two words correctly in a sentence. I want to translate completely. How It can be done??? Help me??
if i give an example as “Als Jugendlicher war Tom sehr beliebt.” that means “As a teenager, Tom was very popular.” in English but i get output as “you you you to to to you”. Its somewhat translating the sentence partially but how to get the exact output?????
Perhaps you model has overfit?
Perhaps try running the example again and fit a new model?
Perhaps develop a larger model on a different dataset?
Perhaps use a pre-trained model?
Jass
This model is only a toy and will not in reality translate anything. This only uses 10K sentences (or segments) and I think you will need to train with getting on for 1 million sentences to get a reasonable performance. Remember that Google have put huge resources into developing neural translation. I found this tutorial very good for learning using python, keras and tensorflow etc but its a bit like learning to weld. In my case the instructor demonstrated how to do it in five minutes, but I never managed to master it.
Yes, this tutorial (like all of them on my site) is an example for educational purposes.
It’s a starting point to kick-start your own project.
The trouble is it does not look like kick-starting my own project. Yesterday I tried to train a model with 149,000 sentences. It had an English vocabulary of 12004 words and max length of 12 but 59 GB memory was not enough. This turns out to be a known problem (Khan 201, p61 https://arxiv.org/abs/1709.07809) and vocabularies are restricted to between 20000 and 80000 words.
The main lesson here, for me, is that NMT is not all that it is cracked up to be.
This is just one approach, don’t judge a whole field based on a single tutorial.
Perhaps try one of the efficient implementations provided by stanford:
https://nlp.stanford.edu/projects/nmt/
Hi Browniee,
Thank you very much for nice representation of simple neural machine translation system,
Could you please provide the link for trained model. I could’nt find over there and i am not been able to train even with the use of gtx-1070 8gb graphics , 12 core processor 😐
Sorry, I cannot share a link to a trained model. I don’t want to get into the business of hosting models.
Hi Jason,
Can you please tell me what code should I use for hindi-english transliteration instead of
line = normalize(‘NFD’, line).encode(‘ascii’, ‘ignore’)
line = line.decode(‘UTF-8’) ?
I am not familiar with that translation, perhaps try experimenting?
Here’s my output
train
src=[फर्ग्यूसन], target=[ferguson], predicted=[raymond]
src=[काम्प्लैक्स], target=[complex], predicted=[raymond]
src=[लूकीज], target=[lookeys], predicted=[raymond]
src=[च्यवनप्राश], target=[chyavanprash], predicted=[raymond]
src=[कौशल], target=[koshala], predicted=[raymond]
src=[माइम], target=[mime], predicted=[raymond]
src=[अनअनपेन्टियम], target=[ununpentium], predicted=[raymond]
src=[केडीईलिब्स], target=[kdelibs], predicted=[raymond]
src=[जैस], target=[jais], predicted=[raymond]
src=[दक्षिणा], target=[dakshina], predicted=[raymond]
/usr/local/lib/python3.6/dist-packages/nltk/translate/bleu_score.py:490: UserWarning:
Corpus/Sentence contains 0 counts of 2-gram overlaps.
BLEU scores might be undesirable; use SmoothingFunction().
warnings.warn(_msg)
BLEU-1: 0.000054
BLEU-2: 0.007376
BLEU-3: 0.052566
BLEU-4: 0.085885
test
src=[ड्रेगन], target=[dragons], predicted=[raymond]
src=[कंवर्जेंस], target=[convergence], predicted=[raymond]
src=[हेदुआ], target=[hedua], predicted=[raymond]
src=[शुएब], target=[shoaib], predicted=[raymond]
src=[ब्रेंट], target=[brent], predicted=[raymond]
src=[करने], target=[kane], predicted=[raymond]
src=[हेस्टिंग्स], target=[hastings], predicted=[raymond]
src=[कैप्टिव], target=[captive], predicted=[raymond]
src=[नाटिका], target=[natika], predicted=[raymond]
src=[शंभु], target=[sambhu], predicted=[raymond]
BLEU-1: 0.000000
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
Can you please help me to figure out why only one output is coming ?
Nice progress, hang in there.
Hi,
The article really helpfull. I try the code in english-indonesia corpus, but the validate data training 0 samples. How can it solves?
Perhaps confirm that you have loaded your dataset correctly?
I download the data from your suggestion. I am sure that i load the correct data.
I also try the deu-eng like the example. I achieved nice bleu.
Well done!
Nice presentation Jason! May I ask do we need to mask all the padding tokens in the targeted set so that it will not be included in the loss function? If we want to try that, then what changes do we need to make?
Or you think the following embedding layer already did it? But I thought this is just for embedding layer right? It will not affect how the loss function is calculated.
model.add(Embedding(ger_vocab_size, 512, input_length=ger_length, mask_zero=True))
Thanks.
Yes, it is a good idea to mask padded values.
Yes, the embedding layer can do it for you.
After executing the code
filename =’model.h5′
checkpoint = ModelCheckpoint(filename, monitor=’val_loss’, verbose=1, save_best_only=True, mode=’min’)
model.fit(trainX, trainY, epochs=60, batch_size=64, validation_data=(testX, testY), callbacks=[checkpoint], verbose=2)
the model is not saved although it completed 30 epochs
Sorry to hear that, I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thanks, sir for the nice post and your quick reply
After the model is saved in model.h5 then i executed
model = load_model(‘model.h5’)
and the next statement is
translation = model.predict(source, verbose=0)
what here the source is can we give the source as text file containing sentences?
The “source” is the data prepared in the same way as training data (same transforms) and represents one or more samples that you wish to have translated.
Thanks Jason
This is the code for German to English what if we have to make it for English to German? where code requires change?
Can we please help?
Yes, you can change the code for this case, e.g. the inputs and the outputs of the model.
I do not have the capacity to outline what to change or to change it for you. More here:
https://machinelearningmastery.com/faq/single-faq/can-you-change-the-code-in-the-tutorial-to-___
Hello Jason,
thanks for the nice tutorial.
During the evaluation (2. part of your codes) there was error as follows:
File “xxx.py” , line 57, in evaluate_model
raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
I have tried with several NLTK versions, but have the same error.
Can you give me any suggestions?
Sorry to hear that, I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Try this
evaluate_model(load_model(‘model.h5’), eng_tokenizer, testX, test[:,:2])
Hi Jason,
Thanks for your fast reply. I have checked the error in Internet.
“ValueError: too many values to unpack (expected 2)” is due to the dimension difference.
I opened raw_dataset and relized that this data set has 3 columns, therefore I changed your code a little bit, just adding “,test”. And your code works fine, again.
_________________________________________________________________________
raw_target, raw_src = raw_dataset[i] #original code with error
raw_target, raw_src, test = raw_dataset[i] #it runs! test is for the 3. column of raw_dataset
_________________________________________________________________________
B.t.w. the 3. column of raw_dataset has strange content such as:
“ccby france attribution …”
I think maybe this is due to different versions of python packages. The raw_dataset has the 1. and 2. clean columns but somehow the unuseful 3. column, which leads the error. Anyway, after adding “, test” as mentioned above. The 2. part of your code works well.
Jiasheng
Happy to hear that you have made progress!
really thanks to @Bonasaint King ,your correction helped me a lot.
once again thank you so much sir.
Big thanks to Bonsaint King. It also solved my problem. The example in the book was not corrected.
Thanks Bonsaint. You’re Wonderful!
hi,
every thing worked but the piece of code below doesnt generate model.h5
filename = ‘model.h5’
checkpoint = ModelCheckpoint(‘model.h5′, monitor=’val_loss’, verbose=1, ave_best_only=True, mode=’min’)
model.fit(trainX, trainY, epochs=30, batch_size=64,validation_data=(testX, testY), callbacks=[checkpoint], verbose=2)
Perhaps try a different configuration?
I explain more here:
https://machinelearningmastery.com/check-point-deep-learning-models-keras/
Hello Jason, kindly can you tell me what is this error:
File “mtTest1.py”, line 16
file = open(filename, mode=’rt’, encoding=’utf-8′)
^
IndentationError: expected an indented block
Looks like you need to change your indenting.
Thanks Jason, this error stands for insufficient RAM ?
train
Traceback (most recent call last):
File “mtTest4.py”, line 95, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “mtTest4.py”, line 64, in evaluate_model
raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
No, it may suggest a copy-pate error.
I made a copy paste exactly from the example but still shows the same error !
Sorry to hear that, I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Finally I fixed the error :
raw_target, raw_src= raw_dataset[i] changed to => raw_target, raw_src,test = raw_dataset[i]
and got the below results:
train
src=[er respektiert mich], target=[he respects me], predicted=[he respects me]
src=[sei tapfer], target=[be brave], predicted=[be brave]
src=[uns wird es gut gehen], target=[well be fine], predicted=[well be fine]
src=[tom drehte durch], target=[tom went nuts], predicted=[tom went pale]
src=[wer fastet], target=[whos fasting], predicted=[whos fasting]
src=[wahlen sie mich], target=[vote for me], predicted=[vote for me]
src=[sind sie im ruhestand], target=[are you retired], predicted=[are you retired]
src=[darf ich gehen], target=[may i go], predicted=[can i go]
src=[wir brauchen das], target=[we need this], predicted=[we need this]
src=[tom wird tanzen], target=[tom will dance], predicted=[tom will dance]
BLEU-1: 0.874297
BLEU-2: 0.822932
BLEU-3: 0.727685
BLEU-4: 0.407115
test
src=[tom gesellte sich zu uns], target=[tom joined us], predicted=[tom grabbed us]
src=[ich bin besser], target=[im better], predicted=[im am better]
src=[ich muss mich sputen], target=[i must hurry], predicted=[i must to you]
src=[seid diskret], target=[be discreet], predicted=[be discreet]
src=[er ist sauber], target=[its clean], predicted=[its is]
src=[es war meine absicht], target=[it was my plan], predicted=[it was be]
src=[konnt ihr mich auslassen], target=[can you skip me], predicted=[can you read]
src=[schau genau zu], target=[watch closely], predicted=[look closely]
src=[boston ist der hammer], target=[boston is great], predicted=[my my fun]
src=[ich benotige sie], target=[i need them], predicted=[i need you]
BLEU-1: 0.551442
BLEU-2: 0.427450
BLEU-3: 0.347021
BLEU-4: 0.171442
Well done!
Sir,
My requirement is to do a style translation of English language from informal to formal style. Is it correct to take this approach for my task ?
Wow, sounds like a fun project.
Perhaps try it and see?
Hi Jason,
I just recently stumbled upon your website. Your work is absolutely awesome!
Thanks for sharing your knowledge!
This tutorial is also really great. But I’m wondering, is there a way to save the whole machine translation output to a txt file?
Because, I only get 10 translations. Is there a way to see the remaining 990 sentences from the test set?
Thank you!
Thanks!
Yes, you can store the results in a numpy array and save the numpy array directly to file, e.g. savetxt()
https://docs.scipy.org/doc/numpy/reference/generated/numpy.savetxt.html
hii sir.. i am getting
value error: too many values to unpack (expected 2) at model_evalute() function this error at the end of code.
i just changed training & test data sets size to 1500 and 500.
how can i solve this issue.
can you help me plz..
Perhaps start with the original working value, and slowly adapt it for your needs?
yes..i also tried with the same values for training and testing.but again same problem is coming.
clearly the error was this.
ValueError Traceback (most recent call last)
in
86 # test on some training sequences
87 print(‘train’)
—> 88 evaluate_model(model, eng_tokenizer, trainX, train)
89 # test on some test sequences
90 print(‘test’)
in evaluate_model(model, tokenizer, sources, raw_dataset)
55 source = source.reshape((1, source.shape[0]))
56 translation = predict_sequence(model, eng_tokenizer, source)
—> 57 raw_target, raw_src = raw_dataset[i]
58 if i < 10:
59 print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
ValueError: too many values to unpack (expected 2)
I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi, I am facing the same issue even though I’ve copied the code as it is. Please Help.
ValueError Traceback (most recent call last)
in
86 # test on some training sequences
87 print(‘train’)
—> 88 evaluate_model(model, eng_tokenizer, trainX, train)
89 # test on some test sequences
90 print(‘test’)
in evaluate_model(model, tokenizer, sources, raw_dataset)
55 source = source.reshape((1, source.shape[0]))
56 translation = predict_sequence(model, eng_tokenizer, source)
—> 57 raw_target, raw_src = raw_dataset[i]
58 if i < 10:
59 print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
ValueError: too many values to unpack (expected 2)
This may help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
First,this is back propagation or not?
second, if have aback propagation which pleases you used and please mark the line
Yes, we always use backprop.
It occurs when you call fit()
thank you sir
model.fit(trainX, trainY, epochs=30, batch_size=64, validation_data=(testX, testY), callbacks=[checkpoint], verbose=2)
epochs=30 is backprop, i am right sir!
It will use backprop to update the weights, yes.
hi Jason . . .i have faced problem on Preparation parts (last two rows)..working on ethiopian language pairs
Saved: AAO.pkl
Traceback (most recent call last):
File “D:\Python Projects\Amh-AO\1_Prepare-AAO.py”, line 58, in
print(‘[%s] => [%s]’ % (clean_pairs[i,0], clean_pairs[i,1]))
IndexError: too many indices for array
could you help!
Perhaps confirm that your data was loaded as you expected?
the problem is happened due to the unwanted spaces between words and sentences in the corpus document. i have got an error:
1. [today] => []
[me] => []
[like] => []
[hard] => []
[interesting] => []
[answer] => []
the empty box([]) should show non-english language.
temporary solution . .#line = [re_print.sub(”, w) for w in line] . . .worked
can you suggest permanent solution . . ..
Nice work!
Hi Mr. Daniel am also trying neural machine translation for Ethiopian language. I have got the same problem would you write me the solution in detail please.
Thanks
Traceback (most recent call last):
File “nmt.py”, line 59, in
dataset = load_clean_sentences(‘english-german-both.pkl’)
File “nmt.py”, line 18, in load_clean_sentences
return load(open(filename, ‘rb’))
_pickle.UnpicklingError: invalid load key, ‘H’.
while training we are getting this error. Can you please help us rectify this?
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thank you Jason your tutorial always helped me a lot.
I have the following error what will be the possible reason
NameError Traceback (most recent call last)
in
9 file = open(filename, mode=’rt’, encoding=’utf-8′)
10 # read all text
—> 11 text = file.read()
12 # close the file
13 file.close()
NameError: name ‘file’ is not defined
Perhaps confirm the file was opened as you expected.
please Solution for this problem
Saved: english-amharic.pkl
—————————————————————————
IndexError Traceback (most recent call last)
in
65 # spot check
66 for i in range(100):
—> 67 print(‘[%s] => [%s]’ % (clean_pairs[i,0], clean_pairs[i,1]))
IndexError: too many indices for arra
I need help
—————————————————————————
NameError Traceback (most recent call last)
in
8 return max(len(line.split()) for line in lines)
9 # prepare english tokenizer
—> 10 eng_tokenizer = create_tokenizer(dataset[:, 0])
11 eng_vocab_size = len(eng_tokenizer.word_index) + 1
12 eng_length = max_length(dataset[:, 0])
in create_tokenizer(lines)
1 # fit a tokenizer
2 def create_tokenizer(lines):
—-> 3 tokenizer = Tokenizer()
4 tokenizer.fit_on_texts(lines)
5 return tokenizer
NameError: name ‘Tokenizer’ is not defined
Looks like you might have skipped some lines of code.
This might help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi Jason,
In training I have the following error.
please I need usual help.
thank you!!
C:\Users\Habib\Anaconda3\lib\site-packages\theano\scan_module\scan_perform_ext.py:76: UserWarning: The file scan_perform.c is not available. This donot happen normally. You are probably in a strangesetup. This mean Theano can not use the cython code for scan. If youwant to remove this warning, use the Theano flag’cxx=’ (set to an empty string) to disable all ccode generation.
“The file scan_perform.c is not available. This do”
Sorry to hear that. I am not familiar with this error, but it looks like a problem with your development environment.
This tutorial may help you to setup your environment:
https://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
Hi Jason
This the result I have got is I think the worst
i dont know why
pls help
train
src=[japan und nordkorea unterhalten noch immer keine diplomatischen beziehungen], target=[diplomatic relations have not yet been established between japan and north korea], predicted=[the the the the the the the the the the]
src=[lasst uns losgehen], target=[lets go], predicted=[tom]
src=[tom hat gezahlt], target=[tom paid], predicted=[tom]
src=[ich bin sicher], target=[im sure], predicted=[tom]
src=[mir geht es gut], target=[im fine], predicted=[tom]
src=[er kleidet sich wie ein gentleman aber er spricht und benimmt sich wie ein clown], target=[his dress is that of gentleman but his speech and behavior are those of a clown], predicted=[the the the the the the the the the the the the the]
src=[ist dir schon mal der gedanke gekommen dass ich vielleicht noch ein paar tage in boston konnte bleiben wollen], target=[did it ever occur to you that i might want to stay in boston for a few more days], predicted=[the the the the the the the the the the the the the the the the the]
src=[je mehr zeit tom und maria zusammen verbrachten desto besser lernten sie sich kennen], target=[as tom and mary spent time together they began to get to know each other better], predicted=[the the the the the the the the the the the the the]
src=[tom ist total geistesabwesend und vergisst manchmal die kinder von der schule abzuholen], target=[tom is quite absentminded and sometimes forgets to pick the kids up from school], predicted=[the the the the the the the the the the the the]
src=[tom fand dass der lehrer ihm viel mehr hausaufgaben aufgegeben hatte als er an einem tage schaffen konnte], target=[tom thought the teacher had given him way too much homework to finish in one day], predicted=[the the the the the the the the the the the the the the]
BLEU-1: 0.062208
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
test
src=[einige begebenheiten aus meiner kindheit sind kristallklar andere hingegen sind nur eine dunkle erinnerung], target=[some incidents from my childhood are crystal clear others are just a dim memory], predicted=[the the the the the the the the the the the the]
src=[als ich seine mutter gestern traf sagte diese er ware vor einer woche aus dem krankenhaus entlassen worden], target=[when i saw his mother yesterday she said he had left the hospital a week before], predicted=[the the the the the the the the the the the the the]
src=[es klappt], target=[it works], predicted=[]
src=[letztendlich wird jemand tom sagen mussen dass er sich zu benehmen hat], target=[eventually someone is going to have to tell tom that he needs to behave himself], predicted=[the the the the the the the the the the the the]
src=[tom sagt er habe dem polizisten mitgeteilt er sei nur zum fotografieren dort gewesen], target=[tom says he told the police officer that he was just there to take some pictures], predicted=[the the the the the the the the the the the the]
src=[vertraue mir], target=[trust me], predicted=[]
src=[schauen sie uns zu], target=[watch us], predicted=[tom]
src=[dieses worterbuch dessen dritter band fehlt hat mich hundert dollar gekostet], target=[this dictionary of which the third volume is missing cost me a hundred dollars], predicted=[the the the the the the the the the the]
src=[nimm das hier], target=[use this], predicted=[tom]
src=[wegen seines groen beruflichen geschicks hat der anwalt eine groe klientel], target=[because of his great professional skill the lawyer has a large number of clients], predicted=[the the the the the the the the the the the]
BLEU-1: 0.052077
BLEU-2: 0.000000
BLEU-3: 0.000000
BLEU-4: 0.000000
Perhaps try re-training the model and select a different model based on validation skill.
Hi Jason
I need Help for the following error
C:\Users\Habib\Anaconda3\lib\site-packages\nltk\translate\bleu_score.py:523: UserWarning:
The hypothesis contains 0 counts of 2-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
C:\Users\Habib\Anaconda3\lib\site-packages\nltk\translate\bleu_score.py:523: UserWarning:
The hypothesis contains 0 counts of 3-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
C:\Users\Habib\Anaconda3\lib\site-packages\nltk\translate\bleu_score.py:523: UserWarning:
The hypothesis contains 0 counts of 4-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
warnings.warn(_msg)
These are warnings, not errors, and you can safely ignore them.
Sorry I post the question in the wrong article earlier (but thanks for the quick response), as I’m reading and comparing information across multiple posts. They are all very informative and helpful, thanks!!
So I understand your Franch-to-English example is a seq2seq model, but how about this one – the English-to-German model (this is the one I meant to ask about originally)? It is because the structure of this one seems to be simpler that doesn’t specify the states.
I think my confusion is that what is the difference between a many-to-many RNN Sequence Prediction model and a Seq2seq, or are they just the same? Hope you can help me to clarify that.
Yes, they are the same thing.
sir, I got the one error on this project
Traceback (most recent call last):
File “D:\ANANTH\onlinetry\translatess\punjabi\german\preparedataset1.py”, line 286, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “D:\ANANTH\onlinetry\translatess\punjabi\german\preparedataset1.py”, line 255, in evaluate_model
raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
Sorry to hear that, this might help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi Jason,
great tutorial!
As to the value error: There may be a bug in the evaluation part: Since raw_dataset has 3 items per inner list, the unpacking in line 57 with only two variables can’t work. I completed it with ‘source’ to ‘raw_target, raw_src, source = raw_dataset[i]’ and it worked. Could you check out if that’s the correct code?
I believe the code is correct, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thanks, Jason for an amazing explanation.
I have one question here:
When I am trying English to Hindi, I am getting only English tokens:
[wow] => []
[help] => []
[jump] => []
[jump] => []
…..
….
But code is working for English to German.
[hi] => [hallo]
[hi] => [gru gott]
[run] => [lauf]
[wow] => [potzdonner]
…..
….
I am debugging but not able to resolve……
Perhaps the data preparation is too aggressive at removing non-ascii characters.
HI Uday have solve your probleb? I face same pls help
I solved It.
The problem is at the clean_pairs() Function.
Try commenting some lines there and run again
Well done.
Hi, Jason
Thanks for an amazing tutorial. Is this code still going to work in case we do not reduce the dataset to the first 10 000 examples and use the complete dataset instead?
Perhaps try it, experiment.
First of all, Awesome Tutorial!!
How can I use the model to translate a single string?
Thanks.
You can prepare the single string using the same data preparation as the training data then call model.predict()
Do I need to make a .pkl file just for a single string? or I can do it from the code?
You can do it in the code, e.g. make a prediction directly after fitting the model.
How do I retrain the model?
It seems like I train it until ~1.7 val_loss and then If I run the train program again it starts again from 3.8 val_loss
You can load the saved model and continue training, probably with a smaller learning rate.
I did the following thing:
Made a script that regenerates training and testing files, and another script that loads the module and trains it. after 10 epochs it generates new training and testing files.
but I’m not sure if the model is getting better. every new training starts with ~2.1 val_loss and the file size does not change.
is it normal?
also, how can I change the learning rate?
Thanks in advance.
This will help interpret the learning achieved by the model:
https://machinelearningmastery.com/learning-curves-for-diagnosing-machine-learning-model-performance/
This will help regarding the learning rate:
https://machinelearningmastery.com/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/
Hi Jason. First and foremost, thank you deeply for everything.
I need help with something. I’ve tried going through the example more times than I can count. I’ve re-installed everything many times and when I get to the Tokenizer part, I keep getting this error:
>>> eng_tokenizer = create_tokenizer(dataset[:, 0])
Traceback (most recent call last):
File “”, line 1, in
File “”, line 2, in create_tokenizer
NameError: name ‘Tokenizer’ is not defined
I am at a loss as to what might be wrong. I’ve searched everywhere, even here. You’ve told others to check if they’ve missed code lines. I’ve repeated the code several times to make sure I did not miss a thing, and I keep getting this error.
Could you help me?
Thank you in advance.
You’re welcome.
Looks like you have not imported the Tokenizer class.
I recommend pasting the complete example at the end of the tutorial. This will help:
https://machinelearningmastery.com/faq/single-faq/how-do-i-copy-code-from-a-tutorial
Thank you. By importing from keras, it worked. Now I’m facing some other problems, but I’ll try to fix them before referring back to you…
Thanks! 🙂
If you need help with your development environment, this may help:
https://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
Hi again, Jason. I achieved it! I couldn’t be happier. 🙂
In case it helps anyone: the best way to clean the data (since it has three columns like another person said) is to import to Excel, delete the third column and then save as tab-delimited text file (.txt).
Just one last query: would it be possible to add more training data after training to improve results? Do you have any post explaining this, perhaps? I will be reading more of your posts to try and understand the science behind this.
Sorry if it’s been asked before.
Cheers!
Well done!
Yes, more data will make the model better. The training data we use is small and limited.
I don’t have an example, sorry.
Hi again!
So, as long as I add more datasets and load them with the model, the previous datasets are still saved, right?
Thanks in advance!
Sorry, I don’t understand. Perhaps you can elaborate?
What I mean is, if I do the process all over again with other data (other translations in the desired language combination [for example, EN-DE]) but load the previous model (model.h5), will it learn more from the new data while still making use of the previous datasets loaded?
I hope I was more clear now. Bascially, I mean that if I can add more data for it to learn.
Thanks!
Maybe. It is likely the model will forget the original dataset if you train a lot/aggressively on new data.
I am going to develop bidirectional English-Ethiopian language machine translation by NMT approach…using data that are in different formats in pdf,word ,excel,etc not organized like English-Germen data set in one.What would you recommend me sir?thank you
That sounds like a great project!
I recommend extracting all text into a single format as a first step.
Hi Jason,
Do you have any example to develop a NMT with attention and beam search with Keras.
Do you recommend any example or any of the book for that?
Also any resource that you recommend to build complex generative model with Keras?
Not at this stage.
No.
Many models are complex. Perhaps start with a language model.
Apologies have not followed, can you explain what you referred to by “start with a language model”
You can learn about language models here:
https://machinelearningmastery.com/statistical-language-modeling-and-neural-language-models/
While running the example, I see the following warning:
/Users/XXXX/opt/anaconda2/envs/XXXX/lib/python3.6/site-packages/tensorflow_core/python/framework/indexed_slices.py:433: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
Is this because the way we set up the NMT model?
Also the following which is probably harmless:
2020-03-18 12:31:12.023801: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:561] remapper failed: Invalid argument: MutableGraphView::MutableGraphView error: node ‘loss/time_distributed_1_loss/categorical_crossentropy/weighted_loss/concat’ has self cycle fanin ‘loss/time_distributed_1_loss/categorical_crossentropy/weighted_loss/concat’.
2020-03-18 12:31:12.046204: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:717] Iteration = 0, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-18 12:31:12.060268: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:717] Iteration = 1, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-18 12:31:12.174409: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:561] arithmetic_optimizer failed: Invalid argument: The graph couldn’t be sorted in topological order.
This might help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Code copied as is fails in the evaluate_model. evaluate_model crashes with ValueError:
Traceback (most recent call last):
File “/Users/XXXXX/evaluate.py”, line 96, in
evaluate_model(model, eng_tokenizer, trainX, train)
File “/Users/XXXXX/evaluate.py”, line 64, in evaluate_model
raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
I found the reason, its due to the dataset.
In this dataset there is a third coloumn with contribution. If you download from the given source, you will find there is another column with:
CC-BY 2.0 (France) Attribution: tatoeba.org #2877272 (CM) & #8597805 (Roujin)
The code as is is just perfect. The problem is data has been changed in the given URL.
May be you can mention this in the tutorial.
Nice work!
Thanks Nashid, as of now i am slicing the data to overcome this. you helped me man. i was stuck in this
See this:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi Jason,
I see the BLEU score is not great here. Can you please suggest how I can improve this?
BLEU-1: 0.519256
BLEU-2: 0.388424
BLEU-3: 0.300428
BLEU-4: 0.125028
Can you please suggest how to build a better model?
So you have any book that gives intuition how to build better NMT models and then how to implement them with keras?
These tutorials will help you diagnose issues with your model and improve performance:
https://machinelearningmastery.com/start-here/#better
Am I correct to say the model here is a Generative Auto-encoder? Then why in reddit I see this post “Why are autoencoders not considered as generative?”
Here the first encoder is implemented with a LSTM and the decoder is implemented with the later LSTM.
The output of the first LSTM (encoder) is directly fed into the Decoder.
And here we have implemented this for unsupervised learning.
No, it is not an autoencoder.
The model here is a sequence to sequence prediction model, using an encoder-decoder architecture.
Have you followed any specific paper for this model?
Having a reference would be extremely useful.
No, it is a generic encoder-decoder LSTM model. Basic stuff.
If this is new you, you can get get started with LSTMs here:
https://machinelearningmastery.com/start-here/#lstm
Why cant i unzip the files..please help me
have you downloaded the file from the given link?
If you cannot unzip files on your workstation, I believe my tutorials will be too advanced for you.
Nevertheless, this might help if you are on windows:
https://support.microsoft.com/en-au/help/14200/windows-compress-uncompress-zip-files
Here you have used word embedding for the input sequences from Keras Tokenizer. Is it same as word2vec?
Yes, here is an example:
https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/
For the output sequence you mentioned it needs to be one hot encoded. Why the Keras same tokenizer that we we used for the input sequences will not work?
Input and output data must use a separate tokenizer because they are different languages.
# test on some training sequences
print(‘train’)
evaluate_model(model, eng_tokenizer, trainX, train)
Output: train
—————————————————————————
ValueError Traceback (most recent call last)
in ()
1 print(‘train’)
—-> 2 evaluate_model(model, eng_tokenizer, trainX, train)
in evaluate_model(model, tokenizer, sources, raw_dataset)
5 source = source.reshape((1, source.shape[0]))
6 translation = predict_sequence(model, eng_tokenizer, source)
—-> 7 raw_target, raw_src = raw_dataset[i]
8 if i < 10:
9 print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
ValueError: too many values to unpack (expected 2)
Hi Jason,
I am getting this error, can you please helo me into this?
As per I already gone through FAQ and all comments, I tried all the required things and steps as mentioned in (turorial not work for me) article.
Thanks
I’m sorry to hear that.
Confirm you are using Keras 2.3 and TensorFlow 2.1.
Confirm you copied the complete code example.
Hey there,
Let’s say I’m training the model with 10k samples.
After done training, If I generate a new dataset with 10k samples, Will the model forget the previous dataset it trained? If so. How can you provide the model with a bigger dataset?
Right now my only option is to train only on 30k samples because I ran out of RAM.
Great question! It may forget.
You can address it by keeping the old data around and training on it a little sometimes, or having one large training dataset.
Thanks!
How much phrases do you recommend training the network on? I want eventually to train it on all the dataset.
So I train it at the moment on 28000 training data and 2000 testing. Do you
Think that’s ok?
This is an open question:
https://machinelearningmastery.com/faq/single-faq/how-much-training-data-do-i-need
Hi Jason.
I tried my own dataset in a tab-delimieted .txt file (encoding UTF-8), but it keeps giving me these three errors:
File “”, line 1, in
File “C:\Users\John\Desktop\Attempts\Attempt #4 – Ubuntu\env\lib\site packages\keras\engine\training.py”, line 1239, in fit
validation_freq=validation_freq)
File “C:\Users\John\Desktop\Attempts\Attempt #4 – Ubuntu\env\lib\site-packages\keras\engine\training_arrays.py”, line 210, in fit_loop
verbose=0)
File “C:\Users\John\Desktop\Attempts\Attempt #4 – Ubuntu\env\lib\site-packages\keras\engine\training_arrays.py”, line 469, in test_loop
outs[0] /= num_samples # Index 0 ==
LossIndexError: list index out of range
I copied the whole code correctly and I tried several times… with the dataset from the website you mentioned, it works fine, but with mine it doesn’t. I tried looking everywhere and found no fix…
Keras version is 2.3.0 (I tried with 2.3.1 and the same happens), tensorflow 2.1.0 if it helps.
Thank you in advance.
Sorry, I don’t have the capacity to help you debug loading your custom data, perhaps try posting on stackoverflow?
Thank you for the suggestion! 🙂
You’re welcome.
Hi Jason, if I use the English-Hindi dataset, the Hindi fonts are NOT displayed as a result after cleaning.
Perhaps change the data cleaning to make it appropriate for your specific dataset.
Yes I did by removing the line………..# line = [exp.sub(”, w) for w in line] but this results in this –
[i forgot] => []
[ill pay] => []
[im fine] => []
[im full] => [भर]
[lets go] => []
[answer me] => []
[birds fly] => []
[excuse me] => []
[fantastic] => []
[i fainted] => []
[i fear so] => []
[i laughed] => []
[im bored] => []
[im broke] => []
[im tired] => [थक]
now it shows only some of them. Pls suggest some soln
Sorry, I don’t have the capacity to help you debug your changes.
Ok thanks I got it . I also removed the line #line = [word for word in line if word.isalpha()].
It worked . But can you pls tell what did this line really meant.
Great!
That line collects only words that contain alphanumeric characters.
How to fine tune our NLP model.
Here are some suggestions:
https://machinelearningmastery.com/start-here/#better
ValueError Traceback (most recent call last)
in
86 # test on some training sequences
87 print(‘train’)
—> 88 evaluate_model(model, eng_tokenizer, trainX, train)
89 # test on some test sequences
90 print(‘test’)
in evaluate_model(model, tokenizer, sources, raw_dataset)
55 source = source.reshape((1, source.shape[0]))
56 translation = predict_sequence(model, eng_tokenizer, source)
—> 57 raw_target, raw_src = raw_dataset[i]
58 if i < 10:
59 print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
ValueError: too many values to unpack (expected 2)
Sorry to hear that you are having trouble, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Because of OOM by to_categorical, I used sparse_categorical_crossentropy and removed encode_output and the result was that I could train lots of more data with my system. Is it right?
Sounds good!
Hi Jason , Thanks for your awesome explanation of NMT step by step.
I have tried similar code logics to convert Tamil to English translation .My input file had 130 pair of sentences, my model trained with less deviation with validation & training set.
I have tried both optimizer: RMSPROP as well as ADAM. in both case i have obtained similar result.
When i tried to predict_class of my test data, the output variable had only zeros. Due to this prediction out class in empty data. Please advice which parameter to tune to get desired result. I think many people face similar issue , kindly debug my colab clode & advice me to get result.
Please find my colab link for my project .
code:
preds5 = model1.predict_classes(testX.reshape((testX.shape[0],testX.shape[1])))
preds5
Output:
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
actual predicted
0 she danced with him
1 she hit him
2 she has 2000 books
3 its the third biggest city of serbia
4 leave it to me
5 he has three sons
6 thats our house
7 thats the way
8 who is she
9 see you again
10 is he a friend of yours
11 i am afraid of bears
12 be kind to old people
13 i thought youd be angry
14 raise your hand
https://colab.research.google.com/drive/1JkEI1ukdaz9uqUnWEXAJDUHiuaoEwj2K
With Regards,
N.Shailaja
Sounds like a great project.
Perhaps the tutorials here will help you identify issues with your model and suggest ways to lift performance:
https://machinelearningmastery.com/start-here/#better
Hi Jason
i try this using google colabs i cand load file
from google.colab import files
filename = files.upload()
this error occur
TypeError Traceback (most recent call last)
in ()
56 # load dataset
57 filename = files.upload()
—> 58 doc = load_doc(filename)
59 # split into english-german pairs
60 pairs = to_pairs(doc)
in load_doc(filename)
8 def load_doc(filename):
9 # open the file as read only
—> 10 file = open(filename, mode=’rt’, encoding=’utf-8′)
11 # read all text
12 text = file.read()
TypeError: expected str, bytes or os.PathLike object, not dict
Hi Jason ,
i solved this problem
thank you
Well done!
Try running on your workstation directly.
good work Jason
please I have a problem in the last function evaluate_model() exactly in
raw_target, raw_src = raw_dataset[i] !
when I apply to evaluate_model(model, eng_tokenizer, trainX, train)
I have this error :
in evaluate_model(model, tokenizer, sources, raw_dataset)
55 source = source.reshape((1, source.shape[0]))
56 translation = predict_sequence(model, eng_tokenizer, source)
—> 57 raw_target, raw_src = raw_dataset[i]
58 if i < 10:
59 print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
ValueError: too many values to unpack (expected 2)
I’m sorry to hear that, see this:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thanks so much for your work,
kindly advice how I could use the trained model in trying to translate a new data.
For example, I want to insert the following “I love my mom” and I want to see the translation, how could I do that?
See the example at the end of the tutorial as an example.
Hi! Great tutorial as usual, but I have a question: If I understand the model correctly you predefine the maximum possible output length via RepeatVector(tar_timesteps), so no output sentence can be longer than tar_timesteps? So also during inference it will not be possible to get a longer output than tar_timesteps? Is there a reason you chose this approach over the idea of having a “stop” token, as they use e.g. here https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html, which would provide a more variable output length?
Thanks.
Correct. I did for simplicity.
Yes, an alternative is to use a dynamic rnn, which can be more challenging for beginners.
Hi,
is it necessary to convert non-latin characters into latin? I just wonder what can I do, to be sure that my model will translate i.e. english word “angle” into polish word “kąt” instead of “kat” (what means executioner :)). Can I just omit this part of code?
Thanks for all your hard work!
No, it is just the approach that I chose for this example and it can make some of the code simpler.
Yes, it might be easier to adapt the exampels to work with unicode directly.
Hi Jason,
Thanks for such an informative article. I have one question in another article the neural translation model was build very differently. In that encoder output state were passed to decoder. (https://machinelearningmastery.com/define-encoder-decoder-sequence-sequence-model-neural-machine-translation-keras/)
What is the difference between the way model is defined here and in that article ?
Regards,
Deepak
The linked article uses an dynamic RNN encoder-decoder model, here we use an encoder-decoder based on an LSTM autoencoder (simpler) with fixed length inout.
Thanks again Jason for this great work.
I have a question about BLEU score.
Which one we take (1, 2, 3 or 4) in final to say “i acheaved X score in BLEU” ?
Thank you
You can choose which method to report, or all, and state how you calculated it.
but most of the articles I have recognized do not say the method, they only say that they have reached a number X in BLUE score !!
Yes, many papers are very poorly written and not understandable or reproducible.
Perhaps the dataset you are using has a standard methodology for evaluation and reporting results?
Perhaps contact the author of the paper directly?
Okay sir Jason.
Thank you soo much 🙂
You’re welcome.
Hi Jason thanks for this great tutorial.
I have a question, what if I want the model to be trained on a sequence(input) to sequence(output) data and make the prediction output fixed (say 10 words), I know it doesn’t make scene in the context of translation, but I’m using this architecture for another application, so is that possible?
You can design any model you like.
Hi Jason,
Thanks for the post. Quick question: can I use similar model for string character to character prediction instead of word to word prediction? If yes, what parameters should I change like tokens will be characters instead of words and unique character size instead of vocabulary size, etc. Do you know any examples?
Thanks!
You’re welcome.
No, the model is designed for working with words. A completely different model would be required for character input and output.
Dear thank you very much for your commitment.
i need support from you.
while I’m running the code bellow on Pycharm IDE
import string
import re
from pickle import dump
from unicodedata import normalize
from numpy import array
# load doc into memory
def load_doc(filename):
# open the file as read only
file = open(filename, mode=’rt’, encoding=’utf-8′)
# read all text
text = file.read()
# close the file
file.close()
return text
# split a loaded document into sentences
def to_pairs(doc):
lines = doc.strip().split(‘\n’)
pairs = [line.split(‘\t’) for line in lines]
return pairs
# clean a list of lines
def clean_pairs(lines):
cleaned = list()
# prepare regex for char filtering
re_print = re.compile(‘[^%s]’ % re.escape(string.printable))
# prepare translation table for removing punctuation
table = str.maketrans(”, ”, string.punctuation)
for pair in lines:
clean_pair = list()
for line in pair:
# normalize unicode characters
line = normalize(‘NFD’, line).encode(‘ascii’, ‘ignore’)
line = line.decode(‘UTF-8’)
# tokenize on white space
line = line.split()
# convert to lowercase
line = [word.lower() for word in line]
# remove punctuation from each token
line = [word.translate(table) for word in line]
# remove non-printable chars form each token
line = [re_print.sub(”, w) for w in line]
# remove tokens with numbers in them
line = [word for word in line if word.isalpha()]
# store as string
clean_pair.append(‘ ‘.join(line))
cleaned.append(clean_pair)
return array(cleaned)
# save a list of clean sentences to file
def save_clean_data(sentences, filename):
dump(sentences, open(filename, ‘wb’))
print(‘Saved: %s’ % filename)
# load dataset
filename = ‘deu.txt’
doc = load_doc(filename)
# split into english-german pairs
pairs = to_pairs(doc)
# clean sentences
clean_pairs = clean_pairs(pairs)
# save clean pairs to file
save_clean_data(clean_pairs, ‘english-german.pkl’)
# spot check
for i in range(100):
print(“[%s] => [%s]” % (clean_pairs[i, 0], clean_pairs[i, 1]))
I found the error bellow how can I fix this error?
IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed
Sorry to hear that, these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thanks jason, I’m trying to implement your code on my machine all steps are executed fine but, at the last step while I’m running a code that evaluate the model, it display the error bellow:
in evaluate_model raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
how can I fix this error? Thanks a lot.
my intension is after successfully implement your experiment, I will prepare my own corpus and I will try to develop model for our local language.
Sorry to hear that, the tips here may help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi, I’m trying to use your code to implement an English-Sanskrit translator. I tried your code using the english-german data set and it worked.
The problems in my case are two:
1. I need to use UTF-8 throughout the process. I modified the cleanup code in order to retain the UTF-8 character encoding and it produces an UTF-8 english-sanskrit.pkl file.
When I try the code which should create the model, though, it spits an error:
W tensorflow/core/framework/op_kernel.cc:1753] OP_REQUIRES failed at cudnn_rnn_ops.cc:1517 : Unknown: CUDNN_STATUS_BAD_PARAM
in tensorflow/stream_executor/cuda/cuda_dnn.cc(1496): ‘cudnnSetRNNDataDescriptor( data_desc.get(), data_type, layout, max_seq_length, batch_size, data_size, seq_lengths_array, (void*)&padding_fill)’
2. If I normalize the UTF-8 data source to ASCII, I can complete the creation of the model and also the evaluation of its effectiveness.
The problem is that i get weird results, like:
src=[aham grhe eva tyaktva agatavan], target=[i have left it at home], predicted=[i is you the the]
src=[kintu asyah bhayam asti], target=[but she is afraid], predicted=[i is the the]
src=[idanim samayah atitah], target=[it is getting late], predicted=[i is you]
src=[adya api sarah eva], target=[just soup today also], predicted=[i is the]
Is the dataset (2300 phrases) too small? Or is there another problem?
Thank you in advance for your attention.
Well done!!!
Sorry, I don’t know about that error, you will have to debug it yourself or post to stackoverflow.com
It may be enough. Perhaps run a sensitivity analysis to see how model performance changes with the number of phrases used for training.
Hi, I think it is a problem of corpus size.
I demonstrated that by limiting the size of the german corpus to 2300 and by performing all the steps again.
The results are similar to the ones obtained in Sanskrit:
src=[ich bin spion], target=[im a spy], predicted=[im a]
src=[es ist sieben uhr funfundvierzig], target=[its], predicted=[its]
src=[ich vermisse sie], target=[i miss you], predicted=[i can you]
src=[such dir eine aus], target=[choose one], predicted=[we you]
I think 10000 may be the very minimum size for getting some valid results.
Unfortunately it is extremely difficult to get such amount of modern-day common-usage phrases in Sanskrit.
Anyway, compliments for your site and for your code.
Perhaps you can try a larger (overdetermined) model, and add a ton of strong regularization (weight decay/dropout/etc)?
And, for the UTF-8 encoding, as a last resource if I don’t find a solution for using UTF-8 in the process, Sanskrit can be written in many ways, some of which are plain ASCII, like the Harvard-Kyoto transiteration, so I may convert the text at the beginning of the process and convert it back at the end of it.
Bye
It’s all numbers. Define a set of integers for your chars, and define a process to map from chars to integers and back. It can handle any character set that way.
jason thanks for your post, finally I debug the error and I got the required output.
I have one suggestion on your code, the code that evaluate the precision of the model at line 57 please add variable “test” and re-post it,=============raw_target, raw_src , test= raw_dataset[i] unless it create the error below while runing the code.
in evaluate_model raw_target, raw_src = raw_dataset[i]
ValueError: too many values to unpack (expected 2)
therefore if it is possible update the code.
thanks a lot.
Thanks.
Hello, jason, it is awesome tutorial. i want to develop the language model for our Ethiopian local languages, and I prepared sample corpus from different source and I tried to develop the model and im in trouble, i guess the trouble is while I prepare the sample corpus, while preparing the corpus what are the tips that I have to consider? or the above algorithm works only for those tab-delimited corpus only?
Thanks.
Perhaps use the above code as a starting point and be sure to inspect your raw training data prior to training to see if it contains anything unexpected.
Hello Dear, Do you have any idea how tatoeba dataset including english-germany datasets are prepared? i want to prepare my own dataset based on their standards and requirements.
Thanks.
No, sorry.
Just to make sure my understanding of the translation model here is good… I have 3 questions:
1- How many hidden layers are there in this LSTM encoder-decoder model?
2- What is the purpose of model.add(RepeatVector(tar_timesteps))? I think that this line is separating the encoder and the decoder. Am I right? What lines correspond to the encoder and what lines correspond to the decoder?
3- Where would you add other hidden layers if you wanted to?
Thanks for this great tutorial by the way!
We have one hidden layer in the encoder and one in the encoder.
We repeat the encoded input for each step in the output.
You can add more hidden layers after the existing hidden layers in the encoder and/or decoder.
Thank you very much!
You’re welcome.
How do I translate multilingual text in a single sentence?
Sentence = “ਜਲਦੀ ਮਿਲਦੇ ਹਾਂ जल्द ही फिर मिलेंगे see you soon விரைவில் சந்திப்போம்”
Any approaches or can i use this same model to achieve?
Perhaps you can use the above model as a starting point.
Hi,
I am trying out the code for processing, and I get the following error:
“for i in range(100):
print(‘[%s]=>[%s]’ % (clean_pairs[i,0], clean_pairs[i,1]))
”
Error:IndexError Traceback (most recent call last)
in
49
50 for i in range(100):
—> 51 print(‘[%s]=>[%s]’ % (clean_pairs[i,0], clean_pairs[i,1]))
IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed
Why does this happen, do you know?
Sorry to hear that you’re having trouble, these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
—————————————————————————
NameError Traceback (most recent call last)
in ()
1 # prepare english tokenizer
—-> 2 eng_tokenizer = create_tokenizer(dataset[:, 0])
in create_tokenizer(lines)
1 # fit a tokenizer
2 def create_tokenizer(lines):
—-> 3 tokenizer = Tokenizer()
4 tokenizer.fit_on_texts(lines)
5 return tokenizer
NameError: name ‘Tokenizer’ is not defined
Sorry to hear that, perhaps you skipped some lines of code.
Perhaps try copying the complete example at the end of the section, this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hello, I’m a professional translator (mostly English-to-French) with 20 years of experience. In the last couple of years I’ve stared using DeepL on a fairly regular basis. I would like to be able to use NMT based on more selective data, e.g. exclusively high quality translations. Assuming I use my own production of the past few years, say, about 7 million words, plus some other selected documents I know to be of good quality, would that quantity be enough to train a strong translation system ? Or do systems typically, even with NMT, still require a much larger body of data to get trained properly?
Yes, that sounds like enough data, perhaps try it and see.
Thank you for your reply!
Where do I come from ? I want to start my own translation business after many years in a large organization. I see MT pragmatically as a productivity tool for translation foremost, especially now that it’s giving better results. The technical, scientific and philisophical dimensions are of course very interesting but I have little time for them realistically.
As a translation product I’m looking for high output, yet with no compromise on quality. I rate DeepL highly for what it is, and compared to what was previously available. In the right hands it is very useful (but actually a disservice to non-proficient translators). I asked DeepL if their system could be tailored as I described, using my own corpus, but they don’t allow that option. A slightly better DeepL, say 15-25 % better quality, would be all I need, in order to be able to more “comfortably” deliver high output to my own standards of quality.
It’s tempting to give it a shot
On the plus side, I know what I want.
On the down side, I have almost zero experience in programming,. DeepL and others have teams of qualified people and I’m all by myself with baby skills… have no clear idea of what I would be embarking into, and for how long.
Take care,
goelette
Thanks for sharing.
Hi, thanks so much for the tutorials it help me a lot. I don’t know how to deploy the model so that it can be used either in a standalone app or a website. Please help me out
Perhaps these suggestions will help:
https://machinelearningmastery.com/faq/single-faq/how-do-i-deploy-my-python-file-as-an-application
i am trying to go from german to english and was wondering, if i had made changes to the evaluate to perform this, would this be a valid way of reversing the phrase order?
Note, i was suspecting something within the train script would affect the accuracy of the project, specifically the “trainY = encode_output(trainY, eng_vocab_size)” is what I am believing to have some affect on the data that is going to ultimately be the predicted data in german
the changes i made within the evaluate includes
changing translation = predict_sequence(model, eng_tokenizer, source) to translation = predict_sequence(model, ger_tokenizer, source)
as well as re arranging of these variables raw_target, raw_src = raw_dataset[i] to raw_src, raw_target = raw_dataset[i]
and lastly changing trainX = encode_sequences(ger_tokenizer, ger_length, train[:, 1]), testX = encode_sequences(ger_tokenizer, ger_length, test[:, 1]), evaluate_model(model, eng_tokenizer, trainX, train), evaluate_model(model, eng_tokenizer, testX, test)
to
trainX = encode_sequences(eng_tokenizer, eng_length, train[:, 1]), testX = encode_sequences(ger_tokenizer, eng_length, test[:, 1]), evaluate_model(model, ger_tokenizer, trainX, train), evaluate_model(model, ger_tokenizer, testX, test)
Off the cuff, I think reversing the dataset is the only change required. You can then see if changes to the model, vocab size, etc. impact performance.
I am also starting to believe that the define NMT model it self is what i may need to make a change to inorder to accomplish what i want instead of what i original suggested for modifying with the Train script.
Hi Jason,
First of all, I want to thank you for your amazing work, which I appreciated!!!.
I try the algo using the data set from english to italian and I got some problem during the evaluation. I get the following error: ValueError: too many values to unpack (expected 2). This refers to this line of code: for i, source in enumerate(sources):
# translate encoded source text
source = source.reshape((1, source.shape[0]))
translation = predict_sequence(model, eng_tokenizer, source)
raw_target, raw_src = raw_dataset[i].
I think maybe it is due to the fact that we have too many values with respect to the number of target variables. Could you help me to avoid this error?
I wish you a good day and I thank you in advance for your help.
Cheers,
Perhaps check that the code example in the tutorial works for you first, then slowly adapt it.
My guess is that the dataset was not loaded as you expected. Double check the raw data has only 2 columns and was loaded correctly.
Hi Jason! thankyou for this wonderful tutorial, will this model work for a large number of phrase for ex. if the length of the German and English phrase here is for ex 300 or 400.Also it will be great if you provide some reference of other neural machine translation models which could do this. Thanks!
No, you may need to adapt the model and data preparation for your dataset.
I didn’t get you
No problem, which part?
use this
translation = predict_sequence(model, eng_tokenizer, source)
raw_target, raw_src,*rest = raw_dataset[i]
Hello,
your tutorial is superb!
I would like to do the same thing but also add a translation from English to German.
Is it possible to translate both ways in one notebook?
Thanks a lot!
Sure, fit a separate model for the reverse case.
Please how can I use nmt on long sentences
This will give you some ideas:
https://machinelearningmastery.com/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/
Dr. Brownlee,
Apart from BLEU, do you have any other performance review codes for this project?
Perhaps check modern papers on the topic and see what metrics are common.
Hi there,
I have run the same code (the one published on this page) on my laptop and on a p3.2xlarge AWS instance.
Is it normal to have a very little difference in performance between an NVIDIA GeForce GTX 850M (9 seconds per iteration) and the Tesla V100-SXM2-16GB (3 seconds)?
Here the result of a code reporting the boards used by Tensorflow:
physical_device_desc: “device: 0, name: NVIDIA GeForce GTX 850M, pci bus id: 0000:0a:00.0, compute capability: 5.0”
physical_device_desc: “device: 0, name: Tesla V100-SXM2-16GB, pci bus id: 0000:00:1e.0, compute capability: 7.0”
I thought the difference would be enormous…
Sorry, I’m not an expert in GPU hardware.
Hi Jason,
Thank you for the amazing instructions, can you please add a part to this to do Progressive Loading instead of loading all the data at once, I really want to see how you do it.
You’re welcome.
Thanks for the suggestion.
Hi Jason,
Is there a reason you didn’t use “tf.keras.preprocessing.text.one_hot” for having one-hot for the output?
Yes, the tutorial was written before tf.keras was a thing.
HI jason,
I got an error : NotImplementedError: Cannot convert a symbolic Tensor (lstm/strided_slice:0) to a numpy array. This error may indicate that you’re trying to pass a Tensor to a NumPy call, which is not supported
Sorry to hear that, perhaps these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
GOOD! But… increased the dataset size from 10000 to 15000, i get this error((
numpy.core._exceptions.MemoryError: Unable to allocate 7.97 MiB for an array with shape (57, 36657) and data type float32
…in line…
encoded = to_categorical(sequence, num_classes=vocab_size)
google.colab didn`t help me
You exhausted your memory. Can’t really help unless you replace numpy. Or you can see if you can load data in half-precision (float16). That might help too.
I tried with the English and Hindi Data file and execute the same as the above code. I removed encoding so that I can read Hindi text as well but at the output in the predicted section I get nothing there is no output how should I do this when I wanted to translate my Hindi text into English text
The code here guarantee you must get some output; whether it is sensible in a language or just gibberish is another issue (in that case, maybe the language is too complicated and need a more complex model). If you see nothing there, probably you should check your code.
code looks good but I am getting predicted[] = empty in my case input sentences are in Hindi language and output will be English.
I can’t read Hindi but this line may cause all non-ASCII characters removed: “line = normalize(‘NFD’, line).encode(‘ascii’, ‘ignore’)”
already removed this line before training the model everything is good but after applying the model something making the problem
Maybe something wrong in your input data that caused this?
Input data is in the same format as your first column of input data is in the English Language (that is target language ) and then space and then source language that is Hindi in my case for example
Komal had married only two months ago. कोमल की दो महीने पहले ही शादी हुई थी।
hello Nikhil Garg ,
what is your progress using the English Hindi dataset? I am also interested in the same . So please let me know if u have any progress .
If You can help I would really appreciate although all the other output like plot model and model summary works fine except it differs from your model output and that is understandable but I am not getting any output if you could please help me out in this
can we use BART model to do English to Tamil! ? am beginner with this custom MT
Hello Hemanth…The following will hopefully be interest to you:
https://www.researchgate.net/publication/334115937_Neural_Machine_Translation_for_English-Tamil
ValueError: too many values to unpack (expected 2)
i am getting this error at 3rd last line of code
# test on some training sequences
print(‘train’)
evaluate_model(model, eng_tokenizer, trainX, train)
# test on some test sequences
print(‘test’)
evaluate_model(model, eng_tokenizer, testX, test)
error:
—————————————————————————
ValueError Traceback (most recent call last)
in ()
1 # test on some training sequences
2 print(‘train’)
—-> 3 evaluate_model(model, eng_tokenizer, trainX, train)
4 # test on some test sequences
5 print(‘test’)
in evaluate_model(model, tokenizer, sources, raw_dataset)
6 source = source.reshape((1, source.shape[0]))
7 translation = predict_sequence(model, eng_tokenizer, source)
—-> 8 raw_target, raw_src = raw_dataset[i]
9 if i < 10:
10 print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
ValueError: too many values to unpack (expected 2)
what to do?
Hi Akansha…While I am not able to speak to your specific code listing and debugging, I would recommend that you review the following for additional insight.
https://itsmycode.com/valueerror-too-many-values-to-unpack-expected-2/
Hi author i am facing these while running the code
# prepare german tokenizer
ger_tokenizer = create_tokenizer(dataset[:, 1])
ger_vocab_size = len(ger_tokenizer.word_index) + 1
ger_length = max_length(dataset[:, 1])
# prepare data
trainX = encode_sequences(ger_tokenizer, ger_length, train[:, 1])
testX = encode_sequences(ger_tokenizer, ger_length, test[:, 1])
# load model
model = load_model(‘model.h5’)
translation = model.predict(source, verbose=0)
the error is
NameError Traceback (most recent call last)
in ()
42 # load model
43 model = load_model(‘model.h5’)
—> 44 translation = model.predict(source, verbose=0)
NameError: name ‘source’ is not defined
kindly help me to find out this error where is source file is exist. i want to train the model on roman English
Thank you for this awesome tutorial. I want to know how I can adapt this same code for protein desordered region prediction.
Input is a sequence of protein and output is a binary sequence (1 if the corresponding residus is desordered and 0 otherwise.)
Example:
input: AAAALLLLAKKK
output: 111111100001
Hello
Can I use this procedure to train english to my local language? I have the parallel corpus?
Hi, i have been able to run your code on a windows machine with Python 3.12.2 and Tensorflow 2.16.1 by tweaking the code a little bit but, as you may know, this version of Tensorflow does not support CUDA GPUs, so it works but it uses the CPU and it is therefore very slow.
What would be the code for this encoding-decoding model in C#? I have been able to work with Microsoft’s ML.NET using my Nvidia GPU. ML.NET is a C# port of Tensorflow using Torchsharp-cuda-windows for GPU.
THe code of a simple model for Language Classification is this:
var pipeline = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName:@”col0″,inputColumnName:@”col0″,addKeyValueAnnotationsAsText:false)
.Append(mlContext.MulticlassClassification.Trainers.TextClassification(labelColumnName: @”col0″, sentence1ColumnName: @”col1″))
.Append(mlContext.Transforms.Conversion.MapKeyToValue(outputColumnName:@”PredictedLabel”,inputColumnName:@”PredictedLabel”));
I have not been able to find LSTMs in this library.
Thanks