Gentle introduction to the Encoder-Decoder LSTMs for
sequence-to-sequence prediction with example Python code.
The Encoder-Decoder LSTM is a recurrent neural network designed to address sequence-to-sequence problems, sometimes called seq2seq.
Sequence-to-sequence prediction problems are challenging because the number of items in the input and output sequences can vary. For example, text translation and learning to execute programs are examples of seq2seq problems.
In this post, you will discover the Encoder-Decoder LSTM architecture for sequence-to-sequence prediction.
After completing this post, you will know:
- The challenge of sequence-to-sequence prediction.
- The Encoder-Decoder architecture and the limitation in LSTMs that it was designed to address.
- How to implement the Encoder-Decoder LSTM model architecture in Python with Keras.
Kick-start your project with my new book Long Short-Term Memory Networks With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Encoder-Decoder Long Short-Term Memory Networks
Photo by slashvee, some rights reserved.
Sequence-to-Sequence Prediction Problems
Sequence prediction often involves forecasting the next value in a real valued sequence or outputting a class label for an input sequence.
This is often framed as a sequence of one input time step to one output time step (e.g. one-to-one) or multiple input time steps to one output time step (many-to-one) type sequence prediction problem.
There is a more challenging type of sequence prediction problem that takes a sequence as input and requires a sequence prediction as output. These are called sequence-to-sequence prediction problems, or seq2seq for short.
One modeling concern that makes these problems challenging is that the length of the input and output sequences may vary. Given that there are multiple input time steps and multiple output time steps, this form of problem is referred to as many-to-many type sequence prediction problem.
Need help with LSTMs for Sequence Prediction?
Take my free 7-day email course and discover 6 different LSTM architectures (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Encoder-Decoder LSTM Architecture
One approach to seq2seq prediction problems that has proven very effective is called the Encoder-Decoder LSTM.
This architecture is comprised of two models: one for reading the input sequence and encoding it into a fixed-length vector, and a second for decoding the fixed-length vector and outputting the predicted sequence. The use of the models in concert gives the architecture its name of Encoder-Decoder LSTM designed specifically for seq2seq problems.
… RNN Encoder-Decoder, consists of two recurrent neural networks (RNN) that act as an encoder and a decoder pair. The encoder maps a variable-length source sequence to a fixed-length vector, and the decoder maps the vector representation back to a variable-length target sequence.
— Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
The Encoder-Decoder LSTM was developed for natural language processing problems where it demonstrated state-of-the-art performance, specifically in the area of text translation called statistical machine translation.
The innovation of this architecture is the use of a fixed-sized internal representation in the heart of the model that input sequences are read to and output sequences are read from. For this reason, the method may be referred to as sequence embedding.
In one of the first applications of the architecture to English-to-French translation, the internal representation of the encoded English phrases was visualized. The plots revealed a qualitatively meaningful learned structure of the phrases harnessed for the translation task.
The proposed RNN Encoder-Decoder naturally generates a continuous-space representation of a phrase. […] From the visualization, it is clear that the RNN Encoder-Decoder captures both semantic and syntactic structures of the phrases
— Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
On the task of translation, the model was found to be more effective when the input sequence was reversed. Further, the model was shown to be effective even on very long input sequences.
We were able to do well on long sentences because we reversed the order of words in the source sentence but not the target sentences in the training and test set. By doing so, we introduced many short term dependencies that made the optimization problem much simpler. … The simple trick of reversing the words in the source sentence is one of the key technical contributions of this work
— Sequence to Sequence Learning with Neural Networks, 2014.
This approach has also been used with image inputs where a Convolutional Neural Network is used as a feature extractor on input images, which is then read by a decoder LSTM.
… we propose to follow this elegant recipe, replacing the encoder RNN by a deep convolution neural network (CNN). […] it is natural to use a CNN as an image
encoder”, by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences
— Show and Tell: A Neural Image Caption Generator, 2014.
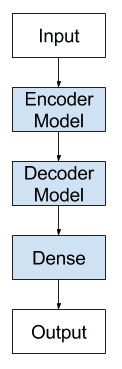
Encoder-Decoder LSTM Model Architecture
Applications of Encoder-Decoder LSTMs
The list below highlights some interesting applications of the Encoder-Decoder LSTM architecture.
- Machine Translation, e.g. English to French translation of phrases.
- Learning to Execute, e.g. calculate the outcome of small programs.
- Image Captioning, e.g. generating a text description for images.
- Conversational Modeling, e.g. generating answers to textual questions.
- Movement Classification, e.g. generating a sequence of commands from a sequence of gestures.
Implement Encoder-Decoder LSTMs in Keras
The Encoder-Decoder LSTM can be implemented directly in the Keras deep learning library.
We can think of the model as being comprised of two key parts: the encoder and the decoder.
First, the input sequence is shown to the network one encoded character at a time. We need an encoding level to learn the relationship between the steps in the input sequence and develop an internal representation of these relationships.
One or more LSTM layers can be used to implement the encoder model. The output of this model is a fixed-size vector that represents the internal representation of the input sequence. The number of memory cells in this layer defines the length of this fixed-sized vector.
|
1 2 |
model = Sequential() model.add(LSTM(..., input_shape=(...))) |
The decoder must transform the learned internal representation of the input sequence into the correct output sequence.
One or more LSTM layers can also be used to implement the decoder model. This model reads from the fixed sized output from the encoder model.
As with the Vanilla LSTM, a Dense layer is used as the output for the network. The same weights can be used to output each time step in the output sequence by wrapping the Dense layer in a TimeDistributed wrapper.
|
1 2 |
model.add(LSTM(..., return_sequences=True)) model.add(TimeDistributed(Dense(...))) |
There’s a problem though.
We must connect the encoder to the decoder, and they do not fit.
That is, the encoder will produce a 2-dimensional matrix of outputs, where the length is defined by the number of memory cells in the layer. The decoder is an LSTM layer that expects a 3D input of [samples, time steps, features] in order to produce a decoded sequence of some different length defined by the problem.
If you try to force these pieces together, you get an error indicating that the output of the decoder is 2D and 3D input to the decoder is required.
We can solve this using a RepeatVector layer. This layer simply repeats the provided 2D input multiple times to create a 3D output.
The RepeatVector layer can be used like an adapter to fit the encoder and decoder parts of the network together. We can configure the RepeatVector to repeat the fixed length vector one time for each time step in the output sequence.
|
1 |
model.add(RepeatVector(...)) |
Putting this together, we have:
|
1 2 3 4 5 |
model = Sequential() model.add(LSTM(..., input_shape=(...))) model.add(RepeatVector(...)) model.add(LSTM(..., return_sequences=True)) model.add(TimeDistributed(Dense(...))) |
To summarize, the RepeatVector is used as an adapter to fit the fixed-sized 2D output of the encoder to the differing length and 3D input expected by the decoder. The TimeDistributed wrapper allows the same output layer to be reused for each element in the output sequence.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Papers
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
- Sequence to Sequence Learning with Neural Networks, 2014.
- Show and Tell: A Neural Image Caption Generator, 2014.
- Learning to Execute, 2015.
- A Neural Conversational Model, 2015.
Keras API
Posts
- How to use an Encoder-Decoder LSTM to Echo Sequences of Random Integers
- Learn to Add Numbers with an Encoder-Decoder LSTM Recurrent Neural Network
- Attention in Long Short-Term Memory Recurrent Neural Networks
Summary
In this post, you discovered the Encoder-Decoder LSTM architecture for sequence-to-sequence prediction
Specifically, you learned:
- The challenge of sequence-to-sequence prediction.
- The Encoder-Decoder architecture and the limitation in LSTMs that it was designed to address.
- How to implement the Encoder-Decoder LSTM model architecture in Python with Keras.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop LSTMs for Sequence Prediction Today!

Develop Your Own LSTM models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Long Short-Term Memory Networks with Python
It provides self-study tutorials on topics like:
CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Skip the Academics. Just Results.






Hi Jason
After applying model.add(TimeDistributed(Dense(…))) what kind of output we will receive?
Regards
Great question!
You will get the output from the Dense at each time step that the wrapper receives as input.
Many thanks
That means we will receive a fixed length output as well?
Given an input sequence of the same size but different meaning?
For example
I like this – input_1
and
I bought car – input_2
Will end up as 2 sequences of the same length in any case?
No, the input and output sequences can be different lengths.
The RepeatVector allows you to specify the fixed-length of the output vector, e.g. the number of times to repeat the fixed-length encoding of the input sequence.
Hi Jason, I had a great time reading your post.
One question: a common method to implement seq2seq is to use the encoder’s output as the initial value for the decoder inner state. Each token the decoder outputs is then fed back as input to the decoder.
In your method you do the other way around, where the encoder’s output is fed as input at each time step.
I wonder if you tried both methods, and if you did – which one worked better for you?
Thanks
Thanks Yoel. Great question!
I have tried the other method, and I had to contrive the implementation in Keras (e.g. it was not natural). This approach is also required when using attention. I hope to cover this in more detail in the future.
As for better, I’m not sure. The simple approach above can get you a long way for seq2seq applications in my experience.
Excellent description Jason. I wonder if you have some examples on graph analysis using Keras.
Regards
M.B.
Sorry, I do not.
Hi thanks for your great blog. I have a question.
I wonder if this example is a simplified version of encoder-decoder? because I didn’t find shifted output vector for the decoder in you code.
thank you
It is a simplified version. See here for a more sophisticated version:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Hi Jason, thank you for this great post.
I was wondering why you haven’t used “return_sequences=true” for the encoder, instead of repeating the last value multiple times?
Thanks.
It would not give fine-grained control over the length of the output sequence.
Nevertheless, if you have some ideas, please try them and see, let me know how you go.
To elaborate – If we use return_sequences = true, then we get the output from each encoder time step that only has partial encoding of what ever the encoder has seen till that point of time. The advantage of using the final encoded state across all output sequences is to have a fully encoded state over the entire input sequences.
Sounds good!
Is there a simple github example illustrating this code in practice?
I have code on my blog, try the search feature.
Hi Jason, Thanks for such an intuitive post. One small question what would be y_train if we are using an autoenoder for feature extraction? Will it be the sequence {x1, x2, x3..xT} or {xT+1, xT+2,…xT+f} or just {xT+1}
The y variable would not be affected if you used feature extraction on the input variables.
My bad, I did not frame the question properly. My question was that if separate autoencoder block is used for feature extraction and the output from the encoder is then fed to another Neural network for prediction of another output variable y, what would be the training output for the auto encoder block, will it be {x1,x2,x3…xT} or {xT+1, xT+2,…xT+f} or just {xT+1} where xT is the input feature vector. I hope I am clear now.
It is really up to you.
I would have the front end model perhaps summarize each time step if there are a lot of features, or summarize the sample or a subset if there are few features.
Hi Jason,,
Suppose I’ve to train a network that summarizes text data. I’ve collected a dataset of text-summary pairs. But I’m bit confused about the training. The source-text contains ‘M’ words while the summary-text contains ‘N’ words (M > N). How to do the training?
I have a suite of posts on the topic, for example:
https://machinelearningmastery.com/?s=text+summarization&submit=Search
Yeah.. I read almost all of them. Great work there. <3.
But I'm still doubtful about the training.
As mentioned in this post (https://machinelearningmastery.com/encoder-decoder-models-text-summarization-keras/), does the source-text length and summary-text length has to fixed before creating the model? The training datasets don't have fixed length source-summary pairs.
Any push towards the right direction would be really helpful.
Yes, you must choose their lengths then pad all data to those lengths.
Hi Jason really nice posts on your blog. I am trying to predict time series but want also a dimensionality reduction to learn the most important features from my signal. the code looks like:
input_dim=1
timesteps=256
samples=17248
batch_size=539
n_dimensions=64
inputs = Input(shape=(timesteps, input_dim))
encoded = LSTM(n_dimensions, activation=’relu’, return_sequences=False, name=”encoder”)(inputs)
decoded = RepeatVector(timesteps)(encoded)
decoded = LSTM(input_dim,activation=’linear’, return_sequences=True, name=’decoder’)(decoded)
autoencoder = Model(inputs,decoded)
encoder = Model(inputs, encoded)
with which I do have to predict when I want a dimensionality reduction with my data ? with auteoncoder.predict or encoder.predict?
Sorry, I cannot debug your code, perhaps post your code and error to stackoverflow?
Hi Jason:
Gave a go to your encoder code. It looks like below:
model = Sequential()
model.add(LSTM(200, input_shape=(n_lag, numberOfBrands)))
model.add(RepeatVector(n_lag))
model.add(LSTM(100, return_sequences=True))
model.add(TimeDistributed(Dense(numberOfBrands)))
model.compile(loss=’mean_squared_error’, optimizer=’adam’,metrics=[‘mae’])
After that when I execute the following line:
history = model.fit(train_X, train_y, epochs=200, batch_size=5, verbose=2), I get the following error:
Error when checking target: expected time_distributed_5 to have 3 dimensions, but got array with shape (207, 30)
I know why. It complains about train_y which has a shape of 207,30! What’s the trick to re-shape Y here to cater for 3D output?
Thanks
It looks like a mismatch between your data and the models expectations. You can either reshape your data or change the input expectations of the model.
For more help with preparing data for the LSTM see this:
https://machinelearningmastery.com/faq/single-faq/how-do-i-prepare-my-data-for-an-lstm
Indeed, the problem is with the shape. Specifically with the RepeatVector layer. What’s the rule to determine the argument for RepeatVector layer? In my model I have passed the time lag, which is clearly not right.
The number of output time steps.
OK so clearly that’s 1 for me, as I am trying to output ‘numberOfBrands’ number of values for one time step i.e. t. Shaping the data is the real challenging part :).
Thanks a lot. You are really helpful
Hey Jason, thank you for a great post! I just have a question, I am trying to build an encoder-decoder LSTM that takes a window of dimension (4800, 15, 39) as input, gives me an encoded vector to which I apply RepeatVector(15) and finally use the repeated encoded vector to output a prediction of the input which is similar to what you are doing in this post. However, I read your other post (https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/) and I can’t figure out the difference between the 2 techniques and which one would be valid in my case.
Thanks a lot, I’m a big fan of your blog.
Well done Christian.
Good question.
The RepeatVector approach is not a “true” encoder decoder, but emulates the behaviour and gives similar skill in my experience. It is more of an auto-encoder type model.
The tutorial you link to is a “true” autoencoder as described in the 2014/2015/etc. papers, but it is a total pain to implement in Keras.
The main difference is the use of the internal state from the encoder seeding the state of the decoder.
If you’re concerned, perhaps try both approaches and use the one that gives better skill.
Hello Jason, thank you for the prompt reply.
I assume you mean the other tutorial I linked to is a “true” encoder decoder* since you said that using the RepeatVector is more of an autoencoder model. Am I correct?
As for the difference between the models, the encoder-decoder LSTM model uses the internal states and the encoded vector to predict the first output vector and then uses that predicted vector to predict the following one and so on. But the autoencoder technique uses solely the predicted vector.
If that is indeed the case, how is the second method (RepeatVector) able to predict the time sequence only by looking at the encoded vector?
I already implemented this technique and it’s giving very good results so I don’t think I’m going to go through the hassle of the encoder-decoder implementation because it has been giving me a lot of trouble
Thanks again!
Correct.
It develops a compressed representation of the input sequence that is interpreted by the decoder.
Hi Jason I used this model as welll for the prediction, I am getting also really good results. But what confuses me if I should use the other one the true encoder decoder or not because: I train this one with a part e.g. AAA of one big data, and I just want that the model can predict this little part, therefore I used subsequences. And than When i predict all the data it should only predict the same part before and not the rest of the data. lets say it should only predict AAA and not the whole data AAABBB. the last should look like AAA AAA.
Sorry, I’m not sure I follow. Can you summarize the inputs/outputs in a sentence?
I try to explain it with an example: train input: AAA, prediction input: AAA-BBB, prediction output: AAA-BBB ( but I was expecting only AAA-AAA). So the model should not predict right. does it have to do something with stateful and reset states ? Or using one submodel for training and one submodel for prediction ?
Perhaps it is the framing of your problem?
Perhaps the chosen model?
Perhaps the chosen config?
…
I know there is many try and fix, many perhaps points… I tested the model the other way around with random data and achieved my expected input/output. I chose already different framings, but did not try yet stateful and reset states , do you think it is worth to try it ?
Yes, if testing modes is cheap/fast.
I also read your post https://machinelearningmastery.com/define-encoder-decoder-sequence-sequence-model-neural-machine-translation-keras/#comment-438058 maybe this would solve my problem ?
Hi Christian, can you share the code which you used to implement that techniques, email (gwkibirige@gmail.com)
Do you have a similar example in R Keras? Because I don’t understanding TimeDistributed. Thank you
Sorry, Id on’t have examples of Keras in R.
I have more on TimeDistributed here:
https://machinelearningmastery.com/timedistributed-layer-for-long-short-term-memory-networks-in-python/
Dear Jason,
Thanks for your nice posts. Have you one on generative (variational) LSTM auto-encoder to able one to capture latent vectors and then generate new timeseries based on training set samples?
Best
I believe I have a great post on LSTM autoencoders scheduled. Not variational autoencoders though.
What do you need help with exactly?
thank you very much
You’re welcome.
A small question which can be very obvious one 😀
U said that 1 means unit size.does it means number of LSTM cells in that layer?
As far as my knowledge number of LSTM cells in the input layer is depend on the number of time stamps in input sequence.am i correct?
If that so what 1 actually means?
The input defines the number of time steps and features to expect for each sample.
The number of units in first hidden layer of the LSTM is unrelated to the input.
Keras defines the input using an argument called input_shape on the first hidden layer, perhaps this is why you are confused?
Jason,
Can you please give an example of how to shape multivariate time series data for a LSTM autoencoder. I have been trying to do this, and failed badly. Thank you.
Perhaps this tutorial will help:
https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
Hi Jason, love your blogs.
I was trying to grasp the Show and Tell paper on image captioning, (https://arxiv.org/pdf/1411.4555.pdf)
(The input image is encoded to a vector and sent as input to a LSTM model )
There they mention:
We empirically verified that feeding the image at each time step as an extra input yields inferior results, as the network can explicitly exploit noise in the image and overfits more easilyunder the LSTM training section.Can you provide some explanation on what this means. Do they remove the timedistributed layer or some other explanation.
This could mean that they tried providing the image as they generated each output word and it did not help.
Hi Jason,
– Please, what does it mean when the loss = nan !
– and how can we choose the parameters “n_steps_in” and “n_features”?
“n_steps_in” does mean the period in the series (the seasonal component) ??
It suggests there is a problem with your problem, perhaps try scaling your data or changing the model config.
You must use experimentation in order to discover the number of features/steps that results in the best performance for your problem.
Hi,
For an application such as abstractive text summarisation, where in we use tools such as GloVe during preprocessing to find relative dependencies between 2 terms, what exactly would the fixed-length vector during the encoding describe?
Also, could you explain the use of Attention in the aforementioned problem?
Thanks.
The vector describes a single word, perhaps read this post:
https://machinelearningmastery.com/what-are-word-embeddings/
I have many posts on attention that may help:
https://machinelearningmastery.com/?s=attention&post_type=post&submit=Search
Hi
Suppose we want to use seq2seq in a way where the output sequence length is NOT known a priori. In fact, we want the decoder to run such that prior steps in the decoding tell the decoder whether or not to generate an output signal or to terminate. In other words, the decoder uses the decoding process itself (and the input and intermediate states) to know when to stop outputting anything. Is this feasible with seq2seq models? Or is it the case that we MUST specify the number of iterations that the decoder will make a priori?
Do you cover any of this in your LSTM book?
You can use a dynamic RNN and process a variable number of time steps in/out as needed.
I don’t have many examples, although here’s one:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Hi jason,
My data consists of 3 columns: 2 features and a sequence that is continuous through time. My goal is to: given the values of the 2 features and a 21 time steps of my sequence, –> predict 7 time steps ahead in the sequence.
Just wanted to confirm that in this case, is the encoder-decoder LSTM is my choice to go??
If the number of input and output steps do not match, then an encoder-decoder might be a good starting point.
Why using the repeat vector? isn’t the encode-decoder trained with the output of the decoder previous timestep? or with teacher forcing?
We are using an auto-encoder based architecture for the encoder-decoder, which I find is as-effective and much simpler.
Also see this:
https://machinelearningmastery.com/lstm-autoencoders/
And this:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Hi Jason,
I have trained date, machine translation model in Keras and it is working as expected as below
=====================Prediction Code====================
EXAMPLES = [‘for 3 May 1979’, ‘5 April 09′, ’21th of August 2016’, ‘Tue 10 Jul 2007’, ‘Saturday May 9 2018’, ‘March 3 2001’, ‘March 3rd 2001’, ‘1 March 2001’]
for example in EXAMPLES:
source = string_to_int(example, Tx, human_vocab)
source = np.array(list(map(lambda x: to_categorical(x, num_classes=len(human_vocab)), source))).swapaxes(0,1)
prediction = model.predict([source, s0, c0])
prediction = np.argmax(prediction, axis = -1)
output = [inv_machine_vocab[int(i)] for i in prediction]
print(“source:”, example)
print(“output:”, ”.join(output),”\n”)
==============output============
source: for 3 May 1979
output: 1979-05-03
source: 5 April 09
output: 2009-05-05
==============================
But save and reuse the model perform very poorly as below
================ save the model======
model.save(“models/my_model.h5”)
========load trained model========
test_model = load_model(“models/my_model.h5”)
this perform very poor
==========test_model prediction=========
source: for 3 May 1979
output: 2222222222
source: 5 April 09
output: 2222222222
===============================
Please help
Well done!
Perhaps confirm you are saving the model (weights and architecture) as well as any data preparation objects.
Yes, i have save the model
model.save(“models/my_model.h5”)
probably this will save the complete model(weights and architecture)
Yes it does.
When i reload the model it’s perform very poorly.
model = load_model(“models/my_model.h5”)
below are the predictions by the model-
source: for 3 May 1979
output: 2222222222
source: 5 April 09
output: 2222222222
why reloaded model is not working as expected?
Ouch.
Ensure you are also saving any data preparation methods used on the data so you can apply them to new data:
https://machinelearningmastery.com/how-to-save-and-load-models-and-data-preparation-in-scikit-learn-for-later-use/
Hi,
I have a request for you, Please write a tutorial on Pointer Networks, ( https://arxiv.org/pdf/1506.03134.pdf ) and its implementation in python with variable input length and utility to add more parameters if necessary.
Thanks in Advance
Especially for convex hull problem.
Thanks for the suggestion!
Hello Jason,
Thanks for the article, I am totally learning from your website and books.
I have 3 questions if you don’t mind:
1- When it says “sequence to sequence LSTM”, does it always means “encoder-decoder LSTM model” ? i.e. is Seq2Seq = enc-dec ?
2- Is there anything in the model configuration, other than the input/output shape, means this model is enc-dec model ?
3- Could you advise any reference for LSTM with attention for time series forecasting, please?
Thanks in advance
Sarah
You’re welcome.
No, any model that can support seq2seq. Most commonly it is an encoder-decoder.
Yes, the architecture indicates encoder-decoder.
I don’t have a tutorial on this topic, sorry.
thanks Jason,
Could you help me to know what is exactly in the architecture indicates encoder-decoder, please?
An encoder-decoder architecture has two models, an encoder model and a decoder model separated by a bottleneck layer which is the output of the encoder.
The above tutorial gives an example.
Hi Jason,
I still don’t understand the use of RepeatVector. If you pass the argument “return_sequence = True” to the LSTM layers of your encoder you’d get a 3D tensor output that would be comptabile [sample, time steps, features] with the decoder input.
It seems to me like using RepeatVector would just repeat your last state X amount of time to fit the required shape.
Or am I missing something ?
Thanks !
important detail: I’m working with fix timesteps (1500), would that be the reason why I don’t need the RepeatVector to account for potentials difference in input and output lengths ?
That is a lot of time steps! Typically we limit time steps to 200-400.
Yes, the encoder-decoder model is intended for seq2seq problems where input and output sequences have different lengths. If this is not the case for your data, perhaps the model is not appropriate.
The idea is to repeat the encoded input sequence for each step required in the output sequence (which could have a different length).
Hi Jason,
Thanks a lot for this article.
I am working with a signal of N timesteps and I would like to know if I can use the argument “return_sequence = True” in place to the RepeatVector layer for a denoising problem (The input sequence and the output sequence have the same number of timesteps = N). The architecture of the auto-encoder is as follows :
auto_encoder_lstm = Sequential()
auto_encoder_lstm.add((LSTM(64, return_sequences=True) , input_shape=(N,1))
auto_encoder_lstm.add(LSTM(64, return_sequences=True)))
auto_encoder_lstm.add(TimeDistributed(Dense(1))
auto_encoder_lstm.compile(optimizer=optimizers.RMSprop(lr=0.0001) , loss=’mse’)
Is my code is correct or I should use RepeatVector ?
Many thanks.
You’re welcome.
No, I don’t think what you describe would be appropriate for a seq2seq model.
Thanks for your response. However, why the reason ?
Indeed, my model takes the noisy signal with size(N,1) as input and try the reconstruct the original signal with the same length as output using the MSE as a loss function. I have tested the BLSTM model and it gives best denoising results for various values of Signal to Noise Ratio (SNR).
Can you clarify your reponse. Thanks.
Sure, the architecture of your model does not decouple encoder and decoder submodels and in turn does not allow variable length input and output sequences. Instead, the output of your model is constrained specifically by the length of the input – the exact problem that encoderdecoder models overcome for seq2seq problems.
Thank you very much
You’re welcome.
Hi Jason,
I have a last question, if my model is incorrect, what is the correct architecture of my Denoising Bidirectional LSTM auto-encoder? .
(It is possibly to remplace the standard LSTM with the bidirectional LSTM in the architecture presented in https://machinelearningmastery.com/lstm-autoencoders/)
Many Thanks.
Sorry, I don’t have an example of a denoising LSTM autoencoder, but the example in the link is a good starting point.
Ok Thank you very much.
You’re welcome.
Thanks, Jason great article I have just one doubt
why we need to use RepeatVector if we are using return_sequences=True in lstm because as far as I know with “return_sequences=True” The lstm will return 3D output only with dimension (#BatchSize, #TimeStamps, #noOfunits)
Looking forward to your reply
To control the length of the output sequence.
Sorry, I didn’t get it could you please elaborate a bit.
In the article, you have written
“the encoder will produce a 2-dimensional matrix of outputs, where the length is defined by the number of memory cells in the layer. The decoder is an LSTM layer that expects a 3D input of [samples, time steps, features] ”
But I think the encoder will produce a 3-dimensional matrix (#BatchSize, #TimeStamps, #noOfunits) not a 2-dimensional matrix.
Perhaps the example of encoder-decoder here will make things clearer for you:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Hi Jason, Thanks for your great work, I learned ML with your blog. So I owe you.
I have a problem with LSTM Autoencoder for Regression,I scaled input and output data in 0 to 1 range , at the end of frist trainning proces when I plot middle vector of model (output of encoder and input vector of decoder model),l saw the range of data between 0 to 8.I plotted some of other layer in encoder and I saw that range again.This reduces the performance of the model. I trid to used BatchNormalization layer after of each layer but thats not worked! (I read somewhere that you said dont use BatchNormalization for LSTM ) .so what can I do for this?
thanks again
Well done on your progress!
Perhaps you can explore alternate methods, such as some of those listed here:
https://machinelearningmastery.com/start-here/#better
LayerNormalization works here?
You can try, but I don’t see any benefit here.
In the text, it sentenced that “That is, the encoder will produce a 2-dimensional matrix of outputs”, however, since the output of the encoder is the output of the lstm, I think that the lstm, thus, the encoder should produce a 1-dimensional matrix.
Maybe there is some error in this sentence, or if I made a mistake, anyone can tell me why ?
Because the return_sequence=True will return you the entire sequence (one per time step) and there are multiple LSTM units. Hence it is 2D
in LSTM(…), if you did not specify return_state agrument, does that mean the decoder will not have any initial hidden/cell states?