An LSTM Autoencoder is an implementation of an autoencoder for sequence data using an Encoder-Decoder LSTM architecture.
Once fit, the encoder part of the model can be used to encode or compress sequence data that in turn may be used in data visualizations or as a feature vector input to a supervised learning model.
In this post, you will discover the LSTM Autoencoder model and how to implement it in Python using Keras.
After reading this post, you will know:
Autoencoders are a type of self-supervised learning model that can learn a compressed representation of input data.
LSTM Autoencoders can learn a compressed representation of sequence data and have been used on video, text, audio, and time series sequence data.
How to develop LSTM Autoencoder models in Python using the Keras deep learning library.
A Gentle Introduction to LSTM Autoencoders Photo by Ken Lund, some rights reserved.
Overview
This post is divided into six sections; they are:
What Are Autoencoders?
A Problem with Sequences
Encoder-Decoder LSTM Models
What Is an LSTM Autoencoder?
Early Application of LSTM Autoencoder
How to Create LSTM Autoencoders in Keras
What Are Autoencoders?
An autoencoder is a neural network model that seeks to learn a compressed representation of an input.
They are an unsupervised learning method, although technically, they are trained using supervised learning methods, referred to as self-supervised. They are typically trained as part of a broader model that attempts to recreate the input.
For example:
1
X=model.predict(X)
The design of the autoencoder model purposefully makes this challenging by restricting the architecture to a bottleneck at the midpoint of the model, from which the reconstruction of the input data is performed.
There are many types of autoencoders, and their use varies, but perhaps the more common use is as a learned or automatic feature extraction model.
In this case, once the model is fit, the reconstruction aspect of the model can be discarded and the model up to the point of the bottleneck can be used. The output of the model at the bottleneck is a fixed length vector that provides a compressed representation of the input data.
Input data from the domain can then be provided to the model and the output of the model at the bottleneck can be used as a feature vector in a supervised learning model, for visualization, or more generally for dimensionality reduction.
A Problem with Sequences
Sequence prediction problems are challenging, not least because the length of the input sequence can vary.
This is challenging because machine learning algorithms, and neural networks in particular, are designed to work with fixed length inputs.
Another challenge with sequence data is that the temporal ordering of the observations can make it challenging to extract features suitable for use as input to supervised learning models, often requiring deep expertise in the domain or in the field of signal processing.
Finally, many predictive modeling problems involving sequences require a prediction that itself is also a sequence. These are called sequence-to-sequence, or seq2seq, prediction problems.
You can learn more about sequence prediction problems here:
Recurrent neural networks, such as the Long Short-Term Memory, or LSTM, network are specifically designed to support sequences of input data.
They are capable of learning the complex dynamics within the temporal ordering of input sequences as well as use an internal memory to remember or use information across long input sequences.
The LSTM network can be organized into an architecture called the Encoder-Decoder LSTM that allows the model to be used to both support variable length input sequences and to predict or output variable length output sequences.
This architecture is the basis for many advances in complex sequence prediction problems such as speech recognition and text translation.
In this architecture, an encoder LSTM model reads the input sequence step-by-step. After reading in the entire input sequence, the hidden state or output of this model represents an internal learned representation of the entire input sequence as a fixed-length vector. This vector is then provided as an input to the decoder model that interprets it as each step in the output sequence is generated.
You can learn more about the encoder-decoder architecture here:
An LSTM Autoencoder is an implementation of an autoencoder for sequence data using an Encoder-Decoder LSTM architecture.
For a given dataset of sequences, an encoder-decoder LSTM is configured to read the input sequence, encode it, decode it, and recreate it. The performance of the model is evaluated based on the model’s ability to recreate the input sequence.
Once the model achieves a desired level of performance recreating the sequence, the decoder part of the model may be removed, leaving just the encoder model. This model can then be used to encode input sequences to a fixed-length vector.
The resulting vectors can then be used in a variety of applications, not least as a compressed representation of the sequence as an input to another supervised learning model.
LSTM Autoencoder Model Taken from “Unsupervised Learning of Video Representations using LSTMs”
In the paper, Nitish Srivastava, et al. describe the LSTM Autoencoder as an extension or application of the Encoder-Decoder LSTM.
They use the model with video input data to both reconstruct sequences of frames of video as well as to predict frames of video, both of which are described as an unsupervised learning task.
The input to the model is a sequence of vectors (image patches or features). The encoder LSTM reads in this sequence. After the last input has been read, the decoder LSTM takes over and outputs a prediction for the target sequence.
More than simply using the model directly, the authors explore some interesting architecture choices that may help inform future applications of the model.
They designed the model in such a way as to recreate the target sequence of video frames in reverse order, claiming that it makes the optimization problem solved by the model more tractable.
The target sequence is same as the input sequence, but in reverse order. Reversing the target sequence makes the optimization easier because the model can get off the ground by looking at low range correlations.
They also explore two approaches to training the decoder model, specifically a version conditioned in the previous output generated by the decoder, and another without any such conditioning.
The decoder can be of two kinds – conditional or unconditioned. A conditional decoder receives the last generated output frame as input […]. An unconditioned decoder does not receive that input.
A more elaborate autoencoder model was also explored where two decoder models were used for the one encoder: one to predict the next frame in the sequence and one to reconstruct frames in the sequence, referred to as a composite model.
… reconstructing the input and predicting the future can be combined to create a composite […]. Here the encoder LSTM is asked to come up with a state from which we can both predict the next few frames as well as reconstruct the input.
LSTM Autoencoder Model With Two Decoders Taken from “Unsupervised Learning of Video Representations using LSTMs”
The models were evaluated in many ways, including using encoder to seed a classifier. It appears that rather than using the output of the encoder as an input for classification, they chose to seed a standalone LSTM classifier with the weights of the encoder model directly. This is surprising given the complication of the implementation.
We initialize an LSTM classifier with the weights learned by the encoder LSTM from this model.
The composite model without conditioning on the decoder was found to perform the best in their experiments.
The best performing model was the Composite Model that combined an autoencoder and a future predictor. The conditional variants did not give any significant improvements in terms of classification accuracy after fine-tuning, however they did give slightly lower prediction errors.
Many other applications of the LSTM Autoencoder have been demonstrated, not least with sequences of text, audio data and time series.
How to Create LSTM Autoencoders in Keras
Creating an LSTM Autoencoder in Keras can be achieved by implementing an Encoder-Decoder LSTM architecture and configuring the model to recreate the input sequence.
Let’s look at a few examples to make this concrete.
Reconstruction LSTM Autoencoder
The simplest LSTM autoencoder is one that learns to reconstruct each input sequence.
For these demonstrations, we will use a dataset of one sample of nine time steps and one feature:
1
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
We can start-off by defining the sequence and reshaping it into the preferred shape of [samples, timesteps, features].
# reshape input into [samples, timesteps, features]
n_in=len(sequence)
sequence=sequence.reshape((1,n_in,1))
Next, we can define the encoder-decoder LSTM architecture that expects input sequences with nine time steps and one feature and outputs a sequence with nine time steps and one feature.
Running the example fits the autoencoder and prints the reconstructed input sequence.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The results are close enough, with very minor rounding errors.
Running the example prints the output sequence that predicts the next time step for each input time step.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that the model is accurate, barring some minor rounding errors.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example both reconstructs and predicts the output sequence, using both decoders.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[array([[[0.10736275],
[0.20335874],
[0.30020815],
[0.3983948 ],
[0.4985725 ],
[0.5998295 ],
[0.700336 ,
[0.8001949 ],
[0.89984304]]], dtype=float32),
array([[[0.16298929],
[0.28785267],
[0.4030449 ],
[0.5104638 ],
[0.61162543],
[0.70776784],
[0.79992455],
[0.8889787 ]]], dtype=float32)]
A plot of the architecture is created for reference.
Composite LSTM Autoencoder for Sequence Reconstruction and Prediction
Keep Standalone LSTM Encoder
Regardless of the method chosen (reconstruction, prediction, or composite), once the autoencoder has been fit, the decoder can be removed and the encoder can be kept as a standalone model.
The encoder can then be used to transform input sequences to a fixed length encoded vector.
We can do this by creating a new model that has the same inputs as our original model, and outputs directly from the end of encoder model, before the RepeatVector layer.
Running the example creates a standalone encoder model that could be used or saved for later use.
We demonstrate the encoder by predicting the sequence and getting back the 100 element output of the encoder.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Obviously, this is overkill for our tiny nine-step input sequence.
It provides self-study tutorials on topics like: CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Hi Jason,
Thanks for the posts, I really enjoy reading this.
I’m trying to use this method to do time series data anomaly detection and I got few questions here:
When you reshape the sequence into [samples, timesteps, features], samples and features always equal to 1. What is the guidance to choose the value here? If the input sequences have variable length, how to set timesteps, always choose max length?
Also, if the input is two dimension tabular data with each row has different length, how will you do the reshape or normalization?
Thanks in advance!
“I am wondering why the output of encoder has a much higher dimension(100), since we usually use encoders to create lower dimensions!”, I have the same question, can you please explain more?
Great article. But reading through it I thought you were tackling the most important problem with sequences – that is they have variable lengths. Turns out it wasn’t. Any chance you could write a tutorial on using a mask to neutralise the padded value? This seems to be more difficult than the rest of the model.
I really likes your posts and they are important.I got a lot of knowledge from your post.
Today, am going to ask your help. I am doing research on local music classifications. the key features of the music is it sequence and it uses five keys out of the seven keys, we call it scale.
1. C – E – F – G – B. This is a major 3rd, minor 2nd, major 2nd, major 3rd, and minor 2nd
2. C – Db – F – G – Ab. This is a minor 2nd, major 3rd, major 2nd, minor 2nd, and major 3rd.
3. C – Db – F – Gb – A. This is a minor 2nd, major 3rd, minor 2nd, minor 3rd, and a minor 3rd.
4. C – D – E – G – A. This is a major 2nd, major 2nd, minor 3rd, major 2nd, and a minor 3rd
it is not dependent on range, rythm, melody and other features.
This key has to be in order. Otherwise it will be out of scale.
So, which tools /algorithm do i need to use for my research purpose and also any sampling mechanism to take 30 sec sample music from each track without affecting the sequence of the keys ?
Hi, can you please explain the use of repeat vector between encoder and decoder?
Encoder is encoding 1-feature time-series into fixed length 100 vector. In my understanding, decoder should take this 100-length vector and transform it into 1-feature time-series.
So, encoder is like many-to-one lstm, and decoder is one-to-many (even though that ‘one’ is a vector of length 100). Is this understanding correct?
Hi Jason?
What is the intuition behind “representing of the input n times for the number of required output steps?”Here n times denotes, let say as in simple LSTM AE, 9 i.e. output step number.
I understand from repeatvector that here sequence are being read and transformed into a single vector(9×100) which is the same 100 dim vector, then the model uses that vector to reconstruct the original sequence.Is it right?
What about using any number except for 9 for the number of required output steps?
Thanks from now on.
# “encoded” is the encoded representation of the input
encoded = LSTM(latent_dim,activation=’relu’)(inputs)
# “decoded” is the lossy reconstruction of the input
decoded = RepeatVector(timesteps)(encoded)
decoded = LSTM(input_dim, activation=’relu’, return_sequences=True)(decoded)
I did not know why, but I always get a poor result than the model using your code.
So my question is: is there any difference between the two method (syntax) under the hood? or they are actually the same ?
I feel like a bit more description could go into how to setup the LSTM autoencoder. Particularly how to tune the bottleneck. Right now when I apply this to my data its basically just returning the mean for everything, which suggests the its too aggressive but I’m not clear on where to change things.
Hi Jason, thanks for the wonderful article, I took some time and wrote a kernel on Kaggle inspired by your content, showing regular time-series approach using LSTM and another one using a MLP but with features encoded by and LSTM autoencoder, as shown here, for anyone interested here’s the link: https://www.kaggle.com/dimitreoliveira/time-series-forecasting-with-lstm-autoencoders
Hey! I am trying to compact the data single row of 217 rows. After running the program it is returning nan values for prediction Can you guide me where did i do wrong?
I have learned a lot from your website. Autoencoder can be used as dimension reduction. Is it possible to merge multiple time-series inputs into one using RNN autoencoder? My data shape is (9500, 20, 5) => (sample size, time steps, features). How to encode-decode into (9500, 20, 1)?
Hi Jason,
I’m a regular reader of your website, I learned a lot from your posts and books!
This one is also very informative, but there’s one thing I can’t fully understand: if the encoder input is [0.1, 0.2, …, 0.9] and the expected decoder output is [0.2, 0.3, …, 0.9], that’s basically a part of the input sequence. I’m not sure why you say it’s “predicting next step for each input step”. Could you please explain? Is an autoencoder a good fit for multi-step time series prediction?
Another question: does training the composite autoencoder imply that the error is averaged for both expected outputs ([seq_in, seq_out])?
From a high-level, algorithms learn by generalizing from many historical examples, For example:
Inputs like this are usually come before outputs like that.
The generalization, e.g. the learned model, can then be used on new examples in the future to predict what is expected to happen or what the expected output will be.
Technically, we refer to this as induction or inductive decision making.
Hi, I am JT.
First of all, thanks for your post that provides an excellent explanation of the concept of LSTM AE models and codes.
If I understand your AE model correclty, features from your LSTM AE vector layer [shape (,100)] does not seem to be time dependent.
So, I have tried to build a time-dependent AE layer by modifying your codes.
Could you check my codes whether my codes are correct to build an AE model that incpude a time-wise AE layer, if you don’t mind?
My codes are below.
from numpy import array
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
# tie it together
model = Model(inputs=visible, outputs=[decoder1, decoder2])
model.summary()
model.compile(optimizer=’adam’, loss=’mse’)
# fit model
model.fit(seq_in, [seq_in,seq_out], epochs=2000, verbose=2)
## The model that feeds seq_in to predict seq_out
hat1= model.predict(seq_in)
## The model that feeds seq_in to predict AE Vector values
model2 = Model(inputs=model.inputs, outputs=model.layers[2].output)
hat_ae= model2.predict(seq_in)
## The model that feeds AE Vector values to predict seq_out
input_vec = Input(shape=(n_in,30))
dec2 = model.layers[4](input_vec)
dec2 = model.layers[6](dec2)
model3 = Model(inputs=input_vec, outputs=dec2)
hat_= model3.predict(hat_ae)
Thanks for the nice post. Being a beginner in machine learning, your posts are really helpful.
I want to build an auto-encoder for data-set of names of a large number of people. I want to encode the entire field instead of doing it character or wise, for example [“Neil Armstrong”] instead of [“N”, “e”, “i”, “l”, ” “, “A”, “r”, “m”, “s”, “t”, “r”, “o”, “n”, “g”] or [“Neil”, “Armstrong”]. How can I do it?
Hey, thanks for the post, I have found it helpful… Although I am confused about one, in my opinion, major point..
– If autoencoders are used to obtain a compressed representation of the input, what is the purpose of taking the output after the encoder part if it is now 100 elements instead of 9? I’m struggling to find a meaning of the 100 element data and how one could use this 100 element data to predict anomalies. It sort of seems like doing the exact opposite of what was stated in the explanation prior to the example. An explanation would be greatly appreciated.
– In the end I’m trying to really understand how after learning the weights by minimizing the reconstruction error of the training set using the AE, how to then use this trained model to predict anomalies in the cross validation and test sets.
Hi Jason, Benjamin is right. The last example you provided for using standalone LSTM encoder. The input sequence is 9 elements but the output of the encoder is 100 elements despite explaining in the first part of the tutorial that encoder part compresses the input sequence and can be used as a feature vector. I am also confused about how the output of 100 elements can be used as a feature representation of 9 elements of the input sequence. A more detail explanation will help. Thank you!
Thank your great post.
As you mentioned in the first section, “Once fit, the encoder part of the model can be used to encode or compress sequence data that in turn may be used as a feature vector input to a supervised learning model”. I fed the feature vector (encode part) to 1 feedforward neural network 1 hidden layer:
n_dimensions=50
Thank for your reply soon.
I saw your post, LSTM layer at the decoder is set “return_sequences=True” and I follow and then error as you saw. Actually, I thought the decoder is not a stacked LSTM (only 1 LSTM layer), so “return_sequences=False” is suitable. I changed as you recommend. Another error:
decoded = TimeDistributed(Dense(features_n))(decoded)
File “/usr/local/lib/python3.4/dist-packages/keras/engine/topology.py”, line 592, in __call__
self.build(input_shapes[0])
File “/usr/local/lib/python3.4/dist-packages/keras/layers/wrappers.py”, line 164, in build
assert len(input_shape) >= 3
AssertionError.
Can you give me an advice?
Thank you
Hi Jason,
I found another way to build full_model. I don’t use autoencoder.predict(train_x) to input to full_model. I used orginal inputs, saved weights of the encoder part in autoencoder model, then set that weights to encoder model. Something like this:
autoencoder.save_weights(‘autoencoder.h5′)
for l1,l2 in zip(full_model.layers[:a],autoencoder.layers[0:a]): #a:the num_layer in the encoder part
l1.set_weights(l2.get_weights())
train full_model:
full_model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history_class=full_model.fit(train_x, train_y, epochs=2, batch_size=256, validation_data=(val_x, val_y))
My full_model run, but the result so bad. Hic, train 0%, test/val: 100%
When I visualize these predictions data on my image, the direction is 90 degree changing (i.e Original data is horizontal but predictions data is vertical).
Why I face this and how can I fix that?
Thank you so much for your great post. I wish you have done this with a real data set like 20 newsgroup data set.
It is at first not clear the different ways of preparing the data for different objectives.
My understanding is that with LSTM Autoencoder we can prepare data in different ways based on the goal. Am I correct?
Or can you please give me the link which is preparing the text data like 20 news_group for this kind of model?
Thank you so much Jason for the link. I have already gone through lots of material, in detail the mini corse in the mentioned link months ago.
My problem mainly is the label data here.
For example, in your code, in the reconstruction part, you have given sequence for both data and label. however, in the prediction part you have given the seq_in, seq_out as the data and the label, and their difference is that seq_out looking at one timestamp forward.
My question according to your example will be if I want to use this LSTM autoencoder for the purpose of topic modeling, Do I need to follow the reconstruction part as I don’t need any prediction?
Based on different objectives I meant, for example if we use this architecture for topic modeling, or sequence generation, or … is preparing the data should be different?
I have a question about the loss function used in the composite model.
Say you have different loss functions for the reconstruction and the prediction/classification parts, and pre-trains the reconstruction part.
In Keras, would it be possible to combine these two loss functions into one when training the model,
such that the model does not lose or diminish its reconstruction ability while traning the prediction/classification part?
If so; could you please point me in the right direction.
Thank you, Jason, but still, I have not got the answer to my question.
Lets put it another way. what is the latent space in this model? is it only a compressed version of the input data?
do you think if I use the architecture of Many to one, I will have one word representation for each sequence of data?
Why am I able to print out the clusters of the topics in autoencoder easily but when it comes to this architecture I am lost!
I don’t think there exists difference between my keras model and the paper’s model.But the problem has confused me for 2 weeks,I can not get a good solution.I really appreciate your help!
hello John!
I’m excited of your keras code for implementing the paper that I just read.
Can you share the full code(especially image processing part) for me to study what you have done?
As I’m newbie of ML but trying to get used to video prediction with Autoencdoer LSTM.
How can I use the cell state of this “Standalone LSTM Encoder” model as an input layer for another model? Suppose in your code for “Keep Standalone LSTM Encoder”, you had “return_state=True” option for the encoder LSTM layer and create the model like:
model = Model(inputs=model.inputs, outputs=[model.layers[0].output, hidden_state, cell_state])
Then one can retrieve the cell state by: model.outputs[2]
The problem is that this will return a “Tensor” and keras complains that it only accept “Input Layer” as an input for ‘Model()’. How can I feed this cell state to another model as input?
“After the encoder-decoder is pre-trained, it is treated as an intelligent feature-extraction blackbox. Specifically, the last LSTM cell states of the encoder are extracted as learned embedding. Then, a prediction network is trained to forecast the next one or more timestamps using the learned embedding as features.”
They trained an LSTM autoencoder and fed the last cell states of last encoder layer to another model. Did I misunderstand it?
The tutorial claims that the deeper architecture gives slightly better results than the more shallow model definition in the previous example. This tutorial uses simple dense layers in its models, so I wonder if something similar could be done with LSTM layers.
I have a theoretical question about autoencoders. I know that autoencoders are suppose to construct the input at the output, and by doing so they will learn a lower-dim representation of the input. Now I want to know if it is possible to use autoencoders to construct something else at the output (let’s say a something that is a modified version of the input).
Thanks for the response. I will check those out. I though about denoising autoencoders, but was not sure if that is applicable to my situations.
Let’s say that I have two versions of a feature vector, one is X, and the other one is X’, which has some meaningful noise (technically not noise, meaningful information). Now my question is whether it is appropriate to use denoising autoencoders in this case to learn about the transition between X to X’ ?
Hi Jason, could you explain the difference between RepeatVector and return_sequence?
It looks like they both repeat vector several times but what’s the difference?
Can we only use return_sequence in the last LSTM encoder layer and don’t use RepeatVector before the first LSTM decoder layer?
Thank you, Jason, now I understand the difference between them. But, here is another question, can we do like this:
”’
encoder = LSTM(100, activation=’relu’, input_shape=(n_in,1), return_sequence=True)
(no RepeatVector layer here, but return_sequence is True in encoder layer)
If yes, what’s the difference between this one and the one you shared (with RepeatVector layer between encoder and decoder, but return_sequence is False in encoder layer)
The repeat vector allows the decoder to use the same representation when creating each output time step.
A stacked LSTM is different in that it will read all input time steps before formulating an output, and in your case, will output an activation for each input time step.
There’s no “best” way, test a suite of models for your problem and use whatever works best.
One point I would like to mention is the Unconditioned Model that Srivastava et al use. a) They do not supply any inputs in the decoder model.. Is this tutorial only using the conditioned model?
b) Even if we are using the any of the 2 models that is mentioned in the paper, we should be passing the hidden state or maybe even the cell state of the encoder model to the models first time step and not to all the time steps..
The tutorial over here shows us that the repeat vector is supplying inputs to all the time steps in the decoder model which should not be the case in any of the models
Also the target time steps in the auto reconstruction decoder model should have been reversed.
Please correct me if I am wrong in understanding the paper. Awaiting for you to clarify my doubt. Thanking you in advance.
My understanding is that repeatvector function utilizes a more “dense” representation of the original inputs. For an encoder lstm with 100 hidden units, all information are compressed into a 100 elements vector (which then duplicated by repeatvector for desired output timesteps). For return_sequence=TRUE, it is a totally different scenario — you end up with 100 x input time steps latent variables. It is more like a sparse autoencoder. Correct me if i am wrong.
Hello Mr.Jason
i want to start a handwritten isolated charactor recognition with RNN and lstm.
i mean, we have a number of charactor images and i want a code to recognize that charactor.
would you please help me to find a basic python code for this purpose, ans so i could start the work?
Thanks for your post, here I want to use LSTM to prediction a time series. For example the series like (1 2 3 4 5 6 7 8 9), and use this series for training. Then the output series is the series of multi-step prediction until it reach the ideal value, like this(9.9 10.8 11.9 12 13.1)
Sorry, maybe I didn’t make it clear. Here I want to use LSTM to prediction a time series. the sequence may like this[10,20,30,40,50,60,70],and use it for training,if time_step is 3. When input[40,50,60],we want the output is 70. when finish training the model, the prediction begin. when input [50,60,70], the output maybe 79 and then use it for next step prediction, the input is [60,70,79] and output might be 89. Until satisfying certain condition(like the output>=100) the the iteration is over.
So how could I realize the prediction process above and where can I find the code
Please, hope to get your reply
And I still have a question, the multi-step LSTM model uses the last three time steps as input and forecast the next two time steps. But in my case, I want to predict the capacity decline trend of Lithium-ion battery, and for example let the data of declining curve of capacity(the cycling number<160) as the training data, then I want to predict the future trend of capacity until it reach the certain value(maybe <=0.7Ah) –failure threshold,which might be achieved at the cycling number of 250 or so. And between the cycling number of 160 and 220, around 90 data need be predicted. So I have no idea how to define time-steps and samples, if the output time-steps defined as 60(220-160=60),the how should I define the time-steps of input, it seems unreasonable.
I am extremely hope to get your reply, Thank you so much
When I’m passing it as an input to the reconstruction LSTM (with an added LSTM and repeat vector layer and 1000 epochs) , I get the following predicted output :
If I have varying numbers such as 2 and 1000 in the same list, is it better to normalize the list by dividing each element by the highest element , and then passing the resulting sequence as an input to the autoencoder ?
thanks for you quick response… I have a confusion, right now when you mention ‘training’, it is only one vector… how can truly train it with batches of multiple vectors.
Hello Jason, I really appreciate your informative posts. But I got to have two questions.
Question 1. Does model.add(LSTM(100, activation='relu', input_shape=(n_in,1))) mean that you are creating an LSTM layer with 100 hidden state?
LSTM structure needs hidden state(h_t) and cell state(c_t) in addition to the input_t, right? So the number 100 there means that with the data whose shape is (9,1) (timestep = 9, input_feature_number = 1), the LSTM layer produces 100-unit long hidden state (h_t)?
Question 2. how small did it get reduced in terms of ‘dimension reduction?’ Can you tell me how smaller the (9, 1) data got to be reduced in the latent vector?
hi jason! can this approach is used for sentence correction? i.e spelling or grammatical mistakes of the input text.
for example I have a huge corpus of unlabelled text, and I trained it using autoencoder technique. I want to built a model that takes input (a variable length) sentence, and output the most probable or corrected sentence based on the training data distribution, is it possible?
Hi Jason, thanks for your greats articles! I have a work where I get several hundreds of galaxy spectra (a graphic where I have a continuous number of frecuencies in the x axis and the number of received photons from each galaxy in the y axis; it’s something like a continuos histogram). I need to make an unsupervised clustering with all this spectra. Do you thing this LSTM autoencoder can be a good option I can use? (Each spectrum has 4000 pairs frecuency-flux).
I was thinking about passing the feature space of the autoencoder with a K-means algorithm or something similar to make the clusters (or better, something like this: https://arxiv.org/abs/1511.06335).
hello and thanks for your tutorial… do you have a similar tutorial with LSTM but with multiple features?
The reason I ask for multiple feature is because I built multiple autoencoder models with different structures but all had timesteps = 30… during training the loss, the rmse, the val_loss and the val_rmse seem all to be within acceptable range ~ 0.05, but when I do prediction and plot the prediction with the original data in one graph, it seems that they both are totally different.
I used MinMaxScaler so I tried to plot the original data and the predictions before I inverse the transform and after, but still the original data and the prediction aren’t even close. So, I think I am having trouble plotting the prediction correctly
Hi Jason
Thanks for the tutorial.
I have a sequence A B C. Each A B and C are vectors with length 25.
my samples are like this: A B C label, A’ B’ C’ label’,….
How should I reshape the data?
what is the size of the input dimension?
my dataset is an array with the shape (10,3,25).(3 features and each feature has 25 features in a vector form)
is it necessary to reshape it?
and what is the value of input_shape for this array?
I have one doubt about the layer concept. Is the LSTM layer (100) means, a hidden layer of 100 neurons from the first LSTM layer output and the data from all these 100 layer will consider as the final state value. Is that correct?
I can not find any relation between output size and the matrix size in each layer. But in each layer the parameter size specified is the total of weight matrix size. Can you please help me to get an idea of the implementation of these numbers.
I can able to understand the structure of the input data into the first LSTM layer. But I am not able to identify the matrix structure in the first Layer and the connection with Second Layer. Can you please give me more guidelines to understand the matrix dimensions in the Layers.
If the LSTM has return_states=False then the output of an LSTM layer is one value for each node, e.g. LSTM(50) returns a vector with 50 elements.
If the LSTM has return_states=True, such as when we stack LSTM layers, then the return will be a sequence for each node where the length of the sequence is the length of the input to the layer, e.g. LSTM(50, input_shape=(100,1)) then the output will be (100,50) or 100 time steps for 50 nodes.
hi, I am a student and I want to forecast a time-series (electrical load) for the next 24 hr.
I want to do it by using an autoencoder boosting with LSTM.
I am looking for a suitable topology and structure for it.Is it possible to help me?
best regards
Hi,
I have a question regarding compositive model. In your tutorial, you have sent all data into LSTM encoder. And decorder1 tries to reconstruct whatever it has been passed to the encoder. The another decorder tries to predict the next sequence.
My question is that once encoder has seen all the data, does it make sense for prediction branch? Since it has already seen all day, definitely it can predict well enough, right?
I don’t know how encoder part works? Does it works differently for two branch. Does encoder part create a single encoded latent space from which both part does their job accordingly?
Could you please help me to figure it out. Thank you.
Perhaps focus on the samples aspect of the data, the model receives a sample, and predicts the output, then the next sample is processed, and predicts an output, so on.
It just so happens when we train the model we provide all the samples in a dataset together.
I am trying to ask with you that whether we have to pass all time steps( in this case 10), or pass first 5 time steps (in this case) to predict the next 5 steps. (I have a data of 10 time steps, my wish is to train a network with two decoder. First decorder should return the reconstruction of input, and second decorder predict the next value).
The question is if I pass all 10 time steps to the network then it will see all the time steps which means it encodes all seen data. from encoding space two decorde will try to reconstruct and predict. It seems that both decoder looks similar then what is the significance of using reconstruction branch decoder? How it helps to prediction decorder in composite model?
Yes, the goal is not to train a predictive model, it is to train an effective encoding of the input.
Using a prediction model as a decoder does not guarantee a better encoding, it is just an alternate strategy to try that may be useful on some problems.
I get NaN values when i apply the reconstruction autoencoder to my data (1,1000,1)
What can be the reason for it and how to resolve?
I am exploring how reshaping data works for LSTMs and have tried dividing my data into batches of 5 with 200 timesteps each but wanted to check how (1,1000,1) works
I had a question. If I am using the Masking layer in the first part of the network, then does the RepeatVector() layer support masking. Because if it does not support masking and replicates each timestep with the same value, then our output loss will not be computed properly. Because ideally in our mse loss for each example we do not want to include the timestep where we had zero paddings.
Could you please share how to ignore the zero padded values while calculating the mse loss function.
But if the reconstructed timesteps corresponding to the padded part is not zero, then the mean square error loss will be vary large I suppose? Can you tell me if I am wrong here because my mse loss is becoming “nan” after certain number of epochs. And is it best to do post padding or pre padding?
Hi Jason, thanks for the article. I’m struggling the same problem with Sounak that the mask actually get lost when LSTM return_sequence = False (also the RepeatVector does not explicitly support masking because it actually change the Timestep dimension), since the mask cannot be passed to the end of the model, the loss will be calculated also for those padded timesteps (I’ve validated this on a simple example), which are not preferred.
Hi Jason,
I really enjoy your posts. Thanks for sharing your expertise. Really appreciate it!
I also have a question regarding this post. In the “Prediction Autoencoder” shouldn’t you split the time sequence in half and try to predict the second half by feeding the first half to the encoder. They way that you have implemented the decoder does not truly predict the sequence because the entire sequence had been summarized and given to it by the encoder. Is that true, or am I missing something here?
I’m working on data reconstruction where input is [0:8] columns of the dataset and required output is the 9th column. However the LSTM autoencoder model returns the same value as output after 10 to 15 timesteps. I have applied the model on different datasets but facing similar issue.
What parameter adjustments must I do to obtain unique reconstructed values?
I’ve read comments regarding the RepeatVector(), yet I’m still skeptical if I understood it correctly.
We are merely copying the last output of the encoder LSTM and feed it to each cell of the decoder LSTM to produce the unconditional sequence. Is it correct?
Also, I’m curious that what happens to the internal state of the encoder LSTM. Is it just discarded and will never be used for the decoder? I wonder if using the internal state of the final LSTM cell of the encoder for the initial internal state of LSTM of the decoder would have any kind of benefit. Or is it just completely unnecessary since all we want is to train the encoder?
Really appreciate your hard work and the tutorials are great. I have learned a lot. Can you please write a tutorial on teacher forcing method in encoder decoder architecture? That would be really helpful.
I would know what is the point to doing an autoencoder.
it seem equivalent to build one side an encoder decoder and in the other side the prediction model , as the two ouput don’t seem being used by each other.
Maybe it would be meaningler to use the decodeur as discriminant for the prediction like a GAN
Is there any way of building an overfitted autoencoder(is overfitting needs to be taken care while training an autoencoder).
and how can one justify that the encoded features obtained are the best compression possible for reconstruction of original.
Also, can you please explain the time distributed layer in terms of the input to this layer. What is the use of time distributed layer. is this layer only useful if working with LSTM layer?
Thanks for all your posts and books, they are very useful in understanding concepts and applying them.
I am having trouble seeing the bottle neck. Is it the 100 unit layer after the input? Should this normally, without a trivial data set for your example, be much smaller than the number of time steps?
Hi Jason,
Thank you so much for writing this great post. But I have a question that really confusing me. Here it is. As the Encoder-Decoder LSTM can benefit the training for output variable length, I’m wondering if it can support the variable multi-step output. I am trying to vary the length of output steps with the “Multiple Parallel Input and Multi-Step Output” example from another post https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/, so the output sequence like:
[[[ 40 45 85]
[ 0 0 0]
[ 0 0 0]]
[[ 50 55 105]
[ 60 65 125]
[ 70 75 145]]
[[ 60 65 125]
[ 70 75 145]
[ 0 0 0]]
[[ 70 75 145]
[ 80 85 165]
[ 0 0 0]]
[[ 80 85 165]
[ 0 0 0]
[ 0 0 0]]]
But my prediction results turned out to be not good. Could you give me some guidance? Is the padding value 0 not suitable? Is the Encoder-Decoder LSTM cannot support the variable length of steps?
Thank you for suggesting me to process one time step at a time. I suddenly realize there is no need to make the output time steps variable since we can predict the output step by step. Did I get it right? Besides, I think there is no rationale difference between the two Encoder-Decoder models from these two posts except for predicting different timesteps and using different Keras function. Is this understanding correct?
Hope to hear from you. Thanks again.
Hi Jason,
I am trying to implement a LSTM autoencoder using encoder-decoder architecture. What if I want to use the functional API of keras and also NOT have my decoder get the inputs from the previous i.e. my decoder LSTM will not have any input but just the hidden and cell state initialized from encoder?(because I want my encoder output to preserve all the information necessary to reconstruct back the signal with giving any inputs to the decoder). Is something like this possible in keras?
the reason I want to use functional API is because I want to use stacked LSTM(multiple layers) and I want the hidden_state from all layers at the last time step of encoder. This is possible only with functional API right?
Hey, @Jason Brownlee, I am working on textual data could you please explain this concept regarding the text? I am calculating errors with glove pre-trained vector but my result is not up to the mark
Hi Jason, I have a question. is last 100*1 vector you printed in the end of article the feature of the sequence? Can this vector be later used as, for example, sequence classification or regression? Thanks!
Hello, dr. Jason, thanks for this useful tutorial!
I built a convolutional Autoencoder (CAE), the result of the reconstructed image from the decoder is better than the original image, and i think if a classifer took a better image it would provide a good output..
so I want to classify the input weather it is a bag, shoes .. etc
Is it better to:
1- delete the decoder and make the encoder as a classifier? (if I did this will it be like a normal CNN?)
2- or do the same as “Composite LSTM Autoencoder in this tutorial” to my CAE
3- take the output of the decoder (better image) to a classifier
I do not know, and I am really new to AI world, your reply will be so useful to me.
Thank you.
so I take the output of the encoder (maybe 8*8 matrix) and make it as input to model that takes the same size (8*8)? no need to connect both CNNs (encoder, classifier)?
Jason, I ran the Prediction LSTM Autoencoder from this post and saw the following error message:
2020-03-28 14:01:53.115186: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 0, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.120793: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 1, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.127457: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] layout failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.190262: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] remapper failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.194523: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] arithmetic_optimizer failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.198763: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 0, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.204018: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 1, topological sort failed with message: The graph couldn’t be sorted in topological order.
However, the code ran and the answer was equivalent to your answer. Have you seen this error? If so, do you know what it means?
I was wondering why you use RepeatVector layer after LSTM to to match the time step size, but you can obtain the same shape tensor by using repeat_sequence = True on the LSTM layer?
To clarify what I meant, please refer to the following code snippet I ran on tensorflow2.0 with eager execution enabled. (I wanted to post a screenshot but I couldnt replay with a picture)
inputs = np.random.random([2, 10, 1]).astype(np.float32)
x = LSTM(4, return_sequences=False)(inputs)
x = RepeatVector(10)(x)
x = LSTM(8, return_sequences=True)(x)
x = TimeDistributed(Dense(5))(x)
print(f”input1:{inputs.shape}”)
print(f”output1: {x.shape}”)
x = LSTM(4, return_sequences=True)(inputs)
x = LSTM(8, return_sequences=True)(x)
x = TimeDistributed(Dense(5))(x)
print(f”input2:{inputs.shape}”)
print(f”output2: {x.shape}”)
I have compared two architectures where the first one emulates your code with repeatvector after the first LSTM layer, and a second architecture where I used return_sequences=True and did not use repeatvector layer.
The output shape of each networks are the same.
Going back to my original question, is there a reason why you used RepeatVector layer instead of putting return_sequences=True on the first LSTM layer?
I actually had the same question as Chad. That second article you linked to does the same thing with ‘RepeatVector’ though. It seems like unless we’re using ‘return_sequence’ with the first LSTM layer (instead of using ‘repeatvector’), this example only works when there’s a one-to-one pairing of single value outputs to input sequences. For example, if multiple sequences could lead to a 0.9 value, I don’t see how this could work since the encoder only uses the last frame of the sequence with return_sequence=False. If the only argument for using “RepeatVector” is that we have to do that to make it fit and not throw an error, then why not use return_sequence and not throw away useful information that the encoder presumably would need? Seems like the proper way to do this would be as Chad outlined above (i.e. with return_sequences=True and without simply repeating the last output so it fits).
The output of the encoder is the bottleneck – it is the internal representation of the entire input sequence. We then condition each step of the output on this representation and the the previous generated output step.
couldn’t respond in proper spot in thread, so sorry this is out of order but looking into it some more, I think I see. Is it basically that while the output of the encoder is just one element (doesn’t return the full sequence), that value could be a very precise number that would then correspond to a full sequence, which the decoder half of it would learn? so like two different sequences ending in 0.9 could be encoded as different floats here, like 3.47 and 5.72 (chosen at random for illustrative purposes), for instance? I was experimenting with this a bit on my own, and indeed if I use return_sequence=True, there’s very little memory that actually gets saved in the encoding, which makes it kinda pointless. What I really want to do is encode sequences of images into small vectors, building on to the autencoder examples here: https://blog.keras.io/building-autoencoders-in-keras.html. This has all been very helpful, so thank you
In this post (https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/), state vectors of the decoder network are initialized by the last layer’s states vectors of encoder network, right (lets call it type1)? However, here you only feed the decoder network’s input using the output of encoder network (repeating the output values, lets call it type2). Inıtial states of the decoder network are zeroed (by automatically?), similar to the initial values of the state vectors of the encoder network?
So, What is the difference between these encoder-decoder networks in terms of usage (e..g when to choose type1 over type2)?
Why didn’t you do the network you explained here with type1? or the one In section 9 of your book (you give an example similar to what you are explaining here. The basic calculator.).
The difference in the architecture is exactly as you say, architectural.
I find both approaches are pretty much the same in practice although the repeatvector method is way simpler to implement. This is the approach I recommend and use in my tutorials.
Hi Jason – It’s unclear why both you and Francois Chollet (https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html) fit a training model, but you don’t reuse it (and the associated learned weights) in the inference step. From reading your code, I don’t understand how the fitted model (train variable) is used in the infenc/infdec models, since the train variable is never used/called again.
Dear Dr Jason,
In the exercises which involve the plot_model function
1
from keras.utils import plot_model
That is in order to produce a graphical model *,png file using plot_model, the python interface may throw an error,
For Windows OS users, in order to get the graphical model via a *.png file, you will have to:
* Install GraphViz binaries
* Set the environment path for the GraphViz program, eg: path=c:\program files (x86)\graphviz 2.38\bin; rest of path ;
*In a command window do the following pip
Hi and thank you for great post.
My question is in composite version you have presented, it seems the forecasting is working independent from construction layers. How can I make a change first reconstruct the input sequence then forecast layers take the extracted features and does forecasting? Can I simply first fit decoder1 then take the output of encoder as input of decoder2 and forecast? I don’t wand to save reconstruction phase.
Thank you
It really depends on the specifics of the model and the data. I recommend controlled experiments in order to discover what works best for your specific dataset.
Let me rephrase my question. I’m not sure whether the input of the forecasting part is extracted features or raw inputs! If, row inputs, how can I use extracted features as input of decoder2?
Thank you
“Regardless of the method chosen (reconstruction, prediction, or composite), once the autoencoder has been fit, the decoder can be removed and the encoder can be kept as a standalone model.”
I have used the same algorithm mentioned here for sequence reconstruction.
But i have a total of 1 sample, 2205 time steps and 1 feature.
I am getting the reconstructed value as ‘Nan’ while using ‘relu’ activation function.
Instead of ‘relu’, if i am using ‘tanh’, the reconstruction works fine without Nan but i am getting the same reconstructed values which is also considered as an error.
Kindly help me to get the correct reconstruction values.
I have tried scaling my data by a technique called Normalization. Now i am not getting Nan errors but the reconstructed values are same which is an error. If i am feeding a total of 10 values to the lstm auto encoder with relu activation function, reconstructions works very fine.
In my case , i need to feed the whole 2205 time steps. What can i do for getting the correct reconstruction. Kindly waiting for your reply.
I split my data (2205 time steps) in to 147 different arrays. Each array now contains 15 elements. So 147*15 = 2205.
Now i am able to input only one array at a time to the model (sequence reconstruction).
How to input this 147 arrays (each array contains 15 elements) at a time to the above mentioned model ( Sequence reconstruction) so that i would get the 147 reconstructed arrays at a time.
Nice and super easy to read the article explaining LSTM autoencoder.
I have a clarification regarding autoencoders being self-supervised. The task of an autoencoder is to learn the compressed representation. The task does not use any kind of label and so is completely unsupervised as opposed to self-supervised.
If the task of the autoencoder were to learn to recreate the image then you could call it self-supervised as you provide a created a label(the same image itself) where non existed.
So I feel that the statement regarding autoencoder being self-supervised is not entirely correct.
I’m trying something different as a part of Master’s research.
I’m working on predicting hourly traffic for individual bike stations (like lime bike or citibike).
So I have this data which has start point and end point entry and the time. I convert this into a timeseries for each station based on hourly number of traffic at the station.
My goal with AE-LSTM is to use all the stations hourly data like an RBM or AE-LSTM where the model predicts next hour’s traffic for all stations. (So it takes in account neighbouring station’s previous hour data and current stations last 24 hour timesteps traffic data)
Now I tried to use the model from this tutorial but I’m stuck with an error –
“ValueError: Error when checking target: expected time_distributed_5 to have 3 dimensions, but got array with shape (11221, 175)”
My input data shape is (11221, 23, 175) and my output should be something like (11221, 175).
The last LSTM layer generates the output size but due to the TimeDistributed layer I get an error.
Any thoughts you may have would be really helpful.
That did not work for some reason but after reading articles on TimeDistributedDense, I think TimeDistributedDense is more important in OneToMany and ManyToMany (predicting multiple time steps).
So I tried with just stacked LSTM layers and a final dense layer it works but I’m not sure if this method will give me good results.
I’m not sure about RepeatVector layer as to what is actually does but I did not include in the only LSTM and Dense Architecture.
I am figuring out “prediction autoencoder LSTM.” I am wondering which part is the prediction because the input is [1 2 3 …9] and output is [ around 2 around 3 … around 9]. I am interested in the value after 9 but this system doesn’t show the result. So it looks like just reconstruction.
So, I would appreciate it if you would let me know which part is the prediction part in this system.
Thank you for your reply.
But, I may have to ask again more specifically.
So, in your example, your input sequence is
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] and output sequence is
[0.1657285 0.28903174 0.40304852 0.5096578 0.6104322 0.70671254 0.7997272 0.8904342 ].
According to your answer, if 0.1657286 is the prediction after input 0.1, what is the prediction after the input 0.9?
Because the last output is 0.8904342 which is the prediction after 0.8, I don’t see the prediction after the input 0.9.
Hi Dr. Jason
Thank you very much for this great article.
I will be very thankful if you guide me about this issue.
In this valuable article, the input is an array with nine elements. I have an array of pre-traind embedding vectors. I guess that in this case, the final output of encoder layer is an array of N 100 dimension vector elements(N is the length of input array). If it is correct, how can I aggregate the input array to a single vector?
I read your another grate article { How to Develop an Encoder-Decoder Model with Attention in Keras}
In more detail, my question Is: when the input array includes embedding vectors, how we can use this architecture(encoder-decoder) to summarize input to one single representation vector.
I will be very thankful if you guide me about this issue.
If you use an embedding before an encoder, then the vector output from the embedding layer for each time step is one time step input for the LSTM layer of the encoder.
In the above examples, you learn from only 10 array sequences input. Does LSTM autoencoder actually learn anything from such a small sample size? I am assuming since it is a deep learning method, the data size should be large? Please correct me if I am wrong.
So the above example has 100 encoding dimensions aka size of the vector encoding (z)? Is it possible to reduce them to 10 with a stacked LSTM layer added before and after the vector encoding? If yes, the command would like this?
what i understand is, by using time-distributed in dense layer, the input from previous LSTM layer for each sequence(sequence =True) executed one by one. If we not using time-distributed, the sequence from LSTM will be grouped in 1 vector and push to dense layer in one time.
Even the process slightly different, but the result should be the same right? i mean both using the same /share weight from that dense layer. So i still confuse why we need the time-distributed, in this case, I mean what’s the advantage if we are not use that.
Hi, thank you so much for such a quality blog, it’s not so common nowadays. I have a question on AE/LSTM-VAE explainability. Is it possible to understand which input variables are most relevant for the embedding? Is it even possible to do something similar to PCA loadings for each dimension of the latent space?
Thanks a lot
Hi Jason,
thanks for this great tutorial. I’m new to ML and I’m still a bit confused about the shape of the input sequence and the corresponding reshaped output.
When you define the input sequence as one sample with 9 timesteps and one feature by sequence = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) the corresponding reshaped output will look like this:
[[[0.1]
[0.2]
[0.3]
[0.4]
[0.5]
[0.6]
[0.7]
[0.8]
[0.9]]]
Could you give an example of how the input and reshaped output sequence would look like for 2 samples, nine timesteps and 3 features.
Thanks for your help!
Regards,
Sascha
Hi Jason, thanks for the informative articles as always. I’m confused about something, where is the bottleneck layer? There are two layers with 100 neurons, I thought there would be a layer in between those two with, say, 50 neurons? Or as many neurons as we want the lower dimensional representation to have
I would like to share my experience on the above code.
I copied the above reconstruction LSTM autoencoder for my one day water temperature, which is (96, 1). Now when I run for fist time the loss is much less and the reconstruction is pretty good. But when, I try to retrain again, loss increases and the reconstruction is not at all good.
Could you help me here how I could fix this issue, and why such issue is coming up.
Thanks Tam, the link was indeed helpful to fix the issue.
I have a next question, which I am not sure how to solve it.
With the same reconstruction LSTM autoencoder design,
I have channel first or # features as input but I want single channel output
“sequence = sequence.reshape((num_samples, num_features, n_in))”
I want out output to be single channel
yhat.shape –> (1, 1, n_in)
You are of great help to my machine learning projects thanks to your blog!
My question;
Can a Kullback-Leibler divergence loss – as in variational autoencoders – be added to the bottleneck of the lstm autoencoder to disentangle the latent variables?
Or does one then need a specialised temporal disentangling term in the case of the lstm autoencoder?
I don’t see LSTM always do it very accurately. You need to experiment and confirm whether you problem and dataset do well with LSTM (or a particular configuration of LSTM). If it does not, maybe you can add some tricks like you said.
I think RepeatedVector() confuses people (include me) because it represents a different architecture than the one shown in the first picture “LSTM Autoencoder Model”. The new architecture should have the edge under “copy” in the picture re-directed pointing to the input at each time step in the decoder. Let me know if I understand it correctly.
I used LSTM Autoencoder for extracting features. And then the classifier that used the extracted features gives less performance than the performance of the same classifier when it was run without the extracted features.
Any explanation for such a case?
Autoencoder is an unsupervised method because you don’t know the class while you encode it. If the autoencoder output suddenly make your “feature” and “class” relationship non-linear (which is possible because autoencoder is a lossy compression), you will see your classifier worse.
Do you mean If I change the output layer of autoencoder to be with linear activation function, would avoid the non-linear relationship?
I tried it and the performance increased a little bit but still less than the classifier that the one without using extraction features.
No. To remove nonlinear relationship entirely, you need to make sure every activation function in each part of the network are linear. But that would make your neural network model handicapped.
If I have multiple time-series (for example, several different sensors recorded at the same time), can I input a time-window of them to a LSTM Autoencoder so that the AT can learn both cross-correlation between them as well as time correlation ?
Will the reconstructed sequence be a result of the cross-correlation also ? Or, instead the AE will output the multiple time-series where each of them will be reconstructed independently from each other.
Hi Jason,
Great posts!
Maybe you can clarify some doubts about the latent space of the standalone autoencoders;
In case of having an input sequence divided in 7 samples, of 200 timesteps each (for example), the latent space generated by the autoencoder will not be a single fixed length encoded vector, but a sequence with as many vectors as the number of samples,
that is to say, each sample will have a different encoded vector. How can I do to obtain a single vector that models all the samples?
I have tried with a stateful LSTM, but the resulting latent space is still a sequence of vectors, so I am not sure if the last vector of this sequence contains the information of all the samples or only the last one.
Hi Jason, thank you for your sharing. It helps me a lot.
I have a question on LSTM Autoencoder, but I cannot find any explanation:
why do we repeat the hidden representation vector for t times and see it as the input of the decoder rather than use the output sequence of the LSTM encoder directly?
Hello James
Thank you for this great tutorial,
I am using AutoEncoder to detect anomalies, and my dataset is a numerical dataset that has ten columns (including the target label),
I don’t know what numbers to choose for the first argument in the encoder and decoder because all the examples I saw are images.
My code:
Hello James,
Thank you for your useful knowledge, I got an error when I reshape the input for the LSTM, can you advise me why i got this error and how to solve it.
# Reshape the input to shape (num_instances, timesteps, num_features)
train_data = train_data.reshape(train_data.shape[0], 1, train_data.shape[1])
Here is the error I got:
InvalidArgumentError: {{function_node __wrapped__Reshape_device_/job:localhost/replica:0/task:0/device:CPU:0}} Input to reshape is a tensor with 114581670 values, but the requested shape has 11458167 [Op:Reshape]
Really appreciate your hard work and the tutorials are great. I have learned a lot.
I was expecting that the LSTM with 2 decoders can outerperform the LSTM with 1 decoder (for prediction), which is oppostite to the results presented above.
I would like to know if you have some explanations for this
Hi Yiqun…When you observe that an LSTM model with one decoder outperforms one with two decoders, especially in a prediction task, there could be several explanations for this unexpected result. Understanding the dynamics of LSTM architectures and the specific setup of your decoders will help in identifying potential reasons. Here are some factors to consider:
### 1. **Model Complexity vs. Dataset Size**
– **Overfitting**: Adding more complexity (e.g., an additional decoder) to the model can lead to overfitting, especially if your dataset is not large enough to justify the extra complexity. Overfitting occurs when a model learns the details and noise in the training data to an extent that it negatively impacts the performance of the model on new data, making the simpler model (with one decoder) potentially more generalizable.
### 2. **Decoder Configuration**
– **Decoder Functionality**: The role and configuration of each decoder in the two-decoder setup are crucial. If the decoders are not properly aligned with distinct aspects of the prediction task or if they interfere with each other (e.g., redundant or conflicting outputs), the model’s performance can degrade.
– **Weight Sharing**: If the decoders share weights or if their training is not well-coordinated (e.g., through attention mechanisms or other forms of output regularization), this might also impact performance adversely.
### 3. **Data Representation and Sequence Learning**
– **Input Sequence Processing**: The way sequences are processed and fed into the LSTM and subsequently into the decoders can significantly influence performance. If the sequence representation or feature extraction is inadequate, adding more decoders won’t necessarily help.
– **Handling of Temporal Dependencies**: One decoder might be more effective at capturing the long-term dependencies required for the prediction task, whereas adding another decoder might lead to a dilution of these dependencies if not managed correctly.
### 4. **Learning Dynamics**
– **Gradient Flow and Learning Stability**: In networks with multiple decoders, especially in deep learning architectures like LSTMs, the flow of gradients during backpropagation can become unstable or inefficient (a problem often referred to as the vanishing or exploding gradient problem). This can make learning less effective compared to a simpler, single-decoder model.
– **Training Procedure**: The training dynamics, including learning rates, batch sizes, and epochs, might need different optimization when moving from one to two decoders. The configuration that worked for a single decoder might not be optimal for a more complex model.
### 5. **Evaluation Metrics and Model Tuning**
– **Metrics Sensitivity**: The evaluation metrics used to assess model performance can sometimes favor simpler models, depending on the task complexity and data characteristics. It’s essential to ensure that the metrics align well with the practical outcomes you expect from the model.
– **Hyperparameter Tuning**: The hyperparameters for the dual-decoder model may need more extensive tuning compared to the single-decoder model. This includes the number of LSTM units, the type of decoders, and their integration method.
### Suggested Steps to Improve the Dual-Decoder Model
– **Hyperparameter Optimization**: Review and optimize the hyperparameters for the two-decoder setup extensively.
– **Regularization Techniques**: Implement regularization strategies such as dropout, L2 regularization, or early stopping to prevent overfitting.
– **Advanced Architectural Features**: Consider integrating attention mechanisms that help the model focus on relevant parts of the input sequence, improving the synergy between the two decoders.
– **Cross-validation**: Use k-fold cross-validation to ensure the robustness of your model’s evaluation across different subsets of your dataset.
By considering these factors and experimenting with different configurations and training settings, you can better understand why your simpler model might currently be outperforming the more complex one and identify potential improvements.
Hello James,
Thank you for your useful knowledge, I was using the LSTM autoencoder for my time-series anomaly detection on AIOPS. I have a doubt when applying the LSTM AE. Let’s say I’m monitoring CPU usage metrics for different machines, for each machine, do I need to build an AE model and train the model only using the CPU usage metrics from that specific machine? Or I can train one AE model using all the CPU usage metrics data I have? This also leads to another question, what if I have other metrics for example, memory usage, do I need to train a new model for different metrics?
I would like to know if you have some recommendation or strategy for this
Hi Wanyi…Great question! When applying LSTM Autoencoders (AEs) for time-series anomaly detection in AIOps, the strategy for model training depends on the nature of your data, the relationships between the metrics, and the scale at which anomalies need to be detected. Here’s a breakdown of the options and recommendations:
—
### **1. Train an Autoencoder for Each Machine Separately**
– **Use case**: When machines exhibit unique behavior patterns and there is little similarity between their CPU usage time-series data.
– **Advantages**:
– The model can better learn the specific patterns and nuances of each machine.
– Anomalies are easier to detect because the model focuses on each machine’s baseline behavior.
– **Disadvantages**:
– High computational cost, as you’ll need to train and maintain a separate model for each machine.
– Does not leverage shared patterns across machines.
—
### **2. Train a Single Autoencoder for All Machines**
– **Use case**: When machines have similar behavior or share general patterns in their CPU usage metrics.
– **Advantages**:
– Lower computational cost, as only one model is needed.
– The model can generalize well across machines if their behavior is consistent.
– **Disadvantages**:
– Anomalies specific to individual machines might be harder to detect due to the model’s generalized view.
**Recommendation**:
– Start by normalizing the CPU usage metrics for each machine (e.g., z-score normalization or min-max scaling) to account for differences in scale.
– Use machine identifiers as part of your feature set if there are subtle variations between machines that you want the model to learn.
—
### **3. Train Separate Models for Each Metric (e.g., CPU and Memory Usage)**
– **Use case**: When different metrics (e.g., CPU and memory usage) exhibit significantly different patterns and relationships.
– **Advantages**:
– Each model can specialize in learning the patterns of a single metric.
– **Disadvantages**:
– You’ll need multiple models if monitoring several metrics, increasing computational complexity.
—
### **4. Train a Multi-Metric Autoencoder**
– **Use case**: When you have multiple metrics for the same machine (e.g., CPU, memory, disk I/O) and there are relationships between these metrics.
– **Advantages**:
– The autoencoder learns both individual patterns and correlations between metrics, potentially providing better anomaly detection.
– Detects anomalies that span across multiple metrics (e.g., unusual correlation between CPU and memory usage).
– **Disadvantages**:
– Requires more sophisticated preprocessing and feature engineering.
– May need more training data to capture the relationships effectively.
**How to Implement**:
– Combine metrics into a single input vector (e.g., concatenate CPU, memory, and disk metrics).
– Normalize each metric independently before feeding it into the model.
– Use a multi-variate LSTM AE architecture.
—
### **Strategies and Recommendations**
1. **Start Simple**:
– If you have a small dataset or are new to anomaly detection, train a single AE model per metric, per machine. This is easier to debug and interpret.
2. **Experiment with Generalization**:
– If machines share similar behavior, try training a single AE model using data from all machines, ensuring metrics are normalized.
3. **Use Multi-Metric Models for Correlated Metrics**:
– For example, train a multi-variate LSTM AE that takes CPU, memory, and disk usage together as input. This can capture inter-metric anomalies.
4. **Data Preprocessing**:
– Always normalize the data to handle scale differences between machines or metrics.
– Consider using sliding windows to convert time-series data into sequences for the LSTM.
5. **Validation and Monitoring**:
– Use a validation set to ensure the model generalizes well to unseen data.
– Regularly monitor the model’s performance using a threshold on reconstruction error, and adjust the threshold as needed.
—
### **When to Retrain the Model**
– If the behavior of a machine or metric changes significantly over time (e.g., hardware upgrades or software changes), you may need to retrain the model to adapt to the new baseline.
—
### **Advanced Recommendations**
– **Transfer Learning**: Train a generic model on data from all machines, then fine-tune it on data from specific machines if needed.
– **Clustering Machines**: Group machines with similar behavior patterns (using clustering methods like K-Means) and train one model per cluster.
– **Anomaly Aggregation**: If using separate models for machines or metrics, aggregate anomaly scores across models to detect overall system anomalies.
—
By combining these strategies, you can design an efficient and scalable anomaly detection system tailored to your AIOps needs.

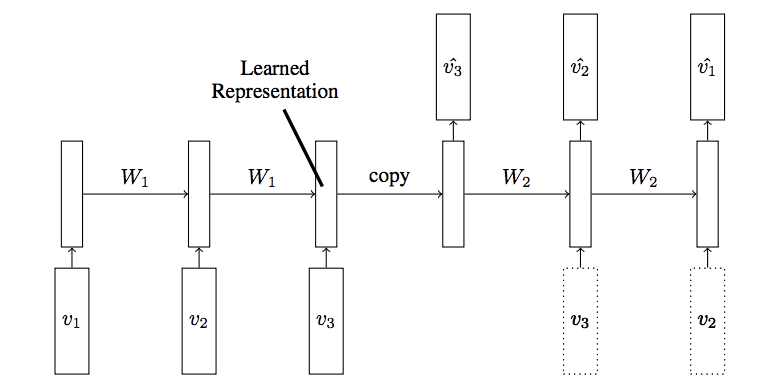
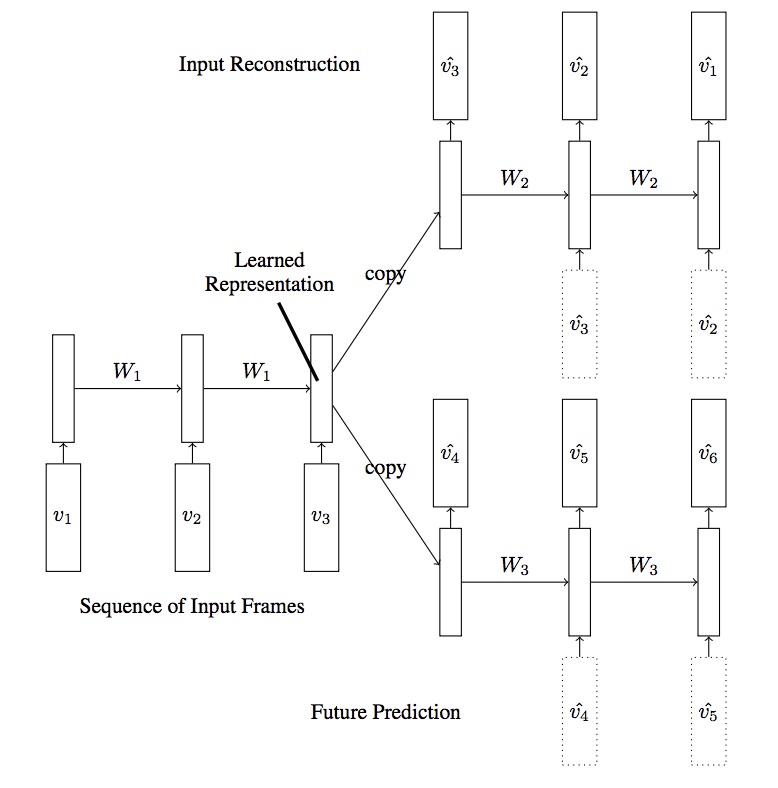
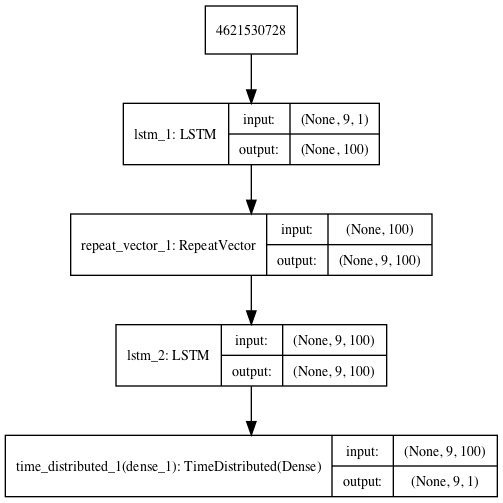
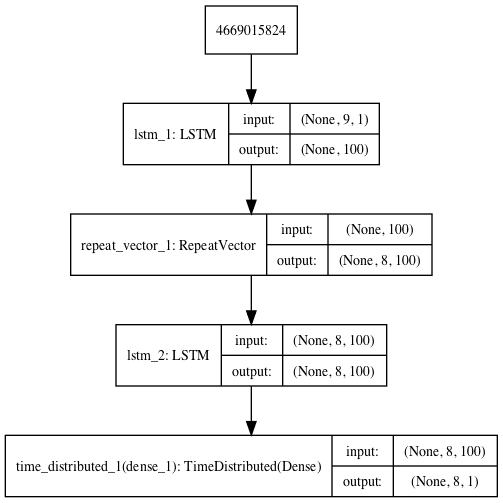
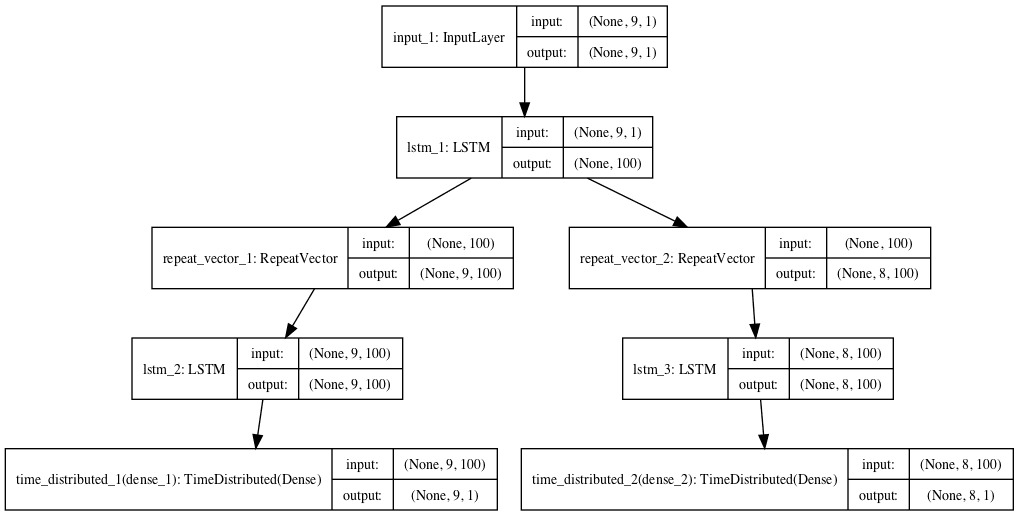







Nice Explained……….
Thanks.
i am trying to apply auto encoders on my unlabelled text data columns to compress the data size can you please provide the resources for it
Hi Sai…The following resource is a great starting point for your query:
https://machinelearningmastery.com/implementing-the-transformer-encoder-from-scratch-in-tensorflow-and-keras/
Very Good and Detailed representation of LSTM.
I have a csv file which contains 3000 values, when i run it in Google colab or jupyter notebook it was much slow What may be the reason?
Thanks.
Perhaps try running on a faster machine, like EC2?
Perhaps try using a more efficient implementation?
Perhaps try using less training data?
Thanks for the great posts! I have learn a lot from them.
Can this approach for classification problems such as sentiment analysis?
Perhaps.
Hi Jason,
Thanks for the posts, I really enjoy reading this.
I’m trying to use this method to do time series data anomaly detection and I got few questions here:
When you reshape the sequence into [samples, timesteps, features], samples and features always equal to 1. What is the guidance to choose the value here? If the input sequences have variable length, how to set timesteps, always choose max length?
Also, if the input is two dimension tabular data with each row has different length, how will you do the reshape or normalization?
Thanks in advance!
The time steps should provide enough history to make a prediction, the features are the observations recorded at each time step.
More on preparing data for LSTMs here:
https://machinelearningmastery.com/faq/single-faq/how-do-i-prepare-my-data-for-an-lstm
Hi,
I am wondering why the output of encoder has a much higher dimension(100), since we usually use encoders to create lower dimensions!
Could you please bring examples if I am wrong?
And what about variable length of samples? You keep saying that LSTM is useful for variable length. So how does it deal with a training set like:
dataX[0] = [1,2,3,4]
dataX[1] = [2,5,7,8,4]
dataX[2] = [0,3]
I am really confused with my second question and I’d be very thankful for your help! 🙂
The model reproduces the output, e.g. a 1D vector with 9 elements.
You can pad the variable length inputs with 0 and use a masking layer to ignore the padded values.
“I am wondering why the output of encoder has a much higher dimension(100), since we usually use encoders to create lower dimensions!”, I have the same question, can you please explain more?
It is a demonstration of the architecture only, feel free to change the model configuration for your specific problem.
Hello,I wonder how to add a layer in the encoder,just add a layer called LSTM?Thank you very much
You can stack LSTM layers directly, this tutorial gives an example:
https://machinelearningmastery.com/stacked-long-short-term-memory-networks/
Great article. But reading through it I thought you were tackling the most important problem with sequences – that is they have variable lengths. Turns out it wasn’t. Any chance you could write a tutorial on using a mask to neutralise the padded value? This seems to be more difficult than the rest of the model.
Yes, I believe I have many tutorials on the topic.
Perhaps start here:
https://machinelearningmastery.com/handle-missing-timesteps-sequence-prediction-problems-python/
I really likes your posts and they are important.I got a lot of knowledge from your post.
Today, am going to ask your help. I am doing research on local music classifications. the key features of the music is it sequence and it uses five keys out of the seven keys, we call it scale.
1. C – E – F – G – B. This is a major 3rd, minor 2nd, major 2nd, major 3rd, and minor 2nd
2. C – Db – F – G – Ab. This is a minor 2nd, major 3rd, major 2nd, minor 2nd, and major 3rd.
3. C – Db – F – Gb – A. This is a minor 2nd, major 3rd, minor 2nd, minor 3rd, and a minor 3rd.
4. C – D – E – G – A. This is a major 2nd, major 2nd, minor 3rd, major 2nd, and a minor 3rd
it is not dependent on range, rythm, melody and other features.
This key has to be in order. Otherwise it will be out of scale.
So, which tools /algorithm do i need to use for my research purpose and also any sampling mechanism to take 30 sec sample music from each track without affecting the sequence of the keys ?
Regards
Perhaps try a suite of models and discover what works best for your specific dataset.
More here:
https://machinelearningmastery.com/faq/single-faq/what-algorithm-config-should-i-use
Hi, can you please explain the use of repeat vector between encoder and decoder?
Encoder is encoding 1-feature time-series into fixed length 100 vector. In my understanding, decoder should take this 100-length vector and transform it into 1-feature time-series.
So, encoder is like many-to-one lstm, and decoder is one-to-many (even though that ‘one’ is a vector of length 100). Is this understanding correct?
The RepeatVector repeats the internal representation of the input n times for the number of required output steps.
Hi Jason?
What is the intuition behind “representing of the input n times for the number of required output steps?”Here n times denotes, let say as in simple LSTM AE, 9 i.e. output step number.
I understand from repeatvector that here sequence are being read and transformed into a single vector(9×100) which is the same 100 dim vector, then the model uses that vector to reconstruct the original sequence.Is it right?
What about using any number except for 9 for the number of required output steps?
Thanks from now on.
To provide input for the LSTM on each output time step for one sample.
Which model is most suited for stock market prediction
None, a time series of prices is a random walk as far as I’ve read.
More here:
https://machinelearningmastery.com/faq/single-faq/can-you-help-me-with-machine-learning-for-finance-or-the-stock-market
Hi,
thanks for the instructive post!
I am trying to repeat your first example (Reconstruction LSTM Autoencoder) using a different syntax of Keras; here is the code:
import numpy as np
from keras.layers import Input, LSTM, RepeatVector
from keras.models import Model
timesteps = 9
input_dim = 1
latent_dim = 100
# input placeholder
inputs = Input(shape=(timesteps, input_dim))
# “encoded” is the encoded representation of the input
encoded = LSTM(latent_dim,activation=’relu’)(inputs)
# “decoded” is the lossy reconstruction of the input
decoded = RepeatVector(timesteps)(encoded)
decoded = LSTM(input_dim, activation=’relu’, return_sequences=True)(decoded)
sequence_autoencoder = Model(inputs, decoded)
encoder = Model(inputs, encoded)
# compile model
sequence_autoencoder.compile(optimizer=’adadelta’, loss=’mse’)
# run model
sequence_autoencoder.fit(sequence,sequence,epochs=300, verbose=0)
# prediction
sequence_autoencoder.predict(sequence,verbose=0)
I did not know why, but I always get a poor result than the model using your code.
So my question is: is there any difference between the two method (syntax) under the hood? or they are actually the same ?
Thanks.
If you have trouble with the code in the tutorial, confirm that your version of Keras is 2.2.4 or higher and TensorFlow is up to date.
I feel like a bit more description could go into how to setup the LSTM autoencoder. Particularly how to tune the bottleneck. Right now when I apply this to my data its basically just returning the mean for everything, which suggests the its too aggressive but I’m not clear on where to change things.
Thanks for the suggestion.
Hi Jason, thanks for the wonderful article, I took some time and wrote a kernel on Kaggle inspired by your content, showing regular time-series approach using LSTM and another one using a MLP but with features encoded by and LSTM autoencoder, as shown here, for anyone interested here’s the link: https://www.kaggle.com/dimitreoliveira/time-series-forecasting-with-lstm-autoencoders
I would love some feedback.
Well done!
Hey! I am trying to compact the data single row of 217 rows. After running the program it is returning nan values for prediction Can you guide me where did i do wrong?
I have some advice here:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Dear Jason
After building and training the model above, how to evaluate the model? (like model.evaluate(train_x, train_y…) in common LSTM)?
Thanks a lot
The model is evaluated by its ability to reconstruct the input. You can use evaluate function or perform the evaluation of the predictions manually.
I have learned a lot from your website. Autoencoder can be used as dimension reduction. Is it possible to merge multiple time-series inputs into one using RNN autoencoder? My data shape is (9500, 20, 5) => (sample size, time steps, features). How to encode-decode into (9500, 20, 1)?
Thank you very much,
Perhaps, that may require some careful design. It might be easier to combine all data to a single input.
Thank you for your reply. Will (9500,100,1) => (9500,20,1) be easier?
Perhaps test it and see.
Hi Jason,
I’m a regular reader of your website, I learned a lot from your posts and books!
This one is also very informative, but there’s one thing I can’t fully understand: if the encoder input is [0.1, 0.2, …, 0.9] and the expected decoder output is [0.2, 0.3, …, 0.9], that’s basically a part of the input sequence. I’m not sure why you say it’s “predicting next step for each input step”. Could you please explain? Is an autoencoder a good fit for multi-step time series prediction?
Another question: does training the composite autoencoder imply that the error is averaged for both expected outputs ([seq_in, seq_out])?
I am demonstrating two ways to learn the encoding, by reproducing the input and by predicting the next step in the output.
Remember, the model outputs a single step at a time in order to construct a sequence.
Good question, I assume the reported error is averaged over both outputs. I’m not sure.
Hi Jason,
Could you please elaborate a bit more on the first question 🙂
as Jimmy pointed out I can’t really understand where you predict the next step in the output.
If for example we had as input [0.1, 0.2, …, 0.8] and as output [0.2, 0.3, …, 0.9] that would make sense for me.
But since we already provide the “next time step” as the input what are we actually learning ?
Hi Nick…The following may be of interest to you:
This is a deep question.
From a high-level, algorithms learn by generalizing from many historical examples, For example:
Inputs like this are usually come before outputs like that.
The generalization, e.g. the learned model, can then be used on new examples in the future to predict what is expected to happen or what the expected output will be.
Technically, we refer to this as induction or inductive decision making.
https://en.wikipedia.org/wiki/Inductive_reasoning
Also see this post:
Why Do Machine Learning Algorithms Work on Data That They Have Not Seen Before?
https://machinelearningmastery.com/what-is-generalization-in-machine-learning/
Hi, I am JT.
First of all, thanks for your post that provides an excellent explanation of the concept of LSTM AE models and codes.
If I understand your AE model correclty, features from your LSTM AE vector layer [shape (,100)] does not seem to be time dependent.
So, I have tried to build a time-dependent AE layer by modifying your codes.
Could you check my codes whether my codes are correct to build an AE model that incpude a time-wise AE layer, if you don’t mind?
My codes are below.
from numpy import array
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
## Data generation
# define input sequence
seq_in = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
# reshape input into [samples, timesteps, features]
n_in = len(seq_in)
seq_in = seq_in.reshape((1, n_in, 1))
# prepare output sequence
seq_out = array([3, 5, 7, 9, 11, 13, 15, 17, 19])
seq_out = seq_out.reshape((1, n_in, 1))
## Model specification
# define encoder
visible = Input(shape=(n_in,1))
encoder = LSTM(60, activation=’relu’, return_sequences=True)(visible)
# AE Vector
AEV = LSTM(30, activation=’relu’, return_sequences=True)(encoder)
# define reconstruct decoder
decoder1 = LSTM(60, activation=’relu’, return_sequences=True)(AEV)
decoder1 = TimeDistributed(Dense(1))(decoder1)
# define predict decoder
decoder2 = LSTM(30, activation=’relu’, return_sequences=True)(AEV)
decoder2 = TimeDistributed(Dense(1))(decoder2)
# tie it together
model = Model(inputs=visible, outputs=[decoder1, decoder2])
model.summary()
model.compile(optimizer=’adam’, loss=’mse’)
# fit model
model.fit(seq_in, [seq_in,seq_out], epochs=2000, verbose=2)
## The model that feeds seq_in to predict seq_out
hat1= model.predict(seq_in)
## The model that feeds seq_in to predict AE Vector values
model2 = Model(inputs=model.inputs, outputs=model.layers[2].output)
hat_ae= model2.predict(seq_in)
## The model that feeds AE Vector values to predict seq_out
input_vec = Input(shape=(n_in,30))
dec2 = model.layers[4](input_vec)
dec2 = model.layers[6](dec2)
model3 = Model(inputs=input_vec, outputs=dec2)
hat_= model3.predict(hat_ae)
Thank you very much
I’m happy to answer questions, but I don’t have the capacity to review and debug your code, sorry.
Thanks for the nice post. Being a beginner in machine learning, your posts are really helpful.
I want to build an auto-encoder for data-set of names of a large number of people. I want to encode the entire field instead of doing it character or wise, for example [“Neil Armstrong”] instead of [“N”, “e”, “i”, “l”, ” “, “A”, “r”, “m”, “s”, “t”, “r”, “o”, “n”, “g”] or [“Neil”, “Armstrong”]. How can I do it?
Wrap your list of strings in one more list/array.
Hey, thanks for the post, I have found it helpful… Although I am confused about one, in my opinion, major point..
– If autoencoders are used to obtain a compressed representation of the input, what is the purpose of taking the output after the encoder part if it is now 100 elements instead of 9? I’m struggling to find a meaning of the 100 element data and how one could use this 100 element data to predict anomalies. It sort of seems like doing the exact opposite of what was stated in the explanation prior to the example. An explanation would be greatly appreciated.
– In the end I’m trying to really understand how after learning the weights by minimizing the reconstruction error of the training set using the AE, how to then use this trained model to predict anomalies in the cross validation and test sets.
–
It is just a demonstration, perhaps I could have given a better example.
For example, you could scale up the input to be 1,000 inputs that is summarized with 10 or 100 values.
Hi Jason, Benjamin is right. The last example you provided for using standalone LSTM encoder. The input sequence is 9 elements but the output of the encoder is 100 elements despite explaining in the first part of the tutorial that encoder part compresses the input sequence and can be used as a feature vector. I am also confused about how the output of 100 elements can be used as a feature representation of 9 elements of the input sequence. A more detail explanation will help. Thank you!
Thanks for the suggestion.
Thank your great post.
As you mentioned in the first section, “Once fit, the encoder part of the model can be used to encode or compress sequence data that in turn may be used as a feature vector input to a supervised learning model”. I fed the feature vector (encode part) to 1 feedforward neural network 1 hidden layer:
n_dimensions=50
Error when fit(): ValueError: Error when checking input: expected input_1 to have 3 dimensions, but got array with shape (789545, 50).
I mix Autoencoder to FFNN and is my method, right? Can you help me shape the feature vector before fed to FFNN
Change the LSTM to not return sequences in the decoder.
Thank for your reply soon.
I saw your post, LSTM layer at the decoder is set “return_sequences=True” and I follow and then error as you saw. Actually, I thought the decoder is not a stacked LSTM (only 1 LSTM layer), so “return_sequences=False” is suitable. I changed as you recommend. Another error:
decoded = TimeDistributed(Dense(features_n))(decoded)
File “/usr/local/lib/python3.4/dist-packages/keras/engine/topology.py”, line 592, in __call__
self.build(input_shapes[0])
File “/usr/local/lib/python3.4/dist-packages/keras/layers/wrappers.py”, line 164, in build
assert len(input_shape) >= 3
AssertionError.
Can you give me an advice?
Thank you
I’m not sure about this error, sorry. Perhaps post code and error to stackoveflow or try debugging?
Hi Jason,
I found another way to build full_model. I don’t use autoencoder.predict(train_x) to input to full_model. I used orginal inputs, saved weights of the encoder part in autoencoder model, then set that weights to encoder model. Something like this:
autoencoder.save_weights(‘autoencoder.h5′)
for l1,l2 in zip(full_model.layers[:a],autoencoder.layers[0:a]): #a:the num_layer in the encoder part
l1.set_weights(l2.get_weights())
train full_model:
full_model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history_class=full_model.fit(train_x, train_y, epochs=2, batch_size=256, validation_data=(val_x, val_y))
My full_model run, but the result so bad. Hic, train 0%, test/val: 100%
Interesting, sounds like more debugging might be required.
Hi Jason,
Thank you for putting in the effort of writing the posts, they are very helpful.
Is it possible to learn representations of multiple time series at the same time? By multiple time-series I don’t mean multivariate.
For eg., if I have time series data from 10 sensors, how can I feed them simultaneously to obtain 10 representations, not a combined one.
Best,
Anshuman
Yes, each series would be a different sample used to train one model.
Hi Jason,
I use MinMaxScaler function to normalize my training and testing data.
After that I did some training process to get model.h5 file.
And then I use this file to predict my testing data.
After that I got some prediction results with range (0,1).
I reverse my original data using inverse_transform function from MinMaxScaler.
But, when I compare my original data (before scaler) with my predictions data, the x,y coordinates are changed like this:
Ori_data = [7.6291,112.74,43.232,96.636,61.033,87.311,91.55,115.28,121.22,136.48,119.52,80.53,172.08,77.987,199.21,94.94,228.03,110.2,117.83,104.26,174.62,103.42,211.92,109.35,204.29,122.91,114.44,125.46,168.69,124.61,194.97,134.78,173.77,141.56,104.26,144.11,125.46,166.99,143.26,185.64,165.3,205.14]
Predicted_data = [94.290375, 220.07372, 112.91617, 177.89548, 133.5322, 149.65489,
161.85602, 99.74797, 178.18903, 60.718987, 86.012276, 113.3682,
111.641655, 90.18026, 134.16464, 82.28861, 155.12575, 78.26058,
99.82883, 145.162, 98.78825, 98.62861, 130.25414, 62.43494,
143.52762, 74.574684, 99.36809, 169.79303, 107.395615, 131.40468,
124.29078, 114.974014, 135.11014, 107.4492, 90.64477, 188.39305,
121.55309, 174.63484, 138.58575, 167.6933, 144.91512, 162.34071]
When I visualize these predictions data on my image, the direction is 90 degree changing (i.e Original data is horizontal but predictions data is vertical).
Why I face this and how can I fix that?
You must ensure that the columns match when calling transform() and inverse_transform().
See this tutorial:
https://machinelearningmastery.com/machine-learning-data-transforms-for-time-series-forecasting/
Hi Jason,
Thank you so much for your great post. I wish you have done this with a real data set like 20 newsgroup data set.
It is at first not clear the different ways of preparing the data for different objectives.
My understanding is that with LSTM Autoencoder we can prepare data in different ways based on the goal. Am I correct?
Or can you please give me the link which is preparing the text data like 20 news_group for this kind of model?
Again thanks for your awesome material
If you are working with text data, perhaps start here:
https://machinelearningmastery.com/start-here/#nlp
Thank you so much Jason for the link. I have already gone through lots of material, in detail the mini corse in the mentioned link months ago.
My problem mainly is the label data here.
For example, in your code, in the reconstruction part, you have given sequence for both data and label. however, in the prediction part you have given the seq_in, seq_out as the data and the label, and their difference is that seq_out looking at one timestamp forward.
My question according to your example will be if I want to use this LSTM autoencoder for the purpose of topic modeling, Do I need to follow the reconstruction part as I don’t need any prediction?
I think I got my answer. Thanks Jason 🙂
No. Perhaps this model would be more useful as a starting point:
https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/
Based on different objectives I meant, for example if we use this architecture for topic modeling, or sequence generation, or … is preparing the data should be different?
Thanks for your post! When you use RepeatVectors(), I guess you are using the unconditional decoder, am I right?
I guess so. Are you referring to a specific model in comparison?
Thanks for the post. Can this be formulated as a sequence prediction research problem
The demonstration is a sequence prediction problem.
Hi Jason,
what a fantastic tutorial!
I have a question about the loss function used in the composite model.
Say you have different loss functions for the reconstruction and the prediction/classification parts, and pre-trains the reconstruction part.
In Keras, would it be possible to combine these two loss functions into one when training the model,
such that the model does not lose or diminish its reconstruction ability while traning the prediction/classification part?
If so; could you please point me in the right direction.
Kind regards
Kristian
Yes, great question!
You can specify a list of loss functions to use for each output of the network.
Dear,
Would it make sense to set statefull = true on the LSTMs layers of an encoder decoder?
Thanks
It really depends on whether you want control over when the internal state is reset, or not.
Thank you, Jason, but still, I have not got the answer to my question.
Lets put it another way. what is the latent space in this model? is it only a compressed version of the input data?
do you think if I use the architecture of Many to one, I will have one word representation for each sequence of data?
Why am I able to print out the clusters of the topics in autoencoder easily but when it comes to this architecture I am lost!
In some sense, yes, but a one value representation is an aggressive projection/compression of the input and may not be useful.
What problem are you having exactly?
Hi Jason,
I am appreciate your tutorial!
Now I’m implementing the paper ‘“Unsupervised Learning of Video Representations using LSTMs.”But my result is not very well.The predict pictures are blurred,not good as the paper’s result.
(You can see my result at here:
https://i.loli.net/2019/03/28/5c9c374d68af2.jpg
https://i.loli.net/2019/03/28/5c9c37af98c65.jpg)
I don’t think there exists difference between my keras model and the paper’s model.But the problem has confused me for 2 weeks,I can not get a good solution.I really appreciate your help!
This my keras model’s code:
Sounds like a great project!
Sorry, I don’t have the capacity to debug your code, I have some suggestions here though:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Thank for your reply.
And I wanna know that what may cause the image of the output to be blurred according to your experience ?Thank you~
In what context exactly?
hello John!
I’m excited of your keras code for implementing the paper that I just read.
Can you share the full code(especially image processing part) for me to study what you have done?
As I’m newbie of ML but trying to get used to video prediction with Autoencdoer LSTM.
How can I use the cell state of this “Standalone LSTM Encoder” model as an input layer for another model? Suppose in your code for “Keep Standalone LSTM Encoder”, you had “return_state=True” option for the encoder LSTM layer and create the model like:
model = Model(inputs=model.inputs, outputs=[model.layers[0].output, hidden_state, cell_state])
Then one can retrieve the cell state by: model.outputs[2]
The problem is that this will return a “Tensor” and keras complains that it only accept “Input Layer” as an input for ‘Model()’. How can I feed this cell state to another model as input?
I think it would be odd to use cell state as an input, I’m not sure I follow what you want to do.
Nevertheless, you can use Keras to evaluate the tensor, get the data, create a numpy array and provide it as input to the model.
Also, this may help:
https://machinelearningmastery.com/return-sequences-and-return-states-for-lstms-in-keras/
That’s the approach used in this paper: https://arxiv.org/pdf/1709.01907.pdf
“After the encoder-decoder is pre-trained, it is treated as an intelligent feature-extraction blackbox. Specifically, the last LSTM cell states of the encoder are extracted as learned embedding. Then, a prediction network is trained to forecast the next one or more timestamps using the learned embedding as features.”
They trained an LSTM autoencoder and fed the last cell states of last encoder layer to another model. Did I misunderstand it?
Sounds odd, perhaps confirm with the authors that they are not referring to hidden states (outputs) instead?
Hello Jason,
Is there any way to stack the LSTM autoencoder?
for example:
model = Sequential()
model.add(LSTM(units, activation=activation, input_shape=(n_in,d)))
model.add(RepeatVector(n_in))
model.add(LSTM( units/2, activation=activation))
model.add(RepeatVector(n_in)
model.add(LSTM(units/2, activation=activation,return_sequences=True))
model.add(LSTM(units, activation=activation, return_sequences=True))
model.add(TimeDistributed(Dense(d)))
is this a correct approach?
Do you see any benefits by stacking the autoencoder?
I have never seen something like this 🙂
Hi George,
Stacked encoder / decoders with a narrowing bottleneck are used in a tutorial on the Keras website in the section “Deep autoencoder”
https://blog.keras.io/building-autoencoders-in-keras.html
The tutorial claims that the deeper architecture gives slightly better results than the more shallow model definition in the previous example. This tutorial uses simple dense layers in its models, so I wonder if something similar could be done with LSTM layers.
Thanks for sharing.
I have a theoretical question about autoencoders. I know that autoencoders are suppose to construct the input at the output, and by doing so they will learn a lower-dim representation of the input. Now I want to know if it is possible to use autoencoders to construct something else at the output (let’s say a something that is a modified version of the input).
Sure.
Perhaps check out conditional generative models, VAEs, GANs.
Thanks for the response. I will check those out. I though about denoising autoencoders, but was not sure if that is applicable to my situations.
Let’s say that I have two versions of a feature vector, one is X, and the other one is X’, which has some meaningful noise (technically not noise, meaningful information). Now my question is whether it is appropriate to use denoising autoencoders in this case to learn about the transition between X to X’ ?
Conditional GANs do this for image to image translation.
Hi Jason, could you explain the difference between RepeatVector and return_sequence?
It looks like they both repeat vector several times but what’s the difference?
Can we only use return_sequence in the last LSTM encoder layer and don’t use RepeatVector before the first LSTM decoder layer?
Yes, they are very different in operation, but similar in effect.
The “return_sequence” argument, returns the LSTM layer outputs for each input time step.
The “RepeatVector” layer copies the output from the LSTM for the last input time step and repeats it n times.
Thank you, Jason, now I understand the difference between them. But, here is another question, can we do like this:
”’
encoder = LSTM(100, activation=’relu’, input_shape=(n_in,1), return_sequence=True)
(no RepeatVector layer here, but return_sequence is True in encoder layer)
decoder = LSTM(100, activation=’relu’, return_sequences=True)(encoder)
decoder = TimeDistributed(Dense(1))(decoder)
”’
If yes, what’s the difference between this one and the one you shared (with RepeatVector layer between encoder and decoder, but return_sequence is False in encoder layer)
The repeat vector allows the decoder to use the same representation when creating each output time step.
A stacked LSTM is different in that it will read all input time steps before formulating an output, and in your case, will output an activation for each input time step.
There’s no “best” way, test a suite of models for your problem and use whatever works best.
Thank you for answering my questions.
Dear Sir,
One point I would like to mention is the Unconditioned Model that Srivastava et al use. a) They do not supply any inputs in the decoder model.. Is this tutorial only using the conditioned model?
b) Even if we are using the any of the 2 models that is mentioned in the paper, we should be passing the hidden state or maybe even the cell state of the encoder model to the models first time step and not to all the time steps..
The tutorial over here shows us that the repeat vector is supplying inputs to all the time steps in the decoder model which should not be the case in any of the models
Also the target time steps in the auto reconstruction decoder model should have been reversed.
Please correct me if I am wrong in understanding the paper. Awaiting for you to clarify my doubt. Thanking you in advance.
Perhaps.
You can consider the implementation inspired by the paper. Not a direct re-implementation.
Thank you for the clarification.. Thank you for the post, it helped
You’re welcome.
My understanding is that repeatvector function utilizes a more “dense” representation of the original inputs. For an encoder lstm with 100 hidden units, all information are compressed into a 100 elements vector (which then duplicated by repeatvector for desired output timesteps). For return_sequence=TRUE, it is a totally different scenario — you end up with 100 x input time steps latent variables. It is more like a sparse autoencoder. Correct me if i am wrong.
Hi Jason,
The blog is very interesting. A paper that I published sometime ago uses LSTM autoencoders for German and Dutch dialect analysis.
Best,
Taraka
Thanks.
Hi Jason,
(Forgot to paste the paper link)
The blog is very interesting. A paper that I published sometime ago uses LSTM autoencoders for German and Dutch dialect analysis.
https://www.aclweb.org/anthology/W16-4803
Best,
Taraka
Thanks for sharing.
Hi Jason,
Thanks for the tutorial, it really helps.
Here is a question about connection between Encoder and Decoder.
In your implementation, you copy the H-dimension hidden vector from Encoder for T times, and convey it as a T*H time series, into the Decoder.
Why chose this way? I’m wondering, there are some another ways to do:
Take hidden vector as the initial state at the first time-step of Decoder, with zero inputs series.
Can this way work?
Best,
Geralt
Because it is an easy way to achieve the desired effect from the paper using the Keras library.
No, I don’t think you’re approach is the spirit of the paper. Try it and see what happens!?
Hello Mr.Jason
i want to start a handwritten isolated charactor recognition with RNN and lstm.
i mean, we have a number of charactor images and i want a code to recognize that charactor.
would you please help me to find a basic python code for this purpose, ans so i could start the work?
thank you
Sounds like a great problem.
Perhaps a CNN-LSTM model would be a good fit!
Hi, Dr Brownlee
Thanks for your post, here I want to use LSTM to prediction a time series. For example the series like (1 2 3 4 5 6 7 8 9), and use this series for training. Then the output series is the series of multi-step prediction until it reach the ideal value, like this(9.9 10.8 11.9 12 13.1)
See this post:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Sorry, maybe I didn’t make it clear. Here I want to use LSTM to prediction a time series. the sequence may like this[10,20,30,40,50,60,70],and use it for training,if time_step is 3. When input[40,50,60],we want the output is 70. when finish training the model, the prediction begin. when input [50,60,70], the output maybe 79 and then use it for next step prediction, the input is [60,70,79] and output might be 89. Until satisfying certain condition(like the output>=100) the the iteration is over.
So how could I realize the prediction process above and where can I find the code
Please, hope to get your reply
Yes, you can get started with time series forecasting with LSTMs in this post:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
I have more advanced posts here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Thanks for your quick reply.
And I still have a question, the multi-step LSTM model uses the last three time steps as input and forecast the next two time steps. But in my case, I want to predict the capacity decline trend of Lithium-ion battery, and for example let the data of declining curve of capacity(the cycling number<160) as the training data, then I want to predict the future trend of capacity until it reach the certain value(maybe <=0.7Ah) –failure threshold,which might be achieved at the cycling number of 250 or so. And between the cycling number of 160 and 220, around 90 data need be predicted. So I have no idea how to define time-steps and samples, if the output time-steps defined as 60(220-160=60),the how should I define the time-steps of input, it seems unreasonable.
I am extremely hope to get your reply, Thank you so much
You can define the model with any number of inputs or outputs that you require.
If you are having trouble working with numpy arrays, perhaps this will help:
https://machinelearningmastery.com/index-slice-reshape-numpy-arrays-machine-learning-python/
Dear Prof,
I have a list as follows :
[5206, 1878, 1224, 2, 329, 89, 106, 901, 902, 149, 8]
When I’m passing it as an input to the reconstruction LSTM (with an added LSTM and repeat vector layer and 1000 epochs) , I get the following predicted output :
[5066.752 1615.2777 1015.1887 714.63916 292.17035 250.14038
331.69427 356.30664 373.15497 365.38977 335.48383]
While some values are almost accurate, most of the others have large deviations from original.
What can be the reason for this, and how do you suggest I fix this ?
No model is perfect.
You can expect error in any model, and variance in neural nets over different training runs, more here:
https://machinelearningmastery.com/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
Thanks, professor.
If I have varying numbers such as 2 and 1000 in the same list, is it better to normalize the list by dividing each element by the highest element , and then passing the resulting sequence as an input to the autoencoder ?
Yes, normalizing input is a good idea in general:
https://machinelearningmastery.com/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/
Hi,
I have two questions, would be grateful if you can help –
1) The above sequence is very small.
How about if the length of vector is around 800. I tried, but its taking too long.
What do you suggest.
2) Also, is it possible to encode a matrix into vector ?
thanks
Perhaps reduce the size of the sequence?
Perhaps try running on a faster computer?
Perhaps try an alternate approach?
thanks for you quick response… I have a confusion, right now when you mention ‘training’, it is only one vector… how can truly train it with batches of multiple vectors.
If you are new to Keras, perhaps start with this tutorial:
https://machinelearningmastery.com/5-step-life-cycle-neural-network-models-keras/
Hello Jason, I really appreciate your informative posts. But I got to have two questions.
Question 1. Does
model.add(LSTM(100, activation='relu', input_shape=(n_in,1)))mean that you are creating an LSTM layer with 100 hidden state?LSTM structure needs hidden state(h_t) and cell state(c_t) in addition to the input_t, right? So the number 100 there means that with the data whose shape is (9,1) (timestep = 9, input_feature_number = 1), the LSTM layer produces 100-unit long hidden state (h_t)?
Question 2. how small did it get reduced in terms of ‘dimension reduction?’ Can you tell me how smaller the (9, 1) data got to be reduced in the latent vector?
100 refers to 100 units/nodes in the first hidden layer, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
You can experiment with different sized bottlenecks to see what works well/best for your specific dataset.
hi jason! can this approach is used for sentence correction? i.e spelling or grammatical mistakes of the input text.
for example I have a huge corpus of unlabelled text, and I trained it using autoencoder technique. I want to built a model that takes input (a variable length) sentence, and output the most probable or corrected sentence based on the training data distribution, is it possible?
Perhaps, I’d encourage you to review the literature first.
How do I shape the data for autoencoder if I have multiple samples
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Hi Jason, thanks for your greats articles! I have a work where I get several hundreds of galaxy spectra (a graphic where I have a continuous number of frecuencies in the x axis and the number of received photons from each galaxy in the y axis; it’s something like a continuos histogram). I need to make an unsupervised clustering with all this spectra. Do you thing this LSTM autoencoder can be a good option I can use? (Each spectrum has 4000 pairs frecuency-flux).
I was thinking about passing the feature space of the autoencoder with a K-means algorithm or something similar to make the clusters (or better, something like this: https://arxiv.org/abs/1511.06335).
Perhaps try it and evaluate the result?
hello and thanks for your tutorial… do you have a similar tutorial with LSTM but with multiple features?
The reason I ask for multiple feature is because I built multiple autoencoder models with different structures but all had timesteps = 30… during training the loss, the rmse, the val_loss and the val_rmse seem all to be within acceptable range ~ 0.05, but when I do prediction and plot the prediction with the original data in one graph, it seems that they both are totally different.
I used MinMaxScaler so I tried to plot the original data and the predictions before I inverse the transform and after, but still the original data and the prediction aren’t even close. So, I think I am having trouble plotting the prediction correctly
You could adapt the examples in this post:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
I would like to thank you for the great post, though I wish you have included more sophisticated model.
For example the same thing with 2 feature rather one feature.
Thanks for the suggestion.
The examples here will be helpful:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Hi Jason
Thanks for the tutorial.
I have a sequence A B C. Each A B and C are vectors with length 25.
my samples are like this: A B C label, A’ B’ C’ label’,….
How should I reshape the data?
what is the size of the input dimension?
Sorry, I don’t follow.
What is the problem that you are having exactly?
my dataset is an array with the shape (10,3,25).(3 features and each feature has 25 features in a vector form)
is it necessary to reshape it?
and what is the value of input_shape for this array?
Perhaps read this first to confirm your data is in the correct format:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Thank you, Jason.
You’re welcome.
Hi Jason,
Thank you for the great work.
I have one doubt about the layer concept. Is the LSTM layer (100) means, a hidden layer of 100 neurons from the first LSTM layer output and the data from all these 100 layer will consider as the final state value. Is that correct?
Yes.
Hello Jason,
Thank you for the quick response and appreciate your kind to respond my doubt. Still I am confused with the diagram provided by Keras.
https://github.com/MohammadFneish7/Keras_LSTM_Diagram
Here they have explained as the output of each layer will the “No of Y variables we are predicting * timesteps”
My doubt is like is the output size is “Y – predicted value” or “Hidden Values”?
Thanks
Perhaps ask the authors of the diagram about it?
I have some general advice here that might help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Thank you Jason for the reply.
I have gone through your post and I am clear about the input format to the initial LSTM layer.
I have the below doubt about the internal structure of Keras.
Suppose I have a code as below.
step_size = 3
model = Sequential()
model.add(LSTM(32, input_shape=(2, step_size), return_sequences = True))
model.add(LSTM(18))
model.add(Dense(1))
model.add(Activation(‘linear’))
I am getting below summary.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 2, 32) 4608
_________________________________________________________________
lstm_2 (LSTM) (None, 18) 3672
_________________________________________________________________
dense_1 (Dense) (None, 1) 19
_________________________________________________________________
activation_1 (Activation) (None, 1) 0
=================================================================
Total params: 8,299
Trainable params: 8,299
Non-trainable params: 0
_________________________________________________________________
None
And I have the below internal layer matrix data.
Layer 1
(3, 128)
(32, 128)
(128,)
Layer 2
(32, 72)
(18, 72)
(72,)
Layer 3
(18, 1)
(1,)
I can not find any relation between output size and the matrix size in each layer. But in each layer the parameter size specified is the total of weight matrix size. Can you please help me to get an idea of the implementation of these numbers.
I believe this will help you understand the input shape to an LSTM model:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Hi Jason,
Thanks for the reply.
I have gone through the post
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
I can able to understand the structure of the input data into the first LSTM layer. But I am not able to identify the matrix structure in the first Layer and the connection with Second Layer. Can you please give me more guidelines to understand the matrix dimensions in the Layers.
Thanks
If the LSTM has return_states=False then the output of an LSTM layer is one value for each node, e.g. LSTM(50) returns a vector with 50 elements.
If the LSTM has return_states=True, such as when we stack LSTM layers, then the return will be a sequence for each node where the length of the sequence is the length of the input to the layer, e.g. LSTM(50, input_shape=(100,1)) then the output will be (100,50) or 100 time steps for 50 nodes.
Does that help?
Thank you Jason for the reply.
Really appreciate the time and effort to give me the answer. It helped me a lot. Thank you very much. You are teaching the whole world. Great !!!
Thanks, I’m glad it helped.
hi, I am a student and I want to forecast a time-series (electrical load) for the next 24 hr.
I want to do it by using an autoencoder boosting with LSTM.
I am looking for a suitable topology and structure for it.Is it possible to help me?
best regards
Perhaps some of the tutorials here will help as a first step:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Hi,
I have a question regarding compositive model. In your tutorial, you have sent all data into LSTM encoder. And decorder1 tries to reconstruct whatever it has been passed to the encoder. The another decorder tries to predict the next sequence.
My question is that once encoder has seen all the data, does it make sense for prediction branch? Since it has already seen all day, definitely it can predict well enough, right?
I don’t know how encoder part works? Does it works differently for two branch. Does encoder part create a single encoded latent space from which both part does their job accordingly?
Could you please help me to figure it out. Thank you.
Perhaps focus on the samples aspect of the data, the model receives a sample, and predicts the output, then the next sample is processed, and predicts an output, so on.
It just so happens when we train the model we provide all the samples in a dataset together.
Does that help?
Thanks for your reply but still not clear to me.
For examples:
we have a 10 time steps data of size 120 (N,10,120). (N is sample numbers)
f5 = frist 5 time steps
l5 = last 5 time steps
while training :
1 Option()
seq_in = (N,f5, 120)
seq_out = (N,l5,120)
model.fit(seq_in, [seq_in,seq_out], epochs=300, verbose=0)
2 Option()
seq_in = (N,10, 120)
seq_out = (N,l5,120)
model.fit(seq_in, [seq_in,seq_out], epochs=300, verbose=0)
Could you please help me to understand that difference between above options? Which way is the correct way to train a network? Thank you.
I don’t follow, sorry.
len(f5) == 5?
Then you’re asking the difference between (N,5,120) and (N,10,120)?
The difference is the number of time steps.
If you are new to array shapes, this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Sorry for inconvenience .
I am trying to ask with you that whether we have to pass all time steps( in this case 10), or pass first 5 time steps (in this case) to predict the next 5 steps. (I have a data of 10 time steps, my wish is to train a network with two decoder. First decorder should return the reconstruction of input, and second decorder predict the next value).
The question is if I pass all 10 time steps to the network then it will see all the time steps which means it encodes all seen data. from encoding space two decorde will try to reconstruct and predict. It seems that both decoder looks similar then what is the significance of using reconstruction branch decoder? How it helps to prediction decorder in composite model?
Thank you once again.
Yes, the goal is not to train a predictive model, it is to train an effective encoding of the input.
Using a prediction model as a decoder does not guarantee a better encoding, it is just an alternate strategy to try that may be useful on some problems.
If you want to use an LSTM for time series prediction, you can start here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Thank you very much your answers.
Hi Jason,
I get NaN values when i apply the reconstruction autoencoder to my data (1,1000,1)
What can be the reason for it and how to resolve?
I am exploring how reshaping data works for LSTMs and have tried dividing my data into batches of 5 with 200 timesteps each but wanted to check how (1,1000,1) works
Sorry to hear that, this might help with reshaping data:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Thanks for replying.
can u identify the lstm model used for reconstruction? is it 1to1 or manyto1?
where can i find explicit examples for lstm models on the website?
You can get started with LSTMs here:
https://machinelearningmastery.com/start-here/#lstm
Including tutorials, a mini-course, and my book.
Hello,
I had a question. If I am using the Masking layer in the first part of the network, then does the RepeatVector() layer support masking. Because if it does not support masking and replicates each timestep with the same value, then our output loss will not be computed properly. Because ideally in our mse loss for each example we do not want to include the timestep where we had zero paddings.
Could you please share how to ignore the zero padded values while calculating the mse loss function.
Masking is only needed for input.
The bottle beck will have a internal representation of the input – after masking.
Masked values are skipped from input.
Hello,
But if the reconstructed timesteps corresponding to the padded part is not zero, then the mean square error loss will be vary large I suppose? Can you tell me if I am wrong here because my mse loss is becoming “nan” after certain number of epochs. And is it best to do post padding or pre padding?
Thanks,
Sounak Ray.
Correct.
The goal is not to create a great predictive model, it is to learn a great intermediate representation.
Sorry to hear that you are getting NANs, I have some suggestions here that might help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi Jason, thanks for the article. I’m struggling the same problem with Sounak that the mask actually get lost when LSTM return_sequence = False (also the RepeatVector does not explicitly support masking because it actually change the Timestep dimension), since the mask cannot be passed to the end of the model, the loss will be calculated also for those padded timesteps (I’ve validated this on a simple example), which are not preferred.
I wonder if you can do experiments to see if it makes a difference to the bottleneck representation that is learned?
Hi Jason,
I really enjoy your posts. Thanks for sharing your expertise. Really appreciate it!
I also have a question regarding this post. In the “Prediction Autoencoder” shouldn’t you split the time sequence in half and try to predict the second half by feeding the first half to the encoder. They way that you have implemented the decoder does not truly predict the sequence because the entire sequence had been summarized and given to it by the encoder. Is that true, or am I missing something here?
You can try that – there are many ways to frame a sequence prediction problem, but that is not the model used in this example.
Recall, we are not developing a prediction model, instead an autoencoder.
Hello,
I’m working on data reconstruction where input is [0:8] columns of the dataset and required output is the 9th column. However the LSTM autoencoder model returns the same value as output after 10 to 15 timesteps. I have applied the model on different datasets but facing similar issue.
What parameter adjustments must I do to obtain unique reconstructed values?
Perhaps try using a different model architecture or different training hyperparameters?
Fantastic! I hope you are getting paid for your time here. 😉
Thanks.
Yes, some readers purchase ebooks to support me:
https://machinelearningmastery.com/products/
Hello,
Thank you for the amazing article!
I’ve read comments regarding the RepeatVector(), yet I’m still skeptical if I understood it correctly.
We are merely copying the last output of the encoder LSTM and feed it to each cell of the decoder LSTM to produce the unconditional sequence. Is it correct?
Also, I’m curious that what happens to the internal state of the encoder LSTM. Is it just discarded and will never be used for the decoder? I wonder if using the internal state of the final LSTM cell of the encoder for the initial internal state of LSTM of the decoder would have any kind of benefit. Or is it just completely unnecessary since all we want is to train the encoder?
Thank you for your time!
Correct.
The internal state from the encoder is discarded. The decoder uses state to create the output.
The construction of each output step is conditional on the bottleneck vector and the state from creating the prior output step.
Really appreciate your hard work and the tutorials are great. I have learned a lot. Can you please write a tutorial on teacher forcing method in encoder decoder architecture? That would be really helpful.
Thanks!
Yes, I believe all of my tutorials for the encoder-decoder use teacher forcing.
I would know what is the point to doing an autoencoder.
it seem equivalent to build one side an encoder decoder and in the other side the prediction model , as the two ouput don’t seem being used by each other.
Maybe it would be meaningler to use the decodeur as discriminant for the prediction like a GAN
It can be used as a feature extraction model for sequence data.
E.g. you could fit a decoder or any model and make predictions.
Is there any way of building an overfitted autoencoder(is overfitting needs to be taken care while training an autoencoder).
and how can one justify that the encoded features obtained are the best compression possible for reconstruction of original.
Also, can you please explain the time distributed layer in terms of the input to this layer. What is the use of time distributed layer. is this layer only useful if working with LSTM layer?
Thanks for all your posts and books, they are very useful in understanding concepts and applying them.
Good question!
Yes. E.g. an autoencoder that does well on a training set but cannot reconstruct test data well .
More on the time distributed layer here:
https://machinelearningmastery.com/timedistributed-layer-for-long-short-term-memory-networks-in-python/
I am having trouble seeing the bottle neck. Is it the 100 unit layer after the input? Should this normally, without a trivial data set for your example, be much smaller than the number of time steps?
Yes, the output of the first hidden layer – the encoder – is the the encoded representation.
Hi Jason,
Thank you so much for writing this great post. But I have a question that really confusing me. Here it is. As the Encoder-Decoder LSTM can benefit the training for output variable length, I’m wondering if it can support the variable multi-step output. I am trying to vary the length of output steps with the “Multiple Parallel Input and Multi-Step Output” example from another post https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/, so the output sequence like:
[[[ 40 45 85]
[ 0 0 0]
[ 0 0 0]]
[[ 50 55 105]
[ 60 65 125]
[ 70 75 145]]
[[ 60 65 125]
[ 70 75 145]
[ 0 0 0]]
[[ 70 75 145]
[ 80 85 165]
[ 0 0 0]]
[[ 80 85 165]
[ 0 0 0]
[ 0 0 0]]]
But my prediction results turned out to be not good. Could you give me some guidance? Is the padding value 0 not suitable? Is the Encoder-Decoder LSTM cannot support the variable length of steps?
Thanks again.
Yes, but you must pad the values. If you cannot use padding with 0, perhaps try -1.
Alternately, you can use a dynamic LSTM and process one time step at a time. This wills how you how:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Thank you for suggesting me to process one time step at a time. I suddenly realize there is no need to make the output time steps variable since we can predict the output step by step. Did I get it right? Besides, I think there is no rationale difference between the two Encoder-Decoder models from these two posts except for predicting different timesteps and using different Keras function. Is this understanding correct?
Hope to hear from you. Thanks again.
Perhaps.
I have tried your model with my input. The loss was getting convergenced before 10 epochs as excepting. However, the loss became bigger after a point in 10th epochs.
5536/42706 [==>………………………] – ETA: 39s – loss: 0.4187
5600/42706 [==>………………………] – ETA: 39s – loss: 0.4190
5664/42706 [==>………………………] – ETA: 39s – loss: 0.4189
5728/42706 [===>……………………..] – ETA: 39s – loss: 0.4188
5792/42706 [===>……………………..] – ETA: 39s – loss: 0.4189
5856/42706 [===>……………………..] – ETA: 39s – loss: 0.4184
5920/42706 [===>……………………..] – ETA: 38s – loss: 0.4185
5984/42706 [===>……………………..] – ETA: 38s – loss: 0.4188
6048/42706 [===>……………………..] – ETA: 38s – loss: 7.7892
6112/42706 [===>……………………..] – ETA: 38s – loss: 8.6366
6176/42706 [===>……………………..] – ETA: 38s – loss: 8.5517
6240/42706 [===>……………………..] – ETA: 38s – loss: 8.4680
6304/42706 [===>……………………..] – ETA: 38s – loss: 8.3862
6368/42706 [===>……………………..] – ETA: 38s – loss: 8.3056
6432/42706 [===>……………………..] – ETA: 38s – loss: 8.2270
6496/42706 [===>……………………..] – ETA: 38s – loss: 8.1499
6560/42706 [===>……………………..] – ETA: 38s – loss: 8.0738
6624/42706 [===>……………………..] – ETA: 38s – loss: 7.9993
6688/42706 [===>……………………..] – ETA: 38s – loss: 7.9269
6752/42706 [===>……………………..] – ETA: 38s – loss: 7.8556
6816/42706 [===>……………………..] – ETA: 38s – loss: 7.7855
6880/42706 [===>……………………..] – ETA: 37s – loss: 7.7169
6944/42706 [===>……………………..] – ETA: 37s – loss: 7.6496
7008/42706 [===>……………………..] – ETA: 37s – loss: 7.5831
7072/42706 [===>……………………..] – ETA: 37s – loss: 7.5183
7136/42706 [====>…………………….] – ETA: 37s – loss: 7.4546
7200/42706 [====>…………………….] – ETA: 37s – loss: 7.3912
7264/42706 [====>…………………….] – ETA: 37s – loss: 7.3297
7328/42706 [====>…………………….] – ETA: 37s – loss: 7.2693
7392/42706 [====>…………………….] – ETA: 37s – loss: 7.2094
7456/42706 [====>…………………….] – ETA: 37s – loss: 7.1505
7520/42706 [====>…………………….] – ETA: 37s – loss: 7.0928
7584/42706 [====>…………………….] – ETA: 37s – loss: 7.0363
7648/42706 [====>…………………….] – ETA: 37s – loss: 6.9807
7712/42706 [====>…………………….] – ETA: 37s – loss: 6.9260
7776/42706 [====>…………………….] – ETA: 37s – loss: 6.8724
7840/42706 [====>…………………….] – ETA: 37s – loss: 6.8196
7904/42706 [====>…………………….] – ETA: 36s – loss: 6.7676
7968/42706 [====>…………………….] – ETA: 36s – loss: 6.7163
8032/42706 [====>…………………….] – ETA: 36s – loss: 6.6655
8096/42706 [====>…………………….] – ETA: 36s – loss: 6.6160
8160/42706 [====>…………………….] – ETA: 36s – loss: 6.5667
8224/42706 [====>…………………….] – ETA: 36s – loss: 6.5184
8288/42706 [====>…………………….] – ETA: 36s – loss: 6.4707
8352/42706 [====>…………………….] – ETA: 36s – loss: 6.4239
8416/42706 [====>…………………….] – ETA: 36s – loss: 6.3782
8480/42706 [====>…………………….] – ETA: 36s – loss: 2378.7514
8544/42706 [=====>……………………] – ETA: 36s – loss: 27760.9716
8608/42706 [=====>……………………] – ETA: 36s – loss: 27755.8645
8672/42706 [=====>……………………] – ETA: 36s – loss: 27978.9607
8736/42706 [=====>……………………] – ETA: 36s – loss: 28032.9492
8800/42706 [=====>……………………] – ETA: 35s – loss: 28025.2542
8864/42706 [=====>……………………] – ETA: 35s – loss: 27902.1603
8928/42706 [=====>……………………] – ETA: 35s – loss: 27837.8133
8992/42706 [=====>……………………] – ETA: 35s – loss: 27830.6104
9056/42706 [=====>……………………] – ETA: 35s – loss: 27731.7000
9120/42706 [=====>……………………] – ETA: 35s – loss: 27630.7813
9184/42706 [=====>……………………] – ETA: 35s – loss: 27768.5311
9248/42706 [=====>……………………] – ETA: 35s – loss: 28076.0159
Nice work.
Perhaps try fitting the model again to see if you get a different result?
Hi Jason,
I am trying to implement a LSTM autoencoder using encoder-decoder architecture. What if I want to use the functional API of keras and also NOT have my decoder get the inputs from the previous i.e. my decoder LSTM will not have any input but just the hidden and cell state initialized from encoder?(because I want my encoder output to preserve all the information necessary to reconstruct back the signal with giving any inputs to the decoder). Is something like this possible in keras?
Yes, I believe that is the normal architecture described in the above tutorial.
If not, perhaps I don’t understand what you’re trying to achieve.
I mean in a functional API(the above mentioned is a sequential api).
this is the code from one of your article:
what if i want my ‘decoder_lstm’ to not have any inputs(in this code, it is give ‘decoder_inputs’ as inputs)
Ah I see. Thanks.
Some experimentation will be required, I don’t have an example for you.
the reason I want to use functional API is because I want to use stacked LSTM(multiple layers) and I want the hidden_state from all layers at the last time step of encoder. This is possible only with functional API right?
Most likely, yes.
Hey, @Jason Brownlee, I am working on textual data could you please explain this concept regarding the text? I am calculating errors with glove pre-trained vector but my result is not up to the mark
Thank you in advance
Perhaps start here:
https://machinelearningmastery.com/start-here/#nlp
Hi Jason,
I am working on time series data.
Can I use RNN Autoencode as time series representation like SAX, PAA
Thank you
Perhaps try it and see?
Great article! Thanks!
Thanks, I’m happy it helped.
Hi Jason, I have a question. is last 100*1 vector you printed in the end of article the feature of the sequence? Can this vector be later used as, for example, sequence classification or regression? Thanks!
In most of the examples we are reconstructing the input sequence of numeric values. Regression, but not really.
The final example is the feature vector.
Hello, dr. Jason, thanks for this useful tutorial!
I built a convolutional Autoencoder (CAE), the result of the reconstructed image from the decoder is better than the original image, and i think if a classifer took a better image it would provide a good output..
so I want to classify the input weather it is a bag, shoes .. etc
Is it better to:
1- delete the decoder and make the encoder as a classifier? (if I did this will it be like a normal CNN?)
2- or do the same as “Composite LSTM Autoencoder in this tutorial” to my CAE
3- take the output of the decoder (better image) to a classifier
I do not know, and I am really new to AI world, your reply will be so useful to me.
Thank you.
You would keep the encoder and use the output of the encoder as input to a new classifier model.
so I take the output of the encoder (maybe 8*8 matrix) and make it as input to model that takes the same size (8*8)? no need to connect both CNNs (encoder, classifier)?
You can connect them if you want or use the encoder as a feature extractor.
Typically extracted features are a 1d vector, e.g. a bottleneck layer.
Is it possible to use autoencoders for lstm time series prediction
Sure. They could extract features, then feed these features into another model to make predictions.
Will there be a blog on autoencoders for lstm time series prediction in machinelearningmastery.com
The above tutorial is exactly this.
Jason, I ran the Prediction LSTM Autoencoder from this post and saw the following error message:
2020-03-28 14:01:53.115186: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 0, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.120793: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 1, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.127457: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] layout failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.190262: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] remapper failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.194523: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] arithmetic_optimizer failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.198763: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 0, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.204018: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 1, topological sort failed with message: The graph couldn’t be sorted in topological order.
However, the code ran and the answer was equivalent to your answer. Have you seen this error? If so, do you know what it means?
Thanks.
I have not seen these warnings before, sorry.
Perhaps try searching/posting on stackoverflow?
Hello Dr.Brownlee
I was wondering why you use RepeatVector layer after LSTM to to match the time step size, but you can obtain the same shape tensor by using repeat_sequence = True on the LSTM layer?
Thank you!
Perhaps that is a new addition?
Where is that in the Keras API?
https://keras.io/layers/recurrent/
Hello Dr.Brownlee
To clarify what I meant, please refer to the following code snippet I ran on tensorflow2.0 with eager execution enabled. (I wanted to post a screenshot but I couldnt replay with a picture)
inputs = np.random.random([2, 10, 1]).astype(np.float32)
x = LSTM(4, return_sequences=False)(inputs)
x = RepeatVector(10)(x)
x = LSTM(8, return_sequences=True)(x)
x = TimeDistributed(Dense(5))(x)
print(f”input1:{inputs.shape}”)
print(f”output1: {x.shape}”)
x = LSTM(4, return_sequences=True)(inputs)
x = LSTM(8, return_sequences=True)(x)
x = TimeDistributed(Dense(5))(x)
print(f”input2:{inputs.shape}”)
print(f”output2: {x.shape}”)
input1:(2, 10, 1)
output1: (2, 10, 5)
input2:(2, 10, 1)
output2: (2, 10, 5)
I have compared two architectures where the first one emulates your code with repeatvector after the first LSTM layer, and a second architecture where I used return_sequences=True and did not use repeatvector layer.
The output shape of each networks are the same.
Going back to my original question, is there a reason why you used RepeatVector layer instead of putting return_sequences=True on the first LSTM layer?
I hope this clarifies. Thank you!!
Yes, it results in a different architecture called an encoder-decoder model:
https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/
I actually had the same question as Chad. That second article you linked to does the same thing with ‘RepeatVector’ though. It seems like unless we’re using ‘return_sequence’ with the first LSTM layer (instead of using ‘repeatvector’), this example only works when there’s a one-to-one pairing of single value outputs to input sequences. For example, if multiple sequences could lead to a 0.9 value, I don’t see how this could work since the encoder only uses the last frame of the sequence with return_sequence=False. If the only argument for using “RepeatVector” is that we have to do that to make it fit and not throw an error, then why not use return_sequence and not throw away useful information that the encoder presumably would need? Seems like the proper way to do this would be as Chad outlined above (i.e. with return_sequences=True and without simply repeating the last output so it fits).
Not quite.
The output of the encoder is the bottleneck – it is the internal representation of the entire input sequence. We then condition each step of the output on this representation and the the previous generated output step.
couldn’t respond in proper spot in thread, so sorry this is out of order but looking into it some more, I think I see. Is it basically that while the output of the encoder is just one element (doesn’t return the full sequence), that value could be a very precise number that would then correspond to a full sequence, which the decoder half of it would learn? so like two different sequences ending in 0.9 could be encoded as different floats here, like 3.47 and 5.72 (chosen at random for illustrative purposes), for instance? I was experimenting with this a bit on my own, and indeed if I use return_sequence=True, there’s very little memory that actually gets saved in the encoding, which makes it kinda pointless. What I really want to do is encode sequences of images into small vectors, building on to the autencoder examples here: https://blog.keras.io/building-autoencoders-in-keras.html. This has all been very helpful, so thank you
The bottleneck is typically a vector, not a single number.
Hello Jason,
In this post (https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/), state vectors of the decoder network are initialized by the last layer’s states vectors of encoder network, right (lets call it type1)? However, here you only feed the decoder network’s input using the output of encoder network (repeating the output values, lets call it type2). Inıtial states of the decoder network are zeroed (by automatically?), similar to the initial values of the state vectors of the encoder network?
So, What is the difference between these encoder-decoder networks in terms of usage (e..g when to choose type1 over type2)?
Why didn’t you do the network you explained here with type1? or the one In section 9 of your book (you give an example similar to what you are explaining here. The basic calculator.).
Best
The difference in the architecture is exactly as you say, architectural.
I find both approaches are pretty much the same in practice although the repeatvector method is way simpler to implement. This is the approach I recommend and use in my tutorials.
Hi Jason – It’s unclear why both you and Francois Chollet (https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html) fit a training model, but you don’t reuse it (and the associated learned weights) in the inference step. From reading your code, I don’t understand how the fitted model (train variable) is used in the infenc/infdec models, since the train variable is never used/called again.
The model/weights for the encoder and decoder are used during inference. Perhaps review the code again?
Dear Dr Jason,
In the exercises which involve the plot_model function
That is in order to produce a graphical model *,png file using plot_model, the python interface may throw an error,
For Windows OS users, in order to get the graphical model via a *.png file, you will have to:
* Install GraphViz binaries
* Set the environment path for the GraphViz program, eg: path=c:\program files (x86)\graphviz 2.38\bin; rest of path ;
*In a command window do the following pip
Your plot_model function should work.
Thank you,
Anthony of Sydney
Great tip!
Hi, there’s still an error with graphviz installation. An error something like this:
stdout, stderr: b” b”‘C:\\Program’ is not recognized as an internal or external command,\operable program or batch file.\r\n”
This can however be resolved using a solution provided here,
https://github.com/conda-forge/graphviz-feedstock/issues/43
Thanks
Hi and thank you for great post.
My question is in composite version you have presented, it seems the forecasting is working independent from construction layers. How can I make a change first reconstruct the input sequence then forecast layers take the extracted features and does forecasting? Can I simply first fit decoder1 then take the output of encoder as input of decoder2 and forecast? I don’t wand to save reconstruction phase.
Thank you
You’re welcome.
Why reconstruct then forecast, why not use input directly to forecast?
For example, see this:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Yes, I have seen that link as well.
I thought forecasting on extracted features may be more accurate.
It really depends on the specifics of the model and the data. I recommend controlled experiments in order to discover what works best for your specific dataset.
Let me rephrase my question. I’m not sure whether the input of the forecasting part is extracted features or raw inputs! If, row inputs, how can I use extracted features as input of decoder2?
Thank you
The input to the decoder are extracted features.
You can define a multi-input model using the functional API and have the input flow to anywhere you like:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Thanks for the excellent (as usual) post Jason.
“Regardless of the method chosen (reconstruction, prediction, or composite), once the autoencoder has been fit, the decoder can be removed and the encoder can be kept as a standalone model.”
If your data are 2D images from a video, it may make more sense to use a 2D convolutional LSTM as outlined [in this post](https://towardsdatascience.com/prototyping-an-anomaly-detection-system-for-videos-step-by-step-using-lstm-convolutional-4e06b7dcdd29). If using this method, is it possible to extract the compressed features from the last layer of the decoder (the “bottleneck”) as you have below?
model = Model(inputs=model.inputs, outputs=model.layers[0].output)
Perhaps try it?
Hi Jason,
Is it possible to make conv1D+LSTM autoencoder? I think i saw some example in pytorch, but not sure if there is any example in Keras?
I don’t see why not. Try experimenting.
Hai sir,
I have used the same algorithm mentioned here for sequence reconstruction.
But i have a total of 1 sample, 2205 time steps and 1 feature.
I am getting the reconstructed value as ‘Nan’ while using ‘relu’ activation function.
Instead of ‘relu’, if i am using ‘tanh’, the reconstruction works fine without Nan but i am getting the same reconstructed values which is also considered as an error.
Kindly help me to get the correct reconstruction values.
Perhaps try scaling your data prior to modeling?
Thank you very much for your response.
Hai sir,
I have tried scaling my data by a technique called Normalization. Now i am not getting Nan errors but the reconstructed values are same which is an error. If i am feeding a total of 10 values to the lstm auto encoder with relu activation function, reconstructions works very fine.
In my case , i need to feed the whole 2205 time steps. What can i do for getting the correct reconstruction. Kindly waiting for your reply.
Thank you
2205 time steps is probably too much, perhaps try splitting your long sequence into subsequences:
https://machinelearningmastery.com/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/
Sir,
I split my data (2205 time steps) in to 147 different arrays. Each array now contains 15 elements. So 147*15 = 2205.
Now i am able to input only one array at a time to the model (sequence reconstruction).
How to input this 147 arrays (each array contains 15 elements) at a time to the above mentioned model ( Sequence reconstruction) so that i would get the 147 reconstructed arrays at a time.
Waiting for your valuable reply
Thank you.
This will help you prepare data for LSTMs:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
You’re welcome.
Thank you very much sir
You’re welcome.
Nice and super easy to read the article explaining LSTM autoencoder.
I have a clarification regarding autoencoders being self-supervised. The task of an autoencoder is to learn the compressed representation. The task does not use any kind of label and so is completely unsupervised as opposed to self-supervised.
If the task of the autoencoder were to learn to recreate the image then you could call it self-supervised as you provide a created a label(the same image itself) where non existed.
So I feel that the statement regarding autoencoder being self-supervised is not entirely correct.
Thanks.
How so?
Hi Jason,
I’m trying something different as a part of Master’s research.
I’m working on predicting hourly traffic for individual bike stations (like lime bike or citibike).
So I have this data which has start point and end point entry and the time. I convert this into a timeseries for each station based on hourly number of traffic at the station.
My goal with AE-LSTM is to use all the stations hourly data like an RBM or AE-LSTM where the model predicts next hour’s traffic for all stations. (So it takes in account neighbouring station’s previous hour data and current stations last 24 hour timesteps traffic data)
Now I tried to use the model from this tutorial but I’m stuck with an error –
“ValueError: Error when checking target: expected time_distributed_5 to have 3 dimensions, but got array with shape (11221, 175)”
My input data shape is (11221, 23, 175) and my output should be something like (11221, 175).
The last LSTM layer generates the output size but due to the TimeDistributed layer I get an error.
Any thoughts you may have would be really helpful.
You may need to reshape your target to be [11221, 175, 1], try that and let me know how you go.
Hi Jason,
That did not work for some reason but after reading articles on TimeDistributedDense, I think TimeDistributedDense is more important in OneToMany and ManyToMany (predicting multiple time steps).
So I tried with just stacked LSTM layers and a final dense layer it works but I’m not sure if this method will give me good results.
I’m not sure about RepeatVector layer as to what is actually does but I did not include in the only LSTM and Dense Architecture.
Can this architecture be called an AE-LSTM?
——————————————————————————————————————–
The old AE-LSTM (with TimeDistributedDense) –
model = Sequential()
model.add(LSTM(64, dropout=0.2,recurrent_dropout=0.2,input_shape=(X0_train.shape[1],X0_train.shape[2]),activation=’relu’))
model.add(keras.layers.RepeatVector(n=X0_train.shape[1]))
model.add(LSTM(64, dropout=0.2,recurrent_dropout=0.2,activation=’relu’, return_sequences=True))
model.add(keras.layers.TimeDistributed(Dense(X0_train.shape[2])))
# Compile model
model.compile(loss=’mse’, optimizer=’adam’)
——————————————————————————————————————–
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 64) 61440
_________________________________________________________________
repeat_vector_1 (RepeatVecto (None, 23, 64) 0
_________________________________________________________________
lstm_2 (LSTM) (None, 23, 64) 33024
_________________________________________________________________
time_distributed_1 (TimeDist (None, 23, 175) 11375
=================================================================
Total params: 105,839
Trainable params: 105,839
Non-trainable params: 0
———————————————————————————————————————
and finally the error –
ValueError: Error when checking target: expected time_distributed_1 to have shape (23, 175) but got array with shape (175, 1)
My goal here is to predict only next hour’s predictions so I think Dense layer is good for my case.
I’m eager to help, but I don’t have the capacity to review/debug your code, see this:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Thank you very much Jason.
It meant a lot that you got back to me.
What I really wanted was to know what exactly the TimeDistributedDense and the RepeatVector layer does?
I found out after some deep search.
Thanks a lot.
Sincerely,
Abhishek
The repeat vector repeats the output of the encode n times, where n is the number of outputs required from the decoder.
The time distributed wrapper allows you to use the same decoder for each step of the output instead of outputting a vector directly.
Hi,
I am figuring out “prediction autoencoder LSTM.” I am wondering which part is the prediction because the input is [1 2 3 …9] and output is [ around 2 around 3 … around 9]. I am interested in the value after 9 but this system doesn’t show the result. So it looks like just reconstruction.
So, I would appreciate it if you would let me know which part is the prediction part in this system.
The first input is 1 and the first output is 2, etc.
Thank you for your reply.
But, I may have to ask again more specifically.
So, in your example, your input sequence is
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] and output sequence is
[0.1657285 0.28903174 0.40304852 0.5096578 0.6104322 0.70671254 0.7997272 0.8904342 ].
According to your answer, if 0.1657286 is the prediction after input 0.1, what is the prediction after the input 0.9?
Because the last output is 0.8904342 which is the prediction after 0.8, I don’t see the prediction after the input 0.9.
Thank you.
We don’t predict an output for the input of 0.9, because we don’t know the answer.
Hi Dr. Jason
Thank you very much for this great article.
I will be very thankful if you guide me about this issue.
In this valuable article, the input is an array with nine elements. I have an array of pre-traind embedding vectors. I guess that in this case, the final output of encoder layer is an array of N 100 dimension vector elements(N is the length of input array). If it is correct, how can I aggregate the input array to a single vector?
I read your another grate article { How to Develop an Encoder-Decoder Model with Attention in Keras}
In more detail, my question Is: when the input array includes embedding vectors, how we can use this architecture(encoder-decoder) to summarize input to one single representation vector.
I will be very thankful if you guide me about this issue.
If you use an embedding before an encoder, then the vector output from the embedding layer for each time step is one time step input for the LSTM layer of the encoder.
You can see an example here:
https://machinelearningmastery.com/develop-neural-machine-translation-system-keras/
Hi, Jason
I have two quention about LSTM.
1. what is the return_states and return_sequences in LSTM ?
2. what is the necessity of the return_states and return_sequences in LSTM ?
I will be very thankful if you guide me about this two issue with example specificly.
Difference between return state and return sequences:
https://machinelearningmastery.com/return-sequences-and-return-states-for-lstms-in-keras/
thanks!!! Can you give any example where return_sequences ana return_states used???
Yes, there are many on the blog, you can use the search box.
In the above examples, you learn from only 10 array sequences input. Does LSTM autoencoder actually learn anything from such a small sample size? I am assuming since it is a deep learning method, the data size should be large? Please correct me if I am wrong.
Not really, it is just a demonstration for how to develop the model, not solve a trivial problem.
So the above example has 100 encoding dimensions aka size of the vector encoding (z)? Is it possible to reduce them to 10 with a stacked LSTM layer added before and after the vector encoding? If yes, the command would like this?
model = Sequential()
model.add(LSTM(100, activation=’relu’, input_shape=(n_in,1)))
model.add(LSTM(10, activation=’relu’, input_shape=(n_in,1)))
model.add(RepeatVector(n_in))
model.add(LSTM(10, activation=’relu’, input_shape=(n_in,1)))
model.add(LSTM(100, activation=’relu’, return_sequences=True))
model.add(TimeDistributed(Dense(1)))
No, it encodes to a 10 element vector.
You can specify any dimensions you like for your dataset.
So 100 is the hidden layers then?
No, 100 refers to 100 nodes or units in the first hidden layer.
Thank you. Can I. write like this then?
9 = input dimensions,
9 = encoding dimensions,
100 = hidden dimensions ,
input-> LSTM(9,100) -> z(n) -> LSTM(100,9) -> Dense(100,9) -> ouput
No, the size of the encoding is define by the size of the bottleneck layer.
Hi Jason.
what i understand is, by using time-distributed in dense layer, the input from previous LSTM layer for each sequence(sequence =True) executed one by one. If we not using time-distributed, the sequence from LSTM will be grouped in 1 vector and push to dense layer in one time.
Even the process slightly different, but the result should be the same right? i mean both using the same /share weight from that dense layer. So i still confuse why we need the time-distributed, in this case, I mean what’s the advantage if we are not use that.
Thanks
Mike
Difference in architecture may mean a difference in results, e.g. outputting a vector step by step vs directly.
Hi, thank you so much for such a quality blog, it’s not so common nowadays. I have a question on AE/LSTM-VAE explainability. Is it possible to understand which input variables are most relevant for the embedding? Is it even possible to do something similar to PCA loadings for each dimension of the latent space?
Thanks a lot
You’re welcome.
Not really. There may be modern model interpretation methods – but I’m not across them sorry.
Hi Jason,
thanks for this great tutorial. I’m new to ML and I’m still a bit confused about the shape of the input sequence and the corresponding reshaped output.
When you define the input sequence as one sample with 9 timesteps and one feature by sequence = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) the corresponding reshaped output will look like this:
[[[0.1]
[0.2]
[0.3]
[0.4]
[0.5]
[0.6]
[0.7]
[0.8]
[0.9]]]
Could you give an example of how the input and reshaped output sequence would look like for 2 samples, nine timesteps and 3 features.
Thanks for your help!
Regards,
Sascha
You’re welcome.
It can be confusing, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
what the purpose of use the RepeatVector layer?
To repeat the bottleneck layer for each step in the output sequence.
very informative blog, loving it
Thanks!
Hi Jason, thanks for the informative articles as always. I’m confused about something, where is the bottleneck layer? There are two layers with 100 neurons, I thought there would be a layer in between those two with, say, 50 neurons? Or as many neurons as we want the lower dimensional representation to have
The layer before the RepeatVector is the bottleneck, e.g. the output of a given LSTM that is fe into the repeatedvecor layer.
Hai sir,
I am having a data of 97500 rows and 87 columns. Would you please tell how I can reshape this data to feed to LSTM AUTOENCODER.
Please specify samples, timesteps, features of my data of 97500 rows and 87 columns.
See this:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Sir,
can you please tell the, Is the ‘row’ and ‘column’ corresponds to ‘samples’ and ‘features’ ?respectively.
if so, in my case there are ‘97500 rows’ and ’87 columns’. Is this corresponds to ‘samples’ and ‘features’?
what is the ‘time step’ in my case?
This will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Hi Jason,
I would like to share my experience on the above code.
I copied the above reconstruction LSTM autoencoder for my one day water temperature, which is (96, 1). Now when I run for fist time the loss is much less and the reconstruction is pretty good. But when, I try to retrain again, loss increases and the reconstruction is not at all good.
Could you help me here how I could fix this issue, and why such issue is coming up.
Thanks.
Probably this is the reason: https://machinelearningmastery.com/different-results-each-time-in-machine-learning/
To “fix” it, you may want to reset the random seed to a fix number before you run. This way, the output will be the same every time.
Thanks Tam, the link was indeed helpful to fix the issue.
I have a next question, which I am not sure how to solve it.
With the same reconstruction LSTM autoencoder design,
I have channel first or # features as input but I want single channel output
“sequence = sequence.reshape((num_samples, num_features, n_in))”
I want out output to be single channel
yhat.shape –> (1, 1, n_in)
Is it possible
Yes, you just need to make your model to have a single output dimension.
Hi Jason,
You are of great help to my machine learning projects thanks to your blog!
My question;
Can a Kullback-Leibler divergence loss – as in variational autoencoders – be added to the bottleneck of the lstm autoencoder to disentangle the latent variables?
Or does one then need a specialised temporal disentangling term in the case of the lstm autoencoder?
I think it can do that.
As in; lstm already does that perfectly, or one can add a loss like Kullback-Leibler without temporal problems such as autocorrelation?
I don’t see LSTM always do it very accurately. You need to experiment and confirm whether you problem and dataset do well with LSTM (or a particular configuration of LSTM). If it does not, maybe you can add some tricks like you said.
I think RepeatedVector() confuses people (include me) because it represents a different architecture than the one shown in the first picture “LSTM Autoencoder Model”. The new architecture should have the edge under “copy” in the picture re-directed pointing to the input at each time step in the decoder. Let me know if I understand it correctly.
I used LSTM Autoencoder for extracting features. And then the classifier that used the extracted features gives less performance than the performance of the same classifier when it was run without the extracted features.
Any explanation for such a case?
Autoencoder is an unsupervised method because you don’t know the class while you encode it. If the autoencoder output suddenly make your “feature” and “class” relationship non-linear (which is possible because autoencoder is a lossy compression), you will see your classifier worse.
Do you mean If I change the output layer of autoencoder to be with linear activation function, would avoid the non-linear relationship?
I tried it and the performance increased a little bit but still less than the classifier that the one without using extraction features.
No. To remove nonlinear relationship entirely, you need to make sure every activation function in each part of the network are linear. But that would make your neural network model handicapped.
Hello, this is a great topic and article.
If I have multiple time-series (for example, several different sensors recorded at the same time), can I input a time-window of them to a LSTM Autoencoder so that the AT can learn both cross-correlation between them as well as time correlation ?
Will the reconstructed sequence be a result of the cross-correlation also ? Or, instead the AE will output the multiple time-series where each of them will be reconstructed independently from each other.
many thanks !
MC
Hi Michele…Hopefully the following will add clarity:
https://analyticsindiamag.com/how-to-do-multivariate-time-series-forecasting-using-lstm/
https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
Hi Jason,
Great posts!
Maybe you can clarify some doubts about the latent space of the standalone autoencoders;
In case of having an input sequence divided in 7 samples, of 200 timesteps each (for example), the latent space generated by the autoencoder will not be a single fixed length encoded vector, but a sequence with as many vectors as the number of samples,
that is to say, each sample will have a different encoded vector. How can I do to obtain a single vector that models all the samples?
I have tried with a stateful LSTM, but the resulting latent space is still a sequence of vectors, so I am not sure if the last vector of this sequence contains the information of all the samples or only the last one.
Thank you!!!
Hi Maria…The following may be of interest to you:
https://stackoverflow.com/questions/43809014/map-series-of-vectors-to-single-vector-using-lstm-in-keras
Hi Maria I am facing the same issue. Did you get the answer?
Hi Jason, thank you for your sharing. It helps me a lot.
I have a question on LSTM Autoencoder, but I cannot find any explanation:
why do we repeat the hidden representation vector for t times and see it as the input of the decoder rather than use the output sequence of the LSTM encoder directly?
Hi Aurora…the following discussion may be of interest:
https://ai.stackexchange.com/questions/16133/what-exactly-is-a-hidden-state-in-an-lstm-and-rnn
Hello James
Thank you for this great tutorial,
I am using AutoEncoder to detect anomalies, and my dataset is a numerical dataset that has ten columns (including the target label),
I don’t know what numbers to choose for the first argument in the encoder and decoder because all the examples I saw are images.
My code:
class AnomalyDetector(Model):
def __init__(self):
super(AnomalyDetector, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Dense(32, activation=”relu”),
layers.Dense(16, activation=”relu”),
layers.Dense(8, activation=”relu”)])
self.decoder = tf.keras.Sequential([
layers.Dense(16, activation=”relu”),
layers.Dense(32, activation=”relu”),
layers.Dense(9, activation=”sigmoid”)])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
Thank you so much.
Hi Sarah…You are very welcome! The following may be of interest:
https://towardsdatascience.com/step-by-step-understanding-lstm-autoencoder-layers-ffab055b6352
Also, for optimal performance, I would recommend that you investigate hyperparameter optimization based upon Bayesian Optimization
https://www.analyticsvidhya.com/blog/2021/05/bayesian-optimization-bayes_opt-or-hyperopt/
Hello James,
Thank you for your useful knowledge, I got an error when I reshape the input for the LSTM, can you advise me why i got this error and how to solve it.
# Reshape the input to shape (num_instances, timesteps, num_features)
train_data = train_data.reshape(train_data.shape[0], 1, train_data.shape[1])
Here is the error I got:
InvalidArgumentError: {{function_node __wrapped__Reshape_device_/job:localhost/replica:0/task:0/device:CPU:0}} Input to reshape is a tensor with 114581670 values, but the requested shape has 11458167 [Op:Reshape]
Thank you in Advance.
Really appreciate your hard work and the tutorials are great. I have learned a lot.
I was expecting that the LSTM with 2 decoders can outerperform the LSTM with 1 decoder (for prediction), which is oppostite to the results presented above.
I would like to know if you have some explanations for this
Hi Yiqun…When you observe that an LSTM model with one decoder outperforms one with two decoders, especially in a prediction task, there could be several explanations for this unexpected result. Understanding the dynamics of LSTM architectures and the specific setup of your decoders will help in identifying potential reasons. Here are some factors to consider:
### 1. **Model Complexity vs. Dataset Size**
– **Overfitting**: Adding more complexity (e.g., an additional decoder) to the model can lead to overfitting, especially if your dataset is not large enough to justify the extra complexity. Overfitting occurs when a model learns the details and noise in the training data to an extent that it negatively impacts the performance of the model on new data, making the simpler model (with one decoder) potentially more generalizable.
### 2. **Decoder Configuration**
– **Decoder Functionality**: The role and configuration of each decoder in the two-decoder setup are crucial. If the decoders are not properly aligned with distinct aspects of the prediction task or if they interfere with each other (e.g., redundant or conflicting outputs), the model’s performance can degrade.
– **Weight Sharing**: If the decoders share weights or if their training is not well-coordinated (e.g., through attention mechanisms or other forms of output regularization), this might also impact performance adversely.
### 3. **Data Representation and Sequence Learning**
– **Input Sequence Processing**: The way sequences are processed and fed into the LSTM and subsequently into the decoders can significantly influence performance. If the sequence representation or feature extraction is inadequate, adding more decoders won’t necessarily help.
– **Handling of Temporal Dependencies**: One decoder might be more effective at capturing the long-term dependencies required for the prediction task, whereas adding another decoder might lead to a dilution of these dependencies if not managed correctly.
### 4. **Learning Dynamics**
– **Gradient Flow and Learning Stability**: In networks with multiple decoders, especially in deep learning architectures like LSTMs, the flow of gradients during backpropagation can become unstable or inefficient (a problem often referred to as the vanishing or exploding gradient problem). This can make learning less effective compared to a simpler, single-decoder model.
– **Training Procedure**: The training dynamics, including learning rates, batch sizes, and epochs, might need different optimization when moving from one to two decoders. The configuration that worked for a single decoder might not be optimal for a more complex model.
### 5. **Evaluation Metrics and Model Tuning**
– **Metrics Sensitivity**: The evaluation metrics used to assess model performance can sometimes favor simpler models, depending on the task complexity and data characteristics. It’s essential to ensure that the metrics align well with the practical outcomes you expect from the model.
– **Hyperparameter Tuning**: The hyperparameters for the dual-decoder model may need more extensive tuning compared to the single-decoder model. This includes the number of LSTM units, the type of decoders, and their integration method.
### Suggested Steps to Improve the Dual-Decoder Model
– **Hyperparameter Optimization**: Review and optimize the hyperparameters for the two-decoder setup extensively.
– **Regularization Techniques**: Implement regularization strategies such as dropout, L2 regularization, or early stopping to prevent overfitting.
– **Advanced Architectural Features**: Consider integrating attention mechanisms that help the model focus on relevant parts of the input sequence, improving the synergy between the two decoders.
– **Cross-validation**: Use k-fold cross-validation to ensure the robustness of your model’s evaluation across different subsets of your dataset.
By considering these factors and experimenting with different configurations and training settings, you can better understand why your simpler model might currently be outperforming the more complex one and identify potential improvements.
Hello James,
Thank you for your useful knowledge, I was using the LSTM autoencoder for my time-series anomaly detection on AIOPS. I have a doubt when applying the LSTM AE. Let’s say I’m monitoring CPU usage metrics for different machines, for each machine, do I need to build an AE model and train the model only using the CPU usage metrics from that specific machine? Or I can train one AE model using all the CPU usage metrics data I have? This also leads to another question, what if I have other metrics for example, memory usage, do I need to train a new model for different metrics?
I would like to know if you have some recommendation or strategy for this
Hi Wanyi…Great question! When applying LSTM Autoencoders (AEs) for time-series anomaly detection in AIOps, the strategy for model training depends on the nature of your data, the relationships between the metrics, and the scale at which anomalies need to be detected. Here’s a breakdown of the options and recommendations:
—
### **1. Train an Autoencoder for Each Machine Separately**
– **Use case**: When machines exhibit unique behavior patterns and there is little similarity between their CPU usage time-series data.
– **Advantages**:
– The model can better learn the specific patterns and nuances of each machine.
– Anomalies are easier to detect because the model focuses on each machine’s baseline behavior.
– **Disadvantages**:
– High computational cost, as you’ll need to train and maintain a separate model for each machine.
– Does not leverage shared patterns across machines.
—
### **2. Train a Single Autoencoder for All Machines**
– **Use case**: When machines have similar behavior or share general patterns in their CPU usage metrics.
– **Advantages**:
– Lower computational cost, as only one model is needed.
– The model can generalize well across machines if their behavior is consistent.
– **Disadvantages**:
– Anomalies specific to individual machines might be harder to detect due to the model’s generalized view.
**Recommendation**:
– Start by normalizing the CPU usage metrics for each machine (e.g., z-score normalization or min-max scaling) to account for differences in scale.
– Use machine identifiers as part of your feature set if there are subtle variations between machines that you want the model to learn.
—
### **3. Train Separate Models for Each Metric (e.g., CPU and Memory Usage)**
– **Use case**: When different metrics (e.g., CPU and memory usage) exhibit significantly different patterns and relationships.
– **Advantages**:
– Each model can specialize in learning the patterns of a single metric.
– **Disadvantages**:
– You’ll need multiple models if monitoring several metrics, increasing computational complexity.
—
### **4. Train a Multi-Metric Autoencoder**
– **Use case**: When you have multiple metrics for the same machine (e.g., CPU, memory, disk I/O) and there are relationships between these metrics.
– **Advantages**:
– The autoencoder learns both individual patterns and correlations between metrics, potentially providing better anomaly detection.
– Detects anomalies that span across multiple metrics (e.g., unusual correlation between CPU and memory usage).
– **Disadvantages**:
– Requires more sophisticated preprocessing and feature engineering.
– May need more training data to capture the relationships effectively.
**How to Implement**:
– Combine metrics into a single input vector (e.g., concatenate CPU, memory, and disk metrics).
– Normalize each metric independently before feeding it into the model.
– Use a multi-variate LSTM AE architecture.
—
### **Strategies and Recommendations**
1. **Start Simple**:
– If you have a small dataset or are new to anomaly detection, train a single AE model per metric, per machine. This is easier to debug and interpret.
2. **Experiment with Generalization**:
– If machines share similar behavior, try training a single AE model using data from all machines, ensuring metrics are normalized.
3. **Use Multi-Metric Models for Correlated Metrics**:
– For example, train a multi-variate LSTM AE that takes CPU, memory, and disk usage together as input. This can capture inter-metric anomalies.
4. **Data Preprocessing**:
– Always normalize the data to handle scale differences between machines or metrics.
– Consider using sliding windows to convert time-series data into sequences for the LSTM.
5. **Validation and Monitoring**:
– Use a validation set to ensure the model generalizes well to unseen data.
– Regularly monitor the model’s performance using a threshold on reconstruction error, and adjust the threshold as needed.
—
### **When to Retrain the Model**
– If the behavior of a machine or metric changes significantly over time (e.g., hardware upgrades or software changes), you may need to retrain the model to adapt to the new baseline.
—
### **Advanced Recommendations**
– **Transfer Learning**: Train a generic model on data from all machines, then fine-tune it on data from specific machines if needed.
– **Clustering Machines**: Group machines with similar behavior patterns (using clustering methods like K-Means) and train one model per cluster.
– **Anomaly Aggregation**: If using separate models for machines or metrics, aggregate anomaly scores across models to detect overall system anomalies.
—
By combining these strategies, you can design an efficient and scalable anomaly detection system tailored to your AIOps needs.