Gentle introduction to the Stacked LSTM
with example code in Python.
The original LSTM model is comprised of a single hidden LSTM layer followed by a standard feedforward output layer.
The Stacked LSTM is an extension to this model that has multiple hidden LSTM layers where each layer contains multiple memory cells.
In this post, you will discover the Stacked LSTM model architecture.
After completing this tutorial, you will know:
- The benefit of deep neural network architectures.
- The Stacked LSTM recurrent neural network architecture.
- How to implement stacked LSTMs in Python with Keras.
Kick-start your project with my new book Long Short-Term Memory Networks With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Gentle Introduction to Stacked Long Short-Term Memory Networks
Photo by Joost Markerink, some rights reserved.
Overview
This post is divided into 3 parts, they are:
- Why Increase Depth?
- Stacked LSTM Architecture
- Implement Stacked LSTMs in Keras
Why Increase Depth?
Stacking LSTM hidden layers makes the model deeper, more accurately earning the description as a deep learning technique.
It is the depth of neural networks that is generally attributed to the success of the approach on a wide range of challenging prediction problems.
[the success of deep neural networks] is commonly attributed to the hierarchy that is introduced due to the several layers. Each layer processes some part of the task we wish to solve, and passes it on to the next. In this sense, the DNN can be seen as a processing pipeline, in which each layer solves a part of the task before passing it on to the next, until finally the last layer provides the output.
— Training and Analyzing Deep Recurrent Neural Networks, 2013
Additional hidden layers can be added to a Multilayer Perceptron neural network to make it deeper. The additional hidden layers are understood to recombine the learned representation from prior layers and create new representations at high levels of abstraction. For example, from lines to shapes to objects.
A sufficiently large single hidden layer Multilayer Perceptron can be used to approximate most functions. Increasing the depth of the network provides an alternate solution that requires fewer neurons and trains faster. Ultimately, adding depth it is a type of representational optimization.
Deep learning is built around a hypothesis that a deep, hierarchical model can be exponentially more efficient at representing some functions than a shallow one.
— How to Construct Deep Recurrent Neural Networks, 2013.
Need help with LSTMs for Sequence Prediction?
Take my free 7-day email course and discover 6 different LSTM architectures (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Stacked LSTM Architecture
The same benefits can be harnessed with LSTMs.
Given that LSTMs operate on sequence data, it means that the addition of layers adds levels of abstraction of input observations over time. In effect, chunking observations over time or representing the problem at different time scales.
… building a deep RNN by stacking multiple recurrent hidden states on top of each other. This approach potentially allows the hidden state at each level to operate at different timescale
— How to Construct Deep Recurrent Neural Networks, 2013
Stacked LSTMs or Deep LSTMs were introduced by Graves, et al. in their application of LSTMs to speech recognition, beating a benchmark on a challenging standard problem.
RNNs are inherently deep in time, since their hidden state is a function of all previous hidden states. The question that inspired this paper was whether RNNs could also benefit from depth in space; that is from stacking multiple recurrent hidden layers on top of each other, just as feedforward layers are stacked in conventional deep networks.
— Speech Recognition With Deep Recurrent Neural Networks, 2013
In the same work, they found that the depth of the network was more important than the number of memory cells in a given layer to model skill.
Stacked LSTMs are now a stable technique for challenging sequence prediction problems. A Stacked LSTM architecture can be defined as an LSTM model comprised of multiple LSTM layers. An LSTM layer above provides a sequence output rather than a single value output to the LSTM layer below. Specifically, one output per input time step, rather than one output time step for all input time steps.
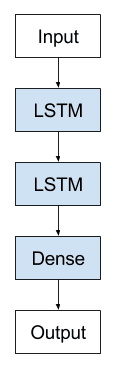
Stacked Long Short-Term Memory Archiecture
Implement Stacked LSTMs in Keras
We can easily create Stacked LSTM models in Keras Python deep learning library
Each LSTMs memory cell requires a 3D input. When an LSTM processes one input sequence of time steps, each memory cell will output a single value for the whole sequence as a 2D array.
We can demonstrate this below with a model that has a single hidden LSTM layer that is also the output layer.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Example of one output for whole sequence from keras.models import Sequential from keras.layers import LSTM from numpy import array # define model where LSTM is also output layer model = Sequential() model.add(LSTM(1, input_shape=(3,1))) model.compile(optimizer='adam', loss='mse') # input time steps data = array([0.1, 0.2, 0.3]).reshape((1,3,1)) # make and show prediction print(model.predict(data)) |
The input sequence has 3 values. Running the example outputs a single value for the input sequence as a 2D array.
|
1 |
[[ 0.00031043]] |
To stack LSTM layers, we need to change the configuration of the prior LSTM layer to output a 3D array as input for the subsequent layer.
We can do this by setting the return_sequences argument on the layer to True (defaults to False). This will return one output for each input time step and provide a 3D array.
Below is the same example as above with return_sequences=True.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Example of one output for each input time step from keras.models import Sequential from keras.layers import LSTM from numpy import array # define model where LSTM is also output layer model = Sequential() model.add(LSTM(1, return_sequences=True, input_shape=(3,1))) model.compile(optimizer='adam', loss='mse') # input time steps data = array([0.1, 0.2, 0.3]).reshape((1,3,1)) # make and show prediction print(model.predict(data)) |
Running the example outputs a single value for each time step in the input sequence.
|
1 2 3 |
[[[-0.02115841] [-0.05322712] [-0.08976141]]] |
Below is an example of defining a two hidden layer Stacked LSTM:
|
1 2 3 4 |
model = Sequential() model.add(LSTM(..., return_sequences=True, input_shape=(...))) model.add(LSTM(...)) model.add(Dense(...)) |
We can continue to add hidden LSTM layers as long as the prior LSTM layer provides a 3D output as input for the subsequent layer; for example, below is a Stacked LSTM with 4 hidden layers.
|
1 2 3 4 5 6 |
model = Sequential() model.add(LSTM(..., return_sequences=True, input_shape=(...))) model.add(LSTM(..., return_sequences=True)) model.add(LSTM(..., return_sequences=True)) model.add(LSTM(...)) model.add(Dense(...)) |
Further Reading
This section provides more resources on the topic if you are looking go deeper.
- How to Construct Deep Recurrent Neural Networks, 2013.
- Training and Analyzing Deep Recurrent Neural Networks, 2013.
- Speech Recognition With Deep Recurrent Neural Networks, 2013.
- Generating Sequences With Recurrent Neural Networks, 2014.
Summary
In this post, you discovered the Stacked Long Short-Term Memory network architecture.
Specifically, you learned:
- The benefit of deep neural network architectures.
- The Stacked LSTM recurrent neural network architecture.
- How to implement stacked LSTMs in Python with Keras.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop LSTMs for Sequence Prediction Today!

Develop Your Own LSTM models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Long Short-Term Memory Networks with Python
It provides self-study tutorials on topics like:
CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Skip the Academics. Just Results.
 From Scratch With Python")





Thanks alot Jason !
Your blog is wonderful
Please keep up the great work
Best regards/ Thabet
Thanks Thabet.
Hello! Iam dealing with a dataset with a shape (5300,5,320,2), actually is an array, of 5 shapes of double arrays, each of them having 320 elements.
How can I train a lstm model with a dataset like this? Because when i run the train is says that can’t train with this shape only if i change it with (5300,5,320,1)..
Yes, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Hi Jason,
After first stack of LSTM layer, Don’t we need ‘input_shape’ or ‘batch_input_shape’? Need your expert comment.
No, the input specification is only needed on the first hidden layer.
Thanks for your response
Can you specify when this approach is needed?
Wonderful work, thanks!
Hard question, nice.
Perhaps generally when you think there may be a hierarchical structure in your sequence data. You can try some stacked LSTMs and see how it impacts model skill.
Stacked LSTMS will likely need more epochs to complete training, use normal model diagnostics.
Hello, could you please explaine more about hierarchical structure? What does this mean?
It just mean stacking different layers to produce the final output. In LSTM, you use one layer of LSTM to convert one sequence to another (e.g. English to French). Then another layer of LSTM to convert that sequence again (e.g. French to German).
Hi Jason, thanks for your work!
If I have a large size of data, I want to train a Stacked LSTMS about 30 layers.
Can you tell me if I train a 30 layers Stacked LSTMS, what do I need to pay attention to?
Why 3 or 4 layers Stacked LSTMS are common?
would the 30 layers Stacked LSTMS work?
That is a lot of layers, I have not developed LSTMs that deep myself. I cannot give you good advice.
Generally, there are diminishing returns beyond 4 layers.
Thank you I think you for your answer, I think that probably there are to much layers and to try to summarize:
Its necessary and a Dropout and/or Dense(1 LSTM,1Drop, 1 Dense) layer for every LSTM layer in a model or that is almost the same that for example (2 LSTM, 1Drop, 1Dense)
Thank you in advance
Hi Jason,
I have implemented a LSTM network with 2 layers and on adding 3rd layer, the performance dropped. LSTM is supposed to avoid vanishing gradient problem, then how the performance drop on adding more layers?
Thank you in advance
You may need to adjust properties of the learning algorithm after increasing the capacity of the model, such as batch size, learning rate and more.
Hello Jason!
Could you please point on how to adjust learning rate and batch size when stacking LSTM layers. I am training a stacked LSTM for time series prediction. I reduced the number of timesteps and the number of LSTM units from what I was using for vanilla LSTM. There is a definite reduction in MSE. However, after ten to twelve epochs, the train loss does not change at all and there is only marginal change in validation loss, in the order of 10e+6, which seems to stop improving after some twenty epochs. Could you help me understand this behavior and get around my problem.
Thanks for this wonderful post.
This can help with learning rate:
https://machinelearningmastery.com/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/
This can help with batch size:
https://machinelearningmastery.com/how-to-control-the-speed-and-stability-of-training-neural-networks-with-gradient-descent-batch-size/
Hello Jason,
Like always, very useful article,
I have a question for you
I am get use to add LSTM labels in this way:
layers=shape = [4, seq_len, 1] # feature, window, output
# neuros=neurons = [128, 128, 32, 1]
LSTM, Dropout and Dense.
model.add(LSTM(250, input_shape=(layers[1], layers[0]), return_sequences=True))
model.add(Dropout(d))
model.add(LSTM(neurons[1], input_shape=(layers[1], layers[0]), return_sequences=True))
model.add(Dropout(d))
model.add(LSTM(neurons[2], input_shape=(layers[1], layers[0]), return_sequences=False))
model.add(Dropout(d))
model.add(Dense(neurons[2],kernel_initializer=”uniform”,activation=’relu’))
model.add(Dense(neurons[2],kernel_initializer=”uniform”,activation=’relu’))
model.add(Dense(layers[0],kernel_initializer=”uniform”,activation=’linear’))
model.compile(loss=’mse’,optimizer=optimizador, metrics=[‘accuracy’])
There is any difference if I add only LSTM I mean something like that
model.add(LSTM(250, input_shape=(layers[1], layers[0]), return_sequences=True))
model.add(LSTM(neurons[1], input_shape=(layers[1], layers[0]), return_sequences=True))
model.add(LSTM(neurons[2], input_shape=(layers[1], layers[0]), return_sequences=False))
model.add(Dense(neurons[2],kernel_initializer=”uniform”,activation=’relu’))
model.add(Dropout(d))
model.compile(loss=’mse’,optimizer=optimizador, metrics=[‘accuracy’])
Thank you in advance
Perhaps you could summarize your question?
Hello Jason,
First of all thank you for all your work on your website it is very useful.
I am implementing in keras a stacked lstm network for solving a many to many sequence problem, I would like to know if for that kind of problem you would still put the parameter return_sequences at the value False for the last lstm layer ?
Thank you in advance.
No need to return the sequence on the last layer.
Perhaps this tutorial will help:
https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/
I’m currently working on a LSTM model using just one hidden layer. I was wondering if you know how to best approach whether or not to expand and add more layers.
Is there a general rule of thumb as to how and why to add more hidden layers and build more deeply when working with time series forecasting?
Also, how well does adding layers scale with the size of training data. I’m trying to compare training data from 1000 (lower end) to over 100,000 points of training.
More layers offers more abstraction of the input sequence.
No good theories or rules of thumb around this that I have seen.
Thanks!
Then I’ll continue my research and see if I can find anything any correlation between adding more layers and the accuracy of the predictions.
Hi Jason, good post. Would you say that the use of a stacked LSTM is equivalent (or better / worse) in terms of predictive capabilities versus a feedforward network of a few hidden layers which then feeds into a single layer LSTM?
My line of thinking is if I had a dataset with interesting relationships between the input features themselves, but also as those features change over time, I would expect to get interesting results both from a feedforward network, and an LSTM … does a stacked LSTM get the best of both worlds?
It can, but it really depends on the specifics of the problem and the relationships being modelled.
For example, deep encoder-decoder LSTMs do prove very effective at NLP problems with long sequences of text.
Hey there.
What happens to the computation time needed to train a stacked LSTM? If i have a LSTM with one layer, does a stacked LSTM with m layers need m times as much computation time?
It depends on your hardware. It is slower, but perhaps not 200% slower.
Dear Jason,
Very interesting approach, however I wonder if this is trained using regular backpropagation. I ask this due to the problems backpropagation has when dealing with deep-NN, particularly:
– Diffusion of gradient problem where gradients that are backpropagated rapidly decrease in magnitude as the depth of the network increases.
– Appearance of many bad local minima.
I know there are some approaches for greedy-training layer by layer, is this performed by Keras automatically? Or perhaps is there a maximum network-depth that can be dealt with regular backpropagation?
Thank you for your help.
Yes, but Backprop through time, you can learn more here:
https://machinelearningmastery.com/gentle-introduction-backpropagation-time/
Yes, Keras does this for us automatically.
Thank you for your reply! However, as BPTT unrolls the network by timesteps, which makes the network seem as an even deeper network as each timestep becomes kind of a new layer; doesn’t this makes the Diffusion of gradient problem worse?
Additionally, I have a small code question, i.e.:
In the part where you add a LSTM layer, say “model.add(LSTM(1, return_sequences=True, input_shape=(3,1)))”, the first parameter which you input as 1, defines the number of “units” in the layer. This usually also defines the number of outputs it would have, I wonder if the “return_sequences=True” supersedes this and outputs as many inputs as you have?
Thank you for your help.
The input_shape defines the shape of inputs to the network.
The 1 refers to the number of units in the first hidden layer which is unrelated to the number of input time steps.
Return sequences returns a vector for each input time step instead of one vector at the end of the input sequence.
Does that mean if there are 100 samples and 60 time steps per sample, return_sequences=True will return 60 vectors of hidden states? But if one hidden state is returned per one sample that goes into the LSTM layer, wouldn’t there be 100 hidden states returned instead of 60?
Hi Robin…Please clarify which code listing portion you are considering.
Hello Jason,
Thanks a lot for your work. Your blog really did spark a huge interest in me towards neural network.
I have read one of your suggested article which is “How to Construct Deep Recurrent Neural Networks”. I wonder whether the novel type of RNN mentioned in that article can be constructed using keras with tensorflow backend.
Again, good job and please keep up the good work!
Best regards,
Kamarul
I don’t know, sorry.
Hello Jason!,
Just as the other people before, first of all thanks for this amazingly helpful blogs and tutorials.
One question regarding this stacked LSTMs NN.
I see you seem to always need a Dense layer to give the final output of the stacked network.
Is that really so? and why is it necessary? does the absence of that Dense layer affect for good or worse the performance of the LSTMs network?
Thanks again,
We need something at the output end of the network to make an output that we can interpret as a prediction.
You could try an LSTM layer, I have never done so.
Can stacked LSTM’s learn feed sequence order? For example let’s say I had a random list of a billion numbers that I wanted returned in order. If numbers that are close together in the sort appear at opposite ends of the sequence the LSTM memory may lose track. However if a stack of LSTM’s could learn to rearrange the sequence as it moves up the stack I imagine that could help.
Currently Im taking a stack of LSTM’s with N outputs and sorting the input sequence between the stacks by one of the output values at each time step. As far as I can tell there is no way to associate gradient with a sorted index so it can only learn to sort through reinforcement (I think).
Interesting question. I think (gut intuition) it may be too challenging for the LSTM.
Hello, Jason
I want to use simple or stack lstm network or arrangement of the layer, in parallel. Because of my feature sequence have information from different domain and have difference in morphology.
You can use a multi-headed model, for example:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Awesome tutorials,
I have a question which can be very basic one but i’m struggling with it.
You said the 1 refers to the number of units.is it means the number of LSTM cells in that layer?
as far as my knowledge number of lstm cells in first layer is same as to number of time stamps,if that so what 1 actually means?
Thank you
No, the number of time steps and the number of LSTM units in the first hidden layer are not related.
what is the number of LSTM units in the first hidden layer then? what controls this?
The input layer to the model is defined by you and is unrelated to the number of units in the first hidden layer of the network.
Oh forget this question.last time i posted it was not shown in the comments area that why i put another one 😀 sorry.
All comments are moderated:
https://machinelearningmastery.com/faq/single-faq/where-is-my-blog-comment
Hi Jason,
The article states that:
“building a deep RNN by stacking multiple recurrent hidden states on top of each other. This approach potentially allows the hidden state at each level to operate at different timescale”
I was wondering what “operate at different timescale” meaning, i.e. the meaning of “timescales” in LSTMs and how stacked LSTM helps with that.
Thanks
Subsequent layers can abstract prior layers.
Hello,
Thank you for a very helpful blog.
I have comment according to Sequential class. Building stacked RNN using keras.layers.RNN + keras.layers.LSTMCell might give better performance (15pct faster):
https://gist.github.com/fchollet/87e9a3e0539ce268222d1d597864c098
Thanks.
Thanks Jason, your perfect
I have a question:
Is it possible to save output of penultimate layer in every epoch in keras?
Thanks
Yes, you could have model with two output layers, one is the normal output and one from the second last layer, then run each epoch manually and save the prediction from the second output layer as required.
Hi Jason,
Is “stacked LSTMs” the same concept with the so-called “Parallel LSTMs”?
What is parallel LSTMs?
Jason,
This is great work, and very generous to provide to the community.
Thank you for doing your work in this way!
Do you have the time and desire to take on some AI work, just to look over some implementations we’ve done, and talk through what is good about it, what may be able to be improved, etc…?
If not, no problem at all, but if you do, please let me know,
Thank you for your time,
Thanks for asking, this is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-you-do-some-consulting
Thanks, Jason, It’s so valuable to me. I am a new to LSTM, I have one question:
Like you mentioned in this blog, It will return one output for each input timestep, And I am here to ensure if I am right in terms of the time step. e.g: The reshaped data is [[[ 0.1][ 0.2][ 0.3]]], The [0.1] represents time step1 input, The [ 0.2] represents time step2 input and The [ 0.3] represents time step3 input. Am I right?
I have more help on how to prepare data for the LSTM here:
https://machinelearningmastery.com/faq/single-faq/how-do-i-prepare-my-data-for-an-lstm
Hello Jason,
As usual fantastic article.
I have a question what is the different between stacking LSTM network one on the other to add more dense layers?
model = Sequential()
model.add(LSTM(…, return_sequences=True..
model.add(LSTM(…))
model.add(Dense(…))
VS
model = Sequential()
model.add(LSTM(…, return_sequences=True…
model.add(Dense(…))
model.add(Dense(…))
That every dense layers is fully connected.
Thanks
Yes, they are different. One is a stacked LSTM and one is an LSTM with lots of dense layers.
Perhaps I don’t follow your question?
Hii
I think my question is not clear
What is the different of stacked LSTM that each LSTM contains one layer to one LSTM that contains multi Dense layers? from the network structure aspects and accuracy ?
If I define the dense layer with the same nueron as in the LSTM stack layer
Thanks
MAK
The difference in the capability between the models really depends on the specific problem.
Generally, more depth of the RNN can help with complex sequence data. More depth of the fully connected would likely be less beneficial. Try both and compare on your problem.
last LSTM(…) return_sequences=True or false?
False.
Hello Jason,
Thanks for your great article.
In case of I have 3 part of data, lets say node a, node b, node c.
node a is a sequence of a’s position, same goes to node b and node c.
so, do I need to make 3 of the LSTM layer at once,
or every node run in different process and own the stacked lstm layer?
Thanks,
Best Regards
Perhaps explore a few different framings of your prediction problem and see what works best?
Thanks, I did the option 2, and it gave a good result, now I need to optimize.
Hello Jason,
if the input dimension is the 2D,
model = Sequential()
model.add(LSTM(…, return_sequences=True…
model.add(LSTM(…, return_sequences=True…
model.add(Dense(…))
model.add(Dense(…))
Can be the stacked LSTM?
No, LSTMs assume each sample has time steps and features.
Thanks.
If I reshpae input as ( none , 1, 10) before beginning model
model.add(LSTM(…, return_sequences=True…
model.add(LSTM(…, return_sequences=True…
model.add(Dense(…, input_shape=(None,1)…
model.add(Dense(1))
Can this model be stacked?
I am studying the completed code above this, but why the code maker did put dense input shape none,1.
All of each layer output shape is 3 dimension
No, I don’t believe so. You must either change the second LSTM to not return sequences or change the dense part of the model to support sequences via a time distributed wrapper.
Hello Jason
your blog helps me every time thanks for that
I have a question
I read an example that uses stacked LSTM for seq2seq problem but the input was given in reverse to network.
please help me why it happens
It can be helpful to provide input in reverse or bidirectional at the same time. See this post:
https://machinelearningmastery.com/develop-bidirectional-lstm-sequence-classification-python-keras/
Hi Jason,
Thanks for the article. I try to understand the main intuition behind on Vanilla and Stacked LSTM. I understand that generally, for the network adding more layer makes it learn difficult tasks better. You have used the sentence like “Given that LSTMs operate on sequence data, it means that the addition of layers adds levels of abstraction of input observations over time. In effect, chunking observations over time or representing the problem at different time scales”. I do not understand here what do you mean exactly about the abstraction of input observations over time. How does it chunk observations over time or representing the problem at different time scales? I would be happy if you could answer this.
Kind Regards,
Gunay
I am hypothesising about what might be going on, we cannot know for sure without an analysis of what each layer has learned.
Hello Jason Brownlee , before I ask my question I would like to thank you for these amazing tutorials on deep learning using LSTMs.
Problem I faced:
My sequence length is 50 and when I gave lstm units to be 100, I started the loss to be nan.
When I changed the LSTM units to be 50, I stopped getting the loss to be nan for the first epoch but it started to give nan after that.
Q: Should the number of LSTM units be decided according to the sequence length (time steps for one example) ?
I don’t think it is related to the number of units.
Perhaps try scaling your data first?
Hi Jason,
Thank you so much for your great tutorials. This website has everything 🙂
I have a question about stacked LSTM? How can I choose the number of layers for the whole stacked LSTM? and does increasing the layers mean more accuracy and better performance?
Thank you in advance
Thanks!
Tune the number of layers based on the skill of the model on your specific dataset.
More explanation here:
https://machinelearningmastery.com/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
Hello Jason,
Thank you very much for your articles about RNN and LSTM. Really helped me through the hard times.
However, I’m still a beginner in this field. Let’s say that I want to make a network with only one LSTM followed by Dense layers.
Should I use “return_sequences = True” on the LSTM or leave it be (so that the value will be False) ?
I’m still confused about where to use “return_sequences = True”. Do we only use it when we want to stack LSTM with another LSTM?
Thank you very much for your assistance.
Return sequences will return the output of the layer for each input, instead of just the output at the end of the sequence.
No, return sequences would be false in most cases.
Thank you for replying.
I have another question. Let’s say we’re going to build stacked LSTM with first LSTM layer contains 200 units and second layer contains 100 units.
I have a hard time visualizing this. If both layers have the same units, I can simply visualize it like first cell of the first LSTM layer passing hidden states to first cell of the second LSTM layer.
If the layers have different units, how do I visualize it?
Thank you very much, you really helped me in understanding Deep Learning in a practical way
No, all outputs from the first layer are passed to each unit in the second layer. Each unit in a layer is like an independent neural network – they do not communicate with each other within the layer or divide the work.
Hi Jason,
Firstly I wanted to thanks for all your blogs which had almost clarified ML doubts that comes to my mind.
I am working on Human activity recognition dataset from UCI, when I used a single layer LSTM (96 cells) I got an accuracy of around 91 % for 30 epochs, but when I tried stacking one more LSTM layer on top of that the accuracy decreases tremendously and after certain epochs the train accuracy stays at around 0.16. Is there any reason behind that ?
You may have to tune the learning rate and batch size for the change in capacity to the model.
More here:
https://machinelearningmastery.com/how-to-control-neural-network-model-capacity-with-nodes-and-layers/
Dear Jason,
When we do the stacked LSTM model as indicated, the last step takes only the state “h_n” from the last layer, or it includes all hidden states “h1”, “h2”, …, “h_n” from all the layers?
Only from the prior layer.
Thank you, sir. Can I say, then, that the regular stacked LSTM in Keras does not implement the deep Encoder-Decoder architecture (proposed by Sutskever, Vynials e Quoc Le/Google), right? Because in this work (I’m not sure you are familiar with this paper, sorry to talk about a specific case) the hidden state to be decoded is not just the last layer hidden state, but it should be the concatenation of all hidden states from all layers. They justify that saying that since the state should capture all of the sentence, using states from all layers help to preserve the enconding of the entire input sentence.
Thanks for the information. I’ve searched the Keras API and that was not clear to me.
Most of the examples I provide use an autoencoder structure:
https://machinelearningmastery.com/lstm-autoencoders/
For an example implemented in the paper, see:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Thanks a lot, Jason. When I have the required time and background I’ll purchase your book too, thanks!
Thanks.
Hi Jason!
This was a very good explanation of stacked LSTM.
I wonder, have you ever encountered or heard of deep gates? I started learning about LSTM a while back but the only gate architecture I’ve seen so far consist of a single layers. This was surprising since I had assumed that the gates could vary in depth.
It’d be a great relief if you could answer this question, it’s bugging me constantly and I can’t find any answers on my google searches.
Sorry, I have not.
Hi,
I was wondering what happens with the states, are they passed between different LSTM layers or the only communication between them is the output sequence?
Typically the states are not passed between layers, only the output of each node at each input time step.
So, specifically in Keras if you have this:
decoded = LSTM(…,return_sequences=True)(inputs, initial_state=[h,c])
output = LSTM(…)(decoded)
which states does the 2nd layer uses for the 1st cell?
If I’m doing an encoder-decoder with multiple LSTM shouldn-t I pass the encoder_states to every LSTM layer in the decoder?
Like this:
decoded = LSTM(…,return_sequences=True)(inputs, initial_state=[h,c])
output = LSTM(…)(decoded, initial_state=[h,c])
Or may be like this:
decoded = LSTM(…,return_sequences=True)(inputs, initial_state=[h1,c1)
output = LSTM(…)(decoded, initial_state=[h2,c2])
where h1,c1 are from the 1st LSTM layer in the encoder and h2,c2 from the 2nd.
Thanks for the answers!
Good question, see this post:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Hey Jason,
I have a question. I think I understand how a stacked LSTM layer is connected if there is only one LSTM cell per layer. I’m not sure however, how the LSTM cells would be connected if there are multiple LSTM cells per layer. Does each cell in the first layer return a sequence which is passed to EVERY single cell in the next layer? I tried to implement that in Keras but the second LSTM layer has a suspiciously low amount of parameter :/ .
I hope I posed the question well. Thanks in advance
Excellent question.
The entire output sequence from one layer is provided as input to each node in the next layer.
Does that make sense?
I really appreciate you, Jason.
I have a stack-GRU for sentiment analysis that always predicts the label of sentiment +1 ane the accuracy is 0.
in your expriece, what are heuristics to improve the results?
Thanks
See this:
https://machinelearningmastery.com/improve-deep-learning-performance/
Thanks for the great tutorial. Is there any way to initialize the second layer LSTM with the final hidden state vector of the first LSTM?
Perhaps, not sure I have done this before – it does not make sense. I recommend experimenting.
Thanks. It’s basically what conditional encoding does where two LSTMs are arranged sequentially. The first set of text is sent through the first LSTM layer, and then another LSTM layer is initialized with the final hidden state vector of the first LSTM. The final prediction is then made using only the final hidden state of the second LSTM.
You might be referring to an encoder-decoder:
https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/
Hi Jason.
Thanks for the great tutorial.
What is the difference between DENSE and LSTM layer?
For example:
Model1- model.add(LSTM(50, input_shape=(x_train.shape[1], x_train.shape[2])))
model.add(Dense(16, activation=’relu’))
Model2- model.add(LSTM(50, return_sequences=True, input_shape=(x_train.shape[1], x_train.shape[2])))
model.add(LSTM(50, activation=’relu’))
Also, how does using more than one dense layer and lstm layer benefit the model?
Thank you very much for your assistance.
Dense is an MLP layer, LSTM is an RNN layer:
https://machinelearningmastery.com/when-to-use-mlp-cnn-and-rnn-neural-networks/
More than one layer increases the capacity of the model:
https://machinelearningmastery.com/how-to-control-neural-network-model-capacity-with-nodes-and-layers/
Thanks Jason for your response.
You are a great person.
You’re welcome.
Hi there! Would it be beneficial to use attention is such an architecture? What would the new model look like?
It may.
I hope to write about this in the future.
Hi Jason,
Very good post.
If I have created data out from a physical equation and I know the response is linear (and stochastic).
There’s really no point in adding more layers, right? How would you go about improving the predictions of data of this type?
Thanks!
Perhaps some of the techniques here will help:
https://machinelearningmastery.com/start-here/#better
hi.mr brownlee.thanks a lot for your works in the field of dl
my question is that whether is their any relation(connection) between units of lstm in a lstm layer?if yes how is the relation.
second:are lstm units of a lstm layer fully connected with lstm units of next lstm layer?
third:we are saying lstm has output so why do you add a dense layer to end of network?
please anwer i’m waiting
A LSTM layer contains one or more LSTM units.
Each LSTM unit in one layer receives all of the outputs for each time step provided by all units in the previous layer.
Hey Jason,
I don’t usually make comments but your posts have been helping me a lot. I am a Master student at Imperial College of London and I have been developing my master thesis around electricity price predictions. I have been stuck on a few problems when designing my first LSTM architectures and some of the posts you have were very helpful. I also got a couple of your e – books which for now have been quite insightful as well.
Thank you for all the information you make available online, it is really a life-saver.
Thank you for your kind words, I’m happy to hear that the tutorials are helpful to your project!
Great tutorial as always! quick question: if I use a stacked model with two or three LSTM, will I have to set the same number of neurons for all of them?
e.g.,
model.add(LSTM(100….
model.add(LSTM(100….
model.add(LSTM(100….
model.add(dense…..
Thanks!
No, the number of nodes in each layer can vary.
Dear Jason, I also need to ask that if I put a BiLSTM layer after a LSTM layer than that model will be recognized as a stacked LSTM model or a hybrid LSTM-BiLSTM model ???
Thank You
Perhaps try it and see if it adds value.
Dear Jason, I don’t get you. Will it be called a stacked LSTM model or a hybrid LSTM-BiLSTM model ???
It would be stacked LSTM. I guess you can call it anything you want.
Hi Jason,
How do I build a RNN model where the number of layers can be passed as an argument?
For example, instead of adding 3 layers, a parameter for number of layers can be passed saying how many layers the model will have?
Thank you for your time.
You can write a custom function to do this directly.
your blog is wonderful!
Thank you!
Thanks Hanna!
Can I get code of stacked lstm for the data prediction in matlab
Sorry, I don’t have any examples for matlab.
Do LSTM layers have any sort of dimension constraints based on the number of cells in the previous layer, like in case of Convolution Layers?
No.
Many thanks for your share.
You’re welcome.
Hi Jason,
I am a beginner in ML. I am working to implement a DL model for sound even detection and I have to use three stacked bidirectional GRU and implement a model (http://s000.tinyupload.com/?file_id=67274108343396417068). Please note that the attached diagram is part of a bigger model. I need help to implement the stacked BiDirectional GRU layers and upsample the output to get the dimension of (512 x 128), which is the dimension of the input feature.
I am trying to implement the model (Fig. 1) from paper (https://arxiv.org/pdf/1911.06878.pdf)
That sounds great.
Are you having a specific problem with your model?
Hi Jason,
Yes, I am facing dimensionality issues.
Actually my feature file dimension (time x frequency) is (512 x x128) . My input layer dimension of the hourglass (HG) is (512, 128, 1). When I input this feature to the hourglass model (as shown in figure 1 of the paper), I get four multi-scale outputs from the hourglass with dimensions :
(None, 64, 16, 128), (None, 128, 32, 128), (None, 256, 64, 128) and (None, 512, 128, 128). Here 128 (index 3 in each output dimension) is no of channel of HG.
Now, according to the paper I need to pass each branch (one of the four multi-scale outputs from HG) through the Bi-GRU > upsampling module > Fully Connected layers > Sigmoid.
Now, the problem is that Bi-GRU accepts 3D input. So I have to use a 1×1 convolution layer to reduce channels from 128 to 1 followed by reshaping the tensor from 4D to 3D.
It is given that “Since the output’s dimensions of all scales are different, the dimension of the input layer and the hidden layer of these GRU modules are also different. The dimension of input layers and hidden layers are [16, 32, 64, 128] and [32, 32, 64, 64] respectively, and the number of the hidden layer is 3”
PROBLEM:
1)should I use return_sequence as True in all three Bi-GRU layers?
2) As Output of Bi-GRU module is 2D/3D (Depends in return_sequence ) but Upsample2D() layer support 4D tensor. So, how to handle this?
Best Regards,
Skyler
Sorry, I’m not familiar with that model so I cannot give you specific advice.
Perhaps you can contact the authors directly?
Perhaps you can prototype a few approaches and use them to learn more about the data and model?
Perhaps you can find an existing implementation from which to learn?
Hello, I have a big problem and I don’t find the answer.
I have this model :
model = Sequential()
model.add(LSTM(units=100, input_shape=(x_train.shape[1],5), return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(units=1))
model.add(Activation(‘linear’))
start = time.time()
model.compile(loss=’mse’, optimizer=’rmsprop’)
My question is : How are connected the lstm cell between each other in a layer ? And I have a difference between the first hidden layer and the second (100 cells and 50) how the lstm neurons are connected between each hidden layer (like the first ouput of layer 1 is connected to all input of the second hidden layer and etc) ?
thanks in advance
What do you mean exactly?
E.g. the output from one layer is passed to the next layer, they are not connected directly (e.g. units operate independently in a layer), rather just data is passed between them.
Here are currently my misunderstandings:
Using keras LSTM, is “units” the number of LSTM cells in a layer?
If so, how are they connected to each other in the same layer?
How is the first layer connected to the second in two cases if the number of units is the same and the number of units is different?
In Keras, a unit is a cell is a node. They are all the same thing.
The output of one layer is passed as input to the next layer.
Each “node” outputs the last value in the sequence unless it is configured to output each value in the sequence (return_sequences=True).
so this representation is not good? https://stackoverflow.com/questions/66855308/how-are-the-hidden-stacked-lstm-layers-interconnected-python
If not good, how should the correct representation be? please
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-you-comment-on-my-stackoverflow-question
Hi Jason, I have a question on running a stacked LSTM model on parallel. In my model, I stacked 4 LSTM layers with bidirectional setup. I was trying to use multiple GPUs to accelerate the training process, but the training time does not seem to be affected. Could you help me on the issue of LSTM parallelism with multiple GPUs.
The structure of my LSTM net looks something like the following:
model= Sequential()
model.add(Bidirectional(LSTM(…),input_shape = (…), merge_mode=’sum’))
model.add(Dropout(…))
model.add(Bidirectional(LSTM(…merge_mode=’sum’))
model.add(Dropout(…))
model.add(Bidirectional(LSTM(…,merge_mode=’sum’))
model.add(Dropout(…))
model.add(Bidirectional(LSTM(…),merge_mode=’sum’))
regressor.add(Dropout(…))
regressor.add(Dense(…, activation=’sigmoid’))
I don’t believe GPUs help much with RNNs like LSTMs.
Hey Jason, I’ve been working on Demand prediction. The data is time-series.
I have a problem, but I have no idea how to improve.
The loss value decreases drastically at the first epoch, then in ten epochs, the loss stops decreasing. It stays almost the same value, just drifts 0.3 ~ -0.3. The performance isn’t bad. But not very good actually. It can get the trend, like peak and valley. However, the value isn’t precise. Do you have any suggestions? I’m just new to LSTM.
Maybe you already reached the potential of your model. In the old time, neural network has only 3 layers (because of computational power is too limited) and the accuracy is not good for many practical use. That’s what it can best do! Only until later we can support building a neural network of more layers, then we see some improvement. I believe your case is similar. Maybe you try a different design of the network?
Hi thanks for sharing knowledge
I have a qestion.
in the context of multiple LSTM layers
is there some general rule for selecting the number of unit for each layer?
[100, 50, 25] ex 50% reduction or any other %
[100,100,100] all equal
[100,200,30] does not matter larger followed bay smaller than larger…
Any suggestion
No rule here. You need to test it out with your data set to find the suitable one.
Great tutorial! Really clarifies things on how to go about stacking LSTMS ????
Great feedback Mayowa!
Our group of 4 people literally opened your image in a new tab, enlarged it, and bowed down in utter gratitude. You’ve saved our project, thank you sir.
Thank you for your feedback and support!