The capacity of a deep learning neural network model controls the scope of the types of mapping functions that it is able to learn.
A model with too little capacity cannot learn the training dataset meaning it will underfit, whereas a model with too much capacity may memorize the training dataset, meaning it will overfit or may get stuck or lost during the optimization process.
The capacity of a neural network model is defined by configuring the number of nodes and the number of layers.
In this tutorial, you will discover how to control the capacity of a neural network model and how capacity impacts what a model is capable of learning.
After completing this tutorial, you will know:
- Neural network model capacity is controlled both by the number of nodes and the number of layers in the model.
- A model with a single hidden layer and sufficient number of nodes has the capability of learning any mapping function, but the chosen learning algorithm may or may not be able to realize this capability.
- Increasing the number of layers provides a short-cut to increasing the capacity of the model with fewer resources, and modern techniques allow learning algorithms to successfully train deep models.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Jan/2020: Updated for changes in scikit-learn v0.22 API.

How to Control Neural Network Model Capacity With Nodes and Layers
Photo by Bernard Spragg. NZ, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- Controlling Neural Network Model Capacity
- Configure Nodes and Layers in Keras
- Multi-Class Classification Problem
- Change Model Capacity With Nodes
- Change Model Capacity With Layers
Controlling Neural Network Model Capacity
The goal of a neural network is to learn how to map input examples to output examples.
Neural networks learn mapping functions. The capacity of a network refers to the range or scope of the types of functions that the model can approximate.
Informally, a model’s capacity is its ability to fit a wide variety of functions.
— Pages 111-112, Deep Learning, 2016.
A model with less capacity may not be able to sufficiently learn the training dataset. A model with more capacity can model more different types of functions and may be able to learn a function to sufficiently map inputs to outputs in the training dataset. Whereas a model with too much capacity may memorize the training dataset and fail to generalize or get lost or stuck in the search for a suitable mapping function.
Generally, we can think of model capacity as a control over whether the model is likely to underfit or overfit a training dataset.
We can control whether a model is more likely to overfit or underfit by altering its capacity.
— Pages 111, Deep Learning, 2016.
The capacity of a neural network can be controlled by two aspects of the model:
- Number of Nodes.
- Number of Layers.
A model with more nodes or more layers has a greater capacity and, in turn, is potentially capable of learning a larger set of mapping functions.
A model with more layers and more hidden units per layer has higher representational capacity — it is capable of representing more complicated functions.
— Pages 428, Deep Learning, 2016.
The number of nodes in a layer is referred to as the width.
Developing wide networks with one layer and many nodes was relatively straightforward. In theory, a network with enough nodes in the single hidden layer can learn to approximate any mapping function, although in practice, we don’t know how many nodes are sufficient or how to train such a model.
The number of layers in a model is referred to as its depth.
Increasing the depth increases the capacity of the model. Training deep models, e.g. those with many hidden layers, can be computationally more efficient than training a single layer network with a vast number of nodes.
Modern deep learning provides a very powerful framework for supervised learning. By adding more layers and more units within a layer, a deep network can represent functions of increasing complexity.
— Pages 167, Deep Learning, 2016.
Traditionally, it has been challenging to train neural network models with more than a few layers due to problems such as vanishing gradients. More recently, modern methods have allowed the training of deep network models, allowing the developing of models of surprising depth that are capable of achieving impressive performance on challenging problems in a wide range of domains.
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Configure Nodes and Layers in Keras
Keras allows you to easily add nodes and layers to your model.
Configuring Model Nodes
The first argument of the layer specifies the number of nodes used in the layer.
Fully connected layers for the Multilayer Perceptron, or MLP, model are added via the Dense layer.
For example, we can create one fully-connected layer with 32 nodes as follows:
|
1 2 |
... layer = Dense(32) |
Similarly, the number of nodes can be specified for recurrent neural network layers in the same way.
For example, we can create one LSTM layer with 32 nodes (or units) as follows:
|
1 2 |
... layer = LSTM(32) |
Convolutional neural networks, or CNN, don’t have nodes, instead specify the number of filter maps and their shape. The number and size of filter maps define the capacity of the layer.
We can define a two-dimensional CNN with 32 filter maps, each with a size of 3 by 3, as follows:
|
1 2 |
... layer = Conv2D(32, (3,3)) |
Configuring Model Layers
Layers are added to a sequential model via calls to the add() function and passing in the layer.
Fully connected layers for the MLP can be added via repeated calls to add passing in the configured Dense layers; for example:
|
1 2 3 4 |
... model = Sequential() model.add(Dense(32)) model.add(Dense(64)) |
Similarly, the number of layers for a recurrent network can be added in the same way to give a stacked recurrent model.
An important difference is that recurrent layers expect a three-dimensional input, therefore the prior recurrent layer must return the full sequence of outputs rather than the single output for each node at the end of the input sequence.
This can be achieved by setting the “return_sequences” argument to “True“. For example:
|
1 2 3 4 |
... model = Sequential() model.add(LSTM(32, return_sequences=True)) model.add(LSTM(32)) |
Convolutional layers can be stacked directly, and it is common to stack one or two convolutional layers together followed by a pooling layer, then repeat this pattern of layers; for example:
|
1 2 3 4 5 6 7 8 |
... model = Sequential() model.add(Conv2D(16, (3,3))) model.add(Conv2D(16, (3,3))) model.add(MaxPooling2D((2,2))) model.add(Conv2D(32, (3,3))) model.add(Conv2D(32, (3,3))) model.add(MaxPooling2D((2,2))) |
Now that we know how to configure the number of nodes and layers for models in Keras, we can look at how the capacity affects model performance on a multi-class classification problem.
Multi-Class Classification Problem
We will use a standard multi-class classification problem as the basis to demonstrate the effect of model capacity on model performance.
The scikit-learn class provides the make_blobs() function that can be used to create a multi-class classification problem with the prescribed number of samples, input variables, classes, and variance of samples within a class.
We can configure the problem to have a specific number of input variables via the “n_features” argument, and a specific number of classes or centers via the “centers” argument. The “random_state” can be used to seed the pseudorandom number generator to ensure that we always get the same samples each time the function is called.
For example, the call below generates 1,000 examples for a three class problem with two input variables.
|
1 2 3 |
... # generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) |
The results are the input and output elements of a dataset that we can model.
In order to get a feeling for the complexity of the problem, we can plot each point on a two-dimensional scatter plot and color each point by class value.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# scatter plot of blobs dataset from sklearn.datasets import make_blobs from matplotlib import pyplot from numpy import where # generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # scatter plot for each class value for class_value in range(3): # select indices of points with the class label row_ix = where(y == class_value) # scatter plot for points with a different color pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # show plot pyplot.show() |
Running the example creates a scatter plot of the entire dataset. We can see that the chosen standard deviation of 2.0 means that the classes are not linearly separable (separable by a line), causing many ambiguous points.
This is desirable as it means that the problem is non-trivial and will allow a neural network model to find many different “good enough” candidate solutions.
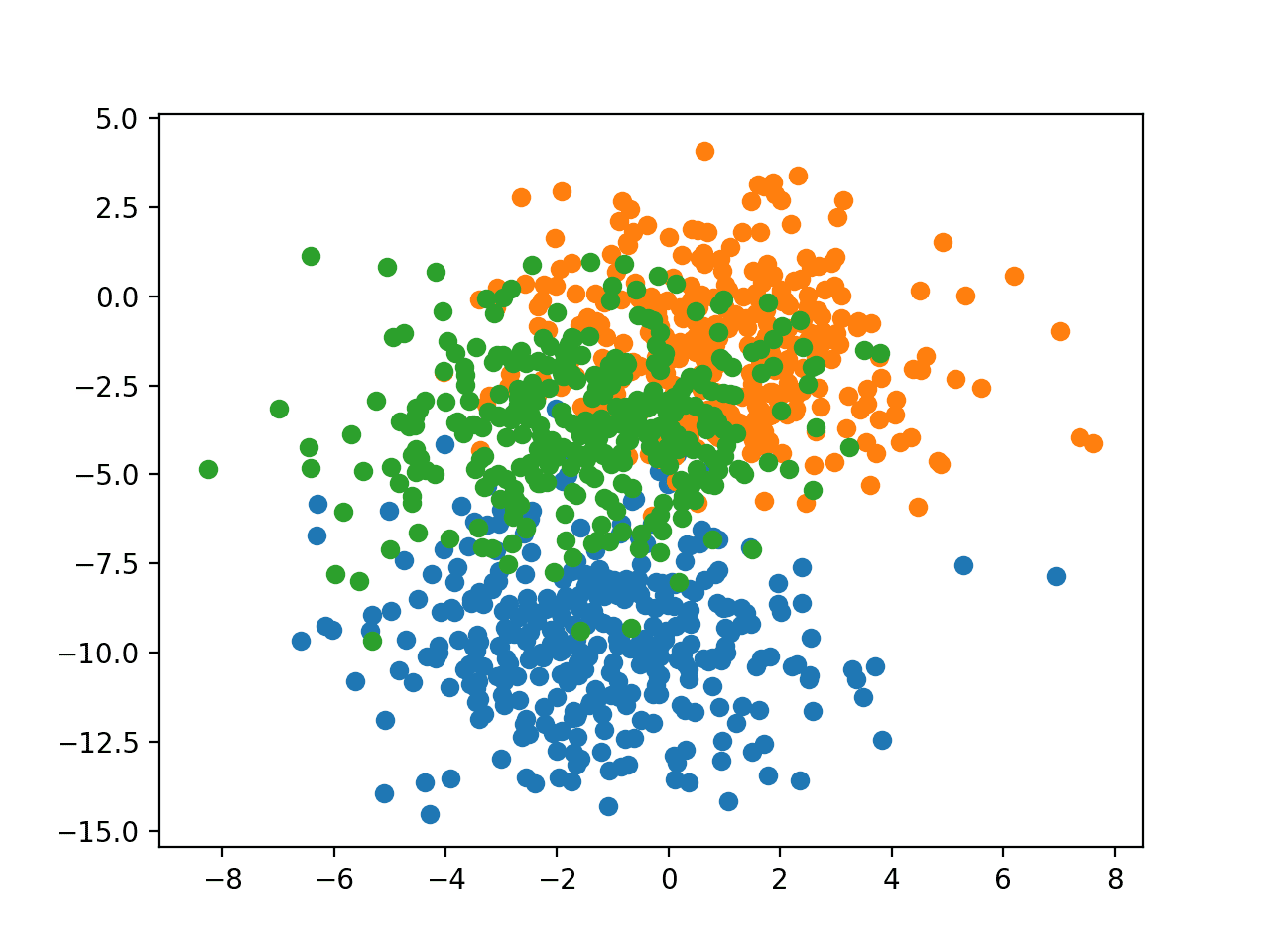
Scatter Plot of Blobs Dataset With Three Classes and Points Colored by Class Value
In order to explore model capacity, we need more complexity in the problem than three classes and two variables.
For the purposes of the following experiments, we will use 100 input features and 20 classes; for example:
|
1 2 3 |
... # generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=20, n_features=100, cluster_std=2, random_state=2) |
Change Model Capacity With Nodes
In this section, we will develop a Multilayer Perceptron model, or MLP, for the blobs multi-class classification problem and demonstrate the effect that the number of nodes has on the ability of the model to learn.
We can start off by developing a function to prepare the dataset.
The input and output elements of the dataset can be created using the make_blobs() function as described in the previous section.
Next, the target variable must be one hot encoded. This is so that the model can learn to predict the probability of an input example belonging to each of the 20 classes.
We can use the to_categorical() Keras utility function to do this, for example:
|
1 2 |
# one hot encode output variable y = to_categorical(y) |
Next, we can split the 1,000 examples in half and use 500 examples as the training dataset and 500 to evaluate the model.
|
1 2 3 4 5 |
# split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, trainy, testX, testy |
The create_dataset() function below ties these elements together and returns the train and test sets in terms of the input and output elements.
|
1 2 3 4 5 6 7 8 9 10 11 |
# prepare multi-class classification dataset def create_dataset(): # generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=20, n_features=100, cluster_std=2, random_state=2) # one hot encode output variable y = to_categorical(y) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, trainy, testX, testy |
We can call this function to prepare the dataset.
|
1 2 |
# prepare dataset trainX, trainy, testX, testy = create_dataset() |
Next, we can define a function that will create the model, fit it on the training dataset, and then evaluate it on the test dataset.
The model needs to know the number of input variables in order to configure the input layer and the number of target classes in order to configure the output layer. These properties can be extracted from the training dataset directly.
|
1 2 |
# configure the model based on the data n_input, n_classes = trainX.shape[1], testy.shape[1] |
We will define an MLP model with a single hidden layer that uses the rectified linear activation function and the He random weight initialization method.
The output layer will use the softmax activation function in order to predict a probability for each target class. The number of nodes in the hidden layer will be provided via an argument called “n_nodes“.
|
1 2 3 4 |
# define model model = Sequential() model.add(Dense(n_nodes, input_dim=n_input, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(n_classes, activation='softmax')) |
The model will be optimized using stochastic gradient descent with a modest learning rate of 0.01 with a high momentum of 0.9, and a categorical cross entropy loss function will be used, suitable for multi-class classification.
|
1 2 3 |
# compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) |
The model will be fit for 100 training epochs, then the model will be evaluated on the test dataset.
|
1 2 3 4 |
# fit model on train set history = model.fit(trainX, trainy, epochs=100, verbose=0) # evaluate model on test set _, test_acc = model.evaluate(testX, testy, verbose=0) |
Tying these elements together, the evaluate_model() function below takes the number of nodes and dataset as arguments and returns the history of the training loss at the end of each epoch and the accuracy of the final model on the test dataset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# fit model with given number of nodes, returns test set accuracy def evaluate_model(n_nodes, trainX, trainy, testX, testy): # configure the model based on the data n_input, n_classes = trainX.shape[1], testy.shape[1] # define model model = Sequential() model.add(Dense(n_nodes, input_dim=n_input, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(n_classes, activation='softmax')) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # fit model on train set history = model.fit(trainX, trainy, epochs=100, verbose=0) # evaluate model on test set _, test_acc = model.evaluate(testX, testy, verbose=0) return history, test_acc |
We can call this function with different numbers of nodes to use in the hidden layer.
The problem is relatively simple; therefore, we will review the performance of the model with 1 to 7 nodes.
We would expect that as the number of nodes is increased, that this would increase the capacity of the model and allow the model to better learn the training dataset, at least to a point limited by the chosen configuration for the learning algorithm (e.g. learning rate, batch size, and epochs).
The test accuracy for each configuration will be printed and the learning curves of training accuracy with each configuration will be plotted.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# evaluate model and plot learning curve with given number of nodes num_nodes = [1, 2, 3, 4, 5, 6, 7] for n_nodes in num_nodes: # evaluate model with a given number of nodes history, result = evaluate_model(n_nodes, trainX, trainy, testX, testy) # summarize final test set accuracy print('nodes=%d: %.3f' % (n_nodes, result)) # plot learning curve pyplot.plot(history.history['loss'], label=str(n_nodes)) # show the plot pyplot.legend() pyplot.show() |
The full code listing is provided below for completeness.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
# study of mlp learning curves given different number of nodes for multi-class classification from sklearn.datasets import make_blobs from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.utils import to_categorical from matplotlib import pyplot # prepare multi-class classification dataset def create_dataset(): # generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=20, n_features=100, cluster_std=2, random_state=2) # one hot encode output variable y = to_categorical(y) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, trainy, testX, testy # fit model with given number of nodes, returns test set accuracy def evaluate_model(n_nodes, trainX, trainy, testX, testy): # configure the model based on the data n_input, n_classes = trainX.shape[1], testy.shape[1] # define model model = Sequential() model.add(Dense(n_nodes, input_dim=n_input, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(n_classes, activation='softmax')) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # fit model on train set history = model.fit(trainX, trainy, epochs=100, verbose=0) # evaluate model on test set _, test_acc = model.evaluate(testX, testy, verbose=0) return history, test_acc # prepare dataset trainX, trainy, testX, testy = create_dataset() # evaluate model and plot learning curve with given number of nodes num_nodes = [1, 2, 3, 4, 5, 6, 7] for n_nodes in num_nodes: # evaluate model with a given number of nodes history, result = evaluate_model(n_nodes, trainX, trainy, testX, testy) # summarize final test set accuracy print('nodes=%d: %.3f' % (n_nodes, result)) # plot learning curve pyplot.plot(history.history['loss'], label=str(n_nodes)) # show the plot pyplot.legend() pyplot.show() |
Running the example first prints the test accuracy for each model configuration.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that as the number of nodes is increased, the capacity of the model to learn the problem is increased. This results in a progressive lowering of the generalization error of the model on the test dataset until 6 and 7 nodes when the model learns the problem perfectly.
|
1 2 3 4 5 6 7 |
nodes=1: 0.138 nodes=2: 0.380 nodes=3: 0.582 nodes=4: 0.890 nodes=5: 0.844 nodes=6: 1.000 nodes=7: 1.000 |
A line plot is also created showing cross entropy loss on the training dataset for each model configuration (1 to 7 nodes in the hidden layer) over the 100 training epochs.
We can see that as the number of nodes is increased, the model is able to better decrease the loss, e.g. to better learn the training dataset. This plot shows the direct relationship between model capacity, as defined by the number of nodes in the hidden layer and the model’s ability to learn.
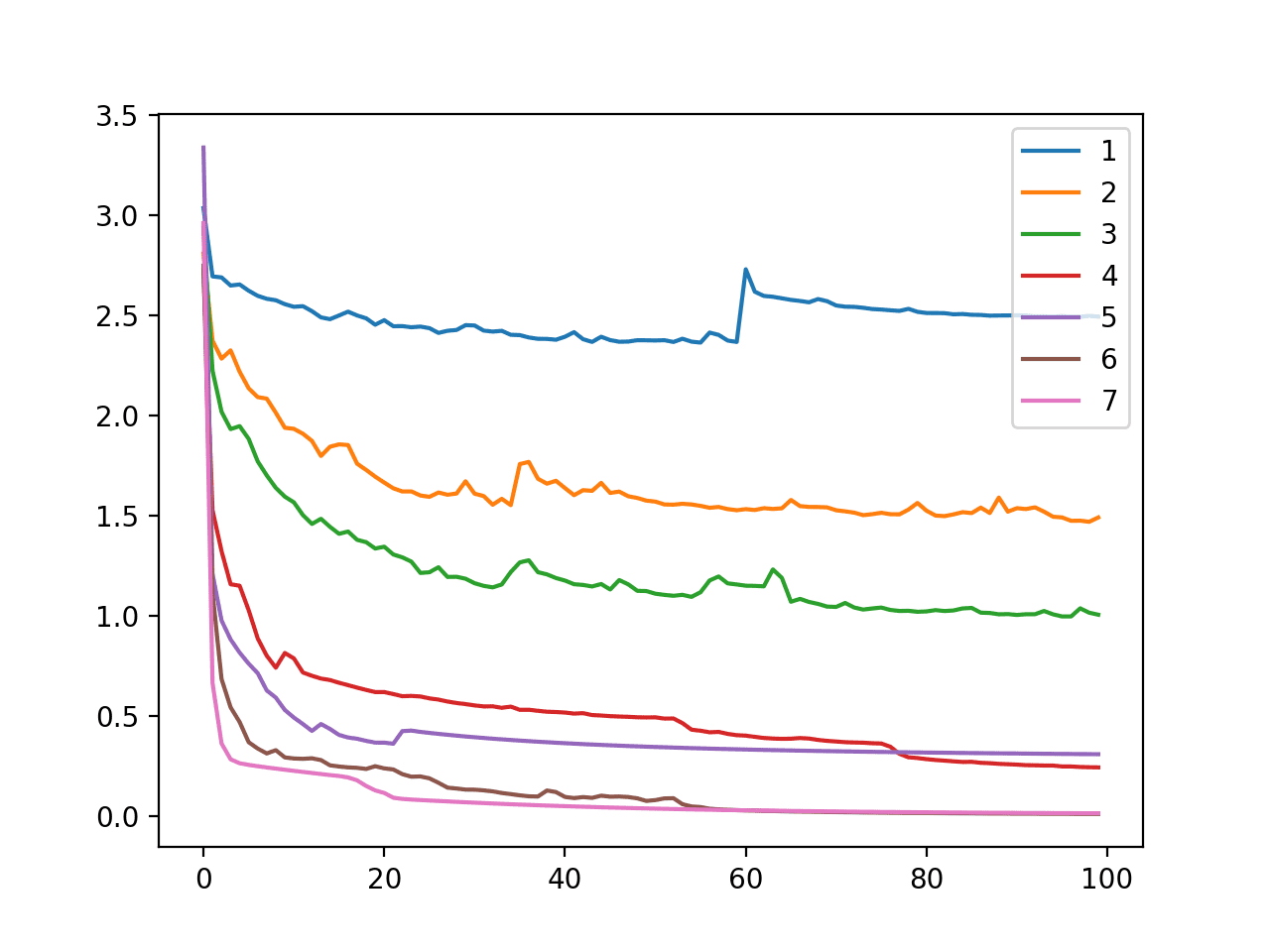
Line Plot of Cross Entropy Loss Over Training Epochs for an MLP on the Training Dataset for the Blobs Multi-Class Classification Problem When Varying Model Nodes
The number of nodes can be increased to the point (e.g. 1,000 nodes) where the learning algorithm is no longer able to sufficiently learn the mapping function.
Change Model Capacity With Layers
We can perform a similar analysis and evaluate how the number of layers impacts the ability of the model to learn the mapping function.
Increasing the number of layers can often greatly increase the capacity of the model, acting like a computational and learning shortcut to modeling a problem. For example, a model with one hidden layer of 10 nodes is not equivalent to a model with two hidden layers with five nodes each. The latter has a much greater capacity.
The danger is that a model with more capacity than is required is likely to overfit the training data, and as with a model that has too many nodes, a model with too many layers will likely be unable to learn the training dataset, getting lost or stuck during the optimization process.
First, we can update the evaluate_model() function to fit an MLP model with a given number of layers.
We know from the previous section that an MLP with about seven or more nodes fit for 100 epochs will learn the problem perfectly. We will, therefore, use 10 nodes in each layer to ensure the model has enough capacity in just one layer to learn the problem.
The updated function is listed below, taking the number of layers and dataset as arguments and returning the training history and test accuracy of the model.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# fit model with given number of layers, returns test set accuracy def evaluate_model(n_layers, trainX, trainy, testX, testy): # configure the model based on the data n_input, n_classes = trainX.shape[1], testy.shape[1] # define model model = Sequential() model.add(Dense(10, input_dim=n_input, activation='relu', kernel_initializer='he_uniform')) for _ in range(1, n_layers): model.add(Dense(10, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(n_classes, activation='softmax')) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # fit model history = model.fit(trainX, trainy, epochs=100, verbose=0) # evaluate model on test set _, test_acc = model.evaluate(testX, testy, verbose=0) return history, test_acc |
Given that a single hidden layer model has enough capacity to learn this problem, we will explore increasing the number of layers to the point where the learning algorithm becomes unstable and can no longer learn the problem.
If the chosen modeling problem was more complex, we could explore increasing the layers and review the improvements in model performance to a point of diminishing returns.
In this case, we will evaluate the model with 1 to 5 layers, with the expectation that at some point, the number of layers will result in a model that the chosen learning algorithm is unable to adapt to the training data.
|
1 2 3 4 5 6 7 8 9 10 11 |
# evaluate model and plot learning curve of model with given number of layers all_history = list() num_layers = [1, 2, 3, 4, 5] for n_layers in num_layers: # evaluate model with a given number of layers history, result = evaluate_model(n_layers, trainX, trainy, testX, testy) print('layers=%d: %.3f' % (n_layers, result)) # plot learning curve pyplot.plot(history.history['loss'], label=str(n_layers)) pyplot.legend() pyplot.show() |
Tying these elements together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
# study of mlp learning curves given different number of layers for multi-class classification from sklearn.datasets import make_blobs from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from keras.utils import to_categorical from matplotlib import pyplot # prepare multi-class classification dataset def create_dataset(): # generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=20, n_features=100, cluster_std=2, random_state=2) # one hot encode output variable y = to_categorical(y) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, trainy, testX, testy # fit model with given number of layers, returns test set accuracy def evaluate_model(n_layers, trainX, trainy, testX, testy): # configure the model based on the data n_input, n_classes = trainX.shape[1], testy.shape[1] # define model model = Sequential() model.add(Dense(10, input_dim=n_input, activation='relu', kernel_initializer='he_uniform')) for _ in range(1, n_layers): model.add(Dense(10, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(n_classes, activation='softmax')) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # fit model history = model.fit(trainX, trainy, epochs=100, verbose=0) # evaluate model on test set _, test_acc = model.evaluate(testX, testy, verbose=0) return history, test_acc # get dataset trainX, trainy, testX, testy = create_dataset() # evaluate model and plot learning curve of model with given number of layers all_history = list() num_layers = [1, 2, 3, 4, 5] for n_layers in num_layers: # evaluate model with a given number of layers history, result = evaluate_model(n_layers, trainX, trainy, testX, testy) print('layers=%d: %.3f' % (n_layers, result)) # plot learning curve pyplot.plot(history.history['loss'], label=str(n_layers)) pyplot.legend() pyplot.show() |
Running the example first prints the test accuracy for each model configuration.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model is capable of learning the problem well with up to three layers, then begins to falter. We can see that performance really drops with five layers and is expected to continue to fall if the number of layers is increased further.
|
1 2 3 4 5 |
layers=1: 1.000 layers=2: 1.000 layers=3: 1.000 layers=4: 0.948 layers=5: 0.794 |
A line plot is also created showing cross entropy loss on the training dataset for each model configuration (1 to 5 layers) over the 100 training epochs.
We can see that the dynamics of the model with 1, 2, and 3 models (blue, orange and green) are pretty similar, learning the problem quickly.
Surprisingly, training loss with four and five layers shows signs of initially doing well, then leaping up, suggesting that the model is likely stuck with a sub-optimal set of weights rather than overfitting the training dataset.
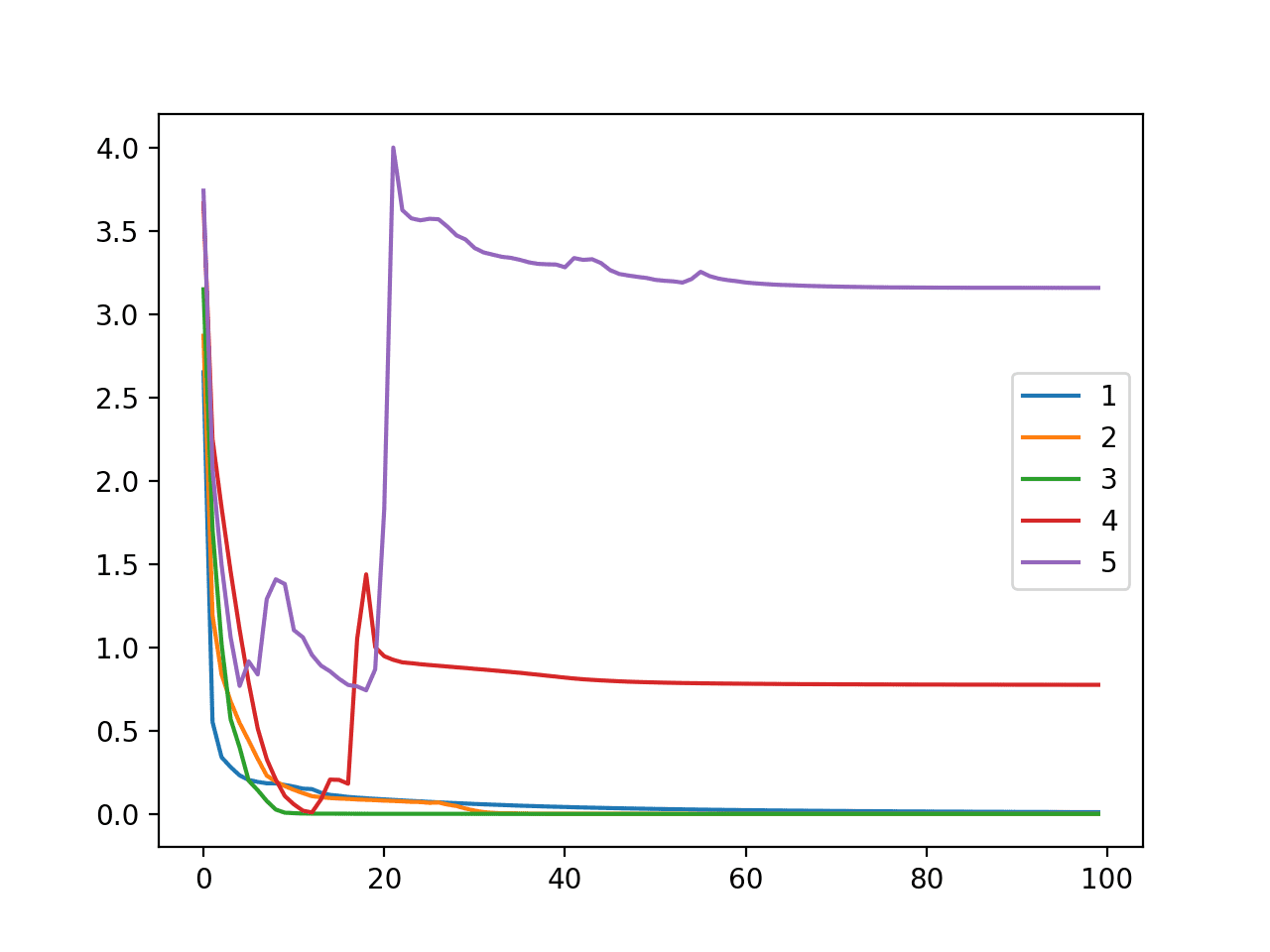
Line Plot of Cross Entropy Loss Over Training Epochs for an MLP on the Training Dataset for the Blobs Multi-Class Classification Problem When Varying Model Layers
The analysis shows that increasing the capacity of the model via increasing depth is a very effective tool that must be used with caution as it can quickly result in a model with a large capacity that may not be capable of learning the training dataset easily.
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
- Too Many Nodes. Update the experiment of increasing nodes to find the point where the learning algorithm is no longer capable of learning the problem.
- Repeated Evaluation. Update an experiment to use the repeated evaluation of each configuration to counter the stochastic nature of the learning algorithm.
- Harder Problem. Repeat the experiment of increasing layers on a problem that requires the increased capacity provided by increased depth in order to perform well.
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Posts
Books
- Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks, 1999.
- Deep Learning, 2016.
API
- Keras Core Layers API
- Keras Convolutional Layers API
- Keras Recurrent Layers API
- Keras Utility Functions
- sklearn.datasets.make_blobs API
Articles
Summary
In this tutorial, you discovered how to control the capacity of a neural network model and how capacity impacts what a model is capable of learning.
Specifically, you learned:
- Neural network model capacity is controlled both by the number of nodes and the number of layers in the model.
- A model with a single hidden layer and a sufficient number of nodes has the capability of learning any mapping function, but the chosen learning algorithm may or may not be able to realize this capability.
- Increasing the number of layers provides a short-cut to increasing the capacity of the model with fewer resources, and modern techniques allow learning algorithms to successfully train deep models.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Better Deep Learning Models Today!

Train Faster, Reduce Overftting, and Ensembles
...with just a few lines of python code
Discover how in my new Ebook:
Better Deep Learning
It provides self-study tutorials on topics like:
weight decay, batch normalization, dropout, model stacking and much more...
Bring better deep learning to your projects!
Skip the Academics. Just Results.






I have a problem that requires 20000 input nodes. What number of layers and nodes in each hidden layer would be good starting point to start experiments?
20K input features?
If so, try reducing them to a subset.
As for the number of nodes and layer in the model, experiment with different sizes and see what works. More details here:
https://machinelearningmastery.com/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
Hi Jason, may I know why the variable X (trainX and testX too) need no one hot encoding?
The input data is numerical, one hot encoding is only required for categorical data.
More here:
https://machinelearningmastery.com/why-one-hot-encode-data-in-machine-learning/
is it possible to use these techniques with k-fold cross-validation rather than a separate test set?
Yes.
why optimization in stages ?
What do you mean exactly? Perhaps you can elaborate?
Instead of connecting every nodes in the hidden layer, how can we select only even nodes or odd nodes to connect?
You can do this with custom code, but not with default Dense layers I believe.
Hey, i noticed one thing, increasing number of nodes to extremes (like 512) and then even adding couple more layers makes the model more accurate on test sample. Even though number of predictors is low, about 50. Sample size is around 1million but it is an unbalanced dataset. And i try to predict low frequency event.
Nice!
Hi Jason,
How we can increase the capacity of machine learning models?
For neural nets, add more layers and nodes.
Other models – it depends on the model.
.
In the above problem
data fits(trains) on Xtrain, ytrain
data evaluates on Xtest, yest
High num. of nodes gives high Capacity .
High capacity causes to Over fitting.
1.
Increasing the nodes increases the capacity to learn the model; using 7 nodes the model learns problem perfectly.
shouldn’t using 7nodes probably over-fit the data?
But instead its performing very well on the test set.
2.
Can’t understand which is better,
using 7 nodes
OR
using 5 nodes(seams to have moderate capacity).?
Please help.
We are not trying to solve the test problem, rather we are showing how changing the model impacts model behavior.
A larger capacity may or may not overfit.
Sorry if this is a dumb question, trying to get up to speed with machine learning, and I’m not sure where to look for this question specifically. Say I have a learned model, but I want to build in some adjustable parameters for the model itself. For example, a model has been trained to mimic the change in an audio signal, looking at input and output samples. That works well. But let’s say I want to add a gain adjustment to that model. I figure I could re-train the data with the gain in the example files set at various levels, but I’m not sure how to go about this. Are nodes and layers the sort of thing that could accomplish this, or is there any other way to add sort of components of the model that work together, and are adjustable?
You could use your existing model as an input to a new model or create a new model for the problem.
Thanks for the reply. I’m a bit confused though, I mean that I want to have the model adjustable, meaning that I want to be able to adjust the gain on the resultant model. The idea is to build an interface to adjust any parameters that I train, if that sort of thing is possible. If I simply use the existing model as an input to a new model, won’t I just end up with a new model with a new gain setting?
Not sure I follow, sorry. Perhaps experiment/prototype and see if the model achieves your desired outcome/system requirements.
Hi Jason!! There is a month I’m trying to solve a speech emotion recognition problem of EMO-DB (7 classes).
The structure of my MLP is as follows:
1 input layer
2 hidden layers (sigmoid activation function)
1 output layer (sigmoid activation function)
But I cannot have good results on my validation sets, despite the problem is a little hard, my features are not so bad…. I would like to ask you what kind of action I could take for increasing my accuracy and having a lower MSE in training….really thanks
Perhaps some of the tips here will help:
https://machinelearningmastery.com/start-here/#better
Hi Jason,
I’m currently working on a project which is about regression problem.
The dataset is really small (less than 500 samples).
In this case, I’ve built a NN with only one hidden layer of around 4 to 5 nodes.
I would love if the increase of the number of nodes will improve the model performance?
I’ve tried to make this experience by using more nodes and evaluating the error. From what I’ve seen, there is no trends (it’s more likely to be zig-zag).
Is it normal?
How can I explain that?
Try it and see, you may need to adjust other aspects of the model like learning rate.
I want to increase the depth of U-net model. the filters are 64,128,256,512.. I want to go deeper . how can I do so?
Increasing depth means adding more layers. The simplest is on the sequential model, call add() multiple times with Dense() layers.
in a dense neural network can we make some changes to back propogation such that only one of the layer’s weights and biases are changed and leaving the others un-changed ??
Yes, you have to mark “layer.trainable = True” or “layer.trainable = False” for each layer.
Hi Jason,
Nice tutorial.
I already have a CNN model having 7 layers, 4 convolutional, 3 fully connected. Now, if the number of input features increase from 8 to 14, should I experiment with different filter size, more number of layers, or more number of filters/neurons per layer?
Hi Sunila…you may want to investigate AutoML:
https://machinelearningmastery.com/autokeras-for-classification-and-regression/