The Encoder-Decoder architecture is popular because it has demonstrated state-of-the-art results across a range of domains.
A limitation of the architecture is that it encodes the input sequence to a fixed length internal representation. This imposes limits on the length of input sequences that can be reasonably learned and results in worse performance for very long input sequences.
In this post, you will discover the attention mechanism for recurrent neural networks that seeks to overcome this limitation.
After reading this post, you will know:
The limitation of the encode-decoder architecture and the fixed-length internal representation.
The attention mechanism to overcome the limitation that allows the network to learn where to pay attention in the input sequence for each item in the output sequence.
5 applications of the attention mechanism with recurrent neural networks in domains such as text translation, speech recognition, and more.
Attention in Long Short-Term Memory Recurrent Neural Networks Photo by Jonas Schleske, some rights reserved.
Problem With Long Sequences
The encoder-decoder recurrent neural network is an architecture where one set of LSTMs learn to encode input sequences into a fixed-length internal representation, and second set of LSTMs read the internal representation and decode it into an output sequence.
This architecture has shown state-of-the-art results on difficult sequence prediction problems like text translation and quickly became the dominant approach.
The encoder-decoder architecture still achieves excellent results on a wide range of problems. Nevertheless, it suffers from the constraint that all input sequences are forced to be encoded to a fixed length internal vector.
This is believed to limit the performance of these networks, especially when considering long input sequences, such as very long sentences in text translation problems.
A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This may make it difficult for the neural network to cope with long sentences, especially those that are longer than the sentences in the training corpus.
Take my free 7-day email course and discover 6 different LSTM architectures (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Attention within Sequences
Attention is the idea of freeing the encoder-decoder architecture from the fixed-length internal representation.
This is achieved by keeping the intermediate outputs from the encoder LSTM from each step of the input sequence and training the model to learn to pay selective attention to these inputs and relate them to items in the output sequence.
Put another way, each item in the output sequence is conditional on selective items in the input sequence.
Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words.
… it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector.
This increases the computational burden of the model, but results in a more targeted and better-performing model.
In addition, the model is also able to show how attention is paid to the input sequence when predicting the output sequence. This can help in understanding and diagnosing exactly what the model is considering and to what degree for specific input-output pairs.
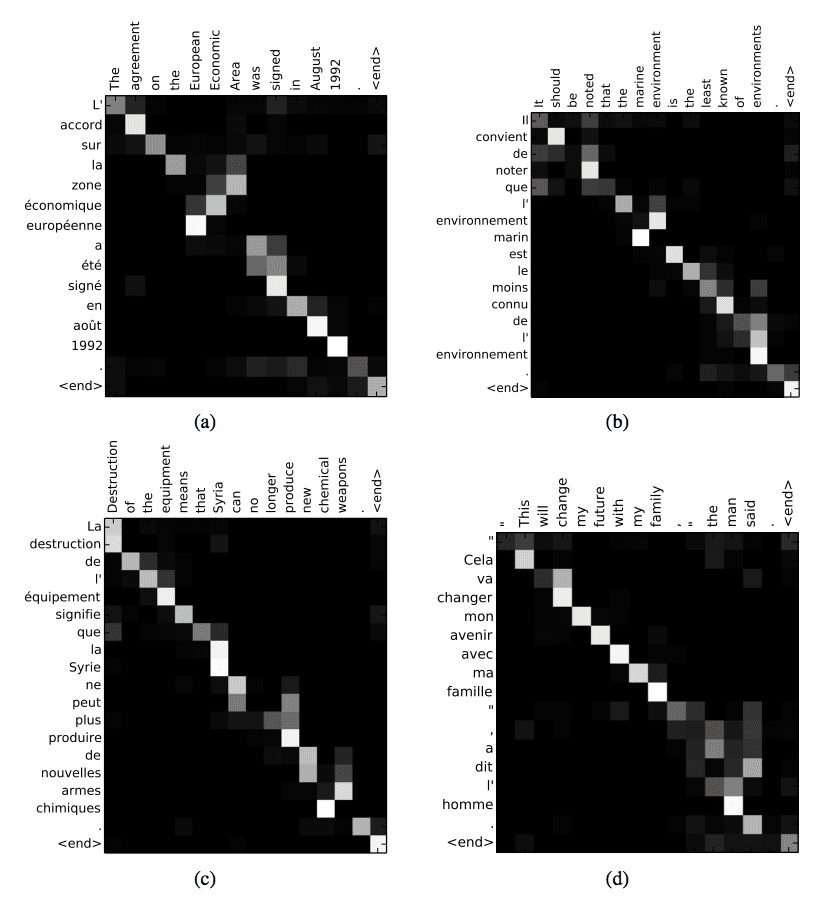
The proposed approach provides an intuitive way to inspect the (soft-)alignment between the words in a generated translation and those in a source sentence. This is done by visualizing the annotation weights… Each row of a matrix in each plot indicates the weights associated with the annotations. From this we see which positions in the source sentence were considered more important when generating the target word.
Convolutional neural networks applied to computer vision problems also suffer from similar limitations, where it can be difficult to learn models on very large images.
As a result, a series of glimpses can be taken of a large image to formulate an approximate impression of the image before making a prediction.
One important property of human perception is that one does not tend to process a whole scene in its entirety at once. Instead humans focus attention selectively on parts of the visual space to acquire information when and where it is needed, and combine information from different fixations over time to build up an internal representation of the scene, guiding future eye movements and decision making.
This section provides some specific examples of how attention is used for sequence prediction with recurrent neural networks.
1. Attention in Text Translation
The motivating example mentioned above is text translation.
Given an input sequence of a sentence in French, translate and output a sentence in English. Attention is used to pay attention to specific words in the input sequence for each word in the output sequence.
We extended the basic encoder–decoder by letting a model (soft-)search for a set of input words, or their annotations computed by an encoder, when generating each target word. This frees the model from having to encode a whole source sentence into a fixed-length vector, and also lets the model focus only on information relevant to the generation of the next target word.
Attentional Interpretation of French to English Translation Taken from Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
2. Attention in Image Descriptions
Different from the glimpse approach, the sequence-based attentional mechanism can be applied to computer vision problems to help get an idea of how to best use the convolutional neural network to pay attention to images when outputting a sequence, such as a caption.
Given an input of an image, output an English description of the image. Attention is used to pay focus on different parts of the image for each word in the output sequence.
We propose an attention based approach that gives state of the art performance on three benchmark datasets … We also show how the learned attention can be exploited to give more interpretability into the models generation process, and demonstrate that the learned alignments correspond very well to human intuition.
Attentional Interpretation of Output Words to Specific Regions on the Input Images Taken from Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2016
Given a premise scenario and a hypothesis about the scenario in English, output whether the premise contradicts, is not related, or entails the hypothesis.
For example:
premise: “A wedding party taking pictures“
hypothesis: “Someone got married“
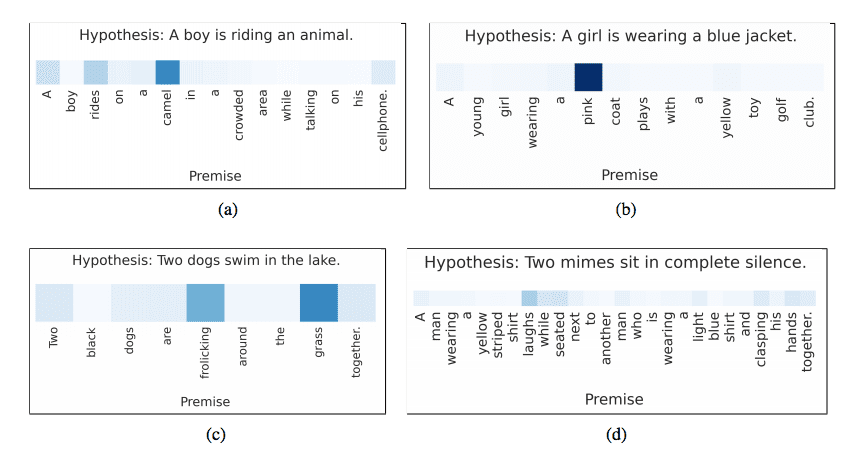
Attention is used to relate each word in the hypothesis to words in the premise, and vise-versa.
We present a neural model based on LSTMs that reads two sentences in one go to determine entailment, as opposed to mapping each sentence independently into a semantic space. We extend this model with a neural word-by-word attention mechanism to encourage reasoning over entailments of pairs of words and phrases. … An extension with word-by-word neural attention surpasses this strong benchmark LSTM result by 2.6 percentage points, setting a new state-of-the-art accuracy…
Attentional Interpretation of Premise Words to Hypothesis Words Taken from Reasoning about Entailment with Neural Attention, 2016
4. Attention in Speech Recognition
Given an input sequence of English speech snippets, output a sequence of phonemes.
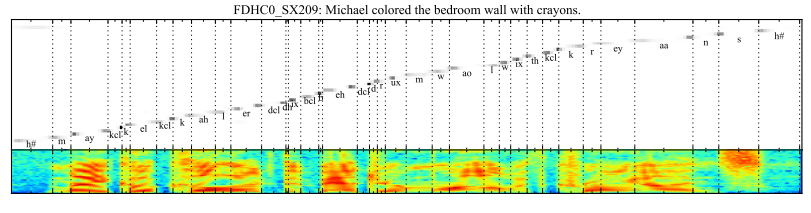
Attention is used to relate each phoneme in the output sequence to specific frames of audio in the input sequence.
… a novel end-to-end trainable speech recognition architecture based on a hybrid attention mechanism which combines both content and location information in order to select the next position in the input sequence for decoding. One desirable property of the proposed model is that it can recognize utterances much longer than the ones it was trained on.
Attentional Interpretation of Output Phoneme Location to Input Frames of Audio Taken from Attention-Based Models for Speech Recognition, 2015
5. Attention in Text Summarization
Given an input sequence of an English article, output a sequence of English words that summarize the input.
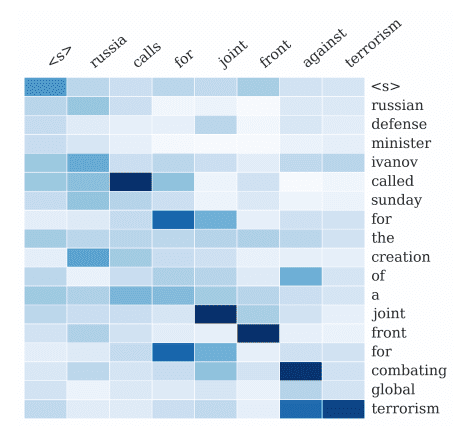
Attention is used to relate each word in the output summary to specific words in the input document.
… a neural attention-based model for abstractive summarization, based on recent developments in neural machine translation. We combine this probabilistic model with a generation algorithm which produces accurate abstractive summaries.
Attentional Interpretation of Words in the Input Document to the Output Summary Taken from A Neural Attention Model for Abstractive Sentence Summarization, 2015.
Further Reading
This section provides additional resources if you would like to learn more about adding attention to LSTMs.
Do you know of some good resources on attention in recurrent neural networks?
Let me know in the comments.
Summary
In this post, you discovered the attention mechanism for sequence prediction problems with LSTM recurrent neural networks.
Specifically, you learned:
That the encoder-decoder architecture for recurrent neural networks uses a fixed-length internal representation that imposes a constraint that limits learning very long sequences.
That attention overcomes the limitation in the encode-decoder architecture by allowing the network to learn where to pay attention to the input for each item in the output sequence.
That the approach has been used across different types sequence prediction problems include text translation, speech recognition, and more.
Do you have any questions about attention in recurrent neural networks?
Ask your questions in the comments below and I will do my best to answer.
It provides self-study tutorials on topics like: CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Thank you so much, Dr. Jason, for this write-up and literature reference. Will appreciate, if sample code on how to use attention model on top of LSTM layer can be upload for text and image analysis.
As far as I can tell, implementing simple attention correctly requires a new custom layer. I hope to prepare an exmaple and post it in the future. The examples I’ve seen out there mostly do not appear to be implemented correctly.
This write-up is indeed a good way to get started with the Attention mechanism. I really look forward to a post on applying attention in Tensorflow/Keras!
Thanks again for all the help in implementing the truncated backprop through time in Keras (around end of June).
The sample image showed in “2. Attention in Image Descriptions” is Figs. 5 in the original paper which is used to illustrate the mistakes of the model. It might be better to show Figs. 4 in the original paper.
We are training attention sequence to sequence model. Two sides are all long documents, so one of the problems using attention model is that the doc-product matrix becomes extremely big and often cause out-of-memory. Do you have any recommendation to solve this problem?
Your post is hlepful to me. Thanks.
Butt I have a question. As I know attention layer has own trainable own matrix. What information will be tarined into this matrix? And hidden states of decoders are not important anymore with attention mrchanism? I don’t understand exactly in this points.
Thank you jason, for this wonderful writeup. I am new to lstm and attention networks…. I wonder if it is possible to use attention mechanism to recogonize multiple objects in an image
do you know if it is possible to develop a LSTM model with attention mechanism for many-to-one problems? if so, is it possible in Keras, TensorFlow or PyTorch?
A great post, as always. Would you please provide us an example of how to develop attention layer for LSTM neural networks for time series prediction in keras?
Hi,
Thanks for the article.
LSTMs can’t be parallelized as they are sequential.
I just have a confusion. Why do we combine LSTMs with attention when we can directly use attention (for example in machine translation task)?
How to implement attention model in LSTM for forecasting rather than classification. so its like how to develop attention layer for LSTM neural networks for time series prediction in keras.. I hope you implemented this. Thanks









Thank you so much, Dr. Jason, for this write-up and literature reference. Will appreciate, if sample code on how to use attention model on top of LSTM layer can be upload for text and image analysis.
Looking forward to it.
Warm Regards
Abbey
I’m glad it helped.
As far as I can tell, implementing simple attention correctly requires a new custom layer. I hope to prepare an exmaple and post it in the future. The examples I’ve seen out there mostly do not appear to be implemented correctly.
This write-up is indeed a good way to get started with the Attention mechanism. I really look forward to a post on applying attention in Tensorflow/Keras!
Thanks again for all the help in implementing the truncated backprop through time in Keras (around end of June).
I’m glad it helped. I have post on how to calculate attention step by step scheduled for mid Oct 2017.
There are several seq2seq with attention mechanism implementation in Tensorflow contrib:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/legacy_seq2seq/python/ops/seq2seq.py
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/seq2seq/python/ops
Thanks Liam.
The sample image showed in “2. Attention in Image Descriptions” is Figs. 5 in the original paper which is used to illustrate the mistakes of the model. It might be better to show Figs. 4 in the original paper.
Thanks for the suggestion.
can we use the attention mechanism when doing text classification?
Yes!
Hi Jason,
Can we use attention mechanism in time series problem?
Since we use many to one architecture, i am not sure to use it or not?
Thx for reply.
I don’t see why not.
Hi, Jason
Have you add the attention mechanism in your LSTM book with keras code?
Not at this stage, I will add attention to the book once Keras finalizes its implementation.
Hi Dr. Jason Brownlee,
We are training attention sequence to sequence model. Two sides are all long documents, so one of the problems using attention model is that the doc-product matrix becomes extremely big and often cause out-of-memory. Do you have any recommendation to solve this problem?
thanks,
Not really off the top of my head beyond use shorter sequences or get more RAM.
Perhaps a careful redesign of the model specific to your problem is required David.
Your post is hlepful to me. Thanks.
Butt I have a question. As I know attention layer has own trainable own matrix. What information will be tarined into this matrix? And hidden states of decoders are not important anymore with attention mrchanism? I don’t understand exactly in this points.
Here is a walk through of the equations that should make it clearer:
https://machinelearningmastery.com/how-does-attention-work-in-encoder-decoder-recurrent-neural-networks/
Hello
Do you think attention will make a difference in a straightforward problem such as next word prediction?
It may.
Thank you jason, for this wonderful writeup. I am new to lstm and attention networks…. I wonder if it is possible to use attention mechanism to recogonize multiple objects in an image
Attention would not be the right mechanism, instead, you would use techniques such as RCNN or YOLO.
Hi Jason,
do you know if it is possible to develop a LSTM model with attention mechanism for many-to-one problems? if so, is it possible in Keras, TensorFlow or PyTorch?
Thanks
I’m not sure off hand, perhaps.
I would expect that you can develop your own implementation on any platform.
I’m not sure about out of the box implementations, sorry.
Hi Jason,
A great post, as always. Would you please provide us an example of how to develop attention layer for LSTM neural networks for time series prediction in keras?
Thanks
Thanks.
Thanks for the suggestion.
Dear Jason,
Would you please explain what is the difference between attention and self-attention?
Thanks
Good question. I hope to cover attention in detail soon.
Thx for the article.
Does it make sense that I combine self attention on top of LSTMs for NLP tasks (e.g. POS tagging and NER) ?
Perhaps develop a prototype to test it?
Hi,
Thanks for the article.
LSTMs can’t be parallelized as they are sequential.
I just have a confusion. Why do we combine LSTMs with attention when we can directly use attention (for example in machine translation task)?
Sorry, I don’t follow your distinction. Perhaps you can elaborate?
How to implement attention model in LSTM for forecasting rather than classification. so its like how to develop attention layer for LSTM neural networks for time series prediction in keras.. I hope you implemented this. Thanks
I hope to write about this topic in the future.
how to develop attention layer for LSTM neural networks for time series prediction in keras?
could suggest you work
I hope to write about this topic in the future.