Gentle introduction to CNN LSTM recurrent neural networks
with example Python code.
Input with spatial structure, like images, cannot be modeled easily with the standard Vanilla LSTM.
The CNN Long Short-Term Memory Network or CNN LSTM for short is an LSTM architecture specifically designed for sequence prediction problems with spatial inputs, like images or videos.
In this post, you will discover the CNN LSTM architecture for sequence prediction.
After completing this post, you will know:
- About the development of the CNN LSTM model architecture for sequence prediction.
- Examples of the types of problems to which the CNN LSTM model is suited.
- How to implement the CNN LSTM architecture in Python with Keras.
Kick-start your project with my new book Long Short-Term Memory Networks With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Convolutional Neural Network Long Short-Term Memory Networks
Photo by Yair Aronshtam, some righs reserved.
CNN LSTM Architecture
The CNN LSTM architecture involves using Convolutional Neural Network (CNN) layers for feature extraction on input data combined with LSTMs to support sequence prediction.
CNN LSTMs were developed for visual time series prediction problems and the application of generating textual descriptions from sequences of images (e.g. videos). Specifically, the problems of:
- Activity Recognition: Generating a textual description of an activity demonstrated in a sequence of images.
- Image Description: Generating a textual description of a single image.
- Video Description: Generating a textual description of a sequence of images.
[CNN LSTMs are] a class of models that is both spatially and temporally deep, and has the flexibility to be applied to a variety of vision tasks involving sequential inputs and outputs
— Long-term Recurrent Convolutional Networks for Visual Recognition and Description, 2015.
This architecture was originally referred to as a Long-term Recurrent Convolutional Network or LRCN model, although we will use the more generic name “CNN LSTM” to refer to LSTMs that use a CNN as a front end in this lesson.
This architecture is used for the task of generating textual descriptions of images. Key is the use of a CNN that is pre-trained on a challenging image classification task that is re-purposed as a feature extractor for the caption generating problem.
… it is natural to use a CNN as an image “encoder”, by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences
— Show and Tell: A Neural Image Caption Generator, 2015.
This architecture has also been used on speech recognition and natural language processing problems where CNNs are used as feature extractors for the LSTMs on audio and textual input data.
This architecture is appropriate for problems that:
- Have spatial structure in their input such as the 2D structure or pixels in an image or the 1D structure of words in a sentence, paragraph, or document.
- Have a temporal structure in their input such as the order of images in a video or words in text, or require the generation of output with temporal structure such as words in a textual description.
Convolutional Neural Network Long Short-Term Memory Network Architecture
Need help with LSTMs for Sequence Prediction?
Take my free 7-day email course and discover 6 different LSTM architectures (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Implement CNN LSTM in Keras
We can define a CNN LSTM model to be trained jointly in Keras.
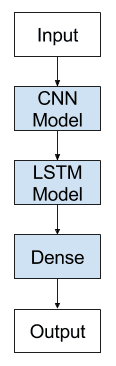
A CNN LSTM can be defined by adding CNN layers on the front end followed by LSTM layers with a Dense layer on the output.
It is helpful to think of this architecture as defining two sub-models: the CNN Model for feature extraction and the LSTM Model for interpreting the features across time steps.
Let’s take a look at both of these sub models in the context of a sequence of 2D inputs which we will assume are images.
CNN Model
As a refresher, we can define a 2D convolutional network as comprised of Conv2D and MaxPooling2D layers ordered into a stack of the required depth.
The Conv2D will interpret snapshots of the image (e.g. small squares) and the polling layers will consolidate or abstract the interpretation.
For example, the snippet below expects to read in 10×10 pixel images with 1 channel (e.g. black and white). The Conv2D will read the image in 2×2 snapshots and output one new 10×10 interpretation of the image. The MaxPooling2D will pool the interpretation into 2×2 blocks reducing the output to a 5×5 consolidation. The Flatten layer will take the single 5×5 map and transform it into a 25-element vector ready for some other layer to deal with, such as a Dense for outputting a prediction.
|
1 2 3 4 |
cnn = Sequential() cnn.add(Conv2D(1, (2,2), activation='relu', padding='same', input_shape=(10,10,1))) cnn.add(MaxPooling2D(pool_size=(2, 2))) cnn.add(Flatten()) |
This makes sense for image classification and other computer vision tasks.
LSTM Model
The CNN model above is only capable of handling a single image, transforming it from input pixels into an internal matrix or vector representation.
We need to repeat this operation across multiple images and allow the LSTM to build up internal state and update weights using BPTT across a sequence of the internal vector representations of input images.
The CNN could be fixed in the case of using an existing pre-trained model like VGG for feature extraction from images. The CNN may not be trained, and we may wish to train it by backpropagating error from the LSTM across multiple input images to the CNN model.
In both of these cases, conceptually there is a single CNN model and a sequence of LSTM models, one for each time step. We want to apply the CNN model to each input image and pass on the output of each input image to the LSTM as a single time step.
We can achieve this by wrapping the entire CNN input model (one layer or more) in a TimeDistributed layer. This layer achieves the desired outcome of applying the same layer or layers multiple times. In this case, applying it multiple times to multiple input time steps and in turn providing a sequence of “image interpretations” or “image features” to the LSTM model to work on.
|
1 2 3 |
model.add(TimeDistributed(...)) model.add(LSTM(...)) model.add(Dense(...)) |
We now have the two elements of the model; let’s put them together.
CNN LSTM Model
We can define a CNN LSTM model in Keras by first defining the CNN layer or layers, wrapping them in a TimeDistributed layer and then defining the LSTM and output layers.
We have two ways to define the model that are equivalent and only differ as a matter of taste.
You can define the CNN model first, then add it to the LSTM model by wrapping the entire sequence of CNN layers in a TimeDistributed layer, as follows:
|
1 2 3 4 5 6 7 8 9 10 |
# define CNN model cnn = Sequential() cnn.add(Conv2D(...)) cnn.add(MaxPooling2D(...)) cnn.add(Flatten()) # define LSTM model model = Sequential() model.add(TimeDistributed(cnn, ...)) model.add(LSTM(..)) model.add(Dense(...)) |
An alternate, and perhaps easier to read, approach is to wrap each layer in the CNN model in a TimeDistributed layer when adding it to the main model.
|
1 2 3 4 5 6 7 8 |
model = Sequential() # define CNN model model.add(TimeDistributed(Conv2D(...)) model.add(TimeDistributed(MaxPooling2D(...))) model.add(TimeDistributed(Flatten())) # define LSTM model model.add(LSTM(...)) model.add(Dense(...)) |
The benefit of this second approach is that all of the layers appear in the model summary and as such is preferred for now.
You can choose the method that you prefer.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Papers on CNN LSTM
- Long-term Recurrent Convolutional Networks for Visual Recognition and Description, 2015.
- Show and Tell: A Neural Image Caption Generator, 2015.
- Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks, 2015.
- Character-Aware Neural Language Models, 2015.
- Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting, 2015.
Keras API
Posts
- Crash Course in Convolutional Neural Networks for Machine Learning
- Sequence Classification with LSTM Recurrent Neural Networks in Python with Keras
Summary
In this post, you discovered the CNN LSTN model architecture.
Specifically, you learned:
- About the development of the CNN LSTM model architecture for sequence prediction.
- Examples of the types of problems to which the CNN LSTM model is suited.
- How to implement the CNN LSTM architecture in Python with Keras.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop LSTMs for Sequence Prediction Today!

Develop Your Own LSTM models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Long Short-Term Memory Networks with Python
It provides self-study tutorials on topics like:
CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Skip the Academics. Just Results.






Would this architecture, with some adaptations, also be suitable to do speech recognition, speaker separation, language detection and other natural language processing tasks?
Perhaps.
I have seen it most used for document classification / sentiment analysis in NLP.
Hi Jason, could you please provide a few references for the use of such CNN + LSTM architectures in the text domain (document classification, sentiment analysis, etc.)?
Perhaps search on scholar.google.com.
Hi, Jason,I am very distressed,I would like to ask you a question.For example, the data of 0-500, the magnitude of data is quite different.When I use LSTM model to predict, the accuracy is too low.Even if the data normalization is not helpful, I would like to ask you, how should the data be processed?Thank you so much!
Perhaps normalize the data first?
cnn + lstm architecture used for speech recognition
– https://arxiv.org/pdf/1610.03022.pdf
Thanks for sharing Dan.
Hi Jason. If the time series data is big and convert to 28*28 2d image as input. Than how the same above model can be changed for power prediction?
The examples in this post of a CNN-LSTM and Conv2DLSTM can be adapted for your problem:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
I want to use Conv1D to process time series data and then input it into LSTM. Can you recommend learning code practice?
Hi J
1 I have the same question as above from ”liming”
2 why all your CNN Time series examples use CNN-1D, and suddenly for the CNN-LSTM the first CNN become a Conv2D ?
as in :
– https://machinelearningmastery.com/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
or
– https://machinelearningmastery.com/how-to-develop-convolutional-neural-networks-for-multi-step-time-series-forecasting/
I don’t follow?
If you have a 1D univariate or multivariate time series, then you would use a Conv1D, for example:
https://machinelearningmastery.com/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
If you have time series of images as input, as in this post, you would use a Conv2D.
what is difference with ConvLSTM2D layer ?
https://github.com/fchollet/keras/blob/master/examples/conv_lstm.py
As far as I know, that layer is not yet supported. I have tried to stay away from it until all the bugs are worked out of it.
ConvLSTM is variant of LSTM which use convolution to replace inner procut within LSTM unit
while CNN LSTM is just stack of layer; CNN followed by LSTM.
Have you used it on a project Dan?
Not yet, I’m just waiting next tensorflow release since it seems that convlstm would be provided as tf.contrib.rnn.ConvLSTMCell, instead I’ve used cnn + lstm on simple speech recognition experiments and it gives better results than stack of lstm. It really works!
Thanks Dan.
I hope to try some examples myself for the blog soon.
@Dan Lim can you share me your script in speech recognition and thanks you.
Hi, Jason.
Do you think the CNNLSTM can solve the regression problem, whose inputs are some time series data and some properties/exogenous data (spatial), not image data? If yes, how to deal with the properties/exogenous data (2D) in CNN. Thank you.
I m having the same question
Perhaps, I have not tried using CNN LSTMs for time series.
Perhaps each series could be processed by a 1D-CNN.
It might not make sense given that the LSTM is already interpreting the long term relationships in the data.
It might be interesting if the CNN can pick out structure that is new/different from the LSTM. Perhaps you could have both a CNN and LSTM interpretation of the series and use another model to integrate and interpret the results.
I tried to use CNN + LSTM for timeseries forecasting, hoping that CNN can uncover some structure in the input signals. So far, it seems to perform worse than a 2-layered LSTM model, even after tuning hyperparameters. I thought I would get your book to look at the details, but sounds like this was not covered in the book? Your previous posting on LSTM model was very helpful. Thank you!
Generally, LSTMs perform worse on every time series problem I have tried them on (20+).
You can learn why here:
https://machinelearningmastery.com/suitability-long-short-term-memory-networks-time-series-forecasting/
I recommend exhausting classical time series methods first, then try sklearn models, and then perhaps try neural nets.
@Jen Liu, would like to see you manage to uncover some of the hidden signals for your implementation. Can you please share some insight on your CNN + LSTM for time series forecasting? thank you.
I have been using the approach recently with great success.
I have posts scheduled on the topic.
Hi,Miles.
I m having the same question. Do you have some research progress on time series using the CNN LSTMs?
Hi do you have a github implementation ?
I have a full code example in my book on LSTMs.
Hello Sir kindly mention your book name and link for book
https://machinelearningmastery.com/lstms-with-python/
Hi Jason,
Thank you for the great work and posts.
I’m starting my studies with deep learning, python and keras.
I would like knowing how to implement the CNN with ELM (extreme learning machine) architecture in Python with Keras for classification task. Do you have a github implementation?
Sorry, I do not.
Thank you for your great examples…
May i ask you full code of the CNN LSTM you explained above?
Because,..i am having errors related to dimensions of CNN and LSTM.
I have followed your previous examples and trying to build VGG-16Net stacked with LSTM.
My database is just 10 different human motion (10 classes) such as walking and running etc…
My code is as below:
# dimensions of our images.
img_width, img_height = 224, 224
train_data_dir = ‘db/train’
validation_data_dir = ‘db/test’
nb_train_samples = 400
nb_validation_samples = 200
num_timesteps = 10 # length of sequence
num_class = 10
epochs = 10
batch_size = 8
lstm_input_len = 224 * 224
input_shape=(224,224,3)
num_chan = 3
# VGG16 as CNN
cnn = Sequential()
cnn.add(ZeroPadding2D((1,1),input_shape=input_shape))
cnn.add(Conv2D(64, 3, 3, activation=’relu’))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(64, 3, 3, activation=’relu’))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering=”th”))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(128, 3, 3, activation=’relu’))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(128, 3, 3, activation=’relu’))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering=”th”))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(256, 3, 3, activation=’relu’))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(256, 3, 3, activation=’relu’))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(256, 3, 3, activation=’relu’))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering=”th”))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation=’relu’))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation=’relu’))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation=’relu’))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering=”th”))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation=’relu’))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation=’relu’))
cnn.add(ZeroPadding2D((1,1)))
cnn.add(Conv2D(512, 3, 3, activation=’relu’))
cnn.add(MaxPooling2D((2,2), strides=(2,2),dim_ordering=”th”))
cnn.add(Flatten())
cnn.add(Dense(4096, activation=’relu’))
cnn.add(Dropout(0.5))
cnn.add(Dense(4096, activation=’relu’))
#LSTM
model = Sequential()
model.add(TimeDistributed(cnn, input_shape=(num_timesteps, 224, 224,num_chan)))
model.add(LSTM(num_timesteps))
model.add(Dropout(.2)) #added
model.add(Dense(num_class, activation=’softmax’))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(rescale=1. / 255)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode=’binary’)
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode=’binary’)
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
I forgot to put error which is :
ValueError: Error when checking input: expected time_distributed_9_input to have 5 dimensions, but got array with shape (8, 224, 224, 3)
You aso need to specify a batch size in the input dimensions to that layer I guess, to get the fifth dimension. Try using:
model.add(TimeDistributed(cnn, input_shape=(None, num_timesteps, 224, 224,num_chan))). TheNonewill then allow variable batch size.yes that worked for me. Thanks
please send me code , didn’t work for me
It doesn’t work for me. Anyone solved the same problem?
What problem are you having exactly?
I met this dimension error too, have you solved it?
please share your Github code i too met with same dimension error
I got the same error, have you solved it? May I ask you the way to solve it?
Sorry, I cannot debug your code. I list some places to get help with code here:
https://machinelearningmastery.com/get-help-with-keras/
Hello. How do you feed inputs to your network ? How is it sure that they are fed sequentially?
Hi Jason,
Assuming there are a data set with time series data (e.g temperature, rainfall) and geographic data(e.g. elevation, slope) for many grid positions, I need to use the data set to predict(regression) future weathers.
I think of a method with LSTM (for time series data) + auxiliary (geographic data) to be a solution. But the results of forecast is not very good. Do you have other better methods? Or do you have a related lessons?
Thank you very much.
Perhaps a deep MLP with a window over lag obs.
Hi Jason,
Could you please explain it in detail? Thank you very much.
This function will help you reshape your time series data to be a supervised learning problem:
https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/
You can then use a neural network model.
Hi Jason, Thanks a lot for this. I am having trouble implementing the same architecture of TimeDistributed CNN with LSTM using functional API. It is throwing an error when I pass the TImeDistributed layer to maxpooling step saying the input is not a tensor. Could you please put few lines of code for the Timedistributed CNN output into LSTM using functional API?
Perhaps try posting your code to stackoverflow?
Having the same problem, help would be appreciated!
Perhaps try using the Sequential API instead?
Perhaps try posting to one of these locations:
https://machinelearningmastery.com/get-help-with-keras/
Hi Jason,
How would I implement a CNN-LSTM classification problem with variable input lengths?
Use padding or truncating to make the inputs the same length:
https://machinelearningmastery.com/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/
With the padding approach, I am worried the LSTM might learn a dependency between sequence length and classification.
My data is structured such that sequences with more inputs are MUCH more likely to be a certain class than sequences with less inputs. However, I don’t want my model to learn this dependency.
Is my intuition correct? I remember reading in your earlier article that the LSTM will learn to ignore the padded sequences, but I wasn’t sure to what extent.
You can use a Mask to ignore padded values.
How to apply conv operation to the sequence itself instead of features (time sample data) ?
What do you mean exactly?
Nice intro, but it’s very incomplete. After reading this I know how to build a CNN LSTM, but I still don’t have any concept of what the input to it looks like, and therefore I don’t know how to train it. What does the input to the network look like, exactly? How do I reconcile the concepts of having a batch size but at the same time my input being a sequence? For someone who has never used RNNs before, this is not at all clear.
It really depends on the application, e.g. the specifics of the problem to which you wish to apply this method.
what is the difference between using the LSTM you show here and using the encoder decoder LSTM model in case of Video and image description?
A difference in architecture.
Can it be used for video summarization. Do you have a code for it?
Perhaps. I don’t have a worked example for video summarization.
You say : ” In both of these cases, conceptually there is a single CNN model and a sequence of LSTM models, one for each time step”
Can you please explain me on how is back propogation working here ? Assuming my sequence length is T, I have confusion as follow :
First interpretation : If a interpret in a way that for each LSTM unit I have corresponding CNN unit. So if input sequence of length T, I have T LSTM’s and corresponding T CNN’s. Then if I am assuming that I am learning weights by back propagation, then shouldn’t all the CNN’s have different weights ? How could all CNN have weight shared across time ?
Second interpretation : Only one CNN and T LSTM. Features across T frames extracted using the same CNN and passed on to T LSTM’s with different weights. But then how is this kind of network learning weights for the CNN.
I have really spent alot of time to understand but I am still confused. Would be really really helpful if you could answer 🙂
This post will help understand BPTT:
https://machinelearningmastery.com/gentle-introduction-backpropagation-time/
The LSTM is taking the interpretation of the input from the CNN (e.g. the CNNs output), which provides more perception of the input in the case of images and sometime text data.
Thanks for sharing BPTT link. I understood how the LSTM weights will be updated. But how about CNN weights ? I have attached the image of simple network.
https://drive.google.com/file/d/1J6-iLpEbNFL32Du-3il_ztw8jrMIZVSD/view?usp=sharing
If back propagation works like that, then after end to end training, wouldn’t all CNN weights be different. I yes then how are they same CNN ?
I believe error is propagated back for each time step.
What should the input look like in terms of shape?
for e.g. for a 45*45 image:
x_train.shape = (num_images, 45,45,num_channels)
y_train.shape =???
heres the code & image is actually 56*56*1
print “building model…”
model = Sequential()
# define CNN model
model.add(TimeDistributed(Conv2D(32, (3, 3), activation = ‘relu’),input_shape = (None, 56, 56, 1)))
model.add(TimeDistributed(MaxPooling2D(pool_size=(2, 2))))
model.add(TimeDistributed(Flatten()))
# define LSTM model
model.add(LSTM(256,activation=’tanh’, return_sequences=True))
model.add(Dropout(0.1))
model.add(LSTM(256,activation=’tanh’, return_sequences=True))
model.add(Dropout(0.1))
model.add(Dense(2))
model.add(Activation(‘softmax’))
model.compile(loss=’binary_crossentropy’,
optimizer=’adam’,
class_mode=’binary’, metrics=[‘accuracy’])
print model.summary()
batch_size=1
nb_epoch=100
print len(final_input)
print len(final_input1)
X_train = numpy.array(final_input)
X_test = numpy.array(final_input1)
#y_train = numpy.array(y_train)
#y_test = numpy.array(y_test)
#y_train = y_train.reshape((10000,1))
#y_test = y_test.reshape((1000,1))
print “printing final shapes…”
print “X_train: “, X_train.shape
print “y_train: “, y_train.shape
print “X_test: “, X_test.shape
print “y_test: “, y_test.shape
print
print(‘Train…’)
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch,
validation_data=(X_test, y_test))
print(‘Evaluate…’)
score, acc = model.evaluate(X_test, y_test, batch_size=batch_size,
show_accuracy=True)
print(‘Test score:’, score)
print(‘Test accuracy:’, acc)
shape = num_images, k
Where k is the number of classes or 1 for binary classification.
Hi, I’m working on a CNN LSTM Network. When I compile the following code I get the error below. I have an input_shape but I still get an error when I compile the code. Can you please help me.
Thank you.
Code :
# Importing the Keras libraries and packages
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers import TimeDistributed
# Initialising the CNN
classifier = Sequential()
# Step 1 – Convolutionclassifier = Sequential()
classifier.add(TimeDistributed(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = ‘relu’)))
Error :
ValueError: The first layer in a Sequential model must get an
input_shapeorbatch_input_shapeargument.That is odd, I’m not sure what is going on there.
Do you have some advice for this situation please ?
Yes, I would recommend carefully debugging your code.
Hi Fathy, did you get the solution of your problem? I am going through same trouble. if you get solution then let me know please
You need to specify the time dimension: input_shape = (#time steps per sample, 64, 64, 3)
Hi Jason,
Thanks for your share!
And is the convLSTM appropriate to solve the sea surface temperature prediction? I mean that we will input a sequence of grid maps and get the next temperature grid map?
Perhaps. Try it and see.
OK. Thank you! And do you have any suggestions for how the model should be modified for this problem?
Hi, did you solve your problem? I am confused about importing these images as input for convLSTM? Can you share the code about data input, please?
Hey there,
Thanks for your informative post… It was very useful!
I want to some similar task but a bit more complicated. Consider that we want to generalize or network to be able to use for different sizes. Therefore we need to look at frames in patch scale and then effect of patches of an image result image effect and then images result for the video. (Note that resizing is not possible in my case!)
In other words consider we want to use video in the network in which each video has a different number of frames and also frames of different videos may have different number of patches considering different frame size for different videos. Therefore the input dimension should be e.g. [None(for batch),None(for frame), None(for patch),100,100,3]
Actually I could not do its programming with Keras or TensorFlow! Would you please help with this?
With videos that have a different number of frames, you could:
– normalize to have the same number of frames
– pad videos to have the same number of frames and maybe use a masking layer
– use a network that is indifferent to sequence length
– … more ideas
With different patch sizes, I think you mean different filter sizes. If so, you can use a multiple input model as described here:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Does that help?
As far as use of masking layer is concerned. Could you please describe how should the masking layer be used in this situation. I mean when I try to use masking layer before cnn (where the padded frames indeed have zero values) then it tells me that CNN does not support masking. If the masking layer is used after the CNN are we sure that the padded frames will have a specific value and what this will be? Isn’t it necessary to not use biases in order to remain zero? As an alternative, not using biases would it be a good idea?
Thank you very much!
Hi Theogani…the following should add clarity:
https://github.com/jzbontar/pixelcnn-pytorch/blob/14c9414602e0694692c77a5e0d87188adcded118/main.py#L17
Hi Jason,
Thanks for your blog! I have some questions about how to apply this integrated model for my data. Now, I have time-series images with multiple bands for crop yield regression, how do I import these data as input for this model? Can you give me any examples or some references I can go to? Thanks so much!
What problem are you having exactly?
You can load images using Python tools, such as PIL.
http://www.pythonware.com/products/pil/
I give a fuller example in the book with contrived images:
https://machinelearningmastery.com/lstms-with-python/
i get an error “ValueError: The first layer in a Sequential model must get an
input_shapeorbatch_input_shapeargument.” when I run the following code of my model:model=Sequential()
K.set_image_dim_ordering(‘th’)
model.add(TimeDistributed(Convolution2D(64, (2,2), border_mode= ‘valid’ , input_shape=(1, 2, 2), activation= ‘relu’)))
model.add(TimeDistributed(Convolution2D(64, (1,1), border_mode= ‘valid’, activation= ‘relu’)))
model.add(TimeDistributed(MaxPooling2D(pool_size=(1,1))))
model.add(TimeDistributed(Convolution2D(64, (1,1), activation= ‘relu’ )))
model.add(TimeDistributed(MaxPooling2D(pool_size=(1,1))))
model.add(TimeDistributed(Dropout(0.0)))
model.add(TimeDistributed(Flatten()))
model.add(TimeDistributed(Dense(16, activation= ‘relu’ )))
model.add(TimeDistributed(Dense(16, activation= ‘relu’ )))
#lstm
m=Sequential()
m.add(LSTM(units = 1, activation=’sigmoid’))
I’m eager to help, but I cannot debug your code for you.
Perhaps post to stackoverflow?
Hey Jason, This example is very enlightening!
I’m currently aiming to do anomaly detection on some radio-astronomic data, which consists is .tiff image files, where horizontal axis is the time stamp, and vertical is frequencies. In this case, using the frequencies axis as a space (since signals come in varied frequencies) do you think it would be better to apply a 1D convolutional layer than just using a normal LSTM layer when encoding the images?. I understand there is a spatial dependence in my data, but it’s only 1-dimensional. I would like to know your opinion about this.
Btw, got your machine learning/deep learning/LSTM bundle, You’ve been my mentor these past months!
Yes, try 1D CNNs.
For example, 1d CNNs are useful for sequences of words as input which has parallels with what you’re describing I think.
Hey Jason your post are really good!, I was reading your book and try to apply the example for time series classification problem using a sequence of time series images like this guy does in his post: http://amunategui.github.io/unconventional-convolutional-networks/index.html
my images are 20000 (each frame is adding next 30 minute price), “50×50″ 1 channel,
The problem is that using all of regularization that I could, almost all of my architectures are about 0.51 accuracy, this is the last that I made:
model = Sequential()
model.add(TimeDistributed(Conv2D(5, (3,3), kernel_initializer=”he_normal”, activation= ‘relu’,kernel_regularizer=l2(0.0001)),
input_shape=(None,img_rows,img_cols,1)))
model.add(TimeDistributed(MaxPooling2D((2, 2), strides=(1,1))))
model.add(TimeDistributed(Dropout(0.75)))
model.add(TimeDistributed(BatchNormalization()))
model.add(TimeDistributed(Conv2D(3, (2,2), kernel_initializer=”he_normal”, activation= ‘relu’,kernel_regularizer=l2(0.0001))))
model.add(TimeDistributed(MaxPooling2D((2, 2), strides=(1, 1))))
model.add(TimeDistributed(Dropout(0.75)))
model.add(TimeDistributed(Flatten()))
model.add(Bidirectional(LSTM(50)))
model.add(Dropout(0.7))
model.add(Dense(num_classes, activation=’softmax’))
model.summary()
model.compile(loss=’binary_crossentropy’, optimizer=keras.optimizers.Adam(lr=1e-6),metrics=[‘accuracy’])
So I wanted to ask you, how could you avoid overffiting in this type of architectures, and if the height and length of the frames affect how the model identify all the patterns, as my problem where I don’t know if due to the very small details varying between my images (because are closely the same) could have an impact in the acc and the overfitting.
It will be really nice if you know how to help me!
Thank you, you have a nice books! 🙂
Interesting approach, I would prefer to model the data directly instead of the images. Perhaps with a 1D cnn.
A good approach to stop overfitting with neural nets is early stopping against a validation dataset.
Keras supports this here:
https://keras.io/callbacks/#earlystopping
Hello Jason,
You help me a lot.
I have a problem here. I have a project use CNN-LSTM model. However, when I use 1D cnn the performance of Maxpooling layer for the filter number is better than Maxpooling layer for the data size. So I have to resize of data after cnn layer by Pernute layer. How do you think about this?
If it results in good performance, then go with it.
Alternately, I wonder if you can explore alternate filter sizes in the CNN layer to change the output size?
Thank you for the answer.
Actually, I have already changed the filter sizes multiple times. I know normally, the Maxpooling layer is applied to reduce the data size not the number of filtes Even keras only support Maxpooling in cnn2D for width or height of data, so I little worry about this.
Greeting Dr.Jason
My thanks to your tutorial. I’ve got some question.
According to your tutorial here https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
I wonder if I could implement your idea of CNN LSTM with that tutorial? If so, what should I change in code? I am trying to do implement it but somehow I stuck with it.
Also, does it make sense to use this model for classification work?
I would appreciated if you answering back Dr.Jason. Thank you so much.
Yes you could.
I have some tutorials on this scheduled.
Dear Jason
Thanks again for your tutorial
Sorry you don’t have tutorial that include dataset which implement CNN (conv2D) and LSTM together
I believe I have an example in the LSTM book and I have some examples scheduled for the blog soon.
Hi Jason,
I am using GRUs for sequence learning in captioning problem. What is meant by training loss in GRU training ? and my loss starts from 9.### and drops down till 0.29## but if I keep training then it starts ti increase again. Any Idea what makes the loss increase again ?
My loss function is
loss_function = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y_true,
logits=y_pred)
loss_mean = tf.reduce_mean(loss_function)
y_true and y_labels are tokens sequences of the captions
Training loss is a measure of how well your model fits the training data.
You can learn more about cross entropy here:
https://en.wikipedia.org/wiki/Loss_functions_for_classification
Hellooo Mr Brownlee
I see in the comments that you have mentioned that you might investigate the ConvLSTM layer now available in Keras. I first want to think you for such an immense contribution, your blog has been extremely useful to me in understanding LSTMs. It must take a lot of your time to keep up with all these comments on top of providing the content that you do. However, I have read many of your posts but the knowledge I have fails me!
I am hoping to take advantage of the ConvLSTM2D for a video segmentation problem. It is a very different application to the sequence predictions frequented on this blog. I have N videos of 500 frames each and each video corresponds to a single 2D segmentation mask. I think it is a many to one problem:
Input: (N, 500, cols, rows, 1)
Output: (N, 1, cols, rows, 1)
As per your post on how to deal with long sequences, I have adjusted my input to contain sequence “fragments” , for example of 50 time steps so that I now have:
Input: (N, 10, 50, cols, rows, 1)
Output (N, 1, 1, cols, rows, 1)
Which does not work out so well because Keras LSTM expects a 5D array, not 6D. My understanding was that I would be able to feed a single sequence at a time into a stateful LSTM (500 images chopped up into fragments of 50) and that I could some how remember the state across the 500 images in this way in order to make a final prediction before deciding whether to update the gradients or not.
My implementation approach did not work with Input: (10, 50, cols, rows, 1) as here “10” is considered as the number of samples and thus corresponding output is required to be (10, 1, cols, rows, 1) ie. a segmentation mask every 50 frames, which is not what I am looking for.
I can duplicate the segmentation 10 times to produce the desired output but I am not sure that is the right way to go.
Or should I wait for the blog posts?
I do have some posts scheduled using the conv2dlstm for time series, but not video.
Nevertheless, I’d encourage you to get the model working first by any means, then make it work well.
Include all 500 frames of video as time steps or just the first 200. Each video is then a sample, then you can treat the rows, cols and channels like any image.
Once you have the model working, check if you need all frames, maybe only use every 5th or 20th frame or something. Evaluate the impact on the model skill.
Okay thanks. I will see what happens
Hi there, could you send a link to your conv2dlstm for time series? I am looking through your book and googling for blog posts but I cant find it. I am specifically looking for an example for conv2dlstm as the encoder part of an encoder/decoder architecture.
Also, as an aside, can these architecture types be made stateful?
Thank you Jason
I believe there is an example on this post:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
I tried to apply cnn+lstm+ctc for scanned text line recognition. would you recommend me any source for better understanding?
Nice work!
Perhaps try some searching on scholar.google.com
Awesome article as always. I would like to clear a question that came up. Do convolutionalLSTMs [https://github.com/keras-team/keras/blob/master/examples/conv_lstm.py] mean the same as convolutional neural networks followed by an LSTM. I understand you are trying to extrapolate features using the CNN before passing it on to a LSTM, so it should technically be the same?
No, a ConvLSTM is different from a CNN-LSTM.
A ConvLSTM will perform convolutions as part of the inputs to the LSTM unit.
A CNN-LSTM is a model architecture that has a CNN model for the input and an LSTM model to process input time steps processed by the CNN model.
Hi Jason,
Thank you for the article.
I was hoping to get your inputs and advice on the model I’m trying to build.
The goal of the model is to act as a PoS tagger using a combination of CNN and LSTM.
CNN portion receives as input, word vector representations from a Glove embedding and hopefully learns information about the word/sequence.
BiLSTM will then process the output from CNN.
A TimeDistributed layer is added at the dense layer for prediction.
The model trains without issues but in terms of performance, the metrics are worse than a pure LSTM model.
Am I constructing the model wrongly?
It’s hard for me to say. Develop then evaluate the model, then use that as feedback as to whether the model is constructed well.
Thanks for the reply Jason.
I have a few iterations of the model ranging from 1 CNN layer + 2 BLSTM layers to 3 CNN + 2 BLSTM.
In all cases, just a pure 2 BLSTM model outperforms them.
I’m kind of stuck, not sure if its a CNN or LSTM issue.
Perhaps this will help:
https://machinelearningmastery.com/improve-deep-learning-performance/
Thank you for the reply Jason, I’ll take a look at the post.
Thanks for the Tutorial, I want to ask about your your keras backend, is it tensorflow or Theano? Thanks
I currently use and recommend TensorFlow, but sometimes it can be challenging to install on some platforms, in that case I recommend Theano.
how do we feed the video frames as input to cnn+lstm model? Im currently working with that and unaware of how this could be done.Could you guide me on this?Basically i want to know regarding the input part of the model.
Each image is one step in a sequence of images (e.g. time steps), each sample is one sequence of images.
I read that you used LSTMs for different problems and you did not find them useful. Your article is about time series regression, but I would like to hear your opinion about time series classification. While reading the literature, I found RNNs/LSTMs to enhance a bit the accuracies in different domains, but I did not see many groundbreaking results with these networks. Do you have any experience if a windowing approach with MLP or CNN is also more useful than LSTM/RNN methods for time series classification?
Yes, I have examples of MLP, CNNs and LSTMs for time series classification here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
I have found CNN LSTM hybrids to be very effective.
thank you sir for these awesome tutorials,it have been a great help me to me…. i tried to implement CNN-lstm using keras but i am getting accuracy of only 0.5. Also accuracy not improving after few epochs….. please guide me sir
from string import punctuation
from os import listdir
from numpy import array,shape
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense,BatchNormalization
from keras.layers import Flatten
from keras.layers import Dropout, Activation
from keras.layers import LSTM
from keras.layers import Embedding
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.callbacks import EarlyStopping
from History import LossHistory
# load doc into memory
def load_doc(filename):
# open the file as read only
file = open(filename, ‘r’)
# read all text
text = file.read()
# close the file
file.close()
return text
# turn a doc into clean tokens
def clean_doc(doc, vocab):
# split into tokens by white space
tokens = doc.split()
# remove punctuation from each token
table = str.maketrans(”, ”, punctuation)
tokens = [w.translate(table) for w in tokens]
# filter out tokens not in vocab
tokens = [w for w in tokens if w in vocab]
tokens = ‘ ‘.join(tokens)
return tokens
# load all docs in a directory
def process_docs(directory, vocab, is_trian):
documents = list()
# walk through all files in the folder
for filename in listdir(directory):
# skip any reviews in the test set
if is_trian and filename.startswith(‘cv9’):
continue
if not is_trian and not filename.startswith(‘cv9’):
continue
# create the full path of the file to open
path = directory + ‘/’ + filename
# load the doc
doc = load_doc(path)
# clean doc
tokens = clean_doc(doc, vocab)
# add to list
documents.append(tokens)
return documents
# load the vocabulary
vocab_filename = ‘vocab.txt’
vocab = load_doc(vocab_filename)
vocab = vocab.split()
vocab = set(vocab)
# load all training reviews
positive_docs = process_docs(‘txt_sentoken/pos’, vocab, True)
negative_docs = process_docs(‘txt_sentoken/neg’, vocab, True)
train_docs = negative_docs + positive_docs
# create the tokenizer
tokenizer = Tokenizer()
# fit the tokenizer on the documents
tokenizer.fit_on_texts(train_docs)
# sequence encode
encoded_docs = tokenizer.texts_to_sequences(train_docs)
# pad sequences
max_length = max([len(s.split()) for s in train_docs])
Xtrain = pad_sequences(encoded_docs, maxlen=max_length, padding=’post’)
# define training labels
ytrain = array([0 for _ in range(900)] + [1 for _ in range(900)])
# load all test reviews
positive_docs = process_docs(‘txt_sentoken/pos’, vocab, False)
negative_docs = process_docs(‘txt_sentoken/neg’, vocab, False)
test_docs = negative_docs + positive_docs
# sequence encode
encoded_docs = tokenizer.texts_to_sequences(test_docs)
# pad sequences
Xtest = pad_sequences(encoded_docs, maxlen=max_length, padding=’post’)
with open(“sentiment.txt”, “w”) as text_file:
for p in test_docs: text_file.write(“%s \n” % p)
# define test labels
ytest = array([0 for _ in range(100)] + [1 for _ in range(100)])
# define vocabulary size (largest integer value)
vocab_size = len(tokenizer.word_index) + 1
print (Xtrain)
print(‘Build model…’)
# print (max_length) # 1209
# print (vocab_size) #13045
# define model
model = Sequential()
model.add(Embedding(vocab_size, 100, input_length=max_length))
model.add(Conv1D(filters=32, kernel_size=8, activation=’relu’))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(100))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation(‘sigmoid’))
model.compile(loss=’binary_crossentropy’,
optimizer=’adam’,
metrics=[‘accuracy’])
early_stop = EarlyStopping(monitor=’val_loss’, patience=10)
train_log = LossHistory()
model.fit(array(Xtrain), array(ytrain),
batch_size = 30,
epochs=10,
callbacks=[early_stop, train_log],
validation_data=(array(Xtest), array(ytest)))
score, acc = model.evaluate(array(Xtest), array(ytest), batch_size=30)
model.save(‘cnn-lstm_model.h5’)
# score, acc = model.evaluate(x_test, y_test, batch_size=batch_size)
print(‘Test score:’, score)
print(‘Test accuracy:’, acc)
I have a guide to diagnosing and improving deep learning model performance here:
https://machinelearningmastery.com/start-here/#better
thankyou sir, i shall refer that
Hi Jason,
What neural network model would you suggest for physical problems? For example: Problems related to Fluid Mechanics? Like the one in the video below shows fluid flow around a circle, and after a while it starts to produce vortices. Which NN architecture would be best suited for a problem like this where in we have say data for 50 time-steps, we train the model for 40 of them and we want to predict data for the next 10 time-steps and compare with the actual results. The data would include the velocity, vorticity and other physical parameters along the domain shown in the video in both x and y direction. I tried using ConvLSTM2D in Keras, but the results are not good.
LInk of the video of the fluid flow problem I was talking about:
https://www.youtube.com/watch?v=JgoHhKiQFKI
I recommend testing a suite of methods in order to discover what works best for your specific dataset.
Hi Dr. Jason,
Excellent Post, Thanks for the sharing the same.
I am currently working on traffic classification problem. It does seem like this approach would be ideal for the case.
I would need your help in below points.
1. I have implemented a traffic classification using normal CNN model (Transfer Learning using ResNet50)
2. Time is important factor as I dont want the image to be classified like A B A B. (Ideal would be A A A A …….. B B B B B ……)
3. Can I combine the LSTM model add the end of this model ?
4. Will this approach make my model better in real world application?
Thank you,
KK
Yes, I recommend prototyping the model and evaluate its performance.
How could one turn this into a hierarchical model? Both hierarchical in space (cnn) and time (lstm)? That way features over a larger area could be correlated with smaller features and extended temporal patterns could be correlated with shorter temporal patterns in these small and large feature spaces.
would it necessarily be something like this:
cnn -> lstm ->
cnn -> lstm -> cnn -> lstm ->
cnn -> lstm -> cnn -> lstm -> cnn -> lstm
cnn -> lstm -> cnn -> lstm -> ^
cnn -> lstm -> ^ ||
|| ||
|| ||
|| ||
summary timeseires data ||
||
||
||
summary summary timeseires data
lots of small feature detection at the beginning which feed to a set of layers that convolve over larger spacial and temporal dimentions, and so on?
A Conv-LSTM hybrid model is sufficient, also a ConvLSTM model.
Both will process time steps of spatial data.
You can then use one model for each level of detail, and use a model to combine their interpretations.
Hello Jason, I used similar model like yours. I used 10 frames per cnn-lstm. My shape is (Sample,10,90,90,1) —> (sample,time,img-shape,img-shape,channel)
The problem is I am getting 10 results for each prediction and I don’t know why. Also these 10 results are different. Do you have any idea?
Thanks
Emre
Unless you use an encoder-decoder, you will get one output per input time step.
Only used one hot encoder for classes ( I have 5 different classes). And I have 50 results (not 10) per each time actually. Should I use encode-decoder for model also? Or how can i solve this problem?
Regards,
Emre
Perhaps try it and compare results?
Have you solved the problem? I also had the same error.
What error?
Hi Sir,
Thanks for the excellent tutorial.
I am working on an Image classification problem where I think CNN+LSTM would be very much useful as I am feeding the image frame fetched from a video.
In this case, how do I need to arrange my image frames?
If it is a general image classification, I would create a folder for each class. But in this lets take I take 3 video sequences which belongs to one class. How I have to arrange the image frames in training and testing?
Thank you,
KK
Images must be arranged in temporal order and into sequences.
You might want to write a custom data generator to yield each sequence or batch of sequences of images.
Hey Jason, how we can do ImageDataGenerator to the images? Becayse of the shape of the images I am getting error.
ValueError: Input to
.fit()should have rank 4. Got array with shape: (11194, 10, 90, 90, 1)Thanks,
Emre
Perhaps this post will help:
https://machinelearningmastery.com/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
I am attempting to build a simple version of the model described in this paper for object detection in video: https://arxiv.org/abs/1903.10172. The architecture is a convNet feature extractor which feeds it’s output to a convLSTM which feeds its output to SSD detection layers. The first step though is just to pretrain convNet+convLSTM end to end on image classification.
The model you’ve described here seems like the proper way to combine the convNet and convLSTM, but I’m confused about input shape. The TimeDistributed layers require a 3D input, with one dimension being time. I understand how I could do this at train time, but at inference time I do not want to feed a 3D tensor to the model. I just want it to process one image at a time. I feel like I’m missing a small detail, and I’m hoping you can help. Thanks!
P.S. The authors of the above mentioned paper have code in a tensorflow/models/research/lstm_object_detection repo, but it seems their code for this version of their work (last updated about a week ago) is incomplete and is very confusing to me.
Hmm, I’m not familiar with the model.
Generally, this will help in understanding input shape:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
And, the CNN-lstms and convlstms in this post may be instructive:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Generally, a CNN-LSTM expects one feature to be an image and for a sample to be a sequence of images, e.g. something like [?, timesteps, rows, cols, channels].
Does that help?
Thanks for the quick reply. I probably shouldn’t have mentioned that specific model, as it’s not really critical to the question. I was just trying to provide some context.
After reading the first link you shared, it seems like what I want to do is have an input of only one timestep, but maintain the internal state over multiple timesteps with the stateful = true parameter. But in that case it doesn’t seem there’s a need for the TimeDistribted layer, except maybe to start out with the input shape that the lstm expects. Otherwise, I could probably just reshape the convNet output to have a time dimension before feeding to convLSTM. Does that sound right to you?
Thanks again! Hopefully I’ll get my model built today.
Perhaps.
There are many ways to frame a give problem. I’d encourage you to brainstorm a couple, then test each. It will help you learn more about the data and the models, and also find what works for your specific dataset.
hello Mr Brownlee
I want to use CNN lstm for image classsification.
i used your CNN lstm code above but i faced to the
“ValueError: The first layer in a Sequential model must get an
input_shapeorbatch_input_shapeargument.” error for the line “model.add(TimeDistributed(cnn,…)”how can i find what is the input shape of this layer?is it my input image shape or the CNN output shape(feature vectors getting from CNN)?
would you please guide me how to fill the brackets of the LSTM model code?for example how to choose the elements of the “model.add(LSTM(…))?
thanks a lot
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
hello Mr Brownlee
thank you for your guidance. i read the link ,but still my cnnLSTM does not work. and the error for timeDistributed code is accured.
i search a lot to solve this problem and finally i have found a suggestion, “using r1.4.0 ,an API documentation for tensorflow”.
my tensorflow version is 1.4.0. and now my question is how can i use this API, i mean should i install it instead of my tensorflow or should i copy it somewhere or something else.
i send you my code(the input images are 28*28)
please help me again,Mr Brownlee.
thank you
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers import LSTM
from keras.layers import TimeDistributed
from keras.utils import np_utils
from keras import backend as K
K.set_image_dim_ordering(‘th’)
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# reshape to be [samples][pixels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype(‘float32’)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype(‘float32′)
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
num_timesteps = 10 # length of sequence
# define CNN model
model = Sequential()
model.add(TimeDistributed(Conv2D(32, (3, 3), input_shape=(1, 28,28), activation=’relu’)))
model.add(TimeDistributed(MaxPooling2D(pool_size=(2, 2))))
model.add(TimeDistributed(Flatten()))
# define LSTM model
model.add(LSTM(num_timesteps))
model.add(Dense(num_classes, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’,optimizer=’adam’,metrics=[‘accuracy’])
#return model
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print(“CNN Error: %.2f%%” % (100-scores[1]*100))
———————————————-
ValueError: The first layer in a Sequential model must get an
input_shapeorbatch_input_shapeargument.Perhaps try updating to the latest version of tensorflow, e.g. 1.13.
thanks alot again
but I typed the below codes in my Anaconda prompt ; and i faced to a exceptions.
what is wrong?
how can i update my tensorflow?
(C:\Users\ASUS\Anaconda3) C:\Users\ASUS>python
Python 3.6.3 |Anaconda custom (64-bit)| (default, Oct 15 2017, 03:27:45) [MSC v.1900 64 bit (AMD64)] on win32
Type “help”, “copyright”, “credits” or “license” for more information.
(C:\Users\ASUS\Anaconda3) C:\Users\ASUS>pip install
You must give at least one requirement to install (see “pip help install”)
You are using pip version 9.0.1, however version 19.1.1 is available.
You should consider upgrading via the ‘python -m pip install –upgrade pip’ command.
(C:\Users\ASUS\Anaconda3) C:\Users\ASUS>pip install -U –no-deps keras tensorflow theano scikit-learn
Exception:
Traceback (most recent call last):
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\basecommand.py”, line 215, in main
status = self.run(options, args)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\commands\install.py”, line 335, in run
wb.build(autobuilding=True)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\wheel.py”, line 749, in build
self.requirement_set.prepare_files(self.finder)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\req\req_set.py”, line 380, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\req\req_set.py”, line 487, in _prepare_file
req_to_install, finder)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\req\req_set.py”, line 428, in _check_skip_installed
req_to_install, upgrade_allowed)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”, line 465, in find_requirement
all_candidates = self.find_all_candidates(req.name)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”, line 423, in find_all_candidates
for page in self._get_pages(url_locations, project_name):
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”, line 568, in _get_pages
page = self._get_page(location)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”, line 683, in _get_page
return HTMLPage.get_page(link, session=self.session)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”, line 811, in get_page
inst = cls(resp.content, resp.url, resp.headers)
File “C:\Users\ASUS\Anaconda3\lib\site-packages\pip\index.py”, line 731, in __init__
namespaceHTMLElements=False,
TypeError: parse() got an unexpected keyword argument ‘transport_encoding’
You are using pip version 9.0.1, however version 19.1.1 is available.
You should consider upgrading via the ‘python -m pip install –upgrade pip’ command.
I don’t know, perhaps try installing one library at a time to narrow it down.
Perhaps also try this tutorial instead:
https://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
i succeed to update my tensorflow.
Now in my Anaconda /lib/site-package i have 2 tensorflow folders:
tensorflow 1.4.0 and tensorflow 1.10.0
should i delete tensorflow 1.4.0?
Perhaps. Also, perhaps try an update to tensorflow 1.13, the latest version.
thank you
Mr.Brownlee
I’m so sorry for asking a lot,
here is the only reference i could trust on it.
After updating, my Anaconda prompt does not work.
i mean it doesn’t stay on the desktop.
these 4 line accure and then it would be closed
C:\Users\ASUS>python C:\Users\ASUS\Anaconda3\etc\keras\load_config.py 1>temp.txt
C:\Users\ASUS>set /p KERAS_BACKEND= 0del temp.txt
C:\Users\ASUS>python -c “import keras” 1>nul 2>&1
Perhaps run the code as-is without redirecting the output?
Hello Mr.Brownlee
I unstalled the Anaconda which was in my system completely ,and again from beginning i have installed Anaconda that all of its libraries are in higher version.e.g tensorflow is 1.13.0 and so on.
Now the problem is that when i run my previous codes i faced to a error below:
import numpy as np
import scipy
import scipy.misc
n_images =16416 #Example value
image_names = [“traincharactor2/image_{0}.bmp”.format(k) for k in range(n_images)]
training_set = []
for img in image_names:
training_set += [scipy.misc.imread(name=img)]
X_train = np.array(training_set).reshape(16416, 28,28);
C:\Users\ASUS\Anaconda3\lib\site-packages\ipykernel_launcher.py:10: DeprecationWarning:
imreadis deprecated!imreadis deprecated in SciPy 1.0.0, and will be removed in 1.2.0.Use
imageio.imreadinstead.# Remove the CWD from sys.path while we load stuff.
I added ” import imageio”
but the below error accure
import numpy as np
import scipy
import scipy.misc
import imageio
n_images =16416 #Example value
image_names = [“traincharactor2/image_{0}.bmp”.format(k) for k in range(n_images)]
training_set = []
for img in image_names:
training_set += [imageio.imread(‘name=img’)]
X_train = np.array(training_set).reshape(16416, 28,28);
FileNotFoundError: No such file: ‘C:\Users\ASUS\name=img’
i triead many syntax for ” training_set += [imageio.imread(‘name=img’)]”
but nothing work
I think you need to change the name of the file that you’re loading.
Hello Mr.Brownlee
I could solve the problem for readin g images.
I start to run the LSTM_CNN for image classification.
like befor,i faced to this error
ValueError: Dimension must be 5 but is 4 for ‘time_distributed_4/conv2d_5/transpose’ (op: ‘Transpose’) with input shapes: [?,10,28,28,1], [4].
here is my code(images are 28*28)
import numpy
#from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers import LSTM
from keras.layers import TimeDistributed
from keras.utils import np_utils
from keras import backend as K
K.set_image_dim_ordering(‘th’)
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# reshape to be [samples][pixels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype(‘float32’)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype(‘float32′)
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
num_timesteps = 10 # length of sequence
# define CNN model
cnn = Sequential()
cnn.add(Conv2D(32, (5, 5), input_shape=(1, 28,28), activation=’relu’))
cnn.add(MaxPooling2D(pool_size=(2, 2)))
cnn.add(Flatten())
# define LSTM model
model = Sequential()
model.add(TimeDistributed(cnn, input_shape=(None, num_timesteps, 28, 28,1)))
model.add(LSTM(num_timesteps))
model.add(Dense(num_classes, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’,optimizer=’adam’,metrics=[‘accuracy’])
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print(“CNN Error: %.2f%%” % (100-scores[1]*100))
i tries alot of way for changing the input_shape, but nothing work.
would you please help me to say what is wrong in the code?!
i really need this code for my study
thanks alot
Sorry, I cannot debug your code for you, perhaps try posting to stackoverflow?
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Also, perhaps the cnn-lstm code example here:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Hello Mr Brownlee
I couldn’t solve my problem yet.
now I want to save the features extracted by a CNN as a vector.
how can i do it?
i want first save cnn features and then feed them to a LSTM.
———
another question is about my database,
for implementing a CNN_LSTM , my training dataset is a folder that the images for all the classes are arrange respectively.the test folder is so as training one.
is it ok for your suggested code above?
I give an example of extracting vectors from a CNN here:
https://machinelearningmastery.com/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
The dataset layout sounds fine.
i wrapped everything with a timedistributed()
still i am having the error
“input tensor must have rank 4”
what shall i do ?
Perhaps start with a working example and adapt it for your problem:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Can we classify IRIS dataset with CNN or RNN?
No, the iris data is not a sequence.
See this post:
https://machinelearningmastery.com/when-to-use-mlp-cnn-and-rnn-neural-networks/
Hello Jason,
I am taking my first steps with lstm and I am facing a strange situation while trying to fit my model. Could you please check my description of the task and correct me if you see any problem? (I am using R, but the code is almost the same 🙂 )
# Context of the problem / data -generators- used
To give you some context, I have dataset of single channel, 2D arrays. A sequence of these 2D arrays should be good enough to create a classifier. The shape of one of these arrays is (180,360,1), and for each day, I have 24 of them.
In this scenario, as far as I can understand, I am trying to build a many-to-one lstm model.
I created a data generator that returns an array of dimensions (batch_size,time_steps,180,360,1).
# Results of test models:
(1)
If I use a “simple” model, without using a LSTM model, but “considering all timesteps together”:
batch_size <- 1 # a batch is just one day
time_steps <- 24 # all the 2D arrays of the day are sent
model %
layer_flatten(input_shape = c(time_steps, 180, 360, 1)) %>%
layer_dense(units = 32, activation = “relu”) %>%
layer_dense(units = 16, activation = “relu”) %>%
layer_dense(units = 1, activation = “sigmoid”)
model %>% compile(
optimizer = “rmsprop”,
loss = “binary_crossentropy”,
metrics = c(“accuracy”)
)
I get a val_acc of ~ 0.76 and a val_loss of ~ 0.56
(2)
If use a CNN + LSTM, using batches of 3 days, and sending for each day 48 time steps (looking 2 days back)
batch_size <- 3 # the batch is of three days
time_steps <- 48 # all the arrays of a day and the day before
model %
time_distributed(
layer_conv_2d(filters = 32, kernel_size = c(5,5), activation = “relu”,
kernel_initializer = ‘he_uniform’),
input_shape = list(24*lookback_d, 180, 360,1)
) %>%
time_distributed(
layer_max_pooling_2d(pool_size = c(3,3))
) %>%
time_distributed(
layer_conv_2d(filters = 32, kernel_size = c(5,5), activation = “relu”,
kernel_initializer = ‘he_uniform’)
) %>%
time_distributed(
layer_flatten()
) %>%
layer_gru(units = 32, dropout = 0.1, recurrent_dropout = 0.5) %>%
layer_dense(units = 16, activation = “relu”) %>%
layer_dense(units = 1, activation = “sigmoid”)
model %>% compile(
optimizer = “rmsprop”,
loss = “binary_crossentropy”,
metrics = c(“accuracy”)
)
I get the same val_acc of ~ 0.75 and a val_loss of ~ 0.55
# Questions:
Could it be possible that these results are almost the same because further tuning is needed in the CNN+LSTM model? Or could it be because the “basic model” created is just very difficult to improve?
Since increasing the amount of days sent on each batch, or the amount of time_steps sent for each day, generates a ResourceExhaustedError (OOM when allocating tensor with shape …. -This occurs in the first conv_2d layer-), do you think I should modify the shape of the data sent to the model with the data generator?
Thank you for your help!
Sorry, i don’t have the capacity to debug your code/problem.
Perhaps try posting to stackoverflow?
can we use CNN with LSTM for signal data for prediction
Sure, I give an example here:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Can it be implemented for Temporal segmentation of time-series of satellite imagery?
Sorry, Id on’t know what that problem is exactly?
Great post Jason. Can we use ConvLSTM to extract human emotions from a series of frames consisting faces instead of face from single frame ? I am working on a practice project to extract human emotions from the video of my kids, the regular CNN spits out human emotions on each frame but I have seen the emotion to peak out at the last frame in a series of frames.
Perhaps try it and see?
Thanks Jason for replying. I am starter with respect to machine learning programming, it took me a lot of effort to figure out a CNN was not helping me to achieve my goal. A general algorithm of how to do it will be of immense help to keep me focused in solving my mvp in my project.
Can I use 2D-CNN for time series prediction? Your response will be valuable to my research
Yes, CNNs can be used for time series, here are many examples:
https://machinelearningmastery.com/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
2D CNNs only make sense for spatio-temporal data, e.g. images over time.
Thanks for the great tutorial.
Please tell me how to use 2D CNN for spatio temporal time series prediction. Is there any tutorial for it?
Thanks for the suggestion, I hope to cover it in the future.
I am designing a spatio temporal multivariate 2D CNN LSTM
13974 sequences and 100 timestamps of 6 locations and 5 variables(features)
train input shape : (13974, 100, 6, 5)
train output shape : (13974, 1, 6, 5)
test input shape : (3494, 100, 6, 5)
test output shape : (3494, 1, 6, 5)
model = Sequential()
model.add(TimeDistributed(Conv2D(32, (3, 3),
padding=’same’),
input_shape=(100, 6, 5,1)))
model.add(TimeDistributed(Activation(‘relu’)))
model.add(TimeDistributed(Conv2D(32, (3, 3))))
model.add(TimeDistributed(Activation(‘relu’)))
model.add(TimeDistributed(MaxPooling2D(pool_size=(2, 2))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Flatten()))
model.add(TimeDistributed(Dense(512)))
model.add(TimeDistributed(Dense(35, name=”first_dense_flow” )))
model.add(LSTM(20, return_sequences=True, name=”lstm_layer_flow”));
model.add(TimeDistributed(Dense(101), name=” time_distr_dense_one_ flow “))
model.add(GlobalAveragePooling1D(name=”global_avg_flow”))
model.compile(loss=’mae’, optimizer=’adam’, metrics=[‘accuracy’]) model.fit(train_input,train_output,epochs=50,batch_size=60)
is my model able to predict the output (13974, 1, 6, 5)
please correct my .
Sorry, I don’t have the capacity to review and debug your code, I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
hi,
I followed your post. built CNN+LSTM model, it is compiling fine.
But their is a issue in fit_generator on training
error is:
Expected 5 dimension for the input but got only four
i have provided images through Image datagenerator having input of dimension 64x64x3 with a batch size of 4
therefore, input fit_generator is taking is: (4,64,64,3)
It suggests a mismatch between the data and the model. You can change one or the other.
Hi Jason: Big fan here. Question: you showed a CNN-LSTM architecture here that could be used for analyzing video data. But how do we pre-process the video data for input into this architecture? I have multiple clips of 2 second videos of human motion with the labels being 0 or 1, I have extracted some of the frames but don’t know how to input them into this NN architecture…
From reading the comments above, it seems like quite a few people are interested in CNN-LSTM for video data! But It is still unclear how that would work… specifically how to structure the project, and how to preprocess the raw data for input… maybe this could be a future tutorial? Thanks Jason 🙂
I give a mock video example in the LSTM book.
It is an array of images, each image is a timestep.
Thanks George.
Good question. I don’t have a worked example, sorry. Trim frames down to a min set (a few per second?) then perhaps use pixel scaling on the image data, just like image classification?
Hi Jason,
Thanks for the great write up. There was no mention of how data is being read into the model. Since its a CNN + LSTM model, the typical ImageDataGenerator would not work, as we are reading a sequence of image.
The typical ImageDataGeneratorvyields (N, W, H, C) data, where N is the batch size, W and H are width and height, and C is the number of channels (3 for RGB, 1 for grayscaled images).
But we need to send a sequence, we need to send several frames. The needed shape is (N, F, W, H, C) — where F is the number of frames for our sequence.
So how can we possibly go on to read the each sequences of images?
Not sure I follow your question, sorry.
There is an example in the LSTM book with images:
https://machinelearningmastery.com/lstms-with-python/
There is an example for time series here:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Hello Jason,
i would like to ask if i can implement CNN on data in CSV file this in traffic flow prediction !!!!!!
and is there any sources that can help me to implement in python by using keras or pytorch libraries.
The data has 2 features date, time and the flow of vehicles per hour.
Thank you.
Perhaps this will help you to get started:
https://machinelearningmastery.com/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
hello, Jason
can I apply unlabeled dataset on CNN+LSTM, this is possible or not?
if you yes, how to work the algorithm
Perhaps, if you reframe the problem as self-supervised learning.
thank you, sir,
do you have any reference and code.
Yes, I give a 2d example in the book.
I have many 1d examples on the blog, you can use the blog search.
Hi Jason,
I am trying out to classify video segments into actions.
I already have the I3D features which are extracted by CNN layer.
Tried to fit them into LSTM model to train, however, the val_acc remains at 45%.
I am suspecting that it didn’t learn the sequence as I did not use a stateful LSTM. But when I read through your writeup above, there was no handling to ensure the sequence is learnt too or I did not understand how it was handled? Can you help me understand how your model makes sure the sequence is learned?
Some more info:
1. As some of the segments are too long/short, I did a truncation/pad using pad_sequence. For truncation, I take the frames from the midpoint of the segment, as I read typically that reflect the actions better.
I read another article of yours mentioning about stateful LSTM, which should be the right way that an LSTM should be used. I think LSTM help to learn the sequence between the segments of a video, thus help to improve the prediction with the segment dependencies. I tried adjusting the batch size to best fit 1 video as 1 batch so that it learns the sequence. But it does not help.
Well done on your progress.
Stateful may or may not help.
I think the tutorials here will help you diagnose issues and lift the skill of your model:
https://machinelearningmastery.com/start-here/#better
Sir can you tell me how lstms can be used for feature selection fron static data
I have not seen LSTMs used for feature selection.
Hello Jason .. So I have a doubt .. does combining lstm with cnn models always give a better result(accuracy) as compared to cnn model alone .. specifically vgg16 model .. for image segmentation ..
No, it really depends on the specifics of the prediction task.
Does it vary like this because it’s image segmentation ? Does video classification has better results ? Also is there any way to compare performance between two models based on just model summary ?
A CNN-LSTM is appropriate for sequences of images, like video. Not segmentation specifically.
Hello Jason can we use Convolutional LSTM for multivariate time series prediction.Basically we have a dataset that has factors like rainfall, temperature,pressure,solar irradiance and solar power output and we need to predict solar power output.So can this method be used?
Yes. See here:
https://machinelearningmastery.com/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
Hello,Jason so basically I wanted to apply Convolutional LSTM on the multivariate Time series data and not just CNN.So is it possible to do so
Sure, see the examples here:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Hi, Jason!
Thanks for the great article, I love your work!
I have a question though: in the article you’ve used the output of an image passed through a CNN as a single timestep for the LSTMs, but I would like to use the output of an image passed through a CNN as multiple timesteps. So, for example, if my CNN output is 32×80, I would like to use this output as 32 timesteps of 80 features each for my LSTMs. How would one do this?
Thank you!
Thanks!
Not sure that makes sense – e.g. dividing a vector of images features into “timesteps” for the LSTM. Can you help me to understand?
My use-case is text recognition in images. If we have an image of a word, seeing the image as a sequence of vertical blocks of features can be useful, if I understood correctly from what I’ve read online. I believe this is because a word is a sequence of characters.
This is how I think it would work: getting an image with a word through CNNs would extract relevant features. By using Pooling layers we can get the output volume to be something like W’ x 1 x F (pooled width, pooled height equal to 1 and F filters/kernels outputs), whereas the input image was W x H x 1 (grayscale). The output can then be seen as distilled information for each of the W’ **time steps**, as both the initial image and the CNNs’ output can be seen as a sequence of ‘vertical’ observations.
Please correct me if something doesn’t make sense, because I’m not a specialist at all. I’ve read about this network type in this article: https://towardsdatascience.com/build-a-handwritten-text-recognition-system-using-tensorflow-2326a3487cd5 so I might have understood incorrectly.
I believe a good approach is to first locate the text, perhaps segment, then OCR it.
I don’t have tutorials on this topic, I recommend checking the literature and discover the start of the art.
Hello Jason, I am always indebted to your for your great tutorials. I am trying to predict a very complex time-series function using LSTM but I have so far difficulty in training LSTM. I am thinking to combine LSTM with 1d CNN. I have following questions:
What would be the difference if I use LSTM first with return_sequences=True and then apply 1d CNN on its output and if I use 1d CNN first and then LSTM (as you have described here). I am conceptualizing it as LSTM to extract temporal features and then 1d CNN to extract some more complex features, since this is a really complicated function. Does this make sense? To be honest I have applied this and have got much better results as compared to LSTM-only model. If my conceptualization is correct, is it possible to visualize what features are being learned by LSTM and what features are being learned by CNN? Thank you very much in advance for your input.
The LSTM may extract features from the raw data that could be useful to the CNN.
Sounds like a CNN-LSTM in this example:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Perhaps try it and see?
Thank you for your work, Jason. Your articles have been giving me a lot of insight.
I have a question: why do you use Flatten after Conv? The feature maps of different activations don’t have any real temporal dependency, right? Why don’t pass the data directly to lstm (without Flatten), where a feature map of one activation would represent a set of features for lstm? (i.e. if conv had 64 kernels, lstm would have 64 “sequences”)
If flattening does make sense, I’d highly appreciate your comment as I didn’t find any papers that would confirm this approach.
Thank you.
Thanks.
Good question, the output of a convolutional layer are multiple 2d feature maps, a dense or LSTM expects a vector input, therefore we flatten.
Papers rarely talk about low level implementation details, try looking at the code provided with a given paper.
I wonder if CNN LSTM is suitable for signature verification system?
can you advise me
Thank you
Perhaps try it and see.
Hi Jason, I was wondering if you guide me. I am so confused in applying CNN + LSTM structure. In my structure, the number of samples and the number of sequence data are 6000 and 20, respectively. Also, the size of the input is 2000*10*1. According to what I understand, I should define the input 5d. But I really don’t know what should be the size of the output. If I define the output size equal to 6000×1, I got the error that it should be 3d. In this case, if I define it 6000x20x1, I think in this case, I make the mistake. Because, for each segment I will have one output. Then, the sequence of the data is not consider. I am so thankful if you guide me.
Perhaps the CNN-LSTM worked example in this tutorial will help:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
HI Jason, May i know how to create the spatio temporal time series forecasting model?
Which specific steps need to add for spatio dependencies ?
A CNN-LSTM would be a good model to start with.
Hi, Jason.
can i use CNN + LSTM in audio clssification
Perhaps try it and see.
Hello Jason,
Thanks you very much for this valuable article. I have a problem with my case that I am confused.
I have a spatio-temporal dataset of mixed static and dynamic features.
My question is that can we use CNN-LSTM for this dataset?
also, in dataset preparation and for the dynamic feature(s), I have the data available for the sequences; however, for the prediction using any built model on this dataset, I only have access to the initial step of the dynamic feature(s) and the static features.
Do you have any suggestions?
Thank you
Yes, you can have a model with multiple inputs, e.g. one for the spatiotemporal elements (cnn-lstm) and one for the static elements (dense).
You can achieve this with the functional API.
This will help you get started:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Thank you very much for your reply.
It seems functional API will perfectly solve the problem of static and dynamic features in my dataset. However; once the model is built, it needs a series of my dynamic feature at different time steps to feed into the model but I only have the initial step to feed into the built model.
Is there a way to do this using these models? Thanks
Yes, the submodel that takes the static features does not need to be aware of “time steps”.
Thank you Jason for your reply. My problem is with the dynamic data. in my dataset, I have a dataset of dynamic (at different time steps) and static features. but my problem is that once any model on the dataset is built, I can only provide the dynamic data at the initial step plus the static data. I don’t have a series of that dynamic feature to feed into the model.
Thanks
You can use a multi-input model with a CNN/LSTM for the dynamic data and a dense input for the static data.
This can be achieved using the functional API:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Dear Jason Brownlee,
Congrats for you very nice tutorial! It is really helpful! By the way, would there be any chance to have a tutorial actually implementing these two options of CNN+LSTM with some real image data (just for the sake of some practical demonstration)?
Thanks 🙂
Thanks!
Yes, I have a few. Perhaps start with the example here:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Hi Jason,
I see that CNNLSTM can be used for applications of generating textual descriptions from sequences of images. My problem is to predict activity curve from series of input images.
If I have series of dynamic 3D medical images (3D spatial+1D time=4D overall) along with activity of different parts in time (series of 1d scalar vectors), can CNNLSTM or any other architectures be used to predict activity curves? And if yes, how the CNN part will be different here because my task is not classification anymore.
Thanks.
Perhaps try it and see if it is effective on your data.
The CNN will extract features from the images, the LSTM will operate on the sequence of extracted features. I’d recommend starting with a pre-trained CNN model if you’re working with photos of every day things.
Hello Jason and thank you for the valuable articles,
I have a dataset including static input parameters, and 1 output that is dependent on time (and I have the data for this output at multiple time steps). I have trained 1D-CNN model (in my case for regression) for each time step on my output. So, lets say I have the data available for 10 time-steps of my output, and I have trained 10 different 1D-CNN models.
Is there a way to use CNN-LSTM on my dataset (which is not image, or text, and it is just a normal tabular dataset) to train it somehow learn the time dependencies of my outputs?
You could have a multi-input model, one input for the time series data and one for static data.
This will help you to define your model:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
the problem I have is that it is only my outputs that are changing in time. for example I have 30 static parameters, and from 31 to 40 is my output parameter at different time steps.
I can build a model between all 30 parameters and the output at first time step (column 31) or with 2nd time step (column 32) separately.
I f I use API to separate them, what would be the inputs for the static model and what would be for the time series?
The static data would be provided as input to the static part of the model and the time series is provided to the part of the model that expects sequence data.
Hello Jason,
I am a little bit confused. If I want to build a one-to-many CNN-LSTM model, how would be the shape of input for CNN and LSTM. you have mentioned in your article that it should be like:
model = Sequential()
model.add(TimeDistributed(Conv2D(…))
model.add(TimeDistributed(MaxPooling2D(…)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(…))
model.add(Dense(…))
for example, If I use 100 photos with the shape of (20,20,1) to train my model which filter size is 64 and kernel size is (3*3), how would be the lines look like? and where should we define the number of time steps that output generates?
thank you
Good question, you can see a worked example in this tutorial:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
I have dataset consists of 10 columns and 1 target variable. Target variable has 4 class labels .
so when i do testing it should predict the class label. Can I use CNN-LSTM for this
A CNN-LSTM would only be appropriate if your data is a time series or sequence of observations.
In which case, the example here will help you to get started – and you can adapt it for classification:
https://machinelearningmastery.com/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
Hi thanks for the tutorial,
I want to frame a problem in this way-
1. want to develop a LSTM-CNN model
2. First I want to apply a historical time series of target variable in LSTM for temporal information extraction.
3. Then I want to apply the output of LSTM and a other input set of variables other than target variable as input into the CNN model.
Is it possible? How can I do this?
# define LSTM model
model = Sequential()
model.add(LSTM(..))
model.add(Dense(…))
cnn=Sequential()
cnn.add(TimeDistributed(model,…))
cnn.add(Conv2D(…))
cnn.add(MaxPooling2D(…))
cnn.add(Flatten())
cnn.add(Dense())
Can we fit LSTM and cnn differently for different input set?
Any idea?
You’re welcome.
That is odd. Perhaps try it and compare results to simpler models to see if it performs better or worse.
AttributeError: ‘KerasTensor’ object has no attribute ‘add’
Sir I am getting this erro
Sorry to hear that, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
It’s pretty confusing where you say to use a “sequence of LSTM models, one for each time step”
Shouldn’t it be just one LSTM model and it is used across all time steps of the input sequence? Using multiple LSTM models makes no sense.
I understand why you think in that way. But indeed the “sequence” happens when the LSTM model produces states c and h and it pass on to the next time step (like recursion in programming).
I’m working in recommendation. My data is a matrix, which row represent a user and column represent a location. If i use i user shared photos as sequence and location photos as sequence . May i use CNN_LSTM to progress a photos as sequence to predict ?
Hi Thaair…Please rephrase or clarify your question so that we may better assist you.
thanks for your nice post. I have a time series of images to extract soil moisture. in addition to these images, some ancillary datasets such as temperature is needed to be involved in the process as input features. I though of using CNN-LSTM. now I ma wondering this method can be useful for this problem or not. I would be grateful if you could share your opinion about it.
thanks in advance.
Hi Mina…Yes, CNN-LSTM models may prove beneficial as well as ensemble diversity:
https://machinelearningmastery.com/ensemble-diversity-for-machine-learning/
many thanks for your time and quick reply.
Dear James Carmichael,
I have a time-series of images with gaps. I want to fill these gaps using a CNN-LSTM algorithm and ancillary datasets. indeed I consider the images with gap as output and use ancillary datasets as inputs. I intend to introduce the algorithm where I have data and where is gap by introducing a binary filter. But I do not have should I implement this part in practice. I would be thankful if you could help me with this issue.
Thanks in advance for you help!
Best,
Mina Rahmani
Can I have the dense layer before the LSTM layer. My problem seems to perform better with that architecture, but I am not sure if it is correct.
Hi Prerna…Absolutely! That is an example of a hybrid model and is certainly an option.
I have problems cancer skin binary classification I used many models like VVG16..and we design a hybrid model merge cnn and lstm and we got best results 90% accuracy my supervision ask me why cnn and lstm give us test result how can I answer it academy !?
Thank you for efforts
Data set
healthy = 420
Not healthy = 510
We splitting data set 3 part training, validation, and testing
Total Parameters of
•The model has a total of 2,432,231 parameters.
I have problems cancer skin binary classification I used many models like VVG16..and we design a hybrid model merge cnn and lstm and we got best results 90% accuracy my supervision ask me why cnn and lstm give us test result how can I answer it academy !?
Thank you for efforts
Data set
healthy = 420
Not healthy = 510
We splitting data set 3 part training, validation, and testing
Hello Jason,
We have model classification skin cancer images we collect data set our self from hospital data set healthy 402 image and unhealthy 510 images we we train many models most of model accuracy about 60 to 87% we design cnn with lSTM and we get 94% accuracy my Supervision my when combined cnn and lstm get best result plz how can I answer it?
Best regards
Hi Yasir…When discussing the results of your CNN-LSTM model with your supervisor, you can organize your explanation to clearly communicate the methods and findings. Here are some key points you might consider including in your discussion:
1. **Dataset Description**: Start by detailing the dataset collected from the hospital, specifying the number of healthy (402) and unhealthy (510) skin cancer images. Explain any preprocessing or augmentation techniques used to prepare the data for training.
2. **Model Comparison**: Briefly outline the performance of the various models that were initially tried, mentioning their accuracy range (60% to 87%). This sets a baseline for understanding the improvement brought by your CNN-LSTM model.
3. **Model Architecture**: Describe the architecture of the CNN-LSTM model you designed. Explain why you chose to combine Convolutional Neural Networks (CNN) with Long Short-Term Memory networks (LSTM). Typically, CNNs are effective for spatial data processing (like images), and LSTMs are good at recognizing patterns in sequence data. Combining them can leverage both spatial and sequential cues, which might be particularly useful if the images or their features have temporal dependencies or if you are using sequential frames or patches.
4. **Training Process**: Share details about the training process, such as the number of epochs, batch size, learning rate, and any special techniques used (like dropout for regularization, or specific optimizers like Adam).
5. **Results**: Highlight the accuracy achieved (94%) and discuss its significance. Compare it to the accuracies of previously tested models to emphasize the improvement. You can also mention other performance metrics if available (like sensitivity, specificity, F1-score).
6. **Interpretation and Hypothesis**: Offer a hypothesis on why the combination of CNN and LSTM resulted in a superior performance. This might involve discussing how the LSTM layers could be capturing additional contextual or textural information that CNN layers alone might miss.
7. **Further Steps**: Suggest further investigations to validate the model, such as cross-validation, external validation with a different dataset, or deploying the model in a clinical setting to monitor its performance in real-world conditions.
8. **Visuals and Demonstrations**: If possible, prepare visual aids like graphs, loss curves, accuracy trends over epochs, or confusion matrices. These can help visually demonstrate the model’s performance and robustness over time.
This structured approach not only clearly communicates your findings and the rationale behind your experimental setup but also demonstrates a thoughtful analysis and understanding of the task at hand.