Text summarization is a problem in natural language processing of creating a short, accurate, and fluent summary of a source document.
The Encoder-Decoder recurrent neural network architecture developed for machine translation has proven effective when applied to the problem of text summarization.
It can be difficult to apply this architecture in the Keras deep learning library, given some of the flexibility sacrificed to make the library clean, simple, and easy to use.
In this tutorial, you will discover how to implement the Encoder-Decoder architecture for text summarization in Keras.
After completing this tutorial, you will know:
- How text summarization can be addressed using the Encoder-Decoder recurrent neural network architecture.
- How different encoders and decoders can be implemented for the problem.
- Three models that you can use to implemented the architecture for text summarization in Keras.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Encoder-Decoder Models for Text Summarization in Keras
Photo by Diogo Freire, some rights reserved.
Tutorial Overview
This tutorial is divided into 5 parts; they are:
- Encoder-Decoder Architecture
- Text Summarization Encoders
- Text Summarization Decoders
- Reading Source Text
- Implementation Models
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Encoder-Decoder Architecture
The Encoder-Decoder architecture is a way of organizing recurrent neural networks for sequence prediction problems that have a variable number of inputs, outputs, or both inputs and outputs.
The architecture involves two components: an encoder and a decoder.
- Encoder: The encoder reads the entire input sequence and encodes it into an internal representation, often a fixed-length vector called the context vector.
- Decoder: The decoder reads the encoded input sequence from the encoder and generates the output sequence.
For more about the Encoder-Decoder architecture, see the post:
Both the encoder and the decoder submodels are trained jointly, meaning at the same time.
This is quite a feat as traditionally, challenging natural language problems required the development of separate models that were later strung into a pipeline, allowing error to accumulate during the sequence generation process.
The entire encoded input is used as context for generating each step in the output. Although this works, the fixed-length encoding of the input limits the length of output sequences that can be generated.
An extension of the Encoder-Decoder architecture is to provide a more expressive form of the encoded input sequence and allow the decoder to learn where to pay attention to the encoded input when generating each step of the output sequence.
This extension of the architecture is called attention.
For more about Attention in the Encoder-Decoder architecture, see the post:
The Encoder-Decoder architecture with attention is popular for a suite of natural language processing problems that generate variable length output sequences, such as text summarization.
The application of architecture to text summarization is as follows:
- Encoder: The encoder is responsible for reading the source document and encoding it to an internal representation.
- Decoder: The decoder is a language model responsible for generating each word in the output summary using the encoded representation of the source document.
Text Summarization Encoders
The encoder is where the complexity of the model resides as it is responsible for capturing the meaning of the source document.
Different types of encoders can be used, although more commonly bidirectional recurrent neural networks, such as LSTMs, are used. In cases where recurrent neural networks are used in the encoder, a word embedding is used to provide a distributed representation of words.
Alexander Rush, et al. uses a simple bag-of-words encoder that discards word order and convolutional encoders that explicitly try to capture n-grams.
Our most basic model simply uses the bag-of-words of the input sentence embedded down to size H, while ignoring properties of the original order or relationships between neighboring words. […] To address some of the modelling issues with bag-of-words we also consider using a deep convolutional encoder for the input sentence.
— A Neural Attention Model for Abstractive Sentence Summarization, 2015.
Konstantin Lopyrev uses a deep stack of 4 LSTM recurrent neural networks as the encoder.
The encoder is fed as input the text of a news article one word of a time. Each word is first passed through an embedding layer that transforms the word into a distributed representation. That distributed representation is then combined using a multi-layer neural network
— Generating News Headlines with Recurrent Neural Networks, 2015.
Abigail See, et al. use a single-layer bidirectional LSTM as the encoder.
The tokens of the article w(i) are fed one-by-one into the encoder (a single-layer bidirectional LSTM), producing a sequence of encoder hidden states h(i).
— Get To The Point: Summarization with Pointer-Generator Networks, 2017.
Ramesh Nallapati, et al. use bidirectional GRU recurrent neural networks in their encoders and incorporate additional information about each word in the input sequence.
The encoder consists of a bidirectional GRU-RNN…
— Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond, 2016.
Text Summarization Decoders
The decoder must generate each word in the output sequence given two sources of information:
- Context Vector: The encoded representation of the source document provided by the encoder.
- Generated Sequence: The word or sequence of words already generated as a summary.
The context vector may be a fixed-length encoding as in the simple Encoder-Decoder architecture, or may be a more expressive form filtered via an attention mechanism.
The generated sequence is provided with little preparation, such as distributed representation of each generated word via a word embedding.
On each step t, the decoder (a single-layer unidirectional LSTM) receives the word embedding of the previous word (while training, this is the previous word of the reference summary; at test time it is the previous word emitted by the decoder)
— Get To The Point: Summarization with Pointer-Generator Networks, 2017.
Alexander Rush, et al. show this cleanly in a diagram where x is the source document, enc is the encoder providing internal representation of the source document, and yc is the sequence of previously generated words.
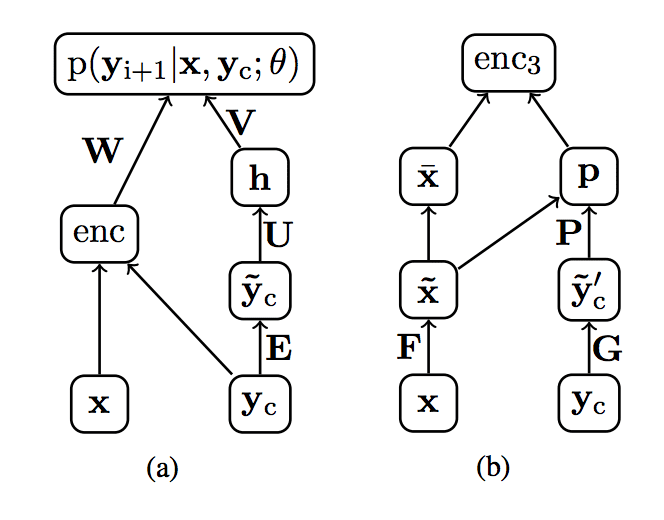
Example of inputs to the decoder for text summarization.
Taken from “A Neural Attention Model for Abstractive Sentence Summarization”, 2015.
Generating words one at a time requires that the model be run until some maximum number of summary words are generated or a special end-of-sequence token is reached.
The process must be started by providing the model with a special start-of-sequence token in order to generate the first word.
The decoder takes as input the hidden layers generated after feeding in the last word of the input text. First, an end-of-sequence symbol is fed in as input, again using an embedding layer to transform the symbol into a distributed representation. […]. After generating each word that same word is fed in as input when generating the next word.
— Generating News Headlines with Recurrent Neural Networks, 2015.
Ramesh Nallapati, et al. generate the output sequence using a GRU recurrent neural network.
… the decoder consists of a uni-directional GRU-RNN with the same hidden-state size as that of the encoder
Reading Source Text
There is flexibility in the application of this architecture depending on the specific text summarization problem being addressed.
Most studies focus on one or just a few source sentences in the encoder, but this does not have to be the case.
For example, the encoder could be configured to read and encode the source document in different sized chunks:
- Sentence.
- Paragraph.
- Page.
- Document.
Equally, the decoder can be configured to summarize each chunk or aggregate the encoded chunks and output a broader summary.
Some work has been done along this path, where Alexander Rush, et al. use a hierarchical encoder model with attention at both the word and the sentence level.
This model aims to capture this notion of two levels of importance using two bi-directional RNNs on the source side, one at the word level and the other at the sentence level. The attention mechanism operates at both levels simultaneously
— A Neural Attention Model for Abstractive Sentence Summarization, 2015.
Implementation Models
In this section, we will look at how to implement the Encoder-Decoder architecture for text summarization in the Keras deep learning library.
General Model
A simple realization of the model involves an Encoder with an Embedding input followed by an LSTM hidden layer that produces a fixed-length representation of the source document.
The Decoder reads the representation and an Embedding of the last generated word and uses these inputs to generate each word in the output summary.
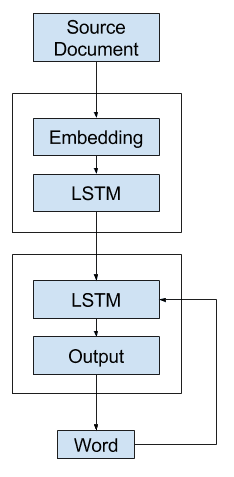
General Text Summarization Model in Keras
There is a problem.
Keras does not allow recursive loops where the output of the model is fed as input to the model automatically.
This means the model as described above cannot be directly implemented in Keras (but perhaps could in a more flexible platform like TensorFlow).
Instead, we will look at three variations of the model that we can implement in Keras.
Alternate 1: One-Shot Model
The first alternative model is to generate the entire output sequence in a one-shot manner.
That is, the decoder uses the context vector alone to generate the output sequence.
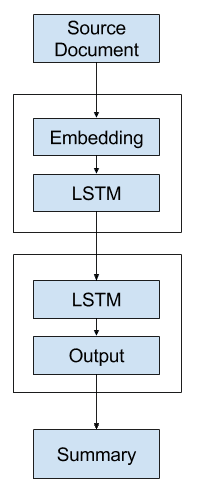
Alternate 1 – One-Shot Text Summarization Model
Here is some sample code for this approach in Keras using the functional API.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
vocab_size = ... src_txt_length = ... sum_txt_length = ... # encoder input model inputs = Input(shape=(src_txt_length,)) encoder1 = Embedding(vocab_size, 128)(inputs) encoder2 = LSTM(128)(encoder1) encoder3 = RepeatVector(sum_txt_length)(encoder2) # decoder output model decoder1 = LSTM(128, return_sequences=True)(encoder3) outputs = TimeDistributed(Dense(vocab_size, activation='softmax'))(decoder1) # tie it together model = Model(inputs=inputs, outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') |
This model puts a heavy burden on the decoder.
It is likely that the decoder will not have sufficient context for generating a coherent output sequence as it must choose the words and their order.
Alternate 2: Recursive Model A
A second alternative model is to develop a model that generates a single word forecast and call it recursively.
That is, the decoder uses the context vector and the distributed representation of all words generated so far as input in order to generate the next word.
A language model can be used to interpret the sequence of words generated so far to provide a second context vector to combine with the representation of the source document in order to generate the next word in the sequence.
The summary is built up by recursively calling the model with the previously generated word appended (or, more specifically, the expected previous word during training).
The context vectors could be concentrated or added together to provide a broader context for the decoder to interpret and output the next word.
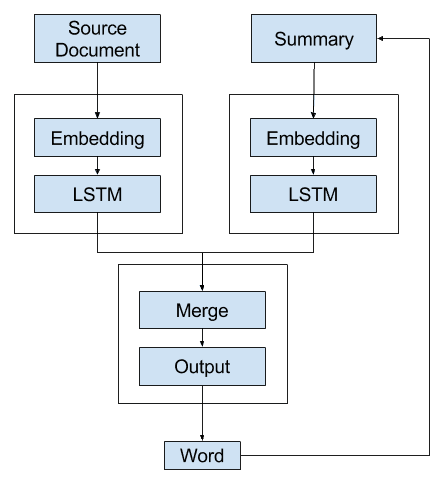
Alternate 2 – Recursive Text Summarization Model A
Here is some sample code for this approach in Keras using the functional API.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
vocab_size = ... src_txt_length = ... sum_txt_length = ... # source text input model inputs1 = Input(shape=(src_txt_length,)) am1 = Embedding(vocab_size, 128)(inputs1) am2 = LSTM(128)(am1) # summary input model inputs2 = Input(shape=(sum_txt_length,)) sm1 = = Embedding(vocab_size, 128)(inputs2) sm2 = LSTM(128)(sm1) # decoder output model decoder1 = concatenate([am2, sm2]) outputs = Dense(vocab_size, activation='softmax')(decoder1) # tie it together [article, summary] [word] model = Model(inputs=[inputs1, inputs2], outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') |
This is better as the decoder is given an opportunity to use the previously generated words and the source document as a context for generating the next word.
It does put a burden on the merge operation and decoder to interpret where it is up to in generating the output sequence.
Alternate 3: Recursive Model B
In this third alternative, the Encoder generates a context vector representation of the source document.
This document is fed to the decoder at each step of the generated output sequence. This allows the decoder to build up the same internal state as was used to generate the words in the output sequence so that it is primed to generate the next word in the sequence.
This process is then repeated by calling the model again and again for each word in the output sequence until a maximum length or end-of-sequence token is generated.
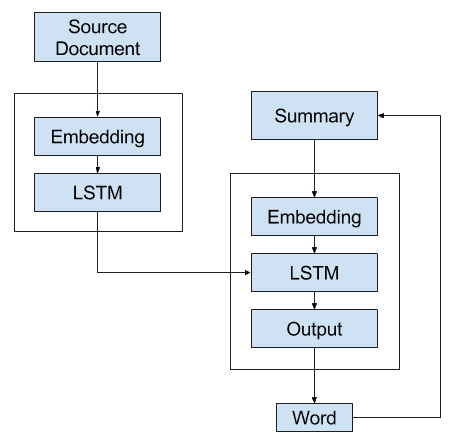
Alternate 3 – Recursive Text Summarization Model B
Here is some sample code for this approach in Keras using the functional API.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
vocab_size = ... src_txt_length = ... sum_txt_length = ... # article input model inputs1 = Input(shape=(src_txt_length,)) article1 = Embedding(vocab_size, 128)(inputs1) article2 = LSTM(128)(article1) article3 = RepeatVector(sum_txt_length)(article2) # summary input model inputs2 = Input(shape=(sum_txt_length,)) summ1 = Embedding(vocab_size, 128)(inputs2) # decoder model decoder1 = concatenate([article3, summ1]) decoder2 = LSTM(128)(decoder1) outputs = Dense(vocab_size, activation='softmax')(decoder2) # tie it together [article, summary] [word] model = Model(inputs=[inputs1, inputs2], outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') |
Do you have any other alternate implementation ideas?
Let me know in the comments below.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Papers
- A Neural Attention Model for Abstractive Sentence Summarization, 2015.
- Generating News Headlines with Recurrent Neural Networks, 2015.
- Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond, 2016.
- Get To The Point: Summarization with Pointer-Generator Networks, 2017.
Related
- Encoder-Decoder Long Short-Term Memory Networks
- Attention in Long Short-Term Memory Recurrent Neural Networks
Summary
In this tutorial, you discovered how to implement the Encoder-Decoder architecture for text summarization in the Keras deep learning library.
Specifically, you learned:
- How text summarization can be addressed using the Encoder-Decoder recurrent neural network architecture.
- How different encoders and decoders can be implemented for the problem.
- Three models that you can use to implement the architecture for text summarization in Keras.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning models for Text Data Today!

Develop Your Own Text models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Natural Language Processing
It provides self-study tutorials on topics like:
Bag-of-Words, Word Embedding, Language Models, Caption Generation, Text Translation and much more...
Finally Bring Deep Learning to your Natural Language Processing Projects
Skip the Academics. Just Results.






Regarding the Recursive Model A, here is a similar approach proposed 5 months ago (with shared embedding): https://github.com/oswaldoludwig/Seq2seq-Chatbot-for-Keras
The advantage of this model can be seen in Section 3.1 of this paper: https://www.researchgate.net/publication/321347271_End-to-end_Adversarial_Learning_for_Generative_Conversational_Agents
Thanks for the links.
You’re welcome!
For the Recursive Model A you can kindly cite the Zenodo document: https://zenodo.org/record/825303#.Wit0jc_TXqA
or the ArXiv paper: https://arxiv.org/abs/1711.10122
Thanks in advance,
Oswaldo Ludwig
Nice!
I provided a general purpose library with the seq2seq model behind my chatbot here: https://github.com/oswaldoludwig/Parallel-Seq2Seq . I called this model Parallel Seq2Seq and explain its advantages in the readme file of this repo.
Thanks for sharing.
Sir, could you explain it with an example.??
Explain what?
Plz explain the whole process with an example. You also didn’t mention inference process.
I do not follow sorry, what would you like me to explain?
Sir, could you please explain how to use pretrained word embeddings like Glove instead of one hot vector for encoder input and decoder input.
See this tutorial:
https://machinelearningmastery.com/use-word-embedding-layers-deep-learning-keras/
It would be nice if you provide some example of using autoencoders in simple classification problems. Using encoders/decoders pretrain (with inputs = outputs “unsupervised pretrain”) to have a high abstraction level of information in the middle then split in half this network and use the encoder to feed a dense NN with softmax (for ex) and execute supervised “post train”. Do you think it is possible with keras ?
Thanks for the suggestion.
Generally, deep MLPs outperform autoencoders for classification tasks.
something like this in keras would be super : https://www.mathworks.com/help/nnet/examples/training-a-deep-neural-network-for-digit-classification.html
Here’s an example of a CNN on that problem:
https://machinelearningmastery.com/handwritten-digit-recognition-using-convolutional-neural-networks-python-keras/
Please provide the code links for Encoder-Decoder Models for Text Summarization in Keras
Thanks for the suggestion.
How well does this work for the following cases?
1) Messy data. e.g. Say I want a summary of a chat conversation I missed.
2) Long content. Can it summarize a book?
Is this actually used in industry or just academic?
Great question, but too hard to answer. I’d recommend either diving into some papers to see examples or run some experiments on your data.
Hi Jason,
thank you for the article.
I tried combining the first approach with the dataset from your article about preparation of news articles for text summarization (https://machinelearningmastery.com/prepare-news-articles-text-summarization/).
Unfortunately, I cannot get the Encoder-Decoder architecture to work, maybe you can provide some help.
After the code from the preparation article I added the following code:
X, y = [' '.join(t['story']) for t in stories], [' '.join(t['highlights']) for t in stories]
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
MAX_SEQUENCE_LENGTH = 1000
tokenizer = Tokenizer()
total = X + y
tokenizer.fit_on_texts(total)
sequences_X = tokenizer.texts_to_sequences(X)
sequences_y = tokenizer.texts_to_sequences(y)
word_index = tokenizer.word_index
data = pad_sequences(sequences_X, maxlen=MAX_SEQUENCE_LENGTH)
labels = pad_sequences(sequences_y, maxlen=100) # test with maxlen=100
# train/test split
TEST_SIZE = 5
X_train, y_train, X_test, y_test = data[:-TEST_SIZE], labels[:-TEST_SIZE], data[-TEST_SIZE:], labels[-TEST_SIZE:]
# create model
# encoder input model
inputs = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
encoder1 = Embedding(len(word_index) + 1, 128, input_length=MAX_SEQUENCE_LENGTH)(inputs)
encoder2 = LSTM(128)(encoder1)
encoder3 = RepeatVector(2)(encoder2)
# decoder output model
decoder1 = LSTM(128, return_sequences=True)(encoder3)
outputs = TimeDistributed(Dense(len(word_index) + 1, activation='softmax'))(decoder1)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam')
batch_size = 32
epochs = 4
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=batch_size, verbose=1)
The error I get is: Error when checking target: expected time_distributed_2 to have 3 dimensions, but got array with shape (3000, 100)
Thank you in advance.
Sorry, I cannot debug your code for you.
Hi Daniel,
I have the same problem as you. Were you able to solve it ?
Thanks.
hey did your code work I am having a problem in fitting it
I’m having the same problem here. Did someone manage to solve this ?
Thank you!
Hey Daniel,did u debug it?
Hello Jason,
May I please know that shall we use conv2dlstm for language modelling
I would recommend using an LSTM for a language model.
Have a basic query, what we get as final output of Decoder is a Vector rt ? How do we convert this to English words please. Do we find cosine similarity with words in vocabulary for ex? …thanks
You can output a one hot encoded vector and map this to an integer, then a word in your vocabulary.
Thanks for your help, all the three models now work for me, thanks also to your article on How to generate a Neural Language Model. I am getting some words in output, but this is far from summary.
However, I am having one more basic query. In your second and third model, there are two inputs : the article, and the summary. Now, while training the model, this is fine. But when predicting the output or generating the summary, the summary will not be known. So how do we input the second input, should it be zeros in place of word indexes ? Please suggest.
Yes, start with zeros, and build up the summary word by word in order to output the following word.
Hi Jason,
Thanks for all the knowledge shared here and the books.
I have 2 questions: one is on prediction and when to save the model. Second is on the padded values.
Rec. Model A works during training (I see the words being added). However, prediction is a bit challenging. When predicting the first word I am not getting anything. I am loading a current summary of numpy.zeros and the source document and expect to predict the first word to update the current summary. This in my mind is the very first iteration for prediction. I hope I am not wrong thus far.
At first I thought that maybe there is a problem with the model weights so I saved the model during training for each word. And i am loading the model saved during the last step of training. model.save(“model.h5”), model_load… so I am not loosing the weights. Model summary prints the architecture correctly, But the result is no word being predicted. Am I correct assuming that the model trained is not correctly saved?
Second question: The sequences are padded with 0 values ‘post’. During training, the model gets these 0 values last and predicts 0 values. What happens to the model and its weights during the last part of the training when it gets these zeros? Does it loses the weights and training?
Thanks again and keep up the good work,
Geo
The model will predict integers that must be mapped to words.
If the model is predicting all zeros, then perhaps the model requires further tuning?
You can use a Masking layer to skip/ignore the padded values.
@Anirban, would you mind sharing the working example codes for 3 models which worked for you, in the article above
Hi Jason, can you please provide a sample running code for one of the architectures on a small text dataset. I shall be grateful to you for the same.
I hope to give an examples in the future.
Sir, i have summary of shape (3000,100,12000) i.e 3000-> examples, 100-> maximum length of summary and 12000-> vocab size. Now i need to convert this shape into categorical values to fins loss using keras to_categorical. But i am getting memory error. I have 8 gb RAM. Please provide appropriate solution.
Is it necessary to convert summaries into categorical or can’t we use embedding on summaries too.If we can then what should be loss because for categorical cross entropy loss we need to convert our summaries into one hot encodings.
Many people are facing this problem. plz suggest solution.
When using embedding layers as input, you must provide sequences of integers, where each int is mapped to a word in the vocab.
I have many examples on the blog.
If you are running out of memory, try using progressive loading. I have an example of this for photo captioning.
yeah sir, but the main problem lies while converting target summaries into categorical data as num_classes in my case is 12000.
AND i have one more doubt.
while training model, i an facing a unknown issue where my training and validation loss is decreasing continously but accuracy has become constant after some time.
Plz answer to second question. I m really stuck in this problem. can’t understand logic behind this issue.
Yes, the output would be a one hot encoding. An output vocab of 12K is very small.
Accuracy is a bad metric for text data. Ignore it.
that means for text data, i should focus on decreasing loss only because in my case, training and validation loss both are decreasing continuously but training and validation accuracy are stuck at a point nearly 0.50.
Yes, focus on loss. Do not measure accuracy on text problems.
hi sir, just wanted to know what is the logic behind abstractive text summarization how does our model is capable to summarize test data as generally in case of classification we have a curve which generalizes our data but in case of text , generalization is not possible since every test data is a new and different from training data.
Great question. The model learns the concepts in the text and how to describe those concepts concisely.
So, in that case there is very less probability that our summaries would match gold- summaries for test data. Then why do we use Bleu or Rouge matrixes for evaluation of our model.
For all the approaches I become following error:
Error when checking target: expected time_distributed_38 to have 3 dimensions, but got array with shape (222, 811)
How can I fix this problem?
Either change your data to meet the expectations of the model or change the model to meet the expectations of the data.
Hallo Jason.
Thank you for your answer. I am beginner and try to learn how to summarize texts.
I wrote a simple example as you see below. but it has problems with shapes.
Could you please tell me how and where in this example, I have to change the data or the model.
Thanks
# Modules
import os
import numpy as np
from keras import *
from keras.layers import *
from keras.models import Sequential
from keras.preprocessing.text import Tokenizer, one_hot
from keras.preprocessing.sequence import pad_sequences
src_txt = [“I read a nice book yesterday”, “I have been living in canada for a long time”, “I study computer science this year in frence”]
sum_txt = [“I read a book”, “I have been in canada”, “I study computer science”]
vocab_size = len(set((” “.join(src_txt)).split() + (” “.join(sum_txt)).split()))
print(“Vocab_size: ” + str(vocab_size))
src_txt_length = max([len(item) for item in src_txt])
print(“src_txt_length: ” + str(src_txt_length))
sum_txt_length = max([len(item) for item in sum_txt])
print(“sum_txt_length: ” + str(sum_txt_length))
# integer encode the documents
encoded_articles = [one_hot(d, vocab_size) for d in src_txt]
encoded_summaries = [one_hot(d, vocab_size) for d in sum_txt]
# pad documents to a max length of 4 words
padded_articles = pad_sequences(encoded_articles, maxlen=10, padding=’post’)
padded_summaries = pad_sequences(encoded_summaries, maxlen=5, padding=’post’)
print(“padded_articles: {}”.format(padded_articles.shape))
print(“padded_summaries: {}”.format(padded_summaries.shape))
# encoder input model
inputs = Input(shape=(src_txt_length,))
encoder1 = Embedding(vocab_size, 128)(inputs)
encoder2 = LSTM(128)(encoder1)
encoder3 = RepeatVector(sum_txt_length)(encoder2)
# decoder output model
decoder1 = LSTM(128, return_sequences=True)(encoder3)
outputs = TimeDistributed(Dense(vocab_size, activation=’softmax’))(decoder1)
# tie it together
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’)
# Fitting the model
model.fit(padded_articles, padded_summaries, epochs=10, batch_size=32)
#model.fit(padded_articles, padded_summaries)
—————————————————————————
ValueError Traceback (most recent call last)
in ()
1 # Fitting the model
—-> 2 model.fit(padded_articles, padded_summaries, epochs=10, batch_size=32)
3 #model.fit(padded_articles, padded_summaries)
C:\Users\diyakopalizi\AppData\Local\Continuum\Anaconda3\lib\site-packages\keras\engine\training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, **kwargs)
1579 class_weight=class_weight,
1580 check_batch_axis=False,
-> 1581 batch_size=batch_size)
1582 # Prepare validation data.
1583 do_validation = False
C:\Users\diyakopalizi\AppData\Local\Continuum\Anaconda3\lib\site-packages\keras\engine\training.py in _standardize_user_data(self, x, y, sample_weight, class_weight, check_batch_axis, batch_size)
1412 self._feed_input_shapes,
1413 check_batch_axis=False,
-> 1414 exception_prefix=’input’)
1415 y = _standardize_input_data(y, self._feed_output_names,
1416 output_shapes,
C:\Users\diyakopalizi\AppData\Local\Continuum\Anaconda3\lib\site-packages\keras\engine\training.py in _standardize_input_data(data, names, shapes, check_batch_axis, exception_prefix)
151 ‘ to have shape ‘ + str(shapes[i]) +
152 ‘ but got array with shape ‘ +
–> 153 str(array.shape))
154 return arrays
155
ValueError: Error when checking input: expected input_23 to have shape (None, 44) but got array with shape (3, 10)
Sorry, I don’t have the capacity to debug code for you. Perhaps post to stackoverflow?
did you solve it?
Ok, thank you.
I have learnt a lot here.
You’re welcome, I’m glad to hear that.
Hi jason!
i want to implement text summarizer using hierarchical LSTM using only tensorflow. I am a beginner and i have got the dataset https://github.com/SignalMedia/Signal-1M-Tools/blob/master/README.md but i am not able to use this dataset as it is too large to handle with my laptop can you tell me how to preprocess this data so that i can tokenize it and use pre trained glove model as embeddings..
Yes, I have a ton of material on how to prepare text data for modeling.
A good place to start is here:
https://machinelearningmastery.com/start-here/#nlp
Hi Jason, thank you for your post, it has been very helpful to approach the problem.
What I don’t understand is the network’s training process. I mean, we don’t have the summary of our document (in the test set), so I suppose that, at the beginning, we start with a zero sequence as summary input.
Then, during the training phase, my guess is that we need to cycle all the words in the summary and set those words as output. So, in terms of number of iteration, we need to perform a “train” operation for each word in the summary, for each entry in our dataset and repeat the process for some epochs.
In some way the process is not really clear in my mind. Could you point me to some resources to understand the training process?
Thank you
The training dataset must have the full documents and the summaries – e.g. something for the model to learn from.
Can you please describe the training process in more detail.
Perhaps re-read the above post and referenced papers?
Also read these posts:
https://machinelearningmastery.com/?s=text+summarization&post_type=post&submit=Search
Hi, Jason
What is the purpose of merge layer in alternate 2? Is that used enable the Dense layer to have knowledge on both input and output ?
To merge the representation of the document and the text generated so far into a single representation for the basis for predicting the next word.
Hi, Thank you for sharing this with us. Can you explain for me why we are using the vocab_size variable ? and how this involves in the AutoEncoder architecture ? If we have a text as example, the vocab_size will represent the number of unique tokens in the text ? Thank you in advance.
The vocab size is the number of words we wish to model.
There is no autoencoder in this example.
Hi Jason, I don’t understand what’s the loss function that’s being used by the decoder. I know that in language translation, we have labelled training data (x, y) of (source language sentence, target language translation). However, in text summarization, do we actually have labelled training data of (source sentence, target summary)? I know that in your code you use the categorical_crossentropy loss function, but what label is the loss computed against?
Yes, you need source and target text to train the model.
When I implement ( Recursive Model B ) I phase issue with the summary input layer.
How to make keras to push output word into the summary layer input.
Printed Error: when checking model input: Expected to see 2 array(s), but instead got the following list of 1 arrays
My current .fit implementation:
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
Model implementation:
# summary
inputs_summary = Input(shape=(count_output,))
layer_summary = Embedding(vocab_size, embed_size)(inputs_summary)
# encoder
input_comm = Input(shape=(input_size,))
layer_comm = Embedding(vocab_size, embed_size)(input_comm)
……
# decoder
decoder1 = concatenate([layer_comm, layer_titles])
……
model = Model(inputs=[input_comm, inputs_summary], outputs=[layer_out])
You can do it yourself with a for loop.
Greetings Jason,
I was hoping you could figure out the following:
In the Recursive Models A & B, I notice that you use two Embedding layers, one for each input:
Input1(source)
Embeddding1…
Input2(summary)
Embedding2….
I know that an embedding layer is composed of the information (shape & weights) of a trained word2vec or glove model—I have trained a word2vec model on the source—-what I don’t know is if in your code the Embedding1 and Embedding2 layers are the same, or if I have to train a word2vec model for the summaries as well to create the Embedding2 layer
the same, or if I have to create a word2vec model of the
and I know that these are composed of the shape of the weights of the word2vec model. What I don’t know is the following:
They could be the same, if that makes sense for the specific problem.
In the third model , “article3” layer outputs the hidden states at each time step that will be concatenated with the output of the embedding layer ? what is th etensor shape of “article3” ?
Thank you
You can print the shapes of the layers as follows:
Hi Jason,
Is there a way to train a model to summarize text without having a target summary during training?
Not with a supervised learning model.
For Alternate 3 model, what will inputs1 and inputs2 be? The code doesn’t do what you describe in the figure.
How is the code of model 3 manage able to do the loop described in the figure? Would you please provide more details.
You would code the loop yourself.
Does the picture make it clear? Which part is confusing exactly?
From my understanding, inputs2 should be the output word. I don’t understand how you feed the output word back to the network again.
Thanks,
R
Perhaps experiment with this tutorial first to get familiar with the architecture:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Hi Jason,
Does the decoder output a meaningful summary of sentences or a bag of words?
It outputs a readable summary.
Can’t you use the similar encoder-decoder architecture to the one in another article you wrote before? But maybe you can add an Embedding layer into it.
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Sure.
I do not understand the use to RepeatVector please explain
It repeats the output of a layer, e.g. a vector, multiple times as input the subsequent layer.
Does that help?
Hi Jason, can you please help? My understanding is that you developed the three models (Alternate 1, 2, and 3) due to the problem you mentioned: “Keras does not allow recursive loops where the output of the model is fed as input to the model automatically.”
However, I don’t see why you wrote that statement. Isn’t that looping exactly what you implemented for the language model text generation in your article “How to Develop a Word-Level Neural Language Model and Use it to Generate Text” at:
https://machinelearningmastery.com/how-to-develop-a-word-level-neural-language-model-in-keras/?
In that article as part of text generation, you created: (1) a loop over N words to generate; (b) called model.predict() to generate the next word; (c) added the generated word to a window of generated words; and (d) used the generated words as input to the next call of model.predict().
Can you please explain the difference?
Yes, Keras does not do it, we have to write a loop to do it.
Why is the model usually fit on “un-embedded” outputs ?
I seen a lot of codes(almost all) where the input is passed through a “Embedding” layer ( in the functional API style of code ) and and the model is fit on “outputs” as the real output sequences.
That would mean, we are mapping( training the parameters of the network in the real sense ) the embedded inputs against the real outputs..which seems a bit a strange.
Does that mean the Dense layer takes care of un-embedded part ?
That would check up with the fact that the “units” parameter is set to the no. of embedding features !
Also, how is the “units” parameter of an LSTM selected ?
Is it set to the length of the padded sequences ( input and outputs sequences alike )
I don’t follow, sorry?
Regarding the number of units, this will help:
https://machinelearningmastery.com/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
Hi Jason,
I have a security dataset and I would like to use either ANN or LSTMN to predict if a website is malicious.
IP Cont OS Domain Attack Sig Threat
0.0.0.0.0 US Windows somedomain.net Comp Server 899238erdjshgh90ds Yes
What is the best way of encoding these columns? Do you have a tutorial link that you could suggest? And Do you think ANN or LSTMN would better to predict/classify the outcome, such as Threat yes or no?
Thank you so much.
Sounds like a great project.
I recommend testing a suite of representations in order to discover what works best.
Perhaps a word embedding would be a useful approach?
Sir, since word embeddings are already fixed lengthed vectors can I directly use them with decoders? However, Encoder converts them to fixed length vectors.
You will end up with a sequence of embeddings, this sequence must also be fixed length.
Hi Jason,
Now, i am working at text to image project and i want to train my captions(texts) and images of dataset to get pickle file. i am still searching about this problem but i found nothing untill now. so i want to ask you to help me to get Text2Image Encoder-Decoder ? do you have any idea about that ?
Thanks in advance.
I have seen some interesting papers on GANs for this task of text to image.
I recommend checking for some of the latest work on the topic via google scholar.
yes i got it and i worked at stack-GAN algorithm but there are already a text and image encoder file ( char-CNN-RNN text embeddings.pickle ) and i want to train it from scratch on my own data set.Could you tell me how to preprocess this file?
I’m looking forward to your reply!
Sorry, I don’t have a tutorial on Stack GAN.
Do you have any working code for the above mentioned 3 models…If it is there means it will be helpful.
Sorry I do not.
Hi Jason,
Thanks for this wonderful article.I have one question regarding the model 2 – “Alternate 2: Recursive Model A” .Does it follow the “teacher forcing strategy” since you are using the already generated summary information also along with the generated representation by the encoder?
Yes, it uses teacher forcing.
Thanks for the answer Jason.
I am a bit curious about the role of start and end tokens in text summarization models.
How does these tokens help the decoder ?
They provide help to the model about how to begin and end an output sequence.
Perhaps this example for photo captioning will make it clearer:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Hi Jason,
Thanks for the post! It is very insightful. I like how you described the pros and cons of each structure as well.
For the Recursive Model B, could you help me understand how should I go about preparing the data?
Given the structure, I am a little confused about how the input should look like. Below are my thoughts:
Assuming:
src_txt_length = 8
sum_txt_length = 4
Then the traditional way of text preparation would end up with something like (I gave the first value for each row as an example):
padded sequence for text:
[w1, w2, w3, w4, w5, 0, 0, 0]
padded sequence for summary:
[s1, s2, 0, 0, 0]
Apparently the above cannot be used directly to Recursive B’s structure (Maybe I’m wrong here).
I thought we will need to take a step further and have something like this:
Input 1:
[[w1, w2, w3, w4,w5, 0, 0, 0], [w1, w2, w3, w4, w5, 0, 0, 0], [w1, w2, w3, w4, w5, 0, 0, 0]]
input 2:
[[0,0,0,0,0], [s1,0,0,0,0], [s1,s2,0,0,0]]
label:
[[one-hot encoded vector for s1], [one-hot encoded vector for s2],[one-hot encoded vector for 0]]
In this way, a batch_size = 1 training, for example, will be using:
[w1, w2, w3, w4,w5, 0, 0, 0] and [0,0,0,0,0] to inference a vector which will be optimized against the one-hot encoded vector for s1
Am I on the right track here? I would appreciate it if you could point me in the right direction!
Thanks in advance!
Perhaps mock up some test examples and try feeding them into the model?
Hi Jason,
Yes, I did build up test examples and the model fits without error.
However, the transformation process I mentioned above is quite tedious. So I wonder if you have other ideas in mind about how to prepare data for such structure.
Sorry, I cannot prepare customized examples – I just don’t have the capacity.
Thank you for this guide.
What would be the training and target data for fitting the model?
I built a model with the following structure
Model: “model_1”
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 5000)] 0
__________________________________________________________________________________________________
embedding_2 (Embedding) (None, 5000, 128) 796928 input_3[0][0]
__________________________________________________________________________________________________
lstm_2 (LSTM) (None, 64) 49408 embedding_2[0][0]
__________________________________________________________________________________________________
input_4 (InputLayer) [(None, 30)] 0
__________________________________________________________________________________________________
repeat_vector_1 (RepeatVector) (None, 30, 64) 0 lstm_2[0][0]
__________________________________________________________________________________________________
embedding_3 (Embedding) (None, 30, 128) 796928 input_4[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 30, 192) 0 repeat_vector_1[0][0]
embedding_3[0][0]
__________________________________________________________________________________________________
lstm_3 (LSTM) (None, 128) 164352 concatenate_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 6226) 803154 lstm_3[0][0]
==================================================================================================
Total params: 2,610,770
Trainable params: 2,610,770
Non-trainable params: 0
When I try
model.fit([texts, summaries], validation_split = 0.1, epochs=epochs, batch_size=batch_size, verbose=1, callbacks=[LossHistory()])
I get a IndexError: list index out of range when processing the first batch, probably for the lack of target data
Can we not use teacher forcing method in the general model that explained at the first? This will circumvent the recursive looping blockade..
Sure, you can train the model anyway you wish.
Recursive Model B can be implemented very simply.
https://imgur.com/mxFXG38
Nice!
Have you used this model on any dataset?
Hi Jason – thanks for this post, its great! I just had a question about what inputs1, inputs2 and outputs mean in the sample code. My understanding is as follows;
inputs1: The entire source sequence [Eg: Say a paragraph with 300 words (post tokenization)]
inputs2: Technically this should be a single word [Predicted word from the previous time-step].
outputs: This should be the entire summary. But would we need this to be TimeDistributed to obtain the summary word-by-word?
Is my understanding correct? Or for inputs2, would that be a sequence of *all* the words until the last step and not just a single word? Thanks in advance!
Yes, or inputs2 would be the whole sequence generated so far.
Thank you much for this very useful post.
I would greatly appreciate if you could also provide some code for (1) fitting (2) prediction for for Alternate 3: Recursive Model A and B,.
In particular, for fitting the confusing part is how to generate inputs2. It seems the outputs is just a single prediction (i.e., Dense layer shape = (vocabulary size))
For prediction, how is the model called, specially because inputs2 is not known and the model again predicts 1 output.
Initially, i thought something like this would work:
for fitting the model:
outputs = [‘this’ , ‘is’ , ‘a’ , ‘summary’]
inputs2_during_fitting = [‘start summarizing’, ‘this’ , ‘is’ , ‘a’]
but i am confused how this would work, when the model spits out one prediction/word every time it is called.
So it cannot train on the entire sequence at once.
for prediction of first word i thought i would pass something like this to the model.
outputs = [‘this’ , ‘is’ , ‘a’ , ‘summary’]
inputs2_during_prediction = [‘start summarizing’, ‘unknown’, ‘unknown’, ‘unknown’]
but how would the model learn that i am asking for the first output word and not the second output word ?
Thank you !
Thanks for the suggestion, I may cover it in the future.
hey Jason, regardin Recursive model B, I don’t unnderstand the workflow very well, in the picture it looks like is a loop, i have implemented just like in the example above, so it does loop or not?
We are looping over an input sequence.
Perhaps start here:
https://machinelearningmastery.com/models-sequence-prediction-recurrent-neural-networks/
hi jason thanks for amazing article. i have a question about 3rd architecture. finaly if wa want to use internal representation of a soruce document we should use output of article2 layer?
Perhaps experiment and see what works?
Hi Jason I prepared my data using your another article and how to use those pkl files here
I don’t know what your data is or how to load it.
Hi Jason,
As per encoder decoder with attention , Decoder processes the input one time step after another. First time step prediction takes last state of encoder as initial state and outputs the decoder output and hidden states and that hidden state serves as initial state for next time step.
How is this iterative process captured in enc-dec with attention architecture using tensorflow. Do we apply loop for each time-steps of decoder . Also what about embedding vector of decoder. Is it calculated outside the loop and accessed or its calculated inside this loop.
The reason i am asking is , i didn’t see any loop and feedback in your decoder architecture
Good question, I often use an autoencoder-based architecture because it is fast and effective:
https://machinelearningmastery.com/lstm-autoencoders/
You can see the other type here:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Model: “model_4”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) [(None, 5000)] 0
_________________________________________________________________
embedding_4 (Embedding) (None, 5000, 128) 799488
_________________________________________________________________
lstm_8 (LSTM) (None, 128) 131584
_________________________________________________________________
repeat_vector_4 (RepeatVecto (None, 125, 128) 0
_________________________________________________________________
lstm_9 (LSTM) (None, 125, 128) 131584
_________________________________________________________________
time_distributed_4 (TimeDist (None, 125, 6246) 805734
=================================================================
Total params: 1,868,390
Trainable params: 1,868,390
Non-trainable params: 0
___________________________
how fit my data ?
Hi Jason,
I tried to use the last architecture with cnn news dataset that you introduced, everything is quite like that but it gives me an error when I try to train the model that I can’t find anywhere,
“ValueError: Layer model_7 expects 2 input(s), but it received 1 input tensors. Inputs received: []”
Sorry to hear that, perhaps one of these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
can u share the code with us plz
Thanks, perhaps in the future.
Hi Jason,
I think if we assume that source and summary have different vocabulary size, the Dense layer should be like this : outputs = Dense(summary_vocab_size, activation=’softmax’)(decoder2)
Yes, you’re right.
then please edit that in the code, so people don’t get confused.
Hello Jason, I have a question about this tutorial. You set an embedding layer for the encoder (hence, the original texts) and an other one for the decoder (the summaries). I deduce that these two embedding models are independent. It means that for the same word, the two models will generate two different embeddings. Why are we OK with this?
Simply speaking the training on the data will make this work. The two embedding may produce different things, and that is not a problem because the text and summary may have different set of vocabularies. What is important is the LSTM layers that receives the embedding output. After training, it will know how to use them.
thank you, Adrian!
Hi Jason,
I used an encoder-decoder model for generating summarization news, but the predicted sequence is like this:
actual: [[‘startseq as of thursday facebook allows users to edit comments rather than retype them each comment will show its editing history in a dropdown menu to give users context editing will be rolled out to users gradually over the next few days endseq’]]
predicted: [‘startseq the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the’]
As you can see it generated a lot of “the”, have you ever encountered such a problem?
do you have any suggestion?