Sequence prediction is a problem that involves using historical sequence information to predict the next value or values in the sequence.
The sequence may be symbols like letters in a sentence or real values like those in a time series of prices. Sequence prediction may be easiest to understand in the context of time series forecasting as the problem is already generally understood.
In this post, you will discover the standard sequence prediction models that you can use to frame your own sequence prediction problems.
After reading this post, you will know:
- How sequence prediction problems are modeled with recurrent neural networks.
- The 4 standard sequence prediction models used by recurrent neural networks.
- The 2 most common misunderstandings made by beginners when applying sequence prediction models.
Kick-start your project with my new book Long Short-Term Memory Networks With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Tutorial Overview
This tutorial is divided into 4 parts; they are:
- Sequence Prediction with Recurrent Neural Networks
- Models for Sequence Prediction
- Cardinality from Timesteps not Features
- Two Common Misunderstandings by Practitioners
Sequence Prediction with Recurrent Neural Networks
Recurrent Neural Networks, like Long Short-Term Memory (LSTM) networks, are designed for sequence prediction problems.
In fact, at the time of writing, LSTMs achieve state-of-the-art results in challenging sequence prediction problems like neural machine translation (translating English to French).
LSTMs work by learning a function (f(…)) that maps input sequence values (X) onto output sequence values (y).
|
1 |
y(t) = f(X(t)) |
The learned mapping function is static and may be thought of as a program that takes input variables and uses internal variables. Internal variables are represented by an internal state maintained by the network and built up or accumulated over each value in the input sequence.
… RNNs combine the input vector with their state vector with a fixed (but learned) function to produce a new state vector. This can in programming terms be interpreted as running a fixed program with certain inputs and some internal variables.
— Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks, 2015
The static mapping function may be defined with a different number of inputs or outputs, as we will review in the next section.
Need help with LSTMs for Sequence Prediction?
Take my free 7-day email course and discover 6 different LSTM architectures (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Models for Sequence Prediction
In this section, will review the 4 primary models for sequence prediction.
We will use the following terminology:
- X: The input sequence value, may be delimited by a time step, e.g. X(1).
- u: The hidden state value, may be delimited by a time step, e.g. u(1).
- y: The output sequence value, may be delimited by a time step, e.g. y(1).
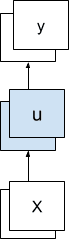
One-to-One Model
A one-to-one model produces one output value for each input value.

One-to-One Sequence Prediction Model
The internal state for the first time step is zero; from that point onward, the internal state is accumulated over the prior time steps.
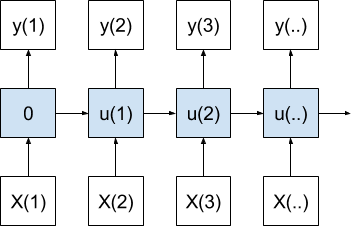
One-to-One Sequence Prediction Model Over Time
In the case of a sequence prediction, this model would produce one time step forecast for each observed time step received as input.
This is a poor use for RNNs as the model has no chance to learn over input or output time steps (e.g. BPTT). If you find implementing this model for sequence prediction, you may intend to be using a many-to-one model instead.
One-to-Many Model
A one-to-many model produces multiple output values for one input value.
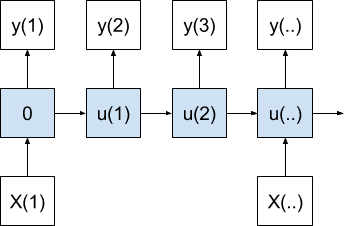
One-to-Many Sequence Prediction Model
The internal state is accumulated as each value in the output sequence is produced.
This model can be used for image captioning where one image is provided as input and a sequence of words are generated as output.
Many-to-One Model
A many-to-one model produces one output value after receiving multiple input values.
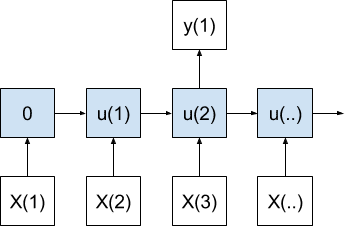
Many-to-One Sequence Prediction Model
The internal state is accumulated with each input value before a final output value is produced.
In the case of time series, this model would use a sequence of recent observations to forecast the next time step. This architecture would represent the classical autoregressive time series model.
Many-to-Many Model
A many-to-many model produces multiple outputs after receiving multiple input values.
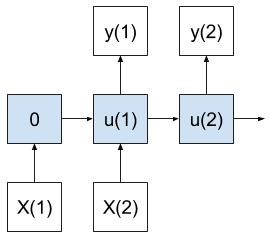
Many-to-Many Sequence Prediction Model
As with the many-to-one case, state is accumulated until the first output is created, but in this case multiple time steps are output.
Importantly, the number of input time steps do not have to match the number of output time steps. Think of the input and output time steps operating at different rates.
In the case of time series forecasting, this model would use a sequence of recent observations to make a multi-step forecast.
In a sense, it combines the capabilities of the many-to-one and one-to-many models.
Cardinality from Timesteps (not Features!)
A common point of confusion is to conflate the above examples of sequence mapping models with multiple input and output features.
A sequence may be comprised of single values, one for each time step.
Alternately, a sequence could just as easily represent a vector of multiple observations at the time step. Each item in the vector for a time step may be thought of as its own separate time series. It does not affect the description of the models above.
For example, a model that takes as input one time step of temperature and pressure and predicts one time step of temperature and pressure is a one-to-one model, not a many-to-many model.
Multiple-Feature Sequence Prediction Model
The model does take two values as input and predicts two values, but there is only a single sequence time step expressed for the input and predicted as output.
The cardinality of the sequence prediction models defined above refers to time steps, not features (e.g. univariate or multivariate sequences).
Two Common Misunderstandings by Practitioners
The confusion of features vs time steps leads to two main misunderstandings when implementing recurrent neural networks by practitioners:
1. Timesteps as Input Features
Observations at previous timesteps are framed as input features to the model.
This is the classical fixed-window-based approach of inputting sequence prediction problems used by multilayer Perceptrons. Instead, the sequence should be fed in one time step at a time.
This confusion may lead you to think you have implemented a many-to-one or many-to-many sequence prediction model when in fact you only have a single vector input for one time step.
2. Timesteps as Output Features
Predictions at multiple future time steps are framed as output features to the model.
This is the classical fixed-window approach of making multi-step predictions used by multilayer Perceptrons and other machine learning algorithms. Instead, the sequence predictions should be generated one time step at a time.
This confusion may lead you to think you have implemented a one-to-many or many-to-many sequence prediction model when in fact you only have a single vector output for one time step (e.g. seq2vec not seq2seq).
Note: framing timesteps as features in sequence prediction problems is a valid strategy, and could lead to improved performance even when using recurrent neural networks (try it!). The important point here is to understand the common pitfalls and not trick yourself when framing your own prediction problems.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Summary
In this tutorial, you discovered the standard models for sequence prediction with recurrent neural networks.
Specifically, you learned:
- How sequence prediction problems are modeled with recurrent neural networks.
- The 4 standard sequence prediction models used by recurrent neural networks.
- The 2 most common misunderstandings made by beginners when applying sequence prediction models.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop LSTMs for Sequence Prediction Today!

Develop Your Own LSTM models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Long Short-Term Memory Networks with Python
It provides self-study tutorials on topics like:
CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Skip the Academics. Just Results.






Thanks for the article. This is very useful. Do you have any examples of forecasting multivariate time series using RNN?
I should have one on the blog soon, it has been scheduled.
Hi Jason,
Thank you very much for your great article and the fabulous blog. I’ve been following you blog
for a few months now and read most of your articles on RNNs.
Like you have mentioned above, I’m struggling to correctly model my time-series prediction problem. It’ll be great if you can help me on this.
I have samples of sensor readings each a vector of 64 timesteps. I would like to use LSTM to learn the structure of the series and predict the next 64 timesteps.
I think I will need to use a Many-to-Many model to the model learns the input and predicts the output (64 values) based on what it has learned. I’m trying to use LSTM for unsupervised anomaly detection problem. I guess what I’m struggling with is that I want my model to learn the most common structure in my long time series and I’m kind of confused how my input should be.
Sorry, for the long description.
Many thanks
I would recommend modeling it as a many-to-many supervised learning problem.
Sorry, I don’t have experience using LSTMs for unsupervised problems, I need to do some reading.
Hi, Jason. I’m always thankful that you posted great examples and posts.
I have simple question.
For predicting/forecasting time series data, are Multilayer NN and RNN(LSTM) techniques the best way to forecasting future data?
Thank you in advance.
Best,
Paul
There is no best way, I would encourage you to evaluate a suite of methods and see what works best for your problem.
Secuence learning is the same as Online learning? What are the differences?
Hi Gustavo,
No, a sequence is the structure of the data and prediction problem.
Learning can be online or offline for sequence prediction the same as simpler regression and classification.
Does that help?
Help indeed thanks best regards
Glad to hear it.
In the case of Many2Many and One2Many in this post, how do you compute the hidden states at the time step, when there is no input. Specifically, in One2Many, how do you compute “u(1)”, despite of the lack of “X(2)”? I think we can only compute Y(1),Y(2), Y(3) as a vector. If I was wrong, could you tell me why with examples such as image captioning or machine translation?
Great question!
It is common to teach the model with “start seq” and “end seq” inputs at the beginning and end of sequences to kick-off or close-off the sequence input or output.
I have used this approach myself with image captioning models and translation.
I investigated many2many(encoder-decoder). As you said, we feed “start” to LSTM to compute “u(1)”. My question included “what the input is necessary to compute “u(2)”. As the result of my investigation, we have to feed “y(2)” to compute “u(2)”.
The below image is more accurate, right?
http://suriyadeepan.github.io/img/seq2seq/seq2seq1.png
Yes, that is one way.
Remember to explore many different framings of the problem to see what works best for your specific data.
OK, thanks! I’ll try it!
Im facing a problem of one-to-many sequence prediction, where given a set of input parameters for a program the model should generate values of resources usage as a function of time (CPU, memory etc.). I have some examples from real-world programs and I already tried simple feed-forward networks, but now Im trying to find state-of-the-art solution for one-to-many sequence generating problem. Until now I’ve only found image captioning example, but it is tailored for predicting words instead of real values. Are you aware of any state-of-the-art solutions for generating one-to-many sequences? If you do, I would be grateful for any references. Thanks!
Caption generation would provide a good model or starting point for your problem.
No CNN front end of course, a big MLP perhaps instead.
Does that help? I’m eager to hear how you go.
Dear Dr, Please I have an important question. Can RNN accumulate knowledge, for example can i contentiously train the network to built bigger knowledge or it is trained once, and if it can contentiously learn . how i can do that
Good question.
You can update the model after it is trained.
Jason,
I am trying to apply ML for a specific problem I want to solve.
Below is the problem statement:
I have a system that is made of many functional blocks. These communicate with each other through events. When the system runs, the log of these events history is generated.
From past experience, I know what the interesting sequences are. I would now like to parse through these event log and see if any of the sequences fall in the interesting category that is known a-priori. One thing to note is that time duration can vary while sequence is intact.
FOr example, event1 t1 event2 t2 event3. Between example and actual sequence, the values of t1, t2 can vary but sequence of events (event1 -> event2 -> event3) remain.
Manually doing this is tedious as there can be millions of such events when the system runs.
Can you suggest what is the best approach to solve this issue>
Sounds like a sequence classification problem:
https://machinelearningmastery.com/sequence-prediction/
Hello Jason, I have a query about a sequence prediction problem where an author used lstm with dense layer for the potential of this combination.
The problem is to use 20 units of time from the past to predict T units of time. For example, predict the sequence of the next 5 units of time. So each sample has 20 units of time where each unit of time is a vector with 10 characteristics.
X = ( samples, 20, 10)
Y = (50)
As you can see the respective “Y” for each sample is a vector of 50 units, which represents the units of time to predict, a time with its respective vector of 10 characteristics concatenated with the remaining 4 times, in total 50. In keras it would be presented in this way:
model= Sequential()
model.add(LSTM(500, input_shape=(20, 10)))
model.add(Dense(10*5)) # 5 times with vector of 10 characteristics each time.
model.compile(optimizer= ‘rmsprop’, loss=’mse’)
According to what I read in this post, it would be a form of a vector, because it is sending its last internal state H as an output and that is being used as a characteristic vector that trains with the desired outputs of the following 5 times. The amazing thing is that this architecture learns, it is not the best but it gets very close, it gains to methods like SAE, ANN. Finally I tested this with my dataset with different output sequences for 10 times, 15 time2, 20 times in the future, just by increasing the number of output neurons desired, it’s like magic.
What would your opinion be? Is it a Seq to Vector? Can it be done in a more effective way ?. Thank you very much.
I have an example on LSTMs for multi-step forecasting that might help:
https://machinelearningmastery.com/multi-step-time-series-forecasting-long-short-term-memory-networks-python/
Hello Jason,
I’m confused with the figure of “One-to-One Sequence Prediction Model Over Time”, and “Many-to-Many Sequence Prediction Model”.
For one to one model, here is a Keras code snippet –
model = Sequential()
model.add(LSTM(….., input_shape=(1, ….)))
model.add(Dense(1))
Now, according to the figure of “One-to-One Sequence Prediction Model Over Time”, I’m assuming the Keras implementation will be –
model = Sequential()
model.add(LSTM(….., input_shape=(time_steps, ….), return_sequences=True))
Now this seems oddly familiar to “Many to Many Sequence Prediction”, where the number of input features are equal to number of output features.
Please let me know where I misunderstood. Also, for the figure, “One-to-One Sequence Prediction Model Over Time”, what would be the correct implementation with Keras?
Thanks.
Btw, Great article on the Time Series prediction 🙂
The “over time” is just the application of the same model to each time step. No difference to the model, just the data.
So, if there are multiple time steps for a one-to-one model, you are saying that the model would be the same, that is, the model would be –
model = Sequential()
model.add(LSTM(….., input_shape=(1, ….)))
model.add(Dense(1))
But, this means that there is only 1 time step. How multiple time steps would fit into this?
I see, I believe you are describing a many to many model.
Ok, if so, then I think, the figure that you’ve shown for “One-to-One Sequence Prediction Model Over Time” should be a “Many to Many” model instead.
Because the only logical Keras implementation I could think for that is –
model = Sequential()
model.add(LSTM(….., input_shape=(n, ….), return_sequence=True))
Which does not seem like a “one-to-one” model. Rather a “many-to-many” instead.
Please let me know if this is clear.
I can mail you in detail if you think the question that I’m asking is not sufficient to describe the problem.
Your code is a many to many, not one to one.
Hi Jason,
Thank you for the blog and it is very helpful. I have a question regarding many to one structure, when we try to use many to one model to do the predication, we also need to have an sequence as the input (contain same number of time steps as training data), do I understand correctly? Or could we just feed the feature at one time stamp to get the predictions?
It means multiple timesptes as input then multiple time steps as output.
It could be actual time series or words in a sentence or other obs where they are ordered by time.
Hi Jason
Thank you very much for your wonderful article.
I am pretty new in the field and I am sure I have not yet fully understood.
If I want to use the power of NN to predict the temperature for example, using the time sequence temperature, pressure, humidity n etc at each time frame as input, what network is it? is it best to use LSTM RNN?
The architecture of the model that I am considering is.
1. time sequence value of temperature, T[], which produces a temporary output O1 at time t
2. time sequence value of pressure, P[], which produces a temporary output O2 at time t
3. time sequence value of humidity, H[], which produces a temporary output O3 at time t
4. finally, O1, O2, O3 will be used to generate the final output at time t, which is the model prediction of the temperature.
Do I actually need to have 4 independent NN? or only 1 which takes all the time sequence features?
And do I really need RNN? i don’t think I need to feed my prediction back into the network, as I can keep feeding the latest measurement as input.
Much appreciate for your time to answer my question.
An RNN or CNN can handle each series directly in one model.
I show how with tutorial examples in this book:
https://machinelearningmastery.com/deep-learning-for-time-series-forecasting/
Hi Jason,
can you please suggest some reading on “strategies on framing timesteps as features in sequence prediction problems” ?
i am having hard time finding relevant literature 🙂
No literature needed, it’s a simple change in code from using past observations as time steps to instead using them as features on a time step.
Oh I see. I actually wanted to use the observations at the timesteps only as output features, without using RNNs.
To elaborate on that; all the input features are for t=0 and these inputs are different kind of data than the output feature. There is only one kind of output feature and it varies over time.
So I have:
X_1, X_2, … , X_n for t=0 and
y_t=0, y_t=1, …, y_t=m
I thought of employing one-to-many RNN (I am not sure if this is a valid case for this!?)
but then I thought maybe I can also frame the different timesteps as different output features and develop a simple feedforward network with backpropagation without using RNN at all.
Do you think this is a valid strategy?
Interesting.
Yes, I’d recommend trying a one-to-many RNN and see how it compares to an MLP or CNN.
i am facing a problem to design a routing sequence resolution for problem tickets in expert system could you please suggest me any algorithm for this problem
I don’t know what you’re referring to, sorry.
Hi jason.,
How to approach the feature representation for sequence prediction problem if I have a set of events arriving in time and I want to predict the next event in time but there can be multiple events incoming at the same timestamp.
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
Great article and great site Jason. Thanks to you I’m learning a lot in ML.
I’m currently facing a sequence prediction problem and I have a doubt.
Is it possible to improve the sequence prediction using some other data apart from the sequence? For example predicting the next symptoms on a patient at a hospital not only using the sequence from other user but the patient age, sex, etc.
The aproaches I’ve found always base their prediction only on the previous sequences, but what if we have some other data that we think can improve the results?
Yes, you could have a model with 2 inputs, one for the sequence and one for the static data.
This post will help you to get started:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Thanks for the help!! I really appreciate it.
On my way to read the article and try it.
Great!
I am little confused what I have learned so far so I would like to ask for clarification. This is my last question, will not be spamming you questions anymore after this!
Suppose we have time series [10, 20, 30, 40, 50, 60, 70, 80, 90]. For example, amount of profits for each day, so this is univariate time series problem. We want to predict next day profits (one-step-forecasting) so now I turn this into supervised time series prediction problem.
In this 1st case, it is about one-to-one modeling since we have one input for one output. Training phase would look like something like this:
[t] -> [t+1]
[10] -> [20]
[20] -> [30]
[30] -> [40]
…
[80] -> [90]
In this 2nd case, it is many-to-one according to your blog here. One input series to one output.
[t-2, t-1, t] -> [t+1]
[10, 20, 30] -> [40]
[40, 50, 60] -> [70]
In this 3rd case, is it many-to-one since we still have one input series for one output?
[t-2, t-1, t] -> [t+1]
[10, 20, 30] -> [40]
[20, 30, 40] -> [50]
[30, 40, 50] -> [60]
…
[60, 70, 80] -> [90]
So far I have built LSTM forecasting model like in 1st case, result is OK. But I am thinking to improve it building LSTM forecasting model like in 3rd case, do you think this kind of modeling make sense? 2nd case seems harder for model to learn since it has less training examples.
Yes, that is many to one, many time steps to one time step.
Yes, it could result in better performance. Also try other models like CNNs and more for comparison.
Great post! I am currently working on Predictive maintenance of devices using analysis of log files. The goal is to sort of cluster the log messages into different workflows (or activities) by analysing the patterns of the log messages and to predict an error whenever it deviates from such activities. The first step was to cluster the content of messages using BOW approach and assign them an ID so we now have sequence of IDs instead of sequence of messages. I am currently exploring HMMs and neural network models to find patterns in the sequence of IDs.
Any insight on forming or recognizing cluster of patterns to form workflows or to improve forming of message IDs would be highly appreciated.
Sounds like a great project.
Sorry, I don’t have any posts on clustering, I hope to get to it in the future.
Can we use this for Genomics sequences?
I don’t see why not?
Let’s say that I have static features associated with every sequence. (i.e. I have temperature/second(sequence) and elevation (static)). How can I incorporate my static features into such models ?
Thanks Jason 🙂
Perhaps a time series with a fixed value. Perhaps as a separate input to the model, e.g. multi-input model.
Hi Jason, Thank you so much for this article.
I have input data of n samples, for one variable – for 1000 timesteps. Hence my Input is of the form [ 1 * 1000 ] and my output is a single number – let say 85.
1 ) Is this Many to One problem ?
2 ) which LSTM model will be better ?
Probably many to one.
Perhaps start with some of these models:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Jason,
So is this the same case as a tensorsliced sequence of shape lets say :
((32, 400), (32, 400))
where 32 is a batch size and the ((, 400), (, 400)) is sequence length ((, IN(Xi), (, OUT(Yi))?
Thanks!
Adding to that, the model is updating its hidden state and predicting a probability distribution in each X 399 times.
I don’t follow, sorry. What is a tensorslice sequence?
Sorry I didn’t elaborate;
I used the tf.data.Dataset.from_tensor_slices((X,y)) to convert a my sequence to the following format:
my X was a sequence of length 400 for each X and my why Y is the X shifted by one index:
X = []
y = []
for i in sequences:
X.append(i[0:-1])
y.append(i[1:])
X.shape, y.shape –> ((17433, 400), (17433, 400))
Sorry, I am not familiar with that function, I cannot give you good advice about it.
Perhaps try posting your question to stackoverflow.
Supposing I want to predict the next sequence of letters in this table:
A B J Q E R
T W U O Z X
R O P J K L
E D F V B T
Q S D W E T
V B N K M O
E Z T V B T
Q S A Q E T
R Q A J S L
E D X V Y T
1) How many inputs must be used for the neural network on this?
2) How many hidden layers must be used?
3) Must I have a prepared array of text character values initialized for the program?
Your data looks like a sequence prediction problem, but whether this specific data is predictable, I have not idea.
Perhaps you can compare an MLP, CNN, and LSTM and compare the results.
The number of inputs depends on how you want to frame the problem. You can choose the number of inputs and number of outputs that you think is appropriate – or try a few approaches and see what works well. This may help you prepare the data after you have chosen:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
The number of nodes and layers in a neural network model must be found by careful experimentation:
https://machinelearningmastery.com/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
As letters, you will have to integer-encode them before modeling. Then either use an embedding or model the integers directly.
You can model it as seq2seq if you want.- it is entirely up to you. If your goal is to predict one line of data given one or more prior lines of data, then this would be a many-to-many problem.
I hope that helps. Let me know how you go.
By the way, the question I posed earlier is a “Many to Many” problem – that is, for the table of letter sequences, 5 possible outcomes from it are expected…
It can be modelled that way if you want.
Hi Jason,
Does it makes sense to use an Encoder-Decoder model, for a many-to-one forecasting scenario?
I am wondering what is the role of decoder in the one-step prediction case, since I think that parsing the output of encoder through dense layer could be similar.
Perhaps try it and compare results to other methods, use it if it gives better results.
Hi Jason,
Thank you for all the information and insights you share through your splendid blog machinelearningmastery.com.
I had one problem, and would like to know how we could use neural networks to solve it.
It is a sequence of lists 2 sequence problem, where the input is a sequence of lists, each list has a fixed no of integers (eg. [3,4,2,7]) so there are many such lists in sequence (think of it like a 2D matrix). The output is a label (number) given to each of the list, for example if the sum of the integers in a list is higest among all the lists than the label for that is 1, if the sum of the integers in a list is lowest among all the lists than the label for that list is 0, if the sum is somewhere in between the highest and lowest then its a fraction between 0 and 1, depending on the sum. The higher the sum, more closer to 1 is the label of the list. Think of the label as a sorting number (can lie anywhere within 0 and 1, 0 means lowest sum while 1 means highest sum).
Do you have any examples or information or any insights on how to model the above problem using Neural networks i.e to train a neural network to sort a sequence of lists based on the sum of integers in each list?
Thank you so much Jason!
You’re welcome.
Perhaps you can experiment with a few different model types and discover what works well or best for your dataset.
This might give you ideas:
https://machinelearningmastery.com/learn-add-numbers-seq2seq-recurrent-neural-networks/
Thanks for a great blog.
I do however have a question if I may.
Many of these examples seems to want to predict the future. I have a situation where I have data from multiple days, each day consisting of data points for each hour, i.e. 24 data points per day for each feature, and target variable. So for each day they each 24 data points are a time series. But each day doesn’t necessarily have any correlation from the previous day(s).
What I actually was thinking about was to input an entire sequence of values (24 data points) for each feature, to predict 24 new values for the target. Hence, I don’t need any forecasting. I don’t need to continue some trend or curve many days or weeks in advance. I just have sequences for each feature consisting of 24 time related data points, to predict 24 target values.
What approach would be good for this ? Because I often see many of these approaches ending up in some type of forecasting – which this really is not.
Hi Derunderon…Please clarify the goals of your model so that we may better assist you. Perhaps deep learning is not the best option.
Hi again, and thanks for the quick response. I will try to elaborate.
I have data from many days. Each day has a data point for each hour, i.e. 24 data points for each day.
I then have a target variable and several predictor variables. In turn all these 24 data points for each variable create some kind of daily curve/structure.
What I would like to do is to give a sequence of values (24 data points, 1 per hour) from each predictor variable to predict a new sequence of target variable values (again 24 new values) from that input. Hence, it is not a forecast, since it will have an input, and the days do not necessarily correlate at all. Two days right after each other could look very different in this case. But one day, and a day 100 days before might be very similar.
The issue is that the input is 24 data points for each feature.
In principle, one might be able to create a model for each hour, and then having 24 models in total to predict each hour. However, I would imagine one losing a bit of information from the other hours since the data points within a day are correlated. So days per se are not necessarily correlated, but hours within a day is.
I’m not sure sure what the best approach is. I just thought this sounded like a maybe solution since it can take sequences of values as input.
Hi again, and thanks for the quick response. I will try to elaborate.
I have data from many days. Each day has a data point for each hour, i.e. 24 data points for each day.
I then have a target variable and several predictor variables. In turn all these 24 data points for each variable create some kind of daily curve/structure.
What I would like to do is to give a sequence of values (24 data points, 1 per hour) from each predictor variable to predict a new sequence of target variable values (again 24 new values) from that input. Hence, it is not a forecast, since it will have an input, and the days do not necessarily correlate at all. Two days right after each other could look very different in this case. But one day, and a day 100 days before might be very similar.
The issue is that the input is 24 data points for each feature.
In principle, one might be able to create a model for each hour, and then having 24 models in total to predict each hour. However, I would imagine one losing a bit of information from the other hours since the data points within a day are correlated. So days per se are not necessarily correlated, but hours within a day is.
I’m not sure sure what the best approach is. I just thought this sounded like a maybe solution since it can take sequences of values as input.