A standard deep learning model for text classification and sentiment analysis uses a word embedding layer and one-dimensional convolutional neural network.
The model can be expanded by using multiple parallel convolutional neural networks that read the source document using different kernel sizes. This, in effect, creates a multichannel convolutional neural network for text that reads text with different n-gram sizes (groups of words).
In this tutorial, you will discover how to develop a multichannel convolutional neural network for sentiment prediction on text movie review data.
After completing this tutorial, you will know:
How to prepare movie review text data for modeling.
How to develop a multichannel convolutional neural network for text in Keras.
How to evaluate a fit model on unseen movie review data.
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Movie Review Dataset
The Movie Review Data is a collection of movie reviews retrieved from the imdb.com website in the early 2000s by Bo Pang and Lillian Lee. The reviews were collected and made available as part of their research on natural language processing.
The reviews were originally released in 2002, but an updated and cleaned up version was released in 2004, referred to as “v2.0”.
The dataset is comprised of 1,000 positive and 1,000 negative movie reviews drawn from an archive of the rec.arts.movies.reviews newsgroup hosted at imdb.com. The authors refer to this dataset as the “polarity dataset.”
Our data contains 1000 positive and 1000 negative reviews all written before 2002, with a cap of 20 reviews per author (312 authors total) per category. We refer to this corpus as the polarity dataset.
The data has been cleaned up somewhat; for example:
The dataset is comprised of only English reviews.
All text has been converted to lowercase.
There is white space around punctuation like periods, commas, and brackets.
Text has been split into one sentence per line.
The data has been used for a few related natural language processing tasks. For classification, the performance of machine learning models (such as Support Vector Machines) on the data is in the range of high 70% to low 80% (e.g. 78%-82%).
More sophisticated data preparation may see results as high as 86% with 10-fold cross-validation. This gives us a ballpark of low-to-mid 80s if we were looking to use this dataset in experiments of modern methods.
… depending on choice of downstream polarity classifier, we can achieve highly statistically significant improvement (from 82.8% to 86.4%)
After unzipping the file, you will have a directory called “txt_sentoken” with two sub-directories containing the text “neg” and “pos” for negative and positive reviews. Reviews are stored one per file with a naming convention cv000 to cv999 for each neg and pos.
Next, let’s look at loading and preparing the text data.
Data Preparation
In this section, we will look at 3 things:
Separation of data into training and test sets.
Loading and cleaning the data to remove punctuation and numbers.
Prepare all reviews and save to file.
Split into Train and Test Sets
We are pretending that we are developing a system that can predict the sentiment of a textual movie review as either positive or negative.
This means that after the model is developed, we will need to make predictions on new textual reviews. This will require all of the same data preparation to be performed on those new reviews as is performed on the training data for the model.
We will ensure that this constraint is built into the evaluation of our models by splitting the training and test datasets prior to any data preparation. This means that any knowledge in the data in the test set that could help us better prepare the data (e.g. the words used) is unavailable in the preparation of data used for training the model.
That being said, we will use the last 100 positive reviews and the last 100 negative reviews as a test set (100 reviews) and the remaining 1,800 reviews as the training dataset.
This is a 90% train, 10% split of the data.
The split can be imposed easily by using the filenames of the reviews where reviews named 000 to 899 are for training data and reviews named 900 onwards are for test.
Loading and Cleaning Reviews
The text data is already pretty clean; not much preparation is required.
Without getting bogged down too much by the details, we will prepare the data in the following way:
Split tokens on white space.
Remove all punctuation from words.
Remove all words that are not purely comprised of alphabetical characters.
Remove all words that are known stop words.
Remove all words that have a length <= 1 character.
We can put all of these steps into a function called clean_doc() that takes as an argument the raw text loaded from a file and returns a list of cleaned tokens. We can also define a function load_doc() that loads a document from file ready for use with the clean_doc() function. An example of cleaning the first positive review is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from nltk.corpus import stopwords
import string
# load doc into memory
def load_doc(filename):
# open the file as read only
file=open(filename,'r')
# read all text
text=file.read()
# close the file
file.close()
returntext
# turn a doc into clean tokens
def clean_doc(doc):
# split into tokens by white space
tokens=doc.split()
# remove punctuation from each token
table=str.maketrans('','',string.punctuation)
tokens=[w.translate(table)forwintokens]
# remove remaining tokens that are not alphabetic
tokens=[wordforwordintokens ifword.isalpha()]
# filter out stop words
stop_words=set(stopwords.words('english'))
tokens=[wforwintokens ifnotwinstop_words]
# filter out short tokens
tokens=[wordforwordintokens iflen(word)>1]
returntokens
# load the document
filename='txt_sentoken/pos/cv000_29590.txt'
text=load_doc(filename)
tokens=clean_doc(text)
print(tokens)
Running the example loads and cleans one movie review.
The tokens from the clean review are printed for review.
We can now use the function to clean reviews and apply it to all reviews.
To do this, we will develop a new function named process_docs() below that will walk through all reviews in a directory, clean them, and return them as a list.
We will also add an argument to the function to indicate whether the function is processing train or test reviews, that way the filenames can be filtered (as described above) and only those train or test reviews requested will be cleaned and returned.
The full function is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# load all docs in a directory
def process_docs(directory,is_trian):
documents=list()
# walk through all files in the folder
forfilename inlistdir(directory):
# skip any reviews in the test set
ifis_trian andfilename.startswith('cv9'):
continue
ifnotis_trian andnotfilename.startswith('cv9'):
continue
# create the full path of the file to open
path=directory+'/'+filename
# load the doc
doc=load_doc(path)
# clean doc
tokens=clean_doc(doc)
# add to list
documents.append(tokens)
returndocuments
We can call this function with negative training reviews as follows:
Next, we need labels for the train and test documents. We know that we have 900 training documents and 100 test documents. We can use a Python list comprehension to create the labels for the negative (0) and positive (1) reviews for both train and test sets.
1
2
trainy=[0for_inrange(900)]+[1for_inrange(900)]
testY=[0for_inrange(100)]+[1for_inrange(100)]
Finally, we want to save the prepared train and test sets to file so that we can load them later for modeling and model evaluation.
The function below-named save_dataset() will save a given prepared dataset (X and y elements) to a file using the pickle API.
1
2
3
4
# save a dataset to file
def save_dataset(dataset,filename):
dump(dataset,open(filename,'wb'))
print('Saved: %s'%filename)
Complete Example
We can tie all of these data preparation steps together.
Running the example cleans the text movie review documents, creates labels, and saves the prepared data for both train and test datasets in train.pkl and test.pkl respectively.
Now we are ready to develop our model.
Develop Multichannel Model
In this section, we will develop a multichannel convolutional neural network for the sentiment analysis prediction problem.
This section is divided into 3 parts:
Encode Data
Define Model.
Complete Example.
Encode Data
The first step is to load the cleaned training dataset.
The function below-named load_dataset() can be called to load the pickled training dataset.
1
2
3
4
5
# load a clean dataset
def load_dataset(filename):
returnload(open(filename,'rb'))
trainLines,trainLabels=load_dataset('train.pkl')
Next, we must fit a Keras Tokenizer on the training dataset. We will use this tokenizer to both define the vocabulary for the Embedding layer and encode the review documents as integers.
The function create_tokenizer() below will create a Tokenizer given a list of documents.
1
2
3
4
5
# fit a tokenizer
def create_tokenizer(lines):
tokenizer=Tokenizer()
tokenizer.fit_on_texts(lines)
returntokenizer
We also need to know the maximum length of input sequences as input for the model and to pad all sequences to the fixed length.
The function max_length() below will calculate the maximum length (number of words) for all reviews in the training dataset.
1
2
3
# calculate the maximum document length
def max_length(lines):
returnmax([len(s.split())forsinlines])
We also need to know the size of the vocabulary for the Embedding layer.
This can be calculated from the prepared Tokenizer, as follows:
1
2
# calculate vocabulary size
vocab_size=len(tokenizer.word_index)+1
Finally, we can integer encode and pad the clean movie review text.
The function below named encode_text() will both encode and pad text data to the maximum review length.
A standard model for document classification is to use an Embedding layer as input, followed by a one-dimensional convolutional neural network, pooling layer, and then a prediction output layer.
The kernel size in the convolutional layer defines the number of words to consider as the convolution is passed across the input text document, providing a grouping parameter.
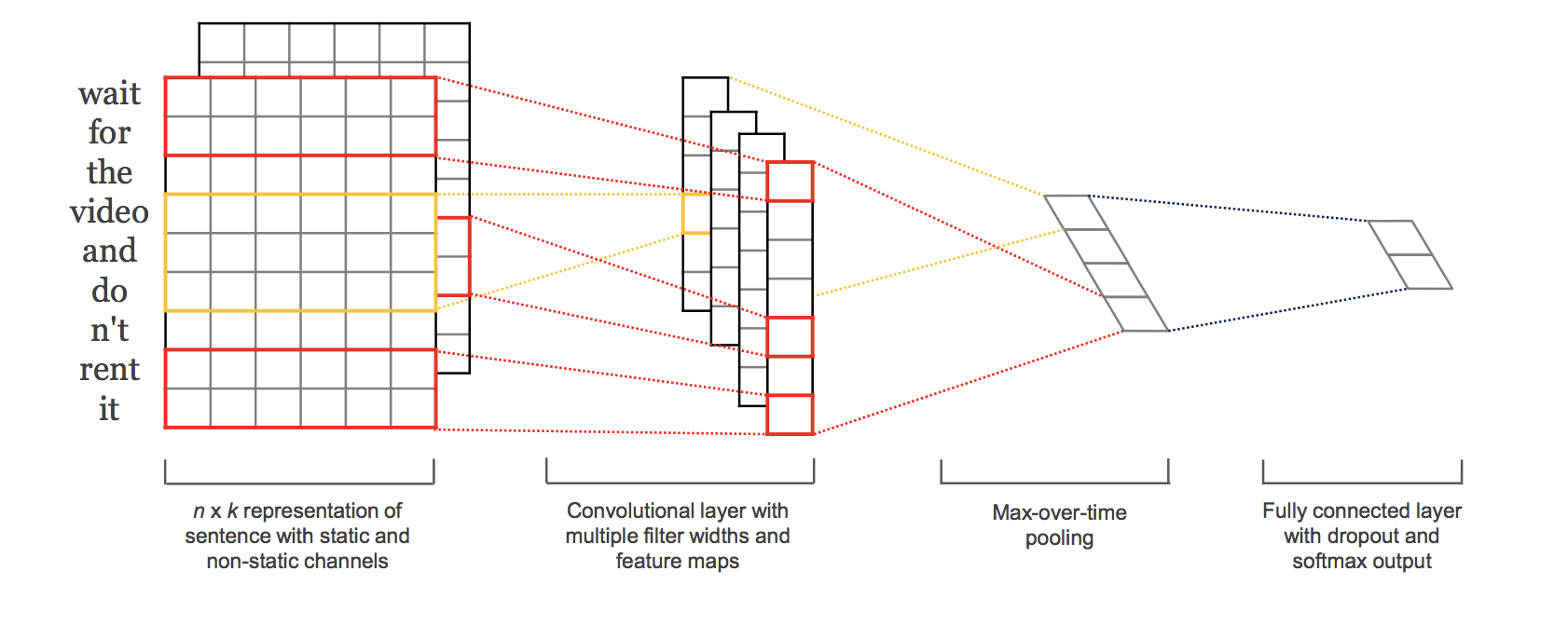
A multi-channel convolutional neural network for document classification involves using multiple versions of the standard model with different sized kernels. This allows the document to be processed at different resolutions or different n-grams (groups of words) at a time, whilst the model learns how to best integrate these interpretations.
In the paper, Kim experimented with static and dynamic (updated) embedding layers, we can simplify the approach and instead focus only on the use of different kernel sizes.
This approach is best understood with a diagram taken from Kim’s paper:
Depiction of the multiple-channel convolutional neural network for text. Taken from “Convolutional Neural Networks for Sentence Classification.”
In Keras, a multiple-input model can be defined using the functional API.
We will define a model with three input channels for processing 4-grams, 6-grams, and 8-grams of movie review text.
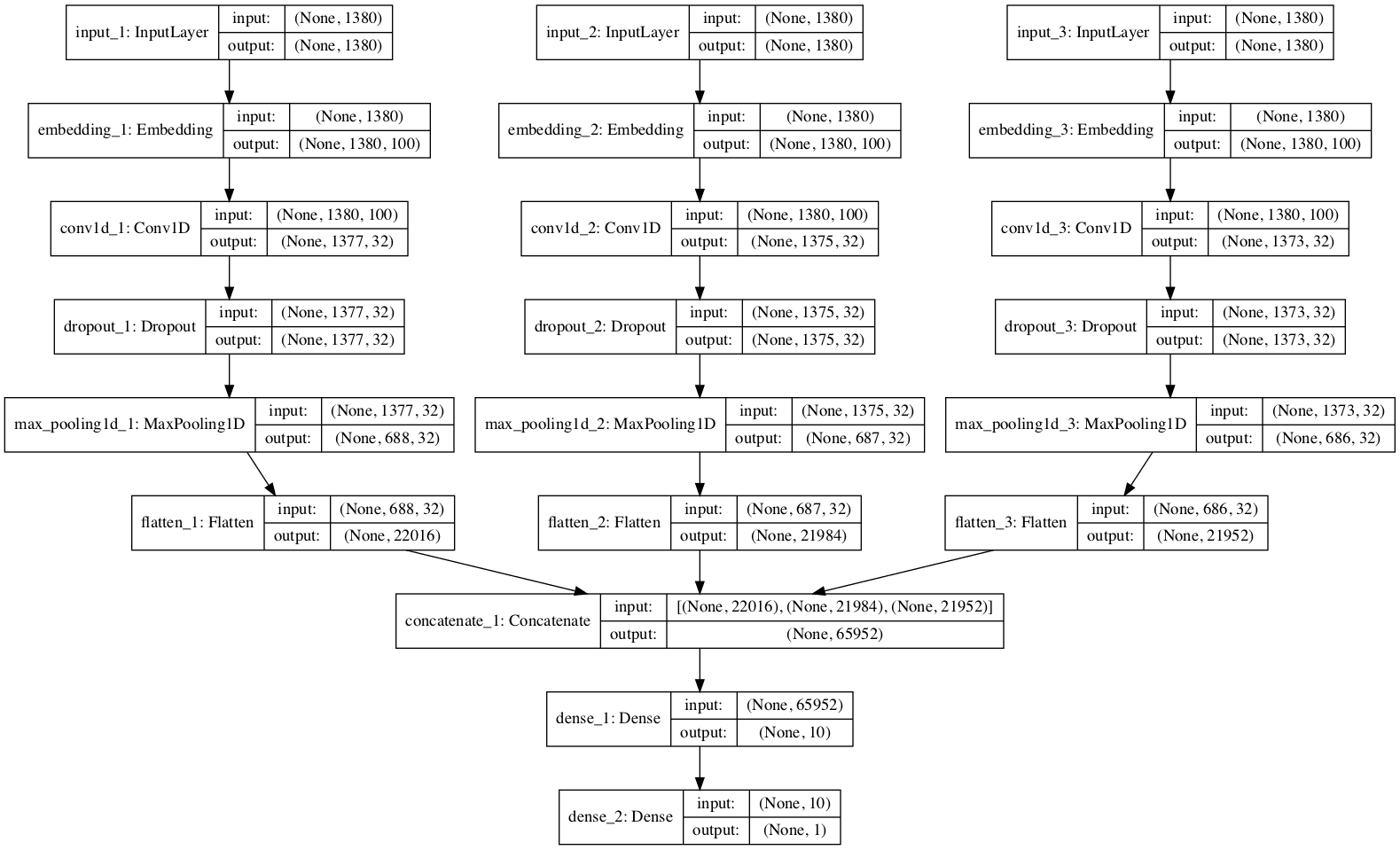
Each channel is comprised of the following elements:
Input layer that defines the length of input sequences.
Embedding layer set to the size of the vocabulary and 100-dimensional real-valued representations.
One-dimensional convolutional layer with 32 filters and a kernel size set to the number of words to read at once.
Max Pooling layer to consolidate the output from the convolutional layer.
Flatten layer to reduce the three-dimensional output to two dimensional for concatenation.
The output from the three channels are concatenated into a single vector and process by a Dense layer and an output layer.
The function below defines and returns the model. As part of defining the model, a summary of the defined model is printed and a plot of the model graph is created and saved to file.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the skill of the model on both the training and test datasets.
1
2
3
4
5
6
Max document length: 1380
Vocabulary size: 44277
(1800, 1380) (200, 1380)
Train Accuracy: 100.000000
Test Accuracy: 87.500000
We can see that, as expected, the skill on the training dataset is excellent, here at 100% accuracy.
We can also see that the skill of the model on the unseen test dataset is also very impressive, achieving 87.5%, which is above the skill of the model reported in the 2014 paper (although not a direct apples-to-apples comparison).
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Different n-grams. Explore the model by changing the kernel size (number of n-grams) used by the channels in the model to see how it impacts model skill.
More or Fewer Channels. Explore using more or fewer channels in the model and see how it impacts model skill.
Deeper Network. Convolutional neural networks perform better in computer vision when they are deeper. Explore using deeper models here and see how it impacts model skill.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Hi
Great article
I think there is a small error, According to this code trainLines would be a list of list, where each list holds tokens for one review. But all the functions to which trainLines is passed(i.e texts_to_sequences, fit_on_texts, max_length) takes a list of strings as input. I think all the lists in trainX and testX should be converted to strings before dumping them into a file.
Wouldn’t the model below be exactly the same? (with just one input, used in the three channels?) Of course, if we also had a single embedding (put the embedding before the channels, and let all convs act on that one) the model would be different.
given that I run the code using different dataset and embedding, Mr.Jason code gave me:
ModelMulitCNN MODEL Accuracy: 0.8785238339313173
ModelMulitCNN MODEL precision_score: 0.7633378932968536
ModelMulitCNN MODEL recall_score: 0.6495925494761351
ModelMulitCNN MODEL f1_score: 0.7018867924528303
while Mr.Francesco code gave me:
ModelMulitCNN MODEL Accuracy: 0.8782675550999487
ModelMulitCNN MODEL precision_score: 0.7424242424242424
ModelMulitCNN MODEL recall_score: 0.6845168800931315
ModelMulitCNN MODEL f1_score: 0.7122955784373107
model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs)
*//
it didn’t work and got the above error. I wonder if there is any problem with this line: model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs) ?
Hi Jason,
Thanks for your this beautiful work. I want to ask you that we are able to evaluate the accuracy of the model but how can we predict the classes of tested documents to analyze results in detail. In a Sequential model we can perform it like model.predict_classes(x_test). However for the Model(inputs=…) object predict_classes feature is not supported. Do you have a suggestion?
Thanks.
Thanks for interest, Jason.
I am actually trying to apply your post for a multiclass case (0:negative,1:neutral,2:positive). After training part I want to compare the accuracy rates for each class to measure the how model is accurate in detail. Then I want to calculate the Precision and Recall. However, I can not use predict_classes() function in Model() object it is just allowed for Sequential() object. When I prefer the fuction model.predict([test_doc, test_doc, test_doc]) it gives me some probabilities below but I am not sure how to map them to class labels (0,1,2).
I have tried similar architectures and came to the conclusion that this type of architecture (with parallel paths) are not good because when the error is back propagated one of the good paths ,that would be learning in the right way, will be affected by a bad path that will increase tha global error. So one good path would be in the right way but it will think it is a bad learning because the global error will increase . (is this ideia right ? )
whe I have “parallel layers” I have to find a way to pretrain before … and the freeze the values and add this layers to the model.
There are some types of backprop that work with different learning rates for each connection and with this mitigate better the error on each connection … maybe this can help on “concurrent paths” during learning . here is one type of bprop like this : https://en.wikipedia.org/wiki/Rprop
The architecture described in Yoon Kim’s paper:
– has one embedding layer (not one for each branch),
– uses global (max-over-time) pooling (not with a pool of size 2),
– applies dropout once, on the concatenation of the max features (not in each branch before the pooling operation).
Do the changes proposed here yield a better predictive performance?
I am facing an issue with the output, like getting different results everytime when I run the same model. The loss and accuracy are also changing all the time.
Thanks for the great tutorial, I performed all the steps and in the last step when I tried to evaluate the model, I got the below results!
Train Accuracy: 50.000000
Test Accuracy: 50.000000
What does this mean! I think this is not logical.
Also I got some warning like the below while running the evaluation code.
2018-01-20 22:21:41.333198: W c:\tf_jenkins\home\workspace\release-win\m\windows
\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library
wasn’t compiled to use AVX2 instructions, but these are available on your machin
e and could speed up CPU computations.
2018-01-20 22:21:41.333808: W c:\tf_jenkins\home\workspace\release-win\m\windows
\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library
wasn’t compiled to use FMA instructions, but these are available on your machine
and could speed up CPU computations.
Sorry sir, I didn’t get a notification that you replied to me.
Could you please tell me what you meant by running the code given the stochastic nature of the algorithm. Thanks in advance.
Hi, First of all thank you so much for the article.
I tried to utilize the multichannel concept in a different way. I am working with relation extraction in natural language where relations are marked already but needs to figure out whether or not there is a valid sentence structure in between those entities. I am thinking to get different representations of a same sentence. For an example sentence (Paris is the capital of France), the real words of the sentence (Paris, is, the, capital, of, France) as first channel’s data, the POS tags of those same tokens (propn, verb, det, noun, adp, propn) as second channel’s data and, dependency tree tags (nsubj, root, det, attr, prep, pobj) as third channel’s data.
I am confused whether I need to encode all the words, pos tags, and dep tags thinking them as a part of the same vocabulary? Or I need to encode those different tokens/representations in their own vocabulary scope?
Actually I am confused on the text to integer encoding step. I mean, should I consider all the different representations of the same sentence as a single list of documents? For example lets say I got three different representations of the sentence “Paris is the capital of France” and collected them in a single document list like below –
all_docs = [[Paris is the capital of France]…, [propn verb det noun adp propn]…, [nsubj root det attr prep pobj]…]
Now if I fit the tokenizer like tokenizer.fit_on_texts(all_docs) into these documents then all the tokens are having different unique integers, right? Is it then valuable if I feed those three encoded representations separately into different channels like input1 = [ints of tokens], input2 = [more ints of tokens], input3 = [some ints of tokens]?
OR
I should consider fitting the tokenizer in three different representations separately and then encode them separately based on the fitted tokenizer. I think the tokenizer would provide some common integers then. Because the encoding scopes are isolated. Will that help in the concatenated layer some how?
Thanks again Jason for your reply and effort for this blog.
would it be possible, looking at the activation patterns, to identify the n-ngrams that mostly affected the classification? With pictures it is possible, but I suppose that with text it should be very difficult, with the embedding inbetween…
I also had the same issue. The reason is that variable is a list object while Keras expects a numpy array. I solved the problem by importing numpy and inserting “trainLabels = numpy.array(trainLabels)”
Thank for this useful post Jason. It’s interesting that even such a minimalistic preprocessing always seem to work fine. When doing text classification (or regression) tasks, do you generally see any value in keeping/including additional information during preprocessing, such as:
(1) Basic sentence-separating punctuations, such as “.”, “!” and “?”
(2) Paragraph separators between groups of sentences
(3) POS tag augmented tokens, e.g., “walking” –> “walking_VERB”, “apple” –> “apple_NOUN”
You should be able to comment out inputs2, embedding2, inputs3 and embedding3, and then feed embedding1 to conv2 and conv3, right? Then you go from [x_in, x_in, x_in] to just x_in for fit(), and predict().
Thanks for yet another amazing post. Apart from purely educational purposes, what do you think would be the differences between using LSTM and CNN in sentiment analysis? Are both approaches completely interchangeable or each of the models might hold advantages/limitations in different setups.
First of all, thank you for what you did here, and generally what you do 🙂
I tested your code on the imdb data, got the similar results, then changed the output to 2 neurons with softmax/argmax training/testing, got marginally better results.
Then I switched to my own 5-class sentiment dataset, but got 98%-ish traning accuracy but 40%-ish testing accuracy, which means its over-fitting, but then read in many papers that generally in the 5-grained SST1 dataset everyone reports an accuracy of 40%-ish. With binary +/- sentiments of course everyone reaches late 80s-90s in accuracy.
What do you suggest to that? Or a setting I could try on top of your code.
If I have more than 2 classes, e.g. positive/negative/neutral, what will my output list (trainLabels) look like? Will it be a a list containing 0’s, 1’s and 2’s or will it be a n*3 matrix, with each column containing 0’s and 1’s?
Hi,
i have created a network which takes two sequences of integers (2 inputs) for one sentence (one related to word embeddings and other related to POS tags) and corresponding embedding layers and then merges them both together before applying the convolution layer. I had called it multi input model.
From this article i understood that it might be multichannel. I am confused that is multiple inputs is necessarily multichannel or multiple parallel convolution layers even on same input is multichannel? If i consider the second definition i would call my network multi-input multichannel?
Also in this case all the convolutions are applied to original input.What is the difference if i stack up convolutions so the result of one is input to another?Thanks.
The inputs are sequence of the same sentence and both are padded to same length..so would it be called different inputs still? and can you please clarify if multichannel is multi-input regardless of parallel or sequential convolutions?
Each head of the model will “read” the data differently.
Perhaps referring to the multiple inputs to the model as “channels” was a poor choice. Different inputs as in the above model are indeed different to different channels for one input. Importantly, we can use different sized kernels and number of filters with different inputs, whereas each channel on one input is fixed to use the same kernel and number of filters.
Thanks alot. I understand that now that multichannel means one input with one or more embeddings for that one input.In your example you are using input multiple times but still its the same input. I have taken your advice and applied convolution of different filter size to each embedding separately instead of merging them together which has improved accuracy. Only one thing,it means it is multi input, i can understand how it can be seen as multi headed..so basically having multiple inputs makes it multiheaded?Thanks
Thank you so much! The precision and recall graphs i plotted through training epochs show sudden spikes in precision while gradual increase in recall.Though recall is higher than precision. Now my dataset has more positive samples than negative ones which lead me to believe that there is chance higher number of FN than FP i.e. lower recall and higher precision but my results are opposite. Can you please elaborate if i have the wrong understanding?
or should i see it this way that since it has more positive samples,classifier is biased towards positive class,leading to more FP and hence lower precision and higher recall?Thanks
I plotted precision-recall curve for both pos and neg class and found the results interesting,
While the curve for the pos class looks very good with oprtimal point at 0.9 and 0.8 for recall and precision respecitvally. The curve for the neg class is a stright line that gives 0.6 for precision and recall or 0.8 with 0.6 and vice versa.
Any idea how this could be?
def max_length(lines):
return max([len(s.split()) for s in lines])
I just copy and paste the code and have this error, I believe that code is actually right, I dont know why I got an error
AttributeError: ‘list’ object has no attribute ‘split’
I have a question on the “Plot of the Multichannel Convolutional Neural Network For Text”.
Why is there always a “none” per box? What does it denote to?
I have a question. Based on this paper, https://arxiv.org/pdf/1510.03820.pdf (A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification), they stated “we set the number of feature maps for this region size to 100”. How do i set the number of feature maps? Is the number of feature maps based on the number of filters per region size?
What’s an intuitive way of understanding how this multi-channeled CNN (or perhaps a basic CNN architecture in general) identify the following (given that the sentiment expressed are only positive or negative):
1.) If more than one sentiment is expressed in the tweet but the positive sentiment is more dominant, then it is a positive tweet, or
2.) If more than one sentiment is expressed in the tweet but the negative sentiment is more dominant, then it is a negative tweet.
What I’m trying to understand here is how CNN is applied to sentence classification. I still don’t get the idea. What i know is CNN when it comes to computer vision, it finds features of pictures. For example a dog with features such ears, nose and eyes.
I think i got.
In convolutional neural networks every network layer acts as a detection filter for the presence of specific features present in the original data. The first layer in a CNN detect (large) features that can be recognized and interpreted relatively easy. Subsequent layers detect increasingly (smaller) features that are more abstract. The last layer of the CNN is able to make an ultra-specific classification by combining all the specific features detected by the previous layers in the input data.
I have a queation about the nagtion words.
When you clean your data with excluding stopwords, you are loosing the nagation words (‘not’ etc.). Don’t you want to leave these words to have better interpretation of the sentence?
For example: “I didn’t like the movie” and “I liked the movie” would look the same after cleaning.
Suleyman SuleymanzadeSeptember 6, 2018 at 7:18 am#
This is two neuron networks that I tried to merge by using concatenate operation. The network should classify IMDB movies reviews by 1-good and 0-bad movies
I have an error in model’s fit (training):
history = conc_model.fit([X_train, X_train], [y_train, y_train], np.reshape([y_train, y_train],(25000,2)),epochs=3, batch_size=(64,64))
TypeError: fit() got multiple values for argument ‘batch_size’.
This is the method that should return trained model. BTW x_train shape (25000, 5) and y_train shape (25000,)
I adapted your version to fit on my data saved in pandas’ dataframe. Since I have a limited data set, the evaluated score has reached to 100% which is a great improvement as compared to my previous, BOW model, 98%.
My first comment on this amazing blog of yours, even though I read a lot of your article, all of them useful.
Anyway I have a question about MaxPooling layers : why do we need them at all ?
Is it just for reducing the dimension ? Because I feel that using it will make us loose some information we learned in the Convolution layer.
###
I my application I want to work with embeddings but n-grams as well. If I have the sentence ‘I like you’, I want to end up with a tensor of dimension [?, 6, d] (d is the dimension of embeddings). The tensor would represent :
‘I’
‘like’
‘you’
‘I like’
‘like you’
‘I like you’
So I want to use the basic embeddings for the 3 first token, and apply a 2-gram convolution layer to get the 2 next token, and finally a 3-gram convolution layer for the last token. Then I concatenate everything (choosing a kernel size adequately).
In this case, why would I want to apply a MaxPooling layer ?
Do you think my approach could work ?
Its very much helpful for me to learn about NLP and its tasks. Thank you very much for your work.. please do the same for computer vision problems too. I can’t find a blogs like yours anywhere for computer vision problems. Please consider it..
Hi Jason! Does a prediction value close to either class mean that it has higher confidence? say 0.99 for this sentence A while 0.65 predicting this sentence B which means that the model predicts with higher confidence on sentence A compared to sentence B OR does it have anything to do with overfitting? a value produced like sentence A is due to being too closely fitted to the data which may cause erroneous predictions for the model in the future because it can prioritize sentences like sentence A?
sorry, I didn’t receive notification about your reply.
I mean if i use one input with one embedding can i use it once with parallel different kernel convolution and this is also called multichannel or not?
sir,
i am doing a project on “paraphrase detection using deep learning”.
i have two inputs, as two sentence . both sentence want to be separate training. how i fit my model???
Hello jason
There is a small typo in the beginning of the example
table = str.maketrans(”, ”, string.punctuation)
but it is fixed in the whole example
table = str.maketrans(”, ”, punctuation)
best
# turn a doc into clean tokens
def clean_doc(doc):
# split into tokens by white space
tokens = doc.split()
# remove punctuation from each token
table = str.maketrans(”, ”, string.punctuation)
tokens = [w.translate(table) for w in tokens]
I’ve followed your article and it was really helpful.
Right now i’m stucked, the model val_loss keeps increasing while the val_acc keeps increasing as well.
I followed your article on improving overfitting, but adding dropout layers didn’t work at all. I tried improving the amount of training data which in fact made the results even worst.
I’ve posted a question explaining top to bottom about my problem in stackoverflow.
It’ll be really helpful if you can take a look at the question.
CNNs would try learning the padded sentences directly which would result in noisy learned representations, how do we ignore padded value so it has no impact on CNN filter learning?
Thanks for this easy-to-follow tutorial. I do not get any improvement with a multi-channel convnet compared to a single convnet with a 3-gram kernel and more filters (128 instead of 32) with GlobalMaxPooling. Do you have any ideas why that would be ? Can you suggest any effective tweaks to improve a multi-label text classifier ?
Thanks for your wonderful tutorial. One query: Can it support multilingual ?. I mean if the dataset in other than English, does it require any change in word embedding ?. Or still, it works.
Thank you, Jason, for your response. Have you used any word embedding(ex:w2v/glove) in your code ?. I could able to see only Keras tokenizer function (correct me if I am wrong). When I ran adapting your code to another language and different dataset, it ran smoothly, so asked if it required any word embedding specifically.
Below is a function for calculating the correlation coefficient. I use it to measure the accuracy degree for a regression problem (text similarity). I use the lstm and the multichannel cnn, however the correlation degree results with -ve values starting from the second epoch.
can you help me and check the correctness of this function?
When I run the complete model as is, I get 50% accuracy rate (see following output). I’ve tried to add more layers to the CNN, used different kernals, tweaked the hyper parameters in the embedding layers .. etc. still getting the same accuracy rate. Would you be able to advise how I can boost the accuracy? Also, I’ve noticed that when I run the code for the first time, I get 99% accuracy rate on test data and 50% on test data.
Max document length: 1380
Vocabulary size: 44277
(1800, 1380) (200, 1380)
Train Accuracy: 50.000000
Test Accuracy: 50.000000
Hi Jason – I tweaked this to run predictions on other text documents using the above movie review data to train on. I had tried to scoring predictions on text strings such as “this movie sucks do not recommend” and got quite poor results (model predicted 65% probability it was a positive review).
Just wondering if there are additional training resources to build into the model to get a truly rounded approach to positive/negative sentiment? It seems to work well with large paragraph/eloquent reviews but not so well with short 5-10 word reviews like “this movie was fantastic”.
How about in each channel I put different embedding?
embedding1=random embedding (channel1)
embedding2=word2vec embedding (channel2)
does this seem right Idea or not?
Hi Jason,
Thanks for your this beautiful work. I want to ask you if we are able to implement Multichannel CNN comprises two CNN channels: word embedding and POS embedding channel. if yes how we can do that.
Thank you for your time
In this tutorial, if we want to implement this CNN with two inputs, first one word embedding and second, POS embedding channel. How we can implement that?
Hi Jason,
Thanks for sharing this work. I was following your work to build a text classifier and noticed that you are using maxpooling of size 2. However, I believe that the original paper uses maxpooling over time (implemented as GlobalMaxPooling1D in Keras). Is there a particular reason for that?
Thanks.
I don’t understand why you added this layer “dense1 = Dense(10, activation=’relu’)(merged)”. I can’t seem to find it in the original paper architecture.
Thanks for the quick reply! Is that the place in the architecture where the Kim (2014) and Zhang & Wallace (2015) place a drop-out and a l2 regularization?
Hi Jason. Thank you for your helpful tutorial. I just wonder that: Can the model you used for classification be used for a regression task with a small change at the last dense layer: activation = linear instead of sigmoid? So for any classification model, we only need to make a small modification on the last layer to use for regression task? Is it that simple? Thanks in advance!
I have one Input layer, one hidden layer and one o/p layer. Since i have only two fields one is dependent and one is independent so i have gave in units as 1 in input and hidden layer.
I tried to know the shape of this, when i checked shape of my X_train it came as 100.
Now what i kept in input is correct or do i need to give shape value in input filed.
Thanks for the article. I tried to improve it by using 1 input and 1 embedding layer – which reduced number of parameters:
Total params: 5,144,937
So – after training for 12 epochs with batch=6 I got same results:
Epoch 12/12
300/300 – 7s – loss: 8.2556e-06 – accuracy: 1.0000
Test Accuracy: 87.500000
As I understand – Embedding layer is not trainable, so I don’t need 3 of them?
Thanks for the great breakdown. If you wanted to modify this to feed in different texts per trainX, so say you had trainX, trainY and trainZ instead. what should you do in terms of modifying the above? does it need the same tokenizer I imagine?? thanks Toby
Thanks for responding, I still have one output I’m trying to predict (ie a classification example). I basically I’m trying to see if changes in my text from one document to the next can help predict my target variable. So I wanted to feed in both documents. I adapted the code above to feed in a different tokenizer, length of words, vocab to its own respective embedding matrix.
My problem is similar to the Quora duplicate questions a little but just wanted to feed a concatenated CNN instead of an LSTM to start with. So far the validation accuracy seems OK but will test against the test set soon.
Does this seem OK? Is this technical called a multi-channel CNN if you are feeding in two different documents?
Hey, Jason Brownlee
Greetings
First of all, thank you very much for your wondaful article and indeed your articles are helping me more than my supervisor. Whenever, I face the problem, first, I search your article related to that problem.
I have one question related to this post, can you please explain the cost associated to this architecture, I am trying similar idea but I have concern about the time it takes. Is it feasible for a problem that needs a quick reactive action?
Hello, Jason Brownlee
Since a multi-channel convolutional neural network for text classification involves using multiple versions of the standard model with different sized kernels. As it is using multiple versions of standard CNN so here can we keep different number of filters along with different embedding dimensions in each channel ? For example, I want to keep 128 filters with kernel size 6 and embedding dimension 64 in channel one. Similarly I am having 64 filters with kernel size set to be 4 and embedding dimension 32 and I am doing the same for the third channel as well (I mean having different filters number, kernel size and embedding dimension). I have only one input for all three channels. Here I want that every channel convolve on the same input differently and try to find the pattern differently.
Can you please shed light on this architecture ?
Thank You
Thank you so much for your quick response
Yes, I am also talking about the same idea that has been discussed in this article using functional API in Keras. Since you have used same number of filters and same embedding dimension in each channel. So I want to explore this idea further by using different number of filters along with different kernel sizes as well as different embedding dimensions in each channel.
One thing more that I am using same input for all the three channels and all the strings in my dataset have the fixed length that I am passing as input.
So what will be the suitable name for this architecture? Multichannel or Mult layers ?
Your response will be highly appreciated.




")


Hi
Great article
I think there is a small error, According to this code trainLines would be a list of list, where each list holds tokens for one review. But all the functions to which trainLines is passed(i.e texts_to_sequences, fit_on_texts, max_length) takes a list of strings as input. I think all the lists in trainX and testX should be converted to strings before dumping them into a file.
The list of tokens is turned back into a string:
Hello Jason
yes but this instruction is missing in your code
I got a traceback with this message list object has no attribute lower
Si I add one line in clean_doc function
tokens = [word for word in tokens if len(word) > 1]
tokens = ‘ ‘.join(tokens)
return tokens
It works well
best
Hi,
thanks for the article. Would it be possible to use only one input and one embedding layer, and branch into convolutions after that?
How would that work?
Wouldn’t the model below be exactly the same? (with just one input, used in the three channels?) Of course, if we also had a single embedding (put the embedding before the channels, and let all convs act on that one) the model would be different.
Yes, nice approach.
How does it compare regarding training/prediction?
given that I run the code using different dataset and embedding, Mr.Jason code gave me:
ModelMulitCNN MODEL Accuracy: 0.8785238339313173
ModelMulitCNN MODEL precision_score: 0.7633378932968536
ModelMulitCNN MODEL recall_score: 0.6495925494761351
ModelMulitCNN MODEL f1_score: 0.7018867924528303
while Mr.Francesco code gave me:
ModelMulitCNN MODEL Accuracy: 0.8782675550999487
ModelMulitCNN MODEL precision_score: 0.7424242424242424
ModelMulitCNN MODEL recall_score: 0.6845168800931315
ModelMulitCNN MODEL f1_score: 0.7122955784373107
Nice, thanks for sharing.
Hi! I followed your tutorial with my own dataset and I changed the last layer for regression task. I got an error like this:
AssertionError: Could not compute output Tensor(“dense_19/Identity:0”, shape=(None, 1), dtype=float32)
How can I fix it? Thank you so much.
You will need to debug the error, I cannot tell the cause off the cuff.
I have tried to debug the error, but it has no improvement. I followed Francesco’s modification when using 1 input layer for all 3 channels, it works.
//*
In the define model:
…
model = Model(inputs=[inputs], outputs=outputs)
…
*//
If I use 1 layer for all 3 channels, it works well. But if I use separated inputs as you used:
//*
inputs1 = Input(shape=(length,))
embedding1 = Embedding(vocab_size, 100)(inputs1)
…
inputs2 = Input(shape=(length,))
embedding2 = Embedding(vocab_size, 100)(inputs2)
…
inputs3 = Input(shape=(length,))
embedding3 = Embedding(vocab_size, 100)(inputs3)
…
model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs)
*//
it didn’t work and got the above error. I wonder if there is any problem with this line: model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs) ?
Thank you!
Perhaps try posting your code and error on stackoverflow.
I’m new to deep learning. Want to develop a CNN model from scratch for text detection in scene images. Can you help me?
That’s more like an object detection problem before you can apply text classification. Please see, for example, https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hi,
Thank you for your effort and good clean article.
You’re welcome.
FYI, the link to the review polarity dataset is wrong. The correct one is: https://www.cs.cornell.edu/people/pabo/movie-review-data/review_polarity.tar.gz
Fixed, thanks.
Hi Jason,
Thanks for your this beautiful work. I want to ask you that we are able to evaluate the accuracy of the model but how can we predict the classes of tested documents to analyze results in detail. In a Sequential model we can perform it like model.predict_classes(x_test). However for the Model(inputs=…) object predict_classes feature is not supported. Do you have a suggestion?
Thanks.
Yes, the document must be provided in an array 3 times.
yhat = model.predict([doc, doc, doc])
Yes I also tried like that but I am not sure how to interpret the probabilities for multiclass classification.
What is the problem exactly?
Thanks for interest, Jason.
I am actually trying to apply your post for a multiclass case (0:negative,1:neutral,2:positive). After training part I want to compare the accuracy rates for each class to measure the how model is accurate in detail. Then I want to calculate the Precision and Recall. However, I can not use predict_classes() function in Model() object it is just allowed for Sequential() object. When I prefer the fuction model.predict([test_doc, test_doc, test_doc]) it gives me some probabilities below but I am not sure how to map them to class labels (0,1,2).
[0.03045881]
[0.39043367]
[0.01636862]
…
[0.7408592 ]
[0.17758404]
[0.21271853]
You can use argmax on the result from predict() to get a class index.
hi Jason,
I also try your post for text classification.However when I try to apply argmax() function like you said I get an array of 0.
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0])
Do you Have any suggestion? Thank in advance.
P.S
Before predict class I prepare text sample like this:
sample = “This is sample text for classification”
tokenizer.fit_on_texts(sample)
sequences = tokenizer.texts_to_sequences(sample)
test_data = pad_sequences(sequences, maxlen=maxlen)
predict = model.predict([test_data,test_data,test_data])
predict.argmax(axis=-1)
If I do something wrong plz correct me! Thank You
Perhaps this will help:
https://machinelearningmastery.com/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
I have tried similar architectures and came to the conclusion that this type of architecture (with parallel paths) are not good because when the error is back propagated one of the good paths ,that would be learning in the right way, will be affected by a bad path that will increase tha global error. So one good path would be in the right way but it will think it is a bad learning because the global error will increase . (is this ideia right ? )
whe I have “parallel layers” I have to find a way to pretrain before … and the freeze the values and add this layers to the model.
Perhaps it depends on the dataset and models involved.
There are some types of backprop that work with different learning rates for each connection and with this mitigate better the error on each connection … maybe this can help on “concurrent paths” during learning . here is one type of bprop like this : https://en.wikipedia.org/wiki/Rprop
Yes, I recommend Adam:
https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/
The architecture described in Yoon Kim’s paper:
– has one embedding layer (not one for each branch),
– uses global (max-over-time) pooling (not with a pool of size 2),
– applies dropout once, on the concatenation of the max features (not in each branch before the pooling operation).
Do the changes proposed here yield a better predictive performance?
Nice!
No idea, why not compare?
Hi Jason,
Thanks for this article. Very helpful.
I am facing an issue with the output, like getting different results everytime when I run the same model. The loss and accuracy are also changing all the time.
Any thoughts on this ?
Machine learning algorithms are stochastic by design. This is a feature, not a bug. Learn more here:
https://machinelearningmastery.com/randomness-in-machine-learning/
Hi Jason,
Thanks for the great tutorial, I performed all the steps and in the last step when I tried to evaluate the model, I got the below results!
Train Accuracy: 50.000000
Test Accuracy: 50.000000
What does this mean! I think this is not logical.
Also I got some warning like the below while running the evaluation code.
2018-01-20 22:21:41.333198: W c:\tf_jenkins\home\workspace\release-win\m\windows
\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library
wasn’t compiled to use AVX2 instructions, but these are available on your machin
e and could speed up CPU computations.
2018-01-20 22:21:41.333808: W c:\tf_jenkins\home\workspace\release-win\m\windows
\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library
wasn’t compiled to use FMA instructions, but these are available on your machine
and could speed up CPU computations.
I’ll appreciate your reply. Thanks in advance
Ignore those warnings.
Perhaps try running the code a second time given the stochastic nature of the algorithm.
Sorry sir, I didn’t get a notification that you replied to me.
Could you please tell me what you meant by running the code given the stochastic nature of the algorithm. Thanks in advance.
Yes, see this post:
https://machinelearningmastery.com/randomness-in-machine-learning/
Hi, First of all thank you so much for the article.
I tried to utilize the multichannel concept in a different way. I am working with relation extraction in natural language where relations are marked already but needs to figure out whether or not there is a valid sentence structure in between those entities. I am thinking to get different representations of a same sentence. For an example sentence (Paris is the capital of France), the real words of the sentence (Paris, is, the, capital, of, France) as first channel’s data, the POS tags of those same tokens (propn, verb, det, noun, adp, propn) as second channel’s data and, dependency tree tags (nsubj, root, det, attr, prep, pobj) as third channel’s data.
I am confused whether I need to encode all the words, pos tags, and dep tags thinking them as a part of the same vocabulary? Or I need to encode those different tokens/representations in their own vocabulary scope?
Regards
Interesting approach.
I guess you could try a few different representations and test whether there is any impact on model skill?
Actually I am confused on the text to integer encoding step. I mean, should I consider all the different representations of the same sentence as a single list of documents? For example lets say I got three different representations of the sentence “Paris is the capital of France” and collected them in a single document list like below –
all_docs = [[Paris is the capital of France]…, [propn verb det noun adp propn]…, [nsubj root det attr prep pobj]…]
Now if I fit the tokenizer like tokenizer.fit_on_texts(all_docs) into these documents then all the tokens are having different unique integers, right? Is it then valuable if I feed those three encoded representations separately into different channels like input1 = [ints of tokens], input2 = [more ints of tokens], input3 = [some ints of tokens]?
OR
I should consider fitting the tokenizer in three different representations separately and then encode them separately based on the fitted tokenizer. I think the tokenizer would provide some common integers then. Because the encoding scopes are isolated. Will that help in the concatenated layer some how?
Thanks again Jason for your reply and effort for this blog.
Perhaps this would be a good place to start to get a handle on data prep:
https://machinelearningmastery.com/start-here/#nlp
Hi Jason,
would it be possible, looking at the activation patterns, to identify the n-ngrams that mostly affected the classification? With pictures it is possible, but I suppose that with text it should be very difficult, with the embedding inbetween…
Thanks
Francesco
It may be, but some hard thinking and development would be required. It’s not obvious sorry.
Hi,
Thank you for this neat article! 🙂
I am facing an issue.
AttributeError: ‘int’ object has no attribute ‘ndim’
in model.fit
Did you try coping all of the code from the final example?
I also had the same issue. The reason is that variable is a list object while Keras expects a numpy array. I solved the problem by importing numpy and inserting “trainLabels = numpy.array(trainLabels)”
i mean variable trainLabels .
I have update the example to correct this issue.
It seems to be a change in Keras 2.1.3.
Thank for this useful post Jason. It’s interesting that even such a minimalistic preprocessing always seem to work fine. When doing text classification (or regression) tasks, do you generally see any value in keeping/including additional information during preprocessing, such as:
(1) Basic sentence-separating punctuations, such as “.”, “!” and “?”
(2) Paragraph separators between groups of sentences
(3) POS tag augmented tokens, e.g., “walking” –> “walking_VERB”, “apple” –> “apple_NOUN”
Do these typically have any significant impact?
It really depends on the application I’m afraid.
For simple classification like tasks, often simpler representations result in better model skill.
You should be able to comment out inputs2, embedding2, inputs3 and embedding3, and then feed embedding1 to conv2 and conv3, right? Then you go from [x_in, x_in, x_in] to just x_in for fit(), and predict().
Hi Jason,
In your NLP book (Chapter 16), you cover n-gram CNN in depth. LSTM’s memory mimic n-grams.
May I ask you why you not use a LSTM classification instead?
Thanks!
Franco
You can use LSTMs, here I was demonstrating how to do it with CNNs.
Thanks Jason!
Indeed, you have a NLP sample in your LSTM book.
Hi Jason,
Thanks for yet another amazing post. Apart from purely educational purposes, what do you think would be the differences between using LSTM and CNN in sentiment analysis? Are both approaches completely interchangeable or each of the models might hold advantages/limitations in different setups.
Best,
Boris
CNN seems to achieve state of the art results. I would start there.
Can we apply this approach to multi class problems? The only change is during fitting and using ‘categorical cross entropy” as loss.Am I correct
Sure.
Hi Jason,
I am beginner on keras and CNN ,I want to know How to give multinputs to train_test_split?
my example:(Xtrain_user,Xtrain_item,Xtest_user,Xtest_item),y_train,y_test=train_test_split((user_reviews,
item_reviews),rating , test_size=0.2, random_state=42)
which X= (user_reviews,item_reviews)
and Y=rating
Perhaps split the data manually using array notation in NumPy:
https://machinelearningmastery.com/index-slice-reshape-numpy-arrays-machine-learning-python/
But I have a dictionnaire for user and for item ,how can I split it ?
Perhaps pick one axis (e.g. users) and divide a list of users in half?
First of all, thank you for what you did here, and generally what you do 🙂
I tested your code on the imdb data, got the similar results, then changed the output to 2 neurons with softmax/argmax training/testing, got marginally better results.
Then I switched to my own 5-class sentiment dataset, but got 98%-ish traning accuracy but 40%-ish testing accuracy, which means its over-fitting, but then read in many papers that generally in the 5-grained SST1 dataset everyone reports an accuracy of 40%-ish. With binary +/- sentiments of course everyone reaches late 80s-90s in accuracy.
What do you suggest to that? Or a setting I could try on top of your code.
The model architecture may require tuning to each different problem.
Hi Jason ,
Thanks for the great article.
If I have more than 2 classes, e.g. positive/negative/neutral, what will my output list (trainLabels) look like? Will it be a a list containing 0’s, 1’s and 2’s or will it be a n*3 matrix, with each column containing 0’s and 1’s?
Thanks a lot
I would recommend a one hot encoding, you can learn more here:
https://machinelearningmastery.com/why-one-hot-encode-data-in-machine-learning/
Hi,
i have created a network which takes two sequences of integers (2 inputs) for one sentence (one related to word embeddings and other related to POS tags) and corresponding embedding layers and then merges them both together before applying the convolution layer. I had called it multi input model.
inp = Input(shape=(data.shape[1],))
e= Embedding(vocab_size, 200, input_length=maxSeqLength, weights=[embedding_matrix], trainable=False)(inp)
inp2 = Input(shape=(embedding_pos.shape[1],))
e1= Embedding(54, 54, input_length=maxSeqLength, weights=[embedding_matrix_pos], trainable=False)(inp2)
mer=concatenate([e,e1],axis=-1)
conv1_1 = Conv1D(filters=100, kernel_size=3)(mer)
conv1_2 = Conv1D(filters=100, kernel_size=4)(mer)
From this article i understood that it might be multichannel. I am confused that is multiple inputs is necessarily multichannel or multiple parallel convolution layers even on same input is multichannel? If i consider the second definition i would call my network multi-input multichannel?
Also in this case all the convolutions are applied to original input.What is the difference if i stack up convolutions so the result of one is input to another?Thanks.
If the inputs are different, it might be better to have a multi-headed CNN rather than a multichannel CNN.
The inputs are sequence of the same sentence and both are padded to same length..so would it be called different inputs still? and can you please clarify if multichannel is multi-input regardless of parallel or sequential convolutions?
Each head of the model will “read” the data differently.
Perhaps referring to the multiple inputs to the model as “channels” was a poor choice. Different inputs as in the above model are indeed different to different channels for one input. Importantly, we can use different sized kernels and number of filters with different inputs, whereas each channel on one input is fixed to use the same kernel and number of filters.
Thanks alot. I understand that now that multichannel means one input with one or more embeddings for that one input.In your example you are using input multiple times but still its the same input. I have taken your advice and applied convolution of different filter size to each embedding separately instead of merging them together which has improved accuracy. Only one thing,it means it is multi input, i can understand how it can be seen as multi headed..so basically having multiple inputs makes it multiheaded?Thanks
Yes.
Thank you so much! The precision and recall graphs i plotted through training epochs show sudden spikes in precision while gradual increase in recall.Though recall is higher than precision. Now my dataset has more positive samples than negative ones which lead me to believe that there is chance higher number of FN than FP i.e. lower recall and higher precision but my results are opposite. Can you please elaborate if i have the wrong understanding?
or should i see it this way that since it has more positive samples,classifier is biased towards positive class,leading to more FP and hence lower precision and higher recall?Thanks
You will need to find a trade-off that makes sense for your specific application and problem.
I plotted precision-recall curve for both pos and neg class and found the results interesting,
While the curve for the pos class looks very good with oprtimal point at 0.9 and 0.8 for recall and precision respecitvally. The curve for the neg class is a stright line that gives 0.6 for precision and recall or 0.8 with 0.6 and vice versa.
Any idea how this could be?
It may suggest that one class is easier to predict than the other.
I did the exact thing on the tutorial but i got a lower test accuracy which is 83.5%. Traning is 100%
You could try running the example a few times to see if you get differing results.
(forgot to reply) Yes, actually got different results after running it a few times.
def max_length(lines):
return max([len(s.split()) for s in lines])
I just copy and paste the code and have this error, I believe that code is actually right, I dont know why I got an error
AttributeError: ‘list’ object has no attribute ‘split’
Environment
Python 3.6
Tensorflow 1.9
Keras 2.2
Ensure the indenting is correct and that you have all of the surrounding code and data.
I have more suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
I have a question on the “Plot of the Multichannel Convolutional Neural Network For Text”.
Why is there always a “none” per box? What does it denote to?
Found the answer: The None dimension in the shape tuple refers to the batch dimension which simply means that the layer can accept input of any size.
Yes.
Good question!
“None” refers to a dimension that is not specified, and in turn is variable.
I have a question. Based on this paper, https://arxiv.org/pdf/1510.03820.pdf (A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification), they stated “we set the number of feature maps for this region size to 100”. How do i set the number of feature maps? Is the number of feature maps based on the number of filters per region size?
The number of feature maps is the first argument to the convolutional layer Conv1D().
I really got lots of questions sorry xD.
What’s an intuitive way of understanding how this multi-channeled CNN (or perhaps a basic CNN architecture in general) identify the following (given that the sentiment expressed are only positive or negative):
1.) If more than one sentiment is expressed in the tweet but the positive sentiment is more dominant, then it is a positive tweet, or
2.) If more than one sentiment is expressed in the tweet but the negative sentiment is more dominant, then it is a negative tweet.
We cannot know what the CNN has learned, only the evaluation of the model performance.
What I’m trying to understand here is how CNN is applied to sentence classification. I still don’t get the idea. What i know is CNN when it comes to computer vision, it finds features of pictures. For example a dog with features such ears, nose and eyes.
I think i got.
In convolutional neural networks every network layer acts as a detection filter for the presence of specific features present in the original data. The first layer in a CNN detect (large) features that can be recognized and interpreted relatively easy. Subsequent layers detect increasingly (smaller) features that are more abstract. The last layer of the CNN is able to make an ultra-specific classification by combining all the specific features detected by the previous layers in the input data.
Perhaps try this simpler tutorial:
https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/
Hi,
I have a question about the input of the model, based on an error I got.
I ran this code on a different data and I had no problems. Then I tried an extention with RandomizedSearchCV, as the following:
model = KerasClassifier(build_fn=create_model, verbose=1, epochs=3, batch_size=32)
param_dist= {“n_strides”: sp_randint(1,3)}
random_grid = RandomizedSearchCV(estimator=model, param_distributions=param_dist, n_iter = 3)
random_grid_result = random_grid.fit([X_train, X_train, X_train], y_train)
I got the following error:
ValueError: Found input variables with inconsistent numbers of samples: [3, 25000]
What may the error be? 25000 is the length of my train data
Sorry, I’m not sure what is going on.
Perhaps post your code and error to stackoverflow?
Sorry for not being understood.
I have explored this further and found out that Keras wrapper don’t support multi input network. That was the problem (https://github.com/keras-team/keras/issues/6451)
So I decided to use Francesco’s comment above (January 25), using one Input for all three channels and that it’s working!
Nice!
Hi,
I have a queation about the nagtion words.
When you clean your data with excluding stopwords, you are loosing the nagation words (‘not’ etc.). Don’t you want to leave these words to have better interpretation of the sentence?
For example: “I didn’t like the movie” and “I liked the movie” would look the same after cleaning.
It really depends on whether they add value on the specific problem you are solving or not.
Perhaps try modeling with and without them?
Great Thanks
This is two neuron networks that I tried to merge by using concatenate operation. The network should classify IMDB movies reviews by 1-good and 0-bad movies
I have an error in model’s fit (training):
history = conc_model.fit([X_train, X_train], [y_train, y_train], np.reshape([y_train, y_train],(25000,2)),epochs=3, batch_size=(64,64))
TypeError: fit() got multiple values for argument ‘batch_size’.
This is the method that should return trained model. BTW x_train shape (25000, 5) and y_train shape (25000,)
def cnn_lstm_merged():
embedding_vecor_length = 32
cnn_model = Sequential()
cnn_model.add(Embedding(top_words, embedding_vecor_length,input_length=max_review_length))
cnn_model.add(Conv1D(filters=32, kernel_size=3, padding=’same’, activation=’relu’))
cnn_model.add(MaxPooling1D(pool_size=2))
cnn_model.add(Flatten())
lstm_model = Sequential()
lstm_model.add(Embedding(top_words, embedding_vecor_length, input_length=max_review_length))
lstm_model.add(LSTM(64, activation = ‘relu’, return_sequences=True))
lstm_model.add(Flatten())
merge = Concatenate([lstm_model, cnn_model])
hidden = Dense(1, activation = ‘sigmoid’)
conc_model = Sequential()
conc_model.add(merge)
conc_model.add(hidden)
conc_model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history = conc_model.fit([X_train, X_train], [y_train, y_train], np.reshape([y_train, y_train],(25000,2)),epochs=3, batch_size=(64,64))
return history
Sorry, I don’t have the capacity to debug your new code, perhaps post it to stackoverflow?
Very Nice Tutorial!
I adapted your version to fit on my data saved in pandas’ dataframe. Since I have a limited data set, the evaluated score has reached to 100% which is a great improvement as compared to my previous, BOW model, 98%.
You can find the complete code at my github:
https://github.com/eanunez/ArticleClassifier/blob/master/cnn/Multi-Channel%20CNN.ipynb
Thank you so much Jason!
Kind Regards,
Emmanuel
Well done!
hello Emmanuel,
thanks for the updated version on your github, when making multi-classes fit, you should add the code
after your code
Thank Jason Brownlee again, i am really one of your fans.
Hi Jason,
My first comment on this amazing blog of yours, even though I read a lot of your article, all of them useful.
Anyway I have a question about MaxPooling layers : why do we need them at all ?
Is it just for reducing the dimension ? Because I feel that using it will make us loose some information we learned in the Convolution layer.
###
I my application I want to work with embeddings but n-grams as well. If I have the sentence ‘I like you’, I want to end up with a tensor of dimension [?, 6, d] (d is the dimension of embeddings). The tensor would represent :
‘I’
‘like’
‘you’
‘I like’
‘like you’
‘I like you’
So I want to use the basic embeddings for the 3 first token, and apply a 2-gram convolution layer to get the 2 next token, and finally a 3-gram convolution layer for the last token. Then I concatenate everything (choosing a kernel size adequately).
In this case, why would I want to apply a MaxPooling layer ?
Do you think my approach could work ?
Thank you and keep up the good work 🙂
Yes, we use the pooling layer to distil the large feature maps down to the most essential.
Try with and without the pooling layer and use the model that gives the best performance.
Hi Jason,
Its very much helpful for me to learn about NLP and its tasks. Thank you very much for your work.. please do the same for computer vision problems too. I can’t find a blogs like yours anywhere for computer vision problems. Please consider it..
Thanks for the suggestion.
Hi Jason,
For one of my input values when i run the CNN code
The output i received is
Epoch 1/100
250/250 [==============================] – 77s 308ms/step – loss: -2.8596 – acc: 0.7843
Epoch 2/100
250/250 [==============================] – 76s 303ms/step – loss: -2.9239 – acc: 0.7863
Epoch 3/100
250/250 [==============================] – 75s 300ms/step – loss: -2.8824 – acc: 0.7904
Epoch 4/100
250/250 [==============================] – 74s 294ms/step – loss: -2.9322 – acc: 0.7851
Do you think the model is correct , as the loss is in negative values.
Thanks,
Negative loss is interesting. Something odd might be going on.
Hello Jason,
I wanted to apply grid search on this model (3-channels) by following your other tutorials but I’m getting this error
>ValueError: Found input variables with inconsistent numbers of samples: [3, 8000]
This is the code:
# grid search
epochs = [1, 10]
batch_size = [16, 32]
param_grid = dict(epochs=epochs, batch_size=batch_size)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=’accuracy’)
grid_result = grid.fit([trainX,trainX,trainX], array(trainLabels))
I have tried googling but I didn’t find any answers for it.
Thank you in advance!
Perhaps try running the grid search loops manually.
Hi Jason! Does a prediction value close to either class mean that it has higher confidence? say 0.99 for this sentence A while 0.65 predicting this sentence B which means that the model predicts with higher confidence on sentence A compared to sentence B OR does it have anything to do with overfitting? a value produced like sentence A is due to being too closely fitted to the data which may cause erroneous predictions for the model in the future because it can prioritize sentences like sentence A?
A larger predicted probability could be interpreted as higher confidence in the prediction.
Thank you so much Jason!
can i used shared input instead of using input on every CNN channel ??
What do you mean exactly?
You have the data once in memory and provide multiple references to it.
sorry, I didn’t receive notification about your reply.
I mean if i use one input with one embedding can i use it once with parallel different kernel convolution and this is also called multichannel or not?
def define_model(length, vocab_size):
inputs1 = Input(shape=(length,))
embedding1 = Embedding(vocab_size, 100)(inputs1)
# channel 1
conv1 = Conv1D(filters=32, kernel_size=4, activation=’relu’)(embedding1)
drop1 = Dropout(0.5)(conv1)
pool1 = MaxPooling1D(pool_size=2)(drop1)
flat1 = Flatten()(pool1)
# channel 2
conv2 = Conv1D(filters=32, kernel_size=6, activation=’relu’)(embedding1)
drop2 = Dropout(0.5)(conv2)
pool2 = MaxPooling1D(pool_size=2)(drop2)
flat2 = Flatten()(pool2)
# channel 3
conv3 = Conv1D(filters=32, kernel_size=8, activation=’relu’)(embedding1)
drop3 = Dropout(0.5)(conv3)
pool3 = MaxPooling1D(pool_size=2)(drop3)
flat3 = Flatten()(pool3)
# merge
merged = concatenate([flat1, flat2, flat3])
# interpretation
dense1 = Dense(10, activation=’relu’)(merged)
outputs = Dense(1, activation=’sigmoid’)(dense1)
model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs)
# compile
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
# summarize
print(model.summary())
plot_model(model, show_shapes=True, to_file=’multichannel.png’)
return model
Yes, I have to call this a mutli-headed model and save “channel” to refer to the depth of a given input.
what do you mean with save “channel” to refer to the depth of a given input.
As in an input image has 3 channels, one for red/blue/green.
And, the depth of a stack of feature maps is referred to as the channels.
sir,
i am doing a project on “paraphrase detection using deep learning”.
i have two inputs, as two sentence . both sentence want to be separate training. how i fit my model???
Perhaps start with a strong definition of your prediction problem:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Hello jason
There is a small typo in the beginning of the example
table = str.maketrans(”, ”, string.punctuation)
but it is fixed in the whole example
table = str.maketrans(”, ”, punctuation)
best
I don’t believe so, are you sure?
Yes only in the first example
# turn a doc into clean tokens
def clean_doc(doc):
# split into tokens by white space
tokens = doc.split()
# remove punctuation from each token
table = str.maketrans(”, ”, string.punctuation)
tokens = [w.translate(table) for w in tokens]
The first example in section “Loading and Cleaning Reviews” import’s string “import string” then uses “string.punctuation”.
It is correct Python code.
Perhaps I misunderstand your comment?
Hello Jason
Yes you are right. I merged the code of two examples that is why I got a traceback
Sorry about that
No problem.
Hi Jason,
I’ve followed your article and it was really helpful.
Right now i’m stucked, the model val_loss keeps increasing while the val_acc keeps increasing as well.
I followed your article on improving overfitting, but adding dropout layers didn’t work at all. I tried improving the amount of training data which in fact made the results even worst.
I’ve posted a question explaining top to bottom about my problem in stackoverflow.
It’ll be really helpful if you can take a look at the question.
Here’s the link
https://stackoverflow.com/questions/55320567/validation-loss-increases-after-3-epochs-but-validation-accuracy-keeps-increasin
I’m looking forward for your answer.
Thanks.
Perhaps try using SGD, reducing the learning rate, and increasing the number of training epochs.
CNNs would try learning the padded sentences directly which would result in noisy learned representations, how do we ignore padded value so it has no impact on CNN filter learning?
Typically CNNs ignore zero padded values, e.g. they use padding all the time as part of performing convolutions.
Hey Jason,
Thanks for this easy-to-follow tutorial. I do not get any improvement with a multi-channel convnet compared to a single convnet with a 3-gram kernel and more filters (128 instead of 32) with GlobalMaxPooling. Do you have any ideas why that would be ? Can you suggest any effective tweaks to improve a multi-label text classifier ?
Best regards
SK
I have some suggestions here that might help:
https://machinelearningmastery.com/start-here/#better
Hey Jason,
Thanks for the very useful link.
Best
Sudheer
You’re welcome.
Hi , jason great article
can you make a article on what are the most common ways to approach a text related Machine Learning problem
Yes, start here:
https://machinelearningmastery.com/start-here/#nlp
I wrote a fake review as
“this was wonderfull movie
this movie is amazing
actors have acted very well and performance was outstanding
i will watch this movie again”
then is used same model to predict if review was good or bad
result was 0.50316983 but i was expecting more as review is straight foreword
i have used more posotive words and avoided any confusting words
so what is the problem here ?
Perhaps the model was overfit, you could try fitting it again?
Hi Jason,
Thanks for your wonderful tutorial. One query: Can it support multilingual ?. I mean if the dataset in other than English, does it require any change in word embedding ?. Or still, it works.
Thanks
You can train your own word embedding for any language as far as I know.
Thank you, Jason, for your response. Have you used any word embedding(ex:w2v/glove) in your code ?. I could able to see only Keras tokenizer function (correct me if I am wrong). When I ran adapting your code to another language and different dataset, it ran smoothly, so asked if it required any word embedding specifically.
Thanks
Yes many times. Perhaps start here:
https://machinelearningmastery.com/use-word-embedding-layers-deep-learning-keras/
What is the difference between CNN and the multichannel CNN?
Why I need to used the multichannel CNN?
It can use a separate kernel size on the same input data and effectively “see” the data at different resolutions at once.
Thank you
You’re welcome.
Below is a function for calculating the correlation coefficient. I use it to measure the accuracy degree for a regression problem (text similarity). I use the lstm and the multichannel cnn, however the correlation degree results with -ve values starting from the second epoch.
can you help me and check the correctness of this function?
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
when I use the correlation coefficient as a metric,
the resulted correlation coefficient values are ranged from -1 to -85.
Does the resulted values means that there is a problem in the model?
Perhaps start by reviewing the loss?
Can the Pearson correlation coefficient decrease and the loss at the same time? what does this means?
I think the loss should decrease while the correlation coefficient should increase during the training time?
Correlation would not make a good loss function.
I run the multichannel cnn model on a text similarity problem.
Every time I run the model, I have different results(loss, accuracy).
Does it is normal to have different loss and accuracy results every time I run the code?
This is to be expected, see this:
https://machinelearningmastery.com/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
how to do sentiment analysis for Galssdoor data with maximum accuracy considering the ratings also ?
Perhaps test a range of data preparation methods and explore a range of CNN models to see what works.
Start here:
https://machinelearningmastery.com/start-here/#nlp
Then use the tutorials here to get better results:
https://machinelearningmastery.com/start-here/#better
What is the advantage of using multichannel CNN over just one CNN?
It can read the input in different ways in parallel, e.g. extract different features from the same input within one model.
Hi Jason,
When I run the complete model as is, I get 50% accuracy rate (see following output). I’ve tried to add more layers to the CNN, used different kernals, tweaked the hyper parameters in the embedding layers .. etc. still getting the same accuracy rate. Would you be able to advise how I can boost the accuracy? Also, I’ve noticed that when I run the code for the first time, I get 99% accuracy rate on test data and 50% on test data.
Max document length: 1380
Vocabulary size: 44277
(1800, 1380) (200, 1380)
Train Accuracy: 50.000000
Test Accuracy: 50.000000
You can discover suggestions for diagnosing and improving deep learning performance here:
https://machinelearningmastery.com/start-here/#better
Hi Jason, thanks for the tutorial. Would you be able to write a tutorial on aspect-based sentiment analysis with Keras? That would be awesome!
What is “aspect-based sentiment analysis”?
How to make a prediction with a sentence using your tutorial
Prepare the text in the same way as the training data, then call model.predict()
For help see this:
https://machinelearningmastery.com/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
Hi Jason – I tweaked this to run predictions on other text documents using the above movie review data to train on. I had tried to scoring predictions on text strings such as “this movie sucks do not recommend” and got quite poor results (model predicted 65% probability it was a positive review).
Just wondering if there are additional training resources to build into the model to get a truly rounded approach to positive/negative sentiment? It seems to work well with large paragraph/eloquent reviews but not so well with short 5-10 word reviews like “this movie was fantastic”.
Nice work, and interesting finding.
Yes, train on more diverse data or data more appropriate for the way the model is intended to be used.
How about in each channel I put different embedding?
embedding1=random embedding (channel1)
embedding2=word2vec embedding (channel2)
does this seem right Idea or not?
Try it. Results matter more than opinions.
Hi Jason,
Thanks for your this beautiful work. I want to ask you if we are able to implement Multichannel CNN comprises two CNN channels: word embedding and POS embedding channel. if yes how we can do that.
Thank you for your time
Yes, have a separate input model for each data source.
In this tutorial, if we want to implement this CNN with two inputs, first one word embedding and second, POS embedding channel. How we can implement that?
Define the two embeddings and connect them to the CNN layers, then merge the output of those layers. All with the functional API.
The above example will provide a starting point you can adapt.
Hi Jason,
Thanks for your this beautiful work. I want to ask you if we are able to use the output of the Multichannel CNN for apply LDA?
I have not tried.
Hi Jason,
Thanks for sharing this work. I was following your work to build a text classifier and noticed that you are using maxpooling of size 2. However, I believe that the original paper uses maxpooling over time (implemented as GlobalMaxPooling1D in Keras). Is there a particular reason for that?
Thanks.
Thanks.
Nice. No reason. Perhaps try other pooling methods and compare results?
Hi Jason,
I don’t understand why you added this layer “dense1 = Dense(10, activation=’relu’)(merged)”. I can’t seem to find it in the original paper architecture.
Can you please explain?
This is just a layer to interpret the merged input. You can experiment with and without it.
Thanks for the quick reply! Is that the place in the architecture where the Kim (2014) and Zhang & Wallace (2015) place a drop-out and a l2 regularization?
Could you sketch how to write that out in keras?
Sorry, I don’t have the capacity to customize the tutorial code for you.
If you are new to Keras, you can get started here:
https://machinelearningmastery.com/start-here/#deeplearning
I don’t recall off the cuff, sorry.
You can change the model anyway you wish.
How can we apply k fold cross validation to this multi-channel CNN ? I need help for that.
Here is an example of using cross-validation for a CNN model:
https://machinelearningmastery.com/how-to-develop-a-cnn-from-scratch-for-fashion-mnist-clothing-classification/
Hi Jason. Thank you for your helpful tutorial. I just wonder that: Can the model you used for classification be used for a regression task with a small change at the last dense layer: activation = linear instead of sigmoid? So for any classification model, we only need to make a small modification on the last layer to use for regression task? Is it that simple? Thanks in advance!
You’re welcome.
Yes. Change the activation function in the output layer, the loss function and the metrics.
Hi Jason
I am working on 1.6 million data from kaggle for sentiment analysis.
I kept only two fields 1: Sentiment 2: Text
Now i want to use ANN to train my model.
Regarding this i have few question.
1: How to decide how many input should be there in input layer and hidden layers.
classifier.add(Dense(units=1 , kernel_initializer=’uniform’, activation=’relu’))
classifier.add(Dense(units=1 , kernel_initializer=’uniform’ , activation=’relu’))
classifier.add(Dense(units=1 , kernel_initializer=’uniform’ , activation=’sigmoid’))
I have one Input layer, one hidden layer and one o/p layer. Since i have only two fields one is dependent and one is independent so i have gave in units as 1 in input and hidden layer.
I tried to know the shape of this, when i checked shape of my X_train it came as 100.
Now what i kept in input is correct or do i need to give shape value in input filed.
Please help
Perhaps test different numbers of inputs and discover what works best for your dataset.
Hi Jason,
While executing the code, I am getting this error: Attribute Error: ‘str’ object has no attribute ‘decode’. How to address this.
Sorry to hear that you’re having trouble, these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thanks for the article. I tried to improve it by using 1 input and 1 embedding layer – which reduced number of parameters:
Total params: 5,144,937
So – after training for 12 epochs with batch=6 I got same results:
Epoch 12/12
300/300 – 7s – loss: 8.2556e-06 – accuracy: 1.0000
Test Accuracy: 87.500000
As I understand – Embedding layer is not trainable, so I don’t need 3 of them?
Nice work!
UPD: I’ve got 90% in one run (other runs 84~88%)
Epoch 15/15
300/300 – 7s – loss: 2.6125e-05 – accuracy: 1.0000
Test Accuracy: 90.499997
Great work!
Thanks for the great breakdown. If you wanted to modify this to feed in different texts per trainX, so say you had trainX, trainY and trainZ instead. what should you do in terms of modifying the above? does it need the same tokenizer I imagine?? thanks Toby
I think you’re referring to a multi-output model, if so you can adapt the model to have multiple outputs directly.
This tutorial will help to get you started:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Thanks for responding, I still have one output I’m trying to predict (ie a classification example). I basically I’m trying to see if changes in my text from one document to the next can help predict my target variable. So I wanted to feed in both documents. I adapted the code above to feed in a different tokenizer, length of words, vocab to its own respective embedding matrix.
My problem is similar to the Quora duplicate questions a little but just wanted to feed a concatenated CNN instead of an LSTM to start with. So far the validation accuracy seems OK but will test against the test set soon.
Does this seem OK? Is this technical called a multi-channel CNN if you are feeding in two different documents?
thanks!
Hard for me to tell sorry.
Perhaps try it and compare results to other methods.
Hey, Jason Brownlee
Greetings
First of all, thank you very much for your wondaful article and indeed your articles are helping me more than my supervisor. Whenever, I face the problem, first, I search your article related to that problem.
I have one question related to this post, can you please explain the cost associated to this architecture, I am trying similar idea but I have concern about the time it takes. Is it feasible for a problem that needs a quick reactive action?
Depends on how quick you want, but neural networks are not fast by its nature. It has much more parameters than other machine learning models.
Got your point. Thank you very much. Stay Blessed.
Hello, Jason Brownlee
Since a multi-channel convolutional neural network for text classification involves using multiple versions of the standard model with different sized kernels. As it is using multiple versions of standard CNN so here can we keep different number of filters along with different embedding dimensions in each channel ? For example, I want to keep 128 filters with kernel size 6 and embedding dimension 64 in channel one. Similarly I am having 64 filters with kernel size set to be 4 and embedding dimension 32 and I am doing the same for the third channel as well (I mean having different filters number, kernel size and embedding dimension). I have only one input for all three channels. Here I want that every channel convolve on the same input differently and try to find the pattern differently.
Can you please shed light on this architecture ?
Thank You
I don’t think sequential model allows you to do this but you can construct one using functional API in Keras
Thank you so much for your quick response
Yes, I am also talking about the same idea that has been discussed in this article using functional API in Keras. Since you have used same number of filters and same embedding dimension in each channel. So I want to explore this idea further by using different number of filters along with different kernel sizes as well as different embedding dimensions in each channel.
One thing more that I am using same input for all the three channels and all the strings in my dataset have the fixed length that I am passing as input.
So what will be the suitable name for this architecture? Multichannel or Mult layers ?
Your response will be highly appreciated.
If you have three channels, definitely multichannel. But it can also be multilayer at the same time.
Thank you for being so cooperative
You’re welcomed.