How to Develop a Convolutional Neural Network From Scratch for MNIST Handwritten Digit Classification.
The MNIST handwritten digit classification problem is a standard dataset used in computer vision and deep learning.
Although the dataset is effectively solved, it can be used as the basis for learning and practicing how to develop, evaluate, and use convolutional deep learning neural networks for image classification from scratch. This includes how to develop a robust test harness for estimating the performance of the model, how to explore improvements to the model, and how to save the model and later load it to make predictions on new data.
In this tutorial, you will discover how to develop a convolutional neural network for handwritten digit classification from scratch.
After completing this tutorial, you will know:
How to develop a test harness to develop a robust evaluation of a model and establish a baseline of performance for a classification task.
How to explore extensions to a baseline model to improve learning and model capacity.
How to develop a finalized model, evaluate the performance of the final model, and use it to make predictions on new images.
Kick-start your project with my new book Deep Learning for Computer Vision, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Dec/2019: Updated examples for TensorFlow 2.0 and Keras 2.3.
Updated Jan/2020: Fixed a bug where models were defined outside the cross-validation loop.
Updated Nov/2021: Updated to use Tensorflow 2.6
How to Develop a Convolutional Neural Network From Scratch for MNIST Handwritten Digit Classification Photo by Richard Allaway, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
MNIST Handwritten Digit Classification Dataset
Model Evaluation Methodology
How to Develop a Baseline Model
How to Develop an Improved Model
How to Finalize the Model and Make Predictions
Want Results with Deep Learning for Computer Vision?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Development Environment
This tutorial assumes that you are using standalone Keras running on top of TensorFlow with Python 3. If you need help setting up your development environment see this tutorial:
The MNIST dataset is an acronym that stands for the Modified National Institute of Standards and Technology dataset.
It is a dataset of 60,000 small square 28×28 pixel grayscale images of handwritten single digits between 0 and 9.
The task is to classify a given image of a handwritten digit into one of 10 classes representing integer values from 0 to 9, inclusively.
It is a widely used and deeply understood dataset and, for the most part, is “solved.” Top-performing models are deep learning convolutional neural networks that achieve a classification accuracy of above 99%, with an error rate between 0.4 %and 0.2% on the hold out test dataset.
The example below loads the MNIST dataset using the Keras API and creates a plot of the first nine images in the training dataset.
Running the example loads the MNIST train and test dataset and prints their shape.
We can see that there are 60,000 examples in the training dataset and 10,000 in the test dataset and that images are indeed square with 28×28 pixels.
1
2
Train: X=(60000, 28, 28), y=(60000,)
Test: X=(10000, 28, 28), y=(10000,)
A plot of the first nine images in the dataset is also created showing the natural handwritten nature of the images to be classified.
Plot of a Subset of Images From the MNIST Dataset
Model Evaluation Methodology
Although the MNIST dataset is effectively solved, it can be a useful starting point for developing and practicing a methodology for solving image classification tasks using convolutional neural networks.
Instead of reviewing the literature on well-performing models on the dataset, we can develop a new model from scratch.
The dataset already has a well-defined train and test dataset that we can use.
In order to estimate the performance of a model for a given training run, we can further split the training set into a train and validation dataset. Performance on the train and validation dataset over each run can then be plotted to provide learning curves and insight into how well a model is learning the problem.
The Keras API supports this by specifying the “validation_data” argument to the model.fit() function when training the model, that will, in turn, return an object that describes model performance for the chosen loss and metrics on each training epoch.
1
2
# record model performance on a validation dataset during training
In order to estimate the performance of a model on the problem in general, we can use k-fold cross-validation, perhaps five-fold cross-validation. This will give some account of the models variance with both respect to differences in the training and test datasets, and in terms of the stochastic nature of the learning algorithm. The performance of a model can be taken as the mean performance across k-folds, given the standard deviation, that could be used to estimate a confidence interval if desired.
We can use the KFold class from the scikit-learn API to implement the k-fold cross-validation evaluation of a given neural network model. There are many ways to achieve this, although we can choose a flexible approach where the KFold class is only used to specify the row indexes used for each spit.
1
2
3
4
5
6
7
8
# example of k-fold cv for a neural net
data=...
# prepare cross validation
kfold=KFold(5,shuffle=True,random_state=1)
# enumerate splits
fortrain_ix,test_ix inkfold.split(data):
model=...
...
We will hold back the actual test dataset and use it as an evaluation of our final model.
How to Develop a Baseline Model
The first step is to develop a baseline model.
This is critical as it both involves developing the infrastructure for the test harness so that any model we design can be evaluated on the dataset, and it establishes a baseline in model performance on the problem, by which all improvements can be compared.
The design of the test harness is modular, and we can develop a separate function for each piece. This allows a given aspect of the test harness to be modified or inter-changed, if we desire, separately from the rest.
We can develop this test harness with five key elements. They are the loading of the dataset, the preparation of the dataset, the definition of the model, the evaluation of the model, and the presentation of results.
Load Dataset
We know some things about the dataset.
For example, we know that the images are all pre-aligned (e.g. each image only contains a hand-drawn digit), that the images all have the same square size of 28×28 pixels, and that the images are grayscale.
Therefore, we can load the images and reshape the data arrays to have a single color channel.
1
2
3
4
5
# load dataset
(trainX,trainY),(testX,testY)=mnist.load_data()
# reshape dataset to have a single channel
trainX=trainX.reshape((trainX.shape[0],28,28,1))
testX=testX.reshape((testX.shape[0],28,28,1))
We also know that there are 10 classes and that classes are represented as unique integers.
We can, therefore, use a one hot encoding for the class element of each sample, transforming the integer into a 10 element binary vector with a 1 for the index of the class value, and 0 values for all other classes. We can achieve this with the to_categorical() utility function.
1
2
3
# one hot encode target values
trainY=to_categorical(trainY)
testY=to_categorical(testY)
The load_dataset() function implements these behaviors and can be used to load the dataset.
1
2
3
4
5
6
7
8
9
10
11
# load train and test dataset
def load_dataset():
# load dataset
(trainX,trainY),(testX,testY)=mnist.load_data()
# reshape dataset to have a single channel
trainX=trainX.reshape((trainX.shape[0],28,28,1))
testX=testX.reshape((testX.shape[0],28,28,1))
# one hot encode target values
trainY=to_categorical(trainY)
testY=to_categorical(testY)
returntrainX,trainY,testX,testY
Prepare Pixel Data
We know that the pixel values for each image in the dataset are unsigned integers in the range between black and white, or 0 and 255.
We do not know the best way to scale the pixel values for modeling, but we know that some scaling will be required.
A good starting point is to normalize the pixel values of grayscale images, e.g. rescale them to the range [0,1]. This involves first converting the data type from unsigned integers to floats, then dividing the pixel values by the maximum value.
1
2
3
4
5
6
# convert from integers to floats
train_norm=train.astype('float32')
test_norm=test.astype('float32')
# normalize to range 0-1
train_norm=train_norm/255.0
test_norm=test_norm/255.0
The prep_pixels() function below implements these behaviors and is provided with the pixel values for both the train and test datasets that will need to be scaled.
1
2
3
4
5
6
7
8
9
10
# scale pixels
def prep_pixels(train,test):
# convert from integers to floats
train_norm=train.astype('float32')
test_norm=test.astype('float32')
# normalize to range 0-1
train_norm=train_norm/255.0
test_norm=test_norm/255.0
# return normalized images
returntrain_norm,test_norm
This function must be called to prepare the pixel values prior to any modeling.
Define Model
Next, we need to define a baseline convolutional neural network model for the problem.
The model has two main aspects: the feature extraction front end comprised of convolutional and pooling layers, and the classifier backend that will make a prediction.
For the convolutional front-end, we can start with a single convolutional layer with a small filter size (3,3) and a modest number of filters (32) followed by a max pooling layer. The filter maps can then be flattened to provide features to the classifier.
Given that the problem is a multi-class classification task, we know that we will require an output layer with 10 nodes in order to predict the probability distribution of an image belonging to each of the 10 classes. This will also require the use of a softmax activation function. Between the feature extractor and the output layer, we can add a dense layer to interpret the features, in this case with 100 nodes.
All layers will use the ReLU activation function and the He weight initialization scheme, both best practices.
We will use a conservative configuration for the stochastic gradient descent optimizer with a learning rate of 0.01 and a momentum of 0.9. The categorical cross-entropy loss function will be optimized, suitable for multi-class classification, and we will monitor the classification accuracy metric, which is appropriate given we have the same number of examples in each of the 10 classes.
The define_model() function below will define and return this model.
After the model is defined, we need to evaluate it.
The model will be evaluated using five-fold cross-validation. The value of k=5 was chosen to provide a baseline for both repeated evaluation and to not be so large as to require a long running time. Each test set will be 20% of the training dataset, or about 12,000 examples, close to the size of the actual test set for this problem.
The training dataset is shuffled prior to being split, and the sample shuffling is performed each time, so that any model we evaluate will have the same train and test datasets in each fold, providing an apples-to-apples comparison between models.
We will train the baseline model for a modest 10 training epochs with a default batch size of 32 examples. The test set for each fold will be used to evaluate the model both during each epoch of the training run, so that we can later create learning curves, and at the end of the run, so that we can estimate the performance of the model. As such, we will keep track of the resulting history from each run, as well as the classification accuracy of the fold.
The evaluate_model() function below implements these behaviors, taking the training dataset as arguments and returning a list of accuracy scores and training histories that can be later summarized.
Once the model has been evaluated, we can present the results.
There are two key aspects to present: the diagnostics of the learning behavior of the model during training and the estimation of the model performance. These can be implemented using separate functions.
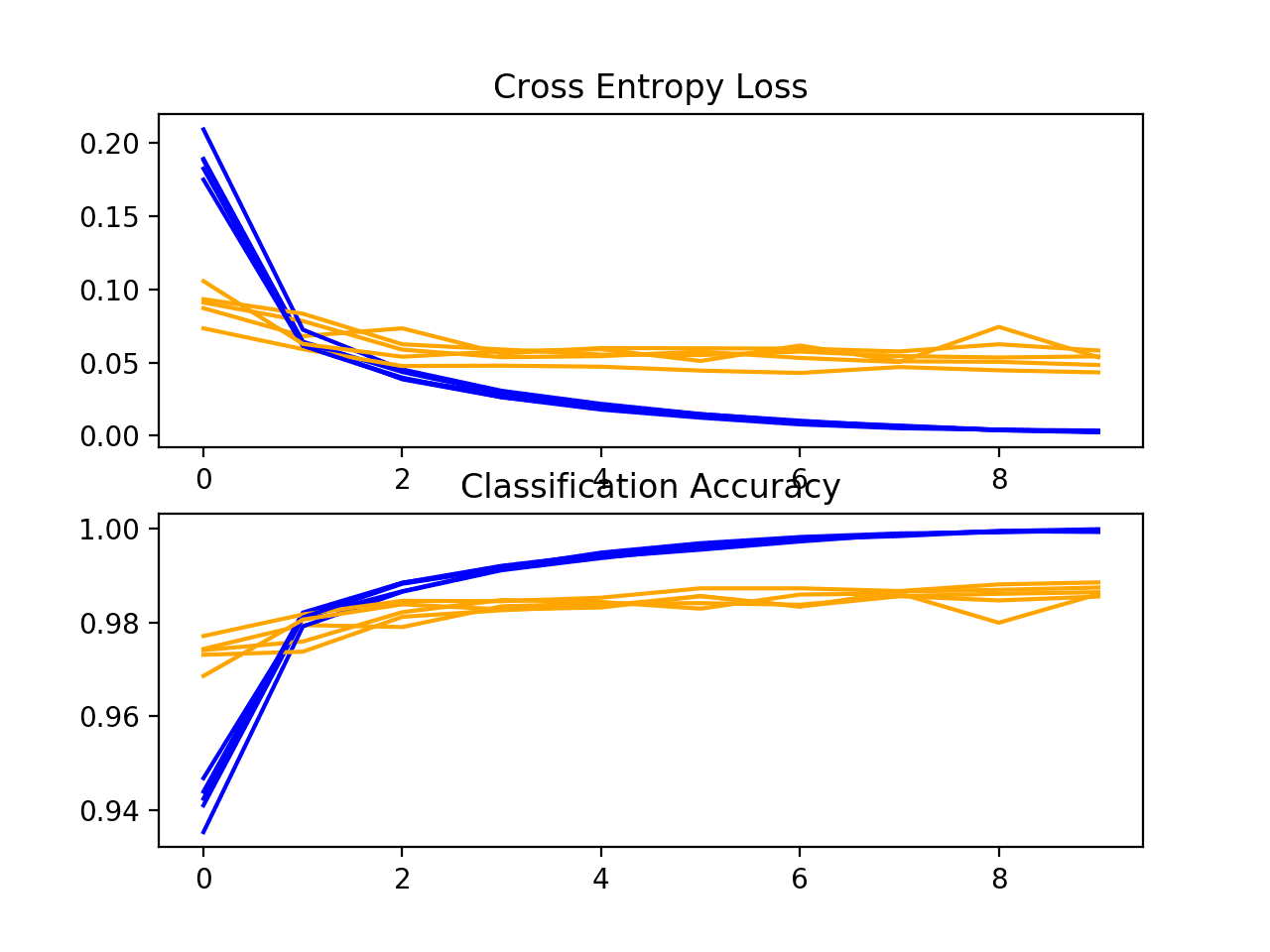
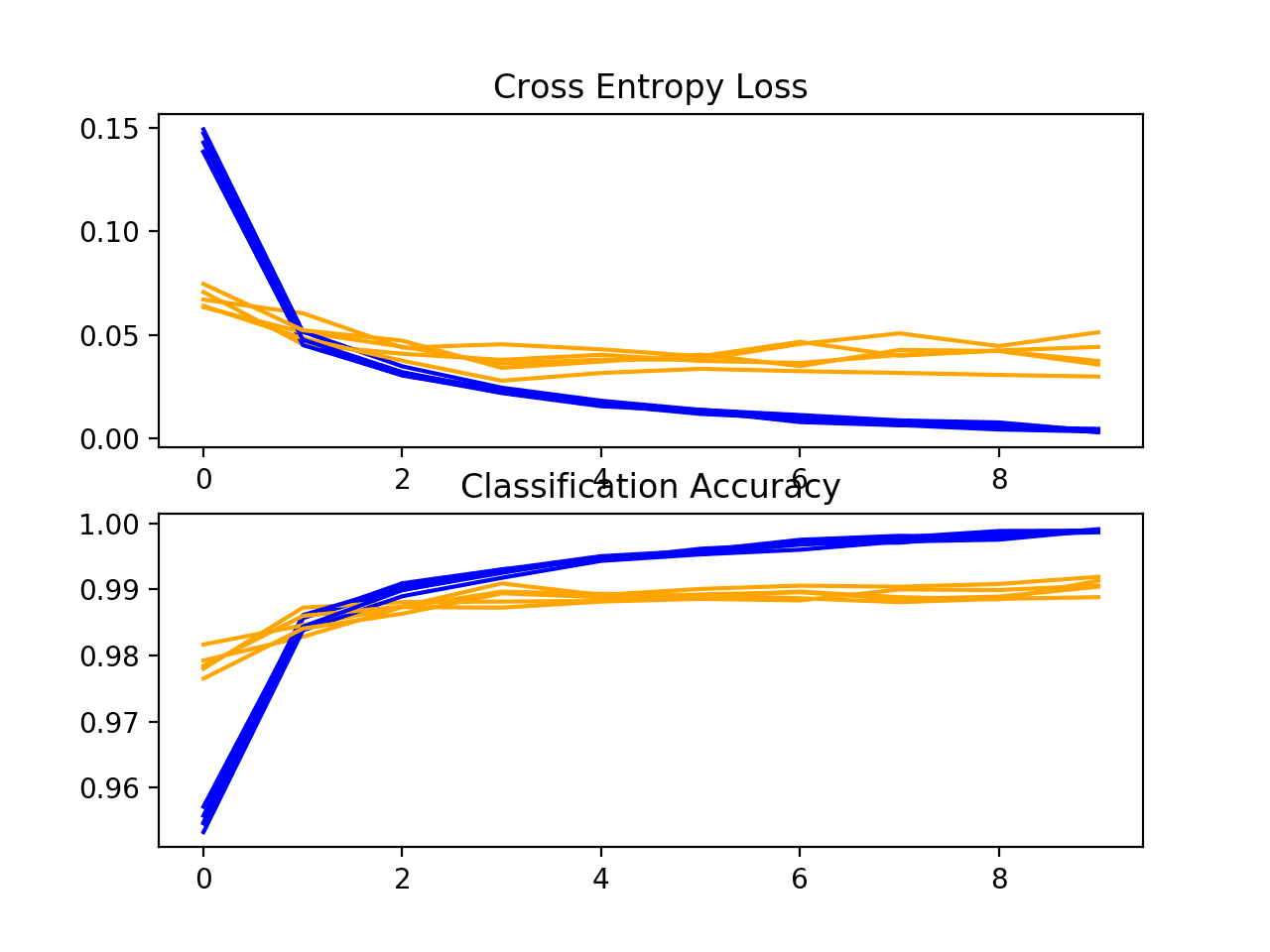
First, the diagnostics involve creating a line plot showing model performance on the train and test set during each fold of the k-fold cross-validation. These plots are valuable for getting an idea of whether a model is overfitting, underfitting, or has a good fit for the dataset.
We will create a single figure with two subplots, one for loss and one for accuracy. Blue lines will indicate model performance on the training dataset and orange lines will indicate performance on the hold out test dataset. The summarize_diagnostics() function below creates and shows this plot given the collected training histories.
Next, the classification accuracy scores collected during each fold can be summarized by calculating the mean and standard deviation. This provides an estimate of the average expected performance of the model trained on this dataset, with an estimate of the average variance in the mean. We will also summarize the distribution of scores by creating and showing a box and whisker plot.
The summarize_performance() function below implements this for a given list of scores collected during model evaluation.
Running the example prints the classification accuracy for each fold of the cross-validation process. This is helpful to get an idea that the model evaluation is progressing.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see two cases where the model achieves perfect skill and one case where it achieved lower than 98% accuracy. These are good results.
1
2
3
4
5
> 98.550
> 98.600
> 98.642
> 98.850
> 98.742
Next, a diagnostic plot is shown, giving insight into the learning behavior of the model across each fold.
In this case, we can see that the model generally achieves a good fit, with train and test learning curves converging. There is no obvious sign of over- or underfitting.
Loss and Accuracy Learning Curves for the Baseline Model During k-Fold Cross-Validation
Next, a summary of the model performance is calculated.
We can see in this case, the model has an estimated skill of about 98.6%, which is reasonable.
1
Accuracy: mean=98.677 std=0.107, n=5
Finally, a box and whisker plot is created to summarize the distribution of accuracy scores.
Box and Whisker Plot of Accuracy Scores for the Baseline Model Evaluated Using k-Fold Cross-Validation
We now have a robust test harness and a well-performing baseline model.
How to Develop an Improved Model
There are many ways that we might explore improvements to the baseline model.
We will look at areas of model configuration that often result in an improvement, so-called low-hanging fruit. The first is a change to the learning algorithm, and the second is an increase in the depth of the model.
Improvement to Learning
There are many aspects of the learning algorithm that can be explored for improvement.
Perhaps the point of biggest leverage is the learning rate, such as evaluating the impact that smaller or larger values of the learning rate may have, as well as schedules that change the learning rate during training.
Another approach that can rapidly accelerate the learning of a model and can result in large performance improvements is batch normalization. We will evaluate the effect that batch normalization has on our baseline model.
Batch normalization can be used after convolutional and fully connected layers. It has the effect of changing the distribution of the output of the layer, specifically by standardizing the outputs. This has the effect of stabilizing and accelerating the learning process.
We can update the model definition to use batch normalization after the activation function for the convolutional and dense layers of our baseline model. The updated version of define_model() function with batch normalization is listed below.
Running the example again reports model performance for each fold of the cross-validation process.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see perhaps a small drop in model performance as compared to the baseline across the cross-validation folds.
1
2
3
4
5
> 98.475
> 98.608
> 98.683
> 98.783
> 98.667
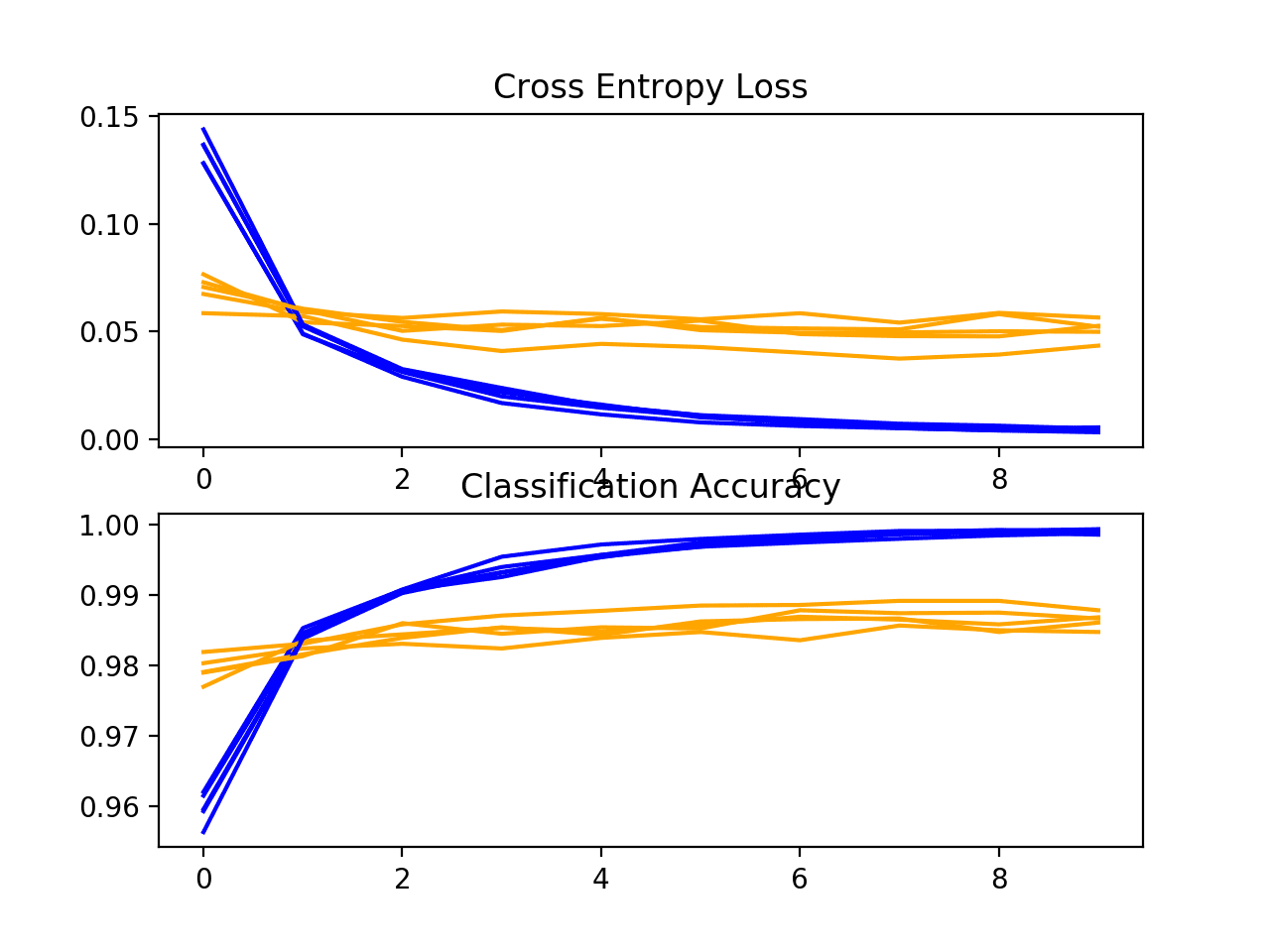
A plot of the learning curves is created, in this case showing that the speed of learning (improvement over epochs) does not appear to be different from the baseline model.
The plots suggest that batch normalization, at least as implemented in this case, does not offer any benefit.
Loss and Accuracy Learning Curves for the BatchNormalization Model During k-Fold Cross-Validation
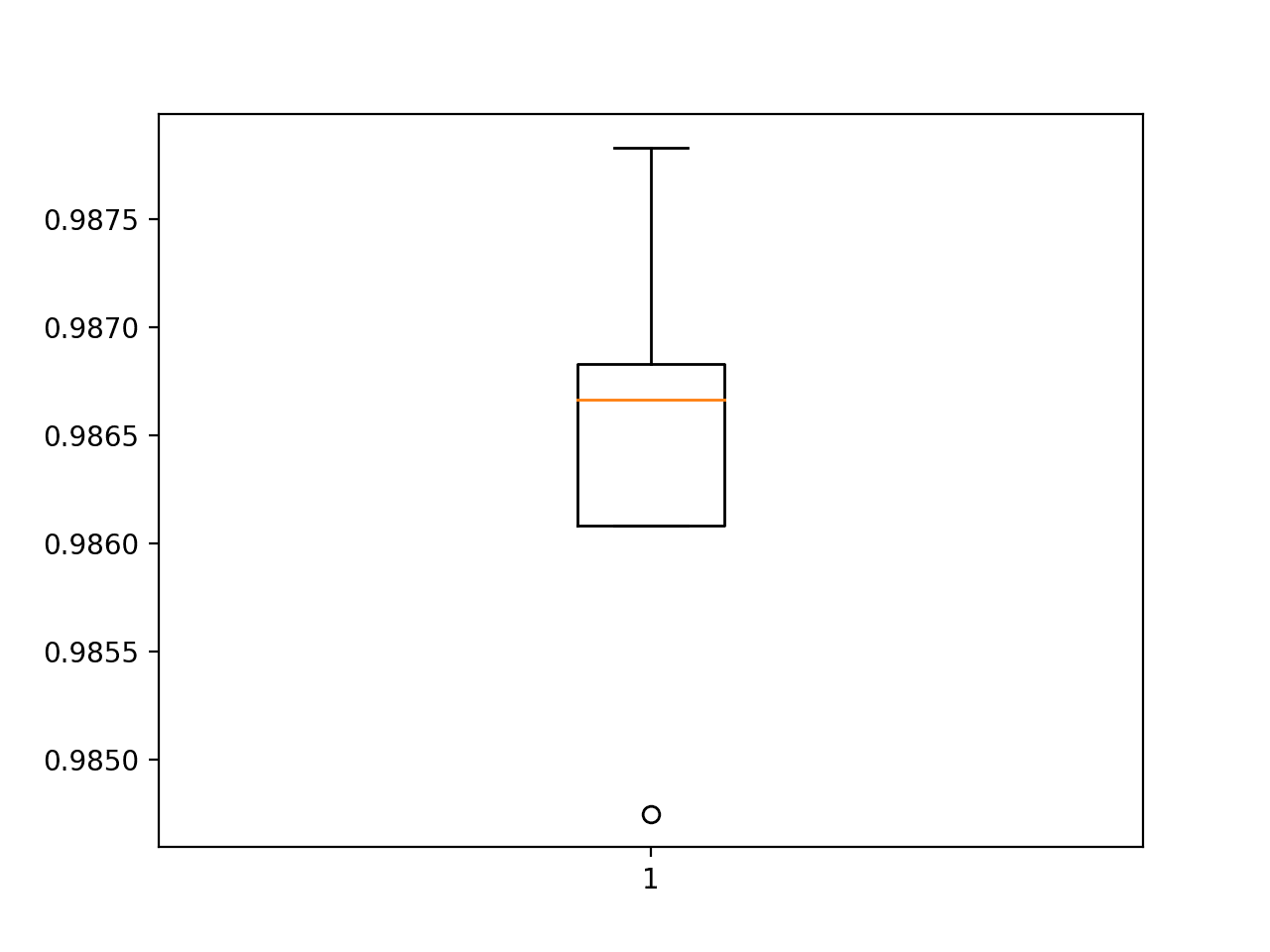
Next, the estimated performance of the model is presented, showing performance with a slight decrease in the mean accuracy of the model: 98.643 as compared to 98.677 with the baseline model.
1
Accuracy: mean=98.643 std=0.101, n=5
Box and Whisker Plot of Accuracy Scores for the BatchNormalization Model Evaluated Using k-Fold Cross-Validation
Increase in Model Depth
There are many ways to change the model configuration in order to explore improvements over the baseline model.
Two common approaches involve changing the capacity of the feature extraction part of the model or changing the capacity or function of the classifier part of the model. Perhaps the point of biggest influence is a change to the feature extractor.
We can increase the depth of the feature extractor part of the model, following a VGG-like pattern of adding more convolutional and pooling layers with the same sized filter, while increasing the number of filters. In this case, we will add a double convolutional layer with 64 filters each, followed by another max pooling layer.
The updated version of the define_model() function with this change is listed below.
Running the example reports model performance for each fold of the cross-validation process.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The per-fold scores may suggest some improvement over the baseline.
1
2
3
4
5
> 99.058
> 99.042
> 98.883
> 99.192
> 99.133
A plot of the learning curves is created, in this case showing that the models still have a good fit on the problem, with no clear signs of overfitting. The plots may even suggest that further training epochs could be helpful.
Loss and Accuracy Learning Curves for the Deeper Model During k-Fold Cross-Validation
Next, the estimated performance of the model is presented, showing a small improvement in performance as compared to the baseline from 98.677 to 99.062, with a small drop in the standard deviation as well.
1
Accuracy: mean=99.062 std=0.104, n=5
Box and Whisker Plot of Accuracy Scores for the Deeper Model Evaluated Using k-Fold Cross-Validation
How to Finalize the Model and Make Predictions
The process of model improvement may continue for as long as we have ideas and the time and resources to test them out.
At some point, a final model configuration must be chosen and adopted. In this case, we will choose the deeper model as our final model.
First, we will finalize our model, but fitting a model on the entire training dataset and saving the model to file for later use. We will then load the model and evaluate its performance on the hold out test dataset to get an idea of how well the chosen model actually performs in practice. Finally, we will use the saved model to make a prediction on a single image.
Save Final Model
A final model is typically fit on all available data, such as the combination of all train and test dataset.
In this tutorial, we are intentionally holding back a test dataset so that we can estimate the performance of the final model, which can be a good idea in practice. As such, we will fit our model on the training dataset only.
After running this example, you will now have a 1.2-megabyte file with the name ‘final_model.h5‘ in your current working directory.
Evaluate Final Model
We can now load the final model and evaluate it on the hold out test dataset.
This is something we might do if we were interested in presenting the performance of the chosen model to project stakeholders.
The model can be loaded via the load_model() function.
The complete example of loading the saved model and evaluating it on the test dataset is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# evaluate the deep model on the test dataset
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import load_model
from tensorflow.keras.utils import to_categorical
# load train and test dataset
def load_dataset():
# load dataset
(trainX,trainY),(testX,testY)=mnist.load_data()
# reshape dataset to have a single channel
trainX=trainX.reshape((trainX.shape[0],28,28,1))
testX=testX.reshape((testX.shape[0],28,28,1))
# one hot encode target values
trainY=to_categorical(trainY)
testY=to_categorical(testY)
returntrainX,trainY,testX,testY
# scale pixels
def prep_pixels(train,test):
# convert from integers to floats
train_norm=train.astype('float32')
test_norm=test.astype('float32')
# normalize to range 0-1
train_norm=train_norm/255.0
test_norm=test_norm/255.0
# return normalized images
returntrain_norm,test_norm
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX,trainY,testX,testY=load_dataset()
# prepare pixel data
trainX,testX=prep_pixels(trainX,testX)
# load model
model=load_model('final_model.h5')
# evaluate model on test dataset
_,acc=model.evaluate(testX,testY,verbose=0)
print('> %.3f'%(acc *100.0))
# entry point, run the test harness
run_test_harness()
Running the example loads the saved model and evaluates the model on the hold out test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The classification accuracy for the model on the test dataset is calculated and printed. In this case, we can see that the model achieved an accuracy of 99.090%, or just less than 1%, which is not bad at all and reasonably close to the estimated 99.753% with a standard deviation of about half a percent (e.g. 99% of scores).
1
> 99.090
Make Prediction
We can use our saved model to make a prediction on new images.
The model assumes that new images are grayscale, that they have been aligned so that one image contains one centered handwritten digit, and that the size of the image is square with the size 28×28 pixels.
Below is an image extracted from the MNIST test dataset. You can save it in your current working directory with the filename ‘sample_image.png‘.
We will pretend this is an entirely new and unseen image, prepared in the required way, and see how we might use our saved model to predict the integer that the image represents (e.g. we expect “7“).
First, we can load the image, force it to be in grayscale format, and force the size to be 28×28 pixels. The loaded image can then be resized to have a single channel and represent a single sample in a dataset. The load_image() function implements this and will return the loaded image ready for classification.
Importantly, the pixel values are prepared in the same way as the pixel values were prepared for the training dataset when fitting the final model, in this case, normalized.
Next, we can load the model as in the previous section and call the predict() function to get the predicted score, and then use argmax() to obtain the digit that the image represents.
1
2
3
# predict the class
predict_value=model.predict(img)
digit=argmax(predict_value)
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# make a prediction for a new image.
from numpy import argmax
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
Running the example first loads and prepares the image, loads the model, and then correctly predicts that the loaded image represents the digit ‘7‘.
1
7
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Tune Pixel Scaling. Explore how alternate pixel scaling methods impact model performance as compared to the baseline model, including centering and standardization.
Tune the Learning Rate. Explore how different learning rates impact the model performance as compared to the baseline model, such as 0.001 and 0.0001.
Tune Model Depth. Explore how adding more layers to the model impact the model performance as compared to the baseline model, such as another block of convolutional and pooling layers or another dense layer in the classifier part of the model.
If you explore any of these extensions, I’d love to know.
Post your findings in the comments below.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials on topics like: classification, object detection (yolo and rcnn), face recognition (vggface and facenet), data preparation and much more...
Finally Bring Deep Learning to your Vision Projects
Sorry dont worry, I somehow got to resolve it. I think I reinstalled stuff.
I have another problem though. How do I add data for learning if in case the data predicted the wrong valiue pelase. I think I need the advise for both how to add as well as how to add the data in the mnist data format. Thanks
Jason you know what, for “17” it returned “7”. Thats actually good, but if you could please tip me as to how can I turn this into “Awesome.” Can I divide the pixel data into 2 dividions based on whitespace or what would be the best way please to recognize “17”. Thanks
Jason,
Thanks much for this tutorial. I had a question on the structure of the CNN. In this (and other descriptions of this problem for the MNIST digit data set) a common structure seems to be that the number of CNN filters is 32. Where each filter is a 5×5 of stride 1. However (and I apologize if this is explained somewhere) I cannot seem to find why 32 filters are chosen. i.e. Why not 16 or 64 ( or 14 or 28). Is it possible to explain why this is so.
Jason,
Thank you for the detailed explanation of this. I wanted to run your code and follow along to see how it worked. When I tried to run the complete example for the baseline cnn model for mnist, I get the following error:
KeyError Traceback (most recent call last)
in
107
108 # entry point, run the test harness
–> 109 run_test_harness()
Hi Jason,
Thanks for the excellent tutorial! I have two questions about K-fold cross-validation. In your “gentle introduction” article you say that the model is discarded each time we switch the hold out set. So here are my questions
1) Here it looks like you don’t discard the model between iterations of the k-fold cross validation. Why?
2) The model’s accuracy gets better each time you do an iteration. Why is taking a simple average fair then? To take it to the extreme: What if you only trained on 1 epoch? Then you’d get 94% on your first fold, then 98.5% on your second fold. And so on, yielding a much poorer average and a huge standard deviation. On the back of this question, I’d also ask why the standard deviation is a fair representation of the model under these circumstances.
Thanks for picking up my previous question Jason. I have another. You say at some point that there are no clear signs of overfitting. But it looks like the orange lines for the validation accuracy are staying relatively low compared to the blue lines for the testing accuracy. Is this not an indicator of overfitting? Or am I misinterpreting the charts?
When I execute the final code I get following error: “AttributeError: module ‘tensorflow’ has no attribute ‘get_default_graph”. I have installed Tensorflow 2.0, will downgrading it to the previous version solve this problem?
I have Tensorflow 2.0 and Keras 2.2.4. I tried updating Keras to 2.3 but can not find the way on Windows 10. I tried also switching to Linux on VB but I have a hard time with permissions there. Do you have any advice for me, I would be really grateful?
Hi Jason,
Thanks for the article!!!
Do you have any plans to implement “Information bottleneck theory” i.e, finding mainly the mutual information among various layers in an architecture?
Does it seem simpler or a harder one for you??
What is the purpose of reshaping the data to a single color channel? Is it necessary for the 2D convolution step in the model definition? I ask because other digit classification examples I’ve looked at go straight to flattening the train/test data but those didn’t have a 2D convolution layer.
If one wanted to create a new MNIST how would they set the data up? In these examples we get to use curated datasets from a dispensary but that does not explain how to set up your data to run the model.
For example what if I wanted to create my own MNIST to determine if the picture is a poker card, how would I go about setting the pictures and telling the machine what that picture is?
Jason, Thank you so much for sharing your knowledge. I just started learning python, tensorflow and machine learning. I understood all the maths and processes but was having difficulty in coding. Your example worked first time. Brilliant.
Do you have a simpler example of CNN with just 4 hidden layers as follows:
1. Input layer of 784 nodes
2. First convolution later : 5x5x32
3. First max pooling layer
4. Second convolution layer 5x5x64
5. Second max pooling layer
6. Out put layer of 10 nodes
Hi Jason. Can I ask why did you reshape the data? The image from the MNIST are already grey scale which are 1 channel. I am not quite understand why you need to do this step. Also what does the trainx.shape[0]/testX.shape[0] do here?
# reshape dataset to have a single channel
trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))
testX = testX.reshape((testX.shape[0], 28, 28, 1))
Hi Jason! Thank you so much, this is a great tutorial!
Just one question, i’m somewhat confused.
Are training our model twice? Once with k-fold validation and then right before saving it, with model.fit?
====
model = define_model()
model.fit(trainX, trainY, epochs=10, batch_size=32, verbose=0)
model.save(‘final_model.h5’)
====
In the k fold cross validation a new model is defined for each k iteration. So does that mean a new model is trained each time? But then what is the use of training new models in each iteration?
By model config you mean an optimal define_model? And once an optimal model is fixed we train on the entire training set? I am not able to relate how will K iterations in the K-fold reflect our understanding of what model configuration is the best.
Yes, a new model is trained each iteration, evaluated, and discarded.
The purpose is to estimate the performance of the model configuration when making predictions on unseen data for your prediction problem.
Once we have this estimate, we can choose to use the configuration (compared to other configurations). A final model can be fit on all data and we can start making predictions for real on new data where we don’t know the label.
Thankyou very much. I had another question. I was trying to run the final model on the unseen test data. however for each run the results vary ofcourse. therefore i decided to run this over 10 runs and average the test results, something like monte carlo simulation. but again in that case where would model = define_model() be places? would that be placed inside the for loop for average or just be defined once before running these 10 iterations, considering this average results is on the test data. since in kfold you discard it.
Hi, i am trying to build a CNN fo the same problem. My output layer has 10 neurons. When i try to fit my model after One-Hot_encoding of y_train and y_test, i get an error that the labels and the logits don’t match. However, without the one-hot encoding the model fits perfectly. Can you please explain?
Hi Jason
Thanks for this amazing tutorial. It will definitely help a lot of budding researchers.
I have a question
Can you please help if instead of single character i have to work on complete self taken handwritten word image (20 different classes,total around 20000 images). How to do it?
Thanks, Jason Brownlee for this excellent tutorial. I am your huge fan and I regularly following your all machine learning and deep earning models.I got a lot of knowledge from this site but After completion of machine learning tutorials there always raise a question in my mind that how can we apply these models in Mobile APPs(Andriod, iOS, etc) so that we get more fun and knowledge by this models. Are you suggest to me any link to have such kind of projects such as weather prediction app . Thanks again.
Thanks for the tutorial Jason Brownlee.
Can I use same model but pass my own dataset (of humans) to it & use it for detecting fall or not fall by making small changes?
Thanks.
hey jason that was a very good tutorial, i did not understand how in the predict_classes we got 7? the model had a softmax activation function as the last layer which will be a probability distribution of 10 float numbers, what i can’t grasp is how did we get back 7?
Hey is this code not compatible for Tensorflow 2? I am getting the following error.
E tensorflow/stream_executor/cuda/cuda_driver.cc:314] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Hello!
Thanks for the wonderful article helped me a lot with my project!
I have a question though, I am trying to take an image from my phone and then use that image to predict the number but it doesn’t work with that. What should I do to that image?
I resized it to 28×28 using online tools and even tried the grayscale version of the image to predict.
Any suggestion or lead will be appreciated!
Thanks in advance!
You will have to prepare the image in an identical manner to the images in the training set. e.g. white foreground, black background, grayscale and same image size.
I load the images from digits dataset of sklearn library (it uses less images number only 1,797 and with much lower resolution 8 x 8 bits vs MNIST 70,000 and 28,28 pixels resolution. On the contrary it is much faster this dataset because it use less data features.
And also I apply for this multi-class problem other library classifier models from Sklearn such as SVC(), logisticRegression(), ExtraTreesClassifier(), XGBClassifier(), RandomForestClassifier(), etc.
My main results are:
– I got 98.4% accuracy and 1.1 of sigma for the simple CNN baseline model (not other deep layers, not other BatchNormalization()) and I got 98.8% from SVC…but only suing the 8×8 pixels resolution which is a great new!.
But when I reduce the final image to be predicted to 8 x 8 pixels, in order to apply my trained model, whereI got such a great score I poorly predict the 7 digit as 9 digit.
My guess is when I load_image of 7 and I clip it to such smaller size of 8×8 pixels, I lost important images features in the process of cutting back the image….where the the MNIST 28×28 pixels still retain key digit features of the image, what do you think?
You have always very interesting articles.
I was able to train a CNN based on the Char74K-dataset. I’m happy of that because the model-file is only 42MB and the time to predict a number is fast.
I did use a kNN-model before (on the same dataset) that had a file size of 680MB!
This is how k-fold cross-validation works, we have a new training set and fit a new model for each fold, then average the performance of all models to get an estimate of model performance when used on unseen data.
I have some experience in MLP but not with CNN. Is there a reason try to use CNN if each sample of my data have shape 16×1 (row) with values between 0,01 to 0,99 and the model shoud perform classification for 15 classes. If I reshape samples from 16×1 to 4×4 then which filter size and a modest number of filters shoud I use? Or better dont reshape and try model with Conv1D layers? Thanks.
Thank you very much for your amazing tutorial. I am running your code using pycharm and I have a GPU with the right CUDA but your code is only running on my CPU.
Thank you very much for this tutorial, helped a lot! I developed my own CNN, which seems to perform pretty well according to the mean accuracy. However, the cross-entropy loss of the validation set is below the loss of the training set. Is this a sign of underfitting? And if so, should I change the model if I would like to apply the model to unseen data?
Thank you very much for this tutorial, helped a lot! I developed my own CNN, which seems to perform pretty well according to the mean accuracy. However, the cross-entropy loss of the validation set is below the loss of the training set. Is this a sign of underfitting? And if so, should I change the model if I would like to apply the model to unseen data?
Previously I was grateful for the tutorial you provided, I learned a lot from here. What if I want to display the probability value of the prediction result? (for example 50.67% something like that)
I created an image with same characteristics as sample_image.png (1490×1480, black background, white foreground), opened it in Paint, typed a “6” (without the quotes, of course), increased the font size to 1000 (so it would occupy most of the canvas), then saved it. However, the code doesn’t seem to recognize it. It seems to think it’s a “1”, “8”, or other numbers.
Hi Jason – fantastic article!! Just wondering why you had to do evaluate to get the accuracy, while it is already being returned by the fit call? I just checked the histories and they have exactly the same stuff returned by the evaluate call. Was there any other reason for the evaluate call?
Thanks for the reply!! I was seeing the same data is passed (testX, testY) for both fit and evaluate calls for validation. As a result, the return object from fit call already has the data to be returned by the evaluate call. Am I making sense?
# fit model
history = model.fit(trainX, trainY, epochs=10, batch_size=32, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
I don’t get why we don’t use the models that we created during the k-fold. I was expecting something like we combine this k models results into one single model and save it. If we don’t do that how’s that useful?
Hello! Thank you Jason for this amazing resource. I am currently working on a rented computer from school – do you think I could do implement this code in CoLabs?
i am developing a model of handwritten character recognition but the accuracy is very low i think it is not only because i have a small datatset, there is something i am not understanding can u help me on the improvement
Could you provide a peer review for a manuscript that has been submitted to the Journal of High School Science (http://jhss.scholasticahq.com) ? The title of the manuscript is : Implementing a Quantum Convolutional Neural Network for Efficient Image Recognition. Abstract: Machine learning has many real-world applications ranging from modeling the universe to computational chemistry. As probability is the bedrock for machine learning, it is essential to optimize both hardware and software to obtain the best results. Classical computers are generally used for machine learning programs. However, learning from high-dimensional data often demands excessive compute time and power, and it may not achieve the highest accuracy. The Quantum Computing environment can be utilized to create a more accurate model than that created via classical computing. To test this quantum advantage, we implemented a Quantum Convolutional Neural Network (QCNN), which parallels the structure of the classical Convolution Neural Network (CNN) in the quantum domain. Due to the lack of quantum computers with many qubits, physicists, namely John Preskill, have introduced the Noisy Intermediate Scale Quantum (NISQ) concept, which constitutes a hybrid interface between classical and quantum computers. In the context of QCNN, the data processing and the cost function optimization would be performed on the classical computer, while the probabilities generated by the Variational Quantum Circuits (VQC) would be evaluated on the quantum computer. The QCNN consists of a classical-to-quantum data encoder, a cluster state quantum circuit to entangle qubit states, a series of Variational Quantum Circuits using Quantum Convolutional and Pooling Layers for efficient feature extraction, a quantum-to-classical data decoder, which would lead to the output. Both the CNN and the QCNN extract features from data like 2D images, and performances can be compared using metrics like accuracy and time.
When i implemented the code i got this error ” AttributeError: ‘Sequential’ object has no attribute ‘predict_classes’ ”
Any suggestions to rectify this error please?
I used this model as an example and when I fed it a handwritten number, it continuously gave wrong predictions. Can you please tell me what could possibly be the problem?
It reads accurately when I used printed numbers with black background.
I did however change the cnn model a little bit to make it Multiple Pooling model.
I can share the code as well, if you like.
Can’t tell because I didn’t see your handwriting. But this MNIST dataset is a 28×28 pixel grayscale with white on black. Try to mimick this set up and it should be much better. If your image is more complex (e.g., you scan it, then the background is not a single color, or the alphabet is more complicated with more strokes than digits) then you will need a larger network to recognize it.
You mention in other answers that the inputs have to be reshaped because the convolutional layers expect an input with a dimension for channels. Do you know if this is unique to keras?
I am trying to classify 56×56 grayscale images (0->255), and so far I have normalized them to [-1,1]. However, they are still 2D as a 56×56 matrix. I am using pytorch. Do you know if I would also need to reshape them to add the single channel?
If you see no difference for more layers, try to stay with the fewer layers one because it save time and memory.
Increasing epochs can help train better, but you may also run into overfitting. So you need to check with validation set to confirm about the “improvement”.
I tried up to 25 epochs and looked at the loss with verbose=1 in the model.fit call. The loss bottoms out at around 20 epochs and then bounces around after that.
Here’s one run from epoch 10 through 25. The model got 99.260% on the test set:
These guys: https://arxiv.org/pdf/2008.10400v2.pdf are getting 99.91% accuracy using a combination of fairly simple techniques: deeper model depth, increased convolution kernel size, data augmentation, batch normalization between all conv2D layers, disabling edge padding in the convolution output to reduce the map sizes between conv2D layers instead of max pooling (which I found quite elegant), and voting between multiple models. They do a good job of analyzing each technique and comparing the results to other common CNNs.
So during training, the model accuracy against the training data goes over 99.9%, but the final accuracy on the test data is 99.26%. Are these results close enough that I can assume the model isn’t over trained? What’s a reasonable difference when both values are over 99%?
Hi,
I don’t know if you will ever see it but if you reply I will thank you, I wanted to try by myself this code because I was hoping to learn more about neural networks.
Unfortunately, I gave Python a picture I made in paint (the computer application) this image was resized to 28*28 and the picture is seen, I checked it.
In the picture, I drew the number 2, and it said that it is four and I tried more unsuccessfully.
I’d like to know where is the problem.
Anyway if you can reply to me in E-mail I will thank you in order to check wether the problem is in the picture or the code.
Yes, the accuracy was 96 percent, this is the reason I find it awkward.
I am not sure whether the problem is in the picture but I’d like to know where is the problem.
Can I send you the picture that I used? maybe the problem is located there.
Anyway, thanks for the help.
James thanks a lot it finally worked, my picture was not good.
I drew the digits in black and the background was white, and this is not the way the computer was trained.
hello james,
Great tutorial. I’ getting “name ‘train’ is not defined” as error while converting from integers to floats. can you please help me with that? Thank you.
Hi Suhas…Yes, that approach is a reasonable one and it is great to know you were able to improve your model accuracy! Dropout is definitely beneficial to avoid overtraining.
Hello @James Carmichael, I wonder how the “to_categorical” works , I have seen documentation and it says if number of classes is not specified then this would be inferred as max(y) + 1 if y is a vector. So to my surprise ,I know that in the Mnist dataset the num classes is 10 but without specifiying this number as a parameter , the function returns a vector of shape (60 000,10) but how ? I would really like to know how this max(y)+1 would work on images and give the right num_classes that is 10.
Thanks in advance for your answer.
Sorry I figured it out, As “y” is a vector of labels from 0 to 9 so max(y)+1 would return 10 (num_classses), which is obvious actually. I was Confused because I had an issue while printing “y” it didn’t show the expected values.
Thanks!
Outdated tutorial. Would not recommend to beginners who are starting out. Over complicating things in modern age. Maybe at the time (5yrs ago!!!) this was fine but things can be done way more simpler and cleaner.
For a paper that I am writing I have been asked to include an (approximate) number of operations for EMNIST Digit classification based on a CNN implementation (any reasonable architecture is ok). I am considering referring to your MNIST networks as I assume they would work fairly well also with EMNIST data.
Do you possibly have an estimate of the number of operations required for any of your networks?
Also, did you actually try using the EMNIST Digit dataset?
its a long time that you posted the tutorial. But i have a problem. No matter which image i use, the output is “1” and i don’t know why. Can you help me?
Hi Karim…It sounds like your model might be overfitting to a particular class or failing to learn properly. Here are a few areas to check:
1. **Data Preprocessing**: Ensure that your images are correctly preprocessed. For MNIST, images should be grayscale (1 channel) and sized at 28×28 pixels, with pixel values normalized (often between 0 and 1 or standardized).
2. **Model Architecture**: If your model architecture is too simple, it might not be able to generalize well. Ensure you have enough layers (e.g., convolutional and dense layers) and units to capture the complexity of digit classification. Overly deep networks without regularization, however, might cause issues too.
3. **Loss Function and Activation**: Verify that you’re using the softmax activation in the final layer with categorical cross-entropy loss for multi-class classification.
4. **Model Training**: If your model is trained with too few epochs or without proper shuffling of the training data, it may not learn effectively. Conversely, overtraining on a limited subset could also make it biased towards a specific output.
5. **Evaluation**: If you’re printing predictions before model convergence or testing, the model could still be outputting random or biased results. Ensure you save and load a trained version of your model when making predictions.
Checking these should help you narrow down the issue. If the problem persists, feel free to share more details about the model structure and training loop for more specific guidance!


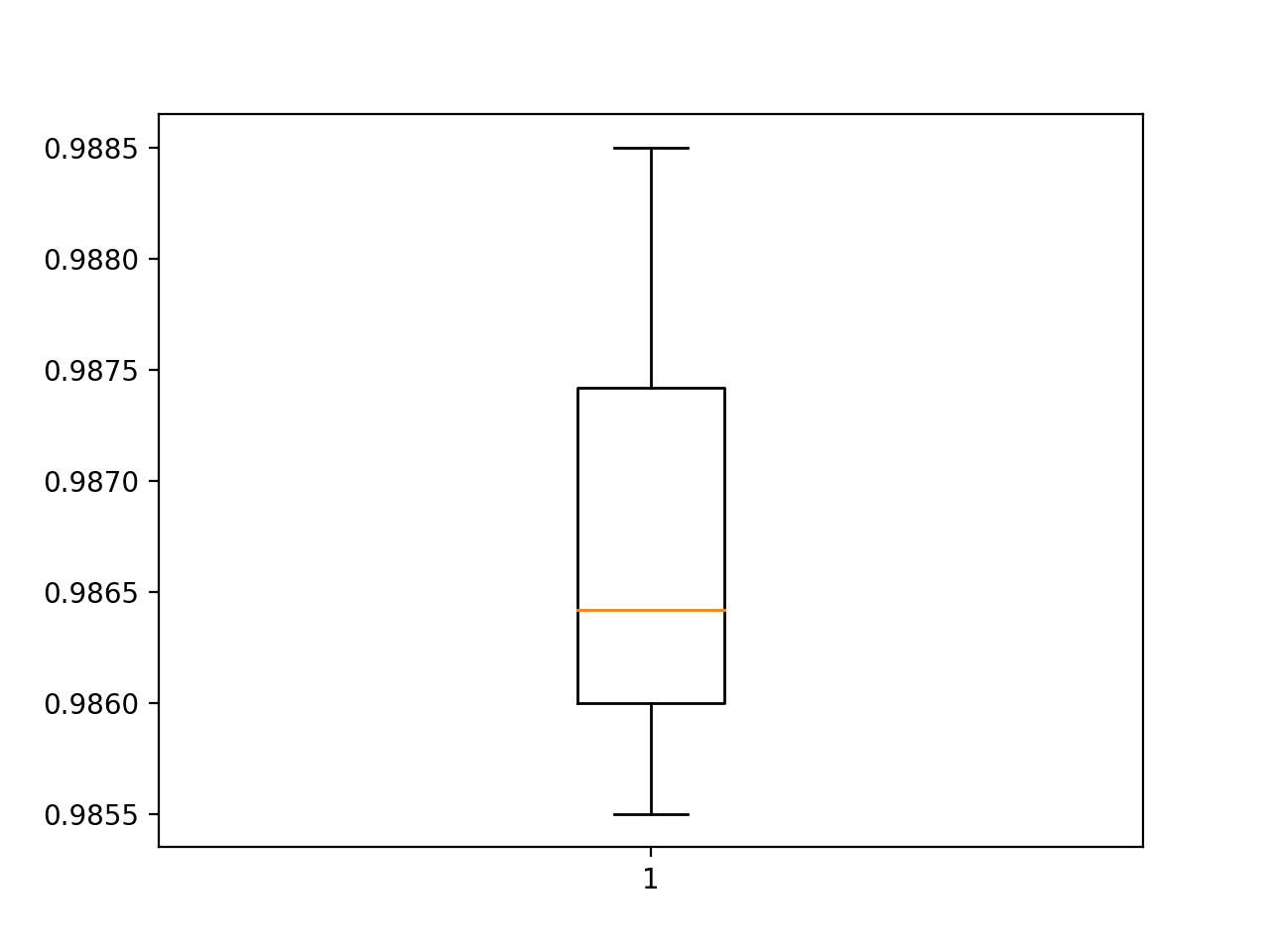
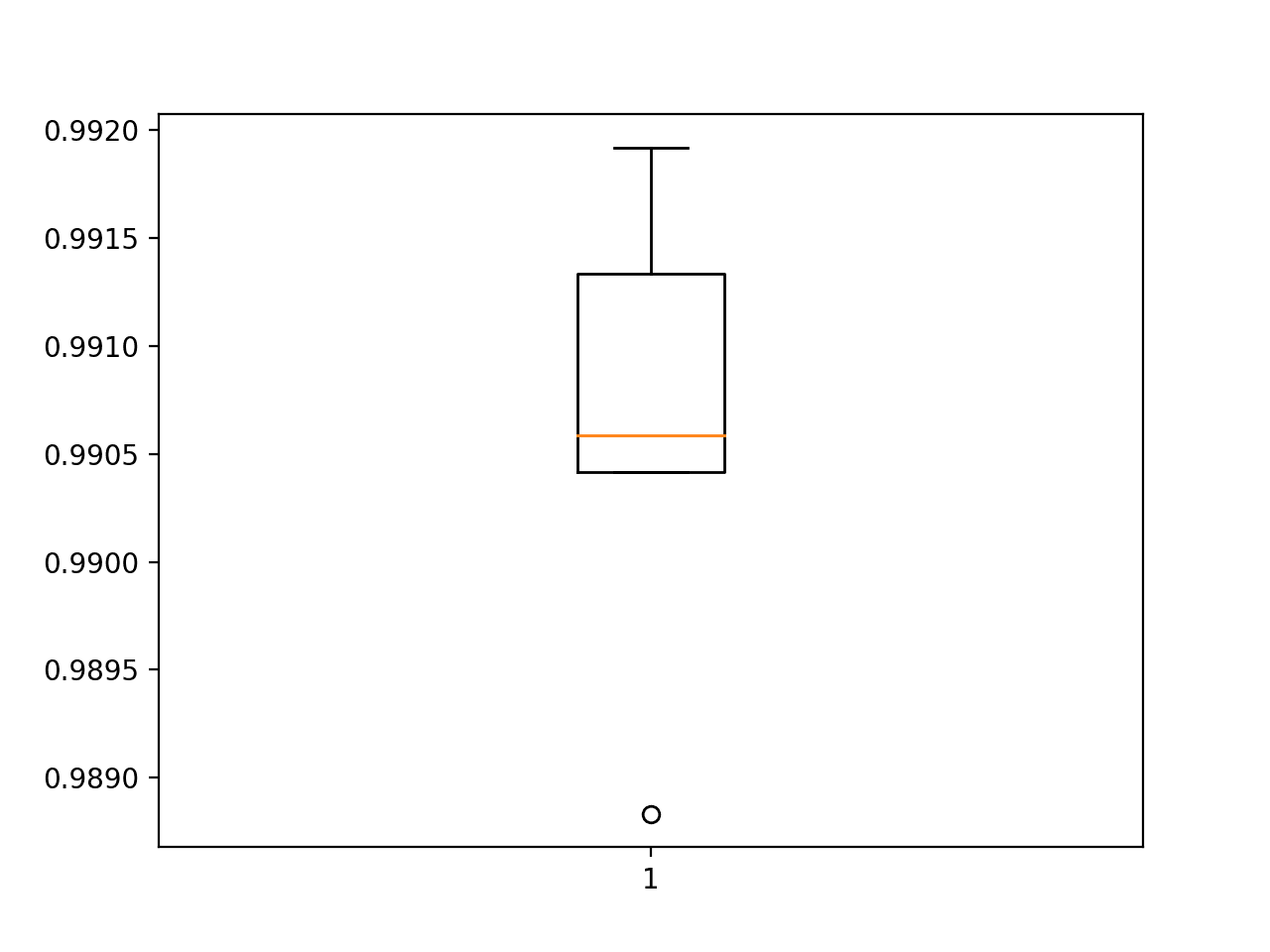

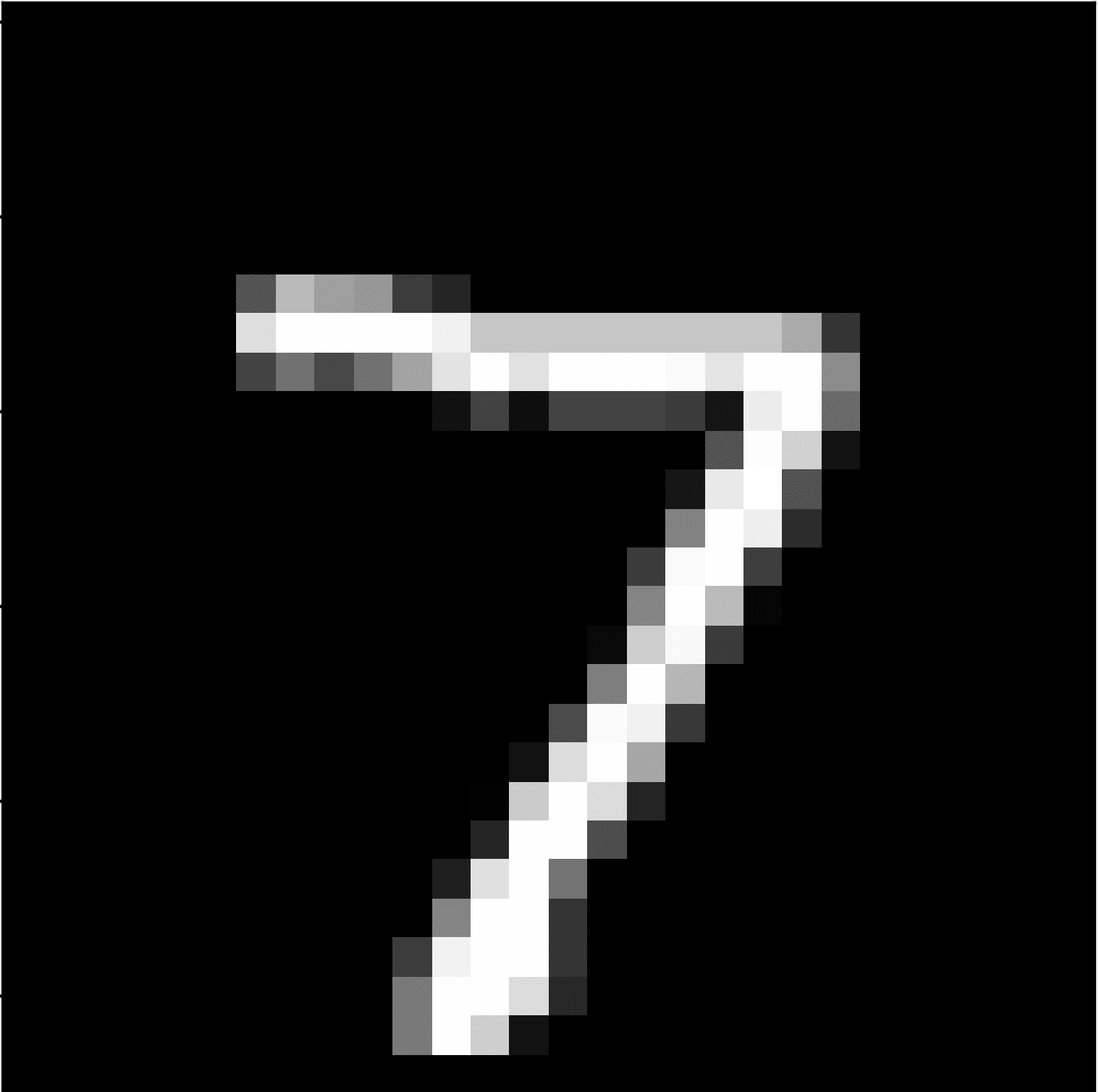{kind=link}







Dear Jason Thank You Very Much For your wonderful Tutorial Please can you build for us A model for Edge detection from scratch using real images.
Great suggestion, thanks.
I have two questions :
first suppose I have images sizes equal to 7611 x 7811 how to deal with this big size images in CNN models.
second question about if our images different sizes not same size.
I recommend reducing the size of your images first, before modeling, e.g. less than 1000 pixels, even less than 500 pixels if you can.
I then recommend normalizing images to the same size.
to reduce the size of the images, which approach is better. Using machine learning or normal image compression methods.
Use image compression algorithms.
when we reducing the size of images that means losing many fine details from these images
Often it does.
How u make this project please help us … We can’t understand how we make this project … Taranpreetkaur
What problem are you having exactly?
Original error was: No module named _multiarray_umath, keras .imageprocessing
Importing the numpy c-extensions failed.
Any ideas please
Sorry to hear that.
Perhaps try checking that your version of Keras and TensorFlow are up to date?
Sorry dont worry, I somehow got to resolve it. I think I reinstalled stuff.
I have another problem though. How do I add data for learning if in case the data predicted the wrong valiue pelase. I think I need the advise for both how to add as well as how to add the data in the mnist data format. Thanks
Happy to hear that.
Perhaps you can refit your model as you get access to new data?
Jason you know what, for “17” it returned “7”. Thats actually good, but if you could please tip me as to how can I turn this into “Awesome.” Can I divide the pixel data into 2 dividions based on whitespace or what would be the best way please to recognize “17”. Thanks
I believe the model supports one character at a time, try splitting multiple characters up into single character input.
Great!! I enjoyed very well.
Thanks!
Jason,
Thanks much for this tutorial. I had a question on the structure of the CNN. In this (and other descriptions of this problem for the MNIST digit data set) a common structure seems to be that the number of CNN filters is 32. Where each filter is a 5×5 of stride 1. However (and I apologize if this is explained somewhere) I cannot seem to find why 32 filters are chosen. i.e. Why not 16 or 64 ( or 14 or 28). Is it possible to explain why this is so.
Regards
Victor
It is arbitrary.
Try different numbers of filters and compare the results.
Jason,
Thank you for the detailed explanation of this. I wanted to run your code and follow along to see how it worked. When I tried to run the complete example for the baseline cnn model for mnist, I get the following error:
KeyError Traceback (most recent call last)
in
107
108 # entry point, run the test harness
–> 109 run_test_harness()
in run_test_harness()
102 scores, histories = evaluate_model(model, trainX, trainY)
103 # learning curves
–> 104 summarize_diagnostics(histories)
105 # summarize estimated performance
106 summarize_performance(scores)
in summarize_diagnostics(histories)
79 pyplot.subplot(212)
80 pyplot.title(‘Classification Accuracy’)
—> 81 pyplot.plot(histories[i].history[‘acc’], color=’blue’, label=’train’)
82 pyplot.plot(histories[i].history[‘val_acc’], color=’orange’, label=’test’)
83 pyplot.show()
KeyError: ‘acc’
Any ideas what it means?
Yes, the API has changed.
I have updated the example.
Thanks for letting me know!
please how can i Train a simple convolutional network for number recognition (MNIST). Thanks. that’s what i want to see.
See the above tutorial for an example.
I want to create a image exactly same as mnist using mspaint for example and test it using the mnist evaluation model using predict_classes API.
Is it possible without using python API.
I don’t see why not.
Hi Jason,
Thanks for the excellent tutorial! I have two questions about K-fold cross-validation. In your “gentle introduction” article you say that the model is discarded each time we switch the hold out set. So here are my questions
1) Here it looks like you don’t discard the model between iterations of the k-fold cross validation. Why?
2) The model’s accuracy gets better each time you do an iteration. Why is taking a simple average fair then? To take it to the extreme: What if you only trained on 1 epoch? Then you’d get 94% on your first fold, then 98.5% on your second fold. And so on, yielding a much poorer average and a huge standard deviation. On the back of this question, I’d also ask why the standard deviation is a fair representation of the model under these circumstances.
Thanks again for the great material!
Alex
You’re welcome.
That looks like an error. I will update the tutorial.
Thanks for point it out!
Thanks for picking up my previous question Jason. I have another. You say at some point that there are no clear signs of overfitting. But it looks like the orange lines for the validation accuracy are staying relatively low compared to the blue lines for the testing accuracy. Is this not an indicator of overfitting? Or am I misinterpreting the charts?
Excellent question Alexander.
They are close enough that I would not classify it as overfitting, instead it is a good fit:
https://machinelearningmastery.com/learning-curves-for-diagnosing-machine-learning-model-performance/
Hello Jason,
When I execute the final code I get following error: “AttributeError: module ‘tensorflow’ has no attribute ‘get_default_graph”. I have installed Tensorflow 2.0, will downgrading it to the previous version solve this problem?
Thank you for your time and this amazing post!
Confirm you have Keras 2.3 and Tensorflow 2.0 installed.
Hello Jason,
I have Tensorflow 2.0 and Keras 2.2.4. I tried updating Keras to 2.3 but can not find the way on Windows 10. I tried also switching to Linux on VB but I have a hard time with permissions there. Do you have any advice for me, I would be really grateful?
You can try:
Or, if you are on anaconda:
Hello Jason,
Thank you for the tutorial and all the answers!
I have my own set of images, each class in a separate folder. What should I do to upload the dataset instead of writing
# load dataset
(trainX, trainY), (testX, testY) = mnist.load_data()
It would be great if you can give some advice!
Here is an example:
https://machinelearningmastery.com/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
Thank you!
You’re welcome.
Hi Jason,
Thanks for the article!!!
Do you have any plans to implement “Information bottleneck theory” i.e, finding mainly the mutual information among various layers in an architecture?
Does it seem simpler or a harder one for you??
I have not heard of it sorry, do you have a link?
def load_image(filename):
# load the image
img = load_img(filename, grayscale=True, target_size=(28, 28))
# convert to array
img = img_to_array(img)
# reshape into a single sample with 1 channel
img = img.reshape(1, 28, 28, 1)
# prepare pixel data
img = img.astype(‘float32’)
img = img / 255.0
return img
what does the ‘filename’ mean in the above code?
It’s an argument to the function – the name of the file you want to load.
Did you mean the saved model’s filename?
No, the function loads an image as it’s name suggests.
Thank you!
You’re welcome.
What is the purpose of reshaping the data to a single color channel? Is it necessary for the 2D convolution step in the model definition? I ask because other digit classification examples I’ve looked at go straight to flattening the train/test data but those didn’t have a 2D convolution layer.
The CNN layer expects data to have a 3d shape including a channels dimension:
https://machinelearningmastery.com/convolutional-layers-for-deep-learning-neural-networks/
If one wanted to create a new MNIST how would they set the data up? In these examples we get to use curated datasets from a dispensary but that does not explain how to set up your data to run the model.
For example what if I wanted to create my own MNIST to determine if the picture is a poker card, how would I go about setting the pictures and telling the machine what that picture is?
Good question, see this:
https://machinelearningmastery.com/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
hi Jason Brownlee,
i want to make model handwriting alphbet so please suggest which dataset is good
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/where-can-i-get-a-dataset-on-___
Jason, Thank you so much for sharing your knowledge. I just started learning python, tensorflow and machine learning. I understood all the maths and processes but was having difficulty in coding. Your example worked first time. Brilliant.
Do you have a simpler example of CNN with just 4 hidden layers as follows:
1. Input layer of 784 nodes
2. First convolution later : 5x5x32
3. First max pooling layer
4. Second convolution layer 5x5x64
5. Second max pooling layer
6. Out put layer of 10 nodes
Thanks.
You can adapt the above example to this directly if you like.
Hi Jason. Can I ask why did you reshape the data? The image from the MNIST are already grey scale which are 1 channel. I am not quite understand why you need to do this step. Also what does the trainx.shape[0]/testX.shape[0] do here?
# reshape dataset to have a single channel
trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))
testX = testX.reshape((testX.shape[0], 28, 28, 1))
Inputs to CNNs must have the channel defined explicitly, which is not the case by default for grayscale images.
Can I ask why the hot encode is 10 binary vectors? Why choose 10?
Because there are 10 classes.
Hi Jason! Thank you so much, this is a great tutorial!
Just one question, i’m somewhat confused.
Are training our model twice? Once with k-fold validation and then right before saving it, with model.fit?
====
model = define_model()
model.fit(trainX, trainY, epochs=10, batch_size=32, verbose=0)
model.save(‘final_model.h5’)
====
Cross-validation will train k models and is used to estimate the performance when making predictions on new data. These models are discarded.
Once we choose a final model config, we fit a model on all data and use it to start making predictions.
Great, that’s what I thought! Thank you again for this amazing tutorial.
You’re welcome.
In the k fold cross validation a new model is defined for each k iteration. So does that mean a new model is trained each time? But then what is the use of training new models in each iteration?
By model config you mean an optimal define_model? And once an optimal model is fixed we train on the entire training set? I am not able to relate how will K iterations in the K-fold reflect our understanding of what model configuration is the best.
Yes, a new model is trained each iteration, evaluated, and discarded.
The purpose is to estimate the performance of the model configuration when making predictions on unseen data for your prediction problem.
Once we have this estimate, we can choose to use the configuration (compared to other configurations). A final model can be fit on all data and we can start making predictions for real on new data where we don’t know the label.
Thankyou very much. I had another question. I was trying to run the final model on the unseen test data. however for each run the results vary ofcourse. therefore i decided to run this over 10 runs and average the test results, something like monte carlo simulation. but again in that case where would model = define_model() be places? would that be placed inside the for loop for average or just be defined once before running these 10 iterations, considering this average results is on the test data. since in kfold you discard it.
You’re welcome.
Yes, you can reduce variance in prediction by fitting multiple final models and averaging their predictions:
https://machinelearningmastery.com/how-to-reduce-model-variance/
This has a code example:
https://machinelearningmastery.com/model-averaging-ensemble-for-deep-learning-neural-networks/
If i am writing this all by making a class name -mnist_classification then
AttributeError: ‘mnist_classification’ object has no attribute ‘astype’
this .astype error is coming please sir can you help me to figure this out
Sorry to hear that, this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi Jason,
Thanks for this tutorial. It’s very helpful.
You’re welcome, I’m happy to hear that.
Hi, i am trying to build a CNN fo the same problem. My output layer has 10 neurons. When i try to fit my model after One-Hot_encoding of y_train and y_test, i get an error that the labels and the logits don’t match. However, without the one-hot encoding the model fits perfectly. Can you please explain?
Perhaps you can use the above tutorial as a starting point and adapt it for your project?
This is the best article about MNIST, but I have a question “Is it necessary to use a GPU with high performance in order to running these codes?”
Thanks!
No, you can run on CPU, it might just take more minutes to run.
Hi Jason
Thanks for this amazing tutorial. It will definitely help a lot of budding researchers.
I have a question
Can you please help if instead of single character i have to work on complete self taken handwritten word image (20 different classes,total around 20000 images). How to do it?
Perhaps the letters in each word images can first be segmented, then classified.
thanks for the reply but i want to do it using segmentation free approach
Perhaps use a CNN to read the images and an LSTM to interpret the image features and output one letter at a time.
Perhaps use a CNN to read the images and an LSTM to interpret the image features and output one letter at a time.
Can you please share more detail how to do it.
Hi Prasad…You may want to consider a CNN-LSTM model for your purpose:
https://machinelearningmastery.com/cnn-long-short-term-memory-networks/
hi Jason
Thanks for this amazing tutorial.
You’re welcome.
Thanks, Jason Brownlee for this excellent tutorial. I am your huge fan and I regularly following your all machine learning and deep earning models.I got a lot of knowledge from this site but After completion of machine learning tutorials there always raise a question in my mind that how can we apply these models in Mobile APPs(Andriod, iOS, etc) so that we get more fun and knowledge by this models. Are you suggest to me any link to have such kind of projects such as weather prediction app . Thanks again.
Thanks.
Sorry, I don’t know about using models on mobile.
I know this is a year late, but see this for a mobile app based on tensorflow and keras: https://medium.com/@timanglade/how-hbos-silicon-valley-built-not-hotdog-with-mobile-tensorflow-keras-react-native-ef03260747f3
Thanks for the tutorial Jason Brownlee.
Can I use same model but pass my own dataset (of humans) to it & use it for detecting fall or not fall by making small changes?
Thanks.
Sure.
Hi do you have any projects done based on Wireless and Mobile Network except human activity recognition using smart phone
I don’t think so. Perhaps try the blog search.
Thanks for the detailed explanation !!
Can you pls do a tutorial on colorization without using pretratined model
Thanks in advance
Great suggestion, thanks!
Waiting for the same 🙂
hey jason that was a very good tutorial, i did not understand how in the predict_classes we got 7? the model had a softmax activation function as the last layer which will be a probability distribution of 10 float numbers, what i can’t grasp is how did we get back 7?
what i mean is how this 10 probabilities turned into 1 predicted number?
and how does it know it is 7, didn’t we hot encode the Y values?
Via argmax:
https://machinelearningmastery.com/argmax-in-machine-learning/
Thanks.
The predict_classes() performs an argmax on the predicted probabilities for you.
If you are new to argmax, see this:
https://machinelearningmastery.com/argmax-in-machine-learning/
thank you jason, everything is clear, really appreciate it!
I’m happy to hear that.
Hey is this code not compatible for Tensorflow 2? I am getting the following error.
E tensorflow/stream_executor/cuda/cuda_driver.cc:314] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Yes, you can learn more here:
https://machinelearningmastery.com/faq/single-faq/do-you-support-tensorflow-2
That error looks like a problem with your development environment.
Hello!
Thanks for the wonderful article helped me a lot with my project!
I have a question though, I am trying to take an image from my phone and then use that image to predict the number but it doesn’t work with that. What should I do to that image?
I resized it to 28×28 using online tools and even tried the grayscale version of the image to predict.
Any suggestion or lead will be appreciated!
Thanks in advance!
You will have to prepare the image in an identical manner to the images in the training set. e.g. white foreground, black background, grayscale and same image size.
Hi Jason,
Great tutorial as always!
I implemented your tutorial with two variants.
I load the images from digits dataset of sklearn library (it uses less images number only 1,797 and with much lower resolution 8 x 8 bits vs MNIST 70,000 and 28,28 pixels resolution. On the contrary it is much faster this dataset because it use less data features.
And also I apply for this multi-class problem other library classifier models from Sklearn such as SVC(), logisticRegression(), ExtraTreesClassifier(), XGBClassifier(), RandomForestClassifier(), etc.
My main results are:
– I got 98.4% accuracy and 1.1 of sigma for the simple CNN baseline model (not other deep layers, not other BatchNormalization()) and I got 98.8% from SVC…but only suing the 8×8 pixels resolution which is a great new!.
But when I reduce the final image to be predicted to 8 x 8 pixels, in order to apply my trained model, whereI got such a great score I poorly predict the 7 digit as 9 digit.
My guess is when I load_image of 7 and I clip it to such smaller size of 8×8 pixels, I lost important images features in the process of cutting back the image….where the the MNIST 28×28 pixels still retain key digit features of the image, what do you think?
thank you Jason
Thanks.
Very nice experiments!
Yes, the larger images perhaps provide more context on challenging cases in the dataset.
Hi Jason,
You have always very interesting articles.
I was able to train a CNN based on the Char74K-dataset. I’m happy of that because the model-file is only 42MB and the time to predict a number is fast.
I did use a kNN-model before (on the same dataset) that had a file size of 680MB!
Thanks,
Hannes
Thanks.
Well done!
Hi Jason,
Great article!!
i just have one doubt, in the evaluate method why are we creating a new model for every fold?
Thanks,
This is how k-fold cross-validation works, we have a new training set and fit a new model for each fold, then average the performance of all models to get an estimate of model performance when used on unseen data.
You can learn more here:
https://machinelearningmastery.com/k-fold-cross-validation/
Thanks for this amazing tutorial!
I have some experience in MLP but not with CNN. Is there a reason try to use CNN if each sample of my data have shape 16×1 (row) with values between 0,01 to 0,99 and the model shoud perform classification for 15 classes. If I reshape samples from 16×1 to 4×4 then which filter size and a modest number of filters shoud I use? Or better dont reshape and try model with Conv1D layers? Thanks.
CNN can be effective if there is a spatial relationship between the inputs in an image or a sequence.
If you have tabular data (e.g. not a images and not sequences), then a CNN does not make sense.
Hi Jason,
Thank you very much for your amazing tutorial. I am running your code using pycharm and I have a GPU with the right CUDA but your code is only running on my CPU.
Is there something that I am missing here?
thank you. 🙂
Sorry Jason, it turned out I had a problem in the CuDNN installation and i did a work around to fix it and it worked. 🙂
Thanks again for this great tutorial. 🙂
No problem!
Happy to hear you fixed the issue.
The code is agnostic to hardware – runs on both.
If it is running on your CPU, then you need to change the configuration of your tensorflow library. I don’t have tutorials on this topic, sorry.
Hi Jason,
Thank you very much for this tutorial, helped a lot! I developed my own CNN, which seems to perform pretty well according to the mean accuracy. However, the cross-entropy loss of the validation set is below the loss of the training set. Is this a sign of underfitting? And if so, should I change the model if I would like to apply the model to unseen data?
You’re welcome.
Well done!
If performance is poor, a learning curve can help diagnose issues, this can help you interpret the learning curve:
https://machinelearningmastery.com/learning-curves-for-diagnosing-machine-learning-model-performance/
Hi Jason,
Thank you very much for this tutorial, helped a lot! I developed my own CNN, which seems to perform pretty well according to the mean accuracy. However, the cross-entropy loss of the validation set is below the loss of the training set. Is this a sign of underfitting? And if so, should I change the model if I would like to apply the model to unseen data?
You’re welcome.
Perhaps focus on the out of sample performance of the model first and optimize that.
Hi Jason,
Previously I was grateful for the tutorial you provided, I learned a lot from here. What if I want to display the probability value of the prediction result? (for example 50.67% something like that)
Thanks!
You can call model.predict() then multiply the result by 100 to get a percentage.
Thank you for the tutorial!
I created an image with same characteristics as sample_image.png (1490×1480, black background, white foreground), opened it in Paint, typed a “6” (without the quotes, of course), increased the font size to 1000 (so it would occupy most of the canvas), then saved it. However, the code doesn’t seem to recognize it. It seems to think it’s a “1”, “8”, or other numbers.
Any suggestions on why?
Perhaps there was some important difference in the image itself or it’s preparation (e.g. pixel scaling) that differed from the training dataset?
Hi Jason – fantastic article!! Just wondering why you had to do evaluate to get the accuracy, while it is already being returned by the fit call? I just checked the histories and they have exactly the same stuff returned by the evaluate call. Was there any other reason for the evaluate call?
Thanks!
No, accuracy on a hold out dataset is not calculated when calling fit. We must make predictions on new data manually or use the evaluate function.
Thanks for the reply!! I was seeing the same data is passed (testX, testY) for both fit and evaluate calls for validation. As a result, the return object from fit call already has the data to be returned by the evaluate call. Am I making sense?
# fit model
history = model.fit(trainX, trainY, epochs=10, batch_size=32, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
Generally it is not a good idea to use test data as validation, I do to keep the examples simple.
Hi Jason, thanks for this great tutorial!
I don’t get why we don’t use the models that we created during the k-fold. I was expecting something like we combine this k models results into one single model and save it. If we don’t do that how’s that useful?
Models created during k-fold cross-validation are discarded. They are only used to estimate the performance of the model/pipeline on unseen examples.
Once we choose a configuration, we can fit a final model on all data and use it to make predictions on new examples:
https://machinelearningmastery.com/train-final-machine-learning-model/
Thanks a lot Jason !!! This tutorial was very very helpful and it solved half of my project problems !!! Thanks a lot again !..
You’re welcome.
Thank you for the great tutorial. Is it possible to use it with a webcam for recognition task?
Perhaps try it and see.
Hello! Thank you Jason for this amazing resource. I am currently working on a rented computer from school – do you think I could do implement this code in CoLabs?
You’re welcome.
Good question, see this:
https://machinelearningmastery.com/faq/single-faq/do-code-examples-run-on-google-colab
Hi Jason,
Thank you very much
If possible, advise on the implementation HMM.
Thanks for the suggestion, perhaps in the future.
i am developing a model of handwritten character recognition but the accuracy is very low i think it is not only because i have a small datatset, there is something i am not understanding can u help me on the improvement
Perhaps try some of these suggestions:
https://machinelearningmastery.com/improve-deep-learning-performance/
Can I use this code for any character dataset ?
Perhaps try it and see.
Could you provide a peer review for a manuscript that has been submitted to the Journal of High School Science (http://jhss.scholasticahq.com) ? The title of the manuscript is : Implementing a Quantum Convolutional Neural Network for Efficient Image Recognition. Abstract: Machine learning has many real-world applications ranging from modeling the universe to computational chemistry. As probability is the bedrock for machine learning, it is essential to optimize both hardware and software to obtain the best results. Classical computers are generally used for machine learning programs. However, learning from high-dimensional data often demands excessive compute time and power, and it may not achieve the highest accuracy. The Quantum Computing environment can be utilized to create a more accurate model than that created via classical computing. To test this quantum advantage, we implemented a Quantum Convolutional Neural Network (QCNN), which parallels the structure of the classical Convolution Neural Network (CNN) in the quantum domain. Due to the lack of quantum computers with many qubits, physicists, namely John Preskill, have introduced the Noisy Intermediate Scale Quantum (NISQ) concept, which constitutes a hybrid interface between classical and quantum computers. In the context of QCNN, the data processing and the cost function optimization would be performed on the classical computer, while the probabilities generated by the Variational Quantum Circuits (VQC) would be evaluated on the quantum computer. The QCNN consists of a classical-to-quantum data encoder, a cluster state quantum circuit to entangle qubit states, a series of Variational Quantum Circuits using Quantum Convolutional and Pooling Layers for efficient feature extraction, a quantum-to-classical data decoder, which would lead to the output. Both the CNN and the QCNN extract features from data like 2D images, and performances can be compared using metrics like accuracy and time.
Sorry I cannot peer review your manuscript.
what if we are asked to design a project to identify digit classification from MNIST using classification algorithm should we use the above oen
Yes
Wonderful tutorial!!
When i implemented the code i got this error ” AttributeError: ‘Sequential’ object has no attribute ‘predict_classes’ ”
Any suggestions to rectify this error please?
I used this model as an example and when I fed it a handwritten number, it continuously gave wrong predictions. Can you please tell me what could possibly be the problem?
It reads accurately when I used printed numbers with black background.
I did however change the cnn model a little bit to make it Multiple Pooling model.
I can share the code as well, if you like.
Can’t tell because I didn’t see your handwriting. But this MNIST dataset is a 28×28 pixel grayscale with white on black. Try to mimick this set up and it should be much better. If your image is more complex (e.g., you scan it, then the background is not a single color, or the alphabet is more complicated with more strokes than digits) then you will need a larger network to recognize it.
You mention in other answers that the inputs have to be reshaped because the convolutional layers expect an input with a dimension for channels. Do you know if this is unique to keras?
I am trying to classify 56×56 grayscale images (0->255), and so far I have normalized them to [-1,1]. However, they are still 2D as a 56×56 matrix. I am using pytorch. Do you know if I would also need to reshape them to add the single channel?
Depends on the way you construct the model, it may or may not necessary.
Why are there two copies of the 64-filter conv2D in the “Increase Model Depth” section:
model.add(Conv2D(64, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’))
I tried this model with both one and two of these layers and got the same results.
As a side note, I did increase the number of epochs to 15 and saw a slight improvement to both the accuracy mean and std deviation.
If you see no difference for more layers, try to stay with the fewer layers one because it save time and memory.
Increasing epochs can help train better, but you may also run into overfitting. So you need to check with validation set to confirm about the “improvement”.
I tried up to 25 epochs and looked at the loss with verbose=1 in the model.fit call. The loss bottoms out at around 20 epochs and then bounces around after that.
Here’s one run from epoch 10 through 25. The model got 99.260% on the test set:
Epoch 10/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0079 – accuracy: 0.9972
Epoch 11/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0061 – accuracy: 0.9980
Epoch 12/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0060 – accuracy: 0.9980
Epoch 13/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0058 – accuracy: 0.9978
Epoch 14/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0045 – accuracy: 0.9984
Epoch 15/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0042 – accuracy: 0.9987
Epoch 16/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0035 – accuracy: 0.9988
Epoch 17/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0031 – accuracy: 0.9991
Epoch 18/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0024 – accuracy: 0.9992
Epoch 19/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0026 – accuracy: 0.9993
Epoch 20/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0020 – accuracy: 0.9994
Epoch 21/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0020 – accuracy: 0.9994
Epoch 22/25
1875/1875 [==============================] – 7s 3ms/step – loss: 0.0027 – accuracy: 0.9991
Epoch 23/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0032 – accuracy: 0.9989
Epoch 24/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0022 – accuracy: 0.9993
Epoch 25/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0020 – accuracy: 0.9993
> 99.260
Not bad a result here!
These guys: https://arxiv.org/pdf/2008.10400v2.pdf are getting 99.91% accuracy using a combination of fairly simple techniques: deeper model depth, increased convolution kernel size, data augmentation, batch normalization between all conv2D layers, disabling edge padding in the convolution output to reduce the map sizes between conv2D layers instead of max pooling (which I found quite elegant), and voting between multiple models. They do a good job of analyzing each technique and comparing the results to other common CNNs.
They’re currently at the top of the rankings here: https://paperswithcode.com/sota/image-classification-on-mnist
Thanks for sharing.
So during training, the model accuracy against the training data goes over 99.9%, but the final accuracy on the test data is 99.26%. Are these results close enough that I can assume the model isn’t over trained? What’s a reasonable difference when both values are over 99%?
Can’t give you any general guidance on what is reasonable or not. But at >99% accuracy, I would assume it is good enough for this purpose.
Hi Patrick…The following resource will provide you insight into how to avoid overfitting in deep neural networks.
https://machinelearningmastery.com/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
Regards,
Thank you
You are very welcome Andrew!
You are very welcome, Andrew!
Hi,
I don’t know if you will ever see it but if you reply I will thank you, I wanted to try by myself this code because I was hoping to learn more about neural networks.
Unfortunately, I gave Python a picture I made in paint (the computer application) this image was resized to 28*28 and the picture is seen, I checked it.
In the picture, I drew the number 2, and it said that it is four and I tried more unsuccessfully.
I’d like to know where is the problem.
Anyway if you can reply to me in E-mail I will thank you in order to check wether the problem is in the picture or the code.
Hi Gilad…Have you checked the overall accuracy of your model?
Yes, the accuracy was 96 percent, this is the reason I find it awkward.
I am not sure whether the problem is in the picture but I’d like to know where is the problem.
Can I send you the picture that I used? maybe the problem is located there.
Anyway, thanks for the help.
99.140 is my right accuracy, sorry for the earlier mistake.
James thanks a lot it finally worked, my picture was not good.
I drew the digits in black and the background was white, and this is not the way the computer was trained.
Thank you for the feedback Gilad! Keep up the great work!
This, according to me, is the best tutorial I have ever gone through. It helped me understand CNN in my very first attempt. Thank you, Dear James.
Thank you for the feedback and support Anbu!
hello james,
Great tutorial. I’ getting “name ‘train’ is not defined” as error while converting from integers to floats. can you please help me with that? Thank you.
Hi Viswa…Thank you for the feedback! Did you copy and paste the code or type it in? There could be an issue related to copying and pasting the code.
Oh! I got it. Thank you so much for tutorial, I’ve learned a lot from you.
Can you please elaborate on why a dense layer with specifically 100 nodes is used to develop a baseline model?
train_norm = train.astype(‘float32’)
Hi Jason, from which library this method come from?
Cause train is not defined in your code and I want to see how the method works.
train_norm = train.astype(‘float32’)
NameError: name ‘train’ is not defined
Hi Carde…Please see the complete code listing near the end of the tutorial.
Is it okay to add dropout() to the digit classification model, because I got the best accuracy when I use the dropout.
Hi Suhas…Yes, that approach is a reasonable one and it is great to know you were able to improve your model accuracy! Dropout is definitely beneficial to avoid overtraining.
where is the final code and the code testing result
Hi abdool…The final code listing is provided in this post. Is it not visible?
hi, for the improved depth, how many hidden layers are involved?
Hi Ashbrocolli…The layers can be found in the in section following the comment below:
“The complete code listing with this change is provided below.”
Hello @James Carmichael, I wonder how the “to_categorical” works , I have seen documentation and it says if number of classes is not specified then this would be inferred as max(y) + 1 if y is a vector. So to my surprise ,I know that in the Mnist dataset the num classes is 10 but without specifiying this number as a parameter , the function returns a vector of shape (60 000,10) but how ? I would really like to know how this max(y)+1 would work on images and give the right num_classes that is 10.
Thanks in advance for your answer.
Sorry I figured it out, As “y” is a vector of labels from 0 to 9 so max(y)+1 would return 10 (num_classses), which is obvious actually. I was Confused because I had an issue while printing “y” it didn’t show the expected values.
Thanks!
Thank you for the update Rabiaa! Great work!
Outdated tutorial. Would not recommend to beginners who are starting out. Over complicating things in modern age. Maybe at the time (5yrs ago!!!) this was fine but things can be done way more simpler and cleaner.
Thank you for your feedback!
Thanks a lot for this interesting work.
I plot the images after loading, reshaping, and normalization, still I obtain the same result, is it normal ?
Hi Jason,
For a paper that I am writing I have been asked to include an (approximate) number of operations for EMNIST Digit classification based on a CNN implementation (any reasonable architecture is ok). I am considering referring to your MNIST networks as I assume they would work fairly well also with EMNIST data.
Do you possibly have an estimate of the number of operations required for any of your networks?
Also, did you actually try using the EMNIST Digit dataset?
Thanks,
Robert
Hi Robert…Please clarify what is meant by “number of operations”. That will enable us to better guide you.
its a long time that you posted the tutorial. But i have a problem. No matter which image i use, the output is “1” and i don’t know why. Can you help me?
Hi Karim…It sounds like your model might be overfitting to a particular class or failing to learn properly. Here are a few areas to check:
1. **Data Preprocessing**: Ensure that your images are correctly preprocessed. For MNIST, images should be grayscale (1 channel) and sized at 28×28 pixels, with pixel values normalized (often between 0 and 1 or standardized).
2. **Model Architecture**: If your model architecture is too simple, it might not be able to generalize well. Ensure you have enough layers (e.g., convolutional and dense layers) and units to capture the complexity of digit classification. Overly deep networks without regularization, however, might cause issues too.
3. **Loss Function and Activation**: Verify that you’re using the
softmaxactivation in the final layer with categorical cross-entropy loss for multi-class classification.4. **Model Training**: If your model is trained with too few epochs or without proper shuffling of the training data, it may not learn effectively. Conversely, overtraining on a limited subset could also make it biased towards a specific output.
5. **Evaluation**: If you’re printing predictions before model convergence or testing, the model could still be outputting random or biased results. Ensure you save and load a trained version of your model when making predictions.
Checking these should help you narrow down the issue. If the problem persists, feel free to share more details about the model structure and training loop for more specific guidance!
Why model is not able to predict the numbers with white background?
Hi Pramendra…Please elaborate on the any experiments you have performed and the results so that we may better guide you.