Object detection is a task in computer vision that involves identifying the presence, location, and type of one or more objects in a given photograph.
It is a challenging problem that involves building upon methods for object recognition (e.g. where are they), object localization (e.g. what are their extent), and object classification (e.g. what are they).
In recent years, deep learning techniques are achieving state-of-the-art results for object detection, such as on standard benchmark datasets and in computer vision competitions. Notable is the “You Only Look Once,” or YOLO, family of Convolutional Neural Networks that achieve near state-of-the-art results with a single end-to-end model that can perform object detection in real-time.
In this tutorial, you will discover how to develop a YOLOv3 model for object detection on new photographs.
After completing this tutorial, you will know:
- YOLO-based Convolutional Neural Network family of models for object detection and the most recent variation called YOLOv3.
- The best-of-breed open source library implementation of the YOLOv3 for the Keras deep learning library.
- How to use a pre-trained YOLOv3 to perform object localization and detection on new photographs.
Kick-start your project with my new book Deep Learning for Computer Vision, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Oct/2019: Updated and tested for Keras 2.3.0 API and TensorFlow 2.0.0.

How to Perform Object Detection With YOLOv3 in Keras
Photo by David Berkowitz, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- YOLO for Object Detection
- Experiencor YOLO3 Project
- Object Detection With YOLOv3
Want Results with Deep Learning for Computer Vision?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
YOLO for Object Detection
Object detection is a computer vision task that involves both localizing one or more objects within an image and classifying each object in the image.
It is a challenging computer vision task that requires both successful object localization in order to locate and draw a bounding box around each object in an image, and object classification to predict the correct class of object that was localized.
The “You Only Look Once,” or YOLO, family of models are a series of end-to-end deep learning models designed for fast object detection, developed by Joseph Redmon, et al. and first described in the 2015 paper titled “You Only Look Once: Unified, Real-Time Object Detection.”
The approach involves a single deep convolutional neural network (originally a version of GoogLeNet, later updated and called DarkNet based on VGG) that splits the input into a grid of cells and each cell directly predicts a bounding box and object classification. The result is a large number of candidate bounding boxes that are consolidated into a final prediction by a post-processing step.
There are three main variations of the approach, at the time of writing; they are YOLOv1, YOLOv2, and YOLOv3. The first version proposed the general architecture, whereas the second version refined the design and made use of predefined anchor boxes to improve bounding box proposal, and version three further refined the model architecture and training process.
Although the accuracy of the models is close but not as good as Region-Based Convolutional Neural Networks (R-CNNs), they are popular for object detection because of their detection speed, often demonstrated in real-time on video or with camera feed input.
A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance.
— You Only Look Once: Unified, Real-Time Object Detection, 2015.
In this tutorial, we will focus on using YOLOv3.
Experiencor YOLO3 for Keras Project
Source code for each version of YOLO is available, as well as pre-trained models.
The official DarkNet GitHub repository contains the source code for the YOLO versions mentioned in the papers, written in C. The repository provides a step-by-step tutorial on how to use the code for object detection.
It is a challenging model to implement from scratch, especially for beginners as it requires the development of many customized model elements for training and for prediction. For example, even using a pre-trained model directly requires sophisticated code to distill and interpret the predicted bounding boxes output by the model.
Instead of developing this code from scratch, we can use a third-party implementation. There are many third-party implementations designed for using YOLO with Keras, and none appear to be standardized and designed to be used as a library.
The YAD2K project was a de facto standard for YOLOv2 and provided scripts to convert the pre-trained weights into Keras format, use the pre-trained model to make predictions, and provided the code required to distill interpret the predicted bounding boxes. Many other third-party developers have used this code as a starting point and updated it to support YOLOv3.
Perhaps the most widely used project for using pre-trained the YOLO models is called “keras-yolo3: Training and Detecting Objects with YOLO3” by Huynh Ngoc Anh or experiencor. The code in the project has been made available under a permissive MIT open source license. Like YAD2K, it provides scripts to both load and use pre-trained YOLO models as well as transfer learning for developing YOLOv3 models on new datasets.
He also has a keras-yolo2 project that provides similar code for YOLOv2 as well as detailed tutorials on how to use the code in the repository. The keras-yolo3 project appears to be an updated version of that project.
Interestingly, experiencor has used the model as the basis for some experiments and trained versions of the YOLOv3 on standard object detection problems such as a kangaroo dataset, racoon dataset, red blood cell detection, and others. He has listed model performance, provided the model weights for download and provided YouTube videos of model behavior. For example:
We will use experiencor’s keras-yolo3 project as the basis for performing object detection with a YOLOv3 model in this tutorial.
In case the repository changes or is removed (which can happen with third-party open source projects), a fork of the code at the time of writing is provided.
Object Detection With YOLOv3
The keras-yolo3 project provides a lot of capability for using YOLOv3 models, including object detection, transfer learning, and training new models from scratch.
In this section, we will use a pre-trained model to perform object detection on an unseen photograph. This capability is available in a single Python file in the repository called “yolo3_one_file_to_detect_them_all.py” that has about 435 lines. This script is, in fact, a program that will use pre-trained weights to prepare a model and use that model to perform object detection and output a model. It also depends upon OpenCV.
Instead of using this program directly, we will reuse elements from this program and develop our own scripts to first prepare and save a Keras YOLOv3 model, and then load the model to make a prediction for a new photograph.
Create and Save Model
The first step is to download the pre-trained model weights.
These were trained using the DarkNet code base on the MSCOCO dataset. Download the model weights and place them into your current working directory with the filename “yolov3.weights.” It is a large file and may take a moment to download depending on the speed of your internet connection.
Next, we need to define a Keras model that has the right number and type of layers to match the downloaded model weights. The model architecture is called a “DarkNet” and was originally loosely based on the VGG-16 model.
The “yolo3_one_file_to_detect_them_all.py” script provides the make_yolov3_model() function to create the model for us, and the helper function _conv_block() that is used to create blocks of layers. These two functions can be copied directly from the script.
We can now define the Keras model for YOLOv3.
|
1 2 |
# define the model model = make_yolov3_model() |
Next, we need to load the model weights. The model weights are stored in whatever format that was used by DarkNet. Rather than trying to decode the file manually, we can use the WeightReader class provided in the script.
To use the WeightReader, it is instantiated with the path to our weights file (e.g. ‘yolov3.weights‘). This will parse the file and load the model weights into memory in a format that we can set into our Keras model.
|
1 2 |
# load the model weights weight_reader = WeightReader('yolov3.weights') |
We can then call the load_weights() function of the WeightReader instance, passing in our defined Keras model to set the weights into the layers.
|
1 2 |
# set the model weights into the model weight_reader.load_weights(model) |
That’s it; we now have a YOLOv3 model for use.
We can save this model to a Keras compatible .h5 model file ready for later use.
|
1 2 |
# save the model to file model.save('model.h5') |
We can tie all of this together; the complete code example including functions copied directly from the “yolo3_one_file_to_detect_them_all.py” script is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 |
# create a YOLOv3 Keras model and save it to file # based on https://github.com/experiencor/keras-yolo3 import struct import numpy as np from keras.layers import Conv2D from keras.layers import Input from keras.layers import BatchNormalization from keras.layers import LeakyReLU from keras.layers import ZeroPadding2D from keras.layers import UpSampling2D from keras.layers.merge import add, concatenate from keras.models import Model def _conv_block(inp, convs, skip=True): x = inp count = 0 for conv in convs: if count == (len(convs) - 2) and skip: skip_connection = x count += 1 if conv['stride'] > 1: x = ZeroPadding2D(((1,0),(1,0)))(x) # peculiar padding as darknet prefer left and top x = Conv2D(conv['filter'], conv['kernel'], strides=conv['stride'], padding='valid' if conv['stride'] > 1 else 'same', # peculiar padding as darknet prefer left and top name='conv_' + str(conv['layer_idx']), use_bias=False if conv['bnorm'] else True)(x) if conv['bnorm']: x = BatchNormalization(epsilon=0.001, name='bnorm_' + str(conv['layer_idx']))(x) if conv['leaky']: x = LeakyReLU(alpha=0.1, name='leaky_' + str(conv['layer_idx']))(x) return add([skip_connection, x]) if skip else x def make_yolov3_model(): input_image = Input(shape=(None, None, 3)) # Layer 0 => 4 x = _conv_block(input_image, [{'filter': 32, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 0}, {'filter': 64, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 1}, {'filter': 32, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 2}, {'filter': 64, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 3}]) # Layer 5 => 8 x = _conv_block(x, [{'filter': 128, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 5}, {'filter': 64, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 6}, {'filter': 128, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 7}]) # Layer 9 => 11 x = _conv_block(x, [{'filter': 64, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 9}, {'filter': 128, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 10}]) # Layer 12 => 15 x = _conv_block(x, [{'filter': 256, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 12}, {'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 13}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 14}]) # Layer 16 => 36 for i in range(7): x = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 16+i*3}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 17+i*3}]) skip_36 = x # Layer 37 => 40 x = _conv_block(x, [{'filter': 512, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 37}, {'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 38}, {'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 39}]) # Layer 41 => 61 for i in range(7): x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 41+i*3}, {'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 42+i*3}]) skip_61 = x # Layer 62 => 65 x = _conv_block(x, [{'filter': 1024, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 62}, {'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 63}, {'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 64}]) # Layer 66 => 74 for i in range(3): x = _conv_block(x, [{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 66+i*3}, {'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 67+i*3}]) # Layer 75 => 79 x = _conv_block(x, [{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 75}, {'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 76}, {'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 77}, {'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 78}, {'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 79}], skip=False) # Layer 80 => 82 yolo_82 = _conv_block(x, [{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 80}, {'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 81}], skip=False) # Layer 83 => 86 x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 84}], skip=False) x = UpSampling2D(2)(x) x = concatenate([x, skip_61]) # Layer 87 => 91 x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 87}, {'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 88}, {'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 89}, {'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 90}, {'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 91}], skip=False) # Layer 92 => 94 yolo_94 = _conv_block(x, [{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 92}, {'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 93}], skip=False) # Layer 95 => 98 x = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 96}], skip=False) x = UpSampling2D(2)(x) x = concatenate([x, skip_36]) # Layer 99 => 106 yolo_106 = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 99}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 100}, {'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 101}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 102}, {'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 103}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 104}, {'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 105}], skip=False) model = Model(input_image, [yolo_82, yolo_94, yolo_106]) return model class WeightReader: def __init__(self, weight_file): with open(weight_file, 'rb') as w_f: major, = struct.unpack('i', w_f.read(4)) minor, = struct.unpack('i', w_f.read(4)) revision, = struct.unpack('i', w_f.read(4)) if (major*10 + minor) >= 2 and major < 1000 and minor < 1000: w_f.read(8) else: w_f.read(4) transpose = (major > 1000) or (minor > 1000) binary = w_f.read() self.offset = 0 self.all_weights = np.frombuffer(binary, dtype='float32') def read_bytes(self, size): self.offset = self.offset + size return self.all_weights[self.offset-size:self.offset] def load_weights(self, model): for i in range(106): try: conv_layer = model.get_layer('conv_' + str(i)) print("loading weights of convolution #" + str(i)) if i not in [81, 93, 105]: norm_layer = model.get_layer('bnorm_' + str(i)) size = np.prod(norm_layer.get_weights()[0].shape) beta = self.read_bytes(size) # bias gamma = self.read_bytes(size) # scale mean = self.read_bytes(size) # mean var = self.read_bytes(size) # variance weights = norm_layer.set_weights([gamma, beta, mean, var]) if len(conv_layer.get_weights()) > 1: bias = self.read_bytes(np.prod(conv_layer.get_weights()[1].shape)) kernel = self.read_bytes(np.prod(conv_layer.get_weights()[0].shape)) kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape))) kernel = kernel.transpose([2,3,1,0]) conv_layer.set_weights([kernel, bias]) else: kernel = self.read_bytes(np.prod(conv_layer.get_weights()[0].shape)) kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape))) kernel = kernel.transpose([2,3,1,0]) conv_layer.set_weights([kernel]) except ValueError: print("no convolution #" + str(i)) def reset(self): self.offset = 0 # define the model model = make_yolov3_model() # load the model weights weight_reader = WeightReader('yolov3.weights') # set the model weights into the model weight_reader.load_weights(model) # save the model to file model.save('model.h5') |
Running the example may take a little less than one minute to execute on modern hardware.
As the weight file is loaded, you will see debug information reported about what was loaded, output by the WeightReader class.
|
1 2 3 4 5 6 7 8 |
... loading weights of convolution #99 loading weights of convolution #100 loading weights of convolution #101 loading weights of convolution #102 loading weights of convolution #103 loading weights of convolution #104 loading weights of convolution #105 |
At the end of the run, the model.h5 file is saved in your current working directory with approximately the same size as the original weight file (237MB), but ready to be loaded and used directly as a Keras model.
Make a Prediction
We need a new photo for object detection, ideally with objects that we know that the model knows about from the MSCOCO dataset.
We will use a photograph of three zebras taken by Boegh on safari, and released under a permissive license.

Photograph of Three Zebras
Taken by Boegh, some rights reserved.
Download the photograph and place it in your current working directory with the filename ‘zebra.jpg‘.
Making a prediction is straightforward, although interpreting the prediction requires some work.
The first step is to load the Keras model. This might be the slowest part of making a prediction.
|
1 2 |
# load yolov3 model model = load_model('model.h5') |
Next, we need to load our new photograph and prepare it as suitable input to the model. The model expects inputs to be color images with the square shape of 416×416 pixels.
We can use the load_img() Keras function to load the image and the target_size argument to resize the image after loading. We can also use the img_to_array() function to convert the loaded PIL image object into a NumPy array, and then rescale the pixel values from 0-255 to 0-1 32-bit floating point values.
|
1 2 3 4 5 6 7 |
# load the image with the required size image = load_img('zebra.jpg', target_size=(416, 416)) # convert to numpy array image = img_to_array(image) # scale pixel values to [0, 1] image = image.astype('float32') image /= 255.0 |
We will want to show the original photo again later, which means we will need to scale the bounding boxes of all detected objects from the square shape back to the original shape. As such, we can load the image and retrieve the original shape.
|
1 2 3 |
# load the image to get its shape image = load_img('zebra.jpg') width, height = image.size |
We can tie all of this together into a convenience function named load_image_pixels() that takes the filename and target size and returns the scaled pixel data ready to provide as input to the Keras model, as well as the original width and height of the image.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# load and prepare an image def load_image_pixels(filename, shape): # load the image to get its shape image = load_img(filename) width, height = image.size # load the image with the required size image = load_img(filename, target_size=shape) # convert to numpy array image = img_to_array(image) # scale pixel values to [0, 1] image = image.astype('float32') image /= 255.0 # add a dimension so that we have one sample image = expand_dims(image, 0) return image, width, height |
We can then call this function to load our photo of zebras.
|
1 2 3 4 5 6 |
# define the expected input shape for the model input_w, input_h = 416, 416 # define our new photo photo_filename = 'zebra.jpg' # load and prepare image image, image_w, image_h = load_image_pixels(photo_filename, (input_w, input_h)) |
We can now feed the photo into the Keras model and make a prediction.
|
1 2 3 4 |
# make prediction yhat = model.predict(image) # summarize the shape of the list of arrays print([a.shape for a in yhat]) |
That’s it, at least for making a prediction. The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# load yolov3 model and perform object detection # based on https://github.com/experiencor/keras-yolo3 from numpy import expand_dims from keras.models import load_model from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array # load and prepare an image def load_image_pixels(filename, shape): # load the image to get its shape image = load_img(filename) width, height = image.size # load the image with the required size image = load_img(filename, target_size=shape) # convert to numpy array image = img_to_array(image) # scale pixel values to [0, 1] image = image.astype('float32') image /= 255.0 # add a dimension so that we have one sample image = expand_dims(image, 0) return image, width, height # load yolov3 model model = load_model('model.h5') # define the expected input shape for the model input_w, input_h = 416, 416 # define our new photo photo_filename = 'zebra.jpg' # load and prepare image image, image_w, image_h = load_image_pixels(photo_filename, (input_w, input_h)) # make prediction yhat = model.predict(image) # summarize the shape of the list of arrays print([a.shape for a in yhat]) |
Running the example returns a list of three NumPy arrays, the shape of which is displayed as output.
These arrays predict both the bounding boxes and class labels but are encoded. They must be interpreted.
|
1 |
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)] |
Make a Prediction and Interpret Result
The output of the model is, in fact, encoded candidate bounding boxes from three different grid sizes, and the boxes are defined the context of anchor boxes, carefully chosen based on an analysis of the size of objects in the MSCOCO dataset.
The script provided by experiencor provides a function called decode_netout() that will take each one of the NumPy arrays, one at a time, and decode the candidate bounding boxes and class predictions. Further, any bounding boxes that don’t confidently describe an object (e.g. all class probabilities are below a threshold) are ignored. We will use a probability of 60% or 0.6. The function returns a list of BoundBox instances that define the corners of each bounding box in the context of the input image shape and class probabilities.
|
1 2 3 4 5 6 7 8 |
# define the anchors anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]] # define the probability threshold for detected objects class_threshold = 0.6 boxes = list() for i in range(len(yhat)): # decode the output of the network boxes += decode_netout(yhat[i][0], anchors[i], class_threshold, input_h, input_w) |
Next, the bounding boxes can be stretched back into the shape of the original image. This is helpful as it means that later we can plot the original image and draw the bounding boxes, hopefully detecting real objects.
The experiencor script provides the correct_yolo_boxes() function to perform this translation of bounding box coordinates, taking the list of bounding boxes, the original shape of our loaded photograph, and the shape of the input to the network as arguments. The coordinates of the bounding boxes are updated directly.
|
1 2 |
# correct the sizes of the bounding boxes for the shape of the image correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w) |
The model has predicted a lot of candidate bounding boxes, and most of the boxes will be referring to the same objects. The list of bounding boxes can be filtered and those boxes that overlap and refer to the same object can be merged. We can define the amount of overlap as a configuration parameter, in this case, 50% or 0.5. This filtering of bounding box regions is generally referred to as non-maximal suppression and is a required post-processing step.
The experiencor script provides this via the do_nms() function that takes the list of bounding boxes and a threshold parameter. Rather than purging the overlapping boxes, their predicted probability for their overlapping class is cleared. This allows the boxes to remain and be used if they also detect another object type.
|
1 2 |
# suppress non-maximal boxes do_nms(boxes, 0.5) |
This will leave us with the same number of boxes, but only very few of interest. We can retrieve just those boxes that strongly predict the presence of an object: that is are more than 60% confident. This can be achieved by enumerating over all boxes and checking the class prediction values. We can then look up the corresponding class label for the box and add it to the list. Each box must be considered for each class label, just in case the same box strongly predicts more than one object.
We can develop a get_boxes() function that does this and takes the list of boxes, known labels, and our classification threshold as arguments and returns parallel lists of boxes, labels, and scores.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# get all of the results above a threshold def get_boxes(boxes, labels, thresh): v_boxes, v_labels, v_scores = list(), list(), list() # enumerate all boxes for box in boxes: # enumerate all possible labels for i in range(len(labels)): # check if the threshold for this label is high enough if box.classes[i] > thresh: v_boxes.append(box) v_labels.append(labels[i]) v_scores.append(box.classes[i]*100) # don't break, many labels may trigger for one box return v_boxes, v_labels, v_scores |
We can call this function with our list of boxes.
We also need a list of strings containing the class labels known to the model in the correct order used during training, specifically those class labels from the MSCOCO dataset. Thankfully, this is provided in the experiencor script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# define the labels labels = ["person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"] # get the details of the detected objects v_boxes, v_labels, v_scores = get_boxes(boxes, labels, class_threshold) |
Now that we have those few boxes of strongly predicted objects, we can summarize them.
|
1 2 3 |
# summarize what we found for i in range(len(v_boxes)): print(v_labels[i], v_scores[i]) |
We can also plot our original photograph and draw the bounding box around each detected object. This can be achieved by retrieving the coordinates from each bounding box and creating a Rectangle object.
|
1 2 3 4 5 6 7 8 9 |
box = v_boxes[i] # get coordinates y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax # calculate width and height of the box width, height = x2 - x1, y2 - y1 # create the shape rect = Rectangle((x1, y1), width, height, fill=False, color='white') # draw the box ax.add_patch(rect) |
We can also draw a string with the class label and confidence.
|
1 2 3 |
# draw text and score in top left corner label = "%s (%.3f)" % (v_labels[i], v_scores[i]) pyplot.text(x1, y1, label, color='white') |
The draw_boxes() function below implements this, taking the filename of the original photograph and the parallel lists of bounding boxes, labels and scores, and creates a plot showing all detected objects.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# draw all results def draw_boxes(filename, v_boxes, v_labels, v_scores): # load the image data = pyplot.imread(filename) # plot the image pyplot.imshow(data) # get the context for drawing boxes ax = pyplot.gca() # plot each box for i in range(len(v_boxes)): box = v_boxes[i] # get coordinates y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax # calculate width and height of the box width, height = x2 - x1, y2 - y1 # create the shape rect = Rectangle((x1, y1), width, height, fill=False, color='white') # draw the box ax.add_patch(rect) # draw text and score in top left corner label = "%s (%.3f)" % (v_labels[i], v_scores[i]) pyplot.text(x1, y1, label, color='white') # show the plot pyplot.show() |
We can then call this function to plot our final result.
|
1 2 |
# draw what we found draw_boxes(photo_filename, v_boxes, v_labels, v_scores) |
We now have all of the elements required to make a prediction using the YOLOv3 model, interpret the results, and plot them for review.
The full code listing, including the original and modified functions taken from the experiencor script, are listed below for completeness.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 |
# load yolov3 model and perform object detection # based on https://github.com/experiencor/keras-yolo3 import numpy as np from numpy import expand_dims from keras.models import load_model from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from matplotlib import pyplot from matplotlib.patches import Rectangle class BoundBox: def __init__(self, xmin, ymin, xmax, ymax, objness = None, classes = None): self.xmin = xmin self.ymin = ymin self.xmax = xmax self.ymax = ymax self.objness = objness self.classes = classes self.label = -1 self.score = -1 def get_label(self): if self.label == -1: self.label = np.argmax(self.classes) return self.label def get_score(self): if self.score == -1: self.score = self.classes[self.get_label()] return self.score def _sigmoid(x): return 1. / (1. + np.exp(-x)) def decode_netout(netout, anchors, obj_thresh, net_h, net_w): grid_h, grid_w = netout.shape[:2] nb_box = 3 netout = netout.reshape((grid_h, grid_w, nb_box, -1)) nb_class = netout.shape[-1] - 5 boxes = [] netout[..., :2] = _sigmoid(netout[..., :2]) netout[..., 4:] = _sigmoid(netout[..., 4:]) netout[..., 5:] = netout[..., 4][..., np.newaxis] * netout[..., 5:] netout[..., 5:] *= netout[..., 5:] > obj_thresh for i in range(grid_h*grid_w): row = i / grid_w col = i % grid_w for b in range(nb_box): # 4th element is objectness score objectness = netout[int(row)][int(col)][b][4] if(objectness.all() <= obj_thresh): continue # first 4 elements are x, y, w, and h x, y, w, h = netout[int(row)][int(col)][b][:4] x = (col + x) / grid_w # center position, unit: image width y = (row + y) / grid_h # center position, unit: image height w = anchors[2 * b + 0] * np.exp(w) / net_w # unit: image width h = anchors[2 * b + 1] * np.exp(h) / net_h # unit: image height # last elements are class probabilities classes = netout[int(row)][col][b][5:] box = BoundBox(x-w/2, y-h/2, x+w/2, y+h/2, objectness, classes) boxes.append(box) return boxes def correct_yolo_boxes(boxes, image_h, image_w, net_h, net_w): new_w, new_h = net_w, net_h for i in range(len(boxes)): x_offset, x_scale = (net_w - new_w)/2./net_w, float(new_w)/net_w y_offset, y_scale = (net_h - new_h)/2./net_h, float(new_h)/net_h boxes[i].xmin = int((boxes[i].xmin - x_offset) / x_scale * image_w) boxes[i].xmax = int((boxes[i].xmax - x_offset) / x_scale * image_w) boxes[i].ymin = int((boxes[i].ymin - y_offset) / y_scale * image_h) boxes[i].ymax = int((boxes[i].ymax - y_offset) / y_scale * image_h) def _interval_overlap(interval_a, interval_b): x1, x2 = interval_a x3, x4 = interval_b if x3 < x1: if x4 < x1: return 0 else: return min(x2,x4) - x1 else: if x2 < x3: return 0 else: return min(x2,x4) - x3 def bbox_iou(box1, box2): intersect_w = _interval_overlap([box1.xmin, box1.xmax], [box2.xmin, box2.xmax]) intersect_h = _interval_overlap([box1.ymin, box1.ymax], [box2.ymin, box2.ymax]) intersect = intersect_w * intersect_h w1, h1 = box1.xmax-box1.xmin, box1.ymax-box1.ymin w2, h2 = box2.xmax-box2.xmin, box2.ymax-box2.ymin union = w1*h1 + w2*h2 - intersect return float(intersect) / union def do_nms(boxes, nms_thresh): if len(boxes) > 0: nb_class = len(boxes[0].classes) else: return for c in range(nb_class): sorted_indices = np.argsort([-box.classes[c] for box in boxes]) for i in range(len(sorted_indices)): index_i = sorted_indices[i] if boxes[index_i].classes[c] == 0: continue for j in range(i+1, len(sorted_indices)): index_j = sorted_indices[j] if bbox_iou(boxes[index_i], boxes[index_j]) >= nms_thresh: boxes[index_j].classes[c] = 0 # load and prepare an image def load_image_pixels(filename, shape): # load the image to get its shape image = load_img(filename) width, height = image.size # load the image with the required size image = load_img(filename, target_size=shape) # convert to numpy array image = img_to_array(image) # scale pixel values to [0, 1] image = image.astype('float32') image /= 255.0 # add a dimension so that we have one sample image = expand_dims(image, 0) return image, width, height # get all of the results above a threshold def get_boxes(boxes, labels, thresh): v_boxes, v_labels, v_scores = list(), list(), list() # enumerate all boxes for box in boxes: # enumerate all possible labels for i in range(len(labels)): # check if the threshold for this label is high enough if box.classes[i] > thresh: v_boxes.append(box) v_labels.append(labels[i]) v_scores.append(box.classes[i]*100) # don't break, many labels may trigger for one box return v_boxes, v_labels, v_scores # draw all results def draw_boxes(filename, v_boxes, v_labels, v_scores): # load the image data = pyplot.imread(filename) # plot the image pyplot.imshow(data) # get the context for drawing boxes ax = pyplot.gca() # plot each box for i in range(len(v_boxes)): box = v_boxes[i] # get coordinates y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax # calculate width and height of the box width, height = x2 - x1, y2 - y1 # create the shape rect = Rectangle((x1, y1), width, height, fill=False, color='white') # draw the box ax.add_patch(rect) # draw text and score in top left corner label = "%s (%.3f)" % (v_labels[i], v_scores[i]) pyplot.text(x1, y1, label, color='white') # show the plot pyplot.show() # load yolov3 model model = load_model('model.h5') # define the expected input shape for the model input_w, input_h = 416, 416 # define our new photo photo_filename = 'zebra.jpg' # load and prepare image image, image_w, image_h = load_image_pixels(photo_filename, (input_w, input_h)) # make prediction yhat = model.predict(image) # summarize the shape of the list of arrays print([a.shape for a in yhat]) # define the anchors anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]] # define the probability threshold for detected objects class_threshold = 0.6 boxes = list() for i in range(len(yhat)): # decode the output of the network boxes += decode_netout(yhat[i][0], anchors[i], class_threshold, input_h, input_w) # correct the sizes of the bounding boxes for the shape of the image correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w) # suppress non-maximal boxes do_nms(boxes, 0.5) # define the labels labels = ["person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"] # get the details of the detected objects v_boxes, v_labels, v_scores = get_boxes(boxes, labels, class_threshold) # summarize what we found for i in range(len(v_boxes)): print(v_labels[i], v_scores[i]) # draw what we found draw_boxes(photo_filename, v_boxes, v_labels, v_scores) |
Running the example again prints the shape of the raw output from the model.
This is followed by a summary of the objects detected by the model and their confidence. We can see that the model has detected three zebra, all above 90% likelihood.
|
1 2 3 4 |
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)] zebra 94.91060376167297 zebra 99.86329674720764 zebra 96.8708872795105 |
A plot of the photograph is created and the three bounding boxes are plotted. We can see that the model has indeed successfully detected the three zebra in the photograph.
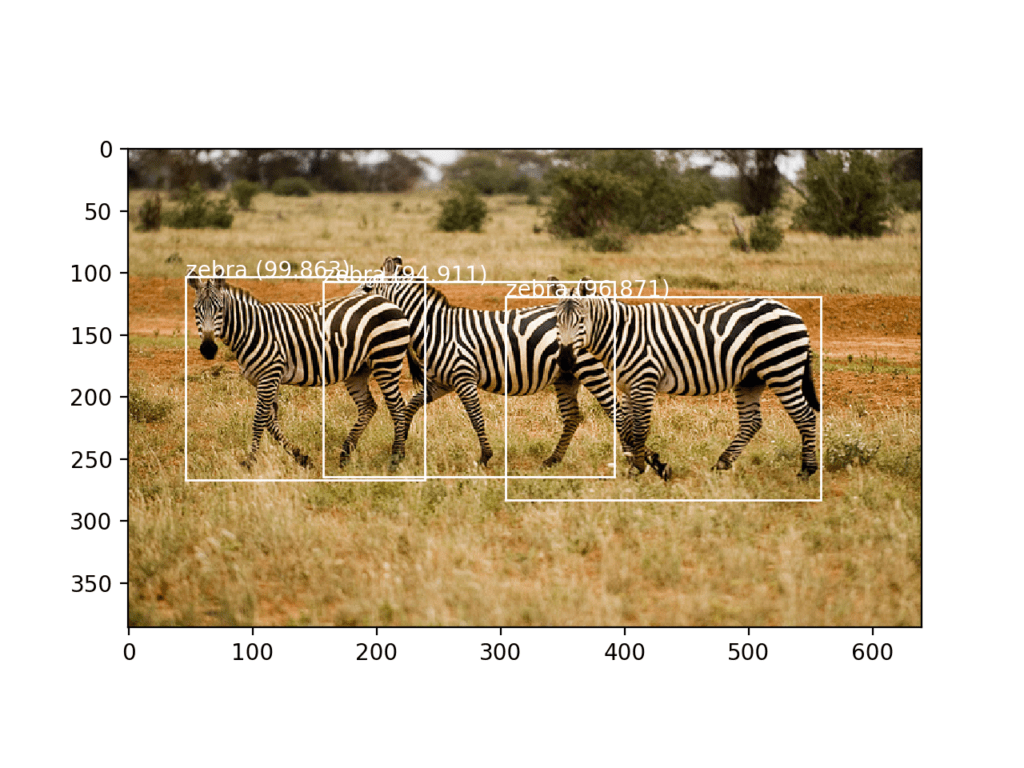
Photograph of Three Zebra Each Detected with the YOLOv3 Model and Localized with Bounding Boxes
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
API
Resources
- YOLO: Real-Time Object Detection, Homepage.
- Official DarkNet and YOLO Source Code, GitHub.
- Official YOLO: Real Time Object Detection.
- Huynh Ngoc Anh, experiencor, Home Page.
- experiencor/keras-yolo3, GitHub.
Other YOLO for Keras Projects
Summary
In this tutorial, you discovered how to develop a YOLOv3 model for object detection on new photographs.
Specifically, you learned:
- YOLO-based Convolutional Neural Network family of models for object detection and the most recent variation called YOLOv3.
- The best-of-breed open source library implementation of the YOLOv3 for the Keras deep learning library.
- How to use a pre-trained YOLOv3 to perform object localization and detection on new photographs.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning Models for Vision Today!

Develop Your Own Vision Models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Computer Vision
It provides self-study tutorials on topics like:
classification, object detection (yolo and rcnn), face recognition (vggface and facenet), data preparation and much more...
Finally Bring Deep Learning to your Vision Projects
Skip the Academics. Just Results.






thank you so much, machine learning for object detection! you have broadened my horizon, but, I am a game developer, so, usually bounding boxes are known, I have personal interest in go game, I wish I could understand machine-learning in go game, could you please give me a pointer?
Thanks.
Sorry, I don’t have any tutorials on games, I cannot give you good advice.
which model use for skin wound care?
Perhaps test a suite of models on your problem and select the one that performs the best.
Awsom @Jason Brownlee, I faced some issue like ValueError: If your data is in the form of symbolic tensors, you should specify the
stepsargument (instead of thebatch_sizeargument, because symbolic tensors are expected to produce batches of input data) when I called Model.predict(image)@Jasin Brownlee, It was very interesting and very well narrated. Could you please include , how would we add additional training set and labels ?
Let say, I want this model to train on additional data, to classify Faces, or Hand Scribbled Digits and alphabets ? Suppose I have an additional training & test data set.
Yes, I give an example here:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
@Jason, Could we use this same Yolo Model to train, instead of Mask R-CNN ?
Yes, but I don’t have a tutorial on this, sorry. I hope to cover it in the future.
Hi Jason, thanks for this very nice tutorial.
It would be really interesting to have at the end an example of training this yolo model on a new custom dataset.
What format the label should have? What loss function to use? Thanks!
Thanks for the suggestion.
Perhaps this example will help:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Thanks, but it would be super cool to have the example with yolov3 instead !
Thanks for the suggestion.
choose steps=2
Nice article,
I found also an interesting beginner’s guide of YOLOv3 here:
https://machinelearningspace.com/the-beginners-guide-to-implementing-yolov3-in-tensorflow-2-0-part-1/
Thanks for sharing.
Amazing post, thanks for sharing
Thanks, I’m glad it was helpful.
Hi sur, I just want to use the Darknet 53 as a features extractor to my dataset
How can I get these features using Darknet 53 only?
Sorry, I don’t have a tutorial on darknet, I cannot give you good off the cuff advice.
Hi Jason,
Thanks for this great lesson. Have you tried to run any custom object using experiencor’s codes namely gen_anchor.py and train.py? If so, have you faced any error? gen_anchor.py threw me some errors even with his own config file for raccoon dataset and unfortunately he’s not being responsive. Thank you!
Kindly also make a blog on How we train a custom object detection with YOLO3
Great suggestion, thanks.
Here’s a custom model for kangaroo detection using Mask RCNN:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Any updates on this??? No where online seems to attempt to even do this…
Hopefully in the future.
Jason, thank you very much for introducing computer vision so clearly! Could you specify in what part we saved our trained model to the disk?
The model was pre-trained, we simply loaded it.
Thank you so much for clean working code!) Could you advise some working and understandable GitHub repository for YOLOv3 for detecting objects on video, experiencer case is not clear in steps(
I hope to cover this in the future, thanks for the suggestion.
Thank you so much Sir! Very amazing and informative tutorial . I am beginner and following your tutorials for learning deep learning.
kindly Sir!
1) use YOLOv3 for camera video or simple video
2) use LSTM for video sequence
It will be great helpful for me
Great suggestion, thanks.
Thanks so much for posting such a good tutorial, thanks!!!
You’re welcome, I’m glad it helps.
Thank you so much sir for your helpful tutorial.
Could you tell me how can i change the number and titles of labels in this model ? or labels are unchangeable ?
The number of classes. Yes, you can fit a new object detection model with the image and classes in your dataset.
I given an example here:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Amazing guide Jason.
At the start I experienced some difficulty with the library, since the latest version of Tensorflow did not work. I downgraded it to v1.12 and it worked.
Thanks for the introduction to CV and YOLOv3. It was fun trying it out with my own images.
Thanks, and well done.
I tested it with TensorFlow 1.13 on Ubuntu Linux and MacOS without incident.
What OS/platform are you on?
i was using pycharm on windows using anaconda as the python interpreter.
Irregardless, I will be moving on to the kangaroo tutorial since I managed to run the process successfully.
Thanks again for creating these tutorials
Nice work.
I am getting “AbortedError: Operation received an exception:Status: 3, message: could not create a dilated convolution forward descriptor, in file tensorflow/core/kernels/mkl_conv_ops.cc:1111
[[{{node conv_1/convolution}}]]” error in predictin step.
Using tensorflow 1.13.1
I have not seen that error before, sorry.
Perhaps try TF 1.14, and check that your keras is up to date?
I have the same error message
Sorry to hear that, I can confirm the example works with the latest versions of all libraries.
Perhaps some of the suggestions here will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Great tutorial Jason. Very well laid out and easy to follow. I’m hoping to extend the tutorial to consider training on a custom data set. Would love to see a follow up blog on this 🙂
Keep up the great work!
Great suggestion, thanks.
Perhaps this post will be helpful:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hi
How to detect objects using YOLO in videos?
Also, is it possible to detect only 1 particular object (say, person) using this?
Perhaps you can process each frame as an image, or every 25th frame.
Hi,
Great tutorial, thank you so much. How can I access the location of an object in an image? I would like to know, for instance, where the zebras are in the image (coordinates of the center of the bounding boxes) and save this data to a file.
The model will output bounding boxes (pixel coordinates) that you can use any way that you wish.
In this tutorial, we simply draw the box.
Hello,
I keep getting the following coordinates :
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)]
No matter how many different images I’m experimenting with, could you please tell me why?
It doesn’t look like a bounding box to me. Can you check?
I didn’t change anything in the code, only the image files, what should I check?
Thanks for an ELI5 guide Jason!
In interpreting the prediction array with decode_netout(), one of the argument was the anchors that you defined:
anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]]
Is this suppose to be an initial guess for a bounding box of where the object may be?
Good question.
It is the shape of the anchor boxes used during training. From the post:
But what those anchors are? What are they used for? I’m guessing I my question is the same as Ivan’s.
They are chosen to best capture objects in the image net dataset, chosen based on that dataset.
They are used when making a prediction to help quickly find objects in your new photos – e.g. bounding boxes in the image data.
Hi Jason,
Question regarding anchors as they are hard coded, is it possible to derive them programmatically from yhat or the three NumPy array values or some other mechanism ?
Also each array of ‘anchors’ having 6 elements is also puzzling, would be nice to know the process/documentation for defining these values.
Good tutorial and helpful in getting started.
A suggestion if you could cover on the the steps to generalize this code e.g. if I pass file path of a photo of a cat or a car etc. code should able to detect that just like it did for zebra ?
Many thanks.
They are derived based on the average size of objects in a training dataset.
You could derive them based on the expected object size in your dataset if you like.
This article helped me understand this.
https://medium.com/analytics-vidhya/yolo-v3-theory-explained-33100f6d193
From what i can gather the algorithm has set bounding box sizes it uses. Each “cell” (IE small division of the larger image) the probability that this cell contains a specific object is computed for each anchor box size.
So if you have an image made up of 10 x 10 cells, and 5 anchor sizes, AND 100 objects to detect you will get an output of size:
10 x 10 x 5 x 100
10 x 10 for each cell
x 5 for each anchor size
x 100 for each object
each of these will be a probability and we take probabilities which meet a certain threshold.
I’m just learning this so PLEASE correct me if i’m mistaken.
Yes, it is along those lines.
Hi Jason,
I have followed through the Experiencor YOLO3 for Keras Project to train with my own data set. If i would like to crop the bounding box from the newly predicted images, how do i go about it?
Thank you
The model will output bounding boxes, you can use them directly on the image pixels.
Thanks a lot for the response Jason. I managed to get good outputs with new images. However, the mAP performance of the model indicates 0.000 which is very strange. Could there be any reasons for it?
Well done.
Perhaps test a suite of images to see if that uncovers more information?
awesome tutorial sir !! Please answer this question https://datascience.stackexchange.com/questions/54306/transfer-learning-on-yolo-using-keras
many thanks
Perhaps you can summarize it briefly for me?
Great work Jason.
Can you also tell me how to train in with a new dataset?
Mainly the format of annotation of the dataset to train with.(The YOLOv2 of this repository used .xml format like that of pascalVOC).
Is it the same or something different?
Also I need train the model with transfer learning.
So which all layers should I train?
If possible can you please give an idea about the code to use?
Thank you
I hope to cover that in the future.
Hi Jason, thx for this example !
note that I found that there is some vertical down shift of the output boxes (it can be seen on your “zebra” image output above, the 3 boxes are sligthly too low. The shift can be really bigger on some other images I tested. Even on 416×416 input images)
Any chance you fix this soon ?
Many thanks anyway!
Thanks, I may investigate.
Hi,
This is an awesome tutorial. I went through it but at the end did not get a picture with bounding boxes as shown. I only got the array values and predictions for zebra and percentages.
A figure with the bounding boxes wasn’t created.
Any ideas?
Thank you
Did you try running the example from the command line:
https://machinelearningmastery.com/faq/single-faq/how-do-i-run-a-script-from-the-command-line
Yes,
I am using Debian stretch subsystem under Windows
Is there in the book any additional content in addition to what is in this article?
Concretely, I would be interested in the training process 😉
Sorry, I don’t have an example of training a YOLO model, only using one.
I do have an example of training a Mask RCNN, which is reported to perform better:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Yes, I have a book on deep learning for computer vision here:
https://machinelearningmastery.com/deep-learning-for-computer-vision/
Does that help?
Thank you for the answer. I know about the book and I’m considering buying it, but I am not sure if I’ll find there what I need.
I need to train the YOLO network using my own data. Is there a proper example in the book? Is there anything more about the YOLO than in this article?
No sorry, the examples in the book focus on training a mask rcnn.
Isn’t the compilation of the model missing?
Not needed in this case.
I want to run this code. But it was too slow. I think it was not run on GPU. How could I test it by GPU? I want to run it in Jupyter Notebook.
Perhaps try running it on an AWS EC2 instance?
Here’s how:
https://machinelearningmastery.com/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
Thanks so much for posting such a good tutorial. My question is how can we use YoloV3 to detect custom classes (labels)? In other words, how to reuse (retrain) it to detect custom objects?
I recommend using Mask R-CNN, I show how here:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Thanks. Which one (Yolo3 and Mask R-CNN) is more accurate and has more precise results?
I believe YOLO models are faster and the R-CNN models are better.
how can train the model with my data
You can follow this tutorial:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Excellent post, as always. One question. I have some yolo weights in .pt (pytorch) form. Is it possible to load this .pt file in some way or transform it so I can load it in a keras implemented yolo? Many thanks!!!
It may be possible to convert them.
Sorry, I don’t have an example of this.
Thanks for your reply, Jason. I’ look it up.
No problem.
I have one technical question about the model. How the last layer knows which units correspond to which cell, since it is denselly connected with the previous one?
Sorry, what do you mean exactly?
The output of the YOLO network is S x S x N values, where S is the number of cells in both image directions. Therefore, the network predicts N values for each cell of the image.
If I understand it correctly, each set on N values delivers a prediction for the corresponding image cell.
My question is how a given image cell corresponds to the particular set of N values if everything is densely connected with everything? In other words, how the networks “know” which set of the predicted values are for which part of the image?
I know that the question can be a liittle bit confusing, but I hope that now I have clarified it better.
Good question.
The raw output of the model passes through some post-processing functions to reduce the set of possible predictions down to a set of useful crisp predictions.
The raw and processed output of the model are discussed more in this post:
https://machinelearningmastery.com/object-recognition-with-deep-learning/
Thank you for the answer!
You’re welcome.
Let me ask about one more thing 😉 The output is a tensor of size n x S x S x (B*5 + C), where n is the number of anchor sizes, S x S is the number of cells, B is the number of anchors for each size and C is the number of classess. In our model we have 3 anchors in 3 different sizes, and the MSCOCO dataset has 80 classes, so the shape of the output tensor should be: (3,S,S,3*5+80), what is (3,S,S,95). However, our output is (3,S,S,255). Why is that?
Not quite, the output is encoded.
You can review the decoding functions in the post to see how the 3d output is interpreted.
Oh, I see it. Thanks again! 😉
I am new to machine learning. if we use pretrained weights for training custom (new) object, Will it detect old objects? for example, pretrained weights detect 80 objects (classes), I used this weight to train my new object (classes). Will it detect 81 objects or only one (new object).
if it is detect only one (new object) how to make it detect 81 object.
Thanks in advance
You will have to train on the a dataset that combines the original training dataset with your new class.
Starting with pre-trained weights would speed this up a lot!
thanks a lot for this excellent post. I have a question. In the function correct_yolo_boxes(), what is the purpose to calculate offsets and scale? I thought offsets and scales are always 0 and 1 respectively, and they have no effect.
I believe we are scaling the boxes to the size of the image.
Hi, is there a typo in the correct_yolo_boxes() implementation? The first line in the function: new_w, new_h = net_w, net_h will make the offsets and scales always 0 and 1.
Thank you for your post, it helped me a lot
Thanks.
So, what about this code?
offset and scale always 0 and 1.
Is this mistake?
what the right code?
Anyone trying to understand how the Yolov3 outputs are in the shapes they are, this(https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b) is an amazing resource.
Thank you for the code walk through Jason!
Thanks for sharing.
Excellent article, thanks.
I trained my own YOLOv3 model with custom classes (fewer than the default 80) using Darknet. I therefore have a new .cfg file as well as weights file.
I would like to perform inference using keras on Tensorflow, rather than Darknet.
Is there a way I can do this using your program above? I don’t see a way to specify my own .cfg file. It only seems to accept the weights file.
Thanks.
There may be a way, I’m not sure off the cuff sorry. Some experimentation may be required.
I tried changing the number of filters from 255 to (num_classes + 5)*3, in each of the 3 YOLO layers. I’m able to get inference results, but they don’t match what I obtained with the original Darknet.
Nice progress!
Thank you so much for such a simple and elaborate explanation.
The code is working fine but I have a problem of not being able to save the model.
I get the following error when I save any model.
Error! F:\NITD\Project\Code\model.h5 is not UTF-8 encoded.
Saving disabled.
That is very odd.
Perhaps it is an issue with your h5py library?
Perhaps try posting/searching on stackoverflow for related issues?
Hi , I’m trying to perform this object detection on video, but i’m getting error . check this out.
ERROR: rectangle() missing required argument ‘rec’ (pos 2)
Here is the sample code. Do you know how to fix this? i tried a lot of things.
def cv(frame, x, y, w, h, v_lables, v_scores):
cv2.rectangle(img = frame,
pt1 = (x, y),
pt2 = (x + w, y + h),
color = (0, 0, 255),
thickness = 2,
lineType = cv2.LINE_AA)
cv2.putText(frame, “{}-{}”.format(v_labels,v_scores), (x + w, y),
cv2.FONT_HERSHEY_SIMPLEX,
fontScale = 1, color = (255, 255, 255), thickness = 1, lineType = cv2.LINE_AA)
return frame
reader = imageio.get_reader(‘video.mp4’)
fps = reader.get_meta_data()[‘fps’]
writer = imageio.get_writer(‘output1.mp4’, fps = fps)
for i,frame in enumerate(reader):
image, image_w, image_h = load_image_pixels(frame, (input_w, input_h))
yhat = model.predict(image)
for j in range(len(yhat)):
boxes += decode_netout(yhat[j][0], anchors[j], class_threshold, input_h, input_w)
correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w)
do_nms(boxes, 0.5)
v_boxes, v_labels, v_scores = get_boxes(boxes, labels, class_threshold)
for z in range(len(v_boxes)):
box = v_boxes[z]
y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax
width = x2 – x1
height = y2 – y1
frame = cv(frame, x1, y1, width, height, v_labels[z], v_scores[z])
writer.append_data(frame)
print(i)
I’m sorry to hear that, I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hello Sachin,
Can you please share your code to detect object on Video?
Thank you
hi sachin, can you please send me the code for video/webcam object detection?
hey can u pls provide me the code for object detection on video
That’s okay i fixed it. Thank you !
I’m happy to hear that.
Can you share the code ?
Hello Jason,
Thank you for the comprehensive tutorial.
2 questions:
1) I tried removing some of the objects in the labels and the image opened without applying the algorithm, there were no markings on it. How can we add objects such as (Jar, Speaker, etc..) or modify this current list?
2) When the algorithm works, it does perform well. could we change the bounding box anchors from the code, or it has to be done from the training source code? In case we wanted to increase the height of the box.
I understand these are in-depth questions, if you could provide any brief steps or research hints from your Books/Posts, that would be appreciated.
Thanks!
You might need to dive into the paper and open source implementation, or jump to mask r-cnn:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Thank you!
I will check it out.
Thanks.
So I tried to predict an image with the same code as written above but I got this error:
ValueError: If your data is in the form of symbolic tensors, you should specify the
stepsargument (instead of thebatch_sizeargument, because symbolic tensors are expected to produce batches of input data).Any idea on what’s wrong here? Thanks in advance!
Perhaps confirm that your libraries are up to date and that you loaded your image as a NumPy array?
the code works for zebra.jpg, but failed to the elephant and carrot pictures which are downloaded from internet
Perhaps double check hat the images were loaded correctly?
it is the threshold that filter out the correct result. anyway it works now.
Happy to hear that.
what do you mean exactly it is the threshold to filter the correct result? the same problem happened to me when i try using an elephant picture it did not give me the BB? Should I have to change the threshold value every-time I give another picture of different class?
the picture outputs a class value as 0.7 while my threshlod is 0.8, so there is no output in the plot picture. when i change the threshlod to 0.6, the plot picture show the correct result
Thanks for a brilliant blog and have a one request
Just like ”custom training on MaskR-CNN” blog also make a blog on YOLO to.
Thanks for the suggestion!
Sir, how to store the objects detected in the bounding box as a separate image.
You can use the bounding box to extract the pixels from the image, e.g. indexes into the array that holds the pixel data.
I give an example in this post:
https://machinelearningmastery.com/how-to-perform-face-detection-with-classical-and-deep-learning-methods-in-python-with-keras/
Thank you for your amazing dedication to teach those of us who are learning through the internet. the internet is my university. Currently I am working on project for detection of malaria parasite from thick blood microscopic images using yolov3 algorithm. what i am afraid of is may be yolov3 will not detect object at parasite level since they are tiny. what is your recommendation for me? I have the microscopic images.
That sounds like a great project.
I would encourage you to test a suite of different models and discover what works best for your specific dataset.
Can we have tutorial for object tracking using discrimitive correlation filter https://arxiv.org/pdf/1611.08461.pdf
Thanks for the suggestion.
Thank you. Your explain very good.
Only question. How I can keep on disk the image with detection object.
Good bless you
Thanks.
What do you mean exactly? How to save an image – if so, see this tutorial:
https://machinelearningmastery.com/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
Very cool example, but decode_netout() is very slow. Any suggestions for making it faster? Aggressively pruning unwanted items?
E.g., what if I’m only interested in one type of label?
Good question. You might have to experiment.
Found an excellent pointer here:
https://github.com/experiencor/keras-yolo3/issues/177
Or replace
if(objectness.all() <= obj_thresh): continue
with
if (objectness <= obj_thresh).all(): continue
It speeds up that function by orders of magnitude.
Thanks for sharing.
I think that the line must be changed like below..
if netout[int(row)][int(col)][b][5:].max() <= obj_thresh: continue
The corrected line works well.
I think original code is a bug. It makes all the boxes valid.
Hi Jason, Thanks for all codes man. My friend, I updated tensorflow to 2.0 version, this code doesn’t work. I changed the importations to tensorflow.keras, but the class “Add” have a problem em this line “return add([skip_connection, x]) if skip else x”. Do u have some tip?
If you use standalone Keras v2.3.0 on top of TensorFlow 2.0, the code works fine.
Thank you very much for sharing, I think I understand more about YOLOv3.
But I still do not understand about meaning of numbers in :
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)]
I think 13*13 or 26*26 and 52*52 is three different sizes of anchor boxes.
But what is meaning of number ‘1’ and ‘255’ ?
Let me thank you again for helping.
Good question.
Yes, the first dimension (1) can be ignored, the middle are the size (13 or 26), and the final are the number of boxes, that will need to be reduced or interpreted.
(1, 13, 13, 255) get into (13, 13, 3, 85) where is 3 – numb of anch_boxes, and 3*85 = 255, it’s just reshape
model.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples)
how can i make detection from this code
See the section titled “Make a Prediction”.
Jason,
What a great talent you have to compile those tutorials. My students use some of them for the initial training.
Question: Do you have one for streaming video content/object recognition that I could use when the new batch of interns arrive?
thanks, peter
Thanks.
Sorry, I don’t have tutorials on working with video data, I hope to cover it in the future.
Hi,
I think there is an error in the following line:
44 netout[…, 4:] = _sigmoid(netout[…, 4:])
It should be:
44 netout[…, 4] = _sigmoid(netout[…, 4])
You can see it by comparing the source code from utils.py in experiencor/keras-yolo3 with yolo3_one_file_to_detect_them_all.py
Thanks, I will schedule time to investigate.
I have made a text file for the anchor boxes which looks like this:
C:\path\00000002.jpg 0.33999999999999997,0.6900000000000001,0.7225,0.26,1 0.7775,0.40249999999999997,0.91,0.265,1 0.68,0.97,0.84,0.8025,1
..
(path x1,y1,x2,y2,class)
I have made it by myself with converting the form from txt file which was like this:
(class x y width height)
*Used a different annotator
Now when I try to run the train.py and put the path to my txt file for my anchors, classes,the path to my foldaer with the photos and the output folder its gives me ERROR :
Using TensorFlow backend.
2019-11-13 08:17:06.054804: I C:\tf_jenkins\workspace\rel-win\M\windows\PY\36\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
……………………………
Traceback (most recent call last):
File “train.py”, line 190, in
_main()
File “train.py”, line 42, in _main
with open(annotation_path) as f:
FileNotFoundError: [Errno 2] No such file or directory: ‘train.txt’
What should I do ?
I’m sorry to hear that, I have some suggestions here that might help:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Hello Jason!
Any chance of you writing a post of how can I retrain this yolo model with a new class? With labeled data? Data labeled with program labelImg (https://github.com/tzutalin/labelImg)
Is it possible to still use Keras for this task?
Thanks in advance,
Denis
Thanks for the suggestion Denis.
Thanks for sharing this tutorial with us.
I am not able to understand how is anchor size associated to yhat in decode_netout. Smaller size output (13,13,255) is being compared with the biggest dimension anchor boxes[116,90, 156,198, 373,326].
When we say anchor box is of dimension 116,90 how does it map to the original image? what are the units of these dimensions?
Pixels.
thank you very much, can you give me details if i want to use this code for multi-view dataset ( any one img has three views)
Sorry, I have not worked with a multi-view dataset. I cannot give you good advice.
Hi Jason,
Thanks for this great lesson. Have you tried to run any custom object using experiencor’s codes namely gen_anchor.py and train.py? If so, have you faced any error? gen_anchor.py threw me some errors even with his own config file for raccoon dataset and unfortunately he’s not being responsive. Thank you!
No. I use mask rcnn instead:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hey Jason thank you for the tutorial. Can you please explain from Line 42 – line 46 in the function: decode_netout. that manipulation part is so vague for me:
boxes = []
netout[…, :2] = _sigmoid(netout[…, :2])
netout[…, 4:] = _sigmoid(netout[…, 4:])
netout[…, 5:] = netout[…, 4][…, np.newaxis] * netout[…, 5:]
netout[…, 5:] *= netout[…, 5:] > obj_thresh
Specially Line 24
netout[…, 5:] = netout[…, 4][…, np.newaxis] * netout[…, 5:]
did you figure this out?
Hi Jason,
Thank you for the clear demonstration of YOLO. However, how do I use this method/model to train a new data set of my own, not a pre-loaded one?
Many thanks
Nadav
See this tutorial:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hey, Thanks for the tutorials, it helped me a lot, I’m implementing yolov3-tiny into android and I am getting an array of [1,2535,85] as output, I am still confused what to do with it?
Like which one is classes probability, which ones are x, y, position, which on is width, height? can you help!
Thanks.
Sorry, I am not familiar with that model.
Did you figure it out?
Hi,
Thank you very much for this detailed tutorial, Could I use binary images in training and testing time?
You’re welcome.
What do you mean exactly?
Thanks for sharing this tutorial with us.
I am a beginner in deep learning and trying to find the accuracy of YOLOv3 for the test dataset. I can run your code to predict for one image but I could not do it for the whole dataset. In addition, I need to print the precision and other parameters that are useful to compare YOLOv3 with other methods like MASK R-CNN. Can you please guide me on how to do it?
Thanks
You’re welcome.
This will help:
https://machinelearningmastery.com/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
Hi,
Thank you very much for this detailed tutorial, I am a beginner in deep learning, Could I use this YOLOv3 for cancer detection in CT scan images?
Perhaps. You will have to train a new model specialized for the domain.
Perhaps consider using a mask rcnn:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hi Jason,
Thanks for sharing the interesting blog!
I have trained object detection using ssd (mobilenet-v1) on custom dataset. The dataset consist of uno playing card images (skip, reverse, and draw four). On all these cards, model performs pretty well as I have trained model only on these 3 card (around 278 images with 829 bounding boxes collected using mobile phone). However, I haven’t trained model on any other card but still it detects other cards (inference using webcam).
How can I fix this?
Please share your view!
Thanking you!
You’re welcome!
Maybe create an “other” class and give examples of all kinds of random examples during training that belong to this class, then write code to ignore this class in operation.
Thanks Jason for the quick response.
Is this also applicable in real world scenario? Bcoz let’s say at the moment I am looking for only three cards (skip, reverse and draw four) and ignoring rest of the cards (nearly 10 cards).
According to my area of interest (skip, reverse and draw four cards), I have collected ~278 images with 829 bounding boxes. As you pointed to include “other” class then I have collect lot more images of other cards. But in the real-world, it is difficult to get images of other class.
Could you please share your views?
Please feel free to correct me.
Thanking you!
Other is just anything that is not the main focus. You are teaching the model to ignore what is not the main focus of the project.
Or you can impose a limit on what the model “sees” further up in the pipeline – e.g. the environment in which you deploy the model.
Great!
Thanks for the explanation. I got your first point. Regarding your second point:
[Jason]: you can impose a limit on what the model “sees”
[Saurabh]: It means I shouldn’t present other class images to the model? Is this true?
Could you please elaborate more on the second point?
Thanking you!
I meant that you have control about how the model will be used and what data will be provided to it. You control the environment and in turn you can ise this to limit the range/complexity when training the model.
Great!
Thanks for the explanation. I appreciate your efforts!
Thanking you!
You’re welcome, I’m happy it was useful.
Great explanation.
What if we have different set of classes? Can we train our new data-set on the same yolo model?
Also, how much time can it take to train if I have 10 different classes of object?
You will have to train a new model, here’s an example:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Is it possible to detect live with score in webcam with percentage? plz give a tutorial for live detection
Thanks for the suggestion.
hi Jason, plz give a tutorial for webcam detection.
Thanks for the suggestion, maybe in the future.
Hello
How can i fit dataset to model this code ?
I want json file or cifar 10 dataset fit to this code.
Perhaps try this tutorial:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
make_yolov3_model()
{‘filter’: 64, ‘kernel’: 3, ‘stride’: 2, ‘bnorm’: True, ‘leaky’: True, ‘layer_idx’: 1},
{‘filter’: 32, ‘kernel’: 1, ‘stride’: 1, ‘bnorm’: True, ‘leaky’: True, ‘layer_idx’: 2},
—-> {‘filter’: 64, ‘kernel’: 3, ‘stride’: 1, ‘bnorm’: True, ‘leaky’: True, ‘layer_idx’: 3}])
ValueError: Variable bnorm_0/moving_mean/biased does not exist, or was not created with tf.get_variable(). Did you mean to set reuse=tf.AUTO_REUSE in VarScope?
i m not able to resolve this error, every time i try to create ,model = make_yolov3_model()
it give me same value error from the dafination of the make_yolov3_model().
Sorry to hear that, this might help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thanks for considering my doubts, At the end of the day i was able to fix it, This problem was coz of version incompatibility (Tensroflow1.13) , later i upgraded everything and the error was gone.
Well done!
Hello Jason,
I tried implementing the above code. However, I don’t see my image being detected by the box.
I get the array and the plot version of zebra as output but not detected.
P.S. I am not using the command prompt
Thanks,
Rahul
Sorry to hear that, my best advice for you to reproduce the result is here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Can you please explain why in
def make_yolov3_model():
input_image = Input(shape=(None, None, 3))
The input shape is set to None,None instead of 416×416 which I guess is the default input for yolo v3.
Secondly if I generate and train a model with this kind of None,None,3 as input the model summary has an input of None,None,3. when I try to convert this model to tflite, it throws an error saying unable to get weights for the input layer – this has been discussed here
https://github.com/qqwweee/keras-yolo3/issues/48#issuecomment-486978323
I have created a new model after training by dropping the loss layer like this
inferenceModel = Model(trainingmodel.input,outputs=[trainingmodel.layers[-7].output]
However I don’t know the keras syntax to correctly remove the None,None,3 input layer and replace it with an input 416,416,3 to the inference model
Can you help.
To keep the cols/rows unbounded.
I don’t know about tflite, sorry.
What about the first query why is the model created with NonexNone instead of 416×416, do you know?
Yes, I believe a None,None input is to make the model general – to let input size be defined by a provided image.
i got it thanks, I can just replace it with fixed size if my training images are going to be of fixed aspect ratio i.e 416×416 – this will solve the tflite conversion issue as well.
Nice work.
A great course!!!Could write a blog with more detail about YOLO? I want learn step by step how to use build a model like YOLO and train it and predict.
Thanks.
Great suggestion!
Hello I downloaded that pretrained weights yolov3.weights and copied this code both are in same folder but I am getting this error file not found
ipython-input-2-3060e4e6db8a> in __init__(self, weight_file)
1 class WeightReader:
2 def __init__(self, weight_file):
—-> 3 with open(weight_file, ‘rb’) as w_f:
4 major, = struct.unpack(‘i’, w_f.read(4))
5 minor, = struct.unpack(‘i’, w_f.read(4))
FileNotFoundError: [Errno 2] No such file or directory: ‘C:\\Users\\Joych\\Downloads\\y1\\YOLOV3-master\\yolov3.weights’
Nevertheless, the error suggests your code and weights are not in the same folder.
i have a proble with this code :
yhat = model.predict(image)
jupiter error :
AbortedError: Operation received an exception:Status: 3, message: could not create a dilated convolution forward descriptor, in file tensorflow/core/kernels/mkl_conv_ops.cc:1111
[[{{node conv_1_2/convolution}}]]
version my keras : 2.3.1
help me please 🙂
Sorry to hear that, I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
want to get the features extracted by darknet 53
is that possible !
Probably. I don’t have an example of using that library, sorry.
Hi …
It was really great and helped me a lot …
I just asked how can I configure this Yolo network with new data like car detection ( fine tune)…
for example for ua_detrac data ?
tnx
Here is an example of training a mask rcnn model:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hi
I need the execution time around 0.05 seconds per frame but this code takes me 12 seconds from reading the image to drawing the boxes. Are there any measures to reduce this time?
Perhaps:
Faster machine?
Different implementation?
Smaller data?
i am also facing this issue if you know how to come up with this, plz lemme know
Hi
Thank you so much for your step-by-step codes ..
I just wanted to ask what should I do if I want to “transfer learning” for my data? For example for vehicles …
You’re welcome.
Good question, see this tutorial:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hi Jason,
I wouldlike to train yolov3 on a new object not exist in coco dataset. what is the approach?
I don’t have an example of training a yolo, but you can learn how to train an rcnn here:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Great article thanks.
I would like to know what is the output array of yolo? Can some one send the whole array and explain decoding of the array.
Thank you so much for such a simple and elaborate explanation.
I want to run the trained YOLOv3 model on GPU for the purpose of object detection. Now, I can run your code (the code you explained above) on the CPU, but I do not know what I should do to run an object detection for an image on GPU. Can you please help me with this issue? I emphasize that I want to do it for just one image object detection, NOT for training the model.
Thank you
If you configure your tensorflow installation to use GPU, then YOLO will run on the GPU.
Thank you for such a great article.
I want to export this yoloV3 model to tensorflow-serving use predict_signature_def() function. However I got output item
‘list’ object has no attribute ‘dtype’.
Do you have a pointer for me to solve this issue ? Thank you so much for your time !
I don’t sorry. Perhaps try posting your question to stackoverflow.
Jason, great article. Enjoyed reading it.
A question on the code for the netout function. Experiencor added a _softmax function to the processing of output array. It seems to affect the confidence level in the output. Just want to get your thoughts.
netout[…, 5:] = netout[…, 4][…, np.newaxis] * _softmax(netout[…, 5:])
Thanks.
Thanks.
I don’t know much about it, sorry. Perhaps contact him directly?
Hi Jason,
I am using an AWS instance with a Tesla-K80 GPU. I first configured Tensorflow to use GPU. Then, I executed the YOLOv3_model.py to predict objects in an image. But it took about 20 seconds to predict objects just in one image. I am wondering that I have made a mistake anywhere since I expected the execution time in milliseconds not 20 seconds. Do you think this execution time is normal for YOLO prediction on GPU??
Thanks
Perhaps the first time is slow as it starts up and subsequent calls are faster.
boxes[i].xmin = int((boxes[i].xmin – x_offset) / x_scale * image_w)
ValueError: cannot convert float NaN to integer
I am getting this error as many values are nan.
Btw great article, thanks.
Looks like you have a nan in your data somehow?
I ran the same images with AlexeyAB trained yolov3 repo and the output is correct.
https://github.com/AlexeyAB/darknet#how-to-train-tiny-yolo-to-detect-your-custom-objects
I am using the same trained weights in your code but in the prediction, there are non-nan array values with many nan arrays also!
Interesting, thanks for sharing.
I am also recieving this error in kaggle notebook. I have correctly copied your code.
this is the error :
—————————————————————————
ValueError Traceback (most recent call last)
in
190 boxes += decode_netout(yhat[i][0], anchors[i], class_threshold, input_h, input_w)
191 # correct the sizes of the bounding boxes for the shape of the image
–> 192 correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w)
193 # suppress non-maximal boxes
194 do_nms(boxes, 0.5)
in correct_yolo_boxes(boxes, image_h, image_w, net_h, net_w)
70 x_offset, x_scale = (net_w – new_w)/2./net_w, float(new_w)/net_w
71 y_offset, y_scale = (net_h – new_h)/2./net_h, float(new_h)/net_h
—> 72 boxes[i].xmin = int((boxes[i].xmin – x_offset) / x_scale * image_w)
73 boxes[i].xmax = int((boxes[i].xmax – x_offset) / x_scale * image_w)
74 boxes[i].ymin = int((boxes[i].ymin – y_offset) / y_scale * image_h)
ValueError: cannot convert float NaN to integer
Sorry to hear that, run on your workstation at the command line instead.
Hi Jason,
Great tutorial . Good explanation and procedure to execute the code.If i change the
input zebra to other image, the result remain same. May i doing any mistake.
My work is on Lane detection on Indian road scens. Is YOLO3 used to detect lane. If yes tell me what modification can i do to achieve lane detection.
Thanks.
No, I believe you will need to train a model on your dataset, or use a pre-trained model for this problem.
Hi, I implemented yolov3 model by following your tutorial, now I want to merge my monodepth depth estimation model with yolov3, how I can do that?
Well done.
Sorry, I don’t have an example.
I’ve come to know that for deciding the shape of anchor boxes , a K-means clustering is used in
YoloV3. So why should we specify these sizes ,
anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]]
while getting predictions from the above model.
Thank you.
They are well performing boxes to start with.
Hi jason,
Awesome article on YOLO. Thank you so much
I just dont understand the anchors concept. As you have mentioned, you have gone through the dataset carefully and created these anchors. If you can explain more, we can get more knowledge to create own anchors for our dataset as well
I did not create the anchors, the developers of the yolo model did that.
Generally, you want some boxes that are the average size of objects in your photos. These are the anchors.
Yes i read some more interesting articles about anchors. As like you have mentioned, we initially give some average size that might cover our object, but as the model gets trained, the anchor boxes are adjusted as per the loss to accommodate the object
Thanks for sharing.
Thank you very much, Jason, exceptionally clear post on a highly sophisticated model. Are you by any chance aware of any attempts to do an object detection in 3D data? Is it even viable to train a model like that without a supercomputer?
You’re welcome.
Sorry, I’m not up to speed with 3d object detection.
Thanks for the great tutorial.
Is there any way to use same implementation but with yolo9000 weights and classes. I want yolov3 to detect more than 80 classes but I don’t have a custom labelled dataset. I want it to use yolo9000 weights and classes. Is this possible?
I don’t know off hand sorry.
Hi Jason,
Can you tell us how to flatten the layer, and add a FC layer after that
I tried this
flat1 = Flatten()(model.outputs)
class1 = Dense(1024, activation=’relu’)(flat1)
output = Dense(2, activation=’softmax’)(class1)
# define new model
model = Model(inputs=model.inputs, outputs=output)
# summarize
model.summary()
And got this error “Layer flatten_1 expects 1 inputs, but it received 3 input tensors. Input received: [, , ]”
I’m eager to help but I don’t have the capacity to debug you changes, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/can-you-change-the-code-in-the-tutorial-to-___
I understand it jason.
model = Model(input_image, [yolo_82, yolo_94, yolo_106]). This is the last layer of our model.
I try to flatten this layer. And thats why i got this error
i thought i should get the outputs from each of these three layers and stack them and then flatten it. Is my idea correct?
Sorry, I don’t understand what you are trying to do, I cannot give you good advice.
please tell how can I customize yolo on my data for training
Perhaps try a mask rcnn, see this tutorial:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Sir i have an question about activation function. Sir please ask me why we use activation function in yolov3 ?
Why do we use activation functions in any neural network model?
Activation functions add non-linearity to the model, allowing it to learn complex representations and relationships.
First thank you for this amazing and clearly tutorial .
i want to ask you about the principale idea of yolo detector ( non maximum suppression) Where did you apply it in the code ?
It is applied after prediction, the do_nms() function.
Hi Jason, thank You for this tutorial .
I am triying to train the model with my own dataset , but i had a probleme with the Y_train i didn’t understand what i should put in the three NUMPY ARRAYS for training.
Sorry, I don’t have an example of training the YOLO model.
This may help:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hi Jason,
Thanks for this great tutorial.
I’m want to know if the yolo family is the models used in mobiles camera app to detect the faces , and how big model like that (237MB) can be integrated in small camera app ?
Sorry, I don’t know about the size of the model or mobile apps.
I would like to ask: How to define anchor box:
anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]]
These come from the paper or original implementation I believe, based on the size of objects in the dataset.
thansk a lot , how can i implement yolo v3 for custom dataset?
I don’t have example of training yolo, but this example of training a mask rcnn might help:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
how can i do it on my own dataset?
See this:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hi Jason, when I run this code, I only get the image printed without boxes or probability values. Just the plain original image. Can you please help?
Sorry to hear that, this may help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hello Jason, I have downloaded weights file and saved it on my PC but when I am reading them using WeightReader, it is giving me file not found error ??
Perhaps ensure the path to the file is correct, and run the script from the command line:
https://machinelearningmastery.com/faq/single-faq/how-do-i-run-a-script-from-the-command-line
Hello Janson, I have a question. do you know a network trainned for identifie the background or escenario in an image?, for instance; the background in this picture is a forest, the background in this picture is a higway
Not off hand, sorry.
Jason, great tutorial, thank you very much! I am interested in retraining the YOLO framework to detect other things, do you cover this in your book or anywhere else?
Thanks
I don’t have an example of re-training a YOLO, but I have an example of re-training a mask rcnn:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Good afternoon Jason. I’m sorry for the inconvenience. Once again congratulations on your explanations. The explanation of Yolo v3 is very good / interesting. However, I have a doubt. The calculated v_boxes provide, in addition to the boxes, the score value for each class of interest. For example, if I have an image with only one object, in my case a car, I can get a single score value, in this case, the corresponding score value only for the car class. How to obtain the corresponding score values for the other classes? That is, obtain the score value for the car class, obtain the score value for the person class and obtain the score value for the bicycle class with respect to the same object.
Prediction will return a list of detected objects for you to enumerate.
Okay, I’ll check. Thank you very much.
Best regards.
You’re welcome.
Good afternoon Jason. I’m sorry for the inconvenience. Is the “objness” variable inside the BoundBox (v_box) the same thing as the confidence score? If so, is the objness the same as the IOU?
Best Regards.
I didn’t write that function, perhaps ask the author directly.
Okay, I’ll ask. Thank you very much.
Hello Mr. Jason
Your article was awesome, complete, exciting and informative.
Here you have used the weights trained by yolov3 that were set to detect zebras.
I need to be able to identify the type of car and its color by the Yolov3 algorithm.
Thank you for your help.
WhatsApp: 09174286232
Thanks!
Perhaps you can adapt the example for your application exactly.
You clearly explained it Jason. Your blog is the first blog that gave me a clear mental picture of machine learning. I have recommended this blog to anyone who asks me where to learn machine learning. After a long time i read this blog on yolov3 which is special. Thanks for your efforts. God bless you
Thanks, I’m happy to hear that!
I’m new to the ML. This article is the best one on the planet. With a single copy and paste, I was able to get my own result image! Thank you so much, Jason!
One thing, would you please help me how to make a joblib dump file, so that I could run it on a flask server? One more Thanks.
Thanks!
Sorry, I don’t have a tutorial on deployment, maybe this will help:
https://machinelearningmastery.com/faq/single-faq/how-do-i-deploy-my-python-file-as-an-application
It helps a lot!
Thank you, Jason!
You’re welcome.
Did anyone compute processing time of above tutorial
It took almost 6-7 second for processing single image
When I used it to process a video, video become very slow
Can anyone provide solution to that problem?
Perhaps run on fewer frames?
Perhaps run on a faster machine?
Perhaps try an alternate implementation?
Sir , I have a image dataset consisting 21 classes .. classes are highly imbalanced , like 5000 cars on the other hand 20 police car , 3 van , 90 suv … so how to handle this issue, i tried focal loss and label smoothing in yolov3 by ultralytics ,,,, but results were worse ,,, they changed a lot in their code base like changed crossentropy loss to bcewithlogistic loss function ,,, I dont know what to do.. should i use 2 stage detector instead like ratina net ?? or manually augment data to increase class instances ??
I don’t have experience with imbalanced object detection tasks, but perhaps some of the techniques here might give you ideas:
https://machinelearningmastery.com/framework-for-imbalanced-classification-projects/
This tutorial is for windows or linux.
Tested on macos, windows and linux.
Hi Jason, thanks for this very nice tutorial.
The output image size of the model is much smaller than the actual size of the input image
How can I see the output image with the same input size?
The model does not output an image, you can interpret the predictions from the model anyway you like.
thank you Jason
You’re welcome.
Hey i’m doing word localization( detection) on handwritten passage document images.. i’m thinking on going with YOLO .. can this model work on it ? each page contains around 40 words on average ..
I think there are more specialized techniques for text localization, I recommend checking the literature.
Hi Jason,
I had a question
How can I use the Yolo network output?
For example, how can I access the coordinates of the b boxes so that when they are in a certain position in the image, something special will be done?
how can i interpret the predictions from the model anyway i like?
You can interpret the predictions any way you like.
The model outputs a rectangle that you can interpret for your image, e.g. draw it or use it to crop your image.
How can I access this rectangle?
Which part of the code allows me to access network outputs?
Thank you for guiding me
The result of calling model.predict()
Thank you so mach Jason
You’re welcome.
The best post on Object Detection Ever!!
Thanks!
What are those anchors?
As mentioned in the tutorial, they are standard object sizes in the training data images.
Thank you for your post. Can we change the input to 1 for gray scale images?
You’re welcome.
Perhaps try duplicating the single grayscale channel to the RGB channels and provide to the model as per normal.
Thanks a lot for this great tutorial, helped me a lot !
You’re very welcome!
Your work is easy to understand. Thanks for your good work. Could you please share the faster RCNN for custom object detection?
Thanks!
This will help to get you started:
https://machinelearningmastery.com/how-to-train-an-object-detection-model-with-keras/
Hello Mr Jason,
Thanks for you great blogs.
I am implementing yolov4 for Webcam live feed. Few observations need your support :
1. When I run yolov4 on video on cpu as offline, it gives fast of 0.2 only
2. For image prediction, it takes 600msec per image.
3. Please clarify: can we run yolov4 for Webcam live feed offline on cpu processor?
4. How can we achieve hardware deployment of yolov4 on cpu for live Webcam feed.
5. I am not able to integrate Webcam with yolov4. Kindly provide any suitable material or link.
Please guide. Thank you so much.
You’re welcome!
Sorry, I have not used yolo with a webcam, I don’t think have good advice for you.
It gives fps ( frames per second) of 0.2 only. That is too slow and hence not possible to run on live video
Perhaps use a different model?
Perhaps use a faster machine?
Perhaps use on fewer frames?
Perhaps use smaller images?
Thanks Mr. Jason for your valuable suggestions.
I tried few suggestions whose observations are as follows:
(1) I tries smaller size, which improves processing time but reduces accuracy. What is the minimum image size to be taken in YOLO for optimum results? or it’s a hyperparameter?
(2) I tried YOLO-tiny version. It improves speed by almost four times but reduces accuracy drastically. For example, white coloured dog is predicted as sheep and also, it misses many objects.
(3) Can reducing number of classes/categoriess will improve processing time?
(3) Can we deploy YOLO on CPU (after training on GPU) ?….YES/NO???
Kindly guide further.
Regards
NKM
Well done!
Not sure about the minimum size, but using very small images may require new anchor box sizes as well.
Yes, reducing the classes will reduce the complexity of the problem and in turn require a smaller model which will be faster.
YOLO can run on CPU just fine, but it may be slower.
Do you have any youtube channel or are you planning to start a one?
Not at this stage, and no plans.
I think video is not an effective way to learn applied machine learning:
https://machinelearningmastery.com/faq/single-faq/do-you-have-videos
Everything was ok but when I run
yhat = model.predict(image).
I get this error :
UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node conv_0_4/convolution (defined at C:\Users\CIEDEV\miniconda3\envs\nabin\lib\site-packages\keras\backend\tensorflow_backend.py:3009) ]] [Op:__inference_keras_scratch_graph_62618]
Function call stack:
keras_scratch_graph
Looks like there might be a problem with your keras installation/configuration.
Hello Mr. Jason.
Thanks for your guidance.
Now, I have implemented custom object detector using YOLO for offline on CPU.
When I run this command on CPU:
!./darknet detector demo data/obj.data cfg/yolov4-obj.cfg yolov4-obj_final.weights -dont_show MVI_1615_VIS.avi -i 0 -out_filename results.avi
I get the following error:
GPU isn’t used
OpenCV version: 3.2.0
names: Using default ‘data/names.list’
Couldn’t open file: data/names.list
Kindly help.
I’m sorry to hear that.
Perhaps check that your libraries are up to date?
Hello. I’ve copied all the code and it runs successfully, but 0 boxes are found.
It still outputs [(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)]
but there are no boxes found, so there is an unchanged picture of the zebras.
Do you know what could be going wrong?
decode_netout takes an nms_thresh now too so I tried playing with that.
That is very strange.
Perhaps some of these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi, i’m experiencing the same thing as Kevin Lin,
I noticed:
loading weights of convolution #99
no convolution #99
loading weights of convolution #100
no convolution #100
loading weights of convolution #101
no convolution #101
loading weights of convolution #102
no convolution #102
loading weights of convolution #103
no convolution #103
loading weights of convolution #104
no convolution #104
loading weights of convolution #105
no convolution #105
So its not loading all the weights especially the last ones. I suppose some mismatch between the weights / architecture?
I can confirm the model loads and operates correctly with the most recent version of Keras and TensorFlow.
Perhaps some of these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
I managed to get it running locally in jupyter. Seems that for some reason it does not work correctly on google colab.
Nice work!
Notebooks generally case many problems for many people:
https://machinelearningmastery.com/faq/single-faq/why-dont-use-or-recommend-notebooks
Dr. Brownlee,
Good afternoon, sir! This tutorial, and your Deep Learning for Computer Vision book in general, are outstanding. I have spent the past few weekends meticulously going through your book (LSTMs are next on the list, then GANs) and have learned a ton. Thank you very much for all your work!
V/r,
Jeremy
Thanks Jeremy!
Hello, Mr. Jason.
I am trying to run YOLO on Webcam, where the live feed comes from the Camera to detect objects.
How can I measure the performance of my model? How can I calculate accuracy, Precision, recall? Now, I am able to measure speed only based on the time taken to execute each frame.
Kindly guide.
You can define a test dataset and select one metric, then calculate the metric for the model’s predictions on that dataset.
while running i found this error
ValueError: Dimension 1 in both shapes must be equal, but are 24 and 25. Shapes are [?,24,24] and [?,25,25]. for ‘{{node functional_1/concatenate/concat}} = ConcatV2[N=2, T=DT_FLOAT, Tidx=DT_INT32](functional_1/up_sampling2d/resize/ResizeNearestNeighbor, functional_1/add_18/add, functional_1/concatenate/concat/axis)’ with input shapes: [?,24,24,256], [?,25,25,512], [] and with computed input tensors: input[2] = .
Can anyone help me?
Perhaps these tips will help:
https://machinelearningmastery.com/ufaqs/why-does-the-code-in-the-tutorial-not-work-for-me/
Thanks to you, your post really help me a lot
You’re welcome.
I didn’t find anywhere how to use and link the data of bounding boxes of recognized objects (yolo/keras outputs) as inputs of a machine learning algorithm. Coukd you please give me any advice?
Best regards
This is called annotating data, I don’t have tutorials on this topic sorry.
Ok,I’ll search for that topic, thanks for the clarification!
You’re welcome.
Hi Jason!
Great tutorial as always. Is immensely helping me with a project of my own.
Nonetheless, I ha a question related to YOLO and the use of it with other Deep Learning models.
See, I want to use a GAN for classification (Separate Discriminator Models With Shared Weights) and I am thinking of using the object detection property from YOLO to increase the accuracy score.
The problem is that I don’t know how to combine these two outputs.
I was thinking of:
1. Getting the output of the GAN model
2. Take the bounding boxes and extracted classes of the YOLO model
And somehow concatenate both outputs (maybe using the Keras API and the concatenate function) but I don’t know if that makes sense.
Hope you can understand this and can help me.
PD: Next month I am planning on buying you CV and GAN books. Maybe you have another book related to computer vision and related subjects?
I’m not sure off the cuff sorry, you will have to write custom code and run some experiments in order to discover what works well in your case.
I don’t have a book or tutorial on exactly this.
Check out yolov3 default for inference, really good help me a lot
https://github.com/trainOwn/yolov3-Inference
Thanks for sharing.
Hi Jason,
I am really pleased that I bought your deep learning for computer vision book, it really helped me with my studies.
I have a question regarding training using additional data like photo meta data.
For example, let us say I want to detect cars and I have a bunch of photos of cars, some real and some model cars. I imagine the DL model would be able to detect the cars but have difficulty distinguishing the models from the real ones.
If there was additional meta data with the photo e.g. 35mm focal length could a layer be added to the model that could take that into account in order to separate the model cars from the real ones?
Thanks!
The model could trained to mark/classify the items differently.
Hi,
Thanks for the reply.
I wasn’t sure that that would work.
For example if I use the image http://www.paudimodel.com/wp-content/uploads/2018/03/Infiniti-QX60-2017-BL-3.jpg which is a 1/18 diecast model of a Infiniti QX60 2017, how would the model know this is the diecast model vs this photo https://www.thecarmagazine.com/wp-content/uploads/2017/04/20170410220126267.jpg of the real thing.
Regards
Hi Jason,
Could you give me a example about Building a custom trained YOLOv3 object detector
because image background is different
Thanks for the suggestion, perhaps in the future.
Hi Jason,
Great tutorial, thanks.
I’m facing a problem. the model can predict my objects and when I run this:
for i in range(len(v_boxes)):
print(v_labels[i], v_scores[i])
I get the scores and labels, but I have no bounding boxes in the plot.
You’re welcome.
Perhaps you can inspect the bounding boxes provided by the model and confirm they have the correct image coordinates.
Hi, Jason,
Great totorial, thanks.
I want to ask a question that I remenber there are 53 layer in yolov3, but the code has 106 layer . Why it’s double? Maybe it is not a good question…But I want to know..
thanks!!
Where did you saw it was 53 layers? This is the web page from the original author of YOLOv3 and it said 106 layers in one of the figures: https://pjreddie.com/darknet/yolo/
Sometimes people count the layers differently. May be counting only the convolution layers?
I got it. It’s my problem..sorry..
I thought that changing from the 19 layers to the 53 layers is the whole architecture…
So there are 53 layers for ImageNet training, and the other 53 layers for detection tasks.
If it’s also wrong, please tell me !
And thank you reply my question !!
Glad you find that out.
Hi,Could you please publish a custom dataset training with yolo using Kears.There are some articles but not clear as you publish
Hey, Awesome tutorial. A newbie here, I have a request, by any chance can I get a function that do’s reverse of what ‘decode_netout()’ does, I mean converts normal image annotations(bbox x-y coordinates, no of faces in image) to netout. I would like to train your implementation for face detection and the train.py script in the ‘experiencor/keras-yolo3’ repo is a bit too difficult for me to understand. Any help is appreciated.
Seems you have to write that function.
Hey
how can I train this model using fit or train_on_batch?
How does the inputs and targets to this model look like?
If you mean to fit it from scratch, you need to get the COCO dataset and train it from scratch like other models. This is not suggested because it will take a very long time (days if not months!) to converge on home computer.
I would be using pretrained weights and training only output layers
I am just confused as to how can I call say train_on_batch on this created model.
How would the x and y parameters to train_on_batch look like?
Please see the documentation for train_on_batch() for possible arguments: https://www.tensorflow.org/api_docs/python/tf/keras/Model#train_on_batch
But to train only the output layers, you need to mark the layer not “trainable”: https://www.tensorflow.org/guide/keras/transfer_learning
Hello,
I am using the line of code:
draw_boxes(image, v_boxes, v_labels, .6) in jupyter notebooks but not image or boxes are being shown. I am not super familiar with opencv, and any advice would be appreciated
Jupyter may need some extra functions or “magic commands” to show it. The difference is that, in command console, you can create a new window and show the picture. In Jupyter, everything have to become HTML before it can show in browser.
Hi Jason, thank you for this great tutorial. I am just wondering that how big effort it would be to develop this YOLOv3 model into YOLOv4 model and would it make any sense?
Similar name but totally different thing. You better adopt the YOLOv4 code and start from scratch.
HI,
how can I get the model accuracy?
Regards.
We use mean average precision (mAP) usually
Hi,
If I want to make this for detecting only one class(person),is it possible? If yes what changes I have to make in code to achieve that?
Yes, possible. The easiest change is to pick one class from the result and discard the rest.
WORKS man my approach was just like you said let the motor under the hood do all the heavy lifting whilst we just do the adjustments and fine tuning. Dont forget to load the pre-required support files before you begin. Accurately predicted the zebra image and then loaded in an image of 10 extinct birds and once more the program accurately predicted all 10.
Keep up the good work.
Hi ScanBopAI! I greatly appreciate the feedback and kind words.
Hi great tutorial Jason!
The yolo v3 folks also have released a weights file for an object detection model trained on Google Open Images dataset (About 500 categories). What changes are required in the above model in order to run inference using those model weights?
Thank you for the feedback Ved!
You may find the following of interest:
https://machinelearningmastery.com/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
Hi Dr.Jason Brownlee
Can i ask how to output the X,Y coordinate of the object
Many thanks
Which model use for Crop & It’s Disease Detection?
Hi Navnath…Please clarify or rephrase your question so that we may better assist you.
Hi great tutorial Jason!
I want to ask how to concatenate 3 layers output.
Thank you
Hi Jack…You may find the following of interest:
https://keras.io/api/layers/merging_layers/concatenate/
Hi Dr Jason,
thanks for this valuable explanation.
Presently, I am working on an object detection problem where it is required to detect objects at two levels. At the first level, it has classes and at the second level, it has subclasses. For example, classes are military ships or commercial ships or private ships. And subclasses for military ships are e.g., Destroyer, frigates, or corvette. For subclass level detection, it is required to add extra CNN and Dense layers to the subclass level detection.
In the present YOLOv4 code, I am not able to update the neural network layer architecture.
Kindly suggest/guide for implementation.
Thank you in anticipation.