It can be challenging for beginners to distinguish between different related computer vision tasks.
For example, image classification is straight forward, but the differences between object localization and object detection can be confusing, especially when all three tasks may be just as equally referred to as object recognition.
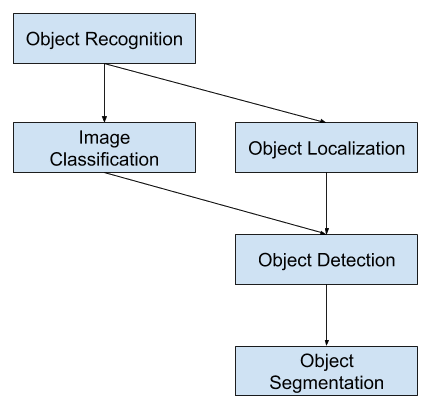
Image classification involves assigning a class label to an image, whereas object localization involves drawing a bounding box around one or more objects in an image. Object detection is more challenging and combines these two tasks and draws a bounding box around each object of interest in the image and assigns them a class label. Together, all of these problems are referred to as object recognition.
In this post, you will discover a gentle introduction to the problem of object recognition and state-of-the-art deep learning models designed to address it.
After reading this post, you will know:
Object recognition is refers to a collection of related tasks for identifying objects in digital photographs.
Region-Based Convolutional Neural Networks, or R-CNNs, are a family of techniques for addressing object localization and recognition tasks, designed for model performance.
You Only Look Once, or YOLO, is a second family of techniques for object recognition designed for speed and real-time use.
Kick-start your project with my new book Deep Learning for Computer Vision, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
A Gentle Introduction to Object Recognition With Deep Learning Photo by Bart Everson, some rights reserved.
Overview
This tutorial is divided into three parts; they are:
What is Object Recognition?
R-CNN Model Family
YOLO Model Family
Want Results with Deep Learning for Computer Vision?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
What is Object Recognition?
Object recognition is a general term to describe a collection of related computer vision tasks that involve identifying objects in digital photographs.
Image classification involves predicting the class of one object in an image. Object localization refers to identifying the location of one or more objects in an image and drawing abounding box around their extent. Object detection combines these two tasks and localizes and classifies one or more objects in an image.
When a user or practitioner refers to “object recognition“, they often mean “object detection“.
… we will be using the term object recognition broadly to encompass both image classification (a task requiring an algorithm to determine what object classes are present in the image) as well as object detection (a task requiring an algorithm to localize all objects present in the image
As such, we can distinguish between these three computer vision tasks:
Image Classification: Predict the type or class of an object in an image.
Input: An image with a single object, such as a photograph.
Output: A class label (e.g. one or more integers that are mapped to class labels).
Object Localization: Locate the presence of objects in an image and indicate their location with a bounding box.
Input: An image with one or more objects, such as a photograph.
Output: One or more bounding boxes (e.g. defined by a point, width, and height).
Object Detection: Locate the presence of objects with a bounding box and types or classes of the located objects in an image.
Input: An image with one or more objects, such as a photograph.
Output: One or more bounding boxes (e.g. defined by a point, width, and height), and a class label for each bounding box.
One further extension to this breakdown of computer vision tasks is object segmentation, also called “object instance segmentation” or “semantic segmentation,” where instances of recognized objects are indicated by highlighting the specific pixels of the object instead of a coarse bounding box.
From this breakdown, we can see that object recognition refers to a suite of challenging computer vision tasks.
Overview of Object Recognition Computer Vision Tasks
Most of the recent innovations in image recognition problems have come as part of participation in the ILSVRC tasks.
This is an annual academic competition with a separate challenge for each of these three problem types, with the intent of fostering independent and separate improvements at each level that can be leveraged more broadly. For example, see the list of the three corresponding task types below taken from the 2015 ILSVRC review paper:
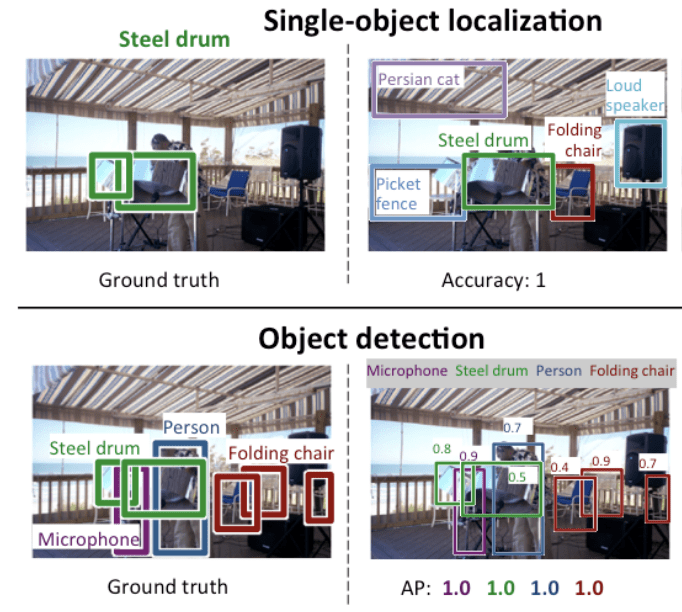
Image classification: Algorithms produce a list of object categories present in the image.
Single-object localization: Algorithms produce a list of object categories present in the image, along with an axis-aligned bounding box indicating the position and scale of one instance of each object category.
Object detection: Algorithms produce a list of object categories present in the image along with an axis-aligned bounding box indicating the position and scale of every instance of each object category.
We can see that “Single-object localization” is a simpler version of the more broadly defined “Object Localization,” constraining the localization tasks to objects of one type within an image, which we may assume is an easier task.
Below is an example comparing single object localization and object detection, taken from the ILSVRC paper. Note the difference in ground truth expectations in each case.
Comparison Between Single Object Localization and Object Detection.Taken From: ImageNet Large Scale Visual Recognition Challenge.
The performance of a model for image classification is evaluated using the mean classification error across the predicted class labels. The performance of a model for single-object localization is evaluated using the distance between the expected and predicted bounding box for the expected class. Whereas the performance of a model for object recognition is evaluated using the precision and recall across each of the best matching bounding boxes for the known objects in the image.
Now that we are familiar with the problem of object localization and detection, let’s take a look at some recent top-performing deep learning models.
R-CNN Model Family
The R-CNN family of methods refers to the R-CNN, which may stand for “Regions with CNN Features” or “Region-Based Convolutional Neural Network,” developed by Ross Girshick, et al.
This includes the techniques R-CNN, Fast R-CNN, and Faster-RCNN designed and demonstrated for object localization and object recognition.
Let’s take a closer look at the highlights of each of these techniques in turn.
It may have been one of the first large and successful application of convolutional neural networks to the problem of object localization, detection, and segmentation. The approach was demonstrated on benchmark datasets, achieving then state-of-the-art results on the VOC-2012 dataset and the 200-class ILSVRC-2013 object detection dataset.
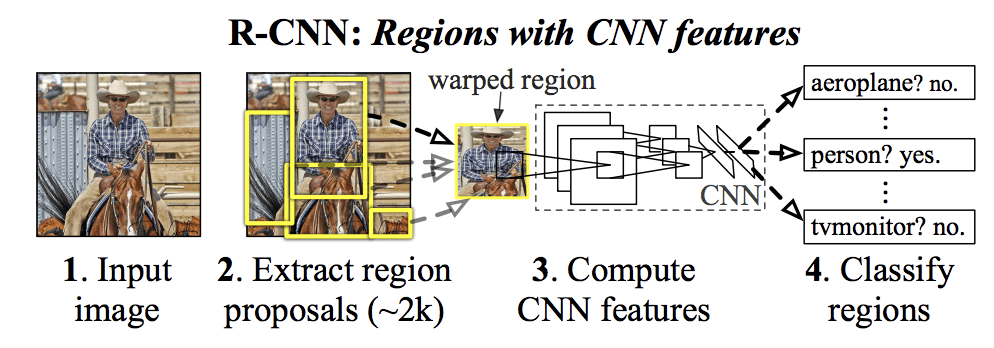
Their proposed R-CNN model is comprised of three modules; they are:
Module 1: Region Proposal. Generate and extract category independent region proposals, e.g. candidate bounding boxes.
Module 2: Feature Extractor. Extract feature from each candidate region, e.g. using a deep convolutional neural network.
Module 3: Classifier. Classify features as one of the known class, e.g. linear SVM classifier model.
The architecture of the model is summarized in the image below, taken from the paper.
Summary of the R-CNN Model ArchitectureTaken from Rich feature hierarchies for accurate object detection and semantic segmentation.
A computer vision technique is used to propose candidate regions or bounding boxes of potential objects in the image called “selective search,” although the flexibility of the design allows other region proposal algorithms to be used.
The feature extractor used by the model was the AlexNet deep CNN that won the ILSVRC-2012 image classification competition. The output of the CNN was a 4,096 element vector that describes the contents of the image that is fed to a linear SVM for classification, specifically one SVM is trained for each known class.
It is a relatively simple and straightforward application of CNNs to the problem of object localization and recognition. A downside of the approach is that it is slow, requiring a CNN-based feature extraction pass on each of the candidate regions generated by the region proposal algorithm. This is a problem as the paper describes the model operating upon approximately 2,000 proposed regions per image at test-time.
Python (Caffe) and MatLab source code for R-CNN as described in the paper was made available in the R-CNN GitHub repository.
Fast R-CNN
Given the great success of R-CNN, Ross Girshick, then at Microsoft Research, proposed an extension to address the speed issues of R-CNN in a 2015 paper titled “Fast R-CNN.”
The paper opens with a review of the limitations of R-CNN, which can be summarized as follows:
Training is a multi-stage pipeline. Involves the preparation and operation of three separate models.
Training is expensive in space and time. Training a deep CNN on so many region proposals per image is very slow.
Object detection is slow. Make predictions using a deep CNN on so many region proposals is very slow.
A prior work was proposed to speed up the technique called spatial pyramid pooling networks, or SPPnets, in the 2014 paper “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.” This did speed up the extraction of features, but essentially used a type of forward pass caching algorithm.
Fast R-CNN is proposed as a single model instead of a pipeline to learn and output regions and classifications directly.
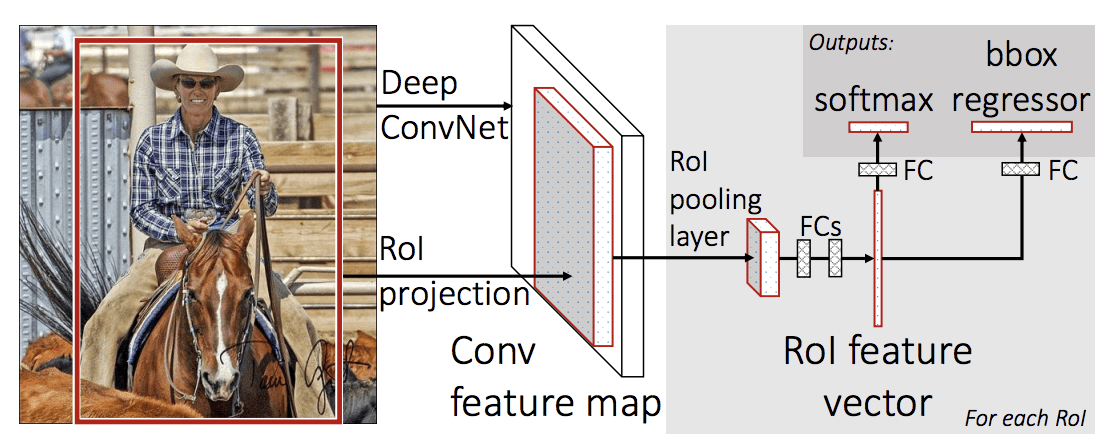
The architecture of the model takes the photograph a set of region proposals as input that are passed through a deep convolutional neural network. A pre-trained CNN, such as a VGG-16, is used for feature extraction. The end of the deep CNN is a custom layer called a Region of Interest Pooling Layer, or RoI Pooling, that extracts features specific for a given input candidate region.
The output of the CNN is then interpreted by a fully connected layer then the model bifurcates into two outputs, one for the class prediction via a softmax layer, and another with a linear output for the bounding box. This process is then repeated multiple times for each region of interest in a given image.
The architecture of the model is summarized in the image below, taken from the paper.
Summary of the Fast R-CNN Model Architecture. Taken from: Fast R-CNN.
The model is significantly faster to train and to make predictions, yet still requires a set of candidate regions to be proposed along with each input image.
Python and C++ (Caffe) source code for Fast R-CNN as described in the paper was made available in a GitHub repository.
The architecture was the basis for the first-place results achieved on both the ILSVRC-2015 and MS COCO-2015 object recognition and detection competition tasks.
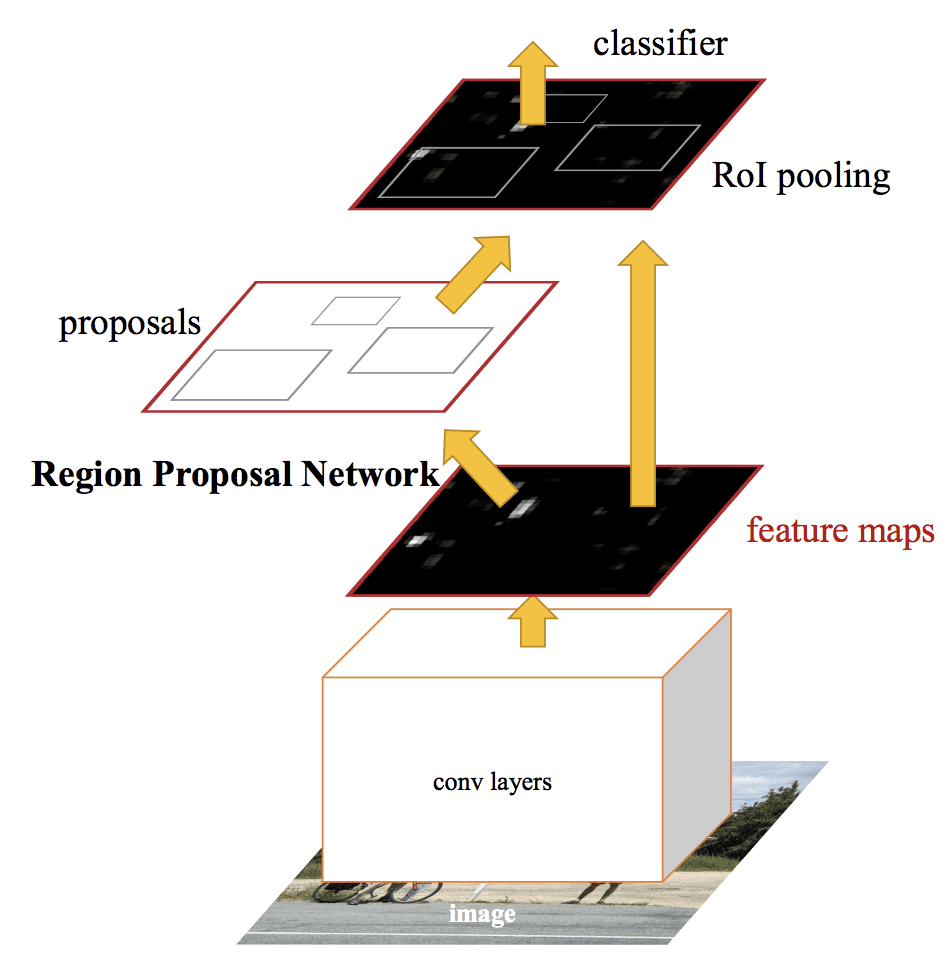
The architecture was designed to both propose and refine region proposals as part of the training process, referred to as a Region Proposal Network, or RPN. These regions are then used in concert with a Fast R-CNN model in a single model design. These improvements both reduce the number of region proposals and accelerate the test-time operation of the model to near real-time with then state-of-the-art performance.
… our detection system has a frame rate of 5fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO 2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks
Although it is a single unified model, the architecture is comprised of two modules:
Module 1: Region Proposal Network. Convolutional neural network for proposing regions and the type of object to consider in the region.
Module 2: Fast R-CNN. Convolutional neural network for extracting features from the proposed regions and outputting the bounding box and class labels.
Both modules operate on the same output of a deep CNN. The region proposal network acts as an attention mechanism for the Fast R-CNN network, informing the second network of where to look or pay attention.
The architecture of the model is summarized in the image below, taken from the paper.
Summary of the Faster R-CNN Model Architecture.Taken from: Faster R-CNN: Towards Real-Time Object Detection With Region Proposal Networks.
The RPN works by taking the output of a pre-trained deep CNN, such as VGG-16, and passing a small network over the feature map and outputting multiple region proposals and a class prediction for each. Region proposals are bounding boxes, based on so-called anchor boxes or pre-defined shapes designed to accelerate and improve the proposal of regions. The class prediction is binary, indicating the presence of an object, or not, so-called “objectness” of the proposed region.
A procedure of alternating training is used where both sub-networks are trained at the same time, although interleaved. This allows the parameters in the feature detector deep CNN to be tailored or fine-tuned for both tasks at the same time.
At the time of writing, this Faster R-CNN architecture is the pinnacle of the family of models and continues to achieve near state-of-the-art results on object recognition tasks. A further extension adds support for image segmentation, described in the paper 2017 paper “Mask R-CNN.”
Python and C++ (Caffe) source code for Fast R-CNN as described in the paper was made available in a GitHub repository.
YOLO Model Family
Another popular family of object recognition models is referred to collectively as YOLO or “You Only Look Once,” developed by Joseph Redmon, et al.
The R-CNN models may be generally more accurate, yet the YOLO family of models are fast, much faster than R-CNN, achieving object detection in real-time.
The approach involves a single neural network trained end to end that takes a photograph as input and predicts bounding boxes and class labels for each bounding box directly. The technique offers lower predictive accuracy (e.g. more localization errors), although operates at 45 frames per second and up to 155 frames per second for a speed-optimized version of the model.
Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second …
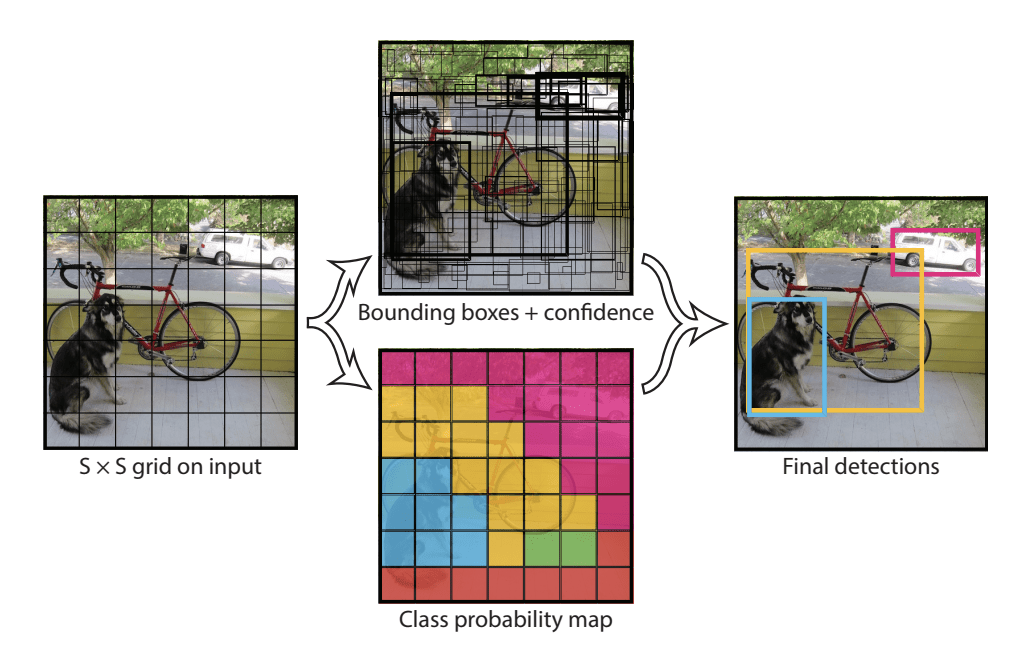
The model works by first splitting the input image into a grid of cells, where each cell is responsible for predicting a bounding box if the center of a bounding box falls within the cell. Each grid cell predicts a bounding box involving the x, y coordinate and the width and height and the confidence. A class prediction is also based on each cell.
For example, an image may be divided into a 7×7 grid and each cell in the grid may predict 2 bounding boxes, resulting in 94 proposed bounding box predictions. The class probabilities map and the bounding boxes with confidences are then combined into a final set of bounding boxes and class labels. The image taken from the paper below summarizes the two outputs of the model.
Summary of Predictions made by YOLO Model.Taken from: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) and YOLOv3
The model was updated by Joseph Redmon and Ali Farhadi in an effort to further improve model performance in their 2016 paper titled “YOLO9000: Better, Faster, Stronger.”
Although this variation of the model is referred to as YOLO v2, an instance of the model is described that was trained on two object recognition datasets in parallel, capable of predicting 9,000 object classes, hence given the name “YOLO9000.”
A number of training and architectural changes were made to the model, such as the use of batch normalization and high-resolution input images.
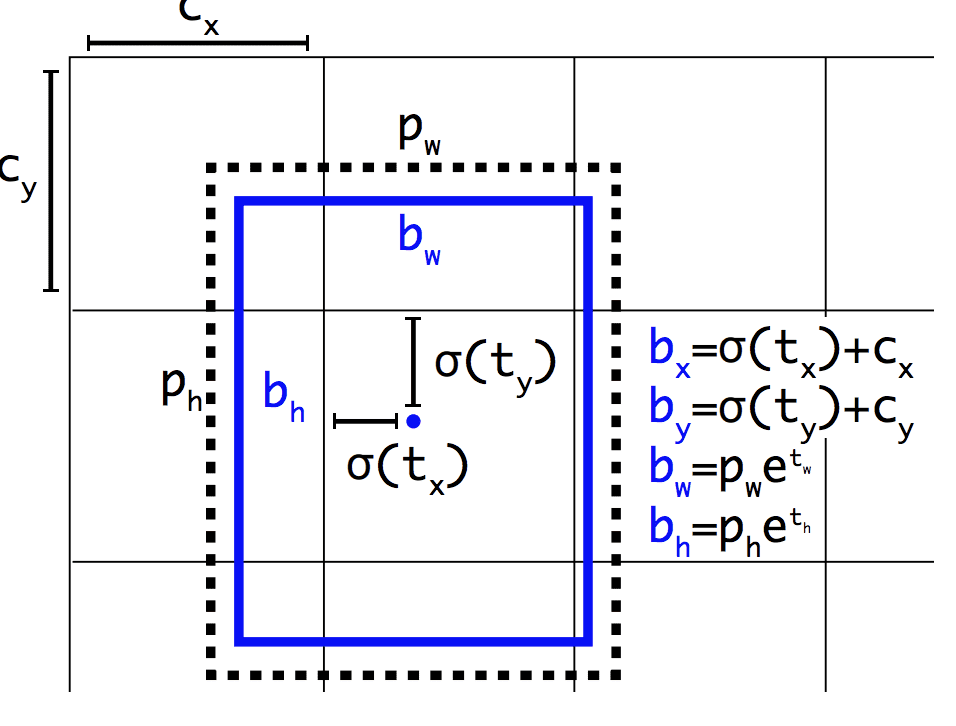
Like Faster R-CNN, YOLOv2 model makes use of anchor boxes, pre-defined bounding boxes with useful shapes and sizes that are tailored during training. The choice of bounding boxes for the image is pre-processed using a k-means analysis on the training dataset.
Importantly, the predicted representation of the bounding boxes is changed to allow small changes to have a less dramatic effect on the predictions, resulting in a more stable model. Rather than predicting position and size directly, offsets are predicted for moving and reshaping the pre-defined anchor boxes relative to a grid cell and dampened by a logistic function.
Example of the Representation Chosen when Predicting Bounding Box Position and ShapeTaken from: YOLO9000: Better, Faster, Stronger
Further improvements to the model were proposed by Joseph Redmon and Ali Farhadi in their 2018 paper titled “YOLOv3: An Incremental Improvement.” The improvements were reasonably minor, including a deeper feature detector network and minor representational changes.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
In this post, you discovered a gentle introduction to the problem of object recognition and state-of-the-art deep learning models designed to address it.
Specifically, you learned:
Object recognition is refers to a collection of related tasks for identifying objects in digital photographs.
Region-Based Convolutional Neural Networks, or R-CNNs, are a family of techniques for addressing object localization and recognition tasks, designed for model performance.
You Only Look Once, or YOLO, is a second family of techniques for object recognition designed for speed and real-time use.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
It provides self-study tutorials on topics like: classification, object detection (yolo and rcnn), face recognition (vggface and facenet), data preparation and much more...
Finally Bring Deep Learning to your Vision Projects
Ive got an “offline” video feed and want to identify objects in that “offline” video feed.
The camera always will be at a fixed angle.
For me accuracy is of utmost importance, can you pls suggest which algorithm will work for me ?
hi ravin, I gets an 6000 videos daily to detect person, check format and background color and detect logo, how we can do stuff at offline without playing. how did you achieve. @jason you can also guide me . also on architecture of same
This material is really great. This gave me a better idea about object localisation and classification. Here I am mentioning all the points that I understood from the blog with respect to object detection.
1. The object detection framework initially uses a CNN model as a feature extractor (Examples VGG without final fully connected layer).
2. This output of the VGG is given to another CNN model known as RPN, which gives a set of areas where potential objects may exists
3. Based on the RPN output, another CNN model (typically a classifier) process the VGG output and gives final results (Object classes and respective bounding boxes)
Now I would like to know what type of CNN combinations are popular for single class object detection problem. If I want to develop a custom model, what are the available resources.
Hey, great article!
I have to make a project where I have to detect and count the number of people in an image which is captured through an Android mobile within a short time. How do I do it?
Hey
It’s a great article and gave me good insight.
I need to detect the yaw, pitch and roll of cars in addition to their x,y,z position in
images from a street. Beside that, I already have mask for the images that show
me where are the cars in the image, so I don’t think I need to localize the
cars in the image. My question is, can I use R-CNN or YOLO to predict the yaw, pitch
and roll of cars in the image (of course, those that are not covered with the
mask and are reasonably close to the camera that is taken the image)
Another Excellent Article Dr. Brownlee,.
I’m confused in the part of the YOLOv1 where the paper’s author mentions that the final layer uses a linear activation function. But the outputs are supposed to be between 0 to 1 for all the x,y and w,h and the confidence of the bounding box. And the output also predicts one of twenty classes. Normally, we use softmax for the classification of classes. But it’s bot mentioned in the paper if they use it or not. And my intuition is to use sigmoid for the x,y and w,h prediction as they have values between 0 to 1. Even that isn’t mentioned anywhere in the paper. If they’re not using sigmoid or softmax, then how does the classification process works.
I went through one of the tensorflow ports of the original darknet implementation. And it seems to just produce linear outputs and couldn’t find any sigmoid or softmax. Wouldn’t that be a little more unconstrained since they have to predict a value between 0 and 1 but they’re predicted value doesn’t have any bounds as it’s linear? Also, if YOLO predicts one of the twenty class probabilities and confidence with a linear function, that seems more confusing!
But the paper says ” We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1. We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.”
How do they bound the values between 0 and 1 if they’re not using a sigmoid or softmax?
Jason, noob question: When training a model with tagged images, does the algorithm only concern itself with the content that’s inside the human-drawn bounding box(es)? Or does it still use the content that lies outside the bounding boxes as well? Perhaps this varies with the type of model you are training and/or the method you use to train it?
Thanks for the reply! So if the model is training with the whole image, would the resulting prediction model be more accurate if the training images were “cropped” in such a way as to remove as much of the area outside the bounding box as possible? In other words, training the model with essentially only what lies inside the box that we want to detect.
I had a question related to this. What model should I use if I want to detect an object that is tilted in any direction, i.e. it is not in the same upright vertical position as the image is. May be tilted at random angles in all different images.
Also, I need to get the coordinates of center of that object. Any pre-trained model that could help here??
Brownlee sir, Really its a amazing. Sir I want to know about Mask R-CNN . can I use it to develop my Mtech project ‘face detection and recognition” , sir please help me in this regard. waiting for your reply eagerly.
After discussing the ILSVRC paper, the article says, “Single-object localization: Algorithms produce a list of object categories present in the image, along with an axis-aligned bounding box indicating the position and scale of one instance of each object category.”
Isn’t the localization process just supposed to be about producing a boundary for the object? Does it also classify the object in a category? Or is this the definition for ‘Single-object detection’ instead?
The definitions of Single-object localization and Object Detection are having the same text. I believe this is a typo. Single-object localization should not have classification. It should only have the bounding rectangle, as Jasraj suggests.
You say “divided into a 7×7 grid and each cell in the grid may predict 2 bounding boxes, resulting in 94 proposed bounding box predictions”, so that means there will be 7*7=49 cells. If each cell predicts two bounding boxes, then the number of proposals is 49*2 = 98 (and not 94).
thanks you very much for the article, fantastic like always. I have a question please:
Regarding the RPN (during training) in Faster RCNN, what happen if the image being processed has no ground truth boxes (background image), do we still get anchor boxes as well even though we don’t have the GT boxes, or does the whole image get recorded as a negative example in this case?
Very informative read. Thanks a lot.
I have a query regarding YOLO1. Its researched paper says –
“Our system divides the input image into an S × S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object”.
I am not able to understand that for new and unseen images (live a live video feed), how algorithm is able to find out where exactly objects are present in the picture and thus their center? Also, in the real time scenario, there will not be any Ground truth to have comparison with, how it finds out IoU and thus the respective probability of having an object in a box.
This is a great article to get some ideas about the algorithms since I’m new to this area. I’m an final year undergraduate currently working on a research topic “Vehicle Detection in Satellite Images”. I would like to know which algorithm can be used or works better for the topic.
Great article! I was confused about the terminology of object detection and I think this article is the best about it. I wanted to ask you, I’m using MobileNetV2 for object detection, but after reading this I’m not sure if that was the correct choice. I need something fast for predictions due to we need this to work on CPU, now we can predict at a 11 FPS, which works well for us, but the bounding box predicted is not oriented and that complicate things a little. What would you recommend to use to have similar FPS (or faster) and a similar accuracy or at least an oriented bounding box? I was thinking in using landmarks but I don’t know if that will suit our needs.
Hello dear, My name is Abdullah and I want to do research on object recognition/classification. I have done my master’s degree in Mathematics 2018. Now I turning here and want to do research in object recognition/classification with major mathematics. Can you suggest to me where I have to go? I am making a research proposal in object recognition/classification with my strength in mathematics. Can you please help me???
Dear Author,
It’s an informative article indeed. Could you please help me giving the information that in this pipeline where is the place of “Object Proposal”? I am a little bit confused about object localization and object proposal.
Thanks in advance
IT IS VERY INFORMATIVE ARTICLE. Can you pls help in giving the information that in text detection in natural images which alogorithm works well and about the synthetic images . i am little bit confused.
What if an MV system is in a room and can detect a window, door and ceiling lamp, and it can match it up with a pre-defined set of the same objects whose attributes include each object’s identification and position in that same room. Shouldn’t a separate system able to extrapolate the vectors to each of those objects and determine its location relative to everything else in the room. Is there a name for this pre-defined framework reference?
Hello, thanks for the very informative article (like yours always are). I have a dataset of powerpoint slides and need to build a model to detect for logos in the slides. The dataset has labels for the presence of logos y={0,1}. Which model would you recommend? Thank you
HELLO SIR, FOR DOING PROJECT ON OBJECT RECOGNITION WHAT ARE THE THINGS WE HAVE TO LEARN AND IS THERE ANY BASIC PAPERS TO STUDY …. I THINK YOUR REPLY WILL BE HELPFUL.
In that book can we get all the information regarding the project (object recognition) and can you please suggest the best courses for python and deep learning so that i will get enough knowledge to do that project(object recognition)
I want to know the history of object recognition, i.e when it was started , what are the algorithms used and what are the negatives ? is it available anywhere?
Great article, Really informative, thank you for sharing.
I’m making a light-weight python based platform for interfacing and controlling
any (supported) devices (mostly for people learning to code, and those that want a framework for automation without having to go through the pain learning how to communicate with said device).
I am in the process of building some tools that would help people perform more interesting programs / bots with these devices one of which is processing captured images.
As I want this to be simple and rather generic, the users currently make two directories, one of images that they want to detect, and one of images that they want to ignore, training/saving the model is taken care of for them. then they can detect the centers of instances of the images they want in a larger images. at the moment I’m using a cnn and then I test various sub images in the larger one hence creating a probability heatmap, and finish the task by finding the peaks which indicate the locations of images the cnn finds. (currently all the sub images take a while (~0.5-1s) to process.
Do you think it would be possible to use an RCNN to perform this task whilst keeping the simplicity similar i.e. somehow avoid the user having to create bounding box datasets?
One idea I had was to plant the training dataset into larger images randomly, this way I would have the bounding box and could train the rcnn on these larger images? Your thoughts would be greatly appreciated.
I’m currently working on data annotation i.e object detection using bounding boxes and also few projects such as weather conditions , road conditions for autonomous cars. I want to upgrade myself to the next process( what’s the next step and annotating the objects) could you please help what course if I learn I can go more deep into the autonomous cars field. I learnt something different from your article regarding object detection, please suggest me what to do to improve my job skills.
for a museum, we would like to be be able if one of 20 specific objects is placed anywhere on a table.
Our original line of thought went from “user selects the object on a touch screen”, to “super expensive touch table that recognizes tags”, to “detect one of twenty nfc/rfid tags placed on reader”, to what I’m wondering about now “use deeplearning to recognize the object any where on the table”
I have however no clue if that is feasible, and what is best and how to proceed.
I did object detection using YOLOv5. Now i want to apply reinforcement learning approach on that detected images. Is there any way to do that? Is there any solution related this? please help me.
Can I get the predicted labels as a list ?(Giving a new image to the detection model and extracting the predicted labels as a list) Like if the test image contains objects of class ‘person’ and ‘dog’ , list should contain [‘person’ , ‘dog’]
If yes please share me the code.
Thanks in advance.
Surely you can. I am not sharing the code but the idea is, usually the prediction is in terms of probability to each label and we select the label as the output. That should be a piece of code outside of the model to prepare these label and there is where you can make that happen.
Hi Jason,
wonder if you can guide me a little bit.
I started new project to deliver people detection however in certain area only (not in the frame of the picture or video). The intention is to warn or give alarm if people entering line-of-fire area, in particulary below crane operating area.
some how, the area is dynamic event by event so the boundary some is not fix. So I wonder if we do virtual boundary using some of helpful object (i.e. briht and colorful cone) and then make a segmentation and then object detection. if those two overlap then raise alarm.
Do you have tutorial or your e-book that cover that thing (especially virtual boundary)?
Thanks
Hi Jason,
Thank you for your great post. I want to perform image segmentation using U-Net for extracting flooded areas. However, my labeled dataset is obtained by some traditional thresholding machine learning models. A technician checks the labels but they may still not be very accurate. I was wondering if there is any chance of getting better results than the traditional model when I train U-Net on the noisy labels? Is there any technique that I can use to improve the results?
Thank you for your help.
Hii, Iam working on a project to detect rotten apples from multiple apples(some fresh and some rotten) using yolov5. But getting the predictions for the fresh apple as rotten as I have only one class i.e the rotten apples. Can you please suggest how can I get correct detections?
I just want to detect the rotten apples and not the fresh ones.
Storing features extracted from an object detection model is crucial for various tasks like content-based image retrieval, similarity search, further training, etc. The process of storing the features can be broken down into the following steps:
1. **Feature Extraction**:
– Process your image or video data using the object detection model.
– After detecting the objects, extract features from these detected regions. The features could be from an intermediate layer of the model or from a dedicated feature extraction layer.
2. **Serialization**:
– Convert the features to a format that is easy to store. Common formats include lists, dictionaries, or NumPy arrays.
3. **Storage Options**:
a. **Flat File (CSV, TXT)**:
– Use Python’s built-in CSV module or Pandas to store the features in CSV format.
– This method is straightforward but may not be the most efficient for very large datasets.
b. **Binary Formats (Pickle, NumPy’s .npy)**:
– Python’s pickle module allows you to serialize Python objects and save them to disk.
– For NumPy arrays, you can use the numpy.save() and numpy.load() methods to store and load arrays respectively.
c. **Databases**:
– **Relational Databases (MySQL, PostgreSQL)**: Convert the features to a format suitable for database storage, such as converting arrays to strings or storing individual elements in table columns.
– **NoSQL Databases (MongoDB, Cassandra)**: These databases can store unstructured data, which might be convenient for complex feature formats.
– **Time Series Databases (InfluxDB)**: Useful if the features are associated with time-stamped data.
d. **Specialized Storage Solutions**:
– **HDF5**: A high-performance storage format suitable for large datasets. Libraries like h5py allow you to easily interact with HDF5 files in Python.
– **Feather**: A fast, lightweight, and easy-to-use binary file format for storing data frames.
e. **Cloud Storage (Amazon S3, Google Cloud Storage)**:
– Useful if you’re working in a cloud environment or if you want to share your datasets across different machines.
4. **Metadata**:
– Along with features, it’s often useful to store metadata like the original file name, the coordinates of the detected object, object class, etc.
– Depending on your storage solution, this could be in a separate table/column or integrated with the feature data.
5. **Compression**:
– If storage space is a concern, consider compressing the features before storing them. Many storage solutions support built-in compression, or you can use libraries like zlib or lz4 in Python.
6. **Backup**:
– Always ensure that you have backups of your data, especially if it’s the result of lengthy computations or hard-to-reproduce feature extractions.
7. **Optimizations**:
– If you find yourself frequently querying or analyzing the stored features, consider using a database index or other optimizations to speed up these operations.
Remember, the choice of storage solution depends on your specific needs, the size of your dataset, and the operations you want to perform on the stored features.








Amazing. Thanks for sharing
Thanks, I’m glad you found it useful.
Hi Jason,
Ive got an “offline” video feed and want to identify objects in that “offline” video feed.
The camera always will be at a fixed angle.
For me accuracy is of utmost importance, can you pls suggest which algorithm will work for me ?
Mask RCNN.
hi ravin, I gets an 6000 videos daily to detect person, check format and background color and detect logo, how we can do stuff at offline without playing. how did you achieve. @jason you can also guide me . also on architecture of same
That is a lot of video!
Perhaps start with simple/fast methods and see how far they get you.
Hi,
I read that FCNs can do pixel level classification, so I’m wondering can FCNs be used to do pixel level regression?
Thanks!
I don’t see why not.
I would like to check whether parking lot available or camera feed vedio. what should I check ?
Good question.
Perhaps model as object detection, at least as a starting point?
Jason,
This material is really great. This gave me a better idea about object localisation and classification. Here I am mentioning all the points that I understood from the blog with respect to object detection.
1. The object detection framework initially uses a CNN model as a feature extractor (Examples VGG without final fully connected layer).
2. This output of the VGG is given to another CNN model known as RPN, which gives a set of areas where potential objects may exists
3. Based on the RPN output, another CNN model (typically a classifier) process the VGG output and gives final results (Object classes and respective bounding boxes)
Now I would like to know what type of CNN combinations are popular for single class object detection problem. If I want to develop a custom model, what are the available resources.
A RCNN or a YOLO would be a great place to start.
greatly NB
Thanks!
Hey, great article!
I have to make a project where I have to detect and count the number of people in an image which is captured through an Android mobile within a short time. How do I do it?
Perhaps start with a data set of images with a known count of people in the image.
Then perhaps test a suite of object detection methods to see what works best on your dataset?
Hey
It’s a great article and gave me good insight.
I need to detect the yaw, pitch and roll of cars in addition to their x,y,z position in
images from a street. Beside that, I already have mask for the images that show
me where are the cars in the image, so I don’t think I need to localize the
cars in the image. My question is, can I use R-CNN or YOLO to predict the yaw, pitch
and roll of cars in the image (of course, those that are not covered with the
mask and are reasonably close to the camera that is taken the image)
Thanks.
I think you need another model that takes the image input and predicts the coordinate outputs.
Hi Jason
I would like to track cyclists riding around a Velodrome. There are 7 cyclists in a race all with different colours.
1. What framework would you use?
2. The predominant feature is colour, would you create 7 classes based on each colour?
Great question, I think some research (what is similar/has been tried before) and prototyping (what works) would be a good idea.
Another Excellent Article Dr. Brownlee,.
I’m confused in the part of the YOLOv1 where the paper’s author mentions that the final layer uses a linear activation function. But the outputs are supposed to be between 0 to 1 for all the x,y and w,h and the confidence of the bounding box. And the output also predicts one of twenty classes. Normally, we use softmax for the classification of classes. But it’s bot mentioned in the paper if they use it or not. And my intuition is to use sigmoid for the x,y and w,h prediction as they have values between 0 to 1. Even that isn’t mentioned anywhere in the paper. If they’re not using sigmoid or softmax, then how does the classification process works.
Thanks!
Good question. Perhaps check the official source code and see exactly what they did?
I went through one of the tensorflow ports of the original darknet implementation. And it seems to just produce linear outputs and couldn’t find any sigmoid or softmax. Wouldn’t that be a little more unconstrained since they have to predict a value between 0 and 1 but they’re predicted value doesn’t have any bounds as it’s linear? Also, if YOLO predicts one of the twenty class probabilities and confidence with a linear function, that seems more confusing!
But the paper says ” We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1. We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.”
How do they bound the values between 0 and 1 if they’re not using a sigmoid or softmax?
Perhaps the quote from the paper has to do with the preparation of the training data for the model.
Jason, noob question: When training a model with tagged images, does the algorithm only concern itself with the content that’s inside the human-drawn bounding box(es)? Or does it still use the content that lies outside the bounding boxes as well? Perhaps this varies with the type of model you are training and/or the method you use to train it?
Any help is greatly appreciated.
Great question!
The model sees the whole image and the bounding box. It learns where to put the box in the image – what is in and what is out.
Thanks for the reply! So if the model is training with the whole image, would the resulting prediction model be more accurate if the training images were “cropped” in such a way as to remove as much of the area outside the bounding box as possible? In other words, training the model with essentially only what lies inside the box that we want to detect.
Correct.
Hi Jason,
Really informative article!
I had a question related to this. What model should I use if I want to detect an object that is tilted in any direction, i.e. it is not in the same upright vertical position as the image is. May be tilted at random angles in all different images.
Also, I need to get the coordinates of center of that object. Any pre-trained model that could help here??
Thank you
Thanks!
Same types of models, although trained to expect these transforms. E.g. data augmentation would be helpful.
Brownlee sir, Really its a amazing. Sir I want to know about Mask R-CNN . can I use it to develop my Mtech project ‘face detection and recognition” , sir please help me in this regard. waiting for your reply eagerly.
Thanks!
I don’t recommend mask rcnn for face recognition, use mtcnn + facenet or vggface2:
https://machinelearningmastery.com/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
Hi
After discussing the ILSVRC paper, the article says, “Single-object localization: Algorithms produce a list of object categories present in the image, along with an axis-aligned bounding box indicating the position and scale of one instance of each object category.”
Isn’t the localization process just supposed to be about producing a boundary for the object? Does it also classify the object in a category? Or is this the definition for ‘Single-object detection’ instead?
Yes, typically classify and draw a box around the object.
The definitions of Single-object localization and Object Detection are having the same text. I believe this is a typo. Single-object localization should not have classification. It should only have the bounding rectangle, as Jasraj suggests.
Thanks for sharing.
You say “divided into a 7×7 grid and each cell in the grid may predict 2 bounding boxes, resulting in 94 proposed bounding box predictions”, so that means there will be 7*7=49 cells. If each cell predicts two bounding boxes, then the number of proposals is 49*2 = 98 (and not 94).
Hello Jason,
thanks you very much for the article, fantastic like always. I have a question please:
Regarding the RPN (during training) in Faster RCNN, what happen if the image being processed has no ground truth boxes (background image), do we still get anchor boxes as well even though we don’t have the GT boxes, or does the whole image get recorded as a negative example in this case?
I will be glad for any help (:
You’re welcome.
If you don’t have bounding boxes in the training data, you cannot train an object detection model.
Very informative read. Thanks a lot.
I have a query regarding YOLO1. Its researched paper says –
“Our system divides the input image into an S × S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object”.
I am not able to understand that for new and unseen images (live a live video feed), how algorithm is able to find out where exactly objects are present in the picture and thus their center? Also, in the real time scenario, there will not be any Ground truth to have comparison with, how it finds out IoU and thus the respective probability of having an object in a box.
Thanks.
Perhaps this worked example will help:
https://machinelearningmastery.com/how-to-perform-object-detection-with-yolov3-in-keras/
Hi Jason,
This is a great article to get some ideas about the algorithms since I’m new to this area. I’m an final year undergraduate currently working on a research topic “Vehicle Detection in Satellite Images”. I would like to know which algorithm can be used or works better for the topic.
Thank you.
I recommend testing a suite of algorithms and configurations on your dataset in order to discover what works best.
It is a good idea to start with transfer learning based approaches.
Hello Sutharsan and Jason,
I am also currently working on the same topic “Vehicle detection in satellite images” and I would like to know what algorithm did you find better.
I recommend testing a suite of different methods in order to discover what works well or best for your specific dataset.
Great article! I was confused about the terminology of object detection and I think this article is the best about it. I wanted to ask you, I’m using MobileNetV2 for object detection, but after reading this I’m not sure if that was the correct choice. I need something fast for predictions due to we need this to work on CPU, now we can predict at a 11 FPS, which works well for us, but the bounding box predicted is not oriented and that complicate things a little. What would you recommend to use to have similar FPS (or faster) and a similar accuracy or at least an oriented bounding box? I was thinking in using landmarks but I don’t know if that will suit our needs.
Thanks for sharing your knowledge!
Perhaps test a suite of models and see which best meets your specific speed requirements.
Hello dear, My name is Abdullah and I want to do research on object recognition/classification. I have done my master’s degree in Mathematics 2018. Now I turning here and want to do research in object recognition/classification with major mathematics. Can you suggest to me where I have to go? I am making a research proposal in object recognition/classification with my strength in mathematics. Can you please help me???
Thanking you
Sorry, I cannot help you with a research proposal.
Dear Author,
It’s an informative article indeed. Could you please help me giving the information that in this pipeline where is the place of “Object Proposal”? I am a little bit confused about object localization and object proposal.
Thanks in advance
Thanks.
I believe “proposals” are candidate predictions.
DEAR SIR
IT IS VERY INFORMATIVE ARTICLE. Can you pls help in giving the information that in text detection in natural images which alogorithm works well and about the synthetic images . i am little bit confused.
Thanks.
Thanks for the suggestion, I hope to write about that topic in the future.
What if an MV system is in a room and can detect a window, door and ceiling lamp, and it can match it up with a pre-defined set of the same objects whose attributes include each object’s identification and position in that same room. Shouldn’t a separate system able to extrapolate the vectors to each of those objects and determine its location relative to everything else in the room. Is there a name for this pre-defined framework reference?
Sorry, I don’t don’t know of models that can do what you describe. It sounds like a “system” (software package) not a single model.
Hello, thanks for the very informative article (like yours always are). I have a dataset of powerpoint slides and need to build a model to detect for logos in the slides. The dataset has labels for the presence of logos y={0,1}. Which model would you recommend? Thank you
Perhaps test a suite of models and discover what works best for your specific dataset.
Thanks for the simple yet detailed article and explanation. I was wondering if there is a way to get bounding boxes with older models like VGG16?
VGG16 is only for feature extraction and classifying images.
HELLO SIR, FOR DOING PROJECT ON OBJECT RECOGNITION WHAT ARE THE THINGS WE HAVE TO LEARN AND IS THERE ANY BASIC PAPERS TO STUDY …. I THINK YOUR REPLY WILL BE HELPFUL.
THANK YOU SIR.
I recommend this book:
https://machinelearningmastery.com/deep-learning-for-computer-vision/
In that book can we get all the information regarding the project (object recognition) and can you please suggest the best courses for python and deep learning so that i will get enough knowledge to do that project(object recognition)
thank you sir.
The book provides examples of object detection and how to apply a pre-trained object detection model and how to train a model for a new dataset.
It is a great place to start.
Otherwise, you can see the free tutorials here:
https://machinelearningmastery.com/start-here/#dlfcv
sir, suggest me python course for data science projects( ML,DL)?
See this:
https://machinelearningmastery.com/faq/single-faq/what-machine-learning-project-should-i-work-on
Sir ,
I want to know the history of object recognition, i.e when it was started , what are the algorithms used and what are the negatives ? is it available anywhere?
Perhaps you can find a few review papers that provide this literature survey.
I recommend searching on scholar.google.com
Great article, Really informative, thank you for sharing.
I’m making a light-weight python based platform for interfacing and controlling
any (supported) devices (mostly for people learning to code, and those that want a framework for automation without having to go through the pain learning how to communicate with said device).
I am in the process of building some tools that would help people perform more interesting programs / bots with these devices one of which is processing captured images.
As I want this to be simple and rather generic, the users currently make two directories, one of images that they want to detect, and one of images that they want to ignore, training/saving the model is taken care of for them. then they can detect the centers of instances of the images they want in a larger images. at the moment I’m using a cnn and then I test various sub images in the larger one hence creating a probability heatmap, and finish the task by finding the peaks which indicate the locations of images the cnn finds. (currently all the sub images take a while (~0.5-1s) to process.
Do you think it would be possible to use an RCNN to perform this task whilst keeping the simplicity similar i.e. somehow avoid the user having to create bounding box datasets?
One idea I had was to plant the training dataset into larger images randomly, this way I would have the bounding box and could train the rcnn on these larger images? Your thoughts would be greatly appreciated.
Thank you so much for the article.
Thanks.
Hard to say, perhaps develop a prototype and test your ideas.
Hi Jason,
I’m currently working on data annotation i.e object detection using bounding boxes and also few projects such as weather conditions , road conditions for autonomous cars. I want to upgrade myself to the next process( what’s the next step and annotating the objects) could you please help what course if I learn I can go more deep into the autonomous cars field. I learnt something different from your article regarding object detection, please suggest me what to do to improve my job skills.
Thanks for your article
Thanks, sorry, I don’t have many tutorials on object detection. I hope to write more on the topic in the future.
Thanks for your response Jason, to continue in the ADAS field if I learn Machine Learning will it be a good move for my future?
What is “ADAS”?
Only you know what will be good for you future.
A confusing typing error in YOLO: ‘if the center of a bounding box falls within it’, it should be the center of an object.
Thanks, fixed.
Hi jason – If I have to draw a bounding box of same class at different locations of the image. Which algorithm should I go for and why?
Most object recognition models support multiple objects in the image.
Perhaps try a few and discover what works well or best for your dataset.
Very informative…
Thanks!
Hi,
for a museum, we would like to be be able if one of 20 specific objects is placed anywhere on a table.
Our original line of thought went from “user selects the object on a touch screen”, to “super expensive touch table that recognizes tags”, to “detect one of twenty nfc/rfid tags placed on reader”, to what I’m wondering about now “use deeplearning to recognize the object any where on the table”
I have however no clue if that is feasible, and what is best and how to proceed.
Perhaps you can try to develop a small prototype to see if it is feasible for your problem/data.
Look at my robotic arm that detects an object and then sorts the object by the number of holes. See the complete documentation and code here: https://github.com/k-karlovic/robotic-object-sorter-with-computer-vision
Thanks for sharing.
Hi
I did object detection using YOLOv5. Now i want to apply reinforcement learning approach on that detected images. Is there any way to do that? Is there any solution related this? please help me.
Sorry, I don’t have any examples of RL, I cannot give you good off the cuff advice on the topic.
Can I get the predicted labels as a list ?(Giving a new image to the detection model and extracting the predicted labels as a list) Like if the test image contains objects of class ‘person’ and ‘dog’ , list should contain [‘person’ , ‘dog’]
If yes please share me the code.
Thanks in advance.
Surely you can. I am not sharing the code but the idea is, usually the prediction is in terms of probability to each label and we select the label as the output. That should be a piece of code outside of the model to prepare these label and there is where you can make that happen.
Hi Jason,
wonder if you can guide me a little bit.
I started new project to deliver people detection however in certain area only (not in the frame of the picture or video). The intention is to warn or give alarm if people entering line-of-fire area, in particulary below crane operating area.
some how, the area is dynamic event by event so the boundary some is not fix. So I wonder if we do virtual boundary using some of helpful object (i.e. briht and colorful cone) and then make a segmentation and then object detection. if those two overlap then raise alarm.
Do you have tutorial or your e-book that cover that thing (especially virtual boundary)?
Thanks
Interesting application Jokonug! While I cannot speak directly to your application, I would highly recommend that you acquire the following ebook:
https://machinelearningmastery.com/deep-learning-for-computer-vision/
Hi Jason,
Thank you for your great post. I want to perform image segmentation using U-Net for extracting flooded areas. However, my labeled dataset is obtained by some traditional thresholding machine learning models. A technician checks the labels but they may still not be very accurate. I was wondering if there is any chance of getting better results than the traditional model when I train U-Net on the noisy labels? Is there any technique that I can use to improve the results?
Thank you for your help.
Hii, Iam working on a project to detect rotten apples from multiple apples(some fresh and some rotten) using yolov5. But getting the predictions for the fresh apple as rotten as I have only one class i.e the rotten apples. Can you please suggest how can I get correct detections?
I just want to detect the rotten apples and not the fresh ones.
Hi Nausheen…Please elaborate on the issues you are encountering with your model so that we may better assist you.
Hello, I want to extract the features of object in image, and store them to uniquely identify object, for example
I have a dog in image , And I want to store dogs feature and identify the dog if next time someone uploads different picture of same dog
Hi Priya,
Storing features extracted from an object detection model is crucial for various tasks like content-based image retrieval, similarity search, further training, etc. The process of storing the features can be broken down into the following steps:
1. **Feature Extraction**:
– Process your image or video data using the object detection model.
– After detecting the objects, extract features from these detected regions. The features could be from an intermediate layer of the model or from a dedicated feature extraction layer.
2. **Serialization**:
– Convert the features to a format that is easy to store. Common formats include lists, dictionaries, or NumPy arrays.
3. **Storage Options**:
a. **Flat File (CSV, TXT)**:
– Use Python’s built-in CSV module or Pandas to store the features in CSV format.
– This method is straightforward but may not be the most efficient for very large datasets.
b. **Binary Formats (Pickle, NumPy’s
.npy)**:– Python’s
picklemodule allows you to serialize Python objects and save them to disk.– For NumPy arrays, you can use the
numpy.save()andnumpy.load()methods to store and load arrays respectively.c. **Databases**:
– **Relational Databases (MySQL, PostgreSQL)**: Convert the features to a format suitable for database storage, such as converting arrays to strings or storing individual elements in table columns.
– **NoSQL Databases (MongoDB, Cassandra)**: These databases can store unstructured data, which might be convenient for complex feature formats.
– **Time Series Databases (InfluxDB)**: Useful if the features are associated with time-stamped data.
d. **Specialized Storage Solutions**:
– **HDF5**: A high-performance storage format suitable for large datasets. Libraries like h5py allow you to easily interact with HDF5 files in Python.
– **Feather**: A fast, lightweight, and easy-to-use binary file format for storing data frames.
e. **Cloud Storage (Amazon S3, Google Cloud Storage)**:
– Useful if you’re working in a cloud environment or if you want to share your datasets across different machines.
4. **Metadata**:
– Along with features, it’s often useful to store metadata like the original file name, the coordinates of the detected object, object class, etc.
– Depending on your storage solution, this could be in a separate table/column or integrated with the feature data.
5. **Compression**:
– If storage space is a concern, consider compressing the features before storing them. Many storage solutions support built-in compression, or you can use libraries like zlib or lz4 in Python.
6. **Backup**:
– Always ensure that you have backups of your data, especially if it’s the result of lengthy computations or hard-to-reproduce feature extractions.
7. **Optimizations**:
– If you find yourself frequently querying or analyzing the stored features, consider using a database index or other optimizations to speed up these operations.
Remember, the choice of storage solution depends on your specific needs, the size of your dataset, and the operations you want to perform on the stored features.
Bro did you copied it from chatgpt