Human activity recognition, or HAR, is a challenging time series classification task.
It involves predicting the movement of a person based on sensor data and traditionally involves deep domain expertise and methods from signal processing to correctly engineer features from the raw data in order to fit a machine learning model.
Recently, deep learning methods such as convolutional neural networks and recurrent neural networks have shown capable and even achieve state-of-the-art results by automatically learning features from the raw sensor data.
In this post, you will discover the problem of human activity recognition and the deep learning methods that are achieving state-of-the-art performance on this problem.
After reading this post, you will know:
- Activity recognition is the problem of predicting the movement of a person, often indoors, based on sensor data, such as an accelerometer in a smartphone.
- Streams of sensor data are often split into subs-sequences called windows, and each window is associated with a broader activity, called a sliding window approach.
- Convolutional neural networks and long short-term memory networks, and perhaps both together, are best suited to learning features from raw sensor data and predicting the associated movement.
Kick-start your project with my new book Deep Learning for Time Series Forecasting, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Deep Learning Models for Human Activity Recognition
Photo by Simon Harrod, some rights reserved.
Overview
This post is divided into five parts; they are:
- Human Activity Recognition
- Benefits of Neural Network Modeling
- Supervised Learning Data Representation
- Convolutional Neural Network Models
- Recurrent Neural Network Models
Human Activity Recognition
Human activity recognition, or HAR for short, is a broad field of study concerned with identifying the specific movement or action of a person based on sensor data.
Movements are often typical activities performed indoors, such as walking, talking, standing, and sitting. They may also be more focused activities such as those types of activities performed in a kitchen or on a factory floor.
The sensor data may be remotely recorded, such as video, radar, or other wireless methods. Alternately, data may be recorded directly on the subject such as by carrying custom hardware or smart phones that have accelerometers and gyroscopes.
Sensor-based activity recognition seeks the profound high-level knowledge about human activities from multitudes of low-level sensor readings
— Deep Learning for Sensor-based Activity Recognition: A Survey, 2018.
Historically, sensor data for activity recognition was challenging and expensive to collect, requiring custom hardware. Now smart phones and other personal tracking devices used for fitness and health monitoring are cheap and ubiquitous. As such, sensor data from these devices is cheaper to collect, more common, and therefore is a more commonly studied version of the general activity recognition problem.
The problem is to predict the activity given a snapshot of sensor data, typically data from one or a small number of sensor types. Generally, this problem is framed as a univariate or multivariate time series classification task.
It is a challenging problem as there are no obvious or direct ways to relate the recorded sensor data to specific human activities and each subject may perform an activity with significant variation, resulting in variations in the recorded sensor data.
The intent is to record sensor data and corresponding activities for specific subjects, fit a model from this data, and generalize the model to classify the activity of new unseen subjects from their sensor data.
Need help with Deep Learning for Time Series?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Benefits of Neural Network Modeling
Traditionally, methods from the field of signal processing were used to analyze and distill the collected sensor data.
Such methods were for feature engineering, creating domain-specific, sensor-specific, or signal processing-specific features and views of the original data. Statistical and machine learning models were then trained on the processed version of the data.
A limitation of this approach is the signal processing and domain expertise required to analyze the raw data and engineer the features required to fit a model. This expertise would be required for each new dataset or sensor modality. In essence, it is expensive and not scalable.
However, in most daily HAR tasks, those methods may heavily rely on heuristic handcrafted feature extraction, which is usually limited by human domain knowledge. Furthermore, only shallow features can be learned by those approaches, leading to undermined performance for unsupervised and incremental tasks. Due to those limitations, the performances of conventional [pattern recognition] methods are restricted regarding classification accuracy and model generalization.
— Deep Learning for Sensor-based Activity Recognition: A Survey, 2018.
Ideally, learning methods could be used that automatically learn the features required to make accurate predictions from the raw data directly. This would allow new problems, new datasets, and new sensor modalities to be adopted quickly and cheaply.
Recently, deep neural network models have started delivering on their promises of feature learning and are achieving stat-of-the-art results for human activity recognition. They are capable of performing automatic feature learning from the raw sensor data and out-perform models fit on hand-crafted domain-specific features.
[…] , the feature extraction and model building procedures are often performed simultaneously in the deep learning models. The features can be learned automatically through the network instead of being manually designed. Besides, the deep neural network can also extract high-level representation in deep layer, which makes it more suitable for complex activity recognition tasks.
— Deep Learning for Sensor-based Activity Recognition: A Survey, 2018.
There are two main approaches to neural networks that are appropriate for time series classification and that have been demonstrated to perform well on activity recognition using sensor data from commodity smart phones and fitness tracking devices.
They are Convolutional Neural Network Models and Recurrent Neural Network Models.
RNN and LSTM are recommended to recognize short activities that have natural order while CNN is better at inferring long term repetitive activities. The reason is that RNN could make use of the time-order relationship between sensor readings, and CNN is more capable of learning deep features contained in recursive patterns.
— Deep Learning for Sensor-based Activity Recognition: A Survey, 2018.
Supervised Learning Data Representation
Before we dive into the specific neural networks that can be used for human activity recognition, we need to talk about data preparation.
Both types of neural networks suitable for time series classification require that data be prepared in a specific manner in order to fit a model. That is, in a ‘supervised learning‘ way that allows the model to associate signal data with an activity class.
A straight-forward data preparation approach that was used both for classical machine learning methods on the hand-crafted features and for neural networks involves dividing the input signal data into windows of signals, where a given window may have one to a few seconds of observation data. This is often called a ‘sliding window.’
Human activity recognition aims to infer the actions of one or more persons from a set of observations captured by sensors. Usually, this is performed by following a fixed length sliding window approach for the features extraction where two parameters have to be fixed: the size of the window and the shift.
— A Dynamic Sliding Window Approach for Activity Recognition, 2011
Each window is also associated with a specific activity. A given window of data may have multiple variables, such as the x, y, and z axes of an accelerometer sensor.
Let’s make this concrete with an example.
We have sensor data for 10 minutes; that may look like:
|
1 2 3 4 5 |
x, y, z, activity 1.1, 2.1, 0.1, 1 1.2, 2.2, 0.2, 1 1.3, 2.3, 0.3, 1 ... |
If the data is recorded at 8 Hz, that means that there will be eight rows of data for one second of elapsed time performing an activity.
We may choose to have one window of data represent one second of data; that means eight rows of data for an 8 Hz sensor. If we have x, y, and z data, that means we would have 3 variables. Therefore, a single window of data would be a 2-dimensional array with eight time steps and three features.
One window would represent one sample. One minute of data would represent 480 sensor data points, or 60 windows of eight time steps. The total 10 minutes of data would represent 4,800 data points, or 600 windows of data.
It is convenient to describe the shape of our prepared sensor data in terms of the number of samples or windows, the number of time steps in a window, and the number of features observed at each time step.
|
1 |
[samples, time steps, features] |
Our example of 10 minutes of accelerometer data recorded at 8 Hz would be summarized as a three-dimensional array with the dimensions:
|
1 |
[600, 8, 3] |
There is no best window size, and it really depends on the specific model being used, the nature of the sensor data that was collected, and the activities that are being classified.
There is a tension in the size of the window and the size of the model. Larger windows require large models that are slower to train, whereas smaller windows require smaller models that are much easier to fit.
Intuitively, decreasing the window size allows for a faster activity detection, as well as reduced resources and energy needs. On the contrary, large data windows are normally considered for the recognition of complex activities
— Window Size Impact in Human Activity Recognition, 2014.
Nevertheless, it is common to use one to two seconds of sensor data in order to classify a current fragment of an activity.
From the results, reduced windows (2 s or less) are demonstrated to provide the most accurate detection performance. In fact, the most precise recognizer is obtained for very short windows (0.25–0.5 s), leading to the perfect recognition of most activities. Contrary to what is often thought, this study demonstrates that large window sizes do not necessarily translate into a better recognition performance.
— Window Size Impact in Human Activity Recognition, 2014.
There is some risk that the splitting of the stream of sensor data into windows may result in windows that miss the transition of one activity to another. As such, it was traditionally common to split data into windows with an overlap such that the first half of the window contained the observations from the last half of the previous window, in the case of a 50% overlap.
[…] an incorrect length may truncate an activity instance. In many cases, errors appear at the beginning or at the end of the activities, when the window overlaps the end of one activity and the beginning of the next one. In other cases, the window length may be too short to provide the best information for the recognition process.
— A Dynamic Sliding Window Approach for Activity Recognition, 2011
It is unclear whether windows with overlap are required for a given problem.
In the adoption of neural network models, the use of overlaps, such as a 50% overlap, will double the size of the training data, which may aid in modeling smaller datasets, but may also lead to models that overfit the training dataset.
An overlap between adjacent windows is tolerated for certain applications; however, this is less frequently used.
— Window Size Impact in Human Activity Recognition, 2014.
Convolutional Neural Network Models
Convolutional Neural Network models, or CNNs for short, are a type of deep neural network that were developed for use with image data, e.g. such as handwriting recognition.
They have proven very effective on challenging computer vision problems when trained at scale for tasks such as identifying and localizing objects in images and automatically describing the content of images.
They are models that are comprised of two main types of elements: convolutional layers and pooling layers.
Convolutional layers read an input, such as a 2D image or a 1D signal, using a kernel that reads in small segments at a time and steps across the entire input field. Each read results in an the input that is projected onto a filter map and represents an internal interpretation of the input.
Pooling layers take the feature map projections and distill them to the most essential elements, such as using a signal averaging or signal maximizing process.
The convolution and pooling layers can be repeated at depth, providing multiple layers of abstraction of the input signals.
The output of these networks is often one or more fully connected layers that interpret what has been read and map this internal representation to a class value.
For more information on convolutional neural networks, can see the post:
CNNs can be applied to human activity recognition data.
The CNN model learns to map a given window of signal data to an activity where the model reads across each window of data and prepares an internal representation of the window.
When applied to time series classification like HAR, CNN has two advantages over other models: local dependency and scale invariance. Local dependency means the nearby signals in HAR are likely to be correlated, while scale invariance refers to the scale-invariant for different paces or frequencies.
— Deep Learning for Sensor-based Activity Recognition: A Survey, 2018.
The first important work using CNNs to HAR was by Ming Zeng, et al in their 2014 paper “Convolutional Neural Networks for Human Activity Recognition using Mobile Sensors.”
In the paper, the authors develop a simple CNN model for accelerometer data, where each axis of the accelerometer data is fed into separate convolutional layers, pooling layers, then concatenated before being interpreted by hidden fully connected layers.
The figure below taken from the paper clearly shows the topology of the model. It provides a good template for how the CNN may be used for HAR problems and time series classification in general.
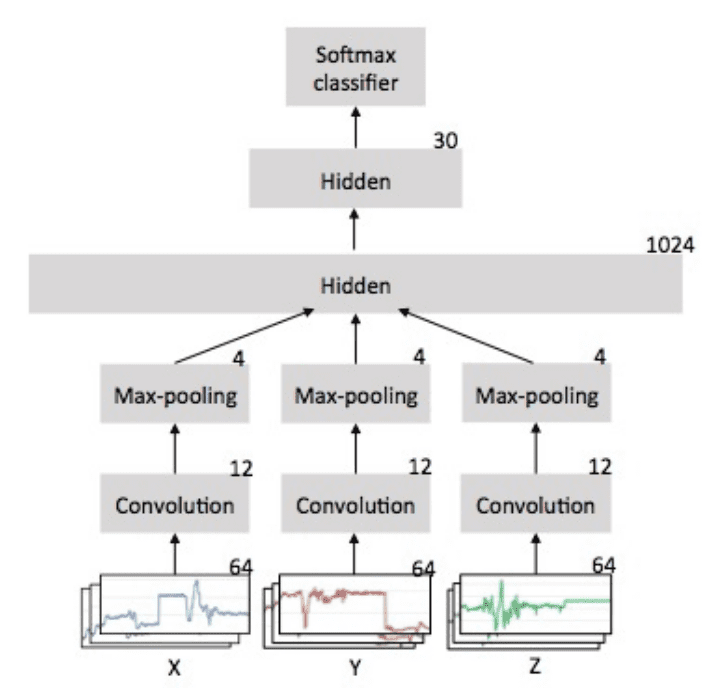
Depiction of CNN Model for Accelerometer Data
Taken from “Convolutional Neural Networks for Human Activity Recognition using Mobile Sensors”
There are many ways to model HAR problems with CNNs.
One interesting example was by Heeryon Cho and Sang Min Yoon in their 2018 paper titled “Divide and Conquer-Based 1D CNN Human Activity Recognition Using Test Data Sharpening.”
In it, they divide activities into those that involve movement, called “dynamic,” and those where the subject is stationary, called “static,” then develop a CNN model to discriminate between these two main classes. Then, within each class, models are developed to discriminate between activities of that type, such as “walking” for dynamic and “sitting” for static.
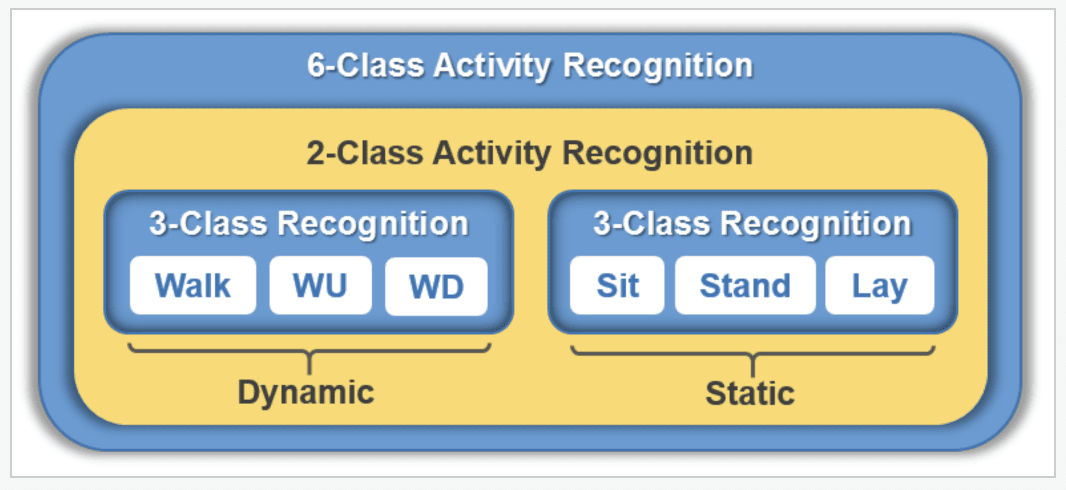
Separation of Activities as Dynamic or Static
Taken from “Divide and Conquer-Based 1D CNN Human Activity Recognition Using Test Data Sharpening”
They refer to this as a two-stage modeling approach.
Instead of straightforwardly recognizing the individual activities using a single 6-class classifier, we apply a divide and conquer approach and build a two-stage activity recognition process, where abstract activities, i.e., dynamic and static activity, are first recognized using a 2-class or binary classifier, and then individual activities are recognized using two 3-class classifiers.
— Divide and Conquer-Based 1D CNN Human Activity Recognition Using Test Data Sharpening, 2018.
Quite large CNN models were developed, which in turn allowed the authors to claim state-of-the-art results on challenging standard human activity recognition datasets.
Another interesting approach was proposed by Wenchao Jiang and Zhaozheng Yin in their 2015 paper titled “Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks.”
Instead of using 1D CNNs on the signal data, they instead combine the signal data together to create “images” which are then fed to a 2D CNN and processed as image data with convolutions along the time axis of signals and across signal variables, specifically accelerometer and gyroscope data.
Firstly, raw signals are stacked row-by-row into a signal image [….]. In the signal image, every signal sequence has the chance to be adjacent to every other sequence, which enables DCNN to extract hidden correlations between neighboring signals. Then, 2D Discrete Fourier Transform (DFT) is applied to the signal image and its magnitude is chosen as our activity image
— Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks, 2015.
Below is a depiction of the processing of raw sensor data into images, and then from images into an “activity image,” the result of a discrete Fourier transform.

Processing of Raw Sensor Data into an Image
Taken from “Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks”
Finally, another good paper on the topic is by Charissa Ann Ronao and Sung-Bae Cho in 2016 titled “Human activity recognition with smartphone sensors using deep learning neural networks.”
Careful study of the use of CNNs is performed showing that larger kernel sizes of signal data are useful and limited pooling.
Experiments show that convnets indeed derive relevant and more complex features with every additional layer, although difference of feature complexity level decreases with every additional layer. A wider time span of temporal local correlation can be exploited (1×9 – 1×14) and a low pooling size (1×2 – 1×3) is shown to be beneficial.
— Human activity recognition with smartphone sensors using deep learning neural networks, 2016.
Usefully, they also provide the full hyperparameter configuration for the CNN models that may provide a useful starting point on new HAR and other sequence classification problems, summarized below.
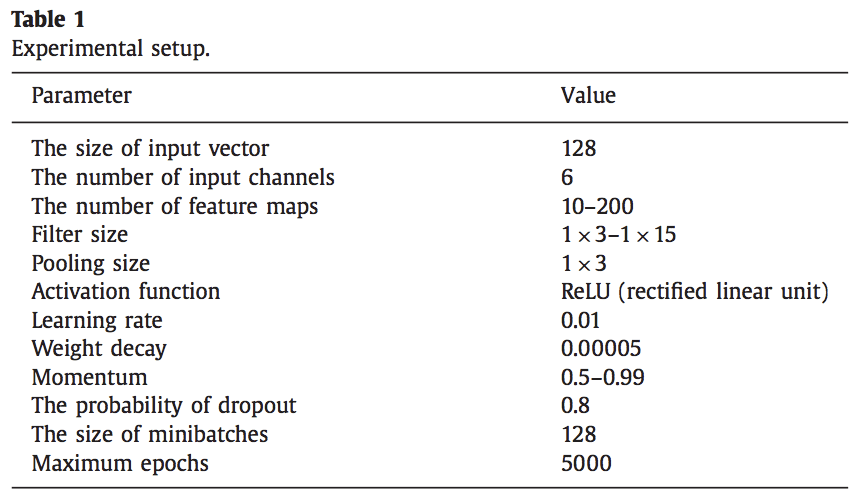
Table of CNN Model Hyperparameter Configuration
Taken from “Human activity recognition with smartphone sensors using deep learning neural networks.”
Recurrent Neural Network Models
Recurrent neural networks, or RNNs for short, are a type of neural network that was designed to learn from sequence data, such as sequences of observations over time, or a sequence of words in a sentence.
A specific type of RNN called the long short-term memory network, or LSTM for short, is perhaps the most widely used RNN as its careful design overcomes the general difficulties in training a stable RNN on sequence data.
LSTMs have proven effective on challenging sequence prediction problems when trained at scale for such tasks as handwriting recognition, language modeling, and machine translation.
A layer in an LSTM model is comprised of special units that have gates that govern input, output, and recurrent connections, the weights of which are learned. Each LSTM unit also has internal memory or state that is accumulated as an input sequence is read and can be used by the network as a type of local variable or memory register.
For more information on long short-term memory networks, see the post:
Like the CNN that can read across an input sequence, the LSTM reads a sequence of input observations and develops its own internal representation of the input sequence. Unlike the CNN, the LSTM is trained in a way that pays specific attention to observations made and prediction errors made over the time steps in the input sequence, called backpropagation through time.
For more information on backpropagation through time, see the post:
LSTMs can be applied to the problem of human activity recognition.
The LSTM learns to map each window of sensor data to an activity, where the observations in the input sequence are read one at a time, where each time step may be comprised of one or more variables (e.g. parallel sequences).
There has been limited application of simple LSTM models to HAR problems.
One example is by Abdulmajid Murad and Jae-Young Pyun in their 2017 paper titled “Deep Recurrent Neural Networks for Human Activity Recognition.”
Important, in the paper they comment on the limitation of CNNs in their requirement to operate on fixed-sized windows of sensor data, a limitation that LSTMs do not strictly have.
However, the size of convolutional kernels restricts the captured range of dependencies between data samples. As a result, typical models are unadaptable to a wide range of activity-recognition configurations and require fixed-length input windows.
— Deep Recurrent Neural Networks for Human Activity Recognition, 2017.
They explore the use of LSTMs that both process the sequence data forward (normal) and both directions (Bidirectional LSTM). Interestingly, the LSTM predicts an activity for each input time step of a subsequence of sensor data, which are then aggregated in order to predict an activity for the window.
There will [be] a score for each time-step predicting the type of activity occurring at time t. The prediction for the entire window T is obtained by merging the individual scores into a single prediction
— Deep Recurrent Neural Networks for Human Activity Recognition, 2017.
The figure below taken from the paper provides a depiction of the LSTM model followed by fully connected layers used to interpret the internal representation of the raw sensor data.
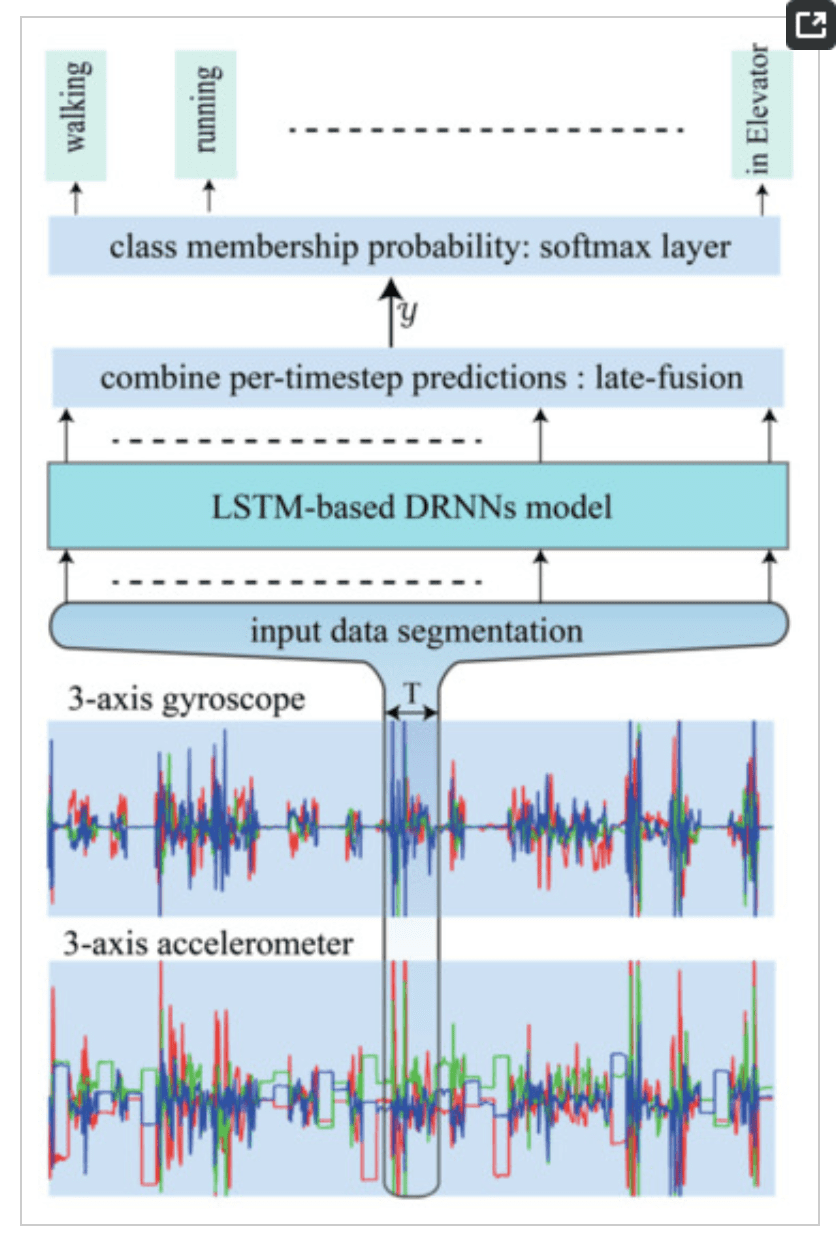
Depiction of LSTM RNN for Activity Recognition
Taken from “Deep Recurrent Neural Networks for Human Activity Recognition.”
It may be more common to use an LSTM in conjunction with a CNN on HAR problems, in a CNN-LSTM model or ConvLSTM model.
This is where a CNN model is used to extract the features from a subsequence of raw sample data, and output features from the CNN for each subsequence are then interpreted by an LSTM in aggregate.
An example of this is in the 2016 paper by Francisco Javier Ordonez and Daniel Roggen titled “Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition.”
We introduce a new DNN framework for wearable activity recognition, which we refer to as DeepConvLSTM. This architecture combines convolutional and recurrent layers. The convolutional layers act as feature extractors and provide abstract representations of the input sensor data in feature maps. The recurrent layers model the temporal dynamics of the activation of the feature maps.
— Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition, 2016.
A deep network architecture is used with four convolutional layers without any pooling layers, followed by two LSTM layers to interpret the extracted features over multiple time steps.
The authors claim that the removal of the pooling layers is a critical part of their model architecture, where the use of pooling layers after the convolutional layers interferes with the convolutional layers’ ability to learn to downsample the raw sensor data.
In the literature, CNN frameworks often include convolutional and pooling layers successively, as a measure to reduce data complexity and introduce translation invariant features. Nevertheless, such an approach is not strictly part of the architecture, and in the time series domain […] DeepConvLSTM does not include pooling operations because the input of the network is constrained by the sliding window mechanism […] and this fact limits the possibility of downsampling the data, given that DeepConvLSTM requires a data sequence to be processed by the recurrent layers. However, without the sliding window requirement, a pooling mechanism could be useful to cover different sensor data time scales at deeper layers.
— Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition, 2016.
The figure below taken from the paper makes the architecture clearer. Note that layers 6 and 7 in the image are in fact LSTM layers.
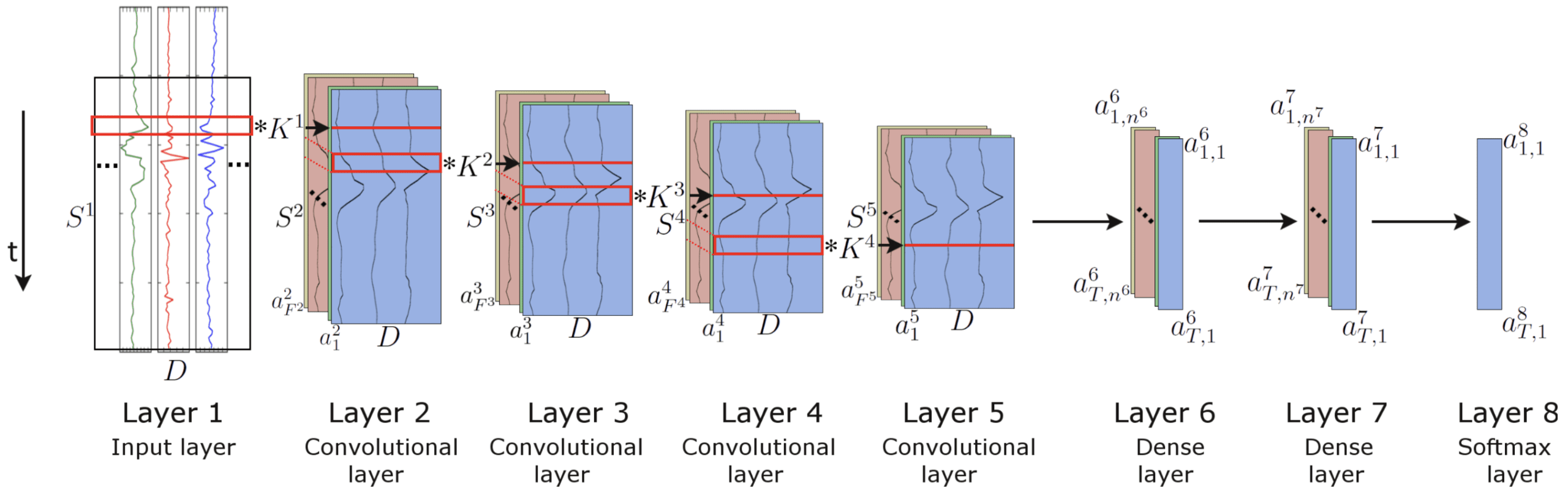
Depiction of CNN LSTM Model for Activity Recognition
Taken from “Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition.”
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
General
Sliding Windows
- A Dynamic Sliding Window Approach for Activity Recognition, 2011.
- Window Size Impact in Human Activity Recognition, 2014.
CNNs
- Convolutional Neural Networks for Human Activity Recognition using Mobile Sensors, 2014.
- Divide and Conquer-Based 1D CNN Human Activity Recognition Using Test Data Sharpening, 2018.
- Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks, 2015.
- Human activity recognition with smartphone sensors using deep learning neural networks, 2016.
RNNs
- Deep Recurrent Neural Networks for Human Activity Recognition, 2017.
- Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition, 2016.
Summary
In this post, you discovered the problem of human activity recognition and the use of deep learning methods that are achieving state-of-the-art performance on this problem.
Specifically, you learned:
- Activity recognition is the problem of predicting the movement of a person, often indoors, based on sensor data, such as an accelerometer in a smartphone.
- Streams of sensor data are often split into subs-sequences called windows and each window is associated with a broader activity, called a sliding window approach.
- Convolutional neural networks and long short-term memory networks, and perhaps both together, are best suited to learning features from raw sensor data and predicting the associated movement.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning models for Time Series Today!

Develop Your Own Forecasting models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Time Series Forecasting
It provides self-study tutorials on topics like:
CNNs, LSTMs,
Multivariate Forecasting, Multi-Step Forecasting and much more...
Finally Bring Deep Learning to your Time Series Forecasting Projects
Skip the Academics. Just Results.






can you implement something as an example to recognize any human activity.
I don’t see why not.
Jason, Have you actually implement an example of this? I would be interested to look at it. Thanks.
Thanks.
Thank you for providing such valuable information.
You’re welcome.
Please provide a prototype so that we can get an idea how to use it for our project
I give many examples of HAR on the blog.
Thanks for the great article Jason. Do you know which approach performed best in terms of classification accuracy? My research pointed at https://github.com/deadskull7/Human-Activity-Recognition-with-Neural-Network-using-Gyroscopic-and-Accelerometer-variables/blob/master/Human%20Activity%20Recognition%20(97.98%20%25).ipynb with a claimed 97.98% accuracy.
I have not tried to get the best results on the HAR problem, just demonstrate the methods.
Also, your link is broken.
Sorry for that, here is the correct one:
https://github.com/deadskull7/Human-Activity-Recognition-with-Neural-Network-using-Gyroscopic-and-Accelerometer-variables
Nice work!
Hi Jason,
Thank you so much for putting all together. Would appreciate if you Can giveus stepbystep implementations with real dataset.
I have many such examples on the blog, perhaps start here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Thanks Jason for an interesting post. Do you also have such post for Markerless MoCap? or Video based activity recognition?
Thanks
Not at this stage, perhaps in the future.
What could be the best algorithm for human activity recognition on ARAS dataset
You must test a suite of algorithms and discover what works best for a given dataset, more details here:
https://machinelearningmastery.com/faq/single-faq/what-algorithm-config-should-i-use
Hi Jason,
I appreciate for sharing this tutorial since it was useful as well as the others.
I have already read some tutorials in your website and codes in github, but their applications were specialized for long distance (when there is a long distance between camera and people). But I am looking for some codes which are suitable for some how circumstances, which there is a short distance between camera and people, as the below links do not work well under circumstances which camera can not capture large spaces (short distance between camera and people).
if you have any idea I will be happy to share it with me.
I am in deadline, thus I will be thanks full if you reply me soon.
the codes which i read in Github are as follows (specialized for long distances between people and cameras):
#########################################################
https://github.com/koba/overhead-camera-people-counter
#############################################################
https://github.com/LukashenkoEvgeniy/People-Counter
###########################################################
https://github.com/akko29/People-Counter
The modeling approach would be very similar.
thanks alot dear Jason for yr posts, I’m looking for a good proposal in the field of mobile sensor based HAR for PHD level, do u have any idea in this field, I’ve searched and studied so many papers but couldn’t find any good idea, that would be great kind of you to help me find a novel idea…thank u so much in advance for yr attention ????????
No, sorry.
I have two questoins.
1- In this approach, sequence of timesteps are modeled to predict the class (activity). As each window is a sequence of timesteps, and that sequence is modeled using LSTM.
Can we also embed the sequence of activities in this model? How to reshape the data, if we also want to model sequence of activities. Like walk -> sit-> stand -> run etc. Perhaps if the model know the sequence of previous activities, it can better predict the class.
2- I think, the article considered one sequence of 10 minutes. how to model this data for LSTM if we have another sequence, for example sequence of activities by another user consisting of 8 minutes.
Yes, interesting approach.
The proposed problem assumes the order of activities are random.
If you want to add history of past activities, perhaps use a multi-input model and use a sequence of activity types as a second input?
Hello Sir,
Thanks for this wonderful article.
can we use ANN( deep MLP) for time series data above?
or is it neccessary to use RNN and CNN always for time series.l?
You can try all 3 approaches and see what works best for your specific dataset.
Hello Sir,
I am just a bit confused between how CNN and LSTM are reading and interpreting here…
CNN is actually reading a whole window of data at once and trying to interpret from it and LSTM is interpreting timesteps….not getting a clear view here..please help
Exactly right – as you say.
The CNN reads across the whole interval at once, the LSTM steps over it step by step.
Both are working hard to interpet any signal in the interval.
Hi Jason, I really love this work. Thank you for sharing.
I want to hear your idea about the subject. If enough activities are collected by 5 different persons, do you think using this method can we recognize the activity of a different person who is not in the group of 5 people?
Thanks.
Perhaps try it and see?
Have you tried this? 🙂
https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition
I don’t know about your project, sorry.
Amazing post, thanks for sharing.
Thanks!
Great work, very useful. Thanks for sharing it 🙂
Thanks!
My opinion
I think that CNN-like deep learning algorithms are insufficient for classification in real-time systems. Although the algorithm seems logical, the readily available functions are incorrect in measuring system success. It needs new algorithm structures. Deep learning algorithms that don’t work on the internet are overflowed. I believe that the success of algorithms exceeds 75%. It is argued that articles reflect reality.
Not sure I agree.
I’m fixing
I don’t believe that the success of algorithms exceeds 75%
i understand the size of the window, but still confused what is the difference between the shift and overlap, in HAR does it mean having 50% overlap is the same with 64 data shift between window (since each window contain 128 data)?
I guess they are not separate concepts, but tightly related – affect each other.
Hello Jason, Thanks for all the knowledge you shared. Do you suggest an Idea how to determine only motorized activity such as driving of cars and motorcycles from the user data?
Perhaps test a suite of models and model configurations and discover what works best for your dataset.
I am researching on detecting badminton in real time(not classifying different strokes), which approach would be better CNN LSTM,ANN and sliding window concept would also not be suitable in this case I suppose, Kindly help.
I recommend testing a suite of diffrent models and different framings of the problem and discover what works best.
Thanks for sharing!
Here I have a question about “Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition, 2016”.
1. Could you please explain in more detail why the pooling layer is not added in
the convolution layer? What happened when “interferes with the convolutional layers’ ability to learn to downsample the raw sensor data” (you mean the ability of the convolution layer extract feature?)?
2. This paper said “without the sliding window requirement, a pooling mechanism could be useful to cover different sensor data time scales at deeper layers.”, but isn’t sliding window mechanism necessary(segmentation in Activity Recognition Chain)? How can HAR work without sliding windows in deep learning?
You’re welcome.
This can help with pooling layers:
https://machinelearningmastery.com/pooling-layers-for-convolutional-neural-networks/
If you have questions about the content of the paper, perhaps contact the authors directly.
Hi Jason, could you please tell me how to load the x,y,z data for model building along with other features please?
Perhaps start with the above tutorial and adapt it for your needs.
i want this project code how it works lstm please give me somesuggestion
No problem, see this:
https://machinelearningmastery.com/how-to-develop-rnn-models-for-human-activity-recognition-time-series-classification/
Hi Jason,Thanks for sharing.
There are same issues in my work.
A little bit differently,I got a raw data of sensor,that may look like:
x, y, z, activityWalk(%), activitySit(%), activityStand(%),
1.1, 2.1, 0.1, 33, 30, 37
1.2, 2.2, 0.2, 21, 39, 40
1.3, 2.3, 0.3, 14, 66, 20
There are activity probability with sensor data
I wanna get some hint about that,thx.
You’re welcome.
Looks good, what’s the problem exactly?
Jason,Thanks for responding
It seems like a activity probability per 1 minutes IMU sensor data
I wanna training IMU sensor data to get higher activity probability
Which session or module should I refer?
I recommend testing a suite of different data preparation methods, models and model configurations in order to discover what works best for your dataset.
The tutorials here will help you to get started:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Jason,Thanks a lot for tutorials
You’re welcome.
Hello Jason,
I want to make a cluster by using DBSCAn from the HAR dataset. How should I proceed? Please advise.
Thanks
Perhaps this might give you ideas:
https://machinelearningmastery.com/clustering-algorithms-with-python/
Thanks jason
Great and amazing content.
Thanks.
Hello Jason
I’m doing project on human activity recognition in real time ,is CNN and LSTM exactly work in real time (using raspberry Pi and accelerometer sensor)
Please give me answer
Yes, I believe these models can be used to make predictions in real time on simple hardware.
This is one of the most incredible blogs Ive read in a very long time.
Thanks!
Dear Jason, thank you for sharing such an interesting overview of deep learning for HAR! We make research on smartphone sensor-based data for fall detection. Recently we have published an article: https://link.springer.com/chapter/10.1007/978-3-030-79457-6_52
where we have used different classifiers to detect falls. Could you suggest any of your models that can be suitable to our dataset for fall detection purposes? Also, it would be interesting if you could share some recommendations about on-device data processing. Thank you in advance!
I recommend testing a suite of algorithms and data preparation schemes in order to discover what works well or best for your specific dataset.
Hey Jason! Thanks for the content. I am a little bit confused about the sliding window representation. If all of the timesteps in the window do not always map to only 1 activity (overlap in activities), how can the model learn to classify one window to a particular activity?
Hi Rohan…the following will hopefully add clarity:
https://machinelearningmastery.com/time-series-forecasting-supervised-learning/#:~:text=The%20use%20of%20prior%20time,or%20size%20of%20the%20lag.
Hey James, thanks for the response. So my understanding of the way the model trains (correct me if I am wrong) is that a for a window (training example), the correct classification would be the activity of the final timestep and the loss will be determined accordingly?
Hi Rohan…You are very welcome! Your understanding is correct. Keep up the great work!
Hey James. Thanks for this amazing article.
You mentioned using raw sensor data for all of the above deep learning models, however, in my case I have prepped my data by doing Principal Components Analysis, thus making a new dataset that is not raw.
Are you knowledgeable on inputting PCA data instead of raw data?
Thanks.
Hi Simon…I have not used that approach extensively. The following resources may help promote some insights:
https://ashutoshtripathi.com/2019/07/11/a-complete-guide-to-principal-component-analysis-pca-in-machine-learning/
Hi James. If my dataset was collected at 25 Hz ( This is a publicly available dataset). So when I am selecting a window size, does this 25Hz has to do anything with the window length and overlap.
Also, if I am implementing this in realtime, would it be necessary to stream data at 25Hz.
Hi Georgy…The following may be of interest to you:
https://stats.stackexchange.com/questions/366387/how-to-decide-moving-window-size-for-time-series-prediction
Thank you for sharing informative article, Keep sharing more
Hi Abogado…You are very welcome! Thank you for your support!