Activity regularization provides an approach to encourage a neural network to learn sparse features or internal representations of raw observations.
It is common to seek sparse learned representations in autoencoders, called sparse autoencoders, and in encoder-decoder models, although the approach can also be used generally to reduce overfitting and improve a model’s ability to generalize to new observations.
In this tutorial, you will discover the Keras API for adding activity regularization to deep learning neural network models.
After completing this tutorial, you will know:
How to create vector norm regularizers using the Keras API.
How to add activity regularization to MLP, CNN, and RNN layers using the Keras API.
How to reduce overfitting by adding activity regularization to an existing model.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Oct/2019: Updated for Keras 2.3 and TensorFlow 2.0.
How to Reduce Generalization Error in Deep Neural Networks With Activity Regularization in Keras Photo by Johan Neven, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Activity Regularization in Keras
Activity Regularization on Layers
Activity Regularization Case Study
Activity Regularization in Keras
Keras supports activity regularization.
There are three different regularization techniques supported, each provided as a class in the keras.regularizers module:
l1: Activity is calculated as the sum of absolute values.
l2: Activity is calculated as the sum of the squared values.
l1_l2: Activity is calculated as the sum of absolute and sum of the squared values.
Each of the l1 and l2 regularizers takes a single hyperparameter that controls the amount that each activity contributes to the sum. The l1_l2 regularizer takes two hyperparameters, one for each of the l1 and l2 methods.
The regularizer class must be imported and then instantiated; for example:
1
2
3
4
# import regularizer
from keras.regularizers import l1
# instantiate regularizer
reg=l1(0.001)
Activity Regularization on Layers
Activity regularization is specified on a layer in Keras.
This can be achieved by setting the activity_regularizer argument on the layer to an instantiated and configured regularizer class.
The regularizer is applied to the output of the layer, but you have control over what the “output” of the layer actually means. Specifically, you have flexibility as to whether the layer output means that the regularization is applied before or after the ‘activation‘ function.
For example, you can specify the function and the regularization on the layer, in which case activation regularization is applied to the output of the activation function, in this case, rectified linear activation function or ReLU.
Alternately, you can specify a linear activation function (the default, that does not perform any transform) which means that the activation regularization is applied on the raw outputs, then, the activation function can be added as a subsequent layer.
The latter is probably the preferred usage of activation regularization as described in “Deep Sparse Rectifier Neural Networks” in order to allow the model to learn to take activations to a true zero value in conjunction with the rectified linear activation function. Nevertheless, the two possible uses of activation regularization may be explored in order to discover what works best for your specific model and dataset.
Let’s take a look at how activity regularization can be used with some common layer types.
MLP Activity Regularization
The example below sets l1 norm activity regularization on a Dense fully connected layer.
1
2
3
4
5
6
# example of l1 norm on activity from a dense layer
Now that we know how to use the activity regularization API, let’s look at a worked example.
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Activity Regularization Case Study
In this section, we will demonstrate how to use activity regularization to reduce overfitting of an MLP on a simple binary classification problem.
Although activity regularization is most often used to encourage sparse learned representations in autoencoder and encoder-decoder models, it can also be used directly within normal neural networks to achieve the same effect and improve the generalization of the model.
This example provides a template for applying activity regularization to your own neural network for classification and regression problems.
Binary Classification Problem
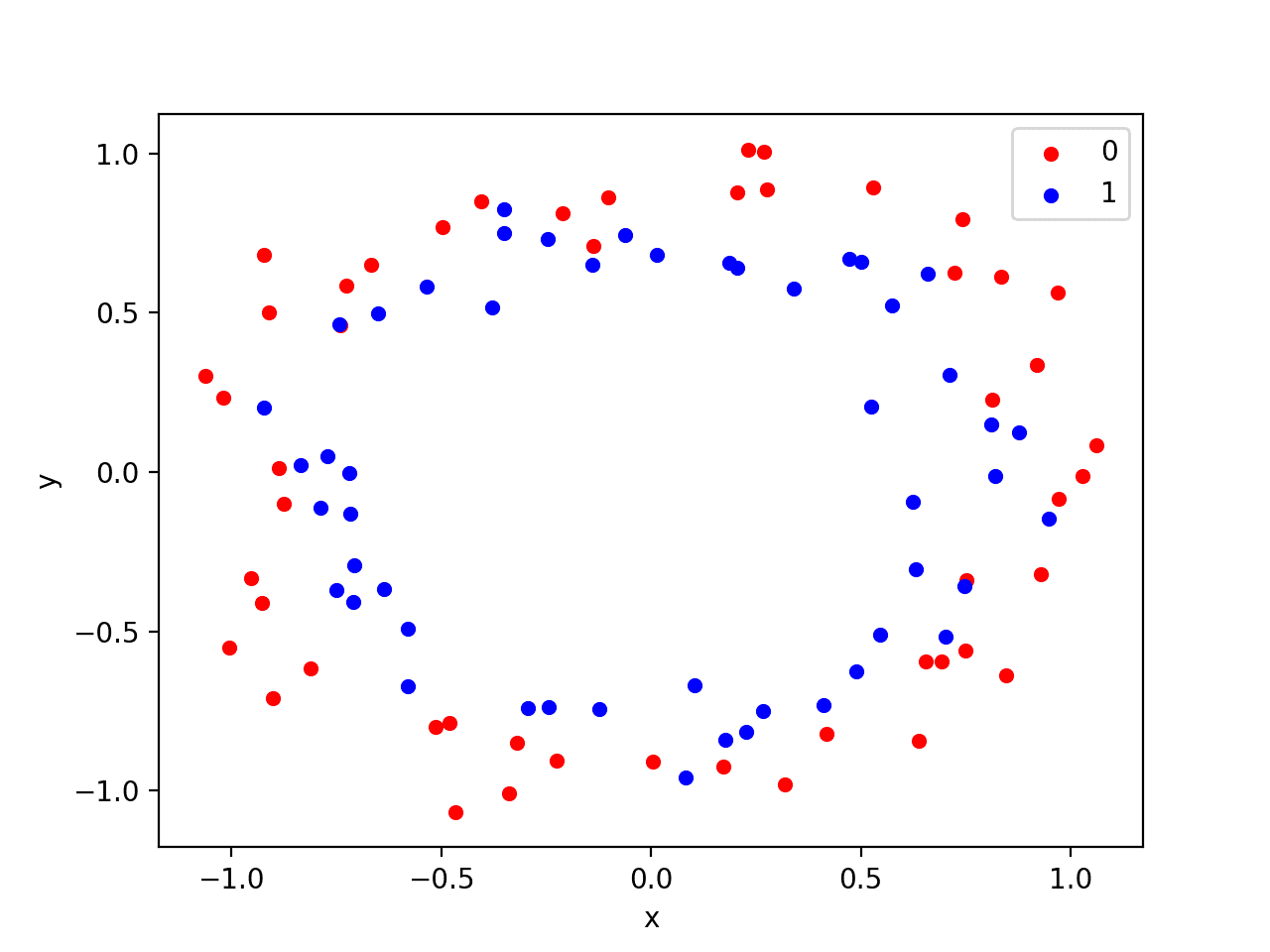
We will use a standard binary classification problem that defines two two-dimensional concentric circles of observations, one circle for each class.
Each observation has two input variables with the same scale and a class output value of either 0 or 1. This dataset is called the “circles” dataset because of the shape of the observations in each class when plotted.
We can use the make_circles() function to generate observations from this problem. We will add noise to the data and seed the random number generator so that the same samples are generated each time the code is run.
We can plot the dataset where the two variables are taken as x and y coordinates on a graph and the class value is taken as the color of the observation.
The complete example of generating the dataset and plotting it is listed below.
Running the example creates a scatter plot showing the concentric circles shape of the observations in each class.
We can see the noise in the dispersal of the points making the circles less obvious.
Scatter Plot of Circles Dataset with Color Showing the Class Value of Each Sample
This is a good test problem because the classes cannot be separated by a line, e.g. are not linearly separable, requiring a nonlinear method such as a neural network to address.
We have only generated 100 samples, which is small for a neural network, providing the opportunity to overfit the training dataset and have higher error on the test dataset: a good case for using regularization.
Further, the samples have noise, giving the model an opportunity to learn aspects of the samples that don’t generalize.
Overfit Multilayer Perceptron
We can develop an MLP model to address this binary classification problem.
The model will have one hidden layer with more nodes that may be required to solve this problem, providing an opportunity to overfit. We will also train the model for longer than is required to ensure the model overfits.
Before we define the model, we will split the dataset into train and test sets, using 30 examples to train the model and 70 to evaluate the fit model’s performance.
The hidden layer uses 500 nodes and the rectified linear activation function. A sigmoid activation function is used in the output layer in order to predict class values of 0 or 1.
The model is optimized using the binary cross entropy loss function, suitable for binary classification problems and the efficient Adam version of gradient descent.
Finally, we will plot the performance of the model on both the train and test set each epoch.
If the model does indeed overfit the training dataset, we would expect the line plot of accuracy on the training set to continue to increase and the test set to rise and then fall again as the model learns statistical noise in the training dataset.
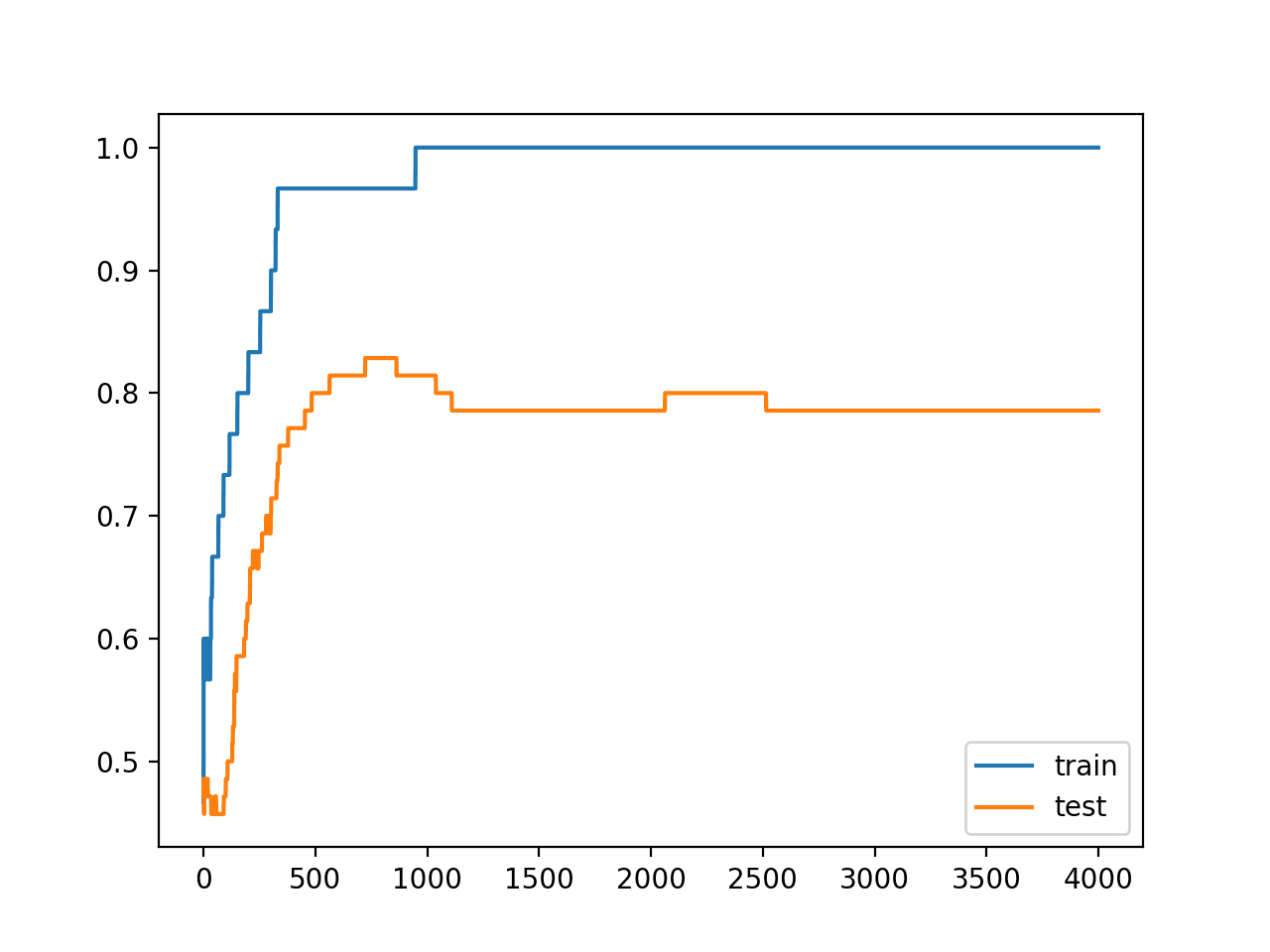
Running the example reports the model performance on the train and test datasets.
We can see that the model has better performance on the training dataset than the test dataset, one possible sign of overfitting.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Because the model is severely overfit, we generally would not expect much, if any, variance in the accuracy across repeated runs of the model on the same dataset.
1
Train: 1.000, Test: 0.786
A figure is created showing line plots of the model accuracy on the train and test sets.
We can see the expected shape of an overfit model where test accuracy increases to a point and then begins to decrease again.
Line Plots of Accuracy on Train and Test Datasets While Training Showing an Overfit
Overfit MLP With Activation Regularization
We can update the example to use activation regularization.
There are a few different regularization methods to choose from, but it is probably a good idea to use the most common, which is the L1 vector norm.
This regularization has the effect of encouraging a sparse representation (lots of zeros), which is supported by the rectified linear activation function that permits true zero values.
We can do this by using the keras.regularizers.l1 class in Keras.
We will configure the layer to use the linear activation function so that we can regularize the raw outputs, then add a relu activation layer after the regularized outputs of the layer. We will set the regularization hyperparameter to 1E-4 or 0.0001, found with a little trial and error.
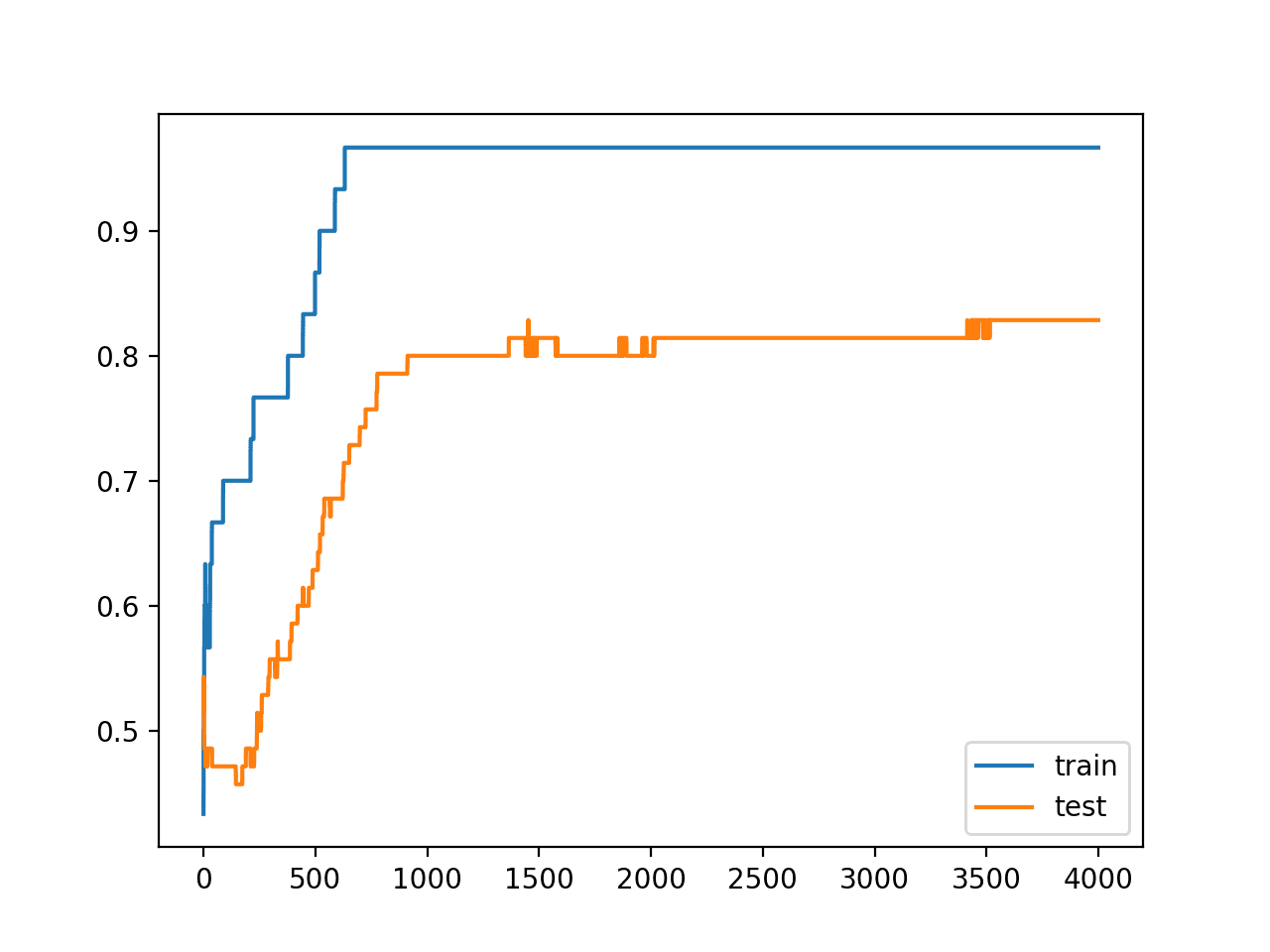
Running the example reports the model performance on the train and test datasets.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that activity regularization resulted in a slight drop in accuracy on the training dataset down from 100% to 96% and a lift in accuracy on the test set up from 78% to 82%.
1
Train: 0.967, Test: 0.829
Reviewing the line plot of train and test accuracy, we can see that it no longer appears that the model has overfit the training dataset.
Model accuracy on both the train and test sets continues to increase to a plateau.
Line Plots of Accuracy on Train and Test Datasets While Training With Activity Regularization
For completeness, we can compare results to a version of the model where activity regularization is applied after the relu activation function.
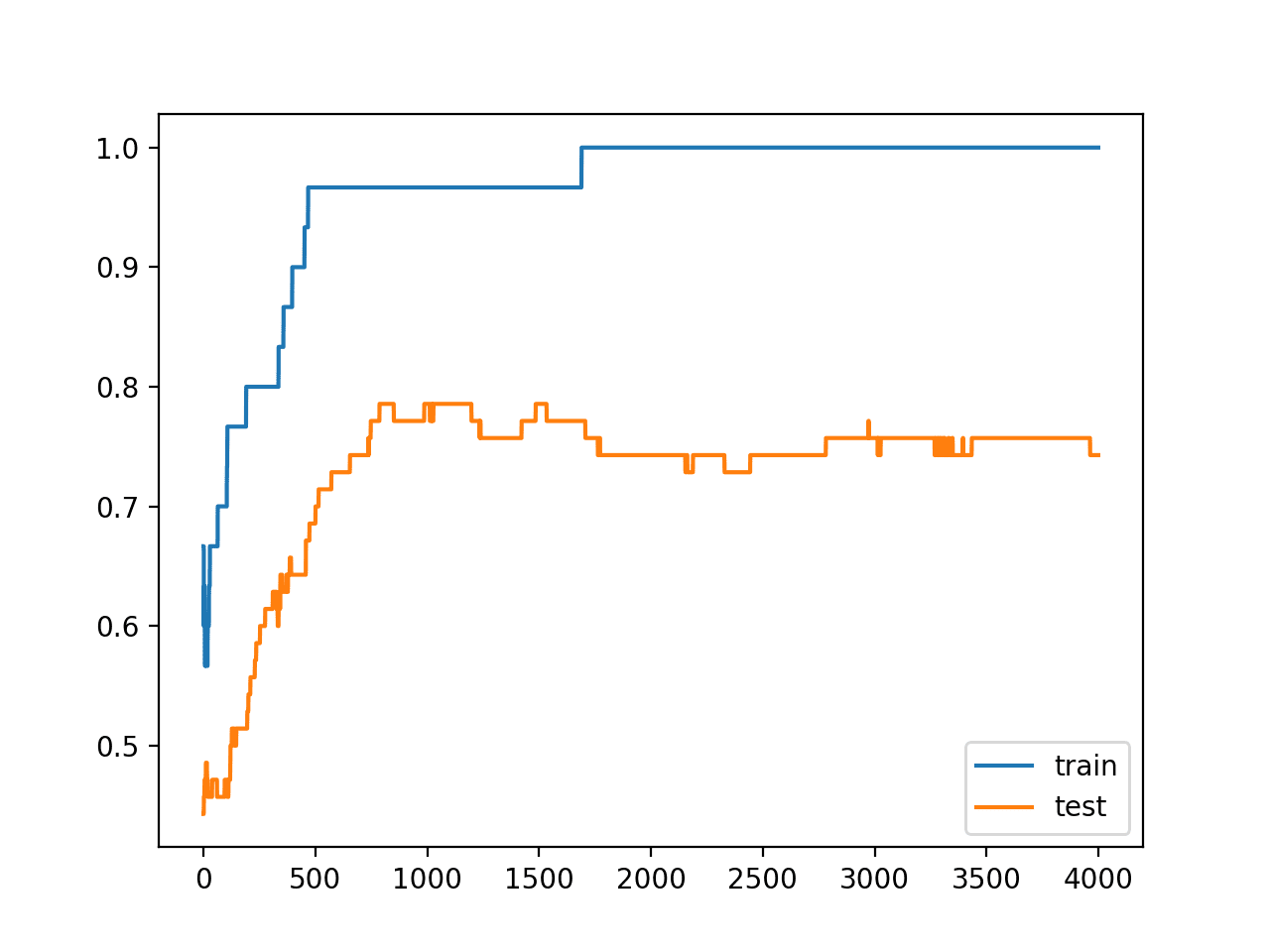
Running the example reports the model performance on the train and test datasets.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that, at least on this problem and with this model, activation regularization after the activation function did not improve generalization error; in fact, it made it worse.
1
Train: 1.000, Test: 0.743
Reviewing the line plot of train and test accuracy, we can see that indeed the model still shows the signs of having overfit the training dataset.
Line Plots of Accuracy on Train and Test Datasets While Training With Activity Regularization, Still Overfit
This suggests that it may be worth experimenting with both approaches for implementing activity regularization with your own dataset, to confirm that you are getting the most out of the method.
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Report Activation Mean. Update the example to calculate the mean activation of the regularized layer and confirm that indeed the activations have been made more sparse.
Grid Search. Update the example to grid search different values for the regularization hyperparameter.
Alternate Norm. Update the example to evaluate the L2 or L1_L2 vector norm for regularizing the hidden layer outputs.
Repeated Evaluation. Update the example to fit and evaluate the model multiple times and report the mean and standard deviation of model performance.
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Thanks for your sharing. But I got a question, what if I would like to add one layer’s output as part of loss? using activity_regulariztion? how should I add this activity_regulariztion into a customised keras layer? Thank you
I’m training a MLP with dense layers 1328->442->147->50->1 with a 100K samples over 50 epochs. However, whenever I add L1 or L2 kernel regularizers to the layers OR apply the StandardScaler to the inputs, it only predicts a single value for every sample (this value approaches the mean of the training set). It’s repeatable given minor changes in topology and various hyperparameters. The loss is greater compared to without these changes. Ever see this before? Any thoughts of if this is a characteristic of my data set or just a mistake someplace.
Thanks for the great content. I frequently look for and find your content in my google search results.
It suggests your model might be unstable. Typically performance degrades gracefully with changes to structure.
Perhaps explore simpler models and see how they compare? Perhaps queue up 10-20 different ideas, kick them off over night and see what looks good in the morning.
Thanks for the time you dedicate to maintain this website, your articles are always well written and thoughful. This place is a go-to for me anytime I need help since I got into data science.
Lately, I have been struggling with some concepts about regularization and I would be grateful if you could expand a little bit what you wrote in this article.
For example, why do you choose activity regularization to prevent overfitting instead of kernel regularization or recurrent regularization ? It seems to me all those technics are pretty much the same. Am I missing something ?
Also, in the case of a multi layer neural network, is it meaningful to add regularization on each layer ? Or only the first layer is needed ?
“””…as described in “Deep Sparse Rectifier Neural Networks” in order to allow the model to learn to take activations to a true zero value in conjunction with the rectified linear activation function.””” here what do you mean as saying take activations to a true zero value? what is true zero value?
I would like to ask one question, please.
Is setting the regularization hyperparameter = 0 tantamount to no regularization?
Like, using your example, is
model.add(Dense(500, input_dim=2, activation=’relu’))
equal to
model.add(Dense(500, input_dim=2, activation=’relu’, activity_regularizer=l1(0.0)))
?
As such, iterating over different regularization hyperparameters, by stating at exactly 0, we would entail the “no regularization at all”-case.
If a imagine the simple regression case, it should, but I am not sure here.
Thanks for sharing. I enjoyed this article very much.
I have a couple of questions:
1. Do you have any insight into what hyper values or range of values produce the best results or any of the regularizers?
2. Are the optimal regularizer and its hyper value a function or dependent on anything or discovering the optimal combination require experimentation with the model?
Hi Jason and thank you for this tutorial! I have one question. I understand that the effect of activity regularization and kernel regularization is different. Is it a common practice to use both of these at the same time, or it can have a negative effect? Thank you!
Great Article !!!!! but please elaborate on why Activity regularizers are needed and how are they are more beneficial than Weight regularization and the maths behind how it penalises.
For example :As in weight regularizers for L1 or L2 regularization absolute value or squared value of weights with a regularization coefficient are added to the LOSS function which leads to smaller weights in order to reduce the loss function.
.
Activity regularization can be helpful to make the output of layers sparse. This in turn can be helpful on some prediction tasks.
They are different from weight reguarlization that make weigghts in nodes sparse, e.g. the model simpler, rather than the output of the model simpler.
Activity regularizaiton can be good for autoencoders and encoder-decoders.
Weight regularization can be good as a general regularization method to reduce overfitting.
I say this in the respective tutorials directly, perhaps re-read.
hi jason ,
above code used L1 activity regualrizer in LSTM……..Why cant use L2 regularizer in LSTM… will L2 is good for prediction task. What will happen if used both L1 and L2 in LSTM layer……..Last one ,can i use L1 or L2 in the last layer ….can i use two dense layer after lstm layer… will it improve the prediction task.
hi jason,
using ensemble techniques to combine lstm with L1 activity regulariser ,lstm with L2 regulariser and lstm with L2 & L1 for better prediction task.
Error:
ValueError: Shapes must be equal rank, but are 0 and 4
From merging shape 0 with other shapes. for ‘{{node AddN}} = AddN[N=2, T=DT_FLOAT](custom_loss/weighted_loss/value, model_6/conv2d_14/ActivityRegularizer/truediv)’ with input shapes: [], [25,50,50,64].
I like to know whether activity_regularizer takes weights or output as an input parameter and how to modify my code to rectify this error.




 From Scratch With Python")



train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print(‘Train: %.3f, Test: %.3f’ % (train_acc, test_acc)) <<< Does not work
here is the error TypeError: must be real number, not list
The example does work.
Ensure your libraries are up to date and that you’re using Python 3.
Ensure that you’re running the example from the command line.
Does that help?
Thanks for this. I had not used this form of regularization before; will do some testing!
Sparse activations can be quite effective!
Hi Jason, what would be the difference between “kernel_regularizer” and “activity_regularizer”?
One regularizes the weight, the other regularizes the activations.
Hello Jason,
Thanks for your sharing. But I got a question, what if I would like to add one layer’s output as part of loss? using activity_regulariztion? how should I add this activity_regulariztion into a customised keras layer? Thank you
Sound interesting, but I’m not sure I follow, can you elaborate what you mean Hayley?
Regularization is part of loss function right? Is there any way to apply regularization in loss function with Keras?
Not always.
We can use regularisation (e.g. L2 norm) to keep the weights small. This is not directly interacting with the loss function.
I’m training a MLP with dense layers 1328->442->147->50->1 with a 100K samples over 50 epochs. However, whenever I add L1 or L2 kernel regularizers to the layers OR apply the StandardScaler to the inputs, it only predicts a single value for every sample (this value approaches the mean of the training set). It’s repeatable given minor changes in topology and various hyperparameters. The loss is greater compared to without these changes. Ever see this before? Any thoughts of if this is a characteristic of my data set or just a mistake someplace.
Thanks for the great content. I frequently look for and find your content in my google search results.
It suggests your model might be unstable. Typically performance degrades gracefully with changes to structure.
Perhaps explore simpler models and see how they compare? Perhaps queue up 10-20 different ideas, kick them off over night and see what looks good in the morning.
Hi Jason,
Thanks for the time you dedicate to maintain this website, your articles are always well written and thoughful. This place is a go-to for me anytime I need help since I got into data science.
Lately, I have been struggling with some concepts about regularization and I would be grateful if you could expand a little bit what you wrote in this article.
For example, why do you choose activity regularization to prevent overfitting instead of kernel regularization or recurrent regularization ? It seems to me all those technics are pretty much the same. Am I missing something ?
Also, in the case of a multi layer neural network, is it meaningful to add regularization on each layer ? Or only the first layer is needed ?
Thanks in advance if you find the time to answer,
Best regards,
Lilian
Thanks!
No, they are quite different. Compare the above tutorial to this tutorial:
https://machinelearningmastery.com/weight-regularization-to-reduce-overfitting-of-deep-learning-models/
e.g.:
activity regularization – train layers to have sparse outputs.
weight regularization – train layers to have sparse weights.
Yes, regularization is added to each layer.
Got it! I will check the tutorial later.
Thanks again for your work!
You’re welcome.
Hi Jason,
“””…as described in “Deep Sparse Rectifier Neural Networks” in order to allow the model to learn to take activations to a true zero value in conjunction with the rectified linear activation function.””” here what do you mean as saying take activations to a true zero value? what is true zero value?
Thank you
0.0
Rather than
0.00000001
Hi Jason,
What is general idea on choosing regularization hyperparameter – low or high value? (such as 0.01 0.0001), how these effect learning?
It puts more or less pressure on the model to have small activations.
Thank you Jason !
You’re welcome.
Thank you for this article once again.
I would like to ask one question, please.
Is setting the regularization hyperparameter = 0 tantamount to no regularization?
Like, using your example, is
model.add(Dense(500, input_dim=2, activation=’relu’))
equal to
model.add(Dense(500, input_dim=2, activation=’relu’, activity_regularizer=l1(0.0)))
?
As such, iterating over different regularization hyperparameters, by stating at exactly 0, we would entail the “no regularization at all”-case.
If a imagine the simple regression case, it should, but I am not sure here.
I believe so.
Thank you for your quick reply.
You’re welcome.
Thanks for sharing. I enjoyed this article very much.
I have a couple of questions:
1. Do you have any insight into what hyper values or range of values produce the best results or any of the regularizers?
2. Are the optimal regularizer and its hyper value a function or dependent on anything or discovering the optimal combination require experimentation with the model?
Generally, I recommend testing a suite of different configurations in order to discover what works best for your model and dataset.
Hi Jason and thank you for this tutorial! I have one question. I understand that the effect of activity regularization and kernel regularization is different. Is it a common practice to use both of these at the same time, or it can have a negative effect? Thank you!
You’re welcome.
Typically you want one or the other. If you want both – try it and see.
Hi, Jason thank you for this post.
why did you decide to use activity regularizer instead of kernel regularizer?
The purpose of the tutorial was to demonstrate activity regularization.
alright thank you. Could you please elaborate on the difference between the two?
Activity regularization is focused on penalizing the output of the nodes, weight regularization is focused on penalizing the weights within the nodes.
We penalize weights to create a sparse representation, we peanlize weights to create a sparse model.
thank you!
You’re welcome.
Great Article !!!!! but please elaborate on why Activity regularizers are needed and how are they are more beneficial than Weight regularization and the maths behind how it penalises.
For example :As in weight regularizers for L1 or L2 regularization absolute value or squared value of weights with a regularization coefficient are added to the LOSS function which leads to smaller weights in order to reduce the loss function.
.
Activity regularization can be helpful to make the output of layers sparse. This in turn can be helpful on some prediction tasks.
They are different from weight reguarlization that make weigghts in nodes sparse, e.g. the model simpler, rather than the output of the model simpler.
Activity regularizaiton can be good for autoencoders and encoder-decoders.
Weight regularization can be good as a general regularization method to reduce overfitting.
I say this in the respective tutorials directly, perhaps re-read.
hi jason ,
above code used L1 activity regualrizer in LSTM……..Why cant use L2 regularizer in LSTM… will L2 is good for prediction task. What will happen if used both L1 and L2 in LSTM layer……..Last one ,can i use L1 or L2 in the last layer ….can i use two dense layer after lstm layer… will it improve the prediction task.
You can use L1 or L2, try both and compare to no regularization on your dataset and use the configuration that results in the best performing model.
hi jason,
using ensemble techniques to combine lstm with L1 activity regulariser ,lstm with L2 regulariser and lstm with L2 & L1 for better prediction task.
Try a range of configurations and discover what works best on your dataset.
Thank you for your explanation sir. I wish to know how to use custom activity_regularizer in CNN (Conv2d). I tried to apply a non-local block ( https://github.com/titu1994/keras-non-local-nets/blob/master/non_local.py ) as a regularize but getting an error. Here is my code:
inp=Input(shape=(50,50,1))
conv1=Conv2D(64,(3,3),padding=”same”,activity_regularizer=non_local_block1)(inp)
relu1=Activation(‘relu’)(conv1)
It fails at conv1
Error:
ValueError: Shapes must be equal rank, but are 0 and 4
From merging shape 0 with other shapes. for ‘{{node AddN}} = AddN[N=2, T=DT_FLOAT](custom_loss/weighted_loss/value, model_6/conv2d_14/ActivityRegularizer/truediv)’ with input shapes: [], [25,50,50,64].
I like to know whether activity_regularizer takes weights or output as an input parameter and how to modify my code to rectify this error.
Perhaps contact the author directly about how to use their code?
hi jason,
can i use l1 regularizer on LSTM input layer and l2 regularizer on LSTM output layer at the same time to reduce overfiiting
If you want, try it and see if it helps.
hi jason,
Can i use L1 regularization on cell state of lstm and L2 regularization on input ,output and forget of lstm
Or can i combined L1 And L2 on lstm output layer of LSTM to prevent overfitting
Perhaps, try it and see.
hi jason ,
range of value to set for l1 and l2 regularization techniques
Small values, typically on a log scale are used.
hi jason,
L1 ,L2 and combine l1+l2 …which regularization technique (l1 or l2 or combined) is best to overcome the overfitting problem with LSTM
You must try each and discover what works best for your dataset and model.
hi jason,
Which activation function helps for multistage classification
Good question, no idea off hand. As a guess – perhaps softmax at each level?
I recommend checking the literature.
thanks a lot..