Weight constraints provide an approach to reduce the overfitting of a deep learning neural network model on the training data and improve the performance of the model on new data, such as the holdout test set.
There are multiple types of weight constraints, such as maximum and unit vector norms, and some require a hyperparameter that must be configured.
In this tutorial, you will discover the Keras API for adding weight constraints to deep learning neural network models to reduce overfitting.
After completing this tutorial, you will know:
How to create vector norm constraints using the Keras API.
How to add weight constraints to MLP, CNN, and RNN layers using the Keras API.
How to reduce overfitting by adding a weight constraint to an existing model.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Mar/2019: fixed typo using equality instead of assignment in some usage examples.
Updated Oct/2019: Updated for Keras 2.3 and TensorFlow 2.0.
How to Reduce Overfitting in Deep Neural Networks With Weight Constraints in Keras Photo by Ian Sane, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Weight Constraints in Keras
Weight Constraints on Layers
Weight Constraint Case Study
Weight Constraints in Keras
The Keras API supports weight constraints.
The constraints are specified per-layer, but applied and enforced per-node within the layer.
Using a constraint generally involves setting the kernel_constraint argument on the layer for the input weights and the bias_constraint for the bias weights.
Generally, weight constraints are not used on the bias weights.
A suite of different vector norms can be used as constraints, provided as classes in the keras.constraints module. They are:
Maximum norm (max_norm), to force weights to have a magnitude at or below a given limit.
Non-negative norm (non_neg), to force weights to have a positive magnitude.
Unit norm (unit_norm), to force weights to have a magnitude of 1.0.
Min-Max norm (min_max_norm), to force weights to have a magnitude between a range.
For example, a constraint can imported and instantiated:
1
2
3
4
# import norm
from keras.constraints import max_norm
# instantiate norm
norm=max_norm(3.0)
Weight Constraints on Layers
The weight norms can be used with most layers in Keras.
In this section, we will look at some common examples.
MLP Weight Constraint
The example below sets a maximum norm weight constraint on a Dense fully connected layer.
Unlike other layer types, recurrent neural networks allow you to set a weight constraint on both the input weights and bias, as well as the recurrent input weights.
The constraint for the recurrent weights is set via the recurrent_constraint argument to the layer.
The example below sets a maximum norm weight constraint on an LSTM layer.
Now that we know how to use the weight constraint API, let’s look at a worked example.
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Weight Constraint Case Study
In this section, we will demonstrate how to use weight constraints to reduce overfitting of an MLP on a simple binary classification problem.
This example provides a template for applying weight constraints to your own neural network for classification and regression problems.
Binary Classification Problem
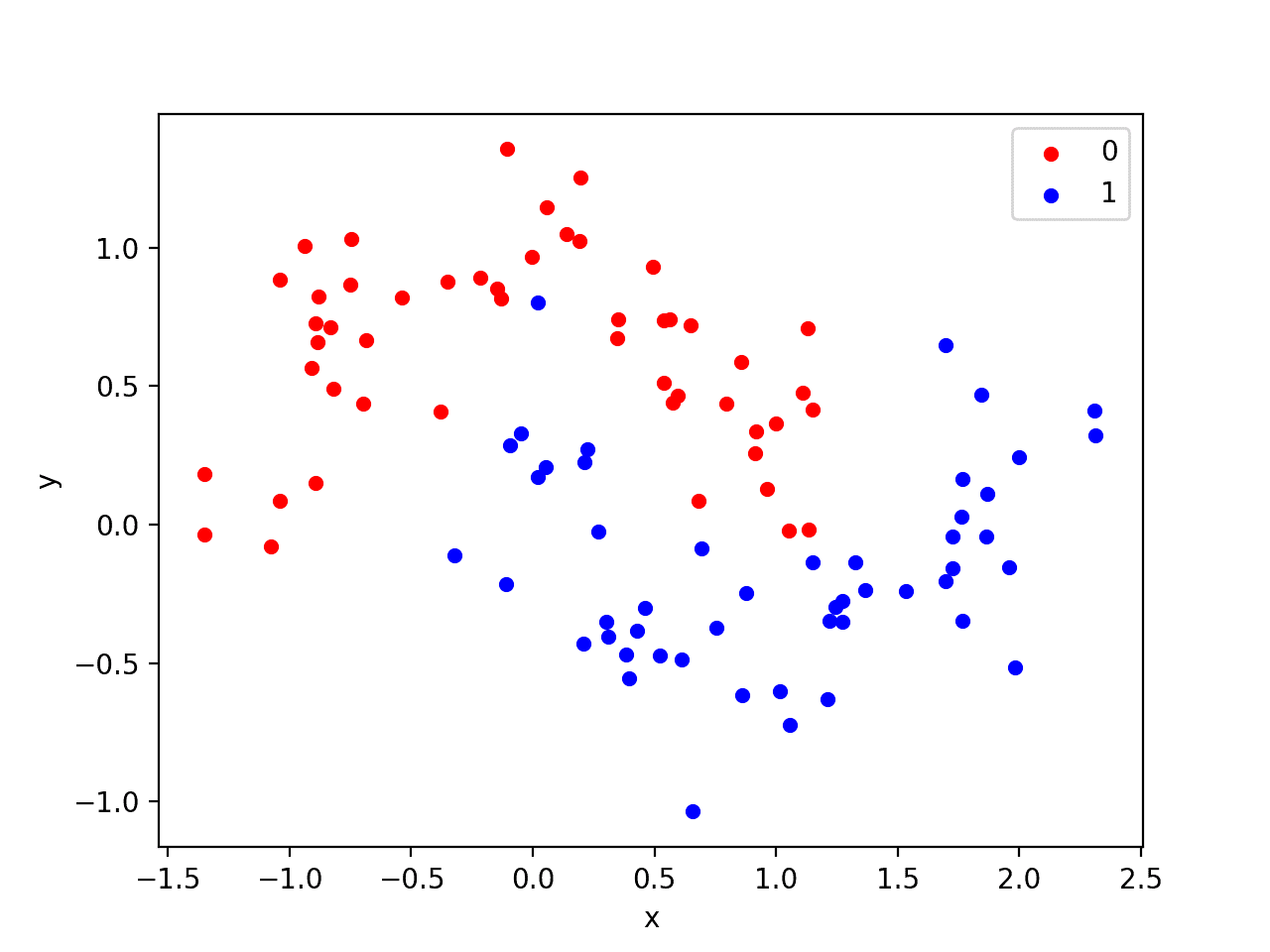
We will use a standard binary classification problem that defines two semi-circles of observations, one semi-circle for each class.
Each observation has two input variables with the same scale and a class output value of either 0 or 1. This dataset is called the “moons” dataset because of the shape of the observations in each class when plotted.
We can use the make_moons() function to generate observations from this problem. We will add noise to the data and seed the random number generator so that the same samples are generated each time the code is run.
We can plot the dataset where the two variables are taken as x and y coordinates on a graph and the class value is taken as the color of the observation.
The complete example of generating the dataset and plotting it is listed below.
Running the example creates a scatter plot showing the semi-circle or moon shape of the observations in each class. We can see the noise in the dispersal of the points making the moons less obvious.
Scatter Plot of Moons Dataset With Color Showing the Class Value of Each Sample
This is a good test problem because the classes cannot be separated by a line, e.g. are not linearly separable, requiring a nonlinear method such as a neural network to address.
We have only generated 100 samples, which is small for a neural network, providing the opportunity to overfit the training dataset and have higher error on the test dataset: a good case for using regularization. Further, the samples have noise, giving the model an opportunity to learn aspects of the samples that don’t generalize.
Overfit Multilayer Perceptron
We can develop an MLP model to address this binary classification problem.
The model will have one hidden layer with more nodes than may be required to solve this problem, providing an opportunity to overfit. We will also train the model for longer than is required to ensure the model overfits.
Before we define the model, we will split the dataset into train and test sets, using 30 examples to train the model and 70 to evaluate the fit model’s performance.
The hidden layer uses 500 nodes in the hidden layer and the rectified linear activation function. A sigmoid activation function is used in the output layer in order to predict class values of 0 or 1.
The model is optimized using the binary cross entropy loss function, suitable for binary classification problems and the efficient Adam version of gradient descent.
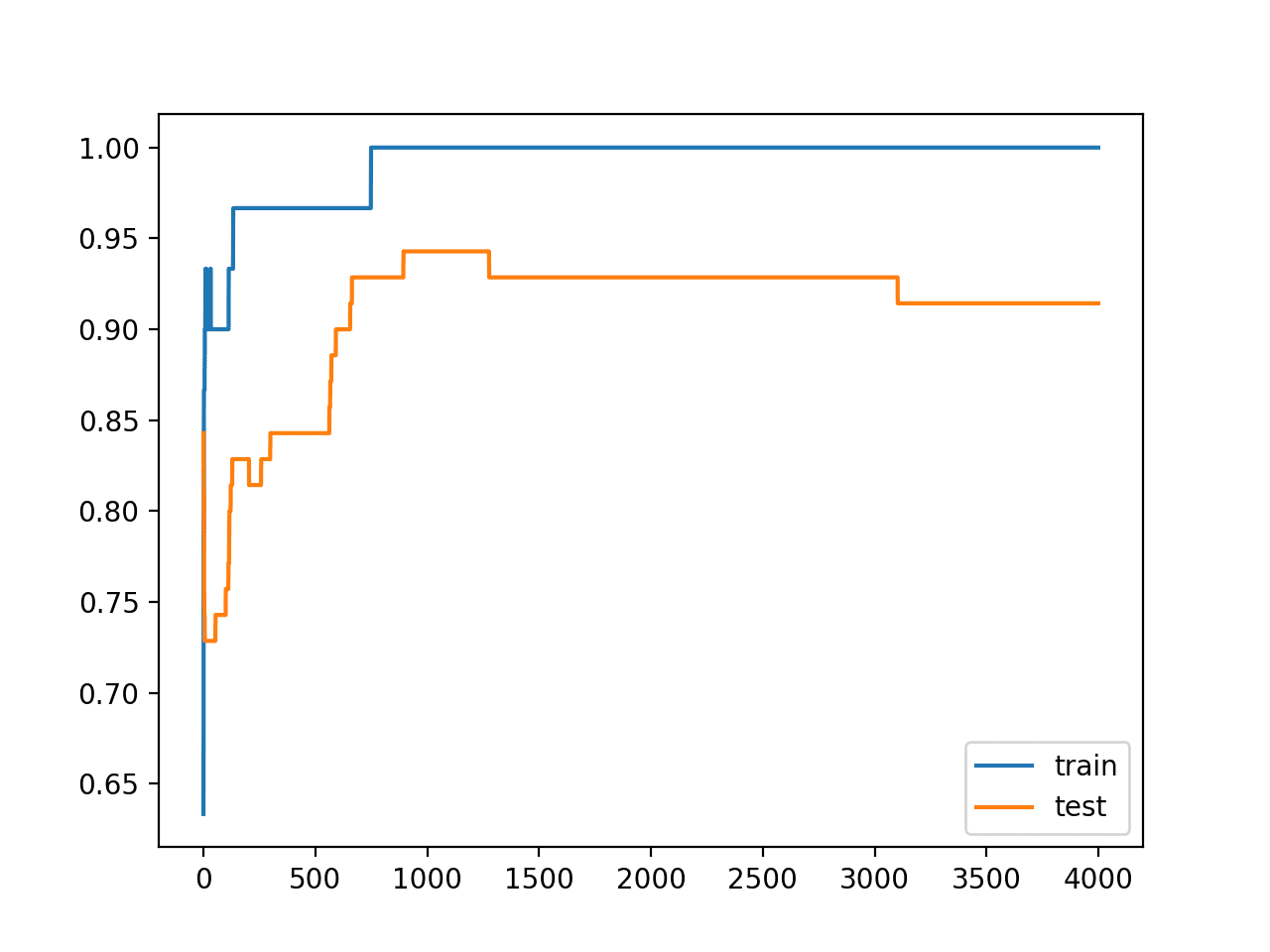
Finally, we will plot the performance of the model on both the train and test set each epoch.
If the model does indeed overfit the training dataset, we would expect the line plot of accuracy on the training set to continue to increase and the test set to rise and then fall again as the model learns statistical noise in the training dataset.
Running the example reports the model performance on the train and test datasets.
We can see that the model has better performance on the training dataset than the test dataset, one possible sign of overfitting.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Because the model is overfit, we generally would not expect much, if any, variance in the accuracy across repeated runs of the model on the same dataset.
1
Train: 1.000, Test: 0.914
A figure is created showing line plots of the model accuracy on the train and test sets.
We can see that expected shape of an overfit model where test accuracy increases to a point and then begins to decrease again.
Line Plots of Accuracy on Train and Test Datasets While Training Showing an Overfit
Overfit MLP With Weight Constraint
We can update the example to use a weight constraint.
There are a few different weight constraints to choose from. A good simple constraint for this model is to simply normalize the weights so that the norm is equal to 1.0.
This constraint has the effect of forcing all incoming weights to be small.
We can do this by using the unit_norm in Keras. This constraint can be added to the first hidden layer as follows:
Running the example reports the model performance on the train and test datasets.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
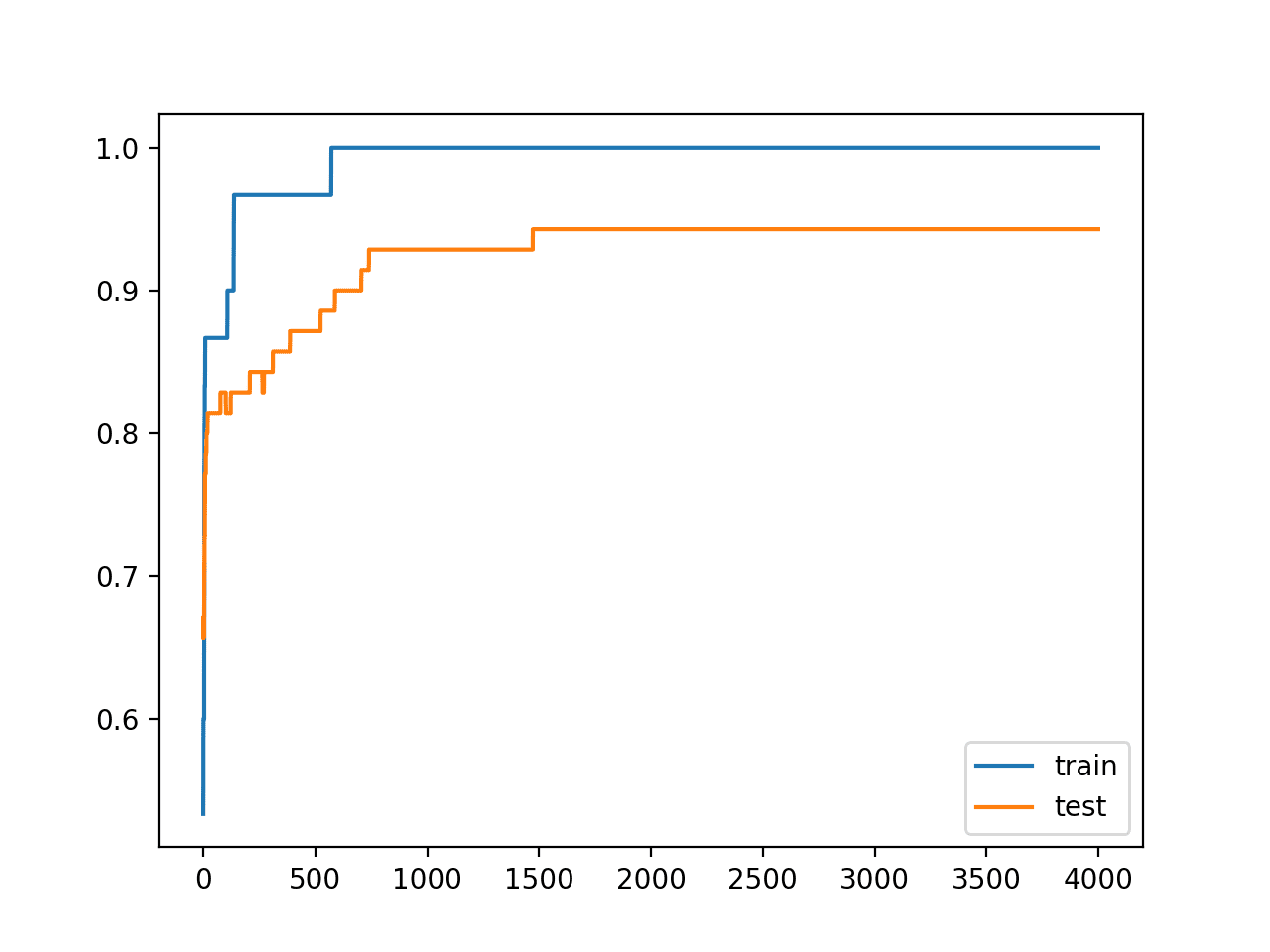
We can see that indeed the strict constraint on the size of the weights has improved the performance of the model on the holdout set without impacting performance on the training set.
1
Train: 1.000, Test: 0.943
Reviewing the line plot of train and test accuracy, we can see that it no longer appears that the model has overfit the training dataset.
Model accuracy on both the train and test sets continues to increase to a plateau.
Line Plots of Accuracy on Train and Test Datasets While Training With Weight Constraints
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Report Weight Norm. Update the example to calculate the magnitude of the network weights and demonstrate that the constraint indeed made the magnitude smaller.
Constrain Output Layer. Update the example to add a constraint to the output layer of the model and compare the results.
Constrain Bias. Update the example to add a constraint to the bias weight and compare the results.
Repeated Evaluation. Update the example to fit and evaluate the model multiple times and report the mean and standard deviation of model performance.
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
I think this tutorial targeted to helping to reduce overfitting via “weight constraint” is close linked to the other tutorial named: How to Reduce Overfitting of a Deep Learning Model with Weight Regularization, that use “weight regularization” techniques instead. So both of tutorials (kernel_constraint vs kernel_regularizer arguments) are have similar implementation and results.
In fact they achieve same test accuracy of 94.3%.
In that sense, I decided to implement also the Grid search “Limiter” Hyperparameter analysis (omitted here), as replication of the “Grid Regularizer” of the previous post and defining an ALPHA parameters list with these setup values = [0.3, 0.6, 0.9, 1., 1.3, 1.6], these are the parameters values used as argument of e.g. min_max_norm (ALPHA are the same value for min and max).
My Alpha exploration indicate that in addition to parameter 1.0 (unit_norm for example), also Alpha parameters values of 0.9 and 1.3 reach the same Test Accuracy maximum (94.3%), but lower and higher values of Alpha parameters have lower accuracy (92.9 % of test data).
Hi Jason,
when using constraints such as max_norm you are tackling the norm of the weight vector w, right? What if I also want to impose contraints on the individual weights (i.e. vector elements w_i?)
Say for example that I want the vector norm of the input layer to be equal to 1, but I also want all the individual weights on this layer to fall between, say, 0 and 0.05.
How would you implement that in a simple case with only one input, one hidden and one output layer? Am I missing something obvious here?
Maybe what is missing from this post is a discussion of the axis= parameter in the max_norm() specification.
Different choices for axis/axes lead to constraints of different strength and meaning. And some choices are better motivated than others in certain contexts.
Does weight constraint only could use in input weight, how about filter weight?
I am wondering we could use this to constraint to have input weight’s minmax for post training quantization.
Kernel constraint can be applied to each layer (hidden layers), should the norm value be a function of number of nodes in the previous hidden layer?
For example, there are two hidden layers 500, 10. If unit norm is applied to both, then weights of first hidden layer will be much smaller than the second layer. So, is it advised to vary the norm value such that weights remain of same magnitude across hidden layers?
Looking forward to your response, haven’t found the answer anywhere.








Is gradient clipping similar to a weight constraint?
Great question!
Not quite.
Weight constraints are applied to the weights and is a regularization technique.
Gradient clipping is applied to the error gradient used to update the weights and is used to avoid exploding gradients.
thanks for sharing,but why like regularization,because no penalty. i think Weight constraints more like normalization
Yes, exactly like the normalization of weights after each update.
Awesome article. This helps to impove theprediction in the kaggle competition, “Don’t call me turkey!”.
Wishes,
I’m happy to hear that, well done!
Does containing the weights in each layer say to sum up to one make the model easier to interpret?
Maybe on the input layer, but perhaps not on hidden layers.
Say if kernel_constraint=max_norm(A). On what basis should I set up the value of ‘A’ ?
Experiment with a range of small integer values, often in [1,4]
On which layer this should be applied ? As most of the networks in CNN are too deeper. Is there a way to figure that out ?
Use on all layers.
Hola Jason:
nice post! . thks.
I think this tutorial targeted to helping to reduce overfitting via “weight constraint” is close linked to the other tutorial named: How to Reduce Overfitting of a Deep Learning Model with Weight Regularization, that use “weight regularization” techniques instead. So both of tutorials (kernel_constraint vs kernel_regularizer arguments) are have similar implementation and results.
In fact they achieve same test accuracy of 94.3%.
In that sense, I decided to implement also the Grid search “Limiter” Hyperparameter analysis (omitted here), as replication of the “Grid Regularizer” of the previous post and defining an ALPHA parameters list with these setup values = [0.3, 0.6, 0.9, 1., 1.3, 1.6], these are the parameters values used as argument of e.g. min_max_norm (ALPHA are the same value for min and max).
My Alpha exploration indicate that in addition to parameter 1.0 (unit_norm for example), also Alpha parameters values of 0.9 and 1.3 reach the same Test Accuracy maximum (94.3%), but lower and higher values of Alpha parameters have lower accuracy (92.9 % of test data).
Thanks
Very nice finding, well done!
nice post
Thanks.
how can i calculate equal error rate? Is there any formula?
What is the equal error rate?
Hi Jason,
I tried using bias_constraint==max_norm(3) in a CNN, and the == causes an error:
SyntaxError: positional argument follows keyword argument
I believe it should be just =
Yes, use a single = for assignment.
I have fixed the examples, thanks.
hello Jason Brownlee
What is the code to add weights manually to LSTM
model.set_weights()
how to use model.set_weights()with LSTM (regression)?
how to add weight from csv file ?
can you help me by code ?
thank you very mach
Sorry, I don’t have the capacity to prepare an example for you.
Why do you want to set model weights from a CSV file?
Because generate weights from an algorithm PSO and I want put in csv and I try to carry it to LSTM
I see. How to you evaluate the weights without using an LSTM structure in the first place?
Hi Jason,
when using constraints such as max_norm you are tackling the norm of the weight vector w, right? What if I also want to impose contraints on the individual weights (i.e. vector elements w_i?)
Say for example that I want the vector norm of the input layer to be equal to 1, but I also want all the individual weights on this layer to fall between, say, 0 and 0.05.
How would you implement that in a simple case with only one input, one hidden and one output layer? Am I missing something obvious here?
Yes.
It sounds like you’re describing weight clipping.
Maybe what is missing from this post is a discussion of the axis= parameter in the max_norm() specification.
Different choices for axis/axes lead to constraints of different strength and meaning. And some choices are better motivated than others in certain contexts.
https://www.tensorflow.org/api_docs/python/tf/keras/constraints/MaxNorm
You can learn more about the axis parameter here:
https://machinelearningmastery.com/numpy-axis-for-rows-and-columns/
Does weight constraint only could use in input weight, how about filter weight?
I am wondering we could use this to constraint to have input weight’s minmax for post training quantization.
Weight constraints can be used with any weights in the network.
Typically they are specified layer-wise.
Kernel constraint can be applied to each layer (hidden layers), should the norm value be a function of number of nodes in the previous hidden layer?
For example, there are two hidden layers 500, 10. If unit norm is applied to both, then weights of first hidden layer will be much smaller than the second layer. So, is it advised to vary the norm value such that weights remain of same magnitude across hidden layers?
Looking forward to your response, haven’t found the answer anywhere.
No.