There are conventions for storing and structuring your image dataset on disk in order to make it fast and efficient to load and when training and evaluating deep learning models.
Once structured, you can use tools like the ImageDataGenerator class in the Keras deep learning library to automatically load your train, test, and validation datasets. In addition, the generator will progressively load the images in your dataset, allowing you to work with both small and very large datasets containing thousands or millions of images that may not fit into system memory.
In this tutorial, you will discover how to structure an image dataset and how to load it progressively when fitting and evaluating a deep learning model.
After completing this tutorial, you will know:
How to organize train, test, and validation image datasets into a consistent directory structure.
How to use the ImageDataGenerator class to progressively load the images for a given dataset.
How to use a prepared data generator to train, evaluate, and make predictions with a deep learning model.
Kick-start your project with my new book Deep Learning for Computer Vision, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Tutorial Overview
This tutorial is divided into three parts; they are:
Dataset Directory Structure
Example Dataset Structure
How to Progressively Load Images
Dataset Directory Structure
There is a standard way to lay out your image data for modeling.
After you have collected your images, you must sort them first by dataset, such as train, test, and validation, and second by their class.
For example, imagine an image classification problem where we wish to classify photos of cars based on their color, e.g. red cars, blue cars, etc.
First, we have a data/ directory where we will store all of the image data.
Next, we will have a data/train/ directory for the training dataset and a data/test/ for the holdout test dataset. We may also have a data/validation/ for a validation dataset during training.
So far, we have:
1
2
3
4
data/
data/train/
data/test/
data/validation/
Under each of the dataset directories, we will have subdirectories, one for each class where the actual image files will be placed.
For example, if we have a binary classification task for classifying photos of cars as either a red car or a blue car, we would have two classes, ‘red‘ and ‘blue‘, and therefore two class directories under each dataset directory.
For example:
1
2
3
4
5
6
7
8
9
10
data/
data/train/
data/train/red/
data/train/blue/
data/test/
data/test/red/
data/test/blue/
data/validation/
data/validation/red/
data/validation/blue/
Images of red cars would then be placed in the appropriate class directory.
For example:
1
2
3
4
5
6
7
8
data/train/red/car01.jpg
data/train/red/car02.jpg
data/train/red/car03.jpg
...
data/train/blue/car01.jpg
data/train/blue/car02.jpg
data/train/blue/car03.jpg
...
Remember, we are not placing the same files under the red/ and blue/ directories; instead, there are different photos of red cars and blue cars respectively.
Also recall that we require different photos in the train, test, and validation datasets.
The filenames used for the actual images often do not matter as we will load all images with given file extensions.
A good naming convention, if you have the ability to rename files consistently, is to use some name followed by a number with zero padding, e.g. image0001.jpg if you have thousands of images for a class.
Want Results with Deep Learning for Computer Vision?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Example Dataset Structure
We can make the image dataset structure concrete with an example.
Imagine we are classifying photographs of cars, as we discussed in the previous section. Specifically, a binary classification problem with red cars and blue cars.
We must create the directory structure outlined in the previous section, specifically:
1
2
3
4
5
6
7
8
9
10
data/
data/train/
data/train/red/
data/train/blue/
data/test/
data/test/red/
data/test/blue/
data/validation/
data/validation/red/
data/validation/blue/
Let’s actually create these directories.
We can also put some photos in the directories.
You can use the creative commons image search to find some images with a permissive license that you can download and use for this example.
Download the photos to your current working directory and save the photo of the red car as ‘red_car_01.jpg‘ and the photo of the blue car as ‘blue_car_01.jpg‘.
We must have different photos for each of the train, test, and validation datasets.
In the interest of keeping this tutorial focused, we will re-use the same image files in each of the three datasets but pretend they are different photographs.
Place copies of the ‘red_car_01.jpg‘ file in data/train/red/, data/test/red/, and data/validation/red/ directories.
Now place copies of the ‘blue_car_01.jpg‘ file in data/train/blue/, data/test/blue/, and data/validation/blue/ directories.
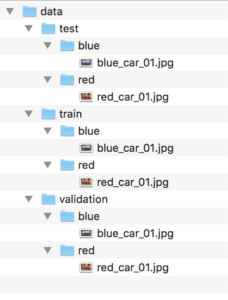
We now have a very basic dataset layout that looks like the following (output from the tree command):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
data
├── test
│ ├── blue
│ │ └── blue_car_01.jpg
│ └── red
│ └── red_car_01.jpg
├── train
│ ├── blue
│ │ └── blue_car_01.jpg
│ └── red
│ └── red_car_01.jpg
└── validation
├── blue
│ └── blue_car_01.jpg
└── red
└── red_car_01.jpg
Below is a screenshot of the directory structure, taken from the Finder window on macOS.
Screenshot of Image Dataset Directory and File Structure
Now that we have a basic directory structure, let’s practice loading image data from file for use with modeling.
How to Progressively Load Images
It is possible to write code to manually load image data and return data ready for modeling.
This would include walking the directory structure for a dataset, loading image data, and returning the input (pixel arrays) and output (class integer).
Thankfully, we don’t need to write this code. Instead, we can use the ImageDataGenerator class provided by Keras.
The main benefit of using this class to load the data is that images are loaded for a single dataset in batches, meaning that it can be used for loading both small datasets as well as very large image datasets with thousands or millions of images.
Instead of loading all images into memory, it will load just enough images into memory for the current and perhaps the next few mini-batches when training and evaluating a deep learning model. I refer to this as progressive loading, as the dataset is progressively loaded from file, retrieving just enough data for what is needed immediately.
Two additional benefits of the using the ImageDataGenerator class is that it can also automatically scale pixel values of images and it can automatically generate augmented versions of images. We will leave these topics for discussion in another tutorial and instead focus on how to use the ImageDataGenerator class to load image data from file.
The pattern for using the ImageDataGenerator class is used as follows:
Construct and configure an instance of the ImageDataGenerator class.
Retrieve an iterator by calling the flow_from_directory() function.
Use the iterator in the training or evaluation of a model.
Let’s take a closer look at each step.
The constructor for the ImageDataGenerator contains many arguments to specify how to manipulate the image data after it is loaded, including pixel scaling and data augmentation. We do not need any of these features at this stage, so configuring the ImageDataGenerator is easy.
1
2
3
...
# create a data generator
datagen=ImageDataGenerator()
Next, an iterator is required to progressively load images for a single dataset.
This requires calling the flow_from_directory() function and specifying the dataset directory, such as the train, test, or validation directory.
The function also allows you to configure more details related to the loading of images. Of note is the ‘target_size‘ argument that allows you to load all images to a specific size, which is often required when modeling. The function defaults to square images with the size (256, 256).
The function also allows you to specify the type of classification task via the ‘class_mode‘ argument, specifically whether it is ‘binary‘ or a multi-class classification ‘categorical‘.
The default ‘batch_size‘ is 32, which means that 32 randomly selected images from across the classes in the dataset will be returned in each batch when training. Larger or smaller batches may be desired. You may also want to return batches in a deterministic order when evaluating a model, which you can do by setting ‘shuffle‘ to ‘False.’
There are many other options, and I encourage you to review the API documentation.
We can use the same ImageDataGenerator to prepare separate iterators for separate dataset directories. This is useful if we would like the same pixel scaling applied to multiple datasets (e.g. trian, test, etc.).
Once the iterators have been prepared, we can use them when fitting and evaluating a deep learning model.
For example, fitting a model with a data generator can be achieved by calling the fit_generator() function on the model and passing the training iterator (train_it). The validation iterator (val_it) can be specified when calling this function via the ‘validation_data‘ argument.
The ‘steps_per_epoch‘ argument must be specified for the training iterator in order to define how many batches of images defines a single epoch.
For example, if you have 1,000 images in the training dataset (across all classes) and a batch size of 64, then the steps_per_epoch would be about 16, or 1000/64.
Similarly, if a validation iterator is applied, then the ‘validation_steps‘ argument must also be specified to indicate the number of batches in the validation dataset defining one epoch.
Once the model is fit, it can be evaluated on a test dataset using the evaluate_generator() function and passing in the test iterator (test_it). The ‘steps‘ argument defines the number of batches of samples to step through when evaluating the model before stopping.
1
2
3
...
# evaluate model
loss=model.evaluate_generator(test_it,steps=24)
Finally, if you want to use your fit model for making predictions on a very large dataset, you can create an iterator for that dataset as well (e.g. predict_it) and call the predict_generator() function on the model.
1
2
3
...
# make a prediction
yhat=model.predict_generator(predict_it,steps=24)
Let’s use our small dataset defined in the previous section to demonstrate how to define an ImageDataGenerator instance and prepare the dataset iterators.
A complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
# example of progressively loading images from file
from keras.preprocessing.image import ImageDataGenerator
Running the example first creates an instance of the ImageDataGenerator with all default configuration.
Next, three iterators are created, one for each of the train, validation, and test binary classification datasets. As each iterator is created, we can see debug messages reporting the number of images and classes discovered and prepared.
Finally, we test out the train iterator that would be used to fit a model. The first batch of images is retrieved and we can confirm that the batch contains two images, as only two images were available. We can also confirm that the images were loaded and forced to the square dimensions of 256 rows and 256 columns of pixels and the pixel data was not scaled and remains in the range [0, 255].
It provides self-study tutorials on topics like: classification, object detection (yolo and rcnn), face recognition (vggface and facenet), data preparation and much more...
Finally Bring Deep Learning to your Vision Projects
Really clear and very useful tutorial as always Jason.
I was wondering what you thought about using Keras from within TensorFlow, i.e using tf.keras.whatever? Thanks
Thank you Jason.
I read the link you suggested, but still have some questions.
1. Normally, when we train our data, we need to shaffle them before training. There is no problem if we can load our data into our memory. I don’t know when you did shaffle when using data_generator. Do I need to shaffle my data after I collected my data?
2. Is it possible to change data into .h5 files, then load into the memory one by one?
In addition, Every time, after I posted a comment, I have to go to your blog where I posted it again to look for if there is your reply. Is it possible to receive an email about your reply or a notification? Many thanks.
You can implement a shuffle as part of your data generator. I don’t have an example.
Thanks for the suggestion about email replies, I’ll look into it.
Paulo Henrique Zen MesserschmidtApril 13, 2019 at 10:31 am#
Jason, thank you for this great tutorial.
I’m trying to solve a problem in my model which seems almost exactly your example, except that i’m rescaling the image pixels by 1./255.
In my model, i’m using the test set to evaluate my model. But each time i run:
model.evaluate_generator(test_it, steps=test.sample // batch size=32) the functiont returns different scores. I’ve already tried to set shuffle=False in test_it, but doesn’t solve the problem.
I’m using checkpointer (callbacks) to save the best params (weights) based on validation_loss. After, i load the weights to the model and applied the evaluate_generator as i said. Am i doing something?
Paulo Henrique Zen MesserschmidtApril 14, 2019 at 2:20 am#
I guess I was not very clear on my question. In fact, when I referred to running the model.evaluate_generator several times, I was referring only to this line of code, keeping the network trained (same weights). But, following your recommendations i set the test generator as:
This was a super clear and useful tutorial, but I seem to be struggling to find a solution to my slightly adjacent problem!
I have all of the data stored in class-based subdirectories, such as “.\data\flower”, “.\data\cat”, etc, where flower and cat are two different classes.
However, while I want to load the images into my model at run-time rather than hold a large number in memory, I would really not like to hard-code my train/validation/test splits without first going through a range of possible splits. If I were to do it exactly as you describe here, I would have to create a copy of the entire data set for each different split I test.
Do you know if there is an optimized way of doing this that doesnt require defining a custom generator? Ideally something that can take a list of filenames with their directories and distribute them to train/val/testing lists respectively, then feed each list into a tensorflow or keras generator at runtime to actually load the images.
Please let me know if I should clarify any of that. Thanks!
One idea would be to write a script to create the validation dataset on disk by moving files around, then create one ImageDataGenerator instance for train and one for val for the two different directories.
Another idea would be to create a custom data generator function/functions that use whatever arguments you like to split the images into train/val.
Thanks Jason,
I have separate test and train sets and I have loaded it successfully using the iterator. Please Help me in defining the model. Its a multi class classification of digits.
I am using the save_to_dir() in flow_from_directory to look at what got generated by the generator and I’m confused by the results. I get widely varying numbers of images going into the folder. Trying all different batch and steps values just making me more confused. In your example of 1000 images with batch size 64 and steps per epoch 16 do you see 1000 or 1024 images if you save_to_dir?
Not sure if I’m not understanding how batch_size,etc. actually generate sets of images or whether save_to_dir actually doesn’t do what I expected (show me all the images used) or whether I’m not getting expected results for some reason.
Examples (using small folders of images to try to understand what it does…):
I have 120 images across 6 classes, so 20 each.
batch_size 6, steps_per_epoch 20 yields 186 images, not 120.
batch_size 32, steps_per_epoch 4 yields 360 images, not 128
batch_size 32, steps_per_epoch 8 yields 576 images, not 256, not double what I got with 4.
batch_size 12, steps_per_epoch 10 yields 252 images
etc.
Where it yields more images than I started with they are flipped or stretched as defined in the ImageDataGenerator() and presumably that is the intent of augmenting – you could use several different modified copies of the same image to get more variety. I just don’t see the batch_sizes and steps making sense with images generated…
Also like in your example I have a validation generator with no stretching or flipping or zooming and for that I really just do want to use the images once I think but I don’t see how to get that result. choosing batch_size of 1 and validation_steps equal to the number of images results in save_to_dir generally saving more images (copies of the intial images):
Thanks! I guess that is the best outcome, all is OK and I should just look in the directory to generally see what the stretching and such did, not get wrapped up in the quantities. This has been driving me crazy.
It is a really good idea to inspect the augmentation that is performed to confirm it makes sense. It is so easy to just run code without thinking hard about it.
Thanks for nice tutorial. I have a question I have .7z large data file which contains images and I am having problem to load image data via .7z file. Any help? Thanks!!
I have used this method to load images but it seems to be very inefficient in terms of utilizing the GPU. My understanding is that you can feed a TF DataSet generator to Keras and gain much more efficiency doing so. Unfortunately I haven’t been able to figure out precisely how to do this. Neither the Keras nor TF documentation has such an example and every blog post or SO answer I’ve seen uses the precanned MNIST or CIFAR datasets which aren’t stored on the file system. It would be great to see a post that shows how to load ImageNet files into Keras. If I ever figure it out I will write such a post! haha
‘Bands as in colours’. So not only red, green and blue (which would be 3 bands) but red, green blue, near infrared, mid infrared …. (so 5 or more band in this example).
E.g. a weather satellite such as Himawari has 16 bands.
Hellow, I dont understand how I have to load data after data generation, or what you mean by flow_from_directory(). I have my data in : C:\Users\sazid\OneDrive – Texas State University\Desktop\Hipe\images\data\train.
I am trying to solve the multilabel image classification problem using CNN. First I tried to load all images and perform mapping of labels with images but there I am facing memory error.
Then I looked at your above solution but I am confused here
# load and iterate training dataset
train_it = datagen.flow_from_directory(‘train/’, class_mode=’categorical’, batch_size=12)
# load and iterate test dataset
test_it = datagen.flow_from_directory(‘test/’, class_mode=’categorical’, batch_size=12)
my question is where we will perform mapping because from above code it seems we directly loading images from a directory and then will pass to model but where and how mapping will perform so the model can train on it
I have a total of 3 labels (Label1, Label2, Label3) and each label further have 3 options (L, M, H)
how we will manage this for data generation because above in this blog there are two classes red and blue and each has related images but in my case how it will be
Thanks for sharing. The problem is that I have 1TB of images to train the unsupervised clustering model. Each epoch take 5 hours. What should I do cut the hours to 1hour?
Thanks
I have a question about adding a condition based on which to draw images from the folder. I have a training set, and in it separate folders for each class. In each there are images of objects from 2 different cameras with the same id but with differnt endings of their names (either ID _cam1 or ID_cam2). I need to use the image only if both of them are present in the folder. How can I add this condition?
Hi Jason, may I ask you if this approach can be used to load progressively from directory numerical data spread over different days? I mean, the network should get as input data a dataset from 1 day, train with it, and go to the other day and so on. The needed generator should load data only for 1 day at a time. (For each day there is a related CSV file of data, the structure is similar to the one you have explained).
Could you please give me some suggestions?
Thank you for this useful much needed post. And I would appreciate it even more if you help me find out how to do data generation for sequences of images e.g. videos for example for video classification. I think as Keras doesn`t have this type of class, we need to develop our own custom data generator, right?
Thank you with this good tutorial. I have one problem. I have a large number of images but basically each class is in its respective folder, but they have not been split into train and validation and test. In fact, I am in one step before you started this tutorial. And as you may guess I can’t load the entire images to divide them into train, validation and test because of the memory limitation. How to deal with this problem?
Thanks for the helpful tutorial. I am working with h5 dataset and I was wondering if there is any solution to load h5 files directly from a directory instead of jpg images?
HI JASON, As usual your tutorial is awesome and I learnt data generators from this. the only concern I have here, I trained a model using this technique and my data was only two categories (dogs,cats). I generated the confusion matrix of prediction of the model that has been trained and the confusion matrix is not that good and is showing result with accuracy around 50% (TP and TN are almost equal to FP and FN). On the other hand another model I generated without data generators and in conventional way e.g. with api’s like train_test_split and through this I’m able to generate a very good confusion matrix i.e. with accuracy like 95% or more. So Please teach me how to tune the confusion matrix in case of keras flow_from_dir and data generators case.
Thanks
JItender
Hi. I was following this tutorial but mine is a bit different, all data-set images are in a folder moreover the filename of the sub-directory of that folder are not the intended class target for my model so flow_from_directory won’t work for my case is there any solution to that?
I have doubt, I have a dataset with more than one category and they are imbalanced so using image generator is there a way to load only equal amount of data from each class or is there some alternate methods?
Hi. i am using this tutorial but mine is a bit different. All images are in a folder, the filename of sub-directory of that folder is not the intended class target so flow_from_directory won’t work. Any Suggestions?
Hi Jason, Thanks a lot for your response, I really appreciate. I’ve cross checked multiple times but I’m not able to identify the issue. Can I post you my program here? Please check at your end. Thanks 🙂
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1. / 255)
Hello Jason, thank you for the very clear blogpost. I am training a ResNet 152 on quite a large dataset (few million pictures) and it is going quite well with this ImageDataGenerator flow_from_directory approach. However, training is still a bit slow. I checked the task manager, and only 20% of GPU and 15% of CPU capacity are being used. I think that having the iterator pull the images from the system could be the bottleneck.
Do you know whether this can indeed be the problem? And additionally, is there a hack that allows you to pre-load batches or cache them, while still using ImageDataGenerator? I can’t figure out how to fix this yet.
I tried this with my model but got stuck with one problem that when training various models with the fit_generator function and ImageDataGenerator, I experience that the first epoch takes much longer than subsequent ones. What is the reason for this?
Thanks….
Your articles are really helpful for beginners. And the facility of getting our questions answered by the writer himself is simply amazing!!!!
Keep it up!
Hello Jason,
I read your article. I want to load more than one image in my code for detection purpose as my code takes single image at a time. I am using retinanet model. I want to load images from the directory which contain 6 classes. Can you help me with it. Please tell me what should i modify in the code so that it can take multiple images as input.
Perhaps change your dataset to match the structure of the example?
Perhaps use an alternate API to load your images?
Perhaps write custom code to load your images?
Rafael do Espirito SantoOctober 2, 2020 at 9:43 am#
Hi Jason,
Thanks for this great tutorial.
I am trying to use flow_from_directory for calibrating a binary classifier with a large dataset ( x_train=21047 images 220×220; x_validation = 2629 images 220×220 and x_test = 2633 220×220).
Hey Jason, Great Job!!!1
I thing I want to ask is I have test data in my drive with images which differ only in the username a bit. Can I use a loop to check for classification if the test data is unlabelled
I need help with loading the images into the subdirectories. I’m working on a completely different set of images on kaggle.com, and I’ve created directories and subdirectories for them, but to actually load the images into the subdirectory is where I’m stuck.
An example of an image format is ‘input_100_10_10.jpg’
The command I use to load the images into the subdirectory is:
fnames = [‘input_{}_{}_{}.jpg’.format(i) for i in range(0, int(15000*0.80), 1)]
for name in fnames:
src = os.path.join(path, name)
dst = os.path.join(train_set, name)
shutil.copyfile(src, dst)
Hey Jason,
I have a question, I want to load only images without labels in using data generator. I am training an autoencoder for image reconstruction on imagenet dataset.
Hi Jason, the custom loader gives (batchX, batchY). I am working on a problem where my keras model has multiple inputs. Can we repurpose the Custom generator to give output something like (batchX1, batchX2, batchY) where X1(image) and X2(some other numerical value) are two different inputs to a keras model.
I am getting below error though i have created data directory structure similar to yours.
FileNotFoundError: [Errno 2] No such file or directory: ‘C:\\Users\\test\\dataset\\training_set\\’
i tried with all combinations off directory path (single fwd slash ,double fwd slash , back slashesh) every thing I tried, nothing is is working. Could you please help me here.
I have a sequence of seven satellite images, to apply a regression task and predict the next sequence in the time series. As there are few images, how do I upload them to the CNN model? Can you use ImageDataGenerator? How would it be?
If we are given images that are in separate folders (based on their classes) under a directory folder,
we can use keras function – flow_from_directory() and create train and validation data sets by specifying validation_split.
But how do we create test data by using flow_from_directory () ??
Hi Jason . With image_dataset_from_directory() , it returned a two batchdatasets objects – one for train and other for validation . And hence was unable to split it further for test dataset .
So finally created my own test image dataset and uploaded to Kaggle. Trying that out .
Thanks !!
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
from sklearn.datasets import make_blobs
import math
from tensorflow.keras.utils import Sequence
batch_size = 30
nb_epoch = 5
# define dataset
X, y = make_blobs(n_samples=3000, centers=2, random_state=1)









Really clear and very useful tutorial as always Jason.
I was wondering what you thought about using Keras from within TensorFlow, i.e using tf.keras.whatever? Thanks
Thanks Tony!
No opinion at this stage. I may cover it later in the year once TF 2.0 is finalized.
Same result at the end of the day, although more confusing for developers because TF gives you so many ways to do the same thing.
Thank you Jason. Your tutorials are always clear and very useful.
If my datasets are not images but large, how can I load my data progressively? Many thanks
You can write a custom data generator to load and yield data in batches.
I give an example in this post for text+images:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Thank you Jason.
I read the link you suggested, but still have some questions.
1. Normally, when we train our data, we need to shaffle them before training. There is no problem if we can load our data into our memory. I don’t know when you did shaffle when using data_generator. Do I need to shaffle my data after I collected my data?
2. Is it possible to change data into .h5 files, then load into the memory one by one?
Many thanks.
Yes, it is a good idea to try and draw the samples randomly.
Sure.
Thank you, Jason.
I couldn’t find where and when you did shuffle.
In addition, Every time, after I posted a comment, I have to go to your blog where I posted it again to look for if there is your reply. Is it possible to receive an email about your reply or a notification? Many thanks.
You can implement a shuffle as part of your data generator. I don’t have an example.
Thanks for the suggestion about email replies, I’ll look into it.
Jason, thank you for this great tutorial.
I’m trying to solve a problem in my model which seems almost exactly your example, except that i’m rescaling the image pixels by 1./255.
In my model, i’m using the test set to evaluate my model. But each time i run:
model.evaluate_generator(test_it, steps=test.sample // batch size=32) the functiont returns different scores. I’ve already tried to set shuffle=False in test_it, but doesn’t solve the problem.
I’m using checkpointer (callbacks) to save the best params (weights) based on validation_loss. After, i load the weights to the model and applied the evaluate_generator as i said. Am i doing something?
Ps.: Sorry, english isn’t my first language.
Many thanks!!
The model will return different scores because the model is different each time it is run – by design.
Neural networks are stochastic learning algorithms.
This will help:
https://machinelearningmastery.com/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
I guess I was not very clear on my question. In fact, when I referred to running the model.evaluate_generator several times, I was referring only to this line of code, keeping the network trained (same weights). But, following your recommendations i set the test generator as:
test_generator = datagen_test.flow_from_directory (
‘content / cell_images / test’, #Test folder path
target_size = (150,150), #all images will be resized to 150×150
batch_size = 1,
class_mode = ‘categorical’
shuffle = False)
And the steps parameter on model.evaluate_generator with the test_generator.samples:
score = model.evaluate_generator (test_generator, test_generator.samples)
Apparently it worked, the accuracy test values are no longer changed if I run this line of code several times for the same neural network weights
Again, many thanks for your response Jason, it helped me a lot.
Well done, I’m happy to hear that.
Hi ? Great job ! but if i do annotation , what about classification which the one is the better for car make model classification ?
I recommend testing a suite of models in order to discover what works best for your specific dataset.
Hi
when i am doing print
(os.getcwd())
it is printing /content.
but i am enable to find this path in my system could you please help out in this.
i am getting No Such Directory error.
Hi Jason,
This was a super clear and useful tutorial, but I seem to be struggling to find a solution to my slightly adjacent problem!
I have all of the data stored in class-based subdirectories, such as “.\data\flower”, “.\data\cat”, etc, where flower and cat are two different classes.
However, while I want to load the images into my model at run-time rather than hold a large number in memory, I would really not like to hard-code my train/validation/test splits without first going through a range of possible splits. If I were to do it exactly as you describe here, I would have to create a copy of the entire data set for each different split I test.
Do you know if there is an optimized way of doing this that doesnt require defining a custom generator? Ideally something that can take a list of filenames with their directories and distribute them to train/val/testing lists respectively, then feed each list into a tensorflow or keras generator at runtime to actually load the images.
Please let me know if I should clarify any of that. Thanks!
Excellent question Jacob.
One idea would be to write a script to create the validation dataset on disk by moving files around, then create one ImageDataGenerator instance for train and one for val for the two different directories.
Another idea would be to create a custom data generator function/functions that use whatever arguments you like to split the images into train/val.
I hope that gives you some ideas.
I have trained my cnn model and now I want test my model now, could you please provide me a testing code for the same.
Yes, I believe you can find an example here:
https://machinelearningmastery.com/start-here/#dlfcv
Hi Jason,
Thank you for the tutorial, you always describe things in a simple way.
Do you have tutorial on how to use TFRecords for keras ?
thanks.
Thanks for the suggestion.
Thanks Jason,
I have separate test and train sets and I have loaded it successfully using the iterator. Please Help me in defining the model. Its a multi class classification of digits.
Perhaps this tutorial will help as a starting point:
https://machinelearningmastery.com/how-to-develop-a-cnn-from-scratch-for-cifar-10-photo-classification/
I am using the save_to_dir() in flow_from_directory to look at what got generated by the generator and I’m confused by the results. I get widely varying numbers of images going into the folder. Trying all different batch and steps values just making me more confused. In your example of 1000 images with batch size 64 and steps per epoch 16 do you see 1000 or 1024 images if you save_to_dir?
Not sure if I’m not understanding how batch_size,etc. actually generate sets of images or whether save_to_dir actually doesn’t do what I expected (show me all the images used) or whether I’m not getting expected results for some reason.
Examples (using small folders of images to try to understand what it does…):
I have 120 images across 6 classes, so 20 each.
batch_size 6, steps_per_epoch 20 yields 186 images, not 120.
batch_size 32, steps_per_epoch 4 yields 360 images, not 128
batch_size 32, steps_per_epoch 8 yields 576 images, not 256, not double what I got with 4.
batch_size 12, steps_per_epoch 10 yields 252 images
etc.
Where it yields more images than I started with they are flipped or stretched as defined in the ImageDataGenerator() and presumably that is the intent of augmenting – you could use several different modified copies of the same image to get more variety. I just don’t see the batch_sizes and steps making sense with images generated…
Also like in your example I have a validation generator with no stretching or flipping or zooming and for that I really just do want to use the images once I think but I don’t see how to get that result. choosing batch_size of 1 and validation_steps equal to the number of images results in save_to_dir generally saving more images (copies of the intial images):
60 total validation images :
batch_size 1, 60 validation_steps, 71 images saved by save_to_dir
batch_size 12, 5 validation_steps, 156 images saved
everything I read about this say batch_size*steps= number of images but I can’t seem to make sense of what happens.
Yes, I believe it prepares more than are needed, e.g. in a queue to ensure the computation is efficient.
Thanks! I guess that is the best outcome, all is OK and I should just look in the directory to generally see what the stretching and such did, not get wrapped up in the quantities. This has been driving me crazy.
It is a really good idea to inspect the augmentation that is performed to confirm it makes sense. It is so easy to just run code without thinking hard about it.
Hello Jason,
Thanks for nice tutorial. I have a question I have .7z large data file which contains images and I am having problem to load image data via .7z file. Any help? Thanks!!
You can unzip 7z file using the 7zip application:
https://www.7-zip.org/download.html
How to plot confusion matrix with this structure?
This will help:
https://machinelearningmastery.com/confusion-matrix-machine-learning/
I have used this method to load images but it seems to be very inefficient in terms of utilizing the GPU. My understanding is that you can feed a TF DataSet generator to Keras and gain much more efficiency doing so. Unfortunately I haven’t been able to figure out precisely how to do this. Neither the Keras nor TF documentation has such an example and every blog post or SO answer I’ve seen uses the precanned MNIST or CIFAR datasets which aren’t stored on the file system. It would be great to see a post that shows how to load ImageNet files into Keras. If I ever figure it out I will write such a post! haha
Great suggestion, thanks Evan.
For the mean time, try larger batches or a custom data generator that loads a ton more data into memory.
Hi Jason,
Thanks for your post and the code.
Do you happen to have pointers re how to use ‘flow_from_directory’ with images that have >4 bands’?
Thank you very much, Mark
Thanks.
What do you mean by “bands”?
Thank you Jason for your question.
‘Bands as in colours’. So not only red, green and blue (which would be 3 bands) but red, green blue, near infrared, mid infrared …. (so 5 or more band in this example).
E.g. a weather satellite such as Himawari has 16 bands.
A hint is provided Rajat Garg by in his post on ‘Training on Large Datasets That Don’t Fit In Memory in Keras’ ( https://medium.com/@mrgarg.rajat/training-on-large-datasets-that-dont-fit-in-memory-in-keras-60a974785d71 ) where he suggests to create a Custom Generator class and then ‘decide in the __getitem__(self, idx) function happens to the dataset when loaded in batches. ‘ e.g. calculate engineered features’.
So not flow_from_directory into ImageDataGenerator but perhaps ImageDataGenerator within a Custom Generator class?
It would be awesome if you had pointers on how to accomodate large image files with >4 bands to be loaded firm disk as well as augmentation.
Thanks for your consideration.
Cheers, Mark
It would be great to get some
Ah, these are called color channels and represent the 3rd dimension of an image representation as an array of pixels.
Great suggestion, thanks.
Hello Dr. Jason,
How can we do the same with large time series data?
Regards
You can develop a data generator to load the data and return one batch of samples at a time.
Hellow, I dont understand how I have to load data after data generation, or what you mean by flow_from_directory(). I have my data in : C:\Users\sazid\OneDrive – Texas State University\Desktop\Hipe\images\data\train.
So how to write my path to load data?
The flow from directory function will take the path yo your dataset.
Hi
I am trying to solve the multilabel image classification problem using CNN. First I tried to load all images and perform mapping of labels with images but there I am facing memory error.
Then I looked at your above solution but I am confused here
# load and iterate training dataset
train_it = datagen.flow_from_directory(‘train/’, class_mode=’categorical’, batch_size=12)
# load and iterate test dataset
test_it = datagen.flow_from_directory(‘test/’, class_mode=’categorical’, batch_size=12)
my question is where we will perform mapping because from above code it seems we directly loading images from a directory and then will pass to model but where and how mapping will perform so the model can train on it
Yes, it assumes /train and /test contain subdirectories of images, where each subdirectory is a class.
I have a slightly different scenario like
I have a total of 3 labels (Label1, Label2, Label3) and each label further have 3 options (L, M, H)
how we will manage this for data generation because above in this blog there are two classes red and blue and each has related images but in my case how it will be
I am confused here
Perhaps change the directories to a flat structure?
Perhaps use a custom data generator?
Hi Jason,
Thanks for sharing. The problem is that I have 1TB of images to train the unsupervised clustering model. Each epoch take 5 hours. What should I do cut the hours to 1hour?
Thanks
Some ideas:
– Use fewer images.
– Use a smaller model.
– Use a faster machine.
Hi,
I have a question about adding a condition based on which to draw images from the folder. I have a training set, and in it separate folders for each class. In each there are images of objects from 2 different cameras with the same id but with differnt endings of their names (either ID _cam1 or ID_cam2). I need to use the image only if both of them are present in the folder. How can I add this condition?
You might need to write some custom code to load or prepare your dataset.
Hi Jason, may I ask you if this approach can be used to load progressively from directory numerical data spread over different days? I mean, the network should get as input data a dataset from 1 day, train with it, and go to the other day and so on. The needed generator should load data only for 1 day at a time. (For each day there is a related CSV file of data, the structure is similar to the one you have explained).
Could you please give me some suggestions?
You can implement your own data generator to feed data to the network.
When I run the code with flow_from_directory(‘dataset/training_set/’…
I got the fallowing message: No such file or directory:’dataset/training_set/’
I’m working in MacOs pycharm
Try running from the command line:
https://machinelearningmastery.com/faq/single-faq/how-do-i-run-a-script-from-the-command-line
How can I use GridSearch with this since I don’thave xtrain anf ytrain?
No, you will have to write a custom for loop over the configurations you want to test.
Thank you for this useful much needed post. And I would appreciate it even more if you help me find out how to do data generation for sequences of images e.g. videos for example for video classification. I think as Keras doesn`t have this type of class, we need to develop our own custom data generator, right?
Yes, you will need a custom generator for video data.
How to develop an improved model [after finishing classification,Model Evaluation Methodology]..
and
How to finalize the model and make prediction with all neccesary evaluation ….
confusion matrix …..
hope for instant replly SIR
SIR SIR
How to improve a deep learning model:
https://machinelearningmastery.com/start-here/#better
How to finalize a model:
https://machinelearningmastery.com/train-final-machine-learning-model/
accuracy: 0.9472 – val_loss: 0.6782 – val_accuracy: 0.9677
WHY
val_accuracy is more than acc ………..
how to callculate TR_accuracy………….>??????
It might not be real, they are an average over the batches. Do a standalone evaluation.
Also, it is possible due to random fluke.
Thank you with this good tutorial. I have one problem. I have a large number of images but basically each class is in its respective folder, but they have not been split into train and validation and test. In fact, I am in one step before you started this tutorial. And as you may guess I can’t load the entire images to divide them into train, validation and test because of the memory limitation. How to deal with this problem?
You’re welcome.
Perhaps you can write a script to randomly split the images into subsets?
Thanks for the helpful tutorial. I am working with h5 dataset and I was wondering if there is any solution to load h5 files directly from a directory instead of jpg images?
You’re welcome.
Yes, you can load an h5 model file with the load_model() function, if the h5 is data, you can use the h5py library.
Thanks for the reply.
You’re welcome.
Sir, Can you please tell me how can we use imagedatagenrator with TPU.
Please help.
The code is agnostic to where it us run. Using a TPU/GPU/CPU is controlled by the tensorflow library.
Hello sir this is very useful for me ,first of all thank you for that.
I just wanted to know after this i want to predict how can i achieve that part?
Call model.predict()
https://machinelearningmastery.com/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
I get this error while running the mentioned code:
ImportError: Could not import PIL.Image. The use of
load_imgrequires PIL.Any suggestions please
Looks like you need to install PIL/Pillow:
https://machinelearningmastery.com/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
Thank you so much for your quickest reply and great support.
You’re welcome.
HI JASON, As usual your tutorial is awesome and I learnt data generators from this. the only concern I have here, I trained a model using this technique and my data was only two categories (dogs,cats). I generated the confusion matrix of prediction of the model that has been trained and the confusion matrix is not that good and is showing result with accuracy around 50% (TP and TN are almost equal to FP and FN). On the other hand another model I generated without data generators and in conventional way e.g. with api’s like train_test_split and through this I’m able to generate a very good confusion matrix i.e. with accuracy like 95% or more. So Please teach me how to tune the confusion matrix in case of keras flow_from_dir and data generators case.
Thanks
JItender
I don’t think the way the data is loaded would impact model performance.
Perhaps confirm that the data prep, architecture and training were the same between your two different programs.
Hi. I was following this tutorial but mine is a bit different, all data-set images are in a folder moreover the filename of the sub-directory of that folder are not the intended class target for my model so flow_from_directory won’t work for my case is there any solution to that?
Perhaps try adapting it for your specific structure?
I have doubt, I have a dataset with more than one category and they are imbalanced so using image generator is there a way to load only equal amount of data from each class or is there some alternate methods?
Perhaps try generating many examples, save them to directory, balance them manually, then use the new dataset for training?
Hi. i am using this tutorial but mine is a bit different. All images are in a folder, the filename of sub-directory of that folder is not the intended class target so flow_from_directory won’t work. Any Suggestions?
Perhaps change your directory structure to meet the expectations of the API.
Perhaps load the images manually.
Hi Jason, Thanks a lot for your response, I really appreciate. I’ve cross checked multiple times but I’m not able to identify the issue. Can I post you my program here? Please check at your end. Thanks 🙂
# Start
def count_files(dir_path, image_type):
return len(list(glob.iglob(dir_path+”/*/*.”+image_type, recursive=True)))
# dimensions of our images.
img_width, img_height = 150, 150
train_data_dir = ‘dataset/animals_finetune/train’
validation_data_dir = ‘dataset/animals_finetune/validation’
nb_train_samples = count_files(train_data_dir,’jpg’)
nb_validation_samples = count_files(validation_data_dir,’jpg’)
print(‘nb_train_samples: ‘, nb_train_samples)
print(‘nb_validation_samples: ‘, nb_validation_samples)
epochs = 50
batch_size = 32
if K.image_data_format() == ‘channels_first’:
input_shape = (3, img_width, img_height)
else:
input_shape = (img_width, img_height, 3)
print(‘input_shape: ‘,input_shape)
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation(‘relu’))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation(‘sigmoid’))
model.compile(loss=’binary_crossentropy’,
optimizer=’rmsprop’,
metrics=[‘accuracy’])
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=’binary’)
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=’binary’)
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
model.save_weights(‘first_try.h5’)
#Confution Matrix and Classification Report
Y_pred = model.predict_generator(validation_generator, nb_validation_samples // batch_size+1)
y_pred = np.argmax(Y_pred, axis=1)
print(‘Confusion Matrix’)
print(confusion_matrix(validation_generator.classes, y_pred))
print(‘Classification Report’)
target_names = [‘cats’, ‘dogs’]
print(classification_report(validation_generator.classes, y_pred, target_names=target_names))
#End
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Hello Jason, thank you for the very clear blogpost. I am training a ResNet 152 on quite a large dataset (few million pictures) and it is going quite well with this ImageDataGenerator flow_from_directory approach. However, training is still a bit slow. I checked the task manager, and only 20% of GPU and 15% of CPU capacity are being used. I think that having the iterator pull the images from the system could be the bottleneck.
Do you know whether this can indeed be the problem? And additionally, is there a hack that allows you to pre-load batches or cache them, while still using ImageDataGenerator? I can’t figure out how to fix this yet.
Perhaps you can pre-generate images and use a large AWS EC2 instance and load much of the images into memory – if that is the bottleneck.
Excellent Effort Jason!!!
I tried this with my model but got stuck with one problem that when training various models with the fit_generator function and ImageDataGenerator, I experience that the first epoch takes much longer than subsequent ones. What is the reason for this?
For example, it took 3492s for the first one and then around 30s for all the subsequent
Thanks!
I don’t know sorry, I don’t recall seeing this issue. Perhaps it’s caching a ton of images into memory up-front.
Thanks….
Your articles are really helpful for beginners. And the facility of getting our questions answered by the writer himself is simply amazing!!!!
Keep it up!
Thanks!
Hello Jason,
I read your article. I want to load more than one image in my code for detection purpose as my code takes single image at a time. I am using retinanet model. I want to load images from the directory which contain 6 classes. Can you help me with it. Please tell me what should i modify in the code so that it can take multiple images as input.
You can use the code in the above tutorial directly to get started.
I have dataset of around 48k size,both (i/p-o/p) of them are images, but that not getting loaded by the way you did, what can be done in that case ?
Some ideas:
Perhaps change your dataset to match the structure of the example?
Perhaps use an alternate API to load your images?
Perhaps write custom code to load your images?
I hope that helps.
please help me in the coding part for the same
Sorry, I don’t have the capacity to prepare code for you. Perhaps you can hire a contractor.
sir , i have some good images and some bad images ….. i want to train only good images and predict bad images to detect bad …
but , i cant train only good images …. can u tell me what should be the code on training part?
For a model to discriminate good/bad images, it must be trained on both good/bad images.
Hi Jason,
Thanks for this great tutorial.
I am trying to use flow_from_directory for calibrating a binary classifier with a large dataset ( x_train=21047 images 220×220; x_validation = 2629 images 220×220 and x_test = 2633 220×220).
Can I use something like this?
calibrated = CalibratedClassifierCV(KerasModel, method=’sigmoid’, cv=5)
STEP_SIZE_TRAIN=train_generator.n//train_generator.batch_size
train_generator.reset()
calibrated.fit_generator(train_generator,train_generator.lables, steps=STEP_SIZE_TRAIN, sample_weight=None)
probs = calibrated.predict_proba_generator(test_generator, steps=STEP_SIZE_TEST,verbose=1)
Sorry, I don’t think the calibrated classifier and keras wrapper with flow from directory are compatible. You may have to write some custom code.
Hey Jason, Great Job!!!1
I thing I want to ask is I have test data in my drive with images which differ only in the username a bit. Can I use a loop to check for classification if the test data is unlabelled
Sorry, I don’t understand your question, perhaps you could rephrase it or elaborate?
I need help with loading the images into the subdirectories. I’m working on a completely different set of images on kaggle.com, and I’ve created directories and subdirectories for them, but to actually load the images into the subdirectory is where I’m stuck.
An example of an image format is ‘input_100_10_10.jpg’
This is the directory and subdirectory I created:
path = ‘../input/chinese-mnist/data/data/’
base_dir = ‘/kaggle/working/mnist’
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, ‘train’)
os.mkdir(train_dir)
train_set = os.path.join(train_dir, ‘train_data’)
os.mkdir(train_set)
The command I use to load the images into the subdirectory is:
fnames = [‘input_{}_{}_{}.jpg’.format(i) for i in range(0, int(15000*0.80), 1)]
for name in fnames:
src = os.path.join(path, name)
dst = os.path.join(train_set, name)
shutil.copyfile(src, dst)
Please let me know what I’m doing wrong
Perhaps these tips will help:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Thanks
Hey Jason,
I have a question, I want to load only images without labels in using data generator. I am training an autoencoder for image reconstruction on imagenet dataset.
train_it = datagen.flow_from_directory(directory=”/dataset/Imagenet2012/train/”,
target_size=(224, 224),
color_mode=”rgb”,
batch_size=32,
class_mode=None,
shuffle=True,
seed=42
)
I have changed class_mode to None but still, I am getting the error given below.
yargument is not supported when data is a generator or Sequence instance. Instead pass targets as the second element of the generator.I want to pass the original image as y variable.
Please help me with this.
Thanks
Not sure sorry, you might have to experiment.
Or develop a custom data generator.
Hi Dr. Jason
Thanks as usual for being with us with your informative article when we need some help.
I have some clarification, when the problem is multi-label classification we will provide “categorical” in the class-mode parameter?
Thanks
Dennis
I recommend checking the docs:
https://keras.io/api/preprocessing/image/
Hi Jason,
thank you for all your good tutorials
My questions are related to the configuration of the simulations.
Can multiple GPUs be used for the training or the inference with Tensorflow 1.15 or the latest version 2.0?
And for the images_per_gpu parameter, how to configure it optimally according to the number of images in the dataset and the number of GPUs?
Thank you very much!
You’re welcome.
I believe so, sorry, I don’t have an example.
Hi Jason, the custom loader gives (batchX, batchY). I am working on a problem where my keras model has multiple inputs. Can we repurpose the Custom generator to give output something like (batchX1, batchX2, batchY) where X1(image) and X2(some other numerical value) are two different inputs to a keras model.
You may need to write a custom data generator and load your data manually.
I give an example here:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Hi Jason,
I am getting below error though i have created data directory structure similar to yours.
FileNotFoundError: [Errno 2] No such file or directory: ‘C:\\Users\\test\\dataset\\training_set\\’
i tried with all combinations off directory path (single fwd slash ,double fwd slash , back slashesh) every thing I tried, nothing is is working. Could you please help me here.
Sorry to hear that, these tips may help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
I would include how to import e.g. ImageDataGenerator.
The above example shows you how to import the class.
I have a sequence of seven satellite images, to apply a regression task and predict the next sequence in the time series. As there are few images, how do I upload them to the CNN model? Can you use ImageDataGenerator? How would it be?
Perhaps a CNN-LSTM model would be more appropriate for a sequence of images.
You may need to write custom code to load your sequences of images dataset.
Thank you for the tip. Would you have a CNN-LSTM tutorial with images?
Yes, there is an example in the LSTM book:
https://machinelearningmastery.com/lstms-with-python/
Hi Jason .
If we are given images that are in separate folders (based on their classes) under a directory folder,
we can use keras function – flow_from_directory() and create train and validation data sets by specifying validation_split.
But how do we create test data by using flow_from_directory () ??
You can separate the images into separate train/test folds first then load them separately.
An alternative might be to use image_dataset_from_directory():
https://keras.io/api/preprocessing/image/
Thanks Jason. Will try image_dataset_from_directory() as the execution is on Kaggle and won’t be able to create separate folders there .
Good luck!
Hi Jason . With image_dataset_from_directory() , it returned a two batchdatasets objects – one for train and other for validation . And hence was unable to split it further for test dataset .
So finally created my own test image dataset and uploaded to Kaggle. Trying that out .
Thanks !!
Good luck!
HI, is here something similiar for audio datasets?
There may be, I don’t know sorry.
Thanks Jason!
How can i use fit_generator() function with X and y as numpy array?
I don’t have an example, sorry. Perhaps check the API documentation.
e.g.:
import tensorflow.keras as keras
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
from sklearn.datasets import make_blobs
import math
from tensorflow.keras.utils import Sequence
batch_size = 30
nb_epoch = 5
# define dataset
X, y = make_blobs(n_samples=3000, centers=2, random_state=1)
Hi Jason
Thank you for all your good tutorials
How can we use this method for semantic segmetation?
We have images and a labels, not any classes
and How to use this to read the image and its label simultaneous?
Seems the code here is deprecated by Keras now. Its replacement is a more powerful function. See if these two links help:
– https://keras.io/api/preprocessing/image/
– https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator