Deep learning neural network models are highly flexible nonlinear algorithms capable of learning a near infinite number of mapping functions.
A frustration with this flexibility is the high variance in a final model. The same neural network model trained on the same dataset may find one of many different possible “good enough” solutions each time it is run.
Model averaging is an ensemble learning technique that reduces the variance in a final neural network model, sacrificing spread in the performance of the model for a confidence in what performance to expect from the model.
In this tutorial, you will discover how to develop a model averaging ensemble in Keras to reduce the variance in a final model.
After completing this tutorial, you will know:
Model averaging is an ensemble learning technique that can be used to reduce the expected variance of deep learning neural network models.
How to implement model averaging in Keras for classification and regression predictive modeling problems.
How to work through a multi-class classification problem and use model averaging to reduce the variance of the final model.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Oct/2019: Updated for Keras 2.3 and TensorFlow 2.0.
Updated Jan/2020: Updated for changes in scikit-learn v0.22 API.
How to Reduce the Variance of Deep Learning Models in Keras With Model Averaging Ensembles Photo by John Mason, some rights reserved.
Tutorial Overview
This tutorial is divided into six parts; they are:
Model Averaging
How to Average Models in Keras
Multi-Class Classification Problem
MLP Model for Multi-Class Classification
High Variance of MLP Model
Model Averaging Ensemble
Model Averaging
Deep learning neural network models are nonlinear methods that learn via a stochastic training algorithm.
This means that they are highly flexible, capable of learning complex relationships between variables and approximating any mapping function, given enough resources. A downside of this flexibility is that the models suffer high variance.
This means that the models are highly dependent on the specific training data used to train the model and on the initial conditions (random initial weights) and serendipity during the training process. The result is a final model that makes different predictions each time the same model configuration is trained on the same dataset.
This can be frustrating when training a final model for use in making predictions on new data, such as operationally or in a machine learning competition.
The high variance of the approach can be addressed by training multiple models for the problem and combining their predictions. This approach is called model averaging and belongs to a family of techniques called ensemble learning.
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
How to Average Models in Keras
The simplest way to develop a model averaging ensemble in Keras is to train multiple models on the same dataset then combine the predictions from each of the trained models.
Train Multiple Models
Training multiple models may be resource intensive, depending on the size of the model and the size of the training data.
You may have to train the models sequentially on the same hardware. For very large models, it may be worth training the models in parallel using cloud infrastructure such as Amazon Web Services.
The number of models required for the ensemble may vary based on the complexity of the problem and model. A benefit of the approach is that you can continue to create models, add them to the ensemble, and evaluate their impact on the performance by making predictions on a holdout test set.
For small models, you can train the models sequentially and keep them in memory for use in your experiment. For example:
Small models can all be loaded into memory at the same time, whereas very large models may have to be loaded one at a time to make a prediction, then later to have the predictions combined.
1
2
3
4
5
6
7
8
9
10
11
12
from keras.models import load_model
...
# load pre-trained ensemble members
n_members=10
models=list()
foriinrange(n_members):
# load model
filename='model_'+str(i+1)+'.h5'
model=load_model(filename)
# store in memory
models.append(model)
...
Combine Predictions
Once the models have been prepared, each model can be used to make a prediction and the predictions can be combined.
In the case of a regression problem where each model is predicting a real-valued output, the values can be collected and the average calculated.
1
2
3
4
5
6
...
# make predictions
yhats=[model.predict(testX)formodel inmodels]
yhats=array(yhats)
# calculate average
outcomes=mean(yhats)
In the case of a classification problem, there are two options.
The first is to calculate the mode of the predicted integer class values.
A downside of this approach is that for small ensembles or problems with a large number of classes, the sample of predictions may not be large enough for the mode to be meaningful.
In the case of a binary classification problem, a sigmoid activation function is used on the output layer and the average of the predicted probabilities can be calculated much like a regression problem.
In the case of a multi-class classification problem with more than two classes, a softmax activation function is used on the output layer and the sum of the probabilities for each predicted class can be calculated before taking the argmax to get the class value.
1
2
3
4
5
6
7
8
...
# make predictions
yhats=[model.predict(testX)formodel inmodels]
yhats=array(yhats)
# sum across ensembles
summed=numpy.sum(yhats,axis=0)
# argmax across classes
outcomes=argmax(summed,axis=1)
These approaches for combining predictions of Keras models will work just as well for Multilayer Perceptron, Convolutional, and Recurrent Neural Networks.
Now that we know how to average predictions from multiple neural network models in Keras, let’s work through a case study.
Multi-Class Classification Problem
We will use a small multi-class classification problem as the basis to demonstrate a model averaging ensemble.
The scikit-learn class provides the make_blobs() function that can be used to create a multi-class classification problem with the prescribed number of samples, input variables, classes, and variance of samples within a class.
We use this problem with 500 examples, with input variables (to represent the x and y coordinates of the points) and a standard deviation of 2.0 for points within each group. We will use the same random state (seed for the pseudorandom number generator) to ensure that we always get the same 500 points.
The results are the input and output elements of a dataset that we can model.
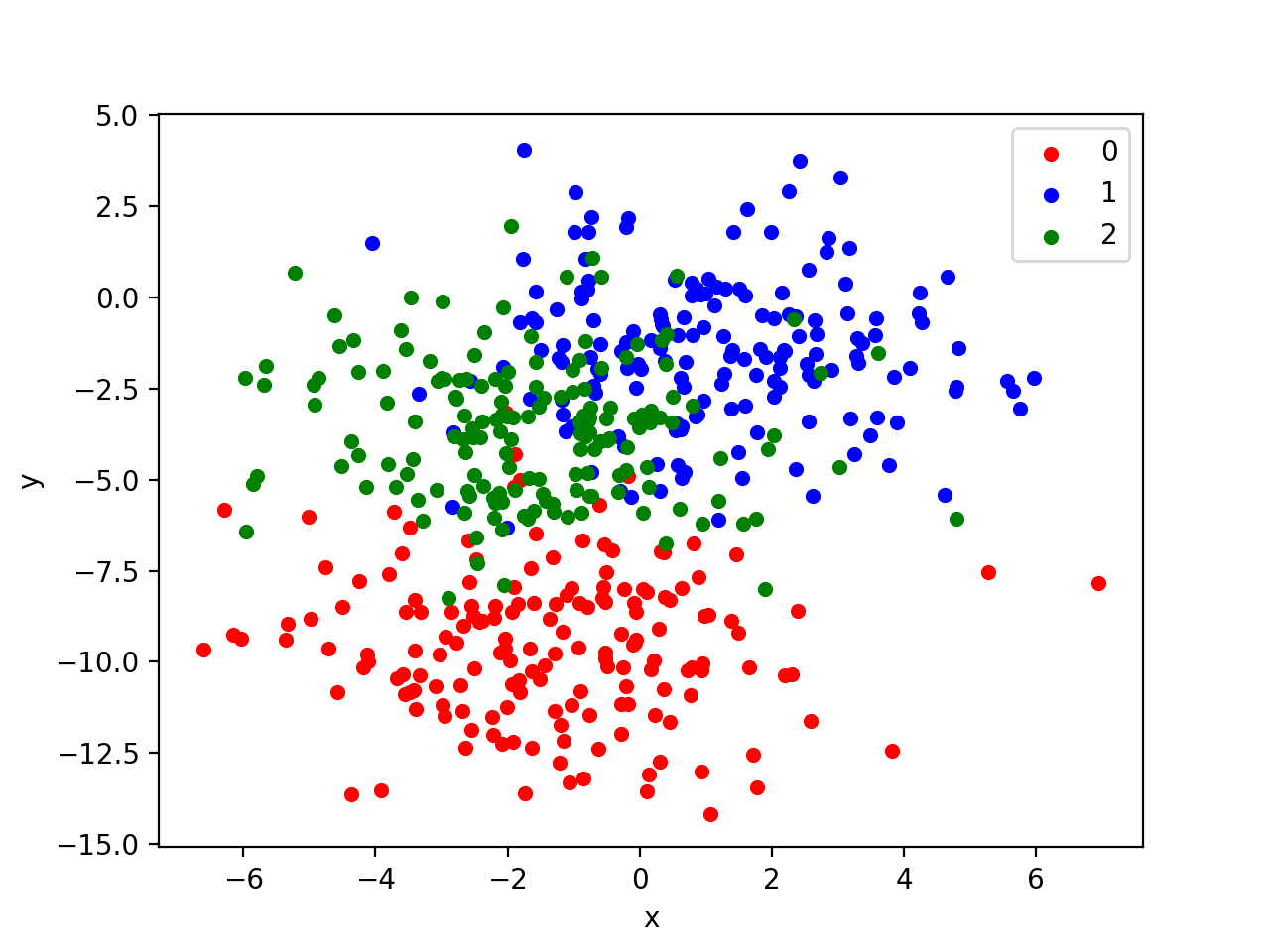
In order to get a feeling for the complexity of the problem, we can graph each point on a two-dimensional scatter plot and color each point by class value.
Running the example creates a scatter plot of the entire dataset. We can see that the standard deviation of 2.0 means that the classes are not linearly separable (separable by a line) causing many ambiguous points.
This is desirable as it means that the problem is non-trivial and will allow a neural network model to find many different “good enough” candidate solutions resulting in a high variance.
Scatter Plot of Blobs Dataset with Three Classes and Points Colored by Class Value
MLP Model for Multi-Class Classification
Now that we have defined a problem, we can define a model to address it.
We will define a model that is perhaps under-constrained and not tuned to the problem. This is intentional to demonstrate the high variance of a neural network model seen on truly large and challenging supervised learning problems.
The problem is a multi-class classification problem, and we will model it using a softmax activation function on the output layer. This means that the model will predict a vector with 3 elements with the probability that the sample belongs to each of the 3 classes. Therefore, the first step is to one hot encode the class values.
1
y=to_categorical(y)
Next, we must split the dataset into training and test sets. We will use the test set both to evaluate the performance of the model and to plot its performance during training with a learning curve. We will use 30% of the data for training and 70% for the test set.
This is an example of a challenging problem where we have more unlabeled examples than we do labeled examples.
1
2
3
4
# split into train and test
n_train=int(0.3*X.shape[0])
trainX,testX=X[:n_train,:],X[n_train:,:]
trainy,testy=y[:n_train],y[n_train:]
Next, we can define and compile the model.
The model will expect samples with two input variables. The model then has a single hidden layer with 15 modes and a rectified linear activation function, then an output layer with 3 nodes to predict the probability of each of the 3 classes and a softmax activation function.
Because the problem is multi-class, we will use the categorical cross entropy loss function to optimize the model and the efficient Adam flavor of stochastic gradient descent.
Running the example first prints the performance of the final model on the train and test datasets.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieved about 84% accuracy on the training dataset and about 76% accuracy on the test dataset; not terrible.
1
Train: 0.847, Test: 0.766
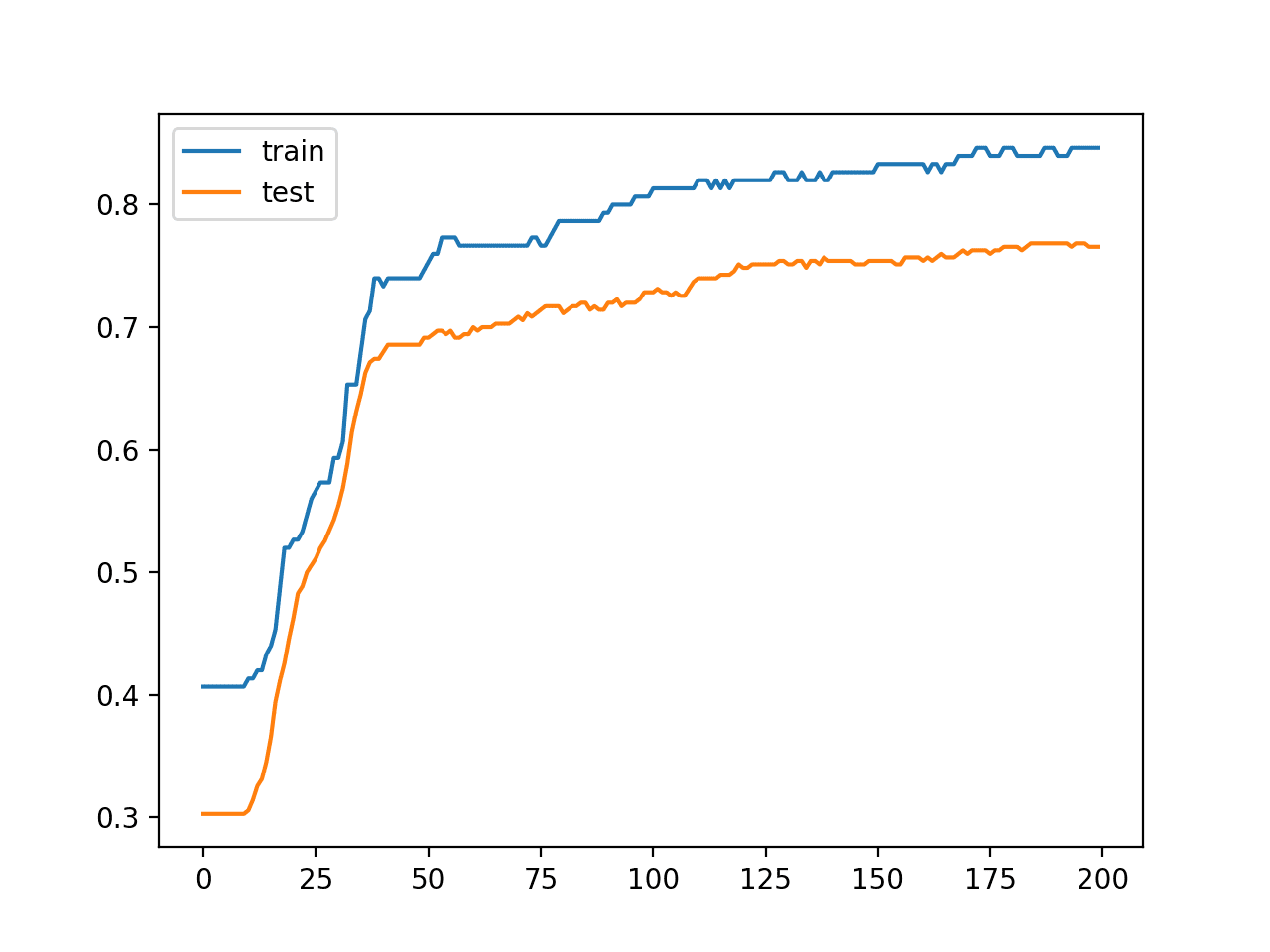
A line plot is also created showing the learning curves for the model accuracy on the train and test sets over each training epoch.
We can see that the model is not really overfit, but is perhaps a little underfit and may benefit from an increase in capacity, more training, and perhaps some regularization. All of these improvements of which we intentionally hold back to force the high variance for our case study.
Line Plot Learning Curves of Model Accuracy on Train and Test Dataset Over Each Training Epoch
High Variance of MLP Model
It is important to demonstrate that the model indeed has a variance in its prediction.
We can demonstrate this by repeating the fit and evaluation of the same model configuration on the same dataset and summarizing the final performance of the model.
To do this, we first split the fit and evaluation of the model out as a function that we can call repeatedly. The evaluate_model() function below takes the train and test dataset, fits a model, then evaluates it, retuning the accuracy of the model on the test dataset.
1
2
3
4
5
6
7
8
9
10
11
12
# fit and evaluate a neural net model on the dataset
We can call this function 30 times, saving the test accuracy scores.
1
2
3
4
5
6
7
# repeated evaluation
n_repeats=30
scores=list()
for_inrange(n_repeats):
score=evaluate_model(trainX,trainy,testX,testy)
print('> %.3f'%score)
scores.append(score)
Once collected, we can summarize the distribution scores, first in terms of the mean and standard deviation, assuming the distribution is Gaussian, which is very reasonable.
1
2
# summarize the distribution of scores
print('Scores Mean: %.3f, Standard Deviation: %.3f'%(mean(scores),std(scores)))
We can then summarize the distribution both as a histogram to show the shape of the distribution and as a box and whisker plot to show the spread and body of the distribution.
1
2
3
4
5
6
# histogram of distribution
pyplot.hist(scores,bins=10)
pyplot.show()
# boxplot of distribution
pyplot.boxplot(scores)
pyplot.show()
The complete example of summarizing the variance of the MLP model on the chosen blobs dataset is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# demonstrate high variance of mlp model on blobs classification problem
from sklearn.datasets import make_blobs
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from numpy import mean
from numpy import std
from matplotlib import pyplot
# fit and evaluate a neural net model on the dataset
print('Scores Mean: %.3f, Standard Deviation: %.3f'%(mean(scores),std(scores)))
# histogram of distribution
pyplot.hist(scores,bins=10)
pyplot.show()
# boxplot of distribution
pyplot.boxplot(scores)
pyplot.show()
Running the example first prints the accuracy of each model on the test set, finishing with the mean and standard deviation of the sample of accuracy scores.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the average of the sample is 77% with a standard deviation of about 1.4%. Assuming a Gaussian distribution, we would expect 99% of accuracy scores to fall between about 73% and 81% (i.e. 3 standard deviations above and below the mean).
We can take the standard deviation of the accuracy of the model on the test set as an estimate for the variance of the predictions made by the model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
> 0.749
> 0.771
> 0.763
> 0.760
> 0.783
> 0.780
> 0.769
> 0.754
> 0.766
> 0.786
> 0.766
> 0.774
> 0.757
> 0.754
> 0.771
> 0.749
> 0.763
> 0.800
> 0.774
> 0.777
> 0.766
> 0.794
> 0.797
> 0.757
> 0.763
> 0.751
> 0.789
> 0.791
> 0.766
> 0.766
Scores Mean: 0.770, Standard Deviation: 0.014
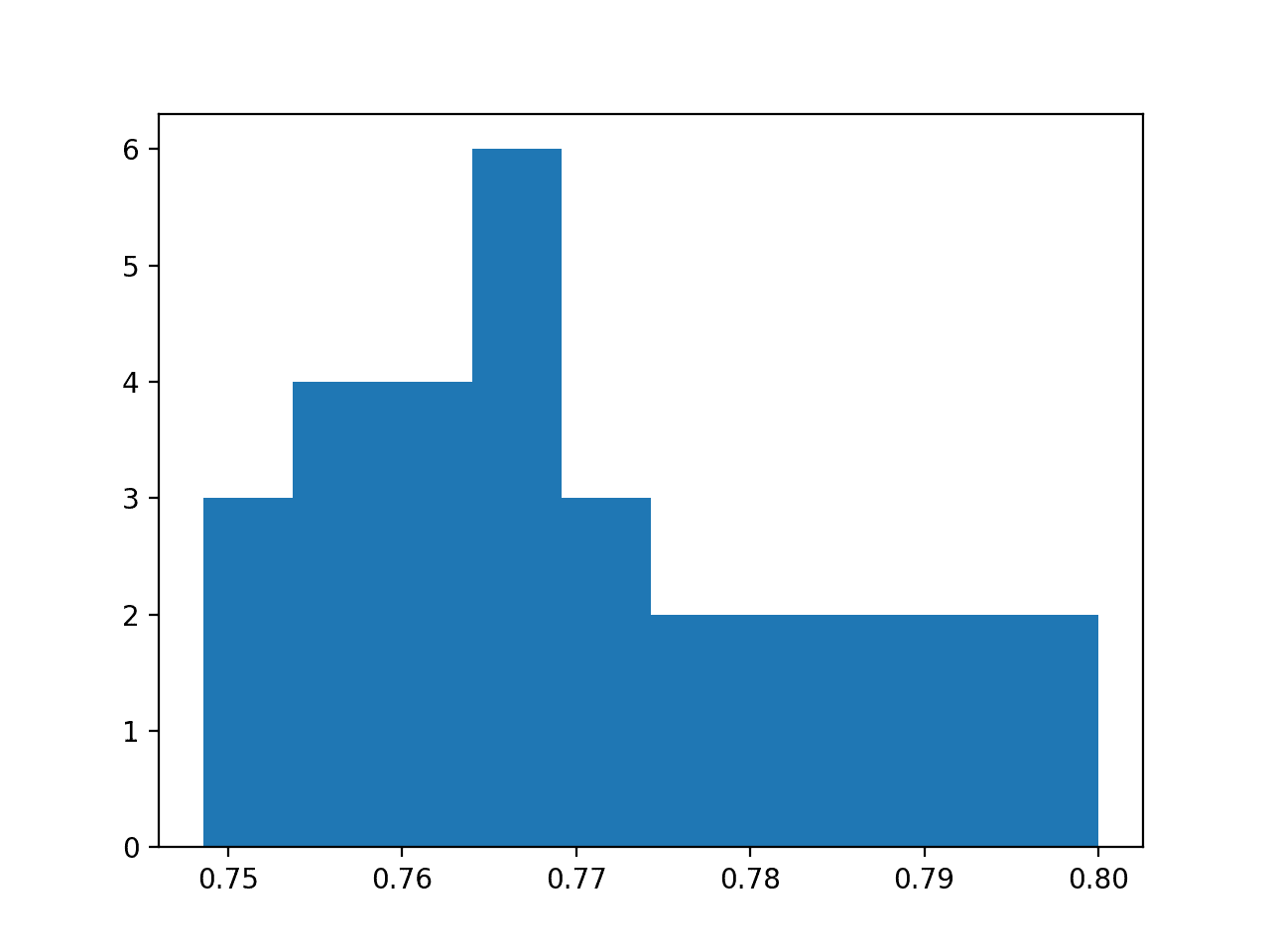
A histogram of the accuracy scores is also created, showing a very rough Gaussian shape, perhaps with a longer right tail.
A large sample and a different number of bins on the plot might better expose the true underlying shape of the distribution.
Histogram of Model Test Accuracy Over 30 Repeats
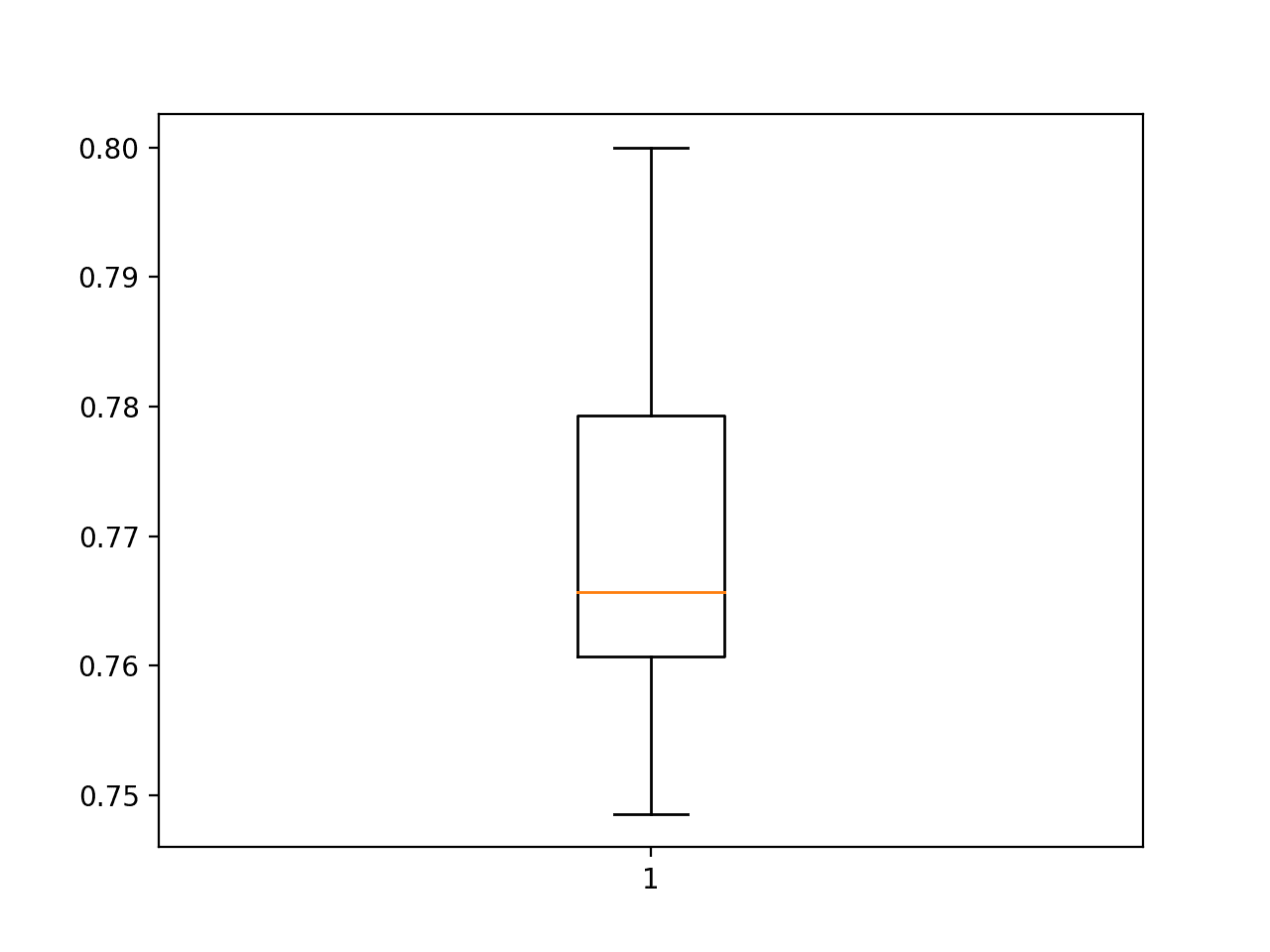
A box and whisker plot is also created showing a line at the median at about 76.5% accuracy on the test set and the interquartile range or middle 50% of the samples between about 78% and 76%.
Box and Whisker Plot of Model Test Accuracy Over 30 Repeats
The analysis of the sample of test scores clearly demonstrates a variance in the performance of the same model trained on the same dataset.
A spread of likely scores of about 8 percentage points (81% – 73%) on the test set could reasonably be considered large, e.g. a high variance result.
Model Averaging Ensemble
We can use model averaging to both reduce the variance of the model and possibly reduce the generalization error of the model.
Specifically, this would result in a smaller standard deviation on the holdout test set and a better performance on the training set. We can check both of these assumptions.
First, we must develop a function to prepare and return a fit model on the training dataset.
Next, we need a function that can take a list of ensemble members and make a prediction for an out of sample dataset. This could be one or more samples arranged in a two-dimensional array of samples and input features.
Hint: you can use this function yourself for testing ensembles and for making predictions with ensembles on new data.
1
2
3
4
5
6
7
8
9
10
# make an ensemble prediction for multi-class classification
def ensemble_predictions(members,testX):
# make predictions
yhats=[model.predict(testX)formodel inmembers]
yhats=array(yhats)
# sum across ensemble members
summed=numpy.sum(yhats,axis=0)
# argmax across classes
result=argmax(summed,axis=1)
returnresult
We don’t know how many ensemble members will be appropriate for this problem.
Therefore, we can perform a sensitivity analysis of the number of ensemble members and how it impacts test accuracy. This means we need a function that can evaluate a specified number of ensemble members and return the accuracy of a prediction combined from those members.
1
2
3
4
5
6
7
8
9
# evaluate a specific number of members in an ensemble
Finally, we can create a line plot of the number of ensemble members (x-axis) versus the accuracy of a prediction averaged across that many members on the test dataset (y-axis).
1
2
3
4
# plot score vs number of ensemble members
x_axis=[iforiinrange(1,n_members+1)]
pyplot.plot(x_axis,scores)
pyplot.show()
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# model averaging ensemble and a study of ensemble size on test accuracy
Running the example first fits 20 models on the same training dataset, which may take less than a minute on modern hardware.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Then, different sized ensembles are tested from 1 member to all 20 members and test accuracy results are printed for each ensemble size.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
1
> 0.740
2
> 0.754
3
> 0.754
4
> 0.760
5
> 0.763
6
> 0.763
7
> 0.763
8
> 0.763
9
> 0.760
10
> 0.760
11
> 0.763
12
> 0.763
13
> 0.766
14
> 0.763
15
> 0.760
16
> 0.760
17
> 0.763
18
> 0.766
19
> 0.763
20
> 0.763
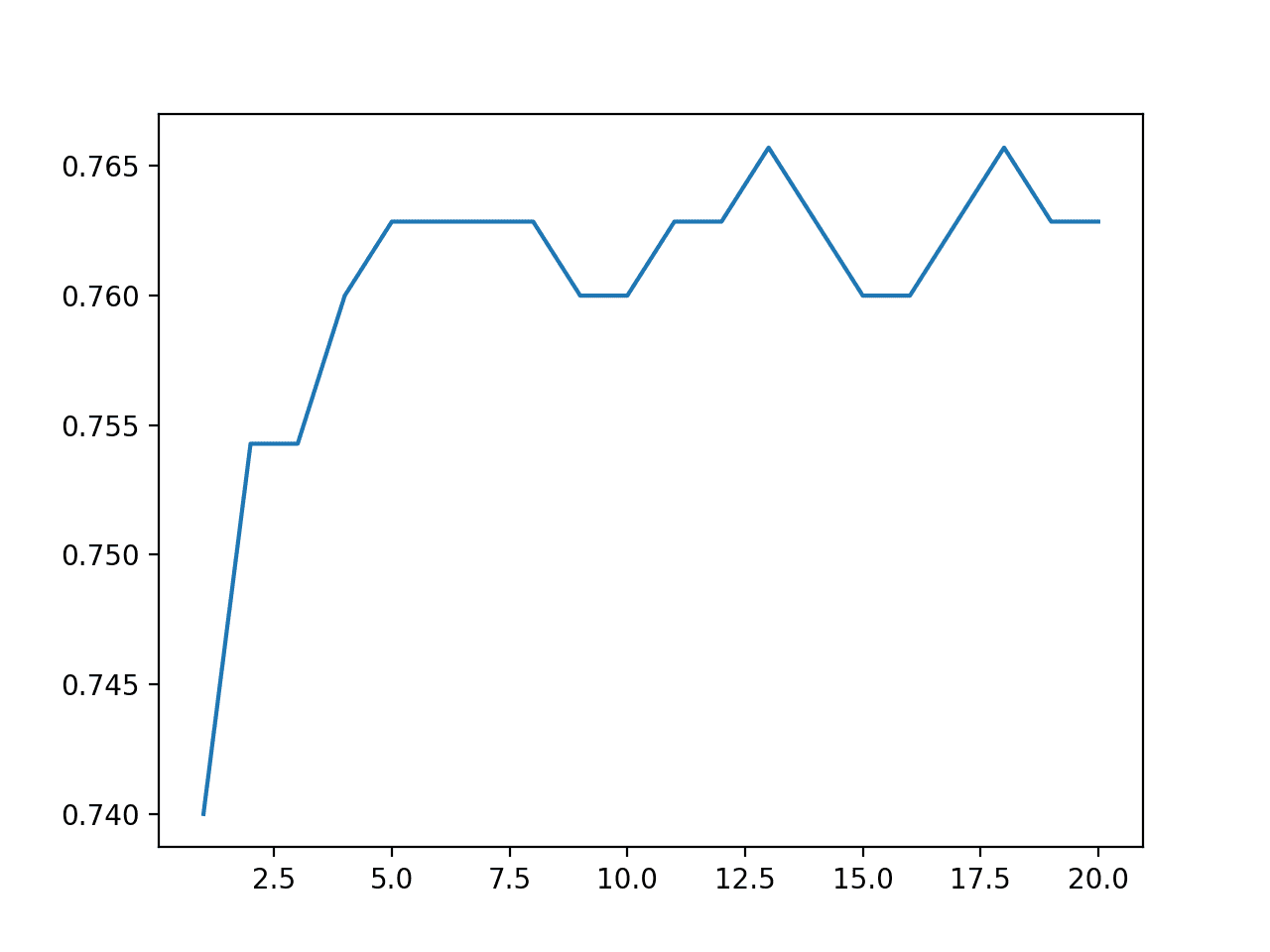
Finally, a line plot is created showing the relationship between ensemble size and performance on the test set.
We can see that performance improves to about five members, after which performance plateaus around 76% accuracy. This is close to the average test set performance observed during the analysis of the repeated evaluation of the model.
Line Plot of Ensemble Size Versus Model Test Accuracy
Finally, we can update the repeated evaluation experiment to use an ensemble of five models instead of a single model and compare the distribution of scores.
The complete example of a repeated evaluated five-member ensemble of the blobs dataset is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# repeated evaluation of model averaging ensemble on blobs dataset
print('Scores Mean: %.3f, Standard Deviation: %.3f'%(mean(scores),std(scores)))
Running the example may take a few minutes as five models are fit and evaluated and this process is repeated 30 times.
The performance of each model on the test set is printed to provide an indication of progress.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The mean and standard deviation of the model performance is printed at the end of the run.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
> 0.769
> 0.757
> 0.754
> 0.780
> 0.771
> 0.774
> 0.766
> 0.769
> 0.774
> 0.771
> 0.760
> 0.766
> 0.766
> 0.769
> 0.766
> 0.771
> 0.763
> 0.760
> 0.771
> 0.780
> 0.769
> 0.757
> 0.769
> 0.771
> 0.771
> 0.766
> 0.763
> 0.766
> 0.771
> 0.769
Scores Mean: 0.768, Standard Deviation: 0.006
In this case, we can see that the average performance of a five-member ensemble on the dataset is 76%. This is very close to the average of 77% seen for a single model.
The important difference is the standard deviation shrinking from 1.4% for a single model to 0.6% with an ensemble of five models. We might expect that a given ensemble of five models on this problem to have a performance fall between about 74% and about 78% with a likelihood of 99%.
Averaging the same model trained on the same dataset gives us a spread for improved reliability, a property often highly desired in a final model to be used operationally.
More models in the ensemble will further decrease the standard deviation of the accuracy of an ensemble on the test dataset given the law of large numbers, at least to a point of diminishing returns.
This demonstrates that for this specific model and prediction problem, that a model averaging ensemble with five members is sufficient to reduce the variance of the model. This reduction in variance, in turn, also means a better on-average performance when preparing a final model.
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Average Class Prediction. Update the example to average the class integer prediction instead of the class probability prediction and compare results.
Save and Load Models. Update the example to save ensemble members to file, then load them from a separate script for evaluation.
Sensitivity of Variance. Create a new example that performs a sensitivity analysis of the number of ensemble members on the standard deviation of model performance on the test set over a given number of repeats and report the point of diminishing returns.
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Hello Jason, great post, as usual!. I am very interested in audio/sound processing and machine / deep learning application to it. Image processing is well covered in ML domain. Unfortunately audio/sound is not. I wonder if by any chance you could kindly point to some knowledge source for the topic? Or even better any introduction blog post would be much appreciated 😉
Sivarama Krishnan RajaramanDecember 30, 2018 at 2:06 am#
Great post. It helps learn a lot about ensemble model predictions. However, I am not sure how to use model.save () in this example to save the ensemble with the optimal number of members for my case. Could you please let know how to save the ensemble members to file for further deployment? Thanks.
Thank you Jason for your great post. I don’t think we can use model.save() to save the ensemble model because model is not defined. We only got ensemble model predictions instead of the model itself. Your advice is highly appreciated.
Thank you Jason. I am sorry that I can’t get it.
I read your tutorial you listed. It is all about using the defined model to save the model itself or model’s weights or model’s architectures. I have no ideas about saving the elements of the ensemble. Are they weights? I don’t think so.
When we want to output the final model for predicting new data, we have to have a saved model instead of redoing ”load several saved models, ensemble together, and then get the predictions”. I hope I can use model.prediction() if I have a saved ensemble model.
Could you please give us an example or a couple of lines to show how to save the elements of the ensemble? Many thanks.
I assume that there is no more point in setting seed in the beginning the code to get reproducible results, correct?
Also, I wonder, if running RandomizedSearchCV with ensemble methods is a common practice? What I mean is that in the function fit_model(params), we can write: rs = RandomizedSearchCV (…); model=rs.fit(X,y). The rest of the code is the same
When I try to use the same method as in this blog to ensemble binary models (14) to solve multiclass problem, I get the following error;
ValueError: Classification metrics can’t handle a mix of multilabel-indicator and binary targets
I am loading the binary models which are already fit in my data to predict some test data. When I use that output array from the prediction to sklearn accuracy score function. I get the that error. How can I solve this? How can I join binary models for multiclass prediction much like OVA system
sir, I am a research student of bscs and my task is to ensemble three deep learning CNN pretrained models. I am using pretrained models but I can’t understand how to ensemble thire results using average, majority voting and weighted average methods in Matlab . could you please help me how could I proceed.
Thanks in advance.
waiting for your guide.
Hi Jason, thank you very much for the useful tutorials. I want to combine some models, not their predicted outputs. something like concatenation, add a new layer to outputs,…..
my problem is I want a way to be able to explain how models are combined, for instance, be able to give weight to each model then combine them by averaging??
totally, could you please tell me some ways of combining models, not results?
The weights used to combine the predictions (e.g. weighted average) from the models might give insight into how the models are being used to create the final output.
One question. I have umbalaced dataset, so I did upsampling , and after that neural networks does not work really well. I tried to do an ensemble of neural network as you did, but nothing! always really low accuracy,in contrast to other models(svc ,logistic regression) which give me really high accuracy.
Could be possible that my dataset would not be trainable with a neural network?
Hi Jason,
This is a great tutorial and I made a bookmark of it. I was puzzled for a long time of ensemble training. After reading, I see it basically to train with different models and average them for the predictions in order to balance the high variance and high bias. Am I correct? I used to just train one best model but like you said. It might not be the best for the test dataset even it looks good for the validation dataset. Thanks so much.
I would like to know how these ensembling values are calculated as it doesn’t seem to be normal average. Is there a hidden function that is used to come up with the answers. Is the answer will alwayd be same if the individual results were same?
Related to this I would like to know for a multi-class classification if I train model using 100 classes, then using 70 classes and then using 50 classes. How can I ensemble (if posible) and what could be the interpretation as there is high chance that using less number of classes will have a higher accuracy.
You will have to check the paper that reports the result. They seem straightforward though, avg is the mean, weighted avg is using model skill as a weight or a soft vote, majority vote is using hard voting.
If models predict different groups of classes, not sure an ensemble makes sense.
In the comment section it is explained as (for average I’m writing here)
predictionsMean = mean(predictionsAllModels,3);
%predictionsAllModels was just the output (the probabilities obtained from ‘classify’) for all %models: predictionsAllModels(:,:,i) = probs;
Till here it is ok.
Do we get one final model after doing ensembling and can apply on test/unseen data? Or we have to run individual network/models again on test data and then do the same aggregate operation on it?
Also, the 20 models are run on model.predict and then the scores from this are averaged. what would the average of the scores from model.evaluate on the test set denote? I am not able to understand the difference.
And after the average of these models are done, be it on model.predict or model.evaluate. How will I know what is my final model? Will all the 20 models be my final model. Say in a real world scenario where I need to submit a model to my customer. how will I know which one to submit.
Thanks for the nice tutorial. I always had the feeling that DL ensemble would work this way, and your article just confirmed my intentions 😉 .
I saw on this thread about one image classifier ensemble design (Faisal July 23, 2020 at 1:07 am) in which the Weighted average technique reduces error to a value similar to an “an average” (3.56%) even when none of the individual models reached that performance. So, let’s say for instance, that I have 5 DL models with around 80% of accuracy each. If I implement any ensemble technique, would I expect any improval on the accuracy? For the purpose of the example, let’s supose that accuracy is the best metric.
Thanks for your attention, and keep up with the good work.
Just to make clear. You use the term “model averaging ensemble” but you use “numpy.sum” to make an ensemble across models. So you meant ensemble with sum. Is that correct?
In my mind, I am expecting the average layer used, which is already provided in Keras. Other layers may work too. The challenge here is what is the best operation for ensemble (sum, multiply, average, etc.).
There are two ways to “average” predictions for classification as derived in the post, the first is the statistical mode of the class label called “hard voting”, the second is the argmax of the summed predicted probabilities, called “soft voting”.
An averaging layer in Keras would not achieve this.
Thanks for the great tutorial,
I am new in machine learning and I am trying to use model averaging ensemble for regression tasks in my model I am using this part of the code to combine predictions
yhats = [model.predict(testX) for model in models]
yhats = array(yhats)
# calculate average
outcomes = mean(yhats)
Also, I am measuring the accuracy of the ensemble by mean squared error, however, in the final result, there is not any change in mean squared error regardless of the number of models. I mean, the squared error remains constant through the number of models.
Therefore, I am wondering if this behaviour can be possible and why? Could you help me with this?
In addition, it would be helpful if you can submit an example for regression.
Perhaps you need to tune the models used in the ensemble?
Perhaps the models are not appropriate for your problem?
Perhaps an ensemble cannot improve the performance for your problem?
Actually it should not be surprised. With one model, its prediction has some variance (measured by the standard deviation). With N models, the average prediction’s variance is reduced by a factor of square root N.








Hello Jason, great post, as usual!. I am very interested in audio/sound processing and machine / deep learning application to it. Image processing is well covered in ML domain. Unfortunately audio/sound is not. I wonder if by any chance you could kindly point to some knowledge source for the topic? Or even better any introduction blog post would be much appreciated 😉
I hope to cover the topic in the future, thanks for the suggestion.
Great post. It helps learn a lot about ensemble model predictions. However, I am not sure how to use model.save () in this example to save the ensemble with the optimal number of members for my case. Could you please let know how to save the ensemble members to file for further deployment? Thanks.
Yes, see this tutorial:
https://machinelearningmastery.com/save-load-keras-deep-learning-models/
Thank you Jason for your great post. I don’t think we can use model.save() to save the ensemble model because model is not defined. We only got ensemble model predictions instead of the model itself. Your advice is highly appreciated.
You can save the elements of the ensemble.
Thank you Jason. I am sorry that I can’t get it.
I read your tutorial you listed. It is all about using the defined model to save the model itself or model’s weights or model’s architectures. I have no ideas about saving the elements of the ensemble. Are they weights? I don’t think so.
When we want to output the final model for predicting new data, we have to have a saved model instead of redoing ”load several saved models, ensemble together, and then get the predictions”. I hope I can use model.prediction() if I have a saved ensemble model.
Could you please give us an example or a couple of lines to show how to save the elements of the ensemble? Many thanks.
No problem.
You can call save() on each model and save to a separate file, then load later and use to make predictions.
I believe there are many examples, here’s one:
https://machinelearningmastery.com/horizontal-voting-ensemble/
Great post Jason,
I assume that there is no more point in setting seed in the beginning the code to get reproducible results, correct?
Also, I wonder, if running RandomizedSearchCV with ensemble methods is a common practice? What I mean is that in the function fit_model(params), we can write: rs = RandomizedSearchCV (…); model=rs.fit(X,y). The rest of the code is the same
I don’t recommend that approach as you will still get variation from input data. More here:
https://machinelearningmastery.com/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
If you have the resources, grid searching by any means is a good idea.
Just to make sure I understand: setting a seed like in the link is not a good idea with ensembles. Correct?
Correct, in fact, I don’t recommend it for neural nets in general.
Instead, it is better to mange the variance in the model and data.
great, i clear understand ensemble because you explains it with real code/
thanks Jason
Thanks.
thank you so much!
You’re welcome.
Hello,
When I try to use the same method as in this blog to ensemble binary models (14) to solve multiclass problem, I get the following error;
ValueError: Classification metrics can’t handle a mix of multilabel-indicator and binary targets
I am loading the binary models which are already fit in my data to predict some test data. When I use that output array from the prediction to sklearn accuracy score function. I get the that error. How can I solve this? How can I join binary models for multiclass prediction much like OVA system
I’m not sure off hand, you will have to debug the fault.
sir, I am a research student of bscs and my task is to ensemble three deep learning CNN pretrained models. I am using pretrained models but I can’t understand how to ensemble thire results using average, majority voting and weighted average methods in Matlab . could you please help me how could I proceed.
Thanks in advance.
waiting for your guide.
Sorry, I don’t have any tutorials for matlab.
Hi Jason, thank you very much for the useful tutorials. I want to combine some models, not their predicted outputs. something like concatenation, add a new layer to outputs,…..
my problem is I want a way to be able to explain how models are combined, for instance, be able to give weight to each model then combine them by averaging??
totally, could you please tell me some ways of combining models, not results?
The weights used to combine the predictions (e.g. weighted average) from the models might give insight into how the models are being used to create the final output.
Really nice!
One question. I have umbalaced dataset, so I did upsampling , and after that neural networks does not work really well. I tried to do an ensemble of neural network as you did, but nothing! always really low accuracy,in contrast to other models(svc ,logistic regression) which give me really high accuracy.
Could be possible that my dataset would not be trainable with a neural network?
Perhaps try other model types?
Perhaps try other model architectures?
Perhaps try other learning configuration?
Perhaps try other data preparation?
1) I did
2) I did
3) I did
4) I did
🙂
There are more ideas here:
https://machinelearningmastery.com/start-here/#better
Once you exhaust all of your ideas, it might be time to move on to a new project.
congratulation for your tutorial!
I didn’t understand why we have to make blobs.
Thanks
It looks like clustering learing
Thanks.
We don’t have to. We are using the blobs dataset as the basis for exploring the models.
Hi Jason,
This is a great tutorial and I made a bookmark of it. I was puzzled for a long time of ensemble training. After reading, I see it basically to train with different models and average them for the predictions in order to balance the high variance and high bias. Am I correct? I used to just train one best model but like you said. It might not be the best for the test dataset even it looks good for the validation dataset. Thanks so much.
Correct.
Hi Jason,
Just started to look about ensembling and read few of your blogs. In another blog it is mentioned
Individual validation errors:
googlenet: 7.23%
squeezneet: 12.89%
resnet18: 7.75%
xception: 3.92%
mobilenetv2: 6.96%
Model ensembling errors:
Average: 3.56%
Weighted average: 3.28% (Xception counted twice).
Majority vote: 4.04%
I would like to know how these ensembling values are calculated as it doesn’t seem to be normal average. Is there a hidden function that is used to come up with the answers. Is the answer will alwayd be same if the individual results were same?
Related to this I would like to know for a multi-class classification if I train model using 100 classes, then using 70 classes and then using 50 classes. How can I ensemble (if posible) and what could be the interpretation as there is high chance that using less number of classes will have a higher accuracy.
Thanks.
You will have to check the paper that reports the result. They seem straightforward though, avg is the mean, weighted avg is using model skill as a weight or a soft vote, majority vote is using hard voting.
If models predict different groups of classes, not sure an ensemble makes sense.
Thanks. I’ll write to the author but to get your expert input, It is from a blog of mathworks website
https://blogs.mathworks.com/deep-learning/2019/06/03/ensemble-learning/
In the comment section it is explained as (for average I’m writing here)
predictionsMean = mean(predictionsAllModels,3);
%predictionsAllModels was just the output (the probabilities obtained from ‘classify’) for all %models: predictionsAllModels(:,:,i) = probs;
Till here it is ok.
getEnsembleError(predictionsMean, YValidation, labels);
What I would like to know is that, which YValidation and labels are these. From first, second,.. model or we need to run somehow again the code?
The function is written like
function getEnsembleError(predictions, YValidation, labels)
[~,mi] = max(predictions,[],2);
predLabels = labels(mi);
validationErrorMean = mean(predLabels ~= YValidation);
disp(“Ensemble validation error: ” + validationErrorMean*100 + “%”)
end
Sorry, I don’t have the capacity to review third party code:
https://machinelearningmastery.com/faq/single-faq/can-you-explain-this-research-paper-to-me
Sorry about asking that question.
A question for clarification about ensembling:
Do we get one final model after doing ensembling and can apply on test/unseen data? Or we have to run individual network/models again on test data and then do the same aggregate operation on it?
Thanks.
The ensemble itself would be the final model and used for making predictions on new data.
Hi Jason, why is the test data passed to model.predict and not model.evaluate?
Also, the 20 models are run on model.predict and then the scores from this are averaged. what would the average of the scores from model.evaluate on the test set denote? I am not able to understand the difference.
And after the average of these models are done, be it on model.predict or model.evaluate. How will I know what is my final model? Will all the 20 models be my final model. Say in a real world scenario where I need to submit a model to my customer. how will I know which one to submit.
Using model.evaluate() would be invalid here.
To make predictions that we can evaluate manually.
Hello Jason,
Thanks for the nice tutorial. I always had the feeling that DL ensemble would work this way, and your article just confirmed my intentions 😉 .
I saw on this thread about one image classifier ensemble design (Faisal July 23, 2020 at 1:07 am) in which the Weighted average technique reduces error to a value similar to an “an average” (3.56%) even when none of the individual models reached that performance. So, let’s say for instance, that I have 5 DL models with around 80% of accuracy each. If I implement any ensemble technique, would I expect any improval on the accuracy? For the purpose of the example, let’s supose that accuracy is the best metric.
Thanks for your attention, and keep up with the good work.
You’re welcome!
Perhaps try it and see.
Hi Jason, thanks for a great tutorial.
Just to make clear. You use the term “model averaging ensemble” but you use “numpy.sum” to make an ensemble across models. So you meant ensemble with sum. Is that correct?
In my mind, I am expecting the average layer used, which is already provided in Keras. Other layers may work too. The challenge here is what is the best operation for ensemble (sum, multiply, average, etc.).
There are two ways to “average” predictions for classification as derived in the post, the first is the statistical mode of the class label called “hard voting”, the second is the argmax of the summed predicted probabilities, called “soft voting”.
An averaging layer in Keras would not achieve this.
Thanks for the great tutorial,
I am new in machine learning and I am trying to use model averaging ensemble for regression tasks in my model I am using this part of the code to combine predictions
yhats = [model.predict(testX) for model in models]
yhats = array(yhats)
# calculate average
outcomes = mean(yhats)
Also, I am measuring the accuracy of the ensemble by mean squared error, however, in the final result, there is not any change in mean squared error regardless of the number of models. I mean, the squared error remains constant through the number of models.
Therefore, I am wondering if this behaviour can be possible and why? Could you help me with this?
In addition, it would be helpful if you can submit an example for regression.
Perhaps you need to tune the models used in the ensemble?
Perhaps the models are not appropriate for your problem?
Perhaps an ensemble cannot improve the performance for your problem?
Hi,
How did the model improve that much if it is just an average of the outputs? It is not clear.
Actually it should not be surprised. With one model, its prediction has some variance (measured by the standard deviation). With N models, the average prediction’s variance is reduced by a factor of square root N.
How can I extract and save average prediction? I also want history plot of epoch vs MSE, is this possible from these ensembles codes?
Hi Farha…You may find the following resource of interest:
https://machinelearningmastery.com/stacking-ensemble-machine-learning-with-python/