The encoder-decoder architecture for recurrent neural networks is the standard neural machine translation method that rivals and in some cases outperforms classical statistical machine translation methods.
This architecture is very new, having only been pioneered in 2014, although, has been adopted as the core technology inside Google’s translate service.
In this post, you will discover the two seminal examples of the encoder-decoder model for neural machine translation.
After reading this post, you will know:
The encoder-decoder recurrent neural network architecture is the core technology inside Google’s translate service.
The so-called “Sutskever model” for direct end-to-end machine translation.
The so-called “Cho model” that extends the architecture with GRU units and an attention mechanism.
Encoder-Decoder Recurrent Neural Network Models for Neural Machine Translation Photo by Fabio Pani, some rights reserved.
Encoder-Decoder Architecture for NMT
The Encoder-Decoder architecture with recurrent neural networks has become an effective and standard approach for both neural machine translation (NMT) and sequence-to-sequence (seq2seq) prediction in general.
The key benefits of the approach are the ability to train a single end-to-end model directly on source and target sentences and the ability to handle variable length input and output sequences of text.
As evidence of the success of the method, the architecture is the core of the Google translation service.
Our model follows the common sequence-to-sequence learning framework with attention. It has three components: an encoder network, a decoder network, and an attention network.
In this post, we will take a closer look at two different research projects that developed the same Encoder-Decoder architecture at the same time in 2014 and achieved results that put the spotlight on the approach. They are:
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Sutskever NMT Model
In this section, we will look at the neural machine translation model developed by Ilya Sutskever, et al. as described in their 2014 paper “Sequence to Sequence Learning with Neural Networks“. We will refer to it as the “Sutskever NMT Model“, for lack of a better name.
This is an important paper as it was one of the first to introduce the Encoder-Decoder model for machine translation and more generally sequence-to-sequence learning.
It is an important model in the field of machine translation as it was one of the first neural machine translation systems to outperform a baseline statistical machine learning model on a large translation task.
The translation task was processed one sentence at a time, and an end-of-sequence (<EOS>) token was added to the end of output sequences during training to signify the end of the translated sequence. This allowed the model to be capable of predicting variable length output sequences.
Note that we require that each sentence ends with a special end-of-sentence symbol “<EOS>”, which enables the model to define a distribution over sequences of all possible lengths.
The model was trained on a subset of the 12 Million sentences in the dataset, comprised of 348 Million French words and 304 Million English words. This set was chosen because it was pre-tokenized.
The source vocabulary was reduced to the 160,000 most frequent source English words and 80,000 of the most frequent target French words. All out-of-vocabulary words were replaced with the “UNK” token.
Model
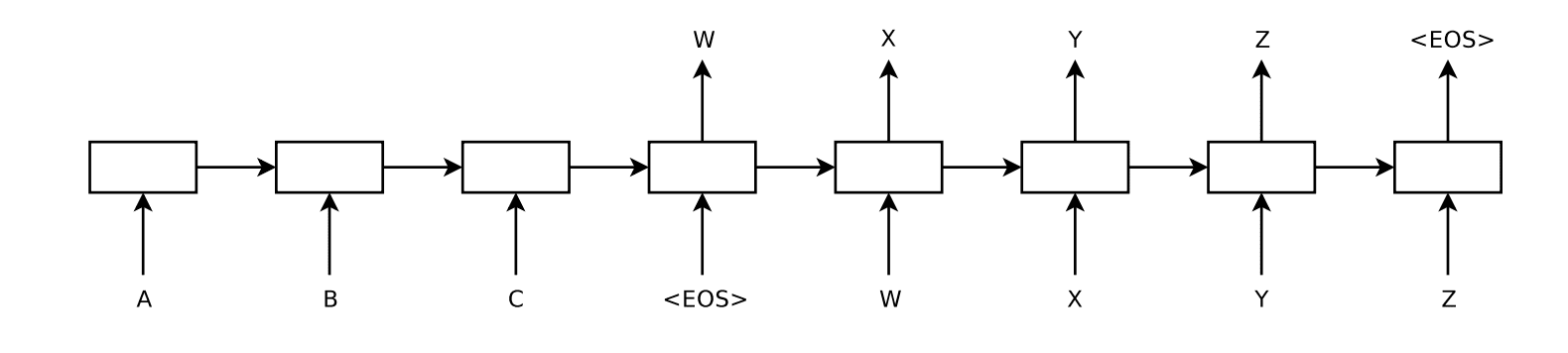
An Encoder-Decoder architecture was developed where an input sequence was read in entirety and encoded to a fixed-length internal representation.
A decoder network then used this internal representation to output words until the end of sequence token was reached. LSTM networks were used for both the encoder and decoder.
The idea is to use one LSTM to read the input sequence, one timestep at a time, to obtain large fixed-dimensional vector representation, and then to use another LSTM to extract the output sequence from that vector
The final model was an ensemble of 5 deep learning models. A left-to-right beam search was used during the inference of the translations.
Depiction of Sutskever Encoder-Decoder Model for Text Translation Taken from “Sequence to Sequence Learning with Neural Networks,” 2014.
Model Configuration
Input sequences were reversed.
A 1000-dimensional word embedding layer was used to represent the input words.
Softmax was used on the output layer.
The input and output models had 4 layers with 1,000 units per layer.
The model was fit for 7.5 epochs where some learning rate decay was performed.
A batch-size of 128 sequences was used during training.
Gradient clipping was used during training to mitigate the chance of gradient explosions.
Batches were comprised of sentences with roughly the same length to speed-up computation.
The model was fit on an 8-GPU machine where each layer was run on a different GPU. Training took 10 days.
The resulting implementation achieved a speed of 6,300 (both English and French) words per second with a minibatch size of 128. Training took about ten days with this implementation.
Result
The system achieved a BLEU score of 34.81, which is a good score compared to the baseline score developed with a statistical machine translation system of 33.30. Importantly, this is the first example of a neural machine translation system that outperformed a phrase-based statistical machine translation baseline on a large scale problem.
… we obtained a BLEU score of 34.81 […] This is by far the best result achieved by direct translation with large neural networks. For comparison, the BLEU score of an SMT baseline on this dataset is 33.30
The final model was used t ore-score the list of best translations and improved the score to 36.5 which brings it close to the best result at the time of 37.0.
You can see a video of the talk associated with the paper here:
Importantly, the Cho Model is used only to score candidate translations and is not used directly for translation like the Sutskever model above. Although extensions to the work to better diagnose and improve the model do use it directly and alone for translation.
Problem
As above, the problem is the English to French translation task from the WMT 2014 workshop.
The source and target vocabulary were limited to the most frequent 15,000 French and English words which covers 93% of the dataset, and out of vocabulary words were replaced with “UNK”.
Model
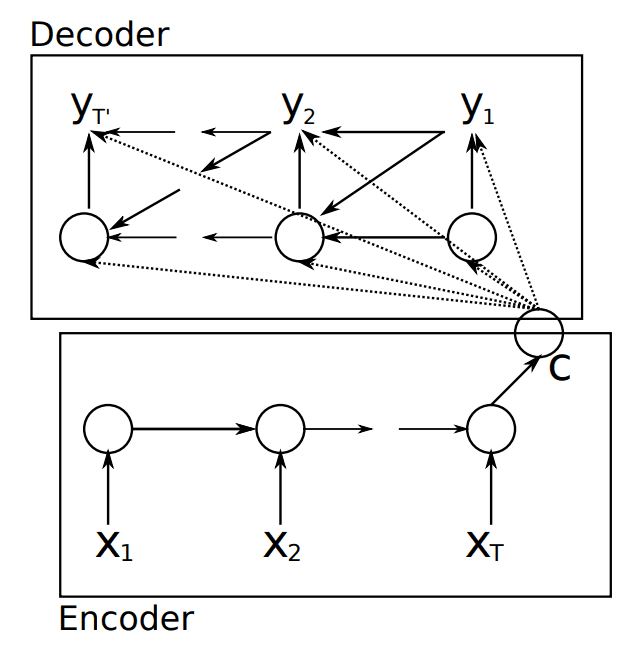
The model uses the same two-model approach, here giving it the explicit name of the encoder-decoder architecture.
… called RNN Encoder–Decoder that consists of two recurrent neural networks (RNN). One RNN encodes a sequence of symbols into a fixed-length vector representation, and the other decodes the representation into another sequence of symbols.
Depiction of the Encoder-Decoder architecture. Taken from “Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation.”
The implementation does not use LSTM units; instead, a simpler recurrent neural network unit is developed called the gated recurrent unit or GRU.
… we also propose a new type of hidden unit that has been motivated by the LSTM unit but is much simpler to compute and implement.
Model Configuration
A 100-dimensional word embedding was used to represent the input words.
The encoder and decoder were configured with 1 layer of 1000 GRU units.
500 Maxout units pooling 2 inputs were used after the decoder.
A batch size of 64 sentences was used during training.
The model was trained for approximately 2 days.
Extensions
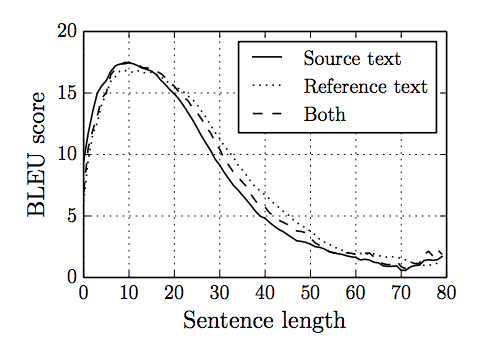
In the paper “On the Properties of Neural Machine Translation: Encoder-Decoder Approaches,” Cho, et al. investigate the limitations of their model. They discover that performance degrades quickly with the increase in the length of input sentences and with the number of words outside of the vocabulary.
Our analysis revealed that the performance of the neural machine translation suffers significantly from the length of sentences.
They provide a useful graph of the performance of the model as the length of the sentence is increased that captures the graceful loss in skill with increased difficulty.
Loss in model skill with increased sentence length. Taken from “On the Properties of Neural Machine Translation: Encoder-Decoder Approaches.”
To address the problem of unknown words, they suggest dramatically increasing the vocabulary of known words during training.
They address the problem of sentence length in a follow-up paper titled “Neural Machine Translation by Jointly Learning to Align and Translate” in which they propose the use of an attention mechanism. Instead of encoding the input sentence to a fixed length vector, a fuller representation of the encoded input is kept and the model learns to use to pay attention to different parts of the input for each word output by the decoder.
Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words.
A wealth of technical details are provided in the paper; for example:
A similarly configured model is used, although with bidirectional layers.
The data is prepared such that 30,000 of the most common words are kept in the vocabulary.
The model is first trained with sentences with a length up to 20 words, then with sentences with a length up to 50 words.
A batch size of 80 sentences is used and the model was fit for 4-6 epochs.
A beam search was used during the inference to find the most likely sequence of words for each translation.
This time the model takes approximately 5 days to train. The code for this follow-up work is also made available.
As with the Sutskever, the model achieved results within the reach of classical phrase-based statistical approaches.
Perhaps more importantly, the proposed approach achieved a translation performance comparable to the existing phrase-based statistical machine translation. It is a striking result, considering that the proposed architecture, or the whole family of neural machine translation, has only been proposed as recently as this year. We believe the architecture proposed here is a promising step toward better machine translation and a better understanding of natural languages in general.
Kyunghyun Cho is also the author of a 2015 series of posts on the Nvidia developer blog on the topic of the encoder-decoder architecture for neural machine translation titled “Introduction to Neural Machine Translation with GPUs.” The series provides a good introduction to the topic and the model; see part 1, part 2, and part 3.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Can this technique be used for transliteration (of proper names)? Or would transliteration be simpler? If so, what is a good sequence-to-sequence model for transliteration English to a Arabic and Visa-versa
I am learning a lot from your wonderful series of posts. Thanks for providing all this knowledge. I have a small query. I tried LSTM and GRU on transliteration task. The BLEU score of GRU came out to be 0.08 where as that of LSTM is 0.72. Why there is a huge difference? GRU is supposed to be working at par with LSTM. Any insight or pointer in this direction?
Hello Jason, I have 2 questions:
How long does seq2seq can process, 10? 100? or as many as 1000?
Can I use the seq2seq as a feature extractor just use the output of encoder as output feature when I feed the encoder and decoder same sequence?
I am interested in the application of NMT in software engineering. But I have some question about differences between various of encoder-decoder structures. Could you help me?
I am interested in taking a document representing product purchases by a customer for some time period in the past and translating it into a document representing highly probable purchase in some interval in the future. I would then use this to create a recommended product list for the customer. Would the techniques you have outlined be capable of extracting the underlying probability structure in previous purchases and then synthesize future purchases?
It is hard to say off the cuff, I’d recommend exploring some prototypes to see if it is viable approach. Or check the literature for similar problems that have been solved/addressed.
that is really a great article. i am new to this field will you plz suggest me some source to get basic practical insight into the encoder-decoder model with attention mechanism…it will be highly appreciated…..thank you !
I want to develop NMT my for my languages Afaan Oromo and Amhraric; i am suffering with spacy can you give how to develop web based machine translation system using RNN








The post was inspiring! Thank you jason.
Thanks, I’m glad to hear that.
It’s an exciting, perfect.
Thanks.
Can this technique be used for transliteration (of proper names)? Or would transliteration be simpler? If so, what is a good sequence-to-sequence model for transliteration English to a Arabic and Visa-versa
I believe so.
Hi Jason,
I am learning a lot from your wonderful series of posts. Thanks for providing all this knowledge. I have a small query. I tried LSTM and GRU on transliteration task. The BLEU score of GRU came out to be 0.08 where as that of LSTM is 0.72. Why there is a huge difference? GRU is supposed to be working at par with LSTM. Any insight or pointer in this direction?
They are different, therefore cannot work on par.
Expect different results from different algorithms across problems.
Very much informative as newcomer to ML-DL like me.
Thank you sir.
Thanks.
Can we use Bidirectional LSTM as a decoder in the encoder-decoder structure?
Sure.
Hello Jason, I have 2 questions:
How long does seq2seq can process, 10? 100? or as many as 1000?
Can I use the seq2seq as a feature extractor just use the output of encoder as output feature when I feed the encoder and decoder same sequence?
Good question, perhaps 200-400 time steps in and out. maybe experiment to see what works.
I am interested in the application of NMT in software engineering. But I have some question about differences between various of encoder-decoder structures. Could you help me?
I can try, what’s your question?
I am interested in taking a document representing product purchases by a customer for some time period in the past and translating it into a document representing highly probable purchase in some interval in the future. I would then use this to create a recommended product list for the customer. Would the techniques you have outlined be capable of extracting the underlying probability structure in previous purchases and then synthesize future purchases?
It is hard to say off the cuff, I’d recommend exploring some prototypes to see if it is viable approach. Or check the literature for similar problems that have been solved/addressed.
that is really a great article. i am new to this field will you plz suggest me some source to get basic practical insight into the encoder-decoder model with attention mechanism…it will be highly appreciated…..thank you !
Yes, perhaps these tutorials will help:
https://machinelearningmastery.com/?s=encoder+decoder+attention&post_type=post&submit=Search
I want to develop NMT my for my languages Afaan Oromo and Amhraric; i am suffering with spacy can you give how to develop web based machine translation system using RNN
Sorry, I don’t know about developing web sites for machine translation.