The encoder-decoder model provides a pattern for using recurrent neural networks to address challenging sequence-to-sequence prediction problems such as machine translation.
Attention is an extension to the encoder-decoder model that improves the performance of the approach on longer sequences. Global attention is a simplification of attention that may be easier to implement in declarative deep learning libraries like Keras and may achieve better results than the classic attention mechanism.
In this post, you will discover the global attention mechanism for encoder-decoder recurrent neural network models.
After reading this post, you will know:
The encoder-decoder model for sequence-to-sequence prediction problems such as machine translation.
The attention mechanism that improves the performance of encoder-decoder models on long sequences.
The global attention mechanism that simplifies the attention mechanism and may achieve better results.
Gentle Introduction to Global Attention for Encoder-Decoder Recurrent Neural Networks Photo by Kathleen Tyler Conklin, some rights reserved.
Overview
This tutorial is divided into 4 parts; they are:
Encoder-Decoder Model
Attention
Global Attention
Global Attention in More Detail
Encoder-Decoder Model
The encoder-decoder model is a way of organizing recurrent neural networks to tackle sequence-to-sequence prediction problems where the number of input and output time steps differ.
The model was developed for the problem of machine translation, such as translating sentences in French to English.
The model involves two sub-models, as follows:
Encoder: An RNN model that reads the entire source sequence to a fixed-length encoding.
Decoder: An RNN model that uses the encoded input sequence and decodes it to output the target sequence.
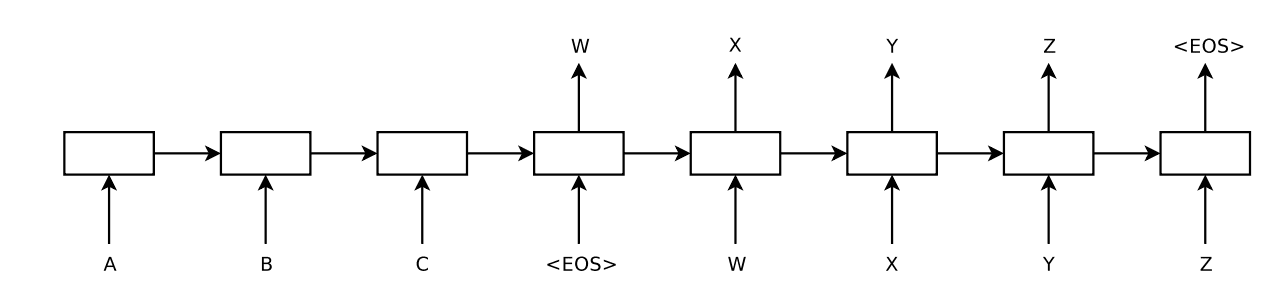
The image below shows the relationship between the encoder and the decoder models.
Example of an Encoder-Decode Network Taken from “Sequence to Sequence Learning with Neural Networks,” 2014.
The Long Short-Term Memory recurrent neural network is commonly used for the encoder and decoder. The encoder output that describes the source sequence is used to start the decoding process, conditioned on the words already generated as output so far. Specifically, the hidden state of the encoder for the last time step of the input is used to initialize the state of the decoder.
The LSTM computes this conditional probability by first obtaining the fixed-dimensional representation v of the input sequence (x1, …, xT) given by the last hidden state of the LSTM, and then computing the probability of y1, …, yT’ with a standard LSTM-LM formulation whose initial hidden state is set to the representation v of x1, …, xT
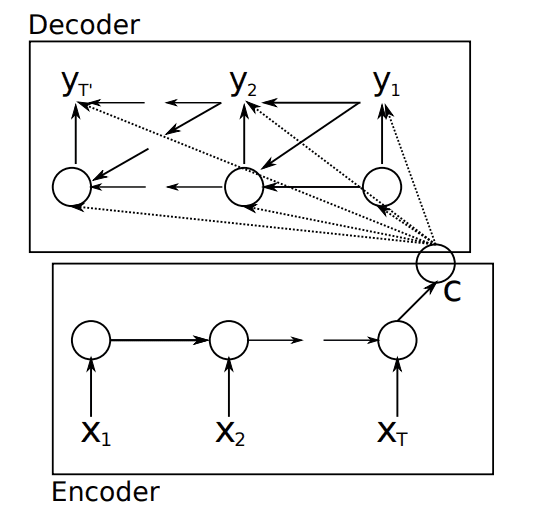
The image below shows the explicit encoding of the source sequence to a context vector c which is used along with the words generated so far to output the next word in the target sequence.
Encoding of Source Sequence to a Context Vector Which is Then Decoded Taken from “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,” 2014.
However, […], both yt and h(t) are also conditioned on yt−1 and on the summary c of the input sequence.
The encoder-decoder model was shown to be an end-to-end model that performed well on challenging sequence-to-sequence prediction problems such as machine translation.
The model appeared to be limited on very long sequences. The reason for this was believed to be the fixed-length encoding of the source sequence.
A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This may make it difficult for the neural network to cope with long sentences, especially those that are longer than the sentences in the training corpus.
In their 2015 paper titled “Neural Machine Translation by Jointly Learning to Align and Translate,” Bahdanau, et al. describe an attention mechanisms to address this issue.
Attention is a mechanism that provides a richer encoding of the source sequence from which to construct a context vector that can then be used by the decoder.
Attention allows the model to learn what encoded words in the source sequence to pay attention to and to what degree during the prediction of each word in the target sequence.
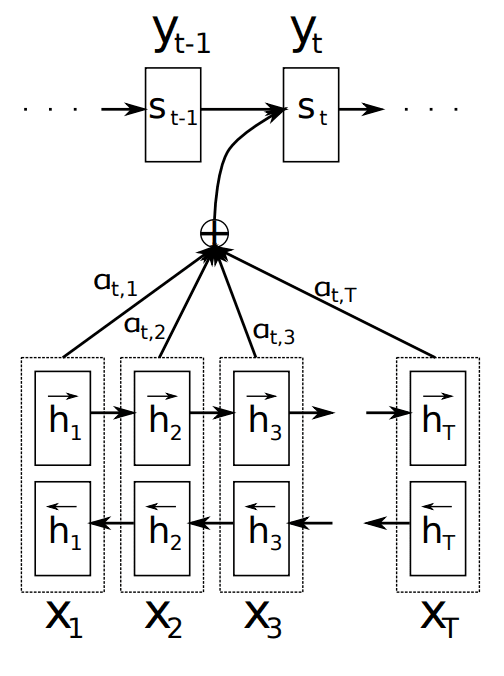
Example of the Encoder-Decoder model with Attention Taken from “Neural Machine Translation by Jointly Learning to Align and Translate,” 2015.
The hidden state for each input time step is gathered from the encoder, instead of the hidden state for the final time step of the source sequence.
A context vector is constructed specifically for each output word in the target sequence. First, each hidden state from the encoder is scored using a neural network, then normalized to be a probability over the encoders hidden states. Finally, the probabilities are used to calculate a weighted sum of the encoder hidden states to provide a context vector to be used in the decoder.
For a fuller explanation for how Bahdanau attention works with a worked example, see the post:
It is proposed as a simplification of the attention mechanism proposed by Bahdanau, et al. in their paper “Neural Machine Translation by Jointly Learning to Align and Translate.” In Bahdanau attention, the attention calculation requires the output of the decoder from the prior time step.
Global attention, on the other hand, makes use of the output from the encoder and decoder for the current time step only. This makes it attractive to implement in vectorized libraries such as Keras.
… our computation path is simpler; we go from ht -> at -> ct -> ~ht then make a prediction […] On the other hand, at any time t, Bahdanau et al. (2015) build from the previous hidden state ht−1 -> at -> ct -> ht, which, in turn, goes through a deep-output and a maxout layer before making predictions.
The model evaluated in the Luong et al. paper is different from the one presented by Bahdanau, et al. (e.g. reversed input sequence instead of bidirectional inputs, LSTM instead of GRU elements and the use of dropout), nevertheless, the results of the model with global attention achieve better results on a standard machine translation task.
… the global attention approach gives a significant boost of +2.8 BLEU, making our model slightly better than the base attentional system of Bahdanau et al.
Next, let’s take a closer look at how global attention is calculated.
Global Attention in More Detail
Global attention is an extension of the attentional encoder-decoder model for recurrent neural networks.
Although developed for machine translation, it is relevant for other language generation tasks, such as caption generation and text summarization, and even sequence prediction tasks in general.
We can divide the calculation of global attention into the following computation steps for an encoder-decoder network that predicts one time step given an input sequence. See the paper for the relevant equations.
Problem. The input sequence is provided as input to the encoder (X).
Encoding. The encoder RNN encodes the input sequence and outputs a sequence of the same length (hs).
Decoding. The decoder interprets the encoding and outputs a target decoding (ht).
Alignment. Each encoded time step is scored using the target decoding, then the scores are normalized using a softmax function. Four different scoring functions are proposed:
dot: the dot product between target decoding and source encoding.
general: the dot product between target decoding and the weighted source encoding.
concat: a neural network processing of the concatenated source encoding and target decoding.
location: a softmax of the weighted target decoding.
Context Vector. The alignment weights are applied to the source encoding by calculating the weighted sum to result in the context vector.
Final Decoding. The context vector and the target decoding are concatenated, weighed, and transferred using a tanh function.
The final decoding is passed through a softmax to predict the probability of the next word in the sequence over the output vocabulary.
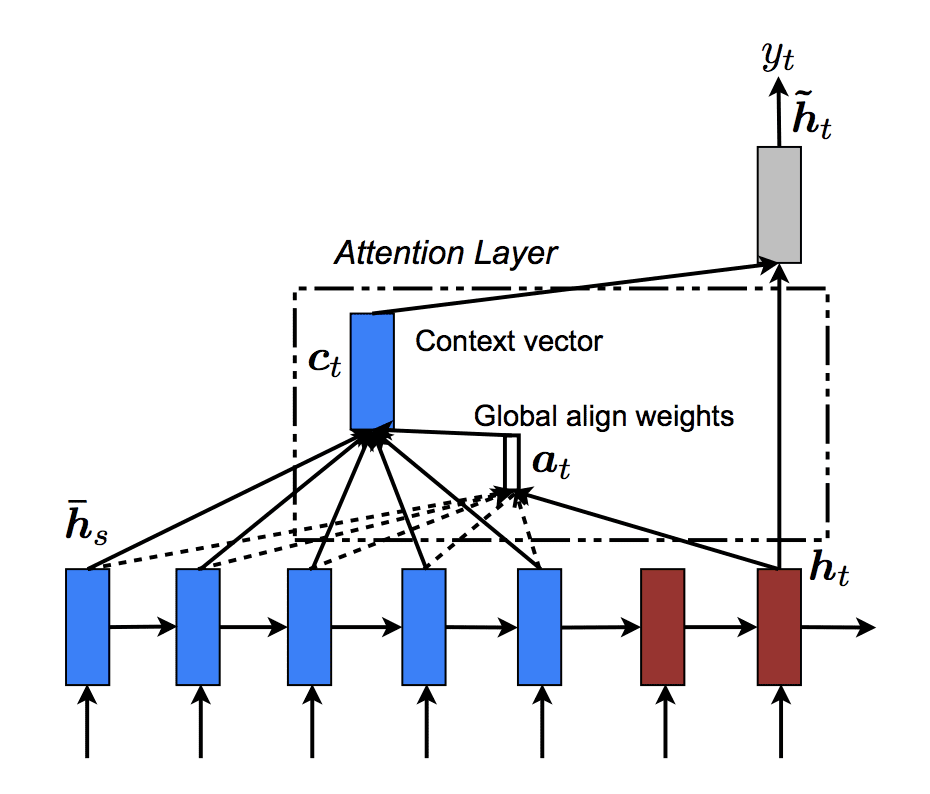
The graphic below provides a high-level idea of the data flow when calculating global attention.
The depiction of Global Attention in an Encoder-Decoder Recurrent Neural Network. Taken from “Effective Approaches to Attention-based Neural Machine Translation.”
The authors evaluated all of the scoring functions and found generally that the simple dot scoring function appeared to perform well.
It is interesting to observe that dot works well for the global attention…
Because of the simpler and more data flow, global attention may be a good candidate for implementing in declarative deep learning libraries such as TensorFlow, Theano, and wrappers like Keras.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials on topics like: CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Thank you so much for your tutorials — they are very helpful. I have been reading several papers on attention mechanisms but I only just really understood the whole picture after reading your posts. Thank you.
I have been trying to implement global attention myself in Keras. Seeing as the variant using the dot alignment score does not require any learnable weights (correct me if I am wrong), shouldn’t it be possible to implement using a lambda function/layer? This should also be possible because at any time step, Luong’s attention mechanism only depends on the source hidden state (h_s) and target hidden state (h_t). My thinking is that an implementation of the dot score at least, does not need to inherit the Recurrent Layer class – but I am not entirely sure. Any thoughts?
Clarification : concerning the dependence, I mean at any time step, the alignment score solely depends on the h_s and the **current** h_t. In contrast to Bahdanau’s where there’s a dependence on the previous h_t as well.
Yes, global attention is straightforward to implement with some transform layers and a lambda. I had a go one afternoon but it got a bit messy and had poor results. I’m hanging out for the built-in attention in Keras myself.
In Luong attention, I’m really not sure how the scoring is done…
If the encoder is outputting [ num_steps, batch_size, enc_hidden_size ], and the current decoder target is [ 1, batch_size, enc_hidden_size ], how do we do the matrix multiplication with rank 3 tensors?
Respected Sir,
I Have some reviews, from which i have extracted some aspects, now i want to generate an abstractive summary, with an attention on aspects as well as on contents, how i can do this
Thank you so much for your valuable tutorials.
please guide me to answer this question: What’s the difference between Attention vs Self-Attention and Multihead Attention? What problems does each other solve that the other can’t?
thank you.








Hi jason
please implement more attention mechanism(such as this one described here) in your tutorials and codes.
thank you.
Thanks. Keras will have attention mechanisms soon enough.
I did implement this myself in Keras and it must have had some serious bugs because results were really poor.
Hello Jason,
Thank you so much for your tutorials — they are very helpful. I have been reading several papers on attention mechanisms but I only just really understood the whole picture after reading your posts. Thank you.
I have been trying to implement global attention myself in Keras. Seeing as the variant using the dot alignment score does not require any learnable weights (correct me if I am wrong), shouldn’t it be possible to implement using a lambda function/layer? This should also be possible because at any time step, Luong’s attention mechanism only depends on the source hidden state (h_s) and target hidden state (h_t). My thinking is that an implementation of the dot score at least, does not need to inherit the Recurrent Layer class – but I am not entirely sure. Any thoughts?
Clarification : concerning the dependence, I mean at any time step, the alignment score solely depends on the h_s and the **current** h_t. In contrast to Bahdanau’s where there’s a dependence on the previous h_t as well.
Yes, global attention is straightforward to implement with some transform layers and a lambda. I had a go one afternoon but it got a bit messy and had poor results. I’m hanging out for the built-in attention in Keras myself.
In Luong attention, I’m really not sure how the scoring is done…
If the encoder is outputting [ num_steps, batch_size, enc_hidden_size ], and the current decoder target is [ 1, batch_size, enc_hidden_size ], how do we do the matrix multiplication with rank 3 tensors?
hi jason can you plaese share this code for the global attention in keras
Sorry, I don’t have a worked example at this stage. I hope to make time to write one in the future.
Respected Sir,
I Have some reviews, from which i have extracted some aspects, now i want to generate an abstractive summary, with an attention on aspects as well as on contents, how i can do this
Perhaps try an abstractive summarization algorithm?
Hi Jason
Thank you so much for your valuable tutorials.
please guide me to answer this question: What’s the difference between Attention vs Self-Attention and Multihead Attention? What problems does each other solve that the other can’t?
thank you.
Sorry, I don’t have a tutorial on this comparison.