When it comes to sequential or time series data, traditional feedforward networks cannot be used for learning and prediction. A mechanism is required to retain past or historical information to forecast future values. Recurrent neural networks, or RNNs for short, are a variant of the conventional feedforward artificial neural networks that can deal with sequential data and can be trained to hold knowledge about the past.
After completing this tutorial, you will know:
Recurrent neural networks
What is meant by unfolding an RNN
How weights are updated in an RNN
Various RNN architectures
Kick-start your project with my book Building Transformer Models with Attention. It provides self-study tutorials with working code to guide you into building a fully-working transformer model that can translate sentences from one language to another...
Let’s get started.
An introduction to recurrent neural networks and the math that powers Them. Photo by Mehreen Saeed, some rights reserved.
Tutorial Overview
This tutorial is divided into two parts; they are:
The working of an RNN
Unfolding in time
Backpropagation through time algorithm
Different RNN architectures and variants
Prerequisites
This tutorial assumes that you are already familiar with artificial neural networks and the backpropagation algorithm. If not, you can go through this very nice tutorial, Calculus in Action: Neural Networks, by Stefania Cristina. The tutorial also explains how a gradient-based backpropagation algorithm is used to train a neural network.
What Is a Recurrent Neural Network
A recurrent neural network (RNN) is a special type of artificial neural network adapted to work for time series data or data that involves sequences. Ordinary feedforward neural networks are only meant for data points that are independent of each other. However, if we have data in a sequence such that one data point depends upon the previous data point, we need to modify the neural network to incorporate the dependencies between these data points. RNNs have the concept of “memory” that helps them store the states or information of previous inputs to generate the next output of the sequence.
Want to Get Started With Building Transformer Models with Attention?
Take my free 12-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
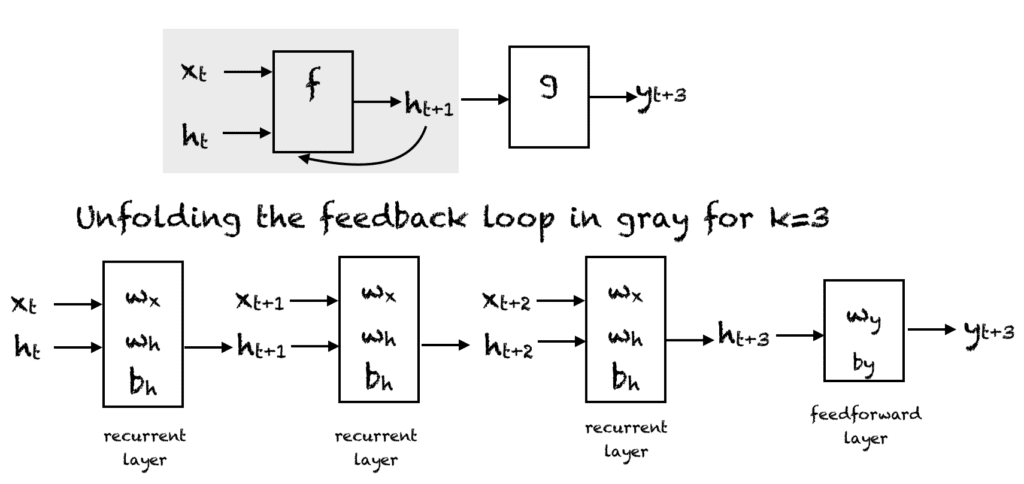
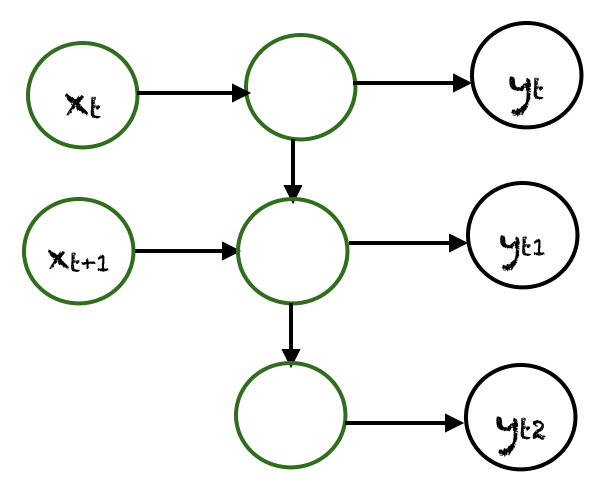
A simple RNN has a feedback loop, as shown in the first diagram of the above figure. The feedback loop shown in the gray rectangle can be unrolled in three time steps to produce the second network of the above figure. Of course, you can vary the architecture so that the network unrolls $k$ time steps. In the figure, the following notation is used:
$x_t \in R$ is the input at time step $t$. To keep things simple, we assume that $x_t$ is a scalar value with a single feature. You can extend this idea to a $d$-dimensional feature vector.
$y_t \in R$ is the output of the network at time step $t$. We can produce multiple outputs in the network, but for this example, we assume that there is one output.
$h_t \in R^m$ vector stores the values of the hidden units/states at time $t$. This is also called the current context. $m$ is the number of hidden units. $h_0$ vector is initialized to zero.
$w_x \in R^{m}$ are weights associated with inputs in the recurrent layer
$w_h \in R^{mxm}$ are weights associated with hidden units in the recurrent layer
$w_y \in R^m$ are weights associated with hidden units to output units
$b_h \in R^m$ is the bias associated with the recurrent layer
$b_y \in R$ is the bias associated with the feedforward layer
At every time step, we can unfold the network for $k$ time steps to get the output at time step $k+1$. The unfolded network is very similar to the feedforward neural network. The rectangle in the unfolded network shows an operation taking place. So, for example, with an activation function f:
Hence, in the feedforward pass of an RNN, the network computes the values of the hidden units and the output after $k$ time steps. The weights associated with the network are shared temporally. Each recurrent layer has two sets of weights: one for the input and the second for the hidden unit. The last feedforward layer, which computes the final output for the kth time step, is just like an ordinary layer of a traditional feedforward network.
The Activation Function
We can use any activation function we like in the recurrent neural network. Common choices are:
The backpropagation algorithm of an artificial neural network is modified to include the unfolding in time to train the weights of the network. This algorithm is based on computing the gradient vector and is called backpropagation in time or BPTT algorithm for short. The pseudo-code for training is given below. The value of $k$ can be selected by the user for training. In the pseudo-code below, $p_t$ is the target value at time step t:
Repeat till the stopping criterion is met:
Set all $h$ to zero.
Repeat for t = 0 to n-k
Forward propagate the network over the unfolded network for $k$ time steps to compute all $h$ and $y$
Compute the error as: $e = y_{t+k}-p_{t+k}$
Backpropagate the error across the unfolded network and update the weights
Types of RNNs
There are different types of recurrent neural networks with varying architectures. Some examples are:
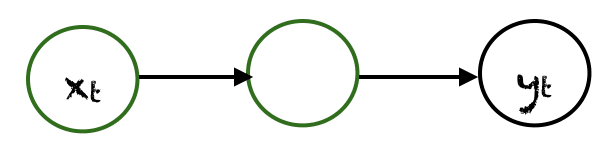
One to One
Here, there is a single $(x_t, y_t)$ pair. Traditional neural networks employ a one-to-one architecture.
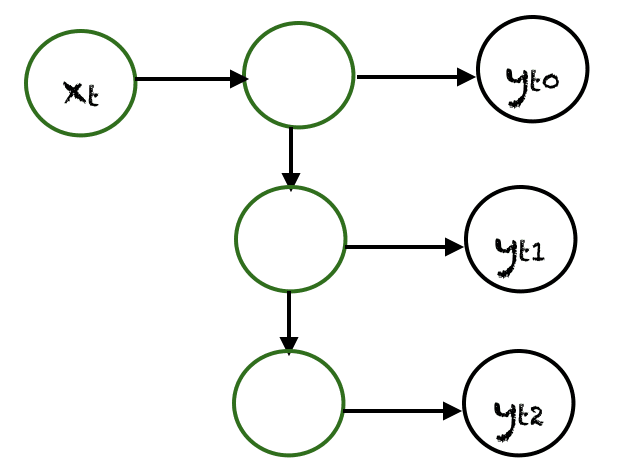
One to Many
In one-to-many networks, a single input at $x_t$ can produce multiple outputs, e.g., $(y_{t0}, y_{t1}, y_{t2})$. Music generation is an example area where one-to-many networks are employed.
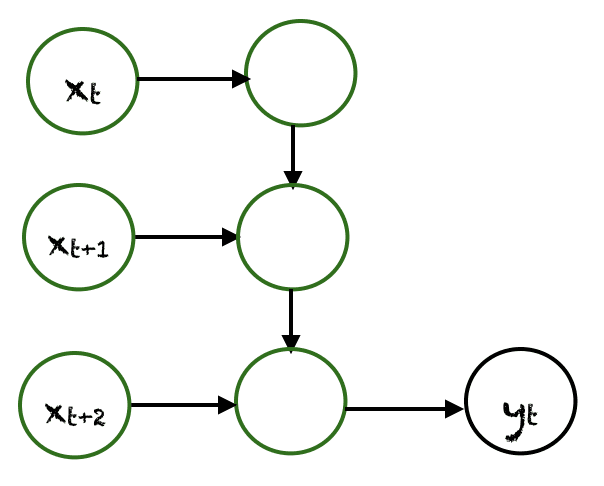
Many to One
In this case, many inputs from different time steps produce a single output. For example, $(x_t, x_{t+1}, x_{t+2})$ can produce a single output $y_t$. Such networks are employed in sentiment analysis or emotion detection, where the class label depends upon a sequence of words.
Many to Many
There are many possibilities for many-to-many. An example is shown above, where two inputs produce three outputs. Many-to-many networks are applied in machine translation, e.g., English to French or vice versa translation systems.
Advantages and Shortcomings of RNNs
RNNs have various advantages, such as:
Ability to handle sequence data
Ability to handle inputs of varying lengths
Ability to store or “memorize” historical information
The disadvantages are:
The computation can be very slow.
The network does not take into account future inputs to make decisions.
Vanishing gradient problem, where the gradients used to compute the weight update may get very close to zero, preventing the network from learning new weights. The deeper the network, the more pronounced this problem is.
Different RNN Architectures
There are different variations of RNNs that are being applied practically in machine learning problems:
Bidirectional Recurrent Neural Networks (BRNN)
In BRNN, inputs from future time steps are used to improve the accuracy of the network. It is like knowing the first and last words of a sentence to predict the middle words.
Gated Recurrent Units (GRU)
These networks are designed to handle the vanishing gradient problem. They have a reset and update gate. These gates determine which information is to be retained for future predictions.
Long Short Term Memory (LSTM)
LSTMs were also designed to address the vanishing gradient problem in RNNs. LSTMs use three gates called input, output, and forget gate. Similar to GRU, these gates determine which information to retain.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials with working code to guide you into building a fully-working transformer models that can translate sentences from one language to another...
Give magical power of understanding human language for Your Projects
Thanks for the great article.
Question about: “At every time step, we can unfold the network for k time steps to get the output at time step k+1”. What is the significance of k here, is it the number of hidden layers? Is it something the user sets as parameter, and if so, what parameter in pytorch does it correspond to?
In the context of Recurrent Neural Networks (RNNs), or variants like LSTMs and GRUs, unfolding refers to the process of expanding the network over time. It’s a conceptual way of visualizing how the model processes a sequence step by step.
k is not the number of hidden layers.
Instead, k represents the number of time steps the network is unrolled for — in other words, how many steps in the sequence you feed into the RNN at once.
Why is k important?
Unrolling the network for k time steps allows it to learn dependencies that span across those time steps. For example:
* If you unroll it for 5 time steps, the network can potentially learn relationships over a span of 5 steps in the sequence.
* It affects how much historical context the model can use when making predictions.
Is k a user-defined parameter?
Yes, it is — but it’s more of a training setup than a fixed parameter inside the RNN module. In PyTorch, you control it by how you organize your input data, not by setting a specific argument in the RNN constructor like nn.RNN or nn.LSTM.
Relevant PyTorch details:
* You decide how many time steps to feed into the RNN during training or inference.
* This is defined by the shape of the input tensor, which is usually:
(seq_len, batch, input_size)
So seq_len is effectively your k.
* PyTorch doesn’t have a built-in “unroll” parameter like some other frameworks (such as Keras, which has an unroll=True option).
Summary:
* k refers to the number of time steps the network is unrolled over — it’s not about hidden layers.
* You define k through the length of the input sequence you provide.
* In PyTorch, this is controlled by the seq_len dimension of your input tensor.








Nice Explanation
Thanks. Glad you like it.
Very nice and clearly explained article, thank you!
Thank you. Glad you liked it.
Very informative and clear. Thank you for posting the tutorial.
Thank you for the great explanation!
You are very welcome Johann!
Very good explaination, thank you so much !
Thank you for your feedback and support Yakoub!
Thanks for the great article.
Question about: “At every time step, we can unfold the network for k time steps to get the output at time step k+1”. What is the significance of k here, is it the number of hidden layers? Is it something the user sets as parameter, and if so, what parameter in pytorch does it correspond to?
Great question! Let’s break it down.
“Unfolding the network for k time steps”
In the context of Recurrent Neural Networks (RNNs), or variants like LSTMs and GRUs, unfolding refers to the process of expanding the network over time. It’s a conceptual way of visualizing how the model processes a sequence step by step.
k is not the number of hidden layers.
Instead, k represents the number of time steps the network is unrolled for — in other words, how many steps in the sequence you feed into the RNN at once.
Why is k important?
Unrolling the network for k time steps allows it to learn dependencies that span across those time steps. For example:
* If you unroll it for 5 time steps, the network can potentially learn relationships over a span of 5 steps in the sequence.
* It affects how much historical context the model can use when making predictions.
Is k a user-defined parameter?
Yes, it is — but it’s more of a training setup than a fixed parameter inside the RNN module. In PyTorch, you control it by how you organize your input data, not by setting a specific argument in the RNN constructor like
nn.RNNornn.LSTM.Relevant PyTorch details:
* You decide how many time steps to feed into the RNN during training or inference.
* This is defined by the shape of the input tensor, which is usually:
(seq_len, batch, input_size)
So
seq_lenis effectively your k.* PyTorch doesn’t have a built-in “unroll” parameter like some other frameworks (such as Keras, which has an
unroll=Trueoption).Summary:
* k refers to the number of time steps the network is unrolled over — it’s not about hidden layers.
* You define k through the length of the input sequence you provide.
* In PyTorch, this is controlled by the
seq_lendimension of your input tensor.