In languages, the order of the words and their position in a sentence really matters. The meaning of the entire sentence can change if the words are re-ordered. When implementing NLP solutions, recurrent neural networks have an inbuilt mechanism that deals with the order of sequences. The transformer model, however, does not use recurrence or convolution and treats each data point as independent of the other. Hence, positional information is added to the model explicitly to retain the information regarding the order of words in a sentence. Positional encoding is the scheme through which the knowledge of the order of objects in a sequence is maintained.
For this tutorial, we’ll simplify the notations used in this remarkable paper, Attention Is All You Need by Vaswani et al. After completing this tutorial, you will know:
What is positional encoding, and why it’s important
Positional encoding in transformers
Code and visualize a positional encoding matrix in Python using NumPy
Kick-start your project with my book Building Transformer Models with Attention. It provides self-study tutorials with working code to guide you into building a fully-working transformer model that can translate sentences from one language to another...
Let’s get started.
A gentle introduction to positional encoding in transformer models Photo by Muhammad Murtaza Ghani on Unsplash, some rights reserved
Tutorial Overview
This tutorial is divided into four parts; they are:
What is positional encoding
Mathematics behind positional encoding in transformers
Implementing the positional encoding matrix using NumPy
Understanding and visualizing the positional encoding matrix
What Is Positional Encoding?
Positional encoding describes the location or position of an entity in a sequence so that each position is assigned a unique representation. There are many reasons why a single number, such as the index value, is not used to represent an item’s position in transformer models. For long sequences, the indices can grow large in magnitude. If you normalize the index value to lie between 0 and 1, it can create problems for variable length sequences as they would be normalized differently.
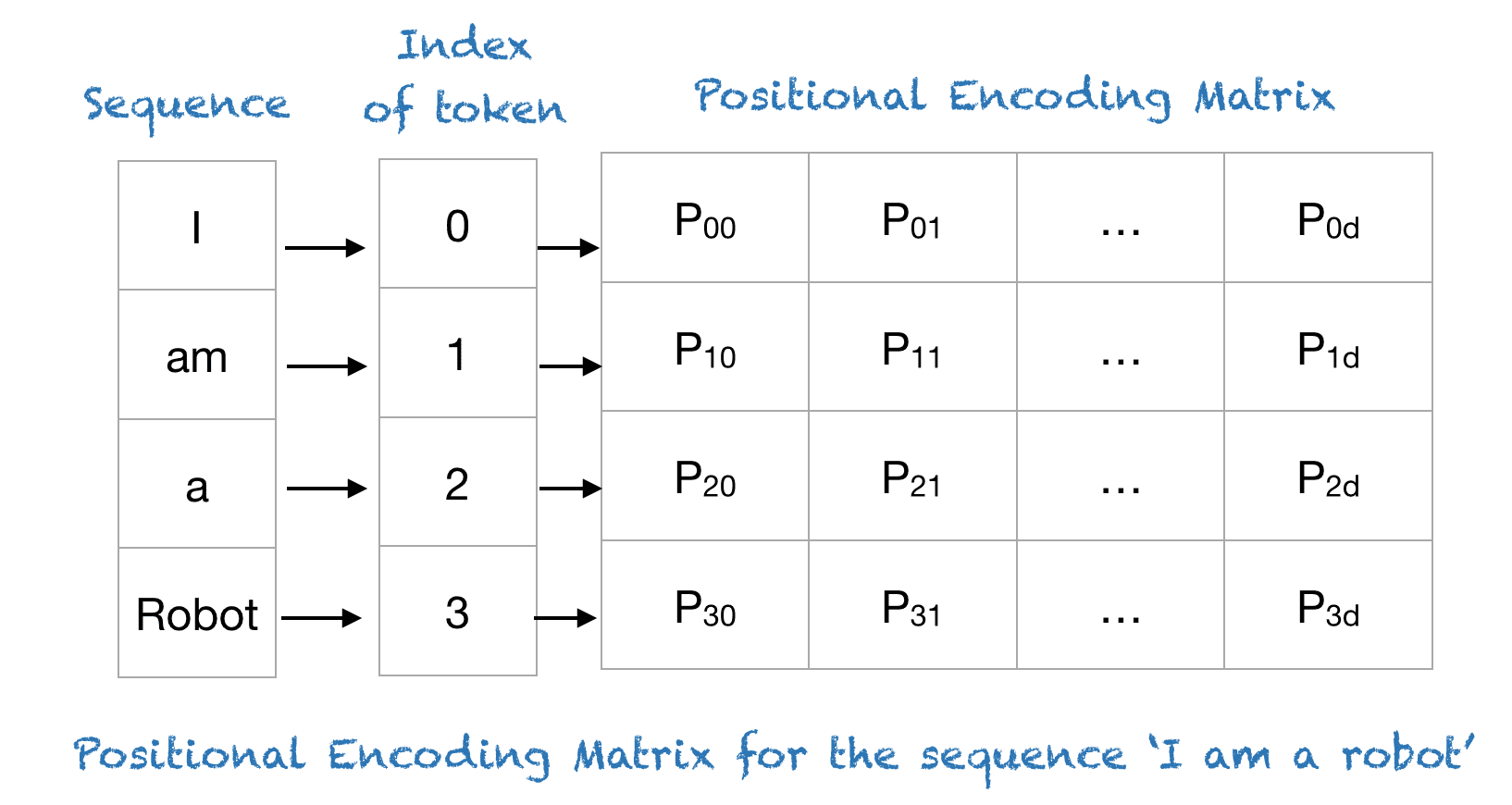
Transformers use a smart positional encoding scheme, where each position/index is mapped to a vector. Hence, the output of the positional encoding layer is a matrix, where each row of the matrix represents an encoded object of the sequence summed with its positional information. An example of the matrix that encodes only the positional information is shown in the figure below.
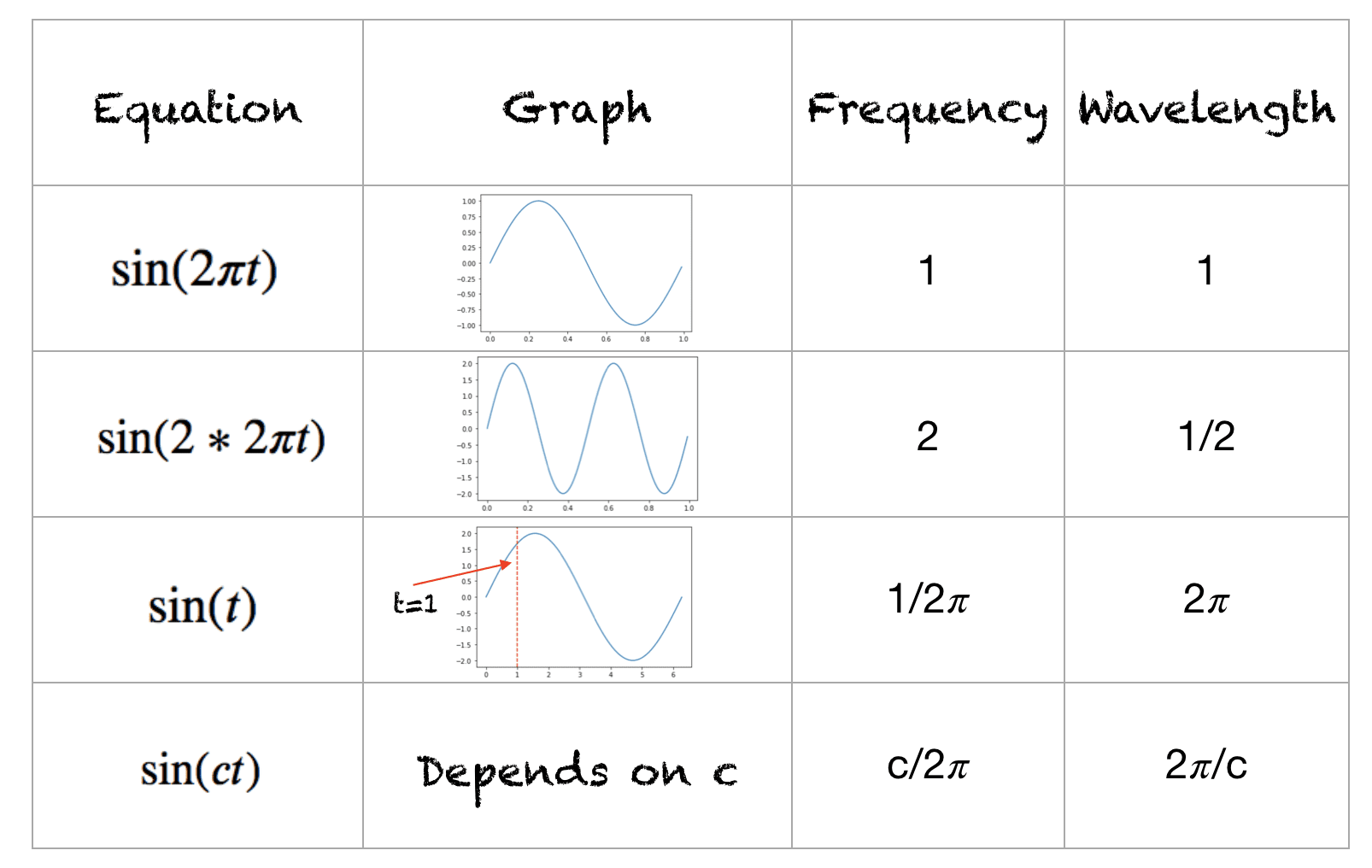
A Quick Run-Through of the Trigonometric Sine Function
This is a quick recap of sine functions; you can work equivalently with cosine functions. The function’s range is [-1,+1]. The frequency of this waveform is the number of cycles completed in one second. The wavelength is the distance over which the waveform repeats itself. The wavelength and frequency for different waveforms are shown below:
Want to Get Started With Building Transformer Models with Attention?
Take my free 12-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Positional Encoding Layer in Transformers
Let’s dive straight into this. Suppose you have an input sequence of length $L$ and require the position of the $k^{th}$ object within this sequence. The positional encoding is given by sine and cosine functions of varying frequencies:
$i$: Used for mapping to column indices $0 \leq i < d/2$, with a single value of $i$ maps to both sine and cosine functions
In the above expression, you can see that even positions correspond to a sine function and odd positions correspond to cosine functions.
Example
To understand the above expression, let’s take an example of the phrase “I am a robot,” with n=100 and d=4. The following table shows the positional encoding matrix for this phrase. In fact, the positional encoding matrix would be the same for any four-letter phrase with n=100 and d=4.
Coding the Positional Encoding Matrix from Scratch
Here is a short Python code to implement positional encoding using NumPy. The code is simplified to make the understanding of positional encoding easier.
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
importnumpy asnp
importmatplotlib.pyplot asplt
defgetPositionEncoding(seq_len,d,n=10000):
P=np.zeros((seq_len,d))
forkinrange(seq_len):
foriinnp.arange(int(d/2)):
denominator=np.power(n,2*i/d)
P[k,2*i]=np.sin(k/denominator)
P[k,2*i+1]=np.cos(k/denominator)
returnP
P=getPositionEncoding(seq_len=4,d=4,n=100)
print(P)
Output
1
2
3
4
[[ 0. 1. 0. 1. ]
[ 0.84147098 0.54030231 0.09983342 0.99500417]
[ 0.90929743 -0.41614684 0.19866933 0.98006658]
[ 0.14112001 -0.9899925 0.29552021 0.95533649]]
Understanding the Positional Encoding Matrix
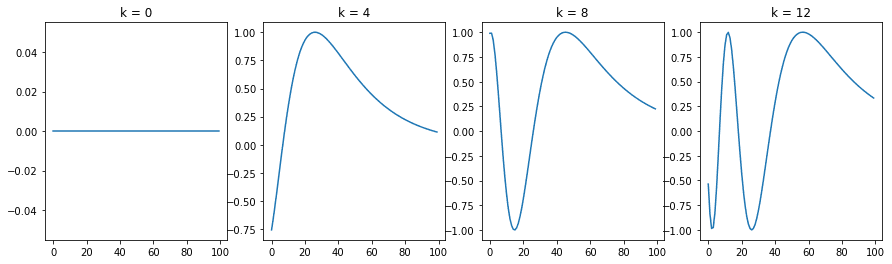
To understand the positional encoding, let’s start by looking at the sine wave for different positions with n=10,000 and d=512.
Python
1
2
3
4
5
6
7
8
9
10
11
defplotSinusoid(k,d=512,n=10000):
x=np.arange(0,100,1)
denominator=np.power(n,2*x/d)
y=np.sin(k/denominator)
plt.plot(x,y)
plt.title('k = '+str(k))
fig=plt.figure(figsize=(15,4))
foriinrange(4):
plt.subplot(141+i)
plotSinusoid(i*4)
The following figure is the output of the above code:
Sine wave for different position indices
You can see that each position $k$ corresponds to a different sinusoid, which encodes a single position into a vector. If you look closely at the positional encoding function, you can see that the wavelength for a fixed $i$ is given by:
$$
\lambda_{i} = 2 \pi n^{2i/d}
$$
Hence, the wavelengths of the sinusoids form a geometric progression and vary from $2\pi$ to $2\pi n$. The scheme for positional encoding has a number of advantages.
The sine and cosine functions have values in [-1, 1], which keeps the values of the positional encoding matrix in a normalized range.
As the sinusoid for each position is different, you have a unique way of encoding each position.
You have a way of measuring or quantifying the similarity between different positions, hence enabling you to encode the relative positions of words.
Visualizing the Positional Matrix
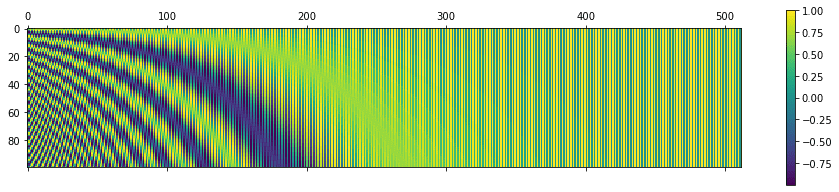
Let’s visualize the positional matrix on bigger values. Use Python’s matshow() method from the matplotlib library. Setting n=10,000 as done in the original paper, you get the following:
Python
1
2
3
P=getPositionEncoding(seq_len=100,d=512,n=10000)
cax=plt.matshow(P)
plt.gcf().colorbar(cax)
The positional encoding matrix for n=10,000, d=512, sequence length=100
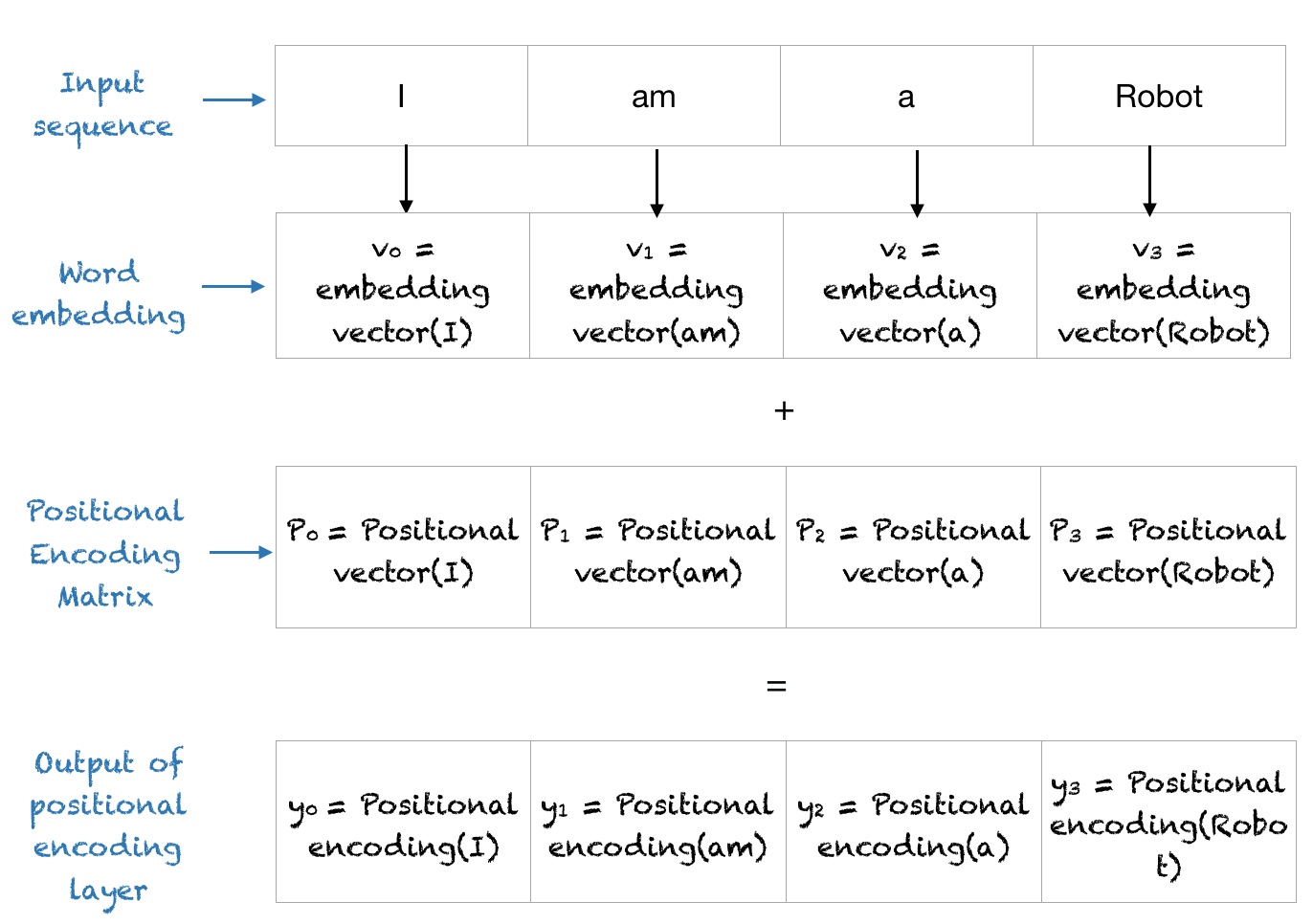
What Is the Final Output of the Positional Encoding Layer?
The positional encoding layer sums the positional vector with the word encoding and outputs this matrix for the subsequent layers. The entire process is shown below.
The positional encoding layer in the transformer
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials with working code to guide you into building a fully-working transformer models that can translate sentences from one language to another...
Give magical power of understanding human language for Your Projects
Yes, that’s right. James, seems you do not try to understand what people in comments are saying to you, I had a feeling that there is no good understanding from your side, or it was just lack of time you were ready to invest into the material you prepared.
I think there’re errors in the trigonometric table section.
The graphs for sin(2 * 2Pi) and sin(t) go beyond the range [-1:1], either the graph is wrong or the formulas on the left are not the corresponding one.
The code doesnt work for an odd embedding vector dimension, the last position would always be left without any assign, could easily be solved with a if statement, but I wonder if odd dimensions for embeddings are even used.
Excuse me if, for time series forecasting with transformer encoder positional encoding and input, masking is necessary. Because I think in chronicle arranged time series, inputs are ordered in time, and there is no any displacement, also when we use walk forward valodation.
The positional encoding for example “I am a robot” looks strange for me, same as the output of “getPositionEncoding” function and many questions arise, which makes me more confused. First question, Values are not unique : P01 and P03 or P03 and P13, which one should contain unique values: rows or cols? As I understood the row size = embedding size, and if a row represents the positional encoding for one token, then we can use same values for row. Second question, values are not linear increasing: P00, P10, P20, P30. There is no order, how do we know which one is first, second, … last one if values are not increasing linearly?
I think this article is not as good as the others on this website. The concept is not clearly explained. Suggest adding more details and having a good logic between the contents.
Thank you for the explanation.
I’m having trouble grasping how this method encodes the relative positions of words.
Is there a formal explanation for this? I understand that for every position “p_i,” it holds that “p_i = T(k) p_i+k,” but I can’t quite comprehend how this concept is beneficial.
I appreciate your assistance in advance.
Do the “Positional vector” and “Positional encoding” functions really take the input words as parameters the way the image under “What Is the Final Output” section implies?
If not, perhaps it would be a good idea to update the image to make them take input index or something as input instead, because it’s confusing the way it is now. It sort of looks like any position containing the word “am” will get the same positional encoding, and that’s not true, is it?
In the transformer paper and in your tutorial the position encoding is just added (not appended) to the embedding vector, so its dimension stays the same. Doesn’t this “spoil” the working of the attention mechanism, as the tokens are thus modified? I assume it still works well enough, because of the high dimensionality of these vectors. But if you add two high-dimensional vectors, will the sum vector still be sufficiently similar to the embedding vector to not confuse it with others? It will be equally similar to the positional encoding vector. So shouldn’t the latter be smaller, as words are still more important than positions (I guess)? Do you know of any paper discussing this?
Thank you. My question was regarding this paragraph:
What Is the Final Output of the Positional Encoding Layer?
The positional encoding layer sums the positional vector with the word encoding and outputs this matrix for the subsequent layers. The entire process is shown below.
I’m curious if “sums” means actually adding two vectors, or it means concatenating two vectors. And why it is adding, not concatenating? what’s the justification of adding two embeddings from two different domains?
The phrase “sums the positional vector with the word encoding and outputs this matrix for the subsequent layers” refers to a process commonly used in the architecture of transformer models, like those underlying many modern natural language processing (NLP) systems.
Let’s break it down:
1. **Word Encoding (Word Embeddings):** Each word (or token) in a sentence is converted into a numerical form, known as an embedding. This embedding captures the semantic meaning of the word in a high-dimensional space. Essentially, similar words have similar embeddings. These embeddings are learned from data and are an integral part of neural network models for language tasks.
2. **Positional Encoding:** Since the transformer architecture does not inherently process sequential data in order (unlike RNNs or LSTMs), it requires a method to understand the order of words in a sentence. Positional encoding is added to solve this problem. It involves generating another set of vectors that encode the position of each word in the sentence. Each positional vector is unique to its position, ensuring that the model can recognize the order of words. The positional encoding is designed so that it can be combined with the word embeddings, usually through addition, without losing the information contained in either.
3. **Summing the Positional Vector with the Word Encoding:** The process involves element-wise addition of the positional encoding vector to the word embedding vector for each word. This combined vector now contains both the semantic information of the word (from the word embedding) and its position in the sentence (from the positional encoding). This is crucial for the model to understand both the meaning of words and how the order of words affects the meaning of the sentence.
4. **Outputting this Matrix for the Subsequent Layers:** The resulting matrix, after summing positional vectors and word embeddings, is then passed through the subsequent layers of the transformer model. These layers include self-attention mechanisms and fully connected networks, which process this combined information to perform tasks such as language understanding, translation, or generation. The matrix effectively serves as the input for these complex operations, allowing the model to consider both the meaning of individual words and their context within the sentence.
This process is fundamental to the functioning of transformer models, enabling them to achieve state-of-the-art performance on a wide range of NLP tasks.
For example, let’s consider a sequence of 5 tokens, where each token is represented by an embedding of 10 dimensions; thus, each token’s embedding shape is 1×10. Instead of directly adding the raw positions 0 to 4 to the embeddings, which might overly alter the original semantic embeddings, a sinusoidal function is utilized. This function takes as inputs the token’s position in the sequence, the index within the embedding dimension, and the total number of dimensions, producing a 1×10 positional embedding for each token.
These positional embeddings are then added to the original token embeddings. In the Transformer architecture, during the calculation of Query, Key, and Value vectors, the matrix multiplication in the attention mechanism tends to assign higher scores to adjacent tokens, unless there is a strong semantic signal from the embeddings that suggests otherwise. This maintains the influence of token proximity unless overridden by significant contextual differences embedded in the tokens.
Thank you for your feedback Pavan! You’ve nicely outlined the concept of positional embeddings in the Transformer model architecture and how they influence the self-attention mechanism. Let’s delve a bit deeper into each of these components and their operational dynamics within the Transformer framework:
### Positional Embeddings
1. **Purpose**: In Transformer models, positional embeddings provide necessary information about the order of tokens in the input sequence. Since the self-attention mechanism by itself doesn’t inherently process sequential data in order (i.e., it treats input as a set of tokens independently of their positions), positional embeddings are crucial for incorporating the sequence order.
2. **Sinusoidal Function**: The positional encoding formula uses sine and cosine functions of different frequencies:
Where:
– \( pos \) is the position of the token in the sequence.
– \( i \) is the dimension index.
– \( d_{\text{model}} \) is the total number of dimensions in the embedding.
– This generates a unique positional embedding for each position, with the pattern allowing the model to learn to attend based on relative positions, as the distance between any two positions can be encoded into the learned weights.
3. **Integration with Token Embeddings**: These positional embeddings are element-wise added to the token embeddings. This way, each token’s representation reflects not only its own inherent meaning but also its position in the sequence.
### Self-Attention Mechanism
1. **Query, Key, Value Vectors**: In the Transformer block, embeddings (integrated with positional information) are transformed into three vectors: Queries, Keys, and Values, which are used in the attention mechanism.
2. **Attention Calculation**: The core of the attention mechanism can be described by the formula:
– \( Q, K, V \) are the matrices of queries, keys, and values.
– \( d_k \) is the dimension of the keys.
– The softmax score determines the degree to which each value is factored into the output based on the dot-product similarity between corresponding query and key.
3. **Role of Proximity and Contextual Similarity**: While the positional embeddings encourage the model to consider adjacent tokens more heavily (since their positional encodings are more similar), the ultimate attention each token receives is determined by a combination of its semantic similarity (as reflected in the query-key relationships) and its relative position. This dual consideration allows the Transformer to maintain context sensitivity, enhancing its ability to handle a wide variety of language understanding tasks.
### Summary
By combining positional embeddings with the token embeddings, Transformers maintain awareness of both the individual token’s meaning and its position in the sequence. This allows for effective modeling of language where the meaning often depends significantly on word order and contextual proximity. The sinusoidal pattern of positional encodings also ensures that the model can generalize to sequences of different lengths and recognize patterns across various positions within the data.









Thanks for the great explanation!
Should the range of k be [0, L) instead of [0, L/2)?
Since the code: for k in range(seq_len)
Hi Yaunmu…the following resource may help clarify:
https://www.inovex.de/de/blog/positional-encoding-everything-you-need-to-know/#:~:text=The%20simplest%20example%20of%20positional,and%20added%20to%20that%20input.
Sorry but I skimmed through the link and I still don’t see why k<L/2.
Hi Seth…It is a rule of thumb as starting point but can be adjusted as needed. More information in general can be found here:
https://towardsdatascience.com/master-positional-encoding-part-i-63c05d90a0c3
Seth G, you are correct.
This is a typo in the tutorial, this should be 0 <= k < L
Hello, I read both links and I think k < L/2 is a mistake. It should be k < L, since k is the index corresponding to the token in the sequence.
On the other hand, i < d/2 makes total sense because the progression of the dimension is built on 2i and 2i+1.
Completely agree with you!
Yes, that’s right. James, seems you do not try to understand what people in comments are saying to you, I had a feeling that there is no good understanding from your side, or it was just lack of time you were ready to invest into the material you prepared.
Thanks Jason great tutorials !
I think there’re errors in the trigonometric table section.
The graphs for sin(2 * 2Pi) and sin(t) go beyond the range [-1:1], either the graph is wrong or the formulas on the left are not the corresponding one.
Thank you for the feedback Yoan B!
Very good! Note that I would add plt.show() to avoid head scratching when pasting the examples into ipython.
Great feedback Tom!
“In the above expression we can see that even positions correspond to sine function and odd positions correspond to even positions.”
Something is wrong or missing in the above statement.
Hi Shrikant…Thank you for the feedback! We will review statement in question.
Very Nicely Explained. Thanks 🙂
You are very welcome! Thank you for your feedback and support Noman!
Hi,
Is it plausible to use positional encoding for time series prediction with LSTM and Conv1D?
Hi abraham…the following resource may prove helpful:
https://shivapriya-katta.medium.com/time-series-forecasting-using-conv1d-lstm-multiple-timesteps-into-future-acc684dcaaa
Hello, I read both links and I think k < L/2 is a mistake. It should be k < L, since k is the index corresponding to the token in the sequence.
On the other hand, i < d/2 makes total sense because the progression of the dimension is built on 2i and 2i+1.
Hi Luca…Thank you for your support and feedback! We will review the content.
Hi, I have two questions
1. Do positional embeddings learn just like word embeddings or the embedding values are assigned just based on sine and the cosine graph?
2. Are positional embedding and word embedding values independent of each other?
Hi Mayank…I highly recommend the following resource.
https://theaisummer.com/positional-embeddings/
The code doesnt work for an odd embedding vector dimension, the last position would always be left without any assign, could easily be solved with a if statement, but I wonder if odd dimensions for embeddings are even used.
Thank you for your feedback A!
Excuse me if, for time series forecasting with transformer encoder positional encoding and input, masking is necessary. Because I think in chronicle arranged time series, inputs are ordered in time, and there is no any displacement, also when we use walk forward valodation.
The positional encoding for example “I am a robot” looks strange for me, same as the output of “getPositionEncoding” function and many questions arise, which makes me more confused. First question, Values are not unique : P01 and P03 or P03 and P13, which one should contain unique values: rows or cols? As I understood the row size = embedding size, and if a row represents the positional encoding for one token, then we can use same values for row. Second question, values are not linear increasing: P00, P10, P20, P30. There is no order, how do we know which one is first, second, … last one if values are not increasing linearly?
Hi sergiu…Please rephrase and/or simplify your query if possible so that we may better assist you.
I think this article is not as good as the others on this website. The concept is not clearly explained. Suggest adding more details and having a good logic between the contents.
Thank you Ryan for your feedback and suggestions!
Hello,
Thank you for the explanation.
I’m having trouble grasping how this method encodes the relative positions of words.
Is there a formal explanation for this? I understand that for every position “p_i,” it holds that “p_i = T(k) p_i+k,” but I can’t quite comprehend how this concept is beneficial.
I appreciate your assistance in advance.
Hi omid…You are very welcome! The following resource may be of interest.
https://machinelearningmastery.com/transformer-models-with-attention/
Do the “Positional vector” and “Positional encoding” functions really take the input words as parameters the way the image under “What Is the Final Output” section implies?
If not, perhaps it would be a good idea to update the image to make them take input index or something as input instead, because it’s confusing the way it is now. It sort of looks like any position containing the word “am” will get the same positional encoding, and that’s not true, is it?
Thank you for your feedback Daniel! Additional details can be found here:
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
Io volevo l’amico Jason dai denti a sciabola
You are the best. I was confused by the explanations that I found on other sites about the math intuition behind the sinusoidal, but now it’s clear.
That is great to know Ali! We appreciate your support and feedback!
In the transformer paper and in your tutorial the position encoding is just added (not appended) to the embedding vector, so its dimension stays the same. Doesn’t this “spoil” the working of the attention mechanism, as the tokens are thus modified? I assume it still works well enough, because of the high dimensionality of these vectors. But if you add two high-dimensional vectors, will the sum vector still be sufficiently similar to the embedding vector to not confuse it with others? It will be equally similar to the positional encoding vector. So shouldn’t the latter be smaller, as words are still more important than positions (I guess)? Do you know of any paper discussing this?
Hi Anonymous…The following resource may be of interest and hopefully fill in some gaps of understanding.
https://towardsdatascience.com/master-positional-encoding-part-i-63c05d90a0c3
the final step is a sum or a concatenation?
Hi afsfg…Please clarify the code sample you are referring to so that we may better assist you.
Thank you. My question was regarding this paragraph:
What Is the Final Output of the Positional Encoding Layer?
The positional encoding layer sums the positional vector with the word encoding and outputs this matrix for the subsequent layers. The entire process is shown below.
I’m curious if “sums” means actually adding two vectors, or it means concatenating two vectors. And why it is adding, not concatenating? what’s the justification of adding two embeddings from two different domains?
Hi afsfg…You are very welcome!
The phrase “sums the positional vector with the word encoding and outputs this matrix for the subsequent layers” refers to a process commonly used in the architecture of transformer models, like those underlying many modern natural language processing (NLP) systems.
Let’s break it down:
1. **Word Encoding (Word Embeddings):** Each word (or token) in a sentence is converted into a numerical form, known as an embedding. This embedding captures the semantic meaning of the word in a high-dimensional space. Essentially, similar words have similar embeddings. These embeddings are learned from data and are an integral part of neural network models for language tasks.
2. **Positional Encoding:** Since the transformer architecture does not inherently process sequential data in order (unlike RNNs or LSTMs), it requires a method to understand the order of words in a sentence. Positional encoding is added to solve this problem. It involves generating another set of vectors that encode the position of each word in the sentence. Each positional vector is unique to its position, ensuring that the model can recognize the order of words. The positional encoding is designed so that it can be combined with the word embeddings, usually through addition, without losing the information contained in either.
3. **Summing the Positional Vector with the Word Encoding:** The process involves element-wise addition of the positional encoding vector to the word embedding vector for each word. This combined vector now contains both the semantic information of the word (from the word embedding) and its position in the sentence (from the positional encoding). This is crucial for the model to understand both the meaning of words and how the order of words affects the meaning of the sentence.
4. **Outputting this Matrix for the Subsequent Layers:** The resulting matrix, after summing positional vectors and word embeddings, is then passed through the subsequent layers of the transformer model. These layers include self-attention mechanisms and fully connected networks, which process this combined information to perform tasks such as language understanding, translation, or generation. The matrix effectively serves as the input for these complex operations, allowing the model to consider both the meaning of individual words and their context within the sentence.
This process is fundamental to the functioning of transformer models, enabling them to achieve state-of-the-art performance on a wide range of NLP tasks.
I think the sentence
“you can see that the wavelength for a fixed i is given by: …”
should be
“you can see that the wavelength for a fixed ‘T’ is given by: …”
and as many already pointed out, K range should be below:
0 <= K < L
For example, let’s consider a sequence of 5 tokens, where each token is represented by an embedding of 10 dimensions; thus, each token’s embedding shape is 1×10. Instead of directly adding the raw positions 0 to 4 to the embeddings, which might overly alter the original semantic embeddings, a sinusoidal function is utilized. This function takes as inputs the token’s position in the sequence, the index within the embedding dimension, and the total number of dimensions, producing a 1×10 positional embedding for each token.
These positional embeddings are then added to the original token embeddings. In the Transformer architecture, during the calculation of Query, Key, and Value vectors, the matrix multiplication in the attention mechanism tends to assign higher scores to adjacent tokens, unless there is a strong semantic signal from the embeddings that suggests otherwise. This maintains the influence of token proximity unless overridden by significant contextual differences embedded in the tokens.
Thank you for your feedback Pavan! You’ve nicely outlined the concept of positional embeddings in the Transformer model architecture and how they influence the self-attention mechanism. Let’s delve a bit deeper into each of these components and their operational dynamics within the Transformer framework:
### Positional Embeddings
1. **Purpose**: In Transformer models, positional embeddings provide necessary information about the order of tokens in the input sequence. Since the self-attention mechanism by itself doesn’t inherently process sequential data in order (i.e., it treats input as a set of tokens independently of their positions), positional embeddings are crucial for incorporating the sequence order.
2. **Sinusoidal Function**: The positional encoding formula uses sine and cosine functions of different frequencies:
\[
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
\]
\[
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
\]
Where:
– \( pos \) is the position of the token in the sequence.
– \( i \) is the dimension index.
– \( d_{\text{model}} \) is the total number of dimensions in the embedding.
– This generates a unique positional embedding for each position, with the pattern allowing the model to learn to attend based on relative positions, as the distance between any two positions can be encoded into the learned weights.
3. **Integration with Token Embeddings**: These positional embeddings are element-wise added to the token embeddings. This way, each token’s representation reflects not only its own inherent meaning but also its position in the sequence.
### Self-Attention Mechanism
1. **Query, Key, Value Vectors**: In the Transformer block, embeddings (integrated with positional information) are transformed into three vectors: Queries, Keys, and Values, which are used in the attention mechanism.
2. **Attention Calculation**: The core of the attention mechanism can be described by the formula:
\[
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
\]
– \( Q, K, V \) are the matrices of queries, keys, and values.
– \( d_k \) is the dimension of the keys.
– The softmax score determines the degree to which each value is factored into the output based on the dot-product similarity between corresponding query and key.
3. **Role of Proximity and Contextual Similarity**: While the positional embeddings encourage the model to consider adjacent tokens more heavily (since their positional encodings are more similar), the ultimate attention each token receives is determined by a combination of its semantic similarity (as reflected in the query-key relationships) and its relative position. This dual consideration allows the Transformer to maintain context sensitivity, enhancing its ability to handle a wide variety of language understanding tasks.
### Summary
By combining positional embeddings with the token embeddings, Transformers maintain awareness of both the individual token’s meaning and its position in the sequence. This allows for effective modeling of language where the meaning often depends significantly on word order and contextual proximity. The sinusoidal pattern of positional encodings also ensures that the model can generalize to sequences of different lengths and recognize patterns across various positions within the data.