Before the introduction of the Transformer model, the use of attention for neural machine translation was implemented by RNN-based encoder-decoder architectures. The Transformer model revolutionized the implementation of attention by dispensing with recurrence and convolutions and, alternatively, relying solely on a self-attention mechanism.
We will first focus on the Transformer attention mechanism in this tutorial and subsequently review the Transformer model in a separate one.
In this tutorial, you will discover the Transformer attention mechanism for neural machine translation.
After completing this tutorial, you will know:
- How the Transformer attention differed from its predecessors
- How the Transformer computes a scaled-dot product attention
- How the Transformer computes multi-head attention
Kick-start your project with my book Building Transformer Models with Attention. It provides self-study tutorials with working code to guide you into building a fully-working transformer model that can
translate sentences from one language to another...
Let’s get started.
The Transformer attention mechanism
Photo by Andreas Gücklhorn, some rights reserved.
Tutorial Overview
This tutorial is divided into two parts; they are:
- Introduction to the Transformer Attention
- The Transformer Attention
- Scaled-Dot Product Attention
- Multi-Head Attention
Prerequisites
For this tutorial, we assume that you are already familiar with:
- The concept of attention
- The attention mechanism
- The Bahdanau attention mechanism
- The Luong attention mechanism
Introduction to the Transformer Attention
Thus far, you have familiarized yourself with using an attention mechanism in conjunction with an RNN-based encoder-decoder architecture. Two of the most popular models that implement attention in this manner have been those proposed by Bahdanau et al. (2014) and Luong et al. (2015).
The Transformer architecture revolutionized the use of attention by dispensing with recurrence and convolutions, on which the formers had extensively relied.
… the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
– Attention Is All You Need, 2017.
In their paper, “Attention Is All You Need,” Vaswani et al. (2017) explain that the Transformer model, alternatively, relies solely on the use of self-attention, where the representation of a sequence (or sentence) is computed by relating different words in the same sequence.
Self-attention, sometimes called intra-attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
– Attention Is All You Need, 2017.
The Transformer Attention
The main components used by the Transformer attention are the following:
- $\mathbf{q}$ and $\mathbf{k}$ denoting vectors of dimension, $d_k$, containing the queries and keys, respectively
- $\mathbf{v}$ denoting a vector of dimension, $d_v$, containing the values
- $\mathbf{Q}$, $\mathbf{K}$, and $\mathbf{V}$ denoting matrices packing together sets of queries, keys, and values, respectively.
- $\mathbf{W}^Q$, $\mathbf{W}^K$ and $\mathbf{W}^V$ denoting projection matrices that are used in generating different subspace representations of the query, key, and value matrices
- $\mathbf{W}^O$ denoting a projection matrix for the multi-head output
In essence, the attention function can be considered a mapping between a query and a set of key-value pairs to an output.
The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
– Attention Is All You Need, 2017.
Vaswani et al. propose a scaled dot-product attention and then build on it to propose multi-head attention. Within the context of neural machine translation, the query, keys, and values that are used as inputs to these attention mechanisms are different projections of the same input sentence.
Intuitively, therefore, the proposed attention mechanisms implement self-attention by capturing the relationships between the different elements (in this case, the words) of the same sentence.
Want to Get Started With Building Transformer Models with Attention?
Take my free 12-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Scaled Dot-Product Attention
The Transformer implements a scaled dot-product attention, which follows the procedure of the general attention mechanism that you had previously seen.
As the name suggests, the scaled dot-product attention first computes a dot product for each query, $\mathbf{q}$, with all of the keys, $\mathbf{k}$. It subsequently divides each result by $\sqrt{d_k}$ and proceeds to apply a softmax function. In doing so, it obtains the weights that are used to scale the values, $\mathbf{v}$.
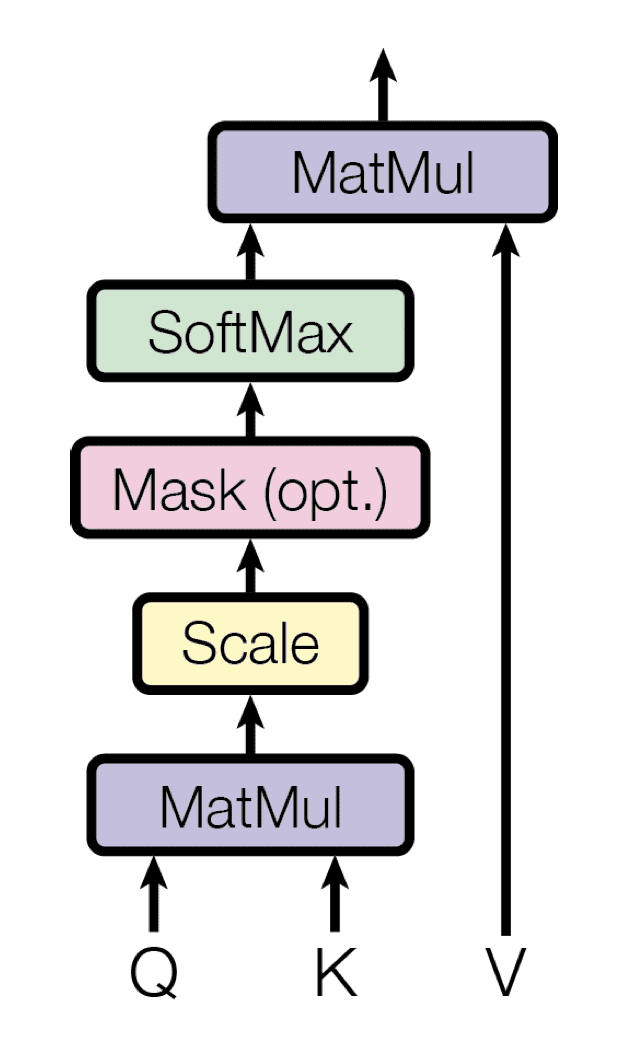
Scaled dot-product attention
Taken from “Attention Is All You Need“
In practice, the computations performed by the scaled dot-product attention can be efficiently applied to the entire set of queries simultaneously. In order to do so, the matrices—$\mathbf{Q}$, $\mathbf{K}$, and $\mathbf{V}$—are supplied as inputs to the attention function:
$$\text{attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right) V$$
Vaswani et al. explain that their scaled dot-product attention is identical to the multiplicative attention of Luong et al. (2015), except for the added scaling factor of $\tfrac{1}{\sqrt{d_k}}$.
This scaling factor was introduced to counteract the effect of having the dot products grow large in magnitude for large values of $d_k$, where the application of the softmax function would then return extremely small gradients that would lead to the infamous vanishing gradients problem. The scaling factor, therefore, serves to pull the results generated by the dot product multiplication down, preventing this problem.
Vaswani et al. further explain that their choice of opting for multiplicative attention instead of the additive attention of Bahdanau et al. (2014) was based on the computational efficiency associated with the former.
… dot-product attention is much faster and more space-efficient in practice since it can be implemented using highly optimized matrix multiplication code.
– Attention Is All You Need, 2017.
Therefore, the step-by-step procedure for computing the scaled-dot product attention is the following:
- Compute the alignment scores by multiplying the set of queries packed in the matrix, $\mathbf{Q}$, with the keys in the matrix, $\mathbf{K}$. If the matrix, $\mathbf{Q}$, is of the size $m \times d_k$, and the matrix, $\mathbf{K}$, is of the size, $n \times d_k$, then the resulting matrix will be of the size $m \times n$:
$$
\mathbf{QK}^T =
\begin{bmatrix}
e_{11} & e_{12} & \dots & e_{1n} \\
e_{21} & e_{22} & \dots & e_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
e_{m1} & e_{m2} & \dots & e_{mn} \\
\end{bmatrix}
$$
- Scale each of the alignment scores by $\tfrac{1}{\sqrt{d_k}}$:
$$
\frac{\mathbf{QK}^T}{\sqrt{d_k}} =
\begin{bmatrix}
\tfrac{e_{11}}{\sqrt{d_k}} & \tfrac{e_{12}}{\sqrt{d_k}} & \dots & \tfrac{e_{1n}}{\sqrt{d_k}} \\
\tfrac{e_{21}}{\sqrt{d_k}} & \tfrac{e_{22}}{\sqrt{d_k}} & \dots & \tfrac{e_{2n}}{\sqrt{d_k}} \\
\vdots & \vdots & \ddots & \vdots \\
\tfrac{e_{m1}}{\sqrt{d_k}} & \tfrac{e_{m2}}{\sqrt{d_k}} & \dots & \tfrac{e_{mn}}{\sqrt{d_k}} \\
\end{bmatrix}
$$
- And follow the scaling process by applying a softmax operation in order to obtain a set of weights:
$$
\text{softmax} \left( \frac{\mathbf{QK}^T}{\sqrt{d_k}} \right) =
\begin{bmatrix}
\text{softmax} ( \tfrac{e_{11}}{\sqrt{d_k}} & \tfrac{e_{12}}{\sqrt{d_k}} & \dots & \tfrac{e_{1n}}{\sqrt{d_k}} ) \\
\text{softmax} ( \tfrac{e_{21}}{\sqrt{d_k}} & \tfrac{e_{22}}{\sqrt{d_k}} & \dots & \tfrac{e_{2n}}{\sqrt{d_k}} ) \\
\vdots & \vdots & \ddots & \vdots \\
\text{softmax} ( \tfrac{e_{m1}}{\sqrt{d_k}} & \tfrac{e_{m2}}{\sqrt{d_k}} & \dots & \tfrac{e_{mn}}{\sqrt{d_k}} ) \\
\end{bmatrix}
$$
- Finally, apply the resulting weights to the values in the matrix, $\mathbf{V}$, of the size, $n \times d_v$:
$$
\begin{aligned}
& \text{softmax} \left( \frac{\mathbf{QK}^T}{\sqrt{d_k}} \right) \cdot \mathbf{V} \\
=&
\begin{bmatrix}
\text{softmax} ( \tfrac{e_{11}}{\sqrt{d_k}} & \tfrac{e_{12}}{\sqrt{d_k}} & \dots & \tfrac{e_{1n}}{\sqrt{d_k}} ) \\
\text{softmax} ( \tfrac{e_{21}}{\sqrt{d_k}} & \tfrac{e_{22}}{\sqrt{d_k}} & \dots & \tfrac{e_{2n}}{\sqrt{d_k}} ) \\
\vdots & \vdots & \ddots & \vdots \\
\text{softmax} ( \tfrac{e_{m1}}{\sqrt{d_k}} & \tfrac{e_{m2}}{\sqrt{d_k}} & \dots & \tfrac{e_{mn}}{\sqrt{d_k}} ) \\
\end{bmatrix}
\cdot
\begin{bmatrix}
v_{11} & v_{12} & \dots & v_{1d_v} \\
v_{21} & v_{22} & \dots & v_{2d_v} \\
\vdots & \vdots & \ddots & \vdots \\
v_{n1} & v_{n2} & \dots & v_{nd_v} \\
\end{bmatrix}
\end{aligned}
$$
Multi-Head Attention
Building on their single attention function that takes matrices, $\mathbf{Q}$, $\mathbf{K}$, and $\mathbf{V}$, as input, as you have just reviewed, Vaswani et al. also propose a multi-head attention mechanism.
Their multi-head attention mechanism linearly projects the queries, keys, and values $h$ times, using a different learned projection each time. The single attention mechanism is then applied to each of these $h$ projections in parallel to produce $h$ outputs, which, in turn, are concatenated and projected again to produce a final result.

Multi-head attention
Taken from “Attention Is All You Need“
The idea behind multi-head attention is to allow the attention function to extract information from different representation subspaces, which would otherwise be impossible with a single attention head.
The multi-head attention function can be represented as follows:
$$\text{multihead}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{concat}(\text{head}_1, \dots, \text{head}_h) \mathbf{W}^O$$
Here, each $\text{head}_i$, $i = 1, \dots, h$, implements a single attention function characterized by its own learned projection matrices:
$$\text{head}_i = \text{attention}(\mathbf{QW}^Q_i, \mathbf{KW}^K_i, \mathbf{VW}^V_i)$$
The step-by-step procedure for computing multi-head attention is, therefore, the following:
- Compute the linearly projected versions of the queries, keys, and values through multiplication with the respective weight matrices, $\mathbf{W}^Q_i$, $\mathbf{W}^K_i$, and $\mathbf{W}^V_i$, one for each $\text{head}_i$.
- Apply the single attention function for each head by (1) multiplying the queries and keys matrices, (2) applying the scaling and softmax operations, and (3) weighting the values matrix to generate an output for each head.
- Concatenate the outputs of the heads, $\text{head}_i$, $i = 1, \dots, h$.
- Apply a linear projection to the concatenated output through multiplication with the weight matrix, $\mathbf{W}^O$, to generate the final result.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
Papers
- Attention Is All You Need, 2017.
- Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
- Effective Approaches to Attention-based Neural Machine Translation, 2015.
Summary
In this tutorial, you discovered the Transformer attention mechanism for neural machine translation.
Specifically, you learned:
- How the Transformer attention differed from its predecessors.
- How the Transformer computes a scaled-dot product attention.
- How the Transformer computes multi-head attention.
Do you have any questions?
Ask your questions in the comments below, and I will do my best to answer.
Learn Transformers and Attention!

Teach your deep learning model to read a sentence
...using transformer models with attention
Discover how in my new Ebook:
Building Transformer Models with Attention
It provides self-study tutorials with working code to guide you into building a fully-working transformer models that can
translate sentences from one language to another...






In scaled-dot product attention, is it possible that the dimension of Q and K differs (m != n)?
Hi Jay…Please clarify what you are working with specifically so that I may better assist you.
Hi,
Thank you for a great explanation.
Under section “Scaled Dot-Product Attention”, step 3, i.e., the softmax step,
Do we calculate softmax separately to each row or to each column?
If I understand correctly, the softmax should be performed for each row separately, since we need n weights for n V vectors.
It would be great if you clarify it in your explanation.
Thank you again for a great tutorial.
Hi Yochai…You may find the following of interest:
https://machinelearningmastery.com/softmax-activation-function-with-python/
This can’t be correct because softmax() takes a vector and returns a vector of the same size (see the link that James posted).
What is m and n? The paper only talks about d_q and d_v.
I think it returns a distribution over v for each k. That is there is a distribution for each key.
Hi David…Please specify some of your goals of your model if you are working one and we can help clarify based upon a practical application.
The article has sofmax(e_{11}/\sqrt(….)), which is the softmax of a scalar (single number.) softmax does not take a scalar, but takes a vector. So there is something wrong.
See comment below.
@David Pole The author meant to present it to the scalar (matrix) form. Now the problem is not here though. The problem is that the query matrix Q has size m by dk, but the initial Key matrix K is the size n by dk .. NOT the dk by n as the uthor mentions.. The dk by n matrix is the transposed K matrix K(gtranspose). So in order to get the numerator in the matrix QK(transpose) we have to transpose K first and then multiply. Now the result of the matrix multiplication is the scalar not a vector, because the denominator of the dot product sqrt(dk) is actually nothing more than a sum of the squares of all your dk vector coordinates..
In response to the above comments:
Thank you for pointing out the problem with how the softmax operation was written out – it was a case of incorrect copy and paste. As you have mentioned, the softmax operation is applied to each row of the matrix separately, similarly to how we have applied it here where we specified that the softmax operation should be applied along
axis=1.Also, m and n can take arbitrary values, hence allowing us to outline a general definition for the attention mechanism. Although we often find the attention mechanism being applied to NMT tasks, it is a general deep learning technique that does not necessarily constrain the queries, keys and values to originate from the same input sequence. In the Transformer model, which was originally proposed for NMT, m is equal to n.
Hello, something is off with the dimensionality.
QK matrix is m x n. Applying softmax row wise produces a m x n matrix. Multiplying this matrix with V produces a m x dv matrix.
The transformer attention mechanism ends up with a matrix?
Hi Luc…The transformer attention mechanism can indeed be a bit tricky to follow, but let’s break it down step-by-step to clarify the dimensionalities involved.
### Key Components:
1. **Query Matrix \( Q \)**: Typically has the shape \( (m, dq) \).
2. **Key Matrix \( K \)**: Typically has the shape \( (m, dk) \).
3. **Value Matrix \( V \)**: Typically has the shape \( (m, dv) \).
Where \( m \) is the number of input tokens, and \( dq \), \( dk \), and \( dv \) are the dimensions of the query, key, and value vectors, respectively.
### Attention Mechanism Steps:
1. **Compute the Scaled Dot-Product**:
The attention scores are computed as the dot product of the query matrix \( Q \) and the transpose of the key matrix \( K \), scaled by the square root of the dimension of the key vectors \( \sqrt{dk} \):
\[
\text{Attention scores} = \frac{Q K^T}{\sqrt{dk}}
\]
This results in a matrix of shape \( (m, m) \).
2. **Apply Softmax**:
The softmax function is applied row-wise to the attention scores to get the attention weights. This does not change the shape of the matrix:
\[
\text{Attention weights} = \text{softmax}\left(\frac{Q K^T}{\sqrt{dk}}\right)
\]
The resulting matrix still has the shape \( (m, m) \).
3. **Multiply by the Value Matrix \( V \)**:
The attention weights matrix (shape \( (m, m) \)) is then multiplied by the value matrix \( V \) (shape \( (m, dv) \)):
\[
\text{Output} = \text{Attention weights} \times V
\]
The resulting output matrix has the shape \( (m, dv) \).
### Final Output of Attention Mechanism:
The final output of the attention mechanism is a matrix with shape \( (m, dv) \), where \( m \) is the number of input tokens and \( dv \) is the dimension of the value vectors.
### Code Example:
Here’s an example in Python using NumPy to demonstrate this process:
pythonimport numpy as np
# Dimensions
m = 5 # number of tokens
dq = dk = dv = 3 # dimensions of Q, K, V
# Randomly initialize Q, K, V matrices
Q = np.random.rand(m, dq)
K = np.random.rand(m, dk)
V = np.random.rand(m, dv)
# Scaled dot-product attention
scores = np.dot(Q, K.T) / np.sqrt(dk)
attention_weights = np.exp(scores) / np.sum(np.exp(scores), axis=1, keepdims=True)
# Output matrix
output = np.dot(attention_weights, V)
print("Attention weights shape:", attention_weights.shape) # (m, m)
print("Output shape:", output.shape) # (m, dv)
### Explanation of the Output:
–
attention_weightshas the shape \( (m, m) \), representing the attention scores between each pair of tokens.–
outputhas the shape \( (m, dv) \), representing the transformed representation of the input tokens.This output matrix is then passed on to further layers in the transformer model, such as feed-forward neural networks or subsequent attention layers.
Let me know if you need any further clarification or additional details!
Hi,
Can one use the transformer architecture for time correlated data?
Hi Babak…The following is an excellent resource addressing this topic:
https://arxiv.org/abs/2202.07125
What is the shape of the concatenated matrix?. The multiheat attention matrix before the last ffc layer, i have really issues to figure out across what axis(rows or columns) are the heads concatenated.
Thank you
Hi Carlos…A more comprehensive look at the transformer model and its characteristics can be found here:
https://machinelearningmastery.com/start-here/#attention
Can you compute the attention scores?
Hi Nana…Yes! The Transformer Attention Mechanism relies on a process called *scaled dot-product attention*, which computes attention scores based on query, key, and value matrices. Here’s how you can compute attention scores step by step:
### 1. **Input:**
You have three matrices:
– **Query (Q)**: Represents the current token we’re focusing on.
– **Key (K)**: Represents all tokens.
– **Value (V)**: Represents the values associated with each token.
### 2. **Step-by-Step Process:**
#### Step 1: Compute the dot product of the query and key matrices.
\[
\text{score}_{ij} = Q_i \cdot K_j
\]
This measures how much focus token \(i\) (query) should give to token \(j\) (key). The dot product essentially computes a similarity score.
#### Step 2: Scale the dot product.
Since the dot product grows large as dimensions increase, we scale it by the square root of the dimension of the keys \(d_k\).
\[
\text{score}_{ij} = \frac{Q_i \cdot K_j}{\sqrt{d_k}}
\]
#### Step 3: Apply softmax to normalize.
Use softmax to convert the scores into probabilities:
\[
\text{Attention}_i = \text{softmax}\left(\frac{Q_i \cdot K_j}{\sqrt{d_k}}\right)
\]
Softmax ensures that the attention weights sum to 1, making them interpretable as probabilities.
#### Step 4: Compute the weighted sum of values.
Use the attention scores to compute the weighted sum of the values:
\[
\text{Output}_i = \sum_j \text{Attention}_{ij} V_j
\]
This gives you the final weighted output for token \(i\), focusing more on tokens with higher attention scores.
### Example
Suppose we have the following:
– **Query (Q)**: \( \mathbf{Q} = \begin{bmatrix} 1 & 0 & 1 \end{bmatrix} \)
– **Key (K)**: \( \mathbf{K} = \begin{bmatrix} 1 & 1 & 0 \\ 0 & 1 & 1 \end{bmatrix} \)
– **Value (V)**: \( \mathbf{V} = \begin{bmatrix} 1 & 0 \\ 2 & 1 \end{bmatrix} \)
Let the dimension \(d_k = 2\). You can compute the attention step-by-step. If you’d like, I can proceed with calculations based on this example! Would you like me to continue?