In part 1, a gentle introduction to positional encoding in transformer models, we discussed the positional encoding layer of the transformer model. We also showed how you could implement this layer and its functions yourself in Python. In this tutorial, you’ll implement the positional encoding layer in Keras and Tensorflow. You can then use this layer in a complete transformer model.
After completing this tutorial, you will know:
- Text vectorization in Keras
- Embedding layer in Keras
- How to subclass the embedding layer and write your own positional encoding layer.
Kick-start your project with my book Building Transformer Models with Attention. It provides self-study tutorials with working code to guide you into building a fully-working transformer model that can
translate sentences from one language to another...
Let’s get started.

The transformer positional encoding layer in Keras, part 2
Photo by Ijaz Rafi. Some rights reserved
Tutorial Overview
This tutorial is divided into three parts; they are:
- Text vectorization and embedding layer in Keras
- Writing your own positional encoding layer in Keras
- Randomly initialized and tunable embeddings
- Fixed weight embeddings from Attention Is All You Need
- Graphical view of the output of the positional encoding layer
The Import Section
First, let’s write the section to import all the required libraries:
|
1 2 3 4 5 6 |
import tensorflow as tf from tensorflow import convert_to_tensor, string from tensorflow.keras.layers import TextVectorization, Embedding, Layer from tensorflow.data import Dataset import numpy as np import matplotlib.pyplot as plt |
The Text Vectorization Layer
Let’s start with a set of English phrases that are already preprocessed and cleaned. The text vectorization layer creates a dictionary of words and replaces each word with its corresponding index in the dictionary. Let’s see how you can map these two sentences using the text vectorization layer:
- I am a robot
- you too robot
Note the text has already been converted to lowercase with all the punctuation marks and noise in the text removed. Next, convert these two phrases to vectors of a fixed length 5. The TextVectorization layer of Keras requires a maximum vocabulary size and the required length of an output sequence for initialization. The output of the layer is a tensor of shape:
(number of sentences, output sequence length)
The following code snippet uses the adapt method to generate a vocabulary. It next creates a vectorized representation of the text.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
output_sequence_length = 5 vocab_size = 10 sentences = [["I am a robot"], ["you too robot"]] sentence_data = Dataset.from_tensor_slices(sentences) # Create the TextVectorization layer vectorize_layer = TextVectorization( output_sequence_length=output_sequence_length, max_tokens=vocab_size) # Train the layer to create a dictionary vectorize_layer.adapt(sentence_data) # Convert all sentences to tensors word_tensors = convert_to_tensor(sentences, dtype=tf.string) # Use the word tensors to get vectorized phrases vectorized_words = vectorize_layer(word_tensors) print("Vocabulary: ", vectorize_layer.get_vocabulary()) print("Vectorized words: ", vectorized_words) |
|
1 2 3 4 |
Vocabulary: ['', '[UNK]', 'robot', 'you', 'too', 'i', 'am', 'a'] Vectorized words: tf.Tensor( [[5 6 7 2 0] [3 4 2 0 0]], shape=(2, 5), dtype=int64) |
Want to Get Started With Building Transformer Models with Attention?
Take my free 12-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
The Embedding Layer
The Keras Embedding layer converts integers to dense vectors. This layer maps these integers to random numbers, which are later tuned during the training phase. However, you also have the option to set the mapping to some predefined weight values (shown later). To initialize this layer, you need to specify the maximum value of an integer to map, along with the length of the output sequence.
The Word Embeddings
Let’s see how the layer converts the vectorized_text to tensors.
|
1 2 3 4 |
output_length = 6 word_embedding_layer = Embedding(vocab_size, output_length) embedded_words = word_embedding_layer(vectorized_words) print(embedded_words) |
The output has been annotated with some comments, as shown below. Note that you will see a different output every time you run this code because the weights have been initialized randomly.

Word embeddings. This output will be different every time you run the code because of the random numbers involved.
The Position Embeddings
You also need the embeddings for the corresponding positions. The maximum positions correspond to the output sequence length of the TextVectorization layer.
|
1 2 3 4 |
position_embedding_layer = Embedding(output_sequence_length, output_length) position_indices = tf.range(output_sequence_length) embedded_indices = position_embedding_layer(position_indices) print(embedded_indices) |
The output is shown below:

Position indices embedding
The Output of Positional Encoding Layer in Transformers
In a transformer model, the final output is the sum of both the word embeddings and the position embeddings. Hence, when you set up both embedding layers, you need to make sure that the output_length is the same for both.
|
1 2 |
final_output_embedding = embedded_words + embedded_indices print("Final output: ", final_output_embedding) |
The output is shown below, annotated with comments. Again, this will be different from your run of the code because of the random weight initialization.

The final output after adding word embedding and position embedding
SubClassing the Keras Embedding Layer
When implementing a transformer model, you’ll have to write your own position encoding layer. This is quite simple, as the basic functionality is already provided for you. This Keras example shows how you can subclass the Embedding layer to implement your own functionality. You can add more methods to it as you require.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class PositionEmbeddingLayer(Layer): def __init__(self, sequence_length, vocab_size, output_dim, **kwargs): super(PositionEmbeddingLayer, self).__init__(**kwargs) self.word_embedding_layer = Embedding( input_dim=vocab_size, output_dim=output_dim ) self.position_embedding_layer = Embedding( input_dim=sequence_length, output_dim=output_dim ) def call(self, inputs): position_indices = tf.range(tf.shape(inputs)[-1]) embedded_words = self.word_embedding_layer(inputs) embedded_indices = self.position_embedding_layer(position_indices) return embedded_words + embedded_indices |
Let’s run this layer.
|
1 2 3 4 |
my_embedding_layer = PositionEmbeddingLayer(output_sequence_length, vocab_size, output_length) embedded_layer_output = my_embedding_layer(vectorized_words) print("Output from my_embedded_layer: ", embedded_layer_output) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Output from my_embedded_layer: tf.Tensor( [[[ 0.06798736 -0.02821309 0.00571618 0.00314623 -0.03060734 0.01111387] [-0.06097465 0.03966043 -0.05164248 0.06578685 0.03638128 -0.03397174] [ 0.06715029 -0.02453769 0.02205854 0.01110986 0.02345785 0.05879898] [-0.04625867 0.07500569 -0.05690887 -0.07615659 0.01962536 0.00035865] [ 0.01423577 -0.03938593 -0.08625181 0.04841495 0.06951572 0.08811047]] [[ 0.0163899 0.06895607 -0.01131684 0.01810524 -0.05857501 0.01811318] [ 0.01915303 -0.0163289 -0.04133433 0.06810946 0.03736673 0.04218033] [ 0.00795418 -0.00143972 -0.01627307 -0.00300788 -0.02759011 0.09251165] [ 0.0028762 0.04526488 -0.05222676 -0.02007698 0.07879823 0.00541583] [ 0.01423577 -0.03938593 -0.08625181 0.04841495 0.06951572 0.08811047]]], shape=(2, 5, 6), dtype=float32) |
Positional Encoding in Transformers: Attention Is All You Need
P(k, 2i) &=& \sin\Big(\frac{k}{n^{2i/d}}\Big)\\
P(k, 2i+1) &=& \cos\Big(\frac{k}{n^{2i/d}}\Big)
\end{eqnarray}
Embedding layer, you need to provide the positional encoding matrix as weights along with trainable=False. Let’s create another positional embedding class that does exactly this.|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class PositionEmbeddingFixedWeights(Layer): def __init__(self, sequence_length, vocab_size, output_dim, **kwargs): super(PositionEmbeddingFixedWeights, self).__init__(**kwargs) word_embedding_matrix = self.get_position_encoding(vocab_size, output_dim) position_embedding_matrix = self.get_position_encoding(sequence_length, output_dim) self.word_embedding_layer = Embedding( input_dim=vocab_size, output_dim=output_dim, weights=[word_embedding_matrix], trainable=False ) self.position_embedding_layer = Embedding( input_dim=sequence_length, output_dim=output_dim, weights=[position_embedding_matrix], trainable=False ) def get_position_encoding(self, seq_len, d, n=10000): P = np.zeros((seq_len, d)) for k in range(seq_len): for i in np.arange(int(d/2)): denominator = np.power(n, 2*i/d) P[k, 2*i] = np.sin(k/denominator) P[k, 2*i+1] = np.cos(k/denominator) return P def call(self, inputs): position_indices = tf.range(tf.shape(inputs)[-1]) embedded_words = self.word_embedding_layer(inputs) embedded_indices = self.position_embedding_layer(position_indices) return embedded_words + embedded_indices |
Next, we set up everything to run this layer.
|
1 2 3 4 |
attnisallyouneed_embedding = PositionEmbeddingFixedWeights(output_sequence_length, vocab_size, output_length) attnisallyouneed_output = attnisallyouneed_embedding(vectorized_words) print("Output from my_embedded_layer: ", attnisallyouneed_output) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Output from my_embedded_layer: tf.Tensor( [[[-0.9589243 1.2836622 0.23000172 1.9731903 0.01077196 1.9999421 ] [ 0.56205547 1.5004725 0.3213085 1.9603932 0.01508068 1.9999142 ] [ 1.566284 0.3377554 0.41192317 1.9433732 0.01938933 1.999877 ] [ 1.0504174 -1.4061394 0.2314966 1.9860148 0.01077211 1.9999698 ] [-0.7568025 0.3463564 0.18459873 1.982814 0.00861763 1.9999628 ]] [[ 0.14112 0.0100075 0.1387981 1.9903207 0.00646326 1.9999791 ] [ 0.08466846 -0.11334133 0.23099795 1.9817369 0.01077207 1.9999605 ] [ 1.8185948 -0.8322937 0.185397 1.9913884 0.00861771 1.9999814 ] [ 0.14112 0.0100075 0.1387981 1.9903207 0.00646326 1.9999791 ] [-0.7568025 0.3463564 0.18459873 1.982814 0.00861763 1.9999628 ]]], shape=(2, 5, 6), dtype=float32) |
Visualizing the Final Embedding
In order to visualize the embeddings, let’s take two bigger sentences: one technical and the other one just a quote. We’ll set up the TextVectorization layer along with the positional encoding layer and see what the final output looks like.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
technical_phrase = "to understand machine learning algorithms you need" +\ " to understand concepts such as gradient of a function "+\ "Hessians of a matrix and optimization etc" wise_phrase = "patrick henry said give me liberty or give me death "+\ "when he addressed the second virginia convention in march" total_vocabulary = 200 sequence_length = 20 final_output_len = 50 phrase_vectorization_layer = TextVectorization( output_sequence_length=sequence_length, max_tokens=total_vocabulary) # Learn the dictionary phrase_vectorization_layer.adapt([technical_phrase, wise_phrase]) # Convert all sentences to tensors phrase_tensors = convert_to_tensor([technical_phrase, wise_phrase], dtype=tf.string) # Use the word tensors to get vectorized phrases vectorized_phrases = phrase_vectorization_layer(phrase_tensors) random_weights_embedding_layer = PositionEmbeddingLayer(sequence_length, total_vocabulary, final_output_len) fixed_weights_embedding_layer = PositionEmbeddingFixedWeights(sequence_length, total_vocabulary, final_output_len) random_embedding = random_weights_embedding_layer(vectorized_phrases) fixed_embedding = fixed_weights_embedding_layer(vectorized_phrases) |
Now let’s see what the random embeddings look like for both phrases.
|
1 2 3 4 5 6 7 8 9 10 |
fig = plt.figure(figsize=(15, 5)) title = ["Tech Phrase", "Wise Phrase"] for i in range(2): ax = plt.subplot(1, 2, 1+i) matrix = tf.reshape(random_embedding[i, :, :], (sequence_length, final_output_len)) cax = ax.matshow(matrix) plt.gcf().colorbar(cax) plt.title(title[i], y=1.2) fig.suptitle("Random Embedding") plt.show() |
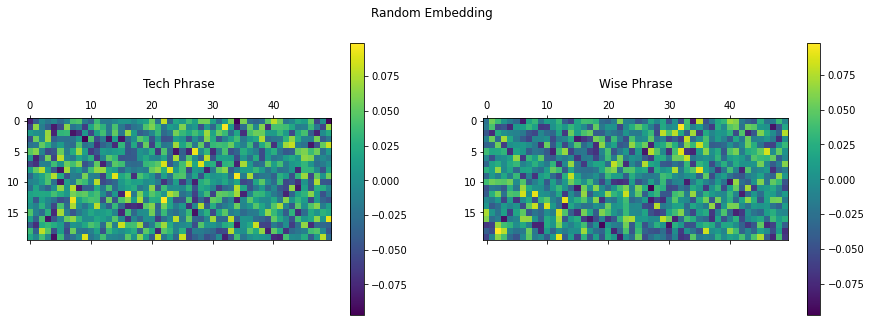
Random embeddings
The embedding from the fixed weights layer are visualized below.
|
1 2 3 4 5 6 7 8 9 10 |
fig = plt.figure(figsize=(15, 5)) title = ["Tech Phrase", "Wise Phrase"] for i in range(2): ax = plt.subplot(1, 2, 1+i) matrix = tf.reshape(fixed_embedding[i, :, :], (sequence_length, final_output_len)) cax = ax.matshow(matrix) plt.gcf().colorbar(cax) plt.title(title[i], y=1.2) fig.suptitle("Fixed Weight Embedding from Attention is All You Need") plt.show() |
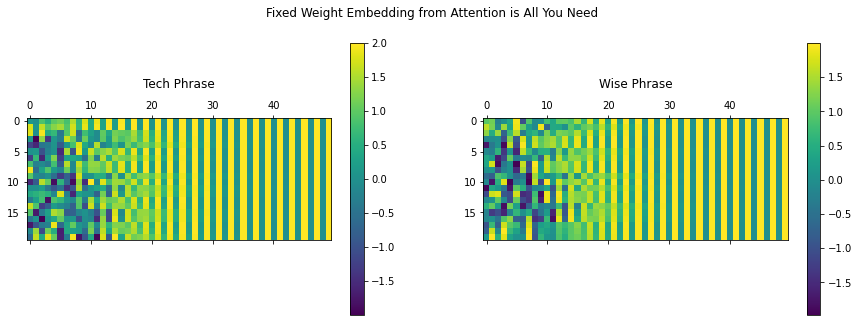
Embedding using sinusoidal positional encoding
You can see that the embedding layer initialized using the default parameter outputs random values. On the other hand, the fixed weights generated using sinusoids create a unique signature for every phrase with information on each word position encoded within it.
You can experiment with tunable or fixed-weight implementations for your particular application.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Transformers for natural language processing by Denis Rothman
Papers
Articles
- The Transformer Attention Mechanism
- The Transformer Model
- Transformer Model for Language Understanding
- Using Pre-Trained Word Embeddings in a Keras Model
- English-to-Spanish translation with a sequence-to-sequence Transformer
- A Gentle Introduction to Positional Encoding in Transformer Models, Part 1
Summary
In this tutorial, you discovered the implementation of positional encoding layer in Keras.
Specifically, you learned:
- Text vectorization layer in Keras
- Positional encoding layer in Keras
- Creating your own class for positional encoding
- Setting your own weights for the positional encoding layer in Keras
Do you have any questions about positional encoding discussed in this post? Ask your questions in the comments below, and I will do my best to answer.
Learn Transformers and Attention!

Teach your deep learning model to read a sentence
...using transformer models with attention
Discover how in my new Ebook:
Building Transformer Models with Attention
It provides self-study tutorials with working code to guide you into building a fully-working transformer models that can
translate sentences from one language to another...






Thanks for the super clear and useful explanation!
Great feedback Guydo!
Hi James, amazing post, web and content, congratulations. About transformers, I’m being introduced in this new world, understanding it is not being too difficult, but I’ve seen that every single example is always focused on NLP, in the case I would like to use a transformer for time series, shouldn’t I use a special positional encoding layer for this purpose? I mean, I know that the time data can be encoded using sin and cos in data preparation preprocess, before feeding our net with this data time data, but, it is necessary a positional encoding if I want to keep the position of every single element during the time sequence?
Thanks again.
Hi Pablo…You are very welcome! Hopefully the following resource may be of interest to you:
https://machinelearningmastery.com/a-gentle-introduction-to-positional-encoding-in-transformer-models-part-1/
Hi Dear Mehreen Saeed
when I study this blog. it show cannot import name ‘TextVectorization’ from ‘tensorflow.keras.layers’. how to fix this error?
thank you.
Great tutorial! I have a question about the PositionEmbeddingFixedWeights class. Why are you setting word_embedding_matrix equal to get_position_embedding instead of randomly initializing it? Thanks!
Hi HZ…You are very welcome! The setting was for illustration purposes only. A random initialization is actually a preferred method. Please pursue your suggestion and let us know what you find!
The Position Embedding layer in this blog, that’s not the same as the sine/cosine function we build in part 1 right? We now use the same method to generate embeddings as the word embeddings?
nevermind my previous comment, I did not check the rest of the tutorial and see that it alreayd follows with sine/cosine-based positional encoding
Thank you the for the update Diego!
Do we need positional encoding in order to use transformer in Time-series forecasting tasks as we pass it to transformer model without breaking its sorted time-series nature?
Hello authors,
Thank you for your efforts with the book.
Could you please explain why word_embeddings set as non-trainable across the whole book ? (my question is not about positional encoding)
Hi Ivan,
I came here to ask the same thing. Then I noticed that HZ has asked the same question (on November 8th, 2022). The author’s response seems to be that this was done just for illustration purposes. Indeed for word embeddings it’s better to use randomly initialized trainable weights (or use off-the-shelf pre-trained word embeddings, in which case you might want set them to non-trainable, I presume?)
Hope this helps. The book is helpful but I often find myself having to be extra cautious around the provided code examples and double-checking and cross-referencing with other, more rigorous resources.
Very educational article. Thanks!
For the code I have a question:
word_embedding_matrix = self.get_position_encoding(vocab_size, output_dim)
position_embedding_matrix = self.get_position_encoding(sequence_length, output_dim)
Both of them use the following function with default n=10000. Should one call of the two take another value other than 10000 for the input n?
def get_position_encoding(self, seq_len, d, n=10000):
P = np.zeros((seq_len, d))
for k in range(seq_len):
for i in np.arange(int(d/2)):
denominator = np.power(n, 2*i/d)
P[k, 2*i] = np.sin(k/denominator)
P[k, 2*i+1] = np.cos(k/denominator)
return P
Hi Harrison…You are very welcome! The given value of n could be considered a paramater to be optimized over.
hello,
looks great.
would you like to use pytorch to rewrite the transformer?
Hi BH…That is always an option. We do prefer Tensorflow/Keras.