Having familiarized ourselves with the theory behind the Transformer model and its attention mechanism, we’ll start our journey of implementing a complete Transformer model by first seeing how to implement the scaled-dot product attention. The scaled dot-product attention is an integral part of the multi-head attention, which, in turn, is an important component of both the Transformer encoder and decoder. Our end goal will be to apply the complete Transformer model to Natural Language Processing (NLP).
In this tutorial, you will discover how to implement scaled dot-product attention from scratch in TensorFlow and Keras.
After completing this tutorial, you will know:
The operations that form part of the scaled dot-product attention mechanism
How to implement the scaled dot-product attention mechanism from scratch
Kick-start your project with my book Building Transformer Models with Attention. It provides self-study tutorials with working code to guide you into building a fully-working transformer model that can translate sentences from one language to another...
Let’s get started.
How to implement scaled dot-product attention from scratch in TensorFlow and Keras Photo by Sergey Shmidt, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Recap of the Transformer Architecture
The Transformer Scaled Dot-Product Attention
Implementing the Scaled Dot-Product Attention From Scratch
Testing Out the Code
Prerequisites
For this tutorial, we assume that you are already familiar with:
Recall having seen that the Transformer architecture follows an encoder-decoder structure. The encoder, on the left-hand side, is tasked with mapping an input sequence to a sequence of continuous representations; the decoder, on the right-hand side, receives the output of the encoder together with the decoder output at the previous time step to generate an output sequence.
The encoder-decoder structure of the Transformer architecture Taken from “Attention Is All You Need“
In generating an output sequence, the Transformer does not rely on recurrence and convolutions.
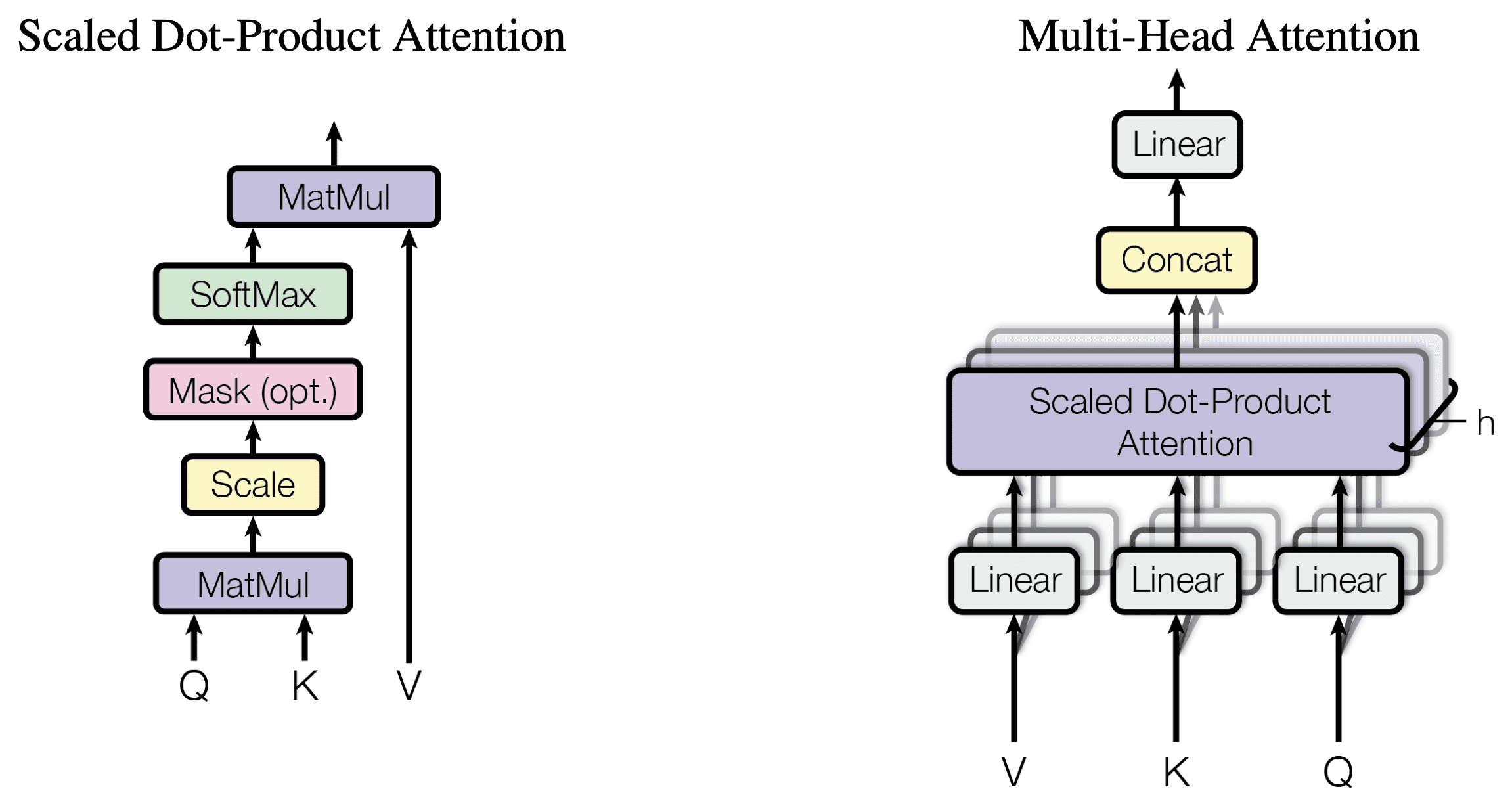
You have seen that the decoder part of the Transformer shares many similarities in its architecture with the encoder. One of the core components that both the encoder and decoder share within their multi-head attention blocks is the scaled dot-product attention.
The Transformer Scaled Dot-Product Attention
First, recall the queries, keys, and values as the important components you will work with.
In the encoder stage, they each carry the same input sequence after this has been embedded and augmented by positional information. Similarly, on the decoder side, the queries, keys, and values fed into the first attention block represent the same target sequence after this would have also been embedded and augmented by positional information. The second attention block of the decoder receives the encoder output in the form of keys and values and the normalized output of the first attention block as the queries. The dimensionality of the queries and keys is denoted by $d_k$, whereas the dimensionality of the values is denoted by $d_v$.
The scaled dot-product attention receives these queries, keys, and values as inputs and first computes the dot-product of the queries with the keys. The result is subsequently scaled by the square root of $d_k$, producing the attention scores. They are then fed into a softmax function, obtaining a set of attention weights. Finally, the attention weights are used to scale the values through a weighted multiplication operation. This entire process can be explained mathematically as follows, where $\mathbf{Q}$, $\mathbf{K}$ and $\mathbf{V}$ denote the queries, keys, and values, respectively:
You may note that the scaled dot-product attention can also apply a mask to the attention scores before feeding them into the softmax function.
Since the word embeddings are zero-padded to a specific sequence length, a padding mask needs to be introduced in order to prevent the zero tokens from being processed along with the input in both the encoder and decoder stages. Furthermore, a look-ahead mask is also required to prevent the decoder from attending to succeeding words, such that the prediction for a particular word can only depend on known outputs for the words that come before it.
These look-ahead and padding masks are applied inside the scaled dot-product attention set to -$\infty$ all the values in the input to the softmax function that should not be considered. For each of these large negative inputs, the softmax function will, in turn, produce an output value that is close to zero, effectively masking them out. The use of these masks will become clearer when you progress to the implementation of the encoder and decoder blocks in separate tutorials.
For the time being, let’s see how to implement the scaled dot-product attention from scratch in TensorFlow and Keras.
Want to Get Started With Building Transformer Models with Attention?
Take my free 12-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Implementing the Scaled Dot-Product Attention from Scratch
For this purpose, you will create a class called DotProductAttention that inherits from the Layer base class in Keras.
In it, you will create the class method, call(), that takes as input arguments the queries, keys, and values, as well as the dimensionality, $d_k$, and a mask (that defaults to None):
The first step is to perform a dot-product operation between the queries and the keys, transposing the latter. The result will be scaled through a division by the square root of $d_k$. You will add the following line of code to the call() class method:
Next, you will check whether the mask argument has been set to a value that is not the default None.
The mask will contain either 0 values to indicate that the corresponding token in the input sequence should be considered in the computations or a 1 to indicate otherwise. The mask will be multiplied by -1e9 to set the 1 values to large negative numbers (remember having mentioned this in the previous section), subsequently applied to the attention scores:
Python
1
2
3
4
...
ifmask isnotNone:
scores+=-1e9*mask
...
The attention scores will then be passed through a softmax function to generate the attention weights:
Python
1
2
3
...
weights=softmax(scores)
...
The final step weights the values with the computed attention weights through another dot-product operation:
# Computing the attention by a weighted sum of the value vectors
returnmatmul(weights,values)
Testing Out the Code
You will be working with the parameter values specified in the paper, Attention Is All You Need, by Vaswani et al. (2017):
Python
1
2
3
4
d_k=64# Dimensionality of the linearly projected queries and keys
d_v=64# Dimensionality of the linearly projected values
batch_size=64# Batch size from the training process
...
As for the sequence length and the queries, keys, and values, you will be working with dummy data for the time being until you arrive at the stage of training the complete Transformer model in a separate tutorial, at which point you will use actual sentences. Similarly, for the mask, leave it set to its default value for the time being:
Python
1
2
3
4
5
6
7
...
input_seq_length=5# Maximum length of the input sequence
In the complete Transformer model, values for the sequence length and the queries, keys, and values will be obtained through a process of word tokenization and embedding. You will be covering this in a separate tutorial.
Returning to the testing procedure, the next step is to create a new instance of the DotProductAttention class, assigning its output to the attention variable:
Python
1
2
3
...
attention=DotProductAttention()
...
Since the DotProductAttention class inherits from the Layer base class, the call() method of the former will be automatically invoked by the magic __call()__ method of the latter. The final step is to feed in the input arguments and print the result:
Python
1
2
...
print(attention(queries,keys,values,d_k))
Tying everything together produces the following code listing:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
fromnumpy importrandom
input_seq_length=5# Maximum length of the input sequence
d_k=64# Dimensionality of the linearly projected queries and keys
d_v=64# Dimensionality of the linearly projected values
batch_size=64# Batch size from the training process
Running this code produces an output of shape (batch size, sequence length, values dimensionality). Note that you will likely see a different output due to the random initialization of the queries, keys, and values.
It provides self-study tutorials with working code to guide you into building a fully-working transformer models that can translate sentences from one language to another...
Give magical power of understanding human language for Your Projects
Hi, thanks for the great article! I appreciate you took the time to add parameters for testing the function, I think the testing would be way more useful if you add random seeding before the random generation of Q, K, V.
As an example, by calling random.seed(42) before generating the three random vector, I get the following output:
Hi Inquisitive…The output matrix \( R \) of the Scaled Dot-Product Attention mechanism represents the attention-weighted sum of the value vectors \( V \). Here’s a detailed interpretation of each step in the formula and what the final \( R \) matrix represents:
### Components of the Scaled Dot-Product Attention
1. **Query (Q)**:
– A matrix that contains queries. Each query vector corresponds to an input token and is used to determine how much attention should be paid to each key.
2. **Key (K)**:
– A matrix that contains keys. Each key vector corresponds to an input token and is used to match against the queries to compute attention scores.
3. **Value (V)**:
– A matrix that contains values. Each value vector corresponds to an input token and holds the information that should be aggregated according to the attention scores.
### Steps of the Scaled Dot-Product Attention
1. **Dot Product of Q and \( K^T \)**:
– The dot product of the query matrix \( Q \) and the transpose of the key matrix \( K \) results in a matrix of raw attention scores.
\[
\text{raw\_scores} = Q \cdot K^T
\]
Each element \( \text{raw\_scores}_{ij} \) represents the attention score between the \( i \)-th query and the \( j \)-th key.
2. **Scaling**:
– The raw attention scores are scaled by the square root of the dimensionality of the key vectors, \( \sqrt{d_k} \). This helps to stabilize the gradients during training and prevents the softmax from becoming too flat or too sharp.
\[
\text{scaled\_scores} = \frac{Q \cdot K^T}{\sqrt{d_k}}
\]
3. **Softmax**:
– The scaled scores are passed through a softmax function to obtain the attention weights. This converts the scores into probabilities that sum to 1 for each query.
\[
\text{attention\_weights} = \text{softmax}\left(\frac{Q \cdot K^T}{\sqrt{d_k}}\right)
\]
Each element \( \text{attention\_weights}_{ij} \) represents the normalized attention score between the \( i \)-th query and the \( j \)-th key.
4. **Weighted Sum with V**:
– The attention weights are used to compute a weighted sum of the value vectors \( V \). This results in the final output matrix \( R \).
\[
R = \text{attention\_weights} \cdot V
\]
Each row of \( R \) is a weighted sum of all the value vectors, where the weights are given by the attention scores corresponding to the respective query.
### Interpretation of \( R \)
The matrix \( R \) represents the attention output. Specifically:
– Each row in \( R \) corresponds to an attention output for a specific query.
– The attention mechanism allows each query to focus on different parts of the input sequence (as represented by the keys and values) and aggregate information from those parts in a weighted manner.
– \( R \) captures the most relevant information from the input sequence, as determined by the attention mechanism.
In summary, \( R \) is the matrix of attention-weighted values, where each output vector (row in \( R \)) is a context vector that summarizes the input sequence in a way that is relevant to the corresponding query. This allows the model to dynamically focus on different parts of the input for different queries, enhancing its ability to understand and process the input data.






 From Scratch in Keras")


TypeError: DotProductAttention.__init__() takes 1 positional argument but 5 were given.
I am getting this error. Instead I have to call attention.cal(….). Any fix for this?
you have to import “from dumpy import random”
*numpy
Hi, thanks for the great article! I appreciate you took the time to add parameters for testing the function, I think the testing would be way more useful if you add random seeding before the random generation of Q, K, V.
As an example, by calling random.seed(42) before generating the three random vector, I get the following output:
[[[0.42829984 0.5291363 0.48467717 … 0.60236526 0.6314437 0.36796492]
[0.42059597 0.51898783 0.46809804 … 0.59751767 0.63140476 0.39604473]
[0.45291767 0.53372955 0.4822161 … 0.5861658 0.61705434 0.35611778]
[0.43538865 0.52972203 0.47826144 … 0.5917443 0.6259302 0.36665624]
[0.42998832 0.5189111 0.48113108 … 0.61032706 0.63044846 0.39192218]]
[[0.6105153 0.50249505 0.40130395 … 0.71487725 0.36341453 0.5512418 ]
[0.58420086 0.5239525 0.4311911 … 0.72335523 0.36001056 0.5697574 ]
[0.5644941 0.5598139 0.44120124 … 0.69758904 0.34060007 0.57147545]
[0.58783877 0.5212065 0.42275837 … 0.70439875 0.34812242 0.5561169 ]
[0.5880349 0.52016133 0.43390357 … 0.70503277 0.35547623 0.56170976]
Thank you for your feedback and suggestions Giovanni!
What is the interpretation of output of the Scaled Dot Product of Attention which is
R =softmax(scale( ( Q @K.T ) ) @ V
What does this R matrix represent ?
Hi Inquisitive…The output matrix \( R \) of the Scaled Dot-Product Attention mechanism represents the attention-weighted sum of the value vectors \( V \). Here’s a detailed interpretation of each step in the formula and what the final \( R \) matrix represents:
### Components of the Scaled Dot-Product Attention
1. **Query (Q)**:
– A matrix that contains queries. Each query vector corresponds to an input token and is used to determine how much attention should be paid to each key.
2. **Key (K)**:
– A matrix that contains keys. Each key vector corresponds to an input token and is used to match against the queries to compute attention scores.
3. **Value (V)**:
– A matrix that contains values. Each value vector corresponds to an input token and holds the information that should be aggregated according to the attention scores.
### Steps of the Scaled Dot-Product Attention
1. **Dot Product of Q and \( K^T \)**:
– The dot product of the query matrix \( Q \) and the transpose of the key matrix \( K \) results in a matrix of raw attention scores.
\[
\text{raw\_scores} = Q \cdot K^T
\]
Each element \( \text{raw\_scores}_{ij} \) represents the attention score between the \( i \)-th query and the \( j \)-th key.
2. **Scaling**:
– The raw attention scores are scaled by the square root of the dimensionality of the key vectors, \( \sqrt{d_k} \). This helps to stabilize the gradients during training and prevents the softmax from becoming too flat or too sharp.
\[
\text{scaled\_scores} = \frac{Q \cdot K^T}{\sqrt{d_k}}
\]
3. **Softmax**:
– The scaled scores are passed through a softmax function to obtain the attention weights. This converts the scores into probabilities that sum to 1 for each query.
\[
\text{attention\_weights} = \text{softmax}\left(\frac{Q \cdot K^T}{\sqrt{d_k}}\right)
\]
Each element \( \text{attention\_weights}_{ij} \) represents the normalized attention score between the \( i \)-th query and the \( j \)-th key.
4. **Weighted Sum with V**:
– The attention weights are used to compute a weighted sum of the value vectors \( V \). This results in the final output matrix \( R \).
\[
R = \text{attention\_weights} \cdot V
\]
Each row of \( R \) is a weighted sum of all the value vectors, where the weights are given by the attention scores corresponding to the respective query.
### Interpretation of \( R \)
The matrix \( R \) represents the attention output. Specifically:
– Each row in \( R \) corresponds to an attention output for a specific query.
– The attention mechanism allows each query to focus on different parts of the input sequence (as represented by the keys and values) and aggregate information from those parts in a weighted manner.
– \( R \) captures the most relevant information from the input sequence, as determined by the attention mechanism.
In summary, \( R \) is the matrix of attention-weighted values, where each output vector (row in \( R \)) is a context vector that summarizes the input sequence in a way that is relevant to the corresponding query. This allows the model to dynamically focus on different parts of the input for different queries, enhancing its ability to understand and process the input data.