Training a neural network or large deep learning model is a difficult optimization task.
The classical algorithm to train neural networks is called stochastic gradient descent. It has been well established that you can achieve increased performance and faster training on some problems by using a learning rate that changes during training.
In this post, you will discover how you can use different learning rate schedules for your neural network models in Python using the Keras deep learning library.
After reading this post, you will know:
How to configure and evaluate a time-based learning rate schedule
How to configure and evaluate a drop-based learning rate schedule
Kick-start your project with my new book Deep Learning With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Jun/2016: First published
Update Mar/2017: Updated for Keras 2.0.2, TensorFlow 1.0.1 and Theano 0.9.0
Update Sep/2019: Updated for Keras 2.2.5 API
Update Jul/2022: Updated for TensorFlow 2.x API
Using learning rate schedules for deep learning models in Python with Keras Photo by Columbia GSAPP, some rights reserved.
Learning Rate Schedule for Training Models
Adapting the learning rate for your stochastic gradient descent optimization procedure can increase performance and reduce training time.
Sometimes, this is called learning rate annealing or adaptive learning rates. Here, this approach is called a learning rate schedule, where the default schedule uses a constant learning rate to update network weights for each training epoch.
The simplest and perhaps most used adaptation of the learning rate during training are techniques that reduce the learning rate over time. These have the benefit of making large changes at the beginning of the training procedure when larger learning rate values are used and decreasing the learning rate so that a smaller rate and, therefore, smaller training updates are made to weights later in the training procedure.
This has the effect of quickly learning good weights early and fine-tuning them later.
Two popular and easy-to-use learning rate schedules are as follows:
Decrease the learning rate gradually based on the epoch
Decrease the learning rate using punctuated large drops at specific epochs
Next, let’s look at how you can use each of these learning rate schedules in turn with Keras.
Need help with Deep Learning in Python?
Take my free 2-week email course and discover MLPs, CNNs and LSTMs (with code).
Click to sign-up now and also get a free PDF Ebook version of the course.
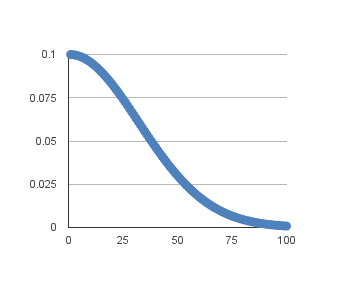
Time-Based Learning Rate Schedule
Keras has a built-in time-based learning rate schedule.
The stochastic gradient descent optimization algorithm implementation in the SGD class has an argument called decay. This argument is used in the time-based learning rate decay schedule equation as follows:
The ionosphere dataset is good for practicing with neural networks because all the input values are small numerical values of the same scale.
A small neural network model is constructed with a single hidden layer with 34 neurons, using the rectifier activation function. The output layer has a single neuron and uses the sigmoid activation function in order to output probability-like values.
The learning rate for stochastic gradient descent has been set to a higher value of 0.1. The model is trained for 50 epochs, and the decay argument has been set to 0.002, calculated as 0.1/50. Additionally, it can be a good idea to use momentum when using an adaptive learning rate. In this case, we use a momentum value of 0.8.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The model is trained on 67% of the dataset and evaluated using a 33% validation dataset.
Running the example shows a classification accuracy of 99.14%. This is higher than the baseline of 95.69% without the learning rate decay or momentum.
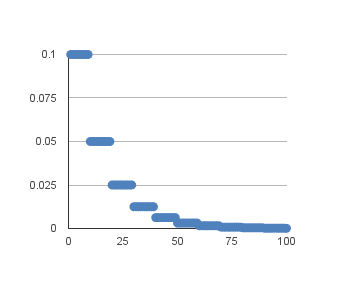
Another popular learning rate schedule used with deep learning models is systematically dropping the learning rate at specific times during training.
Often this method is implemented by dropping the learning rate by half every fixed number of epochs. For example, we may have an initial learning rate of 0.1 and drop it by 0.5 every ten epochs. The first ten epochs of training would use a value of 0.1, and in the next ten epochs, a learning rate of 0.05 would be used, and so on.
If you plot the learning rates for this example out to 100 epochs, you get the graph below showing the learning rate (y-axis) versus epoch (x-axis).
Drop-based learning rate schedule
You can implement this in Keras using the LearningRateScheduler callback when fitting the model.
The LearningRateScheduler callback allows you to define a function to call that takes the epoch number as an argument and returns the learning rate to use in stochastic gradient descent. When used, the learning rate specified by stochastic gradient descent is ignored.
In the code below, we use the same example as before of a single hidden layer network on the Ionosphere dataset. A new step_decay() function is defined that implements the equation:
Here, the InitialLearningRate is the initial learning rate (such as 0.1), the DropRate is the amount that the learning rate is modified each time it is changed (such as 0.5), Epoch is the current epoch number, and EpochDrop is how often to change the learning rate (such as 10).
Notice that the learning rate in the SGD class is set to 0 to clearly indicate that it is not used. Nevertheless, you can set a momentum term in SGD if you want to use momentum with this learning rate schedule.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# Drop-Based Learning Rate Decay
from pandas import read_csv
import math
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.callbacks import LearningRateScheduler
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example results in a classification accuracy of 99.14% on the validation dataset, again an improvement over the baseline for the model of the problem.
This section lists some tips and tricks to consider when using learning rate schedules with neural networks.
Increase the initial learning rate. Because the learning rate will very likely decrease, start with a larger value to decrease from. A larger learning rate will result in a lot larger changes to the weights, at least in the beginning, allowing you to benefit from the fine-tuning later.
Use a large momentum. Using a larger momentum value will help the optimization algorithm continue to make updates in the right direction when your learning rate shrinks to small values.
Experiment with different schedules. It will not be clear which learning rate schedule to use, so try a few with different configuration options and see what works best on your problem. Also, try schedules that change exponentially and even schedules that respond to the accuracy of your model on the training or test datasets.
Summary
In this post, you discovered learning rate schedules for training neural network models.
After reading this post, you learned:
How to configure and use a time-based learning rate schedule in Keras
How to develop your own drop-based learning rate schedule in Keras
Do you have any questions about learning rate schedules for neural networks or this post? Ask your question in the comments, and I will do my best to answer.
Interesting post. Can’t we use this learning rate and momentum for optimizers other than SGD? Since ‘adam’ is performing good with most of the datasets, i wanna try learning rate and momentum tuning for ‘adam’ optimizer. Also, I did a quick research on this and found that ‘adam’ already have decaying learning rate. Is it true? and what about other optimizers?
I would advise you to develop your decay function in excel or something to test and plot it. Use the above linear decay function inputs/outputs as a starting point.
You can then plug your function into one of the examples above.
Thanks for your great poster! It does great help!
One more question: I use the “Drop-Based Learning Rate Schedule”, how can I print out the current learning rate in terminal?
Thanks a lot for this guide! Is there a way to see the code you wrote before the update? I have a constraint and need to use Keras 1.2 currently, and when applying the SGD I get:
File “/usr/lib64/python2.7/site-packages/keras/models.py”, line 924, in fit_generator
pickle_safe=pickle_safe)
File “/usr/lib64/python2.7/site-packages/keras/engine/training.py”, line 1401, in fit_generator
self._make_train_function()
File “/usr/lib64/python2.7/site-packages/keras/engine/training.py”, line 713, in _make_train_function
self.total_loss)
TypeError: unbound method get_updates() must be called with SGD instance as first argument (got list instance instead)
I assume this is because of some API change that I fail to see
Oh, never mind, it is displaying changed lrate per epoch without a for-loop.
There was a lot of displayed information during the training (with verbose=1) and I missed the lrate reports.
Thanks,
Hi Jason,
I know the learning rate can be adjusted in Keras, but all the options seem to only include some decay or decreasing learning rate. I am wondering if it’s possible to create a custom schedule that works like ReduceLROnPlateau, where it is looking to see if the loss stops decreasing for some number of epochs, and if so then it decreases the LR. But after some number of “decreases” it then increases the learning rate the next time loss stagnates, and then continues decreasing again on loss stagnation after that.
My thought here is that you may descend into a local minimum that you may not be able to escape from unless you increase the learning rate, before continuing to descend to the global minimum.
Does it make sense to create a function for learning rate? Would Keras accept that?
Can anyone give me an idea on how I would write that function?
Sure, I don’t think it would be a problem. You may need an object rather than just a function to store state. I have not done this, so some experimentation may be required.
I used the tutorial from this link: https://enlight.nyc/neural-network/ and applied it to a 6 input data set. My values always converge to ~0, .5, or 1 depending on the number of hidden layers. This occurs after the first call to train each time. I suspect this is because it does not include learning rate or bias. Where would you apply the learning rate in this code?
Thanks for your informative posts on working with Keras.
I am using Drop based Learning Schedule as per your tutorial which works fine and can print the changing learning rate with every epoch in the step_decay() function.
Due to shortage of memory, I am saving this model and reloading it in another script.
The model reloads and optimizes from the previous epoch only so learning keeps happening. But I am not able to see the learning rate from the callback. Perhaps the learning rate scheduler callback state is not saved. Do you have any idea on how I can use the previous callback state also in the reloaded model?
Below is my code for scheular where I want to divide the learning rate by 10 from the initial rate when my epoch is at 50% and by 100 when my epoch is at 75%:
def lr_schedule(epochs,lr):
initial_lr = 0.1
if epochs == epochs*0.5:
lr = np.float32(initial_lr/10.0)
return lr
if epochs == epochs*0.75:
lr = np.float32(initial_lr/100.0)
return lr
learning_scheduler=tf.keras.callbacks.LearningRateScheduler(lr_schedule)
from keras.callbacks import ModelCheckpoint
# create data generator
datagen = ImageDataGenerator(rotation_range=15,width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
# fit model
steps = int(X_train.shape[0] / batch_size)
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=batch_size), steps_per_epoch=steps, epochs=epochs, validation_data=(X_test, y_test), callbacks=callbacks_list, verbose=1)
error:
1352 lr = self.schedule(epoch)
1353 if not isinstance(lr, (float, np.float32, np.float64)):
-> 1354 raise ValueError(‘The output of the “schedule” function ‘
1355 ‘should be float.’)
1356 K.set_value(self.model.optimizer.lr, lr)
ValueError: The output of the “schedule” function should be a float.







Great
Thanks Hunaina.
nice post
Hello Jason,
Interesting post. Can’t we use this learning rate and momentum for optimizers other than SGD? Since ‘adam’ is performing good with most of the datasets, i wanna try learning rate and momentum tuning for ‘adam’ optimizer. Also, I did a quick research on this and found that ‘adam’ already have decaying learning rate. Is it true? and what about other optimizers?
I want to implement a learning rate that is exponentially decayed with respect to the cost? For example, the learning rate is updated as follows:
eta = eta0*exp(CostFunction)
Such that a larger learning rate is employed when the cost is large, vice versa.
Do you know to achieve that in Keras? Thank you!
Hi Yuzhen,
I would advise you to develop your decay function in excel or something to test and plot it. Use the above linear decay function inputs/outputs as a starting point.
You can then plug your function into one of the examples above.
Let me know how you go.
Hi Jason!
Thanks for your great poster! It does great help!
One more question: I use the “Drop-Based Learning Rate Schedule”, how can I print out the current learning rate in terminal?
Best,
Got the solution! Just print out
Good question, you might be able to call print() from the custom function. Let me know if that works.
Does the weight decay change once per mini-batch or epoch? According to https://groups.google.com/forum/#!topic/keras-users/7KM2AvCurW0, it updates per mini-batch. In my problem, one epoch contains 800 mini-batches.
If you implement the decay yourself, you can control the schedule, as in the tutorial above (e.g. a function of the epoch not the batch).
Does it make sense to use these techniques of weight decay with adaptive optimizers like adam or rmsprop rather than sgd? or will it be redundant?
I’d like to think it is redundant, but test and see on your problem to know for sure. Data wins.
Thanks a lot for this guide! Is there a way to see the code you wrote before the update? I have a constraint and need to use Keras 1.2 currently, and when applying the SGD I get:
File “/usr/lib64/python2.7/site-packages/keras/models.py”, line 924, in fit_generator
pickle_safe=pickle_safe)
File “/usr/lib64/python2.7/site-packages/keras/engine/training.py”, line 1401, in fit_generator
self._make_train_function()
File “/usr/lib64/python2.7/site-packages/keras/engine/training.py”, line 713, in _make_train_function
self.total_loss)
TypeError: unbound method get_updates() must be called with SGD instance as first argument (got list instance instead)
I assume this is because of some API change that I fail to see
Sorry, I no longer have the older code.
Hi Jason, is there an option to specify momentum when using Adam optimizer in Keras? I can only see the momentum option in SGD.
Not as far as I remember. Double check the API to be sure.
Hi, I have a question here
I wish to print out the learning rate information during the training but it won’t work with this code below:
def step_decay(epoch):
initial_lrate = 0.001
drop = 0.5
epochs_drop = 100.0
lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop))
print (‘epoch: ‘ + str(epoch) + ‘, learning rate: ‘ + str(lrate)) # added
return lrate
NUM_EPOCHS = 700
BATCH_SIZE = 128
for each_epoch in range(0, NUM_EPOCHS):
lrate = callbacks.LearningRateScheduler(step_decay)
callbacks_list = [lrate]
history = model.fit(x_train, y_train, batch_size=BATCH_SIZE, epochs=1, callbacks=callbacks_list, verbose=2, validation_data=[x_test, y_test])
prediction_test = model.predict(x_test).flatten()
Do I have to set ‘epochs’ to NUM_EPOCHS and remove for-loop to display lrate?
Does the example in the post work for you?
Perhaps start with something that works and modify it one piece at a time to achieve your desired outcome?
The example works but I want to display the learning rate during training.
I would expect the print in the callback function to work.
Ensure you’re running from the command line and not in a notebook or ide.
Oh, never mind, it is displaying changed lrate per epoch without a for-loop.
There was a lot of displayed information during the training (with verbose=1) and I missed the lrate reports.
Thanks,
Glad to hear it.
Hi Jason,
I know the learning rate can be adjusted in Keras, but all the options seem to only include some decay or decreasing learning rate. I am wondering if it’s possible to create a custom schedule that works like ReduceLROnPlateau, where it is looking to see if the loss stops decreasing for some number of epochs, and if so then it decreases the LR. But after some number of “decreases” it then increases the learning rate the next time loss stagnates, and then continues decreasing again on loss stagnation after that.
My thought here is that you may descend into a local minimum that you may not be able to escape from unless you increase the learning rate, before continuing to descend to the global minimum.
Does it make sense to create a function for learning rate? Would Keras accept that?
Can anyone give me an idea on how I would write that function?
Thanks!
Sure, I don’t think it would be a problem. You may need an object rather than just a function to store state. I have not done this, so some experimentation may be required.
Hi Jason,
This post helped me a lot. How can i tweak the learning rate value after every epoch?
You can implement this directly as your own method, follow the above tutorial.
I want to know how to use keras to change the learning rate in every layers?
Good question, I’m not sure off hand. Perhaps ask on the Keras user group:
https://machinelearningmastery.com/get-help-with-keras/
Hi, I want to plot the learning rate curve of the adam optimizer, should I code callbacks=[lr] in the fit function
Each model parameter (weight) has a learning rate, plotting each would be challenging.
I used the tutorial from this link: https://enlight.nyc/neural-network/ and applied it to a 6 input data set. My values always converge to ~0, .5, or 1 depending on the number of hidden layers. This occurs after the first call to train each time. I suspect this is because it does not include learning rate or bias. Where would you apply the learning rate in this code?
If you have a question about someone else’s tutorial, perhaps ask them directly?
Hello Dr. Jason,
Thanks for your informative posts on working with Keras.
I am using Drop based Learning Schedule as per your tutorial which works fine and can print the changing learning rate with every epoch in the step_decay() function.
Due to shortage of memory, I am saving this model and reloading it in another script.
The model reloads and optimizes from the previous epoch only so learning keeps happening. But I am not able to see the learning rate from the callback. Perhaps the learning rate scheduler callback state is not saved. Do you have any idea on how I can use the previous callback state also in the reloaded model?
You might have to re-seed it manually.
How should we record the learning rate during training in keras?
tensorboard can plot learning rate in every epochs
Sorry, I don’t have an example of monitoring learning rate for tensorboard.
If we want to know the learning rate during training in every epoch,what we can do use the keras
Many thanks for this very useful tutorial.
Is there is a way to decrease the learning rate automatically when the accuracy decrease?
Yes, you can configure a learning rate schedule to achieve this.
Do you mean “LearningRateScheduler”?
If yes, to the best of my knowledge about “LearningRateScheduler”,
I can set the learning rate manually for a set of epochs.
For example:
def lr_schedule(epoch):
lrate = 0.0007
if epoch > 10:
lrate = 0.0001
return lrate
lr_scheduler=LearningRateScheduler(lr_schedule)
callbacks_list = [lr_scheduler]
history=model.fit(X, Y, epochs=50, batch_size=80,
callbacks = callbacks_list)
But, How does the “LearningRateScheduler” set learning rate automatically?
When the SGD is used, it will locate the instance of the SGD used by the model and set the lr parameter.
Can you give me an example, please?
Sorry, I don’t have the capacity to prepare an example.
so when do you set the value for epoch argument in function step_decay? Does it mean overall epochs?
It is the current epoch number.
Perhaps I don’t understand the question?
Below is my code for scheular where I want to divide the learning rate by 10 from the initial rate when my epoch is at 50% and by 100 when my epoch is at 75%:
def lr_schedule(epochs,lr):
initial_lr = 0.1
if epochs == epochs*0.5:
lr = np.float32(initial_lr/10.0)
return lr
if epochs == epochs*0.75:
lr = np.float32(initial_lr/100.0)
return lr
learning_scheduler=tf.keras.callbacks.LearningRateScheduler(lr_schedule)
from keras.callbacks import ModelCheckpoint
# checkpoint
filepath=”weights-improvement-reg-{epoch:02d}-{val_acc:.2f}.hdf5″
checkpoint = ModelCheckpoint(filepath, monitor=’val_acc’, verbose=1, save_best_only=True, mode=’max’)
callbacks_list = [checkpoint,learning_scheduler]
# create data generator
datagen = ImageDataGenerator(rotation_range=15,width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
# fit model
steps = int(X_train.shape[0] / batch_size)
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=batch_size), steps_per_epoch=steps, epochs=epochs, validation_data=(X_test, y_test), callbacks=callbacks_list, verbose=1)
error:
1352 lr = self.schedule(epoch)
1353 if not isinstance(lr, (float, np.float32, np.float64)):
-> 1354 raise ValueError(‘The output of the “schedule” function ‘
1355 ‘should be float.’)
1356 K.set_value(self.model.optimizer.lr, lr)
ValueError: The output of the “schedule” function should be a float.
I am getting the above error. Kindly help.
Thanks in advance!
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Sorry for that, I saw somebody posted a small code snippet and hence I did. Thanks!
No problem.
sorry forgot to add in my comment:
sgd = tf.keras.optimizers.SGD(lr=0.1,momentum=0.9, decay=1e-4,nesterov=True)
model.compile(loss=’categorical_crossentropy’,optimizer=sgd,metrics=[‘accuracy’])
hi jason,
when i execute above code for another dataset there is no change in loss and accuracy at each epoch.. could you give me suggestion..
I don’t know why that could be. Perhaps try additional loss values?
Hi Jason.
I want to change learning rate with respect to val_accuracy . how to achieve it?
You can configure the callback to monitor val_accuracy.
Hello, very useful post!
Though I’m a wee bit puzzled by the first plot, “Time-based learning rate schedule”.
I thought that what Keras does when it decays the decay rate, is
lr(n) = lr(0) / (1+k*n)
but that seems the plot you get when you compute
lr(n) = lr(n-1) / (1+k*n).
How could you get that type of decay in Keras?
Hi Matteo…The following resource should add clarity:
https://machinelearningmastery.com/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/