Transfer learning is a machine learning method where a model developed for a task is reused as the starting point for a model on a second task.
It is a popular approach in deep learning where pre-trained models are used as the starting point on computer vision and natural language processing tasks given the vast compute and time resources required to develop neural network models on these problems and from the huge jumps in skill that they provide on related problems.
In this post, you will discover how you can use transfer learning to speed up training and improve the performance of your deep learning model.
After reading this post, you will know:
What transfer learning is and how to use it.
Common examples of transfer learning in deep learning.
When to use transfer learning on your own predictive modeling problems.
Kick-start your project with my new book Deep Learning for Computer Vision, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
For an example of how to use transfer learning in computer vision, see the post:
A Gentle Introduction to Transfer Learning with Deep Learning Photo by Mike’s Birds, some rights reserved.
What is Transfer Learning?
Transfer learning is a machine learning technique where a model trained on one task is re-purposed on a second related task.
Transfer learning and domain adaptation refer to the situation where what has been learned in one setting … is exploited to improve generalization in another setting
Transfer learning is related to problems such as multi-task learning and concept drift and is not exclusively an area of study for deep learning.
Nevertheless, transfer learning is popular in deep learning given the enormous resources required to train deep learning models or the large and challenging datasets on which deep learning models are trained.
Transfer learning only works in deep learning if the model features learned from the first task are general.
In transfer learning, we first train a base network on a base dataset and task, and then we repurpose the learned features, or transfer them, to a second target network to be trained on a target dataset and task. This process will tend to work if the features are general, meaning suitable to both base and target tasks, instead of specific to the base task.
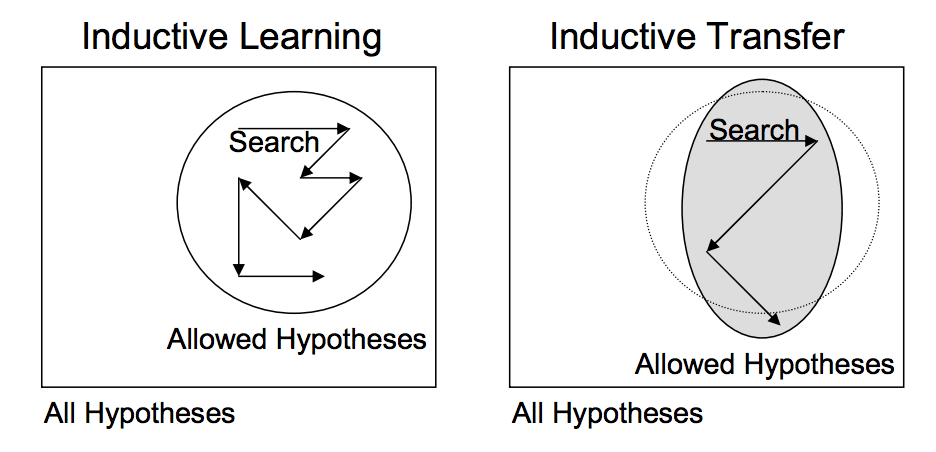
This form of transfer learning used in deep learning is called inductive transfer. This is where the scope of possible models (model bias) is narrowed in a beneficial way by using a model fit on a different but related task.
Depiction of Inductive Transfer Taken from “Transfer Learning”
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Select Source Task. You must select a related predictive modeling problem with an abundance of data where there is some relationship in the input data, output data, and/or concepts learned during the mapping from input to output data.
Develop Source Model. Next, you must develop a skillful model for this first task. The model must be better than a naive model to ensure that some feature learning has been performed.
Reuse Model. The model fit on the source task can then be used as the starting point for a model on the second task of interest. This may involve using all or parts of the model, depending on the modeling technique used.
Tune Model. Optionally, the model may need to be adapted or refined on the input-output pair data available for the task of interest.
Pre-trained Model Approach
Select Source Model. A pre-trained source model is chosen from available models. Many research institutions release models on large and challenging datasets that may be included in the pool of candidate models from which to choose from.
Reuse Model. The model pre-trained model can then be used as the starting point for a model on the second task of interest. This may involve using all or parts of the model, depending on the modeling technique used.
Tune Model. Optionally, the model may need to be adapted or refined on the input-output pair data available for the task of interest.
This second type of transfer learning is common in the field of deep learning.
Examples of Transfer Learning with Deep Learning
Let’s make this concrete with two common examples of transfer learning with deep learning models.
Transfer Learning with Image Data
It is common to perform transfer learning with predictive modeling problems that use image data as input.
This may be a prediction task that takes photographs or video data as input.
For these types of problems, it is common to use a deep learning model pre-trained for a large and challenging image classification task such as the ImageNet 1000-class photograph classification competition.
The research organizations that develop models for this competition and do well often release their final model under a permissive license for reuse. These models can take days or weeks to train on modern hardware.
These models can be downloaded and incorporated directly into new models that expect image data as input.
For more examples, see the Caffe Model Zoo where more pre-trained models are shared.
This approach is effective because the images were trained on a large corpus of photographs and require the model to make predictions on a relatively large number of classes, in turn, requiring that the model efficiently learn to extract features from photographs in order to perform well on the problem.
In their Stanford course on Convolutional Neural Networks for Visual Recognition, the authors caution to carefully choose how much of the pre-trained model to use in your new model.
[Convolutional Neural Networks] features are more generic in early layers and more original-dataset-specific in later layers
It is common to perform transfer learning with natural language processing problems that use text as input or output.
For these types of problems, a word embedding is used that is a mapping of words to a high-dimensional continuous vector space where different words with a similar meaning have a similar vector representation.
Efficient algorithms exist to learn these distributed word representations and it is common for research organizations to release pre-trained models trained on very large corpa of text documents under a permissive license.
These distributed word representation models can be downloaded and incorporated into deep learning language models in either the interpretation of words as input or the generation of words as output from the model.
In his book on Deep Learning for Natural Language Processing, Yoav Goldberg cautions:
… one can download pre-trained word vectors that were trained on very large quantities of text […] differences in training regimes and underlying corpora have a strong influence on the resulting representations, and that the available pre-trained representations may not be the best choice for [your] particular use case.
Transfer learning is an optimization, a shortcut to saving time or getting better performance.
In general, it is not obvious that there will be a benefit to using transfer learning in the domain until after the model has been developed and evaluated.
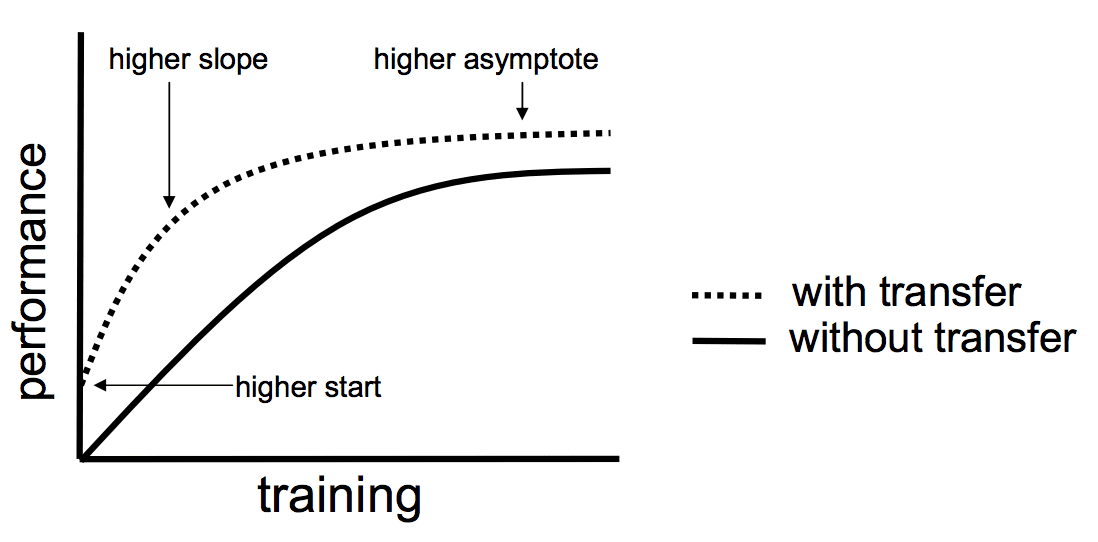
Lisa Torrey and Jude Shavlik in their chapter on transfer learning describe three possible benefits to look for when using transfer learning:
Higher start. The initial skill (before refining the model) on the source model is higher than it otherwise would be.
Higher slope. The rate of improvement of skill during training of the source model is steeper than it otherwise would be.
Higher asymptote. The converged skill of the trained model is better than it otherwise would be.
Three ways in which transfer might improve learning. Taken from “Transfer Learning”.
Ideally, you would see all three benefits from a successful application of transfer learning.
It is an approach to try if you can identify a related task with abundant data and you have the resources to develop a model for that task and reuse it on your own problem, or there is a pre-trained model available that you can use as a starting point for your own model.
On some problems where you may not have very much data, transfer learning can enable you to develop skillful models that you simply could not develop in the absence of transfer learning.
The choice of source data or source model is an open problem and may require domain expertise and/or intuition developed via experience.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials on topics like: classification, object detection (yolo and rcnn), face recognition (vggface and facenet), data preparation and much more...
Finally Bring Deep Learning to your Vision Projects
You repeated a sentence early in the article.
“Transfer learning only works in deep learning if the model features learned from the first task are general.”
Hello Dr. Jason. Thank you so much for sharing clearly and in a succinct way your knowledge and insights on ML and Deep Learning.
Reviewing the pre-trained model references, it appears that Google Inception Model is not longer available. I also checked at https://github.com/tensorflow/models/tree/master/inception but is not available either.
Do you have idea if this is now placed at some other location? Thank you!
Hello Jason,
I am a big fan of your work. I wanted to ask that how to choose a pre-trained model for my specific problem. for example what would be a good pre-trained model that would work well on handwritten arabic alphabet classification?
yes. because all keras pre-trained models require input size (244, 244, 3) while my data has (64, 64, 1) dimensions. also imagenet and character classification are very different problems. Most of the imagenet features are redundant for my problem.
Many thanks for the good explanation..Can i ask you about your suggestion for the most suitable pre-trained model for image super resolution..how can i select it ?
Here is an implementation of image deblurring using GAN [https://blog.sicara.com/keras-generative-adversarial-networks-image-deblurring-45e3ab6977b5].
Asking your question to its author might be fruitful.
Good luck.
Thanks! I have understand this concept. I want to ask a question that, for example there is a pre-trained (OCR) model for English language, and I want to transfer this model into (OCR) for my local language which has completely different alphabets than English. It would help me or not ?
Hi Jason, thank you for this article! I wonder if one could fine-tune a model like resnet, trained for classification, for the purpose of say image filtering? Like local contrast enhancement or denoise etc. What you think? Thanks
Many thanks
I want to ask if I have PDF content fir example drawings and I need model to train I will give the model what is that geometry which pre trained model you can recommend?
I got an idea for transfer learning, I want to share for your opinion but, in the physical-mathematical domain. This is my anology or equivalence (lets call it JGs approach). For example, what about if in order to solve a physical problem (in our case e.g. an image classification), I approach it with some mathematical description such as partial derivatives, Laplace operator, etc. (in our case this could be the neural model architecture, with convolutions, fully connected , data_augmentation, …that we are intend to apply, etc). But because this math are very complexes with only know some few particular solutions under some initial o boundary values (and this could be the pre-trained weights in our ML or DL issue)…son under OTHER boundary or initial or complexes conditions we do not have any (of these analytical) solutions (this could be the case with other image classification or other datasets inputs) …so we can use the pretty well known solution an try to apply for our problem case, where we intend to obtain similars solutions (this is now the transfer learning repurpose in order to search for similar or analogous solutions)…what do you think Mr. Brownlee about the analogy? Of course, as in real life, probably, from time to time, the solutions to our problems are radically different to the ones we try to reused (model or weight for radically different images sets or classification), ..but at least, the transfer learning essay serves as initial inspiration:-))
I have done so but approaches seem to be either about the pre-trained model method or some method which leverages the knowledge that two domains are related and so adds an extra step to the process, such as dimensionality reduction.
The two survey papers also do not mention a simple Develop Model Approach.
Thank you for introduction about transfer learning.
Is it possible to use this model for the calling records data with the attributes likes(source call, dist call, start time, duration and locations) for prediction such as user mobility prediction or characterize traffic on base station etc.?
Hi, It’s me Mr. Sana Ullah Khan, I want to work in detection of malignant cells in breast cytology images, I am confused that how I can use a CNN with transfer learning for detection and classification of malignant cells. I scatch one diagram, as well as i, want to share with you that how I can work. guide me, please
I am using transfer-learning to classify a dataset of images with google inception V3. I got the code retrain.py from the tutorial on tensorflow website https://www.tensorflow.org/hub/tutorials/image_retraining
I run the code on tensorflow virtual environment on my machine and it works like they want. What I am looking for is what should I add or change in the code ” retrain.py” to show the confusion matrix with python and Thanks.
If I understand correctly, transfer learning is largely focused in using pretrained model on a large data set to make predictions on new data. I am wondering how transferrable is pretrained model on a not so large data set, i.e., 10k entries, to similar problems? For example, I have trained a good neural network to do sentiment analysis on ~10k tweets. How confident should I be to use this model to do sentiment analysis on other problems?
Cant explain your good work in words.
Could you please share a working code where we are using Transfer learning to train a naive model from a trained existing model
increamental model , i would to train the existing model when ever new data comes whether it is small or big it has train not from scartch .
i have existing model ,but frequently i will get new data to my model , so that i would to train the existing model without starting from scartch for time saving purpose
this is main motto to achieve .
Please suggest any ideas or methods are available for this requirement.
Hi, I want to use incremental learning concert for human activities classification using imu sensor accelerometer dataset. Please suggest resources and ideas to implement
Could you suggest good models for time series forecasting? I’m doing a research on zakat (tax for Muslims) and I only have 1 year data to make monthly prediction.
I would like to implement a chat bot applications, model has to learn from each conversation from starting onwards,intially we don’t have any conservation,based on user convsersation only model has to learn.
could you suggest me which is apt for this requirement.
Thanks for the information. Are there pre-trained regression models that can be used for transfer learning? I can only find classification models online.
Dear Jason;
Can we apply transfer learning for a regression task? If so, how many training set is minimum to apply transfer learning techniques?
For instance, we have 60 training samples used for training set in one subset image and 40 testing samples used for validation set in other subset image?
I mean to say the domain in particular suppose I am predicting one time series problem using deep learning for electricity estimation can i use the same via transfer learning for stock market prediction or spreading of Dengue .
Hi sir thanks for sharing your thoughts I am trying to implement the concept you told here ….sir besides this i am also trying to write a blog on ML with practical approach I also messaged you on facebook could you please review my site and give me some feedback how can i improve my writing. Many many thanks for your comment by the way .
Hi, if my understanding is correct, in case of image classification and NLP, if I have a pre-trained model, to train on new data, I can reshape the data according to the pre-trained model. I am trying to use transfer learning for a regression problem. Consider I train a base model with 15 parameters and 1 million rows. I train a model. Now if I want to use this model for a similar problem where I have only 14 parameters, one parameter is missing. Will the pre-trained model be of any use. Is there a way I can use transfer learning in such cases?
it is not a univariate data. if one among the 15 parameters is missing, I believe I can impute/fill the missing column and then can use the pre-trained model.
Hi.. could you please guide me that if we train our model from scratch, but not from transfer learning, then what could be the advantages of doing that? Also please guide that in the future, I would propose a modified/cascaded version of DL model, so will it be possible to train it from transfer learning?
Thanks for the reply….i need to ask that can I still train a deep learning model by transfer learning which has not been trained previously on a larger dataset like imagenet? like AlexNet has already been trained in imagenet dataset but if I use any other model which has not been trained yet by using imagenet dataset, then can that model be trained by transfer learning?
Hello,
Would you please give me a complete transfer learning dataset, not imagenet dataset.
In the dataset there are multiple entries and attribute, dataset that includes different domains such as videos, music, games (common users among the domains).
It will be very helpful for me.
Thanks for the intro, good job linking together different sources so I know where to go from here! F. Ameen brought up a similar question, but did not get the answer I was looking for.
My question is: How do you deal with input dimensionality?
Say your data has different dimensionality than that of the pretrained model. For image data, reusing the filters would result in different sized activation maps, and computationally I can reason this is not a problem if you just change the final dense layer. BUT the learned filters will look for patterns of a certain size (e.g. within 3×3 or 5×5 fields). If your images is twice the resolution of those used for pretraining, the filters are too small (and vice versa).
What are good ways to deal with this? Should one take account of this and use initial pooling or up-convolution to size match before sending the image into the pretrained filters?
And what about dense feed forward networks? Should one then just switch out the first (and last) layers? Say your new data has some of the same features as the ones in your pretraining data, do you then just add and/or remove connections between the input layer and first hidden layers? Or switch out the first layer entirely?
You cut off the input layer or layers, define a new input layer and away you go. Filters will still work just fine on a larger image.
In fact, if you use the keras applications api, you can define new input shapes with arbitrary sizes without changing the model. The filters don’t care.
Yes, you cut off the output layers and refit on the new class labels.
I want to done my thesis on prediction by using deep learning my data is not image and also it is not on NIP but i want to use transfer learning. Can I use transfer learning on this issue?
transfer learning is only applied on image and NIP or not?
hello i am doing in HIV statues prediction using DHS dataset .how can use the transfer learning? it is possible to perform prediction using transfer learning??
i did not get the point where we define transfer learning programatically. What i understood was we first train the model from one dataset and then use the same model to re-train again on different dataset to achieve transfer learning. Is this assumption correct.
If yes, once the model is trained on a particular dataset, how to retrain it on another dataset??
Hi. Thanks for this great tutorial. Always helpful. I have got a question on the “Develop Model Approach”. I have two related tasks where I want to learn a model on my emotion detection task and transfer the knowledge to my second task which is empathy detection. Both tasks have labeled datasets. I do not know how I should develop a model on the first task and reuse it on the second task. Do you have any kind of tutorial/GitHub repository in your mind that specifically use transfer learning by this approach (not using the pre-trained models)?
Thanks. One more question please. I am having an argument with someone about something.
Please, does LSTM models accept variable length sequences? My argument is that they don’t. You need to pad it to use it. However, I can’t really defend myself with a scholarly publication.
If I am correct, can you give me a better explanation (Or a link to one you have done in the past) and a link to a paper on this? Thanks.
Hi, hopefully you will be fine. I am using AlexNet pre-trained model for feature extraction only, as the input shape of AlexNet is 227x227x3, but my image dataset contains images of dimension 100x100x3. Do I need to resize my dataset images to 227x227x3 in order to use AlexNet pre-trained model as feature extractor?
Or i can directly input these images to AlexNet?
thanks for the article.
Does transfer learning usually apply to complex models like VGG model or ResNet model?
I would think it makes no sense to transfer a two layer LSTM model trained from one dataset to a new dataset. We can simply train a new model with the new dataset in this case. What do you think please?
Is there any proved methods to perform cross modal learning? I couldn’t find much on the internet.
I have 2 sets of datasets ( labelled data set ‘A’ of images annotated with 5 emotions and another unlabelled dataset ‘B’ of text containing same 5 emotions)
Is there any method out there which can use the learning from labelled image data to classify unlabelled text data?
But my 2 datasets are of different modality. one is labeled images and the other one is unlabeled Text data. Both of them share the same category of emotions.
Perhaps you can use a pre-trained language model and a pre-trained object detection model and integer both models into a new model that accepts both data types. This is called a multi-input model and is common for problems like image captioning.
Thank you so much for your article. I have question regarding the concept of Transfer Learning.
For example, I am using a pretained VGG16 model trained on Fashion-MNIST dataset. I know it is an obvious transfer learning, and it is Inductive transfer learning as per your article If i am not wrong.. But my question is, would it be a homogeneous or heterogenous transfer learning? If its any homo/hetero then will it be a symmetric or asymmetric problem of transfer learning?
I am struggling to find the answer of this question. I have read the definations but still confused..
Thnak you for your response. Let me repharase my question. Classifying fashion images from fashion-mnist dataset using vgg16 pretrained model would be a homogeneous or heterogeneous transfer learning?
Symmetric and Asymetric are further types of homogeneous /heterogeneous transfer learning.
So, In what category my problem solving approach will lie?
Heterogenous transfer learning, source and domain targets have different feature spaces, and generally non overlapping. Homeogeneous is vice versa. So according to my understanding our approach will be heteregeous approach.
I tremendously appreciate the last sentence in your article: “The choice of source data or source model is an open problem and may require domain expertise and/or intuition developed via experience.”
I don’t entirely know how to classify everything about it that I appreciate. Somehow, you phrased it very well, and somehow that phrasing does a very good of setting expectations. It strikes me as the kind of thing I mostly want to know beyond basic, primary definitions, but that ends up taking forever to get “experts” to acknowledge about a subject, or usually a lot of my own reading, learning, and experimentation time to finally realize. Nobody has the perfect answer — it will likely take a lot of learning and experimentation time to arrive at the skill of making selections well.
It sounds obvious in some ways. However, I think skills are too often sold as “just take this class, do a few exercises, and you are then supposed to be an expert that can be expected to do said skill flawlessly in minimized time”.
I am bit confused please guide me on this; Transffering knowledge from VGG16 to Fashion-MNIST would be an inductive transfer learning or transductive transfer learning?
Hi, Dr Thanks for this useful tutorial. I have a question I want to use transfer learning in 5G communication. Can you please help me with how should I start? do you know any model for communication where the inputs are data rate, latency, packet loss, distance, and duration?
I am using transfer learning and I fee some weired behavior of Adam optimizer even with exponential learning rate decay! My validation accuracy and loss both increase simultaneously althoug training accuracy improves gradually and loss decreases. Should I consider this behavior as an overfitting? If I stop it early then it causes in test accuracy drop.
I got what you mean here. I can find a few paper on regression, such as this one: https://arxiv.org/abs/2102.09504
But relatively, it is less often to use transfer learning on regression tasks than on classification. Probably because of the nature of regression problems, the improvement is less charming.
thank you so much !
i used a pre-trained model from timm for training a vision transformer model but just on my small dataset , i observed is take a lot of time than training my Vit model from scratch for this small dataset?? i don’t know what is the reason !
it took 1h for 1 epoch !! it’s normall?? as we know when we use a pretrained model the time of training is reduced ! but in my case vice versa !
Well-written introduction, Just one question. When citing Torrey and Shavlik on the three possible benefits of transfer learning, you mention higher start and higher slope for the source model. Don’t you mean the TARGET model? The source model has already been trained, and it’s being applied to a similar problem (the target) in a related but not identical domain.
Hi Prakash…You’re absolutely correct! When referring to the three possible benefits of transfer learning as outlined by Torrey and Shavlik, the concepts of a **higher starting point** and a **higher slope** are indeed about the **target model**, not the source model. Here’s a clarification:
– **Higher Starting Point:** The target model begins with better performance compared to training from scratch because it leverages the knowledge transferred from the source model.
– **Higher Slope:** The target model can achieve a faster learning rate due to the pre-trained features from the source model, allowing it to converge more quickly.
– **Higher Asymptote:** The target model may reach a higher ultimate performance ceiling compared to training from scratch, assuming the source domain provides highly relevant features.
The source model has already been trained and remains unchanged during transfer learning. These benefits describe how the pre-trained knowledge improves the target model’s learning process in the new domain.
Thank you for pointing that out—it’s an important distinction, and your observation is spot on!








As always, well written and insightful article. The additional resources you provide on this topic are also very helpful! Thanks.
Thanks.
sir i want to know that how to create pretrained network for IDS. will you help me in this regard. will be thankul to you.
Sorry, I’m not aware of pre-trained models for that class problem.
You repeated a sentence early in the article.
“Transfer learning only works in deep learning if the model features learned from the first task are general.”
Thanks, fixed!
Hello Dr. Jason. Thank you so much for sharing clearly and in a succinct way your knowledge and insights on ML and Deep Learning.
Reviewing the pre-trained model references, it appears that Google Inception Model is not longer available. I also checked at https://github.com/tensorflow/models/tree/master/inception but is not available either.
Do you have idea if this is now placed at some other location? Thank you!
Keras has it here:
https://keras.io/applications/
Hello Jason,
I am a big fan of your work. I wanted to ask that how to choose a pre-trained model for my specific problem. for example what would be a good pre-trained model that would work well on handwritten arabic alphabet classification?
Perhaps a model trained on other character data?
yes. because all keras pre-trained models require input size (244, 244, 3) while my data has (64, 64, 1) dimensions. also imagenet and character classification are very different problems. Most of the imagenet features are redundant for my problem.
I believe the models could be adapted and may still add value.
Many thanks for the good explanation..Can i ask you about your suggestion for the most suitable pre-trained model for image super resolution..how can i select it ?
Sorry, I have not worked on super resolution. I don’t have a good suggestion at the moment. Perhaps try a google search?
Here is an implementation of image deblurring using GAN [https://blog.sicara.com/keras-generative-adversarial-networks-image-deblurring-45e3ab6977b5].
Asking your question to its author might be fruitful.
Good luck.
Thanks for sharing.
Thanks! I have understand this concept. I want to ask a question that, for example there is a pre-trained (OCR) model for English language, and I want to transfer this model into (OCR) for my local language which has completely different alphabets than English. It would help me or not ?
I expect it would help.
Just wondering if applying transfer learning is a solution to dealing with small data-set size?
It sure could be, nice one!
Hi Jason, thank you for this article! I wonder if one could fine-tune a model like resnet, trained for classification, for the purpose of say image filtering? Like local contrast enhancement or denoise etc. What you think? Thanks
Sounds like a good idea, try it. Let me know how you go.
Ok, thanks!
Thanks! Helped a lot 🙂
I’m glad to hear that.
Many thanks
I want to ask if I have PDF content fir example drawings and I need model to train I will give the model what is that geometry which pre trained model you can recommend?
Perhaps you might be able to use an existing computer vision model. It would be cheap to try and evaluate the results.
Just wondering what is the difference between transfer learning and unsupervised pre-training?
They are orthogonal ideas. In theory, could use transfer learning with a supervised or an unsupervised learning problem.
Hello sir i need your Help Please if you can .
What do you need help with?
I got an idea for transfer learning, I want to share for your opinion but, in the physical-mathematical domain. This is my anology or equivalence (let
s call it JGs approach). For example, what about if in order to solve a physical problem (in our case e.g. an image classification), I approach it with some mathematical description such as partial derivatives, Laplace operator, etc. (in our case this could be the neural model architecture, with convolutions, fully connected , data_augmentation, …that we are intend to apply, etc). But because this math are very complexes with only know some few particular solutions under some initial o boundary values (and this could be the pre-trained weights in our ML or DL issue)…son under OTHER boundary or initial or complexes conditions we do not have any (of these analytical) solutions (this could be the case with other image classification or other datasets inputs) …so we can use the pretty well known solution an try to apply for our problem case, where we intend to obtain similars solutions (this is now the transfer learning repurpose in order to search for similar or analogous solutions)…what do you think Mr. Brownlee about the analogy? Of course, as in real life, probably, from time to time, the solutions to our problems are radically different to the ones we try to reused (model or weight for radically different images sets or classification), ..but at least, the transfer learning essay serves as initial inspiration:-))Not sure I follow, sorry.
Are you able to simplify the explanation?
Actually, Very vague explanation.. I read it twice. but still I don’t know how to use it in Keras..
Do you have any short simple example with Keras?
Sorry to hear that.
I show how to reuse the VGG model for photo captioning (but it is not short):
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Thanks for this. Lovely introduction to the area.
Do you know of any papers using the “Develop Model Approach’? It seems so simple yet I cannot find any work on this specifically.
Perhaps search for transfer learning on scholar.google.com
I have done so but approaches seem to be either about the pre-trained model method or some method which leverages the knowledge that two domains are related and so adds an extra step to the process, such as dimensionality reduction.
The two survey papers also do not mention a simple Develop Model Approach.
Thank you for introduction about transfer learning.
Is it possible to use this model for the calling records data with the attributes likes(source call, dist call, start time, duration and locations) for prediction such as user mobility prediction or characterize traffic on base station etc.?
I would recommend this process when working on a new predictive modeling problem:
https://machinelearningmastery.com/start-here/#process
Hi, It’s me Mr. Sana Ullah Khan, I want to work in detection of malignant cells in breast cytology images, I am confused that how I can use a CNN with transfer learning for detection and classification of malignant cells. I scatch one diagram, as well as i, want to share with you that how I can work. guide me, please
You can cut the top/bottom off a pre-trained model, add new layers then train the new layers of the model on your new dataset.
Hi, what would be a good pre-trained model that would work well on IMU sensor data for human activities classification?
Hi Ganesha…The following resource will add clarity on the task you are working with:
https://machinelearningmastery.com/deep-learning-models-for-human-activity-recognition/
Thank you very much
Hi Sir I am seeking for a help if you do not mind
I am using transfer-learning to classify a dataset of images with google inception V3. I got the code retrain.py from the tutorial on tensorflow website
https://www.tensorflow.org/hub/tutorials/image_retraining
I run the code on tensorflow virtual environment on my machine and it works like they want. What I am looking for is what should I add or change in the code ” retrain.py” to show the confusion matrix with python and Thanks.
You can learn how to implement a confusion matrix here:
https://machinelearningmastery.com/confusion-matrix-machine-learning/
Hi Sir
Thank youuuu So Much for Your Help and Your Kindness <3
No problem.
Hello
Very good explanation. Thank you
There is a little problem, link to google Inception model is broken. Please update the link.
Thanks, fixed. Here’s the link:
https://github.com/tensorflow/models/tree/master/research/inception
can we apply transfer learning on RNN model using keras.
Sure, this post will give you some ideas:
https://machinelearningmastery.com/lstm-autoencoders/
Thanks Jason for the nice work, as always!
If I understand correctly, transfer learning is largely focused in using pretrained model on a large data set to make predictions on new data. I am wondering how transferrable is pretrained model on a not so large data set, i.e., 10k entries, to similar problems? For example, I have trained a good neural network to do sentiment analysis on ~10k tweets. How confident should I be to use this model to do sentiment analysis on other problems?
Thanks in advance!
Typically a model fit on a very large dataset is a good starting point for use on small datasets.
Going from small to small datasets – it really depends on the tasks involved. I recommend prototype some examples and evaluate performance.
Hi Jason,
Cant explain your good work in words.
Could you please share a working code where we are using Transfer learning to train a naive model from a trained existing model
Thanks,
Ark
Thanks for the suggestion, I will work on some examples.
can we increment the model along with existing model ,each time when ever new data comes without starting from scartch for RNN model
Please suggest me any methods are available for this requirement .
What do you mean by increment the model exactly?
What are you trying to achieve?
increamental model , i would to train the existing model when ever new data comes whether it is small or big it has train not from scartch .
i have existing model ,but frequently i will get new data to my model , so that i would to train the existing model without starting from scartch for time saving purpose
this is main motto to achieve .
Please suggest any ideas or methods are available for this requirement.
Yes, you can continue the training of an existing model with just new data and a small learning rate.
please can you explain what is small learning rate,i mean which parameter i need to tune,why it is useful for increamental model .
Thanks in advance
The “learning rate” for stochastic gradient descent (SGD) optimization algorithm.
Hi, I want to use incremental learning concert for human activities classification using imu sensor accelerometer dataset. Please suggest resources and ideas to implement
Could you suggest good models for time series forecasting? I’m doing a research on zakat (tax for Muslims) and I only have 1 year data to make monthly prediction.
I have some suggestions here:
https://machinelearningmastery.com/time-series-forecasting-methods-in-python-cheat-sheet/
I would like to implement a chat bot applications, model has to learn from each conversation from starting onwards,intially we don’t have any conservation,based on user convsersation only model has to learn.
could you suggest me which is apt for this requirement.
thanks in advance.
Sorry, I don’t have any tutorials on chat bots, cannot give you good off the cuff advice.
kindly, do you find any suggestion for your question?
Hi,
Thanks for the information. Are there pre-trained regression models that can be used for transfer learning? I can only find classification models online.
Thanks.
Not that I have seen.
Dear Jason;
Can we apply transfer learning for a regression task? If so, how many training set is minimum to apply transfer learning techniques?
For instance, we have 60 training samples used for training set in one subset image and 40 testing samples used for validation set in other subset image?
Sure.
Hi! Thanks for the explanation. I am wondering if there are any pre-trained models for regression problems. Are you aware of any such models?
Not that I am aware.
Can you please explain the scope of transfer learning
What do you mean by scope? Problem domains?
I mean to say the domain in particular suppose I am predicting one time series problem using deep learning for electricity estimation can i use the same via transfer learning for stock market prediction or spreading of Dengue .
Perhaps. I’d recommend trying with some experiments.
Hi sir thanks for sharing your thoughts I am trying to implement the concept you told here ….sir besides this i am also trying to write a blog on ML with practical approach I also messaged you on facebook could you please review my site and give me some feedback how can i improve my writing. Many many thanks for your comment by the way .
Well done.
Sorry, I don’t have the capacity to review your blog.
Hi, if my understanding is correct, in case of image classification and NLP, if I have a pre-trained model, to train on new data, I can reshape the data according to the pre-trained model. I am trying to use transfer learning for a regression problem. Consider I train a base model with 15 parameters and 1 million rows. I train a model. Now if I want to use this model for a similar problem where I have only 14 parameters, one parameter is missing. Will the pre-trained model be of any use. Is there a way I can use transfer learning in such cases?
Thank you.
I’m not sure about this, I suspect some careful work is required to use transfer learning on univariate data.
it is not a univariate data. if one among the 15 parameters is missing, I believe I can impute/fill the missing column and then can use the pre-trained model.
What is the advantage of using transfer learning, if we talk about the class distribution of training data?
What do you mean exactly?
In general, transfer learning can shorten the time/effort to develop a new model by leveraging an existing model.
Hi.. could you please guide me that if we train our model from scratch, but not from transfer learning, then what could be the advantages of doing that? Also please guide that in the future, I would propose a modified/cascaded version of DL model, so will it be possible to train it from transfer learning?
Yes, you can discover many examples of training CNNs from scratch here:
https://machinelearningmastery.com/start-here/#dlfcv
Thanks for the reply….i need to ask that can I still train a deep learning model by transfer learning which has not been trained previously on a larger dataset like imagenet? like AlexNet has already been trained in imagenet dataset but if I use any other model which has not been trained yet by using imagenet dataset, then can that model be trained by transfer learning?
Yes. You can train on your own problem, then use that model on different problem of your own.
Hello,
Would you please give me a complete transfer learning dataset, not imagenet dataset.
In the dataset there are multiple entries and attribute, dataset that includes different domains such as videos, music, games (common users among the domains).
It will be very helpful for me.
I cannot prepare a dataset for you.
Hi Jason,
Thanks for the intro, good job linking together different sources so I know where to go from here! F. Ameen brought up a similar question, but did not get the answer I was looking for.
My question is: How do you deal with input dimensionality?
Say your data has different dimensionality than that of the pretrained model. For image data, reusing the filters would result in different sized activation maps, and computationally I can reason this is not a problem if you just change the final dense layer. BUT the learned filters will look for patterns of a certain size (e.g. within 3×3 or 5×5 fields). If your images is twice the resolution of those used for pretraining, the filters are too small (and vice versa).
What are good ways to deal with this? Should one take account of this and use initial pooling or up-convolution to size match before sending the image into the pretrained filters?
And what about dense feed forward networks? Should one then just switch out the first (and last) layers? Say your new data has some of the same features as the ones in your pretraining data, do you then just add and/or remove connections between the input layer and first hidden layers? Or switch out the first layer entirely?
Thanks a lot!
/U
You cut off the input layer or layers, define a new input layer and away you go. Filters will still work just fine on a larger image.
In fact, if you use the keras applications api, you can define new input shapes with arbitrary sizes without changing the model. The filters don’t care.
Yes, you cut off the output layers and refit on the new class labels.
Hello, Dear Jason Brownlee, thank you for sharing this beneficial blog and undoubtedly everyone is getting a lot of benefits.
my question is …Do the pre-trained datasets which relates to ENGLISH characters (A-Z . a-z . 0-9) consist of defective characters in it?
waiting for your reply.
thank you
You’re welcome.
It depends on the model and the choice of vocab.
Can u please suggest me a dataset which consists of defective characters in texts
Not off hand, you can search for datasets here:
https://machinelearningmastery.com/faq/single-faq/where-can-i-get-a-dataset-on-___
where to write those codes
what codes?
I want to done my thesis on prediction by using deep learning my data is not image and also it is not on NIP but i want to use transfer learning. Can I use transfer learning on this issue?
transfer learning is only applied on image and NIP or not?
Yes, if you can fit or find a model trained on a related dataset.
I’m working on malware detection,.Can i find a pre trained model i can use for web-based malware detection?
I’m not aware of one, sorry. Perhaps you can train one?
Really? Possible to train one like that?
Sure, get ta related dataset with a ton more data, fit a model on it, then transfer it to your related problem.
hello i am doing in HIV statues prediction using DHS dataset .how can use the transfer learning? it is possible to perform prediction using transfer learning??
Yes, see an example here for image data:
https://machinelearningmastery.com/how-to-develop-a-convolutional-neural-network-to-classify-photos-of-dogs-and-cats/
i did not get the point where we define transfer learning programatically. What i understood was we first train the model from one dataset and then use the same model to re-train again on different dataset to achieve transfer learning. Is this assumption correct.
If yes, once the model is trained on a particular dataset, how to retrain it on another dataset??
No, we freeze the trained model, add a new output layer and just train that.
Hi. Thanks for this great tutorial. Always helpful. I have got a question on the “Develop Model Approach”. I have two related tasks where I want to learn a model on my emotion detection task and transfer the knowledge to my second task which is empathy detection. Both tasks have labeled datasets. I do not know how I should develop a model on the first task and reuse it on the second task. Do you have any kind of tutorial/GitHub repository in your mind that specifically use transfer learning by this approach (not using the pre-trained models)?
I have text data (not image).
Perhaps try this:
https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/
Thanks. This tutorial (https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/), discusses sentiment analysis without transferring knowledge to the second task. I am looking for a way to freeze the learned weights of the first model and re-use them to initialize the second model’s parameters to learn the second task.
Yes, you can use the tutorial as a staring point and add the use of transfer learning.
You’re welcome.
Perhaps start with a model that is good at detecting faces and use transfer learning for your first task.- like facenet or vggface2.
Hello Jason. Please can I use transfer temporal information for transfer learning? Train on one dataset using LSTM and then use it for another?
Perhaps – try it and see if it helps.
Thanks. One more question please. I am having an argument with someone about something.
Please, does LSTM models accept variable length sequences? My argument is that they don’t. You need to pad it to use it. However, I can’t really defend myself with a scholarly publication.
If I am correct, can you give me a better explanation (Or a link to one you have done in the past) and a link to a paper on this? Thanks.
It can, the dynamic rnn can. I rarely use this version of the model. Here is an example:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Hi, hopefully you will be fine. I am using AlexNet pre-trained model for feature extraction only, as the input shape of AlexNet is 227x227x3, but my image dataset contains images of dimension 100x100x3. Do I need to resize my dataset images to 227x227x3 in order to use AlexNet pre-trained model as feature extractor?
Or i can directly input these images to AlexNet?
You can resize your images, or define a new input layer for the model.
How to resize from 100×100 to 227×227
You can specify the expected shape of inputs when you define the model:
https://machinelearningmastery.com/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
🙂 …. BU
Hi Jason,
thanks for the article.
Does transfer learning usually apply to complex models like VGG model or ResNet model?
I would think it makes no sense to transfer a two layer LSTM model trained from one dataset to a new dataset. We can simply train a new model with the new dataset in this case. What do you think please?
Thanks!
Yes.
Yes, try it and see if it helps.
Here’s an example for tabular data:
https://machinelearningmastery.com/how-to-improve-performance-with-transfer-learning-for-deep-learning-neural-networks/
Dear Jason,
Is there any proved methods to perform cross modal learning? I couldn’t find much on the internet.
I have 2 sets of datasets ( labelled data set ‘A’ of images annotated with 5 emotions and another unlabelled dataset ‘B’ of text containing same 5 emotions)
Is there any method out there which can use the learning from labelled image data to classify unlabelled text data?
All predictive models learn from labeled data to make predictions on unlabelled data.
This is called predictive modeling.
But my 2 datasets are of different modality. one is labeled images and the other one is unlabeled Text data. Both of them share the same category of emotions.
Perhaps you can use a pre-trained language model and a pre-trained object detection model and integer both models into a new model that accepts both data types. This is called a multi-input model and is common for problems like image captioning.
It’s amazing post. I love it
Thanks!
Hi Jason,
Thank you so much for your article. I have question regarding the concept of Transfer Learning.
For example, I am using a pretained VGG16 model trained on Fashion-MNIST dataset. I know it is an obvious transfer learning, and it is Inductive transfer learning as per your article If i am not wrong.. But my question is, would it be a homogeneous or heterogenous transfer learning? If its any homo/hetero then will it be a symmetric or asymmetric problem of transfer learning?
I am struggling to find the answer of this question. I have read the definations but still confused..
Thanks!!
You’re welcome!
What does “homo/hetero” mean when it comes to transfer learning, and why does it matter? My advice is use whatever works best for your dataset.
Hi Jason,
Thnak you for your response. Let me repharase my question. Classifying fashion images from fashion-mnist dataset using vgg16 pretrained model would be a homogeneous or heterogeneous transfer learning?
Symmetric and Asymetric are further types of homogeneous /heterogeneous transfer learning.
So, In what category my problem solving approach will lie?
Thank you!
What is “homogeneous or heterogeneous transfer learning”?
Hi Jason,
Heterogenous transfer learning, source and domain targets have different feature spaces, and generally non overlapping. Homeogeneous is vice versa. So according to my understanding our approach will be heteregeous approach.
Source: https://journalofbigdata.springeropen.com/articles/10.1186/s40537-017-0089-0#:~:text=Heterogeneous%20transfer%20learning%20is%20characterized%20by%20the%20source,which%20may%20be%20present%20in%20these%20cross-domain
Thank you!
Thanks for sharing. It is not something I know about.
I would recommend skipping the taxonomy and focus on discovering what works best for your problem.
I tremendously appreciate the last sentence in your article: “The choice of source data or source model is an open problem and may require domain expertise and/or intuition developed via experience.”
I don’t entirely know how to classify everything about it that I appreciate. Somehow, you phrased it very well, and somehow that phrasing does a very good of setting expectations. It strikes me as the kind of thing I mostly want to know beyond basic, primary definitions, but that ends up taking forever to get “experts” to acknowledge about a subject, or usually a lot of my own reading, learning, and experimentation time to finally realize. Nobody has the perfect answer — it will likely take a lot of learning and experimentation time to arrive at the skill of making selections well.
It sounds obvious in some ways. However, I think skills are too often sold as “just take this class, do a few exercises, and you are then supposed to be an expert that can be expected to do said skill flawlessly in minimized time”.
Thanks for sharing! I’m happy to hear it struck a chord.
Hi Jason,
I am bit confused please guide me on this; Transffering knowledge from VGG16 to Fashion-MNIST would be an inductive transfer learning or transductive transfer learning?
Thank you!
It would be “transfer learning”.
Inductive vs deductive vs transductive is not relevant.
Hi, Dr Thanks for this useful tutorial. I have a question I want to use transfer learning in 5G communication. Can you please help me with how should I start? do you know any model for communication where the inputs are data rate, latency, packet loss, distance, and duration?
You would likely need to train your model on one dataset, then adapt the model for a second related dataset.
Hi Jason,
Thank you so much for your nice article!
I am using transfer learning and I fee some weired behavior of Adam optimizer even with exponential learning rate decay! My validation accuracy and loss both increase simultaneously althoug training accuracy improves gradually and loss decreases. Should I consider this behavior as an overfitting? If I stop it early then it causes in test accuracy drop.
Looking forward to your kind response!
You’re welcome.
Perhaps look at learning curves to see if you’re overfiting:
https://machinelearningmastery.com/learning-curves-for-diagnosing-machine-learning-model-performance/
Dear Sir,
It is interesting topics! Thank you for your contribution!
Please, do you have some tutorial about domain adaptation in visual recognition?
if you have simple coding link in python please attach me!
You’re welcome.
Sorry, I don’t think I have tutorials on “domain adaptation”.
Can be do multiple class text classification with transfer learning
Sure.
Hi Jason,
Can You tell me the logic behind object detection, just like face or any other object.
Yes, see this:
https://machinelearningmastery.com/object-recognition-with-deep-learning/
Hi Jason, do you have a tutorial on how to pre-train your own model from scratch or maybe a material/book to indicate?
Yes, please see this step-by-step tutorial: https://machinelearningmastery.com/tutorial-first-neural-network-python-keras/
Hi Jason, I was meant to how to pre-train a model from scratch before and then fine tune the the trained model parameters on a given task.
What you said is called “transfer learning”. This tutorial may help you understand: https://machinelearningmastery.com/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
This is what I was looking for: https://machinelearningmastery.com/how-to-improve-performance-with-transfer-learning-for-deep-learning-neural-networks/
Have you ever seem throughout literature or in practice transfer learning on regression tasks?
I got what you mean here. I can find a few paper on regression, such as this one: https://arxiv.org/abs/2102.09504
But relatively, it is less often to use transfer learning on regression tasks than on classification. Probably because of the nature of regression problems, the improvement is less charming.
Thank you so much for sharing this paper.
Thank you! Very clear article.
Thank you for the feedback and kind words, Amy!
thank you so much !
i used a pre-trained model from timm for training a vision transformer model but just on my small dataset , i observed is take a lot of time than training my Vit model from scratch for this small dataset?? i don’t know what is the reason !
it took 1h for 1 epoch !! it’s normall?? as we know when we use a pretrained model the time of training is reduced ! but in my case vice versa !
can u help me ,please?
Hi Basma…There are many factors that could affect training time. My recommendations are the following:
1. Investigate early stopping: https://machinelearningmastery.com/feature-selection-to-improve-accuracy-and-decrease-training-time/
2. Utilize Google Colab and the free GPU offered: https://colab.research.google.com/notebooks/gpu.ipynb
Well-written introduction, Just one question. When citing Torrey and Shavlik on the three possible benefits of transfer learning, you mention higher start and higher slope for the source model. Don’t you mean the TARGET model? The source model has already been trained, and it’s being applied to a similar problem (the target) in a related but not identical domain.
Hi Prakash…You’re absolutely correct! When referring to the three possible benefits of transfer learning as outlined by Torrey and Shavlik, the concepts of a **higher starting point** and a **higher slope** are indeed about the **target model**, not the source model. Here’s a clarification:
– **Higher Starting Point:** The target model begins with better performance compared to training from scratch because it leverages the knowledge transferred from the source model.
– **Higher Slope:** The target model can achieve a faster learning rate due to the pre-trained features from the source model, allowing it to converge more quickly.
– **Higher Asymptote:** The target model may reach a higher ultimate performance ceiling compared to training from scratch, assuming the source domain provides highly relevant features.
The source model has already been trained and remains unchanged during transfer learning. These benefits describe how the pre-trained knowledge improves the target model’s learning process in the new domain.
Thank you for pointing that out—it’s an important distinction, and your observation is spot on!