When you’re an absolute beginner it can be very confusing. Frustratingly so.
Even ideas that seem so simple in retrospect are alien when you first encounter them. There’s a whole new language to learn.
I recently received this question:
So using the iris exercise as an example if I were to pluck a flower from my garden how would I use the algorithm to predict what it is?
It’s a great question.
In this post I want to give a gentle introduction to predictive modeling.

Gentle Introduction to Predictive Modeling
1. Sample Data
Data is information about the problem that you are working on.
Imagine we want to identify the species of flower from the measurements of a flower.
The data is comprised of four flower measurements in centimeters, these are the columns of the data.
Each row of data is one example of a flower that has been measured and it’s known species.
The problem we are solving is to create a model from the sample data that can tell us which species a flower belongs to from its measurements alone.

Sample of Iris flower data
2. Learn a Model
This problem described above is called supervised learning.
The goal of a supervised learning algorithm is to take some data with a known relationship (actual flower measurements and the species of the flower) and to create a model of those relationships.
In this case the output is a category (flower species) and we call this type of problem a classification problem. If the output was a numerical value, we would call it a regression problem.
The algorithm does the learning. The model contains the learned relationships.
The model itself may be a handful of numbers and a way of using those numbers to relate input (flower measurements in centimeters) to an output (the species of flower).
We want to keep the model after we have learned it from our sample data.
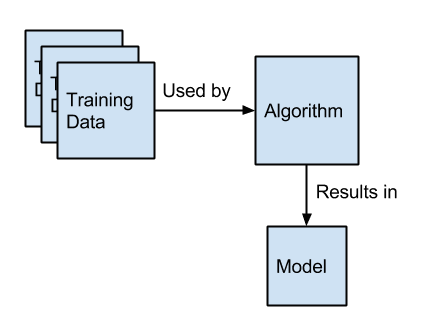
Create a predictive model from training data and an algorithm.
3. Make Predictions
We don’t need to keep the training data as the model has summarized the relationships contained within it.
The reason we keep the model learned from data is because we want to use it to make predictions.
In this example, we use the model by taking measurements of specific flowers of which don’t know the species.
Our model will read the input (new measurements), perform a calculation of some kind with it’s internal numbers and make a prediction about which species of flower it happens to be.
The prediction may not be perfect, but if you have good sample data and a robust model learned from that data, it will be quite accurate.
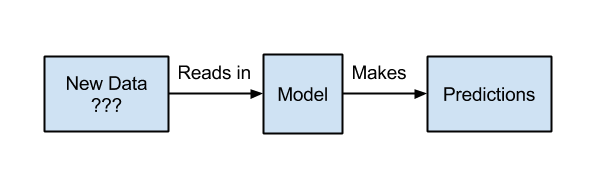
Use the model to make predictions on new data.
Summary
In this post we have taken a very gentle introduction to predictive modeling.
The three aspects of predictive modeling we looked at were:
- Sample Data: the data that we collect that describes our problem with known relationships between inputs and outputs.
- Learn a Model: the algorithm that we use on the sample data to create a model that we can later use over and over again.
- Making Predictions: the use of our learned model on new data for which we don’t know the output.
We used the example of classifying plant species based on flower measurements.
This is in fact a famous example in machine learning because it’s a good clean dataset and the problem is easy to understand.
Action Step
Take a moment and really understand these concepts.
They are the foundation of any thinking or work that you might do in machine learning.
Your action step is to think through the three aspects (data, model, predictions) and relate them to a problem that you would like to work on.
Any questions at all, please ask in the comments. I’m here to help.





Indeed a very clear, concise high level overview of Machine learning based predictive modeling, great read, looking forward to subsequent reads that will be focusing on model/hypothesis creation based on data, again at a high level of abstraction leaving out the statistical wizardry for advance reads
Thanks shahzad.
So are there other ways for doing predictive modeling that do not rely on machine learning?
And additionally: all machine learning algorithms (neural networks, decision trees, SVMs, …) can be considered as part of predictive modeling?
Good point Rhymeface.
Machine Learning is the set of tools we use to create our predictive models. We don’t have to use machine learning. For example, the simplest type of prediction is to use the mean value.
I would rephrase it as predictive modeling is the most common type of problem that we solve with machine learning (e.g. classification and regression problems).
What other ways are there to donpredictive modelling?
Sure, if we have regression dataset, I could give the mean value seen so far or the last value seen as a prediction of what to expect next.
In a classification problem, we could estimate the class as the most frequent class observed.
These methods are pure stats and generally uninteresting, but are examples of predictive modeling without using machine learning.
Loved it! Simple enough for a beginner to understand.
Your post was very clear and i’m excited to read more from your site. I’m new to machine learning and coding. I have very minimal experience in data visualization. But I have rudimentary knowledge in statistics. I guess at this point, i’d like to know where I should start in learning to create algorithms to learn datasets. thanks!!!
Great to have you here Paul.
I hope that I can help you on your machine learning journey.
Hi,
Which learning machines can be adopted for prediction?
I have read your folowing article
(https://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/#comment-316878)
Can I adopt all the algorithms that you mentioned ? and where are positioned the support vector machines in your list?
regards
Hello Jason
This is a good article. Do you have example that shows model created from training data. would we use the machine learning algorithms to create predictive model or we use algorithms after model is created with the new data.
I am new to machine learning and exploring to use it for fault detection problem.
This was a great post, thanks. I am trying to become a DS and am taking IBMs Big Data University and needed this portion on what is predictive modeling cleared up.
This a good post, thank you. If anyone could help me develop a model or an algorithm for a weighted moving window the data samples in the best possible way, it would be really very helpful.
Thanks Harshitha.
I never read such an amazing post like this! I completely understand the topic in one go. Thanks for the post!!
Thanks koti.
This is a good post i must say. I am new to machine learning and exploring to use it for career match or match-making problem. I would like to know which algorithm and technique to use in this type of a problem?
We must discover it through trial and error:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
Could you tell me what is Machine Learning from Predictive Modeling from?
Machine learning algorithms can be used to develop predictive models.
This is good news for me. A beginner, and this is what i need. I am still struggling digest it well based on my work — Building a morphological analyser for my language. Needs a more clear direction. Thanks Jason you are a blessing!
Hang in there!
Thank you Jason for taking the time to put together this resource, it’s been helpful and really interesting to learn from them.
Thanks, I’m glad it helped.
Hello Jason,
Thank for the write up, I thoroughly enjoyed reading this. I’m itching to read more. Please guide further steps. I enjoy your lessons of ML and I’m getting my hands dirty 🙂
Cheers Jason!
Thanks.
Here’s a great place to get started:
https://machinelearningmastery.com/start-here/#getstarted
Thanks a lot Jason. You keep these posts as simple as they can get but you don’t leave out the most important info needed to get deeper into the subject.
Thanks.
How can I apply these to a Beauty salon
Please give some insights
Start by defining your problem:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Hi Jason – I’m slightly confused between ML Model and ML Algorithm. I tend to use these 2 words interchangeably, which may be wrong. Can you please explain with an example?
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-a-model-and-an-algorithm
I ma bright new in predictive modeling from which book I can start to understand modeling.
i have bachelor degree in engineering so I have learned the basic
This process will help you work through new predictive modeling projects:
https://machinelearningmastery.com/start-here/#process
Hi Jason,
It is very good article I am planning to use Machine learning for mechanical assembly of different parts. Suggesting user which parts need to be picked for easy assembly.
Can you please share your experience in sequencing. I want to use combination of sequencing with predictive algorithm. Am I thinking in correct direction?
Regards,
Vajradehi Yadav
Perhaps here is a good place to start:
https://machinelearningmastery.com/start-here/#lstm
Hi Jason,
As far as i know, there are two kind of applications that machine learning can be helpful: regression and classification. So how can I use machine learning for regression (not linear regression).
Thank you very much!!
Sure.
which of your book contain this explanation
I don’t have a book on the absolute basic concepts of machine learning. I focus on teaching how to “do” machine learning.
Excellent article Jason.
Please write one article on deploying Machine Learning models in Production
Perhaps this will help:
https://machinelearningmastery.com/deploy-machine-learning-model-to-production/
Hi Sir Jason Brownlee after reading your blogs I moved my self into an exactly correct direction to do expertise in ML.
Thank you so much
Well done!
Dear Jason after reading your books and articles I became expert in machine learning. Kindly write some about big data analytics.
Best Regards:
Asad Khan
Thanks for the suggestion.
Thanks for the clear and limpid introduction like the water of the rock God bless you
I’m glad it helped.
Dear Jason Bro.
Since few weeks I am following your each post… and thanks would not be enough…. you are simply amezing…
Could you share the list of black box model (especially predictive model), please?
THanks.
Yes, start here:
https://machinelearningmastery.com/start-here/#algorithms
My another question
Is IoT predictive model?
IoT means internet of things, it is not a model, it is a network of devises.
Learn more here:
https://en.wikipedia.org/wiki/Internet_of_things
Hi Jason, thanks for the article!
I have two questions for you.
1) How does what is being referred to in this article differ from a more classical approach to statistics (e.g. logistic regression)? In my field we collect a sample, apply statistics to the data, and draw conclusions from the data. To me this seems the same as steps 1, 2, and 3, respectively.
2) Is there a way to make the process you described recursive? In other words, with repeated sampling, dynamically adjust predictions in a sort of bayesian fashion? I am imagining a prediction that is repeatedly adjusted and improved from exposure to new data, eventually approaching the “true” parameter. I am interested in doing some of this kind of modeling, so any suggestions for python libraries or ML techniques are welcome!
Best,
Nic
Great questions.
There is a lot of overlap. The main difference in applied machine learning is the shift in focus away from an descriptive model towards a predictive model. E.g. predictive skill at the expense of interpretability or result-first (ml) rather than model-first (stats).
A good example is in stats we start with the idea of using a linear regression or a logistic regression then beat the data into shape to meet the expectations/requirements of our pre-chosen model. In ML, we don’t care so much about what the model is, only in what works best.
Sure, models can be re-fit and reevaluated as new observations or new re-sampling of the data are performed. This may give you some ideas:
https://machinelearningmastery.com/spot-check-machine-learning-algorithms-in-python/
really help full info I have ever seen thank our respect Jason.
I have 6 month mobile network historical data so I need to predict those time series data
by using nonlinear autoregressive techniques but I’m confused to extract dataset training and test data . pls support any one my simulation Mat lab
I don’t have matlab examples, but you can find Python examples here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Hello json,
I have finished data science course from “JIGSAW ACADEMY BASED IN BANGALORE(INDIA)” but I still had doubts about the meaning of “Predictive modelling”.After reading this article I had developed a new source of inspiration.
This is the most magical line which explains everything”Your action step is to think through the three aspects (data, model, predictions) and relate them to a problem that you would like to work on.”p
Best Regards
Sandipan Sarkar
Thanks!
Jason Brownlee J, Thank you for helping the Young developers. We appreciate your effort towards to help the people who interested. By Now, I have one questions. Would try to solve this “How to Apply genetic algorithm to the learning phase of
a neural network using Backpropagation”?? Thank you very much.
I don’t have an example of using a GA to find neural network weights, sorry.
I hope to have an example in the future.
It to solve the Regression Problem Like House Price
I think there is a typo at “We don’t need to keen the training data”.
Fantastic website! I’m learning a lot, thanks!
Thanks, fixed!
thank for such a good explianation of predictive Modeling, can you give such a code link
Thanks.
Here’s an example with code:
https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
si tuviera una sola entrada de datos y no tengo inputs, k técnica debo aplicar y el código en Python para predecir, ya que solo tengo una sola variable en el tiempo y a partir de ella deseo predecir…
Perhaps this will help you to frame your problem:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
And this to help you make a prediction:
https://machinelearningmastery.com/make-predictions-scikit-learn/
sir i have no credit card, how i can purchase your book plz suggest
I also support PayPal.
This is a well explained “basic” concept of predictive modelling. I salute you!!!
Thanks!
Thank you.
You’re welcome!
Nice explanation of Predictive modelling
Thanks.
Good explaination it will helpfull for our study.
Thank you sir.
Hi Akash…You are very welcome! We appreciate your support!
Very Crisp and to the point explanation. Thanks a lot !!
Thank you for your feedback Raakhi! We appreciate your support!