How do you get accurate results using machine learning on problem after problem?
The difficulty is that each problem is unique, requiring different data sources, features, algorithms, algorithm configurations and on and on.
The solution is to use a checklist that guarantees a good result every time.
In this post you will discover a checklist that you can use to reliably get good results on your machine learning problems.
Machine Learning Checklist Photo by Crispy, some rights reserved.
Each Data Problem is Different
You have no idea what algorithm will work best on a problem before you start.
Even expert data scientists cannot tell you.
This problem is not limited to the selection of machine learning algorithms. You cannot know what data transforms and what features in the data that if exposed would best present the structure of the problem to the algorithms.
You may have some ideas. You may also have some favorite techniques. But how do you know that the techniques that got you results last time will get you good results this time?
How do you know that the techniques are transferable from one problem to another?
You do not need to start from scratch on every problem.
Just like you can use a machine learning tool or library to leverage best practice implementations of machine learning, you should leverage best practices in working through a problem.
The alternative is that you have to make it up each time you encounter a new problem. The result is that you forget or skip key steps. You take longer than is needed, you get results that are less accurate and you probably have less fun.
How are you supposed to know that you’ve finished working through a machine learning problem unless you have defined the solution and it’s intended use right up front?
How To Get Accurate Results Reliably
You can get accurate results reliably on your machine learning problems.
Firstly, it’s an empirical question. What algorithm? What attributes? You have to think up possibilities and try them out. You have to experiment to find answers to these questions.
Treat each dataset like a search problem. Find a combination that gives good results. The amount of time you spend searching will be related to how good the results are. But there is an inflection point where you switch from making large gains to diminishing returns.
Put another way, the selection of data preparation, data transforms, model selection, model tuning, ensemlbing and so on is a combinatorial problem. There are many combinations that work, there are even many combinations that are good enough.
Often you don’t need the very best solution. In fact the very best solution may be what you don’t want. It can be expensive to find, it can be fragile to perturbations in the data and it may very likely be a product of over fitting.
You want a good solution, that is good enough for the specific needs of the problem that you are working on. Often a good enough solution is fast, cheap and robust. It’s an easier problem to solve.
Also, if you think you need the very best solution, you can use a good enough solution as your first checkpoint.
This simple reframing from “most accurate” to “accurate enough” result is how you can guarantee to get good results on each machine learning problem that you work on.
You Need a Machine Learning Checklist
You can use a checklist to structure your search for the right combination of elements to reliably deliver a good solution to any machine learning problem.
A checklist is a simple tool that guarantees an outcome. They’re used all the time in empirical domains where the knowledge is hard won and a guaranteed outcome is very desirable.
For example in aviation like taking off and the use of a pre-flight checklist. Also in medicine with surgical checklists and other fields such as safety compliance.
If a result is important, why make up a process every time. Follow a well defined set of steps to a solution.
Checklists are part of every day life in aviation. Photo by Jeffery Wong some rights reserved.
Benefits of a Machine Learning Checklist
The 5 benefits of using a checklist to work through machine learning problems are:
Less Work: You don’t have to think up all of the techniques to try on each new problem.
Better Results: By following all of the steps you are guaranteed to get a good result, probably a better result than average. In fact, it ensures you get any result at all. Many projects fail for many reasons.
Starting Point For Improvement: You can use it as a starting point and add to it as you think of more things to try. And you always do.
Future Projects Benefit: All of your future projects will benefit from improvements made to the process.
Customizable Process: You can design the best checklist for your tools, problem types and preferences.
Machine learning algorithms are very powerful, but treat them like a commodity. The specific one that you use matters a lot less if all you’re interested in is accuracy.
In fact, each element of the process becomes a commodity and the idea of favorite methods starts to fade away. I think this is a mature position for problem solving. I think it is probably not appropriate for some endeavors, like academic research.
The academic is deeply invested in a specific algorithm. The practitioner sees algorithms only as a means to an end, the predictions or the predictive model.
Applied Machine Learning Checklist
This section outlines a checklist that you can use to work through an applied machine learning problem.
If you are interested in a version of the checklist that you can download and use on your next problem, check the bottom of this post.
This checklist is based on my previous adaptation of the KDD/Data Mining process onto applied machine learning.
Each point could be a blog post, or even a book. There is a lot of detail squashed down into this checklist. I’ve tried to include links on the reasoning and further reading where appropriate.
Did I miss something important? Let me know in the comments.
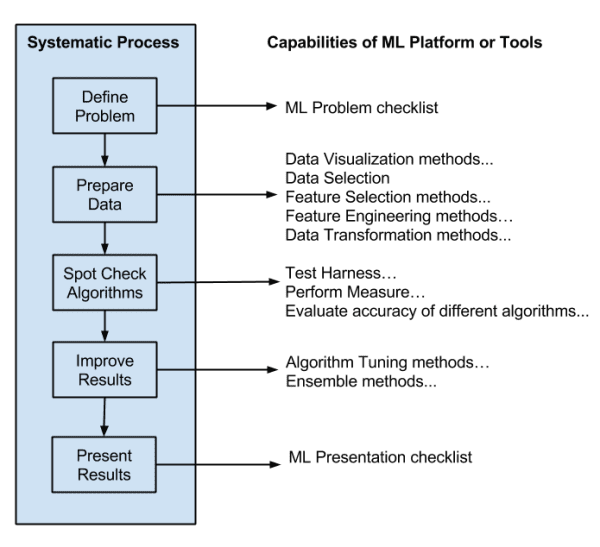
Map your preferred machine learning tools onto your chosen systematic process for working through problems.
Notes On This Example Checklist
This example is highly constrained for brevity. In fact, think of it is a demonstration or proof of principle than the one true checklist for all machine learning problems – which it intentionally is not.
I have constrained this checklist for classification problems working on tabular data.
Also, to keep it digestible, I have kept the level of abstraction reasonably high and limited most sections to three dot points.
Sometimes that is not enough, so I have given specific examples of data transforms and algorithms to try in some parts of the checklist, referred to as interludes.
Let’s dive in.
1. Define The Problem
It is important to have a well developed understanding of the problem before touching any data or algorithms. This will give you the tools to interpret results and the vision for what form the solution will take.
This section is intended to force you to think about all of the data that is and is not available.
Describe the extent of the data that is available.
Describe data that is not available but is desirable.
Describe the data that is available that you don’t need.
2.2 Data Preprocessing
This section is intended to organize the raw data into a form that you can work with in your modeling tools.
Format data so that it is in a form that you can work with.
Clean the data so that it is uniform and consistent.
Sample the data in order to best trade-off redundancy and problem fidelity.
Interlude: Shortlist of Data Sampling
There might be a lot to unpack in the final check on sampling.
There are two important concerns here:
Sample instances: Create a sample of the data that is both representative of the various attribute densities and small enough that you can build and evaluate models quickly. Often it’s not one sample, but many. For example, one for sub-minute model evaluation, one for sub-hour, one for sub-day and so on. More data can change the performance of algorithms.
Sample attributes: Select attributes that best expose the structures in the data to the models. Different models have different requirements, really different preferences because sometimes breaking the “requirements” gives better results.
Below are some ideas for different approaches that you can use to sample your data. Don’t choose, use each one in turn and let the results from your test harness tell you which representation to use.
Random or stratified samples
Rebalance instances by class (more on rebalancing methods)
Remove outliers (more on outlier methods)
Remove highly correlated attributes
Apply dimensionality reduction methods (principle components or t-SNE)
2.3 Data Transformation
This section is intended to create multiple views on the data in order to expose more of the problem structure in the data to modeling algorithms in later steps.
Create linear and non-linear transformations of all attributes
Decompose complex attributes into their constituent parts.
Aggregate denormalized attributes into higher-order quantities.
Interlude: Shortlist of Data Transformations
There is an limited number of data transforms that you can use. There are also old favorites that you can use as a starting point to help tease out whether it is worth exploring specific avenues.
Below is a list of some univariate (single attribute) data transforms you could use.
Square and Cube
Square root
Standardize (e.g. 0 mean and unit variance)
Normalize (e.g. rescale to 0-1)
Descritize (e.g. convert a real to categorical)
Which ones should you use? All of them in turn, again, let the results from your test harness inform you as to the best transformations for your problem.
2.4 Data Summarization
This section is intended to flush out any obvious relationships in the data.
Create univariate plots of each attribute.
Create bivariate plots of each attribute with every other attribute.
Create bivariate plots of each attribute with the class variable
3. Spot Check Algorithms
Now it is time to start building and evaluating models.
This section is intended to help you define a robust method for model evaluation that can reliably be used to compare results.
Create a hold-out validation dataset for use later.
Evaluate and select an appropriate test option.
Select one (or a small set) performance measure used to evaluate models.
3.2 Evaluate Candidate Algorithms
This section is intended to flush quickly out how learnable the problem might be and which algorithms and views on the data may be good for further investigation in the next step.
Select a diverse set of algorithms to evaluate (10-20).
Use common or standard algorithm parameter configurations.
Evaluate each algorithm on each prepared view of the data.
Interlude: Shortlist Algorithms To Try on Classification Problems
Frankly, the list does not matter as much as the strategy of spot checking and not going with your favorite algorithm.
Nevertheless, if you’re working a classification problem throw in a good mix of algorithms that model the problem quite differently. For example:
This section is intended to ensure you capture what you did and learned so that others (and your future self) can make best use of it
Write up project in a short report (1-5 pages).
Convert write-up to a slide deck to share findings with others.
Share code and results with interested parties.
5.2 Operationalize Results
This section is intended to ensure that you deliver on the solution promise made up front.
Adapt the discovered procedure from raw data to result to an operational setting.
Deliver and make use of the predictions.
Deliver and make use of the predictive model.
[sc:process_checklist_cta]
Tips For Getting The Most From This Checklist
I think this checklist, that if followed, is a very powerful tool.
In this section I give you a few additional tips that you can use to get the most out of using the checklist on your own problems.
Simplify the Process. Do not do everything on your first try. Pick two algorithms to spot check, one data transformation, one method of improving results, and so on. Get through one cycle of the checklist, then later start adding on the complexity.
Use Version Control. You will be creating a lot of models and a lot of scripts (if you’re using R or Python). Ensure you do not lose a good result by using version control (like GitHub).
Proceduralize. No result, no transform and no visualization is special. Everything should be created procedurally. This may be a process that you write down if you’re using Weka, or it may be Makefiles if you are using R or Python. You will find bugs in your stuff and you will want to be able to regenerate probably all of your results at the drop of a hat. If it’s all proceduralized from the beginning, this is as simple as typing “make“.
Record All Results. I think it’s good practice for every algorithm run to save predictions in a file. Also to save each data transform and sample in a separate file. You can always run new analysis on the data if it is sitting in a file in a directory as part of your project. This matters a lot more if a result took hours, days or weeks to achieve. This includes cross-validation predictions that can be useful in more complex blending strategies.
Don’t Skip Steps. You can cut a step back to the minimum, but don’t skip any step, even if you think you know it all. The idea of the checklist is to guarantee an outcome. Doctors are very smart and very qualified, but they still need to be reminded to wash their hands. Sometimes you can simply forget a key step in the process that is absolutely key (like defining your problem and realizing you don’t even need machine learning).
I’m Skeptical, Can This Really Work?
It’s just a checklist, not a silver bullet.
You still need to put in the work. You still need to learn about the algorithms and data manipulation methods to get the most from them. You still need to learn about your tools and how to get the most from them.
Try it for yourself.
Prove to yourself that it’s possible to work through a problem end-to-end. Do it in an hour.
Once you get that first result you will see how easy it is and why it’s so important to spend a lot of time up front on the problem definition, on the data preparation and presenting the solution at the backend of the process.
This approach will not get you the very best results.
This checklist delivers good results, reliably, consistently across problems.
You are not going to win Kaggle competitions with one pass through this checklist, bit you will get a result that you can submit and probably sit above 50% of the leaderboard (often much higher).
You can use it to get great results, but it’s a matter of how much time you want to invest.
The checklist is for classification problems on tabular data.
I chose to demonstrate this checklist with classification problems on tabular data.
That does not mean that it is limited to classification problems. You can readily adapt it to other problem types (like regression) and other data types (like images and text).
I have used variations of this checklist on both in the past.
The checklist does not cover technique “XYZ“.
The beauty of the checklist is the simplicity of the idea.
If you don’t like the steps I’ve laid out, replace them with your own. Add in all the techniques you like to use. Build your own checklist!
If you do, I’d love to see a copy.
There’s a lot of redundancy in this approach.
I view working through a machine learning problem as a balance between exploitation and exploration.
You want to exploit everything you know about machine learning, about the data and about the domain. Add those elements into your process for a given problem.
But don’t exclude the exploration. You need to try stuff that you biases suggest will not be the best. Because sometimes, more often than not, your biases are no good. It’s the nature of data and machine learning.
Why not just code-up the pipeline?
Why not! Maybe you should if you’re a systems guy.
I have myself many times with many different tool chains and platforms. It is very hard to find the right level of flexibility in a coded system. There always seems to be a method or a tool that does not fit in neatly.
I suspect many Machine Learning As A Service (MLaaS) create a pipeline much like the above checklist to ensure good results.
I will get good results without knowing why.
This can happen when you’re a beginner.
You can and should dive a little deeper into the final combination of data preparation and modeling algorithms. You should provide all of your procedure with your result so that anyone else can replicate it (say publicly or within your organization if it is a work project).
Good results can standalone if the way they are delivered is reproducible and the evaluation rigorous. The checklist above provides these features if executed well.
Action Step
Use the checklist to complete a project and build some confidence.
thanks for this. I’m using Rule based methods (as opposed to machine learning) to mine some text. Your blog is still relevant in so many ways. Have made a rough checklist to accomodate non-machine learning techniques for text mining.
Hey Jason,
Thanks for this post. Could you give us an example using any dataset on how you’d go about solving the machine learning problem usig this checklist.
I feel a more hands on approach would be easier to adapt for us the newbies.
Thank you
I really love this article. I found myself trapped so many times! countless of exploration and exploitation but somewhere I’m confused of what to do next.
thank you for this 🙂
I think I’ve also become a big fan of your blog and email subscriptions ^^
I like your publications Jason! Thank you for sharing such great knowledge and expertise! I am fairly new to the space of ML but with contributions from great minds like yourself, I am moving fast and steady and surprisingly seem to know and understand ML concepts and best practices better than some glorified data scientists in my place of work. Once again, thank you!!!
Thanks Jason, there’s a huge amount of information packed in these bullet points.
“Sample instances: Create a sample of the data that is both representative of the various attribute densities and small enough that you can build and evaluate models quickly. Often it’s not one sample, but many. For example, one for sub-minute model evaluation, one for sub-hour, one for sub-day and so on. More data can change the performance of algorithms.”
I have a few questions related to this:
1. Do you have some example code in python on how to “create a sample of the data that is both representative of the various attribute densities”. It feels like a lot of knowledge is packed into this one statement. If it’s not possible to share example code, could you point me in the right direction? I know scikit learn can do stratified sampling but only over 1 attribute AFAIK. How can this be done across many features, both categorical and continuous?
2. I like the suggestion of sub-minute model evaluation. This means the dataset has to be quite small which means likely high variance in terms of the “spot check” results. That must be why you are suggesting not one but many samples, right? But small samples also limit the number of features we can introduce in the spot check, correct?
Does this mean that for the sub-minute / sub-hour spot check there’s not much point doing feature engineering (which can increase the dimensionality of the samples) and perhaps limiting yourself to transformations? What would your advice be?
3. Do you already have posts going into more detail on the followings? Or perhaps one of your ebooks?
Random or stratified samples
Rebalance instances by class (more on rebalancing methods)
Remove outliers (more on outlier methods)
Remove highly corrected attributes
4. What did you mean by “Aggregate denormalized attributes into higher-order quantities.” can you give an example?
Generally, don’t forget about the search feature on the blog, it will throw up a lot of the specific posts you are looking for.
1. No, this is problem specific. Perhaps you need to look a descriptive stats of each univariate. Perhaps joint distributions. I can’t be perspective here. Try things and look at associated stats and evaluate the effect using model performance.
2. Perhaps. I believe the point I was making was with regard to the temporal granularity and to consider modeling at different scales. You will have more instances, not fewer at finer granularity. Any variance that is increased is information lost at other scales – this may or may not help in modeling. Different scales may offer different opportunities for feature engineering. Don’t take anything off the table prematurely – try and see.
3.
– Rebalancing: https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
– Outliers: https://machinelearningmastery.com/how-to-identify-outliers-in-your-data/
– feature selection: https://machinelearningmastery.com/an-introduction-to-feature-selection/
– remove highly correlated features: https://machinelearningmastery.com/feature-selection-with-the-caret-r-package/
4. Sure, perhaps all transactions can be squashed into a daily transaction summary by customer with counts and totals. Perhaps a count of the records similar to this record in a time frame can be taken as a feature, etc. Think higher order info that you can expose that the model does not have to spend time on figuring out.
For anyone stumbling across this, this is what I’ve tried for “Sample instances: Create a sample of the data that is both representative of the various attribute densities and small enough that you can build and evaluate models quickly”
1. I built a basic Sampler object that draws n samples without replacement of N size from the original dataset (default is 5% of original dataset).
2. If the number of features is small, I loop through all the features and plot a KDE plot for *each feature* (using seaborn). Each plot has kde lines of all samples along with that of the original dataset to see whether the distribution across features resembles that of the original dataset.
I also annotate on the plot results of Kolmogorov-Smirnov (the test is performed on each sample against the full dataset and the mean and std of pvalues across sample is annotated under the plot.
The goal is to test the stability of sampling at different % levels and ensure it produces representative results. It gives me an idea how small I can go with sample size and still maintain representability.
3. If the number of feature is great where visualisation is not possible, I just build a sampling report with the mean/std pvalues across samples for each feature (in a DataFrame).
Not sure it’s the right approach but it feels generic enough to be helpful (for now at least).
I like snapshots of univaraites with quantile values and q-q plots. I also like calculating the standard error in the mean from different sample sizes.
Calculating a correlation matrix and comparing raw number can help flesh out what is going on with pairwise joint distributions.
It’s a really hard problem and I expect the multivariate stats guys have better tools. Ultimately, mean and stdev CV performance on each sample size (n) is a tough metric to top (in terms of what we are optimizing for).
Some great ideas Jason, will incorporate some of them.
One thing that is particularly relevant for the business I’m working in is that things change over time.
I may try to add another method to my sampler to draw time-bound samples (e.g. draw n samples of customers acquired in 2014 Q1, then another n samples from 2014 Q2…) and then compare whether a) the distributions change over time and ultimately if b) the stability of the “algorithm spot check” results. I believe this isn’t the same as stratified sampling but something completely different (not sure it has a name as such).
The idea is to get a quick feel whether there’s a change in the underlying population over time.
The implications for the modelling may be that if customer behaviour has changed significantly over time, the full dataset that is given to the algorithms may have to be limited to only the last X years as older behaviour is no longer relevant (practically speaking, to the business) and may actually harm the predictive power of the algorithms.
Sorry, this is unrelated to this post, but do you have any resources/tips on determining whether a dataset actually contains multiple subpopulations and whether the full dataset we have to work with should be trimmed/subset before modelling?
Hello Jason, I am new for practical implementation of machine learning techniques and i found your article very helpful.
I have a problem for which i need your experienced advise.
I have movie reviews which is categorized as positive and negative. Now i want to create a classifier that can predict if a movie review has a positive sentiment or a negative sentiment. All the movie reviews are text files. I have not worked with text data mining before.
My questions are:
Which algorithm will suit best for this particular objective?
Do i need to divide my data for training and testing purpose from both categories?
or do i need to crate new dataset which include text one column and other column category(positive and negative) or it can be directly processed?
Do i need to use NLP?
First of all thanks for a great post, very helpful! I have a short question on feature selection. In which step would you evaluate and remove features?
Not directly apparent to me if it should be done before or after spot checking different algorithms. I guess an alternative way to phrase the question would be; does different algorithms benefit differently specific features or is “information value” a feature carry the same regardless of the algorithm?
Thanks for your posts. They are just super awesome!
I want to understand why do we “Spot check various algorithms” first and then “Tune well-performing algorithms”? Why should’nt we first “Tune the available algorithms” and choose the one giving the best result?
If we do the former, we might rule out an algorithm which after being tuned gives better results than the one we would finally select.
Thanks for the great blog post! Will this still work for deep learning, especially with images? Any changes you’d suggest for this checklist? Thanks again!




")



thanks for this. I’m using Rule based methods (as opposed to machine learning) to mine some text. Your blog is still relevant in so many ways. Have made a rough checklist to accomodate non-machine learning techniques for text mining.
Hey Jason,
Thanks for this post. Could you give us an example using any dataset on how you’d go about solving the machine learning problem usig this checklist.
I feel a more hands on approach would be easier to adapt for us the newbies.
Thank you
Jason, this is awesome. Thank you so much.
Fantastic! Thanks for the post. The checklist is quite helpful ~ from the Practitioner Tribe.
Thanks Avaré, I’m glad to hear it.
Hi, I’m having a hard time to getting your checklist to download. I’ve become a big fan of your blog, thank you.
I’m sorry to hear that Michael, you should receive an email with a link to download the checklist.
I really love this article. I found myself trapped so many times! countless of exploration and exploitation but somewhere I’m confused of what to do next.
thank you for this 🙂
I think I’ve also become a big fan of your blog and email subscriptions ^^
I’m so glad to hear that Happy. Good luck with your future machine learning projects.
I like your publications Jason! Thank you for sharing such great knowledge and expertise! I am fairly new to the space of ML but with contributions from great minds like yourself, I am moving fast and steady and surprisingly seem to know and understand ML concepts and best practices better than some glorified data scientists in my place of work. Once again, thank you!!!
Ed
Thanks for your support Ed, I’m glad you found the post useful.
Thanks Jason, there’s a huge amount of information packed in these bullet points.
“Sample instances: Create a sample of the data that is both representative of the various attribute densities and small enough that you can build and evaluate models quickly. Often it’s not one sample, but many. For example, one for sub-minute model evaluation, one for sub-hour, one for sub-day and so on. More data can change the performance of algorithms.”
I have a few questions related to this:
1. Do you have some example code in python on how to “create a sample of the data that is both representative of the various attribute densities”. It feels like a lot of knowledge is packed into this one statement. If it’s not possible to share example code, could you point me in the right direction? I know scikit learn can do stratified sampling but only over 1 attribute AFAIK. How can this be done across many features, both categorical and continuous?
2. I like the suggestion of sub-minute model evaluation. This means the dataset has to be quite small which means likely high variance in terms of the “spot check” results. That must be why you are suggesting not one but many samples, right? But small samples also limit the number of features we can introduce in the spot check, correct?
Does this mean that for the sub-minute / sub-hour spot check there’s not much point doing feature engineering (which can increase the dimensionality of the samples) and perhaps limiting yourself to transformations? What would your advice be?
3. Do you already have posts going into more detail on the followings? Or perhaps one of your ebooks?
Random or stratified samples
Rebalance instances by class (more on rebalancing methods)
Remove outliers (more on outlier methods)
Remove highly corrected attributes
4. What did you mean by “Aggregate denormalized attributes into higher-order quantities.” can you give an example?
Many thanks!
Hi Carmen, great questions.
Generally, don’t forget about the search feature on the blog, it will throw up a lot of the specific posts you are looking for.
1. No, this is problem specific. Perhaps you need to look a descriptive stats of each univariate. Perhaps joint distributions. I can’t be perspective here. Try things and look at associated stats and evaluate the effect using model performance.
2. Perhaps. I believe the point I was making was with regard to the temporal granularity and to consider modeling at different scales. You will have more instances, not fewer at finer granularity. Any variance that is increased is information lost at other scales – this may or may not help in modeling. Different scales may offer different opportunities for feature engineering. Don’t take anything off the table prematurely – try and see.
3.
– Rebalancing: https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
– Outliers: https://machinelearningmastery.com/how-to-identify-outliers-in-your-data/
– feature selection: https://machinelearningmastery.com/an-introduction-to-feature-selection/
– remove highly correlated features: https://machinelearningmastery.com/feature-selection-with-the-caret-r-package/
4. Sure, perhaps all transactions can be squashed into a daily transaction summary by customer with counts and totals. Perhaps a count of the records similar to this record in a time frame can be taken as a feature, etc. Think higher order info that you can expose that the model does not have to spend time on figuring out.
Thanks Jason, really helps.
For anyone stumbling across this, this is what I’ve tried for “Sample instances: Create a sample of the data that is both representative of the various attribute densities and small enough that you can build and evaluate models quickly”
1. I built a basic Sampler object that draws n samples without replacement of N size from the original dataset (default is 5% of original dataset).
2. If the number of features is small, I loop through all the features and plot a KDE plot for *each feature* (using seaborn). Each plot has kde lines of all samples along with that of the original dataset to see whether the distribution across features resembles that of the original dataset.
I also annotate on the plot results of Kolmogorov-Smirnov (the test is performed on each sample against the full dataset and the mean and std of pvalues across sample is annotated under the plot.
The goal is to test the stability of sampling at different % levels and ensure it produces representative results. It gives me an idea how small I can go with sample size and still maintain representability.
3. If the number of feature is great where visualisation is not possible, I just build a sampling report with the mean/std pvalues across samples for each feature (in a DataFrame).
Not sure it’s the right approach but it feels generic enough to be helpful (for now at least).
Wonderful.
I like snapshots of univaraites with quantile values and q-q plots. I also like calculating the standard error in the mean from different sample sizes.
Calculating a correlation matrix and comparing raw number can help flesh out what is going on with pairwise joint distributions.
It’s a really hard problem and I expect the multivariate stats guys have better tools. Ultimately, mean and stdev CV performance on each sample size (n) is a tough metric to top (in terms of what we are optimizing for).
Some great ideas Jason, will incorporate some of them.
One thing that is particularly relevant for the business I’m working in is that things change over time.
I may try to add another method to my sampler to draw time-bound samples (e.g. draw n samples of customers acquired in 2014 Q1, then another n samples from 2014 Q2…) and then compare whether a) the distributions change over time and ultimately if b) the stability of the “algorithm spot check” results. I believe this isn’t the same as stratified sampling but something completely different (not sure it has a name as such).
The idea is to get a quick feel whether there’s a change in the underlying population over time.
The implications for the modelling may be that if customer behaviour has changed significantly over time, the full dataset that is given to the algorithms may have to be limited to only the last X years as older behaviour is no longer relevant (practically speaking, to the business) and may actually harm the predictive power of the algorithms.
Sorry, this is unrelated to this post, but do you have any resources/tips on determining whether a dataset actually contains multiple subpopulations and whether the full dataset we have to work with should be trimmed/subset before modelling?
Nice one, yes, you are combatting the idea of “concept drift” or changes in data over time.
You could also include time vars and let the model learn and exploit this change itself rather than managing it manually. Try both.
No, I don’t have much going into stats/multivariate stats.
Oh, “concept drift”. That’s great Jason, thanks a lot. It’s amazing how easy it is to educate yourself once you have the right terminology 🙂
Glad to hear it Carmen.
Hello Jason, I am new for practical implementation of machine learning techniques and i found your article very helpful.
I have a problem for which i need your experienced advise.
I have movie reviews which is categorized as positive and negative. Now i want to create a classifier that can predict if a movie review has a positive sentiment or a negative sentiment. All the movie reviews are text files. I have not worked with text data mining before.
My questions are:
Which algorithm will suit best for this particular objective?
Do i need to divide my data for training and testing purpose from both categories?
or do i need to crate new dataset which include text one column and other column category(positive and negative) or it can be directly processed?
Do i need to use NLP?
This tutorial will help, it has exactly this problem:
https://machinelearningmastery.com/predict-sentiment-movie-reviews-using-deep-learning/
Lovely article on Machine Learning beginners
Thanks Farrukh.
First of all thanks for a great post, very helpful! I have a short question on feature selection. In which step would you evaluate and remove features?
Not directly apparent to me if it should be done before or after spot checking different algorithms. I guess an alternative way to phrase the question would be; does different algorithms benefit differently specific features or is “information value” a feature carry the same regardless of the algorithm?
Great question.
If automatic, then ideally within each cross validation fold.
In practice, you can often do it as a pre-processing step prior to modeling.
which algorithm is good enough to analyze the sales data set?
We cannot know, try a suite of algorithms to see what works best:
https://machinelearningmastery.com/start-here/#process
Hi Jason, are you familiar with Long-short term memory algorithm? is it suitable for prediction? thanks
Hey Jason,
I would really love to try your checklist, but for whatever reason I cannot send you the required mail.
Could you please send me the checklist, so I can try it on my project.
That would be very kind of you.
Thank you very much
Samuel
No problem, I sent it to you.
Hi Jason,
Having the same issue as other people. The link seems for the checklist seems to be broken. Can you send the checklist?
Thanks
John
Apologies, this has now arrived, the message that the resource is not available mislead me.
Thanks.
Glad to hear it, I’ll fix it up.
Thank you very much for this post. If you include one example with this then it will be better to understand.
Thanks for the suggestion.
Hi Jason,
Thanks for your posts. They are just super awesome!
I want to understand why do we “Spot check various algorithms” first and then “Tune well-performing algorithms”? Why should’nt we first “Tune the available algorithms” and choose the one giving the best result?
If we do the former, we might rule out an algorithm which after being tuned gives better results than the one we would finally select.
Speed. The spot check highlights areas to focus, and tuning is time consuming.
If you have the resources, combine these two steps.
Sure. Thank you so much for the reply.
I have not received the checklist, checked my junk folder but nothing. Can you send it to me?
Sorry to hear that, here’s a direct link:
https://s3.amazonaws.com/MLMastery/MachineLearningChecklist.zip
Hi Jason,
may I ask if the steps and actions as prescribed all proceed in a sequential order or one can tinker with the order to execute each step.
The post above outlines the steps in order. What difficulty are you having exactly?
In step 2.2, did you mean to say “Remove highly **correlated** attributes” instead of “Remove highly corrected attributes”?
Thanks!
Thanks, fixed!
Just beginning to work out how to approach the problem i have and found this article.spot on and very helpful.
many thanks jason
Thanks!
Hi Jason, This question is coming from a new entrants in ML field.
I have done – almost done a project – for a course on ML by IBM on edX. Its NBA team performance prediction.
I have almost done the ‘checklist’ by hunch and zeroed on to the subset of features etc. working best on accuracy, precision , F – score etc.
Now next step – I want to use the solutions to predict performance of a team in a different year not in my data set.
Could you or someone hand hold me a bit in walking me through this issue?
Thanks and rgds.
Yes, you must fit your model on all available data then use that model to make predictions on new data.
If you are using scikit-learn, this will help:
https://machinelearningmastery.com/make-predictions-scikit-learn/
Will try. Thx
Can’t find a download link?
Clicking on the link at the end of the article “Download it now and also get exclusive email tips and tricks.” leads me to the same website (https://machinelearningmastery.com/machine-learning-checklist/)
Thanks for the great blog post! Will this still work for deep learning, especially with images? Any changes you’d suggest for this checklist? Thanks again!
Hi Ayoub…You are very welcome! Yes! The checklist is relevant for machine learning and deep learning.
Marvelous! very helpful! Thank you.
You are very welcome Erick! We appreciate the support!