Weka makes learning applied machine learning easy, efficient, and fun. It is a GUI tool that allows you to load datasets, run algorithms and design and run experiments with results statistically robust enough to publish.
I recommend Weka to beginners in machine learning because it lets them focus on learning the process of applied machine learning rather than getting bogged down by the mathematics and the programming — those can come later.
In this post, I want to show you how easy it is to load a dataset, run an advanced classification algorithm and review the results.
If you follow along, you will have machine learning results in under 5 minutes, and the knowledge and confidence to go ahead and try more datasets and more algorithms.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
1. Download Weka and Install
Visit the Weka Download page and locate a version of Weka suitable for your computer (Windows, Mac, or Linux).
Weka requires Java. You may already have Java installed and if not, there are versions of Weka listed on the download page (for Windows) that include Java and will install it for you. I’m on a Mac myself, and like everything else on Mac, Weka just works out of the box.
If you are interested in machine learning, then I know you can figure out how to download and install software into your own computer. If you need help installing Weka, see the following post that provides step-by-step instructions:
2. Start Weka
Start Weka. This may involve finding it in program launcher or double clicking on the weka.jar file. This will start the Weka GUI Chooser.
The Weka GUI Chooser lets you choose one of the Explorer, Experimenter, KnowledgeExplorer and the Simple CLI (command line interface).
Weka GUI Chooser
Click the “Explorer” button to launch the Weka Explorer.
This GUI lets you load datasets and run classification algorithms. It also provides other features, like data filtering, clustering, association rule extraction, and visualization, but we won’t be using these features right now.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
3. Open the data/iris.arff Dataset
Click the “Open file…” button to open a data set and double click on the “data” directory.
Weka provides a number of small common machine learning datasets that you can use to practice on.
Select the “iris.arff” file to load the Iris dataset.
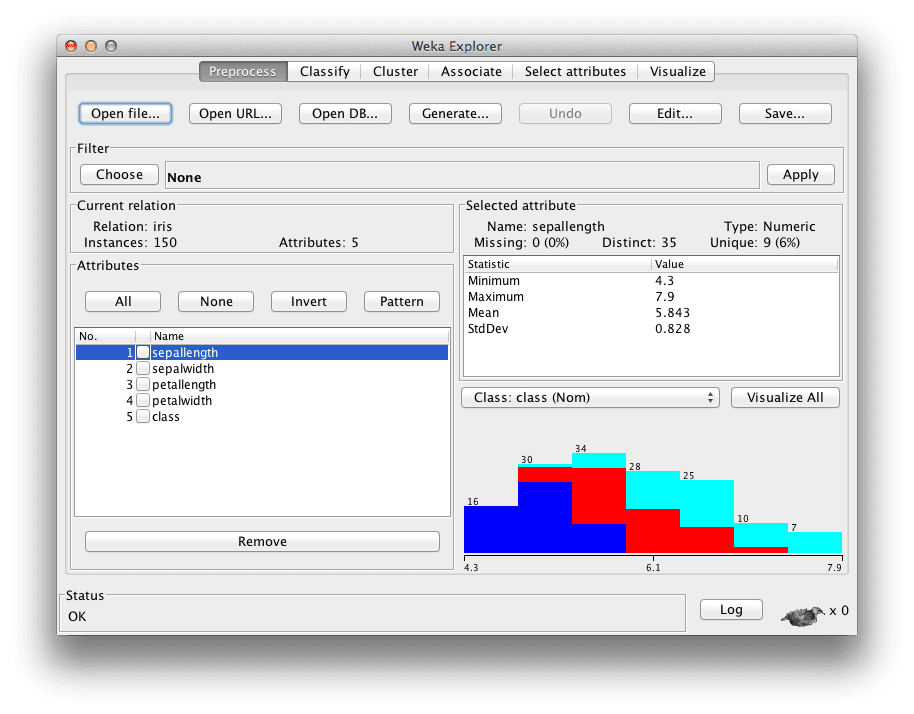
Weka Explorer Interface with the Iris dataset loaded
The Iris Flower dataset is a famous dataset from statistics and is heavily borrowed by researchers in machine learning. It contains 150 instances (rows) and 4 attributes (columns) and a class attribute for the species of iris flower (one of setosa, versicolor, and virginica). You can read more about Iris flower dataset on Wikipedia.
4. Select and Run an Algorithm
Now that you have loaded a dataset, it’s time to choose a machine learning algorithm to model the problem and make predictions.
Click the “Classify” tab. This is the area for running algorithms against a loaded dataset in Weka.
You will note that the “ZeroR” algorithm is selected by default.
Click the “Start” button to run this algorithm.
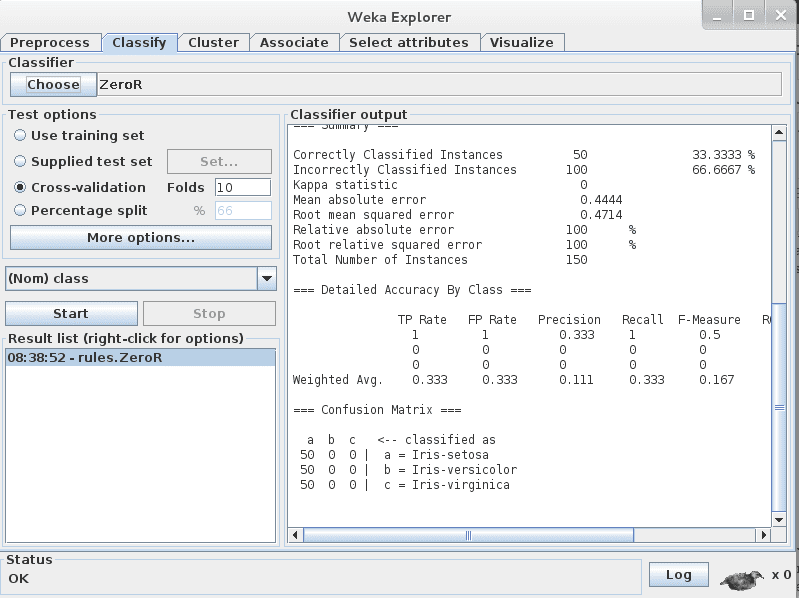
Weka Results for the ZeroR algorithm on the Iris flower dataset
The ZeroR algorithm selects the majority class in the dataset (all three species of iris are equally present in the data, so it picks the first one: setosa) and uses that to make all predictions. This is the baseline for the dataset and the measure by which all algorithms can be compared. The result is 33%, as expected (3 classes, each equally represented, assigning one of the three to each prediction results in 33% classification accuracy).
You will also note that the test options selects Cross Validation by default with 10 folds. This means that the dataset is split into 10 parts: the first 9 are used to train the algorithm, and the 10th is used to assess the algorithm. This process is repeated, allowing each of the 10 parts of the split dataset a chance to be the held-out test set. You can read more about cross validation here.
The ZeroR algorithm is important, but boring.
Click the “Choose” button in the “Classifier” section and click on “trees” and click on the “J48” algorithm.
This is an implementation of the C4.8 algorithm in Java (“J” for Java, 48 for C4.8, hence the J48 name) and is a minor extension to the famous C4.5 algorithm. You can read more about the C4.5 algorithm here.
Click the “Start” button to run the algorithm.
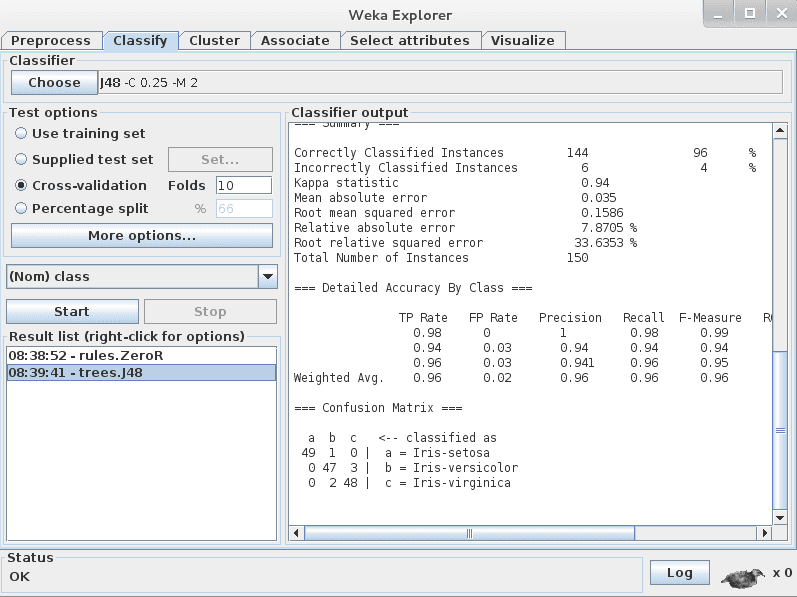
Weka J48 algorithm results on the Iris flower dataset
5. Review Results
After running the J48 algorithm, you can note the results in the “Classifier output” section.
The algorithm was run with 10-fold cross-validation: this means it was given an opportunity to make a prediction for each instance of the dataset (with different training folds) and the presented result is a summary of those predictions.

Just the results of the J48 algorithm on the Iris flower dataset in Weka
Firstly, note the Classification Accuracy. You can see that the model achieved a result of 144/150 correct or 96%, which seems a lot better than the baseline of 33%.
Secondly, look at the Confusion Matrix. You can see a table of actual classes compared to predicted classes and you can see that there was 1 error where an Iris-setosa was classified as an Iris-versicolor, 2 cases where Iris-virginica was classified as an Iris-versicolor, and 3 cases where an Iris-versicolor was classified as an Iris-setosa (a total of 6 errors). This table can help to explain the accuracy achieved by the algorithm.
Summary
In this post, you loaded your first dataset and ran your first machine learning algorithm (an implementation of the C4.8 algorithm) in Weka. The ZeroR algorithm doesn’t really count: it’s just a useful baseline.
You now know how to load the datasets that are provided with Weka and how to run algorithms: go forth and try different algorithms and see what you come up with.
Leave a note in the comments if you can achieve better than 96% accuracy on the Iris dataset.
Discover Machine Learning Without The Code!

Develop Your Own Models in Minutes
...with just a few a few clicks
Discover how in my new Ebook:
Machine Learning Mastery With Weka
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, build models, tuning, and much more...
Finally Bring The Machine Learning To Your Own Projects
Skip the Academics. Just Results.






Well, just learning the tool etc, but using the above setup, I changed the test option to ‘Use Training Set’ and got 98% accuracy.
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.980 0.020 0.961 0.980 0.970 0.955 0.990 0.969 Iris-versicolor
0.960 0.010 0.980 0.960 0.970 0.955 0.990 0.970 Iris-virginica
Weighted Avg. 0.980 0.010 0.980 0.980 0.980 0.970 0.993 0.980
=== Confusion Matrix ===
a b c <– classified as
50 0 0 | a = Iris-setosa
0 49 1 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
I also got 97.3% out of Multilayer Perceptron, with the same cross validation setting of 10 folds.
Really nice work Sandra!
Changing the test option to “use training set” changes the nature of the experiment and the results are not really comparable. This change tells you how well the model performed on the data to which was trained (already knows the answers).
This is good if you are making a descriptive model, but not helpful if you want to use that model to make predictions. To get an idea at how good it is at making predictions, we need to test it on data that it has not “seen” before where it must make predictions that we can compare to the actual results. Cross validation does this for us (10 times in fact).
Great work on Multilayer Perceptron! That’s a complicated algorithm that has a lot of parameters you can play with.
Maybe you could try some other datasets from the “data” directory in Weka.
Execute Weka Nearest Neighbor with K=1 (only 1 nearest neighbor) on the IRIS data set and answer the following questions:
(a) look at the confusion matrix. How many total misclassified instances were there for iris sets?
(b) What is the weighted precision for this classifier?
(c) what is the weighted recall for this classifier?
(d) how many incorrectly classified instances were there in total for this classifier?
(e) which classes had incorrect classifications?
can you answer the above question ASAP please
Hallo Weka users. Please help me. I want to use LAD classifier on time series data from 2010 to 2017 over 17 banks with 4 classes. How do I go about it? Thank you
Perhaps try posting to the Weka users group:
https://machinelearningmastery.com/help-with-weka/
Just wondering why my j48 is disabled?
It may be because it cannot be used on the dataset you have loaded.
How do we handle the choice of Classifier to be used for a problem.
Considering there is an increased accuracy with MultilayerPerceptron as against J48.
MultilayerPerceptron = 97.33% against J48=96%
Great question Oluwole.
We need to evaluate a suite of algorithms and see what works best. This means that we need a robust test harness (so we cannot be fooled by the results). This involves careful selection of a metric and a resampling method like cross validation.
We can then choose an algorithm that both performs well and has low complexity (easy to understand and explain to others/use in production).
because your class is numerical, not nominal. It works on nominal classes only.
Hi, I am new to machine learning and would like to know how to select a model for predicting housing prices. Can I use the weka explorer for this? and if it is possible, Please how do I go about it?
MY GOAL
I want to predict housing prices based on some criteria.
This process will teach you how to work through your own problems end-to-end:
https://machinelearningmastery.com/start-here/#process
functions.SMO 96.27 % with default settings
can you example what do you mean by functions.SMO 96.27 % with default settings?
SMO is the implementation of Support Vector Machines for classification in Weka.
Default settings mean that none of the parameters of the algorithm were modified before the algorithm was run on the dataset.
Hello, congratulations for your articles, they are very helpful! I would like to ask you what are the criteria to determine if a dataset is reliable to choose or not.
Kind regards,
Nikos Vassilakis
Thanks Nikos.
This post may help in defining your problem:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
hello
how did you change the options to enbetter the accuracy
thanks
What’s up, I have seen that occasionally this page renders a 403 server error message. I thought that you would be keen to know. Best wishes
Thanks Mark, much appreciated. I have not seen this myself, but I’ll look into setting up some monitoring.
Great start to what I hope is a newfound joy in machine learning!
An excellent article indeed! Given the classifier (prediction for numeric class) model as well as an instance from a training or test set, do you have any idea about the steps as to how predicted values are calculated specifically under the “Predictions ontest data” sectionof WEKA’s output?
A trained classifier is evaluated by providing it the input attributes (without the numeric output attribute), and the prediction is made. This is repeated for all instances in the test dataset. Weka then provides a summary of the error in the predictions using a number of measures such as mean absolute error and root mean squared error.
Does that answer your question @NoelE?
Really great first lesson, Jason! Salute
By the way, I used MultilayerPerceptron and achieved a 97.333% accuracy.
I’m new in weka,I want use simple CLI,i want delete some attribute from arff file and i inter :
[java weka.filters.unsupervised.attribute.Remove –R 5-34 -i data/kdd_01.arff -o data/kdd_02.arff]
But it doesn’t work!!!
I hope You can help me…
Hi do your tutorials cover the forecast tab? Also how do we narrow down to which algorithm used be used in a particular scenario?
Hi Tushar, I don’t believe there is a forecast tab. What are you referring to exactly.
For finding the best algorithm I teach a process of spot checking with follow-up algorithm tuning.
Hallo Jason,
I am trying an .arff file of my own and i don’t get over 65% correct answers for the model that I built.Is there a way to make it better or does that mean that the data maybe don’t relate with the outcome class?
Thanks.
You could try some different algorithms. You could try some further preparation of your data such as normalization, standardization and feature engineering. You could also try tuning the parameters of an algorithm that is doing well.
Be scientific and methodical in your approach, devise specific questions and investigate them and record what you discover.
How do I normalize my data of arff extension..??? I want to do Naivebayes on my dataset but before this normalization is needed for better result.
open iris dataset in ARFF FORMAT
choose j48 classifier
choose the percentage spilt 66%
how many instance are in correctly classified
what is the mean absolute error made by the classifier
Weka will report the number of misclassified examples in a confusion matrix I believe.
I tried it out and with some tweeking of the MultilayerPerceptron (just set the hidden layers to 10) which gave me a 98% success rate:
Correctly Classified Instances 147 98 %
Incorrectly Classified Instances 3 2 %
Kappa statistic 0.97
Mean absolute error 0.0304
Root mean squared error 0.1296
Relative absolute error 6.8454 %
Root relative squared error 27.4907 %
Total Number of Instances 150
I must say that is is addictive. And quite exhilarating.
Nice work Tobias, try exploring some of the other datasets that come with Weka.
Hi! Where do I modify the hidden layers? Thanks!
In the MultilayerPerceptron algorithm. Take a look at the algorithm properties.
I get the same result (98%) with hidden layers = i (equal number of features)
Nice one, see if the result translates to other problem types from the UCI ML Repo.
I often use the heuristic of the number of nodes in the hidden layer equal to the number of input features.
Another one Jason:
Can Weka,given that a data belongs to a certain class, output a dataset that belongs to that class?Of course, there maybe many datasets that satisfy that class, but there are also certain problems that have unique solutions.
I want to try that with the 8-queens problem.
Thanks a lot for your answers.
Not in the GUI I think Soto. You might need to write a program using the WEKA API to handle this case. I believe I’ve read examples of neural nets being used to solve 8 queens and TSP problems. It all comes down to representation of the problem.
Good luck.
” 3 cases where a Iris-versicolor was classified as a Iris-setosa” in your explanation of the confusion matrix in the post should be ” 3 cases where a Iris-versicolor was classified as a Iris-virginica”. Great post by the way, cheers.
Hi a bit off topic for this lesson but im in need of help! Im using J48-cross validation but i want to change the amount of times the model can run and adjust the weights given to each variable- if that makes sense. also known as the number of epochs/iterations. i have done this before and im sure its a simple fix but i cant remember where or what this is called in weka.
Many thanks
Holly
hello Everyone,
hello Jason, I must say this is exciting, i absolutely have no foundation in computer science or programming and neither was i very good at mathematics but somehow i
am in love with the idea of machine learning, probably because i have a real life scenario i want to experiment with.
I have up to 20 weekends and more of historical data of matches played and i would like to see how weka can predict the outcome of matches played within that 20 week
period.
My data is in tabular form and it is stored in microsoft word.
It is a forecast of football matches played in the past.
Pattern detection is the key, By poring over historical data of matches played in the past, patterns begin to emerge and i use this to forecast what the outcome of
matches will be for the next game.
I use the following attributes for detecting patterns and making predictions which on paper is always 80-100% accurate but when i make a bet, it fails.
(results, team names, codes, week’s color, row number)
Results= Matches that result in DRAWS
Team names = Believe it or not, teams names are used as parameters to make predictions, HOW? They begin with Alphabets.
Codes= These are 3-4 strings either digits or a combo of letters and digits, depending on where they are strategically placed in the table, they offer insight into
detecting patterns.
Weeks Color= In the football forecasting world, there are 4 colours used to represent each week in a month. RED, BLUE, BROWN and PURPLE. These also allows the
forecaster to see emerging patterns.
Row Number= Each week, the data is presented in a table form with two competing teams occupying a row and a number is associated with that row. These numbers are used
to make preditions.
So i would like to TEACH WEKA how i detect these patterns so that my task can be automated and tweaked anyhow i like it.
In plain english, how do i write out my “pattern detecting style” for weka to understand and how do i get this information loaded into weka for processing into my
desired results.
Going by my scenario, What will be my attributes?
What will be my instances?
What will be the claasifiers?
What algorithms do i use to achieve my aim or will i need to write new algorithms?
I sincerely hope someone will come to my rescue.
Thanks
Before reading this post data mining and machine learning was such a celestial intangible things. But this post changed it. Very thanks
Thanks!
Glad to here it!
I am wondering how can i know C4.5 average height and average accuracy. Thanks
Use cross validation and collect statistics on your tree such as depth and accuracy from each fold, then average the results.
can you please help regarding working with multi labels.
Can you pls help me. i actually new to this datamining concepts. i want to know how to extract a features and accuracy of a given url name. for eg: if the url name is http://www.some@url_name.com it will extract the feature is _ and @ in it and i also tells the age of the url and also some feature extraction like ip address, long or short url,httos and ssl ,hsf,redirect page ,anchor tag like that it should extract and it will tell the accuracy too.and then implement using c4.5 classifier algorithm to find whether the given url name is malicious or benign url.
pls some one help me to do this process.
Sounds like a great project. As with any project, you need to start by building up a dataset for you to analyse.
I suspect the words in the URL will be useful, SSL cert or not (https) may be useful, and so on. It is hard to know a priori what will be most useful, I’d recommend brain storming and trying a lot of different features in your model. Also consider using an importance measure or correlation with the output variable to see which features look promising and which appear redundant.
Hi!
I’m trying to use libsvm for classification (2 class) in 10-fold cross-validation mode. The output predictions that I get have an instance#, but I dont know which instances of my dataset do these correspond to. For example, my output predictions looks like this:
inst#, actual, predicted, error, probability distribution
1 2:R 2:R 0 *1
2 2:R 2:R 0 *1
3 2:R 2:R 0 *1
4 2:R 2:R 0 *1
5 1:S 1:S *1 0
6 1:S 1:S *1 0
1 2:R 2:R 0 *1
2 2:R 1:S + *1 0
3 2:R 2:R 0 *1
4 2:R 2:R 0 *1
5 1:S 1:S *1 0
6 1:S 2:R + 0 *1
….
How does my dataset get divided into 10 parts, which files do these instances correspond to?
I’m interested in knowing which files get incorrectly classified. Is there some other/better way to do this?
I have the same question, If anyone have some input please share.
I have installed weka but my smo function is not active,how can i activate it please
i would like to forecast using support vecor machine
Hi Jason. I’ve been playing around for a while with WEKA, and now I get good prediction results. But I still wonder how to apply the model built further?
I mean, I train and tune algorithms and get better results, but then?
When I try to input, say, a set of four attributes corresponding to those of the IRIS set, it doesn’t recognize it as something that it can use in the model.
If I put these four attributes and an empty column, it accepts this, but I don’t know how to predict the class then? How should I set the parameters in WEKA to do that, please?
Thanks by advance.
I am trying to use multilayer Perceptron in WEKA. I want to understand of the 4 predictors, how do I decide which one is the best?
Hi,
I am trying to use different types of classification rules with numeric data (both independent and dependent variables). It will be great if you please let me know about the applicable classification rules and results interpretation using numerical data in Weka or R.
Thanks in advance.
Hello Jason. I have arff file with the skin pixels data. The arff file is large (>500MB). Once I load the data in the WEKA, its give me “Not enough memory …” Is there any solution for this matter? Tq
hi
im just downloading the accepted papers dataset in csv format.
but it cannot be opened throught weka
it says “unable to determined structure as csv. wrong number of values”
what should i do? it will be a big appreciation if you reply as soon as possible.
THANK YOU
link for accepted papers dataset : https://archive.ics.uci.edu/ml/datasets/AAAI+2013+Accepted+Papers#
Hi
Can u mail me the predictive analytics python code of AAAI 2013 accepted papers.
Email:nikhilkumar2838@gmail.com
Hi Jason,
Great website and great efforts 🙂
I’ve just would like to know how to understand the confusion matrix please?
hi i need to know see the algorithm embedded in the software how can i see it and how can i modify or insert a neww one
hi
i want to use data set from uci repository site but when i run the data on weka all attribute show into one attribute.
how should i do?
Once I have trained the model, how do I run it?
For example, I have trained a model to make predictions on bodyfat % according to age, height, weight and abdominal circumference. Now, I want to input parameters about myself too see what the model predicts.
Any help would be appreciated.
I got ~97.3% accuracy with the multilayer perceptron.
Trees.FT with 20 folds produces 98% accuracy (147 correct, 3 incorrect)
Hello,I have data set with numeric prediction.I would like to apply rules learning algorithm in Weka. I noticed that Weka does not support rule based algorithm for numerical prediction as it does for nominal prediction. I do not know why. also, why the accuracy is not shown in the same way as nominal prediction please? also I noticed the forms of the rules are also different? How to calculate the accuracy of the correct classification please? Many thanks
Hi. Can I apply j48 even if dont have any field like “class” in my dataset
Hi! Thanks for the nice guide! I wanted to know whether Weka normalizes the data while using a classifier, or do we need to input normalized data itself? Thankyou very much.
Hi, this is a great work. Thanks for this. One thing. Could you pls elaborate little more about “test options.” Got to know what is the purpose of the ‘use training set option’. But what about the others. Cross validation is already being used. What about other two. ‘supplied test set and percentage split’??
Thank you!
and finally someone explains ML in plain english, i’ve been bashing my head off the desk for weeks working through training material on this. Very well written and explained in a few simple steps. Many thanks for this 🙂
Under Review Results wouldn’t the last comparison be 3 iris-versicolor classified as iris-virginica? I’m having trouble comprehending the pattern in this table, and using the example from Wikipedia it appears to not be the same as you mentioned? Totally new to this so I have no idea what I’m talking about but I’d appreciate some clarification.
Hi. My name is azhar from Peshawar Pakistan..i am phd scholar. I need to work in machine learning in practical manner.
WEKA is a best software but dont knw how to use.
Hi, i have just trained a Random forest classifier for a text classification. I have got the results too. When they say- train your classifier and then test it with different data for evaluation, i want to know what should i do next to evaluate this classifier? Can anyone help me with steps to be followed ? I am not sure of how to save this trained classifier model and upload a test data.
Thanks!
Hi , i want to know how to chose a data base to use it in classification , please help me
i want to use naive bayes and J-48 for this http://archive.ics.uci.edu/ml/datasets/Abalone data set. but its not working. can u please tell me what should i do.
Hi,I have Weka installed on ubuntu .I am trying to get dataset in explorer but i am not getting data folder.How can get data folder?
I have same problem… Its my first day in Weka.. and i’m trying to load the German credit data, available as credit-g.arff in the Weka 3.8 distribution. I cant load this dataset because when I open the “open file” it only shows me the folders that are in my computer, and not the weka dataset….. Please if someone has an idea how to solve this thing…
Hi Dadi, the datasets may not be distributed with your version of Weka.
You can download the zip Weka with the datasets under the title “Other Platforms” here:
http://www.cs.waikato.ac.nz/ml/weka/downloading.html
I hope that helps.
got 96% with NaiveBayes without any modification
Really thankful to u sir. That tutorial was really cool 🙂
Just a quick note that I love the whole site and have never had such an easy time establishing a new direction of endeavor with a high degree of confidence and understanding! This post had me up, running valid data, and evaluating the output from the classifier in under 10 minutes! Simply amazing!
One small issue of note, though. The last paragraph of section 5, just before the Summary, covers the Confusion Matrix. In that paragraph, the third case cited refers to the three instances in which “Iris-versicolor was classified as a Iris-setosa.” My understanding of the table, however, is that there were three instances in which the Iris-versicolor was classified as an Iris-verginica, not Iris-setosa as stated. Naturally Mr. Murphy would select the most ironic location for this confusion of interpretation.
can i use kdd 99 dataset in weka ..? can i detect dos attack using weka ? any suitable classification algorithm ?..reply soon …i dont have enough time…
Thanks for your helpful information.
I have a specific question. Using the steps that you have mentioned we can train a machine learning model in WEKA and test its accuracy. I am wondering how we can classify new instances, with no class labels, using a model that we have trained in WEKA. For example, lets say that we have 1000 instances of positive and negative sentences. We train a machine learning model using an algorithm. Afterwards, we want to label 100 new sentences that have not already been classified with either positive or negative labels. How can we do such a work using WEKA?
Hi,
This is great tutorial to start and understand Weka.
Thanks a lot.
Amazinggggg!
Very useful. My father once tried to define a template to define flowers quality and now I have an idea.
And now I have run my first Machine Learning experimente!
Hi,
I’m new to Weka and I’m trying to figure out how to predict the value of a variable based on the values of other independent variables, in classification. I was wondering how to go about it.
Thanks!
I am making an application based on handwritten digit recognition, it will be an android app. User will click picture of a digit, it will be send to the server then text will be recognized using machine learning.
I will write back-end of my application in java language so does WEKA provide interfacing with java.
Nice post. I got your book on “Master Machine Learning Algorithm”, It is very good but i want to know how to replicate the example on “Logistic Regression” using weka pakage and java but could not. Please assist. Thank you.
Hey,
So we provide only the data set and select a classifier and it automatically classifies is it?
I mean if we provide a new training set?
Hi to every single one, it’s really a good for me to pay a quick visit this website, it includes priceless Information.
A quick question: I ran the SMO classifier, as I needed a Support Vector Machine, and got a set of results that included a list of the features used, under a line that reads, “Machine Linear: showing attribute weights, not support vectors”. Each feature has a value to the left and the label “(normalised)” next to it.
What does this mean, please? Values for each feature was used in the classification so I assume the numbers refer to some sort of weighting i.e. how heavily each feature impacted on the results. Is this the case?
Any chance someone can please explain this in simple terms as I am a beginner, or at least point me to a website with a detailed explanation of the SMO classifier and ALL its results section contents.
I am not seeing the “data” directory when i open Weka console. It only shows me the files on my local drive.
The “data” directory is a sub-directory under your Weka installation.
If you cannot see it, you can download the .zip version of Weka, unzip it and access the data directory:
http://www.cs.waikato.ac.nz/ml/weka/downloading.html
Hi, am quite new to weka. I am faced with a problem of clustering my data. I have a dataset of 13 distinct attributes, though only 12 is significant to the dataset. Am interested in using the kmeans algorithm and the euclidean distance for the distance function.
The problem faced is to cluster the data belonging to 1 class along among the dataset.
How do i go about it.
Please answer is need ASAP.
i’m new in weka, i’ve use my own dataset to run the Libsvm classifier.but the libsvm get error message”it cannot handle numeric class”
i turn it into nominal in the header of .arff file but it make the .arff file unreadable,
How can i fix this problem
Maybe you can use a data filter to convert the numeric class to nominal? Perhaps the Discretize filter?
Also, consider support vector regression.
I am beginner in Weka. i use weka for ECG classification not for a dataset but classify record by record … firstly i convert .mat file to .csv and by weka i convert it to .arff as i can not get relation and header for my file >>>> i have question here in ECG i use .mat file or use annotation files also ????
This post might give you some help converting your files to ARFF:
https://machinelearningmastery.com/load-csv-machine-learning-data-weka/
Hi am beginning of the weka tool. i used audio classification….but result is always below 50%
Great Post!!
Thanks Gagan.
Hi,
I am training data set of posts from Facebook on Naive bayes multinomial,the data gets more classified if i use the üse training set test option but if i use cross folds and percentage split the percentage of the correctly classified instances dropss drastically(i get 40% or below).Why is this happening.i have tried to search for this problem and I cannot find solutions.I repeated with 3 diffrent classifiers
(SMO,IBk anns J45) but the same problem persists.what could be the problem and how do i solve it.
thank you.
Hi Jason,
I have created the model on train data using weka.
For Example:
AGE, SEX, Status
15, male, Reject
19, male, Approve
I tried to run model on test data, it saying the type mismatch for status attribute.
For Example:
AGE, SEX, Status
10, male, ?
21, male, ?
I tried to leave that status attribute without ‘?’ mark and just empty. Still it is saying same error
What I am doing wrong?
Hi Gramcha, test data in Weka needs a known out come. It is testing your model and needs to compare predictions to actual values. You cannot have “?” values in test data.
If you are looking to make predictions on new data, see this post:
https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/
how to apply the model on test data?
Great question.
You can use the train/test split option.
This post has info on how to make predictions on new data:
https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/
Weka is awesome. I believe every statistician should know this!
Thanks Mark, I agree!
Can you please provide a link to example/demo code to classify unlabeled data. I have a set of unlabeled data, training data and test data. Using weka, I am not able to get the label for unlabeled data.
Thanks in anticipation
Hi Justin, this post has what you want:
https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/
Hi everyone
Am getting this error class index is negative (not set)! from WEKA, please can you throw more light on how it can be resolve?
Can you help to do web mining classification using weka tool..
Sorry, I do not have any examples of web mining Deena.
I am dealing with multi class problem weka. Here my doubt is variations in accuracy results with different classifiers with same attributes. EX: With SMO accuracy -84%, Random Forest- 92%. How this much variation comes? and is there any option to enhance smo performance in weka. Let me know as early as possible. thank you.
Yes, different algorithms will get different performance Rajesh.
The goal of applied machine learning is to find the models and model parameters that give the best performance.
Can you guide me how to change the parameters in WEKA? I want to change the classification technique with different parameters values (at least 3 parameters with 3 different value for each), AND their classification results.
Thanks
Sorry, I don’t understand Nor.
You can learn how to use Weka here:
https://machinelearningmastery.com/start-here/#weka
function.MultilayerPerceptron 98% with momentum of 0.11
Very nice Viorel.
I am using AutoWEKA Tab to classify my Owen data-set. Now I want to run the obtained best conditions over another data-set for comparison task. how to do this.
Best
Hi mtokhy, sorry I am not familiar with AutoWEKA.
98% accuracy by choosing training set in test option. Could you please elaborate it ?
Sorry, I don’t understand. Could you restate your question please?
Dear Colleague,
I need help in Weka program. I can not build tree.
Can you please to send you the file excel and help me.
Thank you
I am new to Weka and machine language .I am trying to load following dataset. For the
following dataset the J48 classifier is disabled. I need to generate java class files .Could you please help on the issue
@relation Icelandincnamedataset
@attribute First_Name string
@attribute Last_Name string
@attribute Last_Name_suffix {son , dottir, None }
@attribute Iceland_native {Yes, No}
@data
Bjarni,Benediktsson,son,Yes
Perhaps you need more examples in your data file?
hi,could u suggest a dataset for handwriiten character/digit recognition which works for WEKA? Thanks
Hi Shaurya,
MNIST is the standard for handwritten character recognition. I’m not aware of a version of the data suitable for use with Weka, sorry.
Hello, Gamified online WEKA (www.gamifiedonlineweka.ga) is a very good online alternative to desktop based WEKA with better visualizations do try it.
Thanks for the note ania.
Hey Jason!
Would you please tell me how i can apply the trained models on new data.
I want to build a decision support system that predicts the best radiological procedure for a patient with given indications. I tried Weka but i cant figure out how to apply the models on new patients’ conditions and get the predictions.
Thank you
This post will help Chelly:
https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/
Dear Jason Brownlee, Now i have one Question how many records (attributes and instance) required to conduct analysis/Research or Thesis a minimum and Maximums using data mining technology especially Weka software.
It depends on the complexity of the problem. Generally, more data is better.
Hi Jason!
I will be taking a course in Predictive Analytics through UC San Diego in April and I thought I’d get a start by looking at WEKA. That will be the tool that we will be using in the course.
I liked the example of the iris file that you gave and how it analyzed the data and found a certain number of records misclassified within the data set. I’m trying to understand the real life application of this tool and I’m thinking about my previous role as a manager over all incidents that were reported by customers who are trying to access our websites. Some of those issues were data related problems, eg missing data, incorrect data in the wrong fields, etc.
So would I be able to run analysis of the data and identify records that had these data issues in my dataset and then drill down to the actual record to identify the real root cause and address the issue upstream in the data ETL process?
I believe so Tammi.
Generally, I think Weka is great for learning applied machine learning and the process of working through a predictive modeling problem.
I also think Weka is great for one-off projects.
For something more industrial/operational, programming may be required.
I hope that helps.
Hi Jason!
I thought I posted a comment last night, but don’t see it 🙁 At any rate, here is my question/thought.
I will be taking Predictive Analytics through UC San Diego next month and will be using WEKA in the course. Your example on the Iris made it easier for me to digest how to use this tool and I thank you for that.
I’m thinking about the practical use of this tool in my every day work. I worked for a large insurance company and was responsible for 7 websites and all of the reported issues/incidents within those portals from customers (internal and external). I’m assuming this would be a good tool to look at data related issues, e.g. we get data feeds from mainframe to a repository. In that data, there can be defects, e.g. missing data, incorrect data in wrong field, etc. I’m assuming this will help with this type of issue.
My questions are – is my assumption above correct and if so, does this tool then allow you to easily identify the data at a line level?
Thanks
Comments are moderated by me, usually over 24 hours.
I’ve answered your other comment.
Hello Sir,
how to use Weka KnowledgeFlow Environment . i m trying to use weka knowledge flow
environment bt output not display.
i m working on Chronic Kidney Disease Detection by Analyzing Medical Datasets in Weka .
Thanks
I would recommend using the Explorer and the Experimenter instead.
HI Jason,
Am trying to classify tweets into 3 categories: +ve, -ve and neutral.
Currently I have around 800 tweets. Steps followed by me:
1. Converting tweet text column to string using NomialtoString.
2. Applying StringtoWordVector (stemmer: Snowball, tokenizer: NGramTokenizer or CharNGramTokenizer.
3. Applying AttributeSelection (with default settings) under “preprocess” only so as to automatically select the attributes.
Am getting an accuracy to around 65% with Naive Bayes. How can I improve the result??
I need to know exact process or settinngs to follow. Is there anything else I should be doing??
Thanks
Maybe try some other algorithms?
Maybe try an alternate representation?
Maybe try and filter some of the data.
I have next question:
I have for example 3 attributes and a decision: blue, round, small -> ball
Weka does analyze this dataset and build decisions, but how to see this decisions in the way like: if(blue, round, small) then -> ball
Great respect
Thanks
P.s. Our team is going to implement our own classification algorithm to Weka (LEM2), if you have some similar idea I would appreciate your help
I assume you are using a rule-based model.
You may be able to configure debugging on the model to output the rules.
You may be able to use the Java API to access the learned rules.
I have implemented algorithms for weka and found it straight forward. The documentation is very good.
Here are some algorithms I implemented more than 10 years ago:
http://wekaclassalgos.sourceforge.net/
Hi Jason,
I would like to know if Weka can help in evaluating phishing emails detection model, not only based on words found in the content, but also based on checking other features such as sender IP through online blacklisting service, then increase the probability of being phishing if sender IP is blacklisted? if Weka can help, then how?
All regards
It may Joe, I would recommend spending time formulating the predictive modeling problem before selecting algorithms/platforms.
See this post:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Thanks Jason,
After reading the post, I still have the same question:
Can I know if using Weka in my Java code, is required to check certain mined IP address for blacklisting, then use the result as an input again in Weka? or this can be done with Weka tool alone?
honestly, I’m not a programmer, and try hardly to understand the problem!
You may be able to use Weka, it is impossible for me to say for sure without having a deeper understanding of your dataset.
The tutorial was supposed to give you enough context to translate to your own problem.
My advice would be to try and see.
How to calculate Root Mean Squared Error in WEKA’s result? can I calculate from confusion matrix, may be?
It is calculated automatically for regression problems, not for classification problems.
Hi Jason, I’d like to report some of my weka results – but am struggling with how to put it (what to include etc.). Could you recommend a website or an article where weka results are reported? Thanks!
What do you mean by reported Conny?
Do you mean how to present results?
This post might help:
https://machinelearningmastery.com/how-to-use-machine-learning-results/
Thanks a lot Jason for this great initiative.
I got 100% accuracy with Lazy K-Star using training set ????????
KStar options : -B 20 -M a
Time taken to build model: 0 seconds
=== Evaluation on training set ===
Time taken to test model on training data: 0.06 seconds
=== Summary ===
Correctly Classified Instances 150 100 %
Incorrectly Classified Instances 0 0 %
Kappa statistic 1
Mean absolute error 0.0062
Root mean squared error 0.0206
Relative absolute error 1.3992 %
Root relative squared error 4.3621 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-versicolor
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-virginica
Weighted Avg. 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000
=== Confusion Matrix ===
a b c <– classified as
50 0 0 | a = Iris-setosa
0 50 0 | b = Iris-versicolor
0 0 50 | c = Iris-virginica
Very nice!
IB1 also provided 100 accuracy:
IB1 instance-based classifier
using 1 nearest neighbour(s) for classification
Time taken to build model: 0 seconds
=== Evaluation on training set ===
Time taken to test model on training data: 0 seconds
=== Summary ===
Correctly Classified Instances 150 100 %
Incorrectly Classified Instances 0 0 %
Kappa statistic 1
Mean absolute error 0.0085
Root mean squared error 0.0091
Relative absolute error 1.9219 %
Root relative squared error 1.9335 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-versicolor
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-virginica
Weighted Avg. 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000
=== Confusion Matrix ===
a b c <– classified as
50 0 0 | a = Iris-setosa
0 50 0 | b = Iris-versicolor
0 0 50 | c = Iris-virginica
Thanks for sharing!
Hey. Can anyone help me?
I want to train my neural network by giving a data set:
@attribute activity {A, B, C}
@attribute resource {x, c, e}
@data
A,x
B,x
A,x
B,c
C,e
B,e
A,x
C,x
A,e
B,e
C,e
B,c
C,c
And than, I wan to give for neural network A,c and get the answer that’s is not correct. Because there wasn’t instance like this in my training set.
I am trying to this in Weka by using MultilayerPerceptron. But it doesnt’ work…
Can anyone help me?
This process will help you work through your problem systematically:
https://machinelearningmastery.com/start-here/#process
hii i am new in weka tool .i dont know to how to write a program.so plz help me…….
I recommend learning to use Weka:
https://machinelearningmastery.com/start-here/#weka
hello sir
tomorrow will be my external viva .. my topic is lung nodule using CBIR. NN techinque.
i have a table of feature extraction…that i run according the same way that u told in this PDF.. plz tell me some new things regarding this..
thnks
Sorry, I don’t have examples of feature extraction in my materials. Perhaps you have me confused with someone else?
How can I upload csv file to Weka? I’m getting errors like “number expected, read token[what] line 7”
This post may help you load your data in Weka:
https://machinelearningmastery.com/load-csv-machine-learning-data-weka/
Hi,
Thanks a lot for the article. It helped a lot.
I want to know some more information about weka.
How can I upload my own machine learning algorithm into weka?
I want to do this and check the performance metrics of the algorithm.
Thank You in Advance.
Yes, you can code your own algorithms for Weka, I did this myself back in the day:
http://wekaclassalgos.sourceforge.net/
Sorry, I don’t have tutorials show you how to do this, perhaps in the future.
Hi. I am new to Machine learning and WEKA too.
I am satisfied with your tutorial. So how can i can go to next tutorial? i can’t find it on internet.
Thank you !
English is my second language so i hope you can understand what i want to say.
Start here with Weka:
https://machinelearningmastery.com/start-here/#weka
Thanks for this great machine learning tool. I tried using Weka to classify spambase dataset into either spa or non-spam but it is not giving me the right result. Can you explain how I can use Weka for spam email classification using any dataset? What I first did was to convert the text file to .cvs file, then do select normalize on Weka, and then went on select the classification algorithms that I want. The result I got is below:
=== Run information ===
Scheme: weka.classifiers.functions.MultilayerPerceptron -L 0.3 -M 0.2 -N 500 -V 0 -S 0 -E 20 -H a
Relation: spambase_name
Instances: 47
Attributes: 1
make
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
MultilayerPerceptron
====================
Warning: No model could be built, hence ZeroR model is used:
ZeroR predicts class value: address
Time taken to build model: 0.07 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 0 0 %
Incorrectly Classified Instances 47 100 %
Kappa statistic -0.0217
Mean absolute error 0.0421
Root mean squared error 0.1458
Relative absolute error 100 %
Root relative squared error 100 %
Total Number of Instances 47
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0.000 0.913 0.000 0.000 0.000 -0.427 0.043 0.021 address
0.000 0.109 0.000 0.000 0.000 -0.051 0.043 0.021 all
0.000 0.000 0.000 0.000 0.000 0.000 0.043 0.021 3d
0.000 0.000 0.000 0.000 0.000 0.000 0.043 0.021 our
0.000 0.000 0.000 0.000 0.000 0.000 0.043 0.021 over
0.000 0.000 0.000 0.000 0.000 0.000 0.033 0.021 remove
0.000 0.000 0.000 0.000 0.000 0.000 0.033 0.021 internet
0.000 0.000 0.000 0.000 0.000 0.000 0.033 0.021 order
Sorry, I don’t have an example of working with text data in Weka.
how to decide descision and relationship in classification?
What do you mean exactly?
Nice start for me. Just downloaded Weka and ran the iris data set as described. Making some sense to me now and hope by the end of the course I would be able to pass the knowledge.
Great work George!
Thanks Jason.
I am using Multilayerperceptron for my dataset and I am getting following results.
Time taken to build model: 1064.19 seconds
=== Evaluation on training set ===
=== Summary ===
Correctly Classified Instances 39341 78.7655 %
Incorrectly Classified Instances 10606 21.2345 %
Kappa statistic 0.7819
Mean absolute error 0.0152
Root mean squared error 0.0853
Relative absolute error 31.9084 %
Root relative squared error 55.3309 %
Total Number of Instances 49947
I need more accuracy i.e. accuracy >=90% with same model.
Something odd is going on there…
Sir
can you please elaborate it?
I am working with 49947 records.
How can I plot error graph or ROC curve through WEKA?
Is it possible to build this graph from TP rate and FP rate?
Please reply
I believe Weka has this built-in. Try right clicking on the algorithm results and review the menu options.
Hi Jason, could u please help me with the analysis of this classification output.
=== Run information ===
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: Credit Screening
Instances: 125
Attributes: 11
jobless
purchase_item
sex
unmarried
problem_region
age
money_inbank
pay_monthly
num_month
work_years
granted
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
J48 pruned tree
——————
jobless = n
| work_years <= 2
| | purchase_item = pc: p (4.0)
| | purchase_item = car
| | | pay_monthly 9: p (3.0/1.0)
| | purchase_item = stereo
| | | unmarried = p: n (5.0/1.0)
| | | unmarried = n: p (3.0)
| | purchase_item = jewel
| | | work_years 1
| | | | pay_monthly 9: n (3.0/1.0)
| | purchase_item = medinstru: p (7.0/1.0)
| | purchase_item = bike: n (6.0/1.0)
| | purchase_item = furniture: n (2.0)
| work_years > 2: p (70.0/7.0)
jobless = p: n (14.0/2.0)
Number of Leaves : 13
Size of the tree : 20
Time taken to build model: 0.04 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 95 76 %
Incorrectly Classified Instances 30 24 %
Total Number of Instances 125
=== Detailed Accuracy By Class ===
Precision Recall F-Measure Class
0.809 0.847 0.828 p
0.639 0.575 0.605 n
Weighted Avg. 0.755 0.760 0.756
=== Confusion Matrix ===
a b <– classified as
72 13 | a = p
17 23 | b = n
Which part are you trying to understand?
what is accuracy about in classification in WEKA
Accuracy is the measure of model skill as the total correct predictions divided by the total predictions made and multiplied by 100 to turn it into a percentage.
Hy Mr.Jaon….I am working on diagnosis of thyroid ….i created two separate dataset files…train file and test with with ? instead of output …WEKA works well with trained file but when i execute test file it pops up an error message NOT ENOUGH TRAINING INSTANCES WITH CLASS LABELS (REQUIRED 1,PROVIDED 0)….can you please help me with this
Looks like you might need more examples of each class in your training dataset.
Hi Jason, can we use weeka for LSTM ? If yes , please suggest some tutorial for help.
I don’t believe so.
Hi! Thanks for sahring this post.
I’m newbe at Weka and I’d like to know if you know how to add a new filter to Weka using java commands… I’m trying to add the LSH-IS for instance selection, it’s avaible at this page:
https://github.com/alvarag/LSH-IS/
I’d like to know if you know how to solve this mistake: “Could not find or load main class weka.gui.GUIChooser”
Sorry, I don’t have material on adding new features to Weka.
Great. Useful and fun way to hit the ground running with machine learning. I’ve been doing a bit of research and I was surprised to discover that many machine learning job offers list proficiency in Weka as a requirement! It’s not only a toy after all 🙂
Great to hear!
Ok I got 98.2759 with MultilayerPerceptron and Percentage split 61% fwiw.
Well done!
Ok I beat that with Logistic and using a training set I got 98.6667%. Only 2 wrong!
Cheers!
Ok my last post(sorry!) got 100% using lazy IBk and using a training set.
=== Run information ===
Scheme: weka.classifiers.functions.MultilayerPerceptron -L 0.3 -M 0.2 -N 500 -V 0 -S 0 -E 20 -H a
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
Sigmoid Node 0
Inputs Weights
Threshold -3.5015971588434014
Node 3 -1.0058110853859945
Node 4 9.07503844669134
Node 5 -4.107780453339234
Sigmoid Node 1
Inputs Weights
Threshold 1.0692845992273177
Node 3 3.8988736877894024
Node 4 -9.768910360340264
Node 5 -8.599134493151348
Sigmoid Node 2
Inputs Weights
Threshold -1.007176238343649
Node 3 -4.2184061338270356
Node 4 -3.626059686321118
Node 5 8.805122981737854
Sigmoid Node 3
Inputs Weights
Threshold 3.382485556685675
Attrib sepallength 0.9099827458022276
Attrib sepalwidth 1.5675138827531276
Attrib petallength -5.037338107319895
Attrib petalwidth -4.915469682506087
Sigmoid Node 4
Inputs Weights
Threshold -3.330573592291832
Attrib sepallength -1.1116750023770083
Attrib sepalwidth 3.125009686667653
Attrib petallength -4.133137022912305
Attrib petalwidth -4.079589727871456
Sigmoid Node 5
Inputs Weights
Threshold -7.496091023618089
Attrib sepallength -1.2158878822058787
Attrib sepalwidth -3.5332821317534897
Attrib petallength 8.401834252274096
Attrib petalwidth 9.460215580472827
Class Iris-setosa
Input
Node 0
Class Iris-versicolor
Input
Node 1
Class Iris-virginica
Input
Node 2
Time taken to build model: 0.45 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 146 97.3333 %
Incorrectly Classified Instances 4 2.6667 %
Kappa statistic 0.96
Mean absolute error 0.0327
Root mean squared error 0.1291
Relative absolute error 7.3555 %
Root relative squared error 27.3796 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.960 0.020 0.960 0.960 0.960 0.940 0.996 0.993 Iris-versicolor
0.960 0.020 0.960 0.960 0.960 0.940 0.996 0.993 Iris-virginica
Weighted Avg. 0.973 0.013 0.973 0.973 0.973 0.960 0.998 0.995
=== Confusion Matrix ===
a b c <– classified as
50 0 0 | a = Iris-setosa
0 48 2 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
Nice work.
I have data set i loaded to weka and working fine, the problem is that i want apply j48 on this data set but j48 not activated when i tried to apply it. it maybe not applicable for j48 how can i make my data set applicable for j48.
example :- using the data in this link is not applicable of j48
http://archive.ics.uci.edu/ml/machine-learning-databases/00432/Data/
Thanks
Perhaps your data does not have a classification output?
Hi Jason,
Really ashamed to admit this. I get stucked at the very beginning of this tutorial. I installed Weka version 3.8 and followed the tutorial steps until 3. Open the data/iris.arff Dataset. However, I couldn’t find the location of data directory. Where it supposed to be? Am I missing something?
Thank you very much for your kind reply.
I am sorry… solved. I reinstalled everything and found the directory you mentioned… Thank you.
I’m glad to hear that.
It will be in the location where Weka was installed.
Thanks for sharing your thoughts about website. Regards
I’m glad it helps.
I installed weka and located the iris data set. Will now work through the lesson.
Well done.
Hi Jason, excellent work. I found a paragraph where the confusion matrix and your text do not mach.
..and 3 cases where an Iris-versicolor was classified as an “Iris-setosa” (a total of 6 errors). This table can help to explain the accuracy achieved by the algorithm.
As an iris-setosa or as Iris-virginica?
a b c <– classified as
49 1 0 | a = Iris-setosa
0 47 3 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
Thank you very much for your course and your articles.
Thanks, you can learn more about the confusion matrix here:
https://machinelearningmastery.com/confusion-matrix-machine-learning/
Hi Jason,
I run Weka Version 3.9.2 and got 98.6667% out of Multilayer Perceptron, with the cross validation setting of 10.
=== Confusion Matrix ===
a b c <– classified as
50 0 0 | a = Iris-setosa
0 49 1 | b = Iris-versicolor
0 1 49 | c = Iris-virginica
Does the Weka Version 3.9.2 use a stronger algorithm?
Thank you very much for your site.
Nice work.
No, likely a little random variance in the training of the model across versions of weka.
Hi Jason,
Is it normal for the Precision and Recall to be 1 when the accuracy is 100%?
Yes. More here:
https://en.wikipedia.org/wiki/Precision_and_recall
Ok, I used it for the first time today.
1) First, had some trouble getting Weka Explorer to read the iris ARFF file. Searched around and found some complicated answers in Stack Overflow (no big deal, use R to reformat), found easiest way in Research Gate, just use Notepad++ to see all the hidden non-Ascii7 characters (a bunch, mainly % used for comments, just got rid of all of it) and read that ARFF has problems with special characters (sort of ridiculous but…). Other might skip some searching by knowing this. I spent more time formatting the dataset than running the classifiers.
2) Then ran some of them, per your instruction above, very good. Got same results as you and one (latest?) for the comments back in 2014. 33% to start on ZeroR, 96% on the Trees and also on Naïve Bayes, and 97.33% on the Perceptron. Nice. Is the Perceptron model 1 layer and is there a way to run from Weka more complex deeper neural networks? I will try it also in a couple days as I learn Python/Tensor Flow, and will try the Wela Perceptron on some small image dataset if I can find one quickly.
Thanks for your Weka instruction. May try more, also beyond Weka — thought it’s be an easy way to get some simple classifiers/etc done quickly.
3) Question: is there a way using just Weka tools to produce some plots like the confusion matrix I got for the 97.33%? I’ll look in visualize also but a first look didn’t say.
Bob
Nice work Bob.
Strange to hear about the problems with the dataset, I’ve not seen/heard about that before.
I don’t think Weka has a tool to plot the confusion matrix.
can we Meka instead of weka
What is Meka?
=== Run information ===
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: evaluate on training data
=== Classifier model (full training set) ===
J48 pruned tree
——————
petalwidth 0.6
| petalwidth <= 1.7
| | petallength 4.9
| | | petalwidth 1.5: Iris-versicolor (3.0/1.0)
| petalwidth > 1.7: Iris-virginica (46.0/1.0)
Number of Leaves : 5
Size of the tree : 9
Time taken to build model: 0.07 seconds
=== Evaluation on training set ===
Time taken to test model on training data: 0.02 seconds
=== Summary ===
Correctly Classified Instances 147 98 %
Incorrectly Classified Instances 3 2 %
Kappa statistic 0.97
Mean absolute error 0.0233
Root mean squared error 0.108
Relative absolute error 5.2482 %
Root relative squared error 22.9089 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.980 0.020 0.961 0.980 0.970 0.955 0.990 0.969 Iris-versicolor
0.960 0.010 0.980 0.960 0.970 0.955 0.990 0.970 Iris-virginica
Weighted Avg. 0.980 0.010 0.980 0.980 0.980 0.970 0.993 0.980
=== Confusion Matrix ===
a b c <– classified as
50 0 0 | a = Iris-setosa
0 49 1 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
Well done!
Hi Jason,
Well done and great contribution towards Weka tool and providing quick answers for the queries !! , I am new to weka tool and I m basically a dotnet developer.
I need your suggestion/help for my work. I need to classify the data in CSV file into three categories/domain
4 files
1.The Data is in one CSV file , with Slno, timing stamp, user search query
2.Keyword based on domain 1
3.Keyword based on domain 2
4.Keyword based on domain 3
I want to classify user search query in file one based on the keywords present in other files.
Is it possible to classify this scenario in weka ? if any suggestion on this
Thanks a lot !!
Your help is much appreciated !!
Ravi
I recommend combining all data into one file when working with Weka and consider this framework to help understand the prediction problem:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Thank you Jason!!,
I went through the framework and understood the importance of the problem definition and solution.
I m exploring the way how we can classify the given user search query based on specific keywords from different domains. Also i don’t know how to combine the user query dataset
with keywords
if you any samples or simpler kind of problem , could you please share?
Thanks
Ravi
Sorry, I don’t have examples of this type of problem.
Time taken to build model: 0.41 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 146 97.3333 %
Incorrectly Classified Instances 4 2.6667 %
Kappa statistic 0.96
Mean absolute error 0.0327
Root mean squared error 0.1291
Relative absolute error 7.3555 %
Root relative squared error 27.3796 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.960 0.020 0.960 0.960 0.960 0.940 0.996 0.993 Iris-versicolor
0.960 0.020 0.960 0.960 0.960 0.940 0.996 0.993 Iris-virginica
Weighted Avg. 0.973 0.013 0.973 0.973 0.973 0.960 0.998 0.995
=== Confusion Matrix ===
a b c <– classified as
50 0 0 | a = Iris-setosa
0 48 2 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
Well done!
Hi Jason,
Firstly, congrats for the post!
Secondly, I don’t know what is the meaning of the values between parenthesis.
For example Iris-versicolor (3.0/1.0). What means 3.0/1.0?
petalwidth 0.6
| petalwidth 1.7: Iris-virginica (46.0/1.0)
Thank you!
Where are you drawing those examples from exactly?
Great tutorial, I also want to add, dataset used in weka are arff format.One can also upload their own data set to check out but i have question i tried wisconsin breast cancer dataset from UCI repository.I convert csv file format to arff format.I also applied some classifiers from weka but i have seen few of them are not used for my this dataset while same classifiers i had used for builtin datasets of weka tool.
I dont know why? Is there any solution?
Good question, Weka will only let you use models that are appropriate for your data.
For example, if it a classification problem, then you can only use classification algorithms.
Hello! Nice and helpful tutorial to start up with weka!! I was wondering in case you use Experimenter instead of Explorer, how could you see the results? Do you have any related tutorials?
I am doing the Setup of the dataset, the algorithm and the result destination, then I run the experiment in the Run tab, which runs without an error and then in the Analyse tab I load the result-file.arff, but the result format is much different from the Explorer classifier/clusterer output.
In other words, how can I see the “summary” and the “detailed accuracy by class” of results for experiments ran on the Experimenter?
Also I couldn’t find so far how to visualize results produced from the Experimenter.
The experimenter is really for running experiments only, not data visualization or other tasks performed in the Explorer.
Hello!Is there any method to plot graphs for RMSE for a regression type problem in weka for different algorithms like LibSVM,SMOReg,REPTree etc.??
And if for example we are predicting housing prices,then how can we plot a graph for the predicted and original price??
I’m not sure off hand sorry.
Hii,
In my case its not identifying the class label. Is there any thing to be done for that.
What do you mean exactly?
hey ,thanks a lot of sharing the information of weka tool with me , being student it is very helpful to start with the pictures and the material which you have provided,thanks a lot
You’re very welcome!
Hi,
After installing Weka 3.8 successfully. I followed until step 02. However, at step 03 I am unable to find (or see) the data directory. Can you help me how to find the data directory?
You may need to download the data files separately, see this post:
https://machinelearningmastery.com/download-install-weka-machine-learning-workbench/
i am not talking about the existing data sets in weka folder data i have my own data set in an excel sheet how i call in weka to run an analysis
Yes, you can load new dataset in the same way as the example datasets.
First you must prepare your data and save it as a CSV file.
is it possible in weka to train a classifier from one dataset and test on another dataset.?
Yes, see this post:
https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/
Hello there, Jason Brownlee! I’m Bobby R.J.
Thanks for sharing your knowledge, we are really appreciated it!
Anyway, is there any way to discuss with you? I have trouble in doing my project, especially in doing online/real-time classification…
Please email me at my contact if you have time!
Thank you so much!
You can contact me any time:
https://machinelearningmastery.com/contact/
Correctly Classified Instances 146 97.9866 %
Incorrectly Classified Instances 3 2.0134 %
Kappa statistic 0.9698
Mean absolute error 0.0223
Root mean squared error 0.1189
Relative absolute error 5.008 %
Root relative squared error 25.2267 %
Total Number of Instances 149
Logistic Classifier
Nice work!
Hi Jason,
Needs a java code for calculating a Accuracy, TP rate, FP rate, Precision, MCC, PRC, ROC, confusion matrix from weka, to the console of netbeans IDE. If i’m running any dataset the console of netbeans should be as:
Accuracy=
TP rate=
FP rate=
Precision=
MCC =
ROC =
PRC=
Confusion Matrix=
Regards
Ashish
Perhaps you can call Java functions in the Weka API?
Sorry, I don’t have any examples.
Hi Jason, Thank you for your tutorial!
I used to write machine learning models in python. when I use the WEKA,I am curious if this trained model can be used on unlabeled data sets? Does WEKA have this function?
Good question, it may, I’m not sure off the cuff sorry.
Jason, you have a great approach. Thanks for sharing your knowledge (and encouragement)!
Interesting to see how the number of cross-validation folds evidently affects which samples are grouped together and the resulting correct classification percentages for three different classifiers.
J48 vs cross-validation folds:
2 –> 93.3%
4 –> 95.3%
5 –> 96.0%
7 –> 94.0%
9 –> 96.0%
11 –> 95.3%
12–> 96.0%
13 –> 94.0%
14–> 95.3%
16 –> 94.7%
17 –> 94.0%
18–> 96.0%
19 –> 95.3%
20 –> 96.0%
…
Logistic vs cross-validation folds:
2 –> 94.0%
3 –> 94.7%
5 –> 95.5%
7 –> 97.3%
8 –> 96.0%
11 –> 98.0%
12–> 96.7%
14 –> 98.0%
15–> 96.7%
16 –> 98.0%
17 –> 97.3%
18–> 96.7%
19 –> 98.0%
20 –> 97.3%
…
Multilayer Perceptron vs cross-validation folds:
2 –> 94.7%
3 –> 94.0%
4 –> 95.3%
5 –> 96.0%
6 –> 95.3%
7 –> 96.0%
8 –> 95.3%
9 –> 96.0%
10 –> 97.3%
11 –> 96.7%
12–> 96.0%
13 –> 95.3%
14 –> 97.3%
15–> 96.0%
17 –> 96.7%
18–> 96.0%
19 –> 96.7%
20 –> 97.3%
…
Nice one.
Yes, model evaluation is tricky. There’s little level ground to stand on.
Got 97.3333% accuracy with the Multilayer Perceptron.
Well done!
I managed 98.0392% accuracy with LMT and a percentage split on the data of 66%. While it only did 51 instances, the model only incorrectly classified 1 out of 51 instances. I’d say that’s pretty good.
=== Summary ===
Correctly Classified Instances 50 98.0392 %
Incorrectly Classified Instances 1 1.9608 %
Kappa statistic 0.9704
Mean absolute error 0.0166
Root mean squared error 0.1031
Relative absolute error 3.7161 %
Root relative squared error 21.8099 %
Total Number of Instances 51
=== Confusion Matrix ===
a b c <– classified as
15 0 0 | a = Iris-setosa
0 19 0 | b = Iris-versicolor
0 1 16 | c = Iris-virginica
I'd be inclined to take that model and throw the entire dataset at it to see how it fares.
Well done!
As a followup, I did so. The accuracy held near 98%. Amazing! You’ve got me hooked, Jason. Happy Holidays! 🙂
I’m working on other lessons and having a ball at it. What if I tweak it this way? Or what if I do X or let me try Y. Hey what happens if I use an ensemble algo instead of a classifier?
This is way more fun than the bottom-up approach I’ve been enduring while “learning data science”.
Well done.
I’m so happy to hear about your progress and excitement!
Hello, I have a doubt, when you add one instance Petalwidth= 1.6 cm, Petallength= 4 cm, Sepalwidth= 3.4 cm, Sepallength= 6 cm, In which class will you qualify?
¿Do you need specify the class in the end? o Will be qualify in Iris-setosa (50.0)
Great question!
No, you can make a prediction with just the input data.
See this tutorial for an example:
https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/
hello: i try classifying my loaded datasets via weka gui using deep learning architecture from DL4j but i could find it. the steps i used after data load is weka.classify.function to see DL4J
Sorry, I don’t know about DL4J.
Hello Ibrahim my qustion also same to you
did you know how to use deep learning
First of all, thank you very much for these tutorials. This really helps many of us who would like to get into ML world.
I went through these steps and I’ve one question. In J48 classifier, the FP rate for Iris-versicolor and Iris-virginica is displayed as 0.030.
However, when I try to calculate FP rate from Confusion Matrix,
for Iris-versicolor = 3/50 = 0.06. How did the tool get 0.030? Am i missing something here?
Kindly clarify.
You’re welcome.
Perhaps try other algorithms?
Hello Jason Brownlee, am new to machine learning and data mining. Am writing my final year project on Comparative Analysis of the Performance of Machine Learning Algorithm using Weka and Python. My question is do system processing power affect the result of classifiers on different datasets?
No. Only speed of execution.
Hello,
I am new in Weka and I need some help. Is there any way to run automatically the timeseries forecast package in weka with same specs bbut with different timeseries each time? My data set is 2172 product monthly demand and I want to run for each one the forecast separatly .That means I must run it 2172 times for each algorithm I need. Can help???
Sorry, I don’t know about time series forecasting in Weka.
any idea or tutorial regarding how I can run weka from simple CLI with commands in order to do faster my work? I will adjust it for my timeseries package. Thank you!
It is possible and I have done it, but I don’t have tutorials on the topic, sorry.
I recommend checkin the Weka documentation directly.
I run ZeroR as usual, but not J48. The start button is not active. Why is this happening?
Perhaps ensure you are using exactly the same dataset.
The start button is not active