Raw machine learning data contains a mixture of attributes, some of which are relevant to making predictions.
How do you know which features to use and which to remove? The process of selecting features in your data to model your problem is called feature selection.
In this post you will discover how to perform feature selection with your machine learning data in Weka.
After reading this post you will know:
About the importance of feature selection when working through a machine learning problem.
How feature selection is supported on the Weka platform.
How to use various different feature selection techniques in Weka on your dataset.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.
Update March/2018: Added alternate link to download the dataset as the original appears to have been taken down.
How to Perform Feature Selection With Machine Learning Data in Weka Photo by Peter Gronemann, some rights reserved.
Predict the Onset of Diabetes
The dataset used for this example is the Pima Indians onset of diabetes dataset.
It is a classification problem where each instance represents medical details for one patient and the task is to predict whether the patient will have an onset of diabetes within the next five years.
You can also access this dataset in your Weka installation, under the data/ directory in the file called diabetes.arff.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Feature Selection in Weka
Many feature selection techniques are supported in Weka.
A good place to get started exploring feature selection in Weka is in the Weka Explorer.
Open the Weka GUI Chooser.
Click the “Explorer” button to launch the Explorer.
Open the Pima Indians dataset.
Click the “Select attributes” tab to access the feature selection methods.
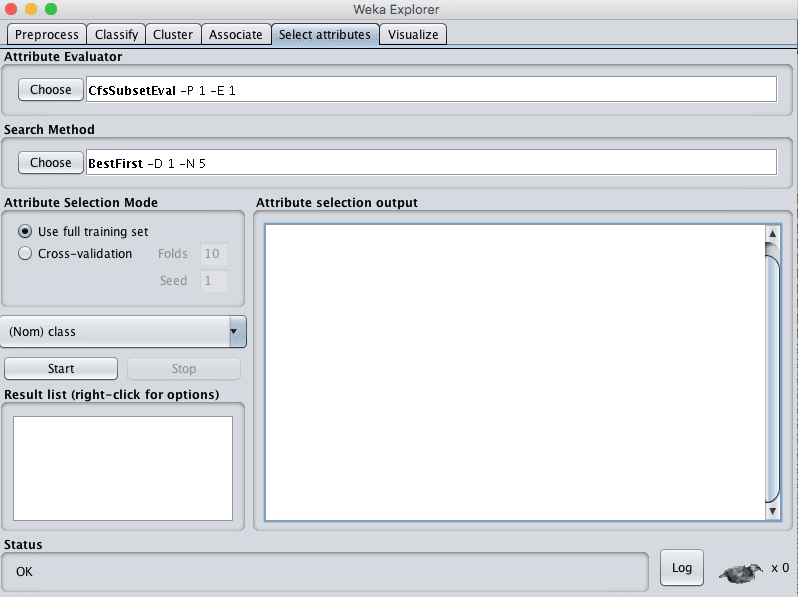
Weka Feature Selection
Feature selection is divided into two parts:
Attribute Evaluator
Search Method.
Each section has multiple techniques from which to choose.
The attribute evaluator is the technique by which each attribute in your dataset (also called a column or feature) is evaluated in the context of the output variable (e.g. the class). The search method is the technique by which to try or navigate different combinations of attributes in the dataset in order to arrive on a short list of chosen features.
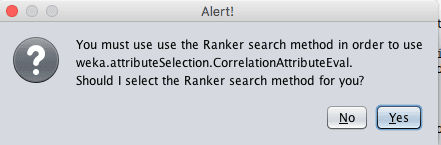
Some Attribute Evaluator techniques require the use of specific Search Methods. For example, the CorrelationAttributeEval technique used in the next section can only be used with a Ranker Search Method, that evaluates each attribute and lists the results in a rank order. When selecting different Attribute Evaluators, the interface may ask you to change the Search Method to something compatible with the chosen technique.
Weka Feature Selection Alert
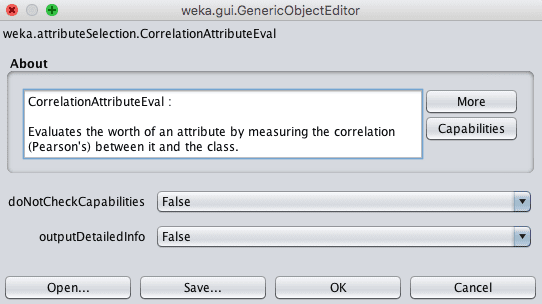
Both the Attribute Evaluator and Search Method techniques can be configured. Once chosen, click on the name of the technique to get access to its configuration details.
Weka Feature Selection Configuration
Click the “More” button to get more documentation on the feature selection technique and configuration parameters. Hover your mouse cursor over a configuration parameter to get a tooltip containing more details.
Weka Feature Selection More Information
Now that we know how to access feature selection techniques in Weka, let’s take a look at how to use some popular methods on our chosen standard dataset.
Correlation Based Feature Selection
A popular technique for selecting the most relevant attributes in your dataset is to use correlation.
You can calculate the correlation between each attribute and the output variable and select only those attributes that have a moderate-to-high positive or negative correlation (close to -1 or 1) and drop those attributes with a low correlation (value close to zero).
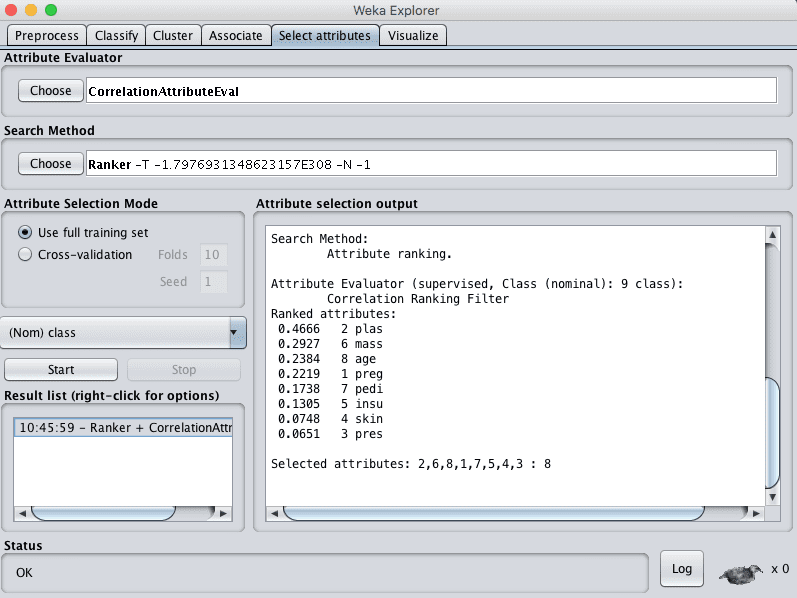
Weka supports correlation based feature selection with the CorrelationAttributeEval technique that requires use of a Ranker search method.
Running this on our Pima Indians dataset suggests that one attribute (plas) has the highest correlation with the output class. It also suggests a host of attributes with some modest correlation (mass, age, preg). If we use 0.2 as our cut-off for relevant attributes, then the remaining attributes could possibly be removed (pedi, insu, skin and pres).
Weka Correlation-Based Feature Selection Method
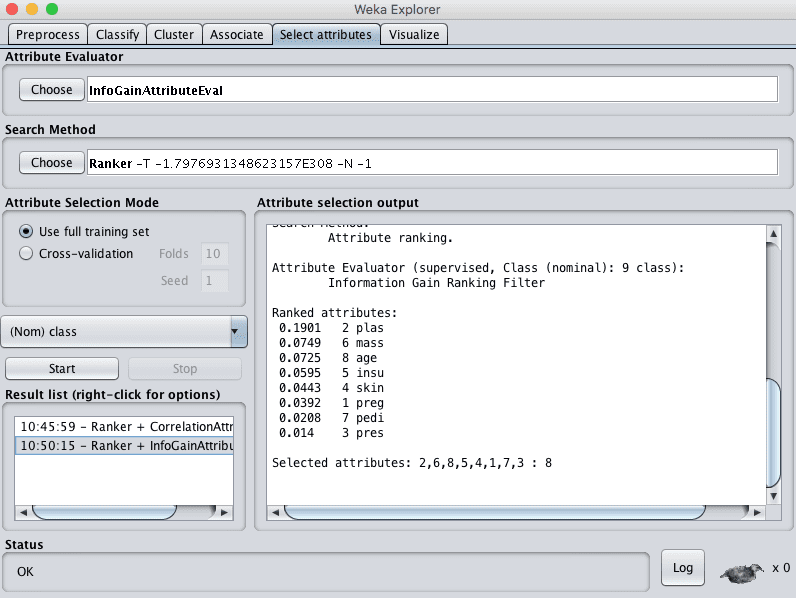
Information Gain Based Feature Selection
Another popular feature selection technique is to calculate the information gain.
You can calculate the information gain (also called entropy) for each attribute for the output variable. Entry values vary from 0 (no information) to 1 (maximum information). Those attributes that contribute more information will have a higher information gain value and can be selected, whereas those that do not add much information will have a lower score and can be removed.
Weka supports feature selection via information gain using the InfoGainAttributeEval Attribute Evaluator. Like the correlation technique above, the Ranker Search Method must be used.
Running this technique on our Pima Indians we can see that one attribute contributes more information than all of the others (plas). If we use an arbitrary cutoff of 0.05, then we would also select the mass, age and insu attributes and drop the rest from our dataset.
Weka Information Gain-Based Feature Selection Method
Learner Based Feature Selection
A popular feature selection technique is to use a generic but powerful learning algorithm and evaluate the performance of the algorithm on the dataset with different subsets of attributes selected.
The subset that results in the best performance is taken as the selected subset. The algorithm used to evaluate the subsets does not have to be the algorithm that you intend to use to model your problem, but it should be generally quick to train and powerful, like a decision tree method.
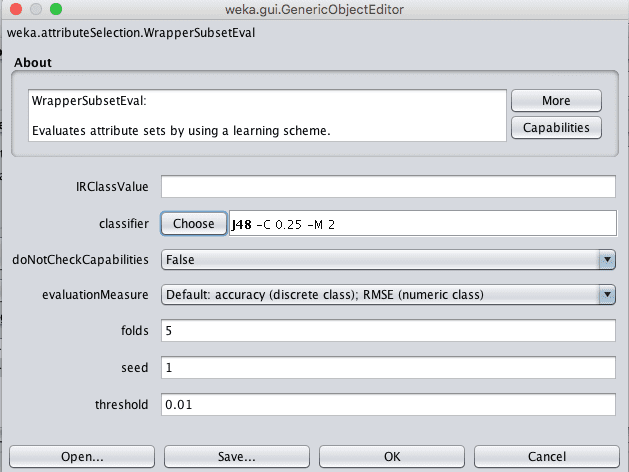
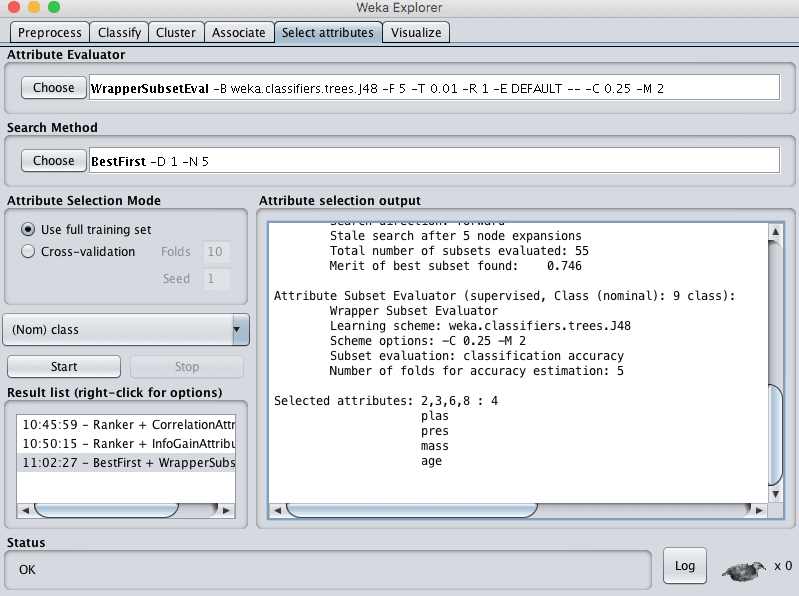
In Weka this type of feature selection is supported by the WrapperSubsetEval technique and must use a GreedyStepwise or BestFirst Search Method. The latter, BestFirst, is preferred if you can spare the compute time.
1. First select the “WrapperSubsetEval” technique.
2. Click on the name “WrapperSubsetEval” to open the configuration for the method.
3. Click the “Choose” button for the “classifier” and change it to J48 under “trees”.
Weka Wrapper Feature Selection Configuration
4. Click “OK” to accept the configuration.
5. Change the “Search Method” to “BestFirst”.
6. Click the “Start” button to evaluate the features.
Running this feature selection technique on the Pima Indians dataset selects 4 of the 8 input variables: plas, pres, mass and age.
Weka Wrapper Feature Selection Method
Select Attributes in Weka
Looking back over the three techniques, we can see some overlap in the selected features (e.g. plas), but also differences.
It is a good idea to evaluate a number of different “views” of your machine learning dataset. A view of your dataset is nothing more than a subset of features selected by a given feature selection technique. It is a copy of your dataset that you can easily make in Weka.
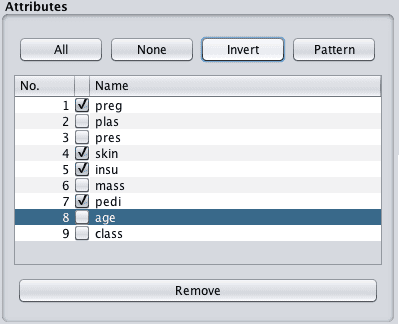
For example, taking the results from the last feature selection technique, let’s say we wanted to create a view of the Pima Indians dataset with only the following attributes: plas, pres, mass and age:
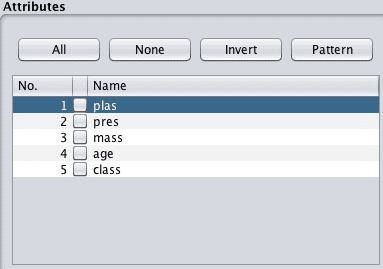
1. Click the “Preprocess” tab.
2. In the “Attributes” selection Tick all but the plas, pres, mass, age and class attributes.
Weka Select Attributes To Remove From Dataset
3. Click the “Remove” button.
4. Click the “Save” button and enter a filename.
You now have a new view of your dataset to explore.
Weka Attributes Removed From Dataset
What Feature Selection Techniques To Use
You cannot know which views of your data will produce the most accurate models.
Therefore, it is a good idea to try a number of different feature selection techniques on your data and in turn create many different views of your data.
Select a good generic technique, like a decision tree, and build a model for each view of your data.
Compare the results to get an idea of which view of your data results in the best performance. This will give you an idea of the view or more specifically features that best expose the structure of your problem to learning algorithms in general.
Summary
In this post you discovered the importance of feature selection and how to use feature selection on your data with Weka.
Specifically, you learned:
How to perform feature selection using correlation.
How to perform feature selection using information gain.
How to perform feature selection by training a model on different subsets of features.
Do you have any questions about feature selection in Weka or about this post? Ask your questions in the comments and I will do my best to answer.
So, the accuracy I receive without any appliance: J48 and all instances and features of the diabettes.arff data set, is 84.11% and the error is 15.88%
After applying any of the CorrelationAttributeEval, the InfoGain and the WwrapperSubsetEval, I receive lower accuracy. Of course this is obvious because I end up removing some features, but how is this good exactly? I am loosing information. This is not good, am I wrong?
We only want to perform feature selection that ultimately benefits the performance of our models.
I use feature selection as a guide, each method gives different hints about what features might be important. Each set/subset can be used as input to train a new model to be compared to a baseline or ensemble together to compete with the baseline.
Worse performance after feature selection still teaches you something. Don’t discard those features, or build a model based on this “new” view of the problem and combine it with models trained on other intelligently selected views of the problem.
I hope gives more insight on a very important topic that you’ve raised.
So, you have used an arbitrary cut-off value for correlation and informationGain in order to select a subset of features.
Is there any method to select a cut-off value?
I have another doubt regarding the feature selection.
In order to select the best subset of features from the output of “InformationGain + Ranker’s” method, I removed low-ranked features one by one and checked the accuracy of my classifier for each subset , and chose the subset that gives maximum accuracy.
However, for some data-set, I got same (maximum) accuracy value for 2 subsets of features.
For example, I have a set of 21 features, and a subset of 10 features and 6 features give the same maximum accuracy out of all possible subsets.
So I am confused for which subset to choose?
Can you help me?
I would suggest try creating a model with the features using each value as a cut-off, and let model skill dictate the features to adopt.
Yes, I like the approach you outline. Fewer features are better (lower complexity, easier to understand). Also, compare these results to a new ensemble model that averages the performance of the models with different numbers of features.
If I use say IG for feature selection and then SVM for classification using cross validation…then the feature selection will ably to the entire dataset and not just the training set….which is not correct I guess…
Dear Jason Brownlee
I would like to ask you about how can I perform PSO as feature selection algorithm within weka ? Is there any way to add PSO to weka program?
thank you in advanced.
If I use Info Gain to select the attributes of the training dataset and take the output in another .arff file using command line. Now we have the training dataset with selected attributes. Is it possible to create the testing data with these selected attributes only. It is very difficult to remove the attributes manually as my data is of very large dimension. – thnx
I got confusing situation. I tried CorrelationAttributeEval with my own data set and specified outputDetailedInfo:true in evaluator’s configuration window. Weka gave me list of correlations for each individual value for each feature. This is great, but there is a single feature with only two possible values and both have similar correlation. As I understand, this means that this feature can’t influance the prediction in any way, since the correlation is similar with any possible value… even if the total correlation of feature is one of the best compared with other features. Am I right?
Hi Jason,
It is a very good explanation. But I wonder, basically what is feature selection? If I sum all the attribute value, why the total is not 1 or 100%?
When performing feature selection, should we perform it in the entire dataset (training and testing) and then split the data? or should we perform it just in training portion?
It is a good idea to perform data prep operations on training data only then apply the operations using coefficients/etc. from training data on the test data.
1. I am facing the same problem with feature selection and without feature selection. Without any feature selection method I got 99.10% accuracy for J48, but using CFS, Chi square and IG with different subsets I got less accuracy like 98.70%, 97% etc. Where I am wrong?
2. It is related to Weka GUI and API, why I am getting different results for the same algorithm using gui and api. I searched a lot, but nothing useful found.
Thanks
It is common to get different results each time the same algorithms is run on the same data, consider using the experiment interface instead and taking the average score over multiple runs.
Dear Jason ,I am using three ML algorithm such as GA for feature selection,ANN and SVM for classification of data set. I want to use wrapper method,can you advice me how to apply crossover and Mutation operation concepts for pre-process.
I have struggled hard but could not find straight answers to few questions which apply to classification problems, your views would be very helpful.
1) While Information Gain and Gini seem reasonable, do Pearson Correlation & Chi-Squared filters apply for binary variables / for classification problem typical of Diabetes dataset?
2) Statistics professors & several online media strongly advocate doing attribute selection as part of the Cross Validation inner loop. Not doing so is a way of cheating since the training data has already been used for attribute selection & biases the estimates to produce smaller errors. Ian Witten’s in his MOOC recommends using the AttributeSelectedClassifier. Should these Filter methods be run on a test / validation set when using the Attribute selection tab in Weka?
Dear Jason,
What is the order of the executions of the attribute evaluator and the search method? I am trying to use ant search (with default evaluator fuzzy rough subset) and CfsSubsetEval for attribute evaluator. In this situation, firstly, the CfsSubsetEval function evaluates the attributes and gives the informative subsets (with merits), then ant search is done on all these subsets by evaluating with fuzzyRoughSubsetEval; is it true?
Thanks
This post is regarding Feature Selection from a ready made CSV or ARFF file which could be made from raw data using excel or some python code etc. Can we generate features from any CSV or ARFF or EXCEL file using windowing (1 seconds or more) with overlap (50% or so) in WEKA ?
Hello Dr.Jason
Thank you for the very informative articles
I am using attribute selection in weka for my graduation research about abnirmal behavior in video scenes.
I was wondering if I had to set the parameters for each search method of the attribute selection?
and also the results of the attribute evaluators I need some explanation.
In weka explorer when we are using the correlation attribute evaluate tap after importing our data. It is assigning the correlation coefficient to each of the feature with respect to deciding variable.
I want to know how weka will know in which column I have placed my deciding variable?
When using InfoGainAttributeEval -> Output is Entropy. What units is this in and how is it calculated? (Entropy is usually measured in Bits from my understanding)
Dear Jason, I’m working on text datasets that represent word frequencies as attributes (which mean I have high dimensionality problem such that a dataset could contain up to 3000 features).
I tried to apply attribute selection (both info gain and correlation) filters but nothing change and the number of attributes is still the same. Does that mean all the attributes are needed? should I continue without applying features selection methods?
there is a lot of search methods for one attribute evaluator,and different combinations can produce different attribute subset. So how to match attribute evaluator and search method?
(eg:CfsSubseteval+bestfirts,CfsSubseteval+greddysteowise,CfsSubseteval+Genetic search)
Hello Jason
Thank for all your great articles, the are very useful.
I’m not a Data Scientist, so i’m not sure to correctly interpret the result of weka.
I have tried to predict fuel consummation of vehicle from their characteristics (40 features) with a deep learning algo, but the precision is two high for the business, error is around 3%.
So, I checked my data with weka with the CorrelationAttributeEval + Ranker algo. I find ranks between -0.01 and 0.02.
Is these low ranks are an indication that these attributes are not really correlated ?
I am working on the feature selection. My data is unbalanced and I used SMOTE to balance the data. After that, I try to see that importance of attributes by using Info gain and correlated based selection. These two methods did not give the same result. I wonder if because I used the processed data rather than the raw data ? I also ran correlation analysis between numeric variables in my data and there is no correlation, should i use Info gain rather than Correlation based feature? The thing is , when looking at the tree, the CorrelationAttributeEval + Ranke gave the order of importance gave the reasonable results..
This is a great article. I have a dataset where all labels are unmeaningful having label1, 2… 30 and having 450 records which are all of them are binomial having missing data except for the ID label. I have two questions please :
1. Being binomial (yes/No) what is your advice on dealing with the missing data in the preprocessing phase.One of the labels has nulls in 120 records, the other labels have between 10 – 30 fields that have missing data?
2. In such circumstances which would be the best attribute selection methods to use in order to compare sufficiently?
Perhaps try a few approaches like removing the records, imputing with a mean, median, mode, a linear model, etc. use a model that can support missing data like xgboost, etc.
Thank you for the nice article and kudos for sticking with this thread. I am in the online Weka class and I am falling in love with the simple but powerful tool.
I had a question.
Are these 3 capabilities in feature selection?
1) Forward Selection: Forward selection is an iterative method in which we start with having no feature in the model.
2) Backward Elimination: In backward elimination, we start with all the features and removes the least significant feature at each iteration
3) Recursive Feature elimination: It is a greedy optimization algorithm which aims to find the best performing feature subset.
sir i applied backward elimination feature selection and infogain with ranker method to our dataset and took common features for machine learning model. backward elimination technique is manually doing in pre-process tab in weka and infogain is automatic way select features i just want to know is it good way to pick features ?
Hi Jason
My datasets are all numeric and some algorithms are not applicable to them such as J48 (they are grey) to measure the accuracy. when I use “cross-validation” or “percentage split” in Weka, I get the following summary report:
I’m directly using feature selection technique using builtin libraries in Python. What’s the difference in results if I’ll use Weka for feature selection?
Hi Jason,
This blog is brilliant and helping me a lot with machine learning. A somewhat unrelated question, but I am testing what happens to my data when I lower the confidence level (using J48 and cross-validation) and to my surprise, the accuracy rose.
Any idea why this might be? It’s completely against what I was expecting.
MOHAMMAD SHOJAESHAFIEIDecember 31, 2019 at 5:30 am#
the best accuracy I get from weka is 44%, what should do with my excel dataset to have better accuracy?
I have used neural networks, Kstar, random forest.
the problem is that data are not well distributed. is there any6 technique to work on the data set?
Great post Jason .
I am doing the preprocessing phase of my dataset , and I just want to know if i can randomly choose some methodd of Feature Selection or there are criteria that I must respect when im choosing ?
My question is: sometimes one feature alone may not show correlation to the output, however, a combination of a number of features will show the correlation. What method do you recommend for selecting features in this case?
Dear,
I run Weka for my dataset. however, if I use Explore, it does not show full output results (accuracy,…) (I click full Evaluation Metrics to display all output results) like this follows:
=== Evaluation on test split ===
Time taken to test model on test split: 0.28 seconds
=== Summary ===
Correlation coefficient 0.6715
Mean absolute error 0.4936
Root mean squared error 0.6244
Relative absolute error 74.1773 %
Root relative squared error 76.5897 %
Total Number of Instances 36000
In the case I use Experimenter, after submitting the dataset and Start, Weka showed that
12:17:54: Started
12:17:55: Class attribute is not nominal!
12:17:55: Interrupted
12:17:55: There was 1 error.
My data set like this following matrix (attribute class: 0,1,2)
A0 A1 A2 A3 A4 A5
0.0122 0.0112 0.2134 0.10321 0.21984 1
….
Hi Jason. Many thanks for the run-through of different feature selection tools – very helpful.
The comparative feature selection subsets/rankings are good, but I’m struggling to understand how/why such major differences arise …
If pres is ranked last of the 8 attributes by both correlation and information gain techniques, then broadly what might be the characteristics of that column and its values that make it so helpful (2nd choice of the 8) for decision tree methods?
Thanks for prompt reply – and for the comprehensive FAQ link – much appreciated.
I’m fairly new to all of this but just worry that if a variable is almost totally non-correlated (as pres seems to be, with the target class) – plus there’s no information gain – I’d be guilty of trying too hard by continuing to seek some method that just happens to work, maybe randomly, and maybe only on this dataset (without generalising well to future instances). But I guess those can be tested too.
Great insights above and elsewhere – thanks very much.
Hi Jason. Many thanks for the informative that ur introduce.
I have confused about selected the higher-ranked features, So I need ur help, please.
When applying the information gain filter, to reduce the high dimensionality of data by calculating the highest ranked.
How to save the features selected from among the many features?
For example, We have 4000 features and only 200 are required, so how can you choose 200 and delete 1800 at once?
I want to use the output of ranked features (e.g 200 F) that have been chosen by Information Gain Filter as input to the Wrapper FS using another program, that’s why I need to know how I can save the selected highest-ranked features by Waka to create a new dataset.
As well As my datasets format in form Term-Frequency.
I used the pre-process tab, used the supervised feature selection method (classifier subsetEval, random forest) to select the features but the results were different when I used the “select attribute” tab using the same method. Can you explain what is the difference between feature selection using the “select attribute” tab and the “pre-process” tab in Weka? Thanks!
And the last question, when I use the “select attribute” tab what is recommended to choose from attribute selection mode? Full training or cross-validation? I wish there was useful documentation about interpreting the results from this tab.
Hi Dr. Lukumba…To use Weka for feature selection and ensure that only 46 of the 54 attributes are used in the classification stage, you can follow these steps:
### Step 1: Load Your Dataset
1. Open Weka.
2. Go to the “Explorer” tab.
3. Click on the “Open file…” button and load your dataset.
### Step 2: Select Attributes
1. Go to the “Select attributes” tab.
2. Choose an attribute selection method:
– For a simple manual selection, you can use the “Remove” filter.
– For more advanced selection, you can use attribute evaluators and search methods.
#### Manual Attribute Removal
1. In the “Filter” panel, click the “Choose” button.
2. Select weka.filters.unsupervised.attribute.Remove.
3. Click on the “Remove” filter to configure it.
4. In the “Remove” filter options, set the “attributeIndices” to the indices of the attributes you want to remove. For example, to remove the first 8 attributes and keep the remaining 46, you would set attributeIndices to 1-8.
5. Click “OK” to apply the filter.
#### Attribute Selection Using Evaluator and Search Method
1. In the “Attribute Evaluator” panel, click the “Choose” button.
2. Select an attribute evaluator, such as weka.attributeSelection.CfsSubsetEval or weka.attributeSelection.InfoGainAttributeEval.
3. In the “Search Method” panel, click the “Choose” button.
4. Select a search method, such as weka.attributeSelection.BestFirst or weka.attributeSelection.Ranker.
5. Configure the evaluator and search method as needed.
6. Click the “Start” button to run the attribute selection process. Weka will select the most relevant attributes based on your chosen evaluator and search method.
### Step 3: Apply the Selected Attributes to the Classifier
1. Go to the “Classify” tab.
2. In the “Filter” panel, click the “Choose” button.
3. Select weka.filters.unsupervised.attribute.Remove.
4. Click on the “Remove” filter to configure it.
5. In the “Remove” filter options, set the “attributeIndices” to the indices of the attributes you want to remove, just as you did in the “Select attributes” tab.
6. Click “OK” to apply the filter.
7. In the “Classifier” panel, choose your classifier (e.g., J48, NaiveBayes, etc.).
8. Click “Start” to run the classification process.
### Example: Removing Specific Attributes
If you want to manually remove specific attributes by index, follow these steps in more detail:
1. **Choose the Remove Filter:**
– In the “Filter” panel, click “Choose” and select weka.filters.unsupervised.attribute.Remove.
2. **Configure the Remove Filter:**
– Click on the filter to open its configuration.
– Set the “attributeIndices” field to the indices of the attributes you want to remove. For example, to keep attributes 9 to 54 (i.e., remove the first 8 attributes), set attributeIndices to 1-8.
3. **Apply the Filter:**
– Click “OK” to apply the filter. You should now see that only the desired attributes are kept in the dataset.
4. **Save the Filtered Dataset (Optional):**
– You can save the filtered dataset by clicking “Save” if you want to reuse it later.
5. **Run the Classifier:**
– Go to the “Classify” tab.
– Select your desired classifier and set up your evaluation parameters.
– Click “Start” to train and evaluate the classifier on the filtered dataset.
By following these steps, you can ensure that only the selected 46 attributes are used in the classification stage in Weka.
Hi faramak…Converting a numeric class to a nominal class for the purpose of using information gain for feature selection can be done, but it is essential to understand the implications and the context in which it is appropriate. Here are some considerations:
### When It May Be Appropriate:
1. **Classification Problem**: If you intend to solve a classification problem rather than a regression problem, converting numeric values into categorical classes (nominal) might make sense. For instance, if you have a continuous target variable like age and you convert it into age groups (e.g., child, teenager, adult, senior), you can then use techniques like information gain.
2. **Discrete Intervals**: If your numeric target can be meaningfully divided into discrete intervals that represent different categories, this approach can be justified. For example, converting temperature readings into categories like ‘cold’, ‘warm’, ‘hot’.
### Potential Issues:
1. **Loss of Information**: Converting numeric data into categorical data can lead to a loss of information, especially if the numeric data has meaningful variations that are smoothed out in the categorical form.
2. **Arbitrary Binning**: The process of converting numeric values to categories often involves arbitrary decisions about bin thresholds, which can introduce bias and reduce the predictive power of your model.
3. **Feature Selection Method**: Information gain is a suitable method for feature selection in classification tasks, but it might not be appropriate if your original problem is a regression task. For regression problems, techniques like correlation coefficients, mutual information regression, or feature importance from models like Random Forests or Gradient Boosting are generally more suitable.
### Alternative Approach:
If your ultimate goal is to perform regression and you want to do feature selection, consider using methods designed for regression tasks:
– **Mutual Information Regression**: Measures the dependency between the input features and the target variable.
– **Correlation Analysis**: Analyzes the linear relationship between each feature and the target variable.
– **Model-Based Feature Importance**: Uses models like Random Forests, Gradient Boosting, or Lasso Regression to evaluate feature importance.
### Practical Steps:
1. **Analyze the Nature of the Data**: Understand the distribution and nature of your numeric target variable. Decide if converting to categorical classes adds meaningful context.
2. **Choose Appropriate Methods**: Use regression-specific feature selection methods if your primary task is regression. For classification, converting numeric to nominal and using information gain might be appropriate.
3. **Validate Your Approach**: If you decide to convert numeric classes to nominal, validate the impact on your model’s performance. Compare the results with those obtained using other feature selection techniques.
If you need further guidance on a specific dataset or problem, feel free to share more details, and I can provide more tailored advice.









Sir what is the difference between classifierattribute eval and wrapperattributeeval in weka.
So, the accuracy I receive without any appliance: J48 and all instances and features of the diabettes.arff data set, is 84.11% and the error is 15.88%
After applying any of the CorrelationAttributeEval, the InfoGain and the WwrapperSubsetEval, I receive lower accuracy. Of course this is obvious because I end up removing some features, but how is this good exactly? I am loosing information. This is not good, am I wrong?
Great question Mark.
We only want to perform feature selection that ultimately benefits the performance of our models.
I use feature selection as a guide, each method gives different hints about what features might be important. Each set/subset can be used as input to train a new model to be compared to a baseline or ensemble together to compete with the baseline.
Worse performance after feature selection still teaches you something. Don’t discard those features, or build a model based on this “new” view of the problem and combine it with models trained on other intelligently selected views of the problem.
I hope gives more insight on a very important topic that you’ve raised.
Hi Jason,
Thanks for this informative article!
So, you have used an arbitrary cut-off value for correlation and informationGain in order to select a subset of features.
Is there any method to select a cut-off value?
I have another doubt regarding the feature selection.
In order to select the best subset of features from the output of “InformationGain + Ranker’s” method, I removed low-ranked features one by one and checked the accuracy of my classifier for each subset , and chose the subset that gives maximum accuracy.
However, for some data-set, I got same (maximum) accuracy value for 2 subsets of features.
For example, I have a set of 21 features, and a subset of 10 features and 6 features give the same maximum accuracy out of all possible subsets.
So I am confused for which subset to choose?
Can you help me?
Thanks!
Thanks Shailesh.
I would suggest try creating a model with the features using each value as a cut-off, and let model skill dictate the features to adopt.
Yes, I like the approach you outline. Fewer features are better (lower complexity, easier to understand). Also, compare these results to a new ensemble model that averages the performance of the models with different numbers of features.
If I use say IG for feature selection and then SVM for classification using cross validation…then the feature selection will ably to the entire dataset and not just the training set….which is not correct I guess…
Dear Jason Brownlee
I would like to ask you about how can I perform PSO as feature selection algorithm within weka ? Is there any way to add PSO to weka program?
thank you in advanced.
Sorry Sadiq, I have not used PSO for feature selection within Weka. I cannot give you good advice.
If I use Info Gain to select the attributes of the training dataset and take the output in another .arff file using command line. Now we have the training dataset with selected attributes. Is it possible to create the testing data with these selected attributes only. It is very difficult to remove the attributes manually as my data is of very large dimension. – thnx
I believe there may be a data filter to apply feature selection and remove unselected features.
Perhaps take a look through some of the data filters for such a filter.
You can then save the filtered features to a new file and work with it directly.
Jason, great post.
I got confusing situation. I tried CorrelationAttributeEval with my own data set and specified outputDetailedInfo:true in evaluator’s configuration window. Weka gave me list of correlations for each individual value for each feature. This is great, but there is a single feature with only two possible values and both have similar correlation. As I understand, this means that this feature can’t influance the prediction in any way, since the correlation is similar with any possible value… even if the total correlation of feature is one of the best compared with other features. Am I right?
Hi Jason,
It is a very good explanation. But I wonder, basically what is feature selection? If I sum all the attribute value, why the total is not 1 or 100%?
Feature selection is a way of cutting down the number of input variables to your model to hopefully get simpler models or better predictions, or both.
When performing feature selection, should we perform it in the entire dataset (training and testing) and then split the data? or should we perform it just in training portion?
It is a good idea to perform data prep operations on training data only then apply the operations using coefficients/etc. from training data on the test data.
Hi Jason,
I have two questions,
1. I am facing the same problem with feature selection and without feature selection. Without any feature selection method I got 99.10% accuracy for J48, but using CFS, Chi square and IG with different subsets I got less accuracy like 98.70%, 97% etc. Where I am wrong?
2. It is related to Weka GUI and API, why I am getting different results for the same algorithm using gui and api. I searched a lot, but nothing useful found.
Thanks
It is common to get different results each time the same algorithms is run on the same data, consider using the experiment interface instead and taking the average score over multiple runs.
See this post:
https://machinelearningmastery.com/randomness-in-machine-learning/
Dear Jason ,I am using three ML algorithm such as GA for feature selection,ANN and SVM for classification of data set. I want to use wrapper method,can you advice me how to apply crossover and Mutation operation concepts for pre-process.
Sorry, I do not have a worked example of GAs for feature selection.
Thanks Jason.
But , why I am getting different results for the same algorithm using Weka GUI and API on the same dataset.
This is to be expected, see this post:
https://machinelearningmastery.com/randomness-in-machine-learning/
Dear Jason,
I want to make a new feature selection algorithm, Can I make this using WEKA?
Yes, you can implement it yourself for use in Weka.
Thanks for your reply
Could you please advice me or give me a link to illustrative example!
Sorry, I do not have an example.
Great post Jason.
I have struggled hard but could not find straight answers to few questions which apply to classification problems, your views would be very helpful.
1) While Information Gain and Gini seem reasonable, do Pearson Correlation & Chi-Squared filters apply for binary variables / for classification problem typical of Diabetes dataset?
2) Statistics professors & several online media strongly advocate doing attribute selection as part of the Cross Validation inner loop. Not doing so is a way of cheating since the training data has already been used for attribute selection & biases the estimates to produce smaller errors. Ian Witten’s in his MOOC recommends using the AttributeSelectedClassifier. Should these Filter methods be run on a test / validation set when using the Attribute selection tab in Weka?
Don’t know sorry.
Dear Jason,
What is the order of the executions of the attribute evaluator and the search method? I am trying to use ant search (with default evaluator fuzzy rough subset) and CfsSubsetEval for attribute evaluator. In this situation, firstly, the CfsSubsetEval function evaluates the attributes and gives the informative subsets (with merits), then ant search is done on all these subsets by evaluating with fuzzyRoughSubsetEval; is it true?
Thanks
Sorry, I cannot give you good advice.
This post is regarding Feature Selection from a ready made CSV or ARFF file which could be made from raw data using excel or some python code etc. Can we generate features from any CSV or ARFF or EXCEL file using windowing (1 seconds or more) with overlap (50% or so) in WEKA ?
I don’t know, sorry.
Hello Dr.Jason
Thank you for the very informative articles
I am using attribute selection in weka for my graduation research about abnirmal behavior in video scenes.
I was wondering if I had to set the parameters for each search method of the attribute selection?
and also the results of the attribute evaluators I need some explanation.
Some experimentation may be required.
Hi Jason,
My assignmant states that I should use attribute selection and do testing to see the best results.
Should I use attrubuteSelectionClassified or the attrubuteSelection?
Is there any link to show mw how to compare results to come with the best set of attributes?
You must experiment to see what subset of features work best for your predictive modeling problem.
Can I use my algorithm for feature selection in weka?
Yes, but you may have to implement it yourself.
In weka explorer when we are using the correlation attribute evaluate tap after importing our data. It is assigning the correlation coefficient to each of the feature with respect to deciding variable.
I want to know how weka will know in which column I have placed my deciding variable?
Thank you, you’ve just opened a new world to me!
I’m glad it helped Arman.
Hi
When using InfoGainAttributeEval -> Output is Entropy. What units is this in and how is it calculated? (Entropy is usually measured in Bits from my understanding)
Thank you kindly
Don
Good question, I would guess “bits”.
https://en.wikipedia.org/wiki/Entropy_(information_theory)
how can I use weka for deep learning based-feature selection for network intrusion detection system?
thank you
I don’t believe Weka supports deep learning.
HI Jason , Really a good post and informatiove explanation.
One simple query
1) You have mentioned wrappersubsete eval for selecting subset of features
Can we use Cfssubset eval for selection of features
2) cn wwe use elbow method ( graph for selecting ) optimal set offeatures using correlation value of each feature with the class.
Perhaps.
Dear Jason,iam working on information extraction for news text using classification of machine learning how can i aapply on WEKA
Sorry, I don’t have examples of working with text data in Weka.
Does any one knows where to fine PSO in Weka?
Thank you
No, sorry.
So much useful article. Thanks
You’re welcome. I’m happy to hear that.
Hi Jason, i how do i test the generated rules (Association rule mining) with new data?
This might help:
https://machinelearningmastery.com/market-basket-analysis-with-association-rule-learning/
Dear Jason, I’m working on text datasets that represent word frequencies as attributes (which mean I have high dimensionality problem such that a dataset could contain up to 3000 features).
I tried to apply attribute selection (both info gain and correlation) filters but nothing change and the number of attributes is still the same. Does that mean all the attributes are needed? should I continue without applying features selection methods?
3K is not a lot. Try modeling the problem directly. Then see if you can get a lift by removing any features.
there is a lot of search methods for one attribute evaluator,and different combinations can produce different attribute subset. So how to match attribute evaluator and search method?
(eg:CfsSubseteval+bestfirts,CfsSubseteval+greddysteowise,CfsSubseteval+Genetic search)
Perhaps trial and error?
Hello Jason
Thank for all your great articles, the are very useful.
I’m not a Data Scientist, so i’m not sure to correctly interpret the result of weka.
I have tried to predict fuel consummation of vehicle from their characteristics (40 features) with a deep learning algo, but the precision is two high for the business, error is around 3%.
So, I checked my data with weka with the CorrelationAttributeEval + Ranker algo. I find ranks between -0.01 and 0.02.
Is these low ranks are an indication that these attributes are not really correlated ?
Thank a lot
Thierry
That might be the case.
Hi Jason,
I am working on the feature selection. My data is unbalanced and I used SMOTE to balance the data. After that, I try to see that importance of attributes by using Info gain and correlated based selection. These two methods did not give the same result. I wonder if because I used the processed data rather than the raw data ? I also ran correlation analysis between numeric variables in my data and there is no correlation, should i use Info gain rather than Correlation based feature? The thing is , when looking at the tree, the CorrelationAttributeEval + Ranke gave the order of importance gave the reasonable results..
Thank you
Regards
Minh-Trung
I would expect feature selection to be unreliable after SMOTE.
Perhaps try fitting models under different feature subsets and compare model performance?
Hi Jason,
This is a great article. I have a dataset where all labels are unmeaningful having label1, 2… 30 and having 450 records which are all of them are binomial having missing data except for the ID label. I have two questions please :
1. Being binomial (yes/No) what is your advice on dealing with the missing data in the preprocessing phase.One of the labels has nulls in 120 records, the other labels have between 10 – 30 fields that have missing data?
2. In such circumstances which would be the best attribute selection methods to use in order to compare sufficiently?
I greatly appreciate your advice.
Mic
Perhaps try a few approaches like removing the records, imputing with a mean, median, mode, a linear model, etc. use a model that can support missing data like xgboost, etc.
Try a suite of feature selection methods and see what results in the best performing models:
https://machinelearningmastery.com/faq/single-faq/what-feature-selection-method-should-i-use
Jason,
Thank you for the nice article and kudos for sticking with this thread. I am in the online Weka class and I am falling in love with the simple but powerful tool.
I had a question.
Are these 3 capabilities in feature selection?
1) Forward Selection: Forward selection is an iterative method in which we start with having no feature in the model.
2) Backward Elimination: In backward elimination, we start with all the features and removes the least significant feature at each iteration
3) Recursive Feature elimination: It is a greedy optimization algorithm which aims to find the best performing feature subset.
They are different approaches of feature selection, and there may be more.
how to apply horizontal and vertical feature selection in weka
What do you mean exactly by horizontal and vertical?
Can I use ant colony optimization technique for feature selection in weka?
I don’t know sorry.
sir i applied backward elimination feature selection and infogain with ranker method to our dataset and took common features for machine learning model. backward elimination technique is manually doing in pre-process tab in weka and infogain is automatic way select features i just want to know is it good way to pick features ?
It is only a good way if it results in a more skillful model on your dataset.
Hi Jason
My datasets are all numeric and some algorithms are not applicable to them such as J48 (they are grey) to measure the accuracy. when I use “cross-validation” or “percentage split” in Weka, I get the following summary report:
• Correlation coefficient 0.5755
• Mean absolute error 1.1628
• Root mean squared error 1.737
• Relative absolute error 81.5909 %
• Root relative squared error 81.9522 %
I am supposed to report the accuracy of the model’s prediction.how can I get the exact accuracy of that? either the accuracy number or graph?
thank you
You cannot report accuracy for a regression problem, you must report error. Learn more here:
https://machinelearningmastery.com/faq/single-faq/how-do-i-calculate-accuracy-for-regression
I am using these algorithms;
Gaussian Process
K-Star
IBK
Random Forest
Sounds like a good start.
Hello Jason!!!
I’m directly using feature selection technique using builtin libraries in Python. What’s the difference in results if I’ll use Weka for feature selection?
Not much really, use the python methods, e.g.:
https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/
Hi Jason,
This blog is brilliant and helping me a lot with machine learning. A somewhat unrelated question, but I am testing what happens to my data when I lower the confidence level (using J48 and cross-validation) and to my surprise, the accuracy rose.
Any idea why this might be? It’s completely against what I was expecting.
Thanks.
Not sure I follow, sorry. Perhaps you can elaborate? What confidence level?
thank you for your guidance
sir i tried wrapper feature selection with SMO in weka but some time did not get selected feature. only the message shows that “evaluated all feature”
Sorry to hear that, I’m not sure what is going on.
Perhaps try posting to the weka user group:
https://machinelearningmastery.com/help-with-weka/
the best accuracy I get from weka is 44%, what should do with my excel dataset to have better accuracy?
I have used neural networks, Kstar, random forest.
the problem is that data are not well distributed. is there any6 technique to work on the data set?
Here are some suggestions:
https://machinelearningmastery.com/machine-learning-performance-improvement-cheat-sheet/
sir how we made feature model using weka tool???
What is a “feature model”?
Great post Jason .
I am doing the preprocessing phase of my dataset , and I just want to know if i can randomly choose some methodd of Feature Selection or there are criteria that I must respect when im choosing ?
thunk you
Good question, see this:
https://machinelearningmastery.com/faq/single-faq/what-feature-selection-method-should-i-use
can we use RT3 and RC4.5 data reduction techniques in WEKA?
I don’t know off-hand, sorry.
Very useful post Jason
My question is: sometimes one feature alone may not show correlation to the output, however, a combination of a number of features will show the correlation. What method do you recommend for selecting features in this case?
Probably a wrapper methods, like RFE (or other search methods).
thnx for your valuable post,
i want to know how can i use rough set -based feature selection in weka
I don’t know about rough sets, sorry.
Dear,
I run Weka for my dataset. however, if I use Explore, it does not show full output results (accuracy,…) (I click full Evaluation Metrics to display all output results) like this follows:
=== Evaluation on test split ===
Time taken to test model on test split: 0.28 seconds
=== Summary ===
Correlation coefficient 0.6715
Mean absolute error 0.4936
Root mean squared error 0.6244
Relative absolute error 74.1773 %
Root relative squared error 76.5897 %
Total Number of Instances 36000
In the case I use Experimenter, after submitting the dataset and Start, Weka showed that
12:17:54: Started
12:17:55: Class attribute is not nominal!
12:17:55: Interrupted
12:17:55: There was 1 error.
My data set like this following matrix (attribute class: 0,1,2)
A0 A1 A2 A3 A4 A5
0.0122 0.0112 0.2134 0.10321 0.21984 1
….
Looks like Weka thinks your data is a regression problem.
Try changing the target to nominal via a filter or manually in the file.
Thanks for this article.. really helpful for using weka filters
You’re welcome.
I got confused while using features selection techniques. In weka I only abled to work 3 techniques
1.Correlation
2. Information gain
3.Decision tree
Can I get the name of altleast 5 other feature selection techniques ?
Nice work!
Yes, consider the suite of wrapper and filter methods in the data prep section.
Hi Jason. Many thanks for the run-through of different feature selection tools – very helpful.
The comparative feature selection subsets/rankings are good, but I’m struggling to understand how/why such major differences arise …
If pres is ranked last of the 8 attributes by both correlation and information gain techniques, then broadly what might be the characteristics of that column and its values that make it so helpful (2nd choice of the 8) for decision tree methods?
Thanks,
Paul
Different feature selection techniques will have different “views” on what is most important to the target variable.
The best approach is to test a suite of different feature selection methods with a suite of different predictive algorithms in order to discover the best combination for your specific dataset:
https://machinelearningmastery.com/faq/single-faq/what-feature-selection-method-should-i-use
Thanks for prompt reply – and for the comprehensive FAQ link – much appreciated.
I’m fairly new to all of this but just worry that if a variable is almost totally non-correlated (as pres seems to be, with the target class) – plus there’s no information gain – I’d be guilty of trying too hard by continuing to seek some method that just happens to work, maybe randomly, and maybe only on this dataset (without generalising well to future instances). But I guess those can be tested too.
Great insights above and elsewhere – thanks very much.
You’re welcome.
Hi Jason. Many thanks for the informative that ur introduce.
I have confused about selected the higher-ranked features, So I need ur help, please.
When applying the information gain filter, to reduce the high dimensionality of data by calculating the highest ranked.
How to save the features selected from among the many features?
For example, We have 4000 features and only 200 are required, so how can you choose 200 and delete 1800 at once?
You’re welcome.
The feature selection method can be used as part of your model in a pipeline. E.g. no need to save.
Or you, can pre-process the data, use the feature selection method to select the features and save the array:
https://machinelearningmastery.com/how-to-save-a-numpy-array-to-file-for-machine-learning/
Dear, Jason Brownlee
I want to use the output of ranked features (e.g 200 F) that have been chosen by Information Gain Filter as input to the Wrapper FS using another program, that’s why I need to know how I can save the selected highest-ranked features by Waka to create a new dataset.
As well As my datasets format in form Term-Frequency.
Best Wishes
Yes, you can apply the feature selection method then save the resulting dataset directly.
I used the pre-process tab, used the supervised feature selection method (classifier subsetEval, random forest) to select the features but the results were different when I used the “select attribute” tab using the same method. Can you explain what is the difference between feature selection using the “select attribute” tab and the “pre-process” tab in Weka? Thanks!
A guess – it might be due to the stochastic nature of the learning algorithm:
https://machinelearningmastery.com/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
And the last question, when I use the “select attribute” tab what is recommended to choose from attribute selection mode? Full training or cross-validation? I wish there was useful documentation about interpreting the results from this tab.
Perhaps the user guide is helpful?
Perhaps the built-in contextual help is useful?
Perhaps these resources will help:
https://machinelearningmastery.com/help-with-weka/
Hi
Can information gain in select attribute in WEKA be greater than 1? If no, should the attribute be removed?
I’m not sure off the cuff, sorry.
Hi there..is there any feature selection using fruit fly optimization in weka?
Hi Musa…The followng may be of interest:
https://www.tutorialspoint.com/weka/weka_feature_selection.htm
Greeting,
I have a dataset with 54 attributes but I want the weka model to only classify 46 of them. How do I select the 46 in the classification stage?
Hi Dr. Lukumba…To use Weka for feature selection and ensure that only 46 of the 54 attributes are used in the classification stage, you can follow these steps:
### Step 1: Load Your Dataset
1. Open Weka.
2. Go to the “Explorer” tab.
3. Click on the “Open file…” button and load your dataset.
### Step 2: Select Attributes
1. Go to the “Select attributes” tab.
2. Choose an attribute selection method:
– For a simple manual selection, you can use the “Remove” filter.
– For more advanced selection, you can use attribute evaluators and search methods.
#### Manual Attribute Removal
1. In the “Filter” panel, click the “Choose” button.
2. Select
weka.filters.unsupervised.attribute.Remove.3. Click on the “Remove” filter to configure it.
4. In the “Remove” filter options, set the “attributeIndices” to the indices of the attributes you want to remove. For example, to remove the first 8 attributes and keep the remaining 46, you would set
attributeIndicesto1-8.5. Click “OK” to apply the filter.
#### Attribute Selection Using Evaluator and Search Method
1. In the “Attribute Evaluator” panel, click the “Choose” button.
2. Select an attribute evaluator, such as
weka.attributeSelection.CfsSubsetEvalorweka.attributeSelection.InfoGainAttributeEval.3. In the “Search Method” panel, click the “Choose” button.
4. Select a search method, such as
weka.attributeSelection.BestFirstorweka.attributeSelection.Ranker.5. Configure the evaluator and search method as needed.
6. Click the “Start” button to run the attribute selection process. Weka will select the most relevant attributes based on your chosen evaluator and search method.
### Step 3: Apply the Selected Attributes to the Classifier
1. Go to the “Classify” tab.
2. In the “Filter” panel, click the “Choose” button.
3. Select
weka.filters.unsupervised.attribute.Remove.4. Click on the “Remove” filter to configure it.
5. In the “Remove” filter options, set the “attributeIndices” to the indices of the attributes you want to remove, just as you did in the “Select attributes” tab.
6. Click “OK” to apply the filter.
7. In the “Classifier” panel, choose your classifier (e.g., J48, NaiveBayes, etc.).
8. Click “Start” to run the classification process.
### Example: Removing Specific Attributes
If you want to manually remove specific attributes by index, follow these steps in more detail:
1. **Choose the Remove Filter:**
– In the “Filter” panel, click “Choose” and select
weka.filters.unsupervised.attribute.Remove.2. **Configure the Remove Filter:**
– Click on the filter to open its configuration.
– Set the “attributeIndices” field to the indices of the attributes you want to remove. For example, to keep attributes 9 to 54 (i.e., remove the first 8 attributes), set
attributeIndicesto1-8.3. **Apply the Filter:**
– Click “OK” to apply the filter. You should now see that only the desired attributes are kept in the dataset.
4. **Save the Filtered Dataset (Optional):**
– You can save the filtered dataset by clicking “Save” if you want to reuse it later.
5. **Run the Classifier:**
– Go to the “Classify” tab.
– Select your desired classifier and set up your evaluation parameters.
– Click “Start” to train and evaluate the classifier on the filtered dataset.
By following these steps, you can ensure that only the selected 46 attributes are used in the classification stage in Weka.
Hi
I have a dataset with numeric class for regression, is it ok to convert numeric class to nominal class and use info gain for feature selection?
Hi faramak…Converting a numeric class to a nominal class for the purpose of using information gain for feature selection can be done, but it is essential to understand the implications and the context in which it is appropriate. Here are some considerations:
### When It May Be Appropriate:
1. **Classification Problem**: If you intend to solve a classification problem rather than a regression problem, converting numeric values into categorical classes (nominal) might make sense. For instance, if you have a continuous target variable like age and you convert it into age groups (e.g., child, teenager, adult, senior), you can then use techniques like information gain.
2. **Discrete Intervals**: If your numeric target can be meaningfully divided into discrete intervals that represent different categories, this approach can be justified. For example, converting temperature readings into categories like ‘cold’, ‘warm’, ‘hot’.
### Potential Issues:
1. **Loss of Information**: Converting numeric data into categorical data can lead to a loss of information, especially if the numeric data has meaningful variations that are smoothed out in the categorical form.
2. **Arbitrary Binning**: The process of converting numeric values to categories often involves arbitrary decisions about bin thresholds, which can introduce bias and reduce the predictive power of your model.
3. **Feature Selection Method**: Information gain is a suitable method for feature selection in classification tasks, but it might not be appropriate if your original problem is a regression task. For regression problems, techniques like correlation coefficients, mutual information regression, or feature importance from models like Random Forests or Gradient Boosting are generally more suitable.
### Alternative Approach:
If your ultimate goal is to perform regression and you want to do feature selection, consider using methods designed for regression tasks:
– **Mutual Information Regression**: Measures the dependency between the input features and the target variable.
– **Correlation Analysis**: Analyzes the linear relationship between each feature and the target variable.
– **Model-Based Feature Importance**: Uses models like Random Forests, Gradient Boosting, or Lasso Regression to evaluate feature importance.
### Practical Steps:
1. **Analyze the Nature of the Data**: Understand the distribution and nature of your numeric target variable. Decide if converting to categorical classes adds meaningful context.
2. **Choose Appropriate Methods**: Use regression-specific feature selection methods if your primary task is regression. For classification, converting numeric to nominal and using information gain might be appropriate.
3. **Validate Your Approach**: If you decide to convert numeric classes to nominal, validate the impact on your model’s performance. Compare the results with those obtained using other feature selection techniques.
If you need further guidance on a specific dataset or problem, feel free to share more details, and I can provide more tailored advice.