Feature selection is the process of identifying and selecting a subset of input variables that are most relevant to the target variable.
Perhaps the simplest case of feature selection is the case where there are numerical input variables and a numerical target for regression predictive modeling. This is because the strength of the relationship between each input variable and the target can be calculated, called correlation, and compared relative to each other.
In this tutorial, you will discover how to perform feature selection with numerical input data for regression predictive modeling.
After completing this tutorial, you will know:
How to evaluate the importance of numerical input data using the correlation and mutual information statistics.
How to perform feature selection for numerical input data when fitting and evaluating a regression model.
How to tune the number of features selected in a modeling pipeline using a grid search.
Kick-start your project with my new book Data Preparation for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
How to Perform Feature Selection for Regression Data Photo by Dennis Jarvis, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Regression Dataset
Numerical Feature Selection
Correlation Feature Selection
Mutual Information Feature Selection
Modeling With Selected Features
Model Built Using All Features
Model Built Using Correlation Features
Model Built Using Mutual Information Features
Tune the Number of Selected Features
Regression Dataset
We will use a synthetic regression dataset as the basis of this tutorial.
Recall that a regression problem is a problem in which we want to predict a numerical value. In this case, we require a dataset that also has numerical input variables.
The make_regression() function from the scikit-learn library can be used to define a dataset. It provides control over the number of samples, number of input features, and, importantly, the number of relevant and redundant input features. This is critical as we specifically desire a dataset that we know has some redundant input features.
In this case, we will define a dataset with 1,000 samples, each with 100 input features where 10 are informative and the remaining 90 are redundant.
The hope is that feature selection techniques can identify some or all of those features that are relevant to the target, or, at the very least, identify and remove some of the redundant input features.
Once defined, we can split the data into training and test sets so we can fit and evaluate a learning model.
We will use the train_test_split() function form scikit-learn and use 67 percent of the data for training and 33 percent for testing.
Running the example reports the size of the input and output elements of the train and test sets.
We can see that we have 670 examples for training and 330 for testing.
1
2
Train (670, 100) (670,)
Test (330, 100) (330,)
Now that we have loaded and prepared the dataset, we can explore feature selection.
Want to Get Started With Data Preparation?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Numerical Feature Selection
There are two popular feature selection techniques that can be used for numerical input data and a numerical target variable.
They are:
Correlation Statistics.
Mutual Information Statistics.
Let’s take a closer look at each in turn.
Correlation Feature Selection
Correlation is a measure of how two variables change together. Perhaps the most common correlation measure is Pearson’s correlation that assumes a Gaussian distribution to each variable and reports on their linear relationship.
For numeric predictors, the classic approach to quantifying each relationship with the outcome uses the sample correlation statistic.
Linear correlation scores are typically a value between -1 and 1 with 0 representing no relationship. For feature selection, we are often interested in a positive score with the larger the positive value, the larger the relationship, and, more likely, the feature should be selected for modeling. As such the linear correlation can be converted into a correlation statistic with only positive values.
The scikit-learn machine library provides an implementation of the correlation statistic in the f_regression() function. This function can be used in a feature selection strategy, such as selecting the top k most relevant features (largest values) via the SelectKBest class.
For example, we can define the SelectKBest class to use the f_regression() function and select all features, then transform the train and test sets.
1
2
3
4
5
6
7
8
9
10
...
# configure to select all features
fs=SelectKBest(score_func=f_regression,k='all')
# learn relationship from training data
fs.fit(X_train,y_train)
# transform train input data
X_train_fs=fs.transform(X_train)
# transform test input data
X_test_fs=fs.transform(X_test)
returnX_train_fs,X_test_fs,fs
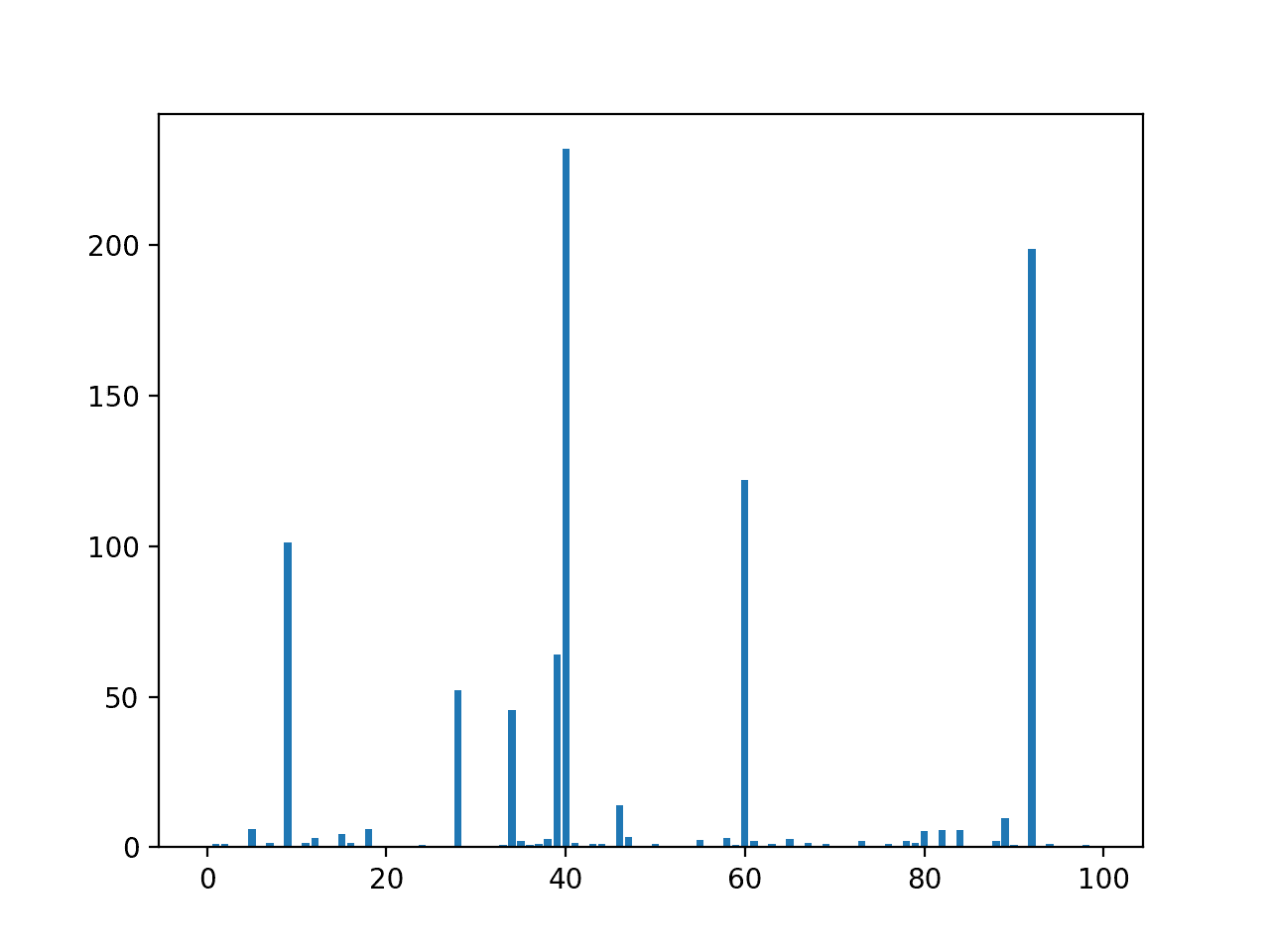
We can then print the scores for each variable (largest is better) and plot the scores for each variable as a bar graph to get an idea of how many features we should select.
Running the example first prints the scores calculated for each input feature and the target variable.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We will not list the scores for all 100 input variables as it will take up too much space. Nevertheless, we can see that some variables have larger scores than others, e.g. less than 1 vs. 5, and others have a much larger scores, such as Feature 9 that has 101.
1
2
3
4
5
6
7
8
9
10
11
Feature 0: 0.009419
Feature 1: 1.018881
Feature 2: 1.205187
Feature 3: 0.000138
Feature 4: 0.167511
Feature 5: 5.985083
Feature 6: 0.062405
Feature 7: 1.455257
Feature 8: 0.420384
Feature 9: 101.392225
...
A bar chart of the feature importance scores for each input feature is created.
The plot clearly shows 8 to 10 features are a lot more important than the other features.
We could set k=10 When configuring the SelectKBest to select these top features.
Bar Chart of the Input Features (x) vs. Correlation Feature Importance (y)
Mutual Information Feature Selection
Mutual information from the field of information theory is the application of information gain (typically used in the construction of decision trees) to feature selection.
Mutual information is calculated between two variables and measures the reduction in uncertainty for one variable given a known value of the other variable.
You can learn more about mutual information in the following tutorial.
Mutual information is straightforward when considering the distribution of two discrete (categorical or ordinal) variables, such as categorical input and categorical output data. Nevertheless, it can be adapted for use with numerical input and output data.
The scikit-learn machine learning library provides an implementation of mutual information for feature selection with numeric input and output variables via the mutual_info_regression() function.
Like f_regression(), it can be used in the SelectKBest feature selection strategy (and other strategies).
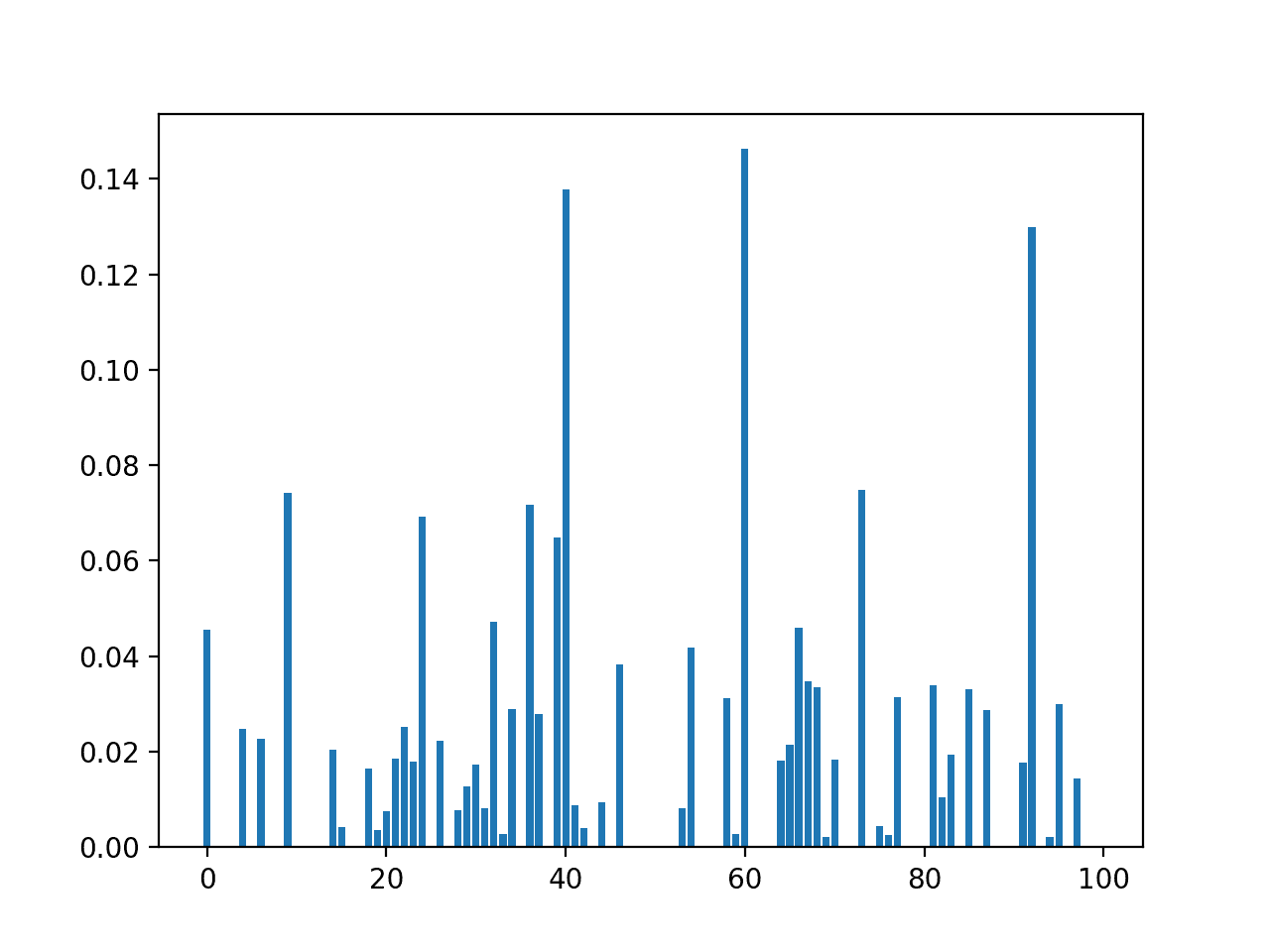
We can perform feature selection using mutual information on the dataset and print and plot the scores (larger is better) as we did in the previous section.
The complete example of using mutual information for numerical feature selection is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# example of mutual information feature selection for numerical input data
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import mutual_info_regression
Running the example first prints the scores calculated for each input feature and the target variable.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Again, we will not list the scores for all 100 input variables. We can see many features have a score of 0.0, whereas this technique has identified many more features that may be relevant to the target.
1
2
3
4
5
6
7
8
9
10
11
Feature 0: 0.045484
Feature 1: 0.000000
Feature 2: 0.000000
Feature 3: 0.000000
Feature 4: 0.024816
Feature 5: 0.000000
Feature 6: 0.022659
Feature 7: 0.000000
Feature 8: 0.000000
Feature 9: 0.074320
...
A bar chart of the feature importance scores for each input feature is created.
Compared to the correlation feature selection method we can clearly see many more features scored as being relevant. This may be because of the statistical noise that we added to the dataset in its construction.
Bar Chart of the Input Features (x) vs. the Mutual Information Feature Importance (y)
Now that we know how to perform feature selection on numerical input data for a regression predictive modeling problem, we can try developing a model using the selected features and compare the results.
Modeling With Selected Features
There are many different techniques for scoring features and selecting features based on scores; how do you know which one to use?
A robust approach is to evaluate models using different feature selection methods (and numbers of features) and select the method that results in a model with the best performance.
In this section, we will evaluate a Linear Regression model with all features compared to a model built from features selected by correlation statistics and those features selected via mutual information.
Linear regression is a good model for testing feature selection methods as it can perform better if irrelevant features are removed from the model.
Model Built Using All Features
As a first step, we will evaluate a LinearRegression model using all the available features.
The model is fit on the training dataset and evaluated on the test dataset.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# evaluation of a model using all input features
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
Running the example prints the mean absolute error (MAE) of the model on the training dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieves an error of about 0.086.
We would prefer to use a subset of features that achieves an error that is as good or better than this.
1
MAE: 0.086
Model Built Using Correlation Features
We can use the correlation method to score the features and select the 10 most relevant ones.
The select_features() function below is updated to achieve this.
1
2
3
4
5
6
7
8
9
10
11
# feature selection
def select_features(X_train,y_train,X_test):
# configure to select a subset of features
fs=SelectKBest(score_func=f_regression,k=10)
# learn relationship from training data
fs.fit(X_train,y_train)
# transform train input data
X_train_fs=fs.transform(X_train)
# transform test input data
X_test_fs=fs.transform(X_test)
returnX_train_fs,X_test_fs,fs
The complete example of evaluating a linear regression model fit and evaluated on data using this feature selection method is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# evaluation of a model using 10 features chosen with correlation
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
Running the example reports the performance of the model on just 10 of the 100 input features selected using the correlation statistic.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we see that the model achieved an error score of about 2.7, which is much larger than the baseline model that used all features and achieved an MAE of 0.086.
This suggests that although the method has a strong idea of what features to select, building a model from these features alone does not result in a more skillful model. This could be because features that are important to the target are being left out, meaning that the method is being deceived about what is important.
1
MAE: 2.740
Let’s go the other way and try to use the method to remove some redundant features rather than all redundant features.
We can do this by setting the number of selected features to a much larger value, in this case, 88, hoping it can find and discard 12 of the 90 redundant features.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# evaluation of a model using 88 features chosen with correlation
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
Running the example reports the performance of the model on 88 of the 100 input features selected using the correlation statistic.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that removing some of the redundant features has resulted in a small lift in performance with an error of about 0.085 compared to the baseline that achieved an error of about 0.086.
1
MAE: 0.085
Model Built Using Mutual Information Features
We can repeat the experiment and select the top 88 features using a mutual information statistic.
The updated version of the select_features() function to achieve this is listed below.
Running the example fits the model on the 88 top selected features chosen using mutual information.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see a further reduction in error as compared to the correlation statistic, in this case, achieving a MAE of about 0.084 compared to 0.085 in the previous section.
1
MAE: 0.084
Tune the Number of Selected Features
In the previous example, we selected 88 features, but how do we know that is a good or best number of features to select?
Instead of guessing, we can systematically test a range of different numbers of selected features and discover which results in the best performing model. This is called a grid search, where the k argument to the SelectKBest class can be tuned.
We can define a Pipeline that correctly prepares the feature selection transform on the training set and applies it to the train set and test set for each fold of the cross-validation.
In this case, we will use the mutual information statistical method for selecting features.
We can then define the grid of values to evaluate as 80 to 100.
Note that the grid is a dictionary mapping of parameter-to-values to search, and given that we are using a Pipeline, we can access the SelectKBest object via the name we gave it ‘sel‘ and then the parameter name ‘k‘ separated by two underscores, or ‘sel__k‘.
In this case, we will evaluate models using the negative mean absolute error (neg_mean_absolute_error). It is negative because the scikit-learn requires the score to be maximized, so the MAE is made negative, meaning scores scale from -infinity to 0 (best).
Running the example grid searches different numbers of selected features using mutual information statistics, where each modeling pipeline is evaluated using repeated cross-validation.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the best number of selected features is 81, which achieves a MAE of about 0.082 (ignoring the sign).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Best MAE: -0.082
Best Config: {'sel__k': 81}
>-1.100 with: {'sel__k': 80}
>-0.082 with: {'sel__k': 81}
>-0.082 with: {'sel__k': 82}
>-0.082 with: {'sel__k': 83}
>-0.082 with: {'sel__k': 84}
>-0.082 with: {'sel__k': 85}
>-0.082 with: {'sel__k': 86}
>-0.082 with: {'sel__k': 87}
>-0.082 with: {'sel__k': 88}
>-0.083 with: {'sel__k': 89}
>-0.083 with: {'sel__k': 90}
>-0.083 with: {'sel__k': 91}
>-0.083 with: {'sel__k': 92}
>-0.083 with: {'sel__k': 93}
>-0.083 with: {'sel__k': 94}
>-0.083 with: {'sel__k': 95}
>-0.083 with: {'sel__k': 96}
>-0.083 with: {'sel__k': 97}
>-0.083 with: {'sel__k': 98}
>-0.083 with: {'sel__k': 99}
>-0.083 with: {'sel__k': 100}
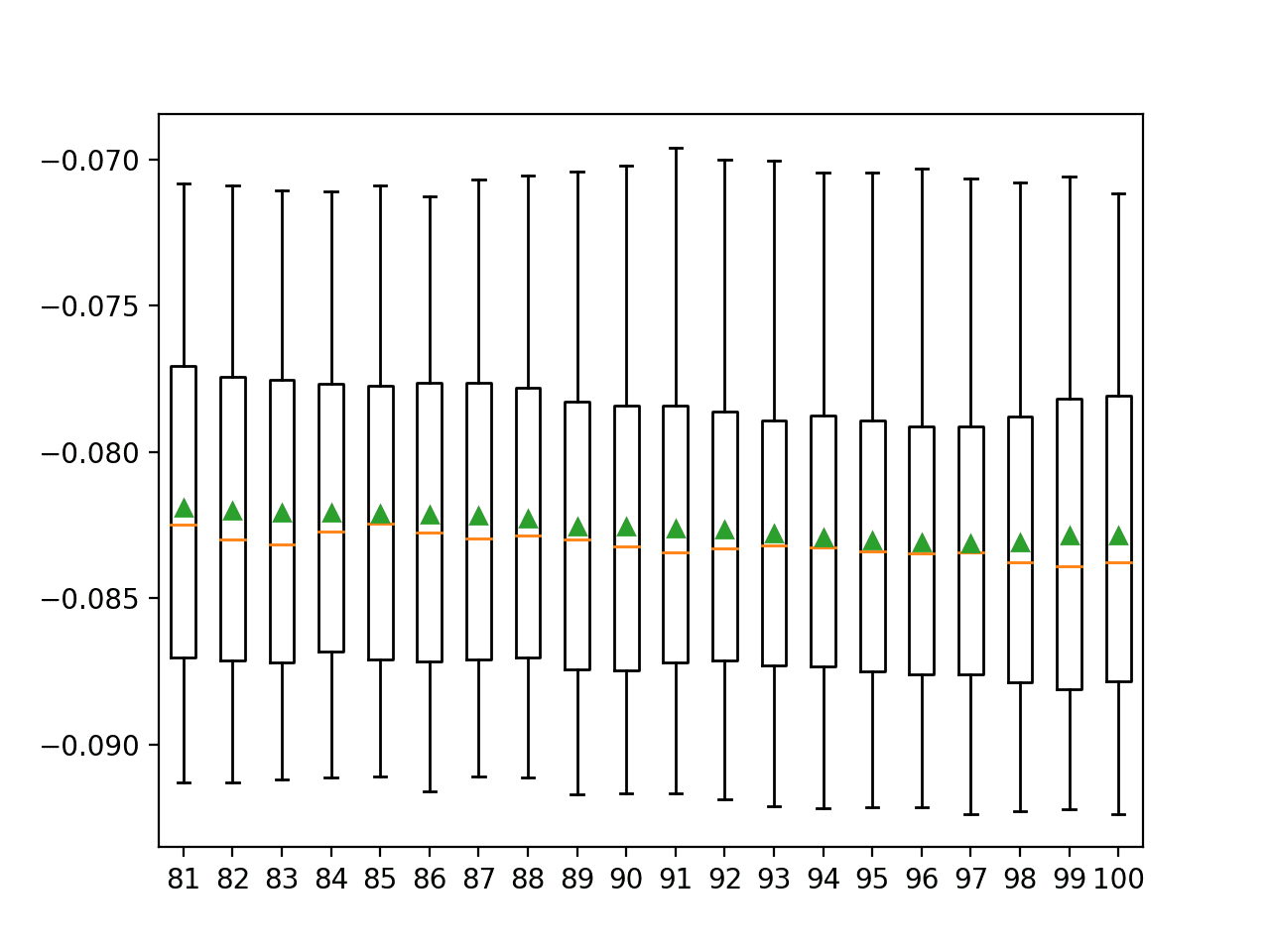
We might want to see the relationship between the number of selected features and MAE. In this relationship, we may expect that more features result in better performance, to a point.
This relationship can be explored by manually evaluating each configuration of k for the SelectKBest from 81 to 100, gathering the sample of MAE scores, and plotting the results using box and whisker plots side by side. The spread and mean of these box plots would be expected to show any interesting relationship between the number of selected features and the MAE of the pipeline.
Note that we started the spread of k values at 81 instead of 80 because the distribution of MAE scores for k=80 is dramatically larger than all other values of k considered and it washed out the plot of the results on the graph.
The complete example of achieving this is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# compare different numbers of features selected using mutual information
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import mutual_info_regression
Running the example first reports the mean and standard deviation MAE for each number of selected features.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, reporting the mean and standard deviation of MAE is not very interesting, other than values of k in the 80s appear better than those in the 90s.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
>81 -0.082 (0.006)
>82 -0.082 (0.006)
>83 -0.082 (0.006)
>84 -0.082 (0.006)
>85 -0.082 (0.006)
>86 -0.082 (0.006)
>87 -0.082 (0.006)
>88 -0.082 (0.006)
>89 -0.083 (0.006)
>90 -0.083 (0.006)
>91 -0.083 (0.006)
>92 -0.083 (0.006)
>93 -0.083 (0.006)
>94 -0.083 (0.006)
>95 -0.083 (0.006)
>96 -0.083 (0.006)
>97 -0.083 (0.006)
>98 -0.083 (0.006)
>99 -0.083 (0.006)
>100 -0.083 (0.006)
Box and whisker plots are created side by side showing the trend of k vs. MAE where the green triangle represents the mean and orange line represents the median of the distribution.
Box and Whisker Plots of MAE for Each Number of Selected Features Using Mutual Information
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials with full working code on: Feature Selection, RFE, Data Cleaning, Data Transforms, Scaling, Dimensionality Reduction,
and much more...
Bring Modern Data Preparation Techniques to Your Machine Learning Projects
Hello Jason,
I have a question about Keras hidden layers (dense).
Is there any best practices to know how many hidden layers is better to add/ define for a network, and how to define an effective value for each (e.g. .Dense(number, activation=’relu’)) the number inside).
Thanks,
Marco
PCA is a type of dimensionality reduction and could be called feature extraction. It projects the data into a lower dimensional space and changes all of the values.
Feature selection does not change the data values, just removes some columns (features).
Have a comment for you. When pipelining for tuning for the number of features in the SelectKBest, shouldn’t the training, validation and test sets be separated. Imagine I want to also choose among different filter method. Then for each feature selection method (either Regression_f or Mutual) I would first tune K by:
results = search.fit(X_train, y_train)
and then I will use test set and performance measure (MAE) to see what method with Best tunning paramer will perform better on the test set. MAE(Test).
You exhausted CV on all data:
results = search.fit(X, y)
and there is no room for comparison of feature selection method on test set. Am I right or off the base?
Hi sir,
I am performing a regression analysis on a high dimensional data (no. of features are more than 10000), can you please suggest any feature selection method ? (does mutual info regression works for high dimensional data?) , I know that the relation is non linear between features and the output value, I want to know whether mutual info regression can capture nonlinear dependency?
Thanks for the post. Among all the feature selection methods for regression problem, how do I know which method to choose? as each methods output slightly different selected features. Thank you!
Hi Jason,
Excellent Turorial!
In realtion to Larissa’s question.
What the easiest way to get the features that actually give the best performing model? Also It’s coefficients? (miltivariant linear regression model)
Thanks in advance.
In this case the shape is 100, subtracting 20 takes it to 80, therefore the range is from 80 to 100. We add 1 because the range stops at the value before the last in the range.
Hello, this coe is for selecting the best number of features that gives the best MAE value (like the 20 first features or the 50 first feaures).
But not the best features that gives MAE value (as features 1, 6, 20, 40,50).
So ho coul i get the more significant features that gives the best MAE values.
Thank you.
Thank you for your very useful posts Jason! The surprise here was to see such a degradation of performance after selection and fit using only the 10 informative features. I was naively expecting at least a similar performing model considering the data was designed with these 10 features being the relevant ones.
I wonder what exactly are all the redundant features adding which produces such better model performance.
It is telling me the method of importance using correlation to target is highly suspect and probably shouldn’t be used at all.
Nice, Just a doubt, in te first output, where we are getting feature scores like Feature 0: 0.455 and so on. Is the feature 0 is the same column (or variable) given in input in X dataframe. For example, if having dataframe with head petal.len, petal.color, flower.color etc. That means feature 0 is petal.len.
Am i right?
Hi @James!
First of all, thank you very much for your always dedicated articles, they are very useful for us!
I would like some advice about feature selection techniques in the field of survival time analysis, I have hundreds of features and I need to reduce them.








Can you please explain lr model in pipeline statement
Yes, it is a linear regression model.
Can you replace ‘lr’ if you want to try other models such as random forest?
Surely you can!
Hello Jason,
I have a question about Keras hidden layers (dense).
Is there any best practices to know how many hidden layers is better to add/ define for a network, and how to define an effective value for each (e.g. .Dense(number, activation=’relu’)) the number inside).
Thanks,
Marco
Good question, see this:
https://machinelearningmastery.com/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
Hello Jason:
Is there any tutorial of features selection for classification problem?
Thanks
Johnny
Yes, perhaps start here:
https://machinelearningmastery.com/rfe-feature-selection-in-python/
And here:
https://machinelearningmastery.com/feature-selection-with-numerical-input-data/
What is the difference between the features selection and features extraction. PCA is different from mutual information technique.
PCA is a type of dimensionality reduction and could be called feature extraction. It projects the data into a lower dimensional space and changes all of the values.
Feature selection does not change the data values, just removes some columns (features).
Sir, can you explain how a set of images will be trained and tested ? So that we can recognise the known image.
Yes, you can get started with image classification here:
https://machinelearningmastery.com/start-here/#dlfcv
Is there any tutorial for Choose a Feature Selection Method regression using Machine Learning?
Perhaps this will help:
https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/
Is there any tutorial for Choosing Non linear Feature Selection Method regression using Machine Learning?
Perhaps start with RFE:
https://machinelearningmastery.com/rfe-feature-selection-in-python/
Hi Jason,
Have a comment for you. When pipelining for tuning for the number of features in the SelectKBest, shouldn’t the training, validation and test sets be separated. Imagine I want to also choose among different filter method. Then for each feature selection method (either Regression_f or Mutual) I would first tune K by:
results = search.fit(X_train, y_train)
and then I will use test set and performance measure (MAE) to see what method with Best tunning paramer will perform better on the test set. MAE(Test).
You exhausted CV on all data:
results = search.fit(X, y)
and there is no room for comparison of feature selection method on test set. Am I right or off the base?
Feature selection is fit on the training set and applied on train, test, val to ensure we avoid data leakage.
The pipeline used in the grid search ensures this is the case, but would assume a pipeline is used in all cases.
Hi sir,
I am performing a regression analysis on a high dimensional data (no. of features are more than 10000), can you please suggest any feature selection method ? (does mutual info regression works for high dimensional data?) , I know that the relation is non linear between features and the output value, I want to know whether mutual info regression can capture nonlinear dependency?
Thank You
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/what-feature-selection-method-should-i-use
Hi Jason,
How can i map the features to the actual column headers from the dataset ?
If you have a list or array of column header names, which is common, then you can use the selected feature index in that array.
If you are new to array indexes, I recommend starting here:
https://machinelearningmastery.com/index-slice-reshape-numpy-arrays-machine-learning-python/
Hi Jason,
Thanks for the post. Among all the feature selection methods for regression problem, how do I know which method to choose? as each methods output slightly different selected features. Thank you!
Good question, I answer it here:
https://machinelearningmastery.com/faq/single-faq/what-feature-selection-method-should-i-use
Thank you!
You’re welcome.
Hello! Thank you very much for your post!
Excellent one!
I would like to know, after discover that 80 features is the best number , how do you know wich features are those 80 selected?
Thank you!
You’re welcome.
You can select them using the algorithm and print their indexes, even map them to column names.
See the section “Which Features Were Selected” in here:
https://machinelearningmastery.com/rfe-feature-selection-in-python/
Hi Jason,
Excellent Turorial!
In realtion to Larissa’s question.
What the easiest way to get the features that actually give the best performing model? Also It’s coefficients? (miltivariant linear regression model)
Thanks in advance.
Coefficient size (for normalized or standardized inputs) can give some idea of feature importance.
Sorry for my question but i didn’t undrestand this line of code
grid[‘sel__k’] = [i for i in range(X.shape[1]-20, X.shape[1]+1)]
-20 refer to what?
-20 subtracts 20 from the value at X.shape[1].
In this case the shape is 100, subtracting 20 takes it to 80, therefore the range is from 80 to 100. We add 1 because the range stops at the value before the last in the range.
I hope that helps.
Sorry ffor my questions , i am a beginner in ML
why should we substract 20 exactly??
Because I wanted to show the effect of model performance with 80 to 100 features. It was arbitrary.
I get it. Thank you
You’re welcome.
Hello, this coe is for selecting the best number of features that gives the best MAE value (like the 20 first features or the 50 first feaures).
But not the best features that gives MAE value (as features 1, 6, 20, 40,50).
So ho coul i get the more significant features that gives the best MAE values.
Thank you.
It depends on how you define “best features”. For me it is the subset that gives the best model performance.
– Perhaps try all subsets.
– Perhaps try feature importance.
– Perhaps try alternate feature selection methods.
Thank you for your very useful posts Jason! The surprise here was to see such a degradation of performance after selection and fit using only the 10 informative features. I was naively expecting at least a similar performing model considering the data was designed with these 10 features being the relevant ones.
I wonder what exactly are all the redundant features adding which produces such better model performance.
It is telling me the method of importance using correlation to target is highly suspect and probably shouldn’t be used at all.
Not suspect, only that the informative features are hard to identify.
Hi, Thanks for the tutorial. Why do SelectKBest scores for f_regression not range in [-1,1]?
Because it is using f_regression in this example, which the score is a F statistic: https://en.wikipedia.org/wiki/F-test
Nice, Just a doubt, in te first output, where we are getting feature scores like Feature 0: 0.455 and so on. Is the feature 0 is the same column (or variable) given in input in X dataframe. For example, if having dataframe with head petal.len, petal.color, flower.color etc. That means feature 0 is petal.len.
Am i right?
That is correct Salman!
How to perform feature importance and selection using XGBRegressor like your tutorial on XGBClassifier for classification problem?
Hi Bilash…You may find the following of interest:
https://machinelearningmastery.com/feature-importance-and-feature-selection-with-xgboost-in-python/
Hi @James!
First of all, thank you very much for your always dedicated articles, they are very useful for us!
I would like some advice about feature selection techniques in the field of survival time analysis, I have hundreds of features and I need to reduce them.
Thank you very much!