After you have found a well performing machine learning model and tuned it, you must finalize your model so that you can make predictions on new data.
In this post you will discover how to finalize your machine learning model, save it to file and load it later in order to make predictions on new data.
After reading this post you will know:
How to train a final version of your machine learning model in Weka.
How to save your finalized model to file.
How to load your finalized model later and use it to make predictions on new data.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.
How to Save Your Machine Learning Model and Make Predictions in Weka Photo by Nick Kenrick, some rights reserved.
Tutorial Overview
This tutorial is broken down into 4 parts:
Finalize Model where you will discover how to train a finalized version of your model.
Save Model where you will discover how to save a model to file.
Load Model where you will discover how to load a model from file.
Make Predictions where you will discover how to make predictions for new data.
The tutorial provides a template that you can use to finalize your own machine learning algorithms on your data problems.
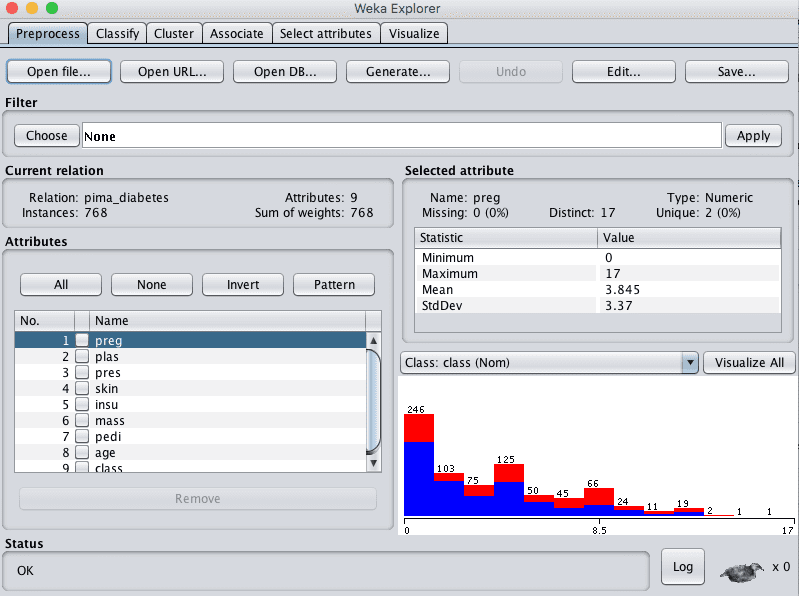
We are going to use the Pima Indians Onset of Diabetes dataset. Each instance represents medical details for one patient and the task is to predict whether the patient will have an onset of diabetes within the next five years. There are 8 numerical input variables and all have varying scales.
We are going to finalize a logistic regression model on this dataset, both because it is a simple algorithm that is well understood and because it does very well on this problem.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
1. Finalize a Machine Learning Model
Perhaps the most neglected task in a machine learning project is how to finalize your model.
Once you have gone through all of the effort to prepare your data, compare algorithms and tune them on your problem, you actually need to create the final model that you intend to use to make new predictions.
Finalizing a model involves training the model on the entire training dataset that you have available.
1. Open the Weka GUI Chooser.
2. Click the “Explorer” button to open the Weka Explorer interface.
3. Load the Pima Indians onset of diabetes dataset from the data/diabetes.arff file.
Weka Load Pima Indians Onset of Diabetes Dataset
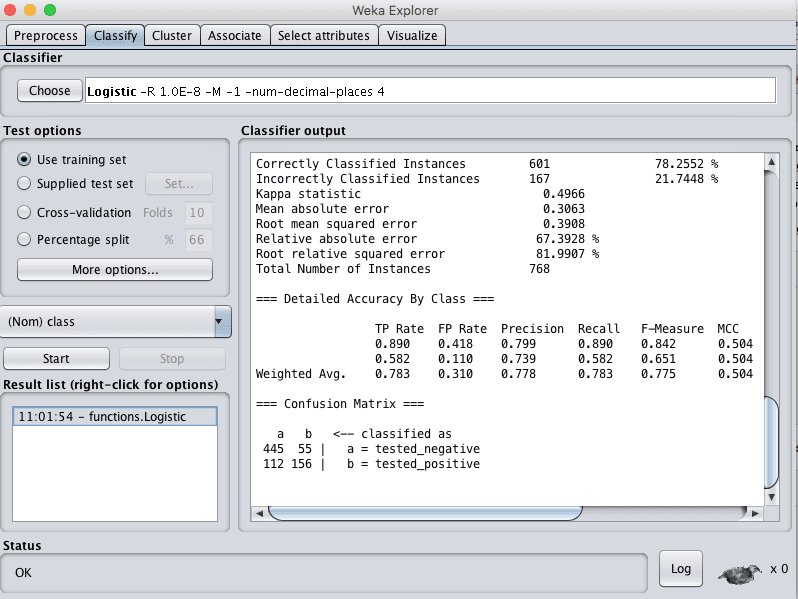
4. Click the “Classify” tab to open up the classifiers.
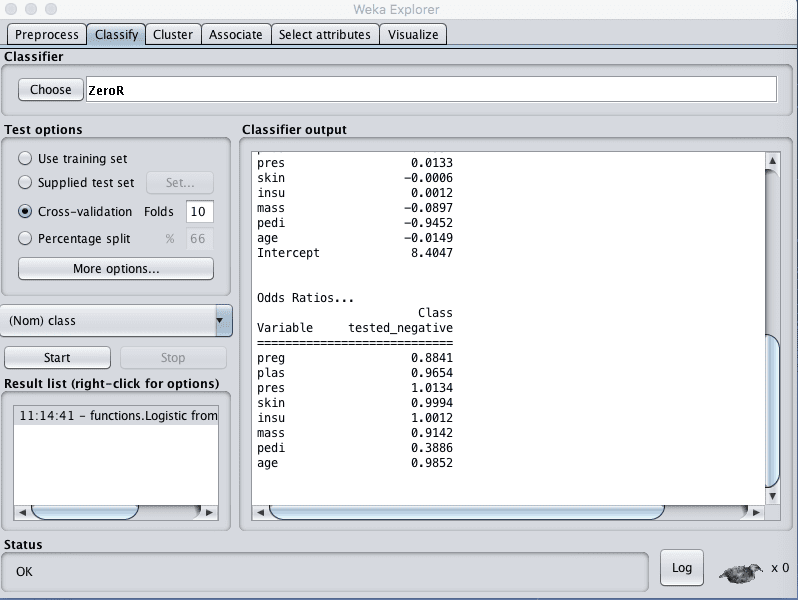
5. Click the “Choose” button and choose “Logistic” under the “functions” group.
6. Select “Use training set” under “Test options”.
7. Click the “Start” button.
Weka Train Logistic Regression Model
This will train the chosen Logistic regression algorithm on the entire loaded dataset. It will also evaluate the model on the entire dataset, but we are not interested in this evaluation.
It is assumed that you have already estimated the performance of the model on unseen data using cross validation as a part of selecting the algorithm you wish to finalize. It is this estimate you prepared previously that you can report when you need to inform others about the skill of your model.
Now that we have finalized the model, we need to save it to file.
2. Save Finalized Model To File
Continuing on from the previous section, we need to save the finalized model to a file on your disk.
This is so that we can load it up at a later time, or even on a different computer in the future and use it to make predictions. We won’t need the training data in the future, just the model of that data.
You can easily save a trained model to file in the Weka Explorer interface.
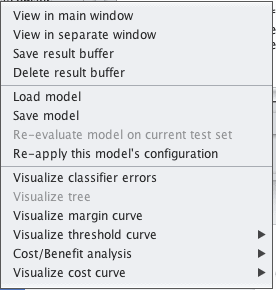
1. Right click on the result item for your model in the “Result list” on the “Classify” tab.
2. Click “Save model” from the right click menu.
Weka Save Model to File
3. Select a location and enter a filename such as “logistic”, click the “Save button.
Your model is now saved to the file “logistic.model”.
It is in a binary format (not text) that can be read again by the Weka platform. As such, it is a good idea to note down the version of Weka you used to create the model file, just in case you need the same version of Weka in the future to load the model and make predictions. Generally, this will not be a problem, but it is a good safety precaution.
You can close the Weka Explorer now. The next step is to discover how to load up the saved model.
3. Load a Finalized Model
You can load saved Weka models from file.
The Weka Explorer interface makes this easy.
1. Open the Weka GUI Chooser.
2. Click the “Explorer” button to open the Weka Explorer interface.
3. Load any old dataset, it does not matter. We will not be using it, we just need to load a dataset to get access to the “Classify” tab. If you are unsure, load the data/diabetes.arff file again.
4. Click the “Classify” tab to open up the classifiers.
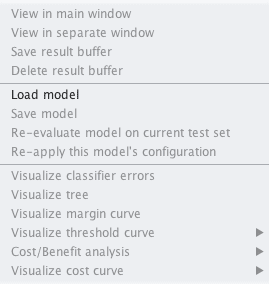
5. Right click on the “Result list” and click “Load model”, select the model saved in the previous section “logistic.model”.
Weka Load Model From File
The model will now be loaded into the explorer.
We can now use the loaded model to make predictions for new data.
Weka Model Loaded From File Ready For Use
4. Make Predictions on New Data
We can now make predictions on new data.
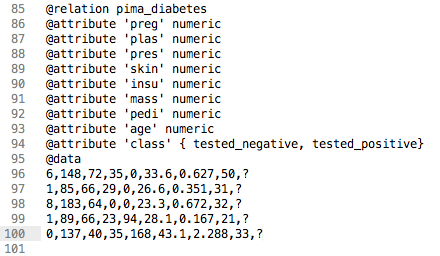
First, let’s create some pretend new data. Make a copy of the file “data/diabetes.arff” and save it as “data/diabetes-new-data.arff“.
Open the file in a text editor.
Find the start of the actual data in the file with the @data on line 95.
We only want to keep 5 records. Move down 5 lines, then delete all the remaining lines of the file.
The class value (output variable) that we want to predict is on the end of each line. Delete each of the 5 output variables and replace them with question mark symbols (?).
Weka Dataset For Making New Predictions
We now have “unseen” data with no known output for which we would like to make predictions.
Continue on from the previous part of the tutorial where we already have the model loaded.
1. On the “Classify” tab, select the “Supplied test set” option in the “Test options” pane.
Weka Select New Dataset On Which To Make New Predictions
2. Click the “Set” button, click the “Open file” button on the options window and select the mock new dataset we just created with the name “diabetes-new-data.arff”. Click “Close” on the window.
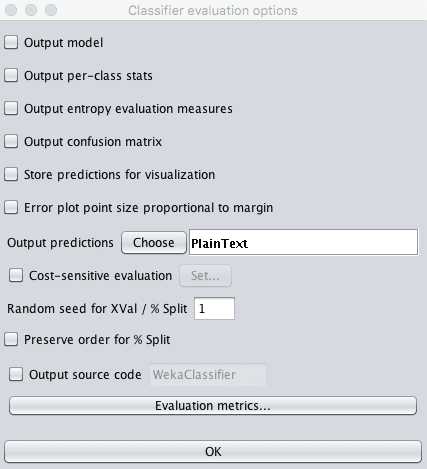
3. Click the “More options…” button to bring up options for evaluating the classifier.
4. Uncheck the information we are not interested in, specifically:
“Output model”
“Output per-class stats”
“Output confusion matrix”
“Store predictions for visualization”
Weka Customized Test Options For Making Predictions
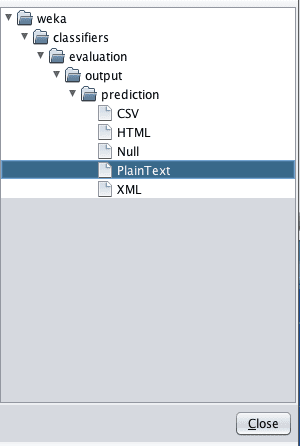
5. For the “Output predictions” option click the “Choose” button and select “PlainText”.
Weka Output Predictions in Plain Text Format
6. Click the “OK” button to confirm the Classifier evaluation options.
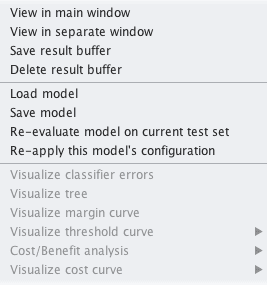
7. Right click on the list item for your loaded model in the “Results list” pane.
8. Select “Re-evaluate model on current test set”.
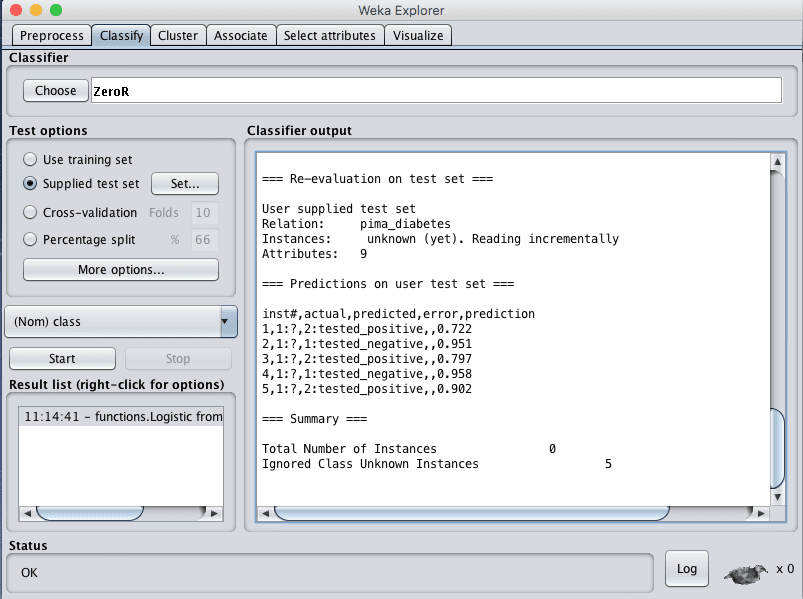
Weka Revaluate Loaded Model On Test Data And Make Predictions
The predictions for each test instance are then listed in the “Classifier Output” pane. Specifically the middle column of the results with predictions like “tested_positive” and “tested_negative”.
You could choose another output format for the predictions, such as CSV, that you could later load into a spreadsheet like Excel. For example, below is an example of the same predictions in CSV format.
Weka Predictions Made on New Data By a Loaded Model
More Information
The Weka Wiki has some more information about saving and loading models as well as making predictions that you may find useful:
In this post you discovered how to finalize your model and make predictions for new unseen data. You can see how you can use this process to make predictions on new data yourself.
Specifically, you learned:
How to train a final instance of your machine learning model.
How to save a finalized model to file for later use.
How to load a model from file and use it to make predictions on new data.
Do you have any questions about how to finalize your model in Weka or about this post? Ask your questions in the comments below and I will do my best to answer them.
Hi
Can I open the saved model by any other program?
I want to use the saved model as a web service, but not using weka for predication.
Is there any way
How do I predict continuous output in Weka? I get “Problem evaluating classifier: Class index is negative (not set)!” error when I try to run model on test set with dependent variable.
Hey, thank you very much for your help!
Just a sidenote for those who have problems with doing the exact same thing as you described using .csv input files: The above description is perfect for .arff but in my case (with .csv) it made predictions for the first 112 lines only and stopped for no reason. Transforming the input (training and test data) solved that problem.
I am looking forward to more tutorials from you 🙂
Thanks for your good work. Please I need your assistance, i am working on crime and i am new in using weka.I have used weka to divide my data set intoo both test and training data set both in CSV format. but the system is complaining whenever I put classfier (such as Bayes, KNN) and i loaded the tested data set on it.
Hello,
Please should train dataset and test dataset be of the same format. If yes why then is my weka complain of incompatible test data set. Also is it the test data that we are converting back to plain test?
Thanks for the tutorial. I have a question, why the number of instances is unknown? and how can I evaluate the accuracy of the prediction? I mean I need to see the number of correctly classified instances and so on…
Hi,
I need to train model on separate genre(blogs data) and test on another genre(hotel reviews). I trained a model by 1. appling StringToWordVector filter(change some settings of filter) 2. attribute selection 3. applied classify Logistic with option “use training set” 4. saved the model. Now I am confused about testing file, should I need to apply all these steps till 3 on test file also? by doing this my train and test file attributes are different but the same format.
Should my training file attribute and test file attribute exactly the same(same to same)? If yes then can I copy the attributes from training file(top to @data) and paste in my test file, is it correct?
If train and test file attributes can be different then there is an error “Data used to train model and test set are not compatible. Would you like to automatically wrap the classifier in “InputMappedClassifier”, what does it mean? if choose Yes what will it do.
Sorry sir, I have many questions. I explored a lot still confused. It will be great help.
Thank you
I have built a logistic regression model in Weka and want to be able to identify what the predictions were for each specific data point. The output I currently have does not allow me to match the predictions to the individual instances.
Hi Jason
Great article. I followed the steps you suggested and I am applying Random Forest classifier. I have the same set of attributes for the training and test set. However in the stage where I predict for unknown data, it ignores all the instances. Below is the message I get in the classifier output:
=== Summary ===
Total Number of Instances 0
Ignored Class Unknown Instances 72
My apology if there was someone asked this question already but i couldn’t find here.
When I used my model to predict new data, the result in output file showed only 101 items/instances. May I ask how to make the model to predict all records (about 5000 records)?
First of all, thank you for making me discovering this Weka. I am one of the many that after a tutorial, after a confusion matrix, I was saying”great!, now what?” 🙂
I just ended a very long course on Data Science and Python on Udemy… is it too daring from me thinking that Weka can substitute python? (at least for simple tasks?)
this blog is really helpful, can you please suggest me how can I make UI application on the top of the model using Python where users can put the data manually and it will give the result like positive or negative
Thanks Jason, this is super helpful. Do you know if there is a way to save particular multilayer percepton configurations? I’m running the percepton classifier and set GUI to true in order to tinker with it, but I can’t for the life of me figure out how to save the tinkered configuration so that I can reuse it. I’ve looked everywhere.
Hmm, that correctly saved the usual parameters like Num Epochs, Learning Rate, etc., but it didn’t save the particular percepton GUI tweaks — say, ones where I connect and disconnect certain nodes to other certain nodes by hand using the percepton GUI.
Did I miss a step, or is there something else I’m supposed to do that’s unique to allowing it to save changes made in the GUI?
Thanks for the tutorial. I am new to Weka and machine learning. The tutorial helped a lot. Just wanted to know how to judge the predicted value for a particular instance? Is the prediction done in order?
Hai.
I ran weka in my Linux os and I got confusion matrix output. Now I would like to use these values
In a grap how can I access this values. What code do I use.
Hi Jason. Thank you for the good tutorial. Is that all there is to making predictions using WEKA? I mean,
a) Choose the appropriate Model (i.e Classifier)
b) Run it on the Supplied Test Set
c) Save the Model
d) Load and dataset in WEKA Explorer just to have access to the Classifier tab
e) Load your Model
f) Open the new file, and finally
g) Re-evaluate the model on the new file for your predictions.
Say I am trying to further tune and test the algorithms, and I have separate test and training sets, which contain different distribution of the instances so that I can choose to mimic real world distribution or keep it 50/50 and see which option gives me better accuracy with the test set (that will have real-world-like distribution). I would not like to save many models, naturally. Could I then re-evaluate without saving it, skipping to step four as soon as I finish cross-validation with the training set?
thank you very much for great tutorials, Dr. Brownlee. They help me a lot in my final project at school.
I would like to perform this kind of predictive modeling techniques at work, but we work with very large data sets (millions of tuples) so my question is – would Weka be able to handle very large data sets?
Weka seems very easy and user friendly tool.
Hi jason,
Im lina and i read each tutorial step on top …. But still confuse, if we use totally new data as a test set, can it run properly? Example on top show you use 5 same data to predict the class….
How can I make website with PMML model implemented to be available for a public use?
For example user input 10 parametrs and receive a result calculated by PMML?
Hi Jason, many thanks for this great work you are involved in. Please, is there any provision for deploying Ripple Down Rule (RIDOR) Learner in WEKA? If it is possible, how can I go about it?
Hello! Many thanks for this tutorial.
I am wondering how come that it does not save the results in a file ? Do I have to cut%paste the output in a csv file ?
Hello. Thanks for the tutorial.
My question is:
Is it possible to perform Cross-validation or Split-percentage in data loaded from a model?
Or if I want to perform any of those two, I have necessarily to load the corresponding training dataset and build a new model for them?
Thanks for the answer.
I have the following situation:
I use a dataset “training.arff” and a classifier, say RandomForest, to generate a model “model1.model”; then I save it.
If I want to evaluate a testing set with it, I load “model1.model” and use the option “reevaluate model on current test set”. Everything is ok until that point.
But if I want to validate my model, I find that there’s no direct way to use CV or split directly over the data used from model1.model. I have necessarily to reload “training.arff”, use CV, and see how it says “building model for training data”, meaning that it is generating another model.
I was wondering if it was possible to validate generated models.
Again, thank you for your feedback
HI thanks for the hard work, it really helped me a lot.
Here’s my question
=== Predictions on user test set ===
inst# actual predicted error prediction
1 1:? 2:tested_positive 0.722
2 1:? 1:tested_negative 0.951
3 1:? 2:tested_positive 0.797
4 1:? 1:tested_negative 0.958
5 1:? 2:tested_positive 0.902
what does the number below prediction means?
the 0.722 ,0.951,0.797
does it mean the probability of the prediction being correct?
Hi, thanks for your informative article.
I have a query about the indexes of test data instances choosen by weka at the time of cross validation. How to get the index of the test data that is being tested ?
As WEKA uses startified cross validation, instances in the test data sets are randomly choosen.
So, How to know the index of the test data instance whose prediction evaluation is being shown in above lines?
i.e
inst# actual predicted error prediction
1 3:Iris-virginica 3:Iris-virginica 0.976
This result is for which instance (among total 50 Iris-virginica) ?
===============
in the main data file first few instances are :
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
Hi, thank you for the wonderful tutorial.
I am using csv instead of arff.
When I supply test set with 145 true and 70 false instances (in that order), the result is shown only for 145 instances. It doesn’t calculate the result for the 70 instances.
If the set is randomly ordered, the result is shown only for the first few instances with same true/false value. For e.g., if the first ten instances are false, and 11th is true, the result (and confusion matrix) is only calculated for the first ten instances.
Please help.
Hello there Jason. Have been following some of your tutorials on here for some time. Glad to see you still answer questions. Mine is regarding the test set. I made all the instances of class in the @data region as “?” like in the example but why is the result of my model’s classification like this?
“Total Number of Instances: 0
Ignored Class Unknown Instances: 7401”
Did I do something wrong? Also the model I used was made with LibSVM.
//Class attribute
Attribute classAttribute = new Attribute(“class”, classes);
ArrayList attributes = new ArrayList(2);
Attribute text=new Attribute(“text”, true);
attributes.add(text);
attributes.add(classAttribute);
// Create the empty dataset “sample” with above attributes
Instances sample = new Instances(“sample”, attributes, 0);
// Make position the class attribute
sample.setClassIndex(classAttribute.index());
// Create empty instance with five attribute values
Instance inst = new DenseInstance(2);
// Set instance values
inst.setValue(text, “What is this are you kidding me 1 2 3 4”);
// Set instance’s dataset to be the dataset “race”
inst.setDataset(sample);
// Set class as missing so we can predict
inst.setClassValue(0); // When I set class as missing, the filter not working at all.
sample.add(inst);
I want to add one more column to the .arff file which I do not want to be used by classifier, but which I want to be present on the prediction output, it is just kind of name for each instance which I need to have in the output – how would I go about it in Explorer?
Thanks a lot.
I also have this problem. I created the model but my test dataset have some extra attributes and weka uses InputMappedClassifier, but it retrains the model instead of just testing it. why is this happening?
I really need your help.
I followed the tutorial steps to make predictions on weka. However, an error occurs:
problem evaluating classifier: class index is negative (not set)!
Thank you.
I was able to predict the model.
One more doubt.
I’m working with prediction of evasion in distance education.
A model created with RandomForest, during training, obtained accuracy of 90.01% and F-measure of 0.906. But when I use the model to make predictions, it classifies all instances as evasion (YES). The database used to test the model is similar to the one used in the training. I have already reviewed the databases and repeated the entire process, but there was no change in the results. Do you have any idea how I could solve it?
Hello Jason,
Thank you for sharing this knowledge with us.
I have question, I am beginner in WEKA and I have go through the steps above, I have read that the test set should have the same number of attributes as the training set, but how it would be possible knowing that I am working on tweets and the word vector would be different.
Can WEKA be used to make two predictions on a given set of data?
Generally, a machine learning system would only make a single prediction among available classes (classification) or predict a single real valued number (regression) based on the given set of features for an instance.
Would it be possible to train a system in WEKA to make two predictions for a given sample?
Although this question could be useful in many angles. A particular use case I would like to use this functionality is predicting an (x,y) coordinate given a set of features of an image. In here, x and y are the two variables to be predicted.
Does WEKA tool have the ability to do this?
i want to predict mental health using weka .i understood these steps but dont know how to create file with some attributes.can u please guide me on that.
I used the weights and thresholds shown by weka for multilayer perceptron (MLP) in my custom C code to do the prediction on the same training data.
However, Weka’s result does not match to my C code implementation results.
In my C code, I am using Feedfoward model (MLP), where the weights and thresholds are obtained from the Weka trained model.
The computation at each node is simple as shown below:
Sum_node = threshold;
for( i = 0 ; i < Num_Input ; i++)
Sum_node += Input[i] * Weight[i][j] ;
hidden_node = 1/(1 + exp(-Sum_node)) ;
Could you please tell me if Weka has different way of implementation for testing a new data?
First of all thanks for this great article, was very helpful. Could you please help me as to how to do the same in java(in eclipse IDE) using the weka.jar library.
I have a data set in .crv format and imported it to weka in .aarf format. I know the set is good —it was provided by my instructor. I’ve written a good decision tree. I want to use three of the attributes in the data to predict if a person has a bladder infection based on the responses, ie is their temperature over 40 degrees and did they have nausea and lumbar pain. What’s the first step to using weka to produce something like that? Do I load the data and use UserClassifier to make a tree? I guess I’m confused—I want weka to cull out the people with high temps and either/or lumbar pain or nauseaandIm not sure how to proceed.
Tank you so much !!
I got very good knowledge from you about How to Save Machine Learning Model and Make Predictions in Weka dear if it is possible you send for how to do predication for all my dataset by using this result
I don’t know. Perhaps a bias against GUIs? or Java?
It’s madness because you can be so productive in Weka without writing a line of code. AND you grok the machine learning/model-building/selection process immediately.
Thanks for the great article. I was wondering if it is possible to implement a trained model outside of the Weka platform.
For example, if I use J48 on a particular data set I can then use the ‘visualize decision tree’ option to use the rules as if statements in another platform on a different data set.
Can I do something similar for other algorithms like Random Forest, SVM’s, etc.?
I suppose the trained model would be some equation/s with coefficients generated by the training data? Thanks for any advice.
Hi Jason,
I have a csv file included 32 attributes of tweet that each attribute is a column of this file. I have a Nomber_of_retwwet’s attribute as production of tweet’s retweet. How can achieve a good response for protection tweet’s retweet?
Hi, Thanks alot for valuable comment and tutorial.
I want to know is there any way to build different models to be able to test all of them on the testing data? (for example use 10-fold CV and repeat it 20 times to have 200 models to be tested 200 times on testing data)!
Hi, I have another question too. I have data of healthy and patient people. But data contain repeated scans for each subject (It means for example the first 4 data belong to patient 1, the other 3 scans belong to patient 2 and so on). To do the CV, a subject with all scans should be on training or testing. Is it possible to do it in Weka when I want to do 10-fold CV?
Thanks alot for your response. Just would you please let me know how I can make group subjects before doing k-fold? Now, I assign a column consist of healthy and patient people. But I think I should assign another column to classify all the people according to their repeated scans.
Using Weka, I have trained a MLP model on a set of data, and I want to continue training it with just a subset of the data (kind of like “transfer learning” I think). I am hoping the the Experimenter resume parameter might help me to do this. Do you know if it is possible?
Thanks a lot it was very useful. is it possible training model with neural network and then classified with decision tree the trained model in Weka ? if it is possible how we can do it? and how we can use of test data set in this situation?
Thanks very much for your instructions for us.
I met a problem while using this, when I load the model and reevaluate with the test set that I created, the results can up all the same classification, which is probably wrong.
Could you help me with what possibly might go wrong with me?
Thanks!!
I did, I even copy and paste the original dataset and leave the target class blank. Still the same.
However, I did use different dataset get 2 different results. But within each datasets, it keeps the same class.
Is that means the problem is my test data?
Today I figured out why. I used my dataset as .csv file. Those two different results are from two different models.(I am working on three models at the same time so it was my mistake).
Anyway, the issue has been resolved by converting the csv file to .arff and change all data type to nominal.
Thanks very much for your time!!
Have a wonderful day!
I wanted to ask if we don’t replace the data with “?” and leave it as is (considering the dataset I’m using is a different dataset with similar attributes), would that change how the model works?
I mean, the “?” was for us to see how well the model performed. If we keep the original value, would the model act differently?
I am making predictions for a particular dataset, when I use the percentage split in the ‘Test option’ and try to save the prediction result into a csv format, the obtained result contains only predicted test dataset but not the training data(predicted). I would like to know if it is possible to obtaing the prediction result for both training and test when I use ‘Percentage Split’.
My questionis why is that I am not able to get the entire attribute, but the with ‘…’ at the end. Is it possible to retaing me entire results? if so can you please help me with it?
Hello Jason,
I had one query. Is it possible to save multiple models at the same time in the WEKA Classifier toolbox. For example, on my dataset, I wish to apply all kinds of algorithms, i e , (Function based, lazy learning based, meta learning and tree based algorithms).
So in total for the same dataset and subset selection, I wish to apply around 10-15 methods. Now, is there any way I can save all these 10-15 models for future reference or does WEKA only permit 1 model to be saved at a time?
hello I need a help from you Jason
I am training a model in weka and importing data from MySql database from xampp. I am doing a web app on xampp where data will be collected from the web app and my model need to predict using those data. can I connect a web service with weka? what is your recommendations? How can I make real time predictions and sent it to my web app back?
My endeavor with WEKA v3.9.6 ends up FAULTY !
Oh god what a cucumber some approach for forecasting in WEKA. Feels like cheating. I’m not sure if i’m getting this right ? If i have 200 columns with equal depth rows in it – matrix (all numerical data except rows and columns names) trained model on it. Now i’m trying to forecast data pattern in new 201 column on basis provided data set pattern in it. If i’m getting this right i cant just add 201 column at the end to 200 in same row depth for so called “new” old dataset coz u mentioned that provided data set must be equal in “shape” to data set that model was trained on (basically this means exact nr. columns/rows in it). So if i want to make forecast for entire new 201 column i have to fit it in – “mask it” within in that new-old provided dataset. If i delete entire 200 column and replace rows in it with “?” i forecast already known data. So i delete first column in dataset and shift entire dataset to the left to have so called “?” 201th column that i want to predict in 200 column in that new-old provided dataset. Somewhat this worked but i get 100% the same false numeric value in entire column depth.
Something went wrong with autoWEKA classifier. Also not clear how to finalize trained model. Using the same classifier with which was model created coz i can choose from menu all the other options ? Practice example tutorial provided isn’t specific on that question either ! If this is the case there a myriad options to choose from. My GPU supports CUDA 2.1 that’s enough to use GPU to boost the things up (DataMiner and Quasar does) but WEKA doesn’t so no GPU boost for WEKA and things are very slow even for Intel Core-5 3570K CPU.
Second run AutoWEKA after 24 hours run didn’t result in any success. AutoWEKA generated many classifier models in menu blue colored named text. Only two succeeded reapplying finalizing model to test dataset set on which was whole model generated, everything else resulted in various errors. When using the same approach for forecasting both models resulting in filling prediction not with numbers but with “?” for actual, predicted and error column at the re-apply model on “new” dataset (was the same as used ia first time).
I planed to use ML for may master diploma in mechanical engineering area of expertise in fluid dynamics and heat transfer. Now i have to reconsider the whole approach and omit the ML part entirely or start new from begining.
As for my experience software only works when example tutorials are used, everything else did not ! Tutors should start to post “fail tutorials” so we all can see what “not to do” and “what else doesn’t work” would be much better approach if u consider Murphy’s Laws altogether (for that matter i’m not sure what i’m doing wrong here … ?). I have read somewhere on net that ANN can learn almost on everything and there is almost no limitations in that matter (except for hardware used).
WEKA on paper (advertised on net) was promising solution for my approach turned out in total failure. Not to mention confusing GUI should be for 2023 age way more intuitive – one have to take tutorial to start to use. There is no straight forward process workflow input-train-test-validate-forecast. Using NN’s for predictions inside known datasets doesn’t make any sense, u can use interpolations technique and other classic statistical tools for that matter. NN’s are only good for pattern recognition and pattern forecast in various fields of science use to see what pattern propagate if model is pattern driven and not chaotic. I cant imagine some can use such software successfully, if u aren’t developer of such software – u can then code it for your self. Everybody else will in high probability percentage likely fail as i was and most likely newer know exactly know what he is doing. As such I’m only user and i don’t have no more time to “spare to burn it in failures”. I was simply follow the tuts and have read as much technical papers on it (looks pretty darn fine on paper) but software in reality is pure pain to use with all the twists and quirks as i found out.
Maybe that post will help someone to clear things up not to fail with WEKA and try to use something else or avoid ML “headache” entirely in choosing other solutions. No wonder people “jump off the ML train”. I’m not criticizing core algorithms of NN’s but everything else around it and how that is implemented resulting IN GUI’s and use procedures. Until there isn’t more user friendly GUI’s and intuitive.
Hey great tutorial, Couple of questions i was making some prediction in my model and noticed it only goes up to 100 instances and wondering if it possible to increase that number since i working on data with more than 100 data point. Also how would won go converting the results given into a csv file?








Hi
Can I open the saved model by any other program?
I want to use the saved model as a web service, but not using weka for predication.
Is there any way
Thanks
I have not done this myself Kanan.
You may be able to using the PMML format:
http://wiki.pentaho.com/display/DATAMINING/PMML+Support+in+Weka
Unfortunately the link says “There is no support for exporting PMML models from Weka yet.”
Thankssssss……
How do I predict continuous output in Weka? I get “Problem evaluating classifier: Class index is negative (not set)!” error when I try to run model on test set with dependent variable.
Great question.
Use a regression algorithm to predict a continus value.
Here is a tutorial to get you started:
https://machinelearningmastery.com/use-regression-machine-learning-algorithms-weka/
Is the M5P not capable of regression predication with categorical and continuous variables? I thought regression trees could do that?
Thank you so much for this tutorial. It is really straightforward. Really enjoy it. Thanks.
I’m really glad to hear that Kayode.
Thank you so much for this tutorial. It is very useful for me.Thanks.
I’m glad to hear that Ametun.
Hey, thank you very much for your help!
Just a sidenote for those who have problems with doing the exact same thing as you described using .csv input files: The above description is perfect for .arff but in my case (with .csv) it made predictions for the first 112 lines only and stopped for no reason. Transforming the input (training and test data) solved that problem.
I am looking forward to more tutorials from you 🙂
Thanks for the tip Diane.
Good day,
Thanks for your good work. Please I need your assistance, i am working on crime and i am new in using weka.I have used weka to divide my data set intoo both test and training data set both in CSV format. but the system is complaining whenever I put classfier (such as Bayes, KNN) and i loaded the tested data set on it.
Please help me on this
What is the error exactly? What is the complaint that Weka is making?
Hello,
Please should train dataset and test dataset be of the same format. If yes why then is my weka complain of incompatible test data set. Also is it the test data that we are converting back to plain test?
Yes, the train and test must be the same format, with the same number of columns.
You may not know the predicted outcome, in which case you can use a ‘?’ value.
Thanks. I really appreciate your efforts, you teaching was superb
Thanks!
Thanks for the tutorial. I have a question, why the number of instances is unknown? and how can I evaluate the accuracy of the prediction? I mean I need to see the number of correctly classified instances and so on…
This tutorial was about making prediction in new data.
If you have data for which you already know the expected output, you can make predictions on it by selecting it as an external test dataset in Weka.
Hi,
I need to train model on separate genre(blogs data) and test on another genre(hotel reviews). I trained a model by 1. appling StringToWordVector filter(change some settings of filter) 2. attribute selection 3. applied classify Logistic with option “use training set” 4. saved the model. Now I am confused about testing file, should I need to apply all these steps till 3 on test file also? by doing this my train and test file attributes are different but the same format.
Should my training file attribute and test file attribute exactly the same(same to same)? If yes then can I copy the attributes from training file(top to @data) and paste in my test file, is it correct?
If train and test file attributes can be different then there is an error “Data used to train model and test set are not compatible. Would you like to automatically wrap the classifier in “InputMappedClassifier”, what does it mean? if choose Yes what will it do.
Sorry sir, I have many questions. I explored a lot still confused. It will be great help.
Thank you
Hi,
I have built a logistic regression model in Weka and want to be able to identify what the predictions were for each specific data point. The output I currently have does not allow me to match the predictions to the individual instances.
Thanks,
Mike
Hi Mike,
The order of the predictions should match the order of the data in your input file used to make predictions.
Awesome article! Very simple and right to the point!
Thanks Bellz.
Hi Jason
Great article. I followed the steps you suggested and I am applying Random Forest classifier. I have the same set of attributes for the training and test set. However in the stage where I predict for unknown data, it ignores all the instances. Below is the message I get in the classifier output:
=== Summary ===
Total Number of Instances 0
Ignored Class Unknown Instances 72
=== Confusion Matrix ===
a b <– classified as
0 0 | a = good
0 0 | b = bad
Can you please suggest what am I doing wrong?
Perhaps the test set data is corrupt or not loading correctly?
kanika sood …can you help me …i m stuck with the same error ???
I got the answer to my earlier question. Here is the questions I have now: Random Forest, BayesNet always predicts only one class for all instances.
Perhaps you need to reframe your problem or collect more data.
If you have all instances of one class, you may need to collect examples of the other class.
This process will help you work through your problem:
https://machinelearningmastery.com/start-here/#process
Elegant, simple, exercise.
Thanks, I’m glad it helped Billy!
My apology if there was someone asked this question already but i couldn’t find here.
When I used my model to predict new data, the result in output file showed only 101 items/instances. May I ask how to make the model to predict all records (about 5000 records)?
There is no limit, pass all inputs to model.predict(X) to get predictions.
Hi Jason thanks for the post! Is there a way to get the top 3 predictions?
What do you mean exactly “top 3 predictions”?
First of all, thank you for making me discovering this Weka. I am one of the many that after a tutorial, after a confusion matrix, I was saying”great!, now what?” 🙂
I just ended a very long course on Data Science and Python on Udemy… is it too daring from me thinking that Weka can substitute python? (at least for simple tasks?)
It can and should for many beginners working on small one-off projects.
Get started with Weka here:
https://machinelearningmastery.com/start-here/#weka
Thank you!!
this blog is really helpful, can you please suggest me how can I make UI application on the top of the model using Python where users can put the data manually and it will give the result like positive or negative
Sorry, I don’t know about UI applications in Python. Perhaps a web interface?
Thanks Jason, this is super helpful. Do you know if there is a way to save particular multilayer percepton configurations? I’m running the percepton classifier and set GUI to true in order to tinker with it, but I can’t for the life of me figure out how to save the tinkered configuration so that I can reuse it. I’ve looked everywhere.
After you fit the model you can save it.
When you run the model, the Explorer window should give you the command line parameters needed to re-create the model configuration at the top.
Hmm, that correctly saved the usual parameters like Num Epochs, Learning Rate, etc., but it didn’t save the particular percepton GUI tweaks — say, ones where I connect and disconnect certain nodes to other certain nodes by hand using the percepton GUI.
Did I miss a step, or is there something else I’m supposed to do that’s unique to allowing it to save changes made in the GUI?
Thank you!
Thanks for the tutorial. I am new to Weka and machine learning. The tutorial helped a lot. Just wanted to know how to judge the predicted value for a particular instance? Is the prediction done in order?
=== Predictions on user test set ===
inst# actual predicted error prediction
1 1:? 2:tested_positive 0.722
2 1:? 1:tested_negative 0.951
3 1:? 2:tested_positive 0.797
4 1:? 1:tested_negative 0.958
5 1:? 2:tested_positive 0.902
Also, what does 2 in 2:tested_positive mean?
Great question. Yes, the order of the predictions will match the order of the observations in the input file.
The prediction is probably a class number (1 or 2) and the associated label in the problem (positive or negative).
Thank you
You’re welcome.
Hai.
I ran weka in my Linux os and I got confusion matrix output. Now I would like to use these values
In a grap how can I access this values. What code do I use.
Sorry, I don’t follow, what do you mean exactly?
Hi Jason. Thank you for the good tutorial. Is that all there is to making predictions using WEKA? I mean,
a) Choose the appropriate Model (i.e Classifier)
b) Run it on the Supplied Test Set
c) Save the Model
d) Load and dataset in WEKA Explorer just to have access to the Classifier tab
e) Load your Model
f) Open the new file, and finally
g) Re-evaluate the model on the new file for your predictions.
Yes! It is perfect for beginners.
You can go deeper on various aspects and I recommend using the Experiment for being systematic in your exploration.
how can I calculate each predictor odd ratio, 95% CI, and P-value.
When I am going to installed new packages, it is showing an error message. How can I solve this problem
Hello Jason,
How can I make predictions and produce Actual value by using R program ?
See this post:
https://machinelearningmastery.com/finalize-machine-learning-models-in-r/
Hello Jason,
Say I am trying to further tune and test the algorithms, and I have separate test and training sets, which contain different distribution of the instances so that I can choose to mimic real world distribution or keep it 50/50 and see which option gives me better accuracy with the test set (that will have real-world-like distribution). I would not like to save many models, naturally. Could I then re-evaluate without saving it, skipping to step four as soon as I finish cross-validation with the training set?
Once you find a good configuration, discard all CV models and train a final model.
See this post on the topic:
https://machinelearningmastery.com/train-final-machine-learning-model/
thank you very much for great tutorials, Dr. Brownlee. They help me a lot in my final project at school.
I would like to perform this kind of predictive modeling techniques at work, but we work with very large data sets (millions of tuples) so my question is – would Weka be able to handle very large data sets?
Weka seems very easy and user friendly tool.
I would recommend taking a sample of your data to model, small enough to fit into memory with Weka.
how to carry out weka result to androide phone
I don’t know, sorry.
Hi jason,
Im lina and i read each tutorial step on top …. But still confuse, if we use totally new data as a test set, can it run properly? Example on top show you use 5 same data to predict the class….
Sorry, I don’t follow. Perhaps you could restate your question or give more context?
Hello,
How can I make website with PMML model implemented to be available for a public use?
For example user input 10 parametrs and receive a result calculated by PMML?
Sorry, I don’t have an example of creating a website from a model.
Hi Jason, many thanks for this great work you are involved in. Please, is there any provision for deploying Ripple Down Rule (RIDOR) Learner in WEKA? If it is possible, how can I go about it?
There may be Ben, but I am not across it sorry.
Hello! Many thanks for this tutorial.
I am wondering how come that it does not save the results in a file ? Do I have to cut%paste the output in a csv file ?
Yes. You will have to save it manually. Weka was built more for exploring models than for using models.
Hello. Thanks for the tutorial.
My question is:
Is it possible to perform Cross-validation or Split-percentage in data loaded from a model?
Or if I want to perform any of those two, I have necessarily to load the corresponding training dataset and build a new model for them?
What do you mean exactly?
CV and split are methods for using a training data to evaluate a model. How could it “come” from the model?
Thanks for the answer.
I have the following situation:
I use a dataset “training.arff” and a classifier, say RandomForest, to generate a model “model1.model”; then I save it.
If I want to evaluate a testing set with it, I load “model1.model” and use the option “reevaluate model on current test set”. Everything is ok until that point.
But if I want to validate my model, I find that there’s no direct way to use CV or split directly over the data used from model1.model. I have necessarily to reload “training.arff”, use CV, and see how it says “building model for training data”, meaning that it is generating another model.
I was wondering if it was possible to validate generated models.
Again, thank you for your feedback
I recommend validating the model prior to saving and making predictions.
hi how can i predict between two different data sets
What do you mean exactly?
HI thanks for the hard work, it really helped me a lot.
Here’s my question
=== Predictions on user test set ===
inst# actual predicted error prediction
1 1:? 2:tested_positive 0.722
2 1:? 1:tested_negative 0.951
3 1:? 2:tested_positive 0.797
4 1:? 1:tested_negative 0.958
5 1:? 2:tested_positive 0.902
what does the number below prediction means?
the 0.722 ,0.951,0.797
does it mean the probability of the prediction being correct?
Yes, the probability of the prediction for the class.
Hi, thanks for your informative article.
I have a query about the indexes of test data instances choosen by weka at the time of cross validation. How to get the index of the test data that is being tested ?
=======
I have choosen:
Dataset : iris.arff
Total instances : 150
Classifier : J48
cross validation: 10 fold
I have also made output prediction as “PlainText”
=============
In the output window I can see like this :-
inst# actual predicted error prediction
1 3:Iris-virginica 3:Iris-virginica 0.976
2 3:Iris-virginica 3:Iris-virginica 0.976
3 3:Iris-virginica 3:Iris-virginica 0.976
4 3:Iris-virginica 3:Iris-virginica 0.976
5 3:Iris-virginica 3:Iris-virginica 0.976
6 1:Iris-setosa 1:Iris-setosa 1
7 1:Iris-setosa 1:Iris-setosa 1
….
…
…
Total 10 test data set .(15 instances in each).
======================
As WEKA uses startified cross validation, instances in the test data sets are randomly choosen.
So, How to know the index of the test data instance whose prediction evaluation is being shown in above lines?
i.e
inst# actual predicted error prediction
1 3:Iris-virginica 3:Iris-virginica 0.976
This result is for which instance (among total 50 Iris-virginica) ?
===============
in the main data file first few instances are :
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
So the main data file starts with Iris-setosa.
The index should be the row number in the file.
Hi, thank you for the wonderful tutorial.
I am using csv instead of arff.
When I supply test set with 145 true and 70 false instances (in that order), the result is shown only for 145 instances. It doesn’t calculate the result for the 70 instances.
If the set is randomly ordered, the result is shown only for the first few instances with same true/false value. For e.g., if the first ten instances are false, and 11th is true, the result (and confusion matrix) is only calculated for the first ten instances.
Please help.
Perhaps the data was not loaded correcty?
How do we get the output prediction in the original form?
What do you mean exactly?
Hello there Jason. Have been following some of your tutorials on here for some time. Glad to see you still answer questions. Mine is regarding the test set. I made all the instances of class in the @data region as “?” like in the example but why is the result of my model’s classification like this?
“Total Number of Instances: 0
Ignored Class Unknown Instances: 7401”
Did I do something wrong? Also the model I used was made with LibSVM.
No, you can ignore that note. We are forcing Weka to do something that it does not want to do – make predictions in the Explorer.
If I have a model build with J48. and StringToWordVector
How do I feed in the data for the model classifier to classify in java ?
Classifier cls = (Classifier) weka.core.SerializationHelper.read(“c:\\identify.model”);
ArrayList classes = new ArrayList(3);
classes.add(“type1”);
classes.add(“type2”);
classes.add(“type3”);
//Class attribute
Attribute classAttribute = new Attribute(“class”, classes);
ArrayList attributes = new ArrayList(2);
Attribute text=new Attribute(“text”, true);
attributes.add(text);
attributes.add(classAttribute);
// Create the empty dataset “sample” with above attributes
Instances sample = new Instances(“sample”, attributes, 0);
// Make position the class attribute
sample.setClassIndex(classAttribute.index());
// Create empty instance with five attribute values
Instance inst = new DenseInstance(2);
// Set instance values
inst.setValue(text, “What is this are you kidding me 1 2 3 4”);
// Set instance’s dataset to be the dataset “race”
inst.setDataset(sample);
// Set class as missing so we can predict
inst.setClassValue(0); // When I set class as missing, the filter not working at all.
sample.add(inst);
System.out.println(sample.toString());
StringToWordVector filter = createFilter(sample);
sample=filter.useFilter(sample, filter);
System.out.println(sample);
I sorry, I don’t have exampels of Java programming with the Weka API, I cannot give you advice.
I want to add one more column to the .arff file which I do not want to be used by classifier, but which I want to be present on the prediction output, it is just kind of name for each instance which I need to have in the output – how would I go about it in Explorer?
Thanks a lot.
I’m not sure off hand, sorry. Perhaps try posting to the weka users group.
Hello Jason! Thank you for your helpful tutorials!
I used MPRegressor and got the following model:
MPRegressor with ridge value 0.01 and 2 hidden units (useCGD=true)
Output unit 0 weight for hidden unit 0: 2.9058790401172043
Hidden unit 0 weights:
-0.2878670472862872 A
0.4012790926803488 B
0.6114550533482614 C
0.09745324473246314 D
-0.26600053341756486 E
Hidden unit 0 bias: -0.1802615484156791
Output unit 0 weight for hidden unit 1: -0.239991138003868
Hidden unit 1 weights:
-6.4472828043452175 A
-4.770061719076585 B
-4.318804805199649 C
-2.077452814137676 D
1.0959052105040001 E
Hidden unit 1 bias: 0.21400772835364332
Output unit 0 bias: -1.2579970537867124
Is there a way I can use this model in excel?
Well don!
I don’t know about using Weka models in excel, sorry.
Hello sir good day!
can you help me how to setup logistic regression model so that its prediction is more than 1 or 2.
=== Predictions on user test set ===
inst# actual predicted error prediction predicted error prediction
1 1:? 4:BSBA 0.328 6:BEED 0.618
is this possible?
Generally, logistic regression is for binary classification problems.
Thanks you sir. So can you tell me sir what function to be use to have a multiple prediction?
It will be very much appreciated.
Almost any other classification algorithm.
I trained a very big dataset with 1gb size but the model file is only 300kb. is this normal?
The size of the model is proportional to the complexity of the model, which can be unrelated to the number of examples in the dataset.
I also have this problem. I created the model but my test dataset have some extra attributes and weka uses InputMappedClassifier, but it retrains the model instead of just testing it. why is this happening?
Perhaps try preparing the new data separately to have identical structure to the training dataset, e.g. in excel or a text editor?
Hello Jason,
I really need your help.
I followed the tutorial steps to make predictions on weka. However, an error occurs:
problem evaluating classifier: class index is negative (not set)!
What should I do to correct the error?
I’m not sure, some ideas:
Perhaps the dataset was not loaded correctly?
Perhaps the class variable was not specified?
Thank you.
I was able to predict the model.
One more doubt.
I’m working with prediction of evasion in distance education.
A model created with RandomForest, during training, obtained accuracy of 90.01% and F-measure of 0.906. But when I use the model to make predictions, it classifies all instances as evasion (YES). The database used to test the model is similar to the one used in the training. I have already reviewed the databases and repeated the entire process, but there was no change in the results. Do you have any idea how I could solve it?
Results:
=== Confusion Matrix ===
a b <– classified as
323 0 | a = SIM
109 0 | b = NAO
Thanks.
Sorry, I don’t follow. What is the problem you are having exactly?
Is the order of rows important in a dataset? can I put all the rows with class “A” first and all the rows with class “B” next?
It can be for LSTMs and for SGD. It really depends on the context.
Often, when fitting a model we want to shuffle the rows each epoch to avoid learning any ordering.
Hello Jason,
Thank you for sharing this knowledge with us.
I have question, I am beginner in WEKA and I have go through the steps above, I have read that the test set should have the same number of attributes as the training set, but how it would be possible knowing that I am working on tweets and the word vector would be different.
your kind assistance is highly appreciated.
You would encode the text to the same length vector, e.g. a bag of words with the same sized vocab.
Can WEKA be used to make two predictions on a given set of data?
Generally, a machine learning system would only make a single prediction among available classes (classification) or predict a single real valued number (regression) based on the given set of features for an instance.
Would it be possible to train a system in WEKA to make two predictions for a given sample?
Although this question could be useful in many angles. A particular use case I would like to use this functionality is predicting an (x,y) coordinate given a set of features of an image. In here, x and y are the two variables to be predicted.
Does WEKA tool have the ability to do this?
I don’t believe weka supports multiple output prediction problems.
i want to predict mental health using weka .i understood these steps but dont know how to create file with some attributes.can u please guide me on that.
Perhaps this framework will help:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
i can use that model in r
Great!
Are you familiar with Tensorflow? Can I train and save a model in tensorflow and make predictions in weka?
Not that I have seen.
hi jason,
can i load that saved model in r.
thank you
Yes, here is an example:
https://machinelearningmastery.com/finalize-machine-learning-models-in-r/
No i asked weka saved model.can i load in java.
Sorry, I don’t have an example of loading models in Java.
sorry jason i want asked can load in r.
You may, I don’t know sorry.
ok thank you.
sorry load in r.
Hi Jason,
I used the weights and thresholds shown by weka for multilayer perceptron (MLP) in my custom C code to do the prediction on the same training data.
However, Weka’s result does not match to my C code implementation results.
In my C code, I am using Feedfoward model (MLP), where the weights and thresholds are obtained from the Weka trained model.
The computation at each node is simple as shown below:
Sum_node = threshold;
for( i = 0 ; i < Num_Input ; i++)
Sum_node += Input[i] * Weight[i][j] ;
hidden_node = 1/(1 + exp(-Sum_node)) ;
Could you please tell me if Weka has different way of implementation for testing a new data?
It may have differences in the implementation.
You can check the source code, it is open source.
How to use Weka in Python?
I don’t see why not.
I don’t have an example, sorry.
Hi Jason,
Do you know the maximal amount of required input data per a weka classifier?
Good question, I answer it here:
https://machinelearningmastery.com/much-training-data-required-machine-learning/
First of all thanks for this great article, was very helpful. Could you please help me as to how to do the same in java(in eclipse IDE) using the weka.jar library.
Sorry, I don’t have any examples in Java.
I have a data set in .crv format and imported it to weka in .aarf format. I know the set is good —it was provided by my instructor. I’ve written a good decision tree. I want to use three of the attributes in the data to predict if a person has a bladder infection based on the responses, ie is their temperature over 40 degrees and did they have nausea and lumbar pain. What’s the first step to using weka to produce something like that? Do I load the data and use UserClassifier to make a tree? I guess I’m confused—I want weka to cull out the people with high temps and either/or lumbar pain or nauseaandIm not sure how to proceed.
Perhaps start here:
https://machinelearningmastery.com/start-here/#weka
Tank you so much !!
I got very good knowledge from you about How to Save Machine Learning Model and Make Predictions in Weka dear if it is possible you send for how to do predication for all my dataset by using this result
Sorry, I cannot make predictions for you.
Please can a use a saved model from explorer in the experimenter.
I don’t think so, off the cuff.
I used WEKA a few years ago and I like a lot. Weka IS the machine learning software to go to years before Python and R.
Can you share any light why WEKA is not as popular as Python/R today?
I agree!
I don’t know. Perhaps a bias against GUIs? or Java?
It’s madness because you can be so productive in Weka without writing a line of code. AND you grok the machine learning/model-building/selection process immediately.
hello,
I am supposed to use weka on the Linux system to calculate unweighted average recall from confusion matrix can i know the script to do it
Sorry, I don’t have any scripts for Weka. I only show how to use the GUI interface.
oh okay, thanks soo much! I have to work on output predictions is there any tutorial which explains output predictions
The above tutorial is exactly that topic.
Hi Jason,
Thanks for the great article. I was wondering if it is possible to implement a trained model outside of the Weka platform.
For example, if I use J48 on a particular data set I can then use the ‘visualize decision tree’ option to use the rules as if statements in another platform on a different data set.
Can I do something similar for other algorithms like Random Forest, SVM’s, etc.?
I suppose the trained model would be some equation/s with coefficients generated by the training data? Thanks for any advice.
Yes, perhaps via the Java API?
Hi Jason,
I have a csv file included 32 attributes of tweet that each attribute is a column of this file. I have a Nomber_of_retwwet’s attribute as production of tweet’s retweet. How can achieve a good response for protection tweet’s retweet?
Sorry, I don’t undertand.
If you’re asking how to work through your dataset, I recommend this process:
https://machinelearningmastery.com/start-here/#process
Hi, Thanks alot for valuable comment and tutorial.
I want to know is there any way to build different models to be able to test all of them on the testing data? (for example use 10-fold CV and repeat it 20 times to have 200 models to be tested 200 times on testing data)!
Yes, you can use the Weka experimenter for this purpose.
Perhaps start with this tutorial:
https://machinelearningmastery.com/regression-machine-learning-tutorial-weka/
Hi, I have another question too. I have data of healthy and patient people. But data contain repeated scans for each subject (It means for example the first 4 data belong to patient 1, the other 3 scans belong to patient 2 and so on). To do the CV, a subject with all scans should be on training or testing. Is it possible to do it in Weka when I want to do 10-fold CV?
Yes, it sounds like each patient should grouped before splitting into folds or train/test splits.
Thanks alot for your response. Just would you please let me know how I can make group subjects before doing k-fold? Now, I assign a column consist of healthy and patient people. But I think I should assign another column to classify all the people according to their repeated scans.
You might have to write some custom code to group the subjects.
Thanks for your answer.
You’re welcome.
Using Weka, I have trained a MLP model on a set of data, and I want to continue training it with just a subset of the data (kind of like “transfer learning” I think). I am hoping the the Experimenter resume parameter might help me to do this. Do you know if it is possible?
Sorry, I’m not sure Weka can achieve this. Perhaps post your question to the weka user group?
Thanks a lot it was very useful. is it possible training model with neural network and then classified with decision tree the trained model in Weka ? if it is possible how we can do it? and how we can use of test data set in this situation?
Yes.
I don’t have an example sorry.
thanks for replying. if you know some other source that can help me and share it, i will be so happy.
See this:
https://machinelearningmastery.com/help-with-weka/
Thanks very much for your instructions for us.
I met a problem while using this, when I load the model and reevaluate with the test set that I created, the results can up all the same classification, which is probably wrong.
Could you help me with what possibly might go wrong with me?
Thanks!!
You’re welcome.
Perhaps confirm that the rows you are making predictions on are all different and that you expect diffrent predictions for each?
I did, I even copy and paste the original dataset and leave the target class blank. Still the same.
However, I did use different dataset get 2 different results. But within each datasets, it keeps the same class.
Is that means the problem is my test data?
That is odd. Perhaps try making predictions on the training data to confirm the model is working correctly?
Today I figured out why. I used my dataset as .csv file. Those two different results are from two different models.(I am working on three models at the same time so it was my mistake).
Anyway, the issue has been resolved by converting the csv file to .arff and change all data type to nominal.
Thanks very much for your time!!
Have a wonderful day!
I’m happy to hear that you resolved your issue!
Hi can you tell me please how extract all the TP and FP values from a data set. I did once and I forgot. I urgently need help and I want a csv file.
TP and FP are calculated based on your predictions. Weka reports these values on a classification dataset for your model in the Explorer.
Hey Jason,
I wanted to ask if we don’t replace the data with “?” and leave it as is (considering the dataset I’m using is a different dataset with similar attributes), would that change how the model works?
I mean, the “?” was for us to see how well the model performed. If we keep the original value, would the model act differently?
Thank!
Some models will error, expecting inputs to be numbers.
Yes, imputing missing values makes models act differently, better or worse based on the type of imputation.
Hi,
I am making predictions for a particular dataset, when I use the percentage split in the ‘Test option’ and try to save the prediction result into a csv format, the obtained result contains only predicted test dataset but not the training data(predicted). I would like to know if it is possible to obtaing the prediction result for both training and test when I use ‘Percentage Split’.
Thank you for your time.
I don’t believe so, at least not through the interface.
Hi Jason,
Thank you for the reply. I will try to run through command line to see if that will return me the training and test result.
And also, when select attributes using PCA my output screen returns with the selected attributes as below,
0.8051 1 -0.077ATS2p-0.077ATS3p-0.077ATS1p-0.077Sp-0.077ATS4p…
My questionis why is that I am not able to get the entire attribute, but the with ‘…’ at the end. Is it possible to retaing me entire results? if so can you please help me with it?
Thank you in advance.
I suspect your IDE or notebook is the cause and why I recommend to not use them:
https://machinelearningmastery.com/faq/single-faq/why-dont-use-or-recommend-notebooks
Hello Jason,
Thank you for your comment, I will try running through the command line.
You’re welcome.
Hello Jason,
I had one query. Is it possible to save multiple models at the same time in the WEKA Classifier toolbox. For example, on my dataset, I wish to apply all kinds of algorithms, i e , (Function based, lazy learning based, meta learning and tree based algorithms).
So in total for the same dataset and subset selection, I wish to apply around 10-15 methods. Now, is there any way I can save all these 10-15 models for future reference or does WEKA only permit 1 model to be saved at a time?
Thank you
I recommend using the experimenter interface:
https://machinelearningmastery.com/compare-performance-machine-learning-algorithms-weka/
hello I need a help from you Jason
I am training a model in weka and importing data from MySql database from xampp. I am doing a web app on xampp where data will be collected from the web app and my model need to predict using those data. can I connect a web service with weka? what is your recommendations? How can I make real time predictions and sent it to my web app back?
Sorry, I don’t know about using Weka in a web service.
Amazing post, thank you
You’re welcome.
Anytime i open a saved model it didn’t display result. please what actually is the problem
Do you have any error message? It would be easier to help if you describe your situation in more detail.
Thank you very much for this easy-to-follow tutorial. It’s very straightforward yet fantastic. It worked with my dataset. Thank you once again.
You are very welcome Alka!
My endeavor with WEKA v3.9.6 ends up FAULTY !
Oh god what a cucumber some approach for forecasting in WEKA. Feels like cheating. I’m not sure if i’m getting this right ? If i have 200 columns with equal depth rows in it – matrix (all numerical data except rows and columns names) trained model on it. Now i’m trying to forecast data pattern in new 201 column on basis provided data set pattern in it. If i’m getting this right i cant just add 201 column at the end to 200 in same row depth for so called “new” old dataset coz u mentioned that provided data set must be equal in “shape” to data set that model was trained on (basically this means exact nr. columns/rows in it). So if i want to make forecast for entire new 201 column i have to fit it in – “mask it” within in that new-old provided dataset. If i delete entire 200 column and replace rows in it with “?” i forecast already known data. So i delete first column in dataset and shift entire dataset to the left to have so called “?” 201th column that i want to predict in 200 column in that new-old provided dataset. Somewhat this worked but i get 100% the same false numeric value in entire column depth.
Something went wrong with autoWEKA classifier. Also not clear how to finalize trained model. Using the same classifier with which was model created coz i can choose from menu all the other options ? Practice example tutorial provided isn’t specific on that question either ! If this is the case there a myriad options to choose from. My GPU supports CUDA 2.1 that’s enough to use GPU to boost the things up (DataMiner and Quasar does) but WEKA doesn’t so no GPU boost for WEKA and things are very slow even for Intel Core-5 3570K CPU.
Second run AutoWEKA after 24 hours run didn’t result in any success. AutoWEKA generated many classifier models in menu blue colored named text. Only two succeeded reapplying finalizing model to test dataset set on which was whole model generated, everything else resulted in various errors. When using the same approach for forecasting both models resulting in filling prediction not with numbers but with “?” for actual, predicted and error column at the re-apply model on “new” dataset (was the same as used ia first time).
I planed to use ML for may master diploma in mechanical engineering area of expertise in fluid dynamics and heat transfer. Now i have to reconsider the whole approach and omit the ML part entirely or start new from begining.
As for my experience software only works when example tutorials are used, everything else did not ! Tutors should start to post “fail tutorials” so we all can see what “not to do” and “what else doesn’t work” would be much better approach if u consider Murphy’s Laws altogether (for that matter i’m not sure what i’m doing wrong here … ?). I have read somewhere on net that ANN can learn almost on everything and there is almost no limitations in that matter (except for hardware used).
WEKA on paper (advertised on net) was promising solution for my approach turned out in total failure. Not to mention confusing GUI should be for 2023 age way more intuitive – one have to take tutorial to start to use. There is no straight forward process workflow input-train-test-validate-forecast. Using NN’s for predictions inside known datasets doesn’t make any sense, u can use interpolations technique and other classic statistical tools for that matter. NN’s are only good for pattern recognition and pattern forecast in various fields of science use to see what pattern propagate if model is pattern driven and not chaotic. I cant imagine some can use such software successfully, if u aren’t developer of such software – u can then code it for your self. Everybody else will in high probability percentage likely fail as i was and most likely newer know exactly know what he is doing. As such I’m only user and i don’t have no more time to “spare to burn it in failures”. I was simply follow the tuts and have read as much technical papers on it (looks pretty darn fine on paper) but software in reality is pure pain to use with all the twists and quirks as i found out.
Maybe that post will help someone to clear things up not to fail with WEKA and try to use something else or avoid ML “headache” entirely in choosing other solutions. No wonder people “jump off the ML train”. I’m not criticizing core algorithms of NN’s but everything else around it and how that is implemented resulting IN GUI’s and use procedures. Until there isn’t more user friendly GUI’s and intuitive.
Hi Ango…Please clarify your question so that we may better assist you.
Hey great tutorial, Couple of questions i was making some prediction in my model and noticed it only goes up to 100 instances and wondering if it possible to increase that number since i working on data with more than 100 data point. Also how would won go converting the results given into a csv file?
Hi Sean…You may find the following tutorial of interest:
https://machinelearningmastery.com/applied-machine-learning-weka-mini-course/