Weka is the perfect platform for studying machine learning.
It provides a graphical user interface for exploring and experimenting with machine learning algorithms on datasets, without you having to worry about the mathematics or the programming.
In this post you will discover how to use Weka Experimenter to improve your results by combining the results of multiple algorithms together into ensembles. If you follow along the step-by-step instructions, you will design and run your an ensemble machine learning experiment in under five minutes.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
1. Download Weka and Install
Visit the Weka Download page and locate a version of Weka suitable for your computer (Windows, Mac or Linux).
Weka requires Java. You may already have Java installed and if not, there are versions of Weka listed on the download page (for Windows) that include Java and will install it for you. I’m on a Mac myself, and like everything else on Mac, Weka just works out of the box.
If you are interested in machine learning, then I know you can figure out how to download and install software into your own computer.
2. Start Weka
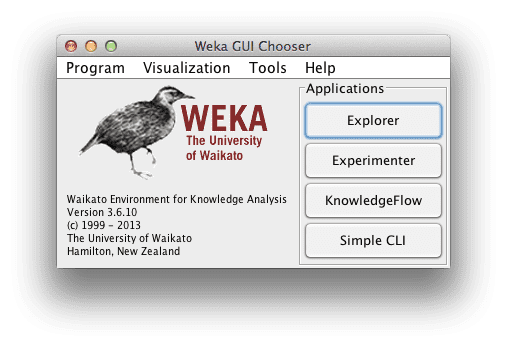
Start Weka. This may involve finding it in program launcher or double clicking on the weka.jar file. This will start the Weka GUI Chooser.
Weka GUI Chooser
The Weka GUI Chooser lets you choose one of the Explorer, Experimenter, KnowledgeExplorer and the Simple CLI (command line interface).
Click the “Experimenter” button to launch the Weka Experimenter.
The Weka Experimenter allows you to design your own experiments of running algorithms on datasets, run the experiments and analyze the results. It’s a powerful tool.
3. Design Experiment
Click the “New” button to create a new experiment configuration.
Test Options
The experimenter configures the test options for you with sensible defaults. The experiment is configured to use Cross Validation with 10 folds. It is a “Classification” type problem and each algorithm + dataset combination is run 10 times (iteration control).
Ionosphere Dataset
Let’s start out by selecting the dataset.
In the “Datasets” select click the “Add new…” button.
Open the “data” directory and choose the “ionosphere.arff” dataset.
The Ionosphere Dataset is a classic machine learning dataset. The problem is to predict the presence (or not) of free electron structure in the ionosphere given radar signals. It is comprised of 16 pairs of real-valued radar signals (34 attributes) and a single class attribute with two values: good and bad radar returns.
The J48 (C4.8) is a powerful decision tree method that performs well on the Ionosphere dataset. In this experiment we are going to investigate whether we can improve upon the result of the J48 algorithm using ensemble methods. We are going to try three popular ensemble methods: Boosting, Bagging and Blending.
Let’s start out by adding the J48 algorithm to the experiment so that we can compare its results to the ensemble versions of the algorithm.
Add the J48 algorithm to the Weka Experimenter.
Click “Add new…” in the “Algorithms” section.
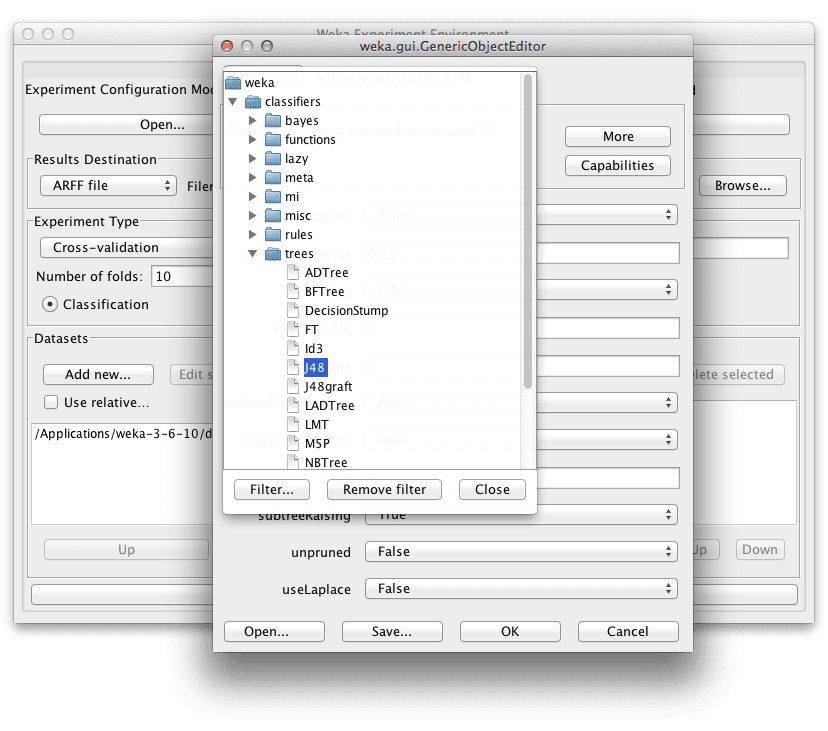
Click the “Choose” button.
Click “J48” under the “tree” selection.
Click the “OK” button on the “AdaBoostM1” configuration.
Boosting
Boosting is an ensemble method that starts out with a base classifier that is prepared on the training data. A second classifier is then created behind it to focus on the instances in the training data that the first classifier got wrong. The process continues to add classifiers until a limit is reached in the number of models or accuracy.
Click the “Choose” button for the “classifier” and select “J48” under the “tree” section and click the “choose” button.
Click the “OK” button on the “AdaBoostM1” configuration.
Bagging
Bagging (Bootstrap Aggregating) is an ensemble method that creates separate samples of the training dataset and creates a classifier for each sample. The results of these multiple classifiers are then combined (such as averaged or majority voting). The trick is that each sample of the training dataset is different, giving each classifier that is trained, a subtly different focus and perspective on the problem.
Click “Add new…” in the “Algorithms” section.
Click the “Choose” button.
Click “Bagging” under the “meta” selection.
Click the “Choose” button for the “classifier” and select “J48” under the “tree” section and click the “choose” button.
Click the “OK” button on the “Bagging” configuration.
Blending
Blending is an ensemble method where multiple different algorithms are prepared on the training data and a meta classifier is prepared that learns how to take the predictions of each classifier and make accurate predictions on unseen data.
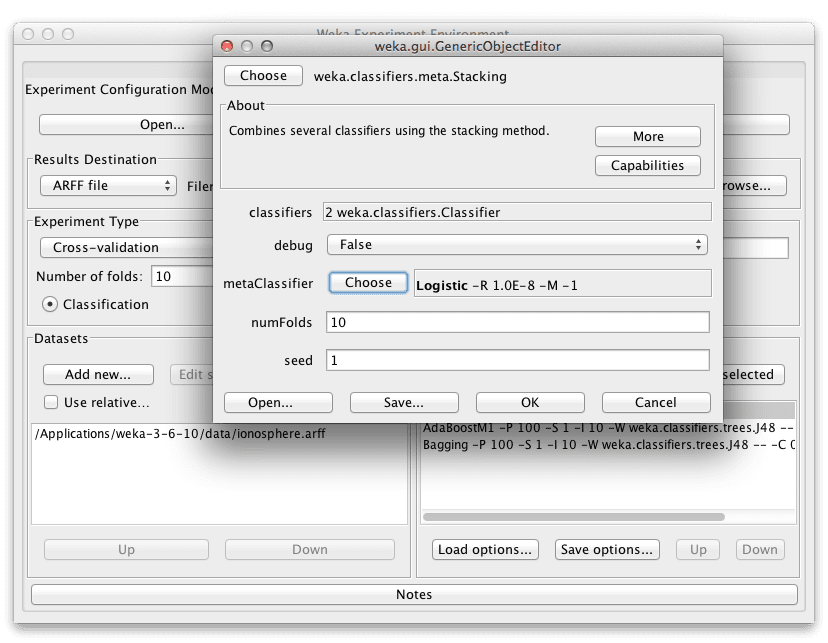
Blending is called Stacking (after the Stacked Generalization method) in Weka. We will add Stacking with two classifiers (J48 and IBk) and use Logistic Regression as the meta classifier.
The J48 and IBk (k-nearest neighbour) are very different algorithms and we want to include algorithms in our blend that are “good” (can make meaningful predictions on the problem) and varied (have a different perspective on the problem and in turn make different useful predictions). Logistic Regression is a good reliable and simple method to learn how to combine the predictions from these two methods and is well suited to this binary classification problem as it produces binary outputs itself.
Configuring and adding the Stacking algorithm that blends J48 and IBk to the Weka Experimenter.
Click “Add new…” in the “Algorithms” section.
Click the “Choose” button.
Click “Stacking” under the “meta” selection.
Click the “Choose” button for the “metaClassifier and select “Logistic” under the “function” section and click the “choose” button.
Click the value (algorithm name, it’s actually a button) for the “classifiers“.
Click “ZeroR” and click the “Delete” button.
Click the “Choose” button for the “classifier” and select “J48” under the “tree” section and click the “Close” button.
Click the “Choose” button for the “classifier” and select “IBk” under the “lazy” section and click the “Close” button.
Click the “X” to close the algorithm chooser.
Click the “OK” button on the “Bagging” configuration.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
4. Run Experiment
Click the “Run” tab at the top of the screen.
This tab is the control panel for running the currently configured experiment.
Click the big “Start” button to start the experiment and watch the “Log” and “Status” sections to keep an eye on how it is doing.
5. Review Results
Click the “Analyse” tab at the top of the screen.
This will open up the experiment results analysis panel.
Algorithm Rank
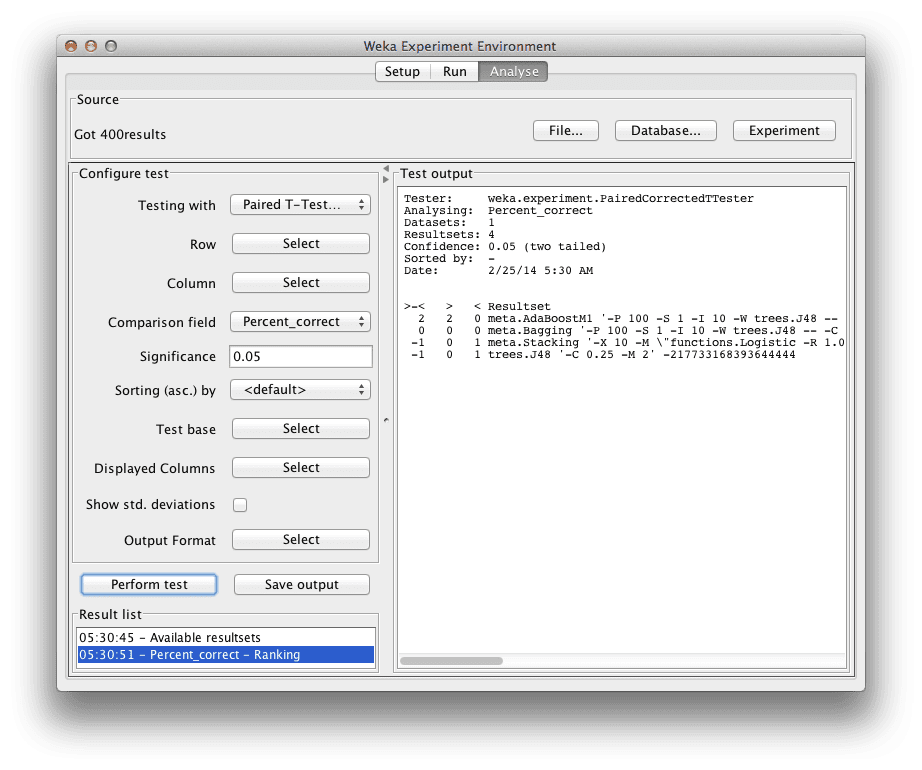
The first thing we want to know is which algorithm was the best. We can do that by ranking the algorithms by the number of times a given algorithm beat the other algorithms.
Click the “Select” button for the “Test base” and choose “Ranking“.
Now Click the “Perform test” button.
The ranking table shows the number of statistically significant wins each algorithm has had against all other algorithms on the dataset. A win, means an accuracy that is better than the accuracy of another algorithm and that the difference was statistically significant.
Algorithm ranking when analyzing results in the Weka Experimenter
We can see that the AdaBoostM1 version of J48 is ranked the highest with 2 significant wins against other algorithms. We can also see that Stacking and plain old J48 are ranked lowest. It is a good sign that J48 is ranked low, it suggests that at least some of the ensemble methods have increased the accuracy on the problem.
Algorithm Accuracy
Next we want to know what scores the algorithms achieved.
Click the “Select” button for the “Test base” and choose the “J48” algorithm in the list and click the “Select” button.
Click the check-box next to “Show std. deviations“.
Now click the “Perform test” button.
Algorithm mean accuracy and statistical significance in the Weka Experimenter.
We can see that the AdaBoostM1 algorithm achieved a classification accuracy of 93.05% (+/- 3.92%). We can see that this a higher value than J48 at 89.74% (+/- 4.38%). We can see a “*” next to the accuracy of J48 in the table and this indicates that the difference between the boosted J48 algorithm is meaningful (statistically significant).
We can also see that the AdaBoostM1 algorithm achieved a result with a value higher than Bagging at 92.40% (+/- 4.40%), but we do not see a little “*” which indicates that the difference is not meaningful (not statistically significant).
Summary
In this post you discovered how to configure a machine learning experiment with one dataset and three ensemble of an algorithm in Weka. You discovered how you can use the Weka experimenter to improve the accuracy of a machine learning algorithm on a dataset using ensemble methods and how to analyze the results.
If you made it this far, why not:
See if you can use other ensemble methods and get a better result.
See if you can use different configuration for the Bagging, Boosting or Blending algorithms and get a better result.
i am happy to see your topics on ensemble methods. i am a researcher, i am doing my wrk in dataming area . i am sending my mail ,pls replay answer to my questions. ramadeviabap@yahoo.co.in.
1. how do bootstrap using weka:?. , pls send the steps to perform that
2. how can i do only oversampling using weka.? pls send spets to works on this
3. how to work smote+bordeline nad smote+boosting using weka ? pls send the steps to work
4. how can i perform 10-fold cross validation using weka? pls send your steps to work on this . is it weka perform 10 times internally? how it works.? is it needed to repeated the 10 – fold cross validation 10 times by changing the seed value from 1 to 10 times and takes the average of the results. whether weka do it automatically , we have to do that manullay? which one is correct.
pls send your valuable information to me,which will help in my thesis
Hi Sir I wish to run my dataset in weka using SVM as classifier and wish to display roc curves and other graphical outputs as performance evaluation.
Can you please suggest me a way to get this done?
and which all majors can I use as performance evaluation criteria for my dataset
Thank you in advance.
How are you Sir. Firstly, thanks for such a wonderful tutorial. I found it very informative. Sir could you please answer my one question? Sir If I want to repeated an experiment 10 times or 100 time is it possible to do it with weka experimenter?
The tutorial has really helped me. I have been using WEKA explorer for the ensemble experiments but now i will revert to using Experimenter. By the way, in your own opinion, can i create an ensemble outlier detector using combined LOF and IQR. I know WEKA filter shows that is possible by making the options available but how can we interpreter the results from distance measure and statistical measures?








hi sir
i am happy to see your topics on ensemble methods. i am a researcher, i am doing my wrk in dataming area . i am sending my mail ,pls replay answer to my questions. ramadeviabap@yahoo.co.in.
1. how do bootstrap using weka:?. , pls send the steps to perform that
2. how can i do only oversampling using weka.? pls send spets to works on this
3. how to work smote+bordeline nad smote+boosting using weka ? pls send the steps to work
4. how can i perform 10-fold cross validation using weka? pls send your steps to work on this . is it weka perform 10 times internally? how it works.? is it needed to repeated the 10 – fold cross validation 10 times by changing the seed value from 1 to 10 times and takes the average of the results. whether weka do it automatically , we have to do that manullay? which one is correct.
pls send your valuable information to me,which will help in my thesis
thank you
Simple and informative as usual, Thanks …
Note: please correct “Click the “OK” button on the “AdaBoostM1” configuration.” in the Ensemble section, bullet point #4
Hie can I use weka for case based reasoning
Weka was not built for this purpose, but you may be able to adapt it if you used the Java API.
Hi Sir I wish to run my dataset in weka using SVM as classifier and wish to display roc curves and other graphical outputs as performance evaluation.
Can you please suggest me a way to get this done?
and which all majors can I use as performance evaluation criteria for my dataset
Thank you in advance.
Wich algorithm has a high accuracy rate in clustering!?
Clustering is not used for classification.
Hi,
how can we combined attributes like composite key and run ensemble classifier. please demonstrate step wise.
thanks
Thanks for help.
You’re welcome Seetharam.
How are you Sir. Firstly, thanks for such a wonderful tutorial. I found it very informative. Sir could you please answer my one question? Sir If I want to repeated an experiment 10 times or 100 time is it possible to do it with weka experimenter?
Yes. Specify the “number of repetition”.
Learn more here:
https://machinelearningmastery.com/design-and-run-your-first-experiment-in-weka/
The tutorial has really helped me. I have been using WEKA explorer for the ensemble experiments but now i will revert to using Experimenter. By the way, in your own opinion, can i create an ensemble outlier detector using combined LOF and IQR. I know WEKA filter shows that is possible by making the options available but how can we interpreter the results from distance measure and statistical measures?
Perhaps try it and see how it impacts model skill?
Thanks for the tutorial. Very useful.
I’m glad it helped.
Dear Sir
I have a model created from ฺ Bagging with MLP. I would like to know what WEKA classifier must be selected to write the code.
Thank you
Sorry, I don’t have tutorials on using the Weka API, perhaps post your question to stackoverflow or the weka user group.
I am user of WEKA from years to now. But I have never used “experimenter” before. And I am excited how it is an efficient tool to be used. Thanks
You’re welcome, I’m happy to hear that I have opened the door for you!