Weka is the perfect platform for learning machine learning. It provides a graphical user interface for exploring and experimenting with machine learning algorithms on datasets, without you having to worry about the mathematics or the programming.
A powerful feature of Weka is the Weka Experimenter interface. Unlike the Weka Explorer that is for filtering data and trying out different algorithms, the Experimenter is for designing and running experiments. The experimental results it produces are robust and are good enough to be published (if you know what you are doing).
In a previous post you learned how to run your first classifier in the Weka Explorer.
In this post you will discover the power of the Weka Experimenter. If you follow along the step-by-step instructions, you will design an run your first machine learning experiment in under five minutes.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.

First Experiment
Photo by mhofstrand, some rights reserved
1. Download and Install Weka
Visit the Weka Download page and locate a version of Weka suitable for your computer (Windows, Mac or Linux).
Weka requires Java. You may already have Java installed and if not, there are versions of Weka listed on the download page (for Windows) that include Java and will install it for you. I’m on a Mac myself, and like everything else on Mac, Weka just works out of the box.
If you are interested in machine learning, then I know you can figure out how to download and install software into your own computer.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
2. Start Weka
Start Weka. This may involve finding it in program launcher or double clicking on the weka.jar file. This will start the Weka GUI Chooser.
Weka GUI Chooser
The Weka GUI Chooser lets you choose one of the Explorer, Experimenter, KnowledgeExplorer and the Simple CLI (command line interface).
Click the “Experimenter” button to launch the Weka Experimenter.
The Weka Experimenter allows you to design your own experiments of running algorithms on datasets, run the experiments and analyze the results. It’s a powerful tool.
3. Design Experiment
Click the “New” button to create a new experiment configuration.
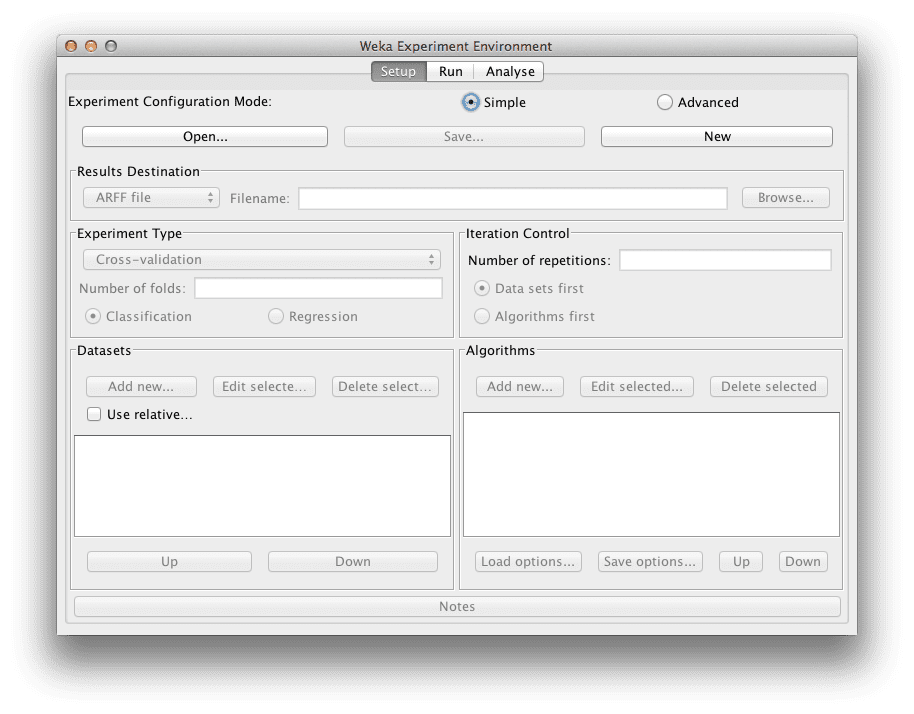
Weka Experimenter
Start a new Experiment
Test Options
The experimenter configures the test options for you with sensible defaults. The experiment is configured to use Cross Validation with 10 folds. It is a “Classification” type problem and each algorithm + dataset combination is run 10 times (iteration control).
Iris flower Dataset
Let’s start out by selecting the dataset.
- In the “Datasets” select click the “Add new…” button.
- Open the “data“directory and choose the “iris.arff” dataset.
The Iris flower dataset is a famous dataset from statistics and is heavily borrowed by researchers in machine learning. It contains 150 instances (rows) and 4 attributes (columns) and a class attribute for the species of iris flower (one of setosa, versicolor, virginica). You can read more about Iris flower dataset on Wikipedia.
Let’s choose 3 algorithms to run our dataset.
ZeroR
- Click “Add new…” in the “Algorithms” section.
- Click the “Choose” button.
- Click “ZeroR” under the “rules” selection.
ZeroR is the simplest algorithm we can run. It picks the class value that is the majority in the dataset and gives that for all predictions. Given that all three class values have an equal share (50 instances), it picks the first class value “setosa” and gives that as the answer for all predictions. Just off the top of our head, we know that the best result ZeroR can give is 33.33% (50/150). This is good to have as a baseline that we demand algorithms to outperform.
OneR
- Click “Add new…” in the “Algorithms” section.
- Click the “Choose” button.
- Click “OneR” under the “rules” selection.
OneR is like our second simplest algorithm. It picks one attribute that best correlates with the class value and splits it up to get the best prediction accuracy it can. Like the ZeroR algorithm, the algorithm is so simple that you could implement it by hand and we would expect that more sophisticated algorithms out perform it.
J48
- Click “Add new…” in the “Algorithms” section.
- Click the “Choose” button.
- Click “J48” under the “trees” selection.
J48 is decision tree algorithm. It is an implementation of the C4.8 algorithm in Java (“J” for Java and 48 for C4.8). The C4.8 algorithm is a minor extension to the famous C4.5 algorithm and is a very powerful prediction algorithm.
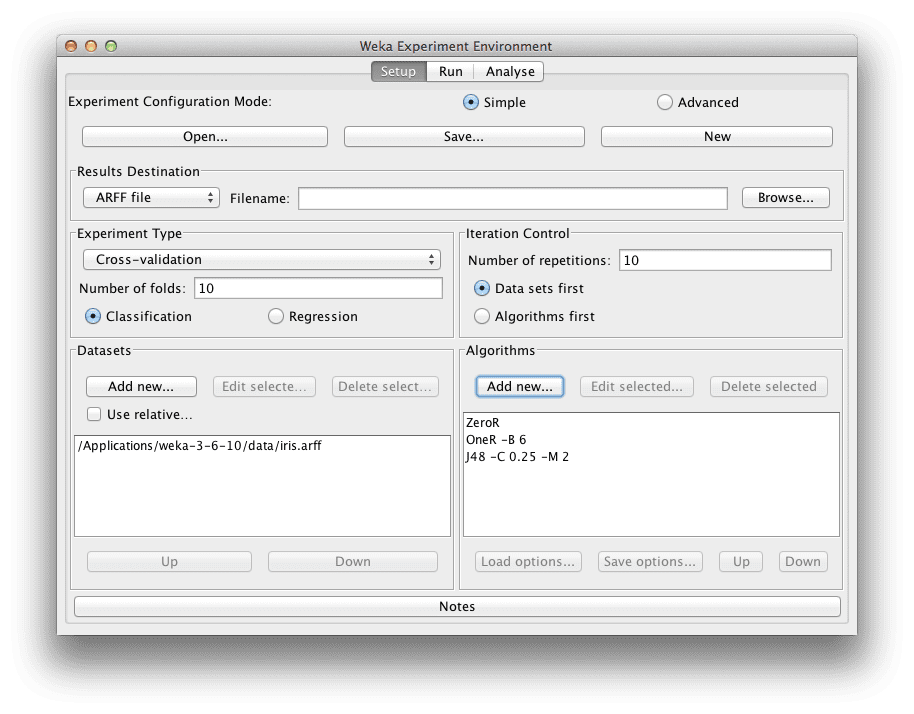
Weka Experimenter
Configure the experiment
We are ready to run our experiment.
4. Run Experiment
Click the “Run” tab at the top of the screen.
This tab is the control panel for running the currently configured experiment.
Click the big “Start” button to start the experiment and watch the “Log” and “Status” sections to keep an eye on how it is doing.

Weka Experimenter
Run the experiment
Given that the dataset is small and the algorithms are fast, the experiment should complete in seconds.
5. Review Results
Click the “Analyse” tab at the top of the screen.
This will open up the experiment results analysis panel.

Weka Experimenter
Load the experiment results
Click the “Experiment” button in the “Source” section to load the results from the current experiment.
Algorithm Rank
The first thing we want to know is which algorithm was the best. We can do that by ranking the algorithms by the number of times a given algorithm beat the other algorithms.
- Click the “Select” button for the “Test base” and choose “Ranking“.
- Now Click the “Perform test” button.

Weka Experimenter
Rank the algorithms in the experiment results
The ranking table shows the number of statistically significant wins each algorithm has had against all other algorithms on the dataset. A win, means an accuracy that is better than the accuracy of another algorithm and that the difference was statistically significant.
We can see that both J48 and OneR have one win each and that ZeroR has two losses. This is good, it means that OneR and J48 are both potentially contenders outperforming out baseline of ZeroR.
Algorithm Accuracy
Next we want to know what scores the algorithms achieved.
- Click the “Select” button for the “Test base” and choose the “ZeroR” algorithm in the list and click the “Select” button.
- Click the check-box next to “Show std. deviations“.
- Now click the “Perform test” button.

Weka Experimenter
Algorithm accuracy compared to ZeroR
In the “Test output” we can see a table with the results for 3 algorithms. Each algorithm was run 10 times on the dataset and the accuracy reported is the mean and the standard deviation in rackets of those 10 runs.
We can see that both the OneR and J48 algorithms have a little “v” next to their results. This means that the difference in the accuracy for these algorithms compared to ZeroR is statistically significant. We can also see that the accuracy for these algorithms compared to ZeroR is high, so we can say that these two algorithms achieved a statistically significantly better result than the ZeroR baseline.
The score for J48 is higher than the score for OneR, so next we want to see if the difference between these two accuracy scores is significant.
- Click the “Select” button for the “Test base” and choose the “J48” algorithm in the list and click the “Select” button.
- Now click the “Perform test” button.
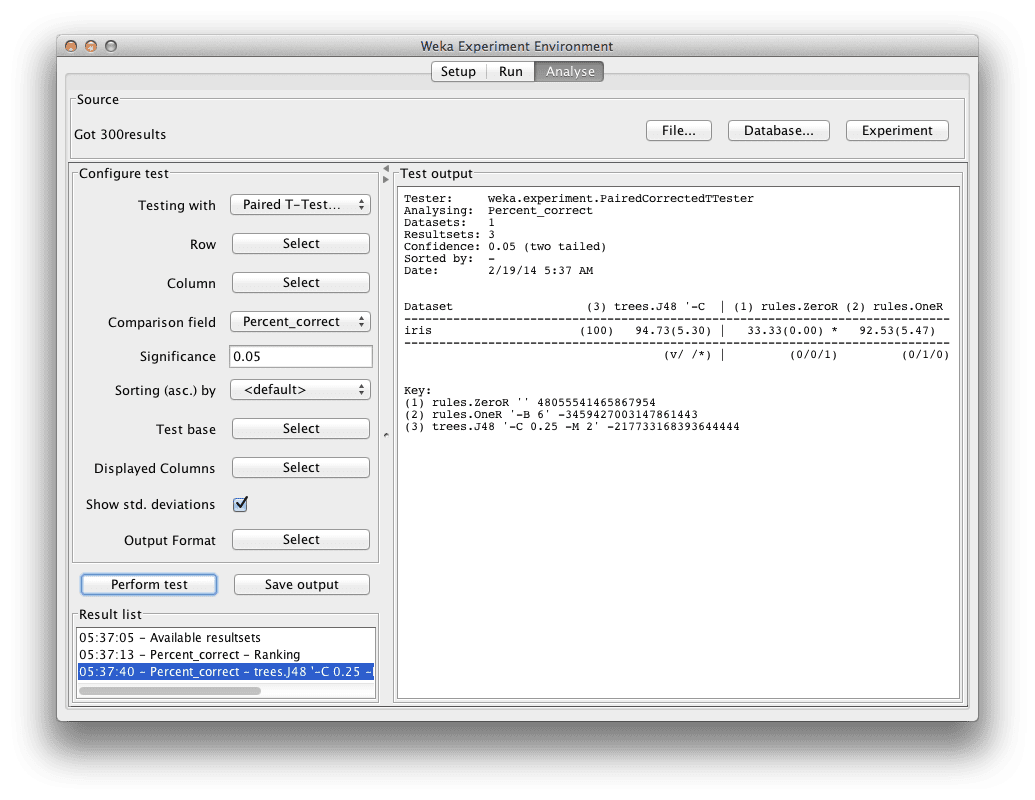
Weka Experimenter
Algorithm accuracy compared to J48
We can see that the ZeroR has a “*” next to its results, indicating that its results compared to the J48 are statistically different. But we already knew this. We do not see a “*” next to the results for the OneR algorithm. This tells us that although the mean accuracy between J48 and OneR is different, the differences is not statistically significant.
All things being equal, we would choose the OneR algorithm to make predictions on this problem because it is the simpler of the two algorithms.
If we wanted to report the results, we would say that the OneR algorithm achieved a classification accuracy of 92.53% (+/- 5.47%) which is statistically significantly better than ZeroR at 33.33% (+/- 5.47%).
Summary
You discovered how to configure a machine learning experiment with one dataset and three algorithms in Weka. You also learned about how to analyse the results from an experiment and the importance of statistical significance when interpreting results.
You now have the skill to design and run experiments with any algorithms provided by Weka on datasets of your choosing and meaningfully and confidently report results that you achieve.
Discover Machine Learning Without The Code!

Develop Your Own Models in Minutes
...with just a few a few clicks
Discover how in my new Ebook:
Machine Learning Mastery With Weka
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, build models, tuning, and much more...
Finally Bring The Machine Learning To Your Own Projects
Skip the Academics. Just Results.






Hi
Thanks for the tutorial. Can you please explain what is the significance of data set first and algorithm first in iteration control panel in weka experiment ?
Respected sir,
i am happy with your notes.
I am also interested in machine learning…. i have to know how to classify satellite image.
does WEKA have a multiple regression algorithm?
It sure does, it is called SimpleLinearRegression.
At the end of your notes, you wrote:
“If we wanted to report the results, we would say that the OneR algorithm achieved a classification accuracy of 92.53% (+/- 5.47%) which is statistically significantly better than ZeroR at 33.33% (+/- 5.47%).”
Is reporting the std from ZeroR as “(+/- 5.47%)” correct? as when I run the experiment, I have the results from ZeroR as 33.33% (+/- 0.00%).
Hi Om, it is a good practice to report the standard deviation and the mean performance, in this case accuracy.
what is the benefit of all this..a main idea
Hi Mah,
The benefit is to discover the combination/s of algorithm, algorithm configuration and dataset representation that result in the better/best predictive performance on your problem.
is it possible to compare association rule mining algorithms also?
It may be, you will need an objective measure of skill. Sorry, I have not done this and perhaps the Experimenter is not setup to do this.
plz list out any four state of art algorithms which are proposed and developed after 2010 and also implemented in weka????
Sorry, I don’t know.
Jason, you tutorial is very useful. I had downloaded weka months ago but, being concentrated in PYTHON, no idea that it was a powerful tool …
Yeah, it is powerful and often overlooked.
I think practitioners should start with Weka and then move on to tools like python and R. It teaches you the process without getting bogged down in syntax.
Hi Jason,
for more complex problems, is it possible to run Weka on a GPU?
Thanks!
Not as far as I know. There may be some third part extensions that support this.
Hi Jason, nice article, however I was following your experiment step by step and got stuck because I was not able to find iris.arff in the data directory. What am I doing wrong?
Thanks.
You might need to download it separately if it is not already there.
Download and unzip the .zip version of Weka to get the data files.
Thank you very much for the tutorial. Very useful material.
You’re welcome, I’m glad it helped.
Great tutorial!
There’s an intro course on Weka on YouTube( https://www.youtube.com/watch?v=LcHw2ph6bss ) as well. The number of options in the software available is really pretty overwhelming.
Thanks for sharing.
Thank you so much Jason for this great tutorial, it is very informative!
I’m just wondering if there is a way to do the same thing but with clustering. I can see that the Experimenter is only dealing with classification.
Is there a way to perform multiple clustering tasks on a specific dataset, say e.g. the SimpleKMeans with different ‘k’ values? Instead of doing this manually by selecting the value of ‘k’ prior to clicking start button.
There may be. Sorry, I don’t have material on clustering algorithms in Weka.
Thank you very much for this helpful article. I would like to ask how can I get the testing time of classifier?
Thank you
I don’t know, sorry.
Perhaps try some custom code, use the API and calculate the timing?
Perhaps run from the command line and wrap it in a script that does the timing?
I followed the steps, I got the output. but I still want deep drive on these algorithms.
No problem, you can start here:
https://machinelearningmastery.com/start-here/#algorithms
Hi,
Can I run Machine Translation on the Weka Platform. I have around 300000 parallel strings and wonder if it is possible to train the model on the platform and if so how much time will it take. Thanks for replying. Happy New year.
I don’t know, sorry.
Hello,
What is the formula used to calculate the standard deviation?
Thank you very much!
It will be the sample standard deviation calculation, described on this page:
https://en.wikipedia.org/wiki/Standard_deviation
Thank you for the tutorial. However, I would like to plot and compare the results on the same graph. Is it possible in Experimenter ?
It may be. I don’t have an example, sorry.
Hi there,
thanks for the tutorial! However, I have a problem using the experimenter: After I set up my experiment and click the start button, the experiment stops after just a few seconds (button start switches, so you could click it again). However, there is no error message or finish message on the screen. When I open the results file, it is basically empty. I really have no idea how to fix this problem and would be more than happy if anyone could help out.
Perhaps confirm that your experiment is setup correctly.
Thank you for this tutorial Sir. Very useful.
You’re very welcome.
thanks for this tutorial sir, I followed through the instructions but I got an error message when clicked on Run. it says “class attribute is not nominal”.
How do I address this? my dataset is made of 5-point Likert scale questionnaire responses.