Machine learning experiments can take a long time. Hours, days, and even weeks in some cases.
This gives you a lot of time to think and plan for additional experiments to perform.
In addition, the average applied machine learning project may require tens to hundreds of discrete experiments in order to find a data preparation model and model configuration that gives good or great performance.
The drawn-out nature of the experiments means that you need to carefully plan and manage the order and type of experiments that you run.
You need to be systematic.
In this post, you will discover a simple approach to plan and manage your machine learning experiments.
With this approach, you will be able to:
- Stay on top of the most important questions and findings in your project.
- Keep track of what experiments you have completed and would like to run.
- Zoom in on the data preparations, models, and model configurations that give the best performance.
Let’s dive in.

How to Plan and Run Machine Learning Experiments Systematically
Photo by Qfamily, some rights reserved.
Confusion of Hundreds of Experiments
I like to run experiments overnight. Lots of experiments.
This is so that when I wake up, I can check results, update my ideas of what is working (and what is not), and kick off the next round of experiments, then spend some time analyzing the findings.
I hate wasting time.
And I hate running experiments that do not get me closer to the goal of finding the most skillful model, given the time and resources I have available.
It is easy to lose track of where you’re up to. Especially after you have results, analysis, and findings from hundreds of experiments.
Poor management of your experiments can lead to bad situations where:
- You’re watching experiments run.
- You’re trying to come up with good ideas of experiments to run right after a current batch has finished.
- You run an experiment that you had already run before.
You never want to be in any of these situations!
If you are on top of your game, then:
- You know exactly what experiments you have run at a glance and what the findings were.
- You have a long list of experiments to run, ordered by their expected payoff.
- You have the time to dive into the analysis of results and think up new and wild ideas to try.
But how can we stay on top of hundreds of experiments?
Design and Run Experiments Systematically
One way that I have found to help me be systematic with experiments on a project is to use a spreadsheet.
Manage the experiments you have done, that are running, and that you want to run in a spreadsheet.
It is simple and effective.
Simple
It is simple in that I or anyone can access it from anywhere and see where we’re at.
I use Google Docs to host the spreadsheet.
There’s no code. No notebook. No fancy web app.
Just a spreadsheet.
Effective
It’s effective because it only contains the information needed with one line per experiment and one column for each piece of information to track on the experiment.
Experiments that are done can be separated from those that are planned.
Only experiments that are planned are set-up and run and their order ensures that the most important experiments are run first.
You will be surprised at how much such a simple approach can free up your time and get you thinking deeply about your project.
Example Spreadsheet
Let’s look at an example.
We can imagine a spreadsheet with the columns below.
These are just an example from the last project I worked on. I recommend adapting these to your own needs.
- Sub-Project: A subproject may be a group of ideas you are exploring, a technique, a data preparation, and so on.
- Context: The context may be the specific objective such as beating a baseline, tuning, a diagnostic, and so on.
- Setup: The setup is the fixed configuration of the experiment.
- Name: The name is the unique identifier, perhaps the filename of the script.
- Parameter: The parameter is the thing being varied or looked at in the experiment.
- Values: The value is the value or values of the parameter that are being explored in the experiment.
- Status: The status is the status of the experiment, such as planned, running, or done.
- Skill: The skill is the North Star metric that really matters on the project, like accuracy or error.
- Question: The question is the motivating question the experiment seeks to address.
- Finding: The finding is the one line summary of the outcome of the experiment, the answer to the question.
To make this concrete, below is a screenshot of a Google Doc spreadsheet with these column headings and a contrived example.
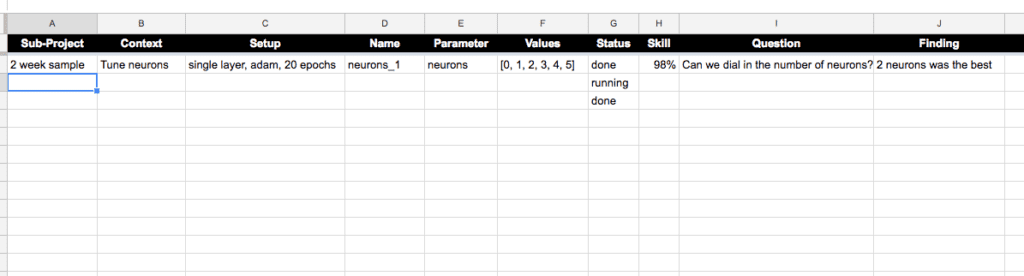
Systematic Experimental Record
I cannot say how much time this approach has saved me. And the number of assumptions that it proved wrong in the pursuit of getting top results.
In fact, I’ve discovered that deep learning methods are often quite hostile to assumptions and defaults. Keep this in mind when designing experiments!
Get The Most Out of Your Experiments
Below are some tips that will help you get the most out of this simple approach on your project.
- Brainstorm: Make the time to frequently review findings and list new questions and experiments to answer them.
- Challenge: Challenge assumptions and challenge previous findings. Play the scientist and design experiments that would falsify your findings or expectations.
- Sub-Projects: Consider the use of sub-projects to structure your investigation where you follow leads or investigate specific methods.
- Experimental Order: Use the row order as a priority to ensure that the most important experiments are run first.
- Deeper Analysis: Save deeper analysis of results and aggregated findings to another document; the spreadsheet is not the place.
- Experiment Types: Don’t be afraid to mix-in different experiment types such as grid searching, spot checks, and model diagnostics.
You will know that this approach is working well when:
- You are scouring API documentation and papers for more ideas of things to try.
- You have far more experiments queued up than resources to run them.
- You are thinking seriously about hiring a ton more EC2 instances.
Summary
In this post, you discovered how you can effectively manage hundreds of experiments that have run, are running, and that you want to run in a spreadsheet.
You discovered that a simple spreadsheet can help you:
- Keep track of what experiments you have run and what you discovered.
- Keep track of what experiments you want to run and what questions they will answer.
- Zoom in on the most effective data preparation, model, and model configuration for your predictive modeling problem.
Do you have any questions about this approach? Have you done something similar yourself?
Let me know in the comments below.






Listing sub-projects in a spreadsheet is great for tracking the effects of single decisions, but what about when there are more? Eg. say you want to see the effect of scaling data (maybe different approaches, maybe only certain variables/columns, etc), and also imputation of missing data (maybe none vs different algorithms).
With N such different decisions to evaluate, it turns into an N-dimensional matrix of results, not so easily represented in a spreadsheet! How do you handle this N-dimensional grid-search of analysis decisions?
One experiment should test one thing.
You can test more, but cause-effect will become tangled.
Agreed. The same principle applies as for troubleshooting a performance problem. Alter one parameter at once and it fixes the problem, you know that’s the cause. Alter several, and any one of them could have made the difference.
Yep. Experimental design in the scientific method and all that.
Thanks for this post, I needed it. I have started to use a table similar to this just a week ago.
What about models with multiple hyperparameters to tune? Are those separate
experiments or do you treat them as one?
Glad to hear it!
I try to treat them as separate experiments if possible.
The interactions may be nonlinear between some parameters, so running multivariate grid searches is still desirable.
Perhaps add new columns or add more detail to the “what is being tested” column.
As you mentioned, there may be interactions between parameters (and other processing decisions).
Running separate experiments makes sense for determining causality, but doesn’t deal with optimizing parameter/decision choices.
How would you use a grid search systematically with your spreadsheet?
I rarely need results that good, and you hit a point of diminishing returns.
Plus, I often am training deep nets that are super slow and it’s rarely possible to even use cross validation.
If you are working on Kaggle or something, then I would recommend searching all combinations. Consider naming the run and listing all hyperparameter ranges tested in the suitable column – the same as any other run. This would work fine for random or grid searching.
A possible solution is to add some sort of “ID” column and then create multiple rows with values of all columns remaining the same for a particular experiment except for the Parameter and Parameter Values column which include the hyperparameters you’re trying to optimize. So if you had a model with two sets of hyperparameter values, you would include two rows associated with ID #1.
Thoughts?
Really nice post! Would be interesting to get see how you use this systematic approach on a particular problem that you also describe (such as one of the problems you’ve worked on earlier on this blog). To see the full problem solving procedure and not just what worked well in the end!
I would love to, but it would be a very long post.
I used it recently on a multvariate time series forecasting problem with LSTM and that was the reason I decided to write this up as a post.
Nice post and good approach. Would like to try it out in my next project.
Thanks for sharing.
Thanks. Please do and let me know how you go. I found it invaluable myself. Massive time saver.
Hi, Jason.
I was looking info about tools to help with the iterative machine learning process. There isn’t a clean reference tool but these projects look like interesting ones:
– Data Version Control: https://dataversioncontrol.com/
– ModelDB: https://mitdbg.github.io/modeldb/
Interesting, thanks for sharing.
I use my own scripts at this stage, but perhaps the time for using a platform is coming…
It would be very interesting to know your expert opinion about these or other similar tools.
We’ll stay tuned 🙂
Thanks for the suggestion.
For this exact reason I started with https://github.com/ChristianSch/Pythia to have a simple api I can push my stats to and look at them.
Since I started a few other, sadly priced, alternatives started. MIght be a worthwile path, depending on the work one does.
Cheers!
Cool, thanks for sharing.
https://randomprojectionai.blogspot.com/
Thanks for sharing Sean, is this your blog?
Yes, it is. I just posted some information about a perspective you can take – deep neural networks as pattern based fuzzy logic.
And then there has been a recent paper by Luke Godfrey and Michael Gashler demonstrating fuzzy logic activation functions for neural network.
Reread your post and wish to see your update on this topic.
Your method is simple and easy. But when we have to manage so many experiments at the same time, manually using the excel sheet is not feasible somehow. Would you like to share your scripts? Thanks.
Thanks for the suggestion, I may write about the scripts I use in the future.
This might also give you some ideas when running on ec2:
https://machinelearningmastery.com/command-line-recipes-deep-learning-amazon-web-services/
absolute trash, logging experiments on a spreadsheet? are you from the 1990’s ?
Thanks for your opinion. Yes, I started ml in the 90s. Some of us are old school.
What is a better way?
I’m from the 1980s and use vi as a code editor. Are you going to trash talk that as well? If so, tread carefully or you’ll piss off a lot of highly competent, influential people, likely bigger and stronger in the field than you. If not, why?
Massive vi fan/user here as well!
Thanks for your great post!.I was akeen to install an experiment tracking API, then I read your post and changed my mind. If it’s simple and functional, take it !! That’s my rule #1. You made my day.
You’re very welcome!