You must be able to load your data before you can start modeling it.
In this post you will discover how you can load your CSV dataset in Weka. After reading this post, you will know:
- About the ARFF file format and how it is the default way to represent data in Weka.
- How to load a CSV file in the Weka Explorer and save it in ARFF format.
- How to load a CSV file in the ArffViewer tool and save it in ARFF format.
This tutorial assumes that you already have Weka installed.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.

How To Load CSV Machine Learning Data in Weka
Photo by Thales, some rights reserved.
How to Talk About Data in Weka
Machine learning algorithms are primarily designed to work with arrays of numbers.
This is called tabular or structured data because it is how data looks in a spreadsheet, comprised of rows and columns.
Weka has a specific computer science centric vocabulary when describing data:
- Instance: A row of data is called an instance, as in an instance or observation from the problem domain.
- Attribute: A column of data is called a feature or attribute, as in feature of the observation.
Each attribute can have a different type, for example:
- Real for numeric values like 1.2.
- Integer for numeric values without a fractional part like 5.
- Nominal for categorical data like “dog” and “cat”.
- String for lists of words, like this sentence.
On classification problems, the output variable must be nominal. For regression problems, the output variable must be real.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Data in Weka
Weka prefers to load data in the ARFF format.
ARFF is an acronym that stands for Attribute-Relation File Format. It is an extension of the CSV file format where a header is used that provides metadata about the data types in the columns.
For example, the first few lines of the classic iris flowers dataset in CSV format looks as follows:
|
1 2 3 4 5 |
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa |
The same file in ARFF format looks as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@RELATION iris @ATTRIBUTE sepallength REAL @ATTRIBUTE sepalwidth REAL @ATTRIBUTE petallength REAL @ATTRIBUTE petalwidth REAL @ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica} @DATA 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa |
You can see that directives start with the at symbol (@) and that there is one for the name of the dataset (e.g. @RELATION iris), there is a directive to define the name and datatype of each attribute (e.g. @ATTRIBUTE sepallength REAL) and there is a directive to indicate the start of the raw data (e.g. @DATA).
Lines in an ARFF file that start with a percentage symbol (%) indicate a comment.
Values in the raw data section that have a question mark symbol (?) indicate an unknown or missing value. The format supports numeric and categorical values as in the iris example above, but also supports dates and string values.
Depending on your installation of Weka, you may or may not have some default datasets in your Weka installation directory under the data/ subdirectory. These default datasets distributed with Weka are in the ARFF format and have the .arff file extension.
Load CSV Files in the ARFF-Viewer
Your data is not likely to be in ARFF format.
In fact, it is much more likely to be in Comma Separated Value (CSV) format. This is a simple format where data is laid out in a table of rows and columns and a comma is used to separate the values on a row. Quotes may also be used to surround values, especially if the data contains strings of text with spaces.
The CSV format is easily exported from Microsoft Excel, so once you can get your data into Excel, you can easily convert it to CSV format.
Weka provides a handy tool to load CSV files and save them in ARFF. You only need to do this once with your dataset.
Using the steps below you can convert your dataset from CSV format to ARFF format and use it with the Weka workbench. If you do not have a CSV file handy, you can use the iris flowers dataset. Download the file from the UCI Machine Learning repository (direct link) and save it to your current working directory as iris.csv.
1. Start the Weka chooser.

Screenshot of the Weka GUI Chooser
2. Open the ARFF-Viewer by clicking “Tools” in the menu and select “ArffViewer”.
3. You will be presented with an empty ARFF-Viewer window.
Weka ARFF Viewer
4. Open your CSV file in the ARFF-Viewer by clicking the “File” menu and select “Open”. Navigate to your current working directory. Change the “Files of Type:” filter to “CSV data files (*.csv)”. Select your file and click the “Open” button.
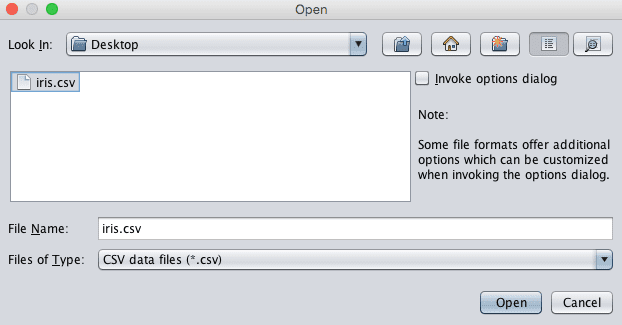
Load CSV In ARFF Viewer
5. You should see a sample of your CSV file loaded into the ARFF-Viewer.
6. Save your dataset in ARFF format by clicking the “File” menu and selecting “Save as…”. Enter a filename with a .arff extension and click the “Save” button.
You can now load your saved .arff file directly into Weka.
Note, the ARFF-Viewer provides options for modifying your dataset before saving. For example you can change values, change the name of attributes and change their data types.
It is highly recommended that you specify the names of each attribute as this will help with analysis of your data later. Also, make sure that the data types of each attribute are correct.
Load CSV Files in the Weka Explorer
You can also load your CSV files directly in the Weka Explorer interface.
This is handy if you are in a hurry and want to quickly test out an idea.
This section shows you how you can load your CSV file in the Weka Explorer interface. You can use the iris dataset again, to practice if you do not have a CSV dataset to load.
1. Start the Weka GUI Chooser.
2. Launch the Weka Explorer by clicking the “Explorer” button.
Screenshot of the Weka Explorer
3. Click the “Open file…” button.
4. Navigate to your current working directory. Change the “Files of Type” to “CSV data files (*.csv)”. Select your file and click the “Open” button.
You can work with the data directly. You can also save your dataset in ARFF format by clicking he “Save” button and typing a filename.
Use Excel for Other File Formats
If you have data in another format, load it in Microsoft Excel first.
It is common to get data in another format such as CSV using a different delimiter or fixed width fields. Excel has powerful tools for loading tabular data in a variety of formats. Use these tools and first load your data into Excel.
Once you have loaded your data into Excel, you can export it into CSV format. You can then work with it in Weka, either directly or by first converting it to ARFF format.
Resources
Below are some additional resources that you may find useful when working with CSV data in Weka.
Summary
In this post you discovered how to load your CSV data into Weka for machine learning.
Specifically, you learned:
- About the ARFF file format and how Weka uses it to represent datasets for machine learning.
- How to load your CSV data using ARFF-Viewer and save it into ARFF format.
- How to load your CSV data directly in the Weka Explorer and use it for modeling.
Do you have any questions about loading data in Weka or about this post? Ask your questions in the comments and I will do my best to answer.
Discover Machine Learning Without The Code!

Develop Your Own Models in Minutes
...with just a few a few clicks
Discover how in my new Ebook:
Machine Learning Mastery With Weka
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, build models, tuning, and much more...
Finally Bring The Machine Learning To Your Own Projects
Skip the Academics. Just Results.






great post
Totally agree the post is very helpful. Thanks, very much appreciated.
Thanks!
Thank you for this helpful post. please I encountered java.io.IOException when trying to view my .CSV file in WEKA. I need your help.
I’m sorry to hear that Ayo.
Maybe your file is too large?
Maybe try loading it in excel first and check that the file is not corrupt?
Hi Jason,
Thanks for the good job you’re doing.
What is the limit of the size of csv file that can be converted into arff format by the weka workbench.
I have a csv file above 2gig and I couldn’t get weka Arff viewer or explorer to load it up for conversion.
Great question, I have no idea Sunkanmi. My guess would be the memory limit of Java (which can be increased) and the memory limit of your hardware.
More details on giving Weka more ram:
https://weka.wikispaces.com/OutOfMemoryException
I get an error message, “java.io.IOE.exception 12 Problem encountered on line:2”
same messagewhether I try to load with tools or directly using Explorer
Sorry to hear that Rodney. I’ve not seen this before. Perhaps try posting to stack overflow or the Weka email list?
Thank you!
You’re welcome Farah.
I have a data set which contains quantity,unit price,duty,model,sepcs,brand names of some products. I initially used Naive Bayes and later used auto weka to determine that my ideal algorithm will be random forest and its gives 10% accuracy rate and runs smoothly,whenever I use test using training data set.
All hell breaks loose, when I copy the same data file and remove the brand names,so that I can use it as a test dataset. I either receive inputmappedclassifier option or errors like – “problem evaluating classifier-index4-size1 or “different nos of lables 15!=1.
Namely, I have placed brand name column for both test and training datasets at the end.I did some online search and used question mark on the brand column of the test data set. I have used random alphanumeric values. I have even converted them into arff format and cross checked the attribute data type on both file,but nothing seems to help. Where am I going wrong?I know I am close.can anyone help?
It would be 100% accuracy and not 10%
When I load the data in weka it’s shows invalid streams
Hi santanu,
This post might help with making predictions on new data:
https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/
Hi Jason, how do i create an ARFF file using mass spectrometry data ? Each instance (mass spectrum) will contain 100’s of attributes, each of which is a pair of mass and intensity values for each peak signal in the spectrum. Typically i have replicates of these mass spectra which represent a disease state and others which represent a normal state/ class. All the examples of other data types show a single outcome for each attribute rahter than the mass/intensity pair i described above. Some examples of mass spec data into Weka would be really helpful
Good question Tom.
Perhaps this post will help you to define what the inputs and outputs of a model might be:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Dear Jason,
i have two problems when load .csv file to weka
1- The file loaded correctly but because of enclosure character the sentences are not loaded completely.
2- When trying to apply stringTowordvector filter this error appear (attribute names are not unique! causes: ‘class’).
Hi Asmaa, sorry, I don’t have good examples of loading textual data in Weka.
i have multiple values for a single attribute. how can i write them
Great question!
Consider making them binary attributes. Have one column for each value, then mark a 1 or a 0 on a row for each column for a given observation.
I hope that helps.
Hi Jason,
Great post! Just curious, is it possible to set this up real time? In that if I have a process that collects data real time via a CSV file that then needs to be converted to arff. Can this be done?
And then once this is done, is it possible to add and delete values from the arff object?
thanks!
I would recommend using the command line interface for Weka to achieve this.
Sorry, I don’t have examples, but consider checking the Weka system/user guide provided with Weka.
How can i introduce 3 indpendent real attributes classes ?
ie: Not one class that contains 3 values No; 3 indpendent real attributes classes
I believe Weka does not support outputting a vector prediction (e.g. 3 classes).
Hello jason,
I have built and followed the steps on this page to transform my CSV file into an arff successfully. However, now that I load the dataset into Weka, it is impossible for me to use a j48 tree. What can I do to build a tree and begin analyzing my data? Thanks!
Best,
Nick
Perhaps you need to make your output variable nominal so you can use classification algorithms?
the first row values are taken as attribute names, thus losing first row values. How can we retain the values and give explicit attribute names?
Good question. I’m not sure off-hand, sorry.
One way would be to specify col names in your file. Or even add a dummy first line to the file.
i tray to open my csv data in weka but is not work erreur [[ file’data.csv’ not recognised as an csv data files file reaon : 1 problem encountered on line 2
Consider double checking your file is a CSV file. Open in a text editor or MS Excel to confirm.
Deer Mr.Brownlee,
I going to use weka for a IDS purpose on KDDcup99 dataset.
I have to use SVM and Entropy on this dataset ,and according to this result I will decrease some attributes from the dataset and make a decision tree for detecting intrusion faster ,
let me know is it possible to use WEKA GUI? or I should use weka library in java?
Sorry, I have not used that dataset in many years. My best advice is to try.
hello Dr.Jason,
please I have a problem with kosarak dataset , I can’t run it into weka
Sorry, I don’t know about that dataset. Perhaps post your error to stack overflow?
Can I open .mat file in Weka?
I don’t know, sorry.
trying to run a .csv file in weka on my MacBook but there is an error which says
invalid stream header:49642c53
Perhaps double check your data file in a text editor and ensure the format matches your expectations.
Excellent post
Thanks.
Hi Jason,
Is there a way to add a column in my test data csv file indicating which data sample it is and then, identifying corresponding prediction score against the individual sample?
Thank you for the excellent post!
FS
Perhaps add in CSV and use a filter to separate and save the separate datasets.
Hi.
I get the error “java.lang.illegalArgumentException: Attribute names are not unique! Causes: ‘vhigh’ ‘2’”. Please help.
I tried to upload .csv file to the weka explorer, but I get this exception and the file doesn’t load.
Perhaps double check your data in a text editor or excel?
hi Jason
after loading .csv file and saving it as a .arff file and opening it in WEKA, my histograms are all in black and white. I have tried many different things but none of them are working. What could the problem be?
thanks for reading.
Marie
Weka things you have a real valued output. Perhaps double check your file?
is there a post that explains how to write the header correctly in order to view the file in weka? i have tried MANY times to create the header, check it and correct errors with extra commas using a text editor and it won’t open at all in the arff viewer. no matter what i do i get an error and the file won’t even open. it looks EXACTLY like an arff opened in my text editor from within weka but weka will not read my csvs at all.
Open an existing .arff file and adapt it for your data.
Or use the ARFF editor provided with Weka.
Thank you so much for your guidance
My probem occurs after converting csv file to arff file, I notice that a new index column is added as attribute, although arff provides index column. So if my csv file has 5 attributes it becomes 6 in arff file.
I don’t know how to fix this.
Perhaps check your CSV file does not have extra columns. Maybe look in excel or a text editor?
MONTHLY MEAN SUNSHINE HOURS
MONTH/YRS 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016
JANUARY 5.3 4.4 7.5 4.5 2 5.2 5.4 5.4 5.5 6.4 5.2 4.6
FEBRUARY 6.7 4.7 7.4 6 2.2 5.2 5.9 4.9 4.1 4.6 5.3 2.2
MARCH 5.5 2.9 5.8 4.7 8.0 3.3 6.1 5.4 5.7 5.6 4.4 4.3
APRIL 5.4 4.8 5.2 5 3.6 5.8 5.1 5.7 5.6 5.8 4.7 5.7
MAY 4.8 3.7 6.1 6 5 5.3 5.6 5.1 5.9 5.8 5.2 5.1
JUNE 4.7 4.6 5.6 5 4.2 3.8 3.3 3.8 4.3 4.5 3 4.3
JULY 2.2 2.3 4.4 3.1 2.9 2.9 2.4 1.7 2.7 2.5 2.1 4.2
AUGUST 1.5 1.4 2.7 2.3 2.2 2.4 1.6 2.6 2.1 1.5 1.6 2.8
SEPTEMBER 3.8 2 3.9 3.1 3.4 3.6 2.5 3.6 2.8 1.8 2.5 2.2
OCTOBER 4.1 3.5 5.9 5.6 3.8 5.5 4.4 4.7 4.7 3.7 5.2 4.9
NOVEMBER 6.7 5.7 7.5 7.6 6.8 6 7 6.3 6.1 5.9 6.8 5.5
DECEMBER 6.3 5.8 7.4 6.1 7.5 7.1 7.3 7.6 6.5 6.2 8.8 4.4
TOTAL 57 45.8 70.4 59 44.4 56.1 56.6 56.8 56 54.3 54.8 50.2
MEAN 4.8 3.8 5.9 5 3.7 4.7 4.7 4.7 4.6 4.5 4.6 4.2
Above is a sample weather data, a word doc. Please is there any modification i should try before loading data into WEKA?
It really depends on the goals of your project.
This might help:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Thank sfor this interesting post Jason. I am more interested in how to use the ARFF-Viewer options for modifying your dataset before saving. Particularly to change their data types. I have played around the interface for such options but didnt get any clue. Please help
Sorry, I don’t have an example of changing data types in the ARFF viewer.
Thank you Jason, this article helps.
I’m glad to hear that.
Jason, I just stumbled upon this post in attempting to leverage WEKA for my own dissertation process. After only a few moments I believe that the resource you have given the rest of us (machinelearningmastery.com) is going to be the key to my success and that of many to come! Just learning how to turn a .csv into .arff has already opened countless doors for me. I now have a preliminary method for my research. Can’t thank you enough!
Well done Mark, I’m glad to hear about your progress! Hang in there.
Great post
I need to learn data mining for a project with code, any suggestions? links?
Thanks
This website is full of tutorials with code, dive in!
Jason can you help me. I cannot get a .CSV file to load in Weka. When I am in tools I get the message. java io.IOException wrong number of values. Read 11, expected 10 read Toek(EOL) line 13 problem encountered on line 13.
My file is a CSV format.
Help please
Perhaps inspect your file in a text editor and confirm it has a CSV format and that the file looks valid.
Jason – how to load a .txt file into weka. I have to classify the reviews of a movie and then find out if the movie is bad or good. I have got bunch of .txt files of each positive reviews and negative reviews files.
Help me how to load them in weka and perform classification
Sorry, I don’t have examples of working with .txt files in Weka, I cannot give you good advice.
Hey Jason, wonderful article!!. It is helpful to a great extent, especially for the beginners. Thank you.
Thanks, I’m glad it helped.
hi Jason
pls help here,
am trying to convert a csv file to arff and am getting this error; unable to determine structure as arff(reason:java io.ioexception:keyword@data expected,real token@attribute id numeric line 3. am using the wdbc breast cancer dataset for my research
Sorry to hear that, perhaps inspect the file in a text editor to get an idea of what the problem might be?
I have a dataset from Kaggle i.e. train.csv and test.csv files. how I work from these two files together?
I read some tutorials where one CSV files are loaded and then split into train and test files.
Typically kaggle test sets don’t have labels.
I recommend focusing on how to load the training set only.
Hi Jason,
I have a csv file and when I want to convert it to arff with weka I get this problem:
java.io.IOException: 42 Problem encountered on line:2
Perhaps the file is too large to fit into memory?
I have glucose values in type >4 and <4 but i want the actual (numerical values)
how do i input into weka
Perhaps you need to collect that data?
Once collected, you can load the data file as a CSV and convert it to ARFF.
I have a condition that import csv file in weka.
‘weka.core.converters.CSVLoader failed to load News.csv
Reason: 2 problem encountered on line: 509’
how can I do to fix it? thanks
Perhaps open your file in a text editor and look for something out of place on line 509?
Dear Jason,
I have a CSV file and when I want to convert it to ARFF I get this error:
java.io.IOexception:1 problem encountered on line:2
Sorry to hear that. Perhaps try posting the file and error to the weka user group?
thank you
You’re welcome.
Thank you for writing this great post. It helped me a lot.
Thanks, I’m happy to hear that!
I have a spreadsheet which I saved in CSV It has 48 Attributes and 58 Instances. Attributes are formatted as numeric two decimal points. When I load it into the the attributes are all 1 and a count is given not the actual numeric. How do fix this
Perhaps confirm a “.” is used for the decimal point and “,” is used to separate columns.
I have many files which I want to load into WEKA. How can I do this?
Perhaps combine them into one file first?
Hi Jason,
Pardon the obviousness of my question – for a regression project, what is the order of the instances in the arff file? the latest data is right at the header or at the end of the file?
Many thanks,
For regression, we assume all instances (rows) are iid. That order instances are created is irrelevant.
If it is relevant, you have a time series problem and you should try to make the instances stationary over time – remove or model the time effect.
Hello,
I´ve downloaded and installed weka workbench for OLM testing purposes. I´ve social workers dataset (as from Ben Davis 92 paper). It is a CSV format file as follows :
In1,”In2″,”In3″,”In4″,”In5″,”In6″,”In7″,”In8″,”In9″,”In10″,”Out1″
2,1,1,2,1,1,2,2,1,1,2
1,2,3,3,2,1,3,1,3,3,5
3,3,2,1,2,2,3,3,3,3,5
2,3,4,2,4,2,2,2,1,2,5
1,2,1,2,2,2,2,1,1,2,3
I´m trying to convert it to ARFF format , as follows :
@attribute In1 numeric
@attribute In2 numeric
@attribute In3 numeric
@attribute In4 numeric
@attribute In5 numeric
@attribute In6 numeric
@attribute In7 numeric
@attribute In8 numeric
@attribute In9 numeric
@attribute In10 numeric
@attribute Out1 numeric
@data
1,2,3,3,2,1,3,1,3,3,5
1,2,1,2,2,2,2,1,1,2,3
1,3,3,1,4,2,1,1,2,3,4
1,2,2,3,3,2,2,1,1,2,4
1,3,3,1,4,2,1,1,2,3,3
1,3,3,1,4,2,1,1,2,3,4
1,3,1,3,2,1,1,1,3,2,5
Everything seems to be working fine for preprocessing step, but when I turn into Classify step, and choose OLM Algorithm with every single property, I´m not able to activate “Start” Button.
It may be the dataset file (but everything seems to be ok in the first step for reading it) .
Do you have any idea what it´s going on ?
Thanks in advance and congratulations for your blog. It is helping me a lot!
Regards,
Francisco
It looks like your data is for regression ensure that you are choosing a regression algorithm.
Hi Jason
I am getting error this way
Index 9 out of bounds for length 9 problem encountered on line:2
What may I do?
Sorry, I’m not sure of the cause of your error, perhaps these steps will help:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Hi, did u solve this problem?
I think am good to go with loading dataset to weka now. Thanks alot for your time and understanding
Well done!
Hi. when I reopen a csv file in which data has been changed, I am shown old data that is no longer in the file. Do you know how to fix this error? Thank you
If you have closed the file before (which triggered a flush on the cache), it should not be like that.