The promise of Data Mining was that algorithms would crunch data and find interesting patterns that you could exploit in your business.
The exemplar of this promise is market basket analysis (Wikipedia calls it affinity analysis). Given a pile of transactional records, discover interesting purchasing patterns that could be exploited in the store, such as offers and product layout.
In this post you will work through a market basket analysis tutorial using association rule learning in Weka. If you follow along the step-by-step instructions, you will run a market basket analysis on point of sale data in under 5 minutes.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.

Market Basket Analysis
Photo by HealthGauge, some rights reserved.
Association Rule Learning
I once did some consulting work for a start-up looking into customer behavior in a SaaS app. We were interested in patterns of behavior that indicated churn or conversion from free to paid accounts.
I spent weeks pouring over the data, looking at correlations and plots. I came up with a bunch of rules that indicated outcomes and presented ideas for possible interventions to influence those outcomes.
I came up with rules like: “User Creates x widgets in y days and logged in n times then they will convert“. I ascribed numbers to the rules such as support (the number of records that match the rule out of all record) and lift (the % increase in predictive accuracy in using the rule to predict a conversion).
It was only after I delivered and presented the report that I released what a colossal mistake I made. I had performed Association Rule Learning by hand, when there are off-the-shelf algorithms that could have done the work for me.
I’m sharing this story so that it sticks in your mind. If you are sifting large datasets for interesting patterns, association rule learning is a suite of methods should be using.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
1. Start the Weka Explorer
In previous tutorials, we have looked at running a classifier, designing and running an experiment, algorithm tuning and ensemble methods. If you need help downloading and installing Weka, please refer to these previous posts.
Weka GUI Chooser
Start the Weka Explorer.
2. Load the Supermarket Datasets
Weka comes with a number of real datasets in the “data” directory of the Weka installation. This is very handy because you can explore and experiment on these well known problems and learn about the various methods in Weka at your disposal.
Load the Supermarket dataset (data/supermarket.arff). This is a dataset of point of sale information. The data is nominal and each instance represents a customer transaction at a supermarket, the products purchased and the departments involved. There is not much information about this dataset online, although you can see this comment (“question of using supermarket.arff for academic research”) from the personal that collected the data.
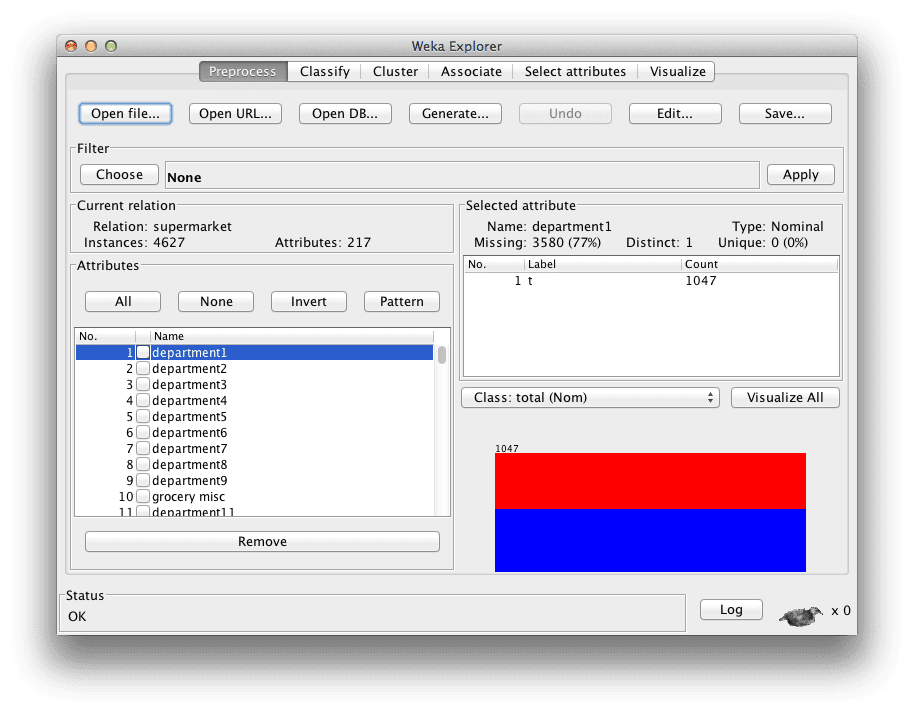
Supermarket dataset loaded in the Weka Explorer
The data contains 4,627 instances and 217 attributes. The data is denormalized. Each attribute is binary and either has a value (“t” for true) or no value (“?” for missing). There is a nominal class attribute called “total” that indicates whether the transaction was less than \$100 (low) or greater than \$100 (high).
We are not interested in creating a predictive model for total. Instead we are interested in what items were purchased together. We are interested in finding useful patterns in this data that may or may not be related to the predicted attributed.
3. Discover Association Rules
Click the “Associate” tab in the Weka Explorer. The “Apriori” algorithm will already be selected. This is the most well known association rule learning method because it may have been the first (Agrawal and Srikant in 1994) and it is very efficient.
In principle the algorithm is quite simple. It builds up attribute-value (item) sets that maximize the number of instances that can be explained (coverage of the dataset). The search through item space is very much similar to the problem faced with attribute selection and subset search.
Click the “Start” button to run Apriori on the dataset.
4. Analyze Results
The real work for association rule learning is in the interpretation of results.
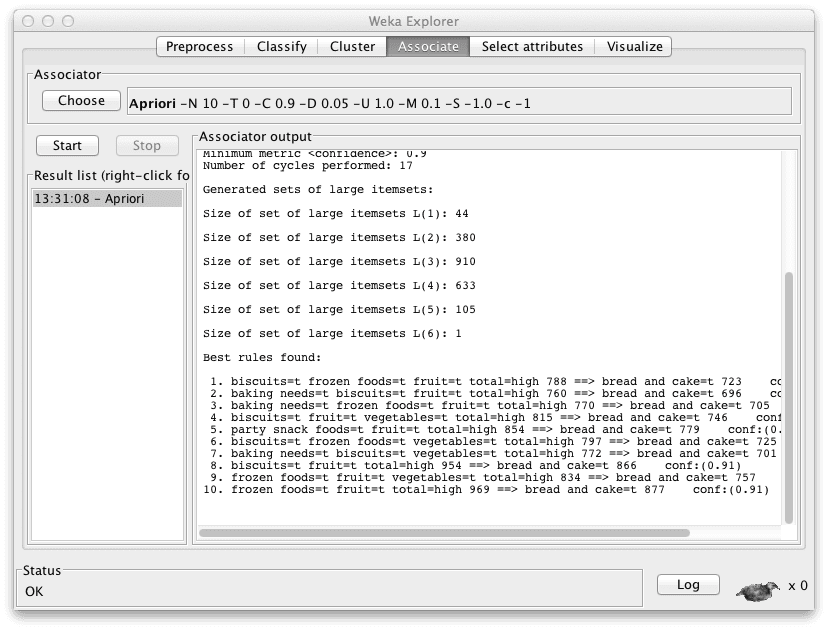
Results for the Apriori Association Rule Learning in Weka
From looking at the “Associator output” window, you can see that the algorithm presented 10 rules learned from the supermarket dataset. The algorithm is configured to stop at 10 rules by default, you can click on the algorithm name and configure it to find and report more rules if you like by changing the “numRules” value.
The rules discovered where:
- biscuits=t frozen foods=t fruit=t total=high 788 ==> bread and cake=t 723 conf:(0.92)
- baking needs=t biscuits=t fruit=t total=high 760 ==> bread and cake=t 696 conf:(0.92)
- baking needs=t frozen foods=t fruit=t total=high 770 ==> bread and cake=t 705 conf:(0.92)
- biscuits=t fruit=t vegetables=t total=high 815 ==> bread and cake=t 746 conf:(0.92)
- party snack foods=t fruit=t total=high 854 ==> bread and cake=t 779 conf:(0.91)
- biscuits=t frozen foods=t vegetables=t total=high 797 ==> bread and cake=t 725 conf:(0.91)
- baking needs=t biscuits=t vegetables=t total=high 772 ==> bread and cake=t 701 conf:(0.91)
- biscuits=t fruit=t total=high 954 ==> bread and cake=t 866 conf:(0.91)
- frozen foods=t fruit=t vegetables=t total=high 834 ==> bread and cake=t 757 conf:(0.91)
- frozen foods=t fruit=t total=high 969 ==> bread and cake=t 877 conf:(0.91)
Very cool, right!
You can see rules are presented in antecedent => consequent format. The number associated with the antecedent is the absolute coverage in the dataset (in this case a number out of a possible total of 4,627). The number next to the consequent is the absolute number of instances that match the antecedent and the consequent. The number in brackets on the end is the support for the rule (number of antecedent divided by the number of matching consequents). You can see that a cutoff of 91% was used in selecting rules, mentioned in the “Associator output” window and indicated in that no rule has a coverage less than 0.91.
I don’t want to go through all 10 rules, it would be too onerous. Here are few observations:
- We can see that all presented rules have a consequent of “bread and cake”.
- All presented rules indicate a high total transaction amount.
- “biscuits” an “frozen foods” appear in many of the presented rules.
You have to be very careful about interpreting association rules. They are associations (think correlations), not necessary causally related. Also, short antecedent are likely more robust than long antecedent that are more likely to be fragile.

Increase Basket Size
Photo by goosmurf, some rights reserved.
If we are interested in total for example, we might want to convince people that buy biscuits, frozen foods and fruit to buy bread and cake so that they result in a high total transaction amount (Rule #1). This may sound plausible, but is flawed reasoning. The product combination does not cause a high total, it is only associated with a high total. Those 723 transactions may have a vast assortment of random items in addition to those in the rule.
What might be interesting to test is to model the path through the store required to collect associated items and seeing if changes to that path (shorter, longer, displayed offers, etc) have an effect on transaction size or basket size.
Summary
In this post you discovered the power of automatically learning association rules from large datasets. You learned that it is much more efficient approach to use an algorithm like Apriori rather than deducing rules by hand.
You performed your first market basket analysis in Weka and learned that the real work is in the analysis of results. You discovered the careful attention to detail required when interpreting rules and that association (correlation) is not the same as causation.
Discover Machine Learning Without The Code!

Develop Your Own Models in Minutes
...with just a few a few clicks
Discover how in my new Ebook:
Machine Learning Mastery With Weka
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, build models, tuning, and much more...
Finally Bring The Machine Learning To Your Own Projects
Skip the Academics. Just Results.






Nice article. I had written about using association rule mining using R in two parts, first part explaining concepts and the second part explaining implementation using R with visualizations.
Check out here http://prdeepakbabu.wordpress.com/2010/11/13/market-basket-analysisassociation-rule-mining-using-r-package-arules/
Great post Deepak, thanks for sharing.
thanks i have understand alot of concepts due to this example.But i m using weka 3.7.1 can u provide me an exmple with a small dataset in weka like weather.arff,.cpu.arff etc.
i will be thankful
Thanks alot sir for your cooperation
But there is a problem that supermarket dataset have large size.
I was try to perform the example but supermarket dataset was unavailable.
Sir if you kindly provide example for other dataset like weather.arrf i will be thankful.
waiting for your kind consideration.
i m working on Arabic text, can your good self provide me the example in arabic dataset and then converted into CSV and ARFF format.
I will be thankful
Dude, you really made my day. THANKS ALOT.
I had another query, how to increase the size of heap? I have tried to edit the runWeka.bat file and runWeka.ini . I tried the xmx and maxheap=2014mb and everything else. But the problem is, I can’t save the edited file.
You can, but you may better off working with a representative sample of your source data.
Is this weka tool is useful for find frequent and infrequent itemset and after that to find association rule?
Hello Jason.
Your article is great to introduce Association Rules with Weka’s Supermarket example.
I would like to point that it is mistaken at this point about explaining the rules meaning:
“The number in brackets on the end is the support for the rule (number of antecedent divided by the number of matching consequents). ”
The figure is the value for Confidence metric, which also implies how the rules are ordered in the output.
Best regards,
Álvaro
i want to use association rule mining to consider count of purchase for each user. For example user A listened item a 3 times. Thanks
please help me, how i can create this rule at weka:
‘‘Click (CDi) and Length of Reading Time (High))___Click (CDj)’’
‘‘Basket placement (CDi) and number of plays (3))____Basket
placement (CDj)’’
Hie.
Your article is great to introduce Association Rules with Weka’s Supermarket example.
Best rules found:
1. biscuits=t frozen foods=t fruit=t total=high 788 ==> bread and cake=t 723 lift:(1.27) lev:(0.03) [155] conv:(3.35)
2. baking needs=t biscuits=t fruit=t total=high 760 ==> bread and cake=t 696 lift:(1.27) lev:(0.03) [149] conv:(3.28)
3. baking needs=t frozen foods=t fruit=t total=high 770 ==> bread and cake=t 705 lift:(1.27) lev:(0.03) [150] conv:(3.27)
4. biscuits=t fruit=t vegetables=t total=high 815 ==> bread and cake=t 746 lift:(1.27) lev:(0.03) [159] conv:(3.26)
5. party snack foods=t fruit=t total=high 854 ==> bread and cake=t 779 lift:(1.27) lev:(0.04) [164] conv:(3.15)
6. biscuits=t frozen foods=t vegetables=t total=high 797 ==> bread and cake=t 725 lift:(1.26) lev:(0.03) [151] conv:(3.06)
7. baking needs=t biscuits=t vegetables=t total=high 772 ==> bread and cake=t 701 lift:(1.26) lev:(0.03) [145] conv:(3.01)
8. biscuits=t fruit=t total=high 954 ==> bread and cake=t 866 lift:(1.26) lev:(0.04) [179] conv:(3)
9. frozen foods=t fruit=t vegetables=t total=high 834 ==> bread and cake=t 757 lift:(1.26) lev:(0.03) [156] conv:(3)
10. frozen foods=t fruit=t total=high 969 ==> bread and cake=t 877 lift:(1.26) lev:(0.04) [179] conv:(2.92)
Nice work!
i want to use association rule mining to consider count of purchase for each user. For example user A listened item a 3 times. Thanks
please help me, how i can create this rule at weka:
and i want to analyze the result for True only not false for items, Thanks.
What If it has Date ? If we need to find the patterns on when purchased and association between them
Yes, often the date can provide a lot of useful information.
Hello Jason! Thank you for such a cool website! I do have a question. What if my dataset is in binary (0,1)? I have a grocery store dataset where each column is an item and the 0 or 1 indicates whether it was bought or not. The row is the receipt, or the list of items bought by an individual. I wanted to find out what items where bought together by using the weka association but the top ten rules generated are always 0 (No). I want to find out the rules that only have 1 because it shows me which items where bought. As it is now the No rules generated in results are telling me what people are not buying. How do I get around this? I hope I am making sense.
examples
1. Vanilla Eclair=No Vanilla Meringue=No Chocolate Croissant=No Almond Bear Claw=No 63188 ==> Almond Tart=No 60738 lift:(1) lev:(0) [206] conv:(1.08)
2. Vanilla Eclair=No Vanilla Meringue=No Chocolate Croissant=No Blueberry Danish=No 63064 ==> Almond Tart=No 60618 lift:(1) lev:(0) [205] conv:(1.08)
3. Chocolate Eclair=No Vanilla Eclair=No Vanilla Meringue=No Chocolate Croissant=No 63181 ==> Almond Tart=No 60730 lift:(1) lev:(0) [205] conv:(1.08)
4. Vanilla Eclair=No Apricot Tart=No Vanilla Meringue=No Almond Bear Claw=No 63254 ==> Almond Tart=No 60797 lift:(1) lev:(0) [202] conv:(1.08)
5. Vanilla Eclair=No Apricot Tart=No Vanilla Meringue=No Blueberry Danish=No 63118 ==> Almond Tart=No 60666 lift:(1) lev:(0) [201] conv:(1.08)
6. Chocolate Eclair=No Vanilla Eclair=No Apricot Tart=No Vanilla Meringue=No 63234 ==> Almond Tart=No 60777 lift:(1) lev:(0) [201] conv:(1.08)
7. Vanilla Eclair=No Apricot Tart=No Vanilla Meringue=No Chocolate Croissant=No 63180 ==> Almond Tart=No 60725 lift:(1) lev:(0) [201] conv:(1.08)
It is also possible that there simply are not interesting patterns find, keep that in mind.
It’s a good question. Perhaps the data is not rich enough? Perhaps you can collect more features to describe each outcome?
Hi jason..how can i use those rules if i want to create personalized push notification for my customers?
I already have a dataset which includes the customer’s past purchases. What i am finding difficult is how to send each of them in one click the personalized advert.
It really depends on your application and data.
Very good. Thanks for sharing this analysis.
You’re welcome.
Hi, is it mandatory to have the basket size greater than 1, i mean we need to consider only those invoices were we have more than 1 product purchased to get product association ?
Yes, unless you are looking across purchases for a customer.
Thanks Jason, yes across purchases for a customer can through some good insights as well, will have a look at it.
Hi, i am done with processing the market basket report and its now time to get some insights out of it and recommend.
My question is having looked at Confidence and Lift parameter, which one is the better metric to look at ? secondly i can see some Antecedents have decent support and lift > 1 but the confidence matrix is low with around 15%.
I know that recommendations are very subjective and majorly upto how business looks at each parameters.
But need some directional views on how do we go about in recommending things back to client.
Perhaps find out the goals of the stakeholders and use that to motivate the interpretation.
Or take different stances in the report and then interpret results. E.g. if x is important then the method found that …, otherwise if y is important, the method found that…
I hope that helps.
Nice Blog! Thanks for sharing this useful post.
Thanks.
Hi Jason
For the same example and without changing any parameters, what is the support of the second rule obtained, and how is it obtained?
Hi Jason, how do i select the attributes using association rule to be input for a classifier like MLP?
I’m not sure it is an appropriate approach.
Thanks Jason, is it possible to select best attributes from the generated rules?
No.
Hi Jason, i used wbc dataset that has 9 attributes and class attributes to create association rule model the rules generated are having only 6 attributes and a class attribute. Are the 3 attributes not appearing irrelevant?
I don’t know, sorry.
jason, thank you so much for all of your great tutorials!
my question is, can the apriori algorithm be implemented in python for predicting housing prices (say, for the common boston housing prices dataset)?
Apriori finds patterns, it does not predict.
I believe you want to use a regression algorithm. Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-algorithm-config-should-i-use
Very interesting article Jason!
I think one thing to add is that there is a lot of algorithms that essentially get the same rules given a set of parameters and they differ in computational speed. So depending how wide your dataset is you may want to consider using ECLAT or F-P Growth.
I have recently posted an article with some theory and Python implementation on my blog, so feel free to take a look and let me know what you think: https://pyshark.com/market-basket-analysis-using-association-rule-mining-in-python/
Thanks for sharing.
Hi Jason
Thank you for a great article. I’m working on a school assignment using weka with supermarket dataset. I’m confused about one question and hope you can help ASAP.
Question: Let’s assume that 80% of values are missing in this dataset. Then what is the number of items which average customer’s basket contains (hint: this means that 20% of attributes have the value “t” in an instance on average)?
Thanks
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-you-help-me-with-my-homework-or-assignment
HI ,
This is great. Thank you for this. Can you please tell me how to find the highest rank association rule in this?
Sorry, I don’t have more tutorials on association rules. Perhaps in the future.
“The number in brackets on the end is the support for the rule”
How about NOT?
“Support” are the numbers close to ‘promise’ part and ‘consequent’ part of the rule.
Next article about apriori where author does not know how to explain results.
Thanks.
Hi Jason, I love your article. I just want to point out some typo. I hope it helps.
“I’m sharing this story so that it sticks in your mind. If you are sifting large datasets for interesting patterns, association rule learning is a suite of methods *should* should be using.”
Good catch! Thank you.
Hi Jason,
Thanks for the post always excellent. We love your work! Just a note, I found the link you have provided that is meant to give some info about the data is dead, however, I looked and found another discussion where there are some details about the data set right here:
https://list.waikato.ac.nz/hyperkitty/list/wekalist@list.waikato.ac.nz/thread/M5Y6F2ZMYQFBWJTUHJNRHHRS27RWSNQL/
I hope it helps.
Thanks
Thanks. The link has been updated accordingly.