My name is Artem Yankov, I have worked as a software engineer for Badgeville for the last 3 years. I’m using there Ruby and Scala although my prior background includes use of various languages such as: Assembly, C/C++, Python, Clojure and JS.
I love hacking on small projects and exploring different fields, for instance two almost random fields I’ve looked at were Robotics and Malware Analysis. I can’t say I became an expert, but I did have a lot of fun. A small robot I built looked amazingly ugly but it could mirror my arms motion by “seeing” it through MS Kinect.
I didn’t do any machine learning at all until the last year when I finished Andrew Ng’s course on Coursera and I really loved it.
What is your project called and what does it do?
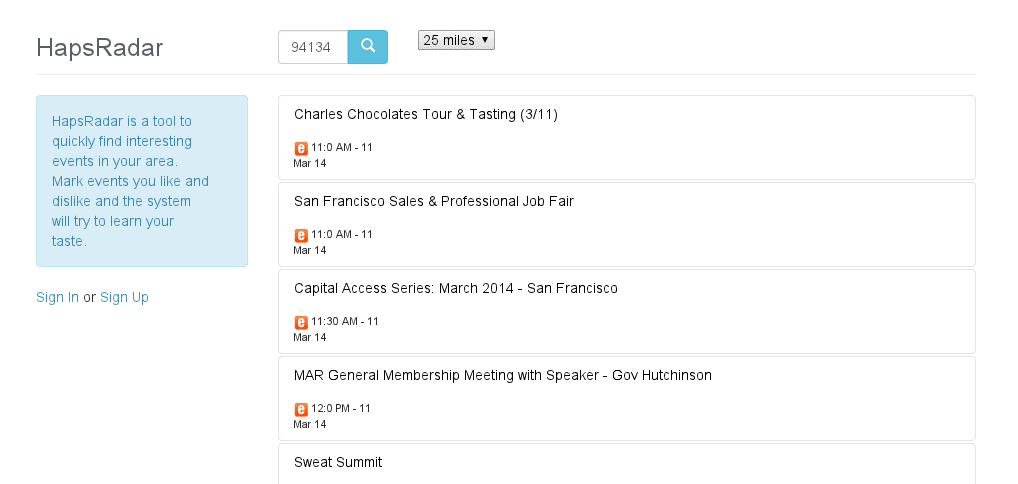
The project is called hapsradar.com and it’s an event recommendation site focused on what’s happening right now or in the near future.
I am a terrible planner of my weekends and I usually find myself wondering what to do if I suddenly decided to do something outside of my home/internet. The typical algorithm for me to find out what’s going on was to go to sites like meetup.com and eventbrite, browse through tons of categories, click lots of buttons and read list of the current events.
So when I finished machine learning course and started to look for projects to practice my skills I thought that I could really automate this event seeking process by fetching event lists from those sites and then building recommendation based on what I like.
HapsRadar by Artem Yankov
The site is very minimalistic and currently provides events only from two sites: meetup.com and eventbrite.com. A user needs to rate at least 100 events before recommendation engine kicks in. Then it runs every night and trains using user likes/dislikes and then trying to predict events user might like.
How did you get started?
I started just because I wanted to practice my machine learning skills and to make it more fun I chose to solve a real problem I had. After some evaluation I decided to use python for my recommender. Here’s the tools I used:
Scala / PlayFramework (for events fetcher and website)
Events are fetched using standard APIs provided by meetup.com and eventbrite.com and stored in postgresql. I emailed them before I started my crawlers to double-check if I can do such a thing, specifically because I wanted to run this crawlers every day to keep my database updated with all the events.
The guys were very nice about that and eventbrite even bumped up my API rate limit without any questions. And meetup.com has a nice streaming API that allows you to subscribe to all the changes as they happening. I wanted to crawl yelp.com as well since they have event lists, but they prohibited this completely.
After I had a first cut of the data I built a simple site that displayed the events within some range of a given zip code (I currently only fetch events for the US).
Now the recommender part. The main material to build my features were the event title and event description. I decided that things like time of the day when event is happening, or how far it is from your home won’t add much of a value because I just wanted a simple answer to the question: is this event relevant to my interests?
Idea #1. Predict topics
Some of the fetched events have tags or categories, some of them don’t.
Initially I thought I should try to use the tagged events to predict tags for untagged events and then use them as training features. After spending some time on that I figured it might not be a good idea. Most of the tagged events had just 1-3 tags and they often were very inaccurate or even completely random.
I think eventbrite allows clients to type anything as a tag and people are just not very good at coming up with the good words. Plus the number of tags per event was usually low and wasn’t enough for judging about the event even if you used human intelligence 🙂
Of course it was possible to find already accurately classified text and use it for predicting topics, but that again, posed a lot of additional questions: Where to get classified text? How relevant it would be to my events descriptions? How many tags I should use? So I decided to find another ideas.
Idea #2. LDA Topic modeling
After some research I found an awesome python library called gensim which implements LDA (Latent Dirichlet Allocation) for topic modelling.
It’s worth noting that the use of topics here is not meant topics defined in English like “sports”, “music” or “programming”. Topics in LDA are probability distributions over words. Roughly speaking it finds clusters of words that come together with the certain probability. Each such cluster is a “topic”. You then feed the model a new document and it’s inferring topics for it as well.
Using LDA is pretty straight forward. First, I cleaned the documents (in my case document is event’s description and title) by removing stop English words, commas, html tags, etc. Then I build dictionary based on all events descriptions:
from gensim import corpora, models
dct = corpora.Dictionary(clean_documents)
Then I filter very rare words
dct.filter_extremes(no_below=2)
To train model all documents need to be converted into bag of words:
corpus = [dct.doc2bow(doc) for doc in clean_documents]
Where num_topics is a number of topics that need to be modelled on the documents. In my case it was 100. Then to convert any document in form of bag of words to its topics representation in form of sparse matrix:
x = lda[doc_bow]
So now I can get a matrix of features for any given event and I can easily get a training matrix for the events user rated:
docs_bow = [dct.doc2bow(doc) for doc in rated_events]
X_train = [lda[doc_bow] for doc_bow in docs_bow]
That looked like more or less decent solution, using SVM (Support Vector Machine) classifier I got about 85% accuracy and when I looked at predicted events for me it did look quite accurate.
Note: Not all classifiers support sparse matrixes and sometimes you need to convert it to a full matrix. Gensim has a way to do that.
Another idea I wanted to try for building features was TF-IDF vectorizer.
Scikit-learn supports it out-of-the-box and what’s it’s doing is assigning a weight for each word in the document based on frequency of this word in the document divided by the frequency of the word in a corpus of the documents. So the weight of the word will be low if you see it very often and that allows to filter out the noise. To build vectorizer out of all the documents:
And then to transform given set of documents to their TF-IDF representation:
X_train = vectorizer.transform(rated_events)
Now, when I tried to feed that to a classifier that was really taking a long time plus results were bad. That’s actually not a surprise because in this case almost every word is a feature. So I started to look for a way to select best performing features.
Scikit-learn provides methods SelectKBest to which you can pass a scoring function and a number of features to select and it performs the magic for you. For scoring I used chi2 (chi-squared test) and I won’t say you exactly why. I just empirically found that it performed better in my case and put “study a theory behind chi2” in my todo bucket.
I’m not happy to admit that but there wasn’t much science involved in how I chose classifier. I just tried bunch of them and choose the one that performed best. In my case it was SVM. As for the parameters I used Grid Search to choose the best ones and all of that scikit-learn provides out of the box. In code it looks like this:
I chose f1-score as a scoring method just because it’s the one I more or less understand. Grid Search will try all combination of the parameters above, perform cross-validations and find the parameters that performs best.
I tried to feed this classifier both X_train with topics modelled with LDA and TF-IDF + Chi2. Both performed similarly, but subjectively it looked like TF-IDF + Chi2 solution generated better predictions. I was pretty much satisfied with the results for the v1 and spent the rest of the time fixing website’s UI.
What are some interesting discoveries you made?
One of the things I learnt is that if you are building a recommendation system and expect your users to come and rate a bunch of things at once so it can work – you are wrong.
I tried the site on my friends and although rating process seemed very easy and fast to me it was pretty hard to make them spend few minutes clicking a “like” button. Although It was alright since my main goal was to practice skills and build a tool for myself I figured if I want to make something bigger out of it I need to figure out how to make rating process simpler.
Another thing I learnt is that in order to be more efficient I need to understand algorithms more. Tweaking parameters is way more fun when you understand what you are doing.
What do you want to do next on the project?
My main problem currently is UI. I want to keep it minimalistic, but I need to figure out how to do the rating process more fun and convenient. Also events browsing could be better.
After this part is done I’m thinking to search for new sources of events: conferences, concerts, etc. Maybe I’ll add a mobile app for that as well.
Hi Jason,
I was looking for some ideas in recommendation system using deep learning/neural networks. I was not able to find one in your blog. It will be great if you could discuss it in your blog.
I would like to ask how both LDA and TFIDF models will behave when the provided documents have words that were not seen in the training time. For sure there will be events in the future that will have new words. Of course we will retrain the model periodically but we can do it every night.







but we can get data to try code? Is it possible to download code in one file
Wow! I found this idea so cool. It inspired me to develop my own side project! Thanks for sharing this story, Jason!
Glad to hear it.
Hi Jason,
I was looking for some ideas in recommendation system using deep learning/neural networks. I was not able to find one in your blog. It will be great if you could discuss it in your blog.
Thanks for the suggestion.
Hi Jason,
I would like to ask how both LDA and TFIDF models will behave when the provided documents have words that were not seen in the training time. For sure there will be events in the future that will have new words. Of course we will retrain the model periodically but we can do it every night.
Thank you!