The chain rule allows us to find the derivative of composite functions.
It is computed extensively by the backpropagation algorithm, in order to train feedforward neural networks. By applying the chain rule in an efficient manner while following a specific order of operations, the backpropagation algorithm calculates the error gradient of the loss function with respect to each weight of the network.
In this tutorial, you will discover the chain rule of calculus for univariate and multivariate functions.
After completing this tutorial, you will know:
- A composite function is the combination of two (or more) functions.
- The chain rule allows us to find the derivative of a composite function.
- The chain rule can be generalised to multivariate functions, and represented by a tree diagram.
- The chain rule is applied extensively by the backpropagation algorithm in order to calculate the error gradient of the loss function with respect to each weight.
Let’s get started.

The Chain Rule of Calculus for Univariate and Multivariate Functions
Photo by Pascal Debrunner, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
- Composite Functions
- The Chain Rule
- The Generalized Chain Rule
- Application in Machine Learning
Prerequisites
For this tutorial, we assume that you already know what are:
You can review these concepts by clicking on the links given above.
Composite Functions
We have, so far, met functions of single and multiple variables (so called, univariate and multivariate functions, respectively). We shall now extend both to their composite forms. We will, eventually, see how to apply the chain rule in order to find their derivative, but more on this shortly.
A composite function is the combination of two functions.
– Page 49, Calculus for Dummies, 2016.
Consider two functions of a single independent variable, f(x) = 2x – 1 and g(x) = x3. Their composite function can be defined as follows:
h = g(f(x))
In this operation, g is a function of f. This means that g is applied to the result of applying the function, f, to x, producing h.
Let’s consider a concrete example using the functions specified above to understand this better.
Suppose that f(x) and g(x) are two systems in cascade, receiving an input x = 5:
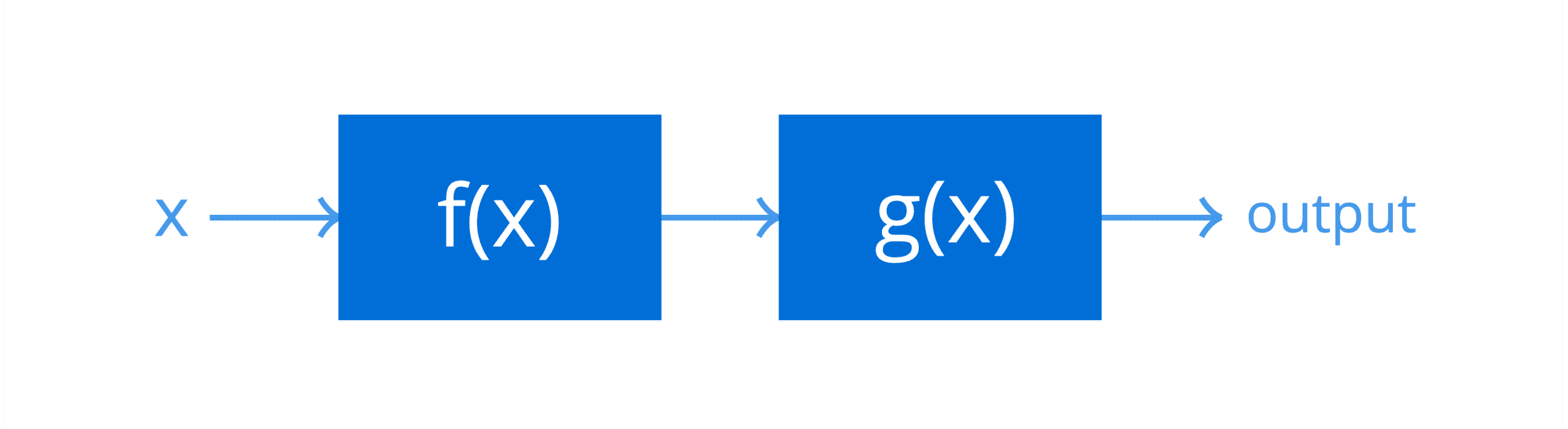
Two Systems in Cascade Representing a Composite Function
Since f(x) is the first system in the cascade (because it is the inner function in the composite), its output is worked out first:
f(5) = (2 × 5) – 1 = 9
This result is then passed on as input to g(x), the second system in the cascade (because it is the outer function in the composite) to produce the net result of the composite function:
g(9) = 93 = 729
We could have, alternatively, computed the net result at one go, if we had performed the following computation:
h = g(f(x)) = (2x – 1)3 = 729
The composition of functions can also be considered as a chaining process, to use a more familiar term, where the output of one function feeds into the next one in the chain.
With composite functions, the order matters.
– Page 49, Calculus for Dummies, 2016.
Keep in mind that the composition of functions is a non-commutative process, which means that swapping the order of f(x) and g(x) in the cascade (or chain) does not produce the same results. Hence:
g(f(x)) ≠ f(g(x))
The composition of functions can also be extended to the multivariate case:
h = g(r, s, t) = g(r(x, y), s(x, y), t(x, y)) = g(f(x, y))
Here, f(x, y) is a vector-valued function of two independent variables (or inputs), x and y. It is made up of three components (for this particular example) that are r(x, y), s(x, y) and t(x, y), and which are also known as the component functions of f.
This means that f(x, y) will map two inputs to three outputs, and will then feed these three outputs into the consecutive system in the chain, g(r, s, t), to produce h.
Want to Get Started With Calculus for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
The Chain Rule
The chain rule allows us to find the derivative of a composite function.
Let’s first define how the chain rule differentiates a composite function, and then break it into its separate components to understand it better. If we had to consider again the composite function, h = g(f(x)), then its derivative as given by the chain rule is:
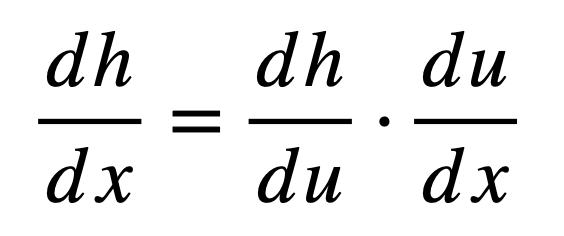
Here, u is the output of the inner function f (hence, u = f(x)), which is then fed as input to the next function g to produce h (hence, h = g(u)). Notice, therefore, how the chain rule relates the net output, h, to the input, x, through an intermediate variable, u.
Recall that the composite function is defined as follows:
h(x) = g(f(x)) = (2x – 1)3
The first component of the chain rule, dh / du, tells us to start by finding the derivative of the outer part of the composite function, while ignoring whatever is inside. For this purpose, we shall apply the power rule:
((2x – 1)3)’ = 3(2x – 1)2
The result is then multiplied to the second component of the chain rule, du / dx, which is the derivative of the inner part of the composite function, this time ignoring whatever is outside:
( (2x – 1)’ )3 = 2
The derivative of the composite function as defined by the chain rule is, then, the following:
h’ = 3(2x – 1)2 × 2 = 6(2x – 1)2
We have, hereby, considered a simple example, but the concept of applying the chain rule to more complicated functions remains the same. We shall be considering more challenging functions in a separate tutorial.
The Generalized Chain Rule
We can generalize the chain rule beyond the univariate case.
Consider the case where x ∈ ℝm and u ∈ ℝn, which means that the inner function, f, maps m inputs to n outputs, while the outer function, g, receives n inputs to produce an output, h. For i = 1, …, m the generalized chain rule states:
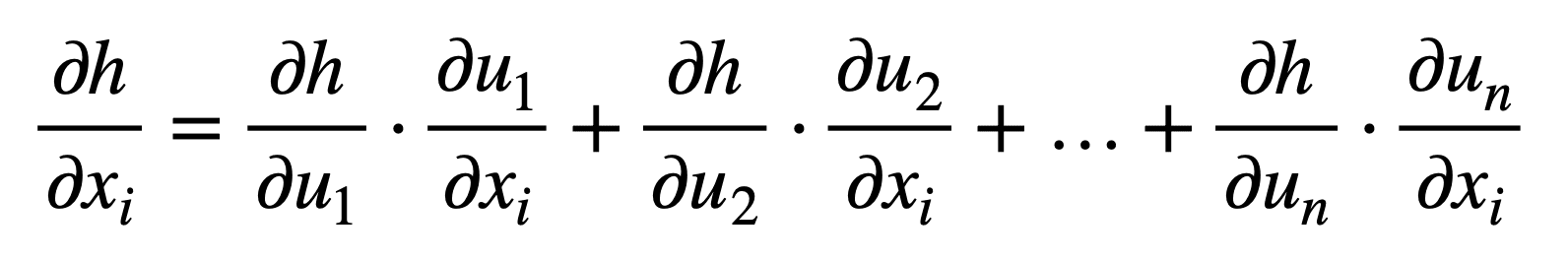
Or in its more compact form, for j = 1, …, n:
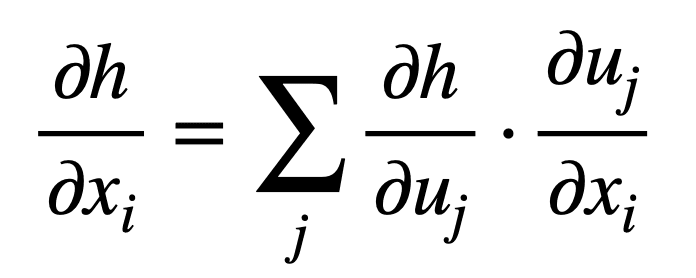
Recall that we employ the use of partial derivatives when we are finding the gradient of a function of multiple variables.
We can also visualize the workings of the chain rule by a tree diagram.
Suppose that we have a composite function of two independent variables, x1 and x2, defined as follows:
h = g(f(x1, x2)) = g(u1(x1, x2), u2(x1, x2))
Here, u1 and u2 act as the intermediate variables. Its tree diagram would be represented as follows:
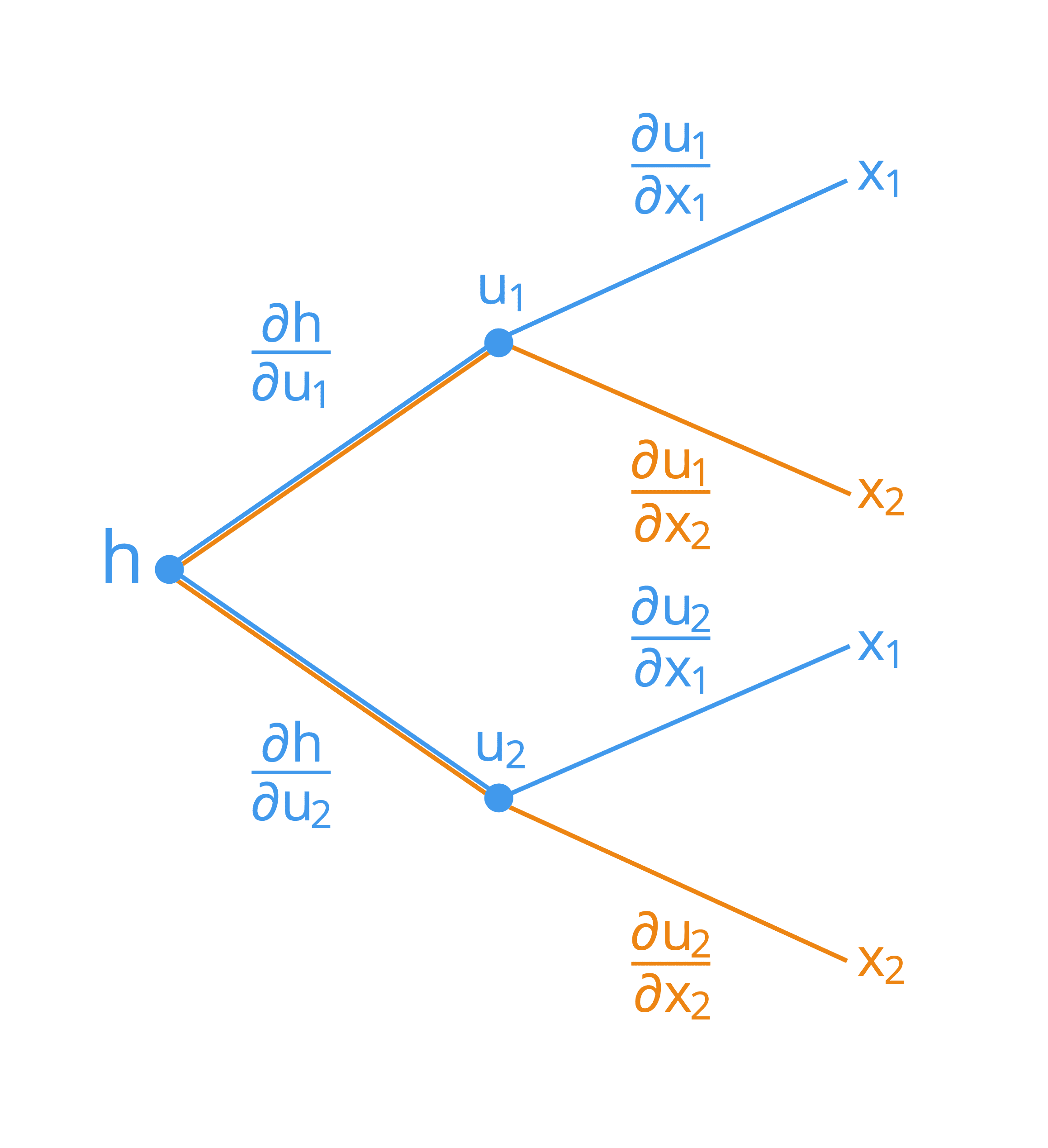
Representing the Chain Rule by a Tree Diagram
In order to derive the formula for each of the inputs, x1 and x2, we can start from the left hand side of the tree diagram, and follow its branches rightwards. In this manner, we find that we form the following two formulae (the branches being summed up have been colour coded for simplicity):
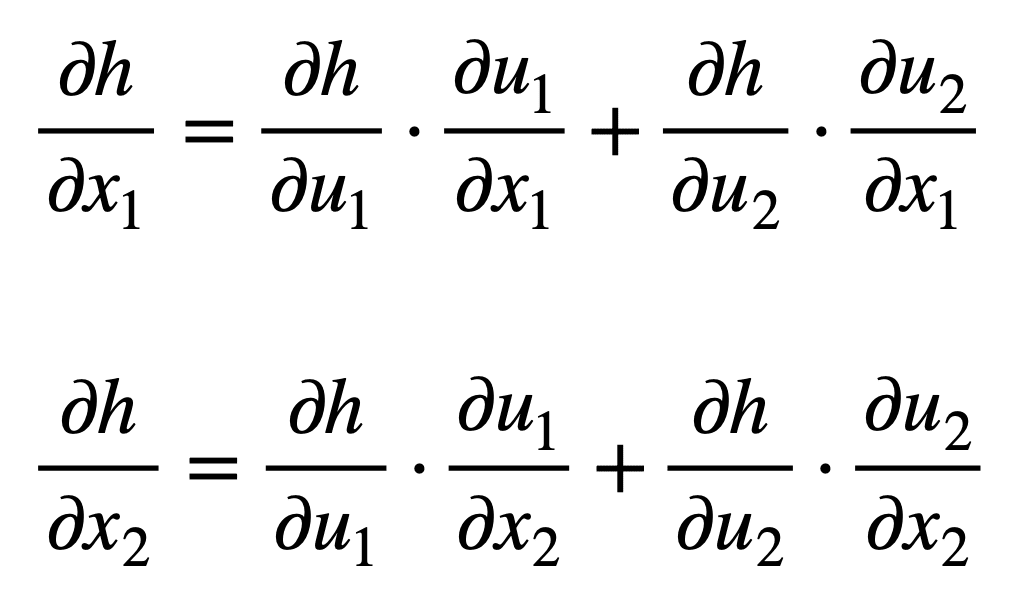
Notice how the chain rule relates the net output, h, to each of the inputs, xi, through the intermediate variables, uj. This is a concept that the backpropagation algorithm applies extensively to optimize the weights of a neural network.
Application in Machine Learning
Observe how similar the tree diagram is to the typical representation of a neural network (although we usually represent the latter by placing the inputs on the left hand side and the outputs on the right hand side). We can apply the chain rule to a neural network through the use of the backpropagation algorithm, in a very similar manner as to how we have applied it to the tree diagram above.
An area where the chain rule is used to an extreme is deep learning, where the function value y is computed as a many-level function composition.
– Page 159, Mathematics for Machine Learning, 2020.
A neural network can, indeed, be represented by a massive nested composite function. For example:
y = fK ( fK – 1 ( … ( f1(x)) … ))
Here, x are the inputs to the neural network (for example, the images) whereas y are the outputs (for example, the class labels). Every function, fi, for i = 1, …, K, is characterized by its own weights.
Applying the chain rule to such a composite function allows us to work backwards through all of the hidden layers making up the neural network, and efficiently calculate the error gradient of the loss function with respect to each weight, wi, of the network until we arrive to the input.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Calculus for Dummies, 2016.
- Single and Multivariable Calculus, 2020.
- Deep Learning, 2017.
- Mathematics for Machine Learning, 2020.
Summary
In this tutorial, you discovered the chain rule of calculus for univariate and multivariate functions.
Specifically, you learned:
- A composite function is the combination of two (or more) functions.
- The chain rule allows us to find the derivative of a composite function.
- The chain rule can be generalised to multivariate functions, and represented by a tree diagram.
- The chain rule is applied extensively by the backpropagation algorithm in order to calculate the error gradient of the loss function with respect to each weight.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Get a Handle on Calculus for Machine Learning!

Feel Smarter with Calculus Concepts
...by getting a better sense on the calculus symbols and terms
Discover how in my new Ebook:
Calculus for Machine Learning
It provides self-study tutorials with full working code on:
differntiation, gradient, Lagrangian mutiplier approach, Jacobian matrix,
and much more...






bismillahir Rehman ir Raheem
So beautiful and so simple. I have read many explanations but never well understood the concept of chain rule and why it is used in gradient descent.
First time I saw such an amazing explanation. Now I dont need to read further.Everything is explained especially by that amazing figure describing the change rule…thank you so much..
Thank you. Glad you like it.
Please Provide mathematical example of chain rule step by step
Thanks for your suggestion. Can you elaborate on which part you want to see more?
This was a perfect explanation for my understanding of the chain rule. Amazing!
Thank you for the feedback Felix!
The math explained in these tutorials are so intelligently clear and elegant!
Thank you for your feedback Sofiane!
I think he was talking about “The Generalized Chain Rule” part in which there is no example for multivariate function to see how this method works on an actual case. It would be very handy if we had an example.
Hi Sofiane…You may find the following of interest:
https://math.hmc.edu/calculus/hmc-mathematics-calculus-online-tutorials/multivariable-calculus/multi-variable-chain-rule/#:~:text=Multivariable%20Chain%20Rules%20allow%20us,ydydt.
If we simplify both these equations the LHS != RHS ,
i.e say for x1 :- LHS = del h/ del x1,
on the other hand :- RHS = 2(del h/ del x1)
If we simplify both these equations the LHS != RHS ,
i.e say for x1 :- LHS = del h/ del x1,
on the other hand :- RHS = 2(del h/ del x1)
Albeit its seems logical, can you throw some light on this.
Thanks
Hi Bhavyaa…It is not clear what your question is. Perhaps you can specify a real function so that we can apply the techniques.
Hi sir,
I have a doubt that when the back propagation is happening, it will be taking the partial derivative with respect to weights right! not input values xi. Can you please make it clear for me. ?
Hi Sasi…Understanding backpropagation can be challenging, but there are plenty of resources that can help you grasp the concept, from introductory materials to in-depth explanations. Here are some recommended resources:
### Books
1. **”Neural Networks and Deep Learning” by Michael Nielsen**:
– This online book provides an excellent introduction to neural networks and backpropagation. It’s well-written and includes interactive elements.
– [Neural Networks and Deep Learning](http://neuralnetworksanddeeplearning.com/)
2. **”Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville**:
– A comprehensive book that covers all aspects of deep learning, including backpropagation. It’s suitable for those who want an in-depth understanding.
– [Deep Learning Book](https://www.deeplearningbook.org/)
3. **”Pattern Recognition and Machine Learning” by Christopher M. Bishop**:
– This book provides a solid foundation in machine learning and includes detailed explanations of neural networks and backpropagation.
– [Pattern Recognition and Machine Learning](https://www.springer.com/gp/book/9780387310732)
### Online Courses
1. **Coursera: “Neural Networks and Deep Learning” by Andrew Ng**:
– Part of the Deep Learning Specialization on Coursera, this course offers a clear and concise introduction to neural networks and backpropagation.
– [Coursera Neural Networks and Deep Learning](https://www.coursera.org/learn/neural-networks-deep-learning)
2. **Udacity: “Deep Learning Nanodegree”**:
– This nanodegree program includes extensive content on neural networks and backpropagation, with hands-on projects to reinforce learning.
– [Udacity Deep Learning Nanodegree](https://www.udacity.com/course/deep-learning-nanodegree–nd101)
3. **edX: “Deep Learning with Python and PyTorch” by IBM**:
– This course covers the fundamentals of deep learning, including backpropagation, with practical examples using PyTorch.
– [edX Deep Learning with Python and PyTorch](https://www.edx.org/course/deep-learning-with-python-and-pytorch)
### Video Tutorials
1. **3Blue1Brown: “Neural Networks” series**:
– This YouTube series provides an intuitive visual explanation of neural networks and backpropagation. It’s highly recommended for beginners.
– [3Blue1Brown Neural Networks](https://www.youtube.com/watch?v=aircAruvnKk&list=PLZHQObOWTQDOQy_NGj2xdtonG8zfYBa8G)
2. **StatQuest with Josh Starmer**:
– Josh Starmer’s videos break down complex topics into easy-to-understand segments. His video on backpropagation is particularly helpful.
– [StatQuest: Backpropagation](https://www.youtube.com/watch?v=Ilg3gGewQ5U)
### Tutorials and Articles
1. **Stanford University’s CS231n: Convolutional Neural Networks for Visual Recognition**:
– This course includes detailed lecture notes on neural networks and backpropagation, along with practical assignments.
– [CS231n Lecture Notes](http://cs231n.github.io/)
2. **Machine Learning Mastery: “A Gentle Introduction to Backpropagation”**:
– An accessible article that introduces backpropagation step-by-step.
– [Machine Learning Mastery](https://machinelearningmastery.com/gentle-introduction-backpropagation/)
3. **Towards Data Science: “Backpropagation Demystified”**:
– An article that breaks down the backpropagation algorithm with clear explanations and visual aids.
– [Towards Data Science](https://towardsdatascience.com/backpropagation-demystified-6c2edc9f0d56)
### Practice and Implementation
1. **Kaggle**:
– Participate in Kaggle competitions and work on datasets to practice implementing neural networks and backpropagation.
– [Kaggle](https://www.kaggle.com/)
2. **GitHub Repositories**:
– Explore repositories that include implementations of neural networks and backpropagation in various programming languages.
– Example: [Neural Network and Deep Learning Examples](https://github.com/rasbt/deeplearning-models)
By exploring these resources, you’ll gain a solid understanding of backpropagation and how it is used to train neural networks effectively.