Calculus for Machine Learning Crash Course.
Get familiar with the calculus techniques in machine learning in 7 days.
Calculus is an important mathematics technique behind many machine learning algorithms. You don’t always need to know it to use the algorithms. When you go deeper, you will see it is ubiquitous in every discussion on the theory behind a machine learning model.
As a practitioner, we are most likely not going to encounter very hard calculus problems. If we need to do one, there are tools such as computer algebra systems to help, or at least, verify our solution. However, what is more important is understanding the idea behind calculus and relating the calculus terms to its use in our machine learning algorithms.
In this crash course, you will discover some common calculus ideas used in machine learning. You will learn with exercises in Python in seven days.
This is a big and important post. You might want to bookmark it.
Let’s get started.
Calculus for Machine Learning (7-Day Mini-Course)
Photo by ArnoldReinhold, some rights reserved.
Who Is This Crash-Course For?
Before we get started, let’s make sure you are in the right place.
This course is for developers who may know some applied machine learning. Maybe you know how to work through a predictive modeling problem end to end, or at least most of the main steps, with popular tools.
The lessons in this course do assume a few things about you, such as:
- You know your way around basic Python for programming.
- You may know some basic linear algebra.
- You may know some basic machine learning models.
You do NOT need to be:
- A math wiz!
- A machine learning expert!
This crash course will take you from a developer who knows a little machine learning to a developer who can effectively talk about the calculus concepts in machine learning algorithms.
Note: This crash course assumes you have a working Python 3.7 environment with some libraries such as SciPy and SymPy installed. If you need help with your environment, you can follow the step-by-step tutorial here:
Crash-Course Overview
This crash course is broken down into seven lessons.
You could complete one lesson per day (recommended) or complete all of the lessons in one day (hardcore). It really depends on the time you have available and your level of enthusiasm.
Below is a list of the seven lessons that will get you started and productive with data preparation in Python:
- Lesson 01: Differential calculus
- Lesson 02: Integration
- Lesson 03: Gradient of a vector function
- Lesson 04: Jacobian
- Lesson 05: Backpropagation
- Lesson 06: Optimization
- Lesson 07: Support vector machine
Each lesson could take you 5 minutes or up to 1 hour. Take your time and complete the lessons at your own pace. Ask questions, and even post results in the comments below.
The lessons might expect you to go off and find out how to do things. I will give you hints, but part of the point of each lesson is to force you to learn where to go to look for help with and about the algorithms and the best-of-breed tools in Python. (Hint: I have all of the answers on this blog; use the search box.)
Post your results in the comments; I’ll cheer you on!
Hang in there; don’t give up.
Lesson 01: Differential Calculus
In this lesson, you will discover what is differential calculus or differentiation.
Differentiation is the operation of transforming one mathematical function to another, called the derivative. The derivative tells the slope, or the rate of change, of the original function.
For example, if we have a function $f(x)=x^2$, its derivative is a function that tells us the rate of change of this function at $x$. The rate of change is defined as: $$f'(x) = \frac{f(x+\delta x)-f(x)}{\delta x}$$ for a small quantity $\delta x$.
Usually we will define the above in the form of a limit, i.e.,
$$f'(x) = \lim_{\delta x\to 0} \frac{f(x+\delta x)-f(x)}{\delta x}$$
to mean $\delta x$ should be as close to zero as possible.
There are several rules of differentiation to help us find the derivative easier. One rule that fits the above example is $\frac{d}{dx} x^n = nx^{n-1}$. Hence for $f(x)=x^2$, we have the derivative $f'(x)=2x$.
We can confirm this is the case by plotting the function $f'(x)$ computed according to the rate of change together with that computed according to the rule of differentiation. The following uses NumPy and matplotlib in Python:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import numpy as np import matplotlib.pyplot as plt # Define function f(x) def f(x): return x**2 # compute f(x) = x^2 for x=-10 to x=10 x = np.linspace(-10,10,500) y = f(x) # Plot f(x) on left half of the figure fig = plt.figure(figsize=(12,5)) ax = fig.add_subplot(121) ax.plot(x, y) ax.set_title("y=f(x)") # f'(x) using the rate of change delta_x = 0.0001 y1 = (f(x+delta_x) - f(x))/delta_x # f'(x) using the rule y2 = 2 * x # Plot f'(x) on right half of the figure ax = fig.add_subplot(122) ax.plot(x, y1, c="r", alpha=0.5, label="rate") ax.plot(x, y2, c="b", alpha=0.5, label="rule") ax.set_title("y=f'(x)") ax.legend() plt.show() |
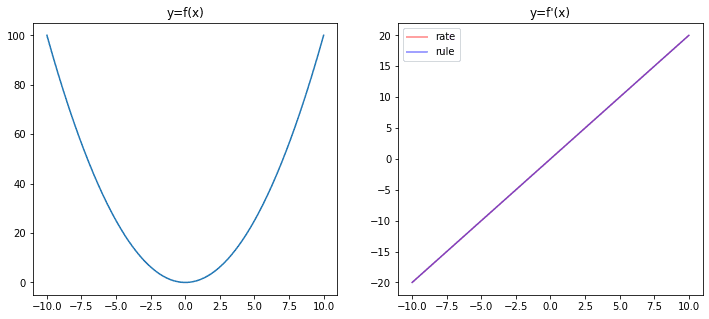
In the plot above, we can see the derivative function found using the rate of change and then using the rule of differentiation coincide perfectly.
Your Task
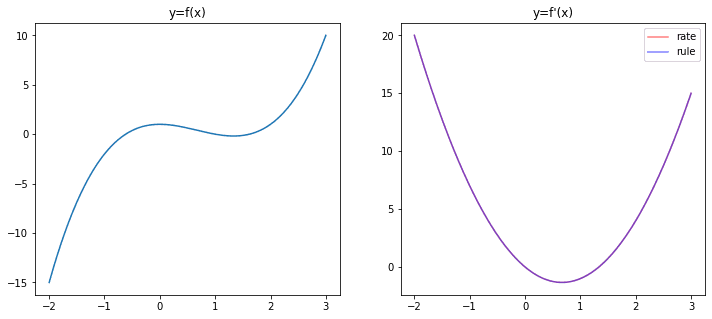
We can similarly do a differentiation of other functions. For example, $f(x)=x^3 – 2x^2 + 1$. Find the derivative of this function using the rules of differentiation and compare your result with the result found using the rate of limits. Verify your result with the plot above. If you’re doing it correctly, you should see the following graph:
In the next lesson, you will discover that integration is the reverse of differentiation.
Lesson 02: Integration
In this lesson, you will discover integration is the reverse of differentiation.
If we consider a function $f(x)=2x$ and at intervals of $\delta x$ each step (e.g., $\delta x = 0.1$), we can compute, say, from $x=-10$ to $x=10$ as:
$$
f(-10), f(-9.9), f(-9.8), \cdots, f(9.8), f(9.9), f(10)
$$
Obviously, if we have a smaller step $\delta x$, there are more terms in the above.
If we multiply each of the above with the step size and then add them up, i.e.,
$$
f(-10)\times 0.1 + f(-9.9)\times 0.1 + \cdots + f(9.8)\times 0.1 + f(9.9)\times 0.1
$$
this sum is called the integral of $f(x)$. In essence, this sum is the area under the curve of $f(x)$, from $x=-10$ to $x=10$. A theorem in calculus says if we put the area under the curve as a function, its derivative is $f(x)$. Hence we can see the integration as a reverse operation of differentiation.
As we saw in Lesson 01, the differentiation of $f(x)=x^2$ is $f'(x)=2x$. This means for $f(x)=2x$, we can write $\int f(x) dx = x^2$ or we can say the antiderivative of $f(x)=x$ is $x^2$. We can confirm this in Python by calculating the area directly:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import numpy as np import matplotlib.pyplot as plt def f(x): return 2*x # Set up x from -10 to 10 with small steps delta_x = 0.1 x = np.arange(-10, 10, delta_x) # Find f(x) * delta_x fx = f(x) * delta_x # Compute the running sum y = fx.cumsum() # Plot plt.plot(x, y) plt.show() |
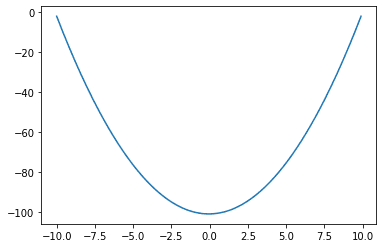
This plot has the same shape as $f(x)$ in Lesson 01. Indeed, all functions differ by a constant (e.g., $f(x)$ and $f(x)+5$) that have the same derivative. Hence the plot of the antiderivative computed will be the original shifted vertically.
Your Task
Consider $f(x)=3x^2-4x$, find the antiderivative of this function and plot it. Also, try to replace the Python code above with this function. If you plot both together, you should see the following:
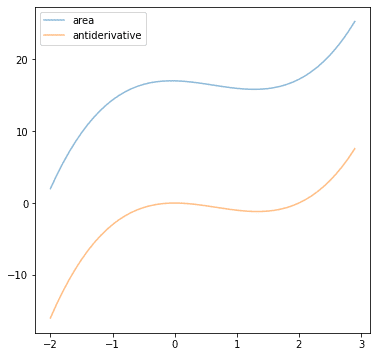
Post your answer in the comments below. I would love to see what you come up with.
These two lessons are about functions with one variable. In the next lesson, you will discover how to apply differentiation to functions with multiple variables.
Lesson 03: Gradient of a vector function
In this lesson, you will learn the concept of gradient of a multivariate function.
If we have a function of not one variable but two or more, the differentiation is extended naturally to be the differentiation of the function with respect to each variable. For example, if we have the function $f(x,y) = x^2 + y^3$, we can write the differentiation in each variable as:
$$
\begin{aligned}
\frac{\partial f}{\partial x} &= 2x \\
\frac{\partial f}{\partial y} &= 3y^2
\end{aligned}
$$
Here we introduced the notation of a partial derivative, meaning to differentiate a function on one variable while assuming the other variables are constants. Hence in the above, when we compute $\frac{\partial f}{\partial x}$, we ignored the $y^3$ part in the function $f(x,y)$.
A function with two variables can be visualized as a surface on a plane. The above function $f(x,y)$ can be visualized using matplotlib:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import numpy as np import matplotlib.pyplot as plt # Define the range for x and y x = np.linspace(-10,10,1000) xv, yv = np.meshgrid(x, x, indexing='ij') # Compute f(x,y) = x^2 + y^3 zv = xv**2 + yv**3 # Plot the surface fig = plt.figure(figsize=(6,6)) ax = fig.add_subplot(projection='3d') ax.plot_surface(xv, yv, zv, cmap="viridis") plt.show() |
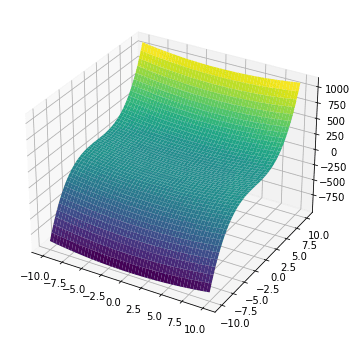
The gradient of this function is denoted as:
$$\nabla f(x,y) = \Big(\frac{\partial f}{\partial x},\; \frac{\partial f}{\partial y}\Big) = (2x,\;3y^2)$$
Therefore, at each coordinate $(x,y)$, the gradient $\nabla f(x,y)$ is a vector. This vector tells us two things:
- The direction of the vector points to where the function $f(x,y)$ is increasing the fastest
- The size of the vector is the rate of change of the function $f(x,y)$ in this direction
One way to visualize the gradient is to consider it as a vector field:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import numpy as np import matplotlib.pyplot as plt # Define the range for x and y x = np.linspace(-10,10,20) xv, yv = np.meshgrid(x, x, indexing='ij') # Compute the gradient of f(x,y) fx = 2*xv fy = 2*yv # Convert the vector (fx,fy) into size and direction size = np.sqrt(fx**2 + fy**2) dir_x = fx/size dir_y = fy/size # Plot the surface plt.figure(figsize=(6,6)) plt.quiver(xv, yv, dir_x, dir_y, size, cmap="viridis") plt.show() |
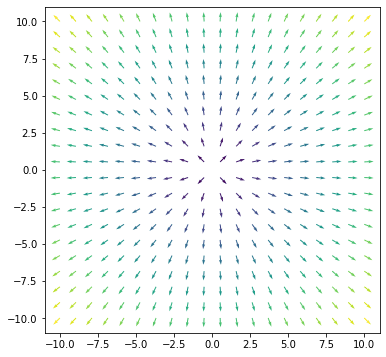
The viridis color map in matplotlib will show a larger value in yellow and a lower value in purple. Hence we see the gradient is “steeper” at the edges than in the center in the above plot.
If we consider the coordinate (2,3), we can check which direction $f(x,y)$ will increase the fastest using the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import numpy as np def f(x, y): return x**2 + y**3 # 0 to 360 degrees at 0.1-degree steps angles = np.arange(0, 360, 0.1) # coordinate to check x, y = 2, 3 # step size for differentiation step = 0.0001 # To keep the size and direction of maximum rate of change maxdf, maxangle = -np.inf, 0 for angle in angles: # convert degree to radian rad = angle * np.pi / 180 # delta x and delta y for a fixed step size dx, dy = np.sin(rad)*step, np.cos(rad)*step # rate of change at a small step df = (f(x+dx, y+dy) - f(x,y))/step # keep the maximum rate of change if df > maxdf: maxdf, maxangle = df, angle # Report the result dx, dy = np.sin(maxangle*np.pi/180), np.cos(maxangle*np.pi/180) gradx, grady = dx*maxdf, dy*maxdf print(f"Max rate of change at {maxangle} degrees") print(f"Gradient vector at ({x},{y}) is ({dx*maxdf},{dy*maxdf})") |
Its output is:
|
1 2 |
Max rate of change at 8.4 degrees Gradient vector at (2,3) is (3.987419245872443,27.002750276227097) |
The gradient vector according to the formula is (4,27), which the numerical result above is close enough.
Your Task
Consider the function $f(x,y)=x^2+y^2$, what is the gradient vector at (1,1)? If you get the answer from partial differentiation, can you modify the above Python code to confirm it by checking the rate of change at different directions?
Post your answer in the comments below. I would love to see what you come up with.
In the next lesson, you will discover the differentiation of a function that takes vector input and produces vector output.
Lesson 04: Jacobian
In this lesson, you will learn about Jacobian matrix.
The function $f(x,y)=(p(x,y), q(x,y))=(2xy, x^2y)$ is one with two input and two outputs. Sometimes we call this function taking vector arguments and returning a vector value. The differentiation of this function is a matrix called the Jacobian. The Jacobian of the above function is:
$$
\mathbf{J} =
\begin{bmatrix}
\frac{\partial p}{\partial x} & \frac{\partial p}{\partial y} \\
\frac{\partial q}{\partial x} & \frac{\partial q}{\partial y}
\end{bmatrix}
=
\begin{bmatrix}
2y & 2x \\
2xy & x^2
\end{bmatrix}
$$
In the Jacobian matrix, each row has the partial differentiation of each element of the output vector, and each column has the partial differentiation with respect to each element of the input vector.
We will see the use of Jacobian later. Since finding a Jacobian matrix involves a lot of partial differentiations, it would be great if we could let a computer check our math. In Python, we can verify the above result using SymPy:
|
1 2 3 4 5 6 |
from sympy.abc import x, y from sympy import Matrix, pprint f = Matrix([2*x*y, x**2*y]) variables = Matrix([x,y]) pprint(f.jacobian(variables)) |
Its output is:
|
1 2 3 4 |
⎡ 2⋅y 2⋅x⎤ ⎢ ⎥ ⎢ 2 ⎥ ⎣2⋅x⋅y x ⎦ |
We asked SymPy to define the symbols x and y and then defined the vector function f. Afterward, the Jacobian can be found by calling the jacobian() function.
Your Task
Consider the function
$$
f(x,y) = \begin{bmatrix}
\frac{1}{1+e^{-(px+qy)}} & \frac{1}{1+e^{-(rx+sy)}} & \frac{1}{1+e^{-(tx+uy)}}
\end{bmatrix}
$$
where $p,q,r,s,t,u$ are constants. What is the Jacobian matrix of $f(x,y)$? Can you verify it with SymPy?
In the next lesson, you will discover the application of the Jacobian matrix in a neural network’s backpropagation algorithm.
Lesson 05: Backpropagation
In this lesson, you will see how the backpropagation algorithm uses the Jacobian matrix.
If we consider a neural network with one hidden layer, we can represent it as a function:
$$
y = g\Big(\sum_{k=1}^M u_k f_k\big(\sum_{i=1}^N w_{ik}x_i\big)\Big)
$$
The input to the neural network is a vector $\mathbf{x}=(x_1, x_2, \cdots, x_N)$ and each $x_i$ will be multiplied with weight $w_{ik}$ and fed into the hidden layer. The output of neuron $k$ in the hidden layer will be multiplied with weight $u_k$ and fed into the output layer. The activation function of the hidden layer and output layer are $f$ and $g$, respectively.
If we consider
$$z_k = f_k\big(\sum_{i=1}^N w_{ik}x_i\big)$$
then
$$
\frac{\partial y}{\partial x_i} = \sum_{k=1}^M \frac{\partial y}{\partial z_k}\frac{\partial z_k}{\partial x_i}
$$
If we consider the entire layer at once, we have $\mathbf{z}=(z_1, z_2, \cdots, z_M)$ and then
$$
\frac{\partial y}{\partial \mathbf{x}} = \mathbf{W}^\top\frac{\partial y}{\partial \mathbf{z}}
$$
where $\mathbf{W}$ is the $M\times N$ Jacobian matrix, where the element on row $k$ and column $i$ is $\frac{\partial z_k}{\partial x_i}$.
This is how the backpropagation algorithm works in training a neural network! For a network with multiple hidden layers, we need to compute the Jacobian matrix for each layer.
Your Task
The code below implements a neural network model that you can try yourself. It has two hidden layers and a classification network to separate points in 2-dimension into two classes. Try to look at the function backward() and identify which is the Jacobian matrix.
If you play with this code, the class mlp should not be modified, but you can change the parameters on how a model is created.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 |
from sklearn.datasets import make_circles from sklearn.metrics import accuracy_score import numpy as np np.random.seed(0) # Find a small float to avoid division by zero epsilon = np.finfo(float).eps # Sigmoid function and its differentiation def sigmoid(z): return 1/(1+np.exp(-z.clip(-500, 500))) def dsigmoid(z): s = sigmoid(z) return 2 * s * (1-s) # ReLU function and its differentiation def relu(z): return np.maximum(0, z) def drelu(z): return (z > 0).astype(float) # Loss function L(y, yhat) and its differentiation def cross_entropy(y, yhat): """Binary cross entropy function L = - y log yhat - (1-y) log (1-yhat) Args: y, yhat (np.array): nx1 matrices which n are the number of data instances Returns: average cross entropy value of shape 1x1, averaging over the n instances """ return ( -(y.T @ np.log(yhat.clip(epsilon)) + (1-y.T) @ np.log((1-yhat).clip(epsilon)) ) / y.shape[1] ) def d_cross_entropy(y, yhat): """ dL/dyhat """ return ( - np.divide(y, yhat.clip(epsilon)) + np.divide(1-y, (1-yhat).clip(epsilon)) ) class mlp: '''Multilayer perceptron using numpy ''' def __init__(self, layersizes, activations, derivatives, lossderiv): """remember config, then initialize array to hold NN parameters without init""" # hold NN config self.layersizes = tuple(layersizes) self.activations = tuple(activations) self.derivatives = tuple(derivatives) self.lossderiv = lossderiv # parameters, each is a 2D numpy array L = len(self.layersizes) self.z = [None] * L self.W = [None] * L self.b = [None] * L self.a = [None] * L self.dz = [None] * L self.dW = [None] * L self.db = [None] * L self.da = [None] * L def initialize(self, seed=42): """initialize the value of weight matrices and bias vectors with small random numbers.""" np.random.seed(seed) sigma = 0.1 for l, (n_in, n_out) in enumerate(zip(self.layersizes, self.layersizes[1:]), 1): self.W[l] = np.random.randn(n_in, n_out) * sigma self.b[l] = np.random.randn(1, n_out) * sigma def forward(self, x): """Feed forward using existing `W` and `b`, and overwrite the result variables `a` and `z` Args: x (numpy.ndarray): Input data to feed forward """ self.a[0] = x for l, func in enumerate(self.activations, 1): # z = W a + b, with `a` as output from previous layer # `W` is of size rxs and `a` the size sxn with n the number of data # instances, `z` the size rxn, `b` is rx1 and broadcast to each # column of `z` self.z[l] = (self.a[l-1] @ self.W[l]) + self.b[l] # a = g(z), with `a` as output of this layer, of size rxn self.a[l] = func(self.z[l]) return self.a[-1] def backward(self, y, yhat): """back propagation using NN output yhat and the reference output y, generates dW, dz, db, da """ # first `da`, at the output self.da[-1] = self.lossderiv(y, yhat) for l, func in reversed(list(enumerate(self.derivatives, 1))): # compute the differentials at this layer self.dz[l] = self.da[l] * func(self.z[l]) self.dW[l] = self.a[l-1].T @ self.dz[l] self.db[l] = np.mean(self.dz[l], axis=0, keepdims=True) self.da[l-1] = self.dz[l] @ self.W[l].T def update(self, eta): """Updates W and b Args: eta (float): Learning rate """ for l in range(1, len(self.W)): self.W[l] -= eta * self.dW[l] self.b[l] -= eta * self.db[l] # Make data: Two circles on x-y plane as a classification problem X, y = make_circles(n_samples=1000, factor=0.5, noise=0.1) y = y.reshape(-1,1) # our model expects a 2D array of (n_sample, n_dim) # Build a model model = mlp(layersizes=[2, 4, 3, 1], activations=[relu, relu, sigmoid], derivatives=[drelu, drelu, dsigmoid], lossderiv=d_cross_entropy) model.initialize() yhat = model.forward(X) loss = cross_entropy(y, yhat) score = accuracy_score(y, (yhat > 0.5)) print(f"Before training - loss value {loss} accuracy {score}") # train for each epoch n_epochs = 150 learning_rate = 0.005 for n in range(n_epochs): model.forward(X) yhat = model.a[-1] model.backward(y, yhat) model.update(learning_rate) loss = cross_entropy(y, yhat) score = accuracy_score(y, (yhat > 0.5)) print(f"Iteration {n} - loss value {loss} accuracy {score}") |
In the next lesson, you will discover the use of differentiation to find the optimal value of a function.
Lesson 06: Optimization
In this lesson, you will learn an important use of differentiation.
Because the differentiation of a function is the rate of change, we can make use of differentiation to find the optimal point of a function.
If a function attained its maximum, we would expect it to move from a lower point to the maximum, and if we move further, it falls to another lower point. Hence at the point of maximum, the rate of change of a function is zero. And vice versa for the minimum.
As an example, consider $f(x)=x^3-2x^2+1$. The derivative is $f'(x) = 3x^2-4x$ and $f'(x)=0$ at $x=0$ and $x=4/3$. Hence these positions of $x$ are where $f(x)$ is at its maximum or minimum. We can visually confirm it by plotting $f(x)$ (see the plot in Lesson 01).
Your task
Consider the function $f(x)=\log x$ and find its derivative. What will be the value of $x$ when $f'(x)=0$? What does it tell you about the maximum or minimum of the log function? Try to plot the function of $\log x$ to visually confirm your answer.
In the next lesson, you will discover the application of this technique in finding the support vector.
Lesson 07: Support vector machine
In this lesson, you will learn how we can convert support vector machine into an optimization problem.
In a two-dimensional plane, any straight line can be represented by the equation:
$$ax+by+c=0$$
in the $xy$-coordinate system. A result from the study of coordinate geometry says that for any point $(x_0,y_0)$, its distance to the line $ax+by+c=0$ is:
$$
\frac{\vert ax_0+by_0+c \vert}{\sqrt{a^2+b^2}}
$$
Consider the points (0,0), (1,2), and (2,1) in the $xy$-plane, in which the first point and the latter two points are in different classes. What is the line that best separates these two classes? This is the basis of a support vector machine classifier. The support vector is the line of maximum separation in this case.
To find such a line, we are looking for:
$$
\begin{aligned}
\text{minimize} && a^2 + b^2 \\
\text{subject to} && -1(0a+0b+c) &\ge 1 \\
&& +1(1a+2b+c) &\ge 1 \\
&& +1(2a+1b+c) &\ge 1
\end{aligned}
$$
The objective $a^2+b^2$ is to be minimized so that the distances from each data point to the line are maximized. The condition $-1(0a+0b+c)\ge 1$ means the point (0,0) is of class $-1$; similarly for the other two points, they are of class $+1$. The straight line should put these two classes in different sides of the plane.
This is a constrained optimization problem, and the way to solve it is to use the Lagrange multiplier approach. The first step in using the Lagrange multiplier approach is to find the partial differentials of the following Lagrange function:
$$
L = a^2+b^2 + \lambda_1(-c-1) + \lambda_2 (a+2b+c-1) + \lambda_3 (2a+b+c-1)
$$
and set the partial differentials to zero, then solve for $a$, $b$, and $c$. It would be too lengthy to demonstrate here, but we can use SciPy to find the solution to the above numerically:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import numpy as np from scipy.optimize import minimize def objective(w): return w[0]**2 + w[1]**2 def constraint1(w): "Inequality for point (0,0)" return -1*w[2] - 1 def constraint2(w): "Inequality for point (1,2)" return w[0] + 2*w[1] + w[2] - 1 def constraint3(w): "Inequality for point (2,1)" return 2*w[0] + w[1] + w[2] - 1 # initial guess w0 = np.array([1, 1, 1]) # optimize bounds = ((-10,10), (-10,10), (-10,10)) constraints = [ {"type":"ineq", "fun":constraint1}, {"type":"ineq", "fun":constraint2}, {"type":"ineq", "fun":constraint3}, ] solution = minimize(objective, w0, method="SLSQP", bounds=bounds, constraints=constraints) w = solution.x print("Objective:", objective(w)) print("Solution:", w) |
It will print:
|
1 2 |
Objective: 0.8888888888888942 Solution: [ 0.66666667 0.66666667 -1. ] |
The above means the line to separate these three points is $0.67x + 0.67y – 1 = 0$. Note that if you provided $N$ data points, there would be $N$ constraints to be defined.
Your Task
Let’s consider the points (-1,-1) and (-3,-1) to be the first class together with (0,0) and point (3,3) to be the second class together with points (1,2) and (2,1). In this problem of six points, can you modify the above program and find the line that separates the two classes? Don’t be surprised to see the solution remain the same as above. There is a reason for it. Can you tell?
Post your answer in the comments below. I would love to see what you come up with.
This was the final lesson.
The End!
(Look How Far You Have Come)
You made it. Well done!
Take a moment and look back at how far you have come.
You discovered:
- What is differentiation, and what it means to a function
- What is integration
- How to extend differentiation to a function of vector argument
- How to do differentiation on a vector-valued function
- The role of Jacobian in the backpropagation algorithm in neural networks
- How to use differentiation to find the optimum points of a function
- Support vector machine is a constrained optimization problem, which would need differentiation to solve
Summary
How did you do with the mini-course?
Did you enjoy this crash course?
Do you have any questions? Were there any sticking points?
Let me know. Leave a comment below.
Get a Handle on Calculus for Machine Learning!

Feel Smarter with Calculus Concepts
...by getting a better sense on the calculus symbols and terms
Discover how in my new Ebook:
Calculus for Machine Learning
It provides self-study tutorials with full working code on:
differntiation, gradient, Lagrangian mutiplier approach, Jacobian matrix,
and much more...






{kind=link}
Will I be getting a certificate or something to show that I have completed this ‘calculus for machine learning’ course?
If yes, then I’ll be taking this course without any second thoughts!
Hi Harlincoln…there is no certificate, however you will gain much more confidence with calculus upon its completion.
Jason,
when I entered the code for the first mini I got the error message:
AttributeError: ‘AxesSubplot’ object has no attribute ‘plt’
Did a search in Stack Overlfow and Googled it…could not find a solution…Using Jupyter Notebooks (anaconda) and Windows 10 as OS. My notebook environment is py3-TF2.0.
What did I do wrong?
Hi Charlie…The following resource may be of some help:
https://www.statology.org/module-matplotlib-has-no-attribute-plot/
Hi, I enjoyed this mini-course. I found it to be extremely informative and useful. I could do every lesson but for the last lesson, I got the same solution as above, but what is the reason behind the same solution?
For lesson 6, I found the maximum was at x=infinity, and for lesson 5, the Jacobian matrix is the dz[ l ] matrix.
Lesson 4, Gradient vector at (1,1) is (2.000070710675876,2.0000707106758764). And I am not able to share the plots here.
Thank you for this course.
Regards
Hi,
Can somebody explain how I can represent the following notation like a mathematical notation. What math tool to use to visualize this expression.
$$f'(x) = \lim_{\delta x\to 0} \frac{f(x+\delta x)-f(x)}{\delta x}$$
Thanks
GL
Hi Srini…The following tool may assist you:
https://www.tutorialspoint.com/latex_equation_editor.htm
Thank you very much for such a good explanation with examples
Hi!
This is what I came up with for lesson 2
def f(x):
return (3*x**2) – (4*x)
def ff(x):
return (x**3) – (2*x**2)
delta_x = 0.1
x = np.arange(-10,10,delta_x)
fx = f(x) * delta_x
y = fx.cumsum()
plt.plot(x, y)
plt.plot(x, ff(x))
plt.show
Thank you for the feedback Jakob!
When I entered the integral I only got back the upper curve; the program did not reproduce the lower curve…
Hi Charles…Did you copy and paste the code or type it in?
Hi,
I have a question about Lesson 03, the second code box, line 10: Shouldn’t that read “fy = 3*yv**2” since the differentiation of y^3 is 3y^2?
Hi Heinz…Please post the exact line you are referring to.
Heinz was talking about these lines
# Compute the gradient of f(x,y)
fx = 2*xv
fy = 2*yv
This should actually be
# Compute the gradient of f(x,y)
fx = 2*xv
fy = 3*yv**2
The resulting vector field would then actually correspond to the plot of the function plot would then actually correspond to the function from above ( f(x,y) = x^2 + y^3 )
In any case, thank you for the tutorial, it has been very useful so far.
Thank you for your feedback!
The result will not coincide, because the function has a cube root,a square root and a constant.That is my thinking Jason help me.
Jason@machinelearningmastery.com.
Hi Stephen…Please specify which result you see an issue with so that we may better assist you.
Hello,
In lesson 3, it isn’t obvious to me why delta x is calculated from multiplying the step size and sine of an angle instead of cosine of an angle. I thought x-component comes from multiplying by the cosine of an angle. I’d be grateful if you can find time to explain a bit. Thanks!
Hi Thin…the derivative of sine is cosine.
#!/home/emad/anaconda3/bin/python
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return 3 * x**2 – 4 * x
def finteg(x):
return x**3 – 2 * x**2
def compute_area_under_curve():
# Set up x from -10 to 10 with small steps
delta_x = 0.1
x = np.arange(-10, 10, delta_x)
# Find f(x) * delta_x
fx = f(x) * delta_x
# Compute the running sum
y = fx.cumsum()
return x, y
def compute_antiderivative_points():
delta_x = 0.1
x = np.arange(-10, 10, delta_x)
y = finteg(x)
return x, y
def plot_curve(x, y, x1, y1):
plt.plot(x, y, c=”r”, alpha=0.5, label=”antiderivative”)
plt.plot(x1, y1, c=”b”, alpha=0.5, label=”area”)
plt.legend()
plt.show()
def main():
# Plot antiderivative
x1, y1 = compute_antiderivative_points()
# Plot area under curve
x, y = compute_area_under_curve()
plot_curve(x, y, x1, y1)
if __name__ == “__main__”:
main()
Keep up the great work Emad!
import numpy as np
def f(x, y):
return x**2+y**2
angles=np.arange(0, 360, 0.1)
x,y=1, 1
step=0.0001
maxdf, maxangle= -np.inf, 0
for angle in angles:
rad = angle * np.pi / 180
dx, dy= np.sin(rad)*step, np.cos(rad)*step
df = (f(x+dx, y+dy) – f(x,y))/step
if df > maxdf:
maxdf, maxangle= df, angle
dx,dy=np.sin(maxangle*np.pi/180), np.cos(maxangle*np.pi/180)
gradx,grady=dx*maxdf, dy*maxdf
print(f”Max rate of change at {maxangle} degrees”)
print(f”Gradient vector at ({x},{y}) is ({dx*maxdf},{dy*maxdf})”)
Max rate of change at 359.90000000000003 degrees
Gradient vector at (1,1) is (-0.0034847336058503437,1.9966032560898956)
I checked code with ur code nothing is incorrect but then also I’m getting above incorrect ans can u tell me what’s wrong I’m doing??
Hi Sahil…Thanks for asking.
I’m eager to help, but I just don’t have the capacity to debug code for you.
I am happy to make some suggestions:
Consider aggressively cutting the code back to the minimum required. This will help you isolate the problem and focus on it.
Consider cutting the problem back to just one or a few simple examples.
Consider finding other similar code examples that do work and slowly modify them to meet your needs. This might expose your misstep.
Consider posting your question and code to StackOverflow.
Hello,
I have recently completed the section on derivatives and I have implemented the differentiation formula as explained in the lesson. My code gave me some great outputs and I have been able to compute the derivative for all the T-ratios successfully. My code however, blows up when I try the exponential function. I checked my list of values for e^x and found out that the list grows quickly as expected for an exponential with values reaching as high as 10^43.
I am aware of a term called catastrophic cancellation which is very common in numerical methods and I think because the step is too small and the input value is so large, the difference in the numerator of the limit blows up and the system saturates to 0. Is there a way to verify whether this is really happening? In case, if this is what is going on, is there a way to get around this problem?
Hi Sumit…please elaborate more on what you mean by your code “blowing up” so that may better assist you.
thanks a lot for a such splendid tutorials.
I want your help to find subject for my master thesis in computer vision or NLP If possible.
Hi Alradaee…While we cannot recommend a subject for your research, we do recommend the following resource as a starting point:
https://machinelearningmastery.com/deep-learning-for-nlp/