In this post, we will take a tour of the most popular machine learning algorithms.
It is useful to tour the main algorithms in the field to get a feeling of what methods are available.
There are so many algorithms that it can feel overwhelming when algorithm names are thrown around and you are expected to just know what they are and where they fit.
I want to give you two ways to think about and categorize the algorithms you may come across in the field.
The first is a grouping of algorithms by their learning style.
The second is a grouping of algorithms by their similarity in form or function (like grouping similar animals together).
Both approaches are useful, but we will focus in on the grouping of algorithms by similarity and go on a tour of a variety of different algorithm types.
After reading this post, you will have a much better understanding of the most popular machine learning algorithms for supervised learning and how they are related.
Kick-start your project with my new book Master Machine Learning Algorithms, including step-by-step tutorials and the Excel Spreadsheet files for all examples.
Let’s get started.
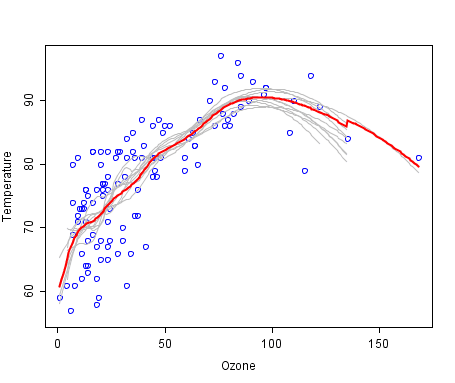
A cool example of an ensemble of lines of best fit. Weak members are grey, the combined prediction is red. Plot from Wikipedia, licensed under public domain.
Algorithms Grouped by Learning Style
There are different ways an algorithm can model a problem based on its interaction with the experience or environment or whatever we want to call the input data.
It is popular in machine learning and artificial intelligence textbooks to first consider the learning styles that an algorithm can adopt.
There are only a few main learning styles or learning models that an algorithm can have and we’ll go through them here with a few examples of algorithms and problem types that they suit.
This taxonomy or way of organizing machine learning algorithms is useful because it forces you to think about the roles of the input data and the model preparation process and select one that is the most appropriate for your problem in order to get the best result.
Let’s take a look at three different learning styles in machine learning algorithms:
1. Supervised Learning
Input data is called training data and has a known label or result such as spam/not-spam or a stock price at a time.
A model is prepared through a training process in which it is required to make predictions and is corrected when those predictions are wrong. The training process continues until the model achieves a desired level of accuracy on the training data.
Example problems are classification and regression.
Example algorithms include: Logistic Regression and the Back Propagation Neural Network.
2. Unsupervised Learning
Input data is not labeled and does not have a known result.
A model is prepared by deducing structures present in the input data. This may be to extract general rules. It may be through a mathematical process to systematically reduce redundancy, or it may be to organize data by similarity.
Example problems are clustering, dimensionality reduction and association rule learning.
Example algorithms include: the Apriori algorithm and K-Means.
3. Semi-Supervised Learning
Input data is a mixture of labeled and unlabelled examples.
There is a desired prediction problem but the model must learn the structures to organize the data as well as make predictions.
Example problems are classification and regression.
Example algorithms are extensions to other flexible methods that make assumptions about how to model the unlabeled data.
Overview of Machine Learning Algorithms
When crunching data to model business decisions, you are most typically using supervised and unsupervised learning methods.
A hot topic at the moment is semi-supervised learning methods in areas such as image classification where there are large datasets with very few labeled examples.
Algorithms Grouped By Similarity
Algorithms are often grouped by similarity in terms of their function (how they work). For example, tree-based methods, and neural network inspired methods.
I think this is the most useful way to group algorithms and it is the approach we will use here.
This is a useful grouping method, but it is not perfect. There are still algorithms that could just as easily fit into multiple categories like Learning Vector Quantization that is both a neural network inspired method and an instance-based method. There are also categories that have the same name that describe the problem and the class of algorithm such as Regression and Clustering.
We could handle these cases by listing algorithms twice or by selecting the group that subjectively is the “best” fit. I like this latter approach of not duplicating algorithms to keep things simple.
In this section, we list many of the popular machine learning algorithms grouped the way we think is the most intuitive. The list is not exhaustive in either the groups or the algorithms, but I think it is representative and will be useful to you to get an idea of the lay of the land.
Please Note: There is a strong bias towards algorithms used for classification and regression, the two most prevalent supervised machine learning problems you will encounter.
If you know of an algorithm or a group of algorithms not listed, put it in the comments and share it with us. Let’s dive in.
Regression Algorithms
Regression is concerned with modeling the relationship between variables that is iteratively refined using a measure of error in the predictions made by the model.
Regression methods are a workhorse of statistics and have been co-opted into statistical machine learning. This may be confusing because we can use regression to refer to the class of problem and the class of algorithm. Really, regression is a process.
The most popular regression algorithms are:
Ordinary Least Squares Regression (OLSR)
Linear Regression
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS)
Instance-based Algorithms
Instance-based learning model is a decision problem with instances or examples of training data that are deemed important or required to the model.
Such methods typically build up a database of example data and compare new data to the database using a similarity measure in order to find the best match and make a prediction. For this reason, instance-based methods are also called winner-take-all methods and memory-based learning. Focus is put on the representation of the stored instances and similarity measures used between instances.
The most popular instance-based algorithms are:
k-Nearest Neighbor (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM)
Locally Weighted Learning (LWL)
Support Vector Machines (SVM)
Regularization Algorithms
An extension made to another method (typically regression methods) that penalizes models based on their complexity, favoring simpler models that are also better at generalizing.
I have listed regularization algorithms separately here because they are popular, powerful and generally simple modifications made to other methods.
The most popular regularization algorithms are:
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net
Least-Angle Regression (LARS)
Decision Tree Algorithms
Decision tree methods construct a model of decisions made based on actual values of attributes in the data.
Decisions fork in tree structures until a prediction decision is made for a given record. Decision trees are trained on data for classification and regression problems. Decision trees are often fast and accurate and a big favorite in machine learning.
The most popular decision tree algorithms are:
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5 and C5.0 (different versions of a powerful approach)
Bayesian methods are those that explicitly apply Bayes’ Theorem for problems such as classification and regression.
The most popular Bayesian algorithms are:
Naive Bayes
Gaussian Naive Bayes
Multinomial Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN)
Bayesian Network (BN)
Clustering Algorithms
Clustering, like regression, describes the class of problem and the class of methods.
Clustering methods are typically organized by the modeling approaches such as centroid-based and hierarchal. All methods are concerned with using the inherent structures in the data to best organize the data into groups of maximum commonality.
The most popular clustering algorithms are:
k-Means
k-Medians
Expectation Maximisation (EM)
Hierarchical Clustering
Association Rule Learning Algorithms
Association rule learning methods extract rules that best explain observed relationships between variables in data.
These rules can discover important and commercially useful associations in large multidimensional datasets that can be exploited by an organization.
The most popular association rule learning algorithms are:
Apriori algorithm
Eclat algorithm
Artificial Neural Network Algorithms
Artificial Neural Networks are models that are inspired by the structure and/or function of biological neural networks.
They are a class of pattern matching that are commonly used for regression and classification problems but are really an enormous subfield comprised of hundreds of algorithms and variations for all manner of problem types.
Note that I have separated out Deep Learning from neural networks because of the massive growth and popularity in the field. Here we are concerned with the more classical methods.
The most popular artificial neural network algorithms are:
Perceptron
Multilayer Perceptrons (MLP)
Back-Propagation
Stochastic Gradient Descent
Hopfield Network
Radial Basis Function Network (RBFN)
Deep Learning Algorithms
Deep Learning methods are a modern update to Artificial Neural Networks that exploit abundant cheap computation.
They are concerned with building much larger and more complex neural networks and, as commented on above, many methods are concerned with very large datasets of labelled analog data, such as image, text. audio, and video.
The most popular deep learning algorithms are:
Convolutional Neural Network (CNN)
Recurrent Neural Networks (RNNs)
Long Short-Term Memory Networks (LSTMs)
Stacked Auto-Encoders
Deep Boltzmann Machine (DBM)
Deep Belief Networks (DBN)
Dimensionality Reduction Algorithms
Like clustering methods, dimensionality reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarize or describe data using less information.
This can be useful to visualize dimensional data or to simplify data which can then be used in a supervised learning method. Many of these methods can be adapted for use in classification and regression.
Uniform Manifold Approximation and Projection for Dimension Reduction (UMAP)
Ensemble Algorithms
Ensemble methods are models composed of multiple weaker models that are independently trained and whose predictions are combined in some way to make the overall prediction.
Much effort is put into what types of weak learners to combine and the ways in which to combine them. This is a very powerful class of techniques and as such is very popular.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Weighted Average (Blending)
Stacked Generalization (Stacking)
Gradient Boosting Machines (GBM)
Gradient Boosted Regression Trees (GBRT)
Random Forest
Other Machine Learning Algorithms
Many algorithms were not covered.
I did not cover algorithms from specialty tasks in the process of machine learning, such as:
Feature selection algorithms
Algorithm accuracy evaluation
Performance measures
Optimization algorithms
I also did not cover algorithms from specialty subfields of machine learning, such as:
This tour of machine learning algorithms was intended to give you an overview of what is out there and some ideas on how to relate algorithms to each other.
I’ve collected together some resources for you to continue your reading on algorithms. If you have a specific question, please leave a comment.
Other Lists of Machine Learning Algorithms
There are other great lists of algorithms out there if you’re interested. Below are few hand selected examples.
List of Machine Learning Algorithms: On Wikipedia. Although extensive, I do not find this list or the organization of the algorithms particularly useful.
Machine Learning Algorithms Category: Also on Wikipedia, slightly more useful than Wikipedias great list above. It organizes algorithms alphabetically.
CRAN Task View: Machine Learning & Statistical Learning: A list of all the packages and all the algorithms supported by each machine learning package in R. Gives you a grounded feeling of what’s out there and what people are using for analysis day-to-day.
Top 10 Algorithms in Data Mining: on the most popular algorithms for data mining. Another grounded and less overwhelming take on methods that you could go off and learn deeply.
How to Study Machine Learning Algorithms
Algorithms are a big part of machine learning. It’s a topic I am passionate about and write about a lot on this blog. Below are few hand selected posts that might interest you for further reading.
How to Learn Any Machine Learning Algorithm: A systematic approach that you can use to study and understand any machine learning algorithm using “algorithm description templates” (I used this approach to write my first book).
How to Research a Machine Learning Algorithm: A systematic approach that you can use to research machine learning algorithms (works great in collaboration with the template approach listed above).
How to Investigate Machine Learning Algorithm Behavior: A methodology you can use to understand how machine learning algorithms work by creating and executing very small studies into their behavior. Research is not just for academics!
Sometimes you just want to dive into code. Below are some links you can use to run machine learning algorithms, code them up using standard libraries or implement them from scratch.
Jason,
I enjoy your blog and your writing style of explaining a complex topic in simple terms.
I have one request. Do you have a cheat sheet in choosing the right algorithm. I would like to know when to use what ML algorithm as a starters guideline?
Thank you,
Bk
An algorithm is a procedure. Like learning a tree from data. The outcome of an algorithm is a model or a classifier, like the tree used to make predictions.
Then I don’t quite understand the listing of both Back-Propagation and Hopfield Network under the title of “Artificial Neural Network Algorithms”. Back-Propagation is clearly a training algorithm, whereas a Hopfield Network is probably a classifier?
Hi Jason, very interesting article … I am bit of newbie … i come across “machine learning algorithms”, “machine learning methods” and “machine learning models” phrases.
I think i understand algorithm and models. What is specific nuance of “method”?
Yes Please
Release a ebook on reinforcement learning and Unsupervised Deep learning too . You are awesome Jason. You made things very simple for us to understand this difficult concepts .
Where do newbies (with no analytics/stats background) start learning about this algorithms? And more so how does one use them with Big Data tools like Hadoop?
Hi qnaguru, I’d recommend starting small and experimenting with algorithms on small datasets using a tool like Weka. It’s a GUI tool and provides a bunch of standard datasets and algorithms out of the box.
I’d suggest you build up some skill on small datasets before moving onto big data tools like Hadoop and Mahout.
I would also read a couple of books to give you some background into the possibilities and limitations. Nate Silver; The Signal and The Noise & Danial Kahneman; Thinking Fast and Slow.
The best written one I have found is: “The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition”. However you probably need to have some background on maths/stats/computing before reading that (especially if you are planning to implement them too). For general algorithms implementation I recommend reading also “Numerical Recipes 3rd Edition: The Art of Scientific Computing”.
It’s a good point. Computers are fast enough that you can enumerate the search space faster than a GA can converge (at least with the classical toy problems).
Thanks Alex, you can also check out my 2011 book of algorithm recipes titled Clever Algorithms: Nature-Inspired Programming Recipes. In it I cover 5 different estimation of distribution algorithms and 10 different evolutionary algorithms.
Hi guys, this is great! What about recommendation systems? I’m fascinated about, how netflix, amazon and others websites can recommend items based on my taste.
Where does imagination lie? Would it be a Unsupervised Feedback Learning? Maybe its Neural Deep Essemble Networks. I presume dreaming = imagination while sleeping, hence daydreaming is imagining of new learning algorithms 🙂
I lot of people swear by this chart for helping you narrow down which machine learning approach to take: http://scikit-learn.org/stable/_static/ml_map.png. It doesn’t seem to cover all the types you list in your article. Perhaps a more thorough chart would be useful.
This is nice and useful…I have been feeling heady with too much data and this kinda gives me a menu from which to choose what all is on offer to help me make sense of stuff 🙂 Thanks
You might want to include entropy-based methods in your summary. I use relative-entropy based monitoring in my work to identify anomalies in time series data. This approach has a better recall rate and lower false positive rates when tested with synthetic data using injected outliers. Just an idea, your summary is excellent for such a high level conceptual overview.
Thank’s for this tour, it is very useful ! But I disagree with you for the LDA method, which is in the Kernel Methods. First of all, by LDA, do you mean Linear Discriminant Analysis ? Because if it’s not, the next parts of my comment are useless :p
If you are talking about this method, then you should put KLDA (which stand for Kernel LDA) and not simply LDA. Because LDA is more a dimension reduction method than a kernel method (It finds the best hyperplane that optimize the Fisher discriminant in order to project data on it).
Next, I don’t know if we can view the RBF as a real machine learning method, it’s more a mapping function I think, but it is clearly used for mapping to a higher dimension.
Except these two points, the post is awesome ! Thank’s again.
In my humble opinion, LDA and the likes of such algorithms can make a separate category by themselves as they both reduce dimensionality and can be used as classifiers.
@Vincent, I think he mentions Radial Based Network or RBN, which is artificial neural network (ANN) that uses radial basis functions [1]. Jason is correct in placing it under ANN classification.
Great post, but I agree with Vincent. Kernel Methods are not machine learning methods by themselve, but more an extension that allows to overcome some difficulties encountered when input data are not linearly separable. SVM and LDA are not Kernel-based, but their definition can be adapted to make use of the famous kernel-trick, giving birth to KSVM and KLDA, that are able to separate data linearly in a higher-dimensional space. Kernel trick can be applied to a wide variety of Machine learning methods:
– LDA
– SVM
– PCA
– KMeans
and the list goes on…
Moreover, I don’t think that RBF can be considered a machine learning method. It is a kernel function used alongside the kernel trick to project the data in a high-dimensional space. So the listing in “Kernel methods” seems to have a typing error :p
Last point, don’t you think LDA could be added to the “Dimensionality Reduction” category ? In fact, it’s more an open question but, mixture methods (clustering) and factor analysis could be considered “Dimensionality Reduction methods” since data can be labeled either by it’s cluster id, or its factors.
Thanks again for this post, giving an overview of machin learning methods is a great thing.
I had this confusion and had to look it up.
– Radial Based Function (RBF) can be used as a kernel
– Radial Based Network (RBN) is a artificial neural network that uses radial basis functions
Hi qnaguru, I have collected some nice reference books to start digging Machine learning. I would suggest you to start with “Introduction to statistical learning” and after that you can look into “The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition”, “Probabilistic Machine Learning by David Barber”.
Very nice taxonomy of methods. Two small quibbles, both in the Decision Tree section.
1) MARS isn’t a tree method, it’s a spline method. You list it already in the regression group, though could even go in the regularization group. (not a natural fit in any, IMHO).
2) Random Forests is an ensemble method and sticks out a bit in the trees group. Yes, they are trees, but so is the MART (TreeNet) and some flavors of Adaboost. Since you already have an ensembles and RF is already there, I think you can safely remove it from the Trees.
Again, you’ve done a great job with this list. Congrats!
Greate article. my knowledge in Machne learning is improving in bredth not in depth.how should i improve my learning.i have done some real time implementations with Regression analysis.and Random forest.and also i am atteding coursera courses.how would i get real time experience on ML R with Hadoop.
Thanks Mr.Brownly for your useful guide.Where can we find the implementations of all of these algorithms?I’ve installed weka but it doesnot have some of these algorithms
Great Post!
I am currently learning Sparse Coding. And I have difficulty putting Sparse Coding into the categories you created.
–What is your idea about Sparse Coding?
–Which category should it belong to?
Can you provide some suggestions for learning sparse coding
— what mathematical foundations should I have?
— any good tutorial resources?
— can you suggest a learning roadmap
I am now taking convex optimization course. Is it a correct roadmap?
Where does ranking fit into the machine learning algorithms? Is it by any chance under some of the categories mentioned in the article? The only time I find ranking mentioned in relation to machine learn is when I specifically search for ranking, none of the machine learning articles discuss it.
What methods/algorithms are suitable for applying to trading patterns analysis. I mean looking at the trading graphs of the last 6 months (e.g. SPY). Currently, I am looking at the graphs visually. Can an algorithm come to my aid (I am currently enrolled in an online data mining course) ?
Great list. Definitely cleared things up for me, Jason! I do have a question concerning Batch Gradient Descent and the Normal Equation. Are these considered Estimators?
I would love to see a post that addresses the different types of estimators / optimizers that could be used for each of these algorithms that is simple to understand. Also where does feature scaling (min max scaling & standardization) and other things fall into all of this? Are they also optimizers? So many things!
Intrigued by your comments above about recommendation systems ie.
“I would call recommender a higher-order system that internally is solving regression or classification problems.” and,
“You can break a recommender down into a classification or a regression problem.”
Could you please expand on your thought process? In general, I find that people talk about building or wanting a “classifier” since it is the de-jeure buzzword (and related to deep learning) when in fact, a recommender or something else will do the job. Anyway, great discussion.
Hi Jason,
I’m trying to implement object detection through computer vision through Machine Learning but I’m hitting a wall when trying to find a suitable approach. Can you suggest which kind of algorithm will help me? I’d like to research more on it.
Hi.. i am working on finding the missing values by using machine learning approaches..
Any body can suggest new methods to be used..
I am a research scholar
just a small question: In my opinion k-NN, SVM, Naive Bayes, Decision Trees, MaxEnt (even if it’s not mentioned here) are all considered to be instance-based, isn’t it right?
i started reading and i feel i don’t succeed to understand it.
I don’t understand which algorithm is good for which type of problem.
I think that little example for each algorithm will be useful.
Jason: Nice addition of the simple graphic to each of the “families” of machine learning algorithms. This is a change from what I recall was a previous version of this post. The diagram helps visualize the activity of the family and thus aid developing an internal model of how the members of the family operate.
The Bayesian Algorithms graphic should be reworked. In particular,
1) the area under both density functions should integrate to one. While no scale is provided, the prior appears to integrate to a much smaller number than the posterior.
2) in general, a posterior is narrower / more concentrated than a prior given an observation.
3) (interpreting the baseline as zero density) a posterior typically concentrates the probability of the prior in a smaller range; it never “moves” probability to a range where the prior density was zero.
Can you recommend any algorithm to my problem below please?
I need one that does time series analysis that does Bayesian analysis too.
For test set,
I’m given data for hourly price movements for half a day, and tasked to predict for the second half of day. Clearly a time series (TS) problems.
But on top of that I’m also given information on 10 discrete factors for each day in the training and testing set.
Do you know of any algo that creates multiple TS models conditional upon the values (or bands) of the various discrete factors at the onset?
Hi Jason
I would be very grateful if you could let me know which neural network is useful for multivariate time series classification.For example, classifying patient and healthy people when we have multiple time series of each feature.
Did you find any solution for this? I have the same problem. I was thinking about convolution neural networks and use the feature space to create a heatmap image and use that as input. For example, each row in the pixel image will be a RGB value mapped from a feature and each column will be a specific time point. That way you have all multivariate time series in one image. You might need to reduce the dimensionality of the time interval though if they are very high, alternatively take partitions of the time interval in sections of the image (first 500 time points in the upper half of the image for example). I have no idea if this would work, just some thoughts…
I have a good background in artificial intelligence and machine learning, and I must say this is a really good list, I would not have done the categories any other way, it’s very close to perfection. Very pertinent information.
However, it would be nice to include Learning Style categories for reinforcement learning, genetic algorithms and probabilistic models, (but meanwhile you already mention them at the end so this gives a good pointer for the readers).
The ending links are very good, particularly the “How to Study Machine Learning Algorithms”. It would be also nice to put a list of machine learning online courses (coursera, udacity, etc. – there’s even a course by Geoffrey Hinton!), and links to tutorials on how to check and verify that your ML algo works well on your dataset (cross-validation, generalization curve, ROC, confusion matrix, etc.).
Also, thank’s to previous commenters, your comments are also very pertinent and a good addition to the article!
To develop my suggestion for adding Learning Style categories: I think these classes of learning algorithms should be added, since they are used more and more (albeit being less popular than the currently listed methods) and they cannot be replaced by other classes of learning, they bring their own capabilities:
– Reinforcement learning models a reward/punishment way of learning. This allows to explore and memorize the states of an environment or the actions with a way very similar on how the actual brain learns using the pleasure circuit (TD-Learning). It also has a very useful ability: blocking, which naturally allows a reinforcement learning model to only use the stimuli and information that is useful to predict the reward, the useless stimuli will be “blocked” (ie, filtered out). This is currently being used in combination with deep learning to model more biologically plausible and powerful neural networks, that can for example maybe solve the Go game problem (see Google’s DeepMind AlphaGo).
– Genetic algorithms, as a previous commenter said, are best used when facing a very high dimension problem or multimodal optimizations (where you have multiple equally good solutions, aka multiple equilibriums). Also, a big advantage is that genetic algorithms are derivative-free cost optimization methods, so they are VERY generic and can be applied to virtually any problem and find a good solution (even if other algorithms may find better ones).
– Probabilistic models (eg, monte-carlo, markov chains, markovian processes, gaussian mixtures, etc.) and probabilistic graphical models (eg, bayesian networks, credal networks, markov graphs, etc.) are great for uncertain situations and for inference, since they can manipulate uncertain values and hidden variables. Graphical models are kinda close to deep learning, but they are more flexible (it’s easier to define a PGM from a semantic of what you want to do than a deep learning network).
– Maybe mention at the end Fuzzy Logic, which is not a machine learning algorithm per se but is close to probabilistic models, except that it can be seen as a superset that also allows to define a possibility value (see possibilistic logic, and the works by Edwin Jaynes).
I’m just getting started on learning about machine learning algorithms. I still need some time to digest what I’ve read here. My background comes from finance/investing and therefore I’ve been trying to learn more about how machine learning is used in investing. I come from a fundamental investing background and therefore I’m curious if you have an insight. Given there are so many algorithms (and different branches https://www.youtube.com/watch?v=B8J4uefCQMc which I thought this was an interesting video) I wanted to ask how do you know which type of branch/algorithm in machine learning would be more useful for investing?
perumahan di semarang atasJuly 13, 2016 at 5:07 pm#
Excellent post. I was checking constantly this blog and I’m impressed!
Very useful information particularly the last part :
) I care for such information a lot. I was looking for this
certain information for a long time. Thank you and good luck.
Appreciating the dedication you put into your site and
detailed information you offer. It’s nice to come across
a blog every once in a while that isn’t the same old
rehashed material. Excellent read! I’ve bookmarked your site and I’m including your RSS feeds
to my Google account.
You listed logistic regression as an regression algorithm. I always believed method is the base of neuronal networks, and thus more a classifier than a regression algorithm.
I fully agree with your opinion. The outcome of a (simple) logistic regression is binary and the algorithm should be part of a classification method, like the neural networks you mentioned.
Hello sir. Thank you so much for your help. But as we know Machine Learning require a strong ‘Math’ background. I am very interested math but, i am little bit week in that. So,I want good understandable resources for math required in Machine Learning. Thank you.
I teach an approach to getting started without the theory or math understanding. By treating ML as a tool you can use to solve problems and deliver value. The deep mathematical understanding can come later if and when you need it in order to deliver better solutions.
Jason, thanks for the write-up. When it comes it supervised learning using regression analysis all examples I have found deal with simple scalar inputs and perhaps multiple features of one input. What if an input data is more complicated, say two values where one is a quadratic curve and another is a real number? I have data that consists of two pairs of values: univariate quadratic function (represented as quadratic functions or an array of points) and a real value R. Each quadratic function F rather predictably changes its skew/shape based on its real value pair R and becomes(changes) into F’. Given a new real value R’, it becomes F” and so on. This is the training data and I have about thousand pairs of functions and real values. Based on a current function F and a new real value R can we predict the shape of F’ using supervised learning and regression analysis? If so, what should I look out for? Any help would be much appreciated!
What about Best-subset Selection, Stepwise selection, Backward Selection as Dimension reduction?? This is Regularization methods but you also can use it as shinkage dimension.
This is useful, but it could be made more useful for someone new to the field, specifcally in the section where algorithms are grouped by similarity, by clarifying exactly what is being learned. Eg Regression algorithms learn the curve that best fits the data points, Bayesian learning algorithms learn the parameters and structure of a Bayesian network, Decision Tree algorithms learn the structure of the decision tree, etc.
Additionally some kind of task based classification would be helpful. Eg if you’re trying to classify then the following kinds of ML algorithms are best, if you’re trying to do inference then rule learning and bayesian network learning are good, if you’re curve fitting then regression is good, etc.
Just to clarify that first point I made: eg when you write Naive Bayes, its not the Naive Bayes method itself that’s being learned, nor whether a given fruit is an apple or pear, but the structure and parameters of that network that apply Bayes method and can then be used to classify a given fruit
This article depicted almost all algorithms theoretically best at least for me (as a beginner)
But i am new to ML so i am not able to relate algorithms use cases in a real life problems/scenarios. Can u please suggest me some links where i could be able to relate each algorithms with a different real time/real life business problem?
Hi Anuj, it is generally helpful think of predictive modeling problems in terms of classification (predict a class or category) and regression (predict a number).
You can then divide algorithms into classification and regression types.
I am totally new to the topic – so it is a good starting point. In other ‘domains’ of methods, patterns or algorithm types I am more familiar with one could typically define generic weaknesses/pains, strengths/gains and things to look at with care (e.g. how to set parameters). I wonder what those would be for each of the algorithm groups you specified.
I have seen that you described use cases, e.g. one could use Bayesian Algorithms and Decision Tree Algorithms for classification. But when would I e.g. prefer the one over the other for classification? …just an example…
It’s a great question Steffen, and very hard to answer.
The best practical approach to find the best/good algorithms for a given problem is trial and error. Heuristics provide a good guide, but sometimes/often you can get best results by breaking some rules or modeling assumptions.
I recommend empirical trial and error (or a bake-off of methods) on a given problem as the best approach.
Your page, no your website is gold. I have very poor knowledge in Machine learning, and you helped me in few paragraphs to learn more when to use which algorithm.
I am yet to go through your book, but I decided a thank you is a must. Thanks a lot.
Master Machine Learning Algorithms – With this book, Is it possible to understand how the algorithm works and how to build the predictive models for different kinds training sets.
And by seeing the problem or train data, can we say that the machine learning (tree based, knn, Naive base or optimisation ) and the algorithms (cart, c4.5) are best suitable.
I can purchase that above book that you have mentioned –
But I am more concerned with how the algorithm works (more illustration) and apply in machine learning. Present i am using R.
It does not teach how algorithms work, instead, after reading it you will be able to confidently work through your own machine learning problems and get usable results with R.
Hey Jason.
So I’m writing my thesis on MLAs in Motion Analysis (focussing on instrumented insoles) and I was wondering which type of MLA would be the most useful and if your ebook has the information I need (like what kind of data needs what kind of MLA) or if I should keep scouring PubMed for answers. Mostly I found C4.5, CART, Naïve Bayes, Multi-Layer Perceptrons, and Support Vector Machines (especially SVM, it seems like the most popular in rehab technologies), but I want to be thorough. After all my degree depends on it 😛
Your summary on this page was already very helpful, so thank you for that!
Hi Cara, I do not cover the problem of motion analysis directly.
I would advise evaluating a suite of algorithms on the problem and see what works best. Use what others have tried in the literature as a heuristic or suggestions of things to try.
Yes, there will be a number of ways. Generally, machine learning is intended to learn the mapping/rules automatically from examples of the data input and output.
Perhaps try this approach, try a few different methods. You may even come up with an objectively better mapping.
I’m new in Machine learning and i have a question,, all the algorithm can i use it in the supervised learning ?? and how to know what is the best model can i use it for the classification image?
Jason, am happy to find your site where machine learning and its algorithm are discussed. Its comforting. Am working on Natural Language Processing and intend to add a machine learning algorithm to it but alas you listed NLP under other type of machine learning algorithm. That’s startling! Because my aim was to locate the best algorithm to use.
Sir need a formal introduction for “Grouping of algorithms by similarity in form or function”. Everywhere on internet it comes under the supervised learning style classified a scluster classification so is it a part of learning style??
thanks for sharing this great stuff. I need to choose an ML algorithm on a non-rigid object detection in an image data base ( smoke, cloud,…). Do you have any suggestion on the proper algorithm or a way to find it out. I come to the point to use CNN. Still not sure why should it be ?
tnx a lot
I would like know about the How an ‘algorithms’ works on “Machines”?
Here, please consider “Machines” as a “Humans” or “biological VIRUS” or “any living cells”.
I would say biological individuals have a logical series of an algorithm, which is regulates their commands and response. These algorithms we may call as a ‘Genetic Material’ as ‘DNA or RNA’; but I would like to see them as an “ALGORITHMS” which is regulates there all activities like responses and commands. Because, particular DNA or RNA sequences have special type of code, which can be used by different performers, here performers are Enzymes.
My query is that, can we able to form algorithms like DNA or RNA which can be able to run a Machine?
It can be possible to form a Human made Biological VIRUS that can be cure our infected cells within a Human Body?
Great article Jason…and a engaging comments section which is rarely the case.
Appreciate the effort and many thanks to all the others. The comments are as informative as the article itself
Hi Dr. Jason;
I have problem with Fast Orthogonal Search (FOS) for dimensionality reduction. So do you have any suggestion to build it on MATLAB.
thanks
Hello Jason, could you label all the algorithms on this page as supervised, unsupervised, or semi-supervised? It’s easy enough to understand what these three different types are, but which ones are which? Thanks.
Hi Jason, thanks for your great article! I would propose an alternative classification of ml algorithms into two groups: (i) those which always produce the same model when trained from the same dataset with the récords presented in the same order and (ii) those which produce a different model each time. But I would be interested on your thoughts about this.
Best regards, David
Thanks for your reply, Jason. Yes, the continuos scale would be better. Some years ago I worked with simulated annealing/gradient descent, genetic algs. and neural networks (which performed random jumps to escape local minimums). However, on the other hand, the information gain calculation inside a rule
induction algorithm such as M5Rules always follows the same path (?) Could be the basis for an article ;-
Thank you for the reply sir. Say I collected a large amount of data e.g. temperature for a period of time. I was wondering how to apply machine learning in interpreting the data. That is why my idea was to produce a function out from the graph, is this still relevant to machine learning?
Hi Jason
I have created several supervised models with some regression and classification estimators. I want to know how to create a data driven application using these models? Could you explain what does it mean?
For sometime now, I have been looking for an authoritative paper on taxonomy, survey and classification of ML algorithms with examples. This article is absoulutely a step in that direction — can be massaged into a taxonomy/survey paper?
Nonetheless as other readers noticed, it is missing some topics: preprocessing including anomaly detection and feature selection, NLP, genetic algorithms, recommender systems etc.
Wonder if you know of any academic work on the topic. I did not find any in ACM CSUR.
Hi Jason
i am work on classification project and i have uncertain rules in the final classifier.
which algorithm you thing it will be more efficient in this case ?
What algorithms can one use to retrain a Model every day using new data that has user feedback as to whether the model classified the Response into correct Label, and if not the correct label is provided by the user. I want to retrain the model using this feedback and going forward give more weight to the signatures with correct labels.
Which Optimisation Algorithm is best? Genetic Algorithm (or) ABC Algorithm (or) Support Vector Machine (or) Paricle swam Optimisation (or) Ant Colony Optimisation.And explain it
I am a beginner in programming and I am planning to use Machine Learning algorithm to calibrate sensor data against reference data (in Python). What are some algorithms that you would suggest?
Suppose consider a scenario where a patient took drug (X) and develop five possible side effect (X-a, X-b, X-c, X-d,X-e).
I need to find out the signal i.e. causal relationship between drug and its side effect based on few parameters (like seriousness, suspected etc..).
If the parameter is present, I give score as 1, if not present- score as 0 and -1 for not applicable.
Which algorithm should I use to find the best drug-event relation based on score or any alternative approach do u prefer.
Is it possible to incorporate machine learning into the heuristic or semi-heuristic algorithms in job scheduling to improve optimisation? If yes, can you recommend some materials on this to me?
Nice article. Under semi-supervised learning, there is a statement “the model must learn the structures ..”. I believe you meant Algorithm here..Even you clarified this in your FAQ, algorithm is the one learns from data to create a prediction model. Agree ?
I am a newcomer to machine learning. I majored in geosciences at the university and only studied Python for two months.For students like me, how to prepare for machine learning, and there are many directions for machine learning, such as computer vision. Natural language processing, deep learning. Should we study machine learning as a whole, or choose a direction to study.I will graduate in April next year, how can I find a job related to machine learning. I am a student from China. My English may not be very good. Please don’t mind my mistakes.Thanks.
Thanks for the post, how could you categorize ReLU, GANs and RBM in this mindmap? If you put activation functions such as logistic regression and linear regression under the Regression section, should ReLU be there as well? And likewise, should GANs and RBM under Deep Learning?
In follow up with this comment, I was wondering if you have any post about RBM. I just found a reference to “http://videolectures.net/deeplearning2015_lee_boltzmann_machines/” in one of your posts.
Hello Jason your article is crystal clear so that it is useful for everyone and particularly me. I am beginner to this field and I want to know which algorithm will be suitable for detecting and classifying an object based on thermal image?? I have a set of data for example such as chair , table , phone etc. and I want to classify them based on detected thermal image. Could you please give some suggestions ???
You made it really very clear.
I believe many who work for several years in this field struggle to figure it out what they are doing and how is it related to big picture of ML and AI.
People also very much confused and consider, NN or DNN is all about AI, where in my view ML (statistical method, NN based method, any mathematical algorithmic formulation), Bio/Brain-inspired algorithm (genetic algorithm, SWARM etc), cryptography, cognitive etc. that all are subset of AI. Some are partially overlapped and some majorly overlapped with each other.
hello jason,
This article was wonderful.But my question is how can I learn the algorithms in a systematic way in order to clear the interview from the technical part.I hope you do understand.Thanks
I am feeling motivated and now work harder to start the career in Machine-Learning, hope will get similar success. Thanks for sharing your Machine-Learning experience.
This is a very interesting, but more important amusing post.
It is provoking, extremely well written and easy to read, after reading it a sort of road map has formed which is fantastic for a newbi just like yours truly.
Only one thing troubles me a little bit, a tendency that may lead many newcomers to think that math is unimporttant, machine learning is not easy at all, it requieres lots and lots of mathematics and deisregarding them buy telling the story of someone that came, understood and jumped to program lots of code but hiding the fact that she was alrady an engineer, or mathematician, or statistican, etc .
Any way, Jason, I have just been converted and will follow your blog very closely since I am convinced your writtings will be very helpful for a chnage of carrer from theoretical physicist to data scientist
and generally speaking, compare these algorithms. I would add HDT, Jackknife regression, density estimation, attribution modeling (to optimize marketing mix), linkage (in fraud detection), indexation (to create taxonomies or for clustering large data sets consisting of text), bucketisation, and time series algorithms.
Machine learning is currently one of the major methods of artificial intelligence. Logistic regression, Random Forest and Deep Learning are three common machine learning methods. Please explain how these three methods perform Supervised Learning.
Can you suggest a deep learning algorithm that learns the relationships existing between consecutive(adjacent) data points.
For example predicting a structure by identifying the relationships among 3D coordinates?
Great summary and broad perspective of artificial intelligence techniques to apply in order to develop algorithms using machine learning! Thanks to Mr. Jason Brownlee !!
Very nice summary! One confusion for me: I can understand that knn belongs to instance-based algorithms, but why SVM also belongs to this category? Any material you would suggest to explain this? Thank you!
SVM finds support vectors – points in the feature space – used to define the boundary between the classes. E.g. it’s probably an instance-based method given this understanding.
I read your post again, because I really think it is a great classification way for different ML algorithms! I have one question about unsupervised ML when I was reading again your post, maybe you can help?
Which algorithms that you listed in your post belong to unsupervised ML? Clustering? In principle, we don’t need to split the data to training and test dataset for the model performance evaluation for unsupervised ML algorithms, instead, we need to input our entire dataset for training, right? If so, how can we know whether we should use this unsupervised method or not?
This was really awesome….
Kudos to you Jason….
What are the subsets of ML alongside of DL???
DL is subset of ML right???? Like that what are the other subsets??? Plz help…????
I want to estimate the elastic modulus of an aluminium metal plate with density, resonant frequencies and plate dimensions as inputs. And the elastic modulus as the output.
which is the best algorithm to do so, and where can I get the algorithm to optimize?
This was really awesome….
Kudos to you Jason….
What are the subsets of ML alongside of DL???
DL is subset of ML right???? Like that what are the other subsets??? Plz help
Awesome insight for Beginner like me in ML. I am starting with the Andrew’s ML course at coursera. I have programming experience of more than 10 years, I was wondering what does a machine learning expert exactly do after solving a complex ML problem? I mean the algorithm is optimized and hypothesis is predicting the correct results, then what will the expert do? Gets fired 🙂
and this list has a separate group called
“Classification Algorithms” that you don’t have, and he put there algorithms from multiple your group, is this an error? it looks like he confused “Algorithm Type” and “Problem Type” here, am I right?
I have been reading posts regarding this topic and https://www.google.com/ post is one of the most interesting and informative one I have read. Thank you for this!
My colleagues argue that Statistical forecasting shouldn’t be confused with Machine learning although there was no clear justification. So wanted to understand if there is any such argument?
There is such a school of thought. But in practice, why should you care if you found a model that works for your problem? Linear regression for example, we can find a close form solution for least square error. We can also find a solution using SGD. You can’t just say if I use a close form solution using matrices then it is not a good model.
Hi Jason, thanks for the detailed taxonomy. I was trying to find where Catboost (https://catboost.ai/) will fit, but didn’t find it. I guess it falls under ensemble techniques, isn’t it?
hello
am umer i have a final year project “:priority based distribution of sensor nodes in a wireless sensor network”
in which i have to randomly deploy sensor nodes in any defined area from which i have to fetch the data
then after deployment sensor nodes make a network and after network creation they sense data just like i wanna fetch and extract the number of troops from the network area in my project and on the basis of this sensed data these nodes using machine learning algorithum define the area in 4 zones (on the bases of sensed data )just like if no of troops >500=critical zone
1# most critical
2# critical
3# less critical
4# normal
and also make the nodes as efficient if the number of nodes on most critical zone less then normal zone so these nodes moves from normal to critical zone to protect the network from data loss
this is all my project anyone help me please
Generally, I recommend that you complete homework and assignments yourself.
You have chosen a course and (perhaps) have even paid money to take the course. You have chosen to invest in yourself via self-education.
In order to get the most out of this investment, you must do the work.
Also, you (may) have paid the teachers, lectures and support staff to teach you. Use that resource and ask for help and clarification about your homework or assignment from them. They work for you in some sense, and no one knows more about your homework or assignment and how it will be assed than them.
Nevertheless, if you are still struggling, perhaps you can boil your difficulty down to one sentence and contact me.
Great post! I am actually getting ready to across this information, It’s very helpful to me. Also great with all of the valuable information you have Keep up the good work you are doing well.
Thank you for this insightful post. It’s been very helpful.
I particularly like how you grouped algorithms by “similarity”. As far as I understand, “similarity” here refers to the algorithm’s underlying mathematical/algorithmic theory/approach; not the algorithm’s objective. Accordingly, for example, both linear and logistic regression belong to regression algorithms although the former’s objective is regression and the latter’s one is classification.
That’s why it makes sense to me that SOM, for example, belongs to instance-based algorithms although there’s a group for dimensionality reduction, which is SOM’s objective. The same applies to MLP belonging to ANN algorithms although there’s group for clustering.
What I’m trying to say is that, unless I’m mistaken, shouldn’t clustering and dimensionality reduction be excluded as groups? In case you agree, I’d be interested to know where you’d add k-means and PCA then.
I would also like to know where you’d add DBSCAN.
Thank you
[…] Learning is a Machine Learning algorithm type that involves training a machine learning model on a labeled dataset. In supervised learning, the […]
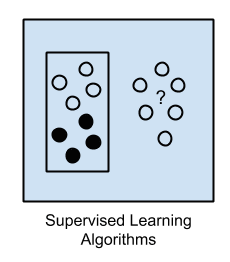 Input data is called training data and has a known label or result such as spam/not-spam or a stock price at a time.
Input data is called training data and has a known label or result such as spam/not-spam or a stock price at a time.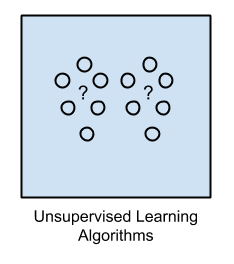 Input data is not labeled and does not have a known result.
Input data is not labeled and does not have a known result.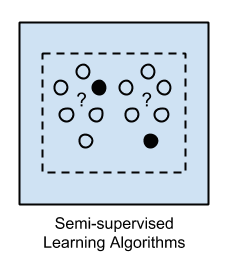 Input data is a mixture of labeled and unlabelled examples.
Input data is a mixture of labeled and unlabelled examples.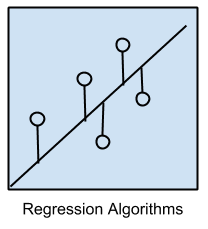 Regression is concerned with modeling the relationship between variables that is iteratively refined using a measure of error in the predictions made by the model.
Regression is concerned with modeling the relationship between variables that is iteratively refined using a measure of error in the predictions made by the model.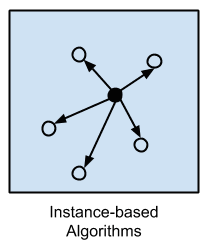 Instance-based learning model is a decision problem with instances or examples of training data that are deemed important or required to the model.
Instance-based learning model is a decision problem with instances or examples of training data that are deemed important or required to the model.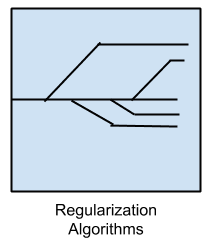 An extension made to another method (typically regression methods) that penalizes models based on their complexity, favoring simpler models that are also better at generalizing.
An extension made to another method (typically regression methods) that penalizes models based on their complexity, favoring simpler models that are also better at generalizing.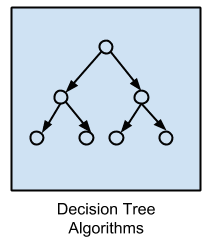 Decision tree methods construct a model of decisions made based on actual values of attributes in the data.
Decision tree methods construct a model of decisions made based on actual values of attributes in the data.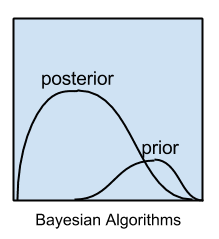 Bayesian methods are those that explicitly apply Bayes’ Theorem for problems such as classification and regression.
Bayesian methods are those that explicitly apply Bayes’ Theorem for problems such as classification and regression.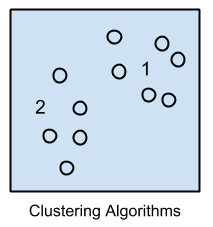 Clustering, like regression, describes the class of problem and the class of methods.
Clustering, like regression, describes the class of problem and the class of methods.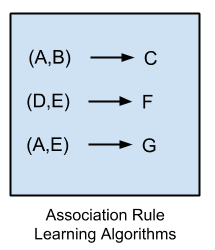 Association rule learning methods extract rules that best explain observed relationships between variables in data.
Association rule learning methods extract rules that best explain observed relationships between variables in data.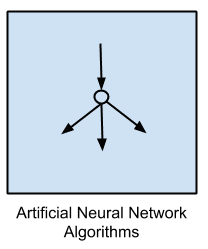 Artificial Neural Networks are models that are inspired by the structure and/or function of biological neural networks.
Artificial Neural Networks are models that are inspired by the structure and/or function of biological neural networks. Deep Learning methods are a modern update to Artificial Neural Networks that exploit abundant cheap computation.
Deep Learning methods are a modern update to Artificial Neural Networks that exploit abundant cheap computation. Like clustering methods, dimensionality reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarize or describe data using less information.
Like clustering methods, dimensionality reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarize or describe data using less information. Ensemble methods are models composed of multiple weaker models that are independently trained and whose predictions are combined in some way to make the overall prediction.
Ensemble methods are models composed of multiple weaker models that are independently trained and whose predictions are combined in some way to make the overall prediction.






What about reinforcement learning algorithms in algorithm similarity classification?
There is also one called Gibbs algorithm under Bayesian Learning
Good point bruce, I left out those methods. Would you like me to write a post about reinforcement learning methods?
Yes!!!!
P.S. Please :0
Jason,
I enjoy your blog and your writing style of explaining a complex topic in simple terms.
I have one request. Do you have a cheat sheet in choosing the right algorithm. I would like to know when to use what ML algorithm as a starters guideline?
Thank you,
Bk
Choosing the “right” algorithm for a problem is a process:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
Hello Jason,hope u r fine!
How can we make a recommender system with the help of Neural network
&
how to implement Collaborative filtering with Neural network
What is the difference between a classifier and algorithm? Both r same?
Hi Sam,
An algorithm is a procedure. Like learning a tree from data. The outcome of an algorithm is a model or a classifier, like the tree used to make predictions.
Then I don’t quite understand the listing of both Back-Propagation and Hopfield Network under the title of “Artificial Neural Network Algorithms”. Back-Propagation is clearly a training algorithm, whereas a Hopfield Network is probably a classifier?
Nice post!
That is fair. Rather than backprop we should list MLP.
Hi Jason, very interesting article … I am bit of newbie … i come across “machine learning algorithms”, “machine learning methods” and “machine learning models” phrases.
I think i understand algorithm and models. What is specific nuance of “method”?
Good question, this will help:
https://machinelearningmastery.com/difference-between-algorithm-and-model-in-machine-learning/
Yes Please
Release a ebook on reinforcement learning and Unsupervised Deep learning too . You are awesome Jason. You made things very simple for us to understand this difficult concepts .
Thanks for the suggestion Sameer.
Absolutely. I keep turning to Jason books/blogs over and over again for various tasks and it all works with little tweaking
Thanks!
Jason’s materials helped me do my Ph.D. research with success. Many thanks to him
Thanks! Well done on your phd!
I would really like that too
Where do newbies (with no analytics/stats background) start learning about this algorithms? And more so how does one use them with Big Data tools like Hadoop?
Hi qnaguru, I’d recommend starting small and experimenting with algorithms on small datasets using a tool like Weka. It’s a GUI tool and provides a bunch of standard datasets and algorithms out of the box.
I’d suggest you build up some skill on small datasets before moving onto big data tools like Hadoop and Mahout.
qnaguru,
I would recommend the Coursera courses.
I would also read a couple of books to give you some background into the possibilities and limitations. Nate Silver; The Signal and The Noise & Danial Kahneman; Thinking Fast and Slow.
The best written one I have found is: “The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition”. However you probably need to have some background on maths/stats/computing before reading that (especially if you are planning to implement them too). For general algorithms implementation I recommend reading also “Numerical Recipes 3rd Edition: The Art of Scientific Computing”.
I’m a huge fan of Numerical Recipes, thanks for the book refs.
Not a single one for recommender systems?
I would call recommender a higher-order system that internally is solving regression or classification problems. Do you agree?
exactly
genetic algorithms seem to be dying a slow death these days (discussed previously https://news.ycombinator.com/item?id=7712824 )
It’s a good point. Computers are fast enough that you can enumerate the search space faster than a GA can converge (at least with the classical toy problems).
I enjoyed this post but I think that this is a misinformed statement. Genetic Algorithms are most useful in large search spaces (enumerating here would be impossible, were talking about spaces that could be 10^100) and highly complex non-convex functions. Modern algorithms are much more sophisticated than the simple techniques used in the 80s e.g. (http://en.wikipedia.org/wiki/CMA-ES) and (http://en.wikipedia.org/wiki/Estimation_of_distribution_algorithm). Here is a nice fun recent application: http://www.cc.gatech.edu/~jtan34/project/learningBicycleStunts.html
Thanks Alex, you can also check out my 2011 book of algorithm recipes titled Clever Algorithms: Nature-Inspired Programming Recipes. In it I cover 5 different estimation of distribution algorithms and 10 different evolutionary algorithms.
Hi guys, this is great! What about recommendation systems? I’m fascinated about, how netflix, amazon and others websites can recommend items based on my taste.
Good point.
You can break a recommender down into a classification ore regression problem.
True, or even use rule induction like Apriori…
Where does imagination lie? Would it be a Unsupervised Feedback Learning? Maybe its Neural Deep Essemble Networks. I presume dreaming = imagination while sleeping, hence daydreaming is imagining of new learning algorithms 🙂
This is too deep for me @mycall
I lot of people swear by this chart for helping you narrow down which machine learning approach to take: http://scikit-learn.org/stable/_static/ml_map.png. It doesn’t seem to cover all the types you list in your article. Perhaps a more thorough chart would be useful.
Thanks for the link vas!
Thanks for sharing and is posted on my wall. Useful but not exhaustive. missing some topics: preprocessing including feature selection, NLP
Thid is great. I had always been looking for “all types” of ML algorithms available. I enjoyed reading this and look forward to further reading
You’re very welcome @Nevil.
This is nice and useful…I have been feeling heady with too much data and this kinda gives me a menu from which to choose what all is on offer to help me make sense of stuff 🙂 Thanks
That is a great way to think about @UD, a menu of algorithms.
You might want to include entropy-based methods in your summary. I use relative-entropy based monitoring in my work to identify anomalies in time series data. This approach has a better recall rate and lower false positive rates when tested with synthetic data using injected outliers. Just an idea, your summary is excellent for such a high level conceptual overview.
HI Tim
Can you give me some reference from which I can learn about relative-entropy based monitoring ?
Thank you ! Really worth my time !
Thanks @Tim, I’ll add a section on time series algorithms I think.
Hi,
Thank’s for this tour, it is very useful ! But I disagree with you for the LDA method, which is in the Kernel Methods. First of all, by LDA, do you mean Linear Discriminant Analysis ? Because if it’s not, the next parts of my comment are useless :p
If you are talking about this method, then you should put KLDA (which stand for Kernel LDA) and not simply LDA. Because LDA is more a dimension reduction method than a kernel method (It finds the best hyperplane that optimize the Fisher discriminant in order to project data on it).
Next, I don’t know if we can view the RBF as a real machine learning method, it’s more a mapping function I think, but it is clearly used for mapping to a higher dimension.
Except these two points, the post is awesome ! Thank’s again.
Thanks @Vincent, I’ll look into moving the algorithms around a bit in their groupings.
In my humble opinion, LDA and the likes of such algorithms can make a separate category by themselves as they both reduce dimensionality and can be used as classifiers.
Another stellar example is the t-SNE.
You’re right. What posted here is just one of the many ways to put them into categories. Thanks for the comment.
@Vincent, I think he mentions Radial Based Network or RBN, which is artificial neural network (ANN) that uses radial basis functions [1]. Jason is correct in placing it under ANN classification.
[1] https://en.wikipedia.org/wiki/Radial_basis_function_network
Great post, but I agree with Vincent. Kernel Methods are not machine learning methods by themselve, but more an extension that allows to overcome some difficulties encountered when input data are not linearly separable. SVM and LDA are not Kernel-based, but their definition can be adapted to make use of the famous kernel-trick, giving birth to KSVM and KLDA, that are able to separate data linearly in a higher-dimensional space. Kernel trick can be applied to a wide variety of Machine learning methods:
– LDA
– SVM
– PCA
– KMeans
and the list goes on…
Moreover, I don’t think that RBF can be considered a machine learning method. It is a kernel function used alongside the kernel trick to project the data in a high-dimensional space. So the listing in “Kernel methods” seems to have a typing error :p
Last point, don’t you think LDA could be added to the “Dimensionality Reduction” category ? In fact, it’s more an open question but, mixture methods (clustering) and factor analysis could be considered “Dimensionality Reduction methods” since data can be labeled either by it’s cluster id, or its factors.
Thanks again for this post, giving an overview of machin learning methods is a great thing.
Great comments @Rémi I’ll move things around a bit.
I had this confusion and had to look it up.
– Radial Based Function (RBF) can be used as a kernel
– Radial Based Network (RBN) is a artificial neural network that uses radial basis functions
Hi qnaguru, I have collected some nice reference books to start digging Machine learning. I would suggest you to start with “Introduction to statistical learning” and after that you can look into “The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition”, “Probabilistic Machine Learning by David Barber”.
Very nice taxonomy of methods. Two small quibbles, both in the Decision Tree section.
1) MARS isn’t a tree method, it’s a spline method. You list it already in the regression group, though could even go in the regularization group. (not a natural fit in any, IMHO).
2) Random Forests is an ensemble method and sticks out a bit in the trees group. Yes, they are trees, but so is the MART (TreeNet) and some flavors of Adaboost. Since you already have an ensembles and RF is already there, I think you can safely remove it from the Trees.
Again, you’ve done a great job with this list. Congrats!
Dean
Thanks Dean, I’ll take your comments on board.
Greate article. my knowledge in Machne learning is improving in bredth not in depth.how should i improve my learning.i have done some real time implementations with Regression analysis.and Random forest.and also i am atteding coursera courses.how would i get real time experience on ML R with Hadoop.
Thanks Mr.Brownly for your useful guide.Where can we find the implementations of all of these algorithms?I’ve installed weka but it doesnot have some of these algorithms
You may have to make use of other platforms like R and scikit-learn.
Were you looking for an implementation of a specific algorithm?
Great Post!
I am currently learning Sparse Coding. And I have difficulty putting Sparse Coding into the categories you created.
–What is your idea about Sparse Coding?
–Which category should it belong to?
Can you provide some suggestions for learning sparse coding
— what mathematical foundations should I have?
— any good tutorial resources?
— can you suggest a learning roadmap
I am now taking convex optimization course. Is it a correct roadmap?
Where does ranking fit into the machine learning algorithms? Is it by any chance under some of the categories mentioned in the article? The only time I find ranking mentioned in relation to machine learn is when I specifically search for ranking, none of the machine learning articles discuss it.
which algorithm is the more efficient of the similarity algorithm .?
Assess similarity algorithms using computational complexity and empirically test them and see Amelie.
What methods/algorithms are suitable for applying to trading patterns analysis. I mean looking at the trading graphs of the last 6 months (e.g. SPY). Currently, I am looking at the graphs visually. Can an algorithm come to my aid (I am currently enrolled in an online data mining course) ?
Sounds like a timeseries problem, consider stating out with an auto-regression.
Hi Jason,
Its a great article. I wish if you could give a list of machine learning algorithms popular in medical research domain.
regards,
Saima Safdar
Great list. Definitely cleared things up for me, Jason! I do have a question concerning Batch Gradient Descent and the Normal Equation. Are these considered Estimators?
I would love to see a post that addresses the different types of estimators / optimizers that could be used for each of these algorithms that is simple to understand. Also where does feature scaling (min max scaling & standardization) and other things fall into all of this? Are they also optimizers? So many things!
Thanks so much for spreading your knowledge!
Hi Jason
Intrigued by your comments above about recommendation systems ie.
“I would call recommender a higher-order system that internally is solving regression or classification problems.” and,
“You can break a recommender down into a classification or a regression problem.”
Could you please expand on your thought process? In general, I find that people talk about building or wanting a “classifier” since it is the de-jeure buzzword (and related to deep learning) when in fact, a recommender or something else will do the job. Anyway, great discussion.
Great stuff here Jason! Regarding your comments on 12/26, I’ll vote yes to seeing a post on reinforcement learning methods
Hi Jason,
I’m trying to implement object detection through computer vision through Machine Learning but I’m hitting a wall when trying to find a suitable approach. Can you suggest which kind of algorithm will help me? I’d like to research more on it.
Hi.. i am working on finding the missing values by using machine learning approaches..
Any body can suggest new methods to be used..
I am a research scholar
Hi Jason,
just a small question: In my opinion k-NN, SVM, Naive Bayes, Decision Trees, MaxEnt (even if it’s not mentioned here) are all considered to be instance-based, isn’t it right?
Awesome post now I know where I stand.
i started reading and i feel i don’t succeed to understand it.
I don’t understand which algorithm is good for which type of problem.
I think that little example for each algorithm will be useful.
Hi,
How can I classify the support vector machines and its extensions in your list?
Jason: Nice addition of the simple graphic to each of the “families” of machine learning algorithms. This is a change from what I recall was a previous version of this post. The diagram helps visualize the activity of the family and thus aid developing an internal model of how the members of the family operate.
A simple but powerful effect.
The Bayesian Algorithms graphic should be reworked. In particular,
1) the area under both density functions should integrate to one. While no scale is provided, the prior appears to integrate to a much smaller number than the posterior.
2) in general, a posterior is narrower / more concentrated than a prior given an observation.
3) (interpreting the baseline as zero density) a posterior typically concentrates the probability of the prior in a smaller range; it never “moves” probability to a range where the prior density was zero.
Hi jason,
Can you recommend any algorithm to my problem below please?
I need one that does time series analysis that does Bayesian analysis too.
For test set,
I’m given data for hourly price movements for half a day, and tasked to predict for the second half of day. Clearly a time series (TS) problems.
But on top of that I’m also given information on 10 discrete factors for each day in the training and testing set.
Do you know of any algo that creates multiple TS models conditional upon the values (or bands) of the various discrete factors at the onset?
Hi Jason
Thank you very much for your sharing,I would like to know about Machine Learning methods (algorithms) which are useful in Prediction.
Hi Jason
I would be very grateful if you could let me know which neural network is useful for multivariate time series classification.For example, classifying patient and healthy people when we have multiple time series of each feature.
Did you find any solution for this? I have the same problem. I was thinking about convolution neural networks and use the feature space to create a heatmap image and use that as input. For example, each row in the pixel image will be a RGB value mapped from a feature and each column will be a specific time point. That way you have all multivariate time series in one image. You might need to reduce the dimensionality of the time interval though if they are very high, alternatively take partitions of the time interval in sections of the image (first 500 time points in the upper half of the image for example). I have no idea if this would work, just some thoughts…
I have a good background in artificial intelligence and machine learning, and I must say this is a really good list, I would not have done the categories any other way, it’s very close to perfection. Very pertinent information.
However, it would be nice to include Learning Style categories for reinforcement learning, genetic algorithms and probabilistic models, (but meanwhile you already mention them at the end so this gives a good pointer for the readers).
The ending links are very good, particularly the “How to Study Machine Learning Algorithms”. It would be also nice to put a list of machine learning online courses (coursera, udacity, etc. – there’s even a course by Geoffrey Hinton!), and links to tutorials on how to check and verify that your ML algo works well on your dataset (cross-validation, generalization curve, ROC, confusion matrix, etc.).
Also, thank’s to previous commenters, your comments are also very pertinent and a good addition to the article!
To develop my suggestion for adding Learning Style categories: I think these classes of learning algorithms should be added, since they are used more and more (albeit being less popular than the currently listed methods) and they cannot be replaced by other classes of learning, they bring their own capabilities:
– Reinforcement learning models a reward/punishment way of learning. This allows to explore and memorize the states of an environment or the actions with a way very similar on how the actual brain learns using the pleasure circuit (TD-Learning). It also has a very useful ability: blocking, which naturally allows a reinforcement learning model to only use the stimuli and information that is useful to predict the reward, the useless stimuli will be “blocked” (ie, filtered out). This is currently being used in combination with deep learning to model more biologically plausible and powerful neural networks, that can for example maybe solve the Go game problem (see Google’s DeepMind AlphaGo).
– Genetic algorithms, as a previous commenter said, are best used when facing a very high dimension problem or multimodal optimizations (where you have multiple equally good solutions, aka multiple equilibriums). Also, a big advantage is that genetic algorithms are derivative-free cost optimization methods, so they are VERY generic and can be applied to virtually any problem and find a good solution (even if other algorithms may find better ones).
– Probabilistic models (eg, monte-carlo, markov chains, markovian processes, gaussian mixtures, etc.) and probabilistic graphical models (eg, bayesian networks, credal networks, markov graphs, etc.) are great for uncertain situations and for inference, since they can manipulate uncertain values and hidden variables. Graphical models are kinda close to deep learning, but they are more flexible (it’s easier to define a PGM from a semantic of what you want to do than a deep learning network).
– Maybe mention at the end Fuzzy Logic, which is not a machine learning algorithm per se but is close to probabilistic models, except that it can be seen as a superset that also allows to define a possibility value (see possibilistic logic, and the works by Edwin Jaynes).
hi,
you have nicely illustrated the algos,thanks.
cheers,
vicky | techvicky.com
Hi Jason,
I’m just getting started on learning about machine learning algorithms. I still need some time to digest what I’ve read here. My background comes from finance/investing and therefore I’ve been trying to learn more about how machine learning is used in investing. I come from a fundamental investing background and therefore I’m curious if you have an insight. Given there are so many algorithms (and different branches https://www.youtube.com/watch?v=B8J4uefCQMc which I thought this was an interesting video) I wanted to ask how do you know which type of branch/algorithm in machine learning would be more useful for investing?
Best,
Ting
Thank you for this great article.
It really helps untangling the variety of algorithm types and muddling through the complexity of this interesting field.
I’m glad to hear that Marc.
Very useful one.
Thanks Jitu.
not able to download anything. Just keeps cinfirming my subscriptions
Sorry to hear that. After you confirm your subscription you will be emailed the mindmap.
Perhaps check one of your other email folders?
Great insight, thank you for the write up.
You’re welcome Francis.
Excellent post. I was checking constantly this blog and I’m impressed!
Very useful information particularly the last part :
) I care for such information a lot. I was looking for this
certain information for a long time. Thank you and good luck.
I’m glad you found it useful.
Hi Jason,
I would like to know the class for SVM.
It does not fit neatly into this taxonomy.
Appreciating the dedication you put into your site and
detailed information you offer. It’s nice to come across
a blog every once in a while that isn’t the same old
rehashed material. Excellent read! I’ve bookmarked your site and I’m including your RSS feeds
to my Google account.
Thanks.
You listed logistic regression as an regression algorithm. I always believed method is the base of neuronal networks, and thus more a classifier than a regression algorithm.
I fully agree with your opinion. The outcome of a (simple) logistic regression is binary and the algorithm should be part of a classification method, like the neural networks you mentioned.
Hello sir. Thank you so much for your help. But as we know Machine Learning require a strong ‘Math’ background. I am very interested math but, i am little bit week in that. So,I want good understandable resources for math required in Machine Learning. Thank you.
I teach an approach to getting started without the theory or math understanding. By treating ML as a tool you can use to solve problems and deliver value. The deep mathematical understanding can come later if and when you need it in order to deliver better solutions.
See this post:
https://machinelearningmastery.com/how-do-i-get-started-in-machine-learning/
Jason, thanks for the write-up. When it comes it supervised learning using regression analysis all examples I have found deal with simple scalar inputs and perhaps multiple features of one input. What if an input data is more complicated, say two values where one is a quadratic curve and another is a real number? I have data that consists of two pairs of values: univariate quadratic function (represented as quadratic functions or an array of points) and a real value R. Each quadratic function F rather predictably changes its skew/shape based on its real value pair R and becomes(changes) into F’. Given a new real value R’, it becomes F” and so on. This is the training data and I have about thousand pairs of functions and real values. Based on a current function F and a new real value R can we predict the shape of F’ using supervised learning and regression analysis? If so, what should I look out for? Any help would be much appreciated!
What about Best-subset Selection, Stepwise selection, Backward Selection as Dimension reduction?? This is Regularization methods but you also can use it as shinkage dimension.
Do any of the algorithms have a feedback loop?
Jason- would like to discuss in detail the ability to project outcomes of sporting events using your algorithms. Have you ever researched?
Please email
utdad1@gmail.com
I have only done a little work in that area Bryan.
You can contact me directly here:
https://machinelearningmastery.com/contact
Thanks for this wonderful tour of the machine learning algoritem zoo — more fun than the real one.
I’m glad you found it useful Howard.
This is useful, but it could be made more useful for someone new to the field, specifcally in the section where algorithms are grouped by similarity, by clarifying exactly what is being learned. Eg Regression algorithms learn the curve that best fits the data points, Bayesian learning algorithms learn the parameters and structure of a Bayesian network, Decision Tree algorithms learn the structure of the decision tree, etc.
Additionally some kind of task based classification would be helpful. Eg if you’re trying to classify then the following kinds of ML algorithms are best, if you’re trying to do inference then rule learning and bayesian network learning are good, if you’re curve fitting then regression is good, etc.
Just to clarify that first point I made: eg when you write Naive Bayes, its not the Naive Bayes method itself that’s being learned, nor whether a given fruit is an apple or pear, but the structure and parameters of that network that apply Bayes method and can then be used to classify a given fruit
Great suggestion, thanks Srinivas.
Hi Jason,
This article depicted almost all algorithms theoretically best at least for me (as a beginner)
But i am new to ML so i am not able to relate algorithms use cases in a real life problems/scenarios. Can u please suggest me some links where i could be able to relate each algorithms with a different real time/real life business problem?
Thanks in advance! 🙂
Hi Anuj, it is generally helpful think of predictive modeling problems in terms of classification (predict a class or category) and regression (predict a number).
You can then divide algorithms into classification and regression types.
This page has a nice list of modern and popular machine learning problems:
https://machinelearningmastery.com/tour-of-real-world-machine-learning-problems/
Hi Jason.
I am beginner of Machine learning. Can you suggest that how to start learning and what are the basic things to need for this.
Best Regards,
Avdhesh
Great question Avdhesh,
I teach a top-down approach to machine learning, you can learn all about it here:
https://machinelearningmastery.com/start-here/#getstarted
Jason, this is an excellent list, thank you.
I am totally new to the topic – so it is a good starting point. In other ‘domains’ of methods, patterns or algorithm types I am more familiar with one could typically define generic weaknesses/pains, strengths/gains and things to look at with care (e.g. how to set parameters). I wonder what those would be for each of the algorithm groups you specified.
I have seen that you described use cases, e.g. one could use Bayesian Algorithms and Decision Tree Algorithms for classification. But when would I e.g. prefer the one over the other for classification? …just an example…
It’s a great question Steffen, and very hard to answer.
The best practical approach to find the best/good algorithms for a given problem is trial and error. Heuristics provide a good guide, but sometimes/often you can get best results by breaking some rules or modeling assumptions.
I recommend empirical trial and error (or a bake-off of methods) on a given problem as the best approach.
Dear Dr. Jason,
Very nice post. thanks
I’m glad you found it useful Khalid.
Hi Jason,
Thank you so much for your article.
How would you suggest NLP can be utilised to measure research performance?
Sorry, I’m not an expert in NLP Tammi.
Hi Jason,
Wonderful post ! Really helped me a lot in understanding different algorithms.
My question is i have seen lot of algorithms apart from the above list.
Can you please post the algorithms, how they work with list of examples.
Example: Cart algorithm (Decision Trees) – How they split, entropy, info gain, gini index and impurity.
I hope you got my question. Likewise for all algorithms.
Sure, I explain how algorithms work in this book:
https://machinelearningmastery.com/master-machine-learning-algorithms/
If you’re more of a coder, I explain how they work with Python code in this book:
https://machinelearningmastery.com/machine-learning-algorithms-from-scratch/
I hope that helps.
Your page, no your website is gold. I have very poor knowledge in Machine learning, and you helped me in few paragraphs to learn more when to use which algorithm.
I am yet to go through your book, but I decided a thank you is a must. Thanks a lot.
Thanks Iman.
Hi Jason,
Thank you for kind reply.
Master Machine Learning Algorithms – With this book, Is it possible to understand how the algorithm works and how to build the predictive models for different kinds training sets.
And by seeing the problem or train data, can we say that the machine learning (tree based, knn, Naive base or optimisation ) and the algorithms (cart, c4.5) are best suitable.
I can purchase that above book that you have mentioned –
But I am more concerned with how the algorithm works (more illustration) and apply in machine learning. Present i am using R.
Hi sbollav, after reading Master Machaine Learning Algorithms you will know how 10 top algorithms work.
For working through predictive modeling problems in R, I would suggest the book: Machine Learning Mastery With R:
https://machinelearningmastery.com/machine-learning-with-r/
It does not teach how algorithms work, instead, after reading it you will be able to confidently work through your own machine learning problems and get usable results with R.
I hope that helps.
Thanks ever so much for your great post
Do you have any idea about PQSQ algorithms? Could you dive in?
Sorry, I have not heard of this type of algorithm.
Hey Jason.
So I’m writing my thesis on MLAs in Motion Analysis (focussing on instrumented insoles) and I was wondering which type of MLA would be the most useful and if your ebook has the information I need (like what kind of data needs what kind of MLA) or if I should keep scouring PubMed for answers. Mostly I found C4.5, CART, Naïve Bayes, Multi-Layer Perceptrons, and Support Vector Machines (especially SVM, it seems like the most popular in rehab technologies), but I want to be thorough. After all my degree depends on it 😛
Your summary on this page was already very helpful, so thank you for that!
Hi Cara, I do not cover the problem of motion analysis directly.
I would advise evaluating a suite of algorithms on the problem and see what works best. Use what others have tried in the literature as a heuristic or suggestions of things to try.
Hi Jason ,
This is really a superb classification of algorithms.
Can you please help me with below.
I have few rules and I classified my target variable as 0 or 1 by these rules.
Now I want Machine to learn these rules and predict my target variable .
Can you please suggest me which algorithm is good to do so.
Why not just use your rules directly Vicky? Why is another algorithm required?
Hi Jason ,
These rules are not straight forward and requires SME judgement.
I wanted to know if there is any possibility to teach machine these rules.
Hi Vicky,
Yes, there will be a number of ways. Generally, machine learning is intended to learn the mapping/rules automatically from examples of the data input and output.
Perhaps try this approach, try a few different methods. You may even come up with an objectively better mapping.
Hi Jason
First thank you for your explanation..
I’m new in Machine learning and i have a question,, all the algorithm can i use it in the supervised learning ?? and how to know what is the best model can i use it for the classification image?
Thank you
Great question Dina,
We cannot know which algorithm will be best for a given problem. We must design experiments to discover it.
See this post on the topic:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
Let’s take a look at four different learning styles in machine learning algorithms:Where is the fourth one ?
Thanks, fixed.
Jason, am happy to find your site where machine learning and its algorithm are discussed. Its comforting. Am working on Natural Language Processing and intend to add a machine learning algorithm to it but alas you listed NLP under other type of machine learning algorithm. That’s startling! Because my aim was to locate the best algorithm to use.
Thanks, it’s great to have you here.
I hope to cover NLP in detail later this year.
Jason, how to use machine learning, NLP or both to predict user next sentence based on previously entered text
I don’t have many NLP examples yet, soon hopefully.
This might help as a start:
https://machinelearningmastery.com/predict-sentiment-movie-reviews-using-deep-learning/
Sir need a formal introduction for “Grouping of algorithms by similarity in form or function”. Everywhere on internet it comes under the supervised learning style classified a scluster classification so is it a part of learning style??
I guess you missed forecasting algorithms like ARIMA, TBATS, Prophet and so on.
I cover time series in detail here:
https://machinelearningmastery.com/start-here/#timeseries
Hi Jason ..You had created a great site.
Keep sharing the good stuff.
God Bless you.
Thanks Deepak!
Hi Jason,
thanks for sharing this great stuff. I need to choose an ML algorithm on a non-rigid object detection in an image data base ( smoke, cloud,…). Do you have any suggestion on the proper algorithm or a way to find it out. I come to the point to use CNN. Still not sure why should it be ?
tnx a lot
Yes, I would recommend a CNN.
How do we decide which machine learning algorithm to use for a specified problem?
A great question, see this post:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
Hi Jason, its amazing material. Do you have any suggestion for online clustering techniques ?
Thanks Kumar, sorry I don’t have material on clustering.
I would like know about the How an ‘algorithms’ works on “Machines”?
Here, please consider “Machines” as a “Humans” or “biological VIRUS” or “any living cells”.
I would say biological individuals have a logical series of an algorithm, which is regulates their commands and response. These algorithms we may call as a ‘Genetic Material’ as ‘DNA or RNA’; but I would like to see them as an “ALGORITHMS” which is regulates there all activities like responses and commands. Because, particular DNA or RNA sequences have special type of code, which can be used by different performers, here performers are Enzymes.
My query is that, can we able to form algorithms like DNA or RNA which can be able to run a Machine?
It can be possible to form a Human made Biological VIRUS that can be cure our infected cells within a Human Body?
Sure, take a look at biologically inspired computational methods.
I have a whole book on the topic:
http://cleveralgorithms.com/nature-inspired/index.html
Great article Jason…and a engaging comments section which is rarely the case.
Appreciate the effort and many thanks to all the others. The comments are as informative as the article itself
Thanks Pavan.
#edit#
“a engaging comments section which is rarely the case on so many other sites”
I work hard to respond to every comment I see. It’s getting harder and harder with 100s per day now.
Hi Dr. Jason;
I have problem with Fast Orthogonal Search (FOS) for dimensionality reduction. So do you have any suggestion to build it on MATLAB.
thanks
I do not, sorry.
I have a doubt can we combine nature inspired algorithm with machine learning to improve accuracy level of our data
Perhaps. For example, genetic algorithms can help turning hyperparameters or choosing features.
I have a book on nature inspired algorithms I wrote right after completing my Ph.D., it’s free online here:
http://cleveralgorithms.com/nature-inspired/index.html
Hello Jason, could you label all the algorithms on this page as supervised, unsupervised, or semi-supervised? It’s easy enough to understand what these three different types are, but which ones are which? Thanks.
Most of applied machine learning (e.g. predictive modeling) is concerned with supervised learning algorithms.
The majority of algorithms listed on this page are supervised.
Hi Jason, thanks for your great article! I would propose an alternative classification of ml algorithms into two groups: (i) those which always produce the same model when trained from the same dataset with the récords presented in the same order and (ii) those which produce a different model each time. But I would be interested on your thoughts about this.
Best regards, David
Nice David. Really this is the axis of “model variance”.
Think of it as a continuum though, not binary. Many (most!) ML algorithms suffer variance of some degree.
Thanks for your reply, Jason. Yes, the continuos scale would be better. Some years ago I worked with simulated annealing/gradient descent, genetic algs. and neural networks (which performed random jumps to escape local minimums). However, on the other hand, the information gain calculation inside a rule
induction algorithm such as M5Rules always follows the same path (?) Could be the basis for an article ;-
Thanks for the suggestion David.
Great job , but you didn’t include References for your topic!!!
Thanks Mirna, what references do you want to see?
Is it possible to produce a function from the unsupervised machine learning?
Sure, what do you mean exactly?
Thank you for the reply sir. Say I collected a large amount of data e.g. temperature for a period of time. I was wondering how to apply machine learning in interpreting the data. That is why my idea was to produce a function out from the graph, is this still relevant to machine learning?
It sounds like you are describing a regression equation, like a line of best fit.
If a line of best fit is good enough for you, then I would recommend using it.
You can use a suite of machine learning algorithms to make predictions, this process will give you an idea of what is involved:
https://machinelearningmastery.com/start-here/#process
Hi Jason
I have created several supervised models with some regression and classification estimators. I want to know how to create a data driven application using these models? Could you explain what does it mean?
You would need to treat it like any other software project and start by defining the goals/requirements of the project.
Thanks Jason. Another superb job. 🙂
For sometime now, I have been looking for an authoritative paper on taxonomy, survey and classification of ML algorithms with examples. This article is absoulutely a step in that direction — can be massaged into a taxonomy/survey paper?
Nonetheless as other readers noticed, it is missing some topics: preprocessing including anomaly detection and feature selection, NLP, genetic algorithms, recommender systems etc.
Wonder if you know of any academic work on the topic. I did not find any in ACM CSUR.
Waiting anxiously! 🙂
Thanks for the suggestion.
I will update the post soon and add more algorithms. I don’t have plans on turning it into a survey sorry.
Hi Jason
i am work on classification project and i have uncertain rules in the final classifier.
which algorithm you thing it will be more efficient in this case ?
Try a suite of algorithms and see what works best on your problem?
What algorithms can one use to retrain a Model every day using new data that has user feedback as to whether the model classified the Response into correct Label, and if not the correct label is provided by the user. I want to retrain the model using this feedback and going forward give more weight to the signatures with correct labels.
Many algorithms are updatable. I would recommend testing a suite of algorithms and see what works on your problem, then pick one that is updatable.
Hi Jason, I’m a front end developer, but now i would like to learn machine learning. Could you guide me to learn it in best way?
My best advice is here:
https://machinelearningmastery.com/start-here/#getstarted
I would recommend that you start with Weka:
https://machinelearningmastery.com/start-here/#weka
Hmmm.. the download map link is broken….
Sorry… spoke too soon.. link of the website went to an error, but just got the download email. Thank you !
Sorry about that, the download works, but the redirect to my thank-you page is broken. I’m working on it.
Support Vector Machines, a supervised ML Algorithm is not there explicitly in the ML Algorithm mindmap.
Am i overlooked?
Correct. You could add it if you wish.
Which Optimisation Algorithm is best? Genetic Algorithm (or) ABC Algorithm (or) Support Vector Machine (or) Paricle swam Optimisation (or) Ant Colony Optimisation.And explain it
There is no best algorithm. Try a suite and see what works best for your specific sample of data and requirements.
Hi Jason, very useful classification. Thank you. I wanted to know that HMM and FST are being considered as machine learning algorithms or not?
Yes, sure.
Thanks for such an awesome blog entry!
You’re welcome, I’m glad it helped!
Awesome work and page Jason! Really a fantastic job you have made. Many many thanks for your effort.
Thanks Alex!
Many thanks for this tour,
I am working on anomaly detection in networks, which kind of algorithms you may suggest,
Thank you
Try many algorithms and see what works best for your specific data.
Hi Jason
May I please know if there are any pre-requisites for ML in python
Not really other than learning some python.
You can get started with ml in python here:
https://machinelearningmastery.com/start-here/#python
Hi Jason,
I am a beginner in programming and I am planning to use Machine Learning algorithm to calibrate sensor data against reference data (in Python). What are some algorithms that you would suggest?
Thanks!
Try a suite of methods to see what works for your specific prediction problem.
Also see this:
https://machinelearningmastery.com/faq/single-faq/what-algorithm-config-should-i-use
Thanks Jason for sharing very nice article.
Suppose consider a scenario where a patient took drug (X) and develop five possible side effect (X-a, X-b, X-c, X-d,X-e).
I need to find out the signal i.e. causal relationship between drug and its side effect based on few parameters (like seriousness, suspected etc..).
If the parameter is present, I give score as 1, if not present- score as 0 and -1 for not applicable.
Which algorithm should I use to find the best drug-event relation based on score or any alternative approach do u prefer.
This process will help you to work through your problem systematically:
https://machinelearningmastery.com/start-here/#process
Hi Jason,
I am currently learing Machine Learning and the link that you shown, is 50% done.
I am bit confused which algorithm is suitable to find best event based on few paramaters.
Is it something Hierarchical clustering or decision tree or any other algorithm which u recommend.
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/what-algorithm-config-should-i-use
Hi Jason,
Is it possible to incorporate machine learning into the heuristic or semi-heuristic algorithms in job scheduling to improve optimisation? If yes, can you recommend some materials on this to me?
Perhaps. I don’t have examples, sorry.
Maybe SVM should be slotted into instance based algos class, but where to put RVM … ;-)?
Agreed.
In Machine Learning: what are State-Of-The-Art Machine Learning Algorithms?
Deep learning.
Dear @Jason thanks for your prompt reply,
So which techniques used in Deep Learning ? can you tell me the list?
The most widely use methods are MLPs, CNNs and LSTMs.
Nice article. Under semi-supervised learning, there is a statement “the model must learn the structures ..”. I believe you meant Algorithm here..Even you clarified this in your FAQ, algorithm is the one learns from data to create a prediction model. Agree ?
Yes.
better explained with more detailed sample codes
Thanks for the suggestion, here are some code examples:
https://machinelearningmastery.com/start-here/#code_algorithms
I am a newcomer to machine learning. I majored in geosciences at the university and only studied Python for two months.For students like me, how to prepare for machine learning, and there are many directions for machine learning, such as computer vision. Natural language processing, deep learning. Should we study machine learning as a whole, or choose a direction to study.I will graduate in April next year, how can I find a job related to machine learning. I am a student from China. My English may not be very good. Please don’t mind my mistakes.Thanks.
Start small, right here:
https://machinelearningmastery.com/start-here/
Hi Jason,
Thanks for the post, how could you categorize ReLU, GANs and RBM in this mindmap? If you put activation functions such as logistic regression and linear regression under the Regression section, should ReLU be there as well? And likewise, should GANs and RBM under Deep Learning?
Relu is an activation function, a part of a neural net, not an algorithm per se.
GAN is an unsupervised neural network algorithm.
RBM is a supervised neural net algorithm and also redundant, replaced by MLPs with Relu.
Logistic regression and linear regression are not activation functions, they are algorithms, solved via least squares.
Hi,
In follow up with this comment, I was wondering if you have any post about RBM. I just found a reference to “http://videolectures.net/deeplearning2015_lee_boltzmann_machines/” in one of your posts.
Thanks.
No, they are no longer useful:
https://machinelearningmastery.com/faq/single-faq/do-you-have-examples-of-the-restricted-boltzmann-machine-rbm
Perhaps it’s worth nothing that Deep Belief Networks, which appear in the above list, are comprised of stacked RBMs.
Thanks.
Its good to learn machine learning. Can the non- computer Science people learn this. Please tell way to learn.
Yes, you can start here:
https://machinelearningmastery.com/start-here/#getstarted
I recommend using Weka that does not need any code:
https://machinelearningmastery.com/start-here/#weka
Hello Jason your article is crystal clear so that it is useful for everyone and particularly me. I am beginner to this field and I want to know which algorithm will be suitable for detecting and classifying an object based on thermal image?? I have a set of data for example such as chair , table , phone etc. and I want to classify them based on detected thermal image. Could you please give some suggestions ???
I would guess a convolutional neural network (CNN) sound perform well.
Please, provide the details whether you provide any online classes or institutions to learn in real time as well as.
No, just ebooks:
https://machinelearningmastery.com/products/
You made it really very clear.
I believe many who work for several years in this field struggle to figure it out what they are doing and how is it related to big picture of ML and AI.
People also very much confused and consider, NN or DNN is all about AI, where in my view ML (statistical method, NN based method, any mathematical algorithmic formulation), Bio/Brain-inspired algorithm (genetic algorithm, SWARM etc), cryptography, cognitive etc. that all are subset of AI. Some are partially overlapped and some majorly overlapped with each other.
Thanks. Perhaps you’re right.
hello jason,
This article was wonderful.But my question is how can I learn the algorithms in a systematic way in order to clear the interview from the technical part.I hope you do understand.Thanks
Sorry, I don’t know about interviews.
hello Jason,
Is there any possibility to use reinforcement learning on regression?
Probably not, the method is more appropriate for an agent in an environment.
I am feeling motivated and now work harder to start the career in Machine-Learning, hope will get similar success. Thanks for sharing your Machine-Learning experience.
Thanks. It’s great to have you here as part of the ML Mastery community.
Hi Jason, I am ambiguous about is MLP is machine learning or deep learning?
This map help:
https://machinelearningmastery.com/neural-networks-crash-course/
Hi Jason,
Can you help me how many types of machine learning algorithms can be used in
1) Semi- Supervised learning.
2) Reinforcement learning.
In general i need to know the name of algorithms in both cases.
Regards
Ashish
Perhaps start here:
https://en.wikipedia.org/wiki/Semi-supervised_learning
And here:
https://en.wikipedia.org/wiki/Reinforcement_learning
Jason
Is it possible to know the completely of deep and machine learning algorithms.
No one knows any field of study completely. In fact, no one knows anything completely.
We all just learn enough to get good enough results, then move on.
Please write on reinforcement learning! I’ll buy your book on day one I promise
Thanks for the suggestion and your support.
Thanks for updating the algorithms. Very useful.
Thanks.
you’re my spiritual supervisor !
Thanks!
This is a very interesting, but more important amusing post.
It is provoking, extremely well written and easy to read, after reading it a sort of road map has formed which is fantastic for a newbi just like yours truly.
Only one thing troubles me a little bit, a tendency that may lead many newcomers to think that math is unimporttant, machine learning is not easy at all, it requieres lots and lots of mathematics and deisregarding them buy telling the story of someone that came, understood and jumped to program lots of code but hiding the fact that she was alrady an engineer, or mathematician, or statistican, etc .
Any way, Jason, I have just been converted and will follow your blog very closely since I am convinced your writtings will be very helpful for a chnage of carrer from theoretical physicist to data scientist
Thanks Mario.
and generally speaking, compare these algorithms. I would add HDT, Jackknife regression, density estimation, attribution modeling (to optimize marketing mix), linkage (in fraud detection), indexation (to create taxonomies or for clustering large data sets consisting of text), bucketisation, and time series algorithms.
Very nice, thanks!
Machine learning is currently one of the major methods of artificial intelligence. Logistic regression, Random Forest and Deep Learning are three common machine learning methods. Please explain how these three methods perform Supervised Learning.
I have tutorials that explain all three, you can search for them on the blog – use the search box.
Which “learning style” are “Deep Learning Algorithms” in?
For example, which learning style is CNN algorithm in?
Supervised learning.
Can you suggest a deep learning algorithm that learns the relationships existing between consecutive(adjacent) data points.
For example predicting a structure by identifying the relationships among 3D coordinates?
Perhaps manifold learning:
https://scikit-learn.org/stable/modules/manifold.html
Should XGBoost algorithm be a part of Ensemble Algorithms?
Yes!
Hi, Thanks for nice information.
You’re welcome!
Great summary and broad perspective of artificial intelligence techniques to apply in order to develop algorithms using machine learning! Thanks to Mr. Jason Brownlee !!
Thanks!
Hi Jason,
Very nice summary! One confusion for me: I can understand that knn belongs to instance-based algorithms, but why SVM also belongs to this category? Any material you would suggest to explain this? Thank you!
SVM finds support vectors – points in the feature space – used to define the boundary between the classes. E.g. it’s probably an instance-based method given this understanding.
I see, then it is much clear for me, thank you Jason!
You’re welcome.
Hi Jason,
I read your post again, because I really think it is a great classification way for different ML algorithms! I have one question about unsupervised ML when I was reading again your post, maybe you can help?
Which algorithms that you listed in your post belong to unsupervised ML? Clustering? In principle, we don’t need to split the data to training and test dataset for the model performance evaluation for unsupervised ML algorithms, instead, we need to input our entire dataset for training, right? If so, how can we know whether we should use this unsupervised method or not?
Many thanks!
Good question, this framework will help you determine if you need supervised learning:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Thank you Jason, this post helps a lot!
You’re welcome.
This was really awesome….
Kudos to you Jason….
What are the subsets of ML alongside of DL???
DL is subset of ML right???? Like that what are the other subsets??? Plz help…????
Yes, deep learning is a subset of machine learning. All of the algorithms listed above sit along side deep learning.
This is so helpful, thank you!
I have a question:
I want to estimate the elastic modulus of an aluminium metal plate with density, resonant frequencies and plate dimensions as inputs. And the elastic modulus as the output.
which is the best algorithm to do so, and where can I get the algorithm to optimize?
thanks in advance!
Good question, I answer it here:
https://machinelearningmastery.com/faq/single-faq/what-algorithm-config-should-i-use
Hi sir, please which Reinforcement learning algorithms fit and perfect to solve continuous computational complexity?
Sorry, I don’t have tutorials on RL, I may write about the topic in the future:
https://machinelearningmastery.com/faq/single-faq/do-you-have-tutorials-on-deep-reinforcement-learning
Are real analysis and measure theory necessary to know to engage in machine/deep learning?
No.
Is theory of computation, type theory, or compiler theory required to write code / be a developer?
Thanks a ton for this post!! Really helped!!
You’re welcome.
Excellent post! To the point! No unnecessary theory. Great going
Regards,
Aashish
Munich, Germany
Thanks!
This was really awesome….
Kudos to you Jason….
What are the subsets of ML alongside of DL???
DL is subset of ML right???? Like that what are the other subsets??? Plz help
Thanks.
DL is a subset of ML:
https://machinelearningmastery.com/faq/single-faq/how-are-ml-and-deep-learning-related
Awesome insight for Beginner like me in ML. I am starting with the Andrew’s ML course at coursera. I have programming experience of more than 10 years, I was wondering what does a machine learning expert exactly do after solving a complex ML problem? I mean the algorithm is optimized and hypothesis is predicting the correct results, then what will the expert do? Gets fired 🙂
A final model is fit on all data ready for making predictions on new cases:
https://machinelearningmastery.com/train-final-machine-learning-model/
The model is deployed and monitored over time, like any software system.
Tour of machine learning is best for beginner students like me.
Thank you
Thanks.
A fantastic overwiew!
Compliments
Thanks!
Hi Jason,
Would you please provide some online machine learning classification tutorial for real time data?
Yes, perhaps start with the examples here:
https://machinelearningmastery.com/start-here/
Shared a nice post about a journey of machine learning algorithms.
Thanks!
Thank you for sharing this valuable content.
I love it. it’s very valuable.
You’re welcome!
Hey Jason!
Thank you so much for these great tips.
I will definitely follow these instructions. Keep writing.
Thanks.
Hannah
You’re welocme.
Hi Jason, thanks for a great summary,
I am new to ML, trying to understand groups of algorithms.
I have stumbled upon a similar summary here
https://www.r-bloggers.com/2019/07/101-machine-learning-algorithms-for-data-science-with-cheat-sheets/
and this list has a separate group called
“Classification Algorithms” that you don’t have, and he put there algorithms from multiple your group, is this an error? it looks like he confused “Algorithm Type” and “Problem Type” here, am I right?
There’s no best way. Perhaps you can ask the author themselves about their approach to grouping algorithms.
Nice explained article
Thanks!
I have been reading posts regarding this topic and this post is one of the most interesting and informative one I have read. Thank you for this!
Thanks.
I have been reading posts regarding this topic and https://www.google.com/ post is one of the most interesting and informative one I have read. Thank you for this!
Thanks!
During this website, I archive lots of information that”s how measure website
thanks a lot Jason (:
You’re welcome.
This post is old but very nice, Thanks for sharing!
You’re welcome!
thank u for sharing such a nice valuable information about machine learning algorithm
You’re welcome!
I liked this post and it is very helpful…any body who help me in research area/topic in natural language processing please?
You can start here:
https://machinelearningmastery.com/start-here/#nlp
Is time series forecasting considered as machine learning model ? If not why ?
Yes it is. Just like regression.
My colleagues argue that Statistical forecasting shouldn’t be confused with Machine learning although there was no clear justification. So wanted to understand if there is any such argument?
There is such a school of thought. But in practice, why should you care if you found a model that works for your problem? Linear regression for example, we can find a close form solution for least square error. We can also find a solution using SGD. You can’t just say if I use a close form solution using matrices then it is not a good model.
How about self-supervised learning?
Thanks, I may cover it in the future.
Hi Jason, thanks for the detailed taxonomy. I was trying to find where Catboost (https://catboost.ai/) will fit, but didn’t find it. I guess it falls under ensemble techniques, isn’t it?
Yes, ensembles.
Your posts are really helpful. Thank you for amazing content.
Thanks. Glad you liked it.
Thanks for sharing a detailed post. This would help me a lot.
thanks for telling me aboutlearning algorithmsand thanks for sharing this article
Hi ulfat…You are very welcome! Please let us know what areas of machine learning interest you most.
Regards,
hello
am umer i have a final year project “:priority based distribution of sensor nodes in a wireless sensor network”
in which i have to randomly deploy sensor nodes in any defined area from which i have to fetch the data
then after deployment sensor nodes make a network and after network creation they sense data just like i wanna fetch and extract the number of troops from the network area in my project and on the basis of this sensed data these nodes using machine learning algorithum define the area in 4 zones (on the bases of sensed data )just like if no of troops >500=critical zone
1# most critical
2# critical
3# less critical
4# normal
and also make the nodes as efficient if the number of nodes on most critical zone less then normal zone so these nodes moves from normal to critical zone to protect the network from data loss
this is all my project anyone help me please
Hello Umer,
Generally, I recommend that you complete homework and assignments yourself.
You have chosen a course and (perhaps) have even paid money to take the course. You have chosen to invest in yourself via self-education.
In order to get the most out of this investment, you must do the work.
Also, you (may) have paid the teachers, lectures and support staff to teach you. Use that resource and ask for help and clarification about your homework or assignment from them. They work for you in some sense, and no one knows more about your homework or assignment and how it will be assed than them.
Nevertheless, if you are still struggling, perhaps you can boil your difficulty down to one sentence and contact me.
Great post! I am actually getting ready to across this information, It’s very helpful to me. Also great with all of the valuable information you have Keep up the good work you are doing well.
Thank you for the feedback and kind words Rahul!
Hello Mr. James
I just want to thank you for this informative post. It helped me a lot, especially the informative discourse of other people. Thanks a bunch
You are very welcome Ramil! We appreciate the support and feedback!
I think that ‘domain adaptation’ shall be an other element in the Group by Similarity.
The problem they try to solve is to match distributions.
One famous algorithm example are GANs.
Thank you for the feedback Peblo!
Thank you for this insightful post. It’s been very helpful.
I particularly like how you grouped algorithms by “similarity”. As far as I understand, “similarity” here refers to the algorithm’s underlying mathematical/algorithmic theory/approach; not the algorithm’s objective. Accordingly, for example, both linear and logistic regression belong to regression algorithms although the former’s objective is regression and the latter’s one is classification.
That’s why it makes sense to me that SOM, for example, belongs to instance-based algorithms although there’s a group for dimensionality reduction, which is SOM’s objective. The same applies to MLP belonging to ANN algorithms although there’s group for clustering.
What I’m trying to say is that, unless I’m mistaken, shouldn’t clustering and dimensionality reduction be excluded as groups? In case you agree, I’d be interested to know where you’d add k-means and PCA then.
I would also like to know where you’d add DBSCAN.
Thank you
Hi Omar…You are very welcome! The following resource should add clarity:
https://machinelearningmastery.com/calculate-principal-component-analysis-scratch-python/
This post is old but very nice, Thanks for sharing!
You are very welcome! We appreciate your support and feedback!
Thanks for that my dear friends!
You are very welcome Jason! Thank you for your feedback!
Nice and complete summary
Thanks Jason
Anyway, where are classified:
– the current and explosive Generative Machine Learning techniques as ChatGPT and others?
– Where are classified GAN Generative Adversarial networks techniques?
– Or where are classified NST Neural Style Transfer?
– Or types of text to images?
– Or images caption
Anyway my big question is:
is ChatGPT and others LLM techniques making all the rest ML/DL obsolete? or according to you is there still room for them?
thank you so much
Nice blog and very useful.
Thank you for the feedback!