A lot is happening in the world of AI at the moment. Some of you may be wondering how machines have the ability to do what they can do. How can they recognise images, understand speech, and even reply to my requests???
Welcome to the world of Deep Learning.
Deep Learning is a subfield of machine learning concerned with algorithms inspired by the structure and function of the brain called artificial neural networks.
Yes, I understand, that sounds very technical and overwhelming, right?
If you are just starting out in the field of deep learning or you had some experience with neural networks some time ago, you may be confused. I know I was confused initially and so were many of my colleagues and friends who learned and used neural networks in the 1990s and early 2000s.
The leaders and experts in the field have ideas of what deep learning is and these specific and nuanced perspectives shed a lot of light on what deep learning is all about.
But what is deep learning? What is it all about? What did deep learning mean to the pioneers and thought leaders of today? If you’re thinking about these questions, then you’re in the right place.
This article will explore what deep learning is by hearing from a range of experts and leaders in the field.
If you’re really keen to learn about deep learning, kick-start your project with my new book Deep Learning With Python, which includes step-by-step tutorials and the Python source code files for all examples.
Kick-start your project with my new book Deep Learning With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s dive in.
What is Deep Learning? Photo by Kiran Foster, some rights reserved.
Andrew Ng on the Essence of Deep Learning
Renowned for his contributions to the field, Andrew Ng, founder of DeepLearning.AI and other platforms such as Coursera formally founded Google Brain. This eventually resulted in the productization of deep learning technologies across a large number of Google services.
Andrew Ng has frequently spoken and written a lot about what deep learning is, making him a great starting point for those who wish to learn more about the field.
– Make learning algorithms much better and easier to use.
– Make revolutionary advances in machine learning and AI.
I believe this is our best shot at progress towards real AI
Later his comments became more nuanced.
As time progressed, Andrew Ng’s insights into deep learning became more refined and nuanced.
According to Andrew, the core of deep learning is the availability of modern computational power and the vast amount of available data to actually train large neural networks. When discussing why now is the time that deep learning is taking off at ExtractConf 2015 in a talk titled “What data scientists should know about deep learning“, he commented:
very large neural networks we can now have and … huge amounts of data that we have access to
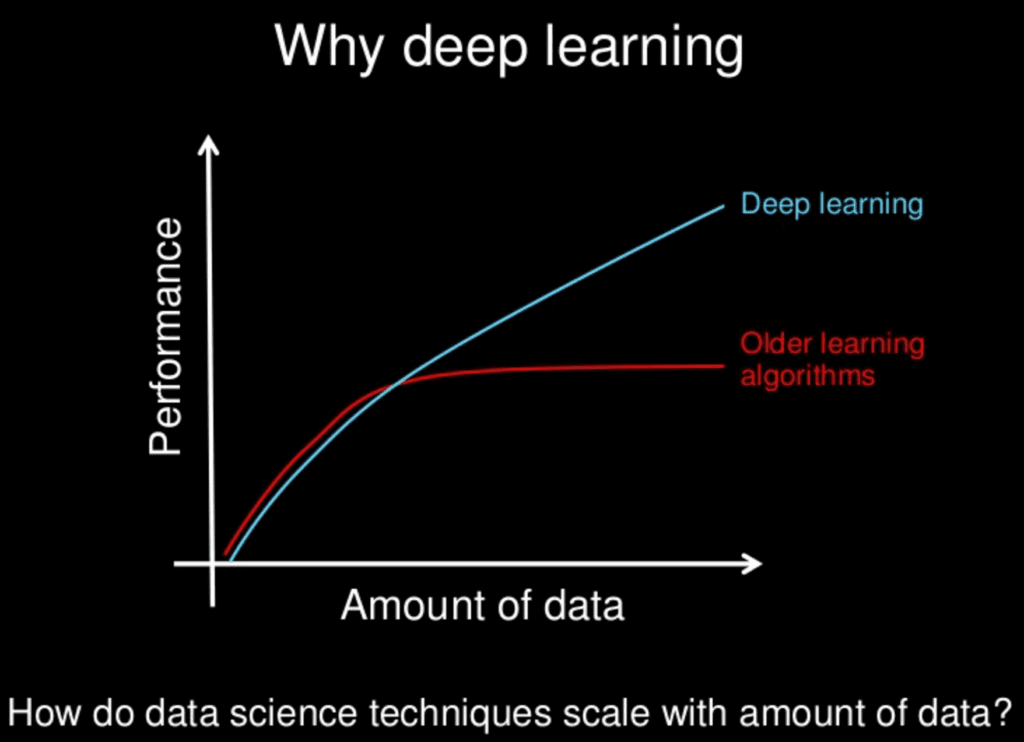
He also commented on the significance of scale in the world of deep learning. As we construct larger neural networks and train them with more and more data, their performance continues to increase. Unlike many traditional machine learning methods that reach a plateau in performance, deep learning stands out.
Crafting bigger neural networks and furnishing them with increasing volumes of data will lead to a rise in efficacy.
Andrew noted:
for most flavors of the old generations of learning algorithms … performance will plateau. … deep learning … is the first class of algorithms … that is scalable. … performance just keeps getting better as you feed them more data
Here is a nice cartoon explaining this from one of his slides:
Why Deep Learning? Slide by Andrew Ng, all rights reserved.
Another point that Andrew Ng highlights is the importance of supervised learning within deep learning. Speaking at the 2015 ExtractConf, he pointed out:
almost all the value today of deep learning is through supervised learning or learning from labeled data
Echoing similar sentiments, during a 2014 lecture at Stanford University titled “Deep Learning,” he stated:
one reason that deep learning has taken off like crazy is because it is fantastic at supervised learning
Andrew often mentions that we should and will see more benefits coming from the unsupervised side of the tracks as the field matures to deal with the abundance of unlabeled data available.
Jeff Dean: The Architect Behind Google’s Deep Learning Infrastructure
Jeff Dean, a driving force behind the Systems and Infrastructure Group at Google, has now been appointed Google’s chief scientist and played a pivotal role and is perhaps partially responsible for the scaling and adoption of deep learning within Google. Jeff was involved in the Google Brain project and the development of large-scale deep learning software DistBelief and later TensorFlow.
When you hear the term deep learning, just think of a large deep neural net. Deep refers to the number of layers typically and so this kind of the popular term that’s been adopted in the press. I think of them as deep neural networks generally.
He has given this talk a few times, and in a modified set of slides for the same talk, Jeff emphasizes the scalability of neural networks indicating that results get better with more data and larger models, which in turn require more computation to train.
It seems like Andrew Ng and Jeff Dean were definitely having the same conversations.
Results Get Better With More Data, Larger Models, More Compute Slide by Jeff Dean, All Rights Reserved.
Deep Learning: The Art of Hierarchical Feature Learning
Another characteristic of deep learning models is their ability to perform automatic feature extraction from raw data, also known as feature learning.
Yoshua Bengio: A Pioneer’s Perspective
Yoshua Bengio is another significant figure in the deep learning domain. Starting out with an interest in automatic feature learning capabilities that large neural networks are capable of achieving.
Deep learning algorithms seek to exploit the unknown structure in the input distribution in order to discover good representations, often at multiple levels, with higher-level learned features defined in terms of lower-level features
He then further expands on this idea in his 2009 technical report titled “Learning Deep Architectures for AI” where he emphasizes the importance of the hierarchy in feature learning.
Deep learning methods aim at learning feature hierarchies with features from higher levels of the hierarchy formed by the composition of lower level features. Automatically learning features at multiple levels of abstraction allow a system to learn complex functions mapping the input to the output directly from data, without depending completely on human-crafted features.
Bengio, in collaboration with Ian Goodfellow and Aaron Courville, published a book titled “Deep Learning” which defines deep learning in terms of the depth of the architecture of the models.
The hierarchy of concepts allows the computer to learn complicated concepts by building them out of simpler ones. If we draw a graph showing how these concepts are built on top of each other, the graph is deep, with many layers. For this reason, we call this approach to AI deep learning.
This book has become a definitive resource within the field, presenting multilayer perceptrons as a core algorithm in deep learning, suggesting that deep learning has effectively integrated artificial neural networks.
Peter Norvig: Google’s Take on Depth and Abstraction
The quintessential example of a deep learning model is the feedforward deep network or multilayer perceptron (MLP).
a kind of learning where the representation you form has several levels of abstraction, rather than a direct input to output
The Evolution of the Term “Deep Learning”. Why Not Simply “Artificial Neural Networks”?
Geoffrey Hinton, a pioneer in the field of artificial neural networks co-published the first paper on the backpropagation algorithm for training multilayer perceptron networks.
In 2006, Hinton co-authored “A Fast Learning Algorithm for Deep Belief Nets” in which the term “deep” signified networks with multiple layers, particularly restricted Boltzmann machines.
Using complementary priors, we derive a fast, greedy algorithm that can learn deep, directed belief networks one layer at a time, provided the top two layers form an undirected associative memory.
This, along with another seminal paper Geoff co-authored titled “Deep Boltzmann Machines” on an undirected deep network were well received by the community as they were shown to be successful examples of greedy layer-wise training of networks, allowing many more layers in feedforward networks.
We describe an effective way of initializing the weights that allows deep autoencoder networks to learn low-dimensional codes that work much better than principal components analysis as a tool to reduce the dimensionality of data.
Echoing Andrew Ng’s sentiments about the fusion of computational power, using vast datasets, and optimal weight initialization, the article conveys:
It has been obvious since the 1980s that backpropagation through deep autoencoders would be very effective for nonlinear dimensionality reduction, provided that computers were fast enough, data sets were big enough, and the initial weights were close enough to a good solution. All three conditions are now satisfied.
Talking with the Royal Society in 2016 titled “Deep Learning“, Geoff commented that Deep Belief Networks were the start of deep learning in 2006. This success, especially in speech recognition, prompted both the neural network and speech recognition sectors to take heed in 2009 titled “Acoustic Modeling using Deep Belief Networks“, achieving state of the art results.
It was the results that made the speech recognition and the neural network communities take notice of the use of “deep” as a differentiator on previous neural network techniques that probably resulted in the name change.
The descriptions of deep learning in the Royal Society talk are very backpropagation-centric as you would expect. Interestingly, Hinton gives 4 reasons why backpropagation (read “deep learning”) did not take off last time around in the 1990s. The first two points resonated highly with Andrew Ng’s comments about datasets being too small and computers being too slow.
What Was Actually Wrong With Backpropagation in 1986? Slide by Geoff Hinton, all rights reserved.
Deep Learning as Scalable Learning Across Domains
Deep learning has shown to particularly excel in scenarios where inputs and often outputs are analog. This means that rather than relying on a few quantities values in tabular format, deep learning has shown to thrive when dealing with pixel data from images, documents of text data or files of audio data.
Yann LeCun: The Visionary Behind Convolutional Neural Networks (CNNs)
Currently serving as the Vice-President, Chief AI Scientist at Meta, Yann LeCun is the father of the network architecture that excels at object recognition in image data called the Convolutional Neural Network (CNN). This technique has and continues to see great success because like multilayer perceptron feedforward neural networks, the technique scales with data and model size and can be trained with backpropagation.
This biases his definition of deep learning as the development of very large CNNs, which have had great success on object recognition in photographs.
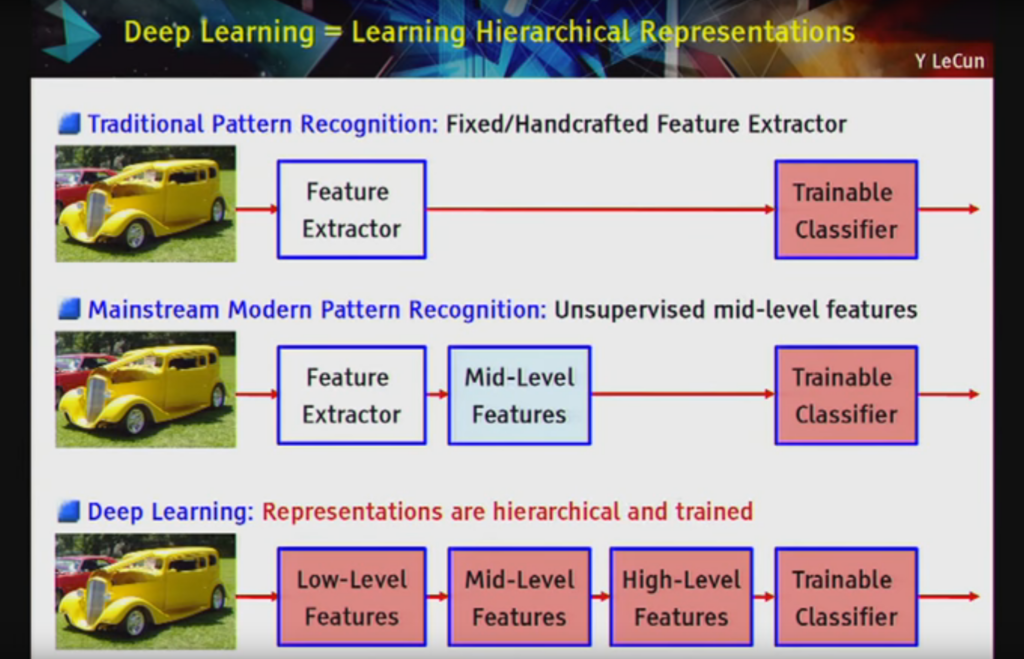
During a 2016 presentation at Lawrence Livermore National Laboratory titled “Accelerating Understanding: Deep Learning, Intelligent Applications, and GPUs” LeCun described deep learning as the pursuit of hierarchical representations and further goes on to say that it as a scalable approach to building object recognition systems:
deep learning [is] … a pipeline of modules all of which are trainable. … deep because [has] multiple stages in the process of recognizing an object and all of those stages are part of the training
Deep Learning = Learning Hierarchical Representations Slide by Yann LeCun, all rights reserved.
Jurgen Schmidhuber: The Innovator Behind Long Short-Term Memory Networks (LSTMs)
Schmidhuber has expressed his reservations about labeling the domain as “deep learning” in his 2014 paper titled “Deep Learning in Neural Networks: An Overview“. He comments on the problematic naming of the field and the differentiation of deep from shallow learning. He also interestingly describes depth in terms of the complexity of the problem rather than the model used to solve the problem.
At which problem depth does Shallow Learning end, and Deep Learning begin? Discussions with DL experts have not yet yielded a conclusive response to this question. […], let me just define for the purposes of this overview: problems of depth > 10 require Very Deep Learning.
Demis Hassabis and the Rise of DeepMind
Demis Hassabis, the visionary behind DeepMind, which was later acquired by Google, heralded a revolutionary fusion of deep learning and reinforcement learning. This combined breakthrough was able to handle complex learning problems like game playing, famously demonstrated in playing Atari games and the game Go with Alpha Go.
In keeping with the naming, they called their new technique a Deep Q-Network, combining Deep Learning with Q-Learning, subsequently dubbing the expansive domain as “Deep Reinforcement Learning”.
In their 2015 nature paper titled “Human-level control through deep reinforcement learning” they comment on the importance of deep neural networks and how it played a pivotal role in their breakthrough and highlighted the need for hierarchical abstraction.
To achieve this,we developed a novel agent, a deep Q-network (DQN), which is able to combine reinforcement learning with a class of artificial neural networks known as deep neural networks. Notably, recent advances in deep neural networks, in which several layers of nodes are used to build up progressively more abstract representations of the data, have made it possible for artificial neural networks to learn concepts such as object categories directly from raw sensory data.
Now coming to bring great minds together, what stands as a landmark paper in the realm of deep learning, Yann LeCun, Yoshua Bengio and Geoffrey Hinton published a paper in Nature titled simply “Deep Learning“. In it, they open with a clean definition of deep learning highlighting the multi-layered approach.
Deep learning allows computational models that are composed of multiple processing layers to learn representations of data with multiple levels of abstraction.
Later the multi-layered approach is described in terms of representation learning and abstraction.
Deep-learning methods are representation-learning methods with multiple levels of representation, obtained by composing simple but non-linear modules that each transform the representation at one level (starting with the raw input) into a representation at a higher, slightly more abstract level. […] The key aspect of deep learning is that these layers of features are not designed by human engineers: they are learned from data using a general-purpose learning procedure.
Although it is a nice and generic description, this holistic description encapsulates the essence of most artificial neural network algorithms, offering a good note to end on.
Summary
In this post you discovered that deep learning is just very big neural networks on a lot more data, requiring bigger computers.
Although early approaches published by Hinton and collaborators focus on greedy layerwise training and unsupervised methods like autoencoders, modern state-of-the-art deep learning is focused on training deep (many layered) neural network models using the backpropagation algorithm. The most popular techniques are:
Multilayer Perceptron Networks.
Convolutional Neural Networks.
Long Short-Term Memory Recurrent Neural Networks.
I hope this has cleared up what deep learning is and how leading definitions fit together under the one umbrella.
If you have any questions about deep learning or about this post, ask your questions in the comments below and I will do my best to answer them.
I think that SVM and similar techniques still have their place. It seems that the niche for deep learning techniques is when you are working with raw analog data, like audio and image data.
first of all I would like to appreciate your effort. This is one of the best blog on deep learning I have read so far.
Well I would like to ask you if we need to extract some data like advertising boards from image, what you suggest is better SVM or CNN or do you have any better algorithm than these two in your mind?
CNN would be extremely better than SVM if and only if you have enough data. The reason that CNN would be better is that CNN work as an automatic feature extractor and you won’t need to bother yourself of feature selection and wondering if the extracted feature would weather work with the model or not. CNN extracts all possible features, from low-level features like edges to higher-level features like faces and objects.
Generally, CNNs are really good at working with image data.
Medical Diagnosis seems like a really broad domain. You may want to narrow your scope and clearly define and frame your problem before selecting specific algorithms.
ECG interpretation may be a good problem for CNNs in that they are images. Another project is the development of a Consultant in Cardiovascular Disease analogous to MYCIN, an Infectious Disease Consultatant developed by Shortliffe & Buchanan @ Stanford ~ 40 years ago which was Rule Based.
hello, may deep learning apply to use in the stock market ?
What I mean : it doesn’t just only use to draw with old data diagram and use the old model but also write down how is the next day to give the number forecast ?
Thank for your reply, I have read some your posts and I am very impressed with your work. About myself , I just start to find out what is this filed and you have many experiences about them. I hope if you have some experiences about the finance especially in stock market…pls help me some reference to learn it by myself or find the “Tribute”as you mentioned 🙂
loved it , thanks for the overview , answered to a lot of my question
I am trying to find a topic for my Master-PHD proposal in Deep Learning in medical diagnosis and just wondering if there is any hot topic in this field at the moment ? and how can I learn more about this special field of Deep Learning
Hi maisie
I am looking for some information for my master thesis either about CNN and deep learning in medical diagnosis
So plz if u find anything usefull help me cause I’m new in the feild
Thank you so much for your post. I am trying to solve an open problem with regards to embedded short text messages on the social media which are abbreviation, symbol and others. For instance, take bf can be interpret as boy friend or best friend. The input can be represent as character but how can someone encode this as input in neural network, so it can learn and output the target at the same time. Please help.
In your opinion, on what field CNN could be used in developing countries?
Because there seems less raw data than developed countries, i couldn’t think of any use of CNN in developing countries.
Hi… I am an average developer in a developing country and my opinion is “yes”… if you find a way to get all these “disconnected” data together than you can help on gathering these data to make it easier for developing countries not to make the same mistakes as developed countries… thus bringing the cost down on “becoming” a developed country without the cost… the “research” exist… the implementation is the problem…
a very well and nicely explained article for the beginners.
I would like to ask one question, Please tell me any specific example in the area of computer vision, where shallow learning (Conventional Machine Learning) is much better than Deep Learning.
Wonderful summary of Deep Learning – I am doing an undergraduate dissertation/thesis on applying Artificial Intelligence to solving Engineering problems.
Hi… I am just an average normal developer, but I find this article very informative…
May I please ask one question:
If the “internet” and “line speed” was fast enough, would it mean these algorithms could learn itself or are the “programs” currently limited to human interaction during the learning stage…
So my actual question: the “data” according to me is available -> “internet” BUT do we (humanity currently) already have the computational ability to make “sense” of the data via these algorithms AND are the software developed in such a way to ignore human approval?
The data needed to learn for a given problem varies from problem to problem. As does the source of data and the transmission of data from the source to the learning algorithm.
Dr Jason, this is an immensely helpful compilation. I researched quite a bit today to understand what Deep Learning actually is. I must say all articles were helpful, but yours make me feel satisfied about my research today. Thanks again.
Based on my readings so far, I feel predictive analytics is at the core of both machine learning and deep learning is an approach for predictive analytics with accuracy that scales with more data and training. Would like to hear your thoughts on this.
This article is very interesting and useful for a beginner in machine learning like me.
I am thinking about a project (just for my hobby) of designing a stabilization controller for a DIY Quadrotor. Do you have any advice on how and where I should start off? Can algorithms like SVM be used in this specific purpose? Is micro controller (like Arduino) able to handle this problem?
hi jason are you fine i read your article that help me out and the comment section also
may i know that which is the latest algorithm in deep neural network
i need your help about neural network . i am working on neural network thanks
Lots of unnecessary points your explained which make difficult to understand what is actually deep learning is, also unnecessary explanaiton meke me bouring to read the document.
Hi Jason, I have been referring to a few of your blogs for my Machine Learning stuff. One striking feature of your blogs is simplicity which draws me regularly to this place! This is very helpful.:) Talking about Deep Learning vs traditional ML, the general conception is that Deep Learning beats a human being at its ability to do feature abstraction. Is this true?
Also, could you tell me why Deep Learning fails to achieve more than many of the traditional ML algorithms for different datasets despite the assumed superiority of DL in feature abstraction over other algorithms?
Deep learning is great at feature extraction and in turn state of the art prediction on what I call “analog data”, e.g. images, text, audio, etc.
It can be used on tabular data (e.g. spreadsheet of numbers) but this is not it’s sweet spot and often can be beaten by other methods, like gradient boosting.
There is no one algorithm to rule them all, just different algorithms for different problems and our job is to discover what works best on a given problem.
if we use hierarchal training algorithm such as we use unsupervised learning autoencoder with bottleneck (hidden layer, 10,2,10) for training then use the supervised learning with same autoencoder architecture ( hidden layer, 10,2,10) to tune the unsupervised model parameter (weights, bias). These training processes are performed separately.
now the unsupervised autoencoder works as dimension reduction and extract features. does the supervised model work in the same way and extract the feature or just this step conducted in the unsupervised learning
Sir, It is a good intro to deep learning. i’m planning to do phd in diagnosis of heart disease using deep learning. I have data’s of features. I don’t know how to classify those data. Can you please refer some material for numerical data classification using tensor flow.
hi , i have started in my graduation project , and i am creating a medical system based on data comes from medical sensors , and i hope to use deep learning in detecting the disease or the health case based on that data , but i don’t know from where i should start in deep learning
can you help me in doing it ?
Hi Jason, thank you for the excellent overview. May I know how to apply deep learning in predicting adverse drug reactions, particularly in drug-drug interaction?
What does “bigger models” mean? Are there more equations in the model? Are there more variables in the model? Are there more for loops? How exactly is the model “bigger”? What’s an example of a “not big model” and why is that worse? And what exactly is meant by the term “model” in this field? I’m still not clear on that. Like what exactly are the characteristics that make something a “model” and why is another general programming algorithm like, say, a loop that divides numbers successively to determine if an integer is prime, not a “model”? To me that sounds like a “model” for determining if a number is prime, so what is meant in this field by “model”? What are the inherent properties that make something a “model”? Is a model a type of algorithm? Is it a class in object-oriented design? What’s a “model” and what;s a “bigger model”?
Ok, let’s start by what exactly is meant by the term “model” in this field? Because I’m still absolutely not clear on what that means. If I write up some code to solve a problem, how do I know whether or not I’ve “built a model”?
And then what’s the “bigger model” you refer to in this article? Are there more weights and more structure in the training algorithm? How is that achieved? Do you plug in more equations and more variables and decision parameters/whatever? How do you know what additional equations and parameters to plug in, and how do you know those are the right ones as opposed to others? Or does “bigger models” simply refer to running on more overall data, and the training algorithm is the same with the same amount of equations/variables/computations per training example?
how deep learning can be applied in music ? is it possible to analyze existing music to compose new music by computers ?? If yes what type of algorithm should be used ?
I am familiar with machine learning and neural networks. My expertise is optimization and I am just interested in this field. What do you suggest as a good starting point? I prefer to learn it through experience and see how it works on different cases.
Do you think a deep-learning system could be “taught to read” in a manner similar to a young child? That is:
1. Visual input of the words on each page
2. Coordinated (i.e. synchronized) sound input of those words being read
3. Repeat/reinforce as needed by “reading” the same book multiple times
4. Expand the data set by “reading” a variety of books
…with the ultimate goal & test being to present the system with a book it hasn’t “seen” before, and have it “read” that book via a synthesized voice.
(Never mind the robotics to turn the pages, we can leave that part to a human assist.)
i am nazek hassouneh
i am a master student and my thesis in deep learning
i have data set with class label
i will use deep learning for classification
data set is an excel format and will convert to CSV form
data set with 49 attribute and 131,000 records
how can i use deep learning i need tutorial for that
i need specific nueral networks suitable for this data set
Hi Jason
loving your articles on ML and NLP! Apologies if this is a daft question but do the extra layers in deep learning models make them more or less transparent? I am thinking in the context of looking for patterns of helpful comments in forum exchanges – would I be able to recognise the features discovered (e.g. as a series of IFTTT rules) or would they just come out as a series of factor weights?
Very new to this so any pointers most welcome
Keep up the good work
best wishes
Mat
Thanks Jason. I see that people have been making progress on increasing transparency in deep learning https://arxiv.org/abs/1710.09511
I am working my way through your NLP crash course to understand more
Hi ..
It’s a great blog I’ve ever seen , thanks a lot for all your efforts, wish you the best ????
I am a master student and my thesis is about breast cancer diagnosis , I want to know is deep learning algorithm appropriate for my thesis
and if the answer is yes which one is the best
I’m so confused plz help me ????
Very nice one.I want to use deep learning in tourism sector. I can manage to get the tourists data.
Can you tell me how can i use deep learning in tourism sector.
Thanks for sharing these types of soul idea especially for like underresourced country. I am trying to do my thesis by “Object detection by Deep learning for autonomous Vehicle” which method prefer for accomplished my thesis.
a very useful for beginner like me. and right now i’m in doing research with title “analysis on deep learning method for heart disease. which suitable technique i should use ?
thanks very much jason for your valuable information , i have question about features extraction ;
i know features selection , but what means by features extraction which is a property of deep Learning.
I’m a PhD student working on a decentralized IDS (Intrusion Detection System) platform utilizing Big Data, and I’m using machine learning algorithms to detect some signature based attacks.
I’m researching if deep learning would be a good AI method to detect non-signature based attacks (anomalies). I’ve used neural networks to train a specific node to detect a specific signature based attack, but I’m new to deep learning and not sure how apply it into my model.
Would Multilayer Perceptron, Convolutional Neural Network or Long Short-Term Memory Network algorithms applicable at detecting anomalies with gigantic amounts of raw data?
If i am new to this where can i start , eventhough i read the full article its difficult for me to get some technical terms ? So where can i start if i am starting from scratch?
THANK YOU
thank you Doctor Jason Brownlee
For the great effort you make
I have several questions and I hope to be as broad as we used to
CNN is one of the neural networks that can be very deep but my question here is the code that distinguishes between being a normal neural network and being a deep neural network knowing that it can be used in both cases
I have implemented a deep learning application that predicts the status of my client as he will continue his service or not
The Code
import theano
import theano
import tensorflow
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv(‘C:/Python34/Churn_Modelling.csv’)
X = dataset.iloc[:, 3:13].values
y = dataset.iloc[:, 13].values
onehotencoder = OneHotEncoder(categorical_features = [1])
X = onehotencoder.fit_transform(X).toarray()
X = X[:, 1:]
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4)
# Adding the input layer and the first hidden layer
classifier.add(Dense(activation=”relu”, kernel_initializer=”uniform”, units=7, input_dim=11))
# Adding the second hidden layer
classifier.add(Dense(activation=”relu”, kernel_initializer=”uniform”, units=7))
# Adding the output layer
classifier.add(Dense(activation=”sigmoid”, kernel_initializer=”uniform”, units=1))
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
# Creating the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
The Data set
This application was found on the internet and its code is (Can I specify what functions (code) that make it a deep learning)
And you have implemented an application for you to learn about God called Your First Machine Learning Project in Python
What functions are used make me know whether this code is deep learning or machine learning
In the past it was possible to put a lot of layers and use a large data size in MLP
MLB is now one of the deep learning algorithms
What code you have completed makes it a profound learning
Sorry for the delay I would like to explain to me the application has been applied using the deep learning algorithm which is the same algorithm application is not using deep learning
I mean traditional learning is the algorithms in which we do not use depth but similar in use
Like RNN was used by the production of deep learning idea
But I mean what the code will differentiate between RNN and DNN, knowing that RNN and many of the previous algorithms are deep learning algorithms
Dear Mr. Jason, there is one thing I don’t understand. In the article it is said that Deep Learning’s performance get better with more data while other, older algorithms tends to reach a plateau. Can you explain more and give an example about the plateau?
Initially I think the plateau is there because more data can cause overfitting, but after some browsing I found out that more data will decrease the chance of overfitting. It is the number of feature, not the number of data that causes overfitting. The only thing I can think about how more data can create plateau is on heuristic algorithm, which can create more local minima where algorithms can get stuck on.
Hai Sir,
I am Preethi, working with Visual Studio C++. My research problem is related to classification and prediction. Now I am trying to use the deep concept (sparse autoencoder ) in my problem, but I didnt get any C++ package for autoencoder. I found so many python packages, but I have to follow VS C++. OpenCV offers modules for CNN ,not for autoencoders.
Could you pl suggest me any package to use with VS C++?
Does Particle Swarm Optimization and ant bee colony algorithms which comes under artificial intelligence is related to deep learning method or unsupervised learning techniques in machine learning
This article has given me great knowledge on deep learning. currently doing research on data mining. Could you please suggest me how to apply deep learning for cancer classification. Right now I am applying cuckoo search optimization algorithm.
Hi Jason and thank you for such an enlightening article.
What I understood is that the hidden layers act as feature learners from the data. They achieve
this by successively applying nonlinear transformations (with the activation functions) on the input data to map them into a new space: the feature space.
In case of a classification task, the classes become easier (linearly) to separatein this feature space.
What about in the case of regression? What is the function of the hidden layers in a deep neural network model for regression.
I would say: In case of regression, there is the nonlinear transformation of the input data to the feature space and there a linear regression in that new feature space can be applied to aproximate the numerical target variable.
yes sure. It is the non linear kernel that enables the non linear transformation of the input data to the feature space.
Isn’t the same principle as the activation functions in the hidden layers of a deep neural network?
this is regarding deep learning mini cource. i have done some research and read some material about deep learning and for deep learning mini cource – lession 1 – task , below are the details as requested
10 impressive applications of deep learning methods in the field of natural language processing
Hi sir ,I have one question that how to train the cifar 10 dataset with opencv and python such that after training it will generate xml file.
My aim is to ” Detect objects using OpenCV an python ”.
As I am new in this field, so please consider me.
Hello Everyone my thesis topic is “CLEFT FACIAL AESTHETIC OUTCOME EVALUATION BASED ON DEEP TRANSFER LEARNING” how can I use deep learning and transfer learning model and to combine them and develop cleft facial aesthetic outcome measure system please help me I am really worried about it
The post really brought me to light about Deep learning. I don’t know if you can be of help for my M.Sc thesis. I intend to use deep learning to obtain sistolic and diastolic data readings from a wearable device then run it through CNN to produce a more accurate value as its output.
The CNN will run on a parallel architecture to accommodate the processing power.
And being a consultant for an ICT firm, i will also want to know if you are open to take up some consultancy contract with the firm? You can reach me on my email: if you are interested.
Been reading up a lot on machine learning/deep learning, AI thinking how I can use them to UP my marketing ANTE. Will probably need a tech guy to really do it, but just wanted to get a good grasp about the topic and then I came across yours. Great article!
Hi jason
Which part of deep learning needs to cogitated to improve deep learning?
Is it approch of weigh choosing or the structure of neurals (number of layers and number of neuron in each layers or relation between each other)…. ?
Which part it is????
Hi. Being new to ML, this site is looking promising.Thank you.
I was considering using Google AutoML (https://cloud.google.com/automl-tables/docs/ ) on structured and labelled (probabaly JSON) but very large sets of textual data, to encode some near-subjective decision making that could possibly be explicitly coded, but with quite some complexity.
It could just be more elegant and scalable if a machine model could be trained, with human guidance.
If that sounds at all feasible, should I start with machine-learning-in-r-step-by-step and at least get used to the field using the “shallow” ML algorithms mentioned there, or would deep-learning likely prove more beneficial but still be an intelligible subject to a newcomer?
Eventually I’d want to employ this in an app.
Hi. Your posts are really good. I am learning a lot about ML. I would like to know whether deep learning can tacke classification problems when I have an unlabeled or partially labeled dataset.
Jason,
I am a CS student and have taken other classes in DL, yet the current material in an in-depth class has me challenged. I understand the concepts, but have a hard time completing working code with all the pieces in the time I am given.
We just finished RNN & CNN and for the next month will do reinforcement and unsupervised. I will be asked to take a network with distinct architecture and successfully train & test, most times with imported data. I am able to run different pieces of the code, but perfectly setting up all the parameters gives me a lot of trouble.
Hi Jason, I am Ravita Research scholar and doing research on scalable and efficient Job Recommendation using deep learning technique.
I am new in deep learning technique, which algorithm is suitable for job recommendation.i am using CareerBuilder dataset. Pls. suggest me which algorithm give better accuracy and scalabilty.
i loved the text
my question is
im going to work my PHD continue other relative work
he work on automatic image annotation he used CNN
con i continue using hybrid net. like CNN+LSTM+MLP or CNN+RNN something like that ?
Great historical review and research about the persons and conceptual ideas behind the main milestones of Deep Learning development with keys references.
I can see your are not only a great ML/DL populariser, but also and not less, a great scientific researcher of ML/DL
I did a quick skim over the information and plan on going back and rereading it. I was curious I have experience in HTML, CSS, Javascript, PHP, and C++. I am planning to also learn Binary, Python, and Assembly as well as a few others. The reason why is I want to build A.I. that cross the border of weak and strong A.I. and approaches the threshold of Super A.I.s. In order to do so I plan on creating a computer language but want a bunch of references to do so. So, in the end, my question is. What language do you recommend for Deep Learning and other coding languages?
sir, I want to do research in machine learning for predicting disease. I saw a lot of papers about that. most of the papers using small data sets.
I want to increase the size of the data sets what is the best method for large data sets. is it possible with MACHINE LEARNING? or deep learning is easy for large data sets
Hello Jason, Thank you for your amazing blog. I have chosen the Deep Learning course this semester while I have a little information about Machine Learning, (I plan to choose ML course next semester). I wanna know is ML a prerequisite for deep learning? or I can learn Deep Learning algorithms and models and learn other classical ML algorithms simultaneously? Thank you in advance for your answer
Hello Jason,
Can i use deep learning algorithm (CNN) in the resolution of optimization problem, example: I have a matrix with n*m values, in my case I need to select value from this matrix and turn the other to “0” in order to minimize the error or maximize energy?, Is there any matlab code do that?
hi Sir, Hope u fine, my teacher said python is removed from the market in coming 10 year , is this reality in ur vision, and he said js will be the coming language in AI ,…what u think about it.
First, I appreciate your blog; I have read your article carefully, Your content is very valuable to me. I hope people like this blog too. I hope you will gain more experience with your knowledge; That’s why people get more information.
wow its such a great post! im really into digital world and learning been always the best method to keep me motivated. keep sharing ! i recently came to know Amritsar Digital Academy from here you can learn digital marketing course which is such a good and helpful course in today’s era! it worth trying.
Hi Dr. Jason, I have a dataset.
it is a multi-class label classification, I want to apply Deep Neural networks, all the dataset features are probabilities, How can I prepare the data before applying the model. My question is Should I apply data normalization then build the model or do something else?
First, I appreciate your blog; I have read your article carefully, your content is very valuable to me. I hope people like this blog too. I hope you will gain more experience with your knowledge; That’s why people get more information.
Thanks for such amazing article.
Can you please give me a clear explanation about the difference between deep learning and machine learning,
What they mean by shallow learning it is the same as machine learning ?
Hi Ula…You are very welcome! Machine Learning or ML is the study of systems that can learn from experience (e.g. data that describes the past). You can learn more about the definition of machine learning in this post:
What is Machine Learning?
Predictive Modeling is a subfield of machine learning that is what most people mean when they talk about machine learning. It has to do with developing models from data with the goal of making predictions on new data. You can learn more about predictive modeling in this post:
Gentle Introduction to Predictive Modeling
Deep Learning is the application of artificial neural networks in machine learning. As such, it is a subfield of machine learning. You can learn more about deep learning in this post:









If the deep learning is such great algorithm, do you think that other older algorithms (like SVM) are no longer efficient to solve our problems?
I think that SVM and similar techniques still have their place. It seems that the niche for deep learning techniques is when you are working with raw analog data, like audio and image data.
Could you please give me some idea, how deep learning can be applied on social media data i.e. twitter.
Start by defining your problem:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Me too
can you tell what could be research for MS level in deep learning?
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/what-research-topic-should-i-work-on
if I want to reconstruct 3D object, which is better, such as ANN, CNN, deep convolutional auto-encoder?
Perhaps check the literature (scholar.google.comn) and discover what models are state of the art for your problem.
first of all I would like to appreciate your effort. This is one of the best blog on deep learning I have read so far.
Well I would like to ask you if we need to extract some data like advertising boards from image, what you suggest is better SVM or CNN or do you have any better algorithm than these two in your mind?
CNN will give better result as compare to svm in image classification
CNN would be extremely better than SVM if and only if you have enough data. The reason that CNN would be better is that CNN work as an automatic feature extractor and you won’t need to bother yourself of feature selection and wondering if the extracted feature would weather work with the model or not. CNN extracts all possible features, from low-level features like edges to higher-level features like faces and objects.
As an Adult Education instructor (Andragogy), how can I apply deep learning in the conventional classroom environment?
Perhaps start by defining your problem clearly:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Plz, anybody has Matlab code for CNN.
Matlab is not so useful in production environments, it’s more used at school. It’s not really the focus of this site.
To answer your question, I would suggest you read this article – https://www.simplilearn.com/tutorials/deep-learning-tutorial/deep-learning-frameworks as it clearly explains the Deep Learning algorithms
Thanks for sharing.
It summarises deep learning libraries, not algorithms.
Can CNNs perform tasks such as Medical Diagnosis or should they be
combined with another technique such as Reinforement Learning to
optimize performance?
Generally, CNNs are really good at working with image data.
Medical Diagnosis seems like a really broad domain. You may want to narrow your scope and clearly define and frame your problem before selecting specific algorithms.
ECG interpretation may be a good problem for CNNs in that they are images. Another project is the development of a Consultant in Cardiovascular Disease analogous to MYCIN, an Infectious Disease Consultatant developed by Shortliffe & Buchanan @ Stanford ~ 40 years ago which was Rule Based.
So Jason, what is the next discovery after “deep learning”?
No idea Napoleon. Deep learning has enough potential to keep us busy for a long while.
sir plz let me know on what basis cnn is extracting features from an image….
What do you mean exactly?
Okay
Good overview.
Take a look at this:
http://deeplearning4j.org/
It could be a good tool for DL?
Thanks Francesco.
hello, may deep learning apply to use in the stock market ?
What I mean : it doesn’t just only use to draw with old data diagram and use the old model but also write down how is the next day to give the number forecast ?
Hi Jason, deep learning may apply to the stock market.
I am not an expert in finance so I cannot give you expert advice. Try it and see.
You may be interested in this post on time series forecasting with deep learning:
https://machinelearningmastery.com/time-series-prediction-with-deep-learning-in-python-with-keras/
Thank for your reply, I have read some your posts and I am very impressed with your work. About myself , I just start to find out what is this filed and you have many experiences about them. I hope if you have some experiences about the finance especially in stock market…pls help me some reference to learn it by myself or find the “Tribute”as you mentioned 🙂
Thanks Jason, it’s great to have you here.
loved it , thanks for the overview , answered to a lot of my question
I am trying to find a topic for my Master-PHD proposal in Deep Learning in medical diagnosis and just wondering if there is any hot topic in this field at the moment ? and how can I learn more about this special field of Deep Learning
I’m glad to hear it was useful Maisie.
I would suggest talking to medical diagnosis people about big open problems where there is access to lots of data.
Hi maisie
I am looking for some information for my master thesis either about CNN and deep learning in medical diagnosis
So plz if u find anything usefull help me cause I’m new in the feild
Sounds like a great area.
Perhaps start by reviewing recent papers on the topic?
I am already but it seem a bit hard
I am looking for advices so I can continue
i am looking for M tech thesis in this topic…help me explore new areas….
Hi neha, the best person to talk to about research topic ideas is your advisor. Best of luck.
Hi Jason,
Thank you so much for your post. I am trying to solve an open problem with regards to embedded short text messages on the social media which are abbreviation, symbol and others. For instance, take bf can be interpret as boy friend or best friend. The input can be represent as character but how can someone encode this as input in neural network, so it can learn and output the target at the same time. Please help.
Regards
Abbey
Very cool problem Abbey.
I would suggest starting off by collecting a very high-quality dataset of messages and expected translation.
I would then suggest encoding the words as integers and use a word embedding to project the integer vectors into a higher dimensional space.
Let me know how you go.
Hi, thanks for the good overview.
In your opinion, on what field CNN could be used in developing countries?
Because there seems less raw data than developed countries, i couldn’t think of any use of CNN in developing countries.
Sorry Sam, I don’t know.
CNNs are state of the art on many problems that have spatial structure (or structure that can be made spatial).
Anything with images is a great start, domains like text and time series are also interesting.
Hi… I am an average developer in a developing country and my opinion is “yes”… if you find a way to get all these “disconnected” data together than you can help on gathering these data to make it easier for developing countries not to make the same mistakes as developed countries… thus bringing the cost down on “becoming” a developed country without the cost… the “research” exist… the implementation is the problem…
Hello Jason,
a very well and nicely explained article for the beginners.
I would like to ask one question, Please tell me any specific example in the area of computer vision, where shallow learning (Conventional Machine Learning) is much better than Deep Learning.
Great question, I’m not sure off hand. Computer Vision is not really my area of expertise.
This article is useful for learning deep learning .Nice article
Thanks priyanka.
Wonderful summary of Deep Learning – I am doing an undergraduate dissertation/thesis on applying Artificial Intelligence to solving Engineering problems.
Thanks Chris! Good luck with your thesis.
Hi… I am just an average normal developer, but I find this article very informative…
May I please ask one question:
If the “internet” and “line speed” was fast enough, would it mean these algorithms could learn itself or are the “programs” currently limited to human interaction during the learning stage…
So my actual question: the “data” according to me is available -> “internet” BUT do we (humanity currently) already have the computational ability to make “sense” of the data via these algorithms AND are the software developed in such a way to ignore human approval?
The data needed to learn for a given problem varies from problem to problem. As does the source of data and the transmission of data from the source to the learning algorithm.
Dr Jason, this is an immensely helpful compilation. I researched quite a bit today to understand what Deep Learning actually is. I must say all articles were helpful, but yours make me feel satisfied about my research today. Thanks again.
Based on my readings so far, I feel predictive analytics is at the core of both machine learning and deep learning is an approach for predictive analytics with accuracy that scales with more data and training. Would like to hear your thoughts on this.
Thanks. I’m very glad to hear it.
Predictive modeling is a sub-field of machine learning, and is by far the most useful area/the area of interest right now:
https://machinelearningmastery.com/gentle-introduction-to-predictive-modeling/
This article is very interesting and useful for a beginner in machine learning like me.
I am thinking about a project (just for my hobby) of designing a stabilization controller for a DIY Quadrotor. Do you have any advice on how and where I should start off? Can algorithms like SVM be used in this specific purpose? Is micro controller (like Arduino) able to handle this problem?
Thank you in advance
Sounds like a lot of fun.
Consider this process to work through your problem:
https://machinelearningmastery.com/start-here/#process
hi
Is the Deep Learning is suitable for prediction of any diseases like Diabetes using data mining algorithms?
If yes give some ideas to work in it
It may be good, but try a suite of algorithms to see what works best on your problem.
See this post:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
hi jason are you fine i read your article that help me out and the comment section also
may i know that which is the latest algorithm in deep neural network
i need your help about neural network . i am working on neural network thanks
There are many deep learning algorithms.
The most popular are MLPs for tabular data, CNNs for image data and LSTMs for sequence data.
thanks jason in research base which algorithm you suggest for me to work
I would suggest you pick an area that most excites you.
JASON I WANT TO WORK IN MEDICAL AREA OR IMPLEMENT IN TO MEDICAL SITE
Great! I wish you the best of luck.
does deep learning is a solution of over-fitting problem in machine learning?
No, deep learning methods can overfit like any other.
Thanks for the great article. What is the best approach for classifying products based on product description?
Perhaps use an LSTM or CNN or both combined.
Lots of unnecessary points your explained which make difficult to understand what is actually deep learning is, also unnecessary explanaiton meke me bouring to read the document.
Sorry to hear that.
Jason,
What do you think is the future of deep learning?
How many years do you think will it take before a new algorithm becomes popular?
Hi Anthony,
There is not one algorithm, but a population with the headliners: MLP, LSTM and CNN.
I do not know where we are headed, sorry.
I am a student of computer science and am to present a seminar on deep learning, I av no idea of what is all about…..can I get articles dat can aid Me
This post would be a good start.
I do not have much general material, but if you want to know how to use deep learning to solve problems, start here:
https://machinelearningmastery.com/start-here/#deeplearning
Hi Jason, I have been referring to a few of your blogs for my Machine Learning stuff. One striking feature of your blogs is simplicity which draws me regularly to this place! This is very helpful.:) Talking about Deep Learning vs traditional ML, the general conception is that Deep Learning beats a human being at its ability to do feature abstraction. Is this true?
Also, could you tell me why Deep Learning fails to achieve more than many of the traditional ML algorithms for different datasets despite the assumed superiority of DL in feature abstraction over other algorithms?
Deep learning is great at feature extraction and in turn state of the art prediction on what I call “analog data”, e.g. images, text, audio, etc.
It can be used on tabular data (e.g. spreadsheet of numbers) but this is not it’s sweet spot and often can be beaten by other methods, like gradient boosting.
There is no one algorithm to rule them all, just different algorithms for different problems and our job is to discover what works best on a given problem.
Thanks for your response Jason! I appreciate your clarification.
You’re welcome.
I am wondering that if I use a convolutional neural work in my train model, could I say it is deep learning?
Yes.
Sir , it’s a great review about deep learning
My question is what is the difference between deep neural network and CNN.
Is deep learning is applicable to quantitative data( tabular data)
I made a deep neural network model for bulk quantitative data and get a better result than traditional neural method.
What it means sir ?
Is my deep learning technique right?
A CNN is a type of neural network. It can be made deep. Therefore, it is a type of deep neural network.
Yes, neural nets require all input data to be tabular (vectorized).
I cannot know if your model is right. Evaluate it carefully and compare it to other models.
if we use hierarchal training algorithm such as we use unsupervised learning autoencoder with bottleneck (hidden layer, 10,2,10) for training then use the supervised learning with same autoencoder architecture ( hidden layer, 10,2,10) to tune the unsupervised model parameter (weights, bias). These training processes are performed separately.
now the unsupervised autoencoder works as dimension reduction and extract features. does the supervised model work in the same way and extract the feature or just this step conducted in the unsupervised learning
he supervised model will interpret the features and use them to make predictions.
can i say deeplerning == cnn, Do we have types in deep learning
CNN is a type of deep learning. So is RNN and MLP.
Sir, It is a good intro to deep learning. i’m planning to do phd in diagnosis of heart disease using deep learning. I have data’s of features. I don’t know how to classify those data. Can you please refer some material for numerical data classification using tensor flow.
I would recommend following this process when working through a new predictive modeling problem:
https://machinelearningmastery.com/start-here/#process
hi , i have started in my graduation project , and i am creating a medical system based on data comes from medical sensors , and i hope to use deep learning in detecting the disease or the health case based on that data , but i don’t know from where i should start in deep learning
can you help me in doing it ?
My best advice for getting started with deep learning in Python is here:
https://machinelearningmastery.com/start-here/#deeplearning
Hi Jason, thank you for the excellent overview. May I know how to apply deep learning in predicting adverse drug reactions, particularly in drug-drug interaction?
I recommend this process when starting on a new predictive modeling problem:
https://machinelearningmastery.com/start-here/#process
Hi Jason, Can you please tell me the unsupervised deep learning algorithms available? Please refer some link to learn about it.
Sorry, I don’t have material on unsupervised learning algorithms, I don’t find them useful in practice.
What does “bigger models” mean? Are there more equations in the model? Are there more variables in the model? Are there more for loops? How exactly is the model “bigger”? What’s an example of a “not big model” and why is that worse? And what exactly is meant by the term “model” in this field? I’m still not clear on that. Like what exactly are the characteristics that make something a “model” and why is another general programming algorithm like, say, a loop that divides numbers successively to determine if an integer is prime, not a “model”? To me that sounds like a “model” for determining if a number is prime, so what is meant in this field by “model”? What are the inherent properties that make something a “model”? Is a model a type of algorithm? Is it a class in object-oriented design? What’s a “model” and what;s a “bigger model”?
Too many questions for one comment, sorry.
Ok, let’s start by what exactly is meant by the term “model” in this field? Because I’m still absolutely not clear on what that means. If I write up some code to solve a problem, how do I know whether or not I’ve “built a model”?
A model is often referred to as the weights + structure after the training algorithm has been run on data.
It is the “program” that can make predictions on new data.
And then what’s the “bigger model” you refer to in this article? Are there more weights and more structure in the training algorithm? How is that achieved? Do you plug in more equations and more variables and decision parameters/whatever? How do you know what additional equations and parameters to plug in, and how do you know those are the right ones as opposed to others? Or does “bigger models” simply refer to running on more overall data, and the training algorithm is the same with the same amount of equations/variables/computations per training example?
“Larger Models” refers to deeper (more layers) or wider (more neurons per layer), ultimately more representational capacity.
Best summary for students to learn basics of Deep Learning. Thank you Jason
Thanks.
Thank you very much. It is very good summary about deep learning.
Could you give some algorithms used in deep learning , please.
The three to focus on are: Multilayer Perceptron, Convolutional Neural Network and Long Short-Term Memory Network.
how deep learning can be applied in music ? is it possible to analyze existing music to compose new music by computers ?? If yes what type of algorithm should be used ?
Yes, you could classify music or generate music.
Dear Dr Jason Brownlee, I really found this very useful and helpful for beginners to this domain.
Thanks.
I am familiar with machine learning and neural networks. My expertise is optimization and I am just interested in this field. What do you suggest as a good starting point? I prefer to learn it through experience and see how it works on different cases.
I have some advice for getting started here that might help:
https://machinelearningmastery.com/start-here/#deeplearning
Thanx a lot 🙂
What are the objective study of deep learning
Some are interested in the limits of the method and pushing those limits, e.g. academics.
Some are interested in better solutions to hard problem, e.g. engineers.
I focus on the latter here.
Do you think a deep-learning system could be “taught to read” in a manner similar to a young child? That is:
1. Visual input of the words on each page
2. Coordinated (i.e. synchronized) sound input of those words being read
3. Repeat/reinforce as needed by “reading” the same book multiple times
4. Expand the data set by “reading” a variety of books
…with the ultimate goal & test being to present the system with a book it hasn’t “seen” before, and have it “read” that book via a synthesized voice.
(Never mind the robotics to turn the pages, we can leave that part to a human assist.)
A general system of this form could be constructed, not sure about the “like a child” part though.
i am nazek hassouneh
i am a master student and my thesis in deep learning
i have data set with class label
i will use deep learning for classification
data set is an excel format and will convert to CSV form
data set with 49 attribute and 131,000 records
how can i use deep learning i need tutorial for that
i need specific nueral networks suitable for this data set
Perhaps this tutorial will help you get started:
https://machinelearningmastery.com/tutorial-first-neural-network-python-keras/
thank you very much
Very Usefull Article In Deep Learning
Thanks Alexander.
Thanks Jason. Great article as always.
Glad to hear that.
Hi Jason
loving your articles on ML and NLP! Apologies if this is a daft question but do the extra layers in deep learning models make them more or less transparent? I am thinking in the context of looking for patterns of helpful comments in forum exchanges – would I be able to recognise the features discovered (e.g. as a series of IFTTT rules) or would they just come out as a series of factor weights?
Very new to this so any pointers most welcome
Keep up the good work
best wishes
Mat
Layers add layers of abstraction which makes the model more complex/opaque.
Thanks Jason. I see that people have been making progress on increasing transparency in deep learning https://arxiv.org/abs/1710.09511
I am working my way through your NLP crash course to understand more
Thanks for the link.
Hi ..
It’s a great blog I’ve ever seen , thanks a lot for all your efforts, wish you the best ????
I am a master student and my thesis is about breast cancer diagnosis , I want to know is deep learning algorithm appropriate for my thesis
and if the answer is yes which one is the best
I’m so confused plz help me ????
I would recommend starting with CNNs for image data.
Very nice one.I want to use deep learning in tourism sector. I can manage to get the tourists data.
Can you tell me how can i use deep learning in tourism sector.
Thanks
Perhaps start by framing your predictive modeling problem:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Thanks for sharing these types of soul idea especially for like underresourced country. I am trying to do my thesis by “Object detection by Deep learning for autonomous Vehicle” which method prefer for accomplished my thesis.
Good luck with your project!
a very useful for beginner like me. and right now i’m in doing research with title “analysis on deep learning method for heart disease. which suitable technique i should use ?
Thanks.
Perhaps try a suite of methods and see what works best for your specific dataset.
thanks very much jason for your valuable information , i have question about features extraction ;
i know features selection , but what means by features extraction which is a property of deep Learning.
It refers to methods that create features from analog data like images, audio and text:
https://en.wikipedia.org/wiki/Feature_extraction
There is a lot of overlap with feature engineering.
Want to learn more about deep neural network and its variants. Could you please tell me how?
Yes, start here:
https://machinelearningmastery.com/start-here/#deeplearning
Hello Jason,
I’m a PhD student working on a decentralized IDS (Intrusion Detection System) platform utilizing Big Data, and I’m using machine learning algorithms to detect some signature based attacks.
I’m researching if deep learning would be a good AI method to detect non-signature based attacks (anomalies). I’ve used neural networks to train a specific node to detect a specific signature based attack, but I’m new to deep learning and not sure how apply it into my model.
Would Multilayer Perceptron, Convolutional Neural Network or Long Short-Term Memory Network algorithms applicable at detecting anomalies with gigantic amounts of raw data?
Thanks in advance and great article, very useful.
I would recommend testing a suite of methods to see what works best for your specific dataset.
If i am new to this where can i start , eventhough i read the full article its difficult for me to get some technical terms ? So where can i start if i am starting from scratch?
THANK YOU
You can start here:
https://machinelearningmastery.com/start-here/#deeplearning
What about using Deep Learning in regression problems? Can it be useful for problems like ocean wave forecasting in univariate mode?
It may be. Perhaps try it and see how you go.
thank you Doctor Jason Brownlee
For the great effort you make
I have several questions and I hope to be as broad as we used to
CNN is one of the neural networks that can be very deep but my question here is the code that distinguishes between being a normal neural network and being a deep neural network knowing that it can be used in both cases
I have implemented a deep learning application that predicts the status of my client as he will continue his service or not
The Code
import theano
import theano
import tensorflow
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv(‘C:/Python34/Churn_Modelling.csv’)
X = dataset.iloc[:, 3:13].values
y = dataset.iloc[:, 13].values
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X_1 = LabelEncoder()
X[:, 1] = labelencoder_X_1.fit_transform(X[:, 1])
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
onehotencoder = OneHotEncoder(categorical_features = [1])
X = onehotencoder.fit_transform(X).toarray()
X = X[:, 1:]
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Importing the Keras libraries and packages
import keras
from keras.models import Sequential
from keras.layers import Dense
#Initializing Neural Network
classifier = Sequential()
# Adding the input layer and the first hidden layer
classifier.add(Dense(activation=”relu”, kernel_initializer=”uniform”, units=7, input_dim=11))
# Adding the second hidden layer
classifier.add(Dense(activation=”relu”, kernel_initializer=”uniform”, units=7))
# Adding the output layer
classifier.add(Dense(activation=”sigmoid”, kernel_initializer=”uniform”, units=1))
# Compiling Neural Network
classifier.compile(optimizer = ‘adam’, loss = ‘binary_crossentropy’, metrics = [‘accuracy’])
# Fitting our model
classifier.fit(X_train, y_train, batch_size = 50, nb_epoch = 500)
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
# Creating the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
The Data set
This application was found on the internet and its code is (Can I specify what functions (code) that make it a deep learning)
And you have implemented an application for you to learn about God called Your First Machine Learning Project in Python
What functions are used make me know whether this code is deep learning or machine learning
In the past it was possible to put a lot of layers and use a large data size in MLP
MLB is now one of the deep learning algorithms
What code you have completed makes it a profound learning
Sorry for the delay I would like to explain to me the application has been applied using the deep learning algorithm which is the same algorithm application is not using deep learning
You can define deep.
Learn more here:
https://machinelearningmastery.com/what-is-deep-learning/
I’m sorry to urge you Dr. Jason
I would also like a small code showing the use of deep learning about traditional learning
What is “traditional learning” in the context of deep learning?
I mean traditional learning is the algorithms in which we do not use depth but similar in use
Like RNN was used by the production of deep learning idea
But I mean what the code will differentiate between RNN and DNN, knowing that RNN and many of the previous algorithms are deep learning algorithms
Thank you for your patience with me
Generally, any neural network may be referred to as deep learning now. I don’t see a practical distinction other than for marketing.
Dear Mr. Jason, there is one thing I don’t understand. In the article it is said that Deep Learning’s performance get better with more data while other, older algorithms tends to reach a plateau. Can you explain more and give an example about the plateau?
Initially I think the plateau is there because more data can cause overfitting, but after some browsing I found out that more data will decrease the chance of overfitting. It is the number of feature, not the number of data that causes overfitting. The only thing I can think about how more data can create plateau is on heuristic algorithm, which can create more local minima where algorithms can get stuck on.
Sorry, I do not have a direct reference.
Thanks John. I found the article very useful.
I am now confident I know what deep learning is.
Glad to hear it.
A very good blog John. I am a newbie to the field of Deep Learning and this blog has helped me well.
Thanks
I’m glad it helped, also, my name is “Jason”.
Can we detect Malware Infections/DOS/Brute Force Attacks on any Network using Deep Learning?
Probably.
Hi, I want to know what are the deep learning methods using PAC Bayesian. And then compare them with other kind of methods.
would you please clarify for me this problem?
Sorry, I don’t have material on this topic.
https://www.technoonews.com/2018/08/what-is-neural-network.html
technology lover
Thanks for sharing.
My brain just imploded.
Sorry to hear that Sean.
Amazing read and this article has given me a head start to write my Master thesis in this field. Thanks.
I’m glad to hear that.
Hai Sir,
I am Preethi, working with Visual Studio C++. My research problem is related to classification and prediction. Now I am trying to use the deep concept (sparse autoencoder ) in my problem, but I didnt get any C++ package for autoencoder. I found so many python packages, but I have to follow VS C++. OpenCV offers modules for CNN ,not for autoencoders.
Could you pl suggest me any package to use with VS C++?
Waiting for your kind response.
Sorry, I’m not familiar with cpp libraries for deep learning.
Very useful article on Deep Learning
Thanks.
Kindly explain Convolutional Nets Model of Deep Learning in detail.
Sure:
https://machinelearningmastery.com/crash-course-convolutional-neural-networks/
Does Particle Swarm Optimization and ant bee colony algorithms which comes under artificial intelligence is related to deep learning method or unsupervised learning techniques in machine learning
Not really, they are optimization algorithms.
Neural networks are function approximation algorithms.
This article has given me great knowledge on deep learning. currently doing research on data mining. Could you please suggest me how to apply deep learning for cancer classification. Right now I am applying cuckoo search optimization algorithm.
Perhaps try this process:
https://machinelearningmastery.com/start-here/#process
Hey I’m wondering what are your thoughts about AI being implemented into healthcare
Sounds great!
HI,
I am beginner and I want to make a CVML- Computer Vision and Machine Learning lab. What tools and requirement have I need.
Sorry, I don’t know about setting up a lab.
Thanks Jason. This article is so well written and informative.
Thanks.
Thanks. This article is so informative.
I’m glad it helped.
Hi Jason and thank you for such an enlightening article.
What I understood is that the hidden layers act as feature learners from the data. They achieve
this by successively applying nonlinear transformations (with the activation functions) on the input data to map them into a new space: the feature space.
In case of a classification task, the classes become easier (linearly) to separatein this feature space.
What about in the case of regression? What is the function of the hidden layers in a deep neural network model for regression.
Thank you in advance!
I would say: In case of regression, there is the nonlinear transformation of the input data to the feature space and there a linear regression in that new feature space can be applied to aproximate the numerical target variable.
Not quite, the model can learn a non-linear separation of classes.
Same idea, but it learns a non-linear fit for association between the inputs to the output value.
ok, thank you for the response.
Is what I said the case for SVR?
Not quite, an SVM can have a non-linear kernel.
yes sure. It is the non linear kernel that enables the non linear transformation of the input data to the feature space.
Isn’t the same principle as the activation functions in the hidden layers of a deep neural network?
Yes, similar.
Hello Jeson
this is regarding deep learning mini cource. i have done some research and read some material about deep learning and for deep learning mini cource – lession 1 – task , below are the details as requested
10 impressive applications of deep learning methods in the field of natural language processing
1. Text summarization
https://arxiv.org/pdf/1707.02268.pdf
2. Robust real-time detection, tracking, and pose estimation of faces in video streams
https://ieeexplore.ieee.org/abstract/document/1334689
3. Deep Residual Learning for Image Recognition
http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
4. Multi-digit Number Recognition from Street View Imagery
https://arxiv.org/abs/1312.6082
5. Automatic whale counting in satellite images with deep learning
https://www.biorxiv.org/content/10.1101/443671v1.abstract
6. A short-term building cooling load prediction method using deep learning algorithms
https://www.sciencedirect.com/science/article/pii/S0306261917302921
7. Deep learning for pixel-level image fusion: Recent advances and future prospects
https://www.sciencedirect.com/science/article/pii/S1566253517305936
8. Reading Text in the Wild
https://link.springer.com/article/10.1007/s11263-015-0823-z
9. Neural Machine Translation by Jointly Learning to Align and Translate
https://arxiv.org/abs/1409.0473
10. Interleaved Text/Image Deep Mining on a Large-Scale Radiology Database for Automated Image Interpretation
http://www.jmlr.org/papers/volume17/15-176/15-176.pdf
going through 2nd lession . Thank you for availing this information.
Highly appreciated !!
Thanks
Very nice!
Hi
Can you help me for my mastery
Study thé properties of deep learning approximation
Yes, you can get started here:
https://machinelearningmastery.com/start-here/#deeplearning
Hi sir ,I have one question that how to train the cifar 10 dataset with opencv and python such that after training it will generate xml file.
My aim is to ” Detect objects using OpenCV an python ”.
As I am new in this field, so please consider me.
Sorry, I don’t have any tutorials on this topic, I may cover it in the future.
hello dear
how can I start with (Deep learning in medical image analysis) for my thesis
thanks
Perhaps start here:
https://machinelearningmastery.com/start-here/#dlfcv
generally, I should start with computer vision after that and the more specific subject is in medical image analysis, is it right …..thanks
I recommend that you start working on your project directly, rather than study subjects to get ready to work on your project.
Perhaps the most appropriate methods will be deep learning models like pre-trained convolutional neural networks.
Hello Everyone my thesis topic is “CLEFT FACIAL AESTHETIC OUTCOME EVALUATION BASED ON DEEP TRANSFER LEARNING” how can I use deep learning and transfer learning model and to combine them and develop cleft facial aesthetic outcome measure system please help me I am really worried about it
Perhaps start with a strong definition of the problem you’re solving.
This framework will help:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Thanks for the information, now I understand
You’re welcome.
Thanks Jason.
The post really brought me to light about Deep learning. I don’t know if you can be of help for my M.Sc thesis. I intend to use deep learning to obtain sistolic and diastolic data readings from a wearable device then run it through CNN to produce a more accurate value as its output.
The CNN will run on a parallel architecture to accommodate the processing power.
And being a consultant for an ICT firm, i will also want to know if you are open to take up some consultancy contract with the firm? You can reach me on my email: if you are interested.
Thanks for asking, I no longer take consulting projects:
https://machinelearningmastery.com/faq/single-faq/can-you-do-some-consulting
You will find these tutorials very helpful:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Been reading up a lot on machine learning/deep learning, AI thinking how I can use them to UP my marketing ANTE. Will probably need a tech guy to really do it, but just wanted to get a good grasp about the topic and then I came across yours. Great article!
Thanks James.
Hi James ..your articles are always helping. can you please tell me ..how we can train a DQN model with the help of given dataset
I hope to cover that topic in the future.
I am waiting for your tutorial …….as they are the BEST
Thanks.
Thanks for the article. I read a few more articles and decided to work in Tensorflow for deep learning.
Sounds great Harvey!
Hi jason
Which part of deep learning needs to cogitated to improve deep learning?
Is it approch of weigh choosing or the structure of neurals (number of layers and number of neuron in each layers or relation between each other)…. ?
Which part it is????
Great question. Learning rate for sure.
I outline more methods and a framework here:
https://machinelearningmastery.com/start-here/#better
deep learning in itself is an intense topic the way you have elaborate it is great job.please keep sharing such topic.
Thanks.
how can I start with (Deep learning in bitcoin price prediction) for my thesis
This sounds like a time series problem.
Perhaps start here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Hello sir,
Would like to know that how features are extracted in CNN
Great question, I give an example here:
https://machinelearningmastery.com/convolutional-layers-for-deep-learning-neural-networks/
Hi. Being new to ML, this site is looking promising.Thank you.
I was considering using Google AutoML (https://cloud.google.com/automl-tables/docs/ ) on structured and labelled (probabaly JSON) but very large sets of textual data, to encode some near-subjective decision making that could possibly be explicitly coded, but with quite some complexity.
It could just be more elegant and scalable if a machine model could be trained, with human guidance.
If that sounds at all feasible, should I start with machine-learning-in-r-step-by-step and at least get used to the field using the “shallow” ML algorithms mentioned there, or would deep-learning likely prove more beneficial but still be an intelligible subject to a newcomer?
Eventually I’d want to employ this in an app.
I think it is a good idea to get familiar with the basics of working through small problems end to end first.
It is the process I teach here:
https://machinelearningmastery.com/start-here/#getstarted
Hi. Your posts are really good. I am learning a lot about ML. I would like to know whether deep learning can tacke classification problems when I have an unlabeled or partially labeled dataset.
Thanks!
Yes, this sounds like semi-supervised learning.
I recommend testing a range of methods on your problem in order to discover what works best, including deep learning techniques.
Jason,
I am a CS student and have taken other classes in DL, yet the current material in an in-depth class has me challenged. I understand the concepts, but have a hard time completing working code with all the pieces in the time I am given.
We just finished RNN & CNN and for the next month will do reinforcement and unsupervised. I will be asked to take a network with distinct architecture and successfully train & test, most times with imported data. I am able to run different pieces of the code, but perfectly setting up all the parameters gives me a lot of trouble.
do you think your new book will help me?
Setting the right parameters gives everyone trouble.
The reason is there are no good theories for how to do it – the best we have is careful experimentation which basically means trial and error.
My books are not a magic bullet, it sounds like you’re getting good guidance from your course already.
If you need more advice on how to configure neural nets and diagnose faults, the tutorials here will help:
https://machinelearningmastery.com/start-here/#better
Hi Jason, I am Ravita Research scholar and doing research on scalable and efficient Job Recommendation using deep learning technique.
I am new in deep learning technique, which algorithm is suitable for job recommendation.i am using CareerBuilder dataset. Pls. suggest me which algorithm give better accuracy and scalabilty.
Good question, perhaps this will help:
https://machinelearningmastery.com/when-to-use-mlp-cnn-and-rnn-neural-networks/
i loved the text
my question is
im going to work my PHD continue other relative work
he work on automatic image annotation he used CNN
con i continue using hybrid net. like CNN+LSTM+MLP or CNN+RNN something like that ?
Perhaps.
How would you implement Predective mechanism for IT Service Management -Problems using Deep Learning
I would recommend testing a suite of algorithms for a problem and discover what works best, rather than starting with the solution (deep learning).
what are the reason(s) for the recent takeoff of deep learning?
It works really well on very hard problems.
I want to create a speech to text using ANN-based cuckoo search optimisation. Can you guide me through
I don’t have tutorials on this topic, sorry.
Talking about deep learning, Airlangga University conducted a study of the Multi Projection Deep Learning Network for Segmentation in 3D Medical Radiographic Images. Want to know more? Visit the following link:
http://news.unair.ac.id/2019/12/19/multi-projection-deep-learning-network-untuk-segmentasi-pada-gambar-radiografi-medis-3d/
Thank You
Thanks for sharing.
Great historical review and research about the persons and conceptual ideas behind the main milestones of Deep Learning development with keys references.
I can see your are not only a great ML/DL populariser, but also and not less, a great scientific researcher of ML/DL
Thanks Jason
Thanks.
I did a quick skim over the information and plan on going back and rereading it. I was curious I have experience in HTML, CSS, Javascript, PHP, and C++. I am planning to also learn Binary, Python, and Assembly as well as a few others. The reason why is I want to build A.I. that cross the border of weak and strong A.I. and approaches the threshold of Super A.I.s. In order to do so I plan on creating a computer language but want a bunch of references to do so. So, in the end, my question is. What language do you recommend for Deep Learning and other coding languages?
Python:
https://machinelearningmastery.com/faq/single-faq/what-programming-language-should-i-use-for-machine-learning
Buen artículo, he tenido que leerlo dos veces.
Thanks!
sir, I want to do research in machine learning for predicting disease. I saw a lot of papers about that. most of the papers using small data sets.
I want to increase the size of the data sets what is the best method for large data sets. is it possible with MACHINE LEARNING? or deep learning is easy for large data sets
Yes, see this:
https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/
it is not about an imbalanced dataset. if we are using thousands or lakhs of datasets are
using instead of hundreds of datasets.
The best method for large datasets is the method that performs the best on your dataset, and meets the requirements of your project.
Is deep learning is used instead of using machine learning for predicting heart disease. for bigger data sets
Deep learning is a type of machine learning.
You must discover what works best for your dataset.
Sir not about imbalanced data sets. In case if we are using thousands or lakhs of records are using instead of hundreds of recods.
The best method for large datasets is the method that performs the best on your dataset, and meets the requirements of your project.
I am a Physics student….I have no basics for any computer language… But would like to learn about DL and ML …. Where should I start
You may need to learn some Python first:
https://machinelearningmastery.com/faq/single-faq/how-do-i-get-started-with-python-programming
Then start here:
https://machinelearningmastery.com/start-here/#deeplearning
Hello sir, Can you provide an example for using deep learning to classify data that is in the form of CSV files?
Yes, there are many on the blog, perhaps start here:
https://machinelearningmastery.com/tutorial-first-neural-network-python-keras/
hi sir : i need to build a project for detected baby crying … so i need a model for sound of crying baby in AI algorithm can you help me plz ..
Sorry, I don’t have tutorials on working with audio data. I cannot give you good off the cuff advice.
Hello Jason, Thank you for your amazing blog. I have chosen the Deep Learning course this semester while I have a little information about Machine Learning, (I plan to choose ML course next semester). I wanna know is ML a prerequisite for deep learning? or I can learn Deep Learning algorithms and models and learn other classical ML algorithms simultaneously? Thank you in advance for your answer
I think you can learn both at the same time.
Hello Jason,
Can i use deep learning algorithm (CNN) in the resolution of optimization problem, example: I have a matrix with n*m values, in my case I need to select value from this matrix and turn the other to “0” in order to minimize the error or maximize energy?, Is there any matlab code do that?
I don’t think this is a deep learning problem, it sounds like straight linalg.
I don’t have any examples that use matlab code sorry.
Thanks
can you provide the MLP algorithm for hand written digit classification using sklearn dataset?
Yes, there are many on the blog, use the search box.
hi Sir, Hope u fine, my teacher said python is removed from the market in coming 10 year , is this reality in ur vision, and he said js will be the coming language in AI ,…what u think about it.
Perhaps ask your teacher why they think this and make up your own mind.
(base) C:\Users\226399\Kerasprojects>python beach1.py
Data Type:uint8
Min:0.000
Max: 255.000
After Normalization
Min:0.000,Max:1.000
Well done!
Thanks for sharing. Informative Article.
You’re welcome.
Hello Sir, i have tuned a model for facial emotion recognition and the highest accuracy so far is about 54% on average but i used ResNet50
could you help me how can i improve the accuracy ..
Yes, see these suggestions:
https://machinelearningmastery.com/start-here/#better
thank you so much
You’re welcome!
How do we cite your 2015 Extract Conference? How do we cite your useful comments? How do we cite extracts from slides you have used in conferences?
You mean providing URLs?
First, I appreciate your blog; I have read your article carefully, Your content is very valuable to me. I hope people like this blog too. I hope you will gain more experience with your knowledge; That’s why people get more information.
Very good explanation.. Really appreciate the efforts!!!
other people interested to learn more about data science can go to- learnbay.co
wow its such a great post! im really into digital world and learning been always the best method to keep me motivated. keep sharing ! i recently came to know Amritsar Digital Academy from here you can learn digital marketing course which is such a good and helpful course in today’s era! it worth trying.
Thank you for the feedback, Deepika!
Can tell us about the deep learning interview questions?
Hi Camila…the following looks like a great start:
https://www.indeed.com/career-advice/interviewing/deep-learning-interview-questions
Hi Dr. Jason, I have a dataset.
it is a multi-class label classification, I want to apply Deep Neural networks, all the dataset features are probabilities, How can I prepare the data before applying the model. My question is Should I apply data normalization then build the model or do something else?
Thanks
Regards!
First, I appreciate your blog; I have read your article carefully, your content is very valuable to me. I hope people like this blog too. I hope you will gain more experience with your knowledge; That’s why people get more information.
Thank you for the support and feedback wbaynews!
can you point out how to start project like tax fraud analysis
Hi Hossam…While we do not have any content specific to this topic, you may find the following of interest:
https://www.tandfonline.com/doi/full/10.1080/08839514.2021.2012002
Deep learning in itself is an intense topic the way you have elaborate it is a great job. please keep sharing such topics.
Thank you for the support and feedback Prabham! We greatly appreciate it!
Thanks for such amazing article.
Can you please give me a clear explanation about the difference between deep learning and machine learning,
What they mean by shallow learning it is the same as machine learning ?
Hi Ula…You are very welcome! Machine Learning or ML is the study of systems that can learn from experience (e.g. data that describes the past). You can learn more about the definition of machine learning in this post:
What is Machine Learning?
Predictive Modeling is a subfield of machine learning that is what most people mean when they talk about machine learning. It has to do with developing models from data with the goal of making predictions on new data. You can learn more about predictive modeling in this post:
Gentle Introduction to Predictive Modeling
Deep Learning is the application of artificial neural networks in machine learning. As such, it is a subfield of machine learning. You can learn more about deep learning in this post:
What is Deep Learning?