Training deep neural networks was traditionally challenging as the vanishing gradient meant that weights in layers close to the input layer were not updated in response to errors calculated on the training dataset.
An innovation and important milestone in the field of deep learning was greedy layer-wise pretraining that allowed very deep neural networks to be successfully trained, achieving then state-of-the-art performance.
In this tutorial, you will discover greedy layer-wise pretraining as a technique for developing deep multi-layered neural network models.
After completing this tutorial, you will know:
Greedy layer-wise pretraining provides a way to develop deep multi-layered neural networks whilst only ever training shallow networks.
Pretraining can be used to iteratively deepen a supervised model or an unsupervised model that can be repurposed as a supervised model.
Pretraining may be useful for problems with small amounts labeled data and large amounts of unlabeled data.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Sep/2019: Fixed plot to transform keys into list (thanks Markus)
Updated Oct/2019: Updated for Keras 2.3 and TensorFlow 2.0.
Update Jan/2020: Updated for changes in scikit-learn v0.22 API.
How to Develop Deep Neural Networks With Greedy Layer-Wise Pretraining Photo by Marco Verch, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Greedy Layer-Wise Pretraining
Multi-Class Classification Problem
Supervised Greedy Layer-Wise Pretraining
Unsupervised Greedy Layer-Wise Pretraining
Greedy Layer-Wise Pretraining
Traditionally, training deep neural networks with many layers was challenging.
As the number of hidden layers is increased, the amount of error information propagated back to earlier layers is dramatically reduced. This means that weights in hidden layers close to the output layer are updated normally, whereas weights in hidden layers close to the input layer are updated minimally or not at all. Generally, this problem prevented the training of very deep neural networks and was referred to as the vanishing gradient problem.
An important milestone in the resurgence of neural networking that initially allowed the development of deeper neural network models was the technique of greedy layer-wise pretraining, often simply referred to as “pretraining.”
The deep learning renaissance of 2006 began with the discovery that this greedy learning procedure could be used to find a good initialization for a joint learning procedure over all the layers, and that this approach could be used to successfully train even fully connected architectures.
Pretraining involves successively adding a new hidden layer to a model and refitting, allowing the newly added model to learn the inputs from the existing hidden layer, often while keeping the weights for the existing hidden layers fixed. This gives the technique the name “layer-wise” as the model is trained one layer at a time.
The technique is referred to as “greedy” because the piecewise or layer-wise approach to solving the harder problem of training a deep network. As an optimization process, dividing the training process into a succession of layer-wise training processes is seen as a greedy shortcut that likely leads to an aggregate of locally optimal solutions, a shortcut to a good enough global solution.
Greedy algorithms break a problem into many components, then solve for the optimal version of each component in isolation. Unfortunately, combining the individually optimal components is not guaranteed to yield an optimal complete solution.
Pretraining is based on the assumption that it is easier to train a shallow network instead of a deep network and contrives a layer-wise training process that we are always only ever fitting a shallow model.
… builds on the premise that training a shallow network is easier than training a deep one, which seems to have been validated in several contexts.
There are two main approaches to pretraining; they are:
Supervised greedy layer-wise pretraining.
Unsupervised greedy layer-wise pretraining.
Broadly, supervised pretraining involves successively adding hidden layers to a model trained on a supervised learning task. Unsupervised pretraining involves using the greedy layer-wise process to build up an unsupervised autoencoder model, to which a supervised output layer is later added.
It is common to use the word “pretraining” to refer not only to the pretraining stage itself but to the entire two phase protocol that combines the pretraining phase and a supervised learning phase. The supervised learning phase may involve training a simple classifier on top of the features learned in the pretraining phase, or it may involve supervised fine-tuning of the entire network learned in the pretraining phase.
Unsupervised pretraining may be appropriate when you have a significantly larger number of unlabeled examples that can be used to initialize a model prior to using a much smaller number of examples to fine tune the model weights for a supervised task.
…. we can expect unsupervised pretraining to be most helpful when the number of labeled examples is very small. Because the source of information added by unsupervised pretraining is the unlabeled data, we may also expect unsupervised pretraining to perform best when the number of unlabeled examples is very large.
Although the weights in prior layers are held constant, it is common to fine tune all weights in the network at the end after the addition of the final layer. As such, this allows pretraining to be considered a type of weight initialization method.
… it makes use of the idea that the choice of initial parameters for a deep neural network can have a significant regularizing effect on the model (and, to a lesser extent, that it can improve optimization).
Greedy layer-wise pretraining is an important milestone in the history of deep learning, that allowed the early development of networks with more hidden layers than was previously possible. The approach can be useful on some problems; for example, it is best practice to use unsupervised pretraining for text data in order to provide a richer distributed representation of words and their interrelationships via word2vec.
Today, unsupervised pretraining has been largely abandoned, except in the field of natural language processing […] the advantage of pretraining is that one can pretrain once on a huge unlabeled set (for example with a corpus containing billions of words), learn a good representation (typically of words, but also of sentences), and then use this representation or fine-tune it for a supervised task for which the training set contains substantially fewer examples.
Nevertheless, it is likely better performance may be achieved using modern methods such as better activation functions, weight initialization, variants of gradient descent, and regularization methods.
Today, we now know that greedy layer-wise pretraining is not required to train fully connected deep architectures, but the unsupervised pretraining approach was the first method to succeed.
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Multi-Class Classification Problem
We will use a small multi-class classification problem as the basis to demonstrate the effect of greedy layer-wise pretraining on model performance.
The scikit-learn class provides the make_blobs() function that can be used to create a multi-class classification problem with the prescribed number of samples, input variables, classes, and variance of samples within a class.
The problem will be configured with two input variables (to represent the x and y coordinates of the points) and a standard deviation of 2.0 for points within each group. We will use the same random state (seed for the pseudorandom number generator) to ensure that we always get the same data points.
The results are the input and output elements of a dataset that we can model.
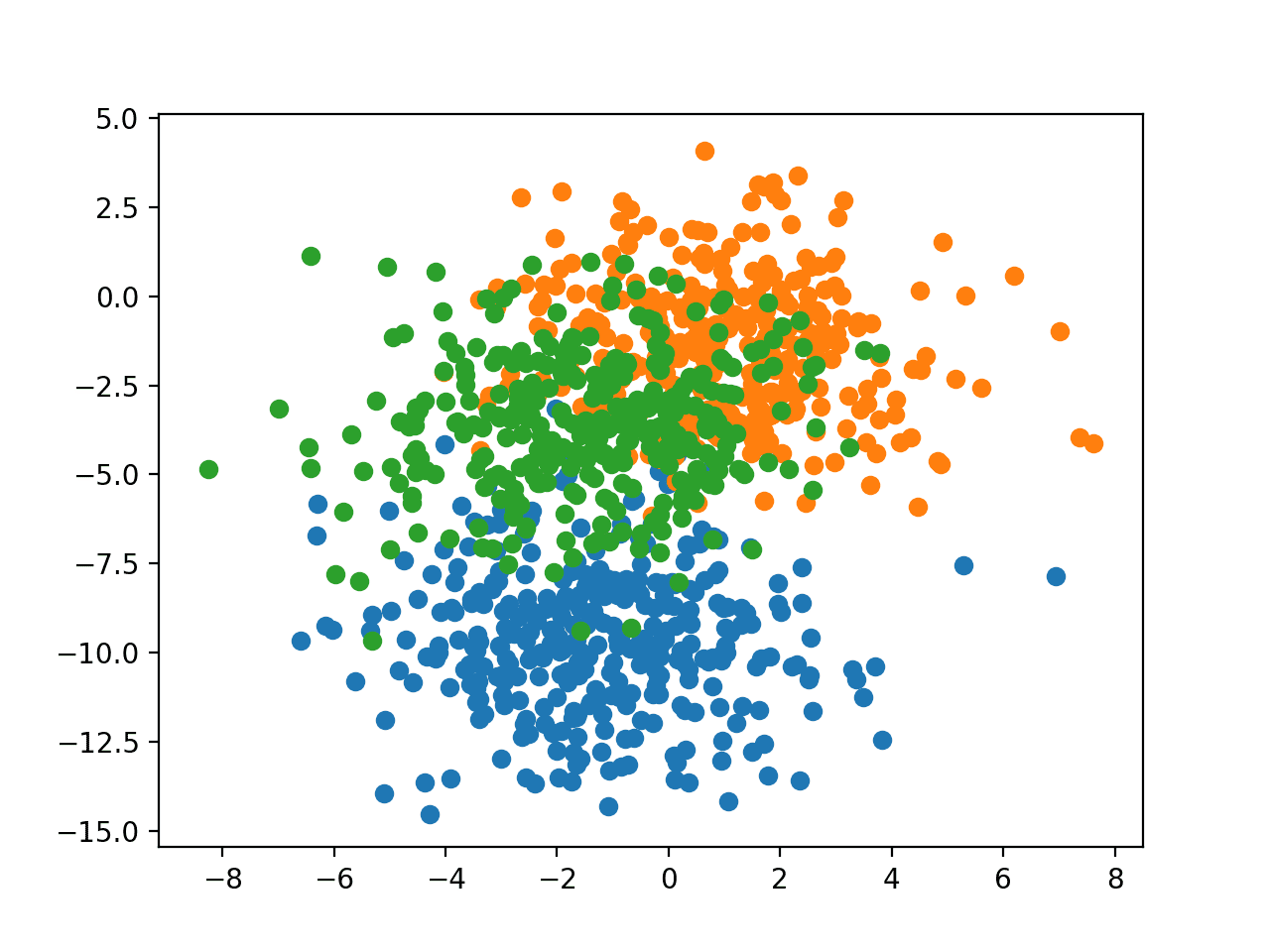
In order to get a feeling for the complexity of the problem, we can plot each point on a two-dimensional scatter plot and color each point by class value.
Running the example creates a scatter plot of the entire dataset. We can see that the standard deviation of 2.0 means that the classes are not linearly separable (separable by a line), causing many ambiguous points.
This is desirable as it means that the problem is non-trivial and will allow a neural network model to find many different “good enough” candidate solutions.
Scatter Plot of Blobs Dataset With Three Classes and Points Colored by Class Value
Supervised Greedy Layer-Wise Pretraining
In this section, we will use greedy layer-wise supervised learning to build up a deep Multilayer Perceptron (MLP) model for the blobs supervised learning multi-class classification problem.
Pretraining is not required to address this simple predictive modeling problem. Instead, this is a demonstration of how to perform supervised greedy layer-wise pretraining that can be used as a template for larger and more challenging supervised learning problems.
As a first step, we can develop a function to create 1,000 samples from the problem and split them evenly into train and test datasets. The prepare_data() function below implements this and returns the train and test sets in terms of the input and output components.
This will be an MLP that expects two inputs for the two input variables in the dataset and has one hidden layer with 10 nodes and uses the rectified linear activation function. The output layer has three nodes in order to predict the probability for each of the three classes and uses the softmax activation function.
The model is fit using stochastic gradient descent with the sensible default learning rate of 0.01 and a high momentum value of 0.9. The model is optimized using cross entropy loss.
We can call this function to calculate and report the accuracy of the base model and store the scores away in a dictionary against the number of layers in the model (currently two, one hidden and one output layer) so we can plot the relationship between layers and accuracy later.
We can now outline the process of greedy layer-wise pretraining.
A function is required that can add a new hidden layer and retrain the model but only update the weights in the newly added layer and in the output layer.
This requires first storing the current output layer including its configuration and current set of weights.
1
2
# remember the current output layer
output_layer=model.layers[-1]
Then removing the output layer from the stack of layers in the model.
1
2
# remove the output layer
model.pop()
All of the remaining layers in the model can then be marked as non-trainable, meaning that their weights cannot be updated when the fit() function is called again.
1
2
3
# mark all remaining layers as non-trainable
forlayer inmodel.layers:
layer.trainable=False
We can then add a new hidden layer, in this case with the same configuration as the first hidden layer added in the base model.
This function can then be called repeatedly based on the number of layers we wish to add to the model.
In this case, we will add 10 layers, one at a time, and evaluate the performance of the model after each additional layer is added to get an idea of how it is impacting performance.
Train and test accuracy scores are stored in the dictionary against the number of layers in the model.
At the end of the run, a line plot is created showing the number of layers in the model (x-axis) compared to the number model accuracy on the train and test datasets.
We would expect the addition of layers to improve the performance of the model on the training dataset and perhaps even on the test dataset.
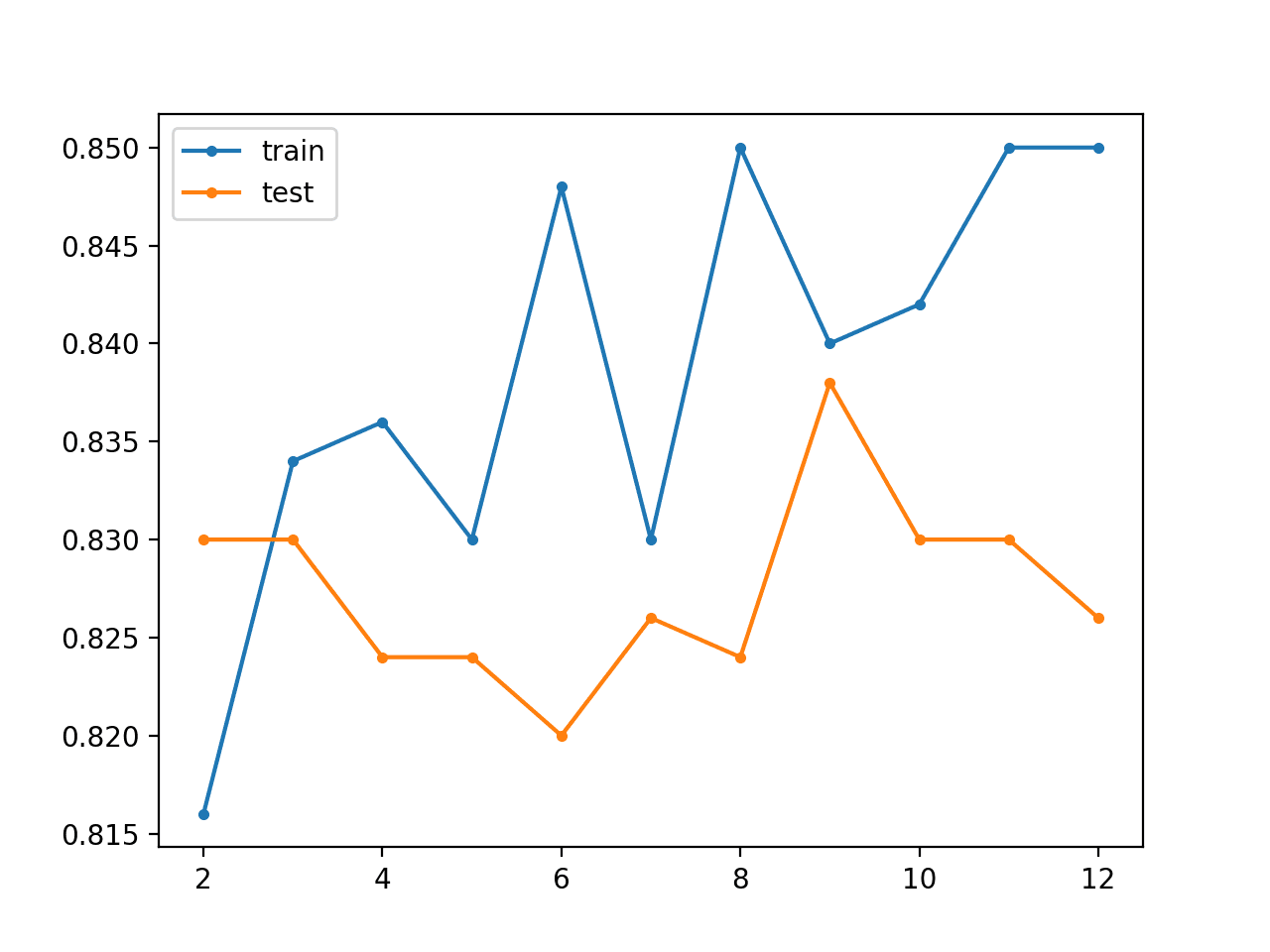
Running the example reports the classification accuracy on the train and test sets for the base model (two layers), then after each additional layer is added (from three to 12 layers).
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the baseline model does reasonably well on this problem. As the layers are increased, we can roughly see an increase in accuracy for the model on the training dataset, likely as it is beginning to overfit the data. We see a rough drop in classification accuracy on the test dataset, likely because of the overfitting.
1
2
3
4
5
6
7
8
9
10
11
> layers=2, train=0.816, test=0.830
> layers=3, train=0.834, test=0.830
> layers=4, train=0.836, test=0.824
> layers=5, train=0.830, test=0.824
> layers=6, train=0.848, test=0.820
> layers=7, train=0.830, test=0.826
> layers=8, train=0.850, test=0.824
> layers=9, train=0.840, test=0.838
> layers=10, train=0.842, test=0.830
> layers=11, train=0.850, test=0.830
> layers=12, train=0.850, test=0.826
A line plot is also created showing the train (blue) and test set (orange) accuracy as each additional layer is added to the model.
In this case, the plot suggests a slight overfitting of the training dataset, but perhaps better test set performance after seven added layers.
Line Plot for Supervised Greedy Layer-Wise Pretraining Showing Model Layers vs Train and Test Set Classification Accuracy on the Blobs Classification Problem
An interesting extension to this example would be to allow all weights in the model to be fine tuned with a small learning rate for a large number of training epochs to see if this can further reduce generalization error.
Unsupervised Greedy Layer-Wise Pretraining
In this section, we will explore using greedy layer-wise pretraining with an unsupervised model.
Specifically, we will develop an autoencoder model that will be trained to reconstruct input data. In order to use this unsupervised model for classification, we will remove the output layer, add and fit a new output layer for classification.
This is slightly more complex than the previous supervised greedy layer-wise pretraining, but we can reuse many of the same ideas and code from the previous section.
The first step is to define, fit, and evaluate an autoencoder model. We will use the same two-layer base model as we did in the previous section, except modify it to predict the input as the output and use mean squared error to evaluate how good the model is at reconstructing a given input sample.
The base_autoencoder() function below implements this, taking the train and test sets as arguments, then defines, fits, and evaluates the base unsupervised autoencoder model, printing the reconstruction error on the train and test sets and returning the model.
We can call this function in order to prepare our base autoencoder to which we can add and greedily train layers.
1
2
# get the base autoencoder
model=base_autoencoder(trainX,testX)
Evaluating an autoencoder model on the blobs multi-class classification problem requires a few steps.
The hidden layers will be used as the basis of a classifier with a new output layer that must be trained then used to make predictions before adding back the original output layer so that we can continue to add layers to the autoencoder.
The first step is to reference, then remove the output layer of the autoencoder model.
1
2
3
4
# remember the current output layer
output_layer=model.layers[-1]
# remove the output layer
model.pop()
All of the remaining hidden layers in the autoencoder must be marked as non-trainable so that the weights are not changed when we train the new output layer.
1
2
3
# mark all remaining layers as non-trainable
forlayer inmodel.layers:
layer.trainable=False
We can now add a new output layer that predicts the probability of an example belonging to reach of the three classes. The model must also be re-compiled using a new loss function suitable for multi-class classification.
The model can then be re-fit on the training dataset, specifically training the output layer on how to make class predictions using the learned features from the autoencoder as input.
The classification accuracy of the fit model can then be evaluated on the train and test datasets.
Finally, we can put the autoencoder back together but removing the classification output layer, adding back the original autoencoder output layer and recompiling the model with an appropriate loss function for reconstruction.
We can tie this together into an evaluate_autoencoder_as_classifier() function that takes the model as well as the train and test sets, then returns the train and test set classification accuracy.
This function can be called to evaluate the baseline autoencoder model and then store the accuracy scores in a dictionary against the number of layers in the model (in this case two).
We are now ready to define the process for adding and pretraining layers to the model.
The process for adding layers is much the same as the supervised case in the previous section, except we are optimizing reconstruction loss rather than classification accuracy for the new layer.
The add_layer_to_autoencoder() function below adds a new hidden layer to the autoencoder model, updates the weights for the new layer and the hidden layers, then reports the reconstruction error on the train and test sets input data. The function does re-mark all prior layers as non-trainable, which is redundant because we already did this in the evaluate_autoencoder_as_classifier() function, but I have left it in, in case you decide to reuse this function in your own project.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# add one new layer and re-train only the new layer
We can now repeatedly call this function, adding layers, and evaluating the effect by using the autoencoder as the basis for evaluating a new classifier.
Tying all of this together, the complete example of unsupervised greedy layer-wise pretraining for the blobs multi-class classification problem is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
# unsupervised greedy layer-wise pretraining for blobs classification problem
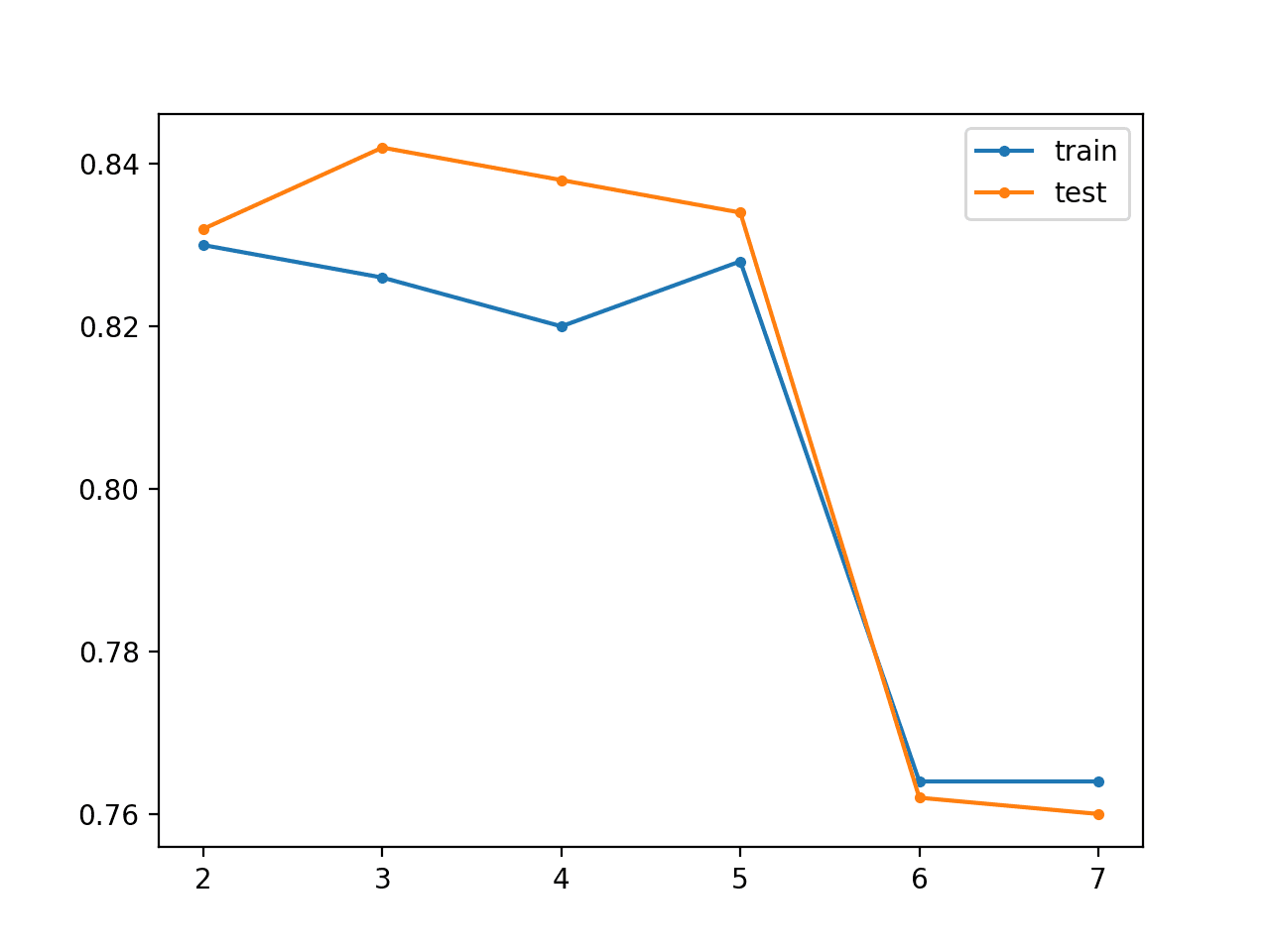
Running the example reports both reconstruction error and classification accuracy on the train and test sets for the model for the base model (two layers) then after each additional layer is added (from three to 12 layers).
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that reconstruction error starts low, in fact near-perfect, then slowly increases during training. Accuracy on the training dataset seems to decrease as layers are added to the encoder, although accuracy test seems to improve as layers are added, at least until the model has five layers, after which performance appears to crash.
A line plot is also created showing the train (blue) and test set (orange) accuracy as each additional layer is added to the model.
In this case, the plot suggests there may be some minor benefits in the unsupervised greedy layer-wise pretraining, but perhaps beyond five layers the model becomes unstable.
Line Plot for Unsupervised Greedy Layer-Wise Pretraining Showing Model Layers vs Train and Test Set Classification Accuracy on the Blobs Classification Problem
An interesting extension would be to explore whether fine tuning of all weights in the model prior or after fitting a classifier output layer improves performance.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
i appreciate your post. I like to read your beautiful post. you touch all the topic and subtopic related to machine learning. i will be happy if you keep on updating more about machine learning in future
In the first example , Supervised Greedy Layer-Wise Pretraining, it seems that it lacks two lines after line 52 : that is to say
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss=’categorical_crossentropy’, optimizer=opt, metrics=[‘accuracy’])
Otherwise, I got a traceback with this message “The model needs to be compiled before being used.”
Well I do not see it in the first example
model.add(Dense(10, activation=’relu’, kernel_initializer=’he_uniform’))
# re-add the output layer
model.add(output_layer)
# fit model
model.fit(trainX, trainy, epochs=100, verbose=0)
but it is present in the second example
Am I wrong ?
in the second example, after we unsupervised trained the autoencoder, why did you freeze the encoder layer in the finetuning phase and only trained the output layer.
I think what the encoder layer have learned in the unsupervised pretraining is used as initialization in the finetuning phase and we finetune the whole model.
Thank you for your tutorials and amazing content. Quick question, if I understood correctly the quotes from the Deep Learning (Bengio) book … Greedy Layer-Wise pretraining is obsolete with modern activation functions, dropouts etc. available in Keras nowadays ? Would you recommend applying it for massive datasets and important neural network architectures, or should it simply be ignored today ?
Also, I heard several sources say “Deep neural networks learn better than wide ones, IF TRAINED CORRECTLY”. Is Greedy Layer-Wise pretraining what they were refering to in that sentence ?
Alternate methods are preferred for smaller models.
The method is described because the approach is still generally intersting for historical reasons and useful in some cases, like transfer learning and in progressively growing large models like GANs.
At a limit deep vs wide does not matter. The specifics of your chosen dataset and model provides the context that matters and you should experiment.
Perhaps test it to see if it’s helpful/useful on your specific problem?
Thankyou for sharing the tutorial,
i have a single time series data and i want to feed mymachine in order to create time series forecasting
but i dont know how to arange my data and feed the machine so it catch the pattern and create the forecast
do you have some advice for me?
thank you
best regards
Hi Dr. Johnson,
Thank you for sharing this code and tutorial. As a new user of Keras, I have a question. I want to design a simple supervised autoencoder network with greedy layer-wise. nodes in layers are 28, 20, 15, 10, 15, 20,28,respectively. When I want to add a new layer I receive an error.
here is my code which hiddennodes in each iteration is one of the above mentioned numbers def add_layer(model, trainX, trainy,hiddennodes):
# remember the current output layer
output_layer = model.layers[-1]
# remove the output layer
model.pop()
# mark all remaining layers as non-trainable
for layer in model.layers:
layer.trainable = False
# add a new hidden layer
model.add(Dense(hiddennodes, activation=’relu’, kernel_initializer=’he_uniform’))
# re-add the output layer
model.add(output_layer)
# fit model
model.fit(trainX, trainy, epochs=100, verbose=0)
But I receive this error: ” Input 0 is incompatible with layer dense_3: expected axis -1 of input shape to have value 20 but got shape (None, 15) ”
I would appreciate it if you could help me.
Best,
Saeid
Why is the second example is considered to be an unsupervised learning problem. We train the model to predict the label X given the input X, so that’s simply an attempt to make the model learn the linear function y = X. So to me this looks like a regression problem.
And running the code on my jupyter notebook ended up with:
[py]
ValueError Traceback (most recent call last)
in
79 print(‘YYYYYYY’)
80
—> 81 pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
82 pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
83 pyplot.legend()
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/pyplot.py in plot(scalex, scaley, data, *args, **kwargs)
2787 return gca().plot(
2788 *args, scalex=scalex, scaley=scaley, **({“data”: data} if data
-> 2789 is not None else {}), **kwargs)
2790
2791
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_axes.py in plot(self, scalex, scaley, data, *args, **kwargs)
1664 “””
1665 kwargs = cbook.normalize_kwargs(kwargs, mlines.Line2D._alias_map)
-> 1666 lines = [*self._get_lines(*args, data=data, **kwargs)]
1667 for line in lines:
1668 self.add_line(line)
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in __call__(self, *args, **kwargs)
223 this += args[0],
224 args = args[1:]
–> 225 yield from self._plot_args(this, kwargs)
226
227 def get_next_color(self):
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in _plot_args(self, tup, kwargs)
389 x, y = index_of(tup[-1])
390
–> 391 x, y = self._xy_from_xy(x, y)
392
393 if self.command == ‘plot’:
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in _xy_from_xy(self, x, y)
268 if x.shape[0] != y.shape[0]:
269 raise ValueError(“x and y must have same first dimension, but ”
–> 270 “have shapes {} and {}”.format(x.shape, y.shape))
271 if x.ndim > 2 or y.ndim > 2:
272 raise ValueError(“x and y can be no greater than 2-D, but have ”
ValueError: x and y must have same first dimension, but have shapes (1,) and (11,)
[/py]
To fix it, I changed the following 2 lines:
[py]
pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
[/py]
To:
[py]
pyplot.plot(list(scores.keys()), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(list(scores.keys()), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
[/py]
Thanks for your recommendation. I tried it using pure python interpreter 3.7 and the behaviour is exactly the same. However the following change makes it to work:
From:
pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
To:
pyplot.plot(list(scores.keys()), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(list(scores.keys()), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
I have implemented this for stacked LSTMs, using the functional API in Keras.
For the first greedy training, with only one LSTM, it should not return the sequence going into the last dense layer. However, when popping the last layer, and adding LSTM layers, return_sequence is needed for the already pre-trained existing LSTM layer.
Any thoughts on how to deal with this problem? I have tried setting return_sequence to true for the first (existing) LSTM layer after the initial training, but not surprisingly, this does not work.
Thank you,
I’d ask a question about dataset. So, how can I split my dataset in this case?
For example, if I have a dataset with 60000 samples:
(?% for unsupervised pretraining)
(?% for supervised fin-tuning)
(?%validation)
(?% test)
You said “An interesting extension would be to explore whether fine tuning of all weights in the model prior or after fitting a classifier output layer improves performance”
A very thorough explanation and I have been following your blog at the first-day for researching on deep learning.
Thank you so much, Jason.
I see some literature mentioned about the fine-tuning stage where indeed the previously trained hidden layers are further trained together with the classification layer. Does this mean to initialize the layer weight just as it learnt previously but does not set training to False?
Hi Jason, thanks again for the great tutorial. I have a question about the unsupervised pre-train part: my understanding is we have some large amount of unlabeled data say, trainX, then we have a relatively small number of labeled data, say trainX1, trainy1, and of course some test data, testX1 and testy1. We should build the autoencoder using trainX (in base_autoencoder function, we have model.fit(trainX, trainX, epochs=100, verbose=0)) and then should we evaluate the model using trainX1 and trainy1 instead of trainX and trainy in evaluate_autoencoder_as_classifier?
Thanks for the post! However, one thing I don’t get is the usage of the autoencoder in the example. As far as I understood the use of autoencoders as preprocessing for classification, they should compress the inputs in order to increase the information content in the “compressed” layer (the one joining the encoder and decoder parts). Thus, if you have some n-dimensional input, the autoencoder could be used to compress it to m dimensions with m<n.
In the example, however, the dimensions are increased. Ideally, the layers should be able to simply pass the information (kind of like an identity function) to the next layers. In my view, adding these additional layers simply adds noise to the data. I feel confirmed by the gradual decrease in classification accuracy in your results.
Can you explain the reason for this layout?








Nice! Thump up first and then read!
Thanks!
very beautiful content, thanks for sharing thank you
Thanks, I’m glad it helped.
i appreciate your post. I like to read your beautiful post. you touch all the topic and subtopic related to machine learning. i will be happy if you keep on updating more about machine learning in future
Thanks.
Amazing, elegant code! I thought this was referred to as cascading layers
Thanks.
I’ve not heard that description before, do you recall where you read it?
Hi Jason,
Thanks for yours always interesting posts
In the first example , Supervised Greedy Layer-Wise Pretraining, it seems that it lacks two lines after line 52 : that is to say
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss=’categorical_crossentropy’, optimizer=opt, metrics=[‘accuracy’])
Otherwise, I got a traceback with this message “The model needs to be compiled before being used.”
Best
Thanks.
Perhaps you missed the compile() line when copying the code?
Well I do not see it in the first example
model.add(Dense(10, activation=’relu’, kernel_initializer=’he_uniform’))
# re-add the output layer
model.add(output_layer)
# fit model
model.fit(trainX, trainy, epochs=100, verbose=0)
but it is present in the second example
Am I wrong ?
Really?
Also, perhaps confirm that you are using Keras 2.2.4+
Hi Dr. Jason,
in the second example, after we unsupervised trained the autoencoder, why did you freeze the encoder layer in the finetuning phase and only trained the output layer.
I think what the encoder layer have learned in the unsupervised pretraining is used as initialization in the finetuning phase and we finetune the whole model.
Am I missing something?!!!!!
Good question.
I chose to fine tune the decoder, but this was arbitrary. You can choose to fine tune the whole model if you wish.
Hi Jason,
Thank you for your tutorials and amazing content. Quick question, if I understood correctly the quotes from the Deep Learning (Bengio) book … Greedy Layer-Wise pretraining is obsolete with modern activation functions, dropouts etc. available in Keras nowadays ? Would you recommend applying it for massive datasets and important neural network architectures, or should it simply be ignored today ?
Also, I heard several sources say “Deep neural networks learn better than wide ones, IF TRAINED CORRECTLY”. Is Greedy Layer-Wise pretraining what they were refering to in that sentence ?
Alternate methods are preferred for smaller models.
The method is described because the approach is still generally intersting for historical reasons and useful in some cases, like transfer learning and in progressively growing large models like GANs.
At a limit deep vs wide does not matter. The specifics of your chosen dataset and model provides the context that matters and you should experiment.
Perhaps test it to see if it’s helpful/useful on your specific problem?
Hi Jason,
Thankyou for sharing the tutorial,
i have a single time series data and i want to feed mymachine in order to create time series forecasting
but i dont know how to arange my data and feed the machine so it catch the pattern and create the forecast
do you have some advice for me?
thank you
best regards
Yes, you can start here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
great, thankyou sir
You’re welcome.
Hi Jason,
Great article as always.
My current model has multi input and I am using keras API. Can I implement greedy layer-wise pretraining on my model?
Thanks
Perhaps try it and compare results to a static MLP model with modern activation functions like relu.
Hi Dr. Johnson,
Thank you for sharing this code and tutorial. As a new user of Keras, I have a question. I want to design a simple supervised autoencoder network with greedy layer-wise. nodes in layers are 28, 20, 15, 10, 15, 20,28,respectively. When I want to add a new layer I receive an error.
here is my code which hiddennodes in each iteration is one of the above mentioned numbers def add_layer(model, trainX, trainy,hiddennodes):
# remember the current output layer
output_layer = model.layers[-1]
# remove the output layer
model.pop()
# mark all remaining layers as non-trainable
for layer in model.layers:
layer.trainable = False
# add a new hidden layer
model.add(Dense(hiddennodes, activation=’relu’, kernel_initializer=’he_uniform’))
# re-add the output layer
model.add(output_layer)
# fit model
model.fit(trainX, trainy, epochs=100, verbose=0)
But I receive this error: ” Input 0 is incompatible with layer dense_3: expected axis -1 of input shape to have value 20 but got shape (None, 15) ”
I would appreciate it if you could help me.
Best,
Saeid
I’m eager to help, but I don’t have the capacity to debug your code. \
I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/can-you-read-review-or-debug-my-code
Thank you.
You’re welcome.
Hi
Why is the second example is considered to be an unsupervised learning problem. We train the model to predict the label X given the input X, so that’s simply an attempt to make the model learn the linear function y = X. So to me this looks like a regression problem.
What exactly am I missing?
Thanks.
And running the code on my jupyter notebook ended up with:
[py]
ValueError Traceback (most recent call last)
in
79 print(‘YYYYYYY’)
80
—> 81 pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
82 pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
83 pyplot.legend()
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/pyplot.py in plot(scalex, scaley, data, *args, **kwargs)
2787 return gca().plot(
2788 *args, scalex=scalex, scaley=scaley, **({“data”: data} if data
-> 2789 is not None else {}), **kwargs)
2790
2791
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_axes.py in plot(self, scalex, scaley, data, *args, **kwargs)
1664 “””
1665 kwargs = cbook.normalize_kwargs(kwargs, mlines.Line2D._alias_map)
-> 1666 lines = [*self._get_lines(*args, data=data, **kwargs)]
1667 for line in lines:
1668 self.add_line(line)
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in __call__(self, *args, **kwargs)
223 this += args[0],
224 args = args[1:]
–> 225 yield from self._plot_args(this, kwargs)
226
227 def get_next_color(self):
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in _plot_args(self, tup, kwargs)
389 x, y = index_of(tup[-1])
390
–> 391 x, y = self._xy_from_xy(x, y)
392
393 if self.command == ‘plot’:
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in _xy_from_xy(self, x, y)
268 if x.shape[0] != y.shape[0]:
269 raise ValueError(“x and y must have same first dimension, but ”
–> 270 “have shapes {} and {}”.format(x.shape, y.shape))
271 if x.ndim > 2 or y.ndim > 2:
272 raise ValueError(“x and y can be no greater than 2-D, but have ”
ValueError: x and y must have same first dimension, but have shapes (1,) and (11,)
[/py]
To fix it, I changed the following 2 lines:
[py]
pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
[/py]
To:
[py]
pyplot.plot(list(scores.keys()), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(list(scores.keys()), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
[/py]
Don’t use a notebook:
https://machinelearningmastery.com/faq/single-faq/why-dont-use-or-recommend-notebooks
Thanks for your recommendation. I tried it using pure python interpreter 3.7 and the behaviour is exactly the same. However the following change makes it to work:
From:
pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
To:
pyplot.plot(list(scores.keys()), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(list(scores.keys()), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
The matplotlib version I’m using is:
>>> matplotlib.__version__
‘3.1.0’
Okay, thanks for the note.
We are reconstructing the input, not predicting.
As stated in the post:
Thanks for your feedback.
Can you please elaborate the relationship between reconstruting the input data with unsupervised learning?
The idea of modeling the input data only is an unsupervised learning task. E.g. modeling the density of the inputs.
The idea of using an autoencoder involves framing the unsupervised learning problem as a supervised learning problem. It is very clever!
Hello! Thanks and congrats for this excellent post.
Just one question:
can I adapt the “add layer” function to add layers with different number of nodes?
Example: 10-6-3-6-10 instead of 10-10-10-10-10
Sure.
Very excellent post.
Thanks.
Thank you for this! As always, very good post.
I have implemented this for stacked LSTMs, using the functional API in Keras.
For the first greedy training, with only one LSTM, it should not return the sequence going into the last dense layer. However, when popping the last layer, and adding LSTM layers, return_sequence is needed for the already pre-trained existing LSTM layer.
Any thoughts on how to deal with this problem? I have tried setting return_sequence to true for the first (existing) LSTM layer after the initial training, but not surprisingly, this does not work.
Sounds fun!
I think you will need to re-define the layer with return_sequences set to true.
If the model does not allow this easily, copy the weights into a new network and redefine the layer.
Thank you,
I’d ask a question about dataset. So, how can I split my dataset in this case?
For example, if I have a dataset with 60000 samples:
(?% for unsupervised pretraining)
(?% for supervised fin-tuning)
(?%validation)
(?% test)
Test different combinations and see what makes sense for your dataset.
Pre-Training would be useful in training CNNs with large supervised data? (True or False) with some explanation.
Please guide.
Perhaps. Depends on the data and the choice of model.
You said “An interesting extension would be to explore whether fine tuning of all weights in the model prior or after fitting a classifier output layer improves performance”
How can I use fine tuning in this example? Thanks
Use a smaller learning rate to fine tune a model.
For fine tuning, it’s correct to change the code in evaluate_autoencoder_as_classifier function :
for layer in model.layers:
layer.trainable = True
Perhaps try a number of things.
Hi Jason,
Example : 10-6-3-6-10 instead of 10-10-10-10-10 give error
regards
Very neat post as always! thanks for share your knowledges!!!
In the penultimate quote says:”Today, unsupervised pretraining has been largely abandoned”
Then did you know what is most wildly used initialize methods today? or what is “State of the art” initialize methods?
Thanks.
Yes, we use deep models with relu instead.
A very thorough explanation and I have been following your blog at the first-day for researching on deep learning.
Thank you so much, Jason.
I see some literature mentioned about the fine-tuning stage where indeed the previously trained hidden layers are further trained together with the classification layer. Does this mean to initialize the layer weight just as it learnt previously but does not set training to False?
Thanks.
Yes, it means we keep the weights from prior training and use a small learning rate to refine them.
Hi Jason, thanks again for the great tutorial. I have a question about the unsupervised pre-train part: my understanding is we have some large amount of unlabeled data say, trainX, then we have a relatively small number of labeled data, say trainX1, trainy1, and of course some test data, testX1 and testy1. We should build the autoencoder using trainX (in base_autoencoder function, we have model.fit(trainX, trainX, epochs=100, verbose=0)) and then should we evaluate the model using trainX1 and trainy1 instead of trainX and trainy in evaluate_autoencoder_as_classifier?
You can try that if you like.
Thanks for the post! However, one thing I don’t get is the usage of the autoencoder in the example. As far as I understood the use of autoencoders as preprocessing for classification, they should compress the inputs in order to increase the information content in the “compressed” layer (the one joining the encoder and decoder parts). Thus, if you have some n-dimensional input, the autoencoder could be used to compress it to m dimensions with m<n.
In the example, however, the dimensions are increased. Ideally, the layers should be able to simply pass the information (kind of like an identity function) to the next layers. In my view, adding these additional layers simply adds noise to the data. I feel confirmed by the gradual decrease in classification accuracy in your results.
Can you explain the reason for this layout?
It is a demonstration of the method – perhaps to a problem that is too simple, ideally we would have used a larger input.