The vanishing gradients problem is one example of unstable behavior that you may encounter when training a deep neural network.
It describes the situation where a deep multilayer feed-forward network or a recurrent neural network is unable to propagate useful gradient information from the output end of the model back to the layers near the input end of the model.
The result is the general inability of models with many layers to learn on a given dataset, or for models with many layers to prematurely converge to a poor solution.
Many fixes and workarounds have been proposed and investigated, such as alternate weight initialization schemes, unsupervised pre-training, layer-wise training, and variations on gradient descent. Perhaps the most common change is the use of the rectified linear activation function that has become the new default, instead of the hyperbolic tangent activation function that was the default through the late 1990s and 2000s.
In this tutorial, you will discover how to diagnose a vanishing gradient problem when training a neural network model and how to fix it using an alternate activation function and weight initialization scheme.
After completing this tutorial, you will know:
- The vanishing gradients problem limits the development of deep neural networks with classically popular activation functions such as the hyperbolic tangent.
- How to fix a deep neural network Multilayer Perceptron for classification using ReLU and He weight initialization.
- How to use TensorBoard to diagnose a vanishing gradient problem and confirm the impact of ReLU to improve the flow of gradients through the model.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Updated Oct/2019: Updated for Keras 2.3 and TensorFlow 2.0.

How to Fix the Vanishing Gradient By Using the Rectified Linear Activation Function
Photo by Liam Moloney, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- Vanishing Gradients Problem
- Two Circles Binary Classification Problem
- Multilayer Perceptron Model for Two Circles Problem
- Deeper MLP Model with ReLU for Two Circles Problem
- Review Average Gradient Size During Training
Vanishing Gradients Problem
Neural networks are trained using stochastic gradient descent.
This involves first calculating the prediction error made by the model and using the error to estimate a gradient used to update each weight in the network so that less error is made next time. This error gradient is propagated backward through the network from the output layer to the input layer.
It is desirable to train neural networks with many layers, as the addition of more layers increases the capacity of the network, making it capable of learning a large training dataset and efficiently representing more complex mapping functions from inputs to outputs.
A problem with training networks with many layers (e.g. deep neural networks) is that the gradient diminishes dramatically as it is propagated backward through the network. The error may be so small by the time it reaches layers close to the input of the model that it may have very little effect. As such, this problem is referred to as the “vanishing gradients” problem.
Vanishing gradients make it difficult to know which direction the parameters should move to improve the cost function …
— Page 290, Deep Learning, 2016.
In fact, the error gradient can be unstable in deep neural networks and not only vanish, but also explode, where the gradient exponentially increases as it is propagated backward through the network. This is referred to as the “exploding gradient” problem.
The term vanishing gradient refers to the fact that in a feedforward network (FFN) the backpropagated error signal typically decreases (or increases) exponentially as a function of the distance from the final layer.
— Random Walk Initialization for Training Very Deep Feedforward Networks, 2014.
Vanishing gradients is a particular problem with recurrent neural networks as the update of the network involves unrolling the network for each input time step, in effect creating a very deep network that requires weight updates. A modest recurrent neural network may have 200-to-400 input time steps, resulting conceptually in a very deep network.
The vanishing gradients problem may be manifest in a Multilayer Perceptron by a slow rate of improvement of a model during training and perhaps premature convergence, e.g. continued training does not result in any further improvement. Inspecting the changes to the weights during training, we would see more change (i.e. more learning) occurring in the layers closer to the output layer and less change occurring in the layers close to the input layer.
There are many techniques that can be used to reduce the impact of the vanishing gradients problem for feed-forward neural networks, most notably alternate weight initialization schemes and use of alternate activation functions.
Different approaches to training deep networks (both feedforward and recurrent) have been studied and applied [in an effort to address vanishing gradients], such as pre-training, better random initial scaling, better optimization methods, specific architectures, orthogonal initialization, etc.
— Random Walk Initialization for Training Very Deep Feedforward Networks, 2014.
In this tutorial, we will take a closer look at the use of an alternate weight initialization scheme and activation function to permit the training of deeper neural network models.
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Two Circles Binary Classification Problem
As the basis for our exploration, we will use a very simple two-class or binary classification problem.
The scikit-learn class provides the make_circles() function that can be used to create a binary classification problem with the prescribed number of samples and statistical noise.
Each example has two input variables that define the x and y coordinates of the point on a two-dimensional plane. The points are arranged in two concentric circles (they have the same center) for the two classes.
The number of points in the dataset is specified by a parameter, half of which will be drawn from each circle. Gaussian noise can be added when sampling the points via the “noise” argument that defines the standard deviation of the noise, where 0.0 indicates no noise or points drawn exactly from the circles. The seed for the pseudorandom number generator can be specified via the “random_state” argument that allows the exact same points to be sampled each time the function is called.
The example below generates 1,000 examples from the two circles with noise and a value of 1 to seed the pseudorandom number generator.
|
1 2 |
# generate circles X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) |
We can create a graph of the dataset, plotting the x and y coordinates of the input variables (X) and coloring each point by the class value (0 or 1).
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# scatter plot of the circles dataset with points colored by class from sklearn.datasets import make_circles from numpy import where from matplotlib import pyplot # generate circles X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # select indices of points with each class label for i in range(2): samples_ix = where(y == i) pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1], label=str(i)) pyplot.legend() pyplot.show() |
Running the example creates a plot showing the 1,000 generated data points with the class value of each point used to color each point.
We can see points for class 0 are blue and represent the outer circle, and points for class 1 are orange and represent the inner circle.
The statistical noise of the generated samples means that there is some overlap of points between the two circles, adding some ambiguity to the problem, making it non-trivial. This is desirable as a neural network may choose one of among many possible solutions to classify the points between the two circles and always make some errors.
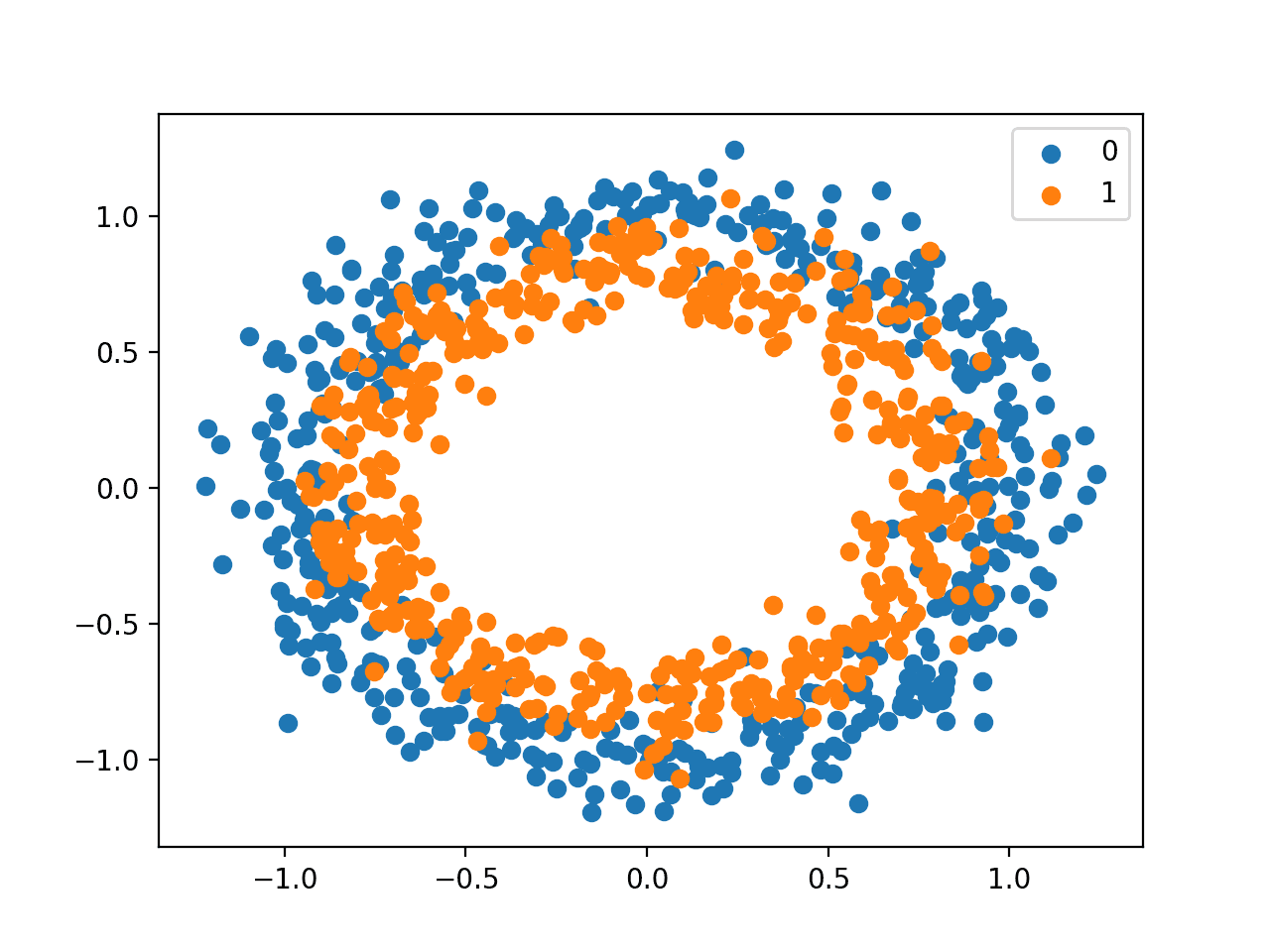
Scatter Plot of Circles Dataset With Points Colored By Class Value
Now that we have defined a problem as the basis for our exploration, we can look at developing a model to address it.
Multilayer Perceptron Model for Two Circles Problem
We can develop a Multilayer Perceptron model to address the two circles problem.
This will be a simple feed-forward neural network model, designed as we were taught in the late 1990s and early 2000s.
First, we will generate 1,000 data points from the two circles problem and rescale the inputs to the range [-1, 1]. The data is almost already in this range, but we will make sure.
Normally, we would prepare the data scaling using a training dataset and apply it to a test dataset. To keep things simple in this tutorial, we will scale all of the data together before splitting it into train and test sets.
|
1 2 3 4 5 |
# generate 2d classification dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # scale input data to [-1,1] scaler = MinMaxScaler(feature_range=(-1, 1)) X = scaler.fit_transform(X) |
Next, we will split the data into train and test sets.
Half of the data will be used for training and the remaining 500 examples will be used as the test set. In this tutorial, the test set will also serve as the validation dataset so we can get an idea of how the model performs on the holdout set during training.
|
1 2 3 4 |
# split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
Next, we will define the model.
The model will have an input layer with two inputs, for the two variables in the dataset, one hidden layer with five nodes, and an output layer with one node used to predict the class probability. The hidden layer will use the hyperbolic tangent activation function (tanh) and the output layer will use the logistic activation function (sigmoid) to predict class 0 or class 1 or something in between.
Using the hyperbolic tangent activation function in hidden layers was the best practice in the 1990s and 2000s, performing generally better than the logistic function when used in the hidden layer. It was also good practice to initialize the network weights to small random values from a uniform distribution. Here, we will initialize weights randomly from the range [0.0, 1.0].
|
1 2 3 4 5 |
# define model model = Sequential() init = RandomUniform(minval=0, maxval=1) model.add(Dense(5, input_dim=2, activation='tanh', kernel_initializer=init)) model.add(Dense(1, activation='sigmoid', kernel_initializer=init)) |
The model uses the binary cross entropy loss function and is optimized using stochastic gradient descent with a learning rate of 0.01 and a large momentum of 0.9.
|
1 2 3 |
# compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) |
The model is trained for 500 training epochs and the test dataset is evaluated at the end of each epoch along with the training dataset.
|
1 2 |
# fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0) |
After the model is fit, it is evaluated on both the train and test dataset and the accuracy scores are displayed.
|
1 2 3 4 |
# evaluate the model _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
Finally, the accuracy of the model during each step of training is graphed as a line plot, showing the dynamics of the model as it learned the problem.
|
1 2 3 4 5 |
# plot training history pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
Tying all of this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# mlp for the two circles classification problem from sklearn.datasets import make_circles from sklearn.preprocessing import MinMaxScaler from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.initializers import RandomUniform from matplotlib import pyplot # generate 2d classification dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # scale input data to [-1,1] scaler = MinMaxScaler(feature_range=(-1, 1)) X = scaler.fit_transform(X) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # define model model = Sequential() init = RandomUniform(minval=0, maxval=1) model.add(Dense(5, input_dim=2, activation='tanh', kernel_initializer=init)) model.add(Dense(1, activation='sigmoid', kernel_initializer=init)) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0) # evaluate the model _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # plot training history pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
Running the example fits the model in just a few seconds.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that in this case, the model learned the problem well, achieving an accuracy of about 81.6% on both the train and test datasets.
|
1 |
Train: 0.816, Test: 0.816 |
A line plot of model accuracy on the train and test sets is created, showing the change in performance over all 500 training epochs.
The plot suggests, for this run, that the performance begins to slow around epoch 300 at about 80% accuracy for both the train and test sets.
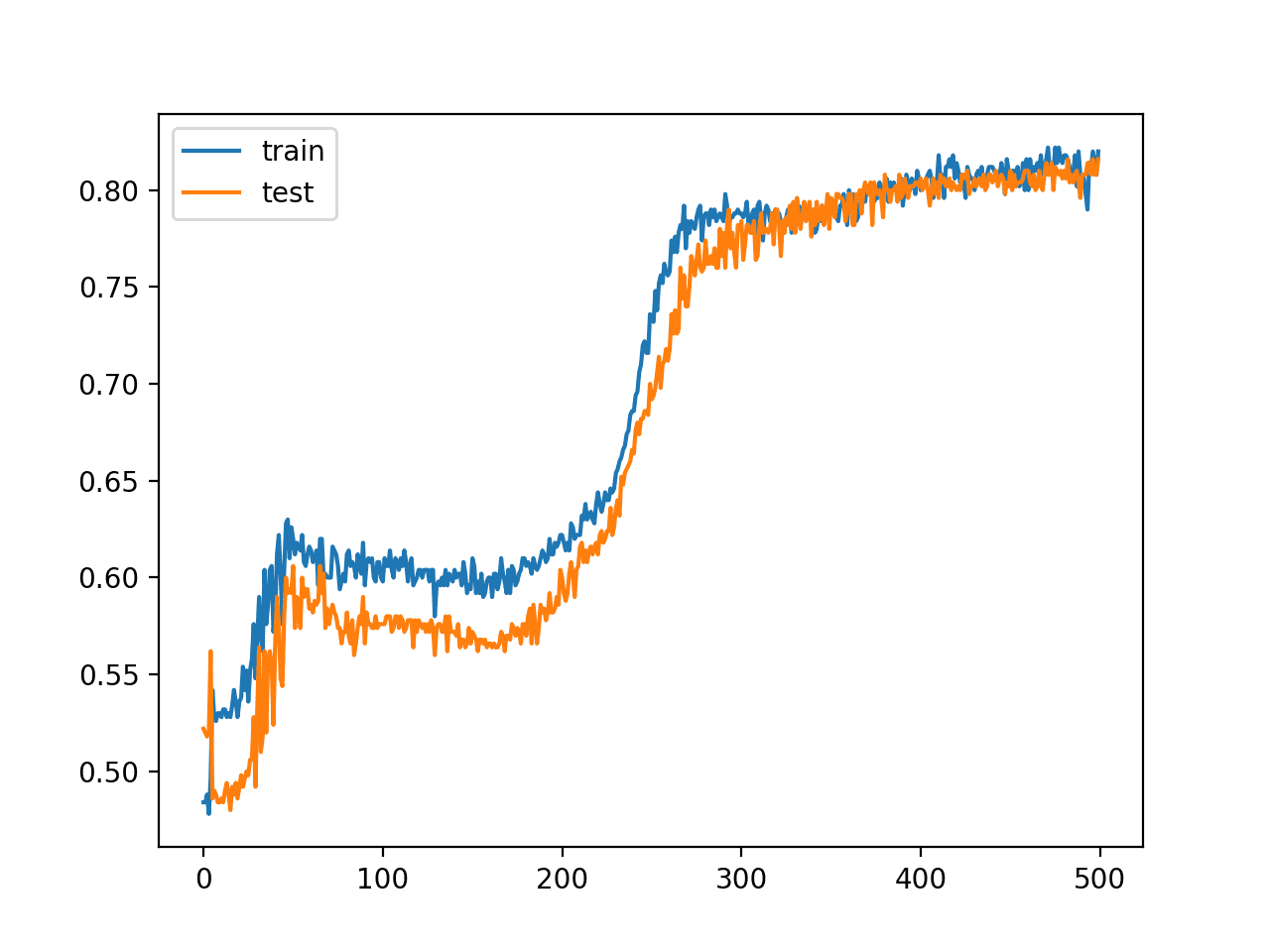
Line Plot of Train and Test Set Accuracy Over Training Epochs for MLP in the Two Circles Problem
Now that we have seen how to develop a classical MLP using the tanh activation function for the two circles problem, we can look at modifying the model to have many more hidden layers.
Deeper MLP Model for Two Circles Problem
Traditionally, developing deep Multilayer Perceptron models was challenging.
Deep models using the hyperbolic tangent activation function do not train easily, and much of this poor performance is blamed on the vanishing gradient problem.
We can attempt to investigate this using the MLP model developed in the previous section.
The number of hidden layers can be increased from 1 to 5; for example:
|
1 2 3 4 5 6 7 8 9 |
# define model init = RandomUniform(minval=0, maxval=1) model = Sequential() model.add(Dense(5, input_dim=2, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(1, activation='sigmoid', kernel_initializer=init)) |
We can then re-run the example and review the results.
The complete example of the deeper MLP is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# deeper mlp for the two circles classification problem from sklearn.datasets import make_circles from sklearn.preprocessing import MinMaxScaler from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.initializers import RandomUniform from matplotlib import pyplot # generate 2d classification dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) scaler = MinMaxScaler(feature_range=(-1, 1)) X = scaler.fit_transform(X) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # define model init = RandomUniform(minval=0, maxval=1) model = Sequential() model.add(Dense(5, input_dim=2, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(1, activation='sigmoid', kernel_initializer=init)) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0) # evaluate the model _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # plot training history pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
Running the example first prints the performance of the fit model on the train and test datasets.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that performance is quite poor on both the train and test sets achieving around 50% accuracy. This suggests that the model as configured could not learn the problem nor generalize a solution.
|
1 |
Train: 0.530, Test: 0.468 |
The line plots of model accuracy on the train and test sets during training tell a similar story. We can see that performance is bad and actually gets worse as training progresses.
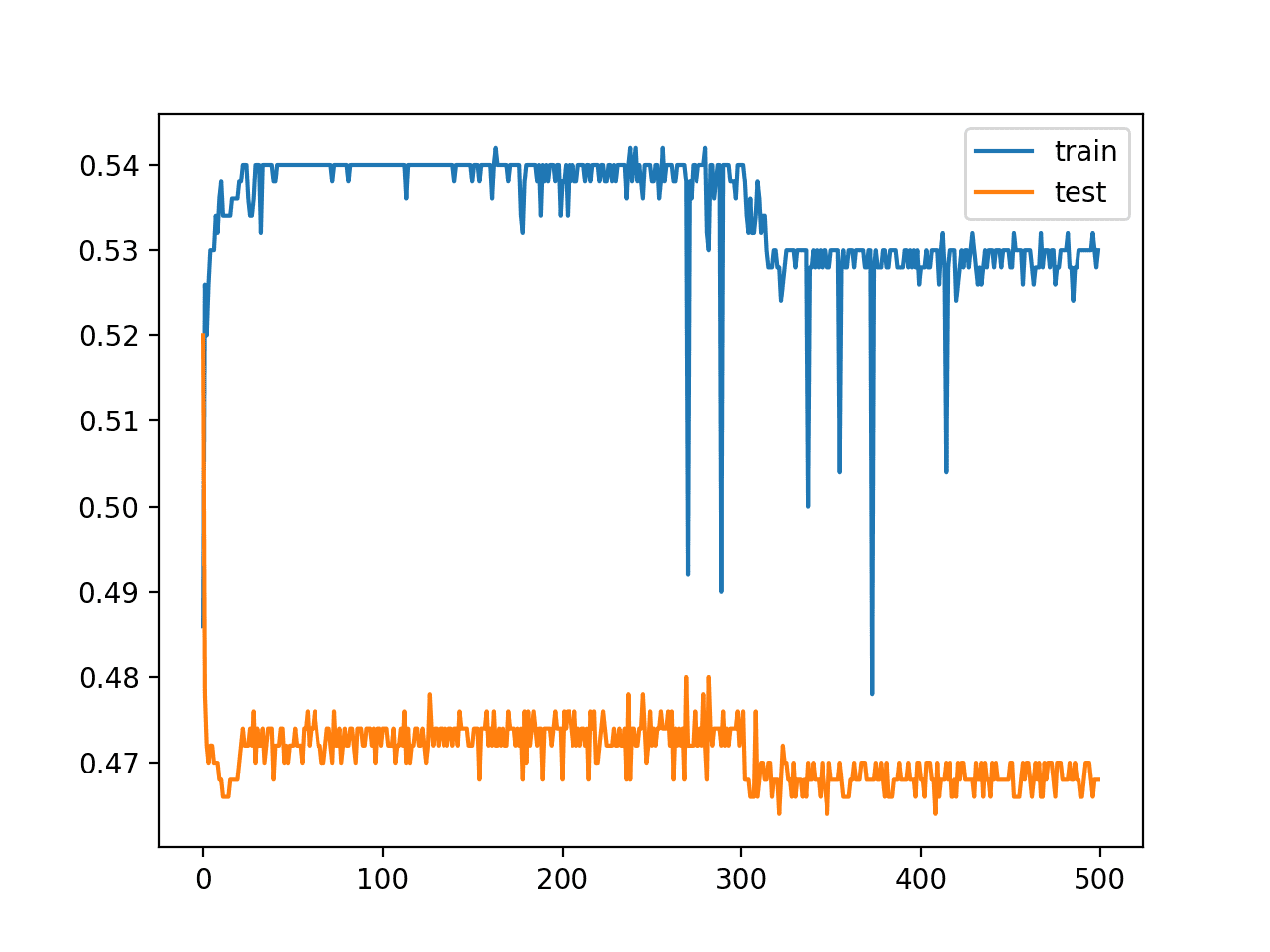
Line Plot of Train and Test Set Accuracy of Over Training Epochs for Deep MLP in the Two Circles Problem
Deeper MLP Model with ReLU for Two Circles Problem
The rectified linear activation function has supplanted the hyperbolic tangent activation function as the new preferred default when developing Multilayer Perceptron networks, as well as other network types like CNNs.
This is because the activation function looks and acts like a linear function, making it easier to train and less likely to saturate, but is, in fact, a nonlinear function, forcing negative inputs to the value 0. It is claimed as one possible approach to addressing the vanishing gradients problem when training deeper models.
When using the rectified linear activation function (or ReLU for short), it is good practice to use the He weight initialization scheme. We can define the MLP with five hidden layers using ReLU and He initialization, listed below.
|
1 2 3 4 5 6 7 8 |
# define model model = Sequential() model.add(Dense(5, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) |
Tying this together, the complete code example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# deeper mlp with relu for the two circles classification problem from sklearn.datasets import make_circles from sklearn.preprocessing import MinMaxScaler from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.initializers import RandomUniform from matplotlib import pyplot # generate 2d classification dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) scaler = MinMaxScaler(feature_range=(-1, 1)) X = scaler.fit_transform(X) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # define model model = Sequential() model.add(Dense(5, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0) # evaluate the model _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # plot training history pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
Running the example prints the performance of the model on the train and test datasets.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that this small change has allowed the model to learn the problem, achieving about 84% accuracy on both datasets, outperforming the single layer model using the tanh activation function.
|
1 |
Train: 0.836, Test: 0.840 |
A line plot of model accuracy on the train and test sets over training epochs is also created. The plot shows quite different dynamics to what we have seen so far.
The model appears to rapidly learn the problem, converging on a solution in about 100 epochs.
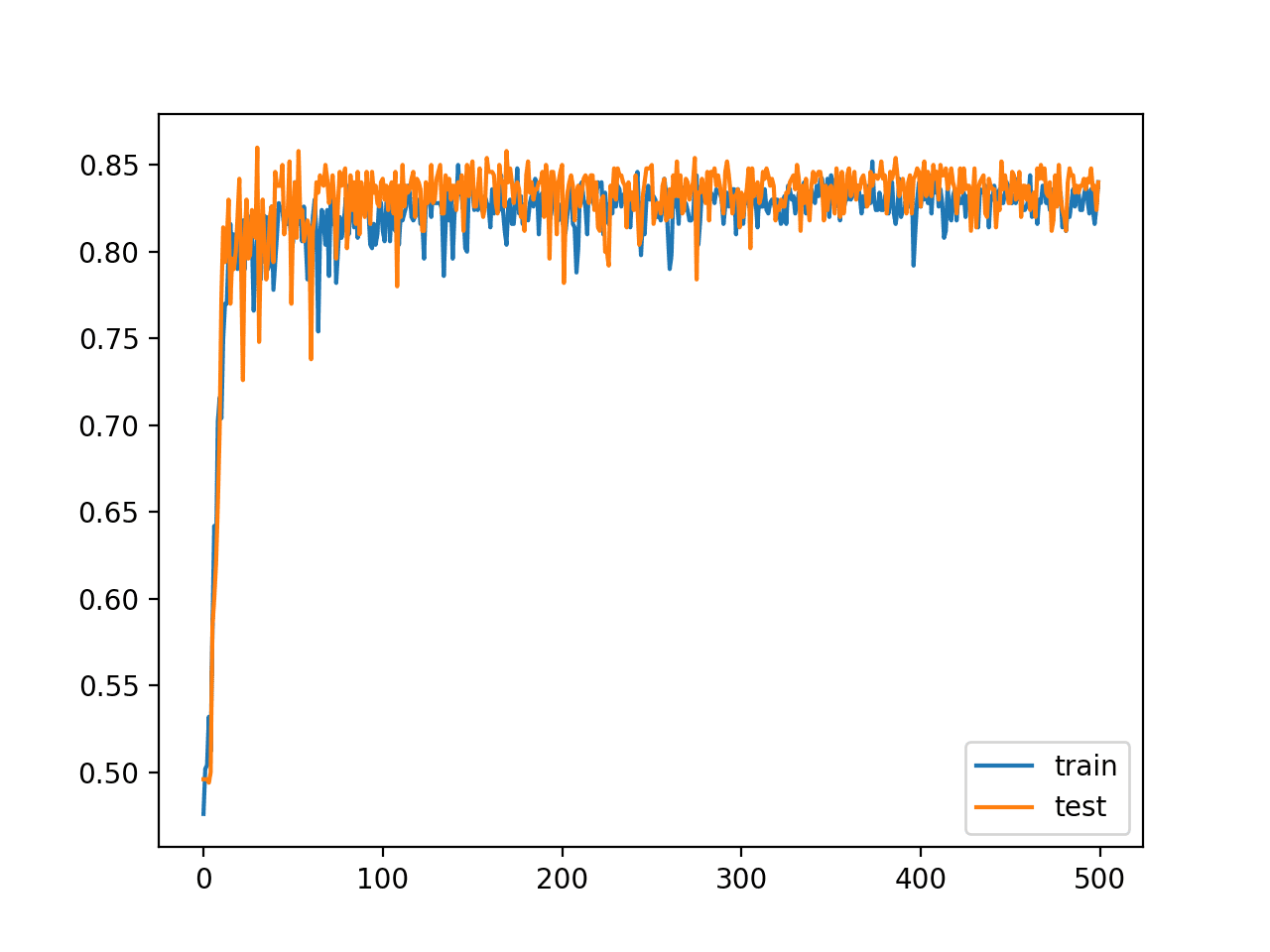
Line Plot of Train and Test Set Accuracy of Over Training Epochs for Deep MLP with ReLU in the Two Circles Problem
Use of the ReLU activation function has allowed us to fit a much deeper model for this simple problem, but this capability does not extend infinitely. For example, increasing the number of layers results in slower learning to a point at about 20 layers where the model is no longer capable of learning the problem, at least with the chosen configuration.
For example, below is a line plot of train and test accuracy of the same model with 15 hidden layers that shows that it is still capable of learning the problem.
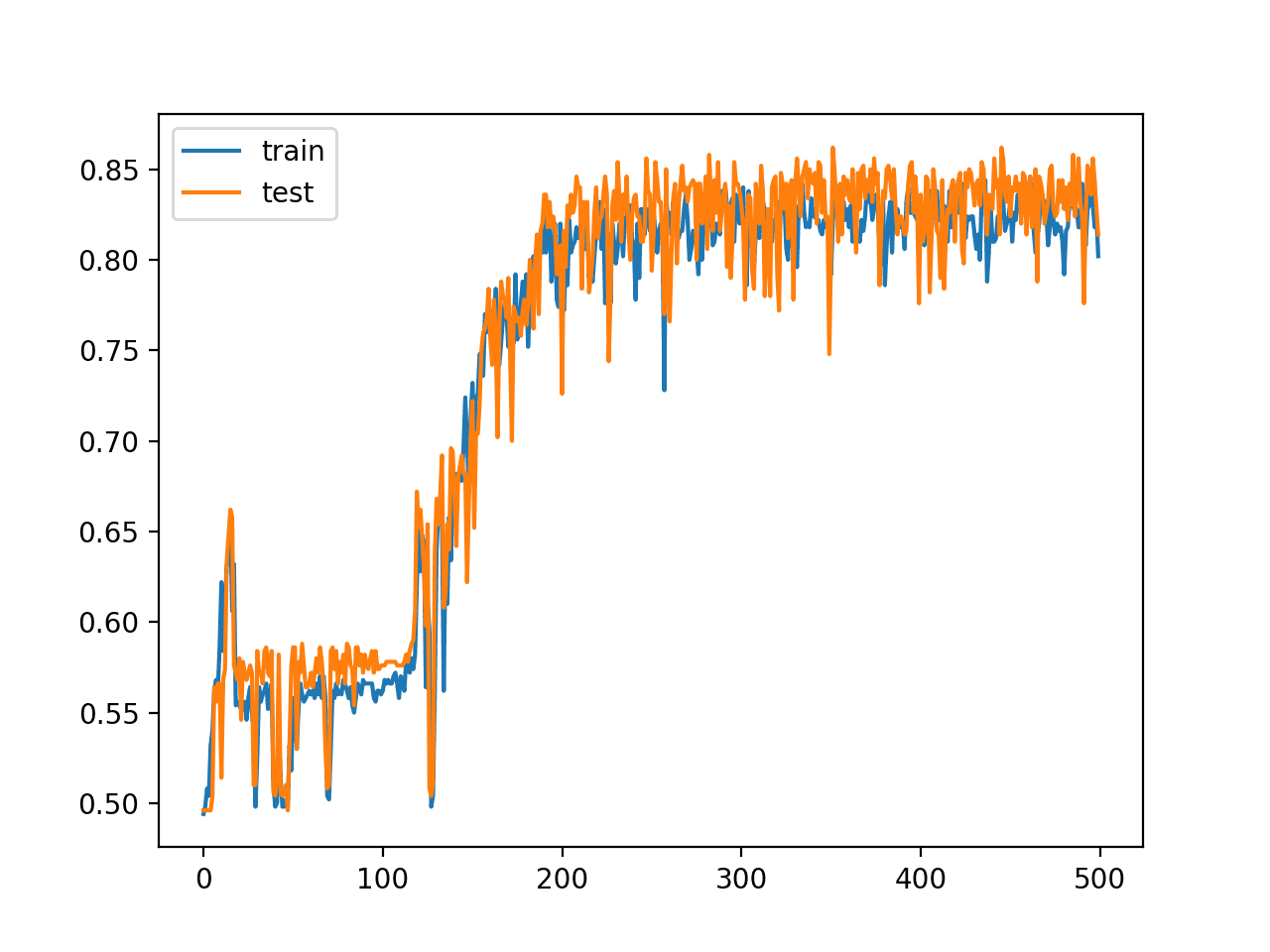
Line Plot of Train and Test Set Accuracy of Over Training Epochs for Deep MLP with ReLU with 15 Hidden Layers
Below is a line plot of train and test accuracy over epochs with the same model with 20 layers, showing that the configuration is no longer capable of learning the problem.
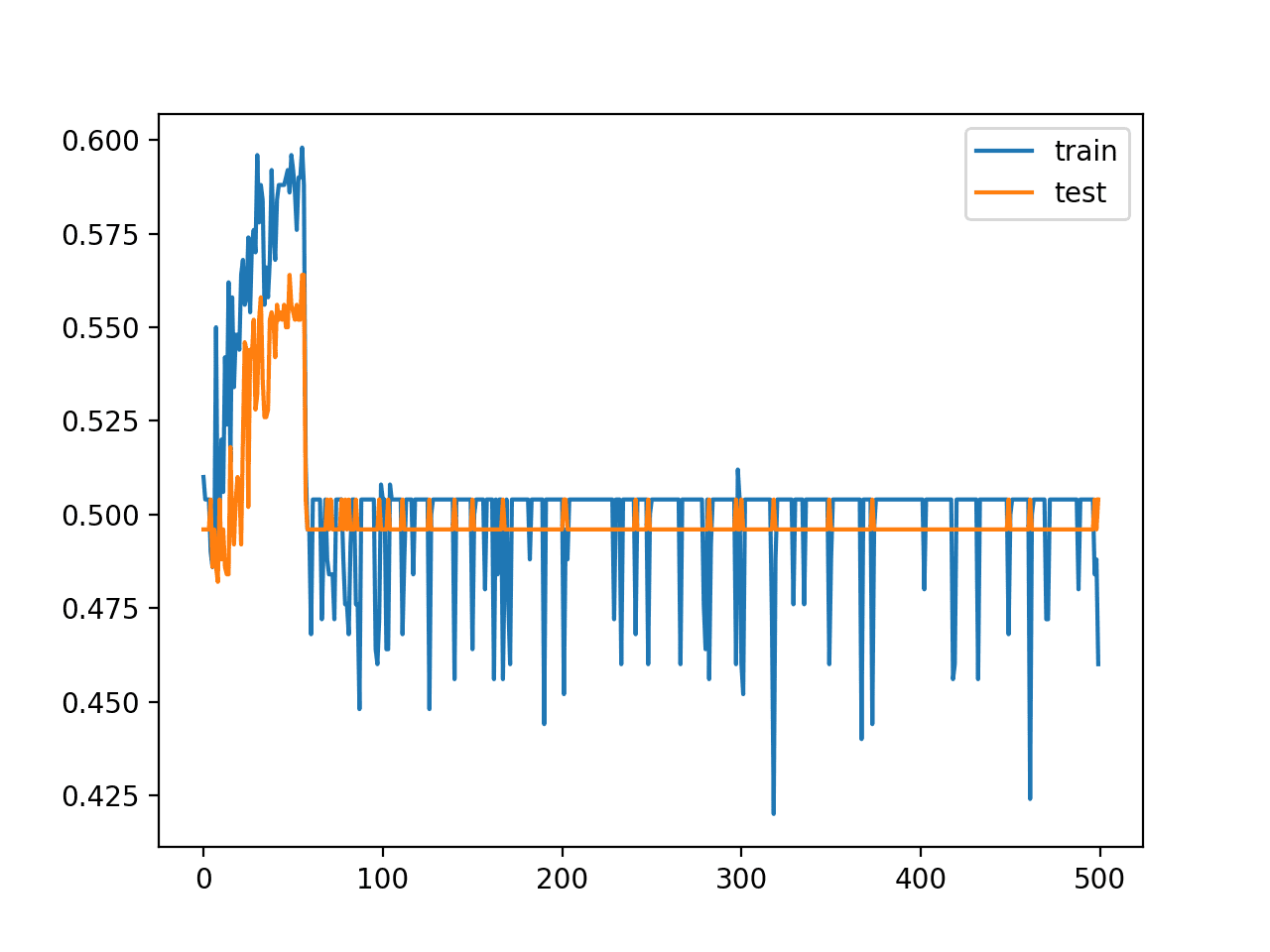
Line Plot of Train and Test Set Accuracy of Over Training Epochs for Deep MLP with ReLU with 20 Hidden Layers
Although use of the ReLU worked, we cannot be confident that use of the tanh function failed because of vanishing gradients and ReLU succeed because it overcame this problem.
Review Average Gradient Size During Training
This section assumes that you are using the TensorFlow backend with Keras. If this is not the case, you can skip this section.
In the cases of using the tanh activation function, we know the network has more than enough capacity to learn the problem, but the increase in layers has prevented it from doing so.
It is hard to diagnose a vanishing gradient as a cause for bad performance. One possible signal is to review the average size of the gradient per layer per training epoch.
We would expect layers closer to the output to have a larger average gradient than those layers closer to the input.
Keras provides the TensorBoard callback that can be used to log properties of the model during training such as the average gradient per layer. These statistics can then be reviewed using the TensorBoard interface that is provided with TensorFlow.
We can configure this callback to record the average gradient per-layer per-training epoch, then ensure the callback is used as part of training the model.
|
1 2 3 4 |
# prepare callback tb = TensorBoard(histogram_freq=1, write_grads=True) # fit model model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0, callbacks=[tb]) |
We can use this callback to first investigate the dynamics of the gradients in the deep model fit using the hyperbolic tangent activation function, then later compare the dynamics to the same model fit using the rectified linear activation function.
First, the complete example of the deep MLP model using tanh and the TensorBoard callback is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# deeper mlp for the two circles classification problem with callback from sklearn.datasets import make_circles from sklearn.preprocessing import MinMaxScaler from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.initializers import RandomUniform from keras.callbacks import TensorBoard # generate 2d classification dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) scaler = MinMaxScaler(feature_range=(-1, 1)) X = scaler.fit_transform(X) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # define model init = RandomUniform(minval=0, maxval=1) model = Sequential() model.add(Dense(5, input_dim=2, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(5, activation='tanh', kernel_initializer=init)) model.add(Dense(1, activation='sigmoid', kernel_initializer=init)) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # prepare callback tb = TensorBoard(histogram_freq=1, write_grads=True) # fit model model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0, callbacks=[tb]) |
Running the example creates a new “logs/” subdirectory with a file containing the statistics recorded by the callback during training.
We can review the statistics in the TensorBoard web interface. The interface can be started from the command line, requiring that you specify the full path to your logs directory.
For example, if you run the code in a “/code” directory, then the full path to the logs directory will be “/code/logs/“.
Below is the command to start the TensorBoard interface to be executed on your command line (command prompt). Be sure to change the path to your logs directory.
|
1 |
python -m tensorboard.main --logdir=/code/logs/ |
Next, open your web browser and enter the following URL:
If all went well, you will see the TensorBoard web interface.
Plots of the average gradient per layer per training epoch can be reviewed under the “Distributions” and “Histograms” tabs of the interface. The plots can be filtered to only show the gradients for the Dense layers, excluding the bias, using the search filter “kernel_0_grad“.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
First, line plots are created for each of the 6 layers (5 hidden, 1 output). The names of the plots indicate the layer, where “dense_1” indicates the hidden layer after the input layer and “dense_6” represents the output layer.
We can see that the output layer has a lot of activity over the entire run, with average gradients per epoch at around 0.05 to 0.1. We can also see some activity in the first hidden layer with a similar range. Therefore, gradients are getting through to the first hidden layer, but the last layer and last hidden layer is seeing most of the activity.
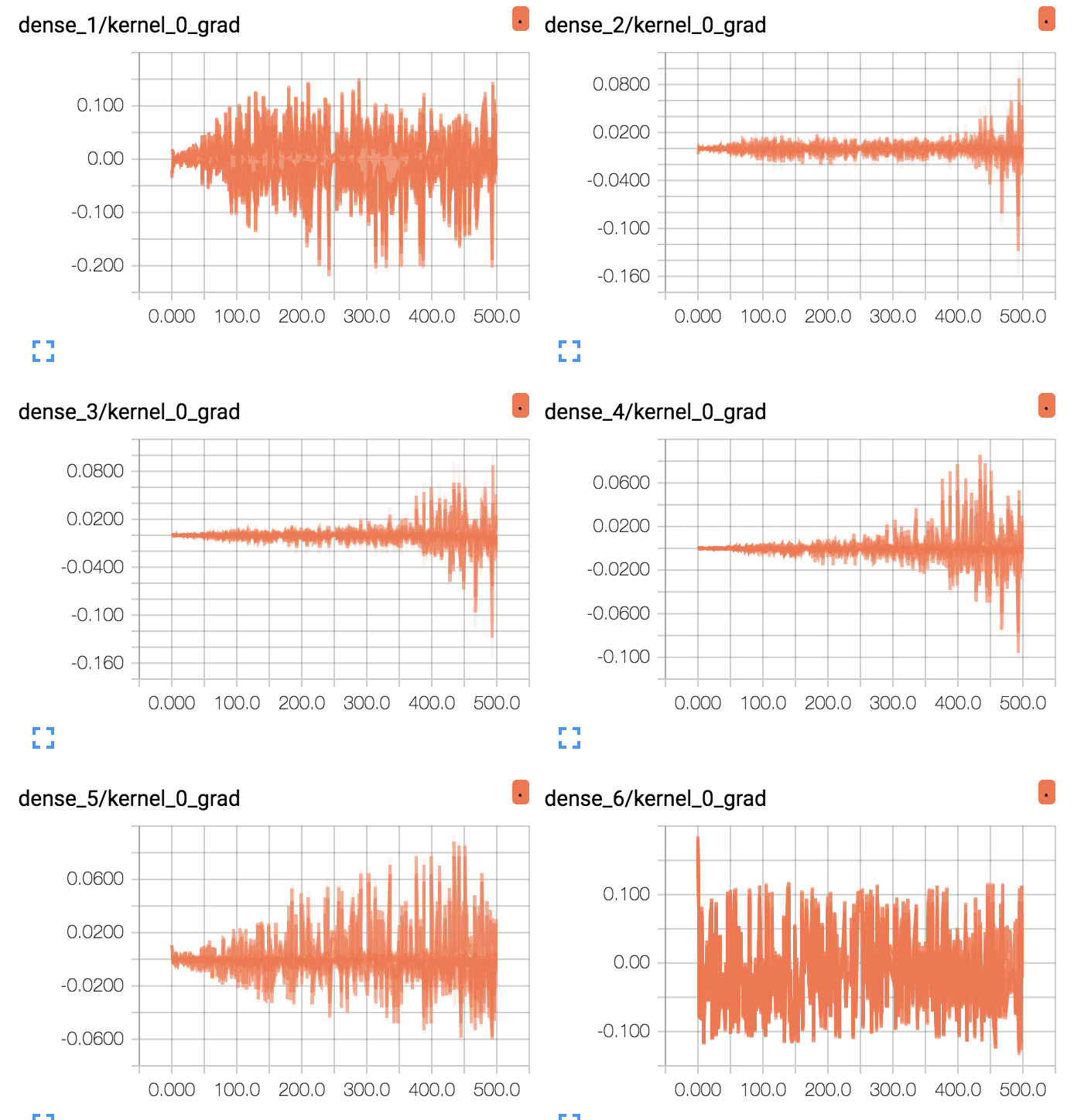
TensorBoard Line Plots of Average Gradients Per Layer for Deep MLP With Tanh
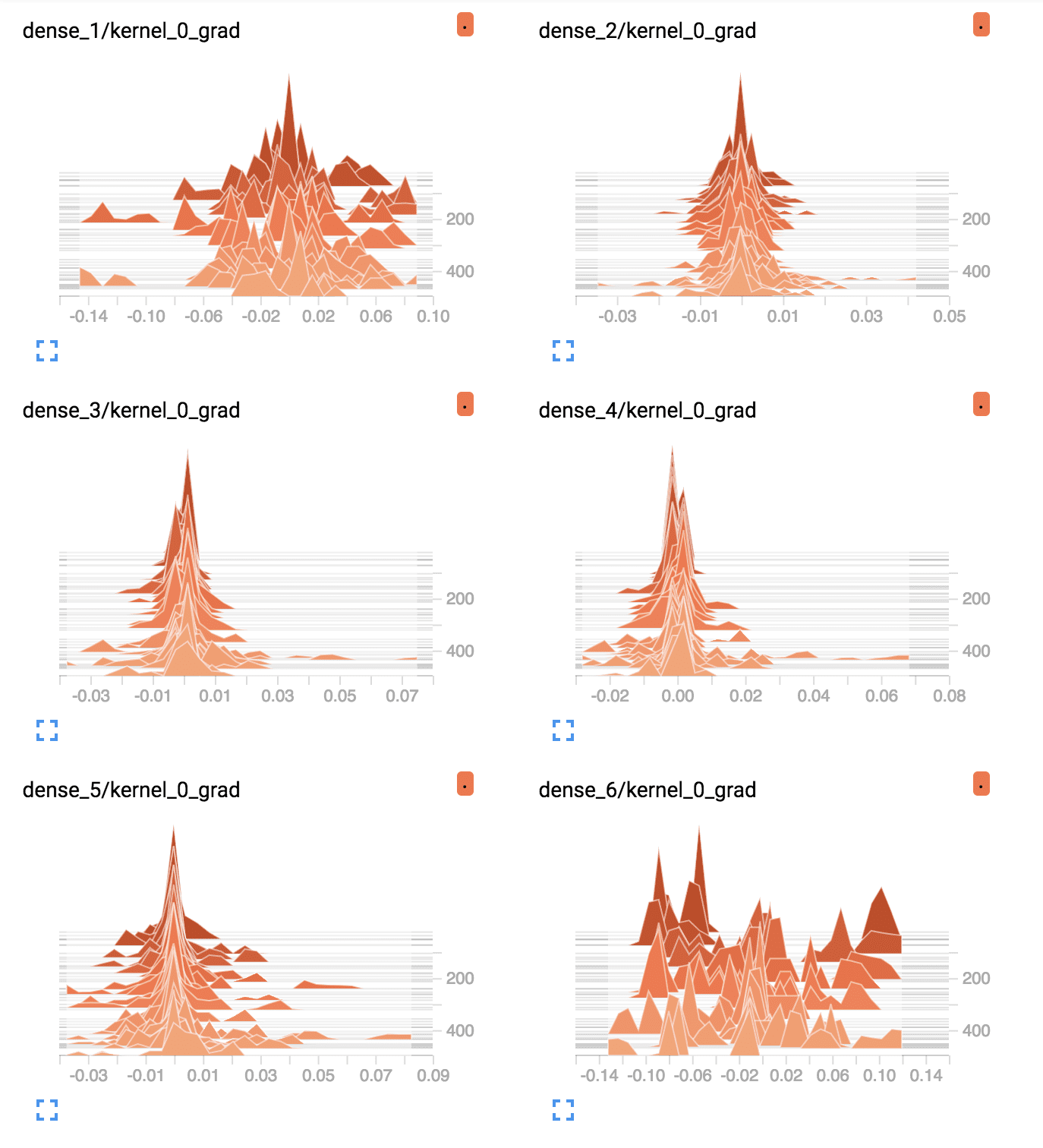
TensorBoard Density Plots of Average Gradients Per Layer for Deep MLP With Tanh
We can collect the same information from the deep MLP with the ReLU activation function.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# deeper mlp with relu for the two circles classification problem with callback from sklearn.datasets import make_circles from sklearn.preprocessing import MinMaxScaler from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.callbacks import TensorBoard # generate 2d classification dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) scaler = MinMaxScaler(feature_range=(-1, 1)) X = scaler.fit_transform(X) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # define model model = Sequential() model.add(Dense(5, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(5, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) # compile model opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # prepare callback tb = TensorBoard(histogram_freq=1, write_grads=True) # fit model model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0, callbacks=[tb]) |
The TensorBoard interface can be confusing if you are new to it.
To keep things simple, delete the “logs” subdirectory prior to running this second example.
Once run, you can start the TensorBoard interface the same way and access it through your web browser.
The plots of the average gradient per layer per training epoch show a different story as compared to the gradients for the deep model with tanh.
We can see that the first hidden layer sees more gradients, more consistently with larger spread, perhaps 0.2 to 0.4, as opposed to 0.05 and 0.1 seen with tanh. We can also see that the middle hidden layers see large gradients.
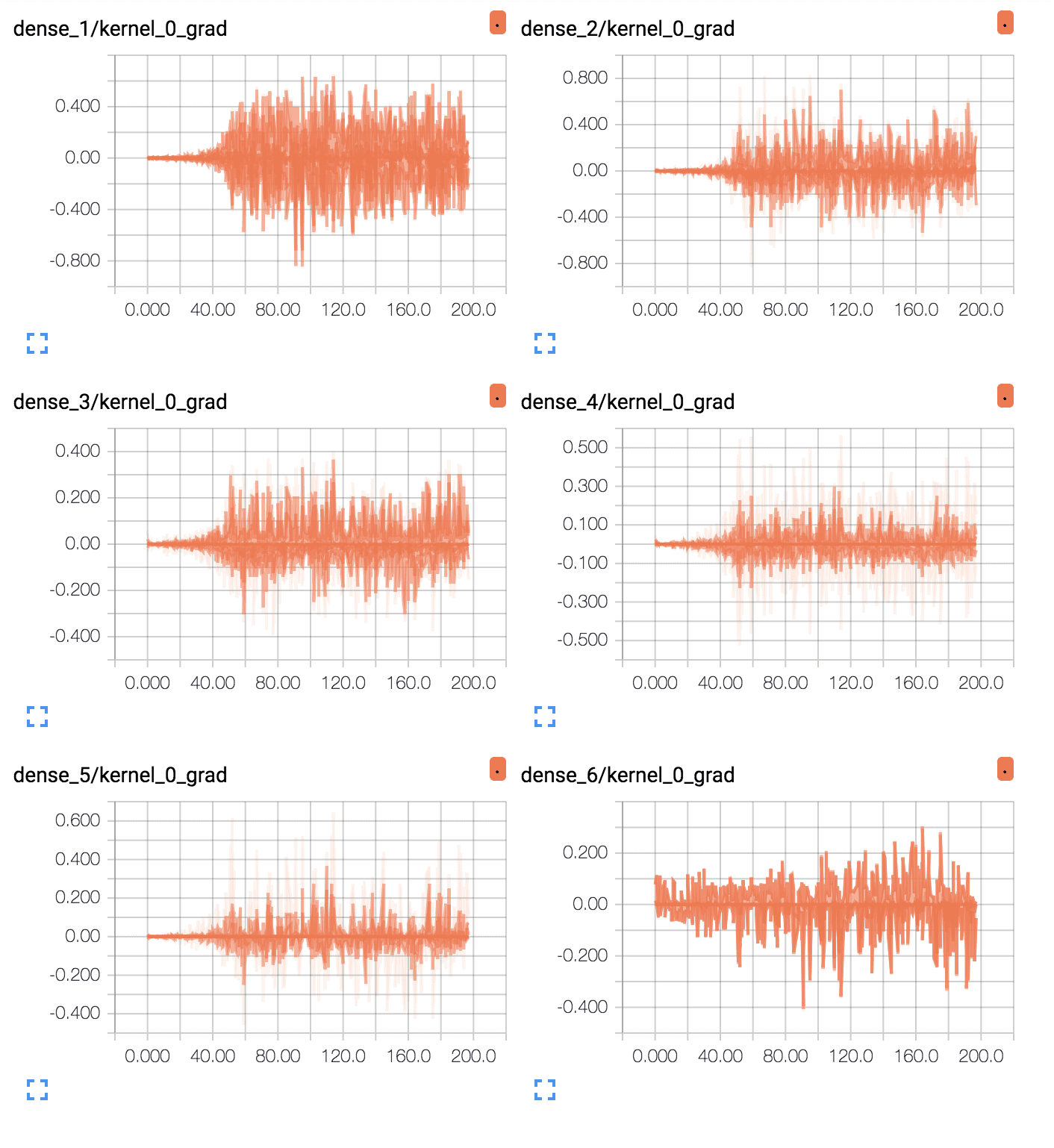
TensorBoard Line Plots of Average Gradients Per Layer for Deep MLP With ReLU
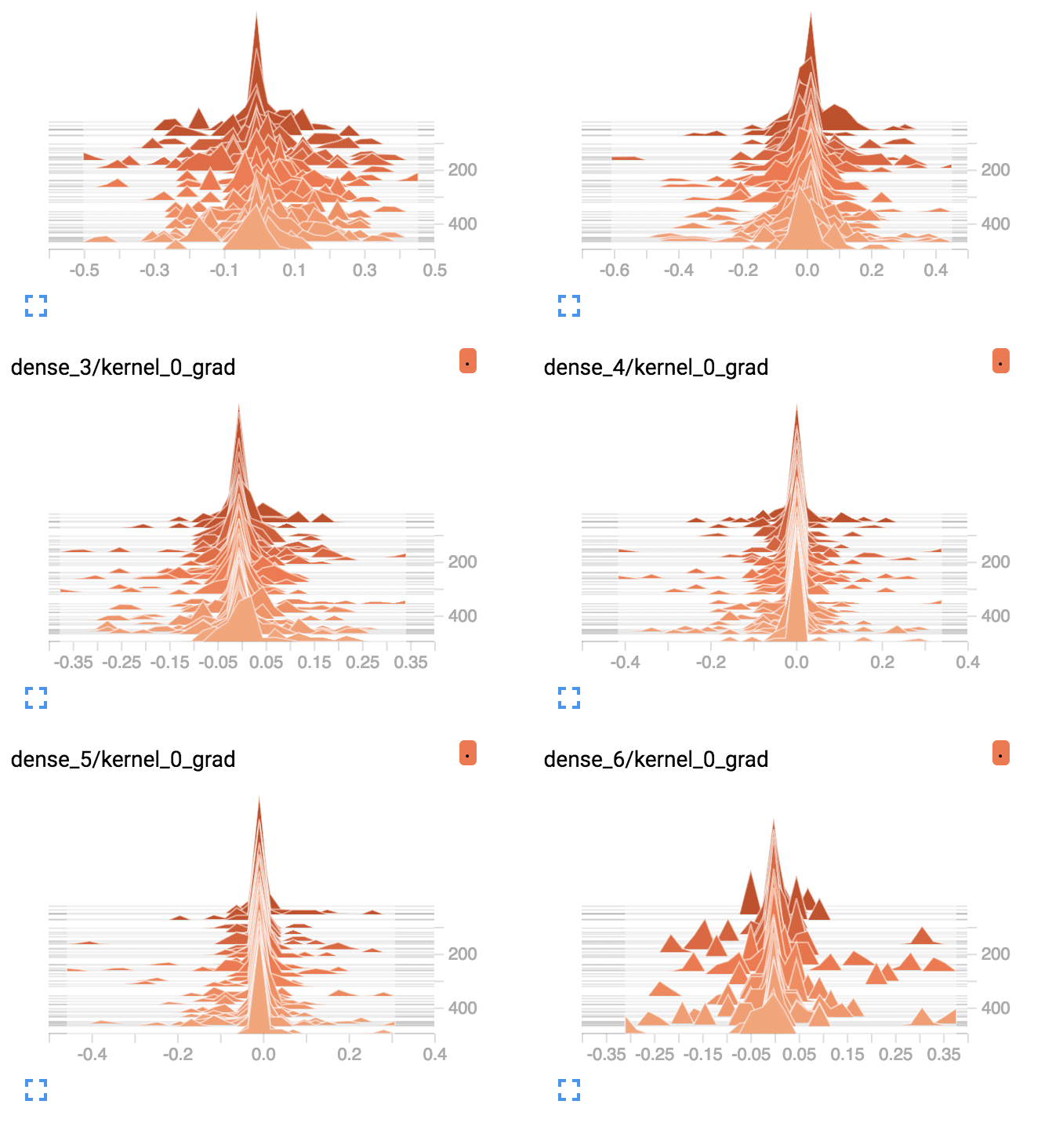
TensorBoard Density Plots of Average Gradients Per Layer for Deep MLP With ReLU
The ReLU activation function is allowing more gradient to flow backward through the model during training, and this may be the cause for improved performance.
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
- Weight Initialization. Update the deep MLP with tanh activation to use Xavier uniform weight initialization and report the results.
- Learning Algorithm. Update the deep MLP with tanh activation to use an adaptive learning algorithm such as Adam and report the results.
- Weight Changes. Update the tanh and relu examples to record and plot the L1 vector norm of model weights each epoch as a proxy for how much each layer is changed during training and compare results.
- Study Model Depth. Create an experiment using the MLP with tanh activation and report the performance of models as the number of hidden layers is increased from 1 to 10.
- Increase Breadth. Increase the number of nodes in the hidden layers of the MLP with tanh activation from 5 to 25 and report performance as the number of layers are increased from 1 to 10.
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Posts
Papers
- Random Walk Initialization for Training Very Deep Feedforward Networks, 2014.
- Gradient Flow in Recurrent Nets: the Difficulty of Learning Long-Term Dependencies, 2001.
Books
- Section 8.2.5 Long-Term Dependencies, Deep Learning, 2016.
- Chapter 5 Why are deep neural networks hard to train?, Neural Networks and Deep Learning.
API
- RandomUniform Keras Weight Initialization API
- SGD Keras Optimizer API
- TensorBoard Keras Callback API
- TensorFlow TensorBoard Guide
Articles
Summary
In this tutorial, you discovered how to diagnose a vanishing gradient problem when training a neural network model and how to fix it using an alternate activation function and weight initialization scheme.
Specifically, you learned:
- The vanishing gradients problem limits the development of deep neural networks with classically popular activation functions such as the hyperbolic tangent.
- How to fix a deep neural network Multilayer Perceptron for classification using ReLU and He weight initialization.
- How to use TensorBoard to diagnose a vanishing gradient problem and confirm the impact of ReLU to improve the flow of gradients through the model.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Better Deep Learning Models Today!

Train Faster, Reduce Overftting, and Ensembles
...with just a few lines of python code
Discover how in my new Ebook:
Better Deep Learning
It provides self-study tutorials on topics like:
weight decay, batch normalization, dropout, model stacking and much more...
Bring better deep learning to your projects!
Skip the Academics. Just Results.

")



")
Thanks for writing! I have a question in regression problem.
What is the most used activation function(linear? sigmoid? relu?) of the output layer in regression problems?
If y is [-1, 1], is it better to use sigmoid or tanh at the output layer?
What’s the case in CNN or RNN?
Perhaps explore different framings of your problem to see what works.
It is common to use a linear function in the output layer for regression.
With Relu, although it looks like it learns very fast and achieves best performance at about 100 epochs. However, when I actually tried epoches = 100, 200, 300, 400, they are mostly much worse than 83%. Does that mean the learning wasn’t stable when the epoch is relative small, i.e. 100 or 200. In practice, a big epoch is generally better and should be chosen?
Less, less training typically means less stability in the result as the optimization process is far from finished.
Hi,
I have a comment on “python -m tensorboard.main –logdir=/code/logs/” line with its associated code snippet that appears before the above line.
I am new to ML so I was wandering I need to save the above code with the name, “tensorboard.main” ? Or is it that running the code generates the preceding label?
Thanks.
No, tensorboard.main is existing code and part of the TensorFlow installation.
That is a complex part of the tutorial that you can freely skip.
Thank you for your response! On the top of the page, you quoted from Deep Learning (I am guessing Goodfellow et al. 2016 pg. 290) that vanishing gradient is described/defined “…as a function of the distance from the final layer”.
So I have 2 questions:
1 – Then, is the training accuracy a metric that qualitatively describe the hidden layer that is so much distance away from the final layer?
2 – If the answer to question “1” is YES, then is that possible to find the hidden layer that the vanishing gradient has occurred? Does running the tensorboard identify the hidden layer responsible for the vanishing gradient? And again, if YES, then could we pinpoint the hidden unit at which the vanishing gradient has happened?
The upshot of the 2 above questions are whether vanishing gradient could be spotted at the precise location where it has occurred. If so, any remedy to overcome it?!
I apologize in advance if my questions have are vague in nature. Thanks.
No, accuracy is a measure of the whole model’s performance.
The vanishing gradient is only a concern when trying to change the weights in a deep model.
Thank you for the post.
My question is about the first 2 learning curves, i e 1) one layer MLP 2) deeper MLP.
In the second case, should we expect a very high training accuracy(not 50%) as the more layers the more chance to overfit the training data?
Yes, accuracy is better with the deeper model.
But, with 20 layers, the model cannot learn.
Thank you for the post and your great explanations that helps interpretation. I have difficulties to get gradient histograms as write_grads seems like deprecated in tensorflow 2. Do you know how to get gradients histograms with new tensorflow release?
No sorry, I hope to update the post soon.
hi,
in a lstm architecture in keras we can use relu on the lstm layers. Is the relu that provide the lstm with the ability to deal with the vanishing gradient problem that occurs in rnn?
LSTMs already handle the vanishing gradient problem.
You can use ReLU with LSTMs and it can help with handling unscaled inputs.
thank you for the post
I have 2 questions
1. why the input layer doesn’t suffer vanishing gradient problem, while the middle layers do.
2. why at the beginning the middle layers don’t have gradient update while layer in training they starts to update.
You’re welcome.
Gradient vanishing is more of a problem the further away from the error signal at the output layer of the model, in general.
All layers/weights are updated each batch.
Hi Jason,
I’m using tenosrflow 1.15.2 to make use of write_grads argument in tensorboard callback since it’s deprecated in later versions. I am using SGD, my data shaped as (400,100,1) and number of epochs=100. I am expecting to see grad. distributions with X=number of epochs=100 but I found it=4k!
I couldn’t relate why since it’s not even equal to number of updates (400*100=40k).
When I tried tensorflow 2.0 or later, I found any distribution or histogram has X=number of epochs=100.
Q1: Could you please explain that?
Q2: What’s the tensorflow version used in the above example?
Thanks alot.
Ramy
Sorry, I don’t know the cause of the issue. Perhaps you can try posting an issue to the project on github?
Hi Jason, and Thank you for your valuable posts and lectures.
I have only one comment that I have same results of deep neural when I used tanh and He initialization instead of RelU and He initialization.
Best Regards
Nice work!
Hi Jason, thanks a lot for an informative post!!! I have questions comparing linear and ReLu activation function:
For both linear and ReLu, slope is constant and so should be gradient. So, is it that parameters are updated by same gradient value at the end of every batch?
Also, when x >0, what is the difference between linear and ReLu and how come ReLu outperforms linear?
Yes, but only if ReLU in the positive region. If negative, ReLU gradient is zero.
ReLU does not outperforms linear. They are different functions for different purposes. If you want to compare, you should compare ReLU with tanh or sigmoid.
Hi Jason, I have experimented with the sigmoid models but my observations do not all suggest vanishing gradients.
I have fitted a feedforward NN with 3 sigmoid hidden layers to perform binary classification. I found the output gradients with respect to the hidden layer weights very close to zero on the 1st and 2nd layers. The loss has not improved and accuracy was frozen the whole time.
However when I use callbacks to view the mean absolute hidden layer outputs on each layer, they do not vanish to zero, i.e. all 3 sigmoid layers do not seem to have saturated. The mean absolute weights on each layer have also been consistently increasing. I wonder why the internal states do not suggest VGP?
I have multiplied the weight matrices on the final epoch together and the product does not have entries close to zero. As theory suggests if eigenvalues of weights are less than 1 the product in backpropagation will shrink to zero.
My observations and code are here. Could you take a look at why some observations do not agree with the theory?
https://datascience.stackexchange.com/questions/106717/sigmoid-activation-functions-do-not-seem-to-cause-vanishing-gradients
Thanks in advance!
Hi Sieg…Please narrow the content of your post to a single concept/question so that I may better assist you.
Hi Jason, thanks for a lot of information. I want to know why ReLU does not give importance to the negative values and makes them 0. What we are achieving by doing this.
Thanks in advance!
Hi Praveen…You are very welcome! Keep in mind that the main purpose of an activation function is to control whether a neuron “fires” or not.
The following discussion may be prove helpful:
https://stats.stackexchange.com/questions/226923/why-do-we-use-relu-in-neural-networks-and-how-do-we-use-it