Deep learning was a recent invention. Partially, it is due to improved computation power that allows us to use more layers of perceptrons in a neural network. But at the same time, we can train a deep network only after we know how to work around the vanishing gradient problem.
In this tutorial, we visually examine why vanishing gradient problem exists.
After completing this tutorial, you will know
- What is a vanishing gradient
- Which configuration of neural network will be susceptible to vanishing gradient
- How to run manual training loop in Keras
- How to extract weights and gradients from Keras model
Let’s get started

Visualizing the vanishing gradient problem
Photo by Alisa Anton, some rights reserved.
Tutorial overview
This tutorial is divided into 5 parts; they are:
- Configuration of multilayer perceptron models
- Example of vanishing gradient problem
- Looking at the weights of each layer
- Looking at the gradients of each layer
- The Glorot initialization
Configuration of multilayer perceptron models
Because neural networks are trained by gradient descent, people believed that a differentiable function is required to be the activation function in neural networks. This caused us to conventionally use sigmoid function or hyperbolic tangent as activation.
For a binary classification problem, if we want to do logistic regression such that 0 and 1 are the ideal output, sigmoid function is preferred as it is in this range:
$$
\sigma(x) = \frac{1}{1+e^{-x}}
$$
and if we need sigmoidal activation at the output, it is natural to use it in all layers of the neural network. Additionally, each layer in a neural network has a weight parameter. Initially, the weights have to be randomized and naturally we would use some simple way to do it, such as using uniform random or normal distribution.
Example of vanishing gradient problem
To illustrate the problem of vanishing gradient, let’s try with an example. Neural network is a nonlinear function. Hence it should be most suitable for classification of nonlinear dataset. We make use of scikit-learn’s make_circle() function to generate some data:
|
1 2 3 4 5 6 7 8 9 |
from sklearn.datasets import make_circles import matplotlib.pyplot as plt # Make data: Two circles on x-y plane as a classification problem X, y = make_circles(n_samples=1000, factor=0.5, noise=0.1) plt.figure(figsize=(8,6)) plt.scatter(X[:,0], X[:,1], c=y) plt.show() |
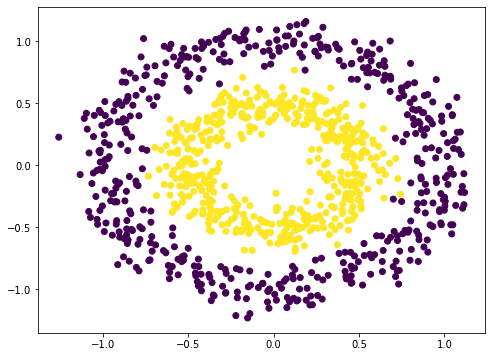
This is not difficult to classify. A naive way is to build a 3-layer neural network, which can give a quite good result:
|
1 2 3 4 5 6 7 8 9 10 11 |
from tensorflow.keras.layers import Dense, Input from tensorflow.keras import Sequential model = Sequential([ Input(shape=(2,)), Dense(5, "relu"), Dense(1, "sigmoid") ]) model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=32, epochs=100, verbose=0) print(model.evaluate(X,y)) |
|
1 2 |
32/32 [==============================] - 0s 1ms/step - loss: 0.2404 - acc: 0.9730 [0.24042171239852905, 0.9729999899864197] |
Note that we used rectified linear unit (ReLU) in the hidden layer above. By default, the dense layer in Keras will be using linear activation (i.e. no activation) which mostly is not useful. We usually use ReLU in modern neural networks. But we can also try the old school way as everyone does two decades ago:
|
1 2 3 4 5 6 7 8 |
model = Sequential([ Input(shape=(2,)), Dense(5, "sigmoid"), Dense(1, "sigmoid") ]) model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=32, epochs=100, verbose=0) print(model.evaluate(X,y)) |
|
1 2 |
32/32 [==============================] - 0s 1ms/step - loss: 0.6927 - acc: 0.6540 [0.6926590800285339, 0.6539999842643738] |
The accuracy is much worse. It turns out, it is even worse by adding more layers (at least in my experiment):
|
1 2 3 4 5 6 7 8 9 10 |
model = Sequential([ Input(shape=(2,)), Dense(5, "sigmoid"), Dense(5, "sigmoid"), Dense(5, "sigmoid"), Dense(1, "sigmoid") ]) model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=32, epochs=100, verbose=0) print(model.evaluate(X,y)) |
|
1 2 |
32/32 [==============================] - 0s 1ms/step - loss: 0.6922 - acc: 0.5330 [0.6921834349632263, 0.5329999923706055] |
Your result may vary given the stochastic nature of the training algorithm. You may see the 5-layer sigmoidal network performing much worse than 3-layer or not. But the idea here is you can’t get back the high accuracy as we can achieve with rectified linear unit activation by merely adding layers.
Looking at the weights of each layer
Shouldn’t we get a more powerful neural network with more layers?
Yes, it should be. But it turns out as we adding more layers, we triggered the vanishing gradient problem. To illustrate what happened, let’s see how are the weights look like as we trained our network.
In Keras, we are allowed to plug-in a callback function to the training process. We are going create our own callback object to intercept and record the weights of each layer of our multilayer perceptron (MLP) model at the end of each epoch.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from tensorflow.keras.callbacks import Callback class WeightCapture(Callback): "Capture the weights of each layer of the model" def __init__(self, model): super().__init__() self.model = model self.weights = [] self.epochs = [] def on_epoch_end(self, epoch, logs=None): self.epochs.append(epoch) # remember the epoch axis weight = {} for layer in model.layers: if not layer.weights: continue name = layer.weights[0].name.split("/")[0] weight[name] = layer.weights[0].numpy() self.weights.append(weight) |
We derive the Callback class and define the on_epoch_end() function. This class will need the created model to initialize. At the end of each epoch, it will read each layer and save the weights into numpy array.
For the convenience of experimenting different ways of creating a MLP, we make a helper function to set up the neural network model:
|
1 2 3 4 5 6 7 8 9 10 11 |
def make_mlp(activation, initializer, name): "Create a model with specified activation and initalizer" model = Sequential([ Input(shape=(2,), name=name+"0"), Dense(5, activation=activation, kernel_initializer=initializer, name=name+"1"), Dense(5, activation=activation, kernel_initializer=initializer, name=name+"2"), Dense(5, activation=activation, kernel_initializer=initializer, name=name+"3"), Dense(5, activation=activation, kernel_initializer=initializer, name=name+"4"), Dense(1, activation="sigmoid", kernel_initializer=initializer, name=name+"5") ]) return model |
We deliberately create a neural network with 4 hidden layers so we can see how each layer respond to the training. We will vary the activation function of each hidden layer as well as the weight initialization. To make things easier to tell, we are going to name each layer instead of letting Keras to assign a name. The input is a coordinate on the xy-plane hence the input shape is a vector of 2. The output is binary classification. Therefore we use sigmoid activation to make the output fall in the range of 0 to 1.
Then we can compile() the model to provide the evaluation metrics and pass on the callback in the fit() call to train the model:
|
1 2 3 4 5 6 7 8 9 |
initializer = RandomNormal(mean=0.0, stddev=1.0) batch_size = 32 n_epochs = 100 model = make_mlp("sigmoid", initializer, "sigmoid") capture_cb = WeightCapture(model) capture_cb.on_epoch_end(-1) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=batch_size, epochs=n_epochs, callbacks=[capture_cb], verbose=1) |
Here we create the neural network by calling make_mlp() first. Then we set up our callback object. Since the weights of each layer in the neural network are initialized at creation, we deliberately call the callback function to remember what they are initialized to. Then we call the compile() and fit() from the model as usual, with the callback object provided.
After we fit the model, we can evaluate it with the entire dataset:
|
1 2 |
... print(model.evaluate(X,y)) |
|
1 |
[0.6649572253227234, 0.5879999995231628] |
Here it means the log-loss is 0.665 and the accuracy is 0.588 for this model of having all layers using sigmoid activation.
What we can further look into is how the weight behaves along the iterations of training. All the layers except the first and the last are having their weight as a 5×5 matrix. We can check the mean and standard deviation of the weights to get a sense of how the weights look like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def plotweight(capture_cb): "Plot the weights' mean and s.d. across epochs" fig, ax = plt.subplots(2, 1, sharex=True, constrained_layout=True, figsize=(8, 10)) ax[0].set_title("Mean weight") for key in capture_cb.weights[0]: ax[0].plot(capture_cb.epochs, [w[key].mean() for w in capture_cb.weights], label=key) ax[0].legend() ax[1].set_title("S.D.") for key in capture_cb.weights[0]: ax[1].plot(capture_cb.epochs, [w[key].std() for w in capture_cb.weights], label=key) ax[1].legend() plt.show() plotweight(capture_cb) |
This results in the following figure: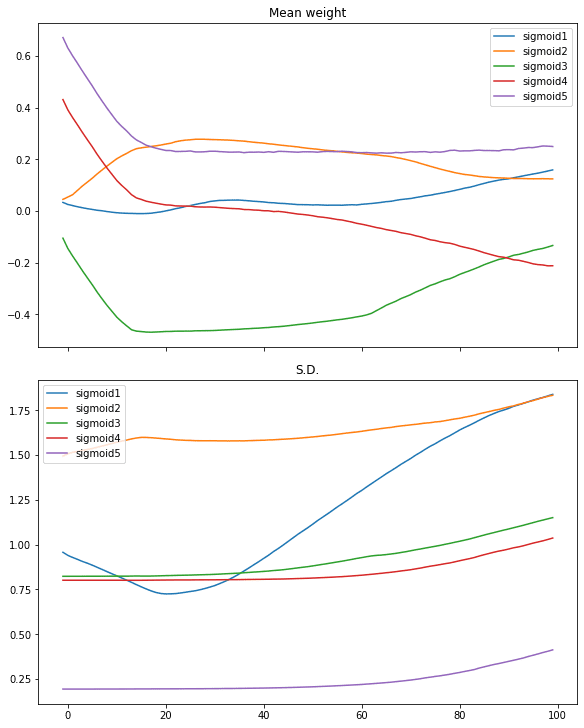
We see the mean weight moved quickly only in first 10 iterations or so. Only the weights of the first layer getting more diversified as its standard deviation is moving up.
We can restart with the hyperbolic tangent (tanh) activation on the same process:
|
1 2 3 4 5 6 7 8 |
# tanh activation, large variance gaussian initialization model = make_mlp("tanh", initializer, "tanh") capture_cb = WeightCapture(model) capture_cb.on_epoch_end(-1) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=batch_size, epochs=n_epochs, callbacks=[capture_cb], verbose=0) print(model.evaluate(X,y)) plotweight(capture_cb) |
|
1 |
[0.012918001972138882, 0.9929999709129333] |
The log-loss and accuracy are both improved. If we look at the plot, we don’t see the abrupt change in the mean and standard deviation in the weights but instead, that of all layers are slowly converged.
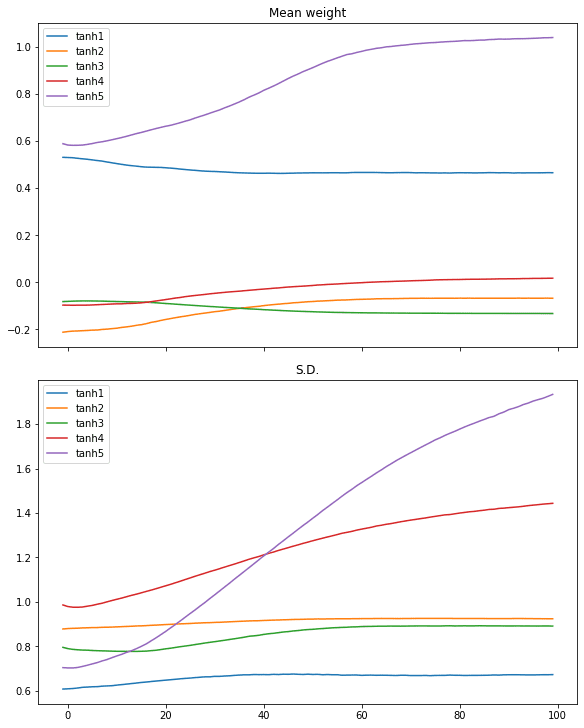
Similar case can be seen in ReLU activation:
|
1 2 3 4 5 6 7 8 |
# relu activation, large variance gaussian initialization model = make_mlp("relu", initializer, "relu") capture_cb = WeightCapture(model) capture_cb.on_epoch_end(-1) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=batch_size, epochs=n_epochs, callbacks=[capture_cb], verbose=0) print(model.evaluate(X,y)) plotweight(capture_cb) |
|
1 |
[0.016895903274416924, 0.9940000176429749] |
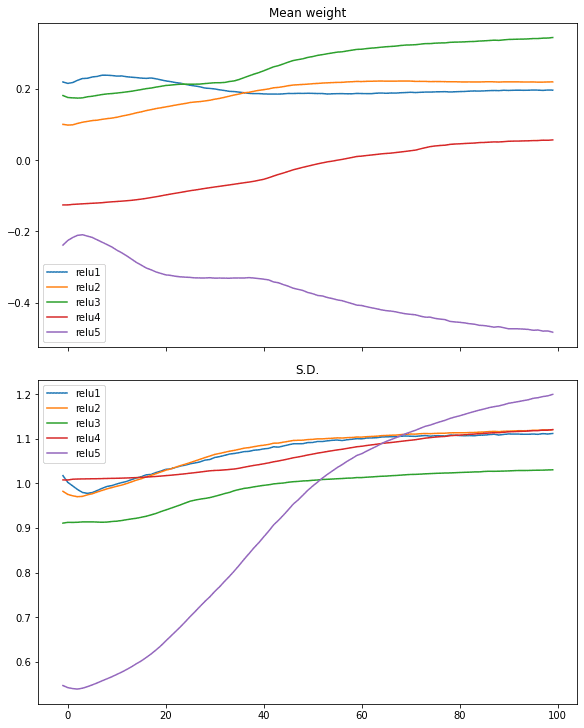
Looking at the gradients of each layer
We see the effect of different activation function in the above. But indeed, what matters is the gradient as we are running gradient decent during training. The paper by Xavier Glorot and Yoshua Bengio, “Understanding the difficulty of training deep feedforward neural networks”, suggested to look at the gradient of each layer in each training iteration as well as the standard deviation of it.
Bradley (2009) found that back-propagated gradients were smaller as one moves from the output layer towards the input layer, just after initialization. He studied networks with linear activation at each layer, finding that the variance of the back-propagated gradients decreases as we go backwards in the network
— “Understanding the difficulty of training deep feedforward neural networks” (2010)
To understand how the activation function related to the gradient as perceived during training, we need to run the training loop manually.
In Tensorflow-Keras, a training loop can be run by turning on the gradient tape, and then make the neural network model produce an output, which afterwards we can obtain the gradient by automatic differentiation from the gradient tape. Subsequently we can update the parameters (weights and biases) according to the gradient descent update rule.
Because the gradient is readily obtained in this loop, we can make a copy of it. The following is how we implement the training loop and at the same time, keep a copy of the gradients:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
optimizer = tf.keras.optimizers.RMSprop() loss_fn = tf.keras.losses.BinaryCrossentropy() def train_model(X, y, model, n_epochs=n_epochs, batch_size=batch_size): "Run training loop manually" train_dataset = tf.data.Dataset.from_tensor_slices((X, y)) train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size) gradhistory = [] losshistory = [] def recordweight(): data = {} for g,w in zip(grads, model.trainable_weights): if '/kernel:' not in w.name: continue # skip bias name = w.name.split("/")[0] data[name] = g.numpy() gradhistory.append(data) losshistory.append(loss_value.numpy()) for epoch in range(n_epochs): for step, (x_batch_train, y_batch_train) in enumerate(train_dataset): with tf.GradientTape() as tape: y_pred = model(x_batch_train, training=True) loss_value = loss_fn(y_batch_train, y_pred) grads = tape.gradient(loss_value, model.trainable_weights) optimizer.apply_gradients(zip(grads, model.trainable_weights)) if step == 0: recordweight() # After all epochs, record again recordweight() return gradhistory, losshistory |
The key in the function above is the nested for-loop. In which, we launch tf.GradientTape() and pass in a batch of data to the model to get a prediction, which is then evaluated using the loss function. Afterwards, we can pull out the gradient from the tape by comparing the loss with the trainable weight from the model. Next, we update the weights using the optimizer, which will handle the learning weights and momentums in the gradient descent algorithm implicitly.
As a refresh, the gradient here means the following. For a loss value $L$ computed and a layer with weights $W=[w_1, w_2, w_3, w_4, w_5]$ (e.g., on the output layer) then the gradient is the matrix
$$
\frac{\partial L}{\partial W} = \Big[\frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2}, \frac{\partial L}{\partial w_3}, \frac{\partial L}{\partial w_4}, \frac{\partial L}{\partial w_5}\Big]
$$
But before we start the next iteration of training, we have a chance to further manipulate the gradient: We match the gradient with the weights, to get the name of each, then save a copy of the gradient as numpy array. We sample the weight and loss only once per epoch, but you can change that to sample in a higher frequency.
With these, we can plot the gradient across epochs. In the following, we create the model (but not calling compile() because we would not call fit() afterwards) and run the manual training loop, then plot the gradient as well as the standard deviation of the gradient:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from sklearn.metrics import accuracy_score def plot_gradient(gradhistory, losshistory): "Plot gradient mean and sd across epochs" fig, ax = plt.subplots(3, 1, sharex=True, constrained_layout=True, figsize=(8, 12)) ax[0].set_title("Mean gradient") for key in gradhistory[0]: ax[0].plot(range(len(gradhistory)), [w[key].mean() for w in gradhistory], label=key) ax[0].legend() ax[1].set_title("S.D.") for key in gradhistory[0]: ax[1].semilogy(range(len(gradhistory)), [w[key].std() for w in gradhistory], label=key) ax[1].legend() ax[2].set_title("Loss") ax[2].plot(range(len(losshistory)), losshistory) plt.show() model = make_mlp("sigmoid", initializer, "sigmoid") print("Before training: Accuracy", accuracy_score(y, (model(X) > 0.5))) gradhistory, losshistory = train_model(X, y, model) print("After training: Accuracy", accuracy_score(y, (model(X) > 0.5))) plot_gradient(gradhistory, losshistory) |
It reported a weak classification result:
|
1 2 |
Before training: Accuracy 0.5 After training: Accuracy 0.652 |
and the plot we obtained shows vanishing gradient:
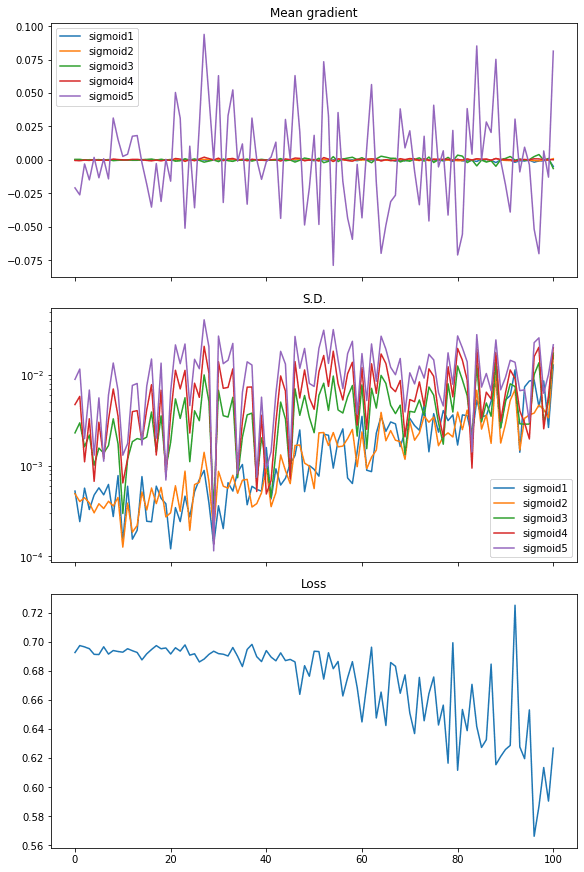
From the plot, the loss is not significantly decreased. The mean of gradient (i.e., mean of all elements in the gradient matrix) has noticeable value only for the last layer while all other layers are virtually zero. The standard deviation of the gradient is at the level of between 0.01 and 0.001 approximately.
Repeat this with tanh activation, we see a different result, which explains why the performance is better:
|
1 2 3 4 5 |
model = make_mlp("tanh", initializer, "tanh") print("Before training: Accuracy", accuracy_score(y, (model(X) > 0.5))) gradhistory, losshistory = train_model(X, y, model) print("After training: Accuracy", accuracy_score(y, (model(X) > 0.5))) plot_gradient(gradhistory, losshistory) |
|
1 2 |
Before training: Accuracy 0.502 After training: Accuracy 0.994 |
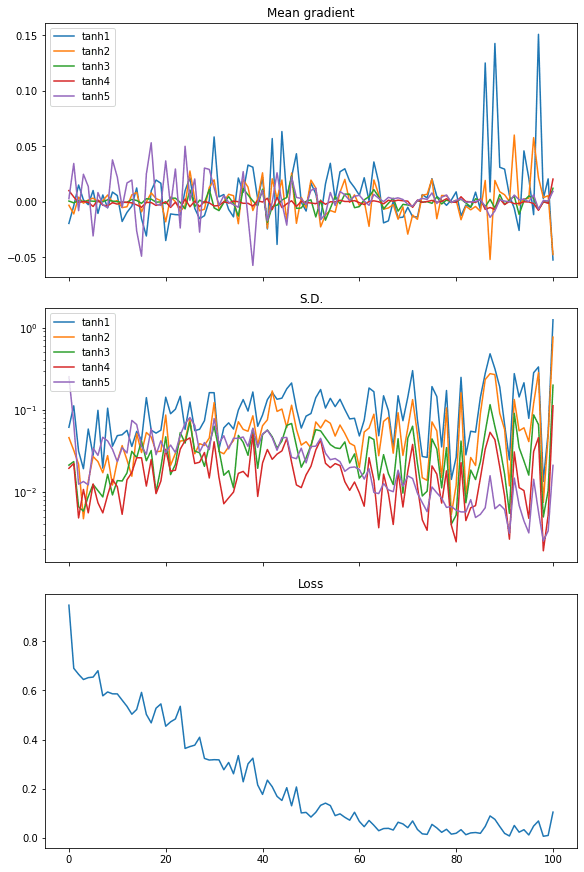
From the plot of the mean of the gradients, we see the gradients from every layer are wiggling equally. The standard deviation of the gradient are also an order of magnitude larger than the case of sigmoid activation, at around 0.1 to 0.01.
Finally, we can also see the similar in rectified linear unit (ReLU) activation. And in this case the loss dropped quickly, hence we see it as the more efficient activation to use in neural networks:
|
1 2 3 4 5 |
model = make_mlp("relu", initializer, "relu") print("Before training: Accuracy", accuracy_score(y, (model(X) > 0.5))) gradhistory, losshistory = train_model(X, y, model) print("After training: Accuracy", accuracy_score(y, (model(X) > 0.5))) plot_gradient(gradhistory, losshistory) |
|
1 2 |
Before training: Accuracy 0.503 After training: Accuracy 0.995 |
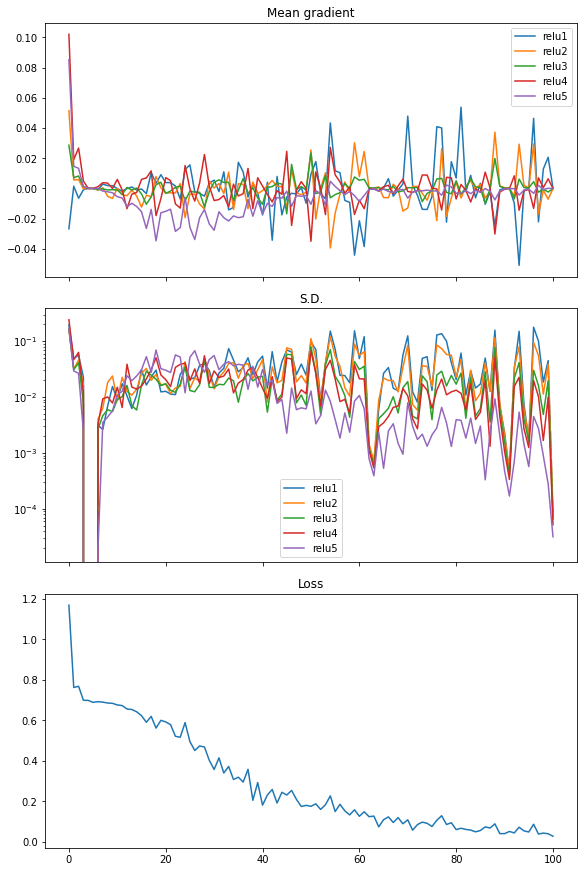
The following is the complete code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 |
import numpy as np import tensorflow as tf from tensorflow.keras.callbacks import Callback from tensorflow.keras.layers import Dense, Input from tensorflow.keras import Sequential from tensorflow.keras.initializers import RandomNormal import matplotlib.pyplot as plt from sklearn.datasets import make_circles from sklearn.metrics import accuracy_score tf.random.set_seed(42) np.random.seed(42) # Make data: Two circles on x-y plane as a classification problem X, y = make_circles(n_samples=1000, factor=0.5, noise=0.1) plt.figure(figsize=(8,6)) plt.scatter(X[:,0], X[:,1], c=y) plt.show() # Test performance with 3-layer binary classification network model = Sequential([ Input(shape=(2,)), Dense(5, "relu"), Dense(1, "sigmoid") ]) model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=32, epochs=100, verbose=0) print(model.evaluate(X,y)) # Test performance with 3-layer network with sigmoid activation model = Sequential([ Input(shape=(2,)), Dense(5, "sigmoid"), Dense(1, "sigmoid") ]) model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=32, epochs=100, verbose=0) print(model.evaluate(X,y)) # Test performance with 5-layer network with sigmoid activation model = Sequential([ Input(shape=(2,)), Dense(5, "sigmoid"), Dense(5, "sigmoid"), Dense(5, "sigmoid"), Dense(1, "sigmoid") ]) model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["acc"]) model.fit(X, y, batch_size=32, epochs=100, verbose=0) print(model.evaluate(X,y)) # Illustrate weights across epochs class WeightCapture(Callback): "Capture the weights of each layer of the model" def __init__(self, model): super().__init__() self.model = model self.weights = [] self.epochs = [] def on_epoch_end(self, epoch, logs=None): self.epochs.append(epoch) # remember the epoch axis weight = {} for layer in model.layers: if not layer.weights: continue name = layer.weights[0].name.split("/")[0] weight[name] = layer.weights[0].numpy() self.weights.append(weight) def make_mlp(activation, initializer, name): "Create a model with specified activation and initalizer" model = Sequential([ Input(shape=(2,), name=name+"0"), Dense(5, activation=activation, kernel_initializer=initializer, name=name+"1"), Dense(5, activation=activation, kernel_initializer=initializer, name=name+"2"), Dense(5, activation=activation, kernel_initializer=initializer, name=name+"3"), Dense(5, activation=activation, kernel_initializer=initializer, name=name+"4"), Dense(1, activation="sigmoid", kernel_initializer=initializer, name=name+"5") ]) return model def plotweight(capture_cb): "Plot the weights' mean and s.d. across epochs" fig, ax = plt.subplots(2, 1, sharex=True, constrained_layout=True, figsize=(8, 10)) ax[0].set_title("Mean weight") for key in capture_cb.weights[0]: ax[0].plot(capture_cb.epochs, [w[key].mean() for w in capture_cb.weights], label=key) ax[0].legend() ax[1].set_title("S.D.") for key in capture_cb.weights[0]: ax[1].plot(capture_cb.epochs, [w[key].std() for w in capture_cb.weights], label=key) ax[1].legend() plt.show() initializer = RandomNormal(mean=0, stddev=1) batch_size = 32 n_epochs = 100 # Sigmoid activation model = make_mlp("sigmoid", initializer, "sigmoid") capture_cb = WeightCapture(model) capture_cb.on_epoch_end(-1) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["acc"]) print("Before training: Accuracy", accuracy_score(y, (model(X).numpy() > 0.5).astype(int))) model.fit(X, y, batch_size=batch_size, epochs=n_epochs, callbacks=[capture_cb], verbose=0) print("After training: Accuracy", accuracy_score(y, (model(X).numpy() > 0.5).astype(int))) print(model.evaluate(X,y)) plotweight(capture_cb) # tanh activation model = make_mlp("tanh", initializer, "tanh") capture_cb = WeightCapture(model) capture_cb.on_epoch_end(-1) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["acc"]) print("Before training: Accuracy", accuracy_score(y, (model(X).numpy() > 0.5).astype(int))) model.fit(X, y, batch_size=batch_size, epochs=n_epochs, callbacks=[capture_cb], verbose=0) print("After training: Accuracy", accuracy_score(y, (model(X).numpy() > 0.5).astype(int))) print(model.evaluate(X,y)) plotweight(capture_cb) # relu activation model = make_mlp("relu", initializer, "relu") capture_cb = WeightCapture(model) capture_cb.on_epoch_end(-1) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["acc"]) print("Before training: Accuracy", accuracy_score(y, (model(X).numpy() > 0.5).astype(int))) model.fit(X, y, batch_size=batch_size, epochs=n_epochs, callbacks=[capture_cb], verbose=0) print("After training: Accuracy", accuracy_score(y, (model(X).numpy() > 0.5).astype(int))) print(model.evaluate(X,y)) plotweight(capture_cb) # Show gradient across epochs optimizer = tf.keras.optimizers.RMSprop() loss_fn = tf.keras.losses.BinaryCrossentropy() def train_model(X, y, model, n_epochs=n_epochs, batch_size=batch_size): "Run training loop manually" train_dataset = tf.data.Dataset.from_tensor_slices((X, y)) train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size) gradhistory = [] losshistory = [] def recordweight(): data = {} for g,w in zip(grads, model.trainable_weights): if '/kernel:' not in w.name: continue # skip bias name = w.name.split("/")[0] data[name] = g.numpy() gradhistory.append(data) losshistory.append(loss_value.numpy()) for epoch in range(n_epochs): for step, (x_batch_train, y_batch_train) in enumerate(train_dataset): with tf.GradientTape() as tape: y_pred = model(x_batch_train, training=True) loss_value = loss_fn(y_batch_train, y_pred) grads = tape.gradient(loss_value, model.trainable_weights) optimizer.apply_gradients(zip(grads, model.trainable_weights)) if step == 0: recordweight() # After all epochs, record again recordweight() return gradhistory, losshistory def plot_gradient(gradhistory, losshistory): "Plot gradient mean and sd across epochs" fig, ax = plt.subplots(3, 1, sharex=True, constrained_layout=True, figsize=(8, 12)) ax[0].set_title("Mean gradient") for key in gradhistory[0]: ax[0].plot(range(len(gradhistory)), [w[key].mean() for w in gradhistory], label=key) ax[0].legend() ax[1].set_title("S.D.") for key in gradhistory[0]: ax[1].semilogy(range(len(gradhistory)), [w[key].std() for w in gradhistory], label=key) ax[1].legend() ax[2].set_title("Loss") ax[2].plot(range(len(losshistory)), losshistory) plt.show() model = make_mlp("sigmoid", initializer, "sigmoid") print("Before training: Accuracy", accuracy_score(y, (model(X) > 0.5))) gradhistory, losshistory = train_model(X, y, model) print("After training: Accuracy", accuracy_score(y, (model(X) > 0.5))) plot_gradient(gradhistory, losshistory) model = make_mlp("tanh", initializer, "tanh") print("Before training: Accuracy", accuracy_score(y, (model(X) > 0.5))) gradhistory, losshistory = train_model(X, y, model) print("After training: Accuracy", accuracy_score(y, (model(X) > 0.5))) plot_gradient(gradhistory, losshistory) model = make_mlp("relu", initializer, "relu") print("Before training: Accuracy", accuracy_score(y, (model(X) > 0.5))) gradhistory, losshistory = train_model(X, y, model) print("After training: Accuracy", accuracy_score(y, (model(X) > 0.5))) plot_gradient(gradhistory, losshistory) |
The Glorot initialization
We didn’t demonstrate in the code above, but the most famous outcome from the paper by Glorot and Bengio is the Glorot initialization. Which suggests to initialize the weights of a layer of the neural network with uniform distribution:
The normalization factor may therefore be important when initializing deep networks because of the multiplicative effect through layers, and we suggest the following initialization procedure to approximately satisfy our objectives of maintaining activation variances and back-propagated gradients variance as one moves up or down the network. We call it the normalized initialization:
$$
W \sim U\Big[-\frac{\sqrt{6}}{\sqrt{n_j+n_{j+1}}}, \frac{\sqrt{6}}{\sqrt{n_j+n_{j+1}}}\Big]
$$
— “Understanding the difficulty of training deep feedforward neural networks” (2010)
This is derived from the linear activation on the condition that the standard deviation of the gradient is keeping consistent across the layers. In the sigmoid and tanh activation, the linear region is narrow. Therefore we can understand why ReLU is the key to workaround the vanishing gradient problem. Comparing to replacing the activation function, changing the weight initialization is less pronounced in helping to resolve the vanishing gradient problem. But this can be an exercise for you to explore to see how this can help improving the result.
Further readings
The Glorot and Bengio paper is available at:
- “Understanding the difficulty of training deep feedforward neural networks”, by Xavier Glorot and Yoshua Bengio, 2010.
(https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf)
The vanishing gradient problem is well known enough in machine learning that many books covered it. For example,
- Deep Learning, by Ian Goodfellow, Yoshua Bengio, and Aaron Courville, 2016.
(https://www.amazon.com/dp/0262035618)
Previously we have posts about vanishing and exploding gradients:
- How to fix vanishing gradients using the rectified linear activation function
- Exploding gradients in neural networks
You may also find the following documentation helpful to explain some syntax we used above:
- Writings a training loop from scratch in Keras: https://keras.io/guides/writing_a_training_loop_from_scratch/
- Writing your own callbacks in Keras: https://keras.io/guides/writing_your_own_callbacks/
Summary
In this tutorial, you visually saw how a rectified linear unit (ReLU) can help resolving the vanishing gradient problem.
Specifically, you learned:
- How the problem of vanishing gradient impact the performance of a neural network
- Why ReLU activation is the solution to vanishing gradient problem
- How to use a custom callback to extract data in the middle of training loop in Keras
- How to write a custom training loop
- How to read the weight and gradient from a layer in the neural network
Develop Better Deep Learning Models Today!

Train Faster, Reduce Overftting, and Ensembles
...with just a few lines of python code
Discover how in my new Ebook:
Better Deep Learning
It provides self-study tutorials on topics like:
weight decay, batch normalization, dropout, model stacking and much more...
Bring better deep learning to your projects!
Skip the Academics. Just Results.






Dr. Tam,
This was another outstanding article! I am finishing my MS in Applied Mathematics in a few weeks and while we have attacked vanishing gradients (in a couple of courses) in great mathematical detail, we never did a graphical analysis of the problem. Your work here really drove home the point and I appreciate it! Hope to see a book from you one day that gathers all of your hard-earned knowledge in one place.
Thanks for the appreciation. Glad you liked it.
This was a very great article! I just wanted to ask how I should get back into coding AI, it’s been about a year (due to many reasons) and I now barely have time as I am studying Mechanical Engineering (although we haven’t gotten to ML yet – In Matlab).
Do you have any fast-track courses? I don’t want to do fast.ai again, it took me way too much time to complete.
I think the closest match are the mini-course series on this blog.
I mean, for example the gradients that you show in this tutorial in the example with Relu activation, except for Relu5, the other layers seems to be similar averages in the first epochs (maybe not the first) and in the last epochs.
Hi Adrian,
Thank you so much for writing this article. This and other articles on this website have been extremely helpful to me. I have two questions regarding this article.
1) Why haven’t you used mean of the absolute value of gradients to determine vanishing gradients? For example, if you have two neurons in a layer, and one changes by -0.25 and the other by 0.25, taking the mean of this gives 0, although the gradients are not vanishing.
2) As the training progresses, do we expect the mean of absolute value of gradients to reduce to zero or close to zero (indicating that the weights are not going to change anymore)?
Hi Mohit…Perhaps the following may add clarity.
https://www.analyticsvidhya.com/blog/2021/06/the-challenge-of-vanishing-exploding-gradients-in-deep-neural-networks/
Great article! Thanks a lot.
There is one thing that is hard to understand for me. Why the gradients have similar averages on each epoch? As I understand the gradients will be larges at the beginning of the training and as the parameters improve the gradients will be each time closer to zero. That is something that I always have seen but never understood.
Thanks again for this website
Hi Guillermo…How does your final gradient value compare to the first one?
I replied in another thread, sorry. I mean, for example the gradients that you show in this tutorial in the example with Relu activation, except for Relu5, the other layers seems to be similar averages in the first epochs (maybe not the first) and in the last epochs.
Amazing explanation and very helpful.
Thank you Anuj! We greatly appreciate your feedback and support!
I tried running the sample code and had following errors. Love this site many great explanations. I will try to fix the errors in time but wanted to share ran on Google Colab.
KeyError Traceback (most recent call last)
in
189 model = make_mlp(“tanh”, initializer, “tanh”)
190 print(“Before training: Accuracy”, accuracy_score(y, (model(X) > 0.5)))
–> 191 gradhistory, losshistory = train_model(X, y, model)
192 print(“After training: Accuracy”, accuracy_score(y, (model(X) > 0.5)))
193 plot_gradient(gradhistory, losshistory)
11 frames
in train_model(X, y, model, n_epochs, batch_size)
158
159 grads = tape.gradient(loss_value, model.trainable_weights)
–> 160 optimizer.apply_gradients(zip(grads, model.trainable_weights))
161
162 if step == 0:
/usr/local/lib/python3.9/dist-packages/keras/optimizers/optimizer_experimental/optimizer.py in apply_gradients(self, grads_and_vars, name, skip_gradients_aggregation, **kwargs)
1138 if not skip_gradients_aggregation and experimental_aggregate_gradients:
1139 grads_and_vars = self.aggregate_gradients(grads_and_vars)
-> 1140 return super().apply_gradients(grads_and_vars, name=name)
1141
1142 def _apply_weight_decay(self, variables):
/usr/local/lib/python3.9/dist-packages/keras/optimizers/optimizer_experimental/optimizer.py in apply_gradients(self, grads_and_vars, name)
632 self._apply_weight_decay(trainable_variables)
633 grads_and_vars = list(zip(grads, trainable_variables))
–> 634 iteration = self._internal_apply_gradients(grads_and_vars)
635
636 # Apply variable constraints after applying gradients.
/usr/local/lib/python3.9/dist-packages/keras/optimizers/optimizer_experimental/optimizer.py in _internal_apply_gradients(self, grads_and_vars)
1164
1165 def _internal_apply_gradients(self, grads_and_vars):
-> 1166 return tf.__internal__.distribute.interim.maybe_merge_call(
1167 self._distributed_apply_gradients_fn,
1168 self._distribution_strategy,
/usr/local/lib/python3.9/dist-packages/tensorflow/python/distribute/merge_call_interim.py in maybe_merge_call(fn, strategy, *args, **kwargs)
49 “””
50 if strategy_supports_no_merge_call():
—> 51 return fn(strategy, *args, **kwargs)
52 else:
53 return distribution_strategy_context.get_replica_context().merge_call(
/usr/local/lib/python3.9/dist-packages/keras/optimizers/optimizer_experimental/optimizer.py in _distributed_apply_gradients_fn(self, distribution, grads_and_vars, **kwargs)
1214
1215 for grad, var in grads_and_vars:
-> 1216 distribution.extended.update(
1217 var, apply_grad_to_update_var, args=(grad,), group=False
1218 )
/usr/local/lib/python3.9/dist-packages/tensorflow/python/distribute/distribute_lib.py in update(self, var, fn, args, kwargs, group)
2635 fn, autograph_ctx.control_status_ctx(), convert_by_default=False)
2636 with self._container_strategy().scope():
-> 2637 return self._update(var, fn, args, kwargs, group)
2638 else:
2639 return self._replica_ctx_update(
/usr/local/lib/python3.9/dist-packages/tensorflow/python/distribute/distribute_lib.py in _update(self, var, fn, args, kwargs, group)
3708 # The implementations of _update() and _update_non_slot() are identical
3709 # except _update() passes
varas the first argument tofn().-> 3710 return self._update_non_slot(var, fn, (var,) + tuple(args), kwargs, group)
3711
3712 def _update_non_slot(self, colocate_with, fn, args, kwargs, should_group):
/usr/local/lib/python3.9/dist-packages/tensorflow/python/distribute/distribute_lib.py in _update_non_slot(self, colocate_with, fn, args, kwargs, should_group)
3714 # once that value is used for something.
3715 with UpdateContext(colocate_with):
-> 3716 result = fn(*args, **kwargs)
3717 if should_group:
3718 return result
/usr/local/lib/python3.9/dist-packages/tensorflow/python/autograph/impl/api.py in wrapper(*args, **kwargs)
593 def wrapper(*args, **kwargs):
594 with ag_ctx.ControlStatusCtx(status=ag_ctx.Status.UNSPECIFIED):
–> 595 return func(*args, **kwargs)
596
597 if inspect.isfunction(func) or inspect.ismethod(func):
/usr/local/lib/python3.9/dist-packages/keras/optimizers/optimizer_experimental/optimizer.py in apply_grad_to_update_var(var, grad)
1211 return self._update_step_xla(grad, var, id(self._var_key(var)))
1212 else:
-> 1213 return self._update_step(grad, var)
1214
1215 for grad, var in grads_and_vars:
/usr/local/lib/python3.9/dist-packages/keras/optimizers/optimizer_experimental/optimizer.py in _update_step(self, gradient, variable)
214 return
215 if self._var_key(variable) not in self._index_dict:
–> 216 raise KeyError(
217 f”The optimizer cannot recognize variable {variable.name}. ”
218 “This usually means you are trying to call the optimizer to ”
KeyError: ‘The optimizer cannot recognize variable tanh1/kernel:0. This usually means you are trying to call the optimizer to update different parts of the model separately. Please call
optimizer.build(variables)with the full list of trainable variables before the training loop or use legacy optimizer `tf.keras.optimizers.legacy.{self.__class__.__name__}.’Hi Jason…Please clarify whether you typed the code in or copied and pasted it? Also, you may want to try it in Google Colab.
Great analysis on the vanishing gradient problem. Appreciated. 🙂
By the way, I had the same coding error as well, and I pasted the code in.