Convolutional neural networks have their roots in image processing. It was first published in LeNet to recognize the MNIST handwritten digits. However, convolutional neural networks are not limited to handling images.
In this tutorial, we are going to look at an example of using CNN for time series prediction with an application from financial markets. By way of this example, we are going to explore some techniques in using Keras for model training as well.
After completing this tutorial, you will know
What a typical multidimensional financial data series looks like?
How can CNN applied to time series in a classification problem
How to use generators to feed data to train a Keras model
How to provide a custom metric for evaluating a Keras model
Let’s get started
Using CNN for financial time series prediction Photo by Aron Visuals, some rights reserved.
Tutorial overview
This tutorial is divided into 7 parts; they are:
Background of the idea
Preprocessing of data
Data generator
The model
Training, validation, and test
Extensions
Does it work?
Background of the idea
In this tutorial we are following the paper titled “CNNpred: CNN-based stock market prediction using a iverse set of variables” by Ehsan Hoseinzade and Saman Haratizadeh. The data file and sample code from the author are available in github:
The goal of the paper is simple: To predict the next day’s direction of the stock market (i.e., up or down compared to today), hence it is a binary classification problem. However, it is interesting to see how this problem are formulated and solved.
We have seen the examples on using CNN for sequence prediction. If we consider Dow Jones Industrial Average (DJIA) as an example, we may build a CNN with 1D convolution for prediction. This makes sense because a 1D convolution on a time series is roughly computing its moving average or using digital signal processing terms, applying a filter to the time series. It should provide some clues about the trend.
However, when we look at financial time series, it is quite a common sense that some derived signals are useful for predictions too. For example, price and volume together can provide a better clue. Also some other technical indicators such as the moving average of different window size are useful too. If we put all these align together, we will have a table of data, which each time instance has multiple features, and the goal is still to predict the direction of one time series.
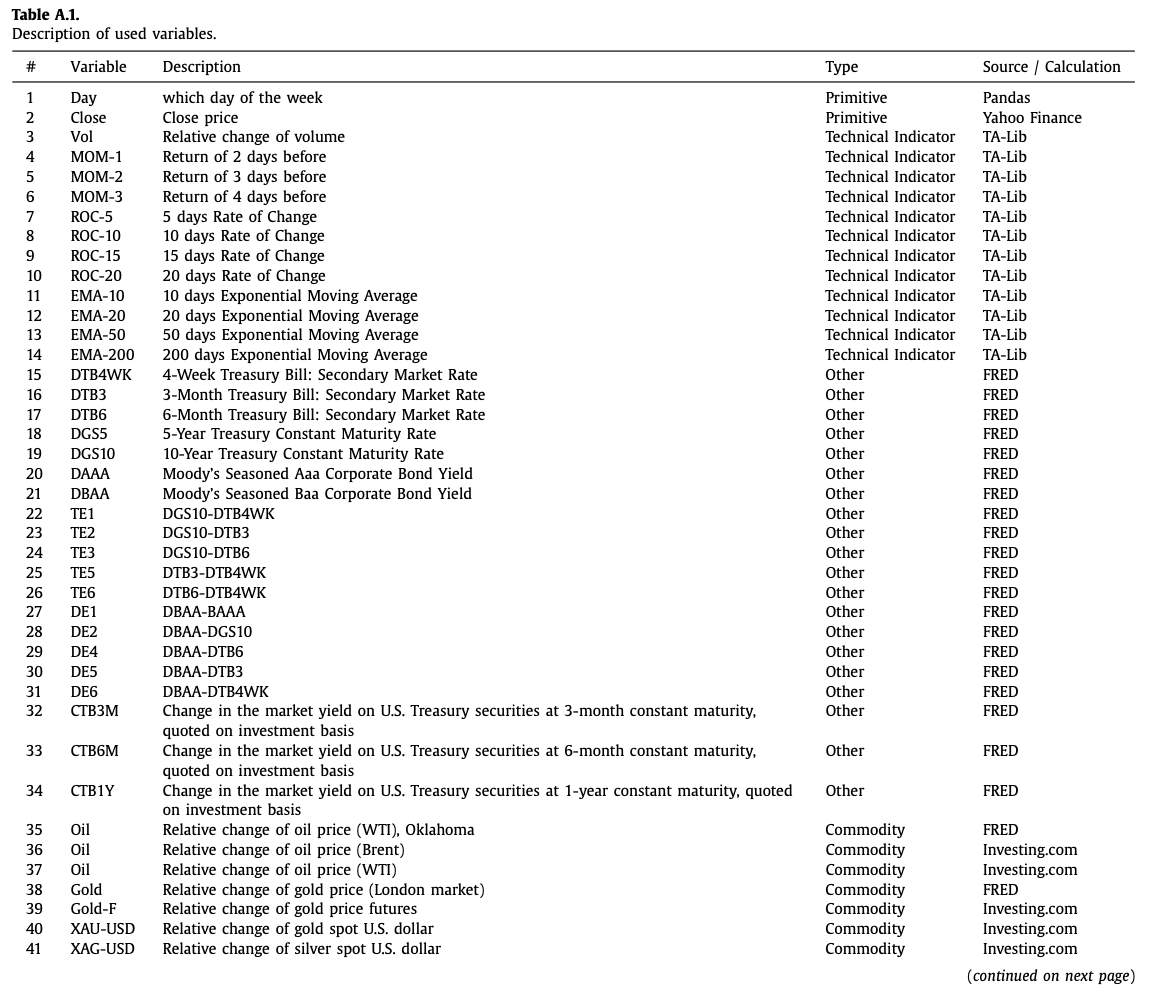
In the CNNpred paper, 82 such features are prepared for the DJIA time series:
Excerpt from the CNNpred paper showing the list of features used.
Unlike LSTM, which there is an explicit concept of time steps applied, we present data as a matrix in CNN models. As shown in the table below, the features across multiple time steps are presented as a 2D array.
Preprocessing of data
In the following, we try to implement the idea of the CNNpred from scratch using Tensorflow’s keras API. While there is a reference implementation from the author in the github link above, we reimplement it differently to illustrate some Keras techniques.
Firstly the data are five CSV files, each for a different market index, under the Dataset directory from github repository above, or we can also get a copy here:
The input data has a date column and a name column to identify the ticker symbol for the market index. We can leave the date column as time index and remove the name column. The rest are all numerical.
As we are going to predict the market direction, we first try to create the classification label. The market direction is defined as the closing index of tomorrow compared to today. If we have read the data into a pandas DataFrame, we can use X["Close"].pct_change() to find the percentage change, which a positive change for the market goes up. So we can shift this to one time step back as our label:
The line of code above is to compute the percentage change of the closing index and align the data with the previous day. Then convert the data into either 1 or 0 for whether the percentage change is positive.
For five data file in the directory, we read each of them as a separate pandas DataFrame and keep them in a Python dictionary:
# Fit the standard scaler using the training dataset
index=X.index[X.index>TRAIN_TEST_CUTOFF]
index=index[:int(len(index)*TRAIN_VALID_RATIO)]
scaler=StandardScaler().fit(X.loc[index,cols])
# Save scale transformed dataframe
X[cols]=scaler.transform(X[cols])
data[name]=X
The result of the above code is a DataFrame for each index, which the classification label is the column “Target” while all other columns are input features. We also normalize the data with a standard scaler.
In time series problems, it is generally reasonable not to split the data into training and test sets randomly, but to set up a cutoff point in which the data before the cutoff is training set while that afterwards is the test set. The scaling above are based on the training set but applied to the entire dataset.
Data generator
We are not going to use all time steps at once, but instead, we use a fixed length of N time steps to predict the market direction at step N+1. In this design, the window of N time steps can start from anywhere. We can just create a large number of DataFrames with large amount of overlaps with one another. To save memory, we are going to build a data generator for training and validation, as follows:
Generator is a special function in Python that does not return a value but to yield in iterations, such that a sequence of data are produced from it. For a generator to be used in Keras training, it is expected to yield a batch of input data and target. This generator supposed to run indefinitely. Hence the generator function above is created with an infinite loop starts with while True.
In each iteration, it randomly pick one DataFrame from the Python dictionary, then within the range of time steps of the training set (i.e., the beginning portion), we start from a random point and take N time steps using the pandas iloc[start:end] syntax to create a input under the variable frame. This DataFrame will be a 2D array. The target label is that of the last time step. The input data and the label are then appended to the list batch. Until we accumulated for one batch’s size, we dispatch it from the generator.
The last four lines at the code snippet above is to dispatch a batch for training or validation. We collect the list of input data (each a 2D array) as well as a list of target label into variables X and y, then convert them into numpy array so it can work with our Keras model. We need to add one more dimension to the numpy array X using np.expand_dims() because of the design of the network model, as explained below.
The Model
The 2D CNN model presented in the original paper accepts an input tensor of shape $N\times m \times 1$ for N the number of time steps and m the number of features in each time step. The paper assumes $N=60$ and $m=82$.
The model comprises of three convolutional layers, as described as follows:
The first convolutional layer has 8 units, and is applied across all features in each time step. It is followed by a second convolutional layer to consider three consecutive days at once, for it is a common belief that three days can make a trend in the stock market. It is then applied to a max pooling layer and another convolutional layer before it is flattened into a one-dimensional array and applied to a fully-connected layer with sigmoid activation for binary classification.
Training, validation, and test
That’s it for the model. The paper used MAE as the loss metric and also monitor for accuracy and F1 score to determine the quality of the model. We should point out that F1 score depends on precision and recall ratios, which are both considering the positive classification. The paper, however, consider the average of the F1 from positive and negative classification. Explicitly, it is the F1-macro metric:
$$
F_1 = \frac{1}{2}\left(
\frac{2\cdot \frac{TP}{TP+FP} \cdot \frac{TP}{TP+FN}}{\frac{TP}{TP+FP} + \frac{TP}{TP+FN}}
+
\frac{2\cdot \frac{TN}{TN+FN} \cdot \frac{TN}{TN+FP}}{\frac{TN}{TN+FN} + \frac{TN}{TN+FP}}
\right)
$$
The fraction $\frac{TP}{TP+FP}$ is the precision with TP and FP the number of true positive and false positive. Similarly $\frac{TP}{TP+FN}$ is the recall. The first term in the big parenthesis above is the normal F1 metric that considered positive classifications. And the second term is the reverse, which considered the negative classifications.
While this metric is available in scikit-learn as sklearn.metrics.f1_score() there is no equivalent in Keras. Hence we would create our own by borrowing code from this stackexchange question:
The training process can take hours to complete. Hence we want to save the model in the middle of the training so that we may interrupt and resume it. We can make use of checkpoint features in Keras:
We set up a filename template checkpoint_path and ask Keras to fill in the epoch number as well as validation F1 score into the filename. We save it by monitoring the validation’s F1 metric, and this metric is supposed to increase when the model gets better. Hence we pass in the mode="max" to it.
It should now be trivial to train our model, as follows:
Two points to note in the above snippets. We supplied "acc" as the accuracy as well as the function f1macro defined above as the metrics parameter to the compile() function. Hence these two metrics will be monitored during training. Because the function is named f1macro, we refer to this metric in the checkpoint’s monitor parameter as val_f1macro.
Separately, in the fit() function, we provided the input data through the datagen() generator as defined above. Calling this function will produce a generator, which during the training loop, batches are fetched from it one after another. Similarly, validation data are also provided by the generator.
Because the nature of a generator is to dispatch data indefinitely. We need to tell the training process on how to define a epoch. Recall that in Keras terms, a batch is one iteration of doing gradient descent update. An epoch is supposed to be one cycle through all data in the dataset. At the end of an epoch is the time to run validation. It is also the opportunity for running the checkpoint we defined above. As Keras has no way to infer the size of the dataset from a generator, we need to tell how many batch it should process in one epoch using the steps_per_epoch parameter. Similarly, it is the validation_steps parameter to tell how many batch are used in each validation step. The validation does not affect the training, but it will report to us the metrics we are interested. Below is a screenshot of what we will see in the middle of training, which we will see that the metric for training set are updated on each batch but that for validation set is provided only at the end of epoch:
After the model finished training, we can test it with unseen data, i.e., the test set. Instead of generating the test set randomly, we create it from the dataset in a deterministic way:
The structure of the function testgen() is resembling that of datagen() we defined above. Except in datagen() the output data’s first dimension is the number of samples in a batch but in testgen() is the the entire test samples.
Using the model for prediction will produce a floating point between 0 and 1 as we are using the sigmoid activation function. We will convert this into 0 or 1 by using the threshold at 0.5. Then we use the functions from scikit-learn to compute the accuracy, mean absolute error and F1 score (which accuracy is just one minus the MAE).
Tying all these together, the complete code is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
import os
import random
import numpy asnp
import pandas aspd
import tensorflow astf
from tensorflow.keras import backend asK
from tensorflow.keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPool2D,Input
from tensorflow.keras.models import Sequential,load_model
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score,f1_score,mean_absolute_error
The original paper called the above model “2D-CNNpred” and there is a version called “3D-CNNpred”. The idea is not only consider the many features of one stock market index but cross compare with many market indices to help prediction on one index. Refer to the table of features and time steps above, the data for one market index is presented as 2D array. If we stack up multiple such data from different indices, we constructed a 3D array. While the target label is the same, but allowing us to look at a different market may provide some additional information to help prediction.
Because the shape of the data changed, the convolutional network also defined slightly different, and the data generators need some modification accordingly as well. Below is the complete code of the 3D version, which the change from the previous 2d version should be self-explanatory:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
import os
import random
import numpy asnp
import pandas aspd
import tensorflow astf
from tensorflow.keras import backend asK
from tensorflow.keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPool2D,Input
from tensorflow.keras.models import Sequential,load_model
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score,f1_score,mean_absolute_error
While the model above is for next-step prediction, it does not stop you from making prediction for k steps ahead if you replace the target label to a different calculation. This may be an exercise for you.
Does it work?
As in all prediction projects in the financial market, it is always unrealistic to expect a high accuracy. The training parameter in the code above can produce slightly more than 50% accuracy in the testing set. While the number of epochs and batch size are deliberately set smaller to save time, there should not be much room for improvement.
In the original paper, it is reported that the 3D-CNNpred performed better than 2D-CNNpred but only attaining the F1 score of less than 0.6. This is already doing better than three baseline models mentioned in the paper. It may be of some use, but not a magic that can help you make money quick.
From machine learning technique perspective, here we classify a panel of data into whether the market direction is up or down the next day. Hence while the data is not an image, it resembles one since both are presented in the form of a 2D array. The technique of convolutional layers can therefore applied, but we may use a different filter size to match the intuition we usually have for financial time series.
Further readings
The original paper is available at:
“CNNPred: CNN-based stock market prediction using several data sources”, by Ehsan Hoseinzade, Saman Haratizadeh, 2019.
(https://arxiv.org/abs/1810.08923)
If you are new to finance application and want to build the connection between machine learning techniques and finance, you may find this book useful:
Machine Learning in Finance: From Theory to Practice, by Matthew F. Dixon, Igor Halperin, and Paul Bilokon. 2000.
(https://www.amazon.com/dp/3030410676/)
On the similar topic, we have a previous post on using CNN for time series, but using 1D convolutional layers;
Now facing new problem, in def datagen() at nest loop while true
has the problem on the following:
if n-seq_len+1 &; 0:
while True:
# Pick one position, then clip a sequence length
while True:
t = random.choice(index)
n = (data.index == t).argmax()
if n-seq_len+1 &; 0: # ****error said invalid syntax
continue # this sample is not enough for one sequence length
frame = data.iloc[n-seq_len+1:n+1][input_cols]
# convert frame with two l
Now facing new problem, in def datagen() at nest loop while true
has the problem on the following:
if n-seq_len+1 < 0:
while True:
# Pick one position, then clip a sequence length
while True:
t = random.choice(index)
n = (data.index == t).argmax()
#index = data.index[data.index < TRAIN_TEST_CUTOFF] , the line below has the problem
if n-seq_len+1 < 0:
continue # this sample is not enough for one sequence length
frame = data.iloc[n-seq_len+1:n+1][input_cols]
# convert frame with two level of indices into 3D array
shape = (len(tickers), len(frame), n_features)
X = np.full(shape, np.nan)
for i,ticker in enumerate(tickers):
at def datagen() still has problem on the following;
if n-seq_len+1 < 0: # Error line , say “invalid syntax”
< doing what ? I do not understand and it made error also.
_________
while True:
# Pick one position, then clip a sequence length
while True:
t = random.choice(index)
n = (data.index == t).argmax()
#index = data.index[data.index < TRAIN_TEST_CUTOFF] , the line below has the problem
if n-seq_len+1 < 0: # Error line , say "invalid syntax"
continue # this sample is not enough for one sequence length
frame = data.iloc[n-seq_len+1:n+1][input_cols]
# convert frame with two level of indices into 3D array
shape = (len(tickers), len(frame), n_features)
Sorry for all these hassles. Something wrong with the plugin for rendering the code here caused all the mess. I fixed it for now, so please copy over the code and try again.
I would say yes but the best way to test this (in Keras) is to build such layers into a model and run “model.summary()” to observe the output. Are the output shape the same?
My work is to develop a model for multioutput prediction (i.e., predicting five outputs by a single model). When I applied Kbest and recursive feature elimination methods to select the best features, I got an error ‘ bad input shape (x, 5)’ (5 is output vectors here). However, PCA works well as it doesn’t depend upon the output vector.
Does it mean that we can apply these feature selection algorithms (Kbest and RFE) only for a single output prediction problem?
I think there is too much information in the csv file. Instead of looking too much data and try to make a fundamental analysis it can also be tried to find a ‘pattern’. With pattern I mean looking only to the open price, close price, max price and min price information of each candlestick.
For example:
Let’s consider the candlestick chart of D1 (1 candlestick = 1 day info). Objective: predict the fifth candlestick (up or down) with the info of the 4 formed before. The less quantity of candlestick the easier a pattern can be found
I will try modifying the input data with this model and let you know the results
Many thanks for your tutorial, which is very helpful.
Can you please let me know how to write a data generator to read all different classes of .txt files (likes the function of “datagen.flow_from_directory” which read all different classes of image files)?
I was trying to run your codes a couple of times but there are certain instability issues happened. Sometimes the prediction rate is about 51%, which is good result, but there are also times the prediction rate will go down to 48%. My guess is that this is related to the initialization step. Do you have any insights on this issue?
Thanks for your suggestion! I do consider the multi-restart idea and similarly using ensemble of results. But I didn’t have any luck for that yet either.
Do you think for a larger dataset this issue will be alleviated?
Hello, Can you tell me what the following lines of code do? They are:
name = X[“Name”][0]
del X[“Name”]
cols = X.columns
X[“Target”] = (X[“Close”].pct_change().shift(-1) > 0).astype(int)
X.dropna(inplace=True)
Since I get a bug here on google colab that return the error :
KeyError : “name”
This only happen when I use my own .csv data files. When I ran the codes using your dataset .csv files, I did not encounter any problem though. My csv files only have 7 columns : Date,Close,Open, HIgh, Low, Vol, Change %.
From what I understood, you are trying to drop the other columns but the Date and Close columns, right?
Thanks in advance!
Thanks for replying, James! I thought my response was not approved,hence the late reply 4 months later, I’m so sorry.There was another error about Integer data type since originally the Vol column had a word “k” as substitute for “thousand”, that can be easily fixed by Find/Replace function of Excel to uniform the data into integer numbers. Other than that, the “Name” error still persists, here is the full error message:
KeyError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3801 try:
-> 3802 return self._engine.get_loc(casted_key)
3803 except KeyError as err:
4 frames
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ‘Name’
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3802 return self._engine.get_loc(casted_key)
3803 except KeyError as err:
-> 3804 raise KeyError(key) from err
3805 except TypeError:
3806 # If we have a listlike key, _check_indexing_error will raise
I am confused with the below code and would like to seek some clarification:
while True:
t = random.choice(index) # pick one time step
Won’t this line of code, always pick up from an index randomly, thus breaking sequence of time series data. As I understand in time series problems, the sequence of time series should be preserved?
What am I missing here? Can you please help me understand this better?
File ~/anaconda3/lib/python3.11/site-packages/keras/src/utils/traceback_utils.py:122, in filter_traceback..error_handler(*args, **kwargs)
119 filtered_tb = _process_traceback_frames(e.__traceback__)
120 # To get the full stack trace, call:
121 # keras.config.disable_traceback_filtering()
–> 122 raise e.with_traceback(filtered_tb) from None
123 finally:
124 del filtered_tb
Cell In[3], line 21, in f1macro(y_true, y_pred)
20 def f1macro(y_true, y_pred):
—> 21 f_pos = f1_m(y_true, y_pred)
22 # negative version of the data and prediction
23 f_neg = f1_m(1-y_true, 1-K.clip(y_pred,0,1))
Hi Khun…The error message you’re seeing, TypeError: Input ‘y’ of ‘Mul’ Op has type float32 that does not match type int64 of argument ‘x’, is common in TensorFlow or similar libraries where you’re attempting to perform a multiplication operation between tensors of different data types.
In this case, one of your tensors has data type float32 and the other has data type int64. TensorFlow requires that both operands in an operation like multiplication have the same data type. Here’s how you can resolve this issue:
1. **Convert Data Types**: You can convert the data type of one tensor to match the other before performing the operation. You can use tf.cast function in TensorFlow to do this. Here’s how you might do it:
python
import tensorflow as tf
x = tf.constant([1, 2, 3], dtype=tf.int64) # Tensor with dtype int64
y = tf.constant([1.1, 2.2, 3.3], dtype=tf.float32) # Tensor with dtype float32
# Convert x to float32
x = tf.cast(x, tf.float32)
# Now multiply
result = x * y
print(result)
2. **Choose Appropriate Data Type**: When defining tensors, if you know you’ll be performing operations between them, it’s often easier to ensure they are created with matching data types from the start.
3. **Check Your Operations**: Always check the data types of your tensors before performing operations if you aren’t sure they match. This can save time debugging type mismatch issues.
This approach of adjusting tensor data types can be adapted to fit the needs of other operations and libraries beyond TensorFlow as well, like NumPy or PyTorch.
You know what was surprising, I had run the same code by copying-pasting in both my local Jupyter Notebook and Colab Jupyter Notebook. It run flawlessly in the Colab Jupyter Notebook.
Hi Elisa…Using Convolutional Neural Networks (CNNs) to predict market movements 5 to 10 days ahead involves several steps, from data preparation to model training and validation. Here’s a general approach:
### 1. Data Collection and Preparation
– **Data Source**: Collect historical price data along with other potentially influential factors such as volume, open interest, macroeconomic indicators, news sentiment, etc.
– **Feature Engineering**: Convert raw data into a format suitable for a CNN. For instance, you could create images of price movements (like candlestick charts) or use sliding windows of price and volume data to create multivariate time series data.
– **Normalization**: Scale the data so that all features contribute equally. This typically involves scaling the data to have zero mean and unit variance.
### 2. Designing the CNN Architecture
– **Input Layer**: Decide on the shape of the input data. If using image-based data, the input could be the image dimensions. If using time series, the input might be in the form of sequences of days’ data.
– **Convolutional Layers**: These layers will help in extracting patterns from the data. You can experiment with the number of layers, filter sizes, and strides.
– **Pooling Layers**: Use pooling to reduce dimensionality between convolutional layers, which helps to make the network less sensitive to the exact location of features.
– **Dense Layers**: After convolutional and pooling layers, add one or more fully connected layers to interpret the features extracted by the convolutions.
– **Output Layer**: This layer should match the prediction task. For market movement, it might be a single neuron with a linear or sigmoid activation function if you’re predicting price change direction.
### 3. Model Training
– **Loss Function**: Choose a suitable loss function, such as mean squared error for regression tasks (if predicting price changes) or cross-entropy loss for classification tasks (if predicting direction of change).
– **Optimizer**: Select an optimizer to minimize the loss function, such as Adam or SGD.
– **Validation Split**: Use part of your data to validate the model during training. This helps in tuning hyperparameters without overfitting.
### 4. Backtesting
– **Simulate Trading**: Use historical data to simulate trading based on model predictions. This helps in estimating how well your model might perform with real investments.
– **Evaluation Metrics**: Use metrics like Sharpe Ratio, Sortino Ratio, or simply the accuracy of predictions to evaluate performance.
### 5. Iteration
– **Model Tuning**: Based on the backtesting results, adjust your model architecture, re-train, and test again.
– **Feature Reassessment**: Continuously add, remove, or modify features and observe how the model performance changes.
### 6. Deployment
– **Real-Time Data Feed**: Ensure the model can ingest real-time data and output predictions consistently.
– **Risk Management**: Implement risk management strategies to limit losses when the model predictions are incorrect.
### Additional Considerations
– **Overfitting**: Be wary of overfitting the model to historical data, which can render it ineffective for future unseen market conditions.
– **Market Noise**: Financial markets are influenced by numerous factors, many of which are not predictable with past data. Thus, maintaining conservative expectations about the predictive accuracy of your model is essential.
This framework should give you a robust starting point for using CNNs in predicting market movements. Adjustments and refinements will likely be necessary based on the specific characteristics of the data and the financial markets you are studying.
Below is a sample Python script that demonstrates the use of a Convolutional Neural Network (CNN) for predicting market movements using historical price data. This example uses TensorFlow and Keras to build the model and assumes that you have historical daily price data in a CSV file.
### Sample Python Script for Market Movement Prediction with CNN
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Dense, Flatten, Dropout
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
# Load the dataset
data = pd.read_csv('historical_prices.csv')
prices = data['Close'].values # Assuming only using close prices
# Function to create dataset for CNN
def create_dataset(data, time_steps=1):
X, y = [], []
for i in range(len(data) - time_steps - 1):
a = data[i:(i + time_steps)]
X.append(a)
y.append(data[i + time_steps])
return np.array(X), np.array(y)
# Normalize the data
scaler = MinMaxScaler(feature_range=(0, 1))
prices_scaled = scaler.fit_transform(prices.reshape(-1, 1))
# Create input and output sets
time_steps = 10 # Number of days to look back for prediction
X, y = create_dataset(prices_scaled, time_steps)
X = X.reshape(X.shape[0], X.shape[1], 1) # Reshaping for CNN input
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Build the CNN model
model = Sequential([
Conv1D(filters=64, kernel_size=2, activation='relu', input_shape=(time_steps, 1)),
MaxPooling1D(pool_size=2),
Flatten(),
Dense(50, activation='relu'),
Dense(1)
])
### Key Components of the Script
– **Data Preprocessing**: Normalizes price data and reshapes it into a format suitable for a CNN.
– **Model Architecture**: Uses a 1D CNN suited for time series data. The model architecture includes convolutional and pooling layers followed by a dense layer for prediction.
– **Training and Evaluation**: Trains the model on the dataset and plots the training and validation loss to help in understanding overfitting.
– **Prediction Visualization**: Visualizes actual vs. predicted prices to evaluate the model’s predictive accuracy.
### Next Steps
– You can enhance the model by incorporating more features like volume, open, and high/low prices.
– Experiment with different architectures, hyperparameters, and feature sets to improve performance.
– Implement backtesting to evaluate the model’s effectiveness in a trading simulation.
I have a feeling that if you change the order of columns (technical indicators etc.), the model will produce different results. I thought CNN looks for spatial patterns – matters if values are next to each other or far away but the order of columns is arbitrary.
You’re absolutely right to question this — and your intuition is spot-on.
Key Insight:
Yes, changing the order of columns (technical indicators) can affect the performance of a CNN model when applied to financial time series data. This is because CNNs rely on local spatial dependencies, and in this context, the order of your features (columns) becomes part of that spatial structure.
—
Why This Happens:
In image processing, which is where CNNs are most commonly used, the position of each pixel has meaning — the model learns spatial patterns like edges and shapes. In tabular or time series data, the order of features (columns) typically doesn’t matter unless you specifically design a spatial or temporal structure.
So, when you feed data into a CNN like this:
[ SMA | RSI | MACD | OBV | ... ] at time t
[ SMA | RSI | MACD | OBV | ... ] at time t+1
and apply a convolution across the feature dimension, you’re telling the model that “SMA next to RSI” means something — which may not be true. If you rearranged the columns, the CNN would learn different patterns, even though the underlying indicators haven’t changed. That’s why feature order can influence the model’s behavior.
—
When CNNs Make Sense for Financial Time Series:
CNNs can be effective for financial data under certain conditions:
* When you use temporal convolution — sliding the filter across time for each indicator. This works well because time is naturally ordered.
* When you reshape the data using domain knowledge into a 2D format where spatial relationships actually mean something — such as clustering indicators by correlation.
—
Alternatives or Improvements:
1. Sort features in a meaningful way, such as by grouping similar indicators, to introduce structure.
2. Use LSTM or Transformer-based models, which handle sequences without assuming spatial locality.
3. Consider hybrid models — for example, use a CNN to extract short-term patterns for each indicator over time, then pass those features into an LSTM or fully connected layer.
4. Try permutation testing — shuffle feature order and observe how much performance changes. This helps you measure how sensitive your CNN is to the input layout.







This has promise,, especially using multiple parameters, but, in general, CNNs are losing out in accuracy compared with Transformers.
Correct. But this shows how simple it is to get something not too far away.
There is error at a line in def datagen() on the following:
index = data.index[data.index < TRAIN_TEST_CUTOFF]
compliler said
“File “C:\Users\TANUNC~1.J\AppData\Local\Temp/ipykernel_10252/1129467454.py”, line 66
index = data.index[data.index < TRAIN_TEST_CUTOFF]
^
SyntaxError: invalid syntax
”
How to solve it ?
waiting your answer, Thanks in advance
The line seems OK but maybe the line before it in your code caused some problem. Can you check if you copied the code correctly?
@tanunchai
The code above seems to say
index = data.index[data.index < TRAIN_TEST_CUTOFF]
Try changing to
index = data.index[data.index < TRAIN_TEST_CUTOFF]
Argh. The code actually says [data.index & l t ; TRAIN_TEST_CUTOFF]
Change to
index = data.index[data.index < TRAIN_TEST_CUTOFF]
Thanks William. There were some hassles with the HTML. I fixed that and the copy should work now.
Thanks you William Smith
How to solve this bug ?
Now facing new problem, in def datagen() at nest loop while true
has the problem on the following:
if n-seq_len+1 &; 0:
while True:
# Pick one position, then clip a sequence length
while True:
t = random.choice(index)
n = (data.index == t).argmax()
if n-seq_len+1 &; 0: # ****error said invalid syntax
continue # this sample is not enough for one sequence length
frame = data.iloc[n-seq_len+1:n+1][input_cols]
# convert frame with two l
Now facing new problem, in def datagen() at nest loop while true
has the problem on the following:
if n-seq_len+1 < 0:
while True:
# Pick one position, then clip a sequence length
while True:
t = random.choice(index)
n = (data.index == t).argmax()
#index = data.index[data.index < TRAIN_TEST_CUTOFF] , the line below has the problem
if n-seq_len+1 < 0:
continue # this sample is not enough for one sequence length
frame = data.iloc[n-seq_len+1:n+1][input_cols]
# convert frame with two level of indices into 3D array
shape = (len(tickers), len(frame), n_features)
X = np.full(shape, np.nan)
for i,ticker in enumerate(tickers):
at def datagen() still has problem on the following;
if n-seq_len+1 < 0: # Error line , say “invalid syntax”
< doing what ? I do not understand and it made error also.
_________
while True:
# Pick one position, then clip a sequence length
while True:
t = random.choice(index)
n = (data.index == t).argmax()
#index = data.index[data.index < TRAIN_TEST_CUTOFF] , the line below has the problem
if n-seq_len+1 < 0: # Error line , say "invalid syntax"
continue # this sample is not enough for one sequence length
frame = data.iloc[n-seq_len+1:n+1][input_cols]
# convert frame with two level of indices into 3D array
shape = (len(tickers), len(frame), n_features)
ModuleNotFoundError: No module named ‘f1metrics’
How to solve this bug ?
—————————————————————————
ModuleNotFoundError Traceback (most recent call last)
C:\Users\TANUNC~1.J\AppData\Local\Temp/ipykernel_2580/1760727365.py in
12 from sklearn.metrics import accuracy_score, f1_score, mean_absolute_error
13
—> 14 from f1metrics import f1macro
15
16 DATADIR = “./Dataset”
ModuleNotFoundError: No module named ‘f1metrics’
_____
Sorry for all these hassles. Something wrong with the plugin for rendering the code here caused all the mess. I fixed it for now, so please copy over the code and try again.
Interesting! What is the difference between using:
– conv1d with kernel_size=n_features and input size N x m
– conv2d with kernel_size=(1, n_features) and input size N x m x 1
Are these two equivalent?
I would say yes but the best way to test this (in Keras) is to build such layers into a model and run “model.summary()” to observe the output. Are the output shape the same?
how to deploy this code on the web app. ?
That’s a vague question – you need to think about what the web app expects and how to wrap the model into a function to talk to the web app
Is FFDNet (fast and flexible denoising convolutional neural networks) suitable for financial time series?
Haven’t tried that.
My question is from the blog https://machinelearningmastery.com/feature-selection-machine-learning-python/
Sorry for asking this question here.
My work is to develop a model for multioutput prediction (i.e., predicting five outputs by a single model). When I applied Kbest and recursive feature elimination methods to select the best features, I got an error ‘ bad input shape (x, 5)’ (5 is output vectors here). However, PCA works well as it doesn’t depend upon the output vector.
Does it mean that we can apply these feature selection algorithms (Kbest and RFE) only for a single output prediction problem?
I answered it on the other post.
I think there is too much information in the csv file. Instead of looking too much data and try to make a fundamental analysis it can also be tried to find a ‘pattern’. With pattern I mean looking only to the open price, close price, max price and min price information of each candlestick.
For example:
Let’s consider the candlestick chart of D1 (1 candlestick = 1 day info). Objective: predict the fifth candlestick (up or down) with the info of the 4 formed before. The less quantity of candlestick the easier a pattern can be found
I will try modifying the input data with this model and let you know the results
Thanks for the feedback Pete! Please share your findings.
Many thanks for your tutorial, which is very helpful.
Can you please let me know how to write a data generator to read all different classes of .txt files (likes the function of “datagen.flow_from_directory” which read all different classes of image files)?
Thanks for this useful article!
I was trying to run your codes a couple of times but there are certain instability issues happened. Sometimes the prediction rate is about 51%, which is good result, but there are also times the prediction rate will go down to 48%. My guess is that this is related to the initialization step. Do you have any insights on this issue?
Hi Yu…The following resource should add clarity:
https://machinelearningmastery.com/stochastic-optimization-for-machine-learning/
Hi, James,
Thanks for your suggestion! I do consider the multi-restart idea and similarly using ensemble of results. But I didn’t have any luck for that yet either.
Do you think for a larger dataset this issue will be alleviated?
Hi, Could you help me i am having an issue with the code
InvalidArgumentError: Graph execution error
It is associated with [[ model.fit(datagen(data, seq_len, batch_size,”Target”,”train”),
validation_data=datagen(data, seq_len, batch_size, “Target”, “valid”),
epochs=n_epochs, steps_per_epoch=400, validation_steps=10, verbose=1,
callbacks=callbacks) ]]
I was able to trace it back to this line within the code in datagen (2DConv):
input_cols = [c for c in df.columns if c != targetcol]
Im using google colab and it says that when i try to single it out and run it
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
After trying: input_cols = [c for c in df.columns if c != targetcol.all()]
The issue persists, i would appreciate your help on it
Hi rk…did you copy and paste the code or type it in? Also, you may want to try to execute your code in Google Colab.
Hello, Can you tell me what the following lines of code do? They are:
name = X[“Name”][0]
del X[“Name”]
cols = X.columns
X[“Target”] = (X[“Close”].pct_change().shift(-1) > 0).astype(int)
X.dropna(inplace=True)
Since I get a bug here on google colab that return the error :
KeyError : “name”
This only happen when I use my own .csv data files. When I ran the codes using your dataset .csv files, I did not encounter any problem though. My csv files only have 7 columns : Date,Close,Open, HIgh, Low, Vol, Change %.
From what I understood, you are trying to drop the other columns but the Date and Close columns, right?
Thanks in advance!
Hi de santos…You are correct. Can you provide any more detail about the error? Is that the entire error message?
Thanks for replying, James! I thought my response was not approved,hence the late reply 4 months later, I’m so sorry.There was another error about Integer data type since originally the Vol column had a word “k” as substitute for “thousand”, that can be easily fixed by Find/Replace function of Excel to uniform the data into integer numbers. Other than that, the “Name” error still persists, here is the full error message:
KeyError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3801 try:
-> 3802 return self._engine.get_loc(casted_key)
3803 except KeyError as err:
4 frames
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ‘Name’
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3802 return self._engine.get_loc(casted_key)
3803 except KeyError as err:
-> 3804 raise KeyError(key) from err
3805 except TypeError:
3806 # If we have a listlike key, _check_indexing_error will raise
KeyError: ‘Name’
I am confused with the below code and would like to seek some clarification:
while True:
t = random.choice(index) # pick one time step
Won’t this line of code, always pick up from an index randomly, thus breaking sequence of time series data. As I understand in time series problems, the sequence of time series should be preserved?
What am I missing here? Can you please help me understand this better?
Hi…This line simply picks a random starting point in the sequence. From there, the sequence is preserved.
Hi,
First, .keras extension is required in the checkpoint file name. .keras extension is added and extension error is eliminated.
Socondly, model.fit function gave following error:
Epoch 1/20
—————————————————————————
TypeError Traceback (most recent call last)
Cell In[8], line 11
3 checkpoint_path = “./cp3d-{epoch}-{val_f1macro:.2f}.h5.keras”
4 callbacks = [
5 ModelCheckpoint(checkpoint_path,
6 monitor=’val_f1macro’, mode=”max”,
7 verbose=0, save_best_only=True, save_weights_only=False, save_freq=”epoch”)
8 ]
—> 11 model.fit(datagen(data, seq_len, batch_size, “DJI”, “Target”, “train”),
12 validation_data=datagen(data, seq_len, batch_size, “DJI”, “Target”, “valid”),
13 epochs=n_epochs, steps_per_epoch=400, validation_steps=10, verbose=1, callbacks=callbacks)
File ~/anaconda3/lib/python3.11/site-packages/keras/src/utils/traceback_utils.py:122, in filter_traceback..error_handler(*args, **kwargs)
119 filtered_tb = _process_traceback_frames(e.__traceback__)
120 # To get the full stack trace, call:
121 #
keras.config.disable_traceback_filtering()–> 122 raise e.with_traceback(filtered_tb) from None
123 finally:
124 del filtered_tb
Cell In[3], line 21, in f1macro(y_true, y_pred)
20 def f1macro(y_true, y_pred):
—> 21 f_pos = f1_m(y_true, y_pred)
22 # negative version of the data and prediction
23 f_neg = f1_m(1-y_true, 1-K.clip(y_pred,0,1))
Cell In[3], line 16, in f1_m(y_true, y_pred)
15 def f1_m(y_true, y_pred):
—> 16 precision = precision_m(y_true, y_pred)
17 recall = recall_m(y_true, y_pred)
18 return 2*((precision*recall)/(precision+recall+K.epsilon()))
Cell In[3], line 10, in precision_m(y_true, y_pred)
9 def precision_m(y_true, y_pred):
—> 10 true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
11 predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
12 precision = true_positives / (predicted_positives + K.epsilon())
TypeError: Input ‘y’ of ‘Mul’ Op has type float32 that does not match type int64 of argument ‘x’.
Hi Khun…The error message you’re seeing,
TypeError: Input ‘y’ of ‘Mul’ Op has type float32 that does not match type int64 of argument ‘x’, is common in TensorFlow or similar libraries where you’re attempting to perform a multiplication operation between tensors of different data types.In this case, one of your tensors has data type
float32and the other has data typeint64. TensorFlow requires that both operands in an operation like multiplication have the same data type. Here’s how you can resolve this issue:1. **Convert Data Types**: You can convert the data type of one tensor to match the other before performing the operation. You can use
tf.castfunction in TensorFlow to do this. Here’s how you might do it:pythonimport tensorflow as tf
x = tf.constant([1, 2, 3], dtype=tf.int64) # Tensor with dtype int64
y = tf.constant([1.1, 2.2, 3.3], dtype=tf.float32) # Tensor with dtype float32
# Convert x to float32
x = tf.cast(x, tf.float32)
# Now multiply
result = x * y
print(result)
2. **Choose Appropriate Data Type**: When defining tensors, if you know you’ll be performing operations between them, it’s often easier to ensure they are created with matching data types from the start.
3. **Check Your Operations**: Always check the data types of your tensors before performing operations if you aren’t sure they match. This can save time debugging type mismatch issues.
This approach of adjusting tensor data types can be adapted to fit the needs of other operations and libraries beyond TensorFlow as well, like NumPy or PyTorch.
Thx James.
You know what was surprising, I had run the same code by copying-pasting in both my local Jupyter Notebook and Colab Jupyter Notebook. It run flawlessly in the Colab Jupyter Notebook.
I’m going to work on it.
Even if I understand the steps to model and test the neural network, how can we use the model to predict market movements 5/10 days ahead?
Hi Elisa…Using Convolutional Neural Networks (CNNs) to predict market movements 5 to 10 days ahead involves several steps, from data preparation to model training and validation. Here’s a general approach:
### 1. Data Collection and Preparation
– **Data Source**: Collect historical price data along with other potentially influential factors such as volume, open interest, macroeconomic indicators, news sentiment, etc.
– **Feature Engineering**: Convert raw data into a format suitable for a CNN. For instance, you could create images of price movements (like candlestick charts) or use sliding windows of price and volume data to create multivariate time series data.
– **Normalization**: Scale the data so that all features contribute equally. This typically involves scaling the data to have zero mean and unit variance.
### 2. Designing the CNN Architecture
– **Input Layer**: Decide on the shape of the input data. If using image-based data, the input could be the image dimensions. If using time series, the input might be in the form of sequences of days’ data.
– **Convolutional Layers**: These layers will help in extracting patterns from the data. You can experiment with the number of layers, filter sizes, and strides.
– **Pooling Layers**: Use pooling to reduce dimensionality between convolutional layers, which helps to make the network less sensitive to the exact location of features.
– **Dense Layers**: After convolutional and pooling layers, add one or more fully connected layers to interpret the features extracted by the convolutions.
– **Output Layer**: This layer should match the prediction task. For market movement, it might be a single neuron with a linear or sigmoid activation function if you’re predicting price change direction.
### 3. Model Training
– **Loss Function**: Choose a suitable loss function, such as mean squared error for regression tasks (if predicting price changes) or cross-entropy loss for classification tasks (if predicting direction of change).
– **Optimizer**: Select an optimizer to minimize the loss function, such as Adam or SGD.
– **Validation Split**: Use part of your data to validate the model during training. This helps in tuning hyperparameters without overfitting.
### 4. Backtesting
– **Simulate Trading**: Use historical data to simulate trading based on model predictions. This helps in estimating how well your model might perform with real investments.
– **Evaluation Metrics**: Use metrics like Sharpe Ratio, Sortino Ratio, or simply the accuracy of predictions to evaluate performance.
### 5. Iteration
– **Model Tuning**: Based on the backtesting results, adjust your model architecture, re-train, and test again.
– **Feature Reassessment**: Continuously add, remove, or modify features and observe how the model performance changes.
### 6. Deployment
– **Real-Time Data Feed**: Ensure the model can ingest real-time data and output predictions consistently.
– **Risk Management**: Implement risk management strategies to limit losses when the model predictions are incorrect.
### Additional Considerations
– **Overfitting**: Be wary of overfitting the model to historical data, which can render it ineffective for future unseen market conditions.
– **Market Noise**: Financial markets are influenced by numerous factors, many of which are not predictable with past data. Thus, maintaining conservative expectations about the predictive accuracy of your model is essential.
This framework should give you a robust starting point for using CNNs in predicting market movements. Adjustments and refinements will likely be necessary based on the specific characteristics of the data and the financial markets you are studying.
Below is a sample Python script that demonstrates the use of a Convolutional Neural Network (CNN) for predicting market movements using historical price data. This example uses TensorFlow and Keras to build the model and assumes that you have historical daily price data in a CSV file.
### Sample Python Script for Market Movement Prediction with CNN
pythonimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Dense, Flatten, Dropout
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
# Load the dataset
data = pd.read_csv('historical_prices.csv')
prices = data['Close'].values # Assuming only using close prices
# Function to create dataset for CNN
def create_dataset(data, time_steps=1):
X, y = [], []
for i in range(len(data) - time_steps - 1):
a = data[i:(i + time_steps)]
X.append(a)
y.append(data[i + time_steps])
return np.array(X), np.array(y)
# Normalize the data
scaler = MinMaxScaler(feature_range=(0, 1))
prices_scaled = scaler.fit_transform(prices.reshape(-1, 1))
# Create input and output sets
time_steps = 10 # Number of days to look back for prediction
X, y = create_dataset(prices_scaled, time_steps)
X = X.reshape(X.shape[0], X.shape[1], 1) # Reshaping for CNN input
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Build the CNN model
model = Sequential([
Conv1D(filters=64, kernel_size=2, activation='relu', input_shape=(time_steps, 1)),
MaxPooling1D(pool_size=2),
Flatten(),
Dense(50, activation='relu'),
Dense(1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
# Train the model
history = model.fit(X_train, y_train, epochs=50, batch_size=32, verbose=1, validation_data=(X_test, y_test))
# Evaluate the model
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()
# Make predictions
predicted_prices = model.predict(X_test)
predicted_prices = scaler.inverse_transform(predicted_prices) # Invert scaling
# Plot predictions
plt.figure(figsize=(10, 6))
plt.plot(scaler.inverse_transform(y_test), label='Actual Price')
plt.plot(predicted_prices, label='Predicted Price')
plt.title('Price Prediction')
plt.xlabel('Time')
plt.ylabel('Price')
plt.legend()
plt.show()
### Key Components of the Script
– **Data Preprocessing**: Normalizes price data and reshapes it into a format suitable for a CNN.
– **Model Architecture**: Uses a 1D CNN suited for time series data. The model architecture includes convolutional and pooling layers followed by a dense layer for prediction.
– **Training and Evaluation**: Trains the model on the dataset and plots the training and validation loss to help in understanding overfitting.
– **Prediction Visualization**: Visualizes actual vs. predicted prices to evaluate the model’s predictive accuracy.
### Next Steps
– You can enhance the model by incorporating more features like volume, open, and high/low prices.
– Experiment with different architectures, hyperparameters, and feature sets to improve performance.
– Implement backtesting to evaluate the model’s effectiveness in a trading simulation.
I have a feeling that if you change the order of columns (technical indicators etc.), the model will produce different results. I thought CNN looks for spatial patterns – matters if values are next to each other or far away but the order of columns is arbitrary.
You’re absolutely right to question this — and your intuition is spot-on.
Key Insight:
Yes, changing the order of columns (technical indicators) can affect the performance of a CNN model when applied to financial time series data. This is because CNNs rely on local spatial dependencies, and in this context, the order of your features (columns) becomes part of that spatial structure.
—
Why This Happens:
In image processing, which is where CNNs are most commonly used, the position of each pixel has meaning — the model learns spatial patterns like edges and shapes. In tabular or time series data, the order of features (columns) typically doesn’t matter unless you specifically design a spatial or temporal structure.
So, when you feed data into a CNN like this:
[ SMA | RSI | MACD | OBV | ... ] at time t
[ SMA | RSI | MACD | OBV | ... ] at time t+1
and apply a convolution across the feature dimension, you’re telling the model that “SMA next to RSI” means something — which may not be true. If you rearranged the columns, the CNN would learn different patterns, even though the underlying indicators haven’t changed. That’s why feature order can influence the model’s behavior.
—
When CNNs Make Sense for Financial Time Series:
CNNs can be effective for financial data under certain conditions:
* When you use temporal convolution — sliding the filter across time for each indicator. This works well because time is naturally ordered.
* When you reshape the data using domain knowledge into a 2D format where spatial relationships actually mean something — such as clustering indicators by correlation.
—
Alternatives or Improvements:
1. Sort features in a meaningful way, such as by grouping similar indicators, to introduce structure.
2. Use LSTM or Transformer-based models, which handle sequences without assuming spatial locality.
3. Consider hybrid models — for example, use a CNN to extract short-term patterns for each indicator over time, then pass those features into an LSTM or fully connected layer.
4. Try permutation testing — shuffle feature order and observe how much performance changes. This helps you measure how sensitive your CNN is to the input layout.