The book Applied Predictive Modeling teaches practical machine learning theory with code examples in R.
It is an excellent book and highly recommended to machine learning practitioners and users of R for machine learning.
In this post you will discover the benefits of this book and how it can help you become a better machine predictive modeler.
About the Book
Applied Predictive Modeling is written by Max Kuhn and Kjell Johnson. Max Kuhn is a director of non-clinical statistics at Pfizer and best known as the developer of the caret package in R. Kjell Johnson is a co-founder of Arbor Analytics and formally a direct at Pfizer.
The book has its own dedicated website that provides some data and code used in the book, and general information about the book contents and errata.
It came out in September 2013, and I remember it sold out very quickly. I had to wait for a second printing to get my copy. The reason it was and still is in such great demand is because it is a fantastic reference written by very skilled authors.
The refer to the process of solving problems with statistics and machine learning algorithms as “Applied Predictive Modeling“, hence the title of the book, but you could just as easily called it applied machine learning.
The focus is on building models from real-world data to make predictions (as opposed to describing the past), and the selection of the best possible model (most accurate) is the paramount objective of the process.

Applied Predictive Modeling
Book Structure
The book is broken down into 4 parts:
- General Strategies: This includes data preparation and test harness design whilst avoiding overfitting.
- Regression Models: The methods used to construct regression models, such as linear, non-linear and decision trees.
- Classification Models: The methods used to construct classification models, again such as linear, non-linear and decision trees.
- Other Considerations: Other important topics such as feature importance, feature selection and improving performance.
The first three parts end with a worked real-world case study. I really enjoyed these chapters, the regression one in particular on predicting the compressive strength of concrete mixtures. I even wrote why this was a clever example.
The structure was solid, focusing on model types and their construction.
One area that I felt deserved some attention was the general process of applied predictive modeling for new problems. This could have been inferred from the worked case study chapters, but would have been valuable if it had been spelled out.
Book Content
Each chapter focuses on the meat of the topic. It is applied information with just enough theory to understand what s going on. I love this. The authors do not dive down into the derivations and the “why” of the algorithms and methods, the focus on “how” they work with an equation here or pseudo code there.
Each chapter has a “Computing” section in which the models and methods explained in the chapter are demonstrated on small datasets, almost always using the caret package in R. I have no problem with this at all. The examples are brief and sufficient to relate to the material of the chapter. I would go as far as to say that using caret is best practice, and I suspect this is one of the reasons that the book is so popular.
Finally, each chapter ends with “Exercises” that encourage you to apply the models and methods explained and demonstrated in the chapter to answer some specific questions. I did not do the exercises (I read the book on the train), but I appreciate that they are there, and encourage readers to consider taking them on.
I did find some repetition. Some of the same algorithms are presented in the regression and classification sections, and were presented twice. I also found the presentation of algorithm after algorithm sometimes a little boring. The content is great, but much of it is probably better suited as a reference than a book to be read end-to-end. That being said, the chapters in the “General Strategies” and “Other Considerations” were the opposite, and I encourage serious practitioners to read these and take a lot of notes.
Theres an introduction to R in one of the appendices for those that need it.
There is also a cute little table that summarizes models and their differences, highlighting suggested pre-processing, number of parameters, and others. I think it’s very cool because it provokes you to think deeper before applying a black box method to your data. It is in Appendix A on page 550 (link to page).
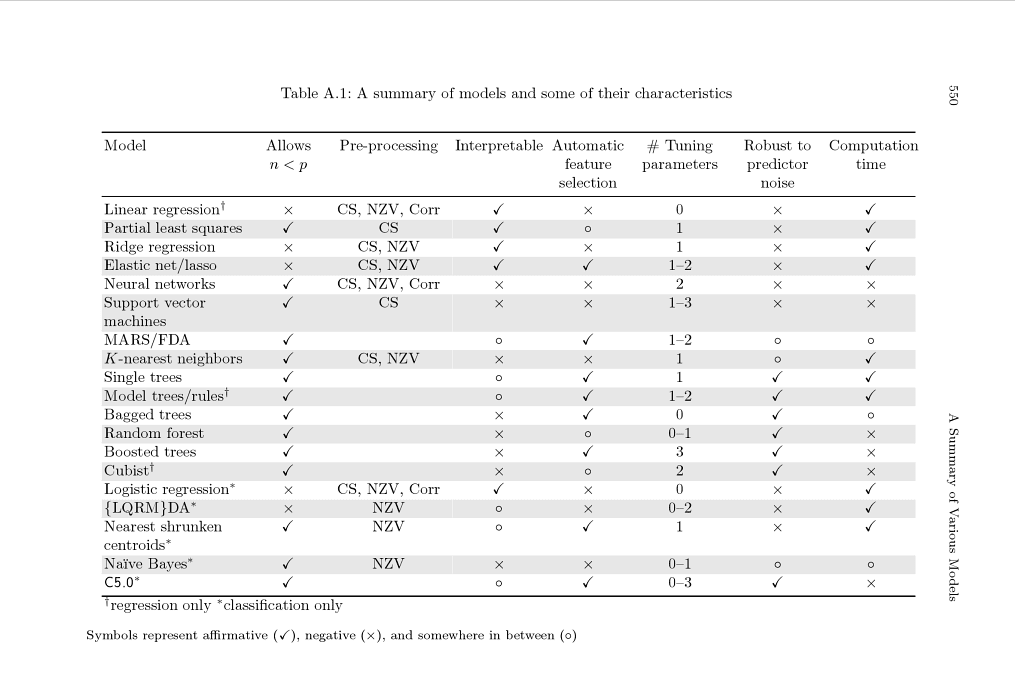
Summary of models and some of their characteristics
Appendix A, Page 550, Applied Predictive Modeling
Need more Help with R for Machine Learning?
Take my free 14-day email course and discover how to use R on your project (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Summary
This book is not for beginners, but rather intermediate machine learning practitioners looking to get into or improve their understanding of specific algorithms or R (or both). It is a lot more accessible and applied than sibling texts like The Elements of Statistical Learning.
I really enjoyed this book and plowed through the whole lot in about a week of commutes. I took a lot of notes, because I appreciated the seasoned approach to practical topics that don’t get enough air time (like overfitting, feature selection class imbalance). I also refer to it as a reference now, because the algorithm descriptions are very good.
If you think this book is for you, grab yourself a copy (and read it!). You won’t regret it.





I have read the ESL and APM both. There is no doubt that APM is superior when it comes to applying machine learning methods. ESL is good if you are studying a graduate course where its the prescribed textbook.
do you have recommendation for beginner book ?
Yes, right here:
https://machinelearningmastery.com/products/